
Distantly Supervised Relation Extraction Method Based on Multi-Level Hierarchical Attention


Abstract
1. Introduction
- We propose a hierarchical structure encoder using GATs to explore the relational details within the hierarchy, establishing new pathways for knowledge transmission and generating relation embeddings that capture the global hierarchical structure.
- We introduce a multi-level classification framework integrated with hierarchical attention, enabling relation classification across multiple granularities. This framework effectively uses sentence bag features and hierarchical relational insights, promoting data denoising and enhancing long-tail relation extraction.
- We conduct extensive experiments on the NYT dataset, comparing the proposed model to several baseline models. The results demonstrate the model’s effectiveness in data denoising and its success in extracting long-tail relations.
2. Related Works
2.1. Label Noise Correction
2.2. Optimization for Data Long-Tail
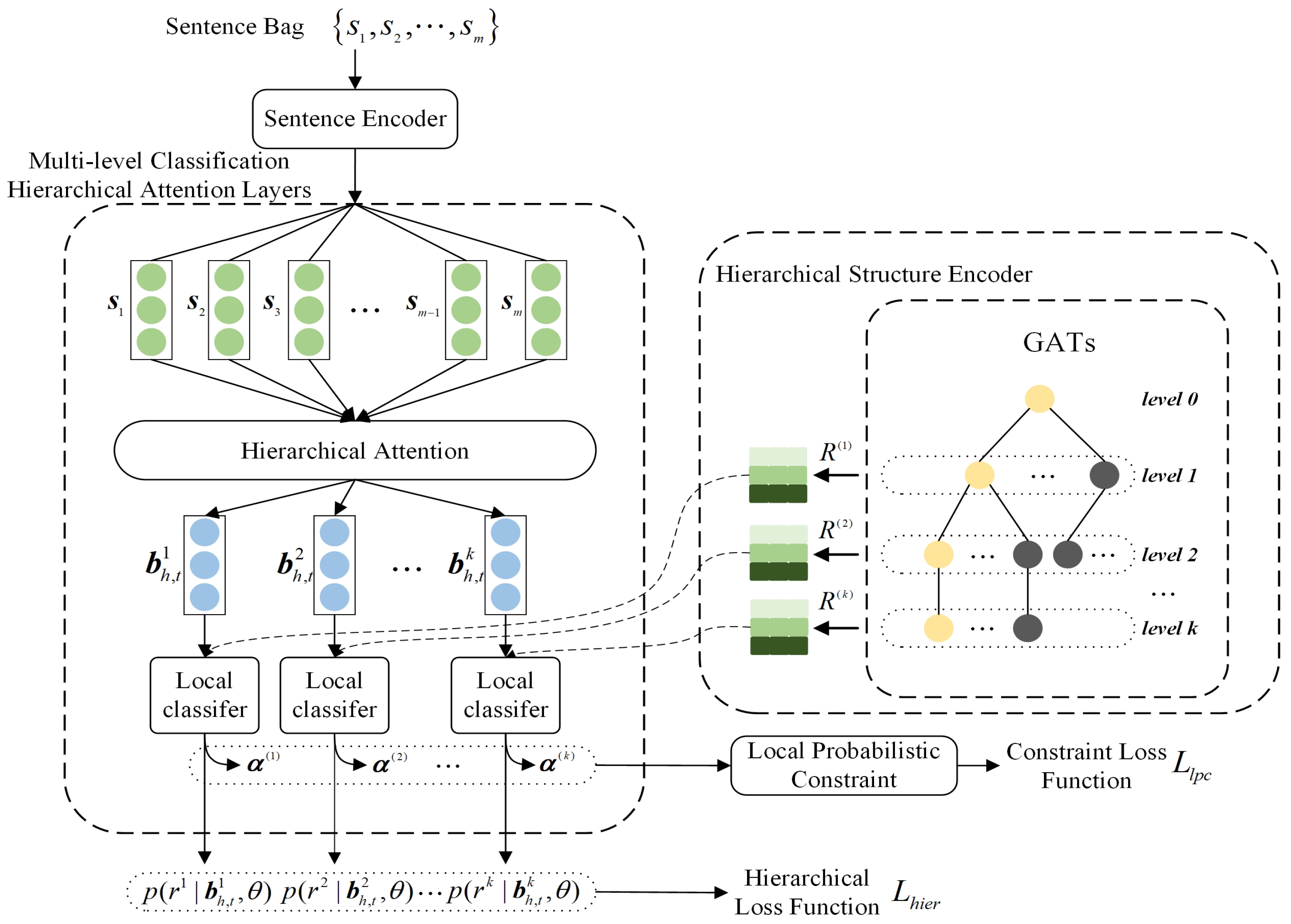
3. Methodology
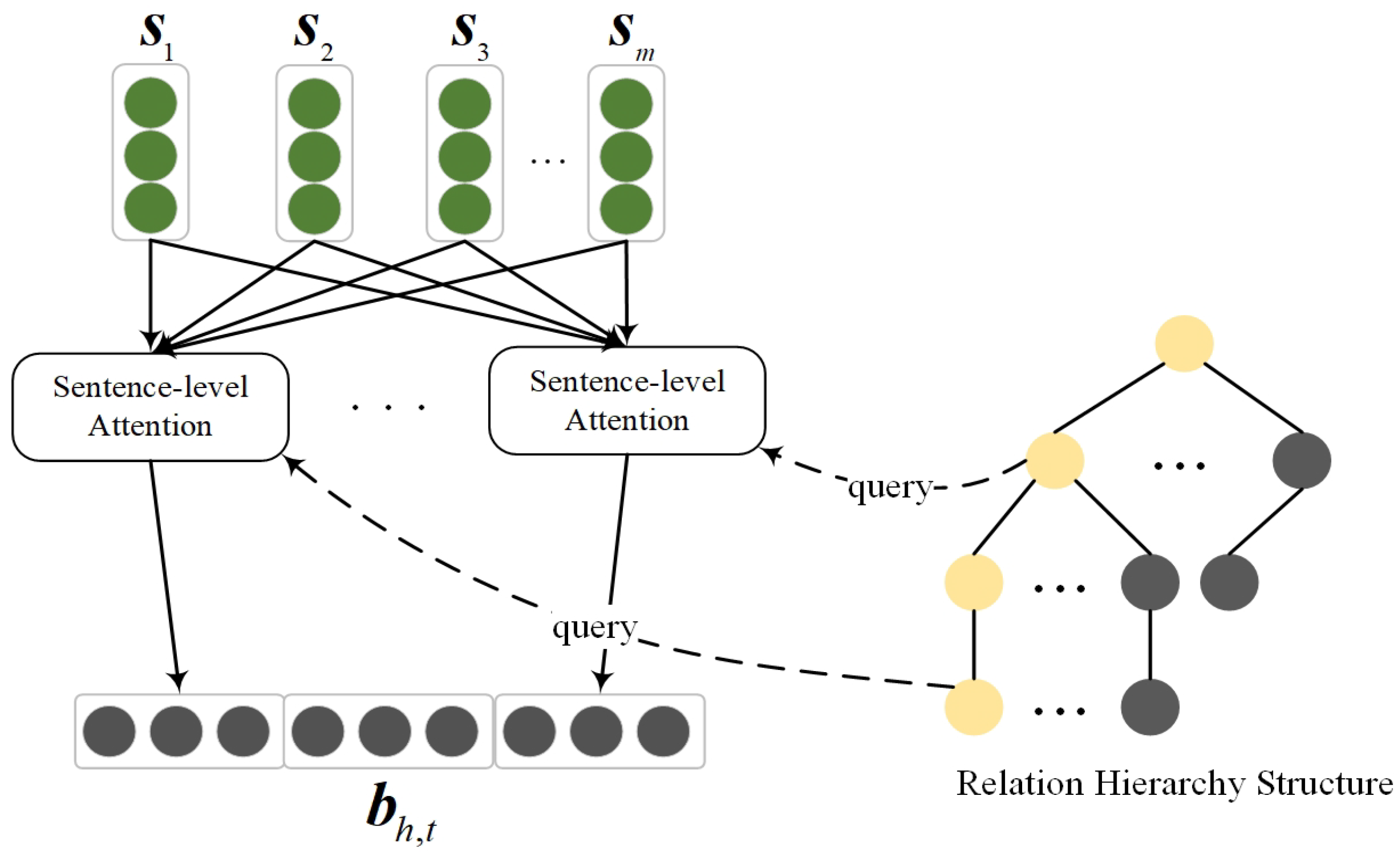
3.1. Hierarchical Structure Encoder
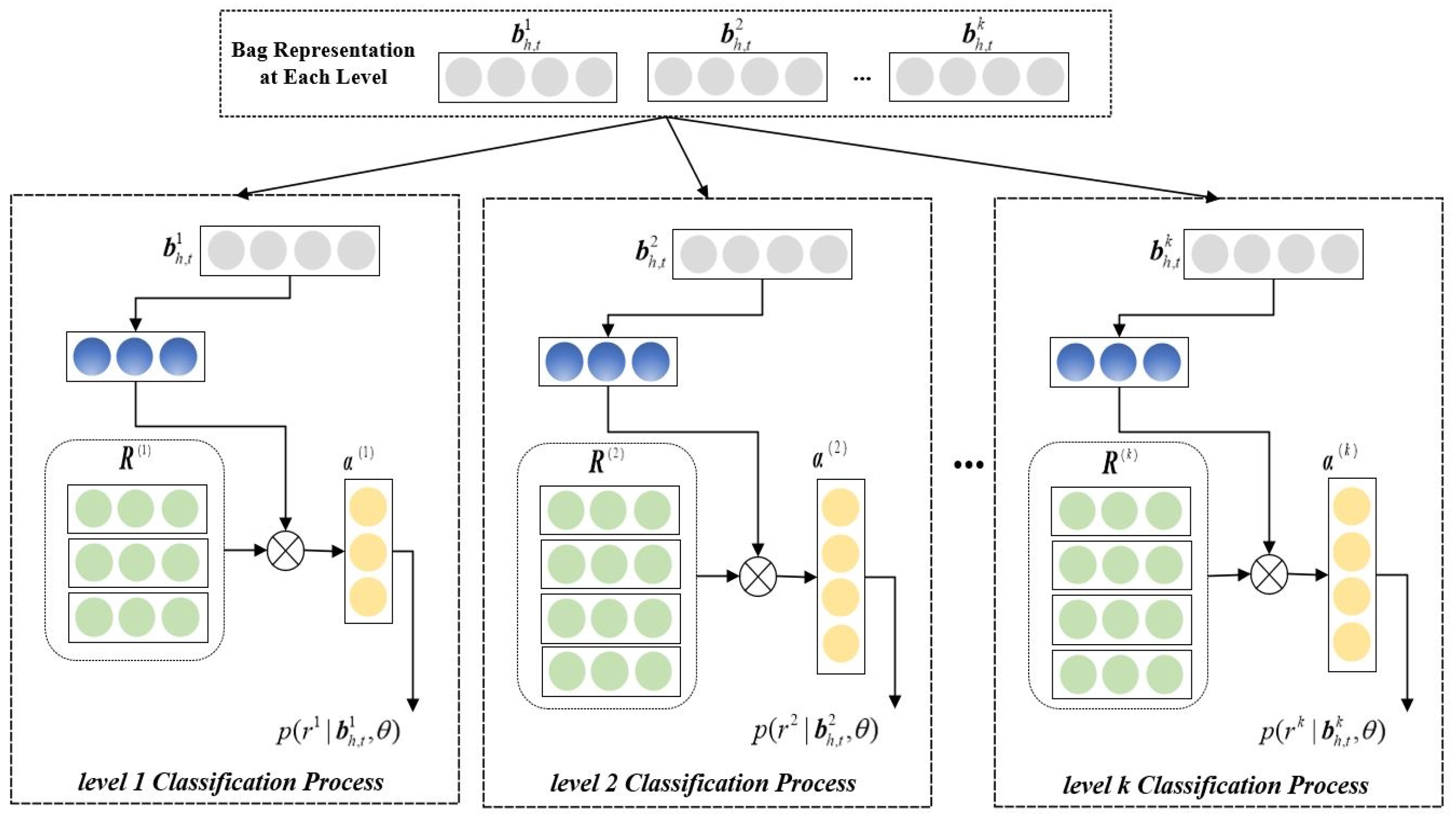
3.2. Multi-Level Classification Hierarchical Attention Layer
3.2.1. Local Probability Constraint
3.2.2. Model Training
4. Experiments
4.1. Datasets
4.2. Baselines
- (1)
- PCNN_MIL [49]: A relation extraction model utilizing a piecewise convolutional neural network (PCNN) for sentence feature encoding, within a multi-instance learning (MIL) framework. PCNN_MIL selects the highest-probability sample from a bag for classification.
- (2)
- PCNN_ATT [50]: This model introduces sentence-level selective attention to address dataset noise, enhancing extraction accuracy.
- (3)
- RESIDE: [51]: This model integrates external information, such as entity type aliases, to enhance the discriminative capability of classification features.
- (4)
- SeG [52]: A model that uses a lightweight gating mechanism instead of attention to address noisy bags in the dataset.
- (1)
- DPEN [53]: This model explores the relationship between relation labels and query entity types, proposing a dynamic parameter augmentation network that selects parameter sets based on different entity types.
- (2)
- PCNN_HATT [32]: This model introduces the hierarchical structure of relations and employs a multi-level attention mechanism to leverage this hierarchy.
- (3)
- PCNN_KATT [33]: An extension of PCNN_HATT, this model delves deeper into the relational information between relation labels, further enhancing the extraction of long-tail relations.
- (4)
- CoRA [48]: A model that uses a relation-augmented attention network as a replacement for selective attention mechanisms.
- (5)
- ToHRE [34]: This model treats the DSRE task as a multi-pass classification problem and introduces a top-down classification strategy to improve relation extraction.
- (6)
- GCEK [22]: This model uses global contextual sentence information to guide the denoising process, generating effective bag-level representations.
- (7)
- MLNRNN [1]: This model uses an iterative keyword semantic aggregator (IKSA) to filter out noisy words and highlights key features, leveraging multi-objective multi-instance learning (MOMIL) and cross-level contrastive learning (CCL) to mitigate the impact of incorrect labels.
- (8)
- MRConRE [24]: This model introduces a meta-relation pattern (MRP) to distinguish clean from noisy instances in each bag, transforming noisy instances into valuable data via relabeling while using contrastive learning for accurate sentence representations.
- (9)
- TAN [31]: This method captures dependencies among relational features by utilizing entity-type and local context information, incorporating a type affinity matrix for improved relation extraction accuracy.
- (10)
- MGCL [9]: This model mitigates noise by leveraging multi-granularity features to create contrastive learning samples and employing an asymmetrical contrastive classification strategy to gain deeper, multi-dimensional insights from text.
4.3. Implementation
4.4. Evaluation Metrics
- (1)
- PR Curve: This plot shows the tradeoff between precision and recall at various thresholds, with recall on the x axis and precision on the y axis. A model that has its PR curve entirely enclosed by another model’s PR curve outperforms the latter.
- (2)
- P@N: This metric calculates precision by selecting the top N samples with the highest predicted probabilities from the prediction results.
- (3)
- AUC: The area under the PR curve. A higher AUC indicates better model performance.
- (4)
- Hits@K: This metric measures the accuracy of predictions by relaxing the condition for a correct prediction. For each prediction, if the true class appears within the top-K predicted classes, the prediction is considered correct.
4.5. Results Analysis
- Denoising Evaluation: This subsection focuses on the model’s performance in mitigating the impact of label noise, comparing the MCHRE model with baseline methods and demonstrating its robustness in noisy data environments.
- Long-Tail Relation Evaluation: Here, we assess the MCHRE model’s capability to extract long-tail relations by using the Hits@K metric and comparing the model’s performance on long-tail relations against existing methods.
- Ablations: In this subsection, we perform an ablation study to evaluate the contribution of each component of the MCHRE model. By removing certain components, we investigate how each part of the model impacts overall performance.
- Selection of The Local Probability Constraint Coefficient: We conduct experiments to explore the effect of varying the local probability constraint coefficient on the model’s performance. This evaluation helps to determine the optimal value for this parameter.
4.5.1. Denoising Evaluation
- (1)
- PCNN_ATT: By incorporating sentence-level selective attention into PCNN_MIL, PCNN_ATT showed significant improvements in relation extraction performance. This highlights the effectiveness of the attention mechanism’s dynamic selection ability in mitigating accuracy issues caused by noisy data. Furthermore, the minimal computational cost of selective attention makes it a valuable component in remote supervision relation extraction models.
- (2)
- RESIDE: RESIDE optimized the sentence encoder and demonstrated improvements across all metrics compared to PCNN_ATT. Additionally, it incorporated external information, further enhancing the model’s ability to resist noise interference. This indicates that both enhancing the sentence encoder and integrating external data are effective strategies for improving DSRE performance.
- (3)
- PCNN_HATT: By introducing relational hierarchy and employing a hierarchical attention mechanism to leverage semantic dependencies between relation labels, PCNN_HATT achieved significant improvements over PCNN_ATT. This suggests that hierarchical structure information is effective for filtering out noisy data.
- (4)
- ToHRE and MCHRE: Both models built upon PCNN_HATT by more effectively utilizing available information. However, MCHRE outperformed ToHRE in terms of P@N and AUC, indicating that MCHRE leverages multiple types of information more efficiently than ToHRE.
- (5)
- Other Methods: Although models like GCEK, MLNRNN, MRConRE, TAN, and MGCL showed some performance improvements, none surpassed the performance of MCHRE, highlighting the crucial role of hierarchical attention and local probability constraints in DSRE.
4.5.2. Long-Tail Relation Evaluation
- (1)
- PCNN_ATT: This model performed the weakest on long-tail relation extraction. The Hits@10 accuracy on the <100 test set is below 5%, demonstrating the severity of the long-tail issue in DSRE datasets.
- (2)
- Hierarchical Optimization: Models such as PCNN_HATT, PCNN_KATT, CoRA, ToHRE, and MCHRE showed substantial improvements in long-tail relation extraction. The effectiveness of leveraging relational hierarchy for mitigating data scarcity is evident, with deeper hierarchical structure utilization further enhancing long-tail extraction.
- (3)
- MCHRE vs. ToHRE: MCHRE outperformed ToHRE across all evaluation metrics, achieving improvements of 5.4%, 3.1%, 7.1%, 4.2%, 2.2%, and 6%. This demonstrates that MCHRE’s multi-level classification framework is more effective in addressing long-tail data.
- (4)
- State-of-the-Art Results: MCHRE achieved the highest accuracy across all six evaluation metrics for both test subsets and all K values. The model demonstrated consistent improvements over baseline methods, making it the leading solution for long-tail relation extraction.
4.5.3. Ablations
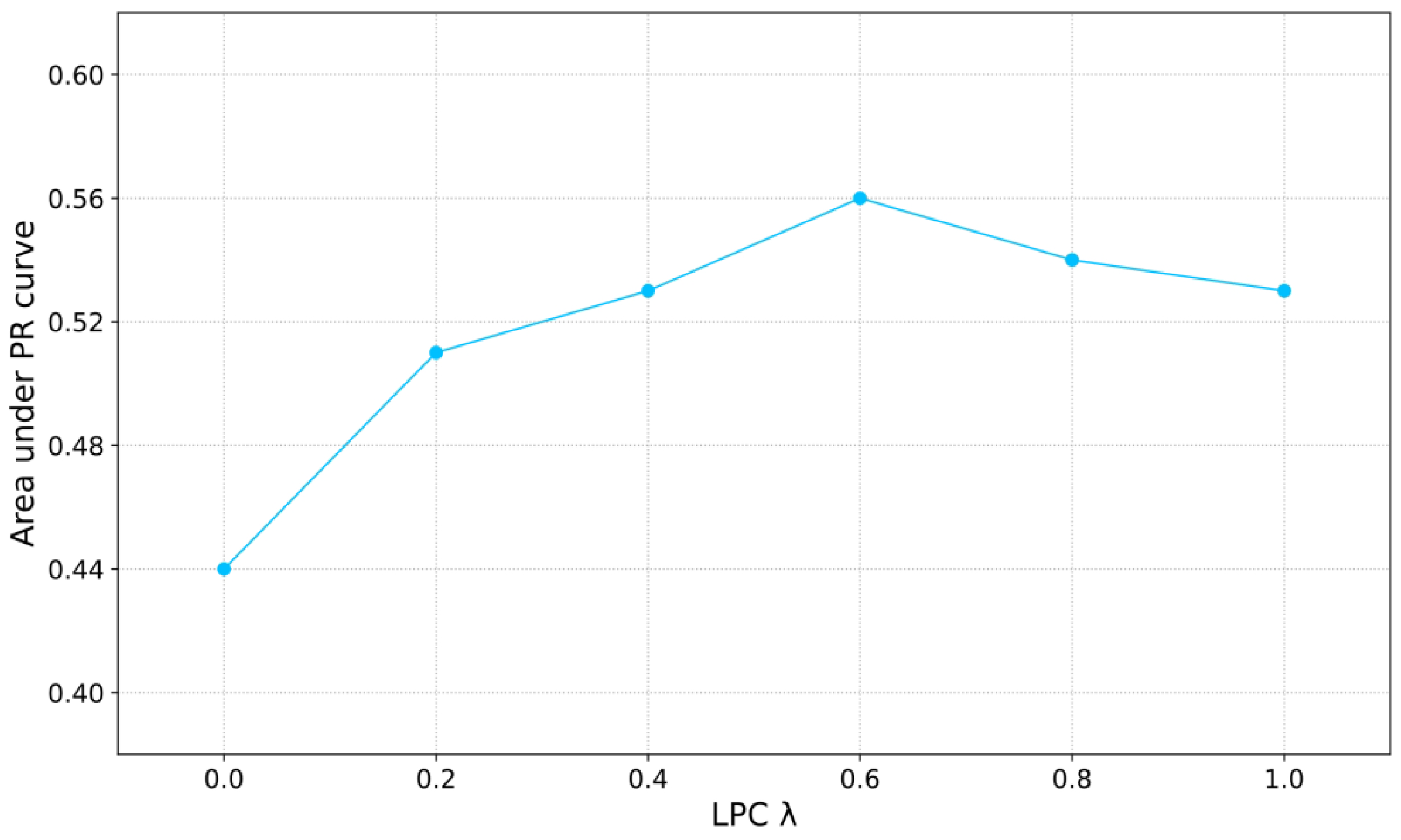
4.5.4. Selection of the Local Probability Constraint Coefficient
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, W.; Yang, Z. Improving Distantly Supervised Relation Extraction with Multi-Level Noise Reduction. AI 2024, 5, 1709–1730. [Google Scholar] [CrossRef]
- Knez, T.; Štravs, M.; Žitnik, S. Semi-Supervised Relation Extraction Corpus Construction and Models Creation for Under-Resourced Languages: A Use Case for Slovene. Information 2025, 16, 143. [Google Scholar] [CrossRef]
- Chen, Z.; Tian, Y.; Wang, L.; Jiang, S. A distantly-supervised relation extraction method based on selective gate and noise correction. In Proceedings of the China National Conference on Chinese Computational Linguistics, Harbin, China, 3–5 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 159–174. [Google Scholar]
- Zheng, Z.; Xu, Y.; Liu, Y.; Zhang, X.; Li, L.; Li, D. Distantly supervised relation extraction based on residual attention and self learning. Neural Process. Lett. 2024, 56, 180. [Google Scholar] [CrossRef]
- Ma, X.; Zhu, Q.; Zhou, Y.; Li, X. Improving question generation with sentence-level semantic matching and answer position inferring. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8464–8471. [Google Scholar]
- Du, J.; Liu, G.; Gao, J.; Liao, X.; Hu, J.; Wu, L. Graph Neural Network-Based Entity Extraction and Relationship Reasoning in Complex Knowledge Graphs. arXiv 2024, arXiv:2411.15195. [Google Scholar]
- Efeoglu, S.; Paschke, A. Retrieval-augmented generation-based relation extraction. arXiv 2024, arXiv:2404.13397. [Google Scholar]
- Han, Y.; Jiang, R.; Li, C.; Huang, Y.; Chen, K.; Yu, H.; Li, A.; Han, W.; Pang, S.; Zhao, X. AT4CTIRE: Adversarial Training for Cyber Threat Intelligence Relation Extraction. Electronics 2025, 14, 324. [Google Scholar] [CrossRef]
- Jian, Z.; Liu, S.; Yin, H. A Multi-granularity Contrastive Learning for Distantly Supervised Relation Extraction. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 352–364. [Google Scholar]
- Fei, H.; Tan, Y.; Huang, W.; Long, J.; Huang, J.; Yang, L. A Multi-teacher Knowledge Distillation Framework for Distantly Supervised Relation Extraction with Flexible Temperature. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Wuhan, China, 6–8 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 103–116. [Google Scholar]
- Liu, R.; Mo, S.; Niu, J.; Fan, S. CETA: A consensus enhanced training approach for denoising in distantly supervised relation extraction. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2247–2258. [Google Scholar]
- Dai, Q.; Heinzerling, B.; Inui, K. Cross-stitching text and knowledge graph encoders for distantly supervised relation extraction. arXiv 2022, arXiv:2211.01432. [Google Scholar]
- Song, W.; Gu, W.; Zhu, F.; Park, S.C. Interaction-and-response network for distantly supervised relation extraction. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 9523–9537. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Li, L.; Xu, N.; Liu, F.; Yuan, C.; Chen, Z.; Lyu, X. AAFormer: Attention-Attended Transformer for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5002805. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Tong, Y.; Lyu, X.; Zhou, J. Semantic Segmentation of Remote Sensing Images by Interactive Representation Refinement and Geometric Prior-Guided Inference. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5400318. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Z.; Zeng, Y.; Zhang, C.; Ma, H. GAP: A novel Generative context-Aware Prompt-tuning method for relation extraction. Expert Syst. Appl. 2024, 248, 123478. [Google Scholar] [CrossRef]
- Sun, H.; Grishman, R. Lexicalized Dependency Paths Based Supervised Learning for Relation Extraction. Comput. Syst. Sci. Eng. 2022, 43, 861. [Google Scholar] [CrossRef]
- Sun, H.; Grishman, R. Employing Lexicalized Dependency Paths for Active Learning of Relation Extraction. Intell. Autom. Soft Comput. 2022, 34, 1416. [Google Scholar] [CrossRef]
- Zhou, K.; Qiao, Q.; Li, Y.; Li, Q. Improving distantly supervised relation extraction by natural language inference. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 14047–14055. [Google Scholar]
- Long, J.; Yin, Z.; Han, Y.; Huang, W. MKDAT: Multi-Level Knowledge Distillation with Adaptive Temperature for Distantly Supervised Relation Extraction. Information 2024, 15, 382. [Google Scholar] [CrossRef]
- Dai, Y.; Zhang, B.; Wang, S. Distantly Supervised Biomedical Relation Extraction via Negative Learning and Noisy Student Self-Training. IEEE/ACM Trans. Comput. Biol. Bioinform. 2024, 21, 1697–1708. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Wan, H.; Lin, Y. Exploiting global context and external knowledge for distantly supervised relation extraction. Knowl.-Based Syst. 2023, 261, 110195. [Google Scholar] [CrossRef]
- Matsubara, T.; Miwa, M.; Sasaki, Y. Distantly Supervised Document-Level Biomedical Relation Extraction with Neighborhood Knowledge Graphs. In Proceedings of the The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 363–368. [Google Scholar]
- Chen, C.; Hao, S.; Liu, J. Distantly supervised relation extraction with a Meta-Relation enhanced Contrastive learning framework. Neurocomputing 2025, 617, 128864. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, Y.; Ji, D. Distantly supervised relation extraction with KB-enhanced reconstructed latent iterative graph networks. Knowl.-Based Syst. 2023, 260, 110108. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, H.; Fan, Z.; Cheng, L.; Wang, Z.; Chen, C. Improving Distantly-Supervised Relation Extraction through Label Prompt. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 606–611. [Google Scholar]
- Yan, T.; Zhang, X.; Luo, Z. Ltacl: Long-tail awareness contrastive learning for distantly supervised relation extraction. Complex Intell. Syst. 2024, 10, 1551–1563. [Google Scholar] [CrossRef]
- Li, R.; Yang, C.; Li, T.; Su, S. Midtd: A simple and effective distillation framework for distantly supervised relation extraction. ACM Trans. Inf. Syst. (TOIS) 2022, 40, 1–32. [Google Scholar] [CrossRef]
- Yang, S.; Liu, Y.; Jiang, Y.; Liu, Z. More refined superbag: Distantly supervised relation extraction with deep clustering. Neural Netw. 2023, 157, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Mao, Y.; Wang, L.; Li, H.; Zhong, Y.; Qin, X. NDGR: A Noise Divide and Guided Re-labeling Framework for Distantly Supervised Relation Extraction. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 98–111. [Google Scholar]
- Song, W.; Zhou, J.; Liu, X. Type affinity network for distantly supervised relation extraction. Neurocomputing 2025, 630, 129684. [Google Scholar] [CrossRef]
- Han, X.; Yu, P.; Liu, Z.; Sun, M.; Li, P. Hierarchical relation extraction with coarse-to-fine grained attention. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2236–2245. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Wang, G.; Chen, X.; Zhang, W.; Chen, H. Long-tail relation extraction via knowledge graph embeddings and graph convolution networks. arXiv 2019, arXiv:1903.01306. [Google Scholar]
- Yu, E.; Han, W.; Tian, Y.; Chang, Y. ToHRE: A top-down classification strategy with hierarchical bag representation for distantly supervised relation extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1665–1676. [Google Scholar]
- Li, T.; Wang, Z. LDRC: Long-tail Distantly Supervised Relation Extraction via Contrastive Learning. In Proceedings of the 2023 7th International Conference on Machine Learning and Soft Computing, Chongqing, China, 5–7 January 2023; pp. 110–117. [Google Scholar]
- Han, R.; Peng, T.; Han, J.; Cui, H.; Liu, L. Distantly supervised relation extraction via recursive hierarchy-interactive attention and entity-order perception. Neural Netw. 2022, 152, 191–200. [Google Scholar] [CrossRef]
- Yu, M.; Chen, Y.; Zhao, M.; Xu, T.; Yu, J.; Yu, R.; Liu, H.; Li, X. Semantic piecewise convolutional neural network with adaptive negative training for distantly supervised relation extraction. Neurocomputing 2023, 537, 12–21. [Google Scholar] [CrossRef]
- Zhu, J.; Dong, J.; Du, H.; Geng, Y.; Fan, S.; Yu, H.; Shao, Z.; Wang, X.; Yang, Y.; Xu, W. Tell me your position: Distantly supervised biomedical entity relation extraction using entity position marker. Neural Netw. 2023, 168, 531–538. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Xu, F.; Tao, F.; Tong, Y.; Gao, H.; Liu, F.; Chen, Z.; Lyu, X. A Cross-Domain Coupling Network for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5005105. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Lin, X.; Jia, W.; Gong, Z. Self-distilled Transitive Instance Weighting for Denoised Distantly Supervised Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 168–180. [Google Scholar]
- Yin, H.; Liu, S.; Jian, Z. Distantly supervised relation extraction via contextual information interaction and relation embeddings. Symmetry 2023, 15, 1788. [Google Scholar] [CrossRef]
- Zeng, B.; Liang, J. Multi-Encoder with Entity-Aware Embedding Framework for Distantly Supervised Relation Extraction. In Proceedings of the 2023 4th International Conference on Computer, Big Data and Artificial Intelligence (ICCBD+ AI), Guiyang, China, 15–17 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 495–500. [Google Scholar]
- Zhang, R.; Liu, J.; Li, L.; Yin, L.; Xu, W.; Cao, W. Knowledge Aware Embedding for Distantly Supervised Relation Extraction. In Proceedings of the 2023 8th International Conference on Computer and Communication Systems (ICCCS), Guangzhou, China, 21–24 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–10. [Google Scholar]
- Peng, T.; Han, R.; Cui, H.; Yue, L.; Han, J.; Liu, L. Distantly supervised relation extraction using global hierarchy embeddings and local probability constraints. Knowl.-Based Syst. 2022, 235, 107637. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Yu, A.; Lyu, X.; Gao, H.; Zhou, J. A Frequency Decoupling Network for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5607921. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A Synergistical Attention Model for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5400916. [Google Scholar] [CrossRef]
- Li, Y.; Shen, T.; Long, G.; Jiang, J.; Zhou, T.; Zhang, C. Improving long-tail relation extraction with collaborating relation-augmented attention. arXiv 2020, arXiv:2010.03773. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Vashishth, S.; Joshi, R.; Prayaga, S.S.; Bhattacharyya, C.; Talukdar, P. Reside: Improving distantly-supervised neural relation extraction using side information. arXiv 2018, arXiv:1812.04361. [Google Scholar]
- Li, Y.; Long, G.; Shen, T.; Zhou, T.; Yao, L.; Huo, H.; Jiang, J. Self-attention enhanced selective gate with entity-aware embedding for distantly supervised relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8269–8276. [Google Scholar]
- Gou, Y.; Lei, Y.; Liu, L.; Zhang, P.; Peng, X. A dynamic parameter enhanced network for distant supervised relation extraction. Knowl.-Based Syst. 2020, 197, 105912. [Google Scholar] [CrossRef]
- Jian, Z.; Liu, S.; Gao, W.; Cheng, J. Distantly Supervised Relation Extraction based on Non-taxonomic Relation and Self-Optimization. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–9. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NYT | #Sentences | #Entity Pairs | #Relation Facts |
|---|---|---|---|
| Train | 522,611 | 281,270 | 18,252 |
| Test | 172,448 | 96,678 | 1950 |
| Hyperparameters | Value |
|---|---|
| Window Size l | 3 |
| Relation Embedding Size | 150 |
| Sentence Embedding Size | 230 |
| Word Embedding Size | 50 |
| Position Embedding Size | 5 |
| LPC coefficient | 0.6 |
| Batch Size B | 160 |
| Epoch Size | 100 |
| Learning Rate | 0.1 |
| Dropout Probability p | 0.5 |
| Models | Evaluation Metrics | ||||
|---|---|---|---|---|---|
| P@100 | P@200 | P@300 | Mean | AUC | |
| PCNN_MIL [49] | 72.3 | 69.7 | 64.1 | 68.7 | 0.36 |
| PCNN_ATT [50] | 76.2 | 73.1 | 67.4 | 72.2 | 0.39 |
| RESIDE [51] | 84.0 | 78.5 | 75.6 | 79.4 | 0.41 |
| SeG [52] | 93.0 | 90.0 | 86.0 | 89.3 | 0.51 |
| GCEK [22] | 85.44 | 80.38 | 74.66 | 80.16 | 0.41 |
| MLNRNN [1] | 94.2 | 88.4 | 83.4 | 88.7 | 0.49 |
| MRConRE [24] | 86.1 | 80.6 | 80.1 | 82.3 | 0.38 |
| TAN [31] | 93.2 | 89.5 | 82.1 | 88.3 | 0.51 |
| MGCL [54] | 89.1 | 86.5 | 82.0 | 86.1 | 0.53 |
| DPEN [53] | 85.0 | 83.0 | 82.7 | 83.6 | 0.35 |
| PCNN_HATT [32] | 88.0 | 79.5 | 75.3 | 80.9 | 0.42 |
| CoRA [48] | 98.0 | 92.5 | 88.3 | 92.9 | 0.53 |
| ToHRE [34] | 91.5 | 82.9 | 79.6 | 84.7 | 0.44 |
| MCHRE (Ours) | 97.6 | 94.1 | 91.0 | 94.2 | 0.56 |
| Testing Subset Conditions | <100 | <200 | ||||
|---|---|---|---|---|---|---|
| Hits@K(macro) | 10 | 15 | 20 | 10 | 15 | 20 |
| PCNN_ATT [50] | <5.0 | 7.4 | 40.7 | 17.2 | 24.2 | 51.5 |
| PCNN_HATT [32] | 29.6 | 51.9 | 61.1 | 41.4 | 60.6 | 68.2 |
| PCNN_KATT [33] | 35.3 | 62.4 | 65.1 | 43.2 | 61.3 | 69.2 |
| DPEN [53] | 57.6 | 62.1 | 66.7 | 64.1 | 68.0 | 71.8 |
| CoRA [48] | 66.6 | 72.0 | 87.0 | 72.7 | 77.3 | 89.4 |
| ToHRE [34] | 62.9 | 75.9 | 81.4 | 69.7 | 80.3 | 84.8 |
| MGCL [54] | 38.6 | 61.9 | 65.5 | 50.9 | 67.2 | 72.2 |
| MCHRE (Ours) | 68.3 | 79.0 | 88.5 | 73.9 | 82.5 | 90.8 |
| Models | P@100 | P@200 | P@300 | Mean | AUC |
|---|---|---|---|---|---|
| MCHRE | 97.6 | 94.1 | 91.0 | 94.2 | 0.56 |
| † | 94.3 | 87.5 | 82.1 | 88.0 | 0.49 |
| ‡ | 90.3 | 82.7 | 77.9 | 83.6 | 0.43 |
| † and ‡ | 88.0 | 79.5 | 75.3 | 80.9 | 0.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xuan, Z.; Zhao, H.; Li, X.; Chen, Z. Distantly Supervised Relation Extraction Method Based on Multi-Level Hierarchical Attention. Information 2025, 16, 364. https://doi.org/10.3390/info16050364
Xuan Z, Zhao H, Li X, Chen Z. Distantly Supervised Relation Extraction Method Based on Multi-Level Hierarchical Attention. Information. 2025; 16(5):364. https://doi.org/10.3390/info16050364
Chicago/Turabian StyleXuan, Zhaoxin, Hejing Zhao, Xin Li, and Ziqi Chen. 2025. "Distantly Supervised Relation Extraction Method Based on Multi-Level Hierarchical Attention" Information 16, no. 5: 364. https://doi.org/10.3390/info16050364
APA StyleXuan, Z., Zhao, H., Li, X., & Chen, Z. (2025). Distantly Supervised Relation Extraction Method Based on Multi-Level Hierarchical Attention. Information, 16(5), 364. https://doi.org/10.3390/info16050364