

Prediction of Disk Failure Based on Classification Intensity Resampling


Abstract
1. Introduction
2. Research Background
2.1. The Current Research Status
2.2. Issues and Challenges
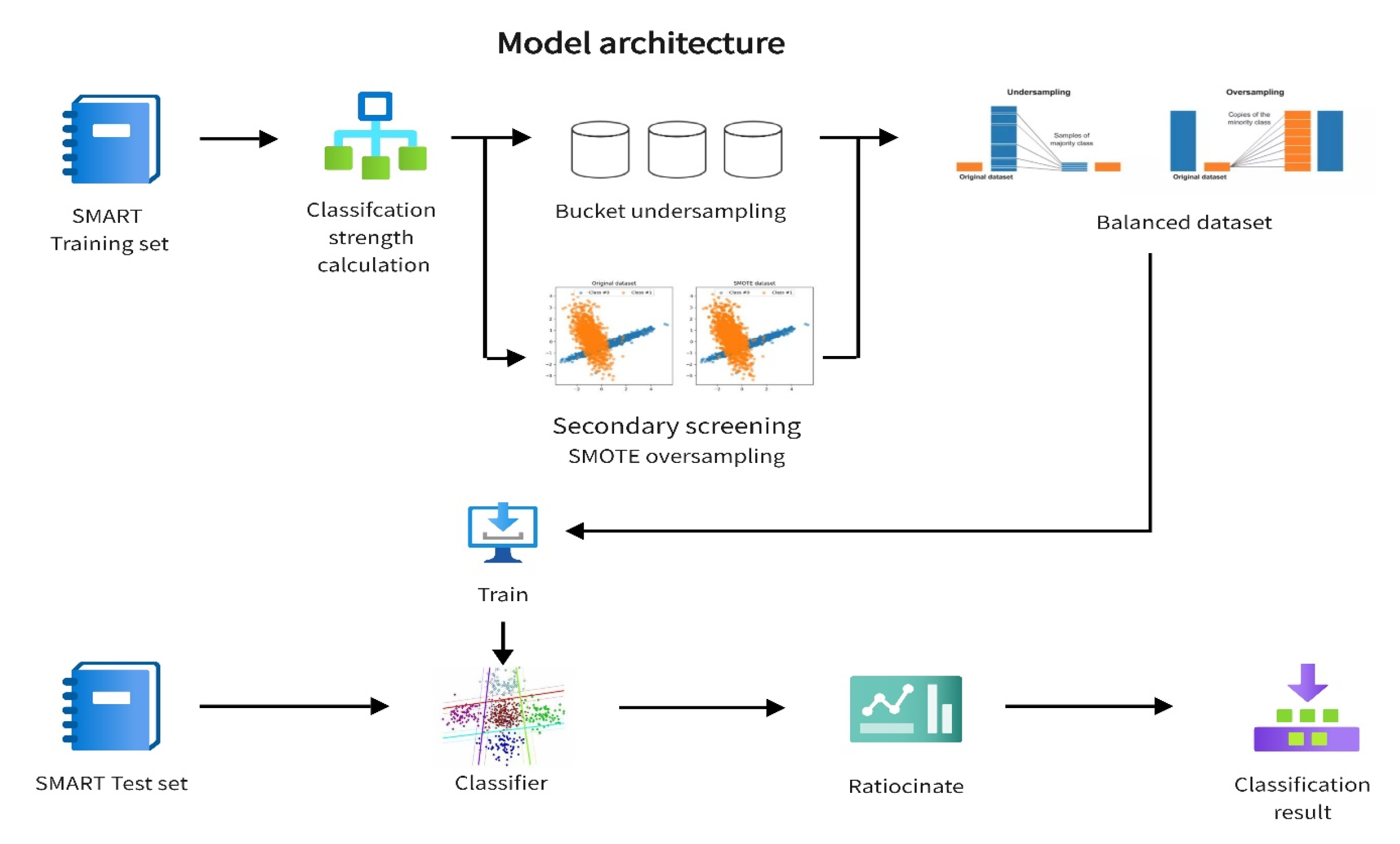
3. Model Architecture
4. Classification Intensity Calculation
- (1)
- Due to the fact that classification intensity is defined by a given learner, the distribution of classification intensity itself varies depending on the learning ability of different classifiers. This enables the model to naturally adapt to the learning process of different classifiers and obtain the optimal optimization process based on the different classification abilities of the learners.
- (2)
- The model can be used to collaborate with any classifier and improve its classification performance on large-scale imbalanced datasets in an integrated manner.
| Algorithm 1 Classification intensity calculation |
| Input: Training set D;
Base learner f Output: Initial classifier ;
Sample classification intensity 1. Initialization: minority sample set in , majority sample set in ; 2. Calculate the number of majority and minority samples , ; 3. Using random majority class subsampling to obtain a majority class subset . Make . 4. Using balanced dataset training initial classifier ; 5. Utilize predict the probability of all samples being misjudged in ; 6. Utilize predict the probability of all samples being hitted in ; return |
5. Bucket Undersampling
| Algorithm 2 Bucket undersampling |
| Input: Majority class sample set N;
Number of buckets divided k; Majority sample classification intensity ; Output: Sample set N after sub-bucket undersampling 1. Determine the probability numerical interval for each sub-bucket with the interval for the i-th bucket 2. Based on distribution, according to the interval of buckets, load each sample point into k buckets, and the samples in each bucket are 3. Calculate the average classification intensity of each bucket with the average classification intensity of the i-th bucket ; 4. Calculate the sampling weight of each bucket, and the sampling weight of the i-th bucket is ; 5. Randomly sample each bucket based on its sampling weight with the i-th bucket having a sampling amount of ; return Return the sample set after sub-bucket undersampling |
6. Secondary Screening SMOTE Oversampling
| Algorithm 3 SMOTE oversampling |
| Input: minority sample x;
x’s adjacent sample set X Output: New Sample 1. Repeat until the required oversampling rate is completed do 2. Calculate the distance between the minority sample x and its k-nearest neighbors and randomly select a neighbor sample 3. Randomly specify proportions 4. Combining x and Two samples, according to Synthesize new sample 5. End repeat return Return New Sample |
| Algorithm 4 Secondary screening oversampling |
| Input: minority class sample set P;
Oversampling rate R; Minority sample classification intensity ; Initial classifier Output: oversampled dataset 1. Calculate the average classification intensity of minority class samples 2. Based on the oversampling rate R, use SMOTE to oversample P and obtain the sampling dataset ; 3. Calculate the classification intensity f for each sample in the oversampling dataset ; 4. Keep Sample points with form an oversampling dataset return Return oversampled datase ; |
7. Classifier Training
| Algorithm 5 Classifier Training |
| Input: Dataset imbalance ratio ;
Undersampled dataset ; Oversampling dataset ; Classifier f Output: Final classifier 1. If then 2. Only using bucket undersampling method to construct a balanced dataset ; 3. Else if then 4. Using bucket undersampling and secondary screening SMOTE oversampling methods to construct a balanced dataset ; 5. End if 6. Train classifier f using a balanced dataset to obtain the final classifier return Return ; |
8. Experiment and Analysis
8.1. Experimental Environment
8.2. Datasets
8.3. Evaluating Indicator
8.4. Experimental Plan and Analysis
- (1)
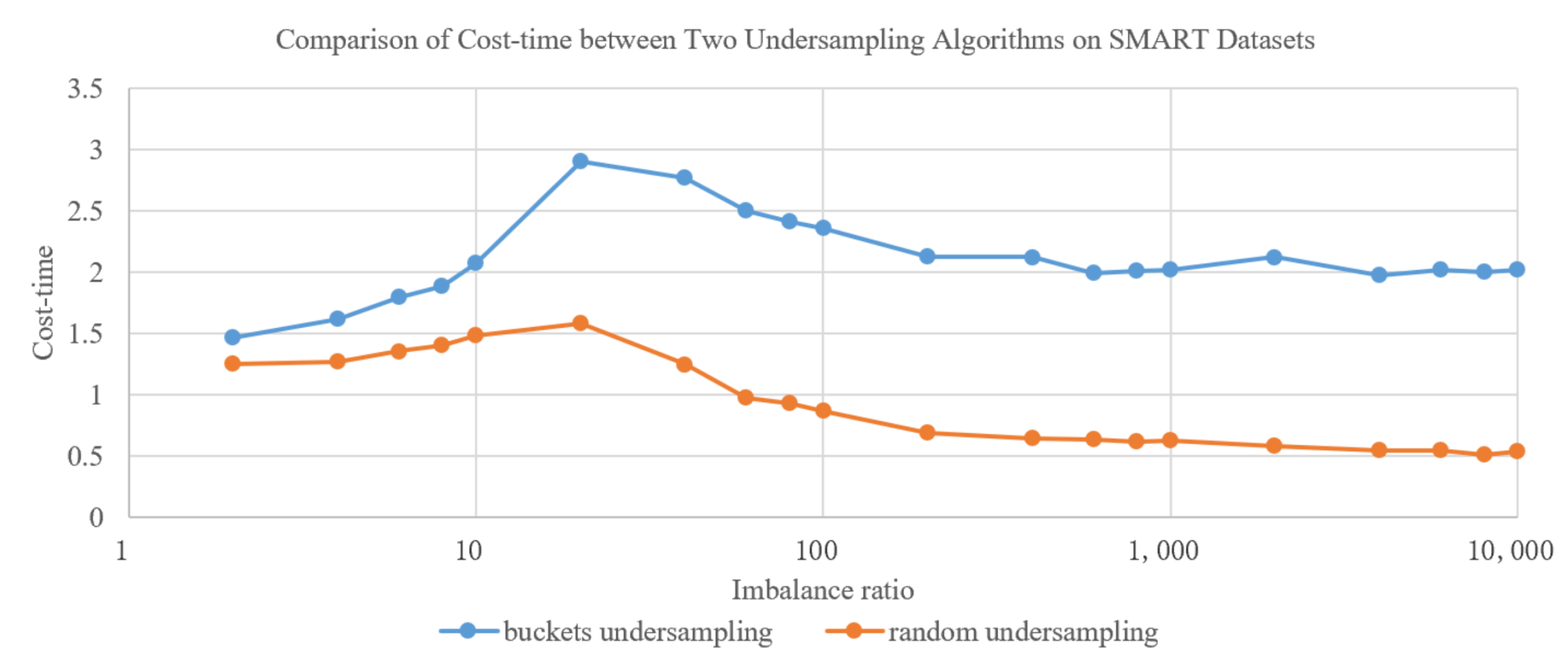
- Comparative analysis of bucket undersampling and random undersampling
- (2)
- Comparative analysis of secondary screening SMOTE oversampling and standard SMOTE oversampling
- (3)
- Comprehensive comparative analysis
- Only using sub-bucket undersampling;
- Only using secondary screening SMOTE oversampling;
- Simultaneous using bucket undersampling and secondary screening SMOTE oversampling
- (4)
- Experimental Conclusion
8.5. Application Effect Analysis
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chaves, I.C. Hard Disk Drive Failure Prediction Method Based On A Bayesian Network. In Proceedings of the The International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Zhu, B.; Wang, G.; Liu, X.; Hu, D.; Lin, S.; Ma, J. Proactive drive failure prediction for large scale storage systems. In Proceedings of the IEEE 29th Symposium on Mass Storage Systems and Technologies, MSST 2013, Long Beach, CA, USA, 6–10 May 2013; pp. 1–5. [Google Scholar]
- Aussel, N.; Jaulin, S.; Gandon, G.; Petetin, Y.; Chabridon, S. Predictive models of hard drive failures based on operational data. In Proceedings of the IEEE International Conference on Machine Learning & Applications, Cancun, Mexico, 18–21 December 2017. [Google Scholar]
- Xu, Y.; Sui, K.; Yao, R.; Zhang, H.; Lin, Q.; Dang, Y.; Li, P.; Jiang, K.; Zhang, W.; Lou, J.G.; et al. Improving Service Availability of Cloud Systems by Predicting Disk Error. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 11–13 July 2018; pp. 481–494. [Google Scholar]
- Botezatu, M.M.; Giurgiu, I.; Bogojeska, J.; Wiesmann, D. Predicting Disk Replacement towards Reliable Data Centers. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 17–13 August 2016; pp. 39–48. [Google Scholar]
- Mohapatra, R.; Coursey, A.; Sengupta, S. Large-scale End-of-Life Prediction of Hard Disks in Distributed Datacenters. In Proceedings of the 2023 IEEE International Conference on Smart Computing (SMARTCOMP), Nashville, TN, USA, 26–30 June 2023; pp. 261–266. [Google Scholar]
- Liu, Y.; Guan, Y.; Jiang, T.; Zhou, K.; Wang, H.; Hu, G.; Zhang, J.; Fang, W.; Cheng, Z.; Huang, P. SPAE: Lifelong disk failure prediction via end-to-end GAN-based anomaly detection with ensemble update. Future Gener. Comput. Syst. 2023, 148, 460–471. [Google Scholar] [CrossRef]
- Guan, Y.; Liu, Y.; Zhou, K.; Qiang, L.I.; Wang, T.; Hui, L.I. A disk failure prediction model for multiple issues. Front. Inf. Technol. Electron. Eng. 2023, 24, 964–979. [Google Scholar] [CrossRef]
- Han, S.; Lee, P.P.; Shen, Z.; He, C.; Liu, Y.; Huang, T. A General Stream Mining Framework for Adaptive Disk Failure Prediction. IEEE Trans. Comput. 2023, 72, 520–534. [Google Scholar] [CrossRef]
- Zach, M.; Olusiji, M.; Madhavan, R.; Alex, B.; Fred, L. Hard Disk Drive Failure Analysis and Prediction: An Industry View. In Proceedings of the 2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks—Supplemental Volume (DSN-S), Porto, Portugal, 27–30 June 2023; pp. 21–27. [Google Scholar]
- Pandey, C.; Angryk, R.A.; Aydin, B. Explaining Full-disk Deep Learning Model for Solar Flare Prediction using Attribution Methods. arXiv 2023, arXiv:2307.15878. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhang, J.; Mani, I. KNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction. In Proceedings of the ICML Workshop on Learning from Imbalanced Datasets, Washington, DC, USA, 21 August 2003. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–8 June 2008. [Google Scholar]
- Elkan, C. The Foundations of Cost-Sensitive Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001. [Google Scholar]
- Liu, X.Y.; Zhou, Z.H. The Influence of Class Imbalance on Cost-Sensitive Lear-ning: An Empirical Study. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, 18–22 December 2006. [Google Scholar]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A New Over-sampling Method in Imbalanced Data Sets Learning. In Proceedings of the Advances in Intelligent Computing, International Conference on Intelligent Computing, ICIC 2005, Hefei, China, 23–26 August 2005. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-Level-SMOTE: Safe-Level-Synthetic Minority Over-Sampling TEchnique for Handling the Class Imbalanced Problem. In Proceedings of the Pacific-asia Conference on Advances in Knowledge Discovery & Data Mining, Bangkok, Thailand, 27–30 April 2009. [Google Scholar]
- Seagate. The SMART Dataset from Nankai University and Baidu, Inc. Available online: http://pan.baidu.com/share/link?shareid=189977&uk=4278294944 (accessed on 19 March 2024).
- Scikit-Learn-Contrib (2016) Imbalanced-Learn (Version 0.9.0) [Source Code]. 2016. Available online: https://github.com/scikit-learn-contrib/imbalanced-learn (accessed on 19 March 2024).
- Pozzolo, A.D.; Boracchi, G.; Caelen, O.; Alippi, C.; Bontempi, G. Credit Card Fraud Detection: A Realistic Modeling and a Novel Learning Strategy. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3784–3797. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Fu, Y.; Wu, L.; Li, X.; Aggarwal, C.; Xiong, H. Automated Feature Selection: A Reinforcement Learning Perspective. IEEE Trans. Knowl. Data Eng. 2023, 35, 2272–2284. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type Basic Idea | Limitations |
|---|---|---|
| Conventional Machine Learning | Based on labeled data, uses supervised machine learning models for classification | Only a very small number of fault samples result in dataset imbalance, which affects classification accuracy. |
| Transfer Learning | Focuses on solving the problem of model transfer training between different disk models. | Sample imbalance issue is not addressed. |
| Data Screening | Divides the dataset based on disk usage life and utilizes similarity metrics to assess the closeness between the state of the hard drive to be predicted and the hard drive states in the training set; a new training set is formed by selecting those hard drives that exhibit high levels of similarity. | Sample imbalance issue is not addressed. |
| ID | Attribute Name |
|---|---|
| 1 | Raw Read Error Rate |
| 3 | Spin Up Time |
| 5 | Reallocated Sector Count |
| 7 | Seek Error Rate |
| 9 | Power On Hours |
| 187 | Reported Uncorrectable Error |
| 189 | High Fly Write |
| 194 | Temperature Celsius |
| 195 | Hardware ECC Recovered |
| 197 | Current Pending Sector Count |
| 5_raw | Reallocated Sector Count |
| Dataset | N_Sample | N_Minority | N_Majority | Imbalance Ratio |
|---|---|---|---|---|
| S1 | 468,936 | 156,312 | 312,624 | 2:1 |
| S2 | 781,560 | 156,312 | 625,248 | 4:1 |
| S3 | 1,094,184 | 156,312 | 937,872 | 6:1 |
| S4 | 1,406,808 | 156,312 | 1,250,496 | 8:1 |
| S5 | 1,719,432 | 156,312 | 1,563,120 | 10:1 |
| S6 | 3,282,552 | 156,312 | 3,126,240 | 20:1 |
| S7 | 3,946,394 | 96,253 | 3,850,141 | 40:1 |
| S8 | 3,914,310 | 64,169 | 3,850,141 | 60:1 |
| S9 | 3,898,267 | 48,126 | 3,850,141 | 80:1 |
| S10 | 3,888,642 | 38,501 | 3,850,141 | 100:1 |
| S11 | 3,869,391 | 19,250 | 3,850,141 | 200:1 |
| S12 | 3,859,766 | 9625 | 3,850,141 | 400:1 |
| S13 | 3,856,557 | 6416 | 3,850,141 | 600:1 |
| S14 | 3,854,953 | 4812 | 3,850,141 | 800:1 |
| S15 | 3,853,991 | 3850 | 3,850,141 | 1000:1 |
| S16 | 3,852,066 | 1925 | 3,850,141 | 2000:1 |
| S17 | 3,851,103 | 962 | 3,850,141 | 4000:1 |
| S18 | 3,850,782 | 641 | 3,850,141 | 6000:1 |
| S19 | 3,850,622 | 481 | 3,850,141 | 8000:1 |
| S20 | 3,850,526 | 385 | 3,850,141 | 10,000:1 |
| Dataset | N_Sample | N_Minority | N_Majority | Imbalance Ratio |
|---|---|---|---|---|
| optical_digits | 5620 | 554 | 5066 | 9.14 |
| pen_digits | 10,992 | 1055 | 9937 | 9.42 |
| coil_2000 | 9822 | 586 | 9236 | 15.76 |
| letter_img | 20,000 | 734 | 19,266 | 26.25 |
| webpage | 34,780 | 981 | 33,799 | 34.45 |
| mammography | 11,183 | 260 | 10,923 | 42.01 |
| protein_homo | 145,751 | 1296 | 144,455 | 111.46 |
| abalone_19 | 4177 | 32 | 4145 | 129.52 |
| creditcard | 284,807 | 492 | 284,315 | 577.88 |
| Positive | Negative | |
|---|---|---|
| True | TP | TN |
| Flase | FP | FN |
| Dataset | Imbalance Ratio | F1-Score | Cost–Time | ||
|---|---|---|---|---|---|
| Buckets Undersampling | Random Undersampling | Buckets Undersampling | Random Undersampling | ||
| optical_digits | 9.14 | 0.9267 | 0.8802 | 0.3406 | 0.2360 |
| pen_digits | 9.42 | 0.9930 | 0.9783 | 0.3409 | 0.2366 |
| coil_2000 | 15.76 | 0.1735 | 0.1743 | 0.3449 | 0.2384 |
| letter_img | 26.25 | 0.9012 | 0.7539 | 0.3430 | 0.2373 |
| webpage | 34.45 | 0.5422 | 0.3514 | 0.4424 | 0.2788 |
| mammography | 42.01 | 0.5010 | 0.3418 | 0.3380 | 0.2335 |
| protein_homo | 111.46 | 0.7539 | 0.3855 | 0.4412 | 0.2734 |
| abalone_19 | 129.52 | 0.0126 | 0.0115 | 0.3364 | 0.2323 |
| creditcard | 577.88 | 0.4744 | 0.0882 | 0.4235 | 0.2582 |
| Dataset | Imbalance Ratio | N_Feature | Buckets Undersampling | Secondary Screening SMOTE | Mixed Sampling |
|---|---|---|---|---|---|
| optical_digits | 9.14 | 65 | 0.9396 | 0.8811 | 0.9289 |
| pen_digits | 9.42 | 17 | 0.9942 | 0.9869 | 0.9862 |
| coil_2000 | 15.76 | 86 | 0.1725 | 0.1319 | 0.2080 |
| letter_img | 26.25 | 17 | 0.9124 | 0.9271 | 0.9272 |
| webpage | 34.45 | 301 | 0.5603 | 0.7109 | 0.6766 |
| mammography | 42.01 | 7 | 0.4984 | 0.7459 | 0.7292 |
| protein_homo | 111.46 | 75 | 0.7714 | 0.8247 | 0.8264 |
| creditcard | 577.88 | 31 | 0.5021 | 0.8432 | 0.8467 |
| Dataset | Imbalance Ratio | N_Feature | Buckets Undersampling | Secondary Screening SMOTE | Mixed Sampling |
|---|---|---|---|---|---|
| optical_digits | 9.14 | 65 | 0.3405 | 0.5751 | 0.6998 |
| pen_digits | 9.42 | 17 | 0.3403 | 0.7423 | 0.8977 |
| coil_2000 | 15.76 | 86 | 0.3480 | 0.6101 | 0.7519 |
| letter_img | 26.25 | 17 | 0.3414 | 0.6489 | 0.7527 |
| webpage | 34.45 | 301 | 0.4488 | 1.5856 | 1.4937 |
| mammography | 42.01 | 7 | 0.3373 | 0.4542 | 0.5665 |
| protein_homo | 111.46 | 75 | 0.4587 | 3.5743 | 1.5278 |
| creditcard | 577.88 | 31 | 0.4297 | 6.5677 | 0.9589 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Guan, J. Prediction of Disk Failure Based on Classification Intensity Resampling. Information 2024, 15, 322. https://doi.org/10.3390/info15060322
Wu S, Guan J. Prediction of Disk Failure Based on Classification Intensity Resampling. Information. 2024; 15(6):322. https://doi.org/10.3390/info15060322
Chicago/Turabian StyleWu, Sheng, and Jihong Guan. 2024. "Prediction of Disk Failure Based on Classification Intensity Resampling" Information 15, no. 6: 322. https://doi.org/10.3390/info15060322
APA StyleWu, S., & Guan, J. (2024). Prediction of Disk Failure Based on Classification Intensity Resampling. Information, 15(6), 322. https://doi.org/10.3390/info15060322