1. Introduction
Large trucks play a crucial role in the freight industry and the global economy. In the United States (US), these trucks were responsible for transporting 65% of the total shipment weight in 2017 [
1]. Despite constituting only 4% of registered vehicles, they are involved in 11% of all fatal crashes in the US [
2]. Furthermore, large truck occupant fatalities increased by 23% from 2020 to 2021. The statistics on fatal crashes involving large trucks highlight the need to study the key factors contributing to the severity of these incidents. However, the disproportionately low proportion of severe and fatal crashes involving large trucks poses a significant challenge, creating highly imbalanced crash data. In the field of data mining and information extraction, the uneven distribution of majority and minority classes is recognized as a class imbalance issue. Models trained on imbalanced datasets often achieve high accuracy scores by predominantly labeling instances as the majority class. In the context of road crash data, the majority class pertains to no-injury or property damage-only crashes, which are not the classes of interest. The class of interest, severe and fatal crashes, typically constitutes the minority class. This class imbalance presents a significant obstacle to accurately estimating the key factors contributing to severe and fatal crashes involving large trucks.
The currently available approaches for the class imbalance issue can be divided into four categories; data-level approaches, algorithm-level approaches, cost-sensitive approaches, and ensemble classifiers. Data-level approaches add a pre-processing step, where the training data are resampled to create a balance between the majority and minority class observations [
3]. Typical data-level approaches encompass oversampling, under-sampling, and a combination of over- and under-sampling (hybrid sampling). Many of studies have reviewed these approaches and made comparisons between them [
4,
5,
6,
7]. In recent years, cluster-based under-sampling of observations involving the majority class coupled with other sampling approaches has become significantly popular [
8,
9,
10,
11]. Cluster-based under-sampling removes redundant observations involving the majority class. This helps the model separate the minority class from the majority class, especially when some regions of the majority and minority classes overlap in the feature space.
Whereas data-level approaches are more of an external process, algorithm-level approaches are more of an internal process. In the algorithm-level approach, existing algorithms are modified to account for the minority class [
12]. In a cost-sensitive approach, the objective is to minimize the total cost of errors for the majority and minority classes [
13]. Ensemble classifiers try to improve the prediction performance of a single classifier by combining the predictions of multiple classifiers [
14]. Algorithm-level and cost-sensitive approaches are difficult to apply for crash severity analysis because crash severity is defined differently across the world.
Several studies on crash severity have employed data-level approaches [
15,
16,
17,
18] and ensemble classifiers [
19] to address the class imbalance issue. However, there is a lack of a comparative study to determine the most effective approach for class imbalance in crash severity analysis. Such a study would contribute to the literature by illustrating the advantages and limitations of different approaches, serving as a valuable reference for future road safety researchers and crash data analysts. The current study specifically focuses on data-level approaches, as they show greater potential in addressing imbalanced learning by enhancing the distribution of datasets rather than relying solely on improvements based on supervised learning methods [
20]. Moreover, data-level approaches are context-agnostic, means they can be applied to different fields with the class imbalance issue.
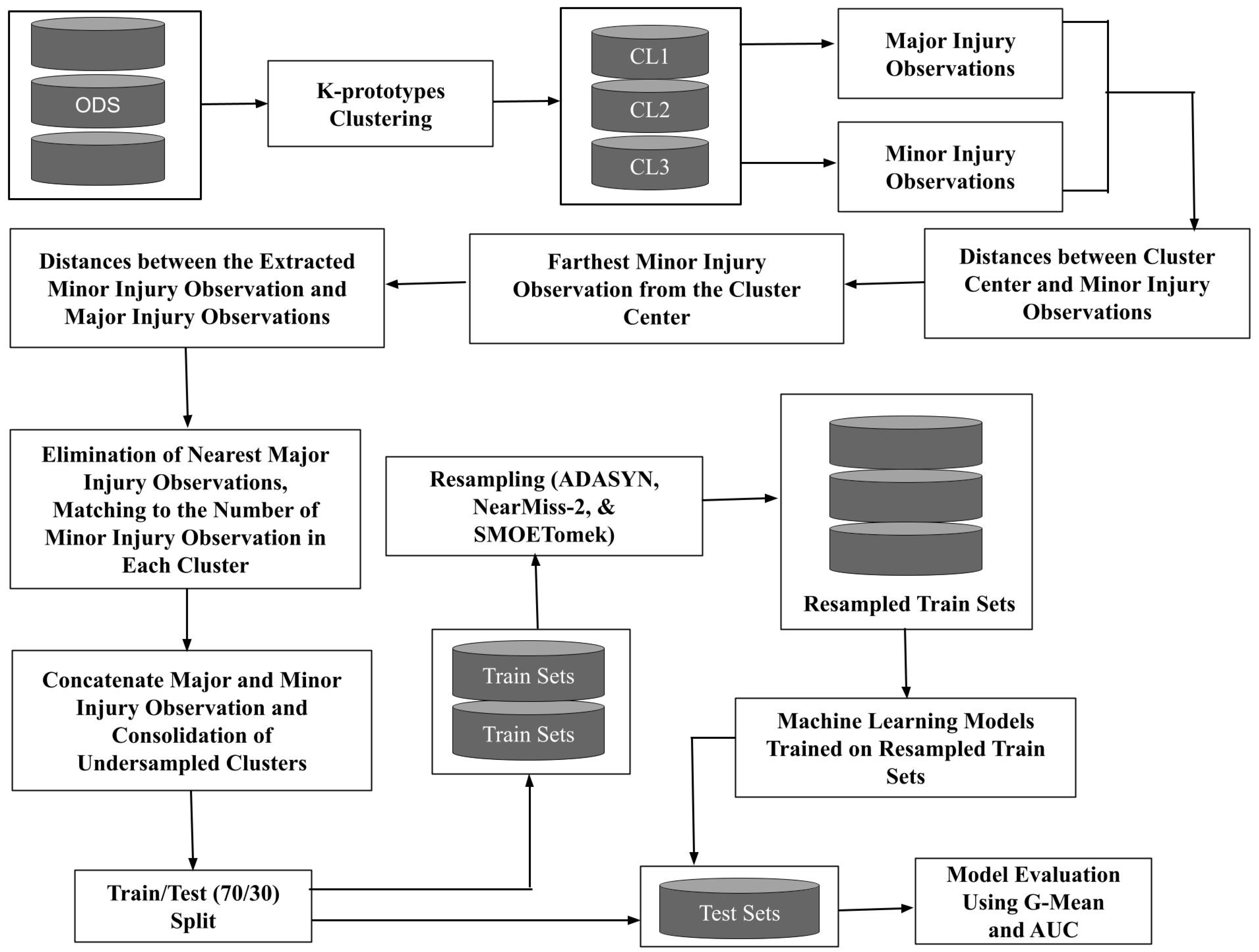
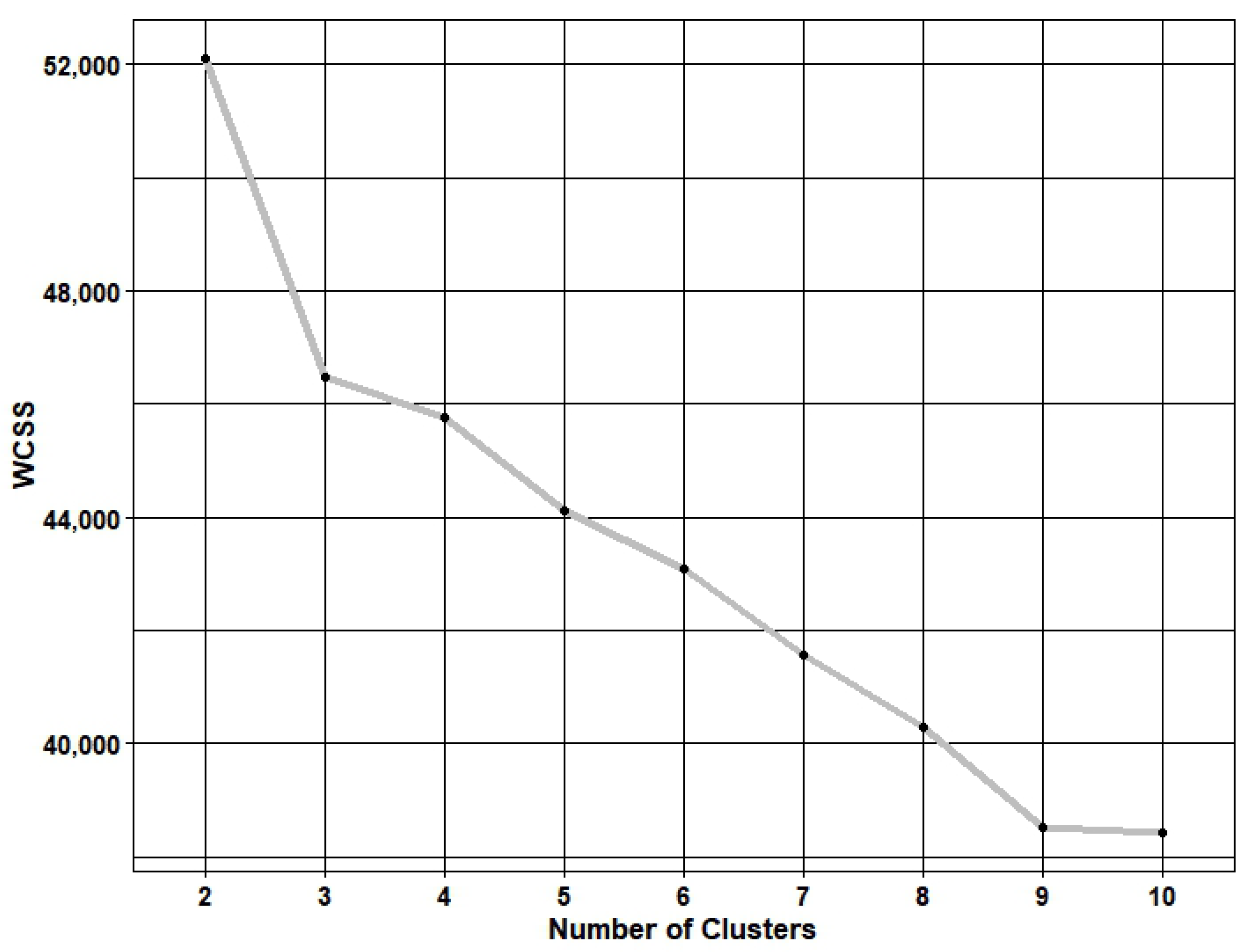
In this study, a novel cluster-based under-sampling (CU) technique was combined with three different sampling approaches (ADASYN, NearMiss-2, and SMOTETomek). Adaptive synthetic sampling (ADASYN) is an over-sampling approach, NearMiss-2 is an under-sampling approach, and SMOTETomek is a hybrid-sampling approach that combines the synthetic minority over-sampling technique (SMOTE) and Tomek links (an under-sampling approach). These sampling approaches were also applied to the data set without CU. The effectiveness of these sampling approaches was evaluated using four machine learning models. Through this experiment, the study aimed to answer the following questions: (1) Does incorporating cluster-based under-sampling improve the performance of the machine learning models? (2) What is the optimal combination of the machine learning model, sampling approach, and ratio for imbalanced crash data? (3) Which sampling approach produces the best results? (4) How do changes in the sampling ratios affect the performance of the machine learning models?
5. Discussion
This study aimed to compare the ADASYN, NearMiss-2, and SMOTETomek sampling approaches that were coupled a novel cluster-based under-sampling (CU) technique. Before applying these sampling approaches to ODS and cluster-based under-sampled data set (CUDS), LR, RF, GBDT and MLP models were employed on the trains sets of ODS and CUDS. The G-Mean and AUC scores indicated that models developed on CUDS are superior to models developed on ODS. The effectiveness CU coupled with ADASYN, NearMiss-2, and SMOTETomek, respectively was also evaluated through the performance of these machine learning models. The ODS was also resampled using these sampling approaches. The comparison between results obtained on resampled ODS and CUDS indicated that CU combined with over-sampling or under-sampling or hybrid-sampling is clearly better than applying the sampling approaches directly to raw imbalanced crash data.
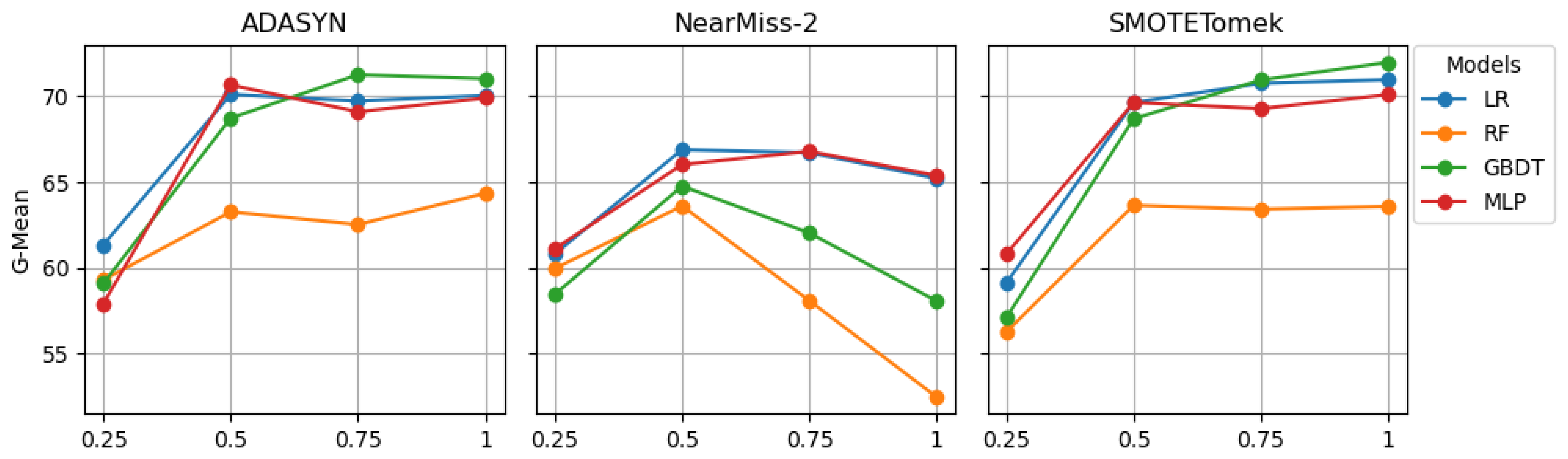
When comparing the models developed on data sets resampled by ADASYN, the highest G-Mean and AUC scores obtained on the resampled CUDS were 1.05 and 1.04 times higher, respectively, than those obtained on the resampled ODS. Similarly, for the models developed on data sets resampled by NearMiss-2, the highest G-Mean and AUC scores obtained on the resampled CUDS were 1.01 and 1.02 times higher, respectively, compared with the resampled ODS. In the case of models developed on data sets resampled by SMOTETomek, the highest G-Mean and AUC scores obtained on the resampled CUDS were 1.07 and 1.05 times higher, respectively, than those obtained on the resampled ODS. These findings consistently underscore the enhanced performance of models trained on the resampled CUDS compared with their counterparts trained on the resampled ODS. In addition, the G-Mean and AUC scores obtained on both the ODS and CUDS suggest that resampling using ADASYN and SMOTETomek produces almost similar results.
When examining the optimal combination of a machine learning model and a sampling approach, the results obtained on the resampled ODS indicated that the GBDT model tends to outperform LR, RF, and MLP when resampling is carried out using ADASYN and SMOTETomek. The optimal sampling ratio with ADASYN was 0.75, while with SMOTETomek, the optimal sampling ratios were 0.75 and 1. Conversely, when resampling was conducted using NearMiss-2, the G-Mean scores suggest that LR is likely to perform well, with an optimal sampling ratio of 0.50, while the AUC scores indicate that the MLP model is more likely to excel with an optimal sampling ratio of 0.25.
Addressing the effectiveness of different models on the resampled CUDS, the G-Mean scores suggested that the GBDT model was the best choice for ADASYN resampling, with an optimal sampling ratio of 0.75. However, the AUC scores favored the MLP model, suggesting its superiority with an optimal sampling ratio of 0.50. In the case of SMOTETomek, both the G-Mean and AUC scores favored the GBDT model as the optimal choice at a sampling ratio of one. On the other hand, for the CUDS resampled by NearMiss-2, both the G-Mean and AUC scores indicate that the LR model is likely to perform the best, especially at a sampling ratio of 0.50. These findings provide valuable insights into the interplay between the machine learning models, sampling approaches, and optimal ratios for addressing class imbalance in crash severity analysis.
Resampling the ODS using ADASYN and SMOTETomek revealed that increasing the sampling ratio from 0.25 to 0.75 significantly enhanced the performance of LR, GBDT, and MLP, while the increase in performance for RF was comparatively more gradual. Furthermore, increasing the sampling ratio from 0.75 to 1 did not result in a substantial change in the models’ performance. In the case of resampling the ODS using NearMiss-2, raising the sampling ratio from 0.25 to 0.50 is likely to improve model performance. However, increasing the ratio from 0.50 to 1 led to a pronounced reduction in the models’ effectiveness. In general, the performances of models are expected to decrease as the number of observations for training decline.
Similar trends were observed when resampling the CUDS using ADASYN and SMOTETomek. Increasing the sampling ratio from 0.25 to 0.50 significantly improved the performance of LR, GBDT, and MLP. The impact of changes in the sampling ratios for resampling the CUDS using NearMiss-2 mirrored that of the ODS. These findings shed light on the nuanced effects of varying sampling ratios on different machine learning models, providing valuable insights for optimizing the handling of class imbalance in crash severity analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}