2. Related Work
The trend to deploy cognitive services boosting the performance of intelligent edge devices has emerged since the introduction of the so-called pervasive and ubiquitous computing paradigm [
2]. This paradigm, in turn, can be attributed to rapid advances in microelectronics, on the one hand, and communication technologies, on the other, which have led to packing more and more miniaturized processing, storage, and sensing components in handheld, portable, and always-connected “smart” devices that can support a wide range of environmentally adaptive and context-aware human-centric services. The latest advances in the domain of machine learning (ML) and artificial intelligence (AI) [
3] build on the infrastructure of ubiquitous computing and the Internet of Things (IoT) to extend intelligence to the edge of networked systems, leading to a paradigm shift of so-called edge AI [
4]. Therefore, in this quest, it is critical to understand and assess performance trade-offs in terms of processing, networking, and storage capabilities as well as autonomous operation of edge devices that support the edge AI model and can lead to enhanced system design and application performance. In this section, we review several works that have addressed the above optimization and performance benchmarking problem by proposing either improved algorithms or improved system designs to accelerate AI processing on edge devices, while maintaining the properties of mobile and autonomous operation (i.e., in terms of system size, weight, power consumption requirements, etc.).
In [
5], the authors focus on the feasibility of implementing deep learning (DL) on microcontrollers for human activity recognition using accelerometer data. It compares random forests, a classical machine learning technique, with convolutional neural networks (CNNs) in terms of classification accuracy and inference speed. The study finds that random forest classifiers are faster and nearly as accurate as a custom small CNN model. The paper discusses the potential of DL for modern microcontrollers and questions its suitability compared to traditional methods, especially considering inference speed and energy consumption. Specifically, this paper mentions the use of the CMSIS-NN hardware acceleration library, which significantly impacts the performance of CNNs on microcontrollers. Enabling this library can improve CNN performance by one to two orders of magnitude. This enhancement is particularly crucial for achieving fast inferences on ARM-based microcontrollers. The impact of CMSIS-NN hardware acceleration is highlighted as more significant than mere updates to the instruction sets of newer microcontroller models, and it is considered essential when the CNN architecture is fixed.
The CMSIS-NN library is designed to accelerate ML models, particularly neural networks (NNs), on ARM Cortex-M processors, which are common in microcontrollers. This acceleration is achieved through a combination of strategies, with the usage of SIMD (single instruction, multiple data) instructions being among them.
Overall, the findings underscore the importance of balancing model complexity and power efficiency, especially for applications on resource-constrained devices like microcontrollers. The use of techniques like quantization can help in optimizing models for better power efficiency without substantially compromising performance; however, according to the authors, the CMSIS-NN library’s impact is compared to the floating-point unit (FPU). For models that are fully quantized and do not require floating-point operations, the FPU has no effect on speed, whereas the CMSIS-NN library significantly improves performance. This suggests that in scenarios where models are optimized for microcontrollers (including quantization and CMSIS-NN optimization), the overall efficiency, including power efficiency, is likely to be enhanced but only if the model is quantized in a floating-point arithmetic system. This is not taking into account any SIMD or other vectoring instructions available that are likely to improve acceleration through parallelism.
The review performed in [
6] provides a comprehensive examination of tools and techniques for efficient edge inference, a key element in AI on edge devices. It discusses the challenges of deploying computationally expensive and power-hungry DL algorithms in end-user applications, especially on resource-constrained devices like mobile phones and wearables. The paper covers four main research directions: novel DL architecture and algorithm design, optimization of existing DL methods, development of algorithm–hardware codesign, and efficient accelerator design for DL deployment. It reviews state-of-the-art tools and techniques for efficient edge inference, emphasizing the balance between computational efficiency and the resource limitations of edge devices. However, the paper also highlights some limitations of MCUs (microcontroller units), such as less memory, slower processing compared to CPUs (central processing units) or GPUs (graphics processing units), lack of parallelization, low clock frequency, and reliance on general-purpose processors that do not support vectorization or thread-level parallelism, indicating that vectorization and parallelism—when implemented—may have a large impact on inference latency and power efficiency.
The work in [
7] explores the challenges and methodologies involved in deploying deep neural networks (DNNs) on low-power, 32-bit microcontrollers. It emphasizes the need for optimization in terms of power consumption, memory, and real-time constraints to facilitate edge computing. The paper introduces a framework called “MicroAI” for training, quantization, and deployment of these networks, highlighting the balance between model accuracy, energy efficiency, and memory footprint. The work also includes a comparative analysis of MicroAI with existing embedded AI frameworks and evaluates performance using various datasets and microcontroller platforms. The paper also highlights ongoing work on 8-bit quantization, which improves inference time and memory footprint but at the cost of a slight decrease in accuracy and more complex implementation. The authors focus on several optimization techniques for fixed-point on 8-bit integer inference, including per-filter quantization, asymmetric range, and non-power of two scale factors. Additionally, the use of SIMD (single instruction, multiple data) instructions in the inference engine is anticipated to further decrease inference time.
The work in [
8] focuses on deploying ML models on IoT devices efficiently in terms of power consumption. It addresses the challenge of running ML algorithms on embedded devices with limited computational and power resources. The study presents experimental results on the power efficiency of well-known ML models, using optimization methods. It compares the results with the idle power consumption of the systems used. Two different systems with distinct architectures were tested, leading to insights about the power efficiency of each architecture. The paper covers topics like system setup, methodology, selected ML models, and frameworks used, and it discusses the measurements and power efficiency results obtained for both microcontroller architectures and various optimization methods that were applied on the selected ML models. The results show that current optimization methods used for reducing inference latency also reduce power consumption. While the referred work [
8] is targeting mostly ML model optimization on a software level and comparing the effect on different generic architectures, we in this paper are focusing on hardware-level optimization methods that are in fact architecture-agnostic acceleration blocks and may be present in various microcontrollers. In a way, our work is an extension of [
8] in the hardware domain.
The PhD thesis of Angelo Garofalo [
9] is the latest work to our knowledge that provides detailed insights into vectoring acceleration and SIMD (single instruction, multiple data) instructions, particularly in the context of RISC-V IoT processors and QNN (quantized neural network) acceleration. This work emphasized the fact that modern MCUs lack support at the ISA (instruction set architecture) level for low-bit-width integer SIMD arithmetic instructions. Most commercial ISAs support only 16-bit or 8-bit data. This limitation affects performance and energy efficiency during computation, especially in the context of DNN models. As a first architecture-aware design of AI-based applications, the thesis evaluates kernel computation optimizations by fully exploiting the target RV32IMCXpulp ISA. These kernels are specialized functions or programs/methods used in microcontrollers for processing data in neural networks, specifically in machine learning applications (e.g., matrix multiplication (MatMul) kernels that are used for performing mathematical operations where two arrays (matrices) are multiplied together). It proposed using hardware loops to accelerate ‘for’ statements and employing 8-bit SIMD instructions to work over multiple SIMD vector elements in parallel, thus increasing the throughput of the computation. Beyond kernel optimizations, the work in [
9] discusses the support for various SIMD instructions. In addition to the dot product, the thesis mentions support for other SIMD instructions, such as maximum, minimum, and average for nibble (4 bits) and crumb (2 bits) packed operands. These are particularly useful for speeding up pooling layers and activation layers based on the rectified linear unit (ReLU) function. A range of arithmetic and logic operations (addition, subtraction, and shift) complete the set of XpulpNN SIMD instructions. Furthermore, the author in [
9] introduces a multi-precision dot-product unit that computes the dot-product operation between two SIMD registers and accumulates partial results over a 32-bit scalar register in one clock cycle. This unit supports a variety of element sizes in SIMD vectors, ranging from two 16-bit to sixteen 2-bit elements, with the ability to interpret operands as signed or unsigned. To address the saturation problem of the RISC-V encoding space and avoid explicitly encoding all combinations of mixed-precision operands, the thesis proposes a power-aware design with virtual SIMD instructions. These instructions are decoded at the ID (instruction decoding) stage, and their precision is specified by a control and status register written by the processor. Finally, the thesis presents the design of an energy-efficient multi-precision arithmetic unit targeting the computing requirements of low-bit-width QNNs. This includes support for sub-byte SIMD operations (8-, 4-, and 2-bits) and is integrated into a cluster of MCU-class RISC-V cores with a new set of ISA domain-specific instructions, named XpulpNN. This aims to bridge the gap between ISA and hardware to improve computing efficiency for QNN workloads at the extreme edge of IoT.
These findings indicate a significant focus on enhancing computational efficiency and flexibility in processing neural network tasks, particularly in resource-constrained environments like IoT devices with various methods including hardware acceleration such as SIMD instructions. Specifically, we can conclude that a lot of effort is put towards fully exploiting available hardware capabilities of modern microcontrollers and/or making new proposals for the reuse of currently available technologies that may benefit ML model processing acceleration. Most of this work is focused on accelerating ML model inference times, thus making the overall systems more efficient; however, while it is stated in many cases, power efficiency improvement is seldomly—if ever—analyzed in a meaningful manner.
Power efficiency, nowadays, is a necessity for every computational system [
10], but additionally in this case, since a microcontroller-based system, which is by definition a resource-constrained system, especially for ML runtime models [
11], may need to be autonomous, its power efficiency is a concern that the designer has to take into account. Furthermore, the work in [
12] does investigate various studies on hardware-based DNN inference optimization techniques that include execution parallelization and caching techniques focusing on inference acceleration rather than power efficiency.
In this manuscript, we will investigate the power efficiency aspect of selected hardware acceleration methods, similar to those presented in the related works but that are currently available for modern microcontrollers and thus ready to be used. Our hypothesis is that there are hardware blocks available for current hardware that may prove useful in making ML runtimes in microcontrollers more power efficient.
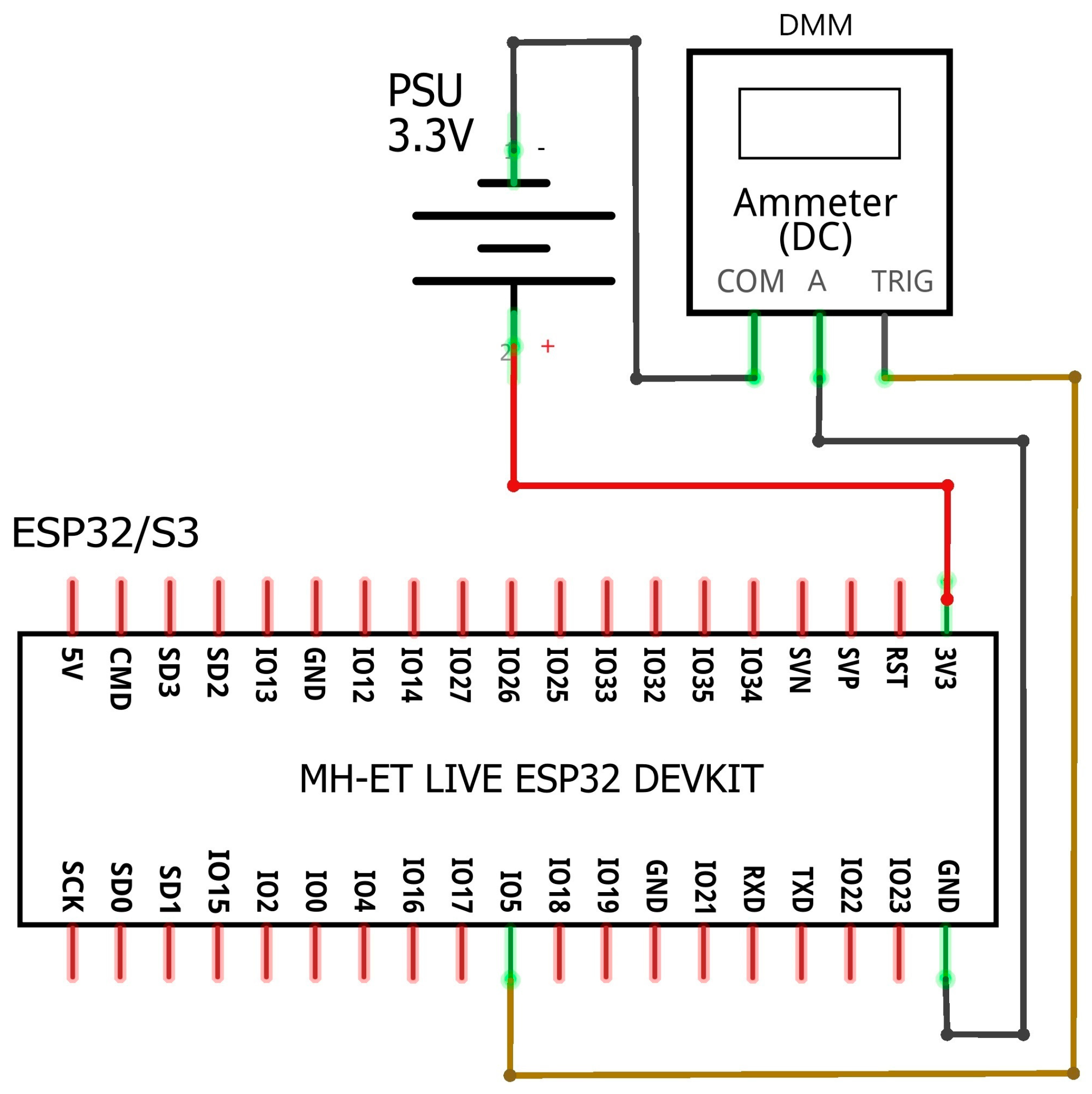
5. ESP32—Selected Development Boards
The ESP32 and ESP32-S3 microcontrollers that we are using are made by Espressif and are available in various forms. Their respective development boards are available from various sources including Espressif. For our experimental setup, we chose two such boards that are low cost and with an abundance of peripherals to support running ML models, such as large amounts of PS RAM (pseudo-static RAM). In order to simplify our setup, we used development boards that offer out-of-the-box connectivity options such as USB/UART and GPIO pins and not barebone modules. Barebone ESP32 comes as an SiP (system-in-package) module with PCB finger soldering edges and it is rather hard to use it without a suitable carrier board.
5.4. Available Development Tools and ML Model Selection
In order to develop the required firmware that needs to contain both the selected ML models as well as any other signaling generation routines used during measurements, we opted to use ESP-IDF (Espressif IoT Development Framework). ESP-IDF is the official development framework for Espressif’s ESP32 and ESP32-S series SoCs (system on chips). It is a comprehensive set of tools and libraries designed to facilitate the creation of applications on the ESP32 platform. At its core, ESP-IDF is built upon FreeRTOS, a real-time operating system that enables multitasking and real-time functionality. This integration of FreeRTOS allows developers to leverage its features such as task scheduling, queues, and inter-task communication mechanisms, enhancing the capability to handle complex operations and multiple processes simultaneously. ESP-IDF supports a wide range of development activities.
Programming in ESP-IDF is primarily conducted in C or C++. SDK provides a comprehensive collection of APIs and libraries, including out-of-the-box TensorFlow Micro (TinyML) [
11] support, significantly reducing the complexity of developing low-level code.
ESP-IDF also includes a full ML library suite, ESP-DL, which is a specialized library designed to facilitate the deployment of deep learning (DL) algorithms on Espressif’s ESP32 series of microcontrollers. ESP-DL addresses the increased processing requirements of edge AI-capable devices by enabling the integration of machine learning and deep learning models directly into IoT devices powered by ESP32 chips. One of the key features of ESP-DL is its optimization for the ESP32 hardware architecture. Although ESP32 is a popular microcontroller, its computational resources are limited compared to typical desktop or server environments where deep learning models are usually trained and run. ESP-DL addresses this by providing a set of tools and APIs specifically optimized for ESP32’s CPU and memory constraints. This allows for efficient execution of deep learning models on these devices.
ESP-DL supports a range of common neural network layers and architectures [
22], making it versatile for various applications. It includes functionalities for basic layers such as convolutional, pooling, and fully connected layers, which are the building blocks of many deep learning models. This allows developers to deploy a variety of neural network models, including those used for image recognition, voice processing, and other sensory data analysis tasks common in IoT applications. Furthermore, ESP-DL aims to simplify the process of bringing pre-trained models onto the ESP32 platform. Typically, models are developed and trained on powerful computing environments using frameworks like TensorFlow or PyTorch. ESP-DL facilitates the conversion and optimization of these models for execution on the ESP32’s resource-constrained environment. This library plays a crucial role in edge computing by enabling smarter IoT devices. With ESP-DL, devices can process data locally, reducing the need to constantly send data to the cloud for processing. This not only speeds up response times but also enhances privacy and reduces bandwidth usage and possibly increases energy efficiency.
The ESP32-DL library currently offers four ready-to-run example ML models that vary in computational requirements from medium to extremely high. These models are pre-trained and optimized to run in ESP32 so no other optimization methods are needed in order to run to this SoC. This gives us the opportunity of directly correlating measurement differences to the core technology used (cache/vectoring) since ML model-wise (software), there is no difference in what is running on EPS32(LX6) and ESP32-S3(LX7) SoCs. The four examples are human face detection, human face recognition, color detection, and cat face detection. However, all these models that are included in ESP-DL as examples are offered as precompiled binaries without any option to either modify them or examine their architecture, exposing only a high-level layer access that permits the users to execute various fundamental functions like loading the model’s input and initiating an inference. While these models are true “black-boxes”, we opted to use them instead of building our own models on TinyML or TFlite because they are compiled under the same library (TensorFlow) version with the same OpCode versions; thus, there is minimal change in compiler optimization variance between them. On the other hand, providing our own models for measurement would most likely require different OpCode versions for some of the modes with a large possibility of affecting the final runtime efficiency of each model.
The human face detection example is centered around identifying human faces within an image using a convolutional neural network (CNN). This example is particularly relevant for real-time applications such as security systems, where detecting the presence of a human face is crucial. The process involves capturing images via a camera module connected to the ESP32, or in our case feeding an image through the device’s storage unit, preprocessing these data to fit the mode’s requirements, and then using a CNN to detect faces. The challenge lies in optimizing the model for ESP32’s limited processing power while maintaining real-time detection capability.
Building on the concept of face detection, the human face recognition example takes it a step further by not only detecting faces but also recognizing and verifying them against a known set of faces. This involves more complex processes, including feature extraction and matching, and requires a more sophisticated approach to model training and implementation. This example has significant implications for personalized user experiences and security applications, such as access control systems, where individual identification is necessary.
The color detection example serves as a demonstration of a color detection service. The code receives a static image composed of various colored blocks as its input. It then produces outputs that include the results of functions such as color enrollment, color detection, color segmentation, and color deletion. These outcomes are displayed in the terminal console.
The cat face detection example diversifies the application of these AI techniques to the animal kingdom, focusing on detecting cat faces. The principles remain similar to human face detection, but the model is specifically trained to recognize feline features. This example illustrates the versatility of the ESP-DL library and ESP32’s capabilities, extending its use to scenarios like pet monitoring or automated animal interaction systems. The implementation involves similar steps of image capture, preprocessing, and optimized model inference to detect cat faces effectively. All four examples are not just demonstrations of technical capability but, like in this case, serve as tools for developers looking to implement AI and ML on edge devices while studying any effects during real-world runtime. They highlight the importance of optimizing deep learning models for constrained environments like ESP32 and demonstrate practical approaches to real-time data processing and output handling. Each model’s expected runtime characteristics according to Espressif’s preliminary analysis available with a description and file size of each example (latency and model size) [
17] are presented in the table below (
Table 3). The power consumption expectation is based on both model size (memory usage) and latency (computational load).
6. Measurement Results
To draw conclusions about how memory caching influences power efficiency while running ML models, we ran all four available models with various I-Cache and D-Cache combinations in ESP32-S3. The older ESP32 did not have user-definable cache size so it was run in its default state of 32 Kbyte of D-Cache. On ESP32-S3, we ran each model with 16, 32, and 64 Kbytes of D-Cache and 16 and 32 Kbytes of I-Cache. We noticed that increasing the I-Cache from 16 Kbytes to 32 Kbytes had minimal, if any, impact on power efficiency and the acceleration of the ML model calculated by the inference time (or inference latency); thus, we only included the combination of 32 Kbyte I-Cache with 16 Kbyte D-Cache. Cache association also had zero impact on efficiency; thus, we left it at a default of four-way for ESP32-S3. ESP32 was fixed at two-way.
Vectoring influence results were drawn from a comparison of ESP32-S3 running on 32 Kbyte of D-Cache against the ESP32’s default state, which has 32 Kbyte of D-Cache. Both inference instances were limited to one core runtime only.
Finally, for human face detection example, which gave us the option to define runtime as one-stage or two-stage inference, with one-stage being a less accurate single inference function and two-stage being a computationally more demanding and accurate model, we ran both types. For the face recognition model, which had the option to run the same model as 16-bit quantized or 8-bit quantized, we took extra measurements for both ESP32-S3 and ESP32.
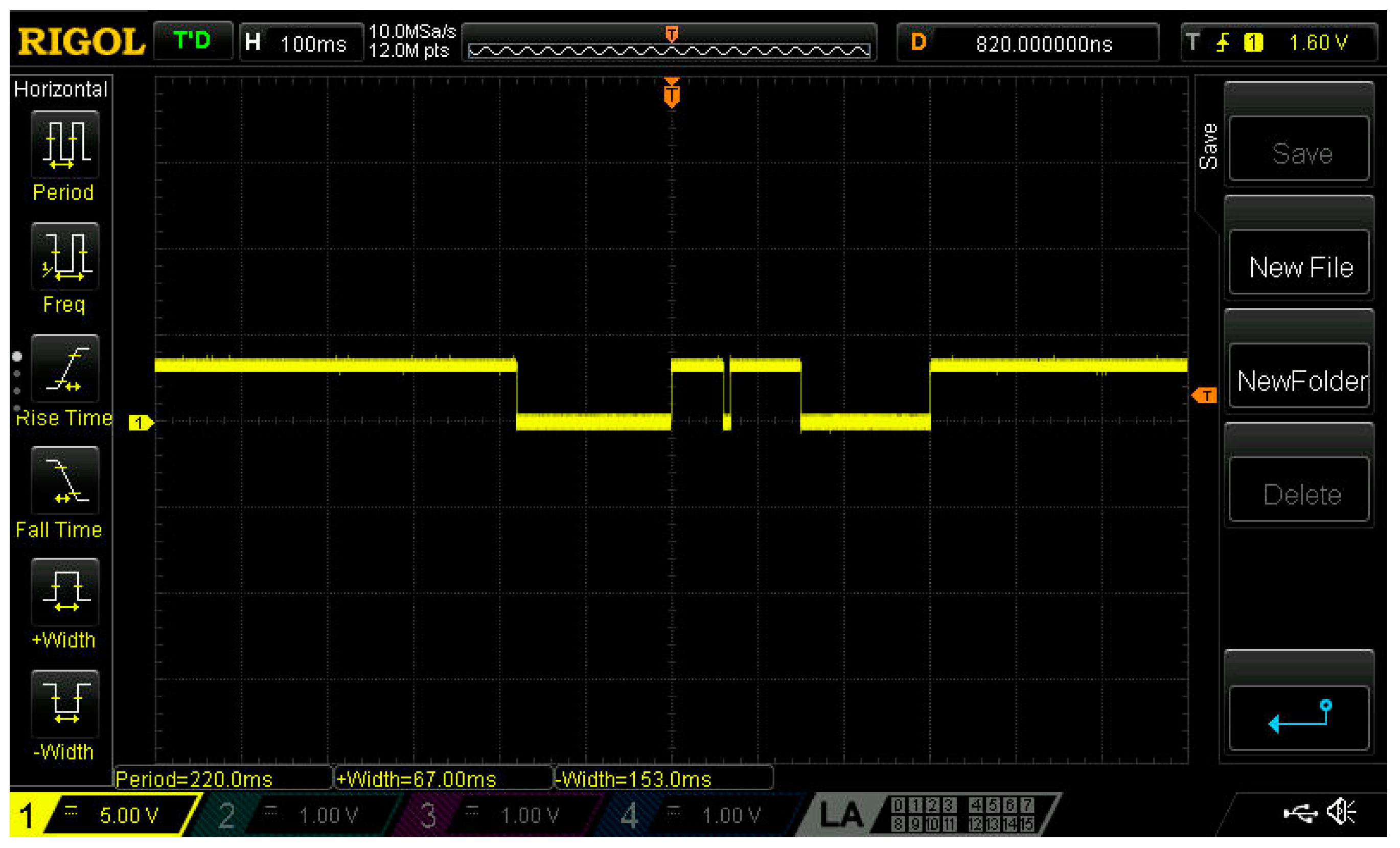
Some of the examples ran more than one inference per code loop. For each such example, we either present one inference in our results, when all the inferences were of the same load (same power consumption result for each one of them), or we present the sum of our measurements for each cycle when different inferences—at least two of them—were of significantly different computational load. This means that during an example execution loop, there may be multiple trigger events, as depicted in
Figure 3. The color detection model in fact runs, in a single run, three different inferences, generating three trigger events that are indicated on the figure as three falling edges. The low-level period after each falling edge is the inference latency time of each inference.
The measurement results include stand-by power, cache usage, inference average power, inference time, and energy used per inference. The latter is the “pure power” [
8] result of the total energy consumed during the inference time minus the stand-by power. Below, we summarize our results in four different tables, one for every selected ML model.
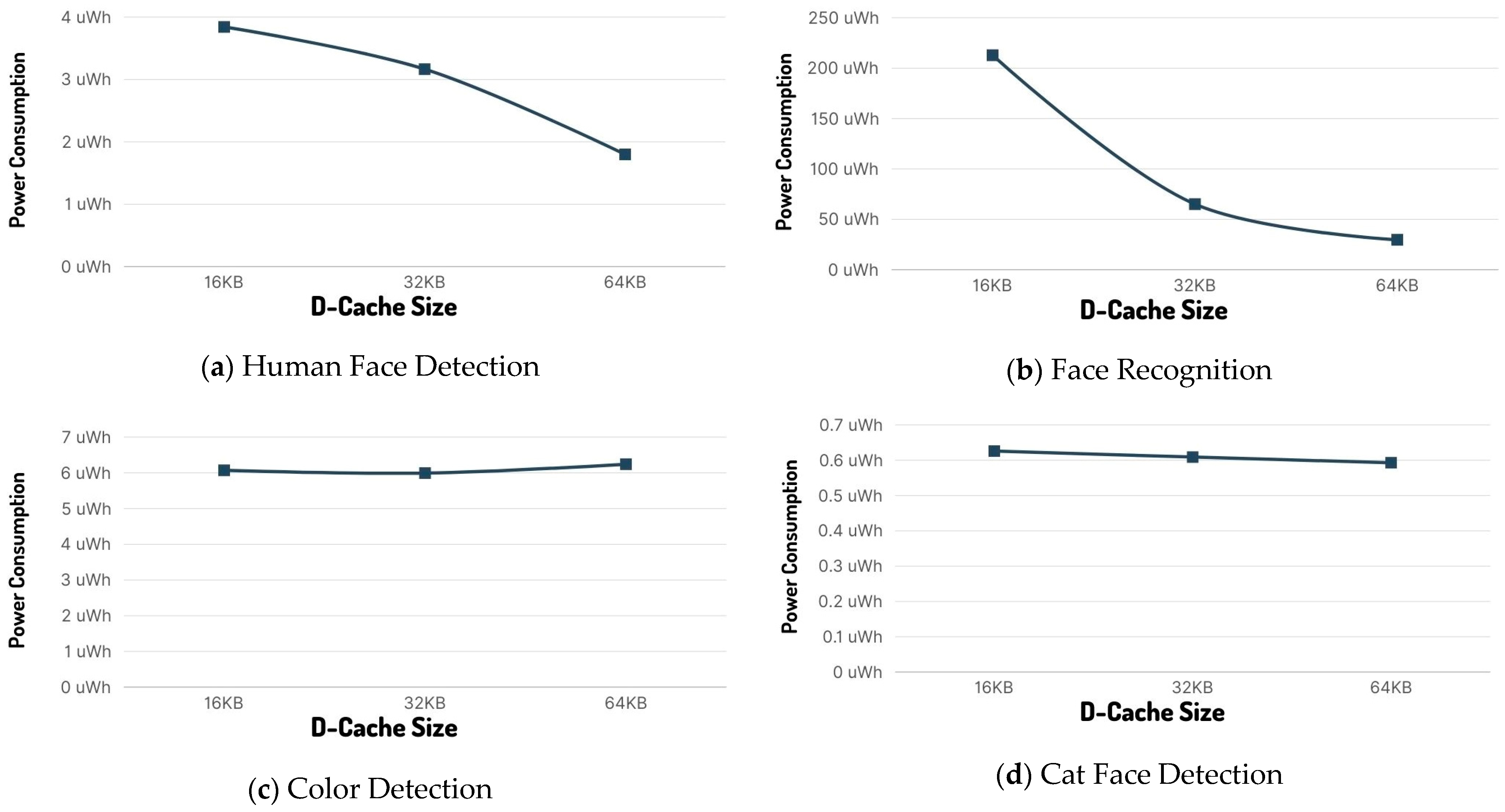
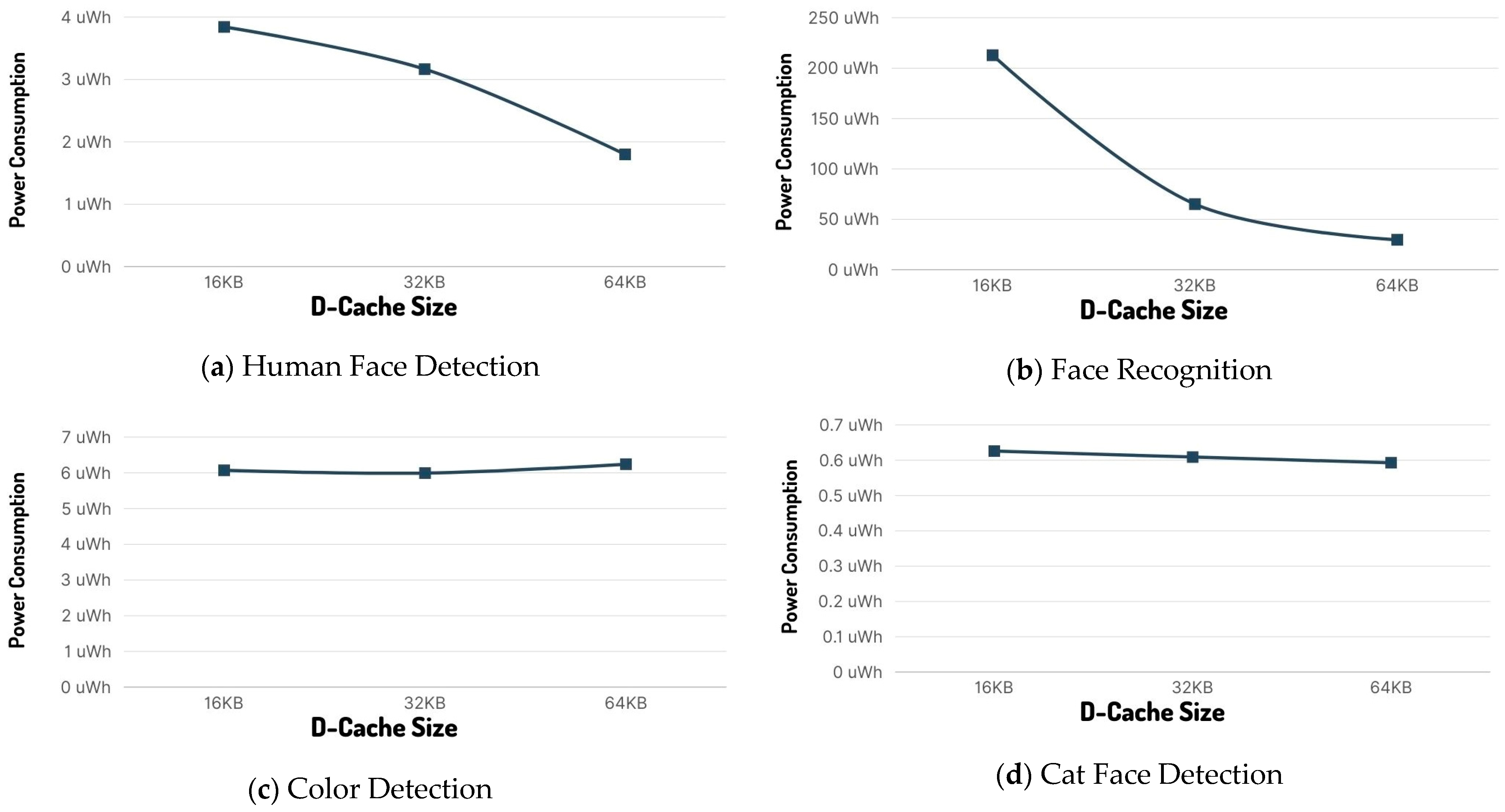
The human face detection model (to which the results shown in
Table 4 are related) is considered a “medium size/load”. From these results, it is apparent that the I-Cache size has minimal effect on both inference time and inference power consumption, while the D-Cache size has a large impact on both. In fact, going from 16 Kbyte to 32 Kbyte increases efficiency by nearly 18%, while increasing cache size to 64 Kbytes halves the power consumption, indicating 53% better power efficiency. Keeping the best cache result of 64 Kbytes of D-Cache and switching to single-stage inference quadruples the power efficiency by dropping the power consumption to 0.461 µWh per inference from 3.843 µWh with 16 Kbyte of D-cache and dual-stage inference.
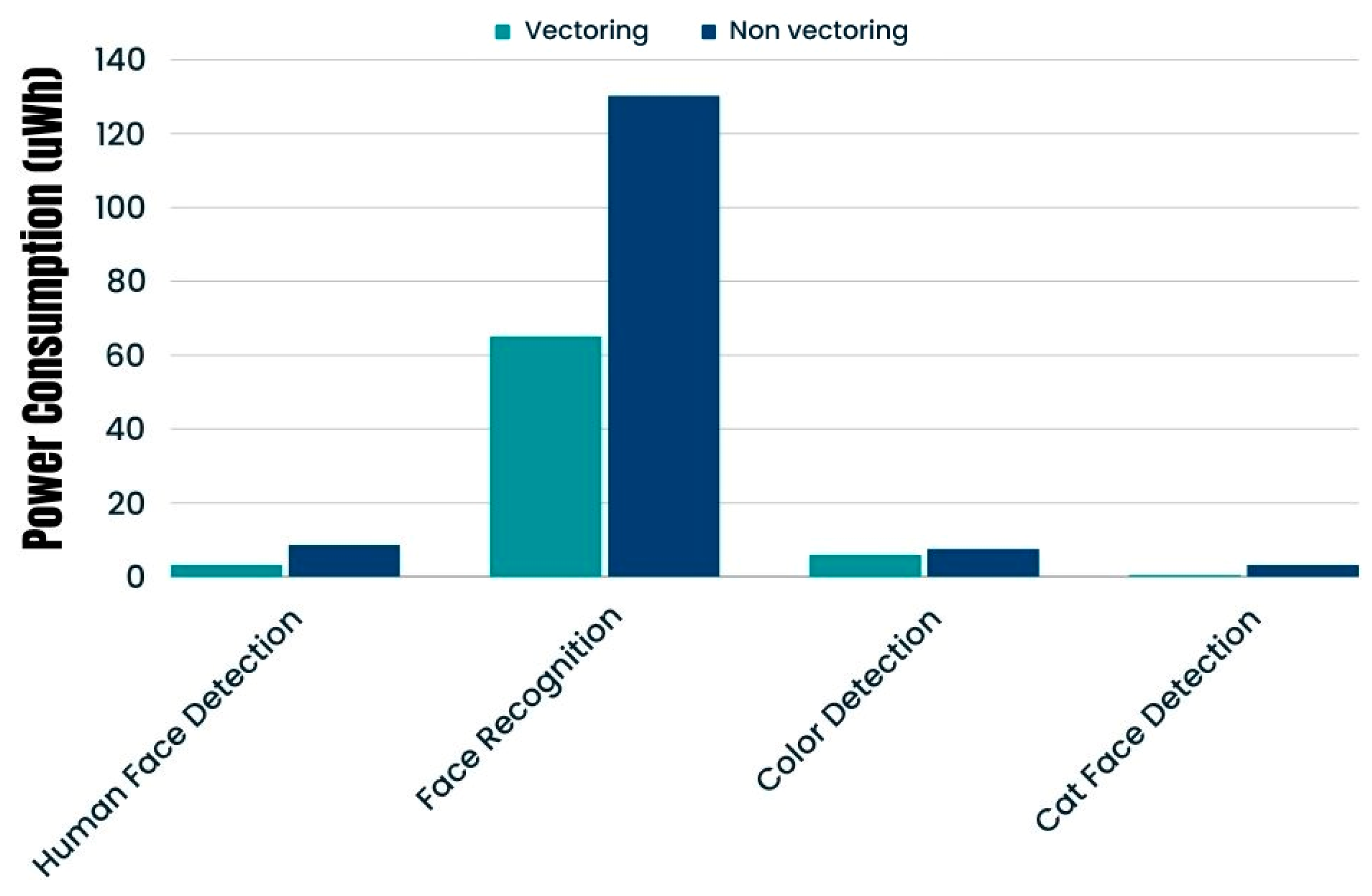
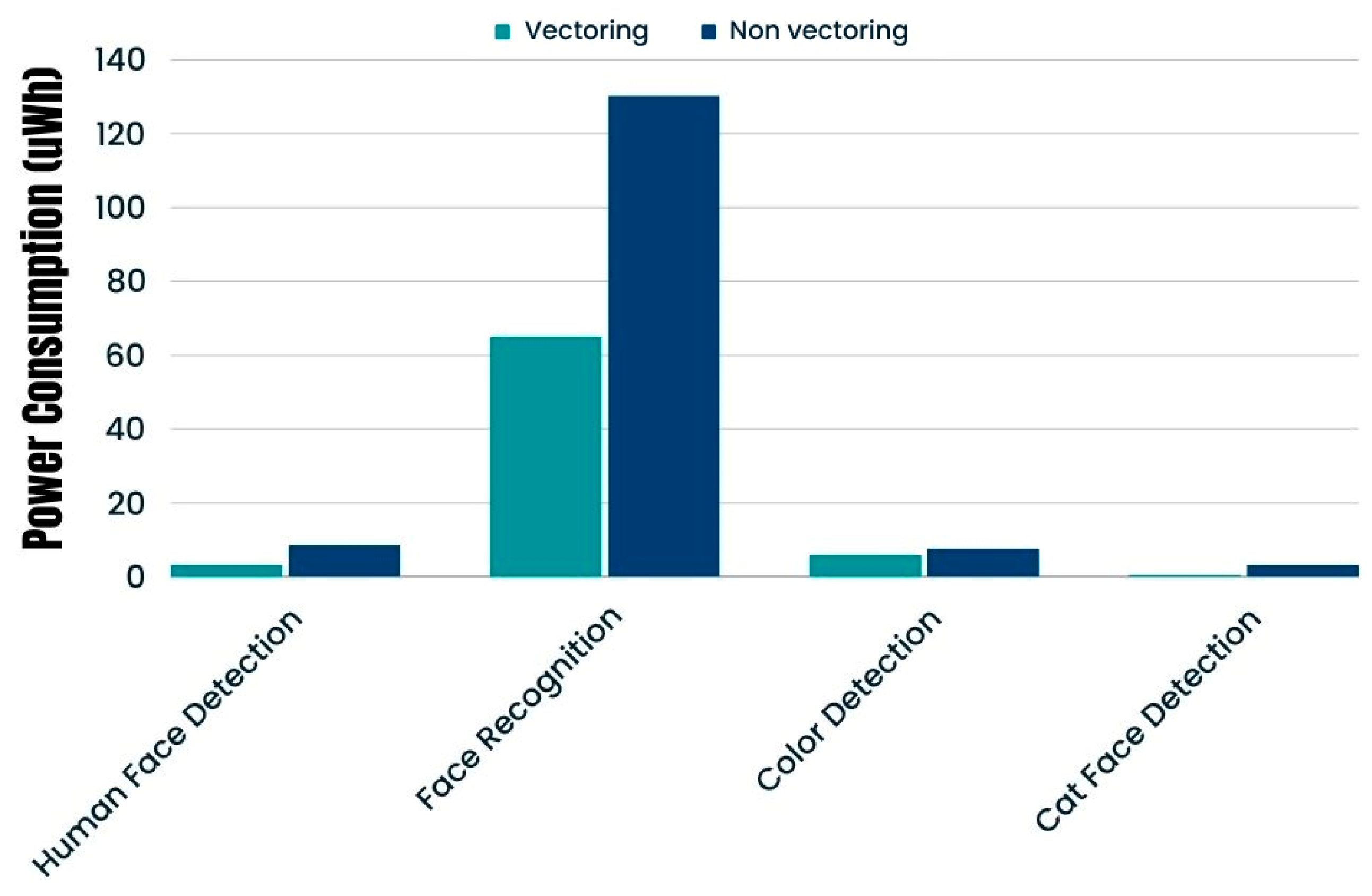
ESP32 against ESP32-S3 with a similar cache setup but with vectoring support enabled displayed a better power efficiency result for ESP32-S3 by 63%. The power efficiency improvement on ESP32-S3 is apparent for both two-stage and one-stage runtime models, and this is attributed to vectoring support with the SIMD arithmetic instructions [
23] enabling the MCU’s core to take better advantage of the available resources by running arithmetic instructions concurrently.
The face recognition model is the largest and most computational-resource-demanding model of our experiment; it runs five inferences of similar computational load per loop of code (cycle), and the results (
Table 5) are presented for one inference per cycle.
Increasing the D-Cache from 16 Kbytes to 32 Kbyte improves power efficiency by 69%, while going to 64 Kbytes of D-Cache drops the power consumption per inference to 29.7 µWh from the initial 212.8 µWh for a total gain of 86%.
Using 8-bit quantization further improves power efficiency by up to 95%; however, comparing the initial power consumption of the 8-bit quantized model with the lowest 16 Kbytes of D-cache to 32 and 64 Kbytes, we notice that power efficiency improvements are statistically the same as the 16-bit quantization as cache size increases.
ESP32 with disabled vectoring is consuming almost 13 times more energy (vectoring increases power efficiency by 92%) in the 8-bit quantized model, indicating that SIMD instructions of ESP32-S3 vastly increase performance when lower width (8-bit) instruction payloads are used; however, in the 16-bit quantized model, the difference is much smaller, with ESP32-S3 being just 50% more power efficient than ESP32. We did the same measurement multiple times, with the same result each time. We had the counter-intuitive result that the 16-bit quantized model was not only more power efficient but also ran faster in comparison with the 8-bit model for ESP32.
The color detection model is a small and non-demanding in computational resources model, as it is indicated in the results (
Table 6) that increasing the cache size had minimal effect on this model, leading us to conclude that 16 Kbytes is more than enough to achieve the maximum performance for its size.Going from the non-vectoring ESP32 to vectoring-enabled ESP32-S3 in similar cache setup increased power efficiency by almost 21%.
The cat face detection model is the most lightweight model of our experiment. Again, because of its small size, increasing the cache size has no real effect on the power efficiency of the model; however, vectoring has a large impact on power consumption, improving it by almost 85%. This power efficiency improvement is a result of increased data processing efficiency because of ESP32′s vectoring instructions. In fact, this capability enables ESP32-S3 to complete the inference function nearly seven times faster that its ESP32 counterpart (
Table 7).
Power consumption per inference diagrams for ESP32-S3 for each ML model are presented below (
Figure 4), while the effects of vectoring usage are easily identifiable in
Figure 5.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}