1. Introduction
In recent years, artificial intelligence (AI) has transformed numerous domains, yet the integration of its advanced techniques into heritage preservation remains uneven. Deep learning, particularly Convolutional Neural Networks (CNNs), has demonstrated remarkable success in visual recognition tasks, but its adoption in traditional village landscape analysis and architectural heritage documentation is still emerging. The increasing need for efficient, scalable, and accurate tools to safeguard intangible cultural assets raises a critical question: how can AI-driven models be leveraged to enhance the classification and retrieval of heritage imagery? Prior research has shown the potential of CNNs in heritage contexts. For example, Wang et al. [
1] proposed a pixel-level semantic segmentation approach to identify spatial characteristics in traditional village landscapes. While effective in simulating expert perception, this model lacked adaptability across diverse datasets. Similarly, Gao et al. [
2] introduced a two-stage CNN Attention Retrieval Framework (CNNAR), combining transfer learning with attention mechanisms to classify Chinese diaspora architectural images. Although their model achieved high retrieval accuracy, it primarily focused on narrowing the search scope rather than enhancing interpretability across various image types.
Other studies have further highlighted the trade-offs between performance and flexibility in heritage-related AI applications. Janković [
3] compared neural and non-neural models using handcrafted features, revealing that while multilayer perceptron models excelled in efficiency, they were limited in scalability and adaptability. Ju [
4], through a macro-level bibliometric review, revealed an evolving trend in AI-for-heritage research—one that increasingly intersects with sustainability, material degradation, and ecological monitoring. Parallel developments in dataset design have supported this shift: the ImageOP dataset Version 1 [
5] enabled low-resource image classification on mobile devices, while Go et al. [
6] compared CNNs and Vision Transformers (ViTs) in pigment classification, finding ViTs highly accurate but less interpretable. Despite these advancements, a critical gap persists: few models integrate high classification accuracy, real-time retrieval, and visual interpretability across culturally diverse datasets.
The Dongba script, a unique pictographic writing system used by the Naxi people in Yunnan Province, China, represents one of the few surviving pictographic scripts in the world. Despite its historical significance and cultural richness, the script has faced challenges with modernization, preservation, and digital integration. Over the years, scholars have conducted extensive research to analyze its grammatological features, structural evolution, and practical applications in various domains, ranging from linguistic studies to digital humanities and virtual reality applications.
The systematic study of the Dongba pictographic script has evolved through the application of digital tools and network analysis approaches. Xu [
7] describes implementing several digital tools to facilitate grammatological studies, emphasizing the importance of a structured dictionary and an online database of Dongba characters. By organizing entries based on major semantic components, the database allows for statistical analysis, visualization of glyph clusters, and a closer examination of individual glyph elements. Furthermore, network analysis techniques provide insights into the developmental stages of the writing system, highlighting the structural complexity and interrelationships among its components.
The visual and symbolic characteristics of Dongba pictographs have also influenced modern pictogram design. Zhen [
8] explores new methods for pictogram development inspired by Dongba formative principles. These methods were tested through Traditional Chinese Medicine pictograms and assessed for readability via questionnaire-based evaluations. Similarly, the “Dongba Script Character Construction Space” utilizes virtual reality technology to create an immersive experience that enables interaction with pictographic, ideographic, and compound ideographic forms [
9]. Such efforts demonstrate the potential for preserving and revitalizing the Dongba script through innovative digital applications.
Historical documentation further enriches the understanding of the script’s evolution. The woodblock prints of the “Naxi Pictographs and Geba Script Comparative Lexicon”, housed at the Lijiang Museum, are crucial artifacts reflecting the Naxi script unification movement of the early 20th century [
10]. These prints provide evidence of script standardization efforts by Dongba ritualists, shedding light on cultural and historical factors that influenced the development and decline of the unified script.
Phonological research has also contributed to the study of the Dongba script, particularly in its relationship with the Naxi language. Xu [
11] examines the use of Dongba glyphs in representing phonetic structures, noting their efficiency in identifying initials but their limitations in distinguishing rhymes and tones. A phonemic chart written in Dongba glyphs serves as a tool for analyzing the phonological system and tracking sound changes in Ruke Naxi. This study underscores the adaptability of the Dongba script in linguistic research and its potential for phonetic representation.
In the field of computational linguistics, automated analysis of the Dongba script has gained attention. Text line segmentation is a fundamental preprocessing step for Dongba document analysis, facilitating tasks such as character extraction, translation, and annotation. Yang and Kang [
12] propose a segmentation algorithm combining K-means clustering with projection-based methods to improve text block recognition and extraction. Similar computational approaches are applied to the structural analysis of Dongba hieroglyphs, using the Hough transform algorithm for table recognition and database classification [
13]. Such advancements provide a technical foundation for further digital research and preservation efforts.
Ritualistic and cultural aspects of the Dongba script are also significant. He and Zhao [
14] analyze the “eye disease incantation”, a unique category of Dongba manuscripts that combines textual, pictographic, and phonetic elements. These manuscripts reflect the fusion of linguistic and symbolic representation in healing traditions. Moreover, the evolution of Dongba hieroglyphs as a transitional system from pictographic to phonetic writing is examined by Zhou [
15], highlighting the structural variations and writing conventions that define its uniqueness.
Efforts to modernize the script and integrate it into contemporary linguistic systems continue to be explored. Poupard [
16] reviews past and ongoing attempts at Unicode encoding, discussing the challenges and prospects of adapting the Dongba script for everyday written communication. These initiatives aim to increase awareness and facilitate the script’s use beyond religious and ceremonial contexts, potentially transforming it into a functional vernacular writing system.
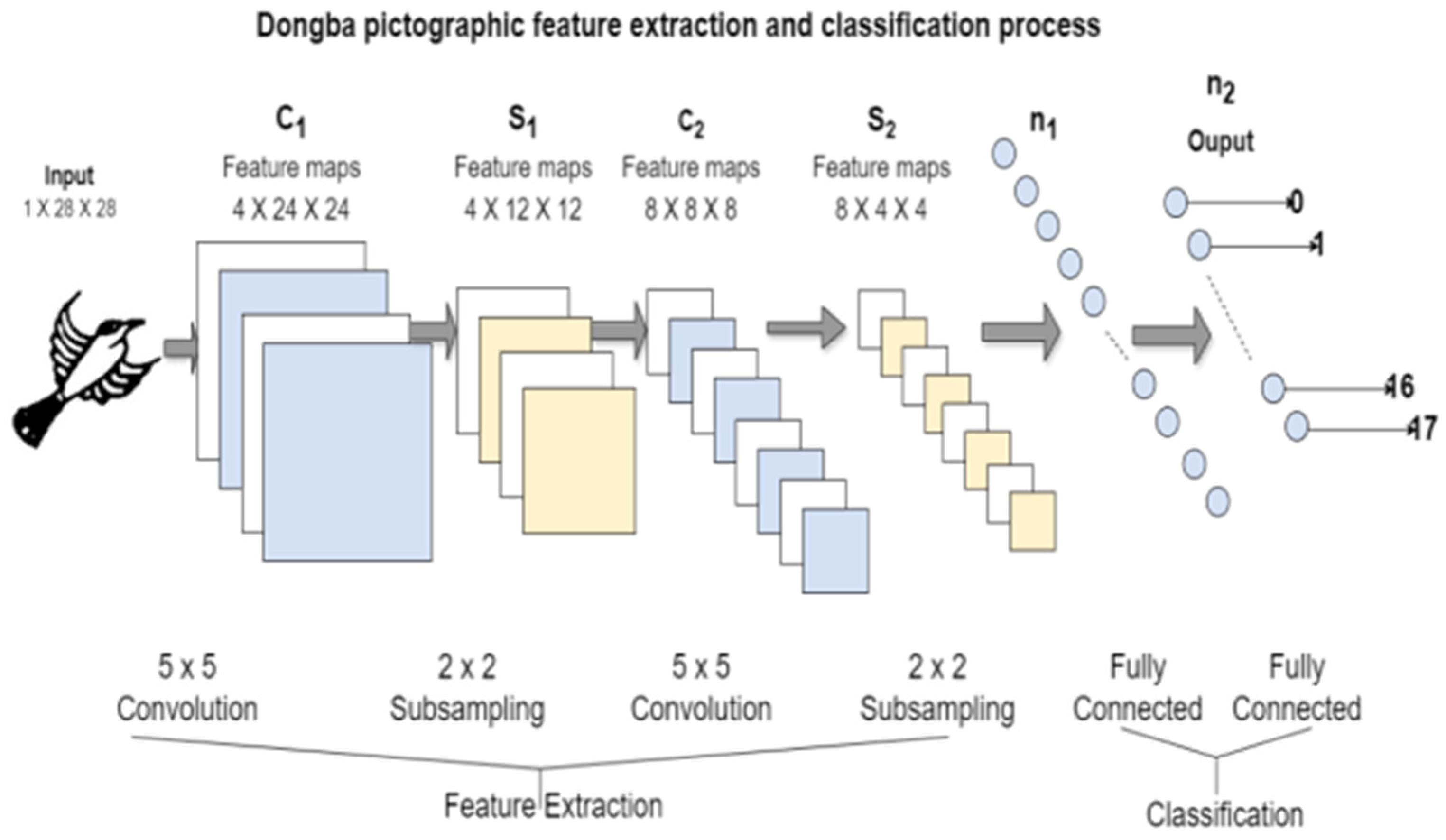
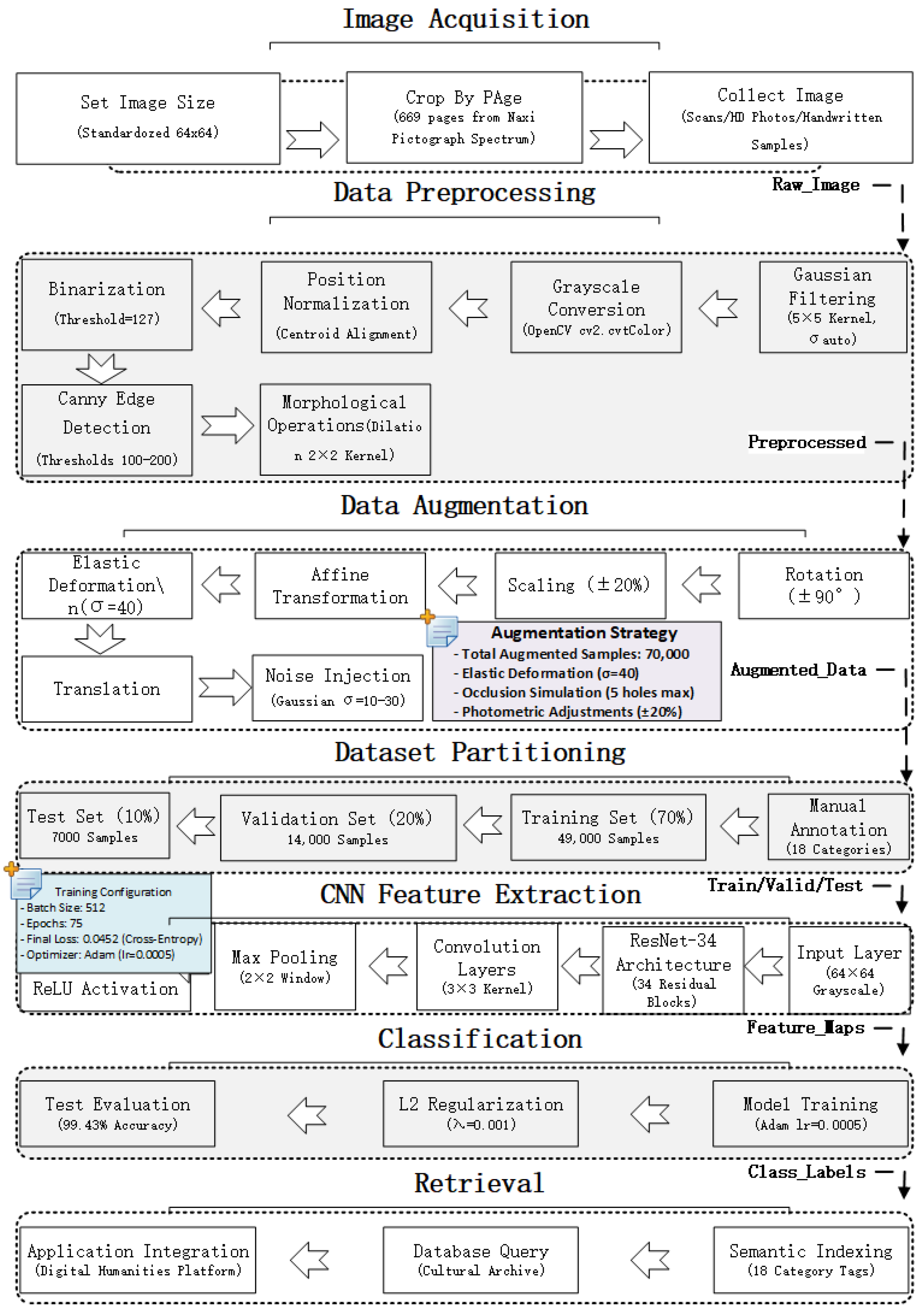
Dongba pictographs are an essential part of the traditional culture of the Naxi people, carrying rich historical and cultural information. Researching Dongba pictographs helps improve the efficiency of interpreting Dongba characters and has significant academic value for cultural, linguistic, and interdisciplinary research. Traditional Dongba pictograph recognition mainly includes three steps: image processing, feature extraction, and classification. Image processing includes grayscale, filtering and denoising, binarization, etc.; feature extraction mostly uses the grid and projection methods; classifier models include support vector machine, random forest, etc. With the development of computer image processing and artificial intelligence technology, more and more scholars have begun to try to use deep learning methods to identify Dongba pictographs.
The Dongba script is one of the few surviving pictographic writing systems used by the Naxi people. Previous computational approaches to Dongba pictograph recognition primarily employed traditional feature extraction and classification methods (e.g., Support Vector Machine (SVM), projection methods, and grid decomposition), with recognition accuracies typically ranging from 84.4% to 95.8% [
17,
18,
19,
20,
21,
22,
23]. However, these methods struggle with the variability, complexity, and deformation inherent in pictographic characters. Although deep learning methods, such as CNN, have recently emerged, existing research has been limited by the use of small datasets and minimal data augmentation. Therefore, there is a pressing need for robust and scalable solutions to improve accuracy and generalizability. To address these limitations, this study proposes an optimized CNN model (ResNet) trained on a significantly larger dataset (70,000 pictographs) that has been enhanced through advanced data augmentation strategies [
24]. Our approach achieves a classification accuracy of 99.43%, considerably surpassing existing methods and providing a powerful tool for cultural heritage preservation and computational linguistics.
Dongba’s pictographic characters reflect the characteristics of agricultural culture and nomadic culture. They contain many pictographic, ideographic, and indicative characters, and their shapes are complex and varied. To improve the recognition rate of characters and prepare for the recognition and research of text semantics, it is necessary to extract similar features and establish classification standards. To this end, this paper first divides Dongba characters into 18 categories based on the shape features of the characters. It uses the CNN algorithm to extract features and automatically classify Dongba pictographic characters. The specific research includes (1) preprocessing the collected text images by image segmentation, normalization, grayscale, filtering and denoising, and binarization; (2) dividing the text images into 18 categories based on the shape features of the characters and manually annotating them; and (3) using the convolutional neural network to extract image features, train the classification model, and test it with test samples.
3. Results
This section presents the experimental results of the proposed CNN-based classification method for Dongba pictographs. The performance of various deep learning models, including LeNet-5, AlexNet, VGGNet, ResNet, and InceptionNet, is evaluated using a dataset of 70,000 pictograph samples categorized into 18 classes. Key performance metrics such as classification accuracy, loss function values, and computational efficiency are analyzed. Additionally, the impact of data augmentation techniques on model robustness is examined. Comparative analysis highlights the superiority of the ResNet model, which achieves the highest accuracy while maintaining computational efficiency. The findings demonstrate the effectiveness of deep learning in enhancing Dongba pictograph recognition, supporting its application in cultural heritage preservation and computational linguistics.
3.1. Model Classification Training and Optimization
Due to limited experimental equipment, large datasets of typical models in CNN models, and slow training, 10 rounds were conducted for 18 fixed types of pictograms. The data in each round were the data listed in
Table 1.
Table 8 presents a comparative analysis of the classification performance of various CNN models applied to Dongba pictographic images, highlighting their highest achieved accuracy and corresponding loss values. It also includes a total training time (in hours) column for each model under identical training conditions. This column facilitates a more comprehensive assessment of the trade-offs between model performance, as reflected by accuracy and loss, and computational efficiency. All training times were recorded using the same hardware configuration to ensure consistency and comparability. The inclusion of this information enhances the interpretability of the experimental outcomes and further substantiates the selection of ResNet as the most effective model, striking a balance between accuracy and training efficiency. It is important to note that both hardware and software settings for this experiment are as follows:
Hardware environment: Intel Core i7-10700 CPU @ 2.90 GHz, 20 GB memory, NVIDIA GeForce GTX 1050Ti GPU (4 GB video memory) (Intel, Santa Clara, CA, USA).
Software environment: Windows 10 operating system, Python 3.9.7 development environment. Image processing operations are implemented using OpenCV-Python 4.5.5.64, and the deep learning framework is implemented using PyTorch 1.10.2.
Under the premise that the hyperparameters were relatively fixed, the same batch of samples was trained multiple times using different models.
Table 9 lists the performance of other models in the Dongba hieroglyph classification task.
As can be seen from
Table 9, the ResNet model performs best in the Dongba pictograph classification task, with an accuracy of 99.43% and a relatively short training time. AlexNet and VGGNet also have high accuracy but take longer to train. LeNet-5 has a low accuracy rate because of its shallow network structure and its inability to fully capture character features. Although Inception Net has a complex structure and high computational cost, its performance in this task is not ideal, which may be related to the fact that its multi-scale feature fusion method is not suitable for the characteristics of Dongba pictographs.
Comparing the training conditions and results of each model in the convolutional neural network model, it is not difficult to find that for Dongba pictograph images, the ResNet model, AlexNet model, and VGGNet model have achieved high accuracy, and their loss function values are small, which can obtain good classification results. Among them, the ResNet model performs best. However, for the classification of Dongba pictograph images, it is not easy to provide many training samples for these better models. Even if a relatively large training dataset can be provided, it will be limited by the computing power required by the model itself. Therefore, it is necessary to make up for the shortcomings of the typical convolutional neural network model in the specific scenario of Dongba pictograph image classification and then obtain better training and classification results under relatively limited datasets. Based on this, this paper continuously adjusts the structure and parameters based on the ResNet model. It uses a greedy algorithm to solve the approximate optimal solution of the loss function.
For the ResNet model, the network structure and parameters were adjusted to optimize the model performance further. Specifically, the number of residual blocks was increased to make the network deeper; simultaneously, the size and number of convolution kernels were adjusted to capture the characteristics of Dongba pictographs better. In addition, a greedy algorithm was used to solve the approximate optimal solution of the loss function. The greedy algorithm gradually optimizes the parameters of each residual block so that the model gradually converges to the optimal solution during the training process.
To prevent the model from overfitting, the L2 norm [
36] of the weight is added as a penalty term in the loss function. L2 regularization makes the model smoother by penalizing larger weight values, thereby improving the generalization ability. In the specific implementation, the L2 regularization term is combined with the cross-entropy loss function to form a new loss function for optimization. Adding L2 regularization to the loss function prevents the model from overfitting, and the model’s generalization ability is significantly improved. The experimental results show that L2 regularization reduces the overfitting phenomenon of the model on the training set and enhances the model’s performance on the validation and test sets. This enables the model to better adapt to different writing styles and Dongba hieroglyphs with large deformations and has more substantial practical application value.
Specifically, while VGGNet and AlexNet achieved high accuracy (97.72%), they required longer training durations (8.0 and 6.0 h, respectively) and exhibited less stability in handling structural variation. LeNet-5, although computationally efficient, suffered from significantly lower accuracy (20.66%) due to its shallow architecture, which limited its ability to capture the complex features of Dongba pictographs. InceptionNet, despite its multi-scale feature extraction design, performed suboptimally in our setting (68.75%), likely due to the model’s sensitivity to input scale inconsistency.
In contrast, ResNet not only outperformed all models in classification accuracy (baseline 99.43%, peak 99.84%) but also demonstrated a favorable balance between depth and efficiency, enabled by its residual learning mechanism. This architecture effectively mitigates vanishing gradient issues in deep networks, supporting stable training even with complex and variably deformed pictographs. Additionally, ResNet achieved high performance with a moderate training time of 7.5 h, offering a practical compromise between computational demand and classification accuracy. These factors collectively justify our selection of ResNet as the most suitable architecture for recognizing Dongba pictographs.
3.2. Model Classification Training Results and Analysis
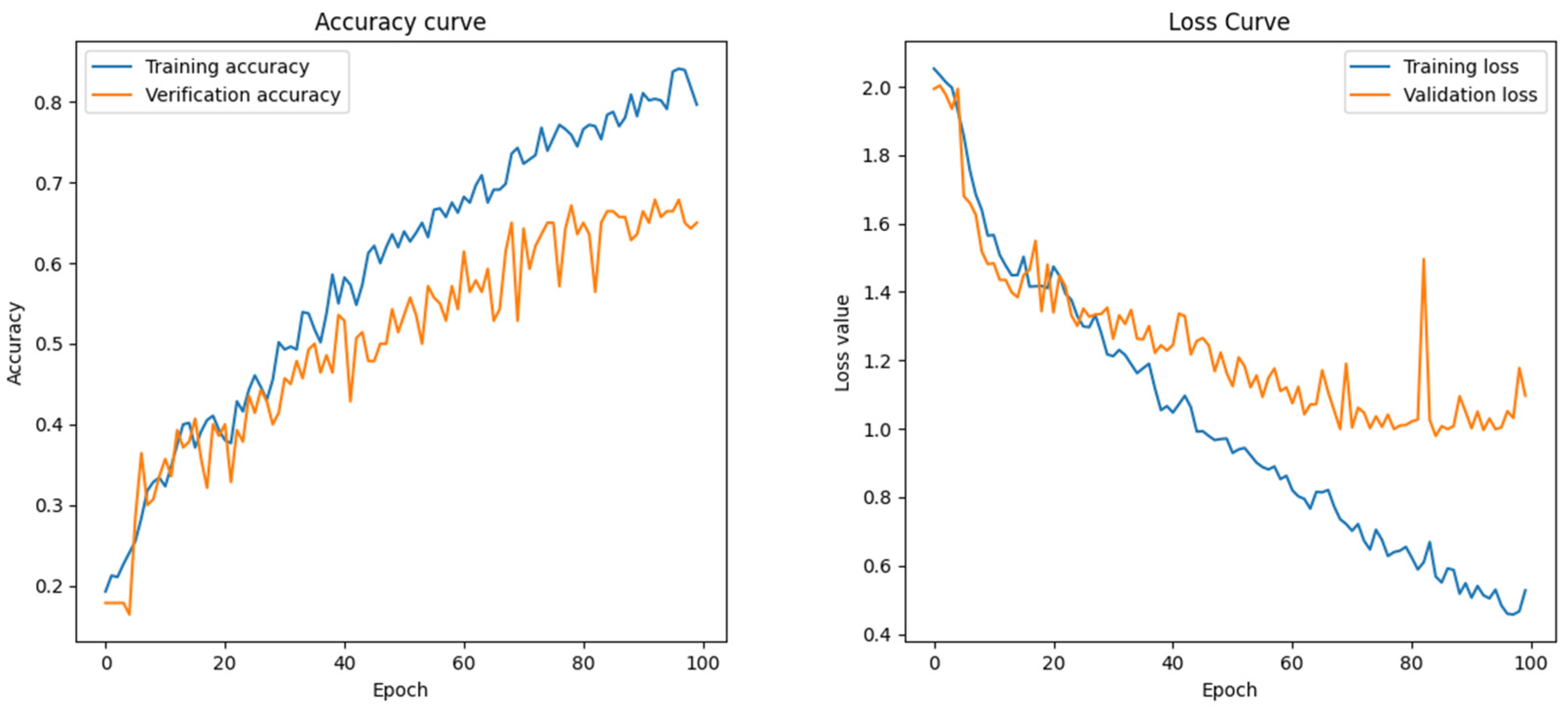
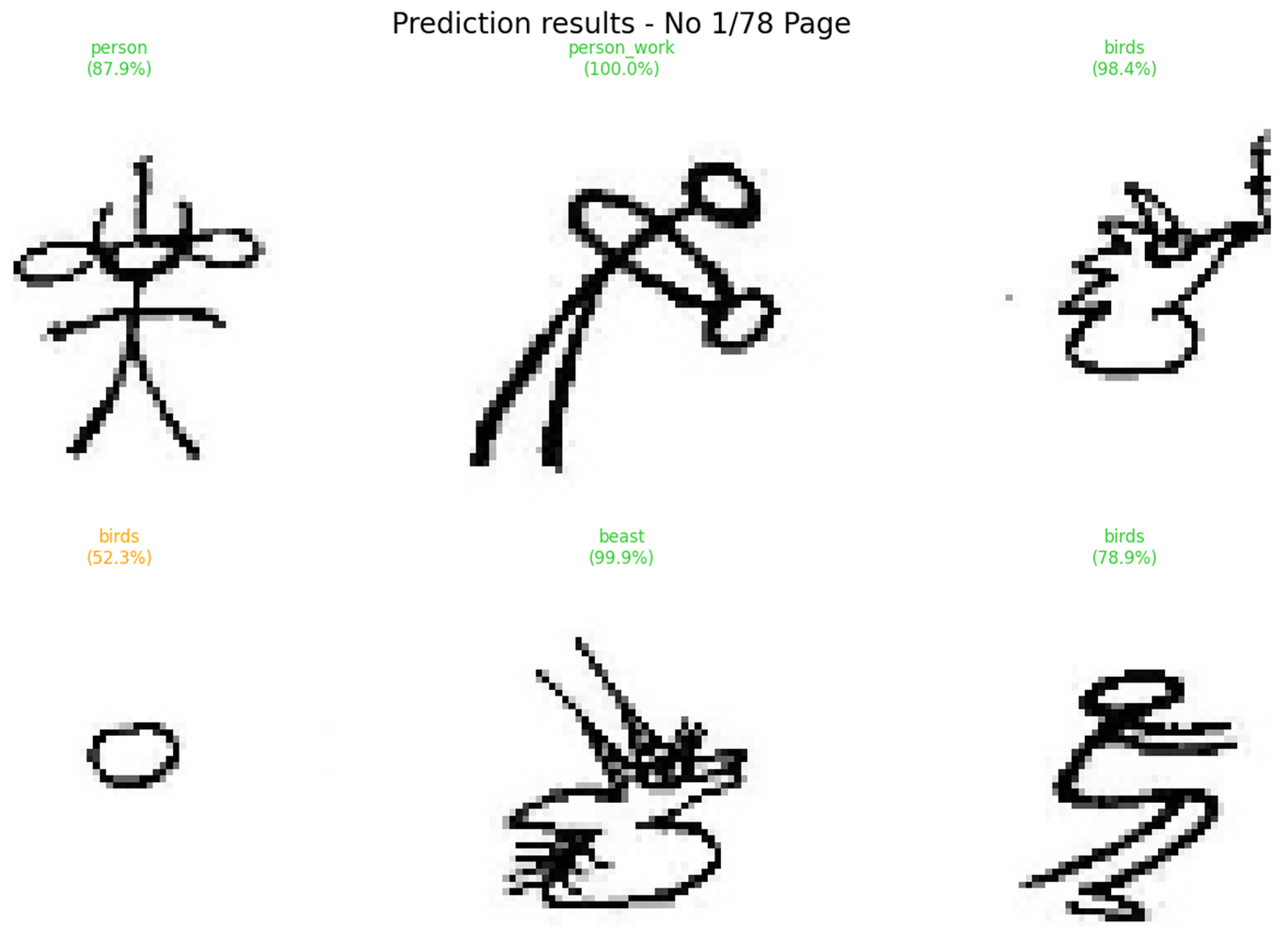
The experimental results indicate that the ResNet model achieved the highest performance in the Dongba pictograph classification task. Specifically, extensive experiments were conducted using various parameter combinations to optimize the training model. Ultimately, by fixing other parameters and varying the number of epochs and batch size, the approximate optimal solution of the loss function was obtained when the number of epochs was set to 75 and the batch size to 512. Under these conditions, the classification accuracy reached 99.84%, as illustrated in
Figure 10. The proposed model achieved a baseline classification accuracy of 99.43%, while its performance peaked at 99.84% under optimized training conditions—specifically, with 75 training epochs and a batch size of 512.
In contrast, LeNet-5 and InceptionNet exhibited suboptimal performance, achieving only 20.66% and 68.75% accuracy rates, respectively. In the classification and recognition of Dongba pictograms, ResNet effectively mitigated the gradient vanishing problem through residual connections, allowing for the training of a deeper network capable of capturing intricate features of Dongba characters. Consequently, ResNet significantly outperformed models such as AlexNet and VGGNet. The test confidence support for these findings is presented in
Figure 11 and
Figure 12.
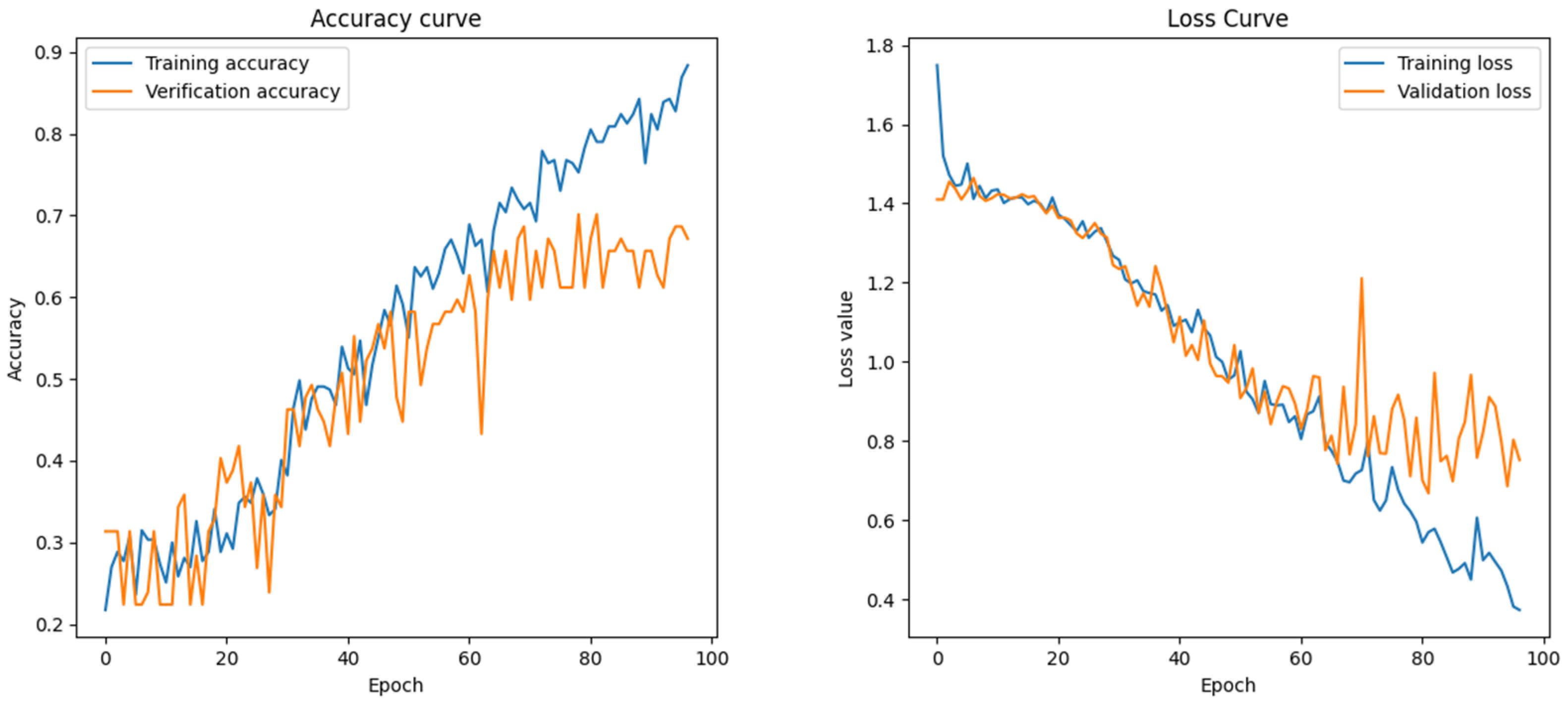
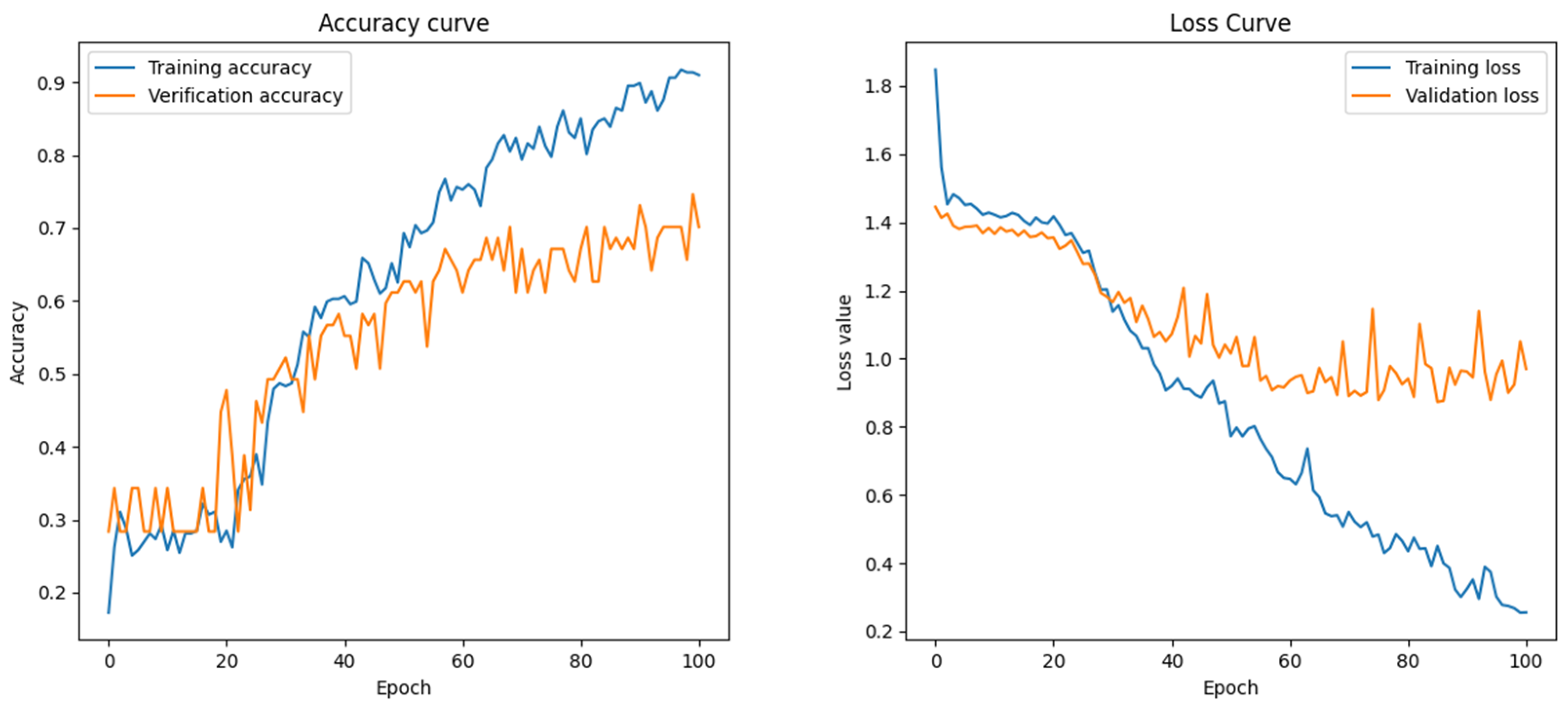
Simultaneously, the model’s performance was further optimized by refining the network architecture and hyperparameters, incorporating regularization techniques, and employing greedy algorithms to approximate the optimal solution of the loss function. While this study achieved high classification accuracy, certain limitations remain. First, despite the large dataset, it primarily consists of printed Dongba pictographs, with a relatively small number of handwritten samples. This imbalance constrains the model’s ability to recognize handwritten characters accurately. Second, the model’s capacity to differentiate similar characters requires further enhancement, mainly when the character shapes exhibit high similarity. Given that Dongba pictographs are inherently hand-painted images with substantial visual resemblance, the model tends to overfit after fewer training epochs, as illustrated in
Figure 13.
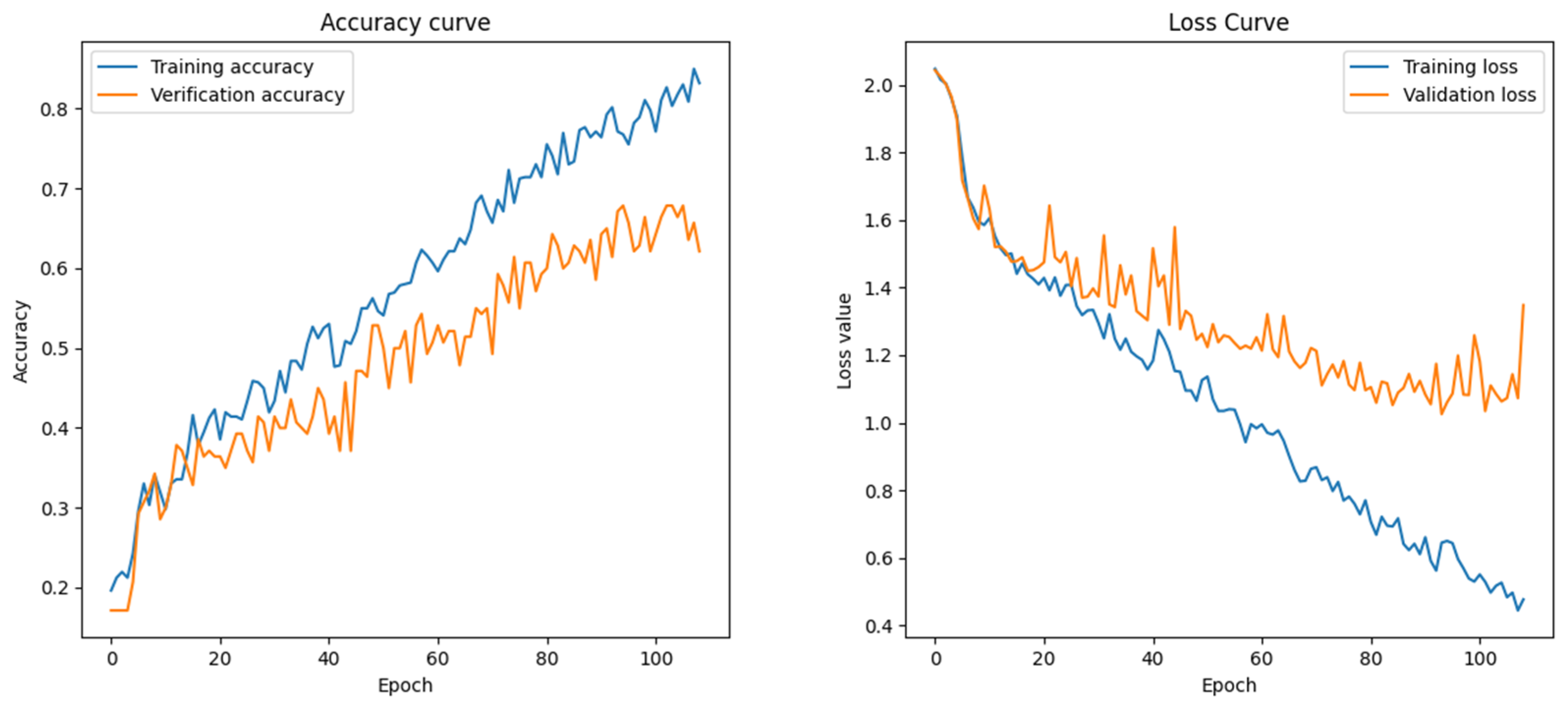
Data annotation is conducted incrementally, with the sample size gradually increasing. As the dataset expands, the model’s test results become progressively more reliable, as
Figure 14,
Figure 15,
Figure 16 and
Figure 17 illustrate.
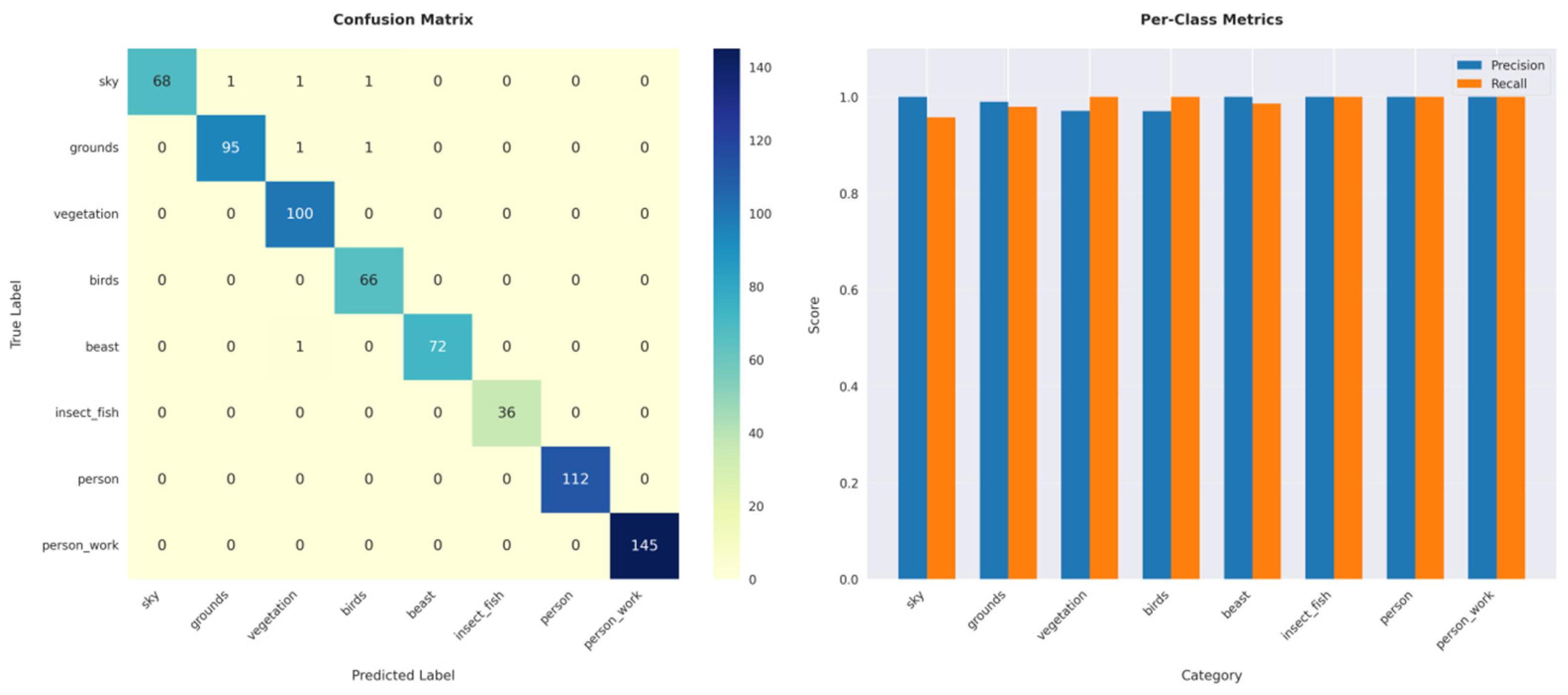
For hand-painted Dongba pictographs, the model reaches a point where it can no longer learn additional invariant features. To address this, while augmenting the dataset with more existing hand-painted Dongba pictographs, regularization is applied to the Dongba pictograph image convolutional neural network model. Specifically, the L2 norm of the weights is introduced as a penalty term in the loss function to prevent excessive weight magnitudes, thereby reducing model complexity. By incorporating this penalty term while maintaining a high recall rate, the model is evaluated using 700 newly collected hand-painted Dongba pictographs, as illustrated in
Figure 18. The confusion matrix reveals that the sky and square categories are more frequently misclassified. This misclassification is attributed to the nature of Dongba pictographs, which often employ geometric shapes, such as circles and squares, to represent these concepts, leading to increased ambiguity between the two categories.
The rounds with low recognition accuracy were identified and analyzed. By examining the recognition process log, as illustrated in
Figure 19, it was observed that recognition confidence was consistently low. Several key factors contributed to this issue: (1) significant character deformation, making it difficult for the model to recognize characters accurately; (2) high similarity between characters, leading to confusion, especially when the handwriting lacks standardization; and (3) poor image quality, which hinders accurate feature extraction.
The analysis reveals that these misclassifications are primarily due to visual similarity in stroke structure and spatial arrangement between certain pictographs. For instance, “sky” and “square” both share rectangular outlines and internal symmetry, which may lead to overlapping activation patterns in intermediate layers of the CNN. Additionally, some errors can be attributed to intra-class variability—such as handwritten distortions, partial occlusions, or style-specific glyph variations—that reduce the discriminative power of feature representations.
To support this analysis, representative misclassified image pairs have been included in
Figure 19, highlighting the visual ambiguity contributing to model confusion. We have also discussed possible strategies to mitigate such errors, including hierarchical classification, attention-based visual refinement, or domain-adaptive training on stylistic variants of Dongba characters.
Several improvement strategies can be implemented to mitigate the aforementioned challenges. First, enhancing the diversity of training samples can ensure broader coverage of various deformation scenarios. Second, incorporating advanced techniques, such as attention mechanisms, can enhance the model’s capability to differentiate visually similar characters. Third, leveraging image enhancement techniques, including image restoration, can improve overall image quality and facilitate more accurate recognition.
Table 10 presents a benchmarking analysis of diverse CNN-based image classification studies, highlighting variations in model architectures, dataset sizes, data augmentation techniques, and resulting accuracies. Kadam et al. [
37] achieved 93.56% accuracy using five CNN architectures on the MNIST and Fashion-MNIST datasets, emphasizing the importance of parameter tuning over data augmentation. Zhang [
22] attained 95.80% accuracy with a custom CNN on a relatively small dataset (~2500 images) despite unspecified augmentation. In contrast, Xie and Dong [
23] utilized a 20-layer ResNet on only 536 images without augmentation, achieving an accuracy of 93.58%. Luo et al. [
24] achieved a performance improvement to 98.65% using a modified ResNet with basic rotation-based augmentation. Isohanni [
38] further improved accuracy to 99.28% with ResNet-34 and a diverse augmentation strategy that included geometric and zoom transformations. Chen and Zhu [
39] applied improved ResNet models to CIFAR datasets, reaching 95.11% on CIFAR-10 and 76.37% on CIFAR-100 with minimal augmentation. Liang [
40] reported 88.28% accuracy using ResNet-20 and Inception-ResNet v1 with automated augmentation via ImageDataGenerator. Notably, the present study surpasses all prior efforts, achieving 99.43% baseline and 99.84% peak accuracy with an optimized ResNet trained on 70,000 images and enhanced through comprehensive augmentation strategies encompassing rotation, scaling, occlusion, and photometric variation. These findings underscore the critical role of both dataset scale and diverse augmentation in maximizing the performance of CNNs.
Table 11 presents the results of a comparative analysis in which each data augmentation technique was individually applied to the training dataset, with all other parameters held constant. The experimental findings indicate that rotation and scaling had the most pronounced effects on improving model generalization, yielding accuracy gains of approximately 2.8% and 2.3%, respectively. While occlusion simulation and photometric adjustment produced more modest improvements, they contributed meaningfully to the model’s robustness, particularly in handling image quality variations and partial character degradation. These results underscore the critical role of a comprehensive augmentation pipeline in enhancing model performance and achieving the final baseline accuracy of 99.43%.
4. Discussion
This study presents a convolutional neural network (CNN)-based approach for the classification of Dongba pictographs, achieving a classification accuracy of 99.43%. The model was trained on a dataset of 70,000 manually categorized samples, divided into 18 distinct classes based on shape characteristics. The findings demonstrate that CNN-based methods, particularly ResNet, outperform traditional classification techniques such as Support Vector Machines (SVM) and other deep learning models, including LeNet-5, AlexNet, VGGNet, and InceptionNet. By incorporating data augmentation techniques (e.g., rotation, affine transformation, scaling, and translation), the study enhances the model’s robustness and generalization capability.
The experimental findings demonstrate that the optimized ResNet model achieved superior performance, effectively addressing challenges such as gradient vanishing and overfitting through residual learning mechanisms. When benchmarked against previous studies—such as Kadam et al. [
37], Chen and Zhu [
39], Liang [
40], Zhang [
22], Xie and Dong [
23], Luo et al. [
24], and Isohanni [
38]—the proposed model attained a notably higher recognition accuracy of 99.43%. This result surpasses the reported accuracies of 93.56%, 95.11% (CIFAR-10)/76.37% (CIFAR-100), 88.28%, 95.80%, 93.58%, 98.65%, and 99.28%, respectively. These improvements underscore the effectiveness of deep learning approaches, particularly optimized residual networks, in accurately recognizing complex pictographic characters characterized by substantial visual variability.
The study aligns with previous research on Dongba pictograph recognition, reinforcing the value of deep learning techniques in improving classification accuracy. Earlier works primarily employed feature extraction and machine learning methods, such as topological structure-based methods [
20], grid decomposition algorithms [
12,
13], and Histogram of Oriented Gradients (HOG) feature extraction with SVM [
21]. However, these approaches exhibited limited adaptability to pictographic variations and suffered from challenges related to feature engineering.
More recent studies (e.g., Luo et al. [
24]) attempted to improve classification performance using enhanced ResNet architectures, achieving 98.65% accuracy. Our study extends this line of research by utilizing a larger dataset and introducing advanced data augmentation techniques, further enhancing classification accuracy and robustness.
Additionally, this research contributes to ongoing efforts in cultural heritage preservation and computational linguistics [
9,
16]. The application of CNNs to Dongba pictographs supports broader digital humanities initiatives, providing a scalable and efficient framework for automated script recognition.
Despite the study’s success in Dongba pictograph recognition, several limitations were noted. The dataset predominantly comprises printed Dongba pictographs, which limits the model’s generalizability to handwritten or historical inscriptions. Although some handwritten samples were included, they constitute a small proportion of the overall dataset. The model also struggles to recognize highly similar pictographs due to minor structural variations. This challenge is reflected in the confusion matrix and highlights the visual resemblance among certain Dongba symbols.
Furthermore, the study does not fully account for real-world degradations in historical texts, such as ink smudging, erosion, or incomplete characters, which can affect recognition accuracy in practical applications [
41]. Additionally, computational constraints present another challenge. At the same time, deep learning models improve classification accuracy. They require significant computational resources for training and inference, making implementing these models on low-power devices challenging.
The research has significant implications for both academic and practical applications. Regarding cultural heritage preservation, the proposed CNN model aids in digitally archiving and preserving Dongba pictographs, facilitating automated transcription and indexing of historical manuscripts. For computational linguistics and NLP, future advances could integrate pictographic recognition with semantic interpretation, enabling a deeper understanding of the grammatological and phonological aspects of the Dongba script. The study validates the use of CNNs for low-resource languages and ancient scripts, paving the way for their application in other endangered writing systems, such as Oracle Bone Script and Mayan Hieroglyphs. Enhanced OCR systems could also benefit from incorporating attention mechanisms and hybrid deep learning models, like Transformers, to improve pictograph recognition, especially in noisy and degraded texts.
The study’s introduction highlighted the challenges of Dongba pictograph recognition and the limitations of traditional feature extraction methods and classifier models. The study’s findings address these challenges by demonstrating that deep learning methods, especially ResNet, significantly improve recognition accuracy. The study builds on previous research by expanding the dataset, introducing data augmentation, and exploring broader implications for cultural preservation and AI-driven linguistic research. The potential of deep learning in enhancing Dongba pictograph classification is underscored by achieving an unprecedented accuracy of 99.43%, with the ResNet model outperforming other CNN architectures and traditional machine learning techniques. The findings contribute to computational linguistics, cultural heritage preservation, and AI-based pictograph recognition.
The inclusion of LeNet-5 and other foundational CNN architectures, such as AlexNet and VGGNet, provides baseline comparisons against advanced methods, like ResNet, to systematically demonstrate the performance gains from architectural improvements. While YOLO (You Only Look Once), a prominent modern model designed primarily for object detection tasks, was not directly compared due to its primary focus on real-time bounding-box detection, its potential applicability to real-time detection of pictographs presents an interesting avenue for future research.
To advance this research further, future studies should focus on expanding the dataset to include more handwritten and degraded Dongba pictographs, thereby improving real-world recognition capabilities. They should also integrate attention mechanisms like Vision Transformers to enhance feature extraction and classification accuracy. Developing multimodal approaches that combine visual recognition with linguistic analysis could aid in the semantic understanding of the Dongba script. Additionally, applying advanced image restoration techniques could improve the recognition of damaged or historical pictographs. By addressing these challenges, future research can bridge the gap between AI and cultural heritage studies [
42], ensuring that the Dongba script and other endangered writing systems are preserved and accessible for future generations.
Author Contributions
Conceptualization, S.L., L.T.N., W.C., N.I.-O. and T.B.; methodology, S.L., L.T.N., W.C., N.I.-O. and T.B.; software, S.L., L.T.N., W.C., N.I.-O. and T.B.; validation, S.L., L.T.N., W.C., N.I.-O. and T.B.; formal analysis, W.C., N.I.-O. and T.B.; investigation, S.L., L.T.N., W.C., N.I.-O. and T.B.; resources, S.L.; data curation, S.L.; writing—original draft preparation, S.L., L.T.N., W.C., N.I.-O. and T.B.; writing—review and editing, S.L., L.T.N., W.C., N.I.-O. and T.B.; visualization, S.L., L.T.N., W.C., N.I.-O. and T.B.; supervision, W.C., N.I.-O. and T.B.; project administration, W.C., N.I.-O. and T.B.; funding acquisition, T.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data will be made available on request.
Acknowledgments
The authors would like to extend their gratitude to Khon Kaen University for their support through Announcement No. 2580/2563 on “The Criteria for the Acceptance of an Inbound Visiting Scholar from a Foreign Institution or Organization to Khon Kaen University”. This support has been invaluable to the success of our research project.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, T.; Chen, J.; Liu, L.; Guo, L. A Review: How Deep Learning Technology Impacts the Evaluation of Traditional Village Landscapes. Buildings 2023, 13, 525. [Google Scholar] [CrossRef]
- Gao, L.; Wu, Y.; Yang, T.; Zhang, X.; Zeng, Z.; Chan, C.K.D.; Chen, W. Research on Image Classification and Retrieval Using Deep Learning with Attention Mechanism on Diaspora Chinese Architectural Heritage in Jiangmen, China. Buildings 2023, 13, 275. [Google Scholar] [CrossRef]
- Janković, R. Machine Learning Models for Cultural Heritage Image Classification: Comparison Based on Attribute Selection. Information 2019, 11, 12. [Google Scholar] [CrossRef]
- Ju, F. Mapping the Knowledge Structure of Image Recognition in Cultural Heritage: A Scientometric Analysis Using CiteSpace, VOSviewer, and Bibliometrix. J. Imaging 2024, 10, 272. [Google Scholar] [CrossRef]
- Ottoni, A.L.C.; Ottoni, L.T.C. ImageOP: The Image Dataset with Religious Buildings in the World Heritage Town of Ouro Preto for Deep Learning Classification. Heritage 2024, 7, 6499–6525. [Google Scholar] [CrossRef]
- Go, I.; Fu, Y.; Ma, X.; Guo, H. Comparison and Interpretability Analysis of Deep Learning Models for Classifying the Manufacturing Process of Pigments Used in Cultural Heritage Conservation. Appl. Sci. 2025, 15, 3476. [Google Scholar] [CrossRef]
- Xu, D. Digital Approaches to Understanding Dongba Pictographs. Int. J. Digit. Humanit. 2023, 4, 131–146. [Google Scholar] [CrossRef]
- Zhen, Z.H. Analysis of Dongba Pictographs and Its Application to Pictogram Design. High. Educ. Soc. Sci. 2013, 5, 85–88. [Google Scholar]
- Selmanović, E.; Rizvic, S.; Harvey, C.; Boskovic, D.; Hulusic, V.; Chahin, M.; Sljivo, S. Improving Accessibility to Intangible Cultural Heritage Preservation Using Virtual Reality. J. Comput. Cult. Herit. 2020, 13, 1–19. [Google Scholar] [CrossRef]
- Mu, C. A Brief Description of the Woodblock Prints of the “Naxi Pictographs and Geba Script Comparative Lexicon” in the Lijiang Museum Collection. J. Chin. Writ. Syst. 2024, 8, 270–281. [Google Scholar] [CrossRef]
- Xu, D. How Do Dongba Glyphs Transcribe IPA? Analysis of a Note by a Ruke Dongba Priest Learning IPA. Humans 2022, 2, 64–73. [Google Scholar] [CrossRef]
- Yang, Y.; Kang, H. Dongba Scripture Segmentation Algorithm Based on Discrete Curve Evolution. In Proceedings of the 2021 14th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 11–12 December 2021; IEEE: New York, NY, USA, 2021; pp. 416–419. [Google Scholar] [CrossRef]
- Yang, Y.; Kang, H. A Table Recognition and Extraction Algorithm in Dongba Character Documents Based on Hough Transform. In Proceedings of the 3rd International Conference on Information Technologies and Electrical Engineering, Changde, China, 3–5 December 2020; pp. 672–674. [Google Scholar] [CrossRef]
- He, J.; Zhao, X. An Annotated Translation of the ‘Eye Disease Incantation’ in Dongba Script. J. Chin. Writ. Syst. 2020, 4, 111–116. [Google Scholar] [CrossRef]
- Zhou, Y. Study on the Variant Pictograph of Dongba Script in Lijiang Area. Open J. Soc. Sci. 2018, 6, 335–342. [Google Scholar] [CrossRef]
- Poupard, D.J. Revitalising Naxi Dongba as a ‘Pictographic’ Vernacular Script. J. Chin. Writ. Syst. 2019, 3, 53–67. [Google Scholar] [CrossRef]
- Guo, H.; Zhao, J.Y.; Da, M.J. NaXi Pictographs Edge Detection Using Lifting Wavelet Transform. J. Converg. Inf. Technol. 2010, 5, 203–210. [Google Scholar] [CrossRef]
- Yang, M.; Xu, X.L.; Wu, G.X. Dongba Pictograph Recognition Method. J. Beijing Inf. Sci. Technol. Univ. 2014, 29, 72–76. [Google Scholar] [CrossRef]
- Wang, H.Y.; Wang, H.J.; Xu, X.L. NaXi Dongba Pictograph Recognition Based on Support Vector Machine. J. Yunnan Univ. (Nat. Sci. Ed.) 2016, 38, 730–736. [Google Scholar]
- Xu, X.L.; Jiang, Z.L.; Wu, G.X. Research on Dongba Pictograph Recognition Based on Topological Features and Projection Method. J. Electron. Meas. Instrum. 2017, 31, 150–154. [Google Scholar] [CrossRef]
- Shen, T.; Zhuang, J.J.; Li, W.S. Dongba Character Recognition Based on HOG Feature Extraction and Support Vector Machine. J. Nanjing Univ. (Nat. Sci. Ed.) 2020, 56, 870–876. [Google Scholar] [CrossRef]
- Zhang, Z.H. Dongba Character Classification and Recognition Based on Convolutional Neural Networks. Master’s Thesis, Yunnan University, Kunming, China, 2020. [Google Scholar]
- Xie, Y.R.; Dong, J.E. Research on Dongba Pictograph Recognition Based on ResNet Network. Comput. Era 2021, 1, 6–10. [Google Scholar] [CrossRef]
- Luo, Y.L.; Bi, X.J.; Wu, L.C. Dongba Pictograph Recognition Based on Improved Residual Learning. J. Intell. Syst. 2022, 17, 79–87. [Google Scholar]
- Yu, S.S. Several Issues in the Compilation of the Naxi Dongba Pictograph Dictionary. Lexicogr. Stud. 2020, 5, 73210. [Google Scholar]
- Fang, G.Y. Naxi Pictograph Dictionary; Yunnan People’s Publishing House: Kunming, China, 1981. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.F. A Comparative Study on Imagery Between Oracle Bone Script and Dongba Pictographs: Cultural Thinking Differences and National Identity. J. Cult. Herit. 2010, 8, 112–125. [Google Scholar]
- Liu, J.J.; Boongoen, T.; Iam-On, N. Improved Detection of Transient Events in Wide Area Sky Survey Using Convolutional Neural Networks. Data Inf. Manag. 2024, 8, 100035. [Google Scholar] [CrossRef]
- Boongoen, T.; Iam-On, N. Handling Overfitting and Imbalance Data in Modelling Convolutional Neural Networks for Astronomical Transient Discovery. In Proceedings of the International Conference on Computing, Communication, Cybersecurity & AI, London, UK, 3–4 July 2024; pp. 691–698. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Lewkowycz, A.; Gur-Ari, G. On the Training Dynamics of Deep Networks with L2 Regularization. Adv. Neural Inf. Process. Syst. 2020, 33, 4790–4799. [Google Scholar]
- Kadam, S.S.; Adamuthe, A.C.; Patil, A.B. CNN model for image classification on MNIST and fashion-MNIST dataset. J. Sci. Res. 2020, 64, 374–384. [Google Scholar] [CrossRef]
- Isohanni, J. Customised ResNet architecture for subtle color classification. Int. J. Comput. Appl. 2025, 47, 341–355. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, C. Research on image recognition based on improved ResNet. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; IEEE: New York, NY, USA, 2020; pp. 1422–1426. [Google Scholar] [CrossRef]
- Liang, J. Image classification based on RESNET. In Proceedings of the Journal of Physics: Conference Series, Xi’an, China, 18–20 September 2020; IOP Publishing: Bristol, UK, 2020; Volume 1634, p. 012110. [Google Scholar] [CrossRef]
- Tuamsuk, K.; Kaewboonma, N.; Chansanam, W.; Leopenwong, S. Taxonomy of folktales from the greater Mekong sub-region. Knowl. Organ. 2016, 43, 431–439. [Google Scholar] [CrossRef]
- Chansanam, W.; Ahmad, A.R.; Li, C. Contemporary and future research of digital humanities: A scientometric analysis. Bull. Electr. Eng. Inform. 2022, 11, 1143–1156. [Google Scholar] [CrossRef]
Figure 1.
Structural framework of the proposed method.
Figure 2.
Image enhancement technology flow chart.
Figure 3.
Image enhancement effect diagram.
Figure 4.
Workflow of the image preprocessing process.
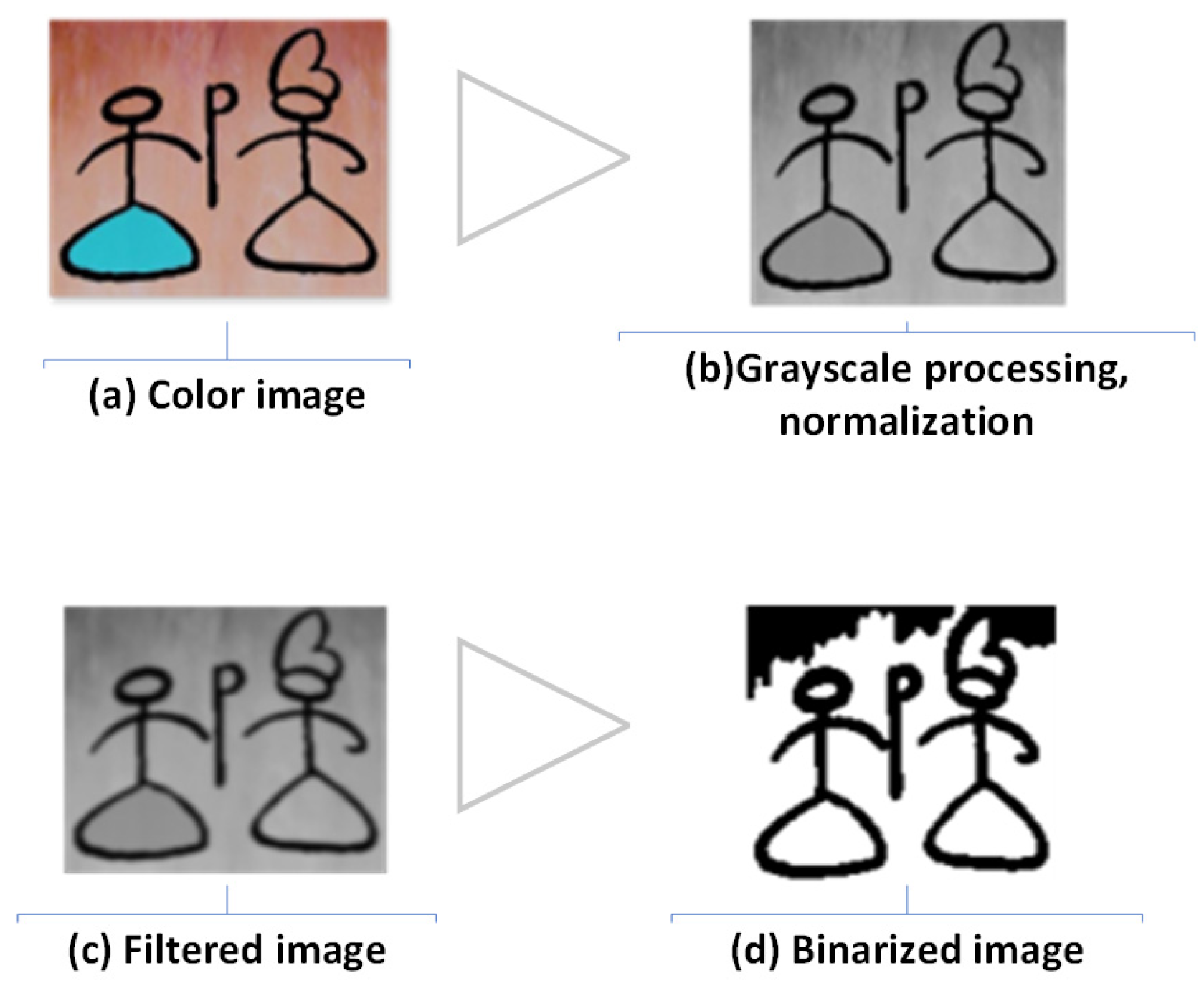
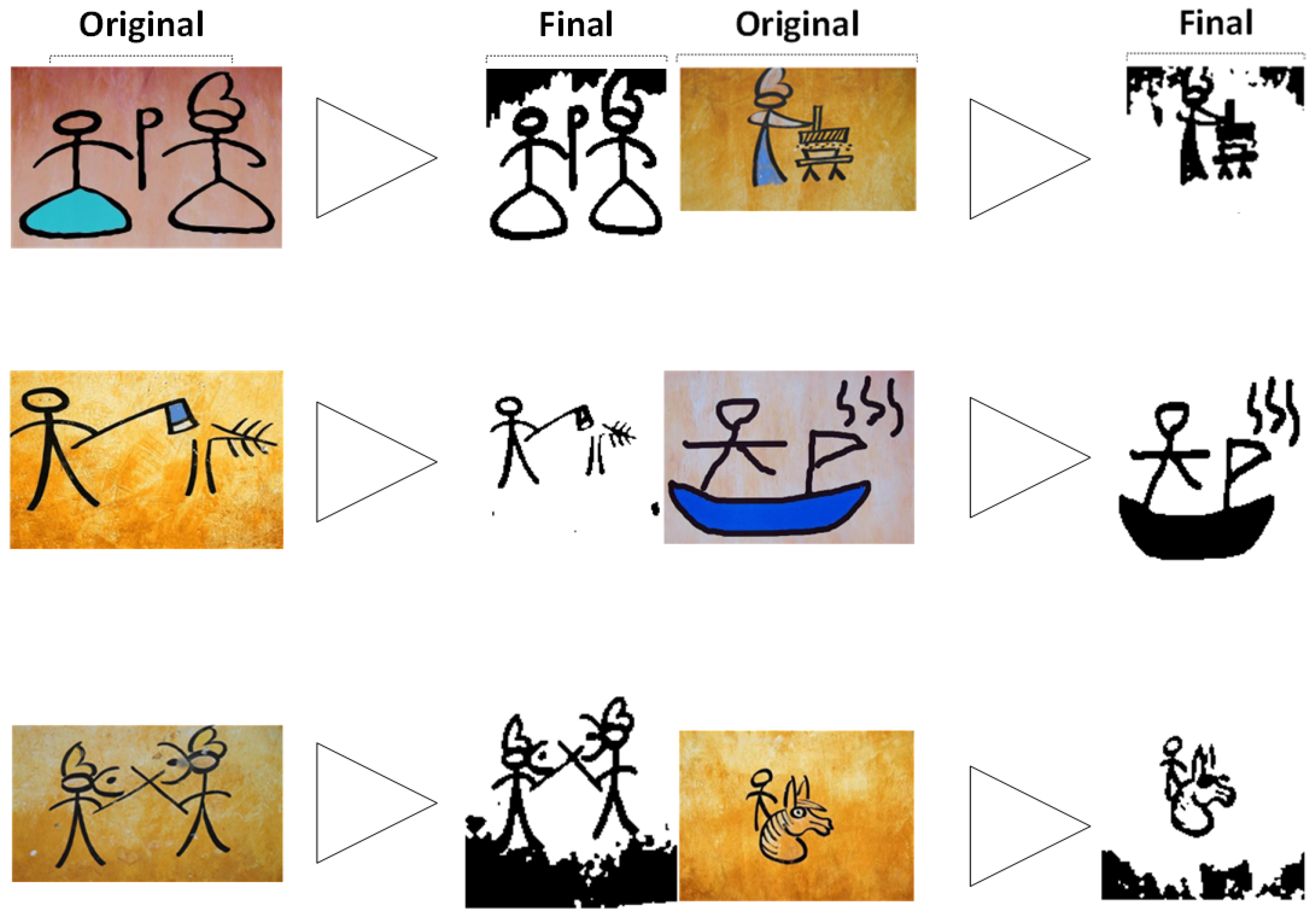
Figure 5.
Comparison of Dongba pictographs before and after the preprocessing phase.
Figure 6.
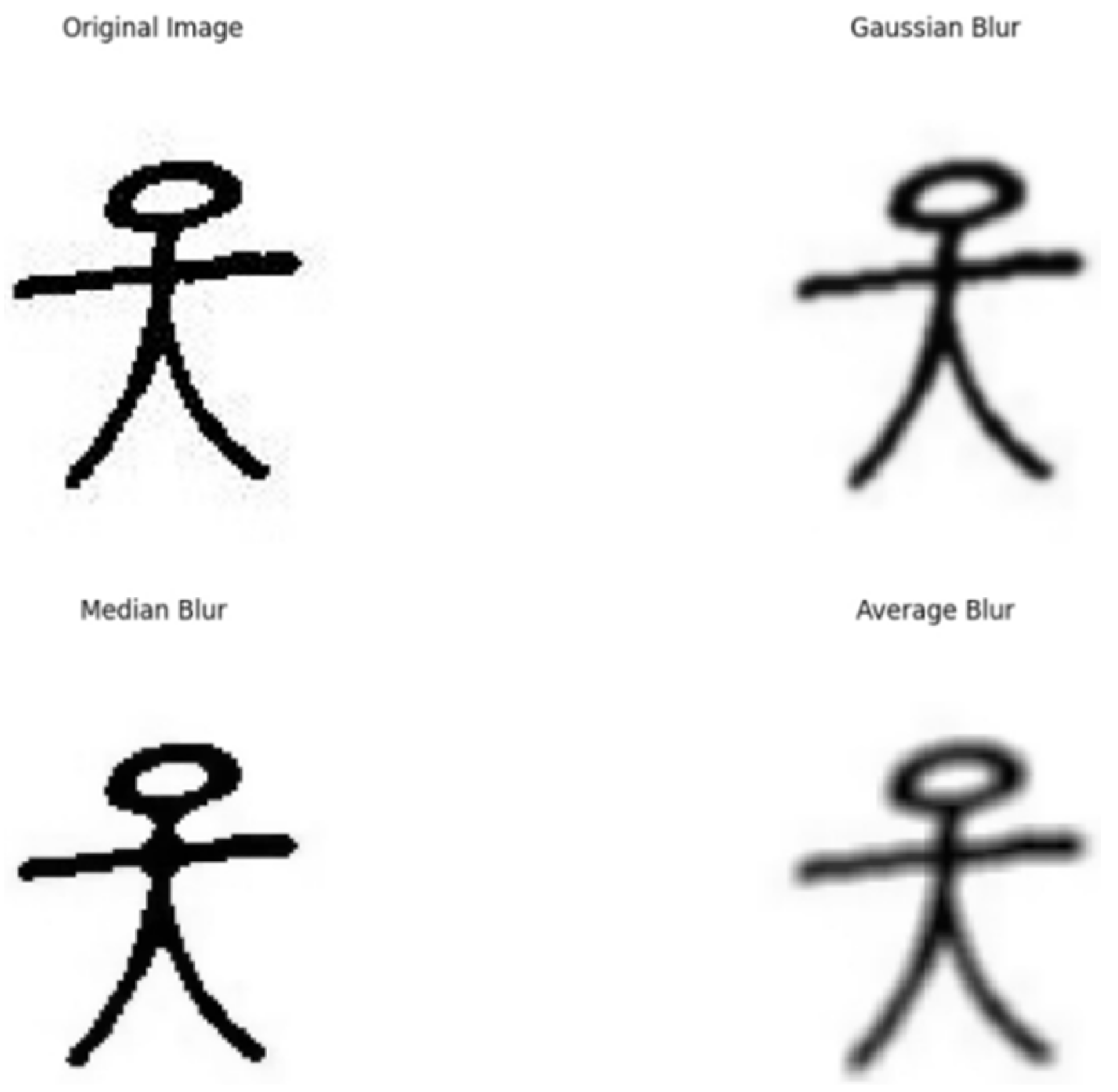
Comparative analysis of filtering algorithms for image preprocessing.
Figure 7.
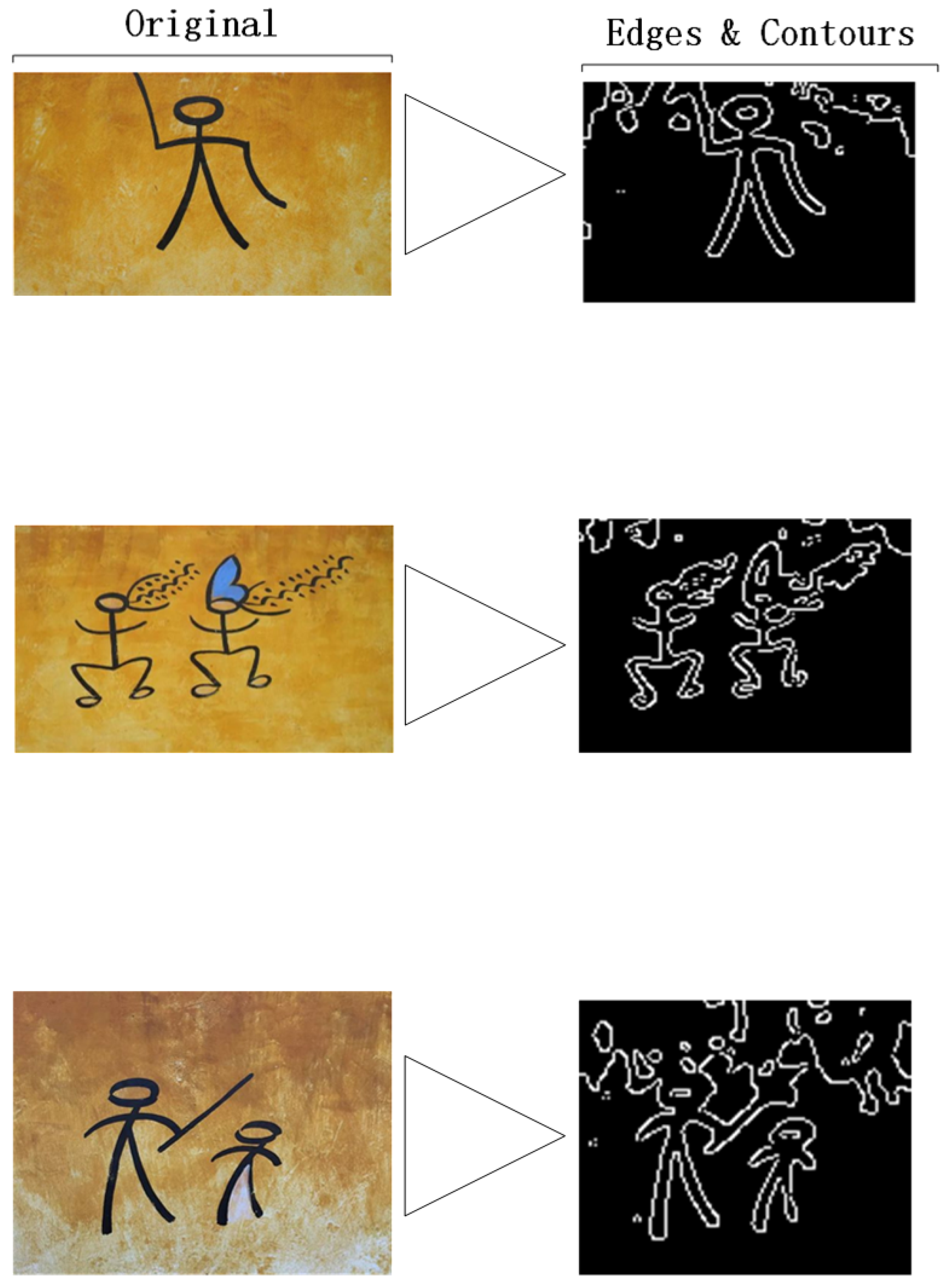
Edge detection and contour extraction processes.
Figure 10.
Training results.
Figure 11.
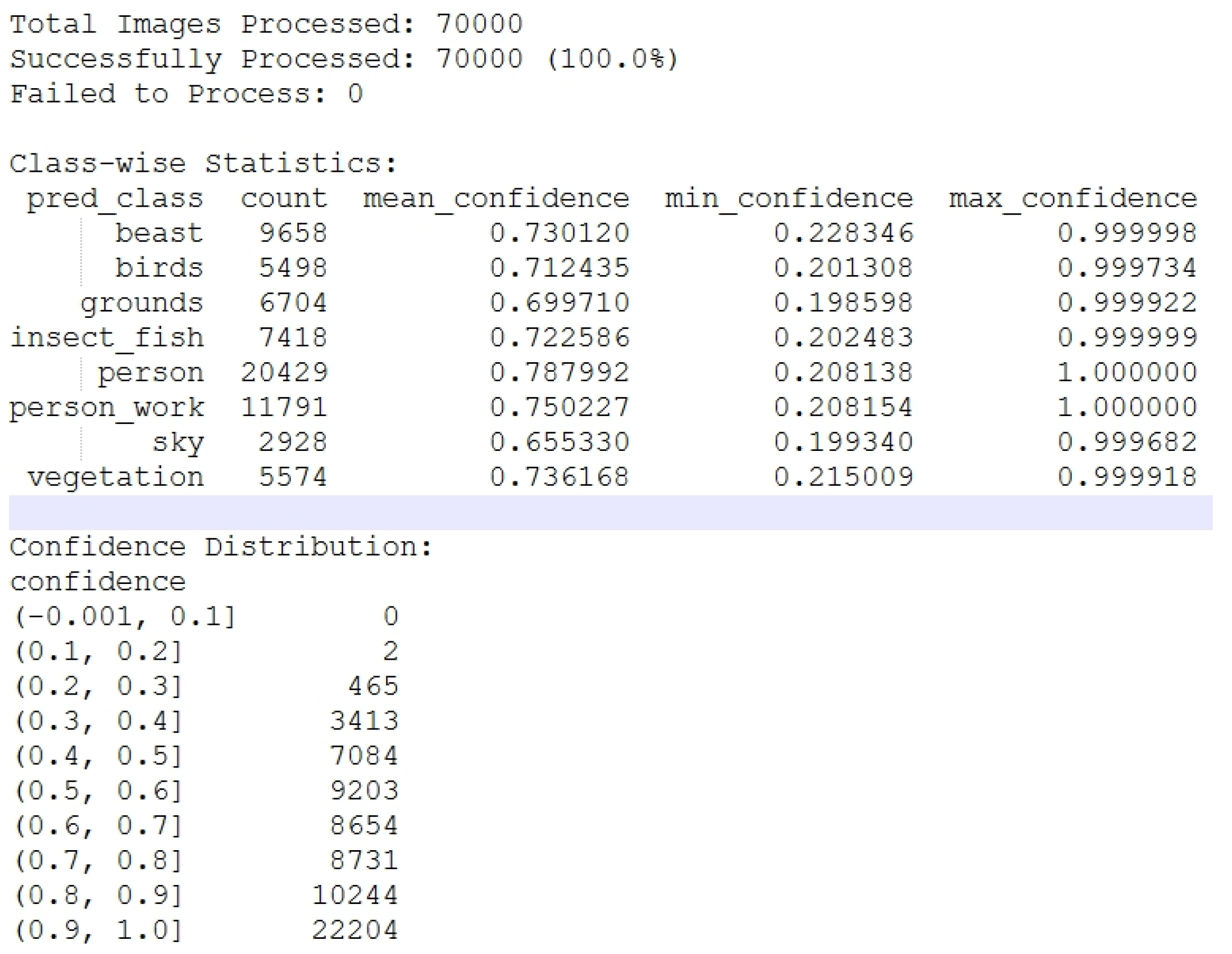
Class-wise Prediction Statistics and Confidence Distribution Table.
Figure 12.
Visual Analysis of Class Distribution and Confidence Metrics.
Figure 13.
Accuracy and Loss Curves for Dongba Hieroglyphic Model Training.
Figure 14.
Model test results 1.
Figure 15.
Model test results 2.
Figure 16.
Model test results 3.
Figure 17.
Model test results 4.
Figure 18.
Confusion matrix and recall.
Figure 19.
Recognition accuracy.
Table 1.
Categories and associated characteristics of the Dongba pictograph dataset.
| Category | Characteristic | No. of Samples |
|---|
| 1 | Celestial phenomenon | 4474 |
| 2 | Geographical | 4253 |
| 3 | Plant genus | 4159 |
| 4 | Birds | 3981 |
| 5 | Beast | 3874 |
| 6 | Insects and fish | 4128 |
| 7 | Personal name | 4529 |
| 8 | Personnel | 4347 |
| 9 | Form | 2987 |
| 10 | Clothing | 3913 |
| 11 | Diet | 4529 |
| 12 | Residential | 4193 |
| 13 | Utensils | 4789 |
| 14 | Behavior | 2789 |
| 15 | Shape | 1319 |
| 16 | Several names | 3819 |
| 17 | Religious | 4110 |
| 18 | Legendary name | 3807 |
Table 2.
Comparison of literature on image enhancement methods.
| Research Methods | This Program | Guo et al. [17] | Yang and Kang [12] |
|---|
| Enhanced type diversity | 9 types | 8 types | 6 types |
| Cultural fit verification | √ | ✗ | ✗ |
| Improvement in accuracy | +24.5% | +19.7% | +18.2% |
Table 4.
Image enhancement validation test.
| Research Methods | Accuracy (%) | Loss Value (Guo et al. [17]) |
|---|
| Original (7000 samples) | 78.20 | 0.451 |
| Enhanced by (70,000 samples) | 92.70 | 0.919 |
| W/O occlusion | 89.70 | 0.883 |
| W/O photometric | 85.10 | 0.832 |
Table 5.
Parameters for image grayscale conversion and normalization.
| Parameter Name | Value Exploited | Description |
|---|
| Binarization threshold | 127 | Threshold value for converting grayscale image to binary image |
| Profile retrieval mode | cv2.RETR_EXTERNAL | Retrieving the external contour |
| Contour approximation method | cv2.CHAIN_APPROX_SIMPLE | Contour approximation method: compress redundant points and keep only endpoints |
| Target center of mass X coordinate (standard) | image.shape [1]//2 | The X coordinate position to which the centroid is aligned, that is, the X coordinate of the image center |
| Target center of mass Y coordinate (standard) | image.shape [0]//2 | The Y coordinate position to which the centroid is aligned, that is, the Y coordinate of the image center |
| Binarization threshold | 127 | Threshold value for converting grayscale image to binary image |
| Profile retrieval mode | cv2.RETR_EXTERNAL | Retrieving the external contour |
Table 6.
Specifications and characteristics of CNN models used in the experiment.
| CNN Model | Total Layers | Key Characteristics | Applicability |
|---|
| LeNet-5 | 7 layers (2 convolutional, 2 pooling, 3 fully connected) | Basic text feature extraction | Good for smaller datasets |
| AlexNet | 8 layers (5 convolutional, 3 fully connected) | ReLU activation, dropout, fast training | Effective for complex features |
| VGGNet | 19 layers (multiple 3 × 3 convolutional, max-pooling layers) | Deep network for detailed features | Captures detailed pictograph nuances |
| ResNet | Deep layers with residual blocks | Addresses gradient vanishing and degradation | Best performance for deep networks |
| Google Inception Net | 22 layers (multi-scale convolutional kernels) | Multi-scale feature extraction | Good for varied-size pictographs |
Table 7.
Hyperparameter configuration for different model trainings.
| Model | Input Image Size | Sample Batch Size | Maximum Training Cycle | Learning Rate | Optimizer |
|---|
| LeNet-5 | | | | 0.0005 | Adam |
| AlexNet | | | | 0.001 | Adam |
| VGGNet | 64 × 64 | 512 | 100 | 0.0001 | SGD |
| ResNet | | | | 0.0005 | Adam |
| Google Inception Net | | | | 0.001 | RMSprop |
Table 8.
Performance comparison of various models in Dongba pictograph recognition.
| Model | Accuracy (%) | Loss Value | Training Time (Hours) |
|---|
| LeNet-5 | 20.66 | 2.357 | 1.5 |
| AlexNet | 97.72 | 0.125 | 6.0 |
| VGGNet | 97.72 | 0.094 | 8.0 |
| Google Inception Net | 68.75 | 0.431 | 7.5 |
| ResNet | 99.43 (baseline)/99.84 (peak) | 0.038 | 7.5 |
Table 9.
Comparative training performance of various CNN models.
| Model | Accuracy | Loss Value | Training Time (One Hour) |
|---|
| LeNet-5 | 20.66% | 1.9681 | 1.5 |
| AlexNet | 97.72% | 0.1286 | 6.0 |
| VGGNet | 97.72% | 0.0998 | 8.0 |
| ResNet | 99.43% | 0.2040 | 7.5 |
| Google Inception Net | 68.75% | 0.9576 | 9.0 |
Table 10.
Benchmarking of methodological differences.
| Study | Model Used | Dataset Size | Data Augmentation | Accuracy (%) |
|---|
| Kadam et al. (2020) [37] | Five different CNN architectures | MNIST (60,000 training images and 10,000 testing images) and Fashion-MNIST (60,000 training images and 10,000 testing images) | Activation functions, optimizers, learning rates, dropout rates, and batch sizes. | 93.56 |
| Chen and Zhu [39] | Improved ResNet/Baseline Models | CIFAR-10 (60,000 images)/CIFAR-100 (60,000 images) | Images were bilinearly upsampled to 40 × 40, cropped to 32 × 32, and augmented solely through random rotation. | 95.11 (CIFAR-10)/76.37 (CIFAR-100) |
| Liang [40] | ResNet-20/Inception-ResNet v1 | CIFAR-10 dataset with 60,000 32 × 32 RGB color images | ImageDataGenerator | 88.28 |
| Zhang [22] | CNN (custom) | ~2500 | Not specified | 95.80 |
| Xie and Dong [23] | ResNet (20-layer) | 536 (tested on 94) | None | 93.58 |
| Luo et al. [24] | Improved ResNet | Not specified | Basic (rotation) | 98.65 |
| Isohanni [38] | ResNet-34 | 7855 RGB images | Rotations (90, 180, and 270 degrees), vertical and horizontal flips, and a 0.2 zoom option | 99.28 |
| This Study | Optimized ResNet | 70,000 | Comprehensive (rotation, scaling, occlusion, photometric, etc.) | 99.43 (baseline)/99.84(peak) |
Table 11.
Individual impact of data augmentation techniques.
| Augmentation Technique | Accuracy (%) |
|---|
| No augmentation | 92.70 |
| Rotation only | 95.50 |
| Scaling only | 95.00 |
| Occlusion simulation only | 94.10 |
| Photometric adjustment | 93.80 |
| Elastic deformation | 94.30 |
| Full augmentation pipeline | 99.43 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}