


Deep Learning-Based Multiple Droplet Contamination Detector for Vision Systems Using a You Only Look Once Algorithm

Abstract
1. Introduction
2. Network
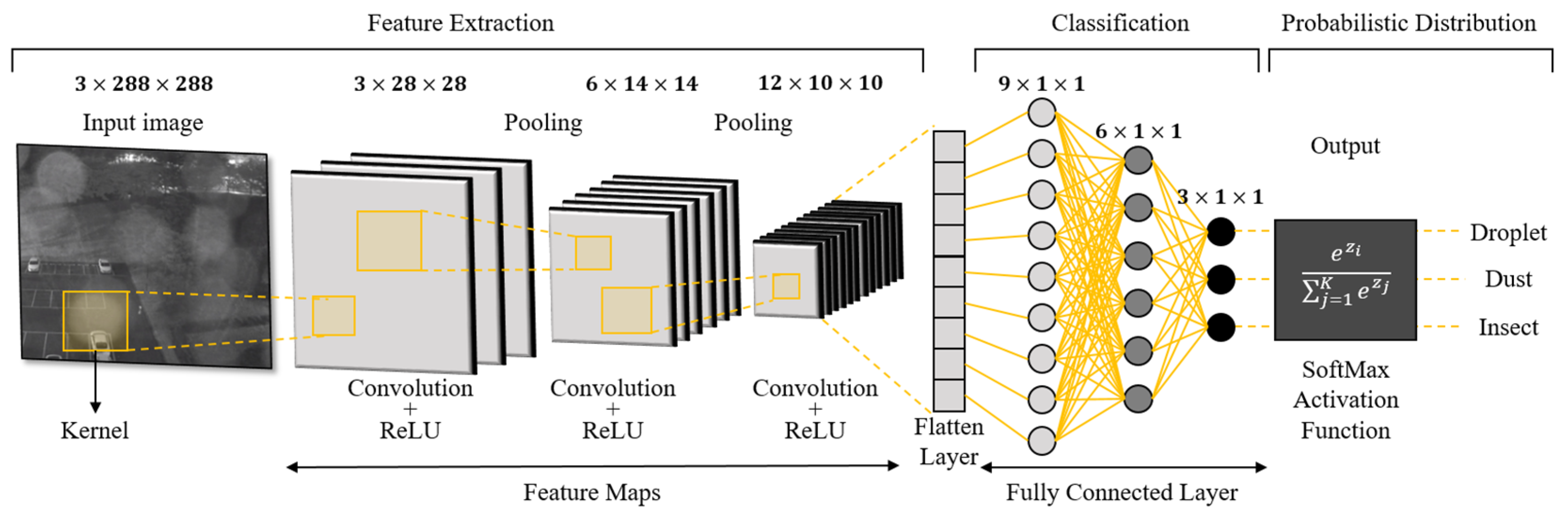
2.1. Convolution Neural Network (CNN)
2.2. You Only Look Once (YOLO) [33]
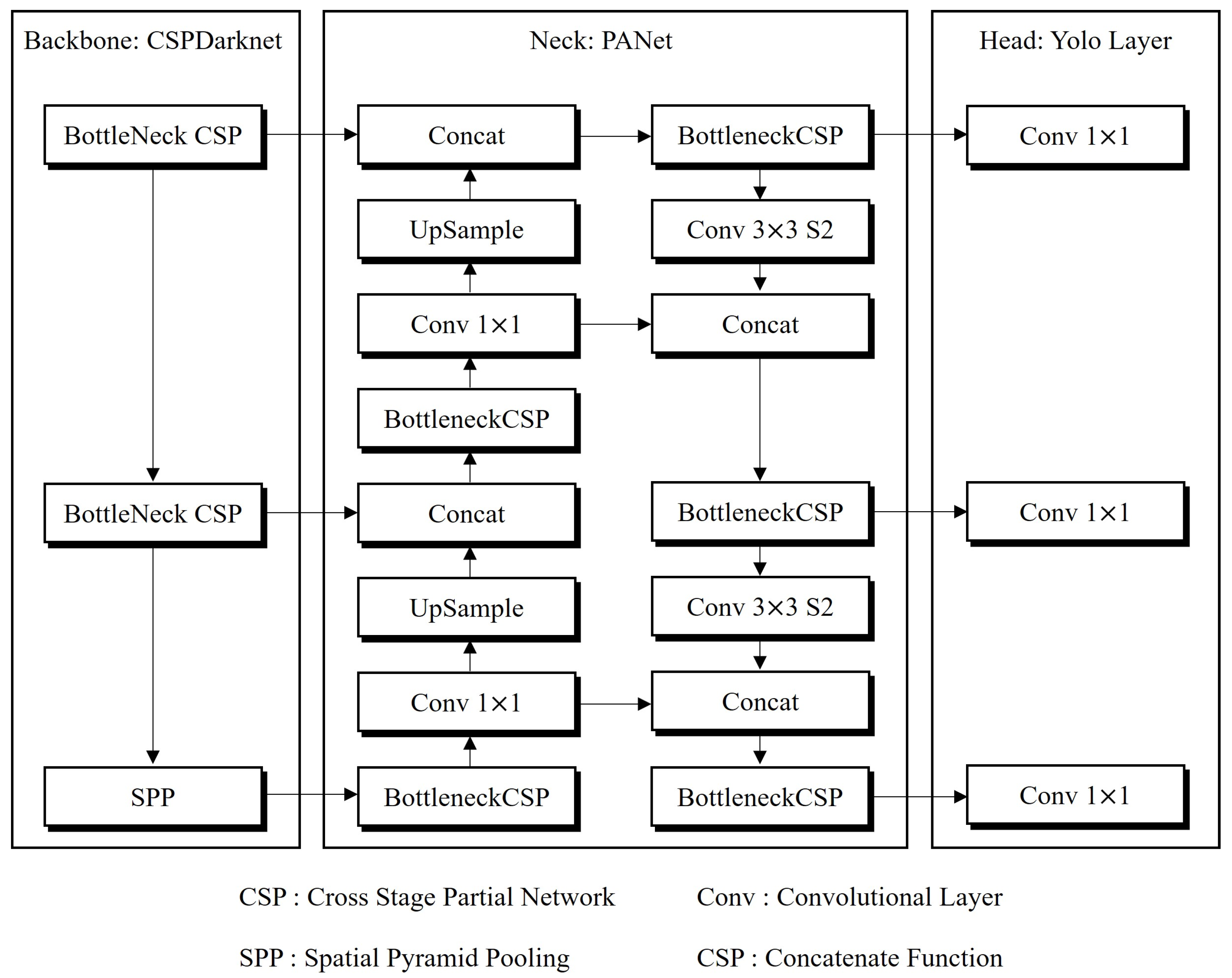
2.3. YOLOv5
3. Methodology
3.1. Step 1. Create an Image Dataset
3.2. Step 2. Training of Algorithms
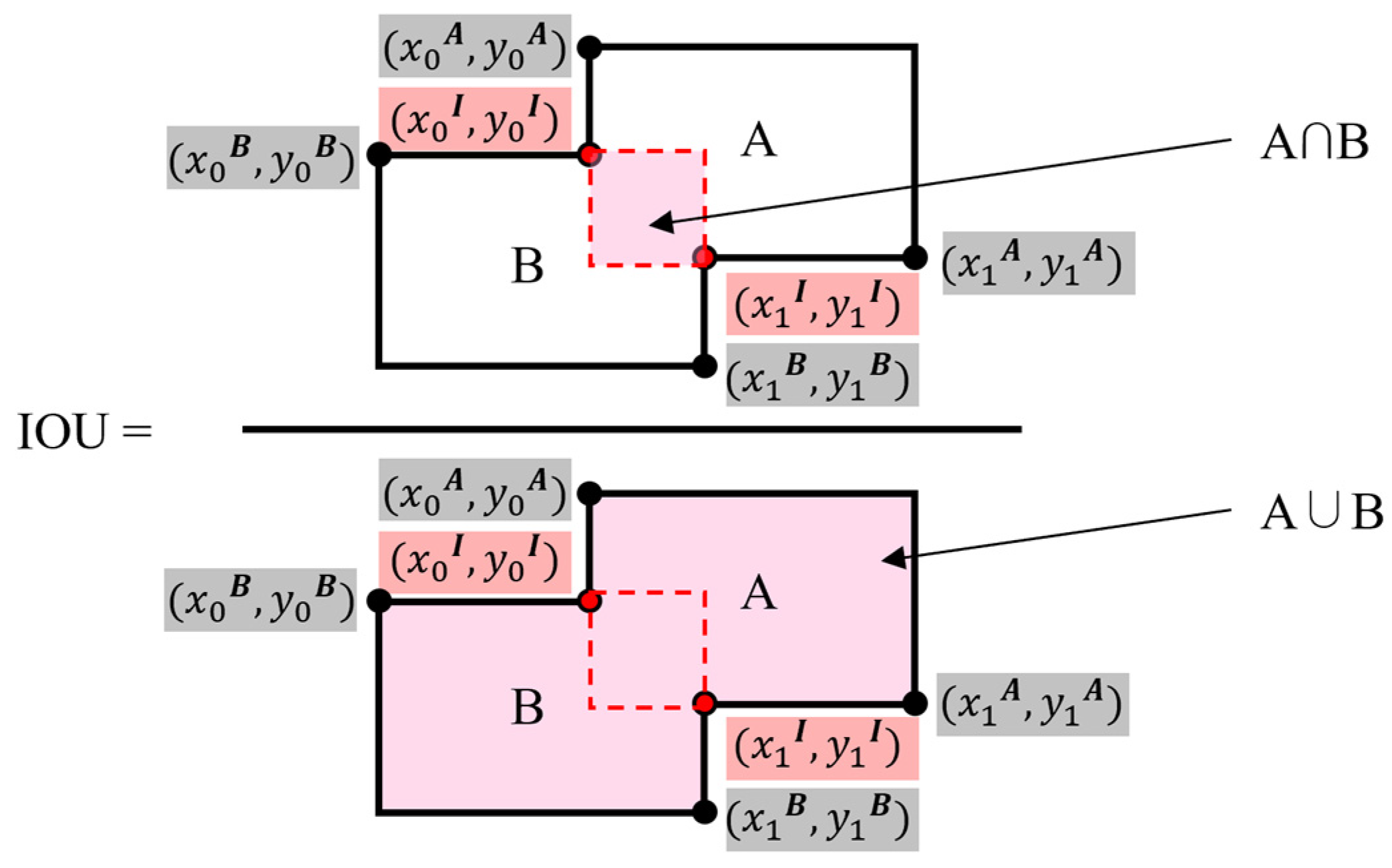
3.3. Step 3. Quantitatively Evaluation of the Detection Performance
4. Result
4.1. Training Loss Analysis of Architectures
4.2. Compare the Detection Performance of Trained Models
4.3. Detection Results
4.4. Integrating Contamination Detection Models with Cleaning Systems
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Road Traffic Deaths, Global Health Observatory Data Repository by World Health Organization. Available online: https://www.who.int/data/gho/data/themes/topics/topic-details/GHO/road-traffic-mortality (accessed on 22 November 2023).
- Bellis, E.; Page, J. National Motor Vehicle Crash Causation Survey (NMVCCS) SAS Analytical Users Manual; Calspan Corp.: Buffalo, NY, USA, 2008; pp. 154–196. [Google Scholar]
- Rolison, J.J.; Regev, S.; Moutari, S.; Feeney, A. What Are the Factors That Contribute to Road Accidents? An Assessment of Law Enforcement Views, Ordinary Drivers’ Opinions, and Road Accident Records. Accid. Anal. Prev. 2018, 115, 11–24. [Google Scholar] [CrossRef]
- Dabral, S.; Kamath, S.; Appia, V.; Mody, M.; Zhang, B.; Batur, U. Trends in Camera Based Automotive Driver Assistance Systems (ADAS). In Proceedings of the 2014 IEEE 57th International Midwest Symposium on Circuits and Systems (MWSCAS), College Station, TX, USA, 3–6 August 2014; ISBN 9781479941322. [Google Scholar]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Ziebinski, A.; Cupek, R.; Erdogan, H.; Waechter, S. A Survey of ADAS Technologies for the Future Perspective of Sensor Fusion. In Proceedings of the Computational Collective Intelligence: 8th International Conference, Halkidiki, Greece, 28–30 September 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zang, S.; Ding, M.; Smith, D.; Tyler, P.; Rakotoarivelo, T.; Kaafar, M.A. The Impact of Adverse Weather Conditions on Autonomous Vehicles: How Rain, Snow, Fog, and Hail Affect the Performance of a Self-Driving Car. IEEE Veh. Technol. Mag. 2019, 14, 103–111. [Google Scholar] [CrossRef]
- Mannetje, T.D.J.C.M.; Murade, C.U.; Van Den Ende, D.; Mugele, F. Electrically assisted drop sliding on inclined planes. Appl. Phys. Lett. 2011, 98, 118–121. [Google Scholar] [CrossRef]
- Hong, J.; Lee, S.J.; Koo, B.C.; Suh, Y.K.; Kang, K.H. Size-selective sliding of sessile drops on a slightly inclined plane using low frequency AC electrowetting. Langmuir 2012, 28, 6307–6312. [Google Scholar] [CrossRef]
- Tan, M.K.; Friend, J.R.; Yeo, L.Y. Microparticle collection and concentration via a miniature surface acoustic wave device. Lab Chip 2007, 7, 618–625. [Google Scholar] [CrossRef] [PubMed]
- Alagoz, S.; Apak, Y. Removal of spoiling materials from solar panel surfaces by applying surface acoustic waves. J. Clean. Prod. 2020, 253, 119992. [Google Scholar] [CrossRef]
- Lee, S.; Kim, D.I.; Kim, Y.Y.; Park, S.-E.; Choi, G.; Kim, Y.; Kim, H.J. Droplet evaporation characteristics on transparent heaters with different wettabilities. RSC Adv. 2017, 7, 45274–45279. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, J.; Kim, Y. Afluoropolymer-coated nanometer-thick Cu Mesh film for a robust and hydrophobic transparent heater. ACS Appl. Nano Mater. 2020, 3, 8672–8678. [Google Scholar] [CrossRef]
- Yong Lee, K.; Hong, J.; Chung, S.K. Smart self-cleaning lens cover for miniature cameras of automobiles. Sens. Actuators B Chem. 2017, 239, 754–758. [Google Scholar] [CrossRef]
- Song, H.; Jang, D.; Lee, J.; Lee, K.Y.; Chung, S.K. SAW-driven self-cleaning drop free glass for automotive sensors. J. Micromech. Microeng. 2021, 31, 12. [Google Scholar] [CrossRef]
- Park, J.; Lee, S.; Kim, D.I.; Kim, Y.Y.; Kim, S.; Kim, H.J.; Kim, Y. Evaporation-rate control of water droplets on flexible transparent heater for sensor application. Sensors 2019, 19, 4918. [Google Scholar] [CrossRef]
- Robins, M.N.; Bean, H.N. Camera Lens Contamination Detection and Indication System and Method. U.S. Patent US6940554B2, 6 September 2005. [Google Scholar]
- Zhang, Y. Self-Detection of Optical Contamination or Occlusion in Vehicle Vision Systems. Opt. Eng. 2008, 47, 067006. [Google Scholar] [CrossRef]
- Lai, C.C.; Li, C.H.G. Video-Based Windshield Rain Detection and Wiper Control Using Holistic-View Deep Learning. In Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; Section III. pp. 1060–1065. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning Discriminative Feature Representation with Pixel-level Supervision for Forest Smoke Recognition. Pattern Recognit. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Cao, Y.; Li, C.; Peng, Y.; Ru, H. MCS-YOLO: A Multiscale Object Detection Method for Autonomous Driving Road Environment Recognition. IEEE Access 2023, 11, 22342–22354. [Google Scholar] [CrossRef]
- Bengio, Y.; LeCun, Y. Scaling Learning Algorithms towards AI. In Large-Scale Kernel Machines; MIT Press: Cambridge, MA, USA, 2007; Volume 34. [Google Scholar]
- Hassan, M.; Wang, Y.; Wang, D.; Li, D.; Liang, Y.; Zhou, Y.; Xu, D. Deep Learning Analysis and Age Prediction from Shoeprints. Forensic Sci. Int. 2021, 327, 110987. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Lee, J.; Chung, S.K. Heat-Driven Self-Cleaning Glass Based on Fast Thermal Response for Automotive Sensors. Phys. Scr. 2023, 98, 085932. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Agatonovic-Kustrin, S.; Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 2000, 22, 717–727. [Google Scholar] [CrossRef]
- Huang, Y.; Sun, S.; Duan, X.; Chen, Z. A study on Deep Neural Networks framework. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2016. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.-R. Explaining Deep Neural Networks and Beyond: A review of Methods and Applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Sarvamangala, D.R.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2022, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. MSFT-YOLO: Improved YOLOv5 Based on Transformer for Detecting Defects of Steel Surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A Small Target Forest Fire Detection Model Based on YOLOv5 Improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, L.; Li, T.; Shi, P. A Smoke Detection Model Based on Improved YOLOv5. Mathematics 2022, 10, 1190. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef]
- Sama, A.K.; Sharma, A. Simulated Uav Dataset for Object Detection. ITM Web Conf. 2023, 54, 02006. [Google Scholar] [CrossRef]
- Bayer, H.; Aziz, A. Object Detection of Fire Safety Equipment in Images and Videos Using Yolov5 Neural Network. In Proceedings of the 33rd Forum Bauinformatik, München, Germany, 7–9 September 2022. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012, C.; Changyu, L.; Laughing, H. ultralytics/yolov5: v3.0. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 December 2020).
- Liu, P.; Zhang, G.; Wang, B.; Xu, H.; Liang, X.; Jiang, Y.; Li, Z. Loss Function Discovery for Object Detection via Convergence-Simulation Driven Search. arXiv 2021, arXiv:2102.04700. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Zhou, B.; Yang, S.; Gong, Z. Real-time Signal Light Detection based on Yolov5 for Railway. IOP Conf. Ser. Earth Environ. Sci. 2021, 769, 042069. [Google Scholar] [CrossRef]
- Stevens, E.; Antiga, L.; Viehmann, T. Deep Learning with PyTorch; Manning Publications: Shelter Island, NY, USA, 2020. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Jia, W.; Xu, S.; Liang, Z.; Zhao, Y.; Min, H.; Li, S.; Yu, Y. Real-time Automatic Helmet Detection of Motorcyclists in Urban Traffic Using Improved YOLOv5 Detector. IET Image Process. 2021, 15, 3623–3637. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Parameters | Optimizer | Learning Rate | Momentum | Image Size | Batch Size | Epochs |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 1,900,000 | SGD | 0.001 | 0.937 | 640 × 640 | 16 | 150 |
| YOLOv5s | 7,200,000 | SGD | 0.001 | 0.937 | 640 × 640 | 16 | 150 |
| YOLOv5m | 21,200,000 | SGD | 0.001 | 0.937 | 640 × 640 | 16 | 150 |
| YOLOv5l | 46,500,000 | SGD | 0.001 | 0.937 | 640 × 640 | 16 | 150 |
| YOLOv5x | 86,700,000 | SGD | 0.001 | 0.937 | 640 × 640 | 16 | 150 |
| Model | mAP 0.5 (%) | mAP 0.5:0.95 (%) | Precision (%) | Recall | F1 Score | GFLOPS | Inference Time Millisecond (ms) |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 76.07 | 34.87 | 77.81 | 67.66 | 70.62 | 4.2 | 3.3 |
| YOLOv5s | 80.47 | 38.88 | 80.69 | 73.65 | 77.00 | 16.0 | 4.8 |
| YOLOv5m | 84.70 | 44.16 | 86.02 | 78.97 | 82.34 | 448.2 | 8.9 |
| YOLOv5l | 86.50 | 48.74 | 88.90 | 80.68 | 84.59 | 108.2 | 14.7 |
| YOLOv5x | 87.46 | 51.90 | 90.28 | 81.47 | 85.64 | 204.4 | 23.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Kim, W.; Yoon, J.; Chung, S.; Kim, D. Deep Learning-Based Multiple Droplet Contamination Detector for Vision Systems Using a You Only Look Once Algorithm. Information 2024, 15, 134. https://doi.org/10.3390/info15030134
Kim Y, Kim W, Yoon J, Chung S, Kim D. Deep Learning-Based Multiple Droplet Contamination Detector for Vision Systems Using a You Only Look Once Algorithm. Information. 2024; 15(3):134. https://doi.org/10.3390/info15030134
Chicago/Turabian StyleKim, Youngkwang, Woochan Kim, Jungwoo Yoon, Sangkug Chung, and Daegeun Kim. 2024. "Deep Learning-Based Multiple Droplet Contamination Detector for Vision Systems Using a You Only Look Once Algorithm" Information 15, no. 3: 134. https://doi.org/10.3390/info15030134
APA StyleKim, Y., Kim, W., Yoon, J., Chung, S., & Kim, D. (2024). Deep Learning-Based Multiple Droplet Contamination Detector for Vision Systems Using a You Only Look Once Algorithm. Information, 15(3), 134. https://doi.org/10.3390/info15030134