This section details the methodology employed for cryptocurrency price forecasting, encompassing data acquisition, preprocessing, model development, and evaluation. The analysis was conducted using Python vs. 3.12.2 and its associated machine learning libraries, leveraging their extensive capabilities for time series analysis and model implementation.
3.1. Datasets
For the training and testing of the models, different datasets were collected, which include the minute step price values of Bitcoin, Ethereum, Binance Coin, Cardano, Solana, XRP, Polkadot, USD Coin, Dogecoin, and Avalanche. The data were obtained using the Python library yfinance vs. 0.2.55, which allows the extraction of cryptocurrency prices, as well as other financial assets, available on the portal finance.yahoo.com. We collected data from 12 May 2024 to 11 June 2024 to train and test the models’ minute step price values over a 30-day period.
The records include the attributes Datetime, Open, High, Low, Close, Adj. Close, and Volume, corresponding to the date and time of the price, opening value of the period, highest value traded during the period, lowest value traded during the period, closing value of the period, adjusted closing value of the period, and volume traded during the period. These fields, or attributes, are common across all financial asset quotations, from cryptocurrencies to stock market or Forex prices.
As can be seen in
Table 1 and
Table 2, although the same function with the same parameters is used to retrieve the data, the number of records is not the same for all cryptocurrencies, varying between 31,670 for Polkadot and 38,216 for Ethereum.
All values are in USD, and the prices vary significantly depending on the cryptocurrency. The average value for Dogecoin is 0.16 USD, the cryptocurrency with the lowest price, while the average value for Bitcoin is 67,948.15 USD, the highest-priced cryptocurrency. In terms of trading volume per minute, Polkadot has the lowest average value, at 76,259.87 USD, while Bitcoin has the highest, at 8,879,468.76 USD.
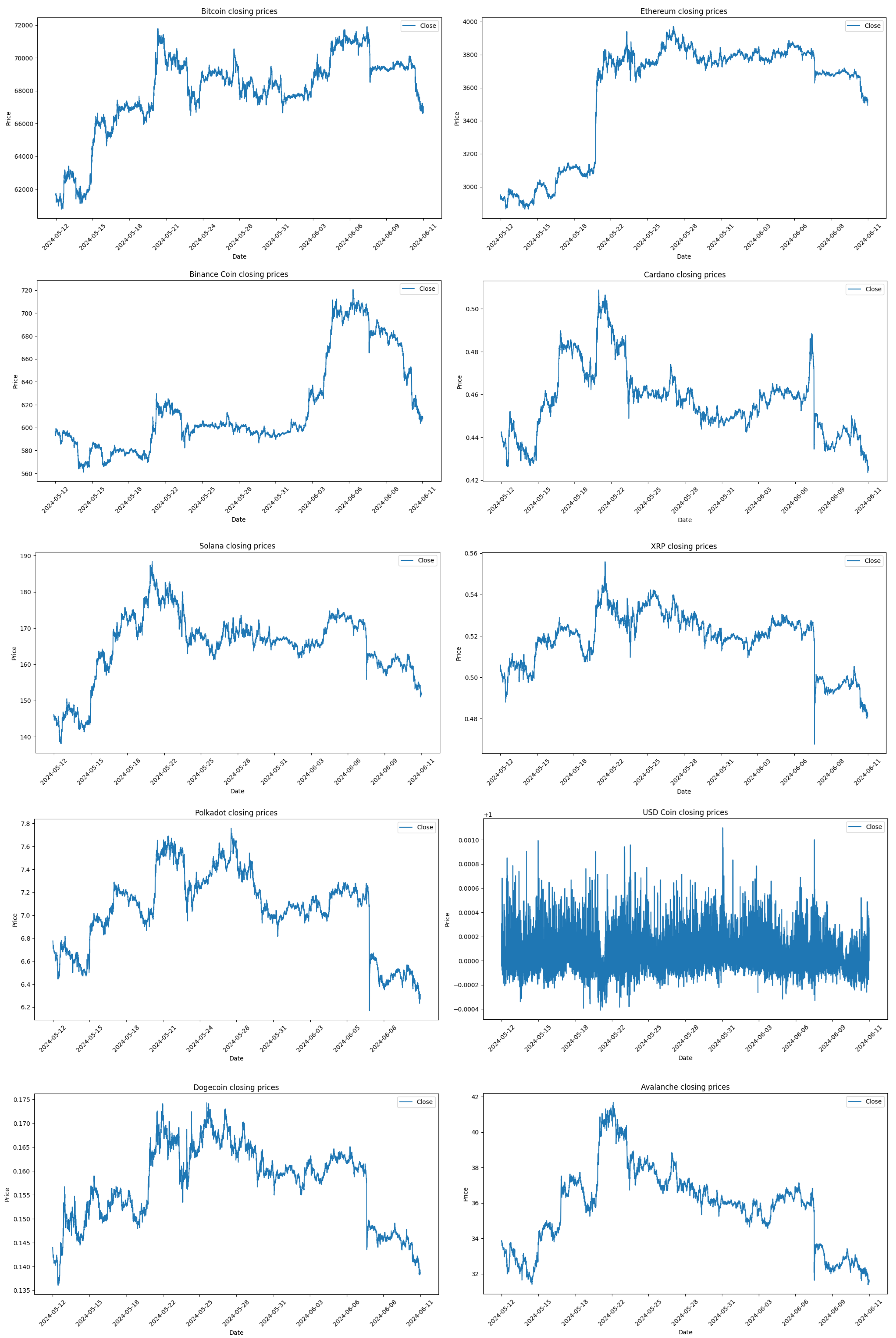
Figure 7 displays the daily closing prices for Bitcoin (BTC), Ethereum (ETH), Binance Coin (BNB), Cardano (ADA), Solana (SOL), XRP, Polkadot (DOT), USD Coin (USDC), Dogecoin (DOGE), and Avalanche (AVAX) over the 30-day data collection period. Most cryptocurrencies, including BTC, ETH, BNB, ADA, SOL, XRP, DOT, DOGE, and AVAX, exhibit a general downward trend in their closing prices over this period. Cryptocurrencies like ADA, XRP, and AVAX show higher short-term volatility compared to BTC and ETH. Stablecoins like USDC stand out for their resilience during such market conditions. The figure highlights a challenging period for most cryptocurrencies with declining prices and varying levels of volatility.
3.4. Models
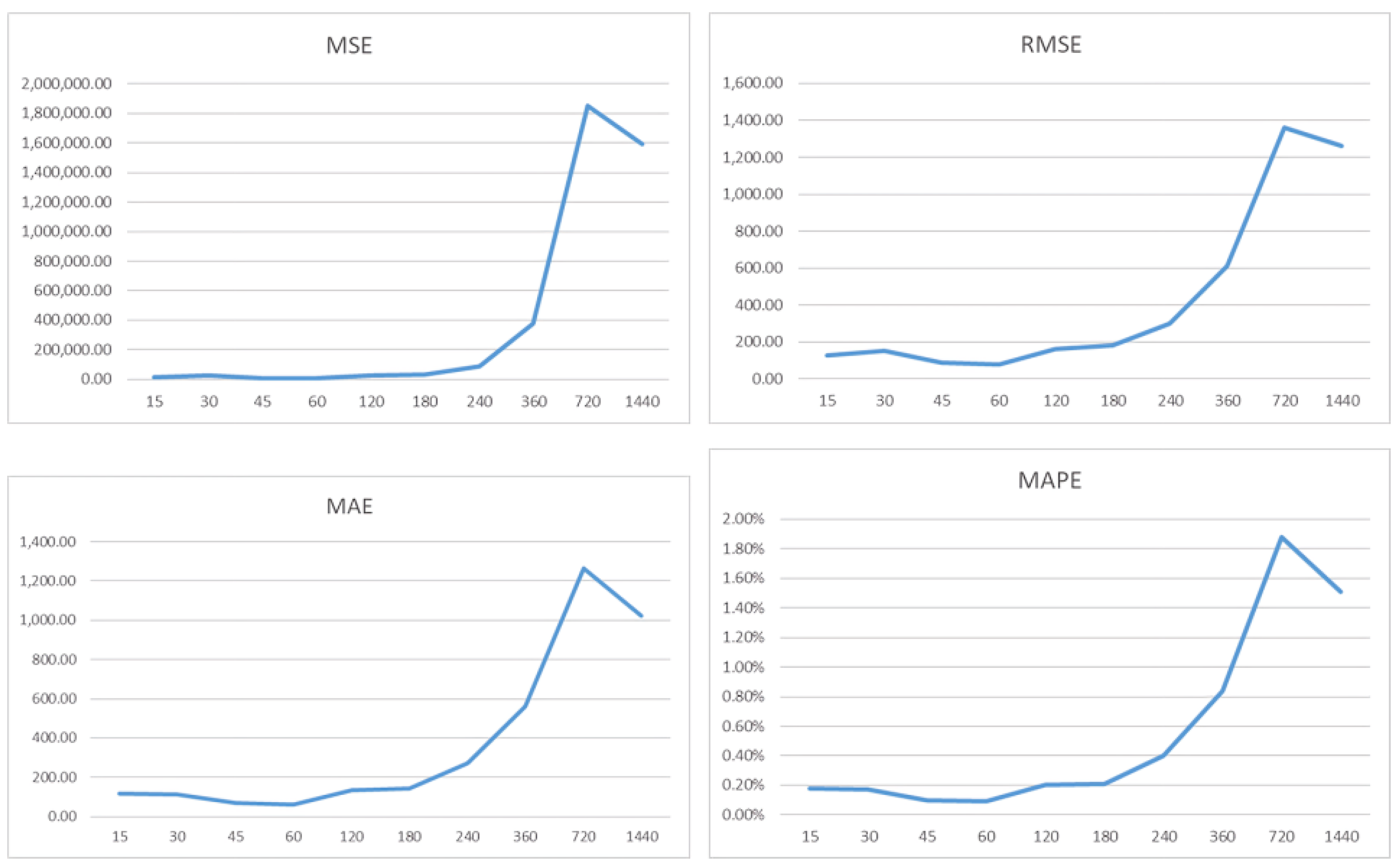
First, we compare the performance of the eight different regression algorithms using the Bitcoin records for 60 min forecasts. This choice is due to the fact that Bitcoin is the most relevant and commonly used cryptocurrency in the analyzed studies. We selected the 60 min timeframe because it is the shortest time horizon under analysis, thereby ensuring optimal performance.
The comparative tests were based on the use of all attributes—Open, High, Low, Close, and Volume—as well as on just the Close attribute. The SARIMA model was only trained and tested using the Close attribute because it has some particularities that distinguish it from the other models, which will be explained next.
In general, the models can be used with data from different time intervals. The records are available through the YFinance API, which allows downloading records by the minute, hour, or day. For minute-level data, the last 30 days of data can be retrieved. For hourly intervals, data from the last 365 days can be retrieved, and for daily records, there are no restrictions. The decision to use minute-level data allows for a much larger amount of records for model training. Some models, such as neural networks, require a large amount of data to achieve better performance. In 30 days, there can be up to 43,200 records, while in one year of hourly data, there can be up to 8760 records, and in five years of daily records, there could only be up to 1825 records. Another relevant aspect of minute-step records is that the variation in values between records is less significant, which also helps to make predictions more accurate. Except for the SARIMA model, where values are trained minute by minute, for all the other models, there is a function to create forecasts in 60 min sequences, also known as sliding windows. This function is adjusted according to the forecast time horizon. Thus, the last 60 min are used to predict the next 60 min.
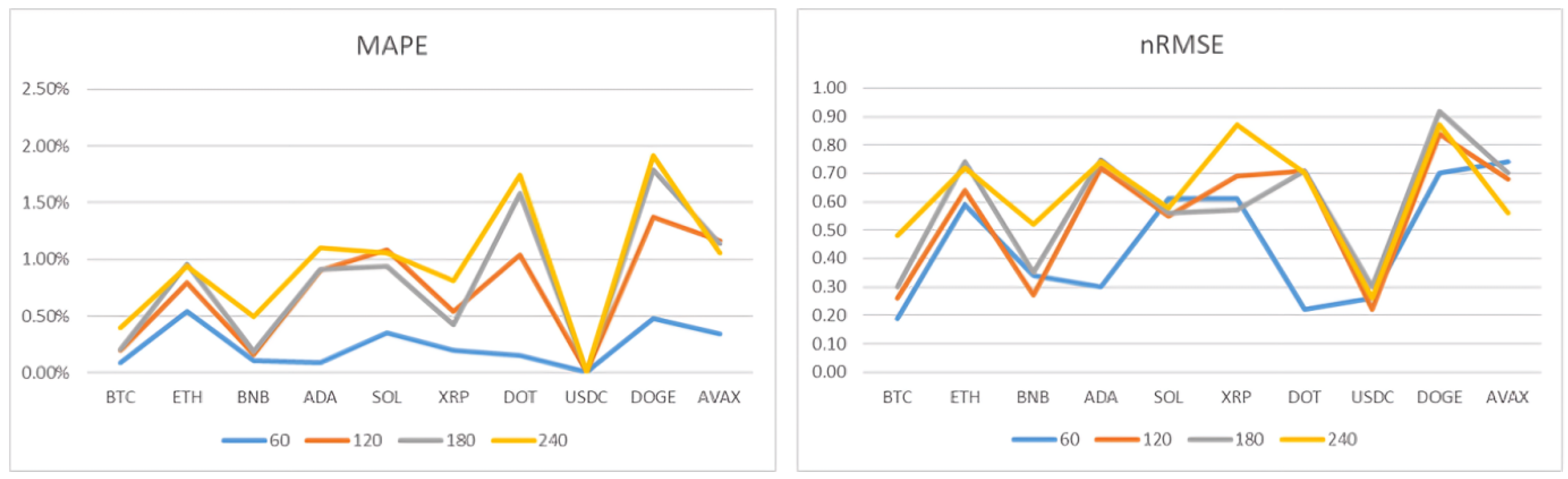
The model’s performance is measured using the metrics previously mentioned: MSE, RMSE, MAE, and MAPE. Additionally, the nRMSE metric is introduced, which corresponds to the RMSE metric but is obtained from normalized values, allowing for a better comparison of model performance across different cryptocurrencies, as each one has different magnitude values.
From the Keras library of the TensorFlow API, long short-term memory (LSTM) [
17] and gated recurrent unit (GRU) [
18] models were trained and evaluated using a grid search to identify the optimal hyperparameters. A 5-fold cross-validation was employed. The hyperparameters considered included the number of neurons (30, 50, 75, 100) and the number of layers (1, 2, 3) with the Adam optimizer. Model performance was evaluated using MAE, RMSE, and MAPE. Based on the results obtained, an architecture of 50 neurons and 2 layers was selected for both LSTM and GRU models, as it provided the best balance between model performance and computational cost. However, for computational reasons (limited resources: Intel i7 12650H 2.30 GHz processor, 16 GB RAM, NVIDIA GeForce RTX 3080 graphics card, from Taipei, Taiwan), a comprehensive hyperparameter search was not feasible for all models. For the remaining models (ARIMA, etc.), the default parameters were employed, providing reasonable baselines against which to compare the performance of the optimized LSTM and GRU models. This approach allowed for a focused analysis of the performance differences between the various model types while managing computational constraints.
The auto-regressive integrated moving average (ARIMA) [
19] model is obtained through the Statsmodels library. The model used is actually SARIMAX, which is used to prepare seasonality and exogenous variables in the ARIMA model, but in this case, there are no exogenous variables in the data obtained, and for that reason, the model is referred to as SARIMA, and not ARIMA or SARIMAX. This model is very resource-intensive, and on the machine where it was tested, it was not even possible to load the entire dataset to train the model. Therefore, subsets of the records were loaded, and the point where the best results were achieved was with only 360 records, meaning the price of the last 360 min. Even so, the model takes a long time to train, which makes it impractical for deployment in an application, as it needs to be retrained with new data to make predictions, unlike the other models that can be saved and reused to make predictions with new data without requiring training the model again.
Linear regression (LR) [
20] is the simplest regression model, and despite its simplicity, its performance was quite interesting. The previous model was observed to more or less follow the price trends but did not predict the major peaks in value variation. LR tends to be even more of a straight line when presented graphically. The main advantage is that it is a very simple and fast model to train.
The Random Forest [
21] model is not very common for time series forecasting, and the training process is also quite heavy when used with a large amount of data. To avoid overloading the training process too much, a model with 100 decision trees was applied. The performance of this model was slightly worse than the previous models.
The support vector machine (SVM) [
22] model, support vector regressor for regression problems, was tested with the kernel parameter set to RBF. This model is also heavy to train with large datasets, but it performs well, especially when trained with all attributes.
The XGBoost [
23] model, in terms of training, is quite fast; however, its performance in validation fell well short of the previous models, especially when trained with all attributes. In the parameters, 100 decision trees, or predictors, were used, along with a learning rate of 0.1.
Lastly, LightGBM [
24], a model derived from XGBoost [
23], achieves better results with faster training. Using default configuration values, its performance, although not as good as neural networks, is better than XGBoost when used with all predictor attributes, but worse when used with only the closing price.
3.4.1. Analysis of Models Performance
Table 3 presents the performance of eight machine learning models developed for predicting Bitcoin prices over a 60-min horizon, with the gated recurrent unit (GRU) model emerging as the top performer across all metrics.
In contrast, models like SARIMA, while suitable for stationary time series, may struggle with the non-stationary nature of cryptocurrency price data, leading to lower prediction accuracy. The LR model demonstrated surprisingly strong performance, indicating the presence of some underlying linear trends in the data. The model’s RMSE of 83.54 and MAPE of 0.10% show the extent of this linear behavior. Although LSTM also demonstrates reasonable accuracy, its greater computational complexity, relative to GRU, does not compensate. The significantly worse performance of ensemble methods (XGBoost, LightGBM) underscores the limitations of traditional and ensemble methods in handling the high volatility and intricate dynamics of cryptocurrency prices.
The GRU model was rigorously evaluated by comparison with the second most efficient model, the LR model. We use MAE as the primary metric for statistically comparing both models because MAE is a more reliable way to measure the overall performance of cryptocurrency data, which can sometimes have huge price changes. MAE is more robust to outliers than MSE or RMSE, is easy to interpret, provides a clear understanding of the model’s typical prediction error, and focuses on the magnitude of the errors, which is directly relevant to assessing the practical usefulness of the model for investment decisions.
We performed two statistical tests on the MAE values obtained from the GRU and LR models applied to the last hour of 10 days in the period 1/09/2024 to 10/09/2024, as presented in
Table 4.
To assess the statistical significance of the GRU model’s superior performance compared to linear regression, the normality assumption was first checked using the Shapiro–Wilk test on the differences in MAE between the two models. The Shapiro–Wilk test yielded a p-value of 0.000144, which is less than the significance level of , indicating a violation of the normality assumption. Therefore, the non-parametric Wilcoxon signed-rank test was used. The Wilcoxon signed-rank test resulted in a p-value of 0.00195, which is less than . We conclude that the MAE of the GRU model was significantly lower than that of the linear regression model (p < 0.001), confirming the superiority of the GRU model.
The GRU model’s superior performance can be attributed to several factors. First, the GRU architecture is particularly well-suited for handling sequential data, such as time series, due to its ability to capture long-term dependencies. This capability is crucial in cryptocurrency markets, where price fluctuations often exhibit complex patterns and temporal correlations. Second, the simplified architecture of the GRU, compared to LSTM, allows for faster training times without compromising accuracy. Third, the optimized hyperparameters identified during our grid search further enhanced the GRU’s performance. This careful optimization ensured that the GRU could effectively model both short-term and long-term patterns in the data.
In conclusion, the GRU model is not only the most accurate model tested but also the most practical for deployment in real-time forecasting systems, where computational efficiency is critical. Its performance highlights the potential for deep learning models to provide accurate, short-term predictions in highly volatile markets like cryptocurrencies.




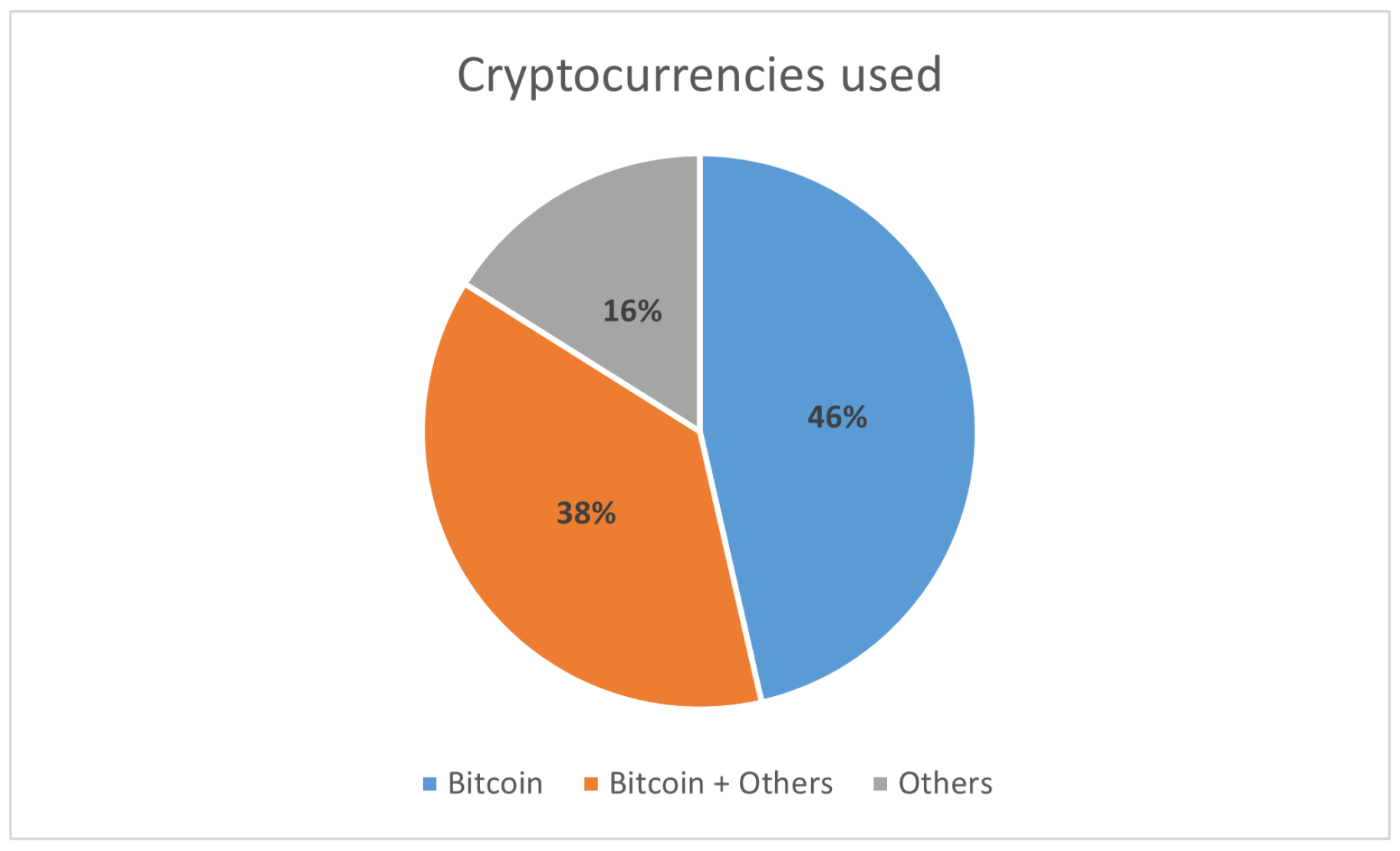
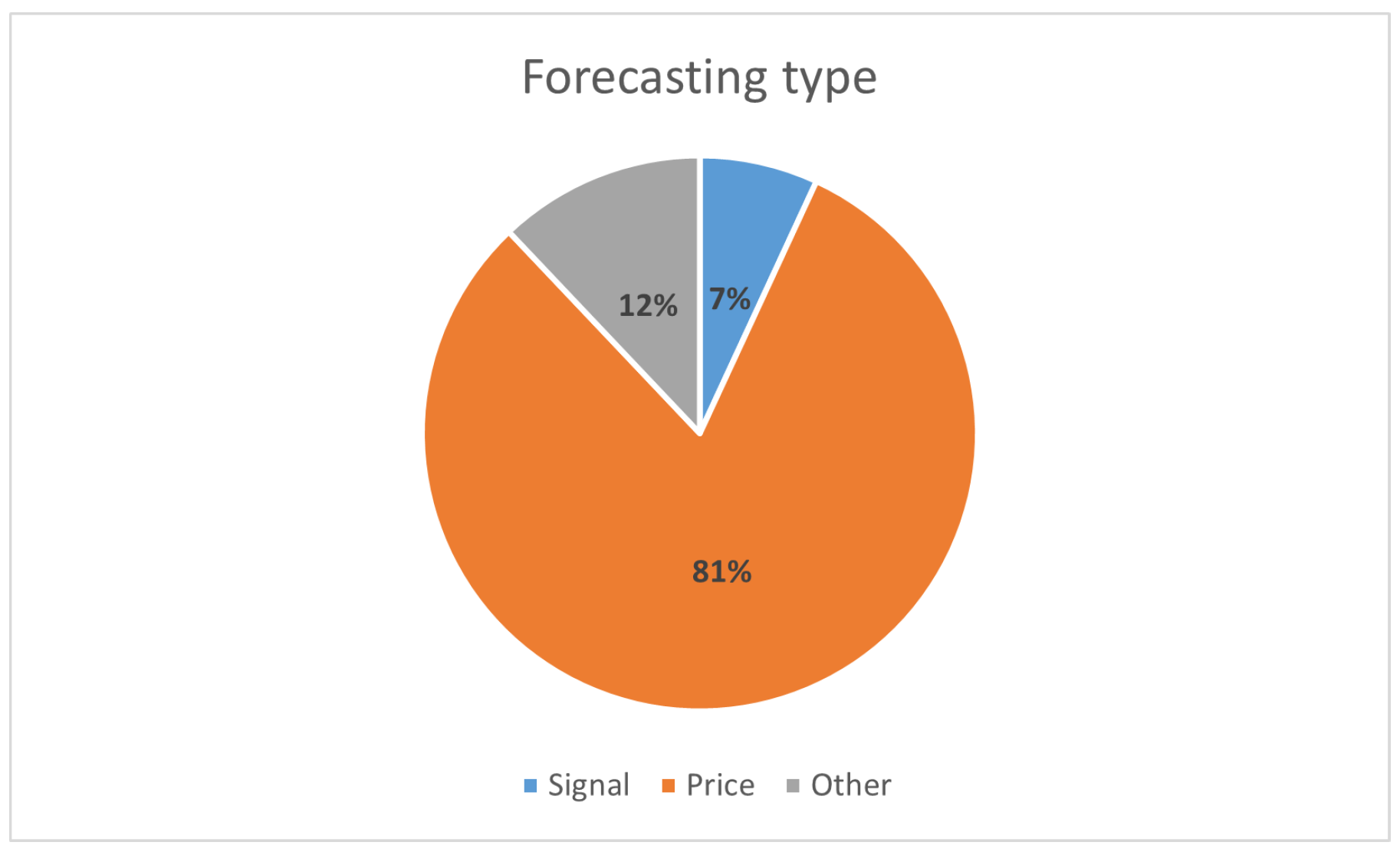


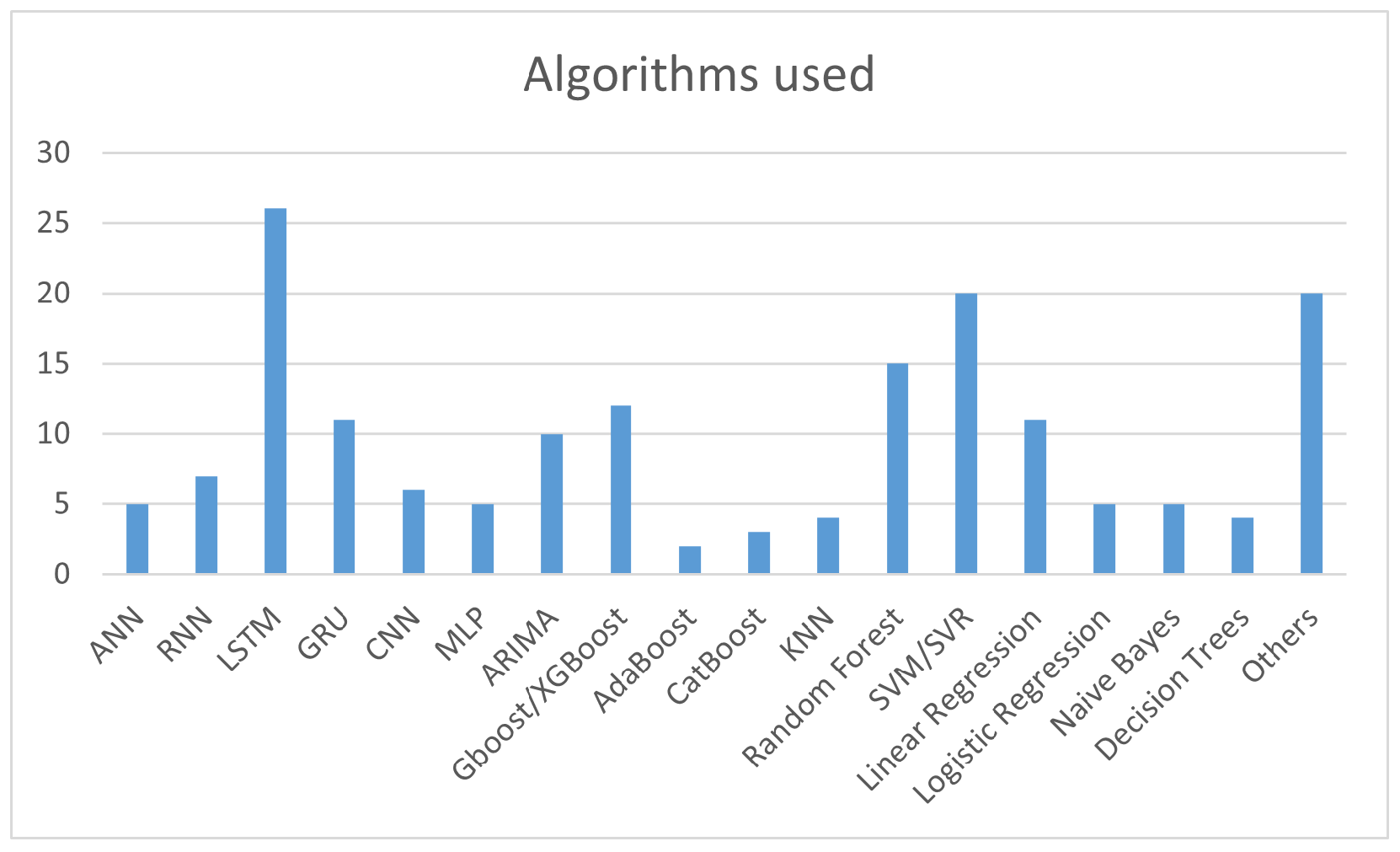



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}