Abstract
The evaluation of large language models (LLMs) increasingly relies on other LLMs acting as automated judges. While this approach offers scalability and efficiency, it raises serious concerns regarding evaluator reliability, positional bias, and ranking stability. This paper presents a scalable framework for diagnosing positional bias and instability in LLM-based evaluation by using controlled pairwise comparisons judged by multiple independent language models. The system supports mirrored comparisons with reversed response order, prompt injection, and surface-level perturbations (e.g., paraphrasing, lexical noise), enabling fine-grained analysis of evaluator consistency and verdict robustness. Over 3600 pairwise comparisons were conducted across five instruction-tuned open-weight models using ten open-ended prompts. The top-performing model (gemma:7b-instruct) achieved a 66.5% win rate. Evaluator agreement was uniformly high, with 100% consistency across judges, yet 48.4% of verdicts reversed under mirrored response order, indicating strong positional bias. Kendall’s Tau analysis further showed that local model rankings varied substantially across prompts, suggesting that semantic context influences evaluator judgment. All evaluation traces were stored in a graph database (Neo4j), enabling structured querying and longitudinal analysis. The proposed framework provides not only a diagnostic lens for benchmarking models but also a blueprint for fairer and more interpretable LLM-based evaluation. These findings underscore the need for structure-aware, perturbation-resilient evaluation pipelines when benchmarking LLMs. The proposed framework offers a reproducible path for diagnosing evaluator bias and ranking instability in open-ended language tasks. Future work will apply this methodology to educational assessment tasks, using rubric-based scoring and graph-based traceability to evaluate student responses in technical domains.
1. Introduction
The rapid adoption of large language models (LLMs) across diverse domains has intensified the need for accurate and transparent evaluation methods. Traditional metrics like BLEU (Bilingual Evaluation Understudy) or ROUGE (Recall-Oriented Understudy for Gisting Evaluation) often fail to capture reasoning depth, rhetorical quality, or contextual relevance—especially in open-ended tasks. As automated evaluators become more prevalent, diagnosing their limitations becomes critical. This study addresses these challenges by introducing a framework that analyzes bias, instability, and semantic variability in model judgment.
1.1. Background and Objectives of This Study
1.1.1. Background
LLMs have become central to modern natural language processing applications, enabling systems to perform tasks such as summarization, translation, dialogue generation, and open-domain question answering with increasing fluency and relevance. Open-weight models like Gemma 7B [1], Mistral 7B [2], Dolphin-Mistral [3], Zephyr 7B-beta [4], and DeepSeek-R1 8B [5] have made these capabilities more accessible to the research community, encouraging comparative experimentation and deployment in real-world contexts. As LLMs are increasingly integrated into sensitive domains—education, law, medicine, governance—their outputs influence decision-making processes and public understanding. This raises an urgent demand for evaluation frameworks that go beyond surface-level accuracy, aiming instead to capture qualities such as argumentative depth, rhetorical balance, and reasoning consistency [6].
Traditional evaluation methods often fall short in this regard [6]. Metrics like BLEU or ROUGE emphasize lexical overlap, not reasoning quality or conceptual integration [7]. Human evaluations, while valuable, are time consuming, subjective, and difficult to scale. In response, recent studies have proposed using LLMs themselves as evaluators—a strategy known as meta-evaluation [8]. While promising in terms of automation and scalability, this approach introduces new concerns regarding the stability of LLM judgments under prompt variation, the presence of position bias in pairwise comparisons, and the consistency of preferences when inputs are semantically equivalent but differ in surface form.
These questions motivate the development of a perturbation-aware, graph-based framework for evaluating LLM outputs via pairwise comparison. Inspired by recent advances in LLM-as-judge pipelines, the framework introduced in this study enables structured diagnosis of positional bias, verdict instability, and semantic inconsistency in evaluator behavior. In this system, multiple LLMs generate responses to open-ended prompts, which are then compared using independent evaluators under controlled conditions—such as reversed response order (A–B and B–A), prompt injection (with or without explicit debiasing), and surface-level perturbations including paraphrasing and lexical noise.
1.1.2. Objectives of This Study
The overarching goal of this study is to establish a scalable, reproducible, and diagnostically rich methodology for assessing both the relative performance of language models and the robustness of LLM-based evaluators. This study has the following specific objectives:
- Design a reproducible and extensible evaluation pipeline that supports pairwise comparisons across multiple LLMs;
- Investigate verdict stability and consistency under controlled variations in prompt structure and input surface form;
- Diagnose position bias by comparing outcomes under reversed response order;
- Measure inter-evaluator agreement across model-agnostic scoring scenarios;
- Store all evaluation traces in a graph database to support structured querying, semantic linkage, and longitudinal analysis.
By addressing these objectives, the framework provides both a practical tool for benchmarking LLMs and a methodological foundation for auditing the fairness, interpretability, and stability of automated evaluation workflows.
1.2. Related Work
The evaluation of LLMs has become a critical challenge as their use expands to domains requiring interpretability, fairness, and reasoning depth [9,10]. Standard metrics—such as BLEU, ROUGE, or multiple-choice accuracy—remain inadequate for open-ended tasks involving ethics, argumentation, or ambiguity [6].
A growing body of work has explored LLMs as evaluators of natural language outputs. ChatEval [11] proposed a multi-agent evaluation system where LLMs rate dialogue responses based on coherence and relevance, demonstrating moderate alignment with human judgments but lacking robustness checks under perturbations. AgentReview [12] simulates peer-review dynamics among LLM agents and shows potential for replicating review-like behavior yet offers no control for evaluator agreement or stability. ArenaHard [13] introduced a leaderboard combining LLM and crowdworker preferences but did not account for order sensitivity or repeated evaluations. Scherrer et al. [14] examined moral belief alignment across LLMs through fixed prompts but did not explore verdict consistency across framing variations or perturbations.
In parallel, self-evaluative strategies have been proposed. TEaR [15] improves machine translation via systematic self-refinement, enhancing fluency and coherence within a single model. Reflexion [16] adds a verbal reinforcement mechanism that allows a model to critique and revise its own outputs. However, these approaches do not allow for comparison between models or judgments by external evaluators. Panickssery et al. [17] found that LLMs systematically favor their own generations, revealing a self-preference bias that threatens fairness in unsupervised evaluation.
Another line of work involves multi-agent and adversarial setups. CAMEL [18] uses role-playing agents to simulate dialogues for evaluating reasoning, while AutoAgents [19] orchestrates agent interactions to explore collaboration and task completion. DEBATE [20] frames evaluation as adversarial challenge, where one LLM critiques another’s outputs. Despite their creativity, these systems primarily focus on interaction quality rather than benchmarking and lack controls for response order, perturbation robustness, or inter-evaluator consistency.
In contrast, the framework introduced in this study combines three key components:
- (i)
- Pairwise comparison of model outputs under controlled perturbations, including response order reversal, lexical noise, and prompt injection;
- (ii)
- Multi-judge evaluation, using three independent LLM-based evaluators (LLaMA 3:8B, OpenHermes, Nous-Hermes 2);
- (iii)
- Graph-based storage of all evaluations in Neo4j, supporting traceability, semantic linkage, and longitudinal analysis.
The experimental setup includes over 3600 pairwise comparisons conducted across five instruction-tuned open-weight models and ten open-ended prompts. Each response pair was evaluated under controlled conditions involving lexical perturbation, reversed order, and prompt injection, and scored independently by three distinct LLM-based judges.
All evaluation traces—responses, verdicts, metadata—were stored in a Neo4j graph database, enabling structured queries and long-term analysis.
This design supports fine-grained diagnosis of position bias, verdict instability, and evaluator agreement. To our knowledge, this is the first open-source framework to combine controlled evaluation, multi-judge consensus, and graph-based traceability into a single, reproducible system.
1.3. Research Gap and Novelty
Despite increasing interest in using LLMs as evaluators of other models, existing approaches often lack methodological rigor and fail to account for known confounding factors in pairwise judgment tasks [21]. Most comparative evaluations rely on single-turn prompts without controlling for response position or phrasing, which can introduce subtle but systematic biases [22]. In many cases, a model’s answer may be favored not because of superior quality but due to its position as the first-listed response or superficial differences in lexical or syntactic form. Moreover, most evaluation pipelines do not implement internal consistency checks—such as reversing response order—or employ multiple evaluator models to validate inter-judge agreement [23].
Another critical limitation lies in the absence of persistent and structured evaluation records. Outputs are often stored as flat tables or unstructured JSON files, which hinders the ability to trace reasoning paths, group-related evaluations, or explore evaluator behavior across conditions [23]. This lack of structured storage restricts both the analytical depth and the reproducibility of findings [24].
To address these limitations, the present study introduces several novel contributions:
- A pairwise evaluation pipeline with strict control over response order (mirrored comparisons), prompt type (standard/injected), and surface-level perturbations (lexical noise, paraphrasing), supporting robustness diagnostics across 3600+ comparisons;
- The use of three independent LLM-based evaluators (LLaMA 3:8B, OpenHermes, Nous-Hermes 2), yielding 100% inter-evaluator agreement across all conditions;
- The systematic identification of position bias, with 48.4% of verdicts reversing when the order of responses was flipped;
- The application of bias-injected prompts to assess evaluator susceptibility to framing effects and test prompt robustness;
- Graph-based storage in Neo4j of all evaluation traces (questions, answers, verdicts, metadata), enabling semantic querying and longitudinal analysis across 10 prompts and five candidate models.
To the best of our knowledge, this is the first open-source framework that integrates multi-model response generation, controlled pairwise comparison, Meta-Evaluator consistency diagnostics, and structured evaluation graphs into a single reproducible system. By combining these elements, this study offers both a diagnostic methodology for benchmarking LLM outputs and a scalable infrastructure for validating the evaluators themselves [7].
2. Materials and Methods
This section describes the architecture, workflow, and evaluation procedures of the proposed Meta-Evaluator framework. The system integrates multi-model response generation, controlled perturbations, pairwise comparison by LLM-based judges, and structured verdict storage. We outline the core components of the framework, including the evaluation pipeline, perturbation controls, prompt variants, scoring models, and graph-based infrastructure.
2.1. System Overview
The Meta-Evaluator framework provides a modular and extensible infrastructure for assessing the quality of responses generated by LLMs through pairwise comparative evaluation. The system was designed to support not only inter-model ranking but also consistency diagnostics, bias detection, and evaluator robustness analysis.
The evaluation process began with an open-ended question, which was submitted in both its original form and a semantically equivalent paraphrase automatically generated by an LLM. Each version of the question was answered by a set of candidate models. The resulting responses were paired exhaustively for comparison. To increase the reliability and diagnostic value of the evaluation, each pair was evaluated under multiple controlled conditions: lexical noise was introduced in the responses (e.g., minor substitutions like “AI” → “A.I.”); the order of presentation (A–B vs. B–A) was alternated to test for position bias; and the prompt used to guide evaluation was either neutral or included an explicit instruction to avoid positional preference (injected prompt).
Each pairwise comparison was independently evaluated by multiple LLM-based judges, allowing for inter-evaluator agreement analysis and bias detection. Given a prompt containing a question and two responses, the evaluator produced a structured JSON verdict specifying which response was preferred and why. This procedure was repeated across all combinations of models, perturbation types, response orderings, prompt variants, and evaluator models, generating a large number of comparison records per question.
All components of the evaluation process—including original and paraphrased questions, generated responses, their perturbed variants, evaluation prompts, verdicts, explanations, and metadata—were stored in a Neo4j graph database. The graph structure captured semantic and procedural relations (e.g., VARIANT_OF, REPHRASES, EVALUATES, FAVORS) and enabled advanced querying and longitudinal analysis of consistency, agreement, and rank stability.
This modular architecture is illustrated in Figure 1, which presents the full evaluation pipeline from question input to verdict generation and graph-based persistence. The diagram highlighted the stages of response generation by candidate models, application of lexical and prompt-level perturbations, pairwise evaluation by multiple LLM judges, and structured storage of all evaluation components. Together, these steps enable controlled experimentation, consistent comparison, and long-term traceability of reasoning evaluations.
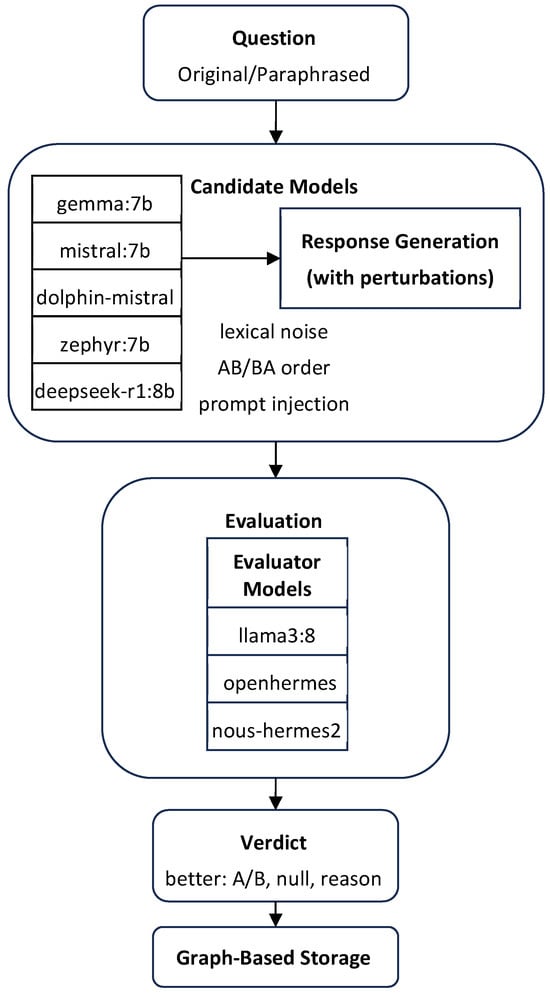
Figure 1.
Overview of the Meta-Evaluator system architecture, illustrating the flow from question input and candidate model generation (Gemma, Mistral, Zephyr, Dolphin, DeepSeek) through perturbation control, LLM-based evaluation, and graph-based storage of results. The candidate models are responsible for generating responses before evaluation.
This end-to-end process is summarized schematically in Figure 2, which illustrates the five main stages of the evaluation workflow. These include the generation of original and paraphrased questions, model response generation, application of controlled perturbations, comparative evaluation using LLM-based judges, and structured storage of verdicts and metadata in a graph database. The figure highlights the sequential inputs, operations, and outputs that characterize each stage, offering a high-level view of how the system supports reproducibility, bias diagnostics, and semantic traceability.
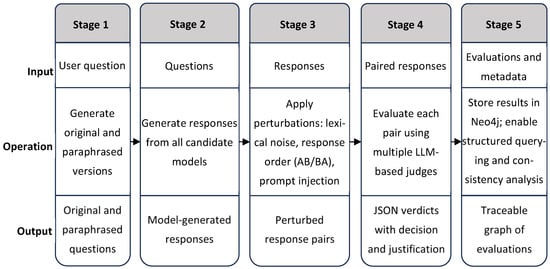
Figure 2.
Schematic representation of the evaluation and traceability workflow in the Meta-Evaluator framework.
2.2. Evaluation Pipeline
The evaluation pipeline consists of a reproducible, multi-stage process designed to generate, perturb, compare, and persist pairwise judgments across multiple models and evaluation conditions. The pipeline is implemented as a combination of batch-executable scripts and modular functions, which automate the full lifecycle of a comparative evaluation task.
For each question, responses were generated by all candidate models. These responses were paired exhaustively using all unordered model combinations (e.g., model A vs. model B). Each pair was processed under two response orderings: A–B and B–A. In addition, the same responses were perturbed lexically (e.g., minor textual alterations or synonym substitutions) to test robustness and were compared under different prompt formulations, including injected instructions discouraging positional bias.
Every unique configuration of the question (original/paraphrased), perturbation type (clean or noisy), prompt type (standard or injected), and order (AB or BA) defined an individual evaluation condition. Each such condition was submitted to all evaluator models, which received the prompt and returned a structured JSON verdict specifying the preferred response and a justification. The evaluation prompt remained fixed in format, ensuring consistency across comparisons.
Each verdict was tagged with metadata including evaluator identity, question ID, model names, order, perturbation type, and prompt variant. A unique pair ID was assigned to each comparison, enabling traceability across all permutations. The system supports both fully automated runs and interactive evaluations via a user interface.
Overall, the pipeline enables systematic experimentation across a factorial combination of models, evaluators, perturbations, and prompt controls, providing the empirical foundation for consistency and agreement analyses described in later sections.
2.3. Perturbation and Prompt Control
To evaluate the robustness and fairness of LLM-based judgments, the Meta-Evaluator framework introduces controlled variation along three axes: response order, lexical noise, and prompt phrasing. These perturbations are applied systematically to isolate and measure their individual and combined effects on evaluator decisions.
Response Order: Each pair of model-generated responses was evaluated twice: once in the original A–B order and once in reversed B–A order. This procedure enables the detection of positional bias, where evaluators may have favored the first or second response irrespective of content. By comparing the outcomes of AB and BA presentations, the system is able to classify evaluations as consistent, biased, or inconclusive.
Lexical Noise: To test the sensitivity of evaluators to superficial textual variation, each model response was perturbed by introducing light lexical modifications (e.g., replacing “AI” with “A.I.” or applying standard synonym substitutions). These perturbations preserved the semantic content while altering surface-level features that may influence fluency or perceived tone. Examples included punctuation changes (e.g., commas, colons), acronym formatting (“AI” → “A.I.”), contractions (“don’t” → “do not”), synonym replacements (“important” → “significant”), or hedging modifiers (“should” → “might be advisable”). Evaluations conducted on noisy versus original responses enabled robustness analysis under minor output transformations.
Prompt Injection: Two versions of the evaluation prompt were used. The standard prompt instructed the evaluator to compare responses based on clarity, accuracy, depth, and helpfulness. The injected variant appended an explicit sentence discouraging position-based preference: “Note: Evaluate objectively. Do not let position influence your judgment.” This addition was used to assess whether framing the prompt affected consistency or bias levels.
Each evaluation in the system was associated with one specific condition from the cross-product of these three dimensions. The system stores metadata for every verdict, allowing researchers to group, compare, and analyze results according to any combination of perturbation factors.
2.4. Evaluator Models and Decision Format
Each pairwise comparison was evaluated independently by multiple LLMs acting as impartial judges. These evaluator models were distinct from the candidate models being compared and were selected for their instruction-following capabilities and ability to provide structured justifications. This separation ensures modularity between generation and judgment, avoiding entanglement between the model being evaluated and the model serving as evaluator. The set of evaluators is configurable and defined at runtime; in the setup used for this study, it included models such as LLaMA 3:8B, OpenHermes, and Nous-Hermes 2.
These models were selected to cover a range of open-weight architectures (e.g., LLaMA, Mistral), parameter scales (7B–13B), and instruction-tuning strategies. The goal was to enable comparative evaluation across diverse design choices within the constraints of open accessibility.
Each evaluator received a prompt that contained the question, two anonymized responses labeled as Answer A and Answer B, and a task instruction asking for a comparison based on helpfulness, clarity, depth, and accuracy. Depending on the evaluation condition, this prompt also included an additional instruction discouraging positional bias.
The evaluator returned a structured output consisting of two fields. The first field, named “better”, specified the preferred response (“A”, “B”, or null if no preference was justified). This standardized format ensures consistency across different evaluator models and enables automated analysis of agreement, bias, and decision stability.
To ensure data integrity, the framework validates the returned output before storage. Each judgment was saved alongside metadata specifying the evaluator identity, comparison ID, response order, prompt variant, perturbation type, and evaluation timestamp. Invalid or incomplete outputs were excluded from further analysis.
2.5. Graph-Based Storage and Traceability
All elements of the evaluation process were stored in a graph database using the Neo4j platform. This design enables persistent, structured representation of questions, responses, evaluations, and their interdependencies. Unlike flat files or tabular formats, the graph model supports semantic relationships between entities and facilitates advanced querying, filtering, and aggregation.
Each node in the graph corresponds to a specific entity: questions, responses, or evaluations. Questions include both original and paraphrased variants, which are linked via a REPHRASES relationship. Each response node is associated with a model identity and can be linked to a base response through a VARIANT_OF relation if lexical perturbation is applied.
Evaluation outcomes are represented as PairwiseEvaluation nodes that capture the full context of each judgment, including evaluator identity, prompt variant, perturbation type, response order, and decision outcome. These nodes are connected to the corresponding question and response nodes using EVALUATES, BETWEEN, and FAVORS relationships, depending on the structure and result of each comparison.
This representation allows for traceability of all decisions, including which evaluator judges which model pair, under what conditions, and with what result. It also facilitates longitudinal analysis across questions, comparison of evaluator behaviors, and detection of systematic biases or inconsistencies. Researchers issue Cypher queries to extract structured insights from the evaluation graph, supporting both exploratory data analysis and formal reporting.
2.6. Prompt Set and Question Variants
This study used 10 open-ended questions designed to probe complex reasoning, ethical judgment, and argumentative clarity in LLMs. The prompts covered a range of topics, including artificial intelligence policy, social justice, governance, and education. Each question was formulated to encourage detailed, nuanced responses that went beyond factual correctness.
The questions were selected to elicit diverse reasoning styles and to challenge evaluators under varying semantic and rhetorical conditions. We specifically included ethically charged, ambiguous, and ideologically sensitive scenarios to test how stable and impartial the evaluators are when scoring nuanced model outputs. These question types are well-suited for revealing position bias, judgment instability, and surface-level sensitivity in evaluation.
For each question, a paraphrased version was automatically generated using a language model. These paraphrases retained the original meaning while varying in lexical and syntactic form, which enabled the evaluation of prompt sensitivity across both response generation and evaluator judgment.
The questions include both general prompts and challenge-style formulations that aimed to expose potential weaknesses in reasoning or evaluator consistency. All items were uniquely identified and programmatically indexed to support traceability throughout the evaluation process. The complete list of questions used in this study is shown in Table 1.

Table 1.
List of evaluation questions used in this study.
3. Results
This section presents the empirical results obtained using the Meta-Evaluator framework. We report on model performance across pairwise comparisons, the consistency and agreement of evaluator judgments, the influence of lexical and structural perturbations, and the stability of model rankings. The analyses aim to quantify bias, detect instability, and assess the robustness of LLM-based evaluation under controlled experimental conditions.
3.1. Model Performance and Win Rates
To evaluate the overall performance of the candidate models, we conducted a series of exhaustive pairwise comparisons using ten open-ended prompts. Each model participated in 1440 evaluations, representing all possible permutations of reversed response order (AB and BA), perturbation type (original, paraphrased, lexical noise), and prompt formulation (standard vs. bias-injected). For each model, we recorded the number of times that it was preferred by the evaluators (Total Wins), the total number of comparisons (Matches), and the resulting win rate percentage. These aggregated results are presented in Table 2.
Table 2.
Total wins, number of comparisons, and win rates for each candidate model across all evaluation conditions.
A more detailed view of the matchups is offered by the head-to-head win matrix, shown in Figure 3. Each cell in the matrix indicates the number of times the model on the row outperformed the model on the column across all relevant evaluation conditions. The asymmetries in this matrix provide additional insight into relative model strengths. For example, gemma:7b-instruct prevailed over deepseek-r1:8b in all 263 recorded comparisons, and maintained consistent superiority over dolphin-mistral:latest (winning 205 of 263 matches). Interestingly, while mistral:7b-instruct and zephyr:7b-beta produced more balanced results in their mutual comparison (141 vs. 122 wins), both outperformed deepseek-r1:8b by large margins.
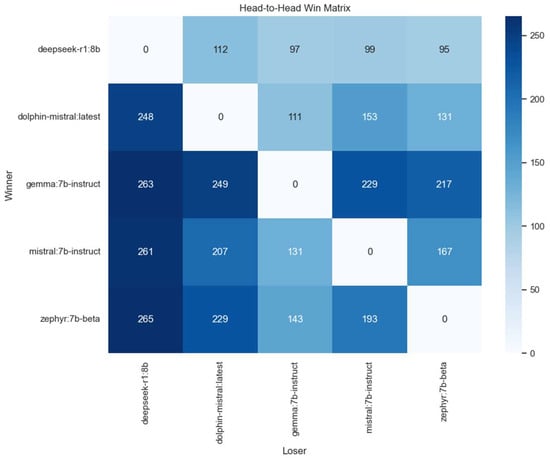
Figure 3.
Head-to-head win matrix indicating the number of victories obtained by the model on the row over the model on the column.
These outcomes reflect the cumulative preferences of multiple independent LLM-based evaluators, each scoring responses under controlled and redundant conditions. As each pairwise comparison was judged multiple times by distinct evaluators and under mirrored response orders, the aggregated win rates provide a robust indication of comparative model quality, minimizing the influence of any single evaluator’s idiosyncrasies.
Taken together, the win distribution and head-to-head results establish a clear performance hierarchy among instruction-tuned open-weight models. The findings emphasize that model architecture alone is not a sufficient predictor of performance; rather, the quality of instruction tuning, response structure, and alignment fidelity significantly shape how models are perceived in open-ended evaluative tasks.
3.2. Evaluator Agreement and Judgment Consistency
A key objective of this study was to evaluate the reliability and internal consistency of LLM-based evaluators under systematically controlled conditions. To this end, we conducted two complementary analyses: one examining verdict stability across mirrored response orderings (AB vs. BA), and another measuring the degree of agreement between multiple evaluators assessing the same comparison.
In the first analysis, each model pair was evaluated twice, once with responses ordered as A–B and again as B–A, under identical prompt and perturbation conditions. We categorized each comparison into one of three stability classes:
- Consistent: Both AB and BA yielded the same verdict;
- Position Bias: Verdicts reversed depending on response order;
- Inconclusive: At least one comparison returned a null or undefined preference.
Out of 1800 mirrored comparisons, 929 (51.6%) were classified as Consistent, 871 (48.4%) exhibited Position Bias, and none were Inconclusive. This distribution is shown in Figure 4.
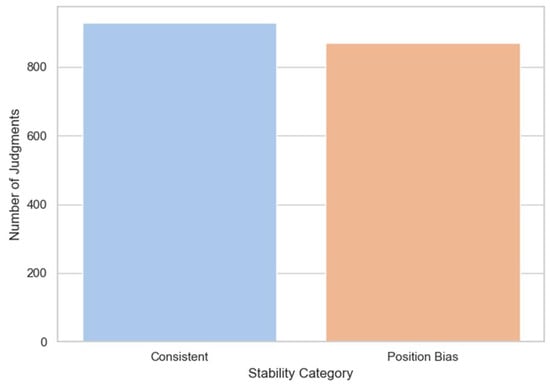
Figure 4.
Distribution of pairwise evaluation outcomes across reversed response orderings (AB vs. BA), classified as Consistent, Position Bias, or Inconclusive.
These findings indicate that nearly half of all judgments were sensitive to the position in which responses were presented, even when the underlying content remained identical. While a slight majority of verdicts were stable, the high rate of positional reversals underscores the importance of testing for order effects in evaluation pipelines. The absence of inconclusive cases may be attributed to the structured nature of the evaluation prompt, which constrained evaluators to produce binary preferences in most cases.
In parallel, we examined the degree of agreement among evaluators (LLaMA 3:8B, OpenHermes, and Nous-Hermes 2) who assessed the same model pairs under identical conditions. Across all 3600 multi-judge comparisons, we observed perfect alignment: in every instance, all evaluators selected the same preferred response (or declared no preference). This uniformity suggests a high level of convergence in evaluative behavior among instruction-tuned models, likely reinforced by the clarity and rigidity of the prompt design.
Nevertheless, the simultaneous presence of near-perfect inter-evaluator agreement and substantial position bias reveals a critical insight: biases can be systematic and shared, rather than random or evaluator-specific. Therefore, structural controls—such as mirrored comparisons and bias-aware prompt variants—are essential for diagnosing and mitigating latent evaluator sensitivity.
3.3. Positional Bias and Perturbation Sensitivity
To further investigate the robustness of evaluator decisions, we analyzed how verdict stability varied across different types of linguistic perturbation applied to model responses. As outlined in the evaluation protocol, each model pair was assessed under three distinct conditions: unmodified responses (original), semantically equivalent paraphrased prompts, and lexically perturbed responses involving small surface-level edits that preserved semantic meaning.
Each comparison was categorized as either Consistent (if the AB and BA orderings yielded the same verdict) or as exhibiting Position Bias (if the evaluator reversed its preference when the order was flipped). The distribution of these outcomes across perturbation types is shown in Figure 5.
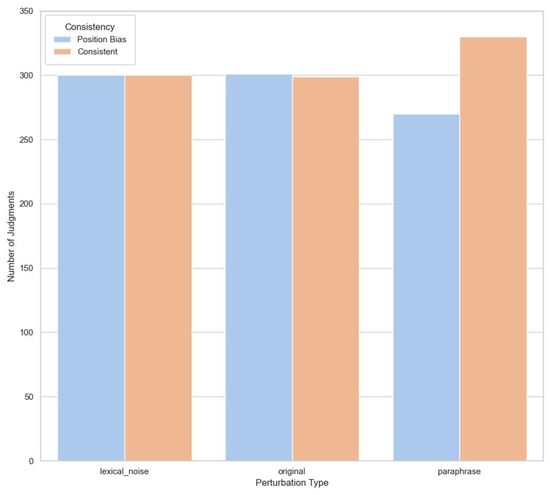
Figure 5.
Distribution of evaluation verdicts across different perturbation types. “Consistent” indicates identical judgments for AB and BA orderings; “Position Bias” indicates reversals due to response order.
The results reveal that lexical perturbations introduced the highest rate of verdict reversals, followed closely by paraphrased inputs. Even in the original (unperturbed) condition, nearly half of the comparisons exhibited position sensitivity. These trends suggest that LLM-based evaluators are not only influenced by response order but that this effect is amplified by superficial textual variations, even when the semantic content remains unchanged.
Lexical perturbations in this context included a range of small but deliberate transformations such as the following:
- Punctuation adjustments (e.g., inserting or removing commas, colons);
- Acronym formatting (e.g., “AI” → “A.I.”);
- Contraction expansions (“don’t” → “do not”);
- Mild synonym substitutions (“artificial intelligence” → “machine intelligence”);
- Hedging intensifiers (“should” → “might be advisable”).
While these changes may seem stylistically trivial, they often shifted evaluator preference, likely due to differences in fluency perception, syntactic rhythm, or how attention was distributed across tokens.
Paraphrasing, though more semantically impactful, had a slightly lower destabilizing effect—possibly because it affects both responses equally and preserves rhetorical balance. In contrast, minor lexical tweaks may subtly favor one response by improving or degrading perceived polish or assertiveness.
Taken together, these findings indicate that structural and lexical presentation artifacts interact with positional bias in non-trivial ways. Reliable evaluation pipelines must therefore account for such perturbation sensitivity to ensure that verdicts reflect semantic content rather than stylistic artifacts. Integrating lexical and rhetorical control checks into evaluation procedures may help improve fairness, especially in high-stakes or comparative benchmarking scenarios.
3.4. Semantic Analysis and Ranking Stability
Beyond pairwise verdicts and evaluator agreement, we investigated the semantic robustness of model rankings across diverse prompts. Specifically, we aimed to determine whether the relative ordering of models remained stable when measured locally—on a per-question basis—compared to the global ranking aggregated across all questions.
To quantify this, we computed Kendall’s Tau [25] for each of the ten evaluation prompts. For each question, we generated a local ranking of models based on their number of wins on that specific prompt. This was then compared to the global ranking derived from total wins across the entire evaluation set. Kendall’s Tau, a rank correlation coefficient ranging from −1.0 to 1.0, was used to assess the ordinal similarity between these two rankings.
Figure 6 displays the resulting distribution of Kendall’s Tau values—one per prompt. A score of τ = 1.0 indicates perfect agreement between local and global model orderings; τ = 0 reflects no correlation; and τ < 0 indicates partial or full reversal. The histogram shows how many questions yielded high, moderate, or low correlation. In this case, the Tau values are spread broadly, indicating that ranking stability varies significantly across prompts. A clustering near 1.0 would have suggested global consistency, but the observed dispersion reveals prompt-dependent variability. The Tau values in our analysis span from −0.60 to 1.00, with a mean of 0.50, revealing substantial variability across prompts.
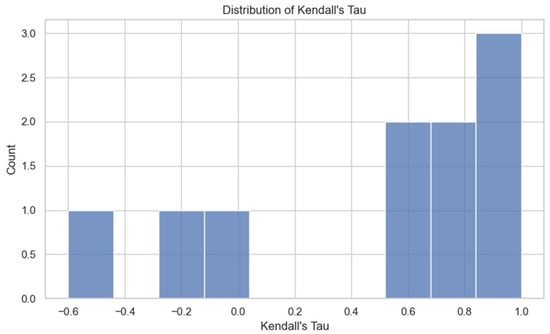
Figure 6.
Distribution of Kendall’s Tau coefficients computed between global model ranking and per-question local rankings.
This dispersion shows that model performance is not uniformly stable across semantic contexts. For some prompts, the local ranking closely mirrors the global trend, while, for others, models that generally performed well were locally outperformed. Such variation highlights how certain prompts—perhaps due to their topic, structure, or ethical framing—may favor specific model behaviors or reasoning styles.
These findings underscore the importance of evaluating ranking stability across tasks, not just aggregating overall performance. Even if global win rates suggest a clear model hierarchy, per-prompt analyses may reveal nuanced strengths and weaknesses. Incorporating semantic clustering or domain-aware grouping of prompts could further illuminate how instruction-tuned LLMs generalize—or fail to generalize—across question types.
Taken together, the results presented in this section provide a multifaceted view of LLM evaluation dynamics. We observed clear performance differences between candidate models, with gemma:7b-instruct leading overall win rates. While evaluator agreement was uniformly high, verdicts were often sensitive to response order, especially under lexical or paraphrased perturbations. Position bias remained prevalent despite prompt standardization, and Kendall’s Tau analysis revealed moderate instability in model rankings across prompts. These findings underscore the need for perturbation-aware, structure-sensitive, and semantically grounded evaluation protocols when benchmarking instruction-tuned LLMs.
4. Discussion
4.1. Interpretation of Results
The experimental results presented in this study reveal several important dynamics in the behavior of both evaluated models and model-based evaluators. First, we observed a clear performance hierarchy among the five instruction-tuned open-weight models. Contrary to the hypothesis of convergence among recent 7B–8B architectures, gemma:7b-instruct demonstrated consistently superior performance, while deepseek-r1:8b, despite its larger parameter count, ranked significantly lower across all evaluation dimensions. This disparity highlights that instruction tuning quality and alignment strategies remain decisive factors, even among models with similar architectural backbones.
Second, the analysis of mirrored comparisons (AB vs. BA) revealed a persistent position bias. Almost half of the pairwise evaluations were sensitive to response ordering, suggesting that evaluators tend to favor responses presented first unless explicitly instructed otherwise. This behavior was most pronounced under lexical perturbation conditions, indicating that even minor surface-level changes can interact with structural bias to influence verdicts.
Furthermore, the consistency observed among evaluators—where all LLM judges agreed in 100% of cases—suggests that the bias is not random or evaluator-specific but rather systematically shared across models. This convergence in judgment does not imply neutrality; rather, it reinforces the need to scrutinize shared biases that may be embedded in instruction-tuned evaluators.
Finally, the variability in Kendall’s Tau coefficients across prompts illustrates that semantic context matters. While some questions yielded local model rankings fully aligned with global trends, others produced reversed orders. This implies that a model’s relative strength can fluctuate significantly depending on the nature of the prompt—whether argumentative, ethical, or policy-oriented—thus challenging the reliability of global win-rate metrics as standalone indicators of general capability.
While several prior studies have reported instability or bias in LLM-based evaluation, most did so anecdotally or under uncontrolled settings [11,14,17]. Our findings provide quantitative confirmation of these concerns: nearly half of all verdicts were sensitive to response order, and semantic ranking stability varied substantially across prompts. Compared to works such as Arena [13] or Reflexion [16], which focus on judgment quality or agent refinement, our framework delivers reproducible, multi-evaluator diagnostics specifically targeted at bias detection and agreement consistency.
Unlike prior work, our framework does not rely on shared benchmark scores or datasets that would enable direct numerical comparison. This is because existing LLM-as-judge systems vary significantly in scope, prompt formats, and evaluation conditions. As a result, a performance comparison was not applicable. Instead, we provide a diagnostic infrastructure for controlled analysis of evaluator bias and verdict instability, which complements rather than replicates existing studies.
4.2. Methodological Implications
The results of this study offer several insights with direct implications for the design of evaluation frameworks that rely on LLM-based judges. Foremost among these is the importance of controlling for structural confounds such as response order, prompt phrasing, and lexical variability. Our findings demonstrate that these factors can substantially alter verdict outcomes, even when the semantic content of responses is preserved. As such, mirrored comparisons (AB and BA) should be treated not as optional diagnostics but as core components of any rigorous evaluation pipeline.
A second methodological insight concerns the role of prompt design. While all evaluators received the same rubric-based instruction set, the introduction of bias-injected prompts—explicitly discouraging order-based preferences—had a modest stabilizing effect on verdicts. This suggests that LLM evaluators, while sensitive to surface presentation, remain partially steerable via prompt framing. Prompt engineering should therefore be leveraged not only for generation but also to calibrate evaluator neutrality.
The use of linguistic perturbations, such as paraphrasing and lexical noise, revealed non-trivial sensitivity patterns. Notably, lexical alterations—though minor and semantically inert—produced the highest rates of position bias. This underscores the need for perturbation-aware evaluation schemes that test verdict robustness across different surface forms. Evaluation pipelines that do not include such checks risk drawing conclusions from artifacts of wording rather than meaningful model behavior.
Finally, the adoption of graph-based storage via Neo4j enabled a high degree of traceability and structural querying, which proved crucial for post hoc analysis. By encoding not just responses and verdicts but also their semantic relationships (e.g., REPHRASES, VARIANT_OF) and evaluation metadata, the framework facilitated advanced insights that would have been difficult to achieve using flat tabular data alone. This reinforces the value of semantic graph infrastructure in LLM evaluation studies—particularly when scaling to large datasets or longitudinal comparisons.
4.3. Practical Recommendations
Based on the empirical findings and methodological observations from this study, we outline several practical recommendations for researchers and practitioners designing or deploying LLM-based evaluation systems.
First, any evaluation framework that relies on LLMs as judges should incorporate mirrored comparisons as a default mechanism. Our analysis shows that nearly half of all verdicts were position-sensitive; thus, evaluating both AB and BA configurations is essential to detect and mitigate structural bias. Ignoring response order effects may lead to overestimating or underestimating model quality, depending on presentation artifacts.
Second, evaluators should be tested under multiple prompt formulations, including those with explicit debiasing instructions. While prompt injection alone does not eliminate bias, it can reduce its magnitude. Evaluation prompts should clearly define decision criteria (e.g., clarity, accuracy, depth, helpfulness) and include reinforcement of neutrality principles when comparing answers.
Third, model evaluation should not be conducted on canonical responses alone. Instead, comparisons should be validated across multiple response variants, including paraphrased and lexically perturbed versions. This approach helps distinguish verdicts driven by semantic reasoning from those influenced by stylistic or formatting features. Evaluations that yield drastically different outcomes under minor textual changes are unlikely to reflect stable preferences.
Fourth, designers of benchmark datasets should consider storing evaluation traces in structured, queryable formats, such as graph databases. As demonstrated in this study, graph-based representations support robust traceability, the semantic linkage between related responses, and longitudinal analysis of evaluator behavior. Flat CSV outputs or static scores do not provide the necessary granularity to investigate evaluator dynamics or track how judgments evolve over time or across perturbation types.
Finally, global win-rate metrics should be interpreted with caution. Our Kendall’s Tau analysis revealed that models can perform well overall but still be inconsistent on specific types of prompts. Practitioners should complement global scores with prompt-level diagnostics and visualize ranking volatility to avoid overgeneralized claims about model superiority.
This study also builds upon the authors’ prior experience in designing structured evaluation pipelines across applied domains. Previous research has explored the use of interpretable machine learning models for assessing behavioral patterns and clinical risks, including mobility decline in older adults, cardiovascular disease prediction, and venous thrombosis detection [26,27,28]. Although these earlier systems did not involve LLMs, they shared a methodological focus on automation, transparency, and traceability—principles that are directly extended and adapted here for the evaluation of language model outputs. This continuity of approach reinforces the applicability of the current framework beyond NLP, particularly in domains where robust and explainable model judgments are critical.
4.4. Limitations
While the evaluation framework presented in this study offers robust mechanisms for diagnosing bias and ensuring verdict traceability, several limitations should be acknowledged.
First, the evaluation was conducted using a relatively small prompt set consisting of ten open-ended questions. Although these were selected to elicit complex reasoning and argumentative responses, the limited number restricts the generalizability of findings. Certain phenomena—such as ranking reversals or semantic specialization—may be more or less pronounced in larger or more diverse prompt collections, including technical, factual, or adversarial questions.
Second, the candidate models were drawn exclusively from recent instruction-tuned, open-weight architectures in the 7B–8B parameter range. Larger proprietary models, multilingual LLMs, and smaller fine-tuned systems were not included. As such, the observed performance stratification and evaluator sensitivity may differ when the framework is applied to models with substantially different training profiles or target domains.
Third, all comparative judgments in this study were made by LLM-based evaluators. While this choice offers scalability and consistency, it also introduces potential shared biases that may go undetected without a human reference baseline. The absence of expert human annotation means that evaluator accuracy, as distinct from internal consistency, could not be validated directly.
Fourth, an additional concern is that evaluator models may exhibit structural bias toward candidate models with similar architecture or tuning. This possibility was not explicitly tested and represents a promising direction for future investigation.
Fifth, the framework focuses on binary pairwise comparisons, which may oversimplify nuanced model behaviors that emerge in multi-turn dialogue, collaborative tasks, or multi-choice settings. Extensions to more complex evaluation formats would require adapting the current schema and validation logic.
Finally, while the Neo4j-based graph representation supports rich structural analysis, it requires additional infrastructure and technical familiarity compared to conventional tabular workflows. Adoption by broader research communities may depend on the availability of higher-level abstractions or visual tools that simplify access to the underlying evaluation graph.
These limitations do not undermine the conclusions of this study but rather highlight important areas for future expansion, particularly in extending coverage, improving external validity, and integrating human-in-the-loop evaluation layers.
4.5. Future Work
The next phase of this research will focus on applying the Meta-Eval framework to a high-impact educational context: the automated evaluation of open-ended student responses using LLMs. Building on the strengths of pairwise comparison, bias diagnostics, and graph-based traceability, the proposed direction aims to develop a modular grading system that leverages rubric-based scoring to assess student answers in computer science and related technical domains.
This effort will be structured in multiple stages. Phase 1 will focus on demonstrating feasibility by evaluating a small set of real or simulated student responses using predefined rubrics (e.g., accuracy, clarity, structure, and terminology). Phase 2 will analyze evaluator consistency across multiple LLMs, measuring intra-model agreement and detecting potential biases in grading patterns. Phase 3 will extend the current Neo4j infrastructure to encode evaluation traces as a semantic graph—linking questions, student responses, rubric criteria, and LLM-generated scores—thereby enabling structured analysis and longitudinal feedback.
This future application offers both scientific and practical value. From a research perspective, it allows us to study the behavior of LLMs when applied to high-stakes educational tasks and to validate automated scoring against human-assigned grades. From an application standpoint, it holds promise for reducing instructor workload, improving feedback consistency, and offering students transparent and justifiable grading outcomes.
Beyond education, future iterations of the Meta-Eval architecture could support multilingual evaluation, multimodal reasoning tasks, or more complex interaction formats such as dialogues or debates. Developing a user-facing interface for graph navigation and evaluation visualization would also enhance adoption by non-technical users.
5. Conclusions
This study introduced a modular and extensible framework for evaluating LLMs using structured pairwise comparisons, perturbation-aware verdict tracking, and LLM-based judges. By systematically varying response order, prompt phrasing, and surface-level text perturbations, the framework enabled fine-grained analysis of evaluator behavior, bias sensitivity, and model performance stability.
The results revealed significant differences in model capability, with some instruction-tuned LLMs consistently outperforming others. Evaluator agreement was uniformly high across models, suggesting strong internal convergence in scoring behavior. However, verdict sensitivity to response order remained pervasive—particularly under lexical and paraphrased perturbations—indicating that even advanced evaluators can be influenced by superficial presentation effects. Additionally, semantic ranking stability varied across prompts, as shown by Kendall’s Tau analysis, reinforcing the need for evaluation designs that account for prompt-specific performance variance.
From a methodological perspective, the use of mirrored comparisons, multiple evaluators, and graph-based storage emerged as critical design elements for ensuring both fairness and transparency in LLM evaluation. The framework’s modularity and traceability offer a reproducible foundation for comparative benchmarking and bias auditing at scale.
Looking ahead, the next phase of this research will apply the framework to educational grading tasks, aiming to evaluate student responses through rubric-aligned LLM judgment. This direction bridges theoretical insights with practical impact, offering the potential to reduce grading effort while ensuring fairness, feedback quality, and evaluative consistency.
Together, these contributions underscore the need for evaluation pipelines that move beyond single-score metrics toward structurally grounded, perturbation-aware, and semantically robust model assessments.
Author Contributions
Conceptualization, C.A., A.A.A. and E.P.; methodology, C.A.; software, A.I., C.A. and A.A.A.; validation, C.A., C.A.A. and E.P.; data curation, A.C. and A.I.; writing—original draft preparation, C.A.; writing—review and editing, A.A.A., E.P. and A.C.; visualization, A.I. and A.C.; supervision, C.A. and C.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The source code of the main modules is available at https://github.com/anghelcata/dialectic-meta-eval.git (accessed on 14 July 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Google AI. Gemma Formatting and System Instructions. Available online: https://ai.google.dev/gemma/docs/formatting (accessed on 14 July 2025).
- Mistral AI. Latest Updates from Mistral AI. Available online: https://mistral.ai/news/ (accessed on 14 July 2025).
- Cognitive Computations. Dolphin-2.8-Mistral-7B. Available online: https://huggingface.co/cognitivecomputations/dolphin-2.8-mistral-7b-v02 (accessed on 14 July 2025).
- Hugging Face. Zephyr-7B-Beta Model Card. Available online: https://huggingface.co/HuggingFaceH4/zephyr-7b-beta (accessed on 14 July 2025).
- DeepSeek AI. DeepSeek-VL: Vision–Language Models by DeepSeek. Available online: https://github.com/deepseek-ai/DeepSeek-VL (accessed on 14 July 2025).
- Bernard, R.; Raza, S.; Das, S.; Murugan, R. EQUATOR: A Deterministic Framework for Evaluating LLM Reasoning with Open-Ended Questions. arXiv 2024. arXiv:2501.00257. [Google Scholar] [CrossRef]
- Hashemi, H.; Eisner, J.; Rosset, C.; Van Durme, B.; Kedzie, C. LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), Bangkok, Thailand, 11–16 August 2024. [Google Scholar] [CrossRef]
- Bhat, V. RubricEval: A Scalable Human–LLM Evaluation Framework for Open-Ended Tasks. Stanford CS224N Final Report. 2023. Available online: https://web.stanford.edu/class/cs224n/final-reports/256846781.pdf (accessed on 14 July 2025).
- Huang, X.; Ruan, W.; Huang, W.; Jin, G.; Dong, Y.; Wu, C.; Bensalem, S.; Mu, R.; Qi, Y.; Zhao, X.; et al. A Survey of Safety and Trustworthiness of Large Language Models Through the Lens of Verification and Validation. Artif. Intell. Rev. 2024, 57, 175. [Google Scholar] [CrossRef]
- Huang, X.; Ruan, W.; Huang, W.; Jin, G.; Dong, Y. A Survey of Safety and Trustworthiness of Large Language Models Through the Lens of Verification and Validation. arXiv 2024. [Google Scholar] [CrossRef]
- Chan, C.; Chen, W.; Su, Y.; Yu, J.; Xue, W.; Zhang, S.; Fu, J.; Liu, Z. ChatEval: Towards Better LLM-Based Evaluators Through Multi-Agent Debate. In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024), Vienna Austria, 7–11 May 2024; Available online: https://openreview.net/forum?id=FQepisCUWu (accessed on 14 July 2025).
- Jin, Y.; Zhao, Q.; Wang, Y.; Chen, H.; Zhu, K.; Xiao, Y.; Wang, J. AgentReview: Exploring Peer Review Dynamics with LLM Agents. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), Singapore, 6–10 November 2024. [Google Scholar] [CrossRef]
- Li, T.; Chiang, W.; Frick, E.; Dunlap, L.; Wu, T.; Zhu, B.; Gonzalez, J.E.; Stoica, I. From Live Data to High-Quality Benchmarks: The ArenaHard Pipeline. LMSYS Blog, 19 April 2024. Available online: https://lmsys.org/blog/2024-04-19-arena-hard (accessed on 14 July 2025).
- Scherrer, N.; Shi, C.; Feder, A.; Blei, D. Evaluating the Moral Beliefs Encoded in LLMs. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; Available online: https://openreview.net/forum?id=O06z2G18me (accessed on 14 July 2025).
- Feng, Z.; Zhang, Y.; Li, H.; Wu, B.; Liao, J.; Liu, W.; Lang, J.; Feng, Y.; Wu, J.; Liu, Z. TEaR: Improving LLM-Based Machine Translation with Systematic Self-Refinement. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025, Mexico City, Mexico, 16–21 June 2025. [Google Scholar] [CrossRef]
- Shinn, N.; Cassano, F.; Gopinath, A.; Naranghan, K.; Yao, S. Reflexion: Language Agents with Verbal Reinforcement Learning. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; Available online: https://papers.nips.cc/paper_files/paper/2023/file/1b44b878bb782e6954cd888628510e90-Paper-Conference.pdf (accessed on 14 July 2025).
- Panickssery, A.; Bowman, S.R.; Feng, S. LLM Evaluators Recognize and Favor Their Own Generations. In Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, 9–15 December 2024; Available online: https://papers.nips.cc/paper_files/paper/2024/hash/7f1f0218e45f5414c79c0679633e47bc-Abstract-Conference.html (accessed on 14 July 2025).
- Li, G.; Hammoud, H.A.A.K.; Itani, H.; Khizbullin, D.; Ghanem, B. CAMEL: Communicative Agents for ‘Mind’ Exploration of Large Language Model Society. arXiv 2023. arXiv:2303.17760. [Google Scholar] [CrossRef]
- Chen, G.; Dong, S.; Shu, Y.; Zhang, G.; Sesay, J.; Karlsson, B.; Fu, J.; Shi, Y. AutoAgents: A Framework for Automatic Agent Generation. arXiv 2023, arXiv:2309.17288. [Google Scholar] [CrossRef]
- Kim, A.; Kim, K.; Yoon, S. DEBATE: Devil’s Advocate-Based Assessment and Text Evaluation. In Findings of the Association for Computational Linguistics; Association for Computational Linguistics: Bangkok, Thailand, 2024. [Google Scholar] [CrossRef]
- Perin, G.; Chen, X.; Liu, S.; Kailkhura, B.; Wang, Z.; Gallagher, B. RankMean: Module-Level Importance Score for Merging Fine-Tuned LLM Models. In Findings of the Association for Computational Linguistics; Association for Computational Linguistics: Bangkok, Thailand, 2024. [Google Scholar] [CrossRef]
- Du, Y.; Li, S.; Torralba, A.; Tenenbaum, J.B.; Mordatch, I. Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv 2023. arXiv:2305.14325. [Google Scholar] [CrossRef]
- Ni, H. Extracting Insights from Unstructured Data with LLMs & Neo4j. Medium. 2025. Available online: https://watchsound.medium.com/extracting-insights-from-unstructured-data-with-llms-neo4j-914b1f193c64 (accessed on 14 July 2025).
- Rebmann, A.; Schmidt, F.D.; Glavaš, G.; van der Aa, H. On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks. arXiv 2025, arXiv:2504.21074. [Google Scholar] [CrossRef]
- Maurice, G. Kendall. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Susnea, I.; Pecheanu, E.; Cocu, A.; Istrate, A.; Anghel, C.; Iacobescu, P. Non-Intrusive Monitoring and Detection of Mobility Loss in Older Adults Using Binary Sensors. Sensors 2025, 25, 2755. [Google Scholar] [CrossRef] [PubMed]
- Iacobescu, P.; Marina, V.; Anghel, C.; Anghele, A.-D. Evaluating Binary Classifiers for Cardiovascular Disease Prediction: Enhancing Early Diagnostic Capabilities. J. Cardiovasc. Dev. Dis. 2024, 11, 396. [Google Scholar] [CrossRef] [PubMed]
- Anghele, A.-D.; Marina, V.; Dragomir, L.; Moscu, C.A.; Anghele, M.; Anghel, C. Predicting Deep Venous Thrombosis Using Artificial Intelligence: A Clinical Data Approach. Bioengineering 2024, 11, 1067. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).