Abstract
The rising prevalence of mental health disorders, particularly depression, highlights the need for improved approaches in therapeutic interventions. Traditional psychotherapy relies on subjective assessments, which can vary across therapists and sessions, making it challenging to track emotional progression and therapy effectiveness objectively. Leveraging the advancements in Natural Language Processing (NLP) and domain-specific Large Language Models (LLMs), this study introduces nBERT, a fine-tuned Bidirectional Encoder Representations from the Transformers (BERT) model integrated with the NRC Emotion Lexicon, to elevate emotion recognition in psychotherapy transcripts. The goal of this study is to provide a computational framework that aids in identifying emotional patterns, tracking patient-therapist emotional alignment, and assessing therapy outcomes. Addressing the challenge of emotion classification in text-based therapy sessions, where non-verbal cues are absent, nBERT demonstrates its ability to extract nuanced emotional insights from unstructured textual data, providing a data-driven approach to enhance mental health assessments. Trained on a dataset of 2021 psychotherapy transcripts, the model achieves an average precision of 91.53%, significantly outperforming baseline models. This capability not only improves diagnostic accuracy but also supports the customization of therapeutic strategies. By automating the interpretation of complex emotional dynamics in psychotherapy, nBERT exemplifies the transformative potential of NLP and LLMs in revolutionizing mental health care. Beyond psychotherapy, the framework enables broader LLM applications in the life sciences, including personalized medicine and precision healthcare.
1. Introduction
Emotion recognition is vital in mental health research as it helps identify emotional patterns in psychotherapy, such as sadness and withdrawal in depression, guiding therapists to tailor interventions [1]. This analysis improves therapeutic approaches and mental health care outcomes [2,3,4]. The World Health Organization (WHO) reports a significant rise in depression cases, affecting around 280 million people globally from 2005 to 2015 [5]. The PENN Emotion Recognition Task (ER40) shows that individuals with anxiety and depression often struggle to identify emotions like sadness, anger, and fear, indicating a bias in processing negative emotions [6]. However, existing methods primarily rely on subjective assessments, making it challenging to systematically track emotional patterns and their impact on therapeutic outcomes. Therefore, developing structured approaches can improve the consistency of emotion analysis in psychotherapy. This highlights the importance of emotion recognition in understanding the social challenges associated with mental health conditions [3,6].
There are numerous natural language processing (NLP) methods utilized for assessing emotion recognition in mental health research. Past research has explored integrating clinical techniques and data mining to identify depression symptoms from various lexicon sources. Mukhiya et al. (2020) developed a depression word embeddings lexicon to identify symptoms from patient texts using the Patient Health Questionnaire-9 (PHQ-9), enabling personalized depression interventions [7]. Various researchers [8,9] have employed the NRC (National Research Council Canada) emotion lexicon [10,11] which provides a comprehensive list of over 14,000 words associated with eight basic emotions and two sentiment polarities. This breadth is an advantage over other lexicons, like Linguistic Inquiry and Word Count (LIWC) [12] and Valence Aware Dictionary and sEntiment Reasoner (VADER) [2], which have a more limited set of emotion categories. LIWC primarily relies on a predefined dictionary and lacks contextual understanding, leading to potential misinterpretations in complex psychological texts [12]. Similarly, VADER focuses mainly on polarity (positive/negative) and is less effective in recognizing nuanced emotions, particularly in professional or domain-specific contexts such as psychotherapy [2,13].
The NRC emotion lexicon serves as a foundation for enhancing machine learning models for text emotion analysis, offering better performance on psychotherapy data than using the lexicon by itself [11]. For instance, The authors of [1] examined language traits in mental health-related Reddit posts by applying the NRC lexicon alongside BERT. It showed 80.3% accuracy in distinguishing sentiment differences from those in non-mental health subreddits. Traditional machine learning models, including SVM, Naive Bayes, and Logistic Regression, have also been utilized alongside the NRC Lexicon, serving as benchmarks for deep learning comparisons [14]. Researchers [14,15,16] have explored hybrid models combining the NRC emotion lexicon with deep learning frameworks like CNN-LSTM and CNN-BiLSTM, enhancing both lexicon-based and contextual analysis. The study [15] analyzed Twitter sentiment data for stock predictions using NRC [11] and other lexicons like VADER [2], achieving a high accuracy of 93.47% with an LSTM model. However, the model’s mean squared error (MSE) of 859.046 indicates a significant prediction error, highlighting the challenge of accurately forecasting stock movements based on sentiment analysis.
The authors of [17] compared BERT’s performance with other deep learning models (CNN, RNN, LSTM, GRU) in categorizing medical topics using healthcare chatbot symptom data. BERT achieved 76.3% accuracy, slightly outperforming the others by 2%. Despite this, achieving high precision in medical subject classification remains challenging, emphasizing the need for model optimization in healthcare contexts [18]. Similarly, applying AI models to small psychotherapy datasets is difficult due to the need for large training datasets. Studies [19,20] emphasize the challenge of acquiring high-quality psychotherapy data while maintaining patient confidentiality. The authors of [21] used an NLP technique combined with SVM, CNN, and Bi-GRU for emotion recognition, achieving 80.1% accuracy. However, detecting emotions in text remains challenging due to the lack of cues, like facial expressions and tone, suggesting the need for diverse data and hybrid models like CNN-Bi-GRU-SVM to capture emotional subtleties. The studies [22,23] call for BERT-based mental health interventions to be tested with more diverse samples to ensure equity and effectiveness.
Our study addresses the interconnected challenges highlighted in the literature above, particularly focusing on the nuanced classification of medical health data with high precision using fine-tuned BERT, necessitating model refinement tailored to specific medical contexts, including the processing of unique therapeutic jargon and linguistic patterns [15,17,18,20]. We address the challenges of recognizing emotions in text, which contain non-verbal clues, by employing the NRC emotion lexicon and improving data homogeneity through preprocessing techniques such as tag standardization, consequently improving the reliability of emotion classification [1,21,23]. These challenges show the need for comprehensive data diversity to enhance emotional analysis and for testing BERT-based interventions across varied demographics to ensure both access and efficacy in mental health care.
This study aims to develop nBERT, a fine-tuned BERT model with specialized preprocessing and the NRC emotion lexicon, to enhance emotion recognition and sentiment analysis in psychotherapy transcripts, improving AI-driven mental health assessments. We meticulously construct a dataset from counseling and psychotherapy transcripts utilizing advanced preprocessing techniques for NLP readiness. Emotion recognition harnesses the NRC lexicon for its broad spectrum of emotional categories, enabling an advanced sentiment evaluation of emotions across the dialogues of therapy. The fine-tuning of nBERT involves a specialized adaptation process where the pre-trained BERT model is further trained on a dataset that is representative of the domain of interest—in this case, mental healthcare through psychotherapy transcripts. This domain-specific fine-tuning incorporates emotional intelligence by leveraging the NRC lexicon. The model is introduced to these categorized emotions during training, allowing it to develop an ability to detect these emotions in text. During the fine-tuning phase, the model’s weights are adjusted to minimize the difference between the predicted emotion categories and the actual labels from the dataset. The results we obtained demonstrate an important improvement in sentiment detection and emotion recognition accuracy, emphasizing its advantages. The proposed work enables tracking emotional shifts to support personalized interventions, clinical decision-making, and therapy assessment. Its insights can be integrated into digital mental health platforms for data-driven monitoring and adaptive interventions. The significant contributions of our study are as follows:
- We develop a fine-tuned nBERT model with domain-specific adjustments for psychotherapy transcripts, which significantly enhances the accuracy and precision of emotion recognition in text-based analysis for mental health research.
- We present the integration of the NRC Emotion Lexicon with an advanced AI model, which allows for the accurate identification and in-depth analysis of a wide range of emotional expressions during psychotherapy sessions.
- We offer empirical evidence proving that our method outperforms existing models. Our findings show significant improvements in emotion recognition accuracy, indicating an important advancement forward in the creation of more effective therapeutic approaches.
2. Literature Review
2.1. Text-Based Emotion Analysis
Text-based emotion detection (or recommendation) relies on machine and deep learning models, but challenges like semantic extraction and non-standard language persist [24,25]. Hybrid rule-based algorithms using emojis, keywords, and semantic relationships have been proposed to address these issues [26,27]. Emotion analysis is rooted in psychological theories, such as Plutchik’s eight basic emotions [27], and leverages lexicons like the NRC emotion dictionary, which maps words to categories like “fear” and “trust” [11]. These lexicons enable rule-based approaches for inferring emotions from text.
The NRC lexicon performs well in detecting emotions in specialized contexts, such as psychotherapy transcripts and clinical notes [9]. It has been applied to social media data, including COVID-19-related microblog comments, to track emotional shifts like changes in “fear” and “trust” over time [11,26,28,29]. Studies have also used the NRC lexicon to analyze text-based counseling in rural communities, identifying patterns linked to depression, anxiety, and stress [30]. Similarly, stress detection models incorporating the NRC lexicon have identified mental health issues in college students [31].
Advanced techniques, such as BERT combined with the NRC lexicon, have achieved 80.3% accuracy in distinguishing mental health subreddits from non-mental health ones [1]. LSTM models have also been effective, with one study achieving 90.37% accuracy in sentiment analysis [32]. GloVe embeddings with LSTM reached 91% accuracy in analyzing airline service feedback [16], while a fusion model of MCNN and LSTM achieved 93% accuracy for Chinese reviews [33]. Despite these advancements, the NRC lexicon’s contextual sensitivity may limit its ability to capture complex emotional dynamics in therapeutic interactions [8,9,32]. Future research should focus on developing more nuanced NLP techniques to better interpret emotional language [1,24].
2.2. BERT in Mental Health
The use of BERT for emotion analysis in psychotherapy texts is crucial as it provides valuable insights into emotional content in user-generated discussions, benefiting fields like psychology and public health [34,35]. BERT-based models have been applied to mental health detection, emotion recognition in conversations, and causal emotion entailment [36,37]. Integrating BERT with the NRC emotion lexicon enhances emotion recognition in psychotherapy texts. Sharma et al. (2020) showed that fine-tuning BERT with the NRC Lexicon outperformed traditional machine learning models in identifying emotional states in therapeutic conversations [38]. However, high computational demand and the lexicon’s limited scope may restrict its ability to recognize diverse emotional nuances [9].
Althoff et al. (2021) applied BERT with the NRC Lexicon to analyze emotional dynamics in online mental health forums, improving insights into emotional experiences and support mechanisms [39]. However, the informal and varied nature of online communication poses challenges in interpreting complex emotions [40]. A study [41] used BERT topic modeling for psychotherapy transcripts to predict metrics like working alliance and symptom severity, but faced limitations in capturing deep therapeutic discourse [29]. A study [17] found BERT outperformed other deep learning models (CNN, RNN, LSTM, GRU) in classifying medical subjects based on chatbot symptom data, with an accuracy of 76.3%. Although not focused on psychotherapy, it highlights BERT’s strong performance in clinical text classification. M. T. Rietberg and J. Geerdink (2023) showed BERT’s applicability in classifying unstructured radiology reports, suggesting its potential for psychotherapy transcript analysis [40]. DistilBERT, a smaller, more efficient version of BERT, outperformed traditional machine learning models in classifying eating disorder-related tweets [18], but its trade-off between efficiency and accuracy can hinder complex mental health data interpretation [17]. The challenge in using BERT for conversational emotion analysis lies in its difficulty in understanding the subtleties of speaker interactions and emotional tone [29,35].
3. Proposed Methodology
Our study’s methodology unfolds across three distinct phases, illustrated in Figure 1, detailed as follows:
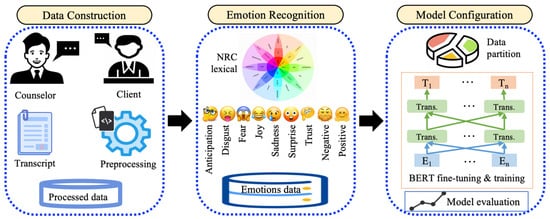
Figure 1.
Overview of proposed methodology for emotion analysis through NRC lexicon integrating with nBERT model configuration.
- Data Construction: This phase involves transforming raw psychotherapy transcripts into a structured format suitable for computational analysis, ensuring data integrity and readiness for AI-based models.
- Emotion Recognition: Utilizes the NRC Lexicon to systematically categorize and quantify emotional expressions within the processed texts, setting the goal for in-depth emotional analysis.
- Model Configuration: Focuses on optimizing BERT through domain-specific adaptation and fine-tuning techniques, aligning the model with the intricacies of psychotherapeutic language to elevate its predictive accuracy and analytical depth.
Further elaboration on each phase is methodically presented in the subsequent subsections.
3.1. Data Construction
Our study utilizes the “Counseling and Psychotherapy Transcripts, Volume II” dataset (https://www.lib.montana.edu/resources/about/677, accessed on 10 February 2025), which includes 2021 transcripts from 505 therapy interactions, offering insights into the client–therapist dynamic and emotional journeys. This diverse corpus, accessible through Montana State University’s network, is crucial for examining conversational emotions and developing nuanced psychotherapy models. To construct the final dataset, we employed a rigorous screening and filtering process, as illustrated in Figure 2. Initially, the dataset contained 70,567 samples. We excluded 60,000 based on criteria such as relevance, completeness, language, session quality, demographics, and therapy types, resulting in 10,567 samples. Further refinement excluded 5000 due to lack of consent and 3546 for missing or incomplete information, yielding 2021 samples for analysis.
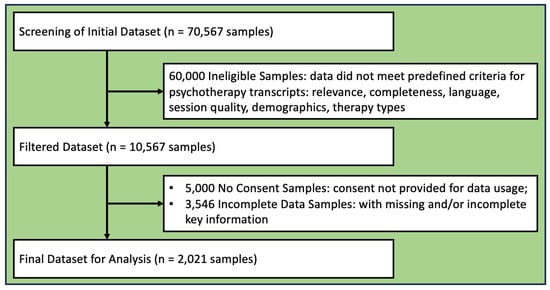
Figure 2.
Flowchart data construction and follow-up of samples with exclusion criteria in the study.
A variety of techniques are employed to preprocess and organize psychotherapeutic transcripts, each contributing uniquely to the depth and quality of analysis possible.
- Dialogue Character Identification: Using regular expressions via Python’s ‘re’ module; this step identifies 31 unique dialogue characters, such as THERAPIST, PATIENT, DR, and NR. This method enhances character-based analysis and filters dialogue participants, offering deeper insights into client emotions and dialogue dynamics.
- Filtering Relevant Files: This step copies files containing specific target characters (e.g., PATIENT, COUNSELOR, THERAPIST) to narrow down the dataset for essential interactions, improving efficiency and reducing processing time, thus optimizing the research workflow.
- Content Preprocessing and Tokenization: It cleans text by removing noise, tokenizing words with NLTK’s ‘word_tokenize’, removing stopwords, and applying lemmatization with the ‘WordNetLemmatizer’. This process reduces text complexity and noise, significantly improving NLP models’ training efficiency, particularly for models like BERT.
- Tag Standardization: Regex pattern matching ensures uniformity in dialogue tags (e.g., converting ‘PATIENT’, ‘PT’ to ‘CLIENT’, and ‘COUNSELOR’, ‘THERAPIST’ to ‘COUNSELOR’), making analysis and categorization consistent and accurate.
- Metadata-Driven Insights: This approach leverages metadata to structure and analyze psychotherapeutic dialogues across five dimensions:
- Gender Analysis: Groups files based on client’s gender, enabling gender-specific dialogue pattern analysis using the ‘pandas’ library.
- Marital Status: Categorizes files by marital status (e.g., single, married, divorced) to study its impact on therapy discussions and outcomes.
- Sexual Orientation: Segregates files by sexual orientation (e.g., heterosexual, bisexual, gay), enhancing inclusivity in therapeutic analysis.
- Psychological Subjects: Organizes files based on psychological themes (e.g., depression, stress) for focused analysis.
- Symptoms Categorization: Groups files by symptoms (e.g., anxiety, anger) to recognize patterns and guide targeted therapeutic interventions.
- Syntactic Parsing: Utilizing spaCy, this method analyzes sentence structures to reveal relationships between subjects, verbs, and objects. It helps identify linguistic patterns in psychotherapeutic transcripts, aiding in the recognition of emotions and enhancing the understanding of mental health dynamics.
Following the dataset refinement process, the final set of 2021 samples was split into 70% training (1414 samples), 20% test (405 samples), and 10% validation (202 samples) using a stratified sampling approach to maintain class distribution balance. To enhance reproducibility, we have documented our data filtering pipeline (Figure 2), specifying exclusion criteria such as session completeness, language consistency, and demographic diversity. From 70,567 initial samples, 60,000 were excluded based on predefined quality rules. Future researchers can replicate this process using similar filtering criteria on publicly available psychotherapy transcripts, prioritizing completeness, speaker clarity, and session structure while allowing flexibility based on dataset-specific characteristics.
3.2. Emotion Recognition
Emotion recognition in psychotherapy transcripts helps track emotional fluctuations and identify recurring patterns, offering quantifiable insights into mental health progression. Our methodology leverages the NRC Emotion Lexicon, a widely validated resource in sentiment analysis, to assign emotion labels with high reliability. The labels (i.e., ground truth) are derived directly from this lexicon, ensuring a consistent and structured mapping of emotional expressions in text. Labels are assigned at the sentence level, allowing for fine-grained analysis of emotional shifts within therapy sessions. This lexicon enables the nuanced identification of a wide range of emotions, including ‘anticipation’, ‘positive’, ‘negative’, ‘joy’, ‘anger’, ‘trust’, ‘surprise’, ‘fear’, ‘disgust’, and ‘sadness’. Unlike other lexicons, such as AFINN or VADER, which primarily focus on polarity (positive/negative), the NRC lexicon provides fine-grained emotion labels, making it well suited for psychotherapy analysis. Its extensive validation across multiple studies further supports the credibility and robustness of these assigned labels in detecting emotional patterns in text-based therapy interactions. Accurate emotion labeling in psychotherapy is essential for understanding the client’s mental health state, guiding personalized therapeutic interventions, and tracking emotional progression over time.
To quantify the emotion recognition process, we employ a systematic approach utilizing analytical methods. The methodology involves mapping each word in the transcripts to the corresponding emotional dimensions as defined by the NRC lexicon. The association between words and emotions is mathematically represented as follows:
In our approach to emotion recognition within psychotherapeutic transcripts, we delve into several innovative techniques to both quantify and understand the emotional dynamics at play.
The emotional score of word w is calculated as follows:
where is the emotional score of word w, is the association score of word w with emotion i, and represents the set of emotions defined by the NRC lexicon. This formula facilitates a rigorous, quantifiable approach to emotion recognition.
Moreover, the aggregated emotional scores across dialogues are calculated using the formula:
where represents the emotion score for a dialogue, N is the total number of words in the dialogue, and is the emotional score of the j-th word in the dialogue. This aggregation provides a structured view of emotional shifts, aiding in the analysis of therapy dynamics over time.
In quantifying the frequency of emotions expressed during therapy sessions, we apply a summation across the emotional spectrum identified within the transcripts. For each emotion from the set of all emotions E, the frequency within a given period or session is calculated as follows:
where N is the total number of words in the transcript, is the j-th word, and is an indicator function that returns 1 if is associated with emotion , and 0 otherwise. This calculation allows us to aggregate and compare the frequencies of various emotions, showing the dominant emotional currents within therapeutic interactions.
For sentiment distribution, emotions are mapped to broader sentiment categories, transforming discrete emotion occurrences into a holistic sentiment overview. This mapping process can be formalized as follows:
where represents the proportion of sentiment k within the discourse, m is the number of emotions mapped to sentiment k, and T is the total count of all emotional expressions identified. This equation enables us to synthesize raw emotion data into a comprehensive sentiment distribution, providing a macro-level perspective on the prevailing emotional trends.
To examine how emotional expressions evolve throughout the therapeutic process, we observe the relationship between the volume of text entries and the average emotional intensity over time. This relationship is quantified through:
where is the average emotional intensity over a period, T represents the total number of time intervals considered, and denotes the emotional intensity at time t. This technique offers a temporal perspective on emotional changes, highlighting moments of significant emotional shifts and providing a deeper understanding of therapeutic progress.
Correlation analysis investigates the relationships between different emotions expressed during therapy sessions. By calculating the correlation coefficients between emotional expressions, we can identify patterns and potential co-occurrences of emotions, suggesting underlying psychological states or shifts in the therapeutic journey. The Pearson correlation coefficient, r, between two emotions, X and Y, is computed as follows:
where and represent the intensity values of emotions X and Y, respectively, while and denote their mean values. The numerator measures the covariance between X and Y, indicating how their variations align. The denominator normalizes this value using the standard deviations of X and Y, ensuring that ranges between and . A correlation close to suggests a strong positive relationship, where both emotions increase together, whereas a value near indicates an inverse relationship. A correlation near zero implies no linear association between the two emotions.
The relationship between clients’ demographic characteristics and their emotional expressions is captured through a matrix representation, enabling the visualization of complex interactions within chord or pie diagrams. For demographic group and emotion , the association is quantified as follows:
where is the number of times emotion is expressed by individuals in demographic group , and is the total number of emotional expressions by that demographic group. This ratio provides the strength of association between specific demographics and emotions, offering insights into how personal backgrounds may shape emotional expressions in psychotherapy.
These emotion recognition techniques not only enrich our understanding of psychotherapeutic dynamics but also play a key role in training and fine-tuning our BERT model. By incorporating emotional insights into the model, we significantly enhance its ability to interpret the nuanced language of therapy sessions, making a seamless transition to model configuration for mental health research.
3.3. nBERT Model Configuration
This work introduces nBERT, a nuanced adaptation of the BERT model [37], particularly refined for emotion recognition within mental healthcare transcripts. The approach is driven by the need to understand and categorize emotional states from psychotherapy texts, which are dense with domain-specific semantics and subtle expressions of sentiment. The systematic architecture of proposed nBERT is depicted in Figure 3.
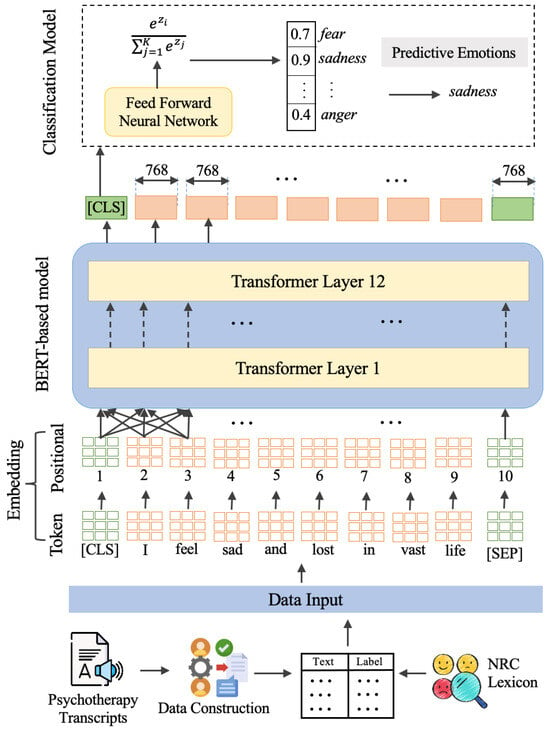
Figure 3.
Schematic representation of the fine-tuned nBERT model framework integrating psychotherapy transcripts with NRC lexicon for enhanced emotion recognition.
3.4. Input Representation
The preprocessing of psychotherapy transcripts constitutes the first step in the data pipeline of our nBERT model. This process transforms the unstructured text data into a structured form that aligns with the operational framework of the transformer-based architecture.
Tokenization employs the WordPiece model, which can be described by a function , where S is a set of all possible substrings of , and W is the predefined vocabulary. For a given substring , the tokenization function yields a token :
Each token w is then mapped to a unique embedding vector , where for nBERT. This mapping is part of a learnable embedding matrix with vocabulary size V.
The insertion of special tokens is formalized as follows [42]: Let T denote a psychotherapy transcript. We define as the transcript prepended and appended with special tokens:
The token ‘[CLS]’ is represented by a unique vector and serves as an aggregation point for the document’s overall sentiment encoding. Similarly, the ‘[SEP]’ token, represented by , provides a demarcation indicating the conclusion of the document.
Positional embeddings are crucial to imbue the model with an understanding of token order. For an input sequence of length N, positional embeddings are denoted as for position n, with a positional embedding matrix . The final input representation for each token is a combination of its token and positional embeddings:
Here, represents the n-th token’s overall embedding in the input sequence, with being the corresponding substring from the transcript.
This preprocessing yields an ordered set of embeddings, , ready for subsequent processing by the nBERT model. In this way, we preserve the narrative flow inherent in psychotherapy dialogues, which is often predictive of the underlying emotional subtext.
3.5. Transformer Architecture and Contextualization
The nBERT architecture leverages the innovative transformer design introduced by [37], a mechanism renowned for its parallelizability and ability to capture long-range dependencies. This architecture is composed of L identical layers, each containing two sub-modules: a multi-head self-attention mechanism and a position-wise feed-forward network.
For each transformer layer l, the multi-head attention operates on an input sequence represented as a matrix , where N is the sequence length and D is the dimensionality of each token’s representation. Each head i in the multi-head attention computes a distinct set of queries , keys , and values [26]:
where are the parameter matrices for the i-th attention head in layer l, and is the size of each head’s key, query, and value vectors.
The output of each attention head is computed as a weighted sum of values, where the weight assigned to each value is computed by a softmax function on the keys and queries [26]:
The outputs of all h attention heads are concatenated and then linearly transformed into the expected dimension D to yield the final output for this sub-layer:
where is the output weight matrix for layer l.
The second sub-module is a feed-forward network applied to each position separately and identically. This is defined as [26]:
where and are parameter matrices, is the inner-layer dimensionality, and are bias vectors.
Fine-tuning nBERT for emotion recognition involves adapting the model’s outputs to correspond to discrete emotional states. This adaptation is achieved by using a labeled dataset , where is the emotional label for the m-th transcript , and M is the number of labeled examples. The output from the final transformer layer L corresponding to the ‘[CLS]’ token, denoted , encapsulates the emotional context and is passed through a task-specific classification head [42]:
where is the vector of logits for K emotional states, and are learnable weights for the classification head, with being the hidden layer size, and are the corresponding bias terms.
The logits Z are then normalized across the K classes using the softmax function to yield the probability distribution over emotional states [43]:
where is the probability that the text T expresses the k-th emotional state.
During training, we minimize a loss function, typically the cross-entropy loss, over the training set D to adjust the model parameters, including , as well as the parameters within the BERT architecture itself. This loss is defined as [43]:
where 1 is the indicator function.
Through fine-tuning, nBERT becomes adept at identifying and classifying nuanced emotional expressions, allowing for a fine-grained understanding of sentiment as conveyed in psychotherapy dialogues.
3.6. Domain-Specific Adaptations
The nBERT architecture is highly effective at enabling domain-specific modifications, which are essential for understanding the complex emotional nuance that is often discussed in mental health dialogue. By utilizing the syntactic and affective lexicons that are specific to the psychotherapy context, this adapted approach improves the interpretive depth of the model. This tailored approach leverages the syntactic and affective lexicons inherent to the psychotherapy context, thereby extending the model’s interpretive depth.
Emotional lexicons, such as the NRC Emotion Lexicon, are comprehensive repositories of words associated with various emotional states. The lexicon L contains pairs , where is a token and is its associated emotional vector. To incorporate this into nBERT, we enrich the attention mechanism with an additional emotional context.
Let represent the matrix of emotional embeddings from L, where is the number of unique emotions considered. The integration into the self-attention mechanism involves a transformation of to generate label-specific query matrices , which attend to the tokens:
where is the learnable parameter matrix transforming emotional embeddings into queries.
In the self-attention formulation [42], we calculate an attention score matrix that captures the emotional relevance of each token to the emotional lexicon:
where is the key matrix derived from the token embeddings of the input sequence, and is the size of the key vectors.
The computation of leads to an emotionally augmented representation of each token, facilitating a more nuanced understanding of the text. The elements in represent the extent to which each token exhibits emotional states as defined by the lexicon. The resulting emotionally informed attention matrix is then used to refine the token embeddings H from the transformer layers, producing a new set of representations that are sensitive to the emotional context:
where is the value matrix corresponding to the input tokens, and the softmax function is applied across the rows of , converting the raw attention scores into a probability distribution that weights the contribution of each value.
The fine-tuning of nBERT concludes with adjustments to the classification layer. The representation of the ‘[CLS]’ token after passing through the transformer layers, now emotionally enriched, is denoted and is subjected to a final classification step [44]:
where is the weight matrix for the classifier, is the bias vector, and represents the softmax function providing a probability distribution over K emotional states. Since softmax assigns probabilities summing to one across all classes, our approach follows a single-label classification scheme, where each instance is assigned the most probable emotion. While this prevents multi-label classification, the hierarchical structure of NRC emotions allows both fine-grained emotion and broader sentiment classification within a single-label framework.
The cross-entropy loss for the classifier is minimized during training, allowing nBERT to finely tune its parameters to the emotional recognition task:
where shows the pairs of text and corresponding emotional labels in the dataset D.
By weaving emotional lexicons directly into the attention fabric of nBERT, as delineated in Algorithm 1, the model becomes adept at capturing the subtle cues and indicators of emotional states expressed within psychotherapy sessions. This domain-specific fine-tuning strategy elevates nBERT’s performance, allowing it not just to understand the lexical semantics, but also the underlying emotional currents, charting new territories in the application of NLP for mental health support and intervention.
| Algorithm 1 Emotion recognition via a fine-tuned nBERT with domain-specific adaptations |
| Require: Psychotherapy Transcripts Dataframe D, Pretrained BERT Model Directory , NRC Emotion Lexicon L, Tokenizer Directory for WordPiece Tokenizer, Training , Validation , and Test data splits, Learning Parameters P including Batch Size, Learning Rate, and Epochs. |
| Ensure: Fine-tuned nBERT model , Performance Metrics: Precision (P), Recall (R), F1-Score, and Accuracy (Acc.). |
|
4. Results
4.1. Experiment Process and Setup
The experimental setup for our study utilized a high-performance computing environment provided by an Anaconda Navigator platform on a Windows 10 x64-based Intel-R Core i7-9700k @ 3.60 GHz system with 32 GB RAM, with the algorithms implemented in Python 3.8.11v. For the task of emotion recognition using the NRC lexicon and the subsequent fine-tuning of nBERT, our experiments were conducted using psychotherapy transcript datasets.
For model evaluation, the dataset was split into training (70%), validation (10%), and test (20%) sets. The validation set was used to fine-tune hyperparameters, and the test set was reserved for final performance assessment. Fine-tuning parameters for nBERT were carefully chosen to optimize the model for the domain-specific task of emotion recognition within psychotherapy dialogues. Details of these parameters are methodically presented in Table 1. Parameters such as the number of epochs, learning rate, and dropout rates were all selected to balance the trade-off between model complexity and generalization ability, ensuring robust performance without overfitting to the training data. The fine-tuning process was meticulously designed to adapt the pre-trained nBERT model to the nuances of the psychotherapy language, improving its predictive performance significantly in comparison to the baseline models.

Table 1.
The parameters setting for the fine-tuning configuration of our proposed nBERT model.
The selection of baseline models including LSTM, GloVe, CNN, and DistilBERT, was strategic, aiming to benchmark against a diverse set of established and state-of-the-art natural language processing techniques. LSTM models were included for their ability to capture long-term dependencies, GloVe for its robust word vector representations, CNN for hierarchical feature extraction from textual data, and DistilBERT as a lighter, more efficient variant of BERT to contrast against our fine-tuned nBERT model’s performance.
Performance metrics, specifically Precision (P), Recall (R), F1-score (F1), and accuracy were employed to provide a comprehensive evaluation of each model’s ability to correctly identify and classify emotions. These metrics were chosen for their standardization in classification tasks, allowing for a clear and comparative assessment of model performances. This rigorous experimental process underpins our model’s state-of-the-art performance in recognizing a spectrum of emotions from psychotherapy transcripts, demonstrating the effectiveness of our proposed method in advancing the domain of mental healthcare analytics.
4.2. Emotions and Sentiment Frequencies
Figure 4a shows a distribution of sentiments with positive sentiments leading, but a significant presence of negative (32.6%) is also noted. This indicates a complex emotional landscape in the therapeutic context where positive breakthroughs coexist with neutrality, possibly indicating areas of non-engagement or processing. Figure 4b compares client and counselor emotions, highlighting both empathetic alignment and the nuanced interplay of emotional expression between them. The elevated ‘anticipation’ and ‘trust’ frequencies suggest forward momentum in therapy, while higher occurrences of ‘negative’ and ‘anger’ may indicate unresolved issues. These separate assessments are combined by analyzing emotional alignment or dissonance over sessions, helping to quantify therapist–client rapport and identify emotional mismatches that may require intervention.
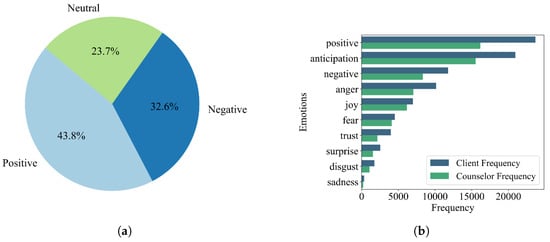
Figure 4.
Sentiment and emotion analysis in psychotherapy sessions: (a) sentiment distribution attained by nBERT; (b) NRC lexicon data depicting the frequency of various emotions as expressed by clients and counselors.
Figure 5 provides a visual representation of the correlation between different emotions expressed in the sessions. Strong positive correlations (as seen with ‘joy’ and ‘positive’, and ‘trust’) suggest these emotions often co-occur, indicating potential emotional states or topics that elicit a similar response. Meanwhile, the presence of some negative correlations, like between ‘sadness’ and ‘positive’ or ‘anger’ and ‘trust’, may suggest emotional polarities that are expected in therapeutic discourse. For limitations, the NRC Lexicon, while robust, may not capture the full range of emotions, particularly those specific to the therapeutic process.
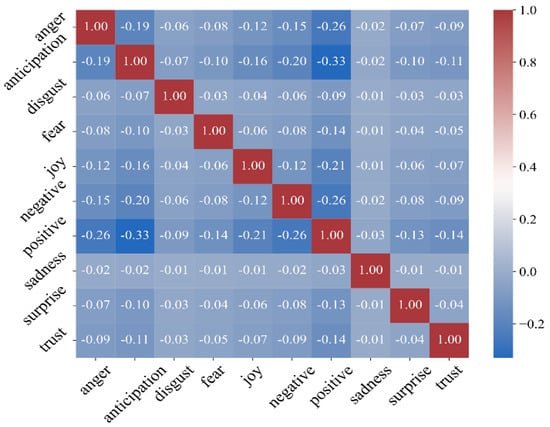
Figure 5.
Correlation matrix of the NRC emotions derived from nBERT analysis in psychotherapy text.
4.3. Client’s NRC-Based Emotion Analysis
Table 2 highlights client statements paired with NRC-identified emotions, demonstrating the lexicon’s ability to capture both specific emotions (e.g., ‘anger’, ‘joy’) and broader sentiment categories (‘positive’, ‘negative’). While ‘anger’ and ‘joy’ represent distinct emotional states, ‘negative’ and ‘positive’ serve as higher-level sentiment classifications, providing a dual-layered analysis of emotional expressions. This structure provides a comprehensive view, helping therapists assess both specific emotions and overall sentiment trends. The NRC lexicon effectively distinguishes between emotional expressions, such as frustration being mapped to ‘anger’ and despondency to ‘sadness’, ensuring meaningful insights for therapists.
Table 2.
Random emotional statements of client and corresponding NRC ten emotions in psychotherapy analysis.
Our results in Figure 6 examine how emotional expression differs across sexual orientation and gender identity, providing insights into therapy engagement and emotional regulation. Based on prior research, we hypothesize that emotional expression varies significantly across demographic groups, influencing how individuals experience and process therapy. The analysis of anger, fear, negativity, and sadness supports this hypothesis, revealing that ‘negative’ emotions occur at 13.5% in heterosexual, 14.5% in bisexual, and 11.5% in gay individuals, suggesting potential disparities in emotional stressors. Additionally, gender-based differences show higher negative emotion prevalence in females (10.6%) compared to males (3.2%), while anger appears at 8.6% in females versus 2.9% in males. These findings align with our hypothesis that emotional patterns in psychotherapy differ across identity groups, requiring tailored therapeutic interventions. Future work could explore whether these patterns correlate with therapy effectiveness or long-term emotional resilience.
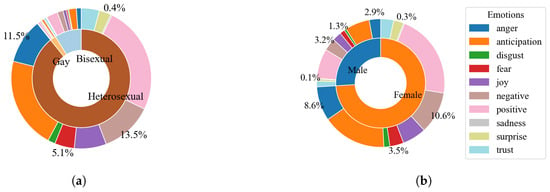
Figure 6.
Emotional identification based on gender (b) and sexual orientation (a) using the NRC lexicon in psychotherapy sessions.
The chord diagrams in Figure 7 provide evidence for our hypothesis that emotional states in therapy are influenced by both life circumstances and mental health symptoms. We hypothesize that marital status and specific symptoms correlate with distinct emotional expressions in therapy sessions. The results show that anger is strongly associated with divorced individuals (11.67%) and anxiety symptoms (12.21%), supporting the hypothesis that relationship disruptions and mental health conditions contribute to heightened emotional distress. Similarly, fear is most prominent among engaged individuals, potentially reflecting stress during life transitions. ‘Negative’ emotions (13.72%) appear frequently in separated individuals, aligning with emotional distress during separation, while widowed individuals show a high prevalence of sadness, consistent with grief-related emotional patterns. These findings confirm our hypothesis that therapists should account for situational and demographic factors when interpreting emotional states in therapy, as emotional responses are not uniform across client populations.
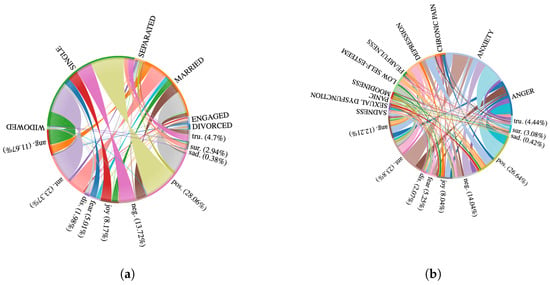
Figure 7.
Emotion recognition across marital statuses during various symptoms (a,b), analyzed using the NRC lexicon.
Figure 8 illustrates the relationship between the number of transcripts and the average emotion intensity over time. While the number of therapy transcripts remains relatively stable, emotional intensity fluctuates significantly, highlighting dynamic therapeutic engagement. Peaks, such as June 2022 reaching an intensity of 6.5, suggest heightened emotional expression, possibly due to breakthroughs. Conversely, the dip to 4.5 in October 2021 may indicate periods of emotional stability or reduced therapeutic intensity. An observed inverse relationship between transcript volume and emotional intensity suggests that more frequent sessions might facilitate emotional regulation, reducing intensity. However, instances where both metrics rise together indicate emotionally charged therapy phases, reflecting deeper engagement. The data presented are aggregated across multiple therapy sessions from different individuals, ensuring that observed fluctuations represent general emotional patterns rather than isolated variations. This aggregation allows for a broader understanding of how therapy engagement evolves over time across diverse clients. While these insights can help therapists tailor interventions by recognizing emotional patterns and adjusting session strategies accordingly, it is important to acknowledge that individual variations in therapy progress may not always align with generalized trends. Thus, contextual understanding remains crucial in interpreting emotional intensity dynamics.
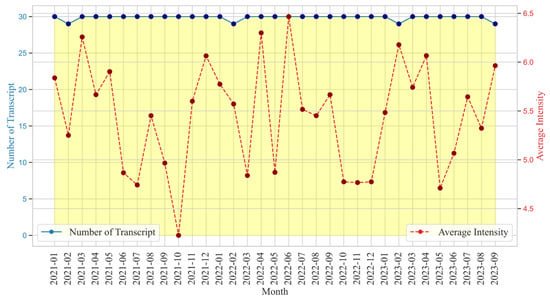
Figure 8.
Temporal analysis of transcript volume and emotional intensity trends over time. The data are aggregated across multiple therapy sessions from different individuals, ensuring that fluctuations represent general patterns rather than isolated cases. Variations in emotional intensity reflect therapy engagement dynamics and potential shifts in emotional processing.
4.4. nBERT Prediction Performance
In evaluating the prediction performance of nBERT as presented in Table 3, we observe significant improvements over the baseline BERT model [37] across several metrics. Specifically, nBERT demonstrates higher precision (P), recall (R), F1-scores, and accuracy (Acc.), with substantial gains in validation accuracy (Val. Acc.) as the training progresses through epochs. These metrics indicate nBERT’s advanced capability to generalize beyond the training data, a crucial advantage in mental healthcare applications where model robustness is paramount.
Table 3.
Performance comparison of proposed nBERT with original BERT [37] model based on 20 Epochs using different matrices.
When compared with the baseline BERT model, nBERT shows a significant improvement, as seen at epoch 20 where nBERT’s precision and F1-score outperform BERT’s by approximately 5.1% and 3.7%, respectively. Specifically, at epoch 6, nBERT’s accuracy surpasses BERT’s by nearly 2.64%, a trend that continues with nBERT maintaining a lead of over 6.8% in validation accuracy by the 20th epoch. These enhancements, stemming from the integration of the NRC lexicon and targeted preprocessing, underline the significant gains achieved by nBERT, making its contextual understanding and sentiment analysis in the mental healthcare domain substantially more refined by these percentages over the original BERT model.
Additionally, the performance trend, as illustrated by the loss graphs Figure 9, shows a steady decrease in both training and validation loss, suggesting that nBERT’s enhancements in domain-specific tuning effectively mitigate overfitting, a common challenge in deep learning models. The improvement in validation accuracy across epochs indicates that the model effectively adapts to psychotherapy transcripts. It shows the importance of domain-specific model tuning and suggests a promising direction for further research to optimize these models’ performance in real-world clinical applications.
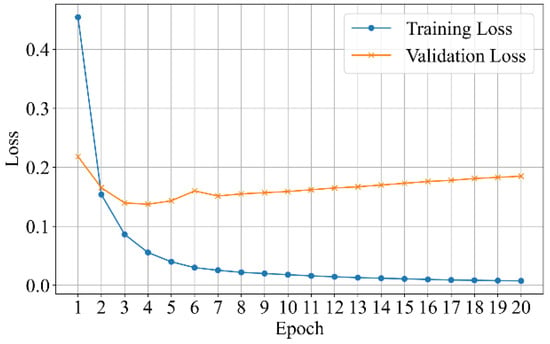
Figure 9.
Training and validation loss curves over 20 epochs, demonstrating stable learning on the training set (1414 samples) and validation set (202 samples). The final test set (405 samples) was used for independent evaluation.
Figure 10 presents nBERT’s emotion classification performance across various NRC-based emotional classes. Particularly, nBERT achieves an effective prediction rate in recognizing ‘Sadness’ and ‘Surprise’, showing its sensitivity to these emotional states. In focusing on the four key negative emotions—anger, sadness, fear, and negative—nBERT’s performance is commendable. ‘Anger’ is well detected with an accuracy of 88.89%, reinforcing the model’s capability to recognize expressions of frustration and ire, which are crucial for therapeutic assessments. The detection of ‘Fear’ presents a modest challenge, with an 87.50% accuracy. Our adapted nBERT model, refined with the NRC lexicon, attained an average precision rate of 91.53% in accurately identifying these key emotions. These evaluations demonstrate nBERT’s robust performance in emotion detection, vital for therapeutic outcome analysis. The model’s ability to discern a wide emotional range with such accuracy is indicative of its practical applicability in monitoring and assessing client well-being.
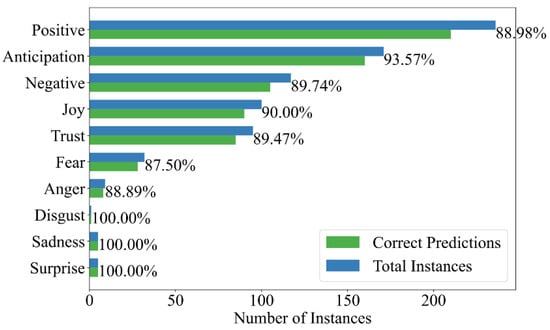
Figure 10.
Comparison of Classes predictions based on NRC emotions by nBERT performance.
However, there is room for improvement, especially in distinguishing nuanced expressions of ‘Fear’. The strong performance in detecting ‘Surprise’ and ‘Sadness’ indicates the model’s effectiveness, while the lower accuracy in ‘Fear’ and ‘Anger’ suggests areas for improvement in future iterations. A closer analysis of misclassified cases reveals that ‘Fear’ is often confused with ‘Surprise’ due to overlapping linguistic patterns, while ‘Anger’ sentiment is sometimes misattributed to ‘Sadness’ due to context ambiguity in psychotherapy dialogues. Additionally, variations in phrasing and lack of explicit emotional indicators in textual data contribute to these errors. Addressing these limitations through refined context modeling and domain-specific adaptation could further improve the model’s sensitivity to subtle emotional cues.
4.5. Comparison with Baseline Models
Evaluating the performance of various algorithms in classifying emotional states, Figure 11 highlights nBERT’s superiority across all key metrics: precision (P), recall (R), F1-score (F1), accuracy (Acc.), and area under the curve (AUC). nBERT consistently outperforms traditional models, such as LSTM, CNN, and GloVe-based architectures, as well as DistilBERT, particularly in detecting emotional symptoms like ‘Fearfulness’ and ‘Chronic Pain’. Notably, in ‘Fearfulness’, nBERT surpasses LSTM by 5%, GloVe by 6%, and matches CNN’s performance, demonstrating its refined understanding of complex emotional states. In ‘Chronic Pain’, nBERT outperforms LSTM by 8%, GloVe by 10%, and even DistilBERT by 1%, affirming its strong generalization capability. These results highlight nBERT’s ability to analyze emotional patterns in psychotherapy, supporting more informed therapeutic interventions. However, the narrow margins in certain metrics indicate competitive performance from other models, suggesting that integrating nBERT with complementary approaches could further improve outcomes. This analysis not only validates nBERT’s effectiveness but also opens possibilities for hybrid models in future healthcare applications.
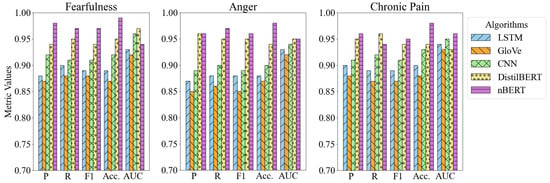
Figure 11.
Performance comparison of baseline models and nBERT in different symptoms.
To validate nBERT’s effectiveness, we compare its performance with state-of-the-art models in Table 4. While trained on different datasets, this comparison serves as an indicative benchmark of relative performance rather than a direct dataset-to-dataset evaluation. Despite dataset variations, the results highlight the benefits of domain-specific fine-tuning for psychotherapy transcripts. Our model outperforms previous methods, which range from 62% (Ensemble 3 with LSTM self-attention) to 91% (RETN with a hybrid residual encoder). nBERT’s fine-tuning with the NRC lexicon achieves a high accuracy rate, outperforming baseline models designed for general emotion recognition.
Table 4.
Comparative analysis of nBERT’s emotion classification accuracy against prior models in mental healthcare.
5. Conclusions
This study highlights that nBERT is a fine-tuned NLP model for emotion recognition in psychotherapy transcripts, supporting structured analysis in mental health research. By enhancing the granularity and reliability of emotion detection, nBERT addresses the gap in textual therapeutic dialogues where non-verbal cues are absent. The model not only excels in detecting negative emotions, such as anger, fear, and sadness, but also demonstrates its potential in transforming client–therapist interactions into actionable insights. This aligns with the broader vision of employing NLP and LLMs in life sciences for innovative and precise diagnostics. The results underline nBERT’s capacity to outperform traditional models across precision, recall, and F1-scores, ensuring robust emotion classification tailored to psychotherapy’s nuanced context.
While nBERT demonstrates effective fine-tuning in psychotherapy transcripts, its generalizability across multilingual contexts and diverse datasets remains an open challenge. Differences in emotional expression, vocabulary, and syntax across languages may lead to overfitting in non-English datasets, requiring future work to explore cross-lingual fine-tuning approaches, such as leveraging multilingual BERT (mBERT) and data augmentation techniques. Additionally, employing transfer learning and cross-domain adaptation strategies could enhance nBERT’s ability to generalize across emotionally complex and linguistically diverse datasets. Evaluating nBERT on datasets with varying emotional complexities will be essential to assess its robustness. Integrating multimodal data (e.g., audio and video) could further enhance emotion recognition by capturing non-verbal cues, particularly in multilingual and cross-cultural therapy settings. Beyond psychotherapy, nBERT offers a blueprint for leveraging LLMs in biomedical research, personalized medicine, and diagnostics, with opportunities for expanding its emotional lexicon to include therapy-specific expressions [4,24,48,49].
Author Contributions
Conceptualization, A.R., S.I. and W.R.; Methodology, A.R., S.A. and N.H.; Software, A.R.; Validation, A.R., N.H. and W.R.; Formal analysis, A.R., S.A., N.H., S.I. and W.R.; Investigation, W.R.; Writing—original draft, A.R.; Writing—review and editing, S.A. and N.H.; Visualization, S.A. and N.H.; Project administration, W.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Post-doctoral Foundation Project of Shenzhen Polytechnic University (Grant No. 6024331008K).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
We thank the reviewers and editors for their valuable time and insightful comments during the peer review of our study.
Conflicts of Interest
Author Sharjeel Imtiaz was employed by the company Loadstop. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Kim, S.; Cha, J.; Kim, D.; Park, E. Understanding mental health issues in different subdomains of social networking services: Computational analysis of text-based Reddit posts. J. Med. Internet Res. 2023, 25, e49074. [Google Scholar] [CrossRef] [PubMed]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Monferrer, M.; García, A.S.; Ricarte, J.J.; Montes, M.J.; Fernández-Caballero, A.; Fernández-Sotos, P. Facial emotion recognition in patients with depression compared to healthy controls when using human avatars. Sci. Rep. 2023, 13, 6007. [Google Scholar] [CrossRef] [PubMed]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V. Emotion-Aware Response Generation Using Affect-Enriched Embeddings with LLMs. arXiv 2024, arXiv:2410.01306. [Google Scholar]
- Senn, S.; Tlachac, M.; Flores, R.; Rundensteiner, E. Ensembles of bert for depression classification. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4691–4694. [Google Scholar]
- Simcock, G.; McLoughlin, L.T.; De Regt, T.; Broadhouse, K.M.; Beaudequin, D.; Lagopoulos, J.; Hermens, D.F. Associations between facial emotion recognition and mental health in early adolescence. Int. J. Environ. Res. Public Health 2020, 17, 330. [Google Scholar] [CrossRef]
- Mukhiya, S.K.; Ahmed, U.; Rabbi, F.; Pun, K.I.; Lamo, Y. Adaptation of IDPT system based on patient-authored text data using NLP. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 226–232. [Google Scholar]
- Zad, S.; Jimenez, J.; Finlayson, M. Hell hath no fury? correcting bias in the nrc emotion lexicon. In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), Bangkok, Thailand, 6 August 2021; pp. 102–113. [Google Scholar]
- Yimu, X. Ethnic minorities’ mentality and homosexuality psychology in literature: A text emotion analysis with NRC lexicon. Appl. Comput. Eng. 2023, 13, 240–250. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. NRC Emotion Lexicon; National Research Council: Ottawa, ON, Canada, 2013; Volume 2, p. 234. [Google Scholar]
- Boyd, R.L.; Ashokkumar, A.; Seraj, S.; Pennebaker, J.W. The Development and Psychometric Properties of LIWC-22; The University of Texas at Austin: Austin, TX, USA, 2022; Volume 10. [Google Scholar]
- Han, P.; Chen, H.; Jiang, Q.; Yang, M. MFB: A Generalized Multimodal Fusion Approach for Bitcoin Price Prediction Using Time-Lagged Sentiment and Indicator Features. Expert Syst. Appl. 2025, 261, 125515. [Google Scholar] [CrossRef]
- Barik, K.; Misra, S.; Ray, A.K.; Bokolo, A. LSTM-DGWO-Based Sentiment Analysis Framework for Analyzing Online Customer Reviews. Comput. Intell. Neurosci. 2023, 2023, 6348831. [Google Scholar] [CrossRef]
- Velu, S.R.; Ravi, V.; Tabianan, K. Multi-lexicon classification and valence-based sentiment analysis as features for deep neural stock price prediction. Sci 2023, 5, 8. [Google Scholar] [CrossRef]
- Samir, H.A.; Abd-Elmegid, L.; Marie, M. Sentiment analysis model for Airline customers’ feedback using deep learning techniques. Int. J. Eng. Bus. Manag. 2023, 15, 18479790231206019. [Google Scholar] [CrossRef]
- Sung, Y.W.; Park, D.S.; Kim, C.G. A Study of BERT-Based Classification Performance of Text-Based Health Counseling Data. CMES-Comput. Model. Eng. Sci. 2023, 135, 795–808. [Google Scholar]
- Benítez-Andrades, J.A.; Alija-Pérez, J.M.; Vidal, M.E.; Pastor-Vargas, R.; García-Ordás, M.T. Traditional machine learning models and bidirectional encoder representations from transformer (BERT)–based automatic classification of tweets about eating disorders: Algorithm development and validation study. JMIR Med. Inform. 2022, 10, e34492. [Google Scholar] [CrossRef]
- Hudon, A.; Beaudoin, M.; Phraxayavong, K.; Dellazizzo, L.; Potvin, S.; Dumais, A. Use of automated thematic annotations for small data sets in a psychotherapeutic context: Systematic review of machine learning algorithms. JMIR Ment. Health 2021, 8, e22651. [Google Scholar] [CrossRef] [PubMed]
- Malgaroli, M.; Hull, T.D.; Zech, J.M.; Althoff, T. Natural language processing for mental health interventions: A systematic review and research framework. Transl. Psychiatry 2023, 13, 309. [Google Scholar] [CrossRef] [PubMed]
- Bharti, S.K.; Varadhaganapathy, S.; Gupta, R.K.; Shukla, P.K.; Bouye, M.; Hingaa, S.K.; Mahmoud, A. Text-Based Emotion Recognition Using Deep Learning Approach. Comput. Intell. Neurosci. 2022, 2022, 2645381. [Google Scholar] [CrossRef]
- Gatto, A.J.; Elliott, T.J.; Briganti, J.S.; Stamper, M.J.; Porter, N.D.; Brown, A.M.; Harden, S.M.; Cooper, L.D.; Dunsmore, J.C. Development and feasibility of an online brief emotion regulation training (BERT) program for emerging adults. Front. Public Health 2022, 10, 858370. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Schoene, A.M.; Ji, S.; Ananiadou, S. Natural language processing applied to mental illness detection: A narrative review. NPJ Digit. Med. 2022, 5, 46. [Google Scholar] [CrossRef]
- Alrasheedy, M.N.; Muniyandi, R.C.; Fauzi, F. Text-Based Emotion Detection and Applications: A Literature Review. In Proceedings of the 2022 International Conference on Cyber Resilience (ICCR), Dubai, United Arab Emirates, 6–7 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–9. [Google Scholar]
- Han, P.; Hong, J.; Chen, H.; Pan, Y.; Jiang, Q. A Hybrid Recommendation Model for Social Network Services Using Twitter Data. In Web Services—ICWS 2022; Zhang, Y., Zhang, L.J., Eds.; Springer: Cham, Switzerland, 2022; pp. 122–129. [Google Scholar]
- Kour, H.; Gupta, M.K. AI assisted attention mechanism for hybrid neural model to assess online attitudes about COVID-19. Neural Process. Lett. 2023, 55, 2265–2304. [Google Scholar] [CrossRef]
- Krommyda, M.; Rigos, A.; Bouklas, K.; Amditis, A. An experimental analysis of data annotation methodologies for emotion detection in short text posted on social media. Informatics 2021, 8, 19. [Google Scholar] [CrossRef]
- Rasool, A.; Jiang, Q.; Qu, Q.; Kamyab, M.; Huang, M. HSMC: Hybrid Sentiment Method for Correlation to Analyze COVID-19 Tweets. In Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery; Springer International Publishing: Cham, Switzerland, 2022; pp. 991–999. [Google Scholar]
- Alturayeif, N.; Luqman, H. Fine-grained sentiment analysis of arabic covid-19 tweets using bert-based transformers and dynamically weighted loss function. Appl. Sci. 2021, 11, 10694. [Google Scholar] [CrossRef]
- Antoniou, M.; Estival, D.; Lam-Cassettari, C.; Li, W.; Dwyer, A.; de Almeida Neto, A. Predicting mental health status in remote and rural farming communities: Computational analysis of text-based counseling. JMIR Form. Res. 2022, 6, e33036. [Google Scholar] [CrossRef]
- Liu, J.; Wang, H. Analysis of educational mental health and emotion based on deep learning and computational intelligence optimization. Front. Psychol. 2022, 13, 898609. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, J.; Lu, R. Research on Text Emotion Analysis Based on LSTM. In Proceedings of the 2023 International Conference on Computer, Vision and Intelligent Technology, Chenzhou, China, 25–28 August 2023; pp. 1–6. [Google Scholar]
- Tang, J.; Su, Q.; Niu, L.; Huang, J.; Su, B.; Lin, S. Emotion analysis of Chinese reviews based on fusion of multi-layer CNN and LSTM. In Proceedings of the 2022 5th International Conference on Image and Graphics Processing, Beijing, China, 7–9 January 2022; pp. 351–356. [Google Scholar]
- Lu, Z. Analysis model of college students’ mental health based on online community topic mining and emotion analysis in novel coronavirus epidemic situation. Front. Public Health 2022, 10, 1000313. [Google Scholar] [CrossRef] [PubMed]
- Chriqui, A.; Yahav, I. HeBERT and HebEMO: A Hebrew BERT model and a tool for polarity analysis and emotion recognition. INFORMS J. Data Sci. 2022, 1, 81–95. [Google Scholar] [CrossRef]
- Makhmudov, F.; Kultimuratov, A.; Cho, Y.I. Enhancing Multimodal Emotion Recognition through Attention Mechanisms in BERT and CNN Architectures. Appl. Sci. 2024, 14, 4199. [Google Scholar] [CrossRef]
- Hou, Z.; Du, Y.; Li, Q.; Li, X.; Chen, X.; Gao, H. A false emotion opinion target extraction model with two stage BERT and background information fusion. Expert Syst. Appl. 2024, 250, 123735. [Google Scholar] [CrossRef]
- Sharma, A.; Miner, A.S.; Atkins, D.C.; Althoff, T. A computational approach to understanding empathy expressed in text-based mental health support. arXiv 2020, arXiv:2009.08441. [Google Scholar]
- Althoff, T.; Clark, K.; Leskovec, J. Large-scale analysis of counseling conversations: An application of natural language processing to mental health. Trans. Assoc. Comput. Linguist. 2016, 4, 463–476. [Google Scholar] [CrossRef]
- Rietberg, M.T.; Nguyen, V.B.; Geerdink, J.; Vijlbrief, O.; Seifert, C. Accurate and reliable classification of unstructured reports on their diagnostic goal using bert models. Diagnostics 2023, 13, 1251. [Google Scholar] [CrossRef]
- Lalk, C.; Steinbrenner, T.; Kania, W.; Popko, A.; Wester, R.; Schaffrath, J.; Eberhardt, S.; Schwartz, B.; Lutz, W.; Rubel, J. Measuring Alliance and Symptom Severity in psychotherapy transcripts using Bert Topic modeling. Adm. Policy Ment. Health Ment. Health Serv. Res. 2024, 51, 509–524. [Google Scholar] [CrossRef]
- Si, S.; Wang, R.; Wosik, J.; Zhang, H.; Dov, D.; Wang, G.; Carin, L. Students need more attention: Bert-based attention model for small data with application to automatic patient message triage. In Proceedings of the Machine Learning for Healthcare Conference, PMLR, Virtual, 7–8 August 2020; pp. 436–456. [Google Scholar]
- Usuga-Cadavid, J.P.; Lamouri, S.; Grabot, B.; Fortin, A. Using deep learning to value free-form text data for predictive maintenance. Int. J. Prod. Res. 2022, 60, 4548–4575. [Google Scholar] [CrossRef]
- Villatoro-Tello, E.; Parida, S.; Kumar, S.; Motlicek, P. Applying attention-based models for detecting cognitive processes and mental health conditions. Cogn. Comput. 2021, 13, 1154–1171. [Google Scholar] [CrossRef] [PubMed]
- Kabir, M.; Ahmed, T.; Hasan, M.B.; Laskar, M.T.R.; Joarder, T.K.; Mahmud, H.; Hasan, K. DEPTWEET: A typology for social media texts to detect depression severities. Comput. Hum. Behav. 2023, 139, 107503. [Google Scholar] [CrossRef]
- Danner, M.; Hadzic, B.; Gerhardt, S.; Ludwig, S.; Uslu, I.; Shao, P.; Weber, T.; Shiban, Y.; Ratsch, M. Advancing mental health diagnostics: GPT-based method for depression detection. In Proceedings of the 2023 62nd Annual Conference of the Society of Instrument and Control Engineers (SICE), Tsu, Japan, 6–9 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1290–1296. [Google Scholar]
- Khan, M.A.; Huang, Y.; Feng, J.; Prasad, B.K.; Ali, Z.; Ullah, I.; Kefalas, P. A multi-attention approach using BERT and stacked bidirectional LSTM for improved dialogue state tracking. Appl. Sci. 2023, 13, 1775. [Google Scholar] [CrossRef]
- Rasool, A. Advancing the Intersection of AI and Bioinformatics. J. Artif. Intell. Bioinform. 2024, 1, 1–2. [Google Scholar] [CrossRef]
- Aslam, S. CEL: A Continual Learning Model for Disease Outbreak Prediction by Leveraging Domain Adaptation via Elastic Weight Consolidation. Interdiscip. Sci. Comput. Life Sci. 2025. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).