1. Introduction
Knowledge representation refers to the process of crafting a structured framework that represents information related to a particular domain of interest. The purpose of knowledge representation is to facilitate reasoning and decision-making concerning the domain of interest [
1]. In order to represent scientific knowledge through a structured framework, knowledge graphs are widely used. A knowledge graph can be described as a systematic representation of facts through entities, relationships, and a semantic framework. Knowledge graphs can also be defined as semantic networks. Semantic networks are structured representations of knowledge or concepts, where nodes represent entities or concepts, and edges represent relationships between entities [
2]. The primary objective of both semantic networks and knowledge graphs is to capture the semantics or meaning of the relationships between entities. Knowledge graphs facilitate the spontaneous exploration and analysis of complex datasets. They enhance decision-making processes and accelerate knowledge discovery.
A significant number of knowledge graphs have been developed so far, such as Freebase, WordNet, ConceptNet, DBpedia, YAGO, and NELL [
1]. These systems have been extensively used for question-answering systems, search engines, and recommendation systems. Since the introduction of semantic networks by Quillian [
3] in 1963, research in this area has been continuously conducted, with various algorithms, mechanisms, and applications being presented. Semantic webs and ontology [
4] are considered to represent the second wave of this research, in which the merging of local and universal ontologies was proposed. Compared with semantic networks, the second wave represents knowledge in a hierarchal structure, and hence, inheritance becomes possible. The most fundamental and influential work was RDF and OWL by the World Wide Web Consortium (W3C). W3C also developed standards and guidelines for web information representation and extraction. Knowledge graphs and knowledge graph learning, which represent the third wave of this research, were introduced in recent years. Information is represented as tuples which form knowledge graphs. Significant progress has been made in recent years in terms of applying machine learning algorithms to knowledge graphs. In their recent survey article [
1], Ji et al. provided a comprehensive summary of the research in this area. In the academic and industrial research communities, the expressions knowledge graph and knowledge base are used indiscriminately [
1]. There is a negligible difference between these two expressions. When considering the graph structure, a knowledge graph can be seen as a graph [
1]. However, when formal semantics are applied, it can be regarded as a knowledge base used for interpreting and inferring facts [
1]. In
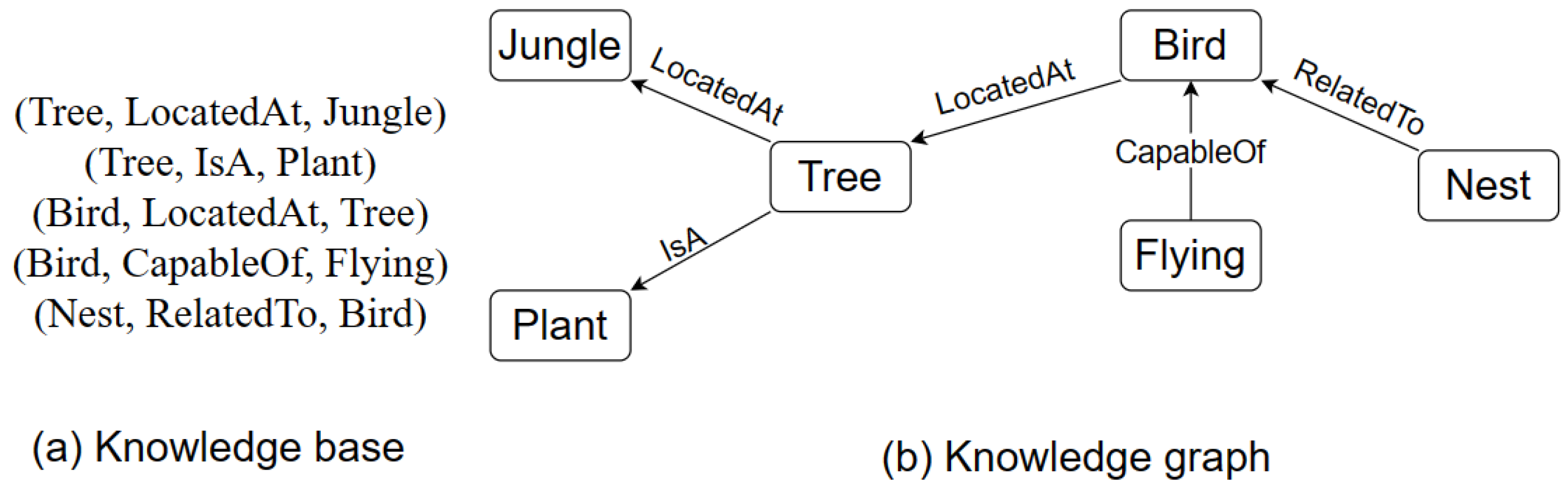
Figure 1a, we can see an example of a knowledge base and
Figure 1b an example of a knowledge graph. In the knowledge base (
Figure 1a) example, knowledge is represented in the form of factual triples. Triples comprise the subject, predicate, and object. For example, Bird, locatedAt, and Tree. In triples, a relationship between subject and object is established through the predicate.
On the other hand, the knowledge graph (
Figure 1b) contains a set of entities (nodes) linked by directed and labeled edges. Each edge represents a relation. The two entities linked by a relation represent a relationship. The entity pointed to by the relation is the head of the relationship, whereas the other entity is called the tail. An entity can be a head as well as a tail in a knowledge graph. For instance, the entity “tree” is the head in the relationship “tree isA plant”, whereas it is a tail in the relation “bird locatedAt tree”.
Structured information can be useful outside of knowledge graphs as well. OMRKBC [
5] is a machine-readable knowledge base designed to enable efficient data access and utilization. The authors of OMRKBC [
5] structured it using the fundamental concept of knowledge graph triples, making it accessible via a variety of systems. OMRKBC [
5] allows users to extract valuable information efficiently through diverse applications and interfaces. Moreover, the authors have introduced an additional framework known as NLIKR [
6], which allows an application to extract definitions of a concept from their dictionary and understand its meaning. This framework provides a definition corresponding to each concept [
6]. The application possesses the capability of accurately estimating the distance and similarity between concepts, thereby enhancing its understanding of their meaning.
In this paper, we propose a domain-specific dictionary between human and machine languages. The inspiration for this dictionary stemmed from an extensive survey of knowledge graphs. There is a unique opportunity to enhance the way medicine information is organized, accessed, and understood. The ultimate goal of this dictionary is to improve the quality of healthcare services. This knowledge graph-driven medicine dictionary will serve as a cornerstone in the realm of medical information systems. Its foundation lies in a well-structured ontology that utilizes knowledge graph triples to represent essential information about medications, their classifications, strengths, side effects, and various attributes. These triples, such as “A-Cold, has dosage form, Syrup”, “A-Cold, type of, allopathic”, etc., form the backbone of our ontology, enabling us to organize and present information in a format that is both machine-readable and human-understandable. This paper will explore the rationale, methodology, and potential benefits of constructing such a medicine dictionary.
The primary aim of this paper is to introduce a novel framework for constructing a comprehensive medicine dictionary using structured triples. While existing resources, such as The Danish Fetal Medicine database [
7], YaTCM [
8], and MEDI database [
9], and knowledge graphs, such as SMR [
10] and SnoMed kg [
11], have contributed to the field, they typically present data in relational table formats or contain triples that are not exclusively focused on medicine-related information. Furthermore, these knowledge graphs primarily serve as repositories of medical knowledge within the medical sector.
What sets our proposed dictionary apart is its unique capability to represent medicine attributes through entities and relations, thereby enabling advanced reasoning abilities. Users of this dictionary will be empowered to effortlessly extract crucial medicine-related details, including generic names, types, strengths, manufacturers, pharmacological descriptions, side effects, and, significantly, a wide range of alternative medicine brands for each primary medicine brand.
The rest of the paper will be organized as follows.
Section 2 will briefly discuss the previous research on knowledge graphs and the findings from the literature survey on knowledge representation learning, acquisition, and applications. In the next section, we will delve into the methodology employed to construct a medicine dictionary. Here, we will briefly lay out our approach, detailing how we harness structured triples to construct our comprehensive medicine dictionary. The methodology section will unveil the techniques and tools utilized in this project. After that, we will explore the practical application of our medicine dictionary. Real-world applications, such as the information extraction mechanism and question-answering techniques, will be discussed. Furthermore, we will showcase our experimental results and compare our work with existing mechanisms. Lastly, this paper will conclude with future research directions and the broader implications of our work.
2. Related Works
The domain of artificial intelligence has an extensive and well-established history of knowledge representation and reasoning, often facilitated by knowledge graphs. These graphs are primarily used to predict missing links within a vast network of information. Knowledge reasoning ability is crucial for representing knowledge in a structured format. Reasoning can be described as the process of analyzing, consolidating, and deriving new information on various aspects based on known facts and inference rules (relationships). It involves accumulating facts, identifying relationships between entities, and developing advanced understandings. Reasoning relies on prior knowledge and experience. Mining, organizing, and effectively managing knowledge from large-scale data are conducted through reasoning capabilities [
12].
The concept of semantic net, proposed by Richens in 1956, can be identified as the origins of diagram-based knowledge interpretation [
1]. The roots of symbolic logic knowledge trace back to the General Problem Solver in 1959 [
1]. As knowledge representation progressed, various methods emerged, including framework-driven language, reasoning-driven systems, and blended manifestation systems. MYCIN [
1], the renowned knowledge reasoning system in medical diagnosis, utilized a rule-based approach. The semantic web’s essential standards, such as Web Ontology Language (OWL) and resource description framework (RDF), were inspired by knowledge representation and reasoning systems [
1]. Semantic databases offer flexibility in depicting complex data relationships and enable sophisticated querying through semantic technologies such as OWL, RDF, and SparQl. Nonetheless, their management complexity and potential performance overhead demand proficiency in semantic standards. Despite scalability, the steep learning curve and limited tooling support can hinder widespread use. RDF serves as a framework for organizing web-based knowledge through structured triples, facilitating the development of interconnected datasets represented in a graph format [
5]. Additionally, it facilitates the querying of these datasets via SparQl. OWL, as a language designed for crafting web ontologies, enables the specification of classes, properties, and logical axioms within specific domains [
5]. OWL builds on RDF and handles complex knowledge models with detailed meanings, enabling automated reasoning and inference based on asserted knowledge. Apart from these, various systems and resources, including WordNet, DBpedia, ConceptNet, YAGO, and Freebase, have been developed to capture and represent knowledge effectively and efficiently.
WordNet [
13] can be described as a lexical database of English words defined through synonyms. In the database, words are bundled as synsets. One synset can be defined as one unique concept. Concepts are linked through lexical relations, thus allowing machines to apply knowledge to reason over the meaning of words. However, the authors of NLIKR [
6] argue that synsets are not enough to describe a word. Their argument was based on the fact that a word representing existence may reveal its characteristics in various ways, and WordNet is not capable of expressing them [
6]. ConceptNet [
14] was constructed using words and phrases connected by relations to model general human knowledge. ConceptNet has the ability to supply a comprehensive collection of general knowledge required by computer applications for the analysis of text based on natural language. However, ConceptNet has a significant drawback in that its relationships are inflexible and limited. Users cannot define custom relationships for their choice of words or phrases. DBPedia [
15] is a collection of structured information on various domains that has been extracted from Wikipedia. However, the knowledge is limited to named entities or concepts.
In recent years, knowledge representation learning has become essential for various applications, such as knowledge graph completion and reasoning. Researchers have explored multiple geometric spaces, including Euclidean, complex, and hyperbolic spaces. A Euclidean space can be described as a three-dimensional geometric space in which the points are denoted by their Cartesian co-ordinates [
1]. It utilizes the principles of Euclidean geometry for calculating distances. A complex space refers to a mathematical concept where numbers are denoted by complex numbers [
16]. This framework expands the one-dimensional real number line into a two-dimensional plane, where each point is depicted by a distinct complex number comprising both real and imaginary parts [
16]. A hyperbolic space refers to a mathematical space that has a negative curvature. It is employed to model complex hierarchical structures to capture the inherent geometry of the dataset [
17]. Notable models, such as RotatE [
16], leverage complex spaces, while ATTH [
17] focuses on hyperbolic spaces to encode hierarchical relationships. TransModE [
18] takes an innovative approach by utilizing modulus spaces, and DiriE [
19] introduces Bayesian inference to tackle uncertainty in knowledge graphs.
RotatE [
16] introduced a novel approach by leveraging complex spaces to encode entities and relations. This model is based on Euler’s identity and treats unitary complex numbers as rotational transformations within the complex plane. RotatE aims to capture relationship structures, including symmetry/anti-symmetry, inversion, and composition. Symmetry refers to a relationship between entities where if entity A is related to entity B, entity B is likewise related to entity A, for example, (Barack Obama, MarriedTo, Michelle Obama), (Michelle Obama, MarriedTo, Barack Obama). If a relationship between entities exists in one direction, it cannot exist in the opposite direction unless the entities are the same; this is known as anti-symmetry. For example, (Parent, IsParentOf, Child). The opposite relationship (Child, IsParentOf, Parent) is not true. Inversion can be defined as a relationship where the direction of a relationship is reversed. For example, (Doctor, Treats, Patient), (Patient, TreatedBy, Doctor). Composition refers to combining multiple relationships to derive new relationships or discover new knowledge. For example, (Alex, StudiesAt, University Of Melbourne), (University Of Melbourne, LocatedIn, Melbourne). By composing the two relationships “StudiesAt” and “LocatedIn”, we can infer another relationship (Alex, LivesIn, Melbourne). Another approach delves into hyperbolic spaces, as seen in the ATTH [
17] model. This model focuses on encoding hierarchical and logical relations within a knowledge graph. The curvature of the hyperbolic space is a crucial parameter that dictates whether relationships should be represented within a curved, tree-like structure or a flatter Euclidean space. Similarly, MuRP [
20] employs hyperbolic geometry to embed hierarchical relationship structures. This model is suitable for encoding hierarchical data with relatively few dimensions, offering scalability benefits. TransModE [
18] takes a unique approach by utilizing modulus spaces, which involves replacing numbers with their remainders after division by a given modulus value. This model is capable of encoding a wide range of relationship structures, including symmetry, anti-symmetry, inversion, and composition. DiriE [
19] adopts a Bayesian inference approach to address the uncertainty associated with knowledge graphs. Entities are represented as Dirichlet distributions and relations as multinomial distributions, allowing the model to quantify and model the uncertainty of large and incomplete knowledge frameworks.
Knowledge graphs require continuous expansion, as they often contain incomplete data. Knowledge graph completion (KGC) aims to add new triples from unstructured text, employing tasks such as relation path analysis. Relation extraction and entity discovery play vital roles in discovering new knowledge from unstructured text. Path analysis entails examining sequences of relations between entities to infer missing or potential relations. Relation extraction and entity discovery are essential for discovering new knowledge from unstructured text, involving tasks such as determining relationships between entities and aligning entities with their types. Distant supervision, also known as weak supervision or self-supervision, is primarily used to infer missing relations [
1]. This approach generates training data by heuristically matching sentences that mention the same entities under the assumption that they may express the same relation [
1]. It is used under the guidance of a relational database. RECON [
21] is a relation extraction model (introduced in 2021) that effectively represents knowledge derived from knowledge graphs using a graph neural network (GNN). This model leverages textual and multiple instance-based mechanisms to learn the background characteristics of concepts, analyze triple context, and aggregate context. Knowledge graph embedding (KGE) has become a popular approach for KGC, with models such as TransMS [
22] addressing the limitations of earlier translation-based models. TransMS projects entities and relations into different embedding spaces, allowing for more flexible and accurate modeling of complex relations. Type-aware attention path reasoning (TAPR) [
23], proposed in 2020, tackles path reasoning in knowledge graphs. It offers greater flexibility in path prediction by considering the structural facts, recorded facts, and characteristic information of knowledge graphs (KG). TAPR leverages character-level information to enrich entity and relation representations and employs path-level attention mechanisms to weight paths and calculate relations between entities.
The integration of structured knowledge, especially knowledge graphs, has significant implications for AI systems. Knowledge-aware applications have emerged in various domains, including language representation learning and recommendation systems. Models such as K-BERT [
24] and ALBERT [
25] offer solutions to integrate knowledge graphs and enhance AI capabilities. For domain-specific knowledge in language representation (LR), K-BERT [
24] was introduced in 2020 as a notable advancement. It addresses the challenges of integrating heterogeneous embedding spaces and handling noise in knowledge graphs. K-BERT extends existing BERT models, allowing them to incorporate domain-specific knowledge from a knowledge graph. ALBERT [
25], introduced in 2022, focuses on fact retrieval from knowledge graphs. This model leverages schema graph expansion (SGE) to extract relevant knowledge from a knowledge graph and integrate it into a pre-trained language model. ALBERT consists of five modules, including a text encoder, classifier, knowledge extractor, graph encoder, and schema graph expander.
As we conclude our exploration of knowledge representation learning, knowledge acquisition, and integration, it becomes evident that while previous endeavors have made significant strides, a distinct opportunity lies on the horizon—a chance to pioneer a revolutionary approach tailored specifically to the field of medicine: the creation of a dynamic and comprehensive medicine dictionary. Unlike prior initiatives, which have generally covered a broad spectrum of medical data, this endeavor focuses solely on consolidating medicine information into a structured knowledge graph format. Inspired by the architecture of knowledge graphs and various other databases, this opportunity presents unparalleled potential to transform the way we understand and utilize medicine knowledge. The uniqueness of this approach lies in its focused representation of medical information as entities and relations, facilitating enhanced information retrieval and question-answering capabilities. Incorporating this approach into medicine holds the potential for substantial benefits, significantly enhancing healthcare practices and outcomes.
3. The Domain-Specific Medicine Dictionary (DSMD) and Its Construction
One perspective of defining a domain-specific dictionary is to characterize it as a knowledge base organized in a knowledge graph architecture comprising entities and relations. Each entity is interconnected with other entities through relationships. A domain-specific dictionary is centered around a particular field of expertise, such as medicine, economics, finance, electronics, cellular biology, etc. The primary objective is to populate this knowledge base with triples to facilitate information extraction and question-answering. Let’s take an example of a knowledge base or knowledge graph in medicine domain:
This domain-specific dictionary serves as a structured and interconnected repository of knowledge tailored to a specific field, which is important for enhancing information retrieval and analysis within that domain.
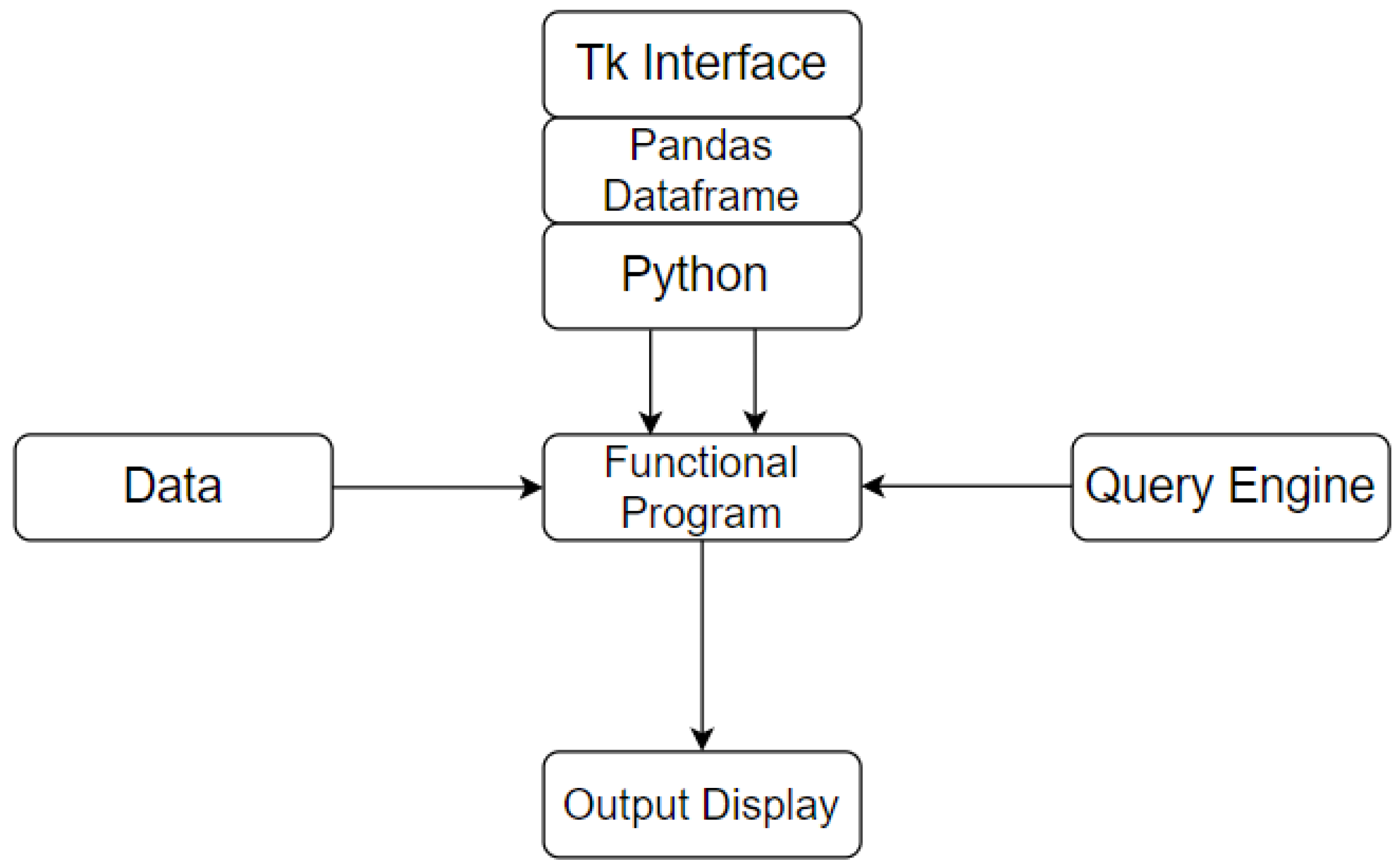
In this section, we present a structured approach to construct a human-machine dictionary in the medicine domain smoothly and effectively. The open source ‘Assorted Medicine Dataset of Bangladesh’ [
26] was used to build a prototype dictionary. Before moving on to the prototype design, we will explore the properties of the dictionary.
3.1. Concepts and Relations
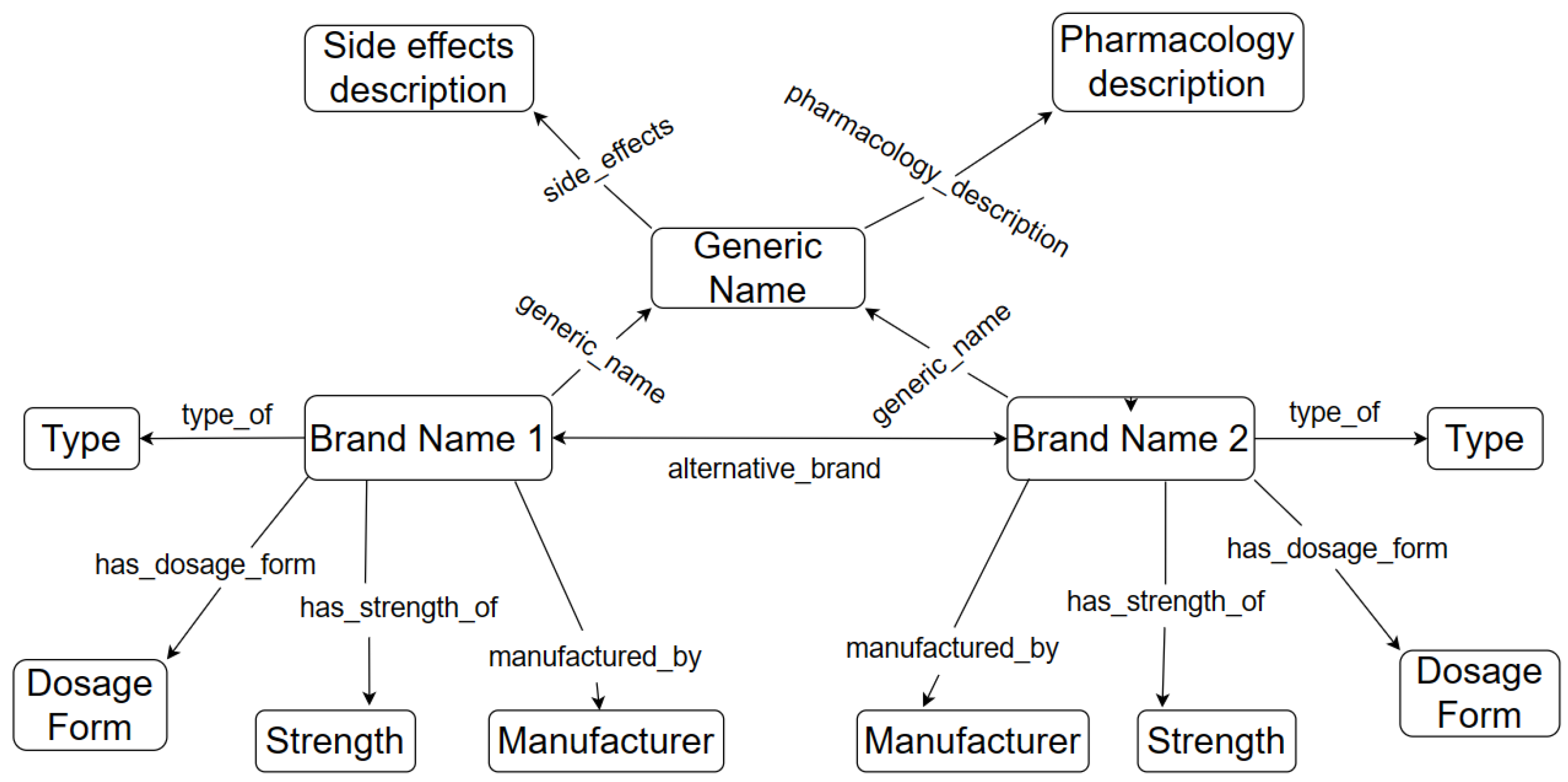
Our knowledge graph will consist of entities and relations. Each entity will be considered a concept, and the concepts will be connected through relations. Examples of entities include A-Cold, A-Cof, Syrup, Allopathic, etc. Entities can be names of medicine brands, generic names, types of medicine, such as herbal or allopathic, dosage forms of medicine, such as tablet or syrup, the strength of medicine, etc. On the other hand, relations will express the connection between concepts. For example, if A-Cold and Syrup are both concepts in the dictionary, what is the appropriate connection or link between them? The link between them can be defined as a relation. Here, the appropriate link between A-Cold and Syrup would be ‘dosage form’. Once the links are identified, we can add a form of triple, such as “(A-Cold, has dosage form, Syrup)”.
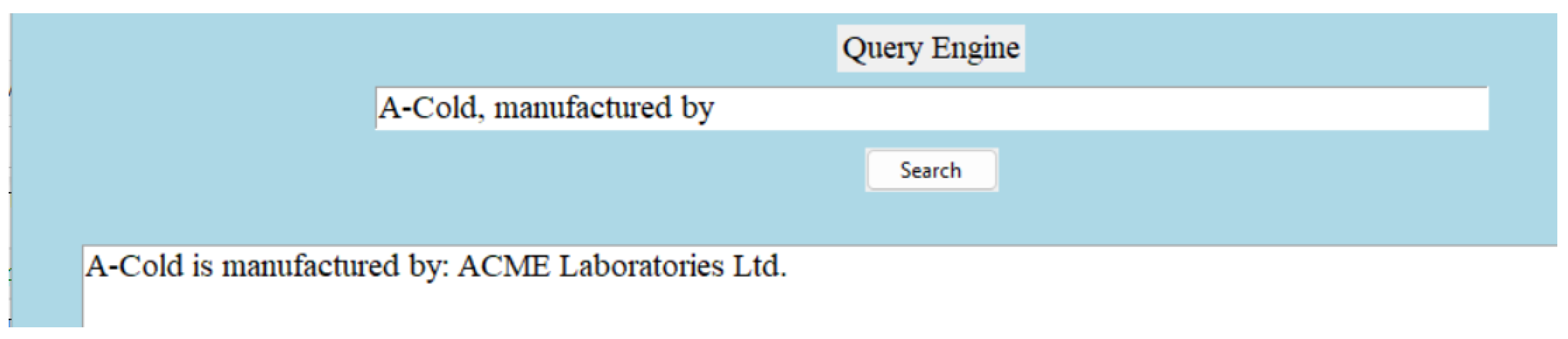
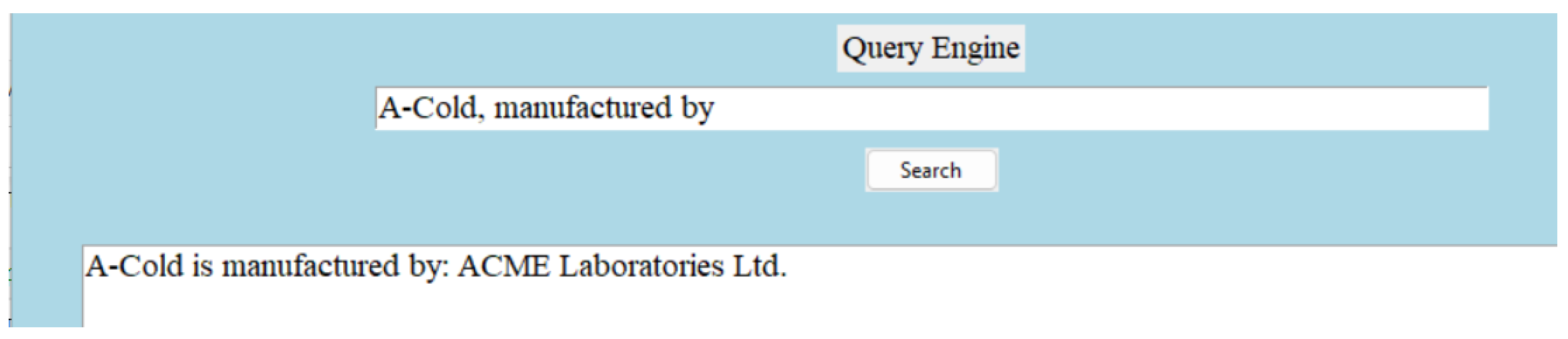
Relations are useful when they establish meaningful connections between entities. Consistency is the most important attribute of a relation. For example, in the triple “(‘A-Cold’, ’manufactured by’, ‘ACME Laboratories Ltd.’)”, the relation ‘manufactured by’ indicates that the medicine ‘A-Cold’ is manufactured by ACME Laboratories Ltd. In order to ensure consistency, whenever the relation ’manufactured by’ is used in the entire knowledge base, it should always point towards the manufacturer. Other valuable attributes of relations are relevance and the clarity of semantics. In the triple “(‘A-Cold’, ‘type of’, ’allopathic’)”, the relation ‘type of’ is relevant, as it specifies the classification of the medicine ‘A-Cold’ within the context of medical domain. In the triple “(‘Bromhexine Hydrochloride’, ‘pharmacology description’, ‘definition’)”, the relation ‘pharmacology description’ has clear semantics, implying that it provides a description or definition of the pharmacology of ’Bromhexine Hydrochloride’. Our dictionary provides a broad definition of the pharmacology for each generic medicine. The word ‘definition’ is used here in the triple to keep it short. All these attributes of relations ensure that machines can interpret the relationship between entities accurately. For instance, the relation ‘generic name is’ indicates that ‘Bromhexine Hydrochloride’ serves as the generic name for ‘A-Cold,’ enabling the machine to understand the relationship between the medicine and its generic identifier. Similarly, the relation ’manufactured by’ indicates that ‘ACME Laboratories Ltd.’ is the manufacturer of ‘A-Cold,’ providing crucial information about the entity responsible for producing the medication. By interpreting these relations appropriately, machines can navigate the knowledge base, extract relevant information, and generate comprehensive insights.
While concepts are collected easily from data, discovering relations is the tricky part. Khanam et al. [
5] established certain rules for discovering relations. One such rule is that a verb, common noun, or an adjective followed by a preposition can be considered as a relation. For example, type of, strength of, manufactured by, etc. We followed this rule to establish a few relations for our dictionary. Some new rules have been discovered as well. The following are two example rules that we have discovered:
An example of a verb phrase is ‘has dosage form’. Examples of noun phrases are ‘generic name’, ‘side effects’, and ’pharmacology description’.
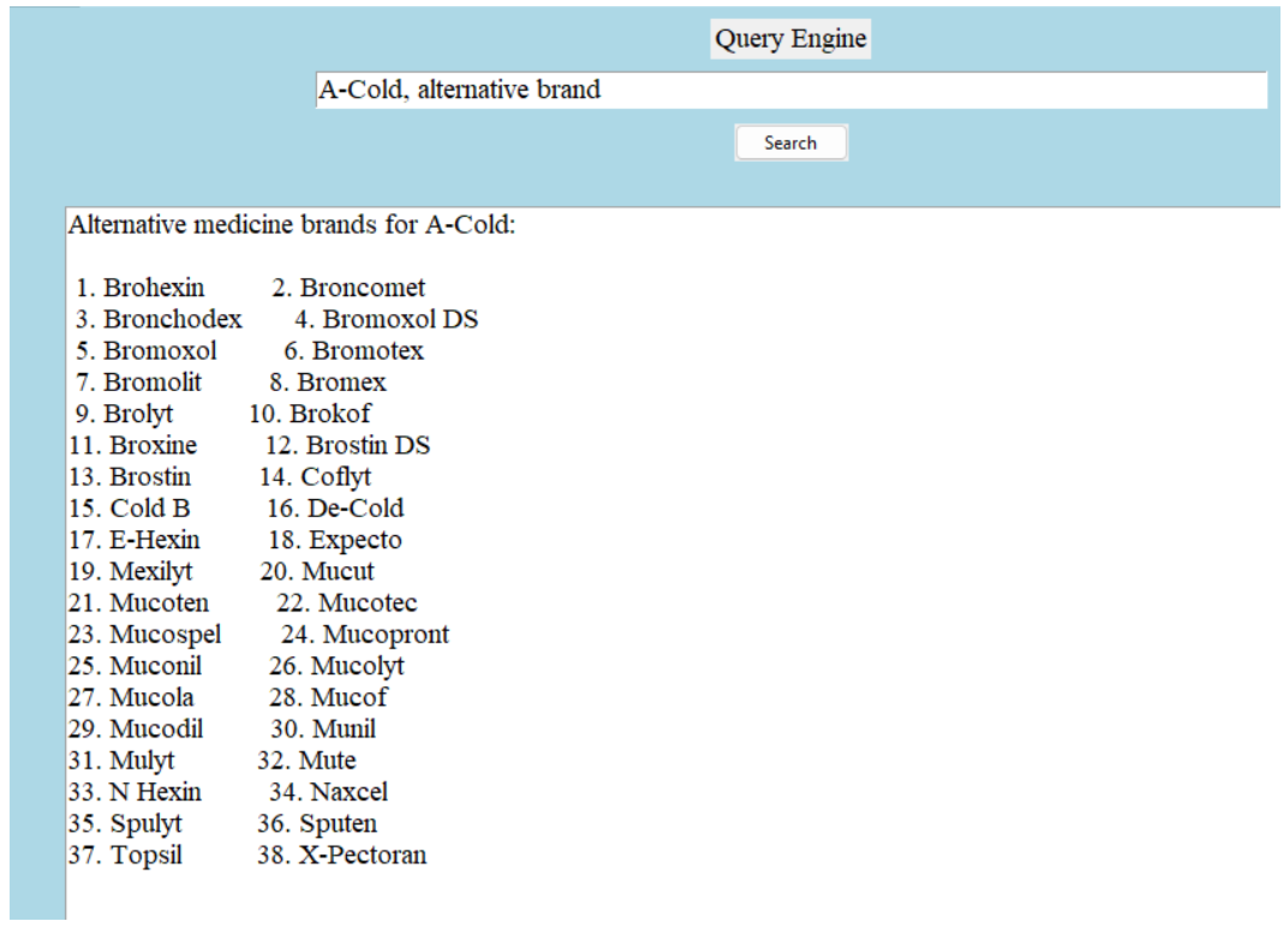
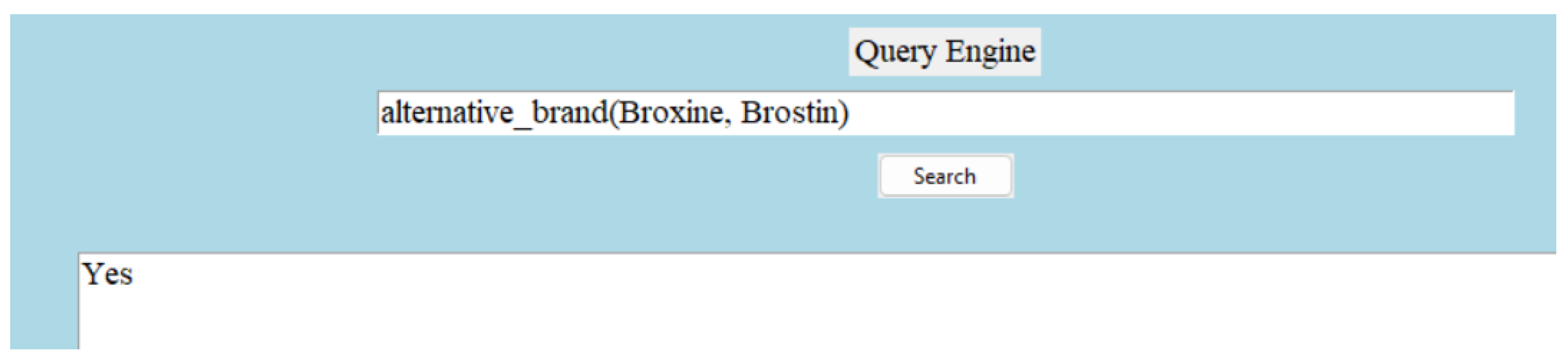
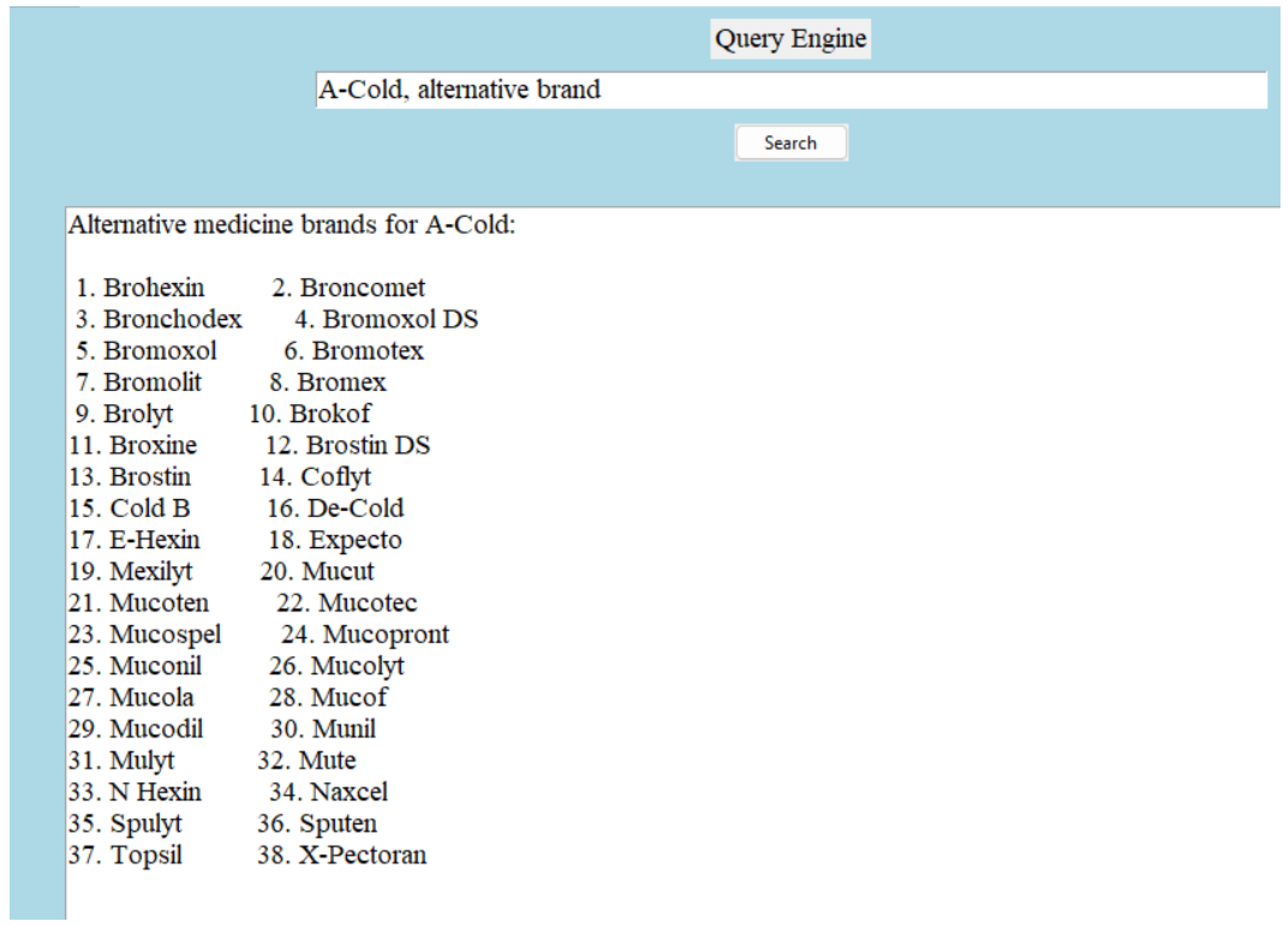
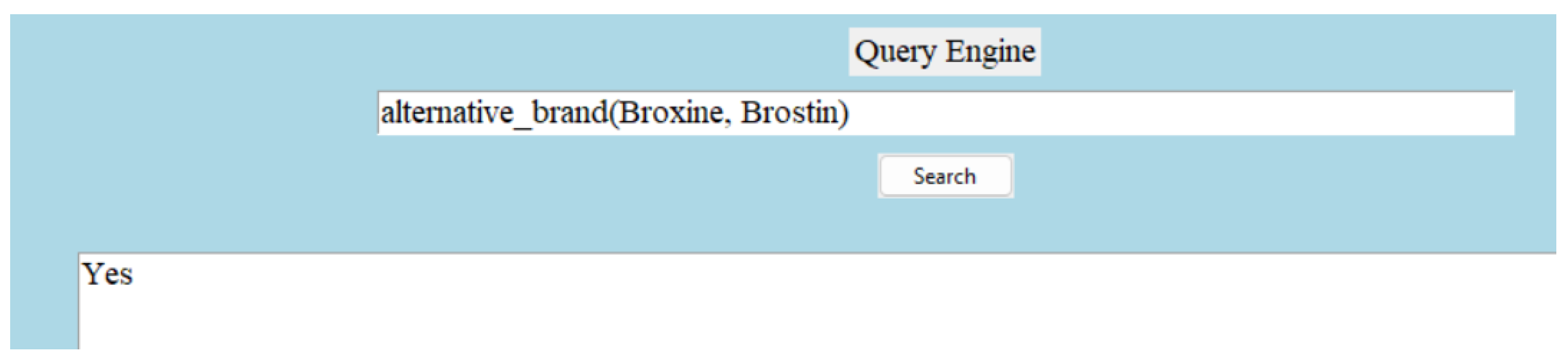
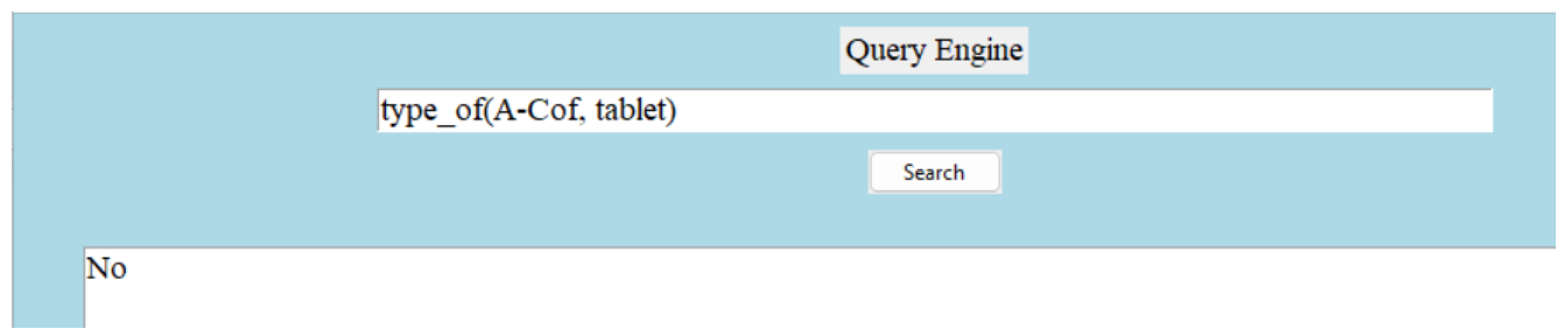
Since we are constructing a medicine dictionary with a limited number of attributes, we decided to keep a limited number of relations in the knowledge graph. The relation types are symmetric, complex, and asymmetric. A symmetric relation is the one in which the positions of the head and tail can be swapped. Let us take an example of a symmetric relation—(A-Cold, alternative brand, Brohexin). The reverse triple—(Brohexin, alternative brand, A-Cold) is true as well. Not all relationships are symmetric, but an inverse relationship can be created easily. For example, (‘A-Cold’, ’has dosage form’, ’Syrup’) can be written as (‘Syrup’, ‘is a form of dosage for’, ‘A-Cold’). A complex relation is defined as a more intricate or multi-layered connection between entities. Complex relation—(A-Cold, pharmacology description, description); this is true because of—(Bromhexine Hydrochloride, pharmacology description, description). More explanations can be found on this in the hierarchical structure and inheritance section. An example of an asymmetric relation is “(A-Cold, type of, allopathic)”. An example of the architecture of the structured triples can be found in
Figure 2.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}