
Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering




Abstract
1. Introduction
2. Related Works
2.1. Phishing URL Detection with Traditional Machine Learning
2.2. Deep Learning and Large Language Models in Security
3. Experimental Setup
3.1. Open-Source LLMs Evaluated
- Meta LLaMA Family: Llama3 (8B and 70B), Llama3.1 (8B and 70B), Llama3.2 (3B), and Llama3.3 (70B)—hypothetical successive improvements of Meta’s LLaMA model series. Parameter counts are indicated by numerical suffixes (e.g., 8B denotes 8 billion parameters).
- Google Gemma 2: Gemma2 variants (2B, 9B, and 27B)—models introduced by Google, designed for efficient multilingual task performance, with the 27B model demonstrating particularly strong capabilities.
- Alibaba Qwen Family: Qwen-7B, Qwen2-7B, and Qwen2.5-7B—iterations of Alibaba’s Qwen model, progressively enhanced for broader general-purpose tasks. Each numerical suffix indicates the parameter size, and successive versions incorporate iterative improvements in architecture and training methodologies.
- Microsoft Phi Family: Phi-3 14B and Phi-4 14B—two models from Microsoft’s Phi series, notable for their relatively smaller size yet exceptional reasoning capabilities. Phi-4, in particular, has been reported to achieve competitive performance relative to significantly larger models due to advanced training methods and synthetic data integration.
- Mistral Family: Mistral-small 24B—based on the Mistral architecture, which garnered attention for its efficient yet strong performance. This 24B variant is evaluated as a representative of mid-scale models.
- DeepSeek Series: DeepSeek R1 variants (1.5B, 7B, 8B, 14B, 32B, and 70B)—a series of open-source models designed for general-purpose tasks, emphasizing scalability and open-source model advancements. The range from very small (1.5B) to very large (70B) allows for the examination of scaling effects within the same family.
3.2. Hardware and Environment
3.3. Dataset and Preprocessing
3.4. Prompt Engineering Techniques
- Zero-shot prompting: This is the simplest approach where the model is directly asked to classify the URL with no examples or role context. We formulated a straightforward instruction, and the model is expected to output a label or a brief answer (e.g., “Phishing” or “Legitimate”). This method leverages the model’s learned knowledge directly, with no additional guidance beyond the question. Listing 1 shows a zero-shot prompting template.
| Listing 1. Zero-shot prompting template |
 |
- Role-playing prompting: In this approach, we asked the model to adopt a specific role or persona relevant to the task. We prompted the model as if it were a cybersecurity analyst or phishing detection expert. Listing 2 shows the role-playing prompting template. By role-playing, we hope the model will internalize the instruction and provide a more informed and context-aware response, potentially improving accuracy. The model might respond with something like: “As a cybersecurity expert, I notice the URL has an IP address instead of a domain, which is suspicious... Therefore, this looks like a phishing URL”.
| Listing 2. Role-playing prompting template |
 |
- Chain-of-thought prompting: Chain-of-thought prompting encourages the model to think step by step and articulate its reasoning before arriving at a final answer. Listing 3 shows the CoT prompting template. Our CoT prompt asked the model to first enumerate a reasoning process, “Let’s reason this out. Is the URL <URL> phishing? Think step by step”, and then after the reasoning, provide a final verdict (phishing or legitimate). The expectation, based on prior work, is that some models might perform better when they explicitly reason about features of the URL (e.g., “The domain looks like paypal.com but has an extra token, which is a known phishing trick, so...”). We included instructions for the model to output the final answer clearly (such as prefixing it with “Final answer:”). This technique has yielded gains for powerful models on various tasks that benefit from intermediate reasoning [23]. However, it also introduces the risk of the model “overthinking” a simple decision, and it certainly increases the amount of text the model must generate for each query, which can slow down inference.
| Listing 3. Chain-of-thought prompting template |
  |
- Few-shot prompting: Few-shot prompting provides the model with a couple of example cases (input–output pairs) before asking it to handle the new input [23]. We constructed a prompt that included a small number of example URLs along with their correct classification as shown in Listing 4. The few-shot examples were chosen to be illustrative of various phishing tactics (like deceptive subdomains, HTTP vs. HTTPS usage, and IP address links) and legitimate URLs. The expectation is that by seeing these examples, an LLM can induce the pattern of the task (much like how GPT-3 demonstrated few-shot learning abilities [23]), potentially improving its accuracy on the test URL. Few-shot prompting essentially primes the model with a mini training set in the prompt itself.
| Listing 4. Few-shot prompting template |
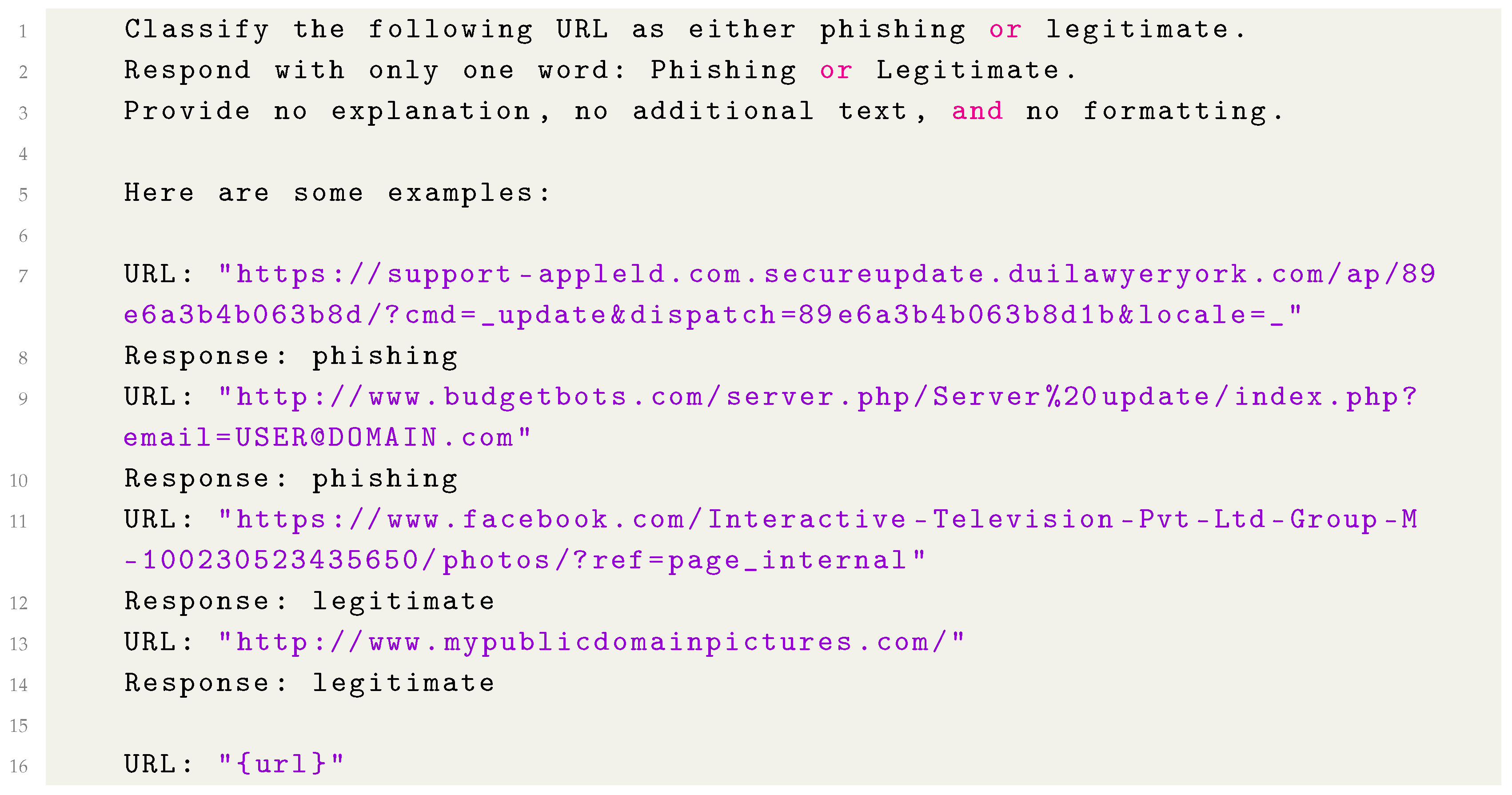 |
3.5. Evaluation Metrics and Procedure
- Accuracy is the overall percentage of URLs correctly classified (phishing identified as phishing and legitimate as legitimate).
- Precision (Positive Predictive Value) = TP/(TP + FP)—the fraction of URLs the model flagged as “phishing” that were actually phishing. High precision means few false alarms (false positives).
- Recall (True Positive Rate) = TP/(TP + FN)—the fraction of actual phishing URLs that the model successfully caught. High recall means few phishing attempts slip past undetected (low false negatives).
- F1-score is the harmonic mean of precision and recall: 2 ∗ Precision ∗ Recall/(Precision + Recall). F1 is a balanced measure that is useful when one wants to account for both error types and the classes are balanced (as in our dataset).
4. Results
4.1. Classification Performance of Different Models and Prompts
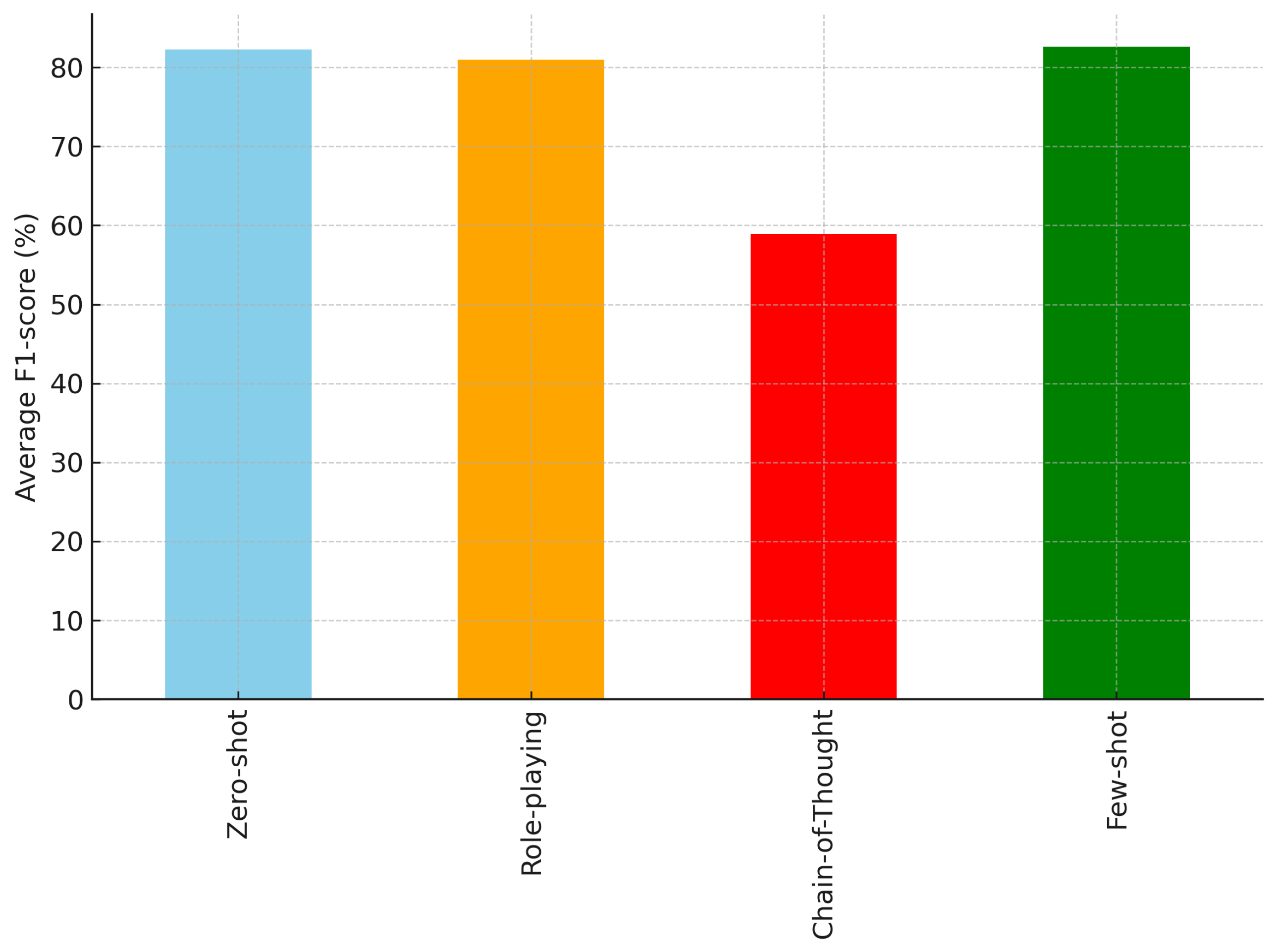
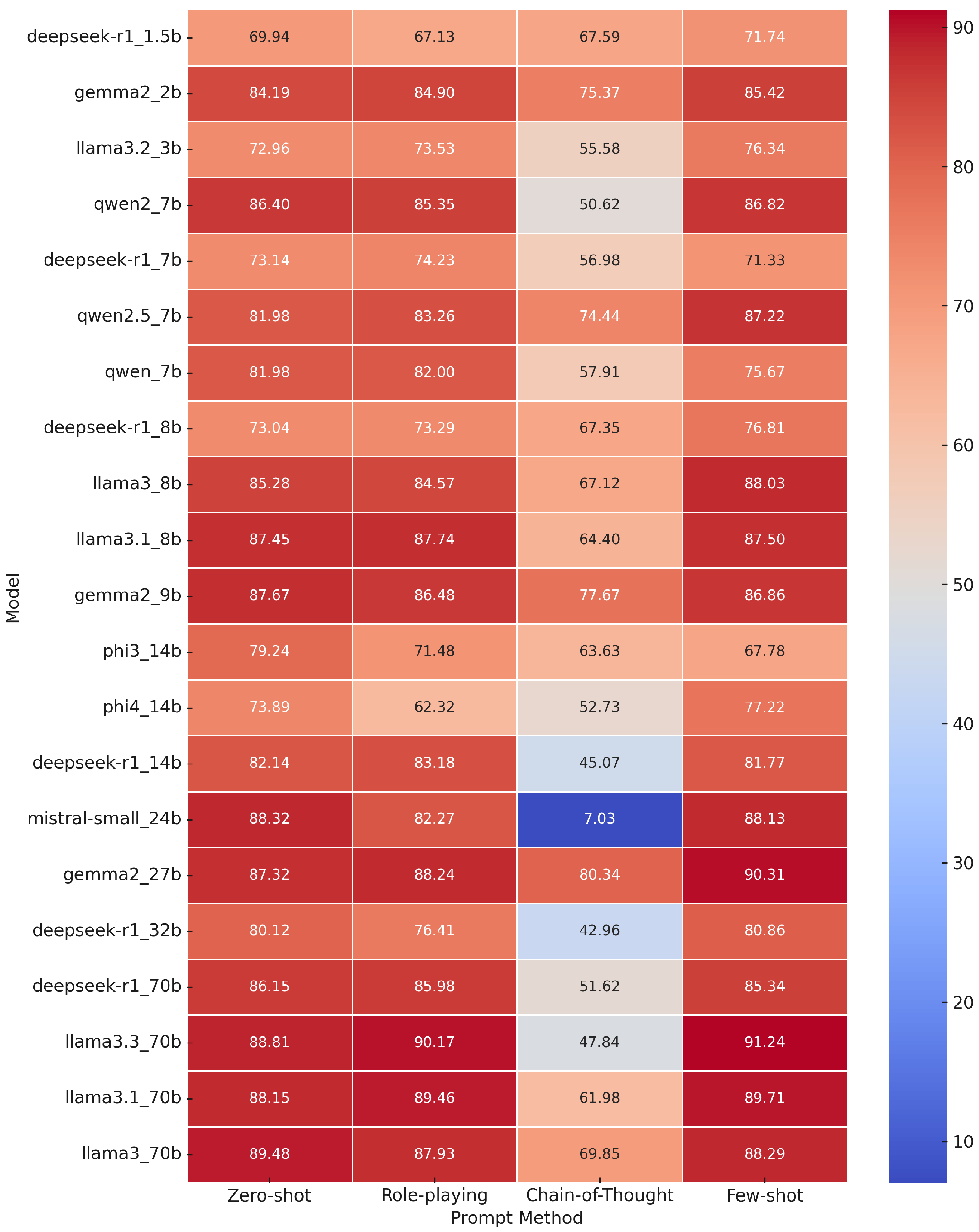
- Few-shot prompting emerged as the best overall strategy. For the vast majority of models, the highest F1-score is achieved with the few-shot prompt (as indicated in bold for a few notable models). The average F1 across all models in the few-shot setting was 82.6%, slightly higher than zero-shot (82.3%) and substantially higher than role-playing (80.9%). Every model of moderate to large size (9B and above) reached its peak performance with the few-shot prompt, often gaining 1–3 percentage points in F1 over zero-shot. For example, the 70B models (“llama3.3_70b” and others) all exceeded 89–90% F1 with few-shot, whereas they were in the high 80s with zero-shot. Llama3.3_70b (70B) in particular achieved the top F1 of 91.24% with few-shot prompting, which is an excellent result on this task—approaching the performance of Claude 2 (92.7% F1) reported by prior work [11]. The few-shot examples likely provided helpful context, effectively teaching the model the concept of phishing detection on-the-fly [23].
- Zero-shot prompting is surprisingly strong and often nearly as good as few-shot for many models. Several models (e.g., llama3_70b with 89.48% F1 zero-shot vs. 88.29% F1 few-shot) actually performed slightly better in zero-shot than few-shot, though by a negligible margin. The differences between zero-shot and role-playing for large models are also small in many cases. This indicates that the largest models might already have sufficient knowledge to perform well without needing examples or elaborate role context. For instance, Llama3_70b led in zero-shot with 89.48% F1. On the other hand, smaller models (below 10B) generally benefited more from few-shot—e.g., llama3.2_3b improved from 72.96% to 76.34% F1 with few-shot, a noticeable jump for a 3B model.
- Role-playing prompts had mixed results. On average, the role persona prompt (acting as a security expert) yielded slightly lower F1 than zero-shot. Some models did improve with role-playing—e.g., llama3.1_8b went from 87.45% (zero-shot) to 87.74% (role), and llama3.3_70b from 88.81% to 90.17%. Claude 2 in the closed-model study similarly saw a benefit from the role-playing prompt [11]. In our case, the largest models seem to respond well to role hints, but a few models were hurt by it. One extreme case is mistral-small_24b, which dropped from 88.32% F1 zero-shot to 82.27% with the role prompt. It appears that the role-playing instruction may have confused some models or caused them to output lengthier explanations (which might have made extracting the final answer harder). Overall, the role prompt was not consistently beneficial across the board, though for some top models it was on par with zero-shot performance.
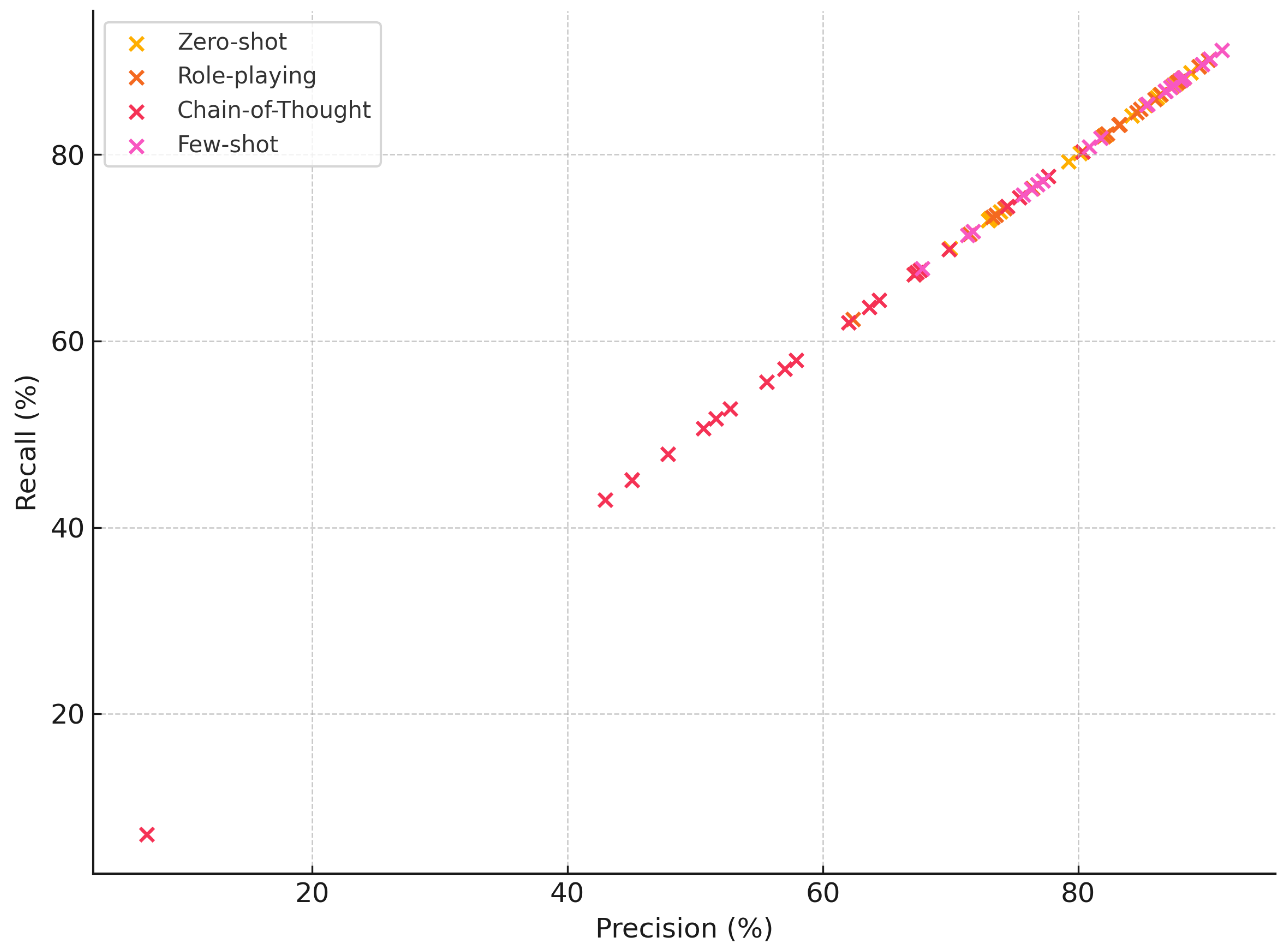
- Chain-of-thought prompting was largely detrimental for this task and these models. This is a striking result: nearly every model saw a large drop in F1 when asked to produce a reasoning chain. The average F1 plummeted to 59% with CoT, compared to 82% with other methods. Some models completely failed in this mode. The most dramatic was again mistral-small_24b, which fell to an abysmal 7.03% F1—essentially failing to correctly classify almost any phishing instances with CoT. We suspect that certain models might not have properly followed the prompt to give a final answer after reasoning, or their reasoning text confounded our simple output parsing. On the flip side, a few models handled CoT relatively well: the Gemma2 series (2b, 9b, and 27b) models stand out, achieving 75–80% F1 with CoT. In fact, gemma2_27b maintained a strong 80.34% F1 with CoT, only modestly lower than its 87–90% with other prompts. This suggests that some models (perhaps those fine-tuned to follow instructions or reason, like the Gemma2 family) can utilize chain-of-thought without completely losing accuracy. However, the largest LLaMA-based models (70B) all saw drops: e.g., llama3_70b went from 89 F1 zero-shot to 69.85% F1 with CoT. Interestingly, in those cases, the recall often remained high but precision dropped significantly, meaning the model would label almost everything as “phishing” when reasoning step-by-step (catching all true phishing but also flagging many legitimate as phishing, hence precision tanked). This aligns with the idea that forcing a model to explain can sometimes lead it to be overly cautious or to apply some memorized rule too broadly.
- The best prompting method was few-shot, giving the top results around 90–91% F1. While few-shot prompting generally yielded the highest F1-scores across models, this trend was not universal. For example, Llama3_70b achieved a slightly higher F1-score with zero-shot prompting (89.48%) compared to its few-shot counterpart (88.29%). Similar patterns were observed with a few other large models, suggesting that for certain architectures, the inherent pre-training quality may be sufficient to generalize well without additional in-context examples. These exceptions underscore that prompt effectiveness is model-dependent, and few-shot prompting, while often beneficial, should not be assumed as optimal in all cases.
- Model size and quality matter—the 70B models and the well-tuned 27B model (Gemma2) dominated the top of the leaderboard. Some mid-size models like Mistral-small 24B and Gemma2 27B actually rivaled the 70B models in zero-shot and few-shot, showing that a well-designed 20–30B model can be as effective as a generic 70B model for this task. In fact, Mistral 24B had 88.3% F1 zero-shot, slightly above some 70B variants (like llama3.1_70b at 88.15%). This is encouraging as smaller models are cheaper to run. On the flip side, extremely small models (below 7B) struggled—e.g., DeepSeek-1.5B was around 70% F1, which is only slightly better than random guessing on this balanced set, missing many phishing cases. So, there is a parameter threshold (somewhere around 2–3B) beyond which the model has enough capacity/knowledge to perform this task reasonably well. The range of 7–13B models generally landed in the 80–88% F1 range with good prompting (e.g., Qwen-7B, 86–87% F1).
- The prompting strategy impacts are clear: unless a task truly needs step-by-step reasoning, chain-of-thought prompting might be unnecessary and even harmful. Few-shot example-based prompting appears to give consistent gains and should be part of the toolkit for deploying LLMs in phishing detection. Role-based prompting can be tried, but one should verify its effect on the particular model—it is not universally helpful.
4.2. Inference Efficiency and Execution Time
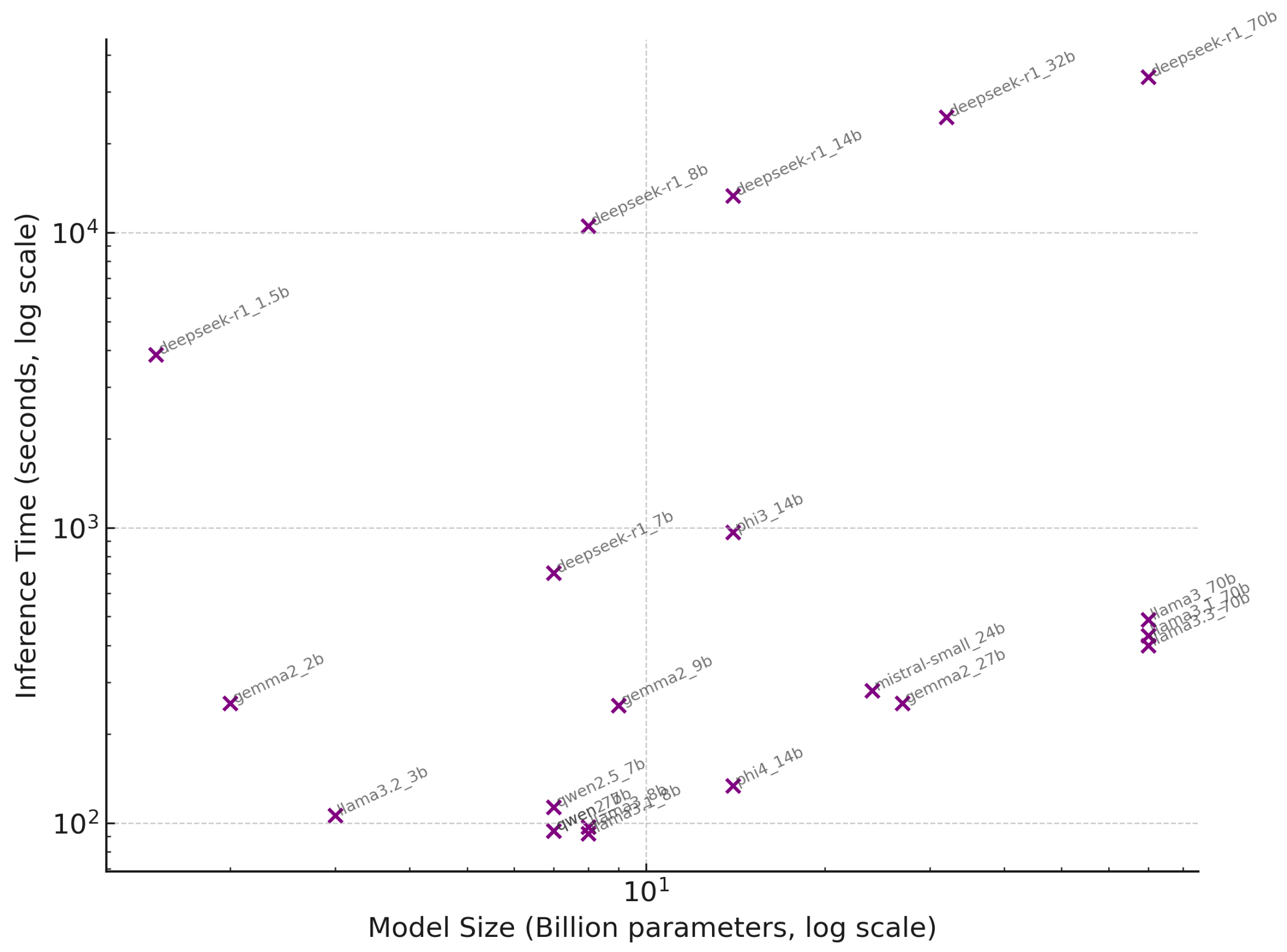
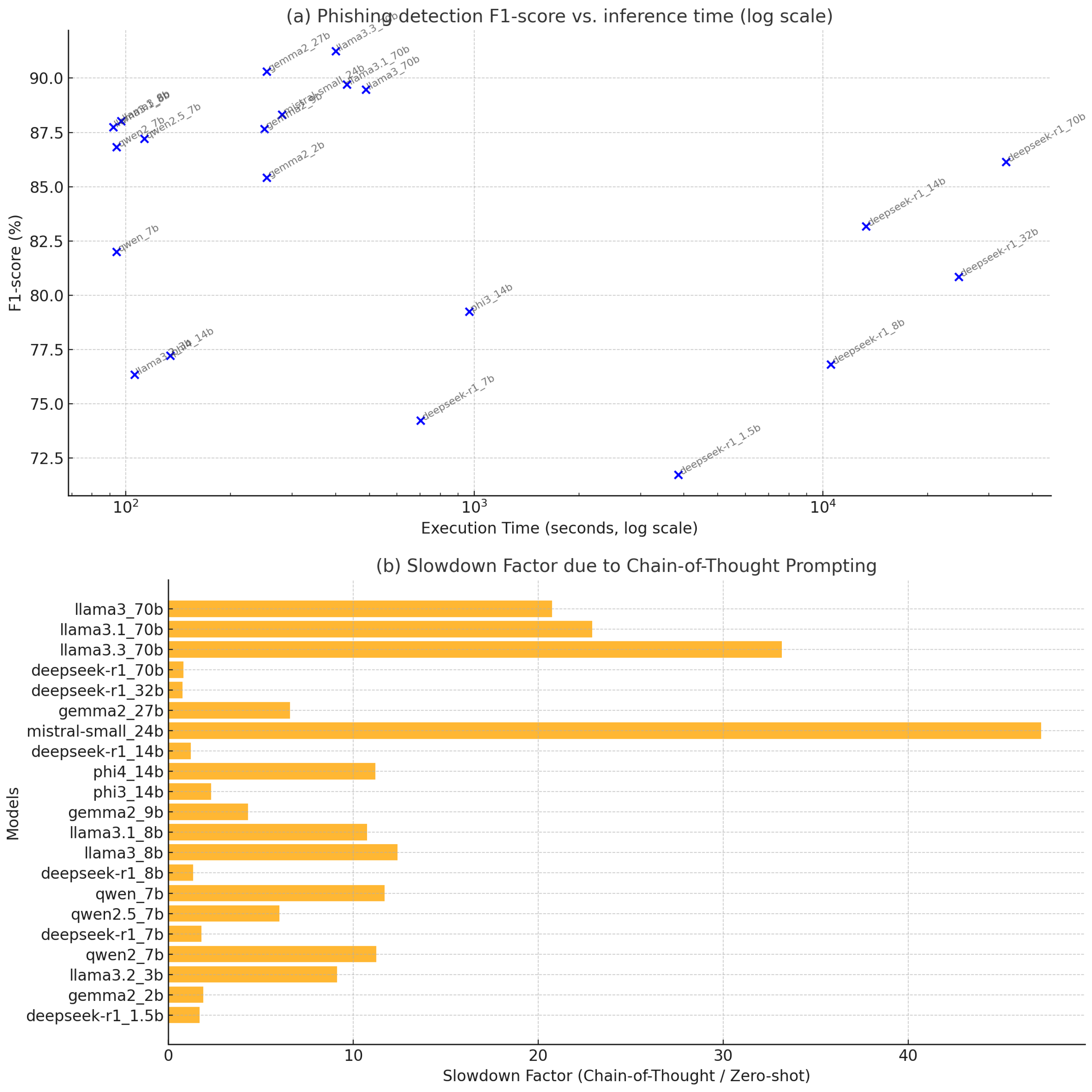
- Model size vs. speed: In general, larger models took longer, but the relationship was not strictly linear and was influenced by model optimizations. For example, in the zero-shot setting, a 7B model like Qwen-7B took about 94 s to run all 1000 URLs, whereas the 70B model (llama3_70b) took 488 s. Roughly, the 70B model was five times slower for 10× the parameter count, which is actually an efficient scaling (thanks to optimized matrix multiplication on our hardware). Another 70B variant (llama3.3_70b) was a bit faster at 400 s, possibly due to using 4-bit quantization. Mid-sized models like 27B and 24B took around 250–280 s, and 13–14B models ranged widely (one “phi4_14b” was quite fast at 134s, whereas “phi3_14b” took 967s, indicating differences in their implementations). Notably, one of the smallest models, DeepSeek-R1 1.5B, was extremely slow at 3854 s (over an hour) for 1000 URLs. This is likely due to the lack of optimization (perhaps it was run on CPU or under an inefficient configuration). In fact, all DeepSeek models were outliers: DeepSeek 8B took 10,540 s, 14B took 13,323 s, and the 70B a whopping 33,586 s (9.3 h) for just 1000 inferences. This suggests that the DeepSeek models were not using GPU acceleration effectively, or had very slow generation (possibly they were not instruction-tuned and thus took many tokens to produce an answer). By contrast, other models of similar size (e.g., LLaMA 7B, 13B, and 70B) clearly were leveraging optimized inference. In a deployment scenario, one would avoid using a model that takes seconds per URL if a competitor model can complete it in 0.1 s with similar accuracy.
- Prompt complexity vs. speed: The length of the prompt and output affected runtime. Zero-shot and role-playing prompts are relatively short (just the instruction and URL, and the output is a one-word answer). Few-shot prompts are longer (they include multiple example URLs and labels), which means the model has to process more tokens for each inference, slowing it down somewhat. We found few-shot prompting to incur a minor overhead: on average few-shot runs were 5–10% slower than zero-shot for the same model. For instance, Qwen-7B zero-shot was 94 s, and with few-shot it was 99 s. This overhead is due to the extra tokens in the prompt that the model must read each time, plus possibly longer outputs if it mirrors the example format. Chain-of-thought prompting, however, had a drastic impact on speed. Because CoT prompts encourage the model to generate a reasoning sequence (several sentences) before the final answer, the number of output tokens per query balloons. As a result, inference time roughly doubled (or worse) under CoT prompting for every model. The average total time for 1000 URLs with CoT was 9896 s versus 4770 s in zero-shot (a 2× increase) across models. For example, Llama3.3-70B took 13,264 s with CoT compared to 400 s zero-shot—over 33× slower! Even small models saw their time shoot up: the 3B model went from 106 s with zero-shot to 968 s with CoT, a 9× slowdown. The reasoning text essentially multiplies the work. This clearly demonstrates a trade-off: while CoT might sometimes boost accuracy (as seen in GPT-3.5 earlier [11]), it comes at a heavy cost in speed. In our case, CoT did not even boost accuracy for open models, so it was all cost and no benefit.
- Fastest models: The absolute fastest run in our tests was by one of the LLaMA-derived 8B models (llama3.1_8b) at about 92 s for 1000 URLs. This equates to 0.092 s per URL on average, or about 11 URLs per second, which is quite usable. Qwen-7B was close at 94s. These models likely utilized GPU and had a relatively small context length (prompt + output) to process. Using a larger batch (feeding multiple URLs at once) could further increase throughput, but we performed this one by one for fidelity to the prompt method.
- Slowest models: As mentioned, DeepSeek models were anomalously slow (taking hours). Excluding those, the slowest was phi3_14b at 967 s with zero-shot—possibly that model had some inefficiency. Most others were within 500 s even up to 70B. This indicates that with proper optimization, even a 70B model can process two URLs per second on a high-end GPU. If we needed to scale to millions of URLs per day (10 per second continuously), a single 70B model instance might fall short, but a cluster or a smaller model could handle it.
5. Discussion
5.1. Open-Source LLMs Can Achieve High Phishing Detection Performance via Prompting
5.2. Prompting Strategies Matter: Few-Shot Outperforms Chain-of-Thought
5.3. Model Size vs. Efficiency Trade-Off
5.4. Limitations and Error Analysis
5.5. Deployment Considerations
5.6. Future Improvements and Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IBM Security. Cost of a Data Breach Report 2024. 2024. Available online: https://www.ibm.com/reports/data-breach (accessed on 31 March 2025).
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Zhao, X.; Langlois, K.; Furst, J.; McClellan, S.; Fleur, R.; An, Y.; Hu, X.; Uribe-Romo, F.; Gualdron, D.; Greenberg, J. When LLM Meets Material Science: An Investigation on MOF Synthesis Labeling. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 6320–6321. [Google Scholar] [CrossRef]
- Hu, H.; Yan, J.; Zhang, X.; Jiao, Z.; Tang, B. Overview of CHIP2023 Shared Task 4: CHIP-YIER Medical Large Language Model Evaluation. In Communications in Computer and Information Science; Springer Nature: Singapore, 2024; pp. 127–134. [Google Scholar] [CrossRef]
- Schur, A.; Groenjes, S. Comparative Analysis for Open-Source Large Language Models. In Communications in Computer and Information Science; Springer Nature: Cham, Switzerland, 2024; pp. 48–54. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A Review on Large Language Models: Architectures, Applications, Taxonomies, Open Issues and Challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Ahmed, T.; Piovesan, N.; De Domenico, A.; Choudhury, S. Linguistic Intelligence in Large Language Models for Telecommunications. In Proceedings of the 2024 IEEE International Conference on Communications Workshops (ICC Workshops), Denver, CO, USA, 9–13 June 2024; pp. 1237–1243. [Google Scholar] [CrossRef]
- Hidayat, F.; Nasution, A.H.; Ambia, F.; Putra, D.F.; Mulyandri. Leveraging Large Language Models for Discrepancy Value Prediction in Custody Transfer Systems: A Comparative Analysis of Probabilistic and Point Forecasting Approaches. IEEE Access 2025, 13, 65643–65658. [Google Scholar] [CrossRef]
- Khalila, Z.; Nasution, A.H.; Monika, W.; Onan, A.; Murakami, Y.; Radi, Y.B.I.; Osmani, N.M. Investigating Retrieval-Augmented Generation in Quranic Studies: A Study of 13 Open-Source Large Language Models. Int. J. Adv. Comput. Sci. Appl. 2025, 16. [Google Scholar] [CrossRef]
- Nasution, A.H.; Onan, A. ChatGPT Label: Comparing the Quality of Human-Generated and LLM-Generated Annotations in Low-Resource Language NLP Tasks. IEEE Access 2024, 12, 71876–71900. [Google Scholar] [CrossRef]
- Trad, F.; Chehab, A. Prompt engineering or fine-tuning? a case study on phishing detection with large language models. Mach. Learn. Knowl. Extr. 2024, 6, 367–384. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, Y.; Yang, X.; Chen, T.; Cheng, X.; Cheng, W. From sample poverty to rich feature learning: A new metric learning method for few-shot classification. IEEE Access 2024, 12, 124990–125002. [Google Scholar] [CrossRef]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based on rough set theory. Expert Syst. Appl. 2014, 41, 5948–5959. [Google Scholar] [CrossRef]
- Koide, T.; Fukushi, N.; Nakano, H.; Chiba, D. Chatspamdetector: Leveraging large language models for effective phishing email detection. arXiv 2024, arXiv:2402.18093. [Google Scholar]
- Heiding, T.; Schiele, T.; Reuter, C. Large Language Models for Phishing Email Detection: GPT-4 vs. Humans. In Proceedings of the 2023 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Delft, The Netherlands, 3–7 July 2023; pp. 269–275. [Google Scholar]
- Trad, B.; Chehab, L. Prompting Large Language Models for Phishing URL Detection. arXiv 2023, arXiv:2311.01786. [Google Scholar]
- Hannousse, A.; Yahiouche, S. Towards benchmark datasets for machine learning based website phishing detection: An experimental study. Eng. Appl. Artif. Intell. 2021, 104, 104347. [Google Scholar] [CrossRef]
- Haq, Q.E.u.; Faheem, M.H.; Ahmad, I. Detecting Phishing URLs Based on a Deep Learning Approach to Prevent Cyber-Attacks. Appl. Sci. 2024, 14, 10086. [Google Scholar] [CrossRef]
- Heiding, F.; Schneier, B.; Vishwanath, A.; Bernstein, J.; Park, P.S. Devising and detecting phishing: Large language models vs. smaller human models. arXiv 2023, arXiv:2308.12287. [Google Scholar]
- Nicklas, F.; Ventulett, N.; Conrad, J. Enhancing Phishing Email Detection with Context-Augmented Open Large Language Models. In Proceedings of the Upper-Rhine Artificial Intelligence Symposium, Offenburg, Germany, 13–14 November 2024; pp. 159–166. [Google Scholar]
- Liu, R.; Geng, J.; Wu, A.J.; Sucholutsky, I.; Lombrozo, T.; Griffiths, T.L. Mind your step (by step): Chain-of-thought can reduce performance on tasks where thinking makes humans worse. arXiv 2024, arXiv:2410.21333. [Google Scholar]
- Hannousse, A.; Yahiouche, S. Web page phishing detection. Mendeley Data 2021, 3, 2021. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D.; Ichter, B. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Wang, Y.; Liu, X.; Peng, N. The Pitfalls of Chain-of-Thought Prompting: Contamination, Misinterpretation, and Overthinking. arXiv 2024, arXiv:2401.01482. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Zero-Shot F1 (%) | Role-Playing F1 (%) | Chain-of-Thought F1 (%) | Few-Shot F1 (%) |
|---|---|---|---|---|
| deepseek-r1_1.5b | 69.94 | 67.13 | 67.59 | 71.74 |
| gemma2_2b | 84.19 | 84.90 | 75.37 | 85.42 |
| llama3.2_3b | 72.96 | 73.53 | 55.58 | 76.34 |
| qwen2_7b | 86.40 | 85.35 | 50.62 | 86.82 |
| deepseek-r1_7b | 73.14 | 74.23 | 56.98 | 71.33 |
| qwen2.5_7b | 81.98 | 83.26 | 74.44 | 87.22 |
| qwen_7b | 81.98 | 82.00 | 57.91 | 75.67 |
| deepseek-r1_8b | 73.04 | 73.29 | 67.35 | 76.81 |
| llama3_8b | 85.28 | 84.57 | 67.12 | 88.03 |
| llama3.1_8b | 87.45 | 87.74 | 64.40 | 87.50 |
| gemma2_9b | 87.67 | 86.48 | 77.67 | 86.86 |
| phi3_14b | 79.24 | 71.48 | 63.63 | 67.78 |
| phi4_14b | 73.89 | 62.32 | 52.73 | 77.22 |
| deepseek-r1_14b | 82.14 | 83.18 | 45.07 | 81.77 |
| mistral-small_24b | 88.32 | 82.27 | 7.03 | 88.13 |
| gemma2_27b | 87.32 | 88.24 | 80.34 | 90.31 |
| deepseek-r1_32b | 80.12 | 76.41 | 42.96 | 80.86 |
| deepseek-r1_70b | 86.15 | 85.98 | 51.62 | 85.34 |
| llama3.3_70b | 88.81 | 90.17 | 47.84 | 91.24 |
| llama3.1_70b | 88.15 | 89.46 | 61.98 | 89.71 |
| llama3_70b | 89.48 | 87.93 | 69.85 | 88.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasution, A.H.; Monika, W.; Onan, A.; Murakami, Y. Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering. Information 2025, 16, 366. https://doi.org/10.3390/info16050366
Nasution AH, Monika W, Onan A, Murakami Y. Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering. Information. 2025; 16(5):366. https://doi.org/10.3390/info16050366
Chicago/Turabian StyleNasution, Arbi Haza, Winda Monika, Aytug Onan, and Yohei Murakami. 2025. "Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering" Information 16, no. 5: 366. https://doi.org/10.3390/info16050366
APA StyleNasution, A. H., Monika, W., Onan, A., & Murakami, Y. (2025). Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering. Information, 16(5), 366. https://doi.org/10.3390/info16050366