
Research on Facial Expression Recognition Algorithm Based on Lightweight Transformer


Abstract
1. Introduction
2. Related Technologies
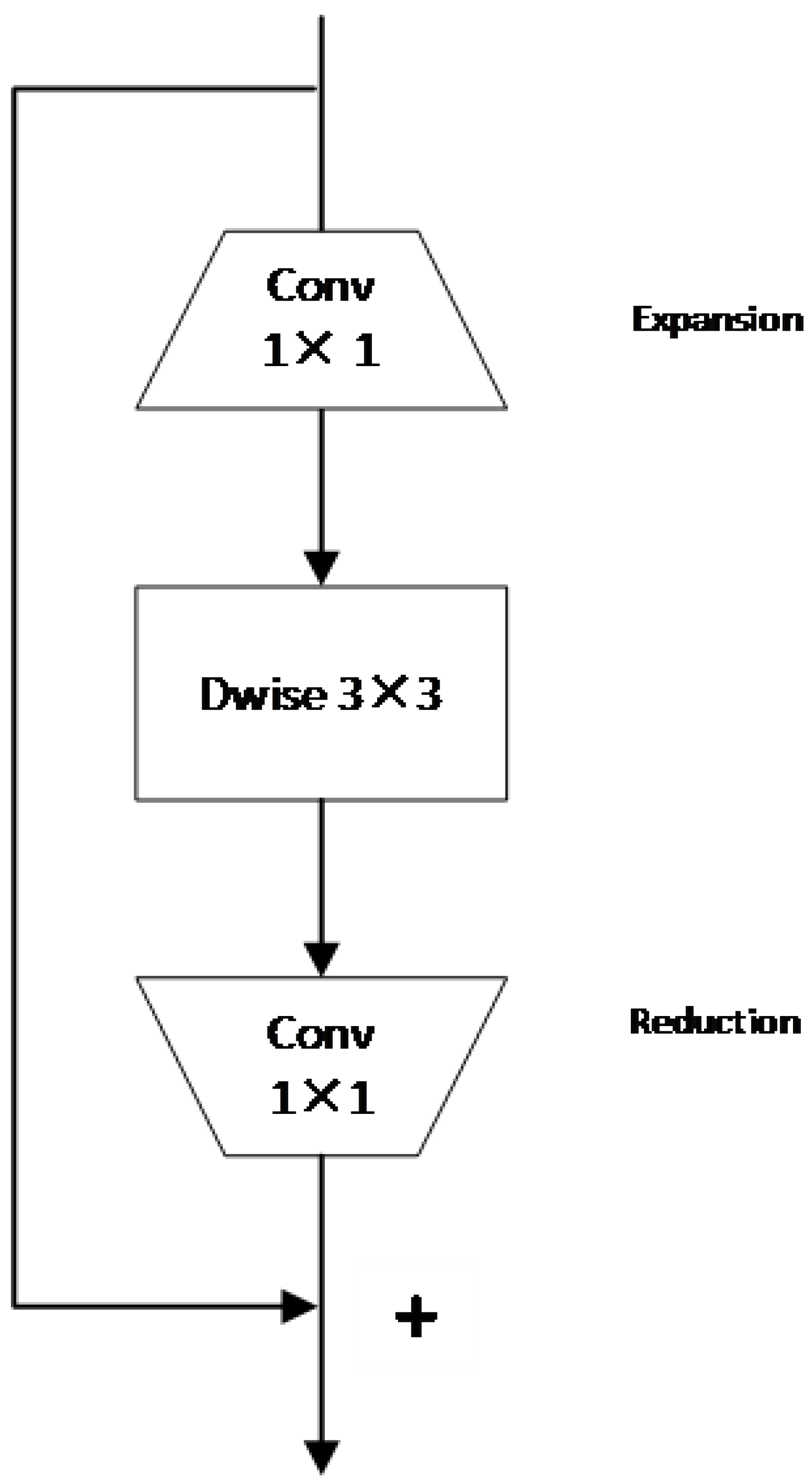
2.1. MobileNetV2
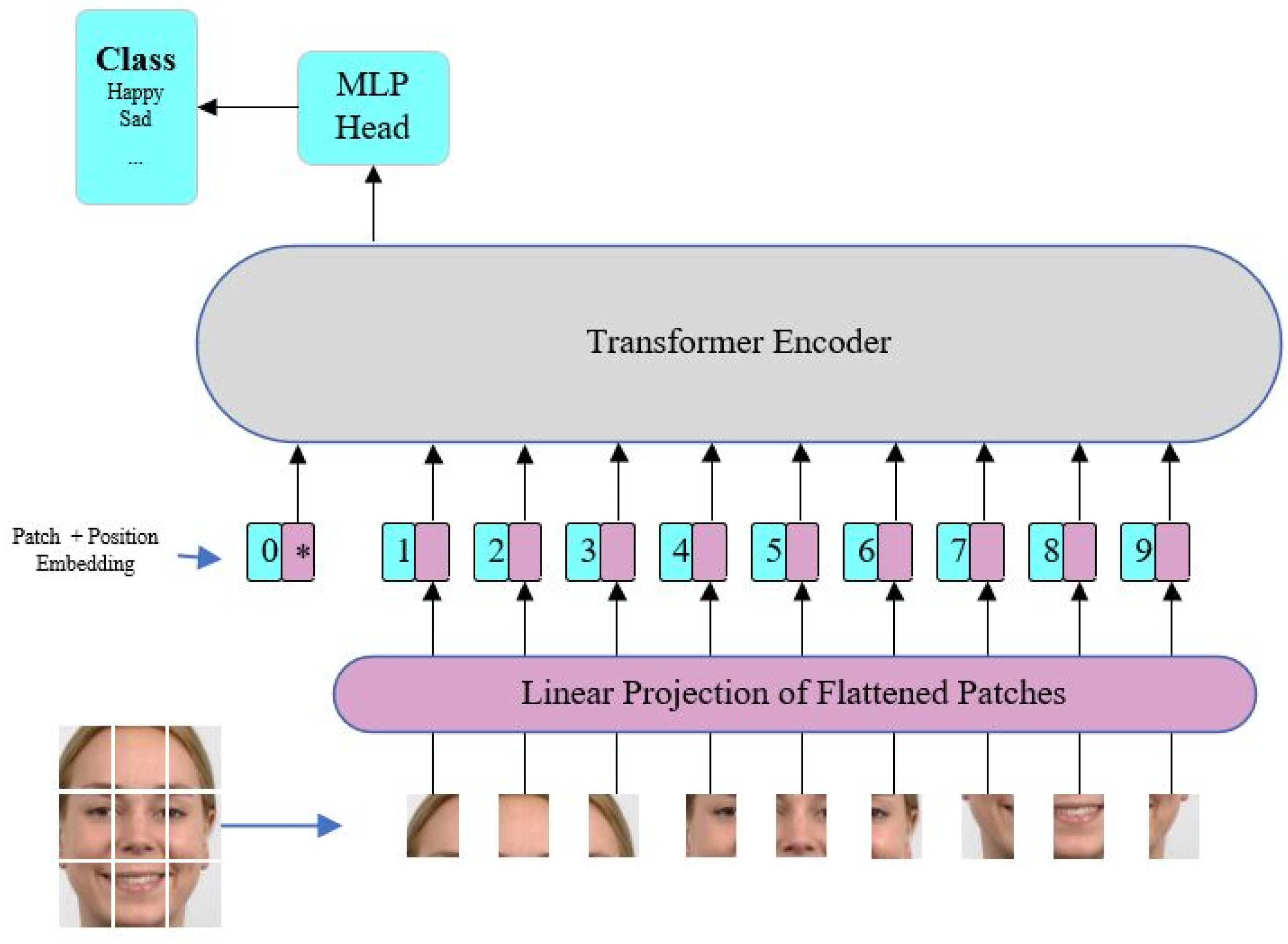
2.2. Vision Transformer
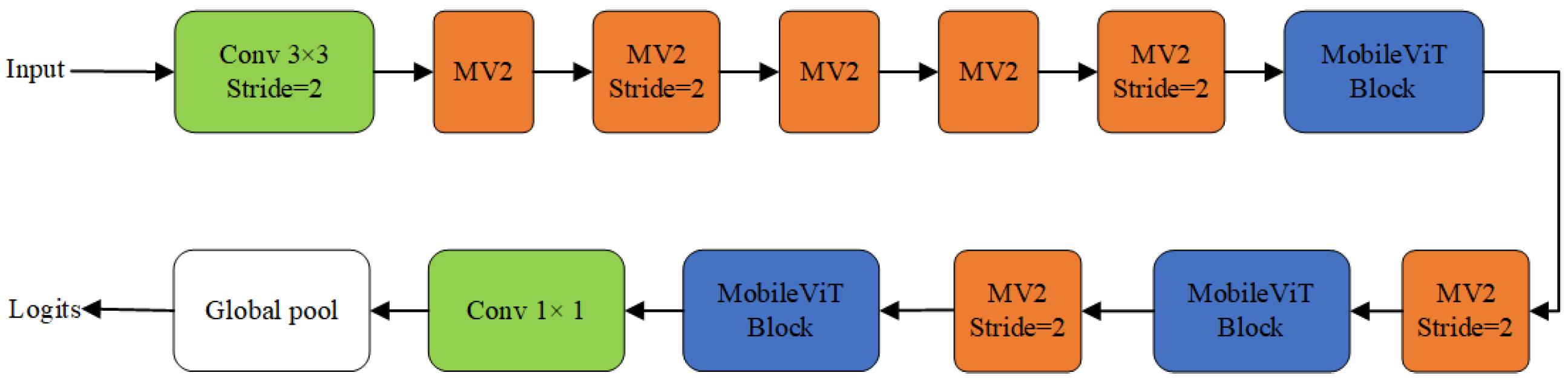
2.3. MobileViT
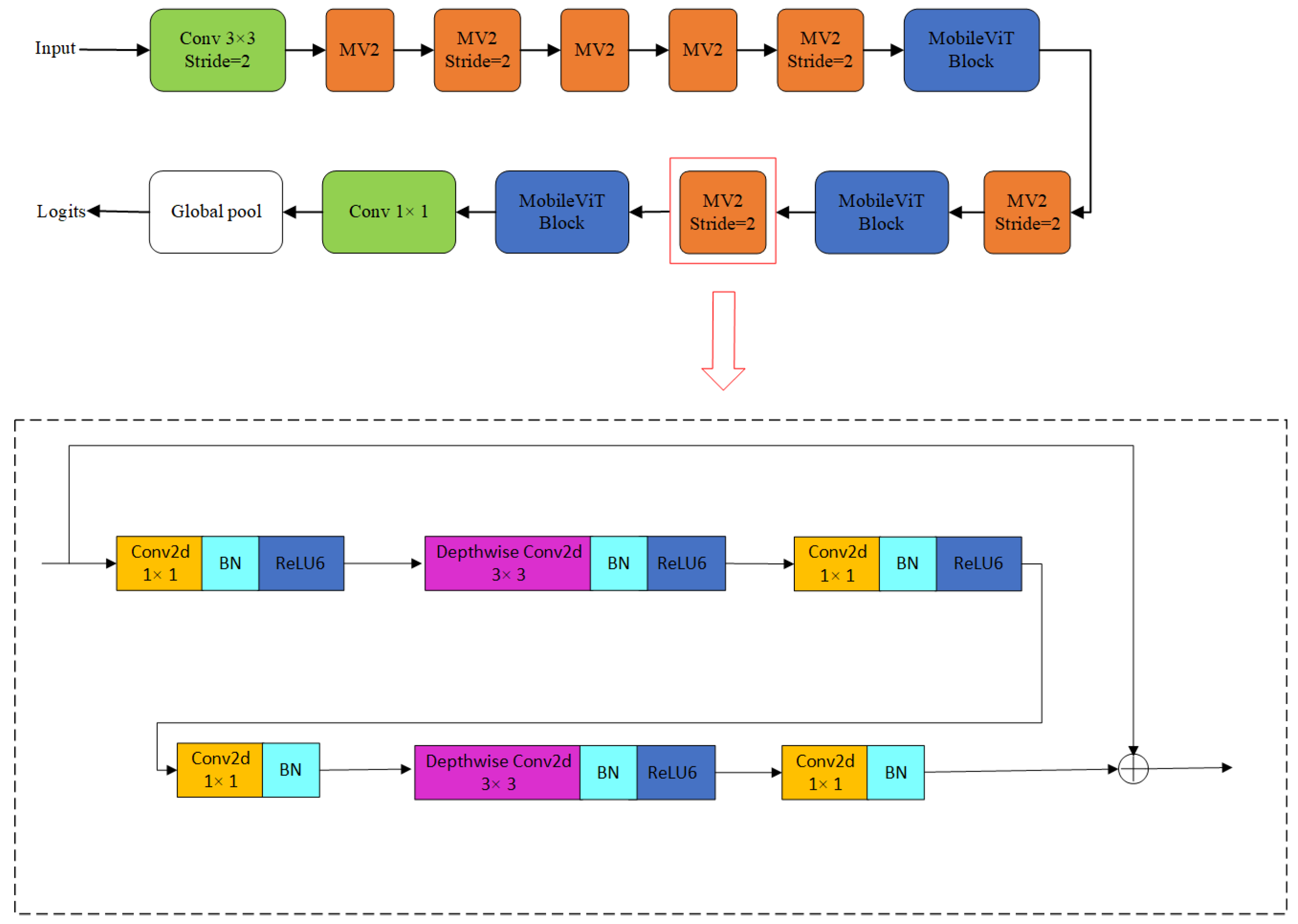
3. Improve the Network
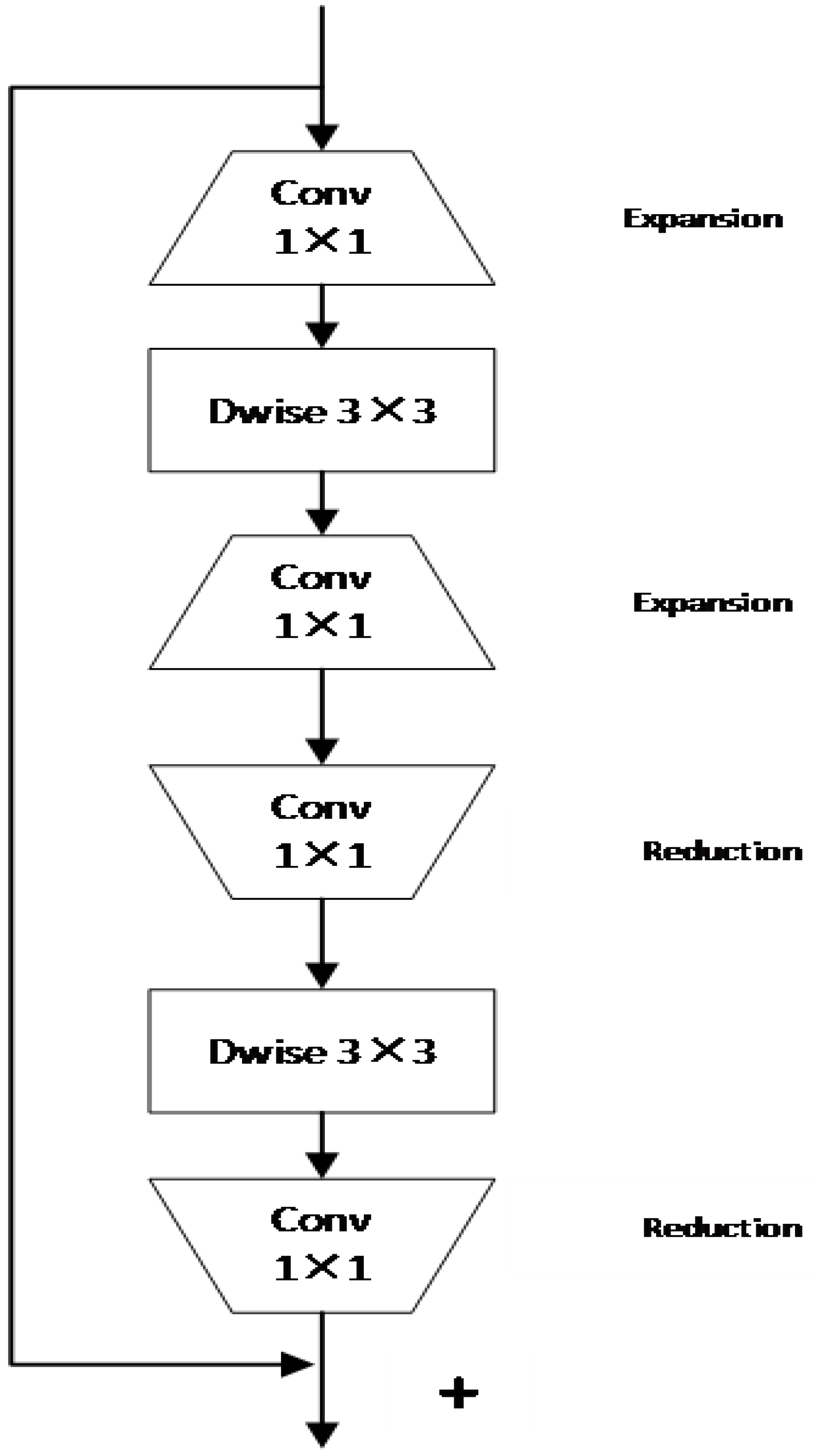
3.1. Fine-Tuning Reciprocating Residual Module
3.2. Improved MobileViT Network Structure
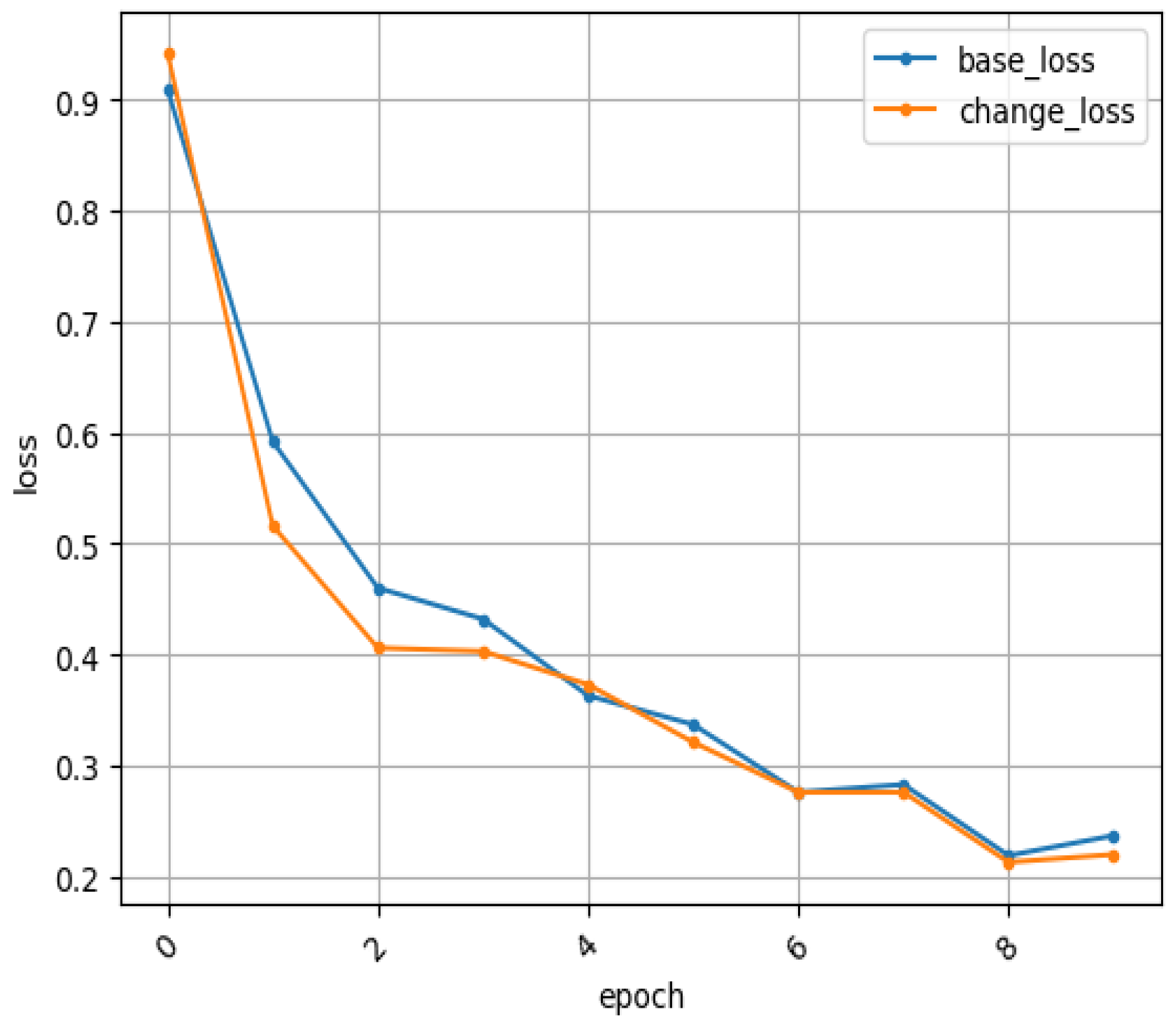
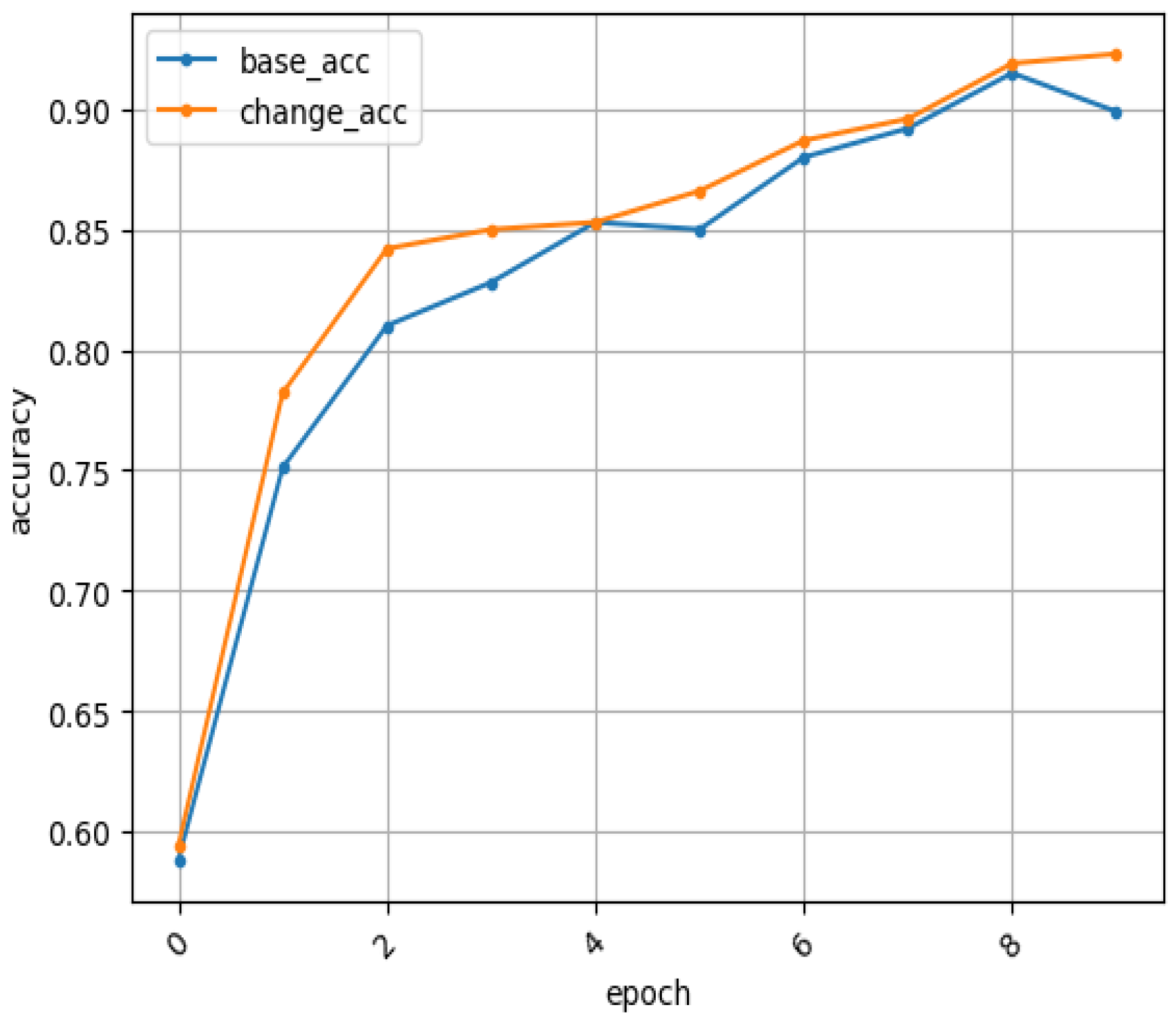
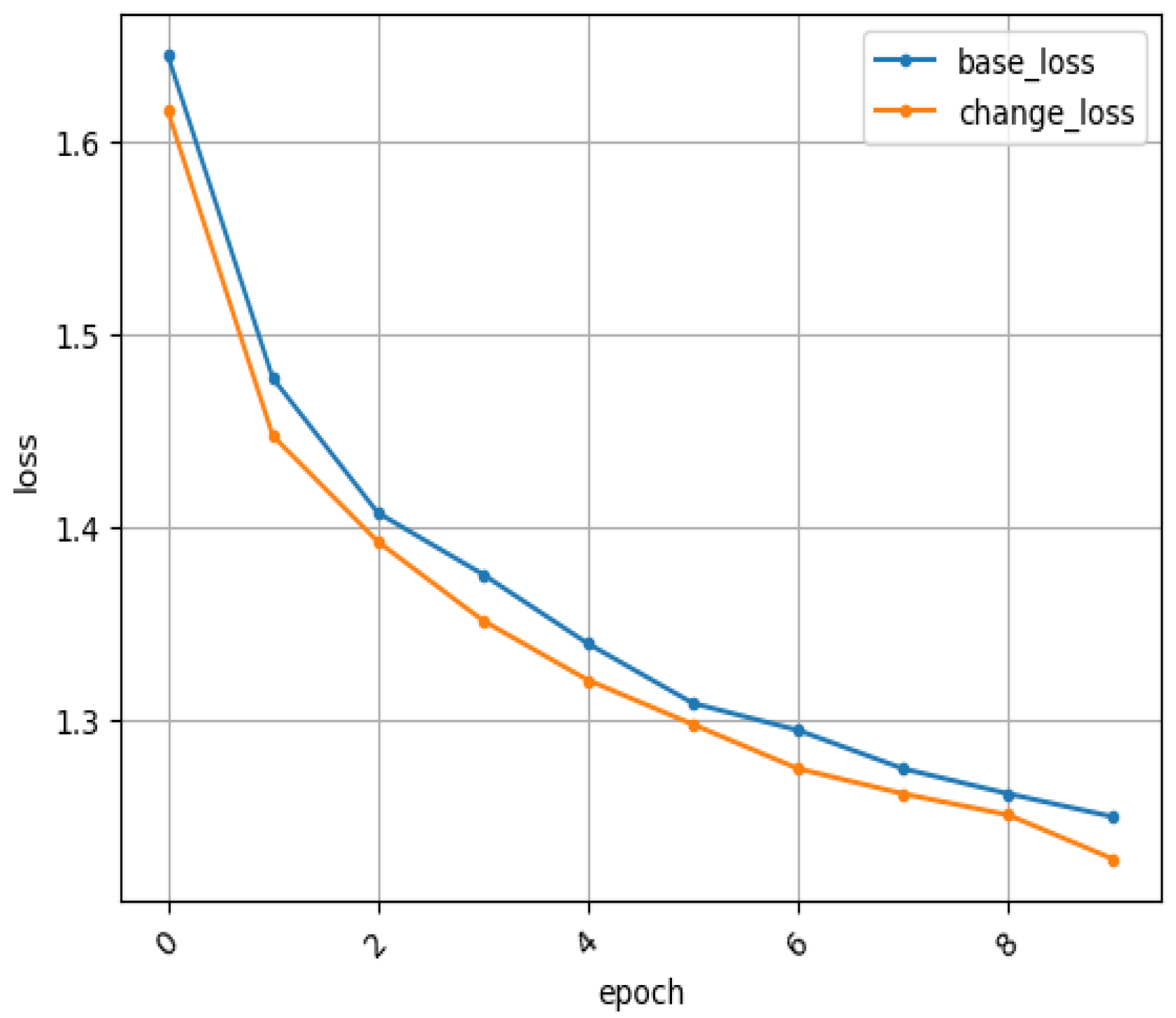
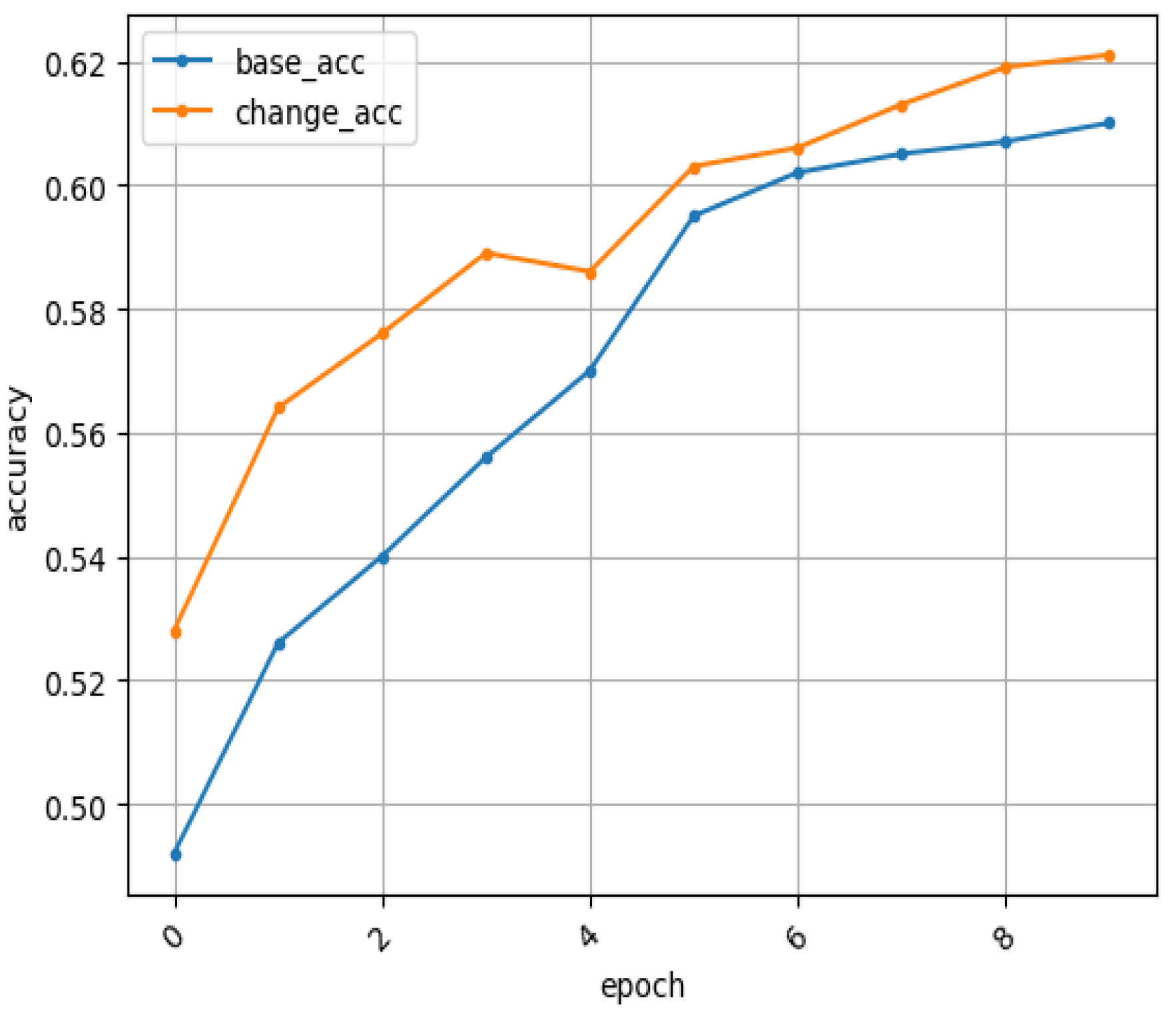
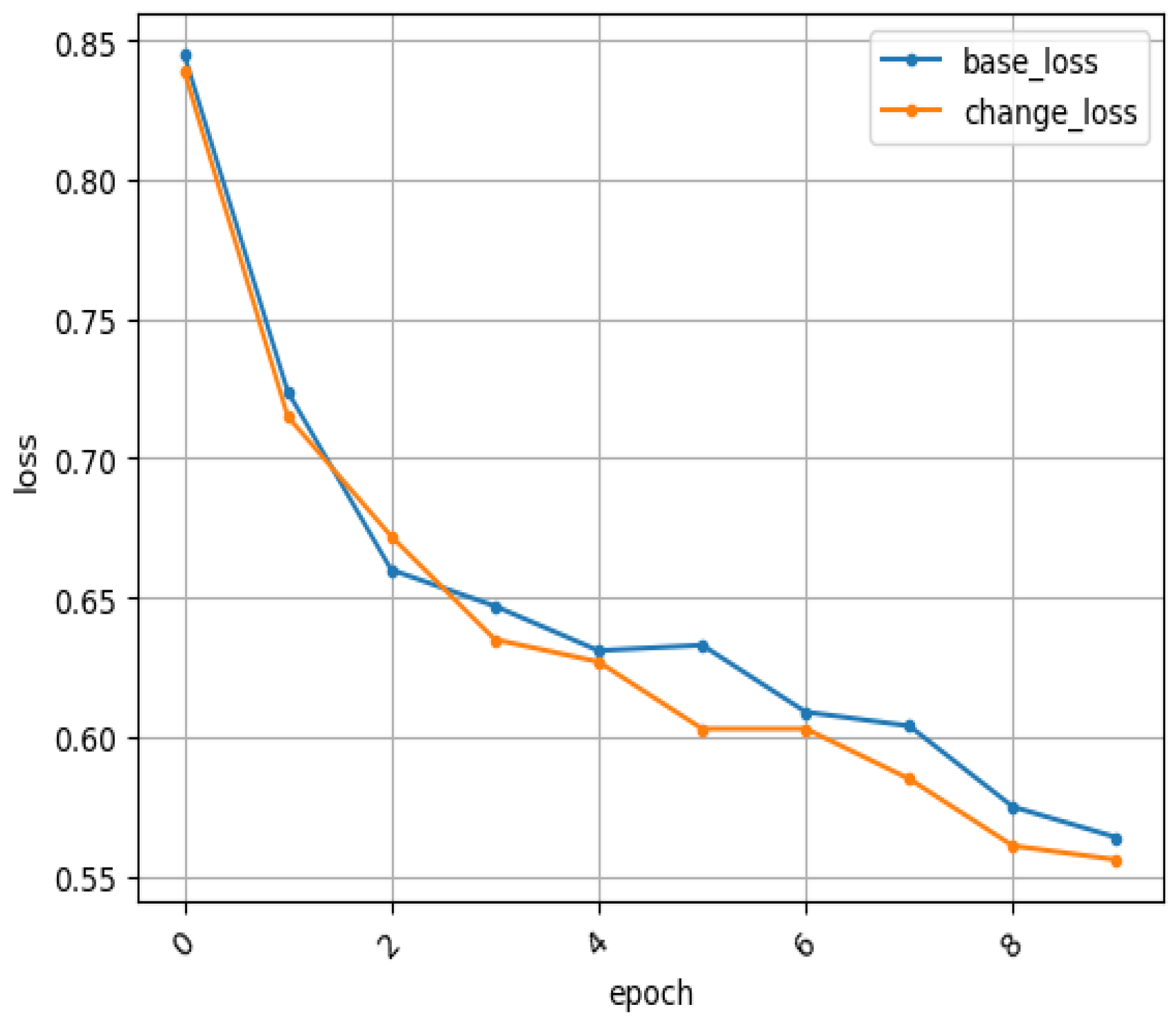
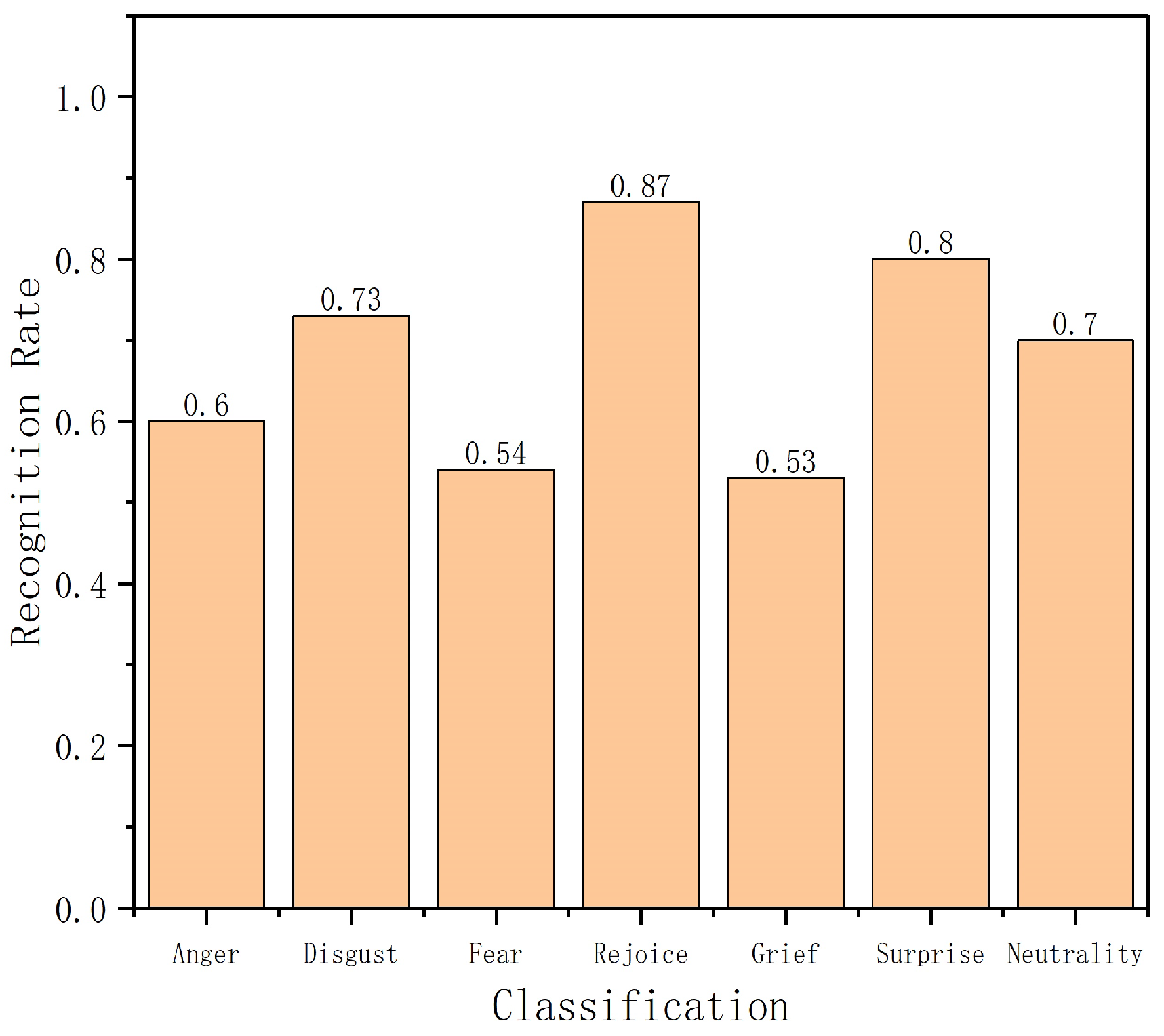
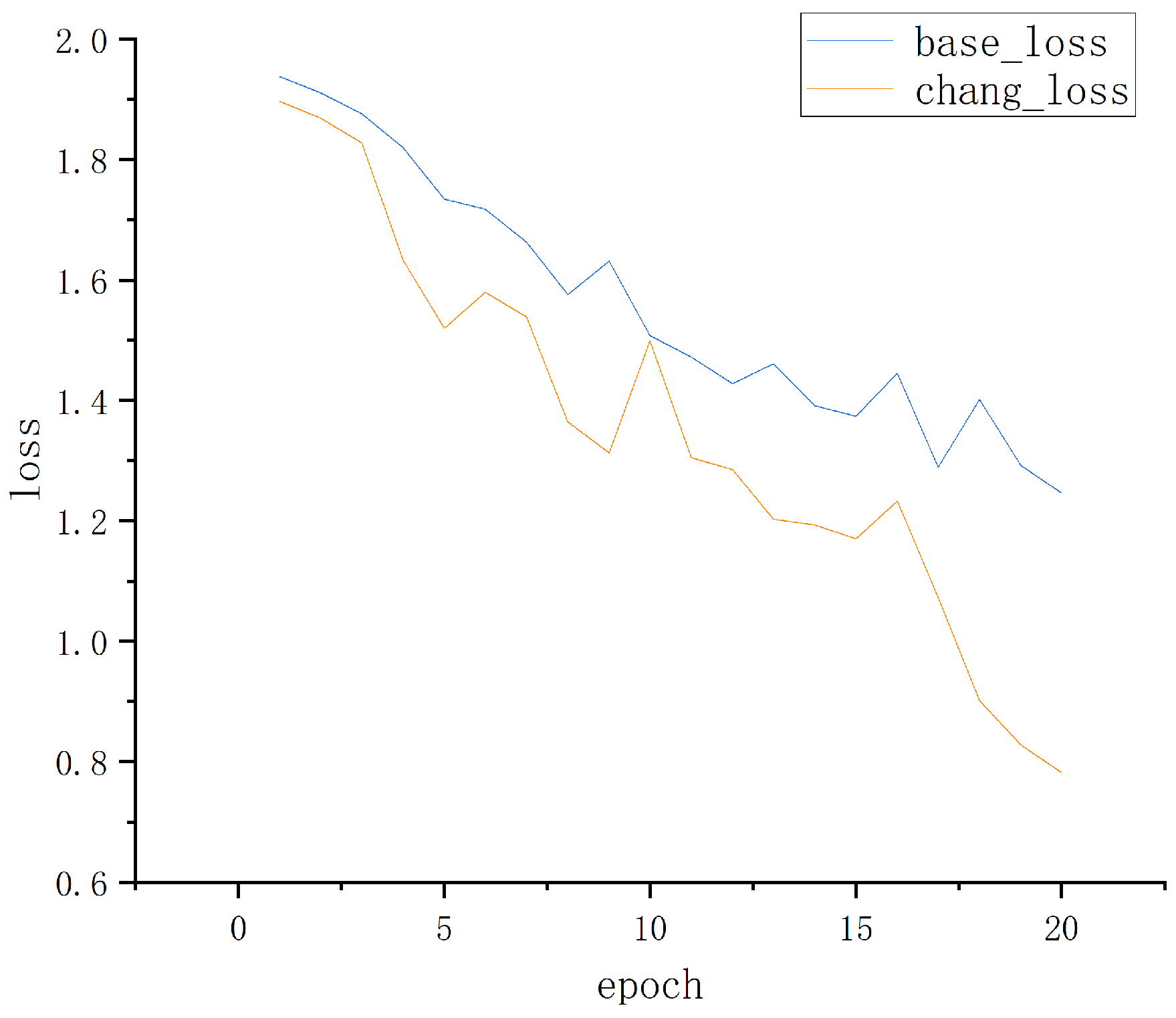
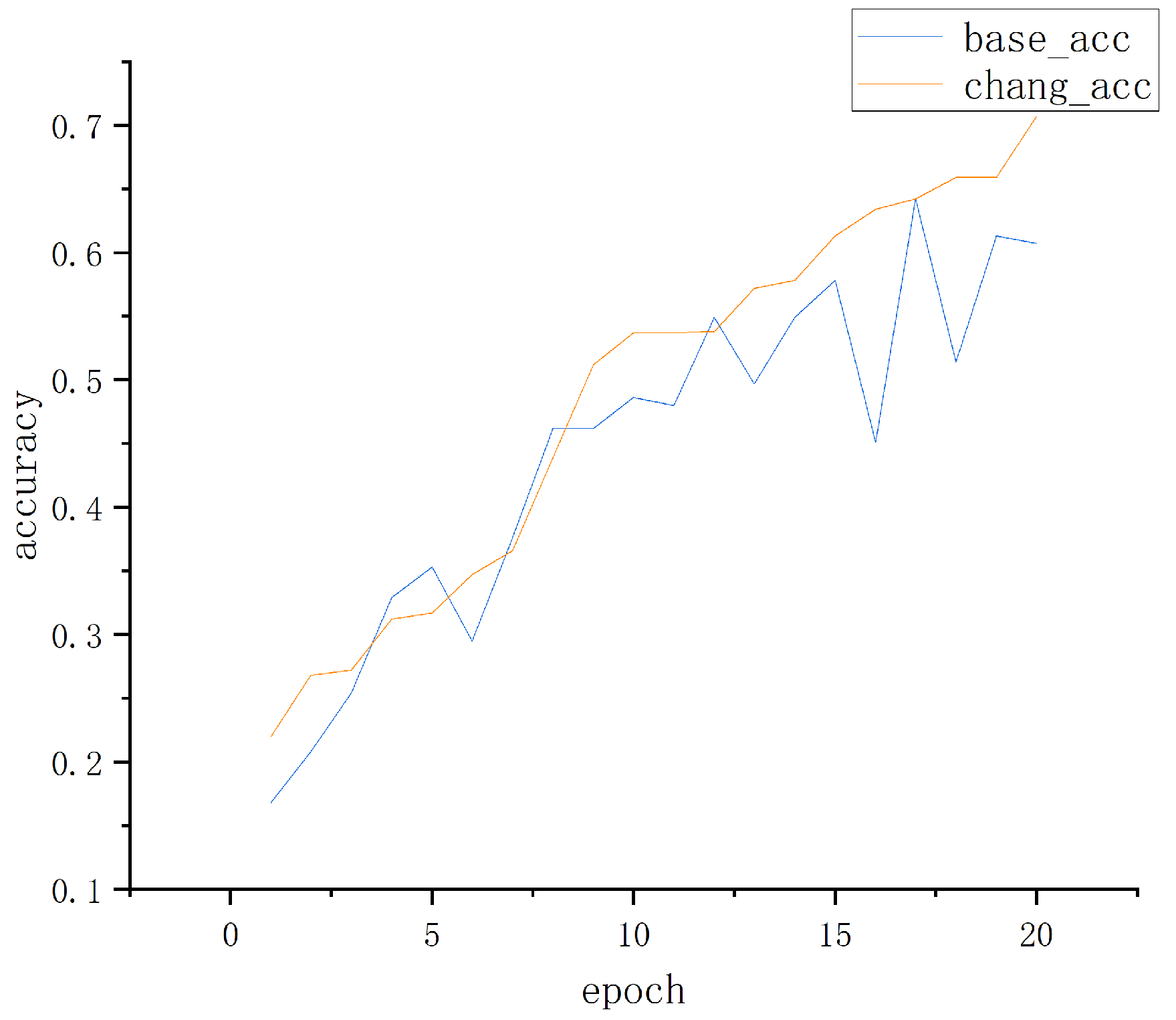
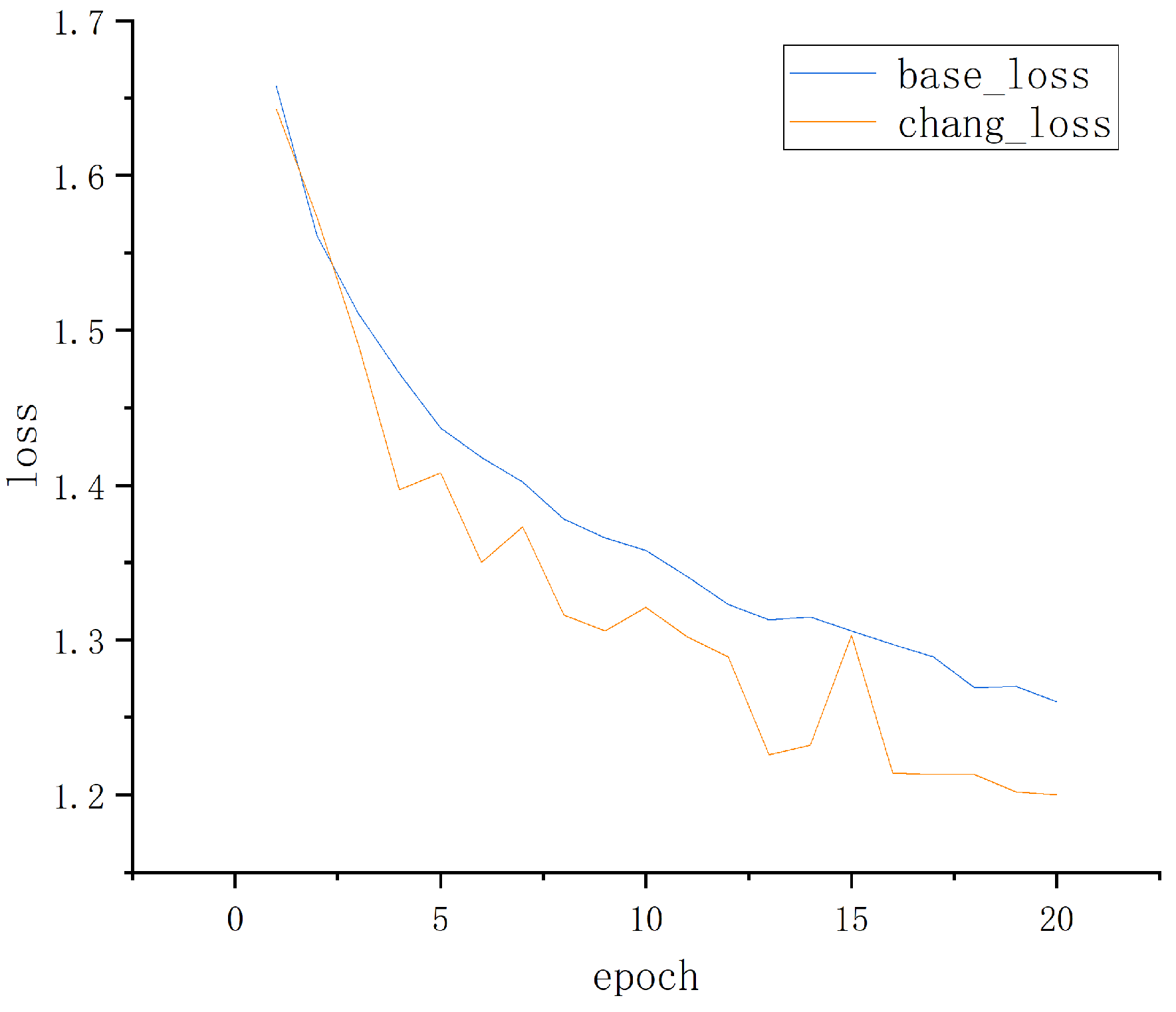
4. Experiments and Result Analysis
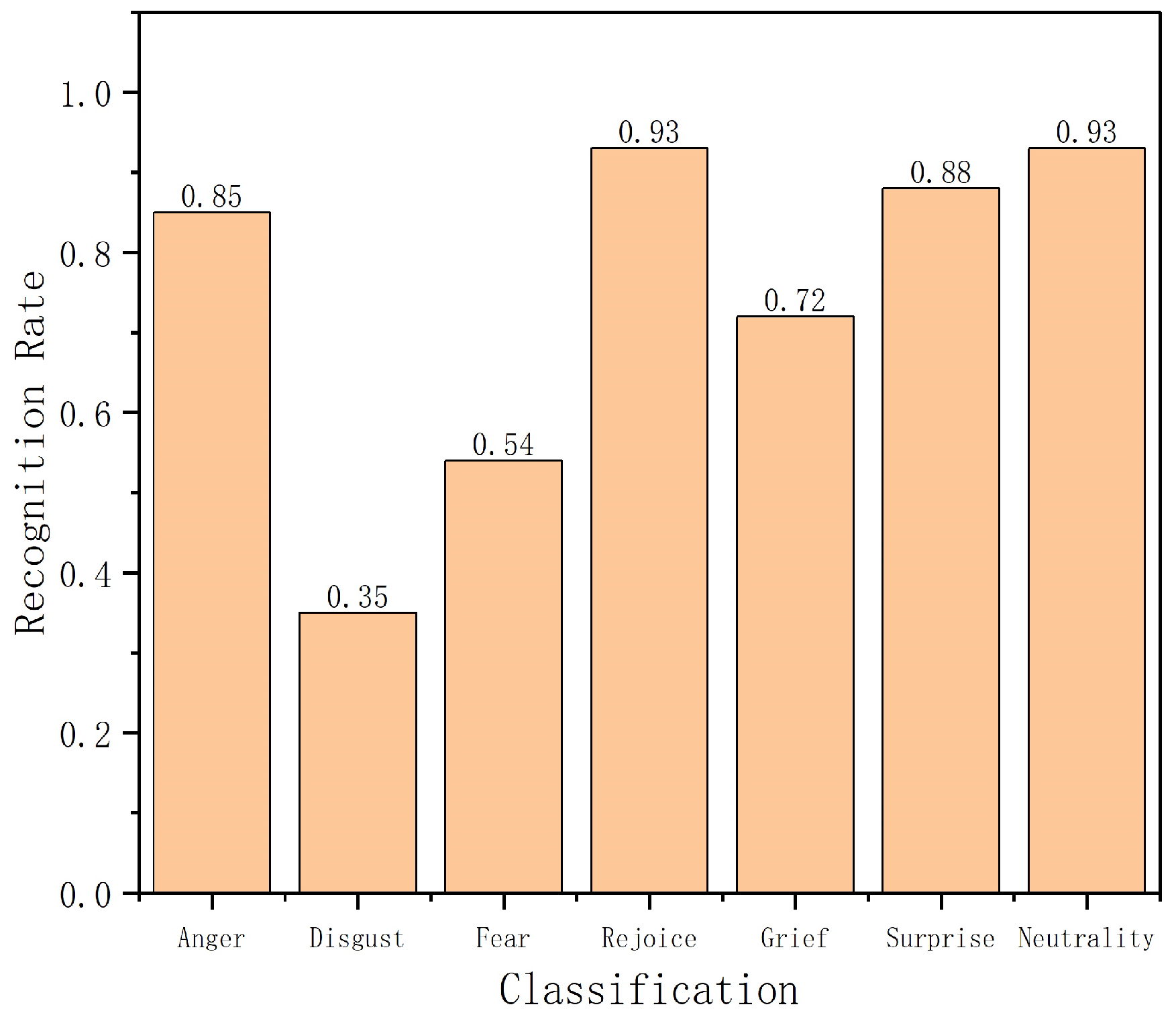
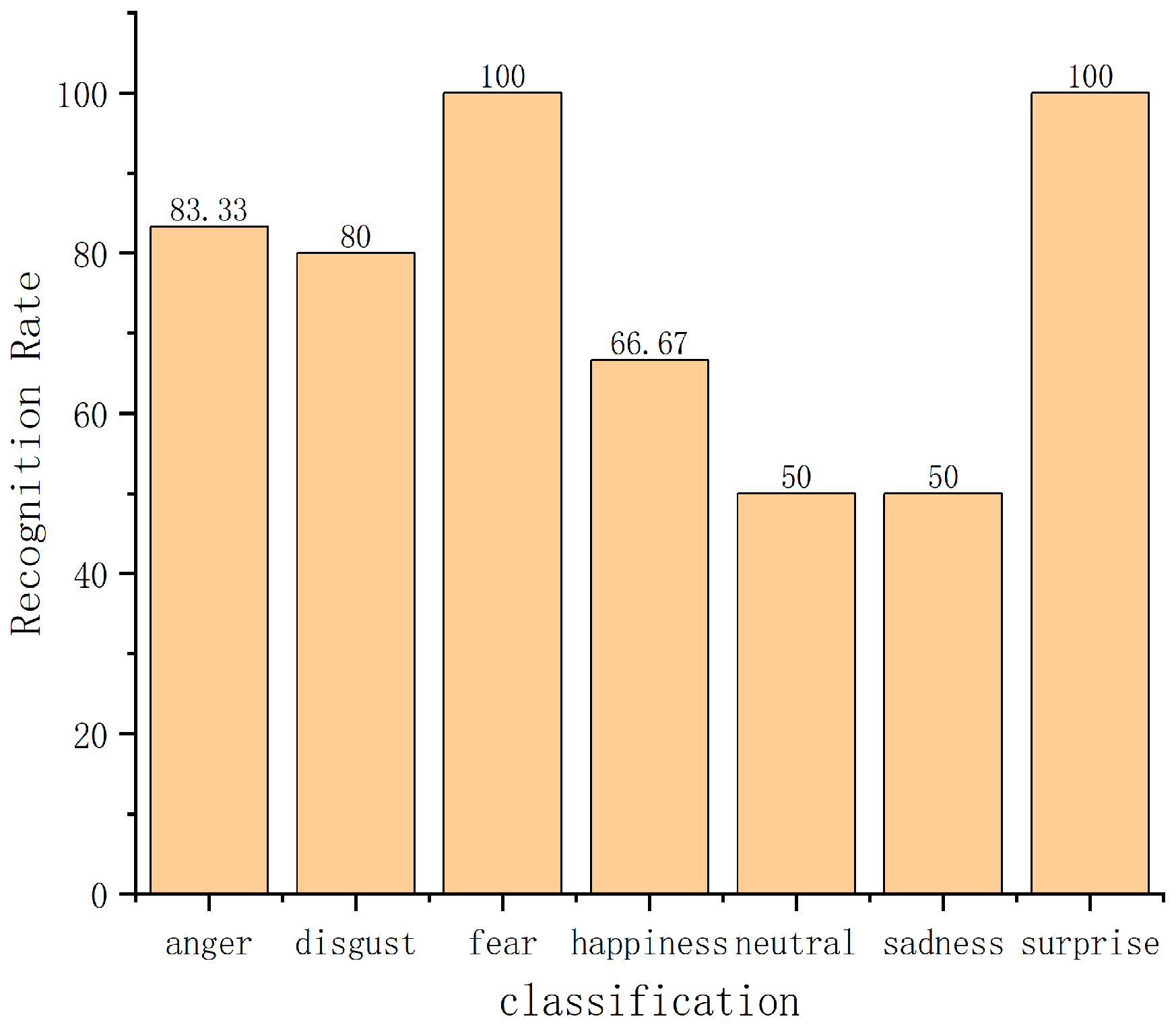
4.1. Experimental Comparison of Database on RaFD
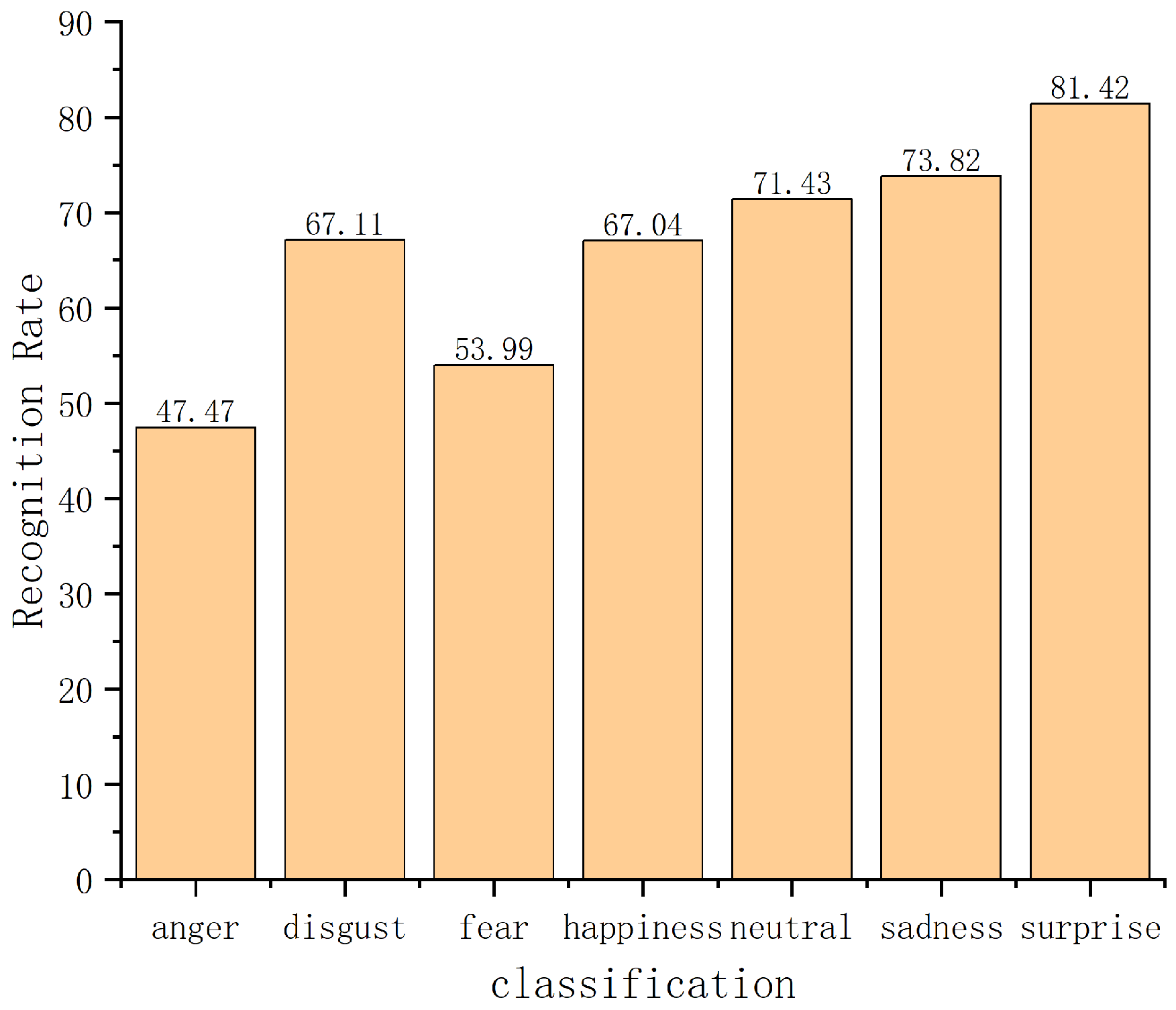
4.2. Experimental Comparison of Database on FER2013 and FER2013Plus
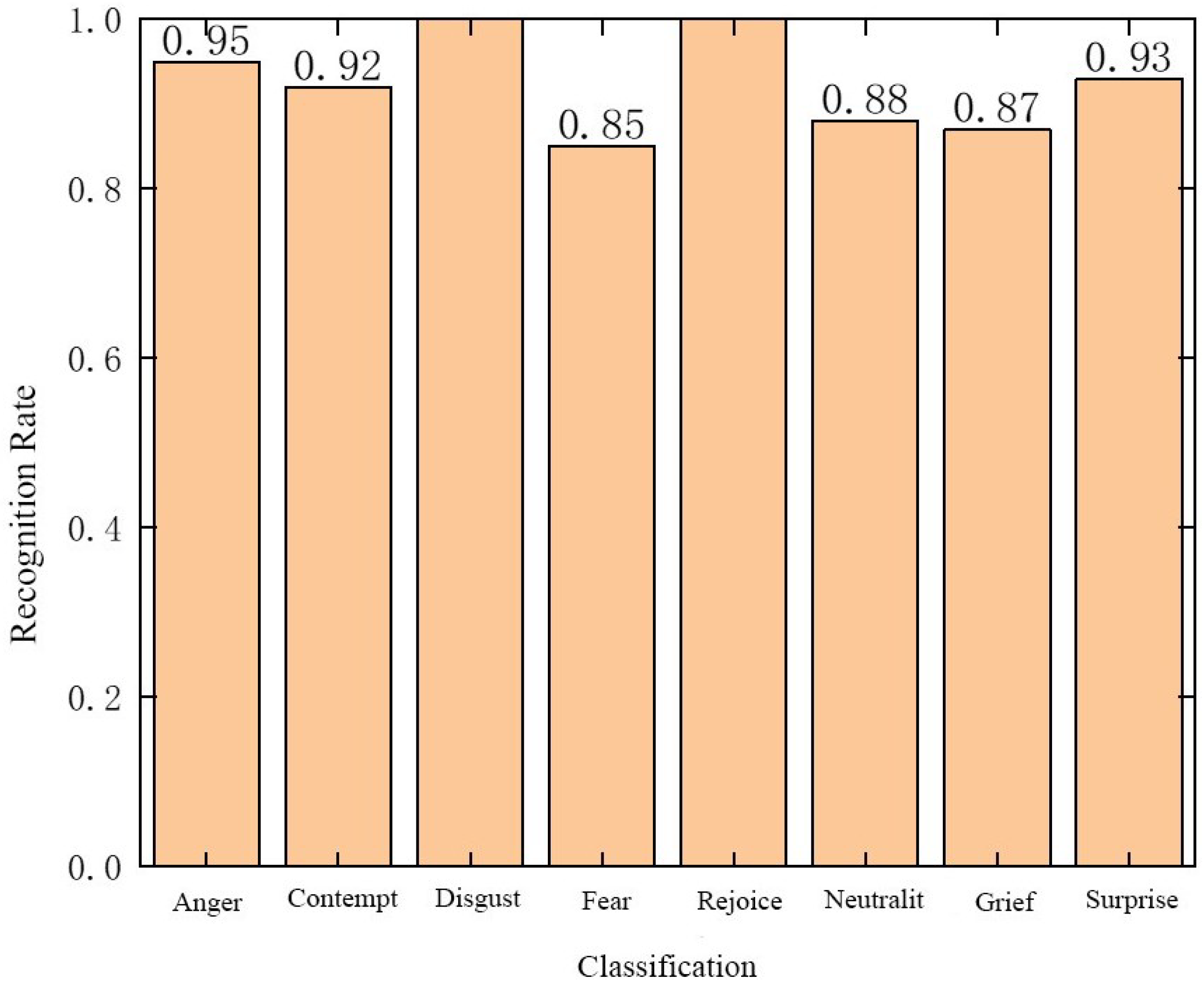
4.3. Experimental Comparison on Other Databases
5. Improved Lightweight Analysis of MobileViT Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Daohui, G.; Hongsheng, L.; Liang, Z.; Ruyi, L.; Peiyi, S.; Qiguang, M. Survey of Lightweight Neural Network. J. Softw. 2020, 31, 2627–2653. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards real-time generic object detection on mobile devices. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6718–6727. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–2 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet V2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50 × fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A decomposable attention model for natural language inference. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2249–2255. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking bottleneck structure for efficient mobile network design. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 680–697. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–2 June 2018; pp. 4510–4520. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Qi, M.; Wang, Y.; Qin, J.; Li, A.; Luo, J.; Van Gool, L. StagNet: An attentive semantic RNN for group activity and individual action recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 549–565. [Google Scholar] [CrossRef]
- Kola, D.G.R.; Samayamantula, S.K. A novel approach for facial expression recognition using local binary pattern with adaptive window. Multimed. Tools Appl. 2021, 80, 2243–2262. [Google Scholar] [CrossRef]
- Lin, Y.; Lan, Y.; Wang, S. A method for evaluating the learning concentration in head-mounted virtual reality interaction. Virtual Real. 2023, 27, 863–885. [Google Scholar] [CrossRef]
- Wu, Q. Research on Technologies and System of Emotion Recognition Based on Lightweight Skip-Layer Attention Convolution Neural Network. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2021. [Google Scholar]
- Chen, T.; Pu, T.; Wu, H.; Xie, Y.; Liu, L.; Lin, L. Cross-domain facial expression recognition: A unified evaluation benchmark and adversarial graph learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9887–9903. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Batra, T.; Baig, M.H.; Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10285–10295. [Google Scholar]
- Zhao, Z.; Liu, Q.; Zhou, F. Robust Lightweight Facial Expression Recognition Network with Label Distribution Training. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3510–3519. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Arithmetic | Accuracy Rate/% |
|---|---|
| Basic network | 91.5 |
| Improved network | 92.3 |
| Arithmetic | Accuracy Rate/% |
|---|---|
| VGG16 [16] | 83.46 |
| VGGNet [11] | 90.13 |
| UCFEAN(GAN) [17] | 92.15 |
| MobileNet | 92.10 |
| FERVR [18] | 92.75 |
| The method of this paper | 92.30 |
| Database | Arithmetic | Accuracy Rate/% |
|---|---|---|
| FER2013 | MobileViT(base) | 61.00 |
| Improved MobileViT | 62.20 | |
| FER2013Plus | MobileViT(base) | 79.30 |
| Improved MobileViT | 80.30 |
| Arithmetic | Accuracy Rate/% |
|---|---|
| F-LiSANet [12] | 72.52 |
| ICID [19] | 76.54 |
| LPL [20] | 78.66 |
| SWD [21] | 79.24 |
| The method of this paper | 80.30 |
| Database | Lightweight Network | Accuracy Rate (%) | Model Parameters (M) | Flops (G) |
|---|---|---|---|---|
| RaFD | ShuffleNet V2 | 90.10 | 1.26 | 0.15 |
| EfficientNet | 95.40 | 4.02 | 0.41 | |
| Densnet | 91.10 | 6.96 | 2.90 | |
| MobileViT(Ours) | 92.30 | 0.95 | 0.27 | |
| FER2013Plus | ShuffleNet V2 | 81.30 | 1.26 | 0.15 |
| EfficientNet | 80.50 | 4.02 | 0.41 | |
| Densnet | 81.80 | 6.96 | 2.90 | |
| MobileViT(Ours) | 80.30 | 0.95 | 0.27 | |
| FER2013 | ShuffleNet V2 | 66.00 | 1.26 | 0.15 |
| EfficientNet | 67.80 | 4.02 | 0.41 | |
| Densnet | 65.60 | 6.96 | 2.90 | |
| MobileViT(Ours) | 62.20 | 0.95 | 0.27 | |
| JAFFE | ShuffleNet V2 | 64.60 | 1.26 | 0.15 |
| EfficientNet | 85.40 | 4.02 | 0.41 | |
| Densnet | 75.60 | 6.96 | 2.90 | |
| MobileViT(Ours) | 70.70 | 0.95 | 0.27 | |
| MMAFEDB | ShuffleNet V2 | 65.70 | 1.26 | 0.15 |
| EfficientNet | 65.50 | 4.02 | 0.41 | |
| Densnet | 66.80 | 6.96 | 2.90 | |
| MobileViT(Ours) | 62.10 | 0.95 | 0.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, B.; Li, N.; Cui, X.; Liu, W.; Yu, Z.; Xie, Y. Research on Facial Expression Recognition Algorithm Based on Lightweight Transformer. Information 2024, 15, 321. https://doi.org/10.3390/info15060321
Jiang B, Li N, Cui X, Liu W, Yu Z, Xie Y. Research on Facial Expression Recognition Algorithm Based on Lightweight Transformer. Information. 2024; 15(6):321. https://doi.org/10.3390/info15060321
Chicago/Turabian StyleJiang, Bin, Nanxing Li, Xiaomei Cui, Weihua Liu, Zeqi Yu, and Yongheng Xie. 2024. "Research on Facial Expression Recognition Algorithm Based on Lightweight Transformer" Information 15, no. 6: 321. https://doi.org/10.3390/info15060321
APA StyleJiang, B., Li, N., Cui, X., Liu, W., Yu, Z., & Xie, Y. (2024). Research on Facial Expression Recognition Algorithm Based on Lightweight Transformer. Information, 15(6), 321. https://doi.org/10.3390/info15060321