

Comparative Analysis of NLP-Based Models for Company Classification

 , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Standards for Company Classification
2.1. Definition and Benefits of Company Classification
2.2. Mainstream Standards
2.3. Issues with the Current Standards
3. Related Literature
4. Materials and Methods
4.1. Dataset
4.2. Methodology
5. Results and Discussion
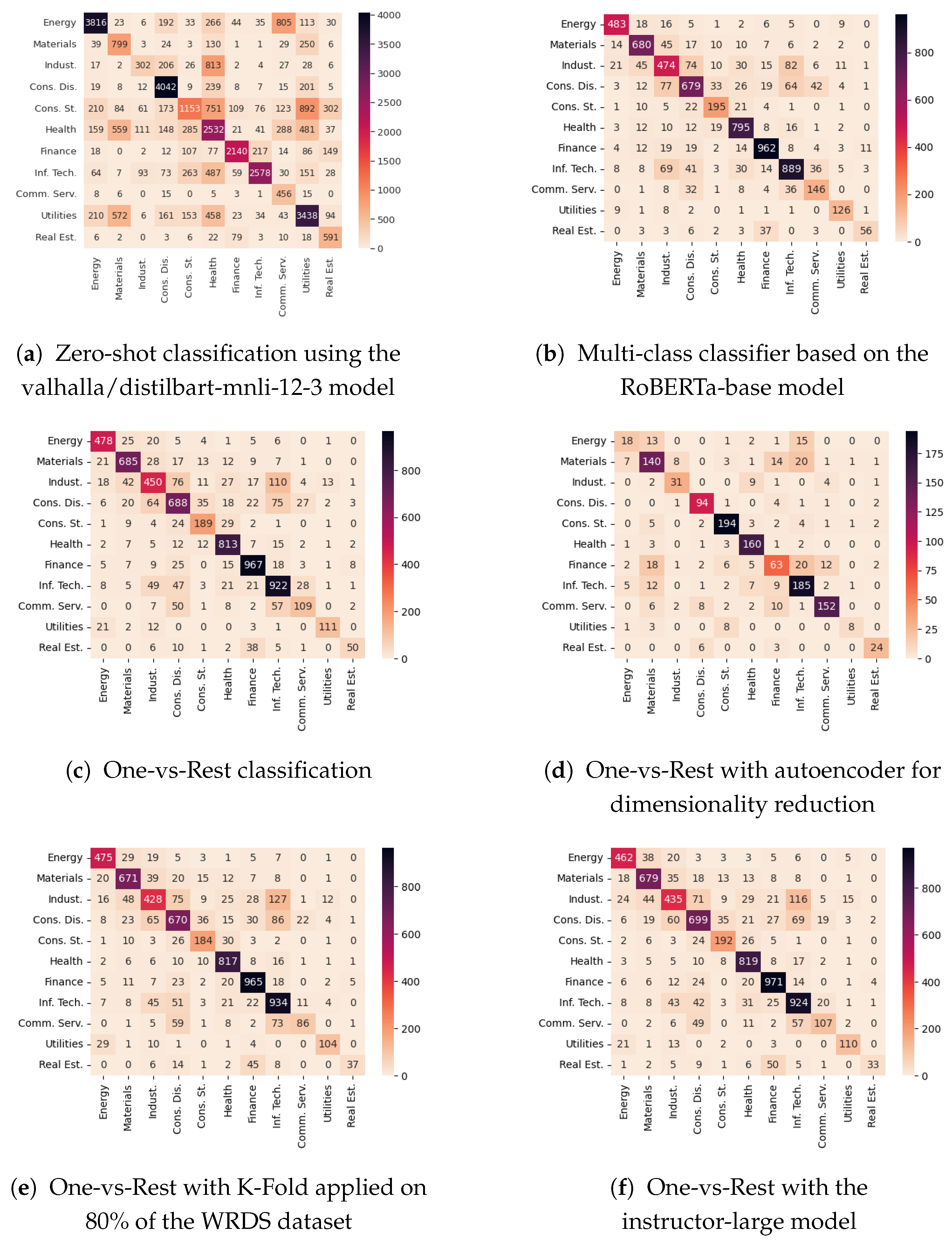
5.1. Zero-Shot Classification
5.2. Multi-Class Classifier Based on Roberta-Base
5.3. One-vs-Rest Classification
5.3.1. One-vs-Rest Classifier Using SVC Estimator with RBF and Cosine Similarity Kernel
5.3.2. One-vs-Rest Classifier Using Dimensionality Reduction with Principal Component Analysis (PCA) and Autoencoder Architecture
5.3.3. Using K-Fold to Clean the WRDS Dataset from the Incorrectly Predicted Descriptions
5.3.4. One-vs-Rest Evaluated on the WRDS Dataset Cleaned Using K-Fold
5.3.5. One-vs-Rest Evaluated on the WRDS Dataset with Omitted Company Names
5.3.6. One-vs-Rest Using Contextual Sentence Transformer
5.4. ChatGPT-Based Classification
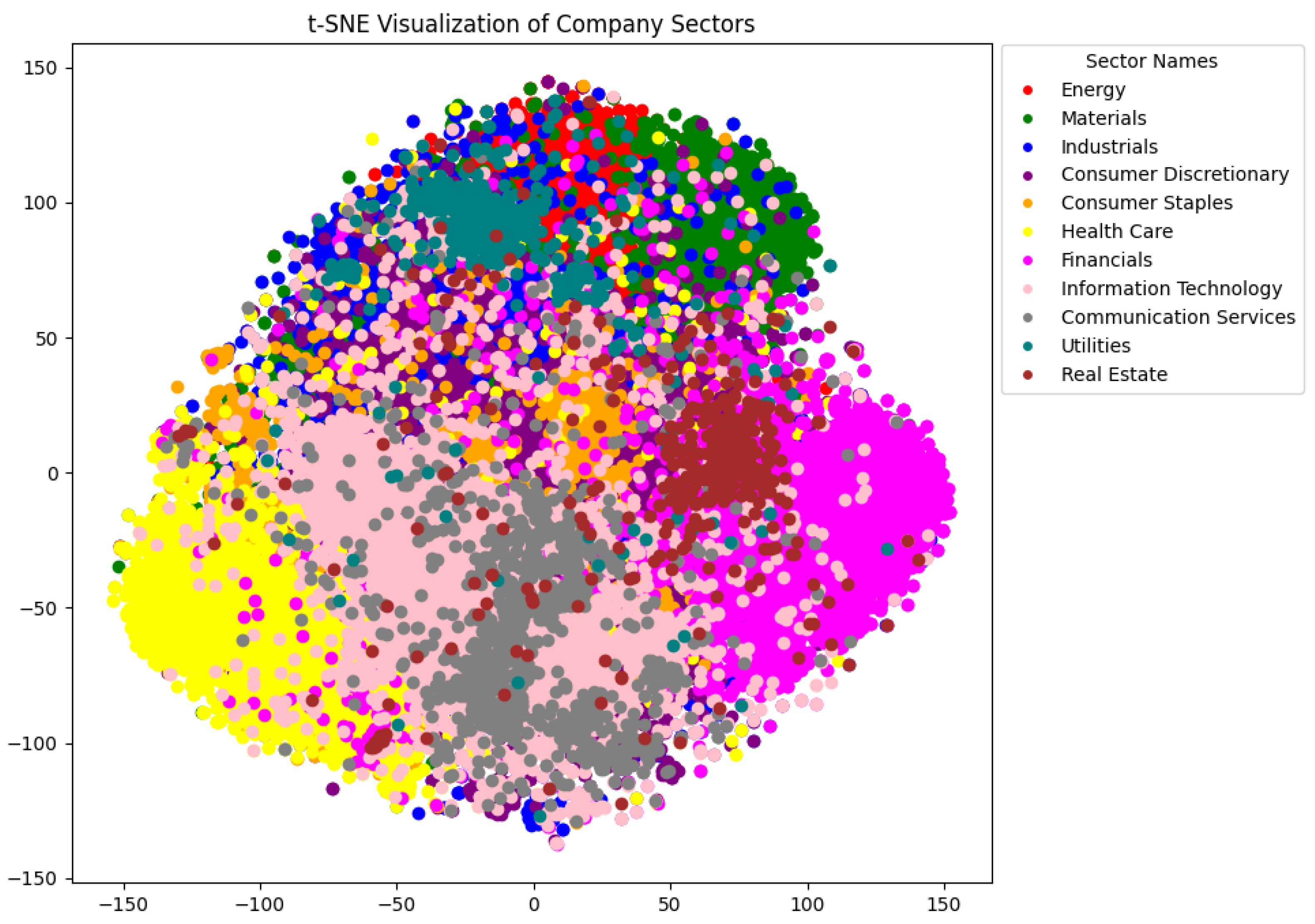
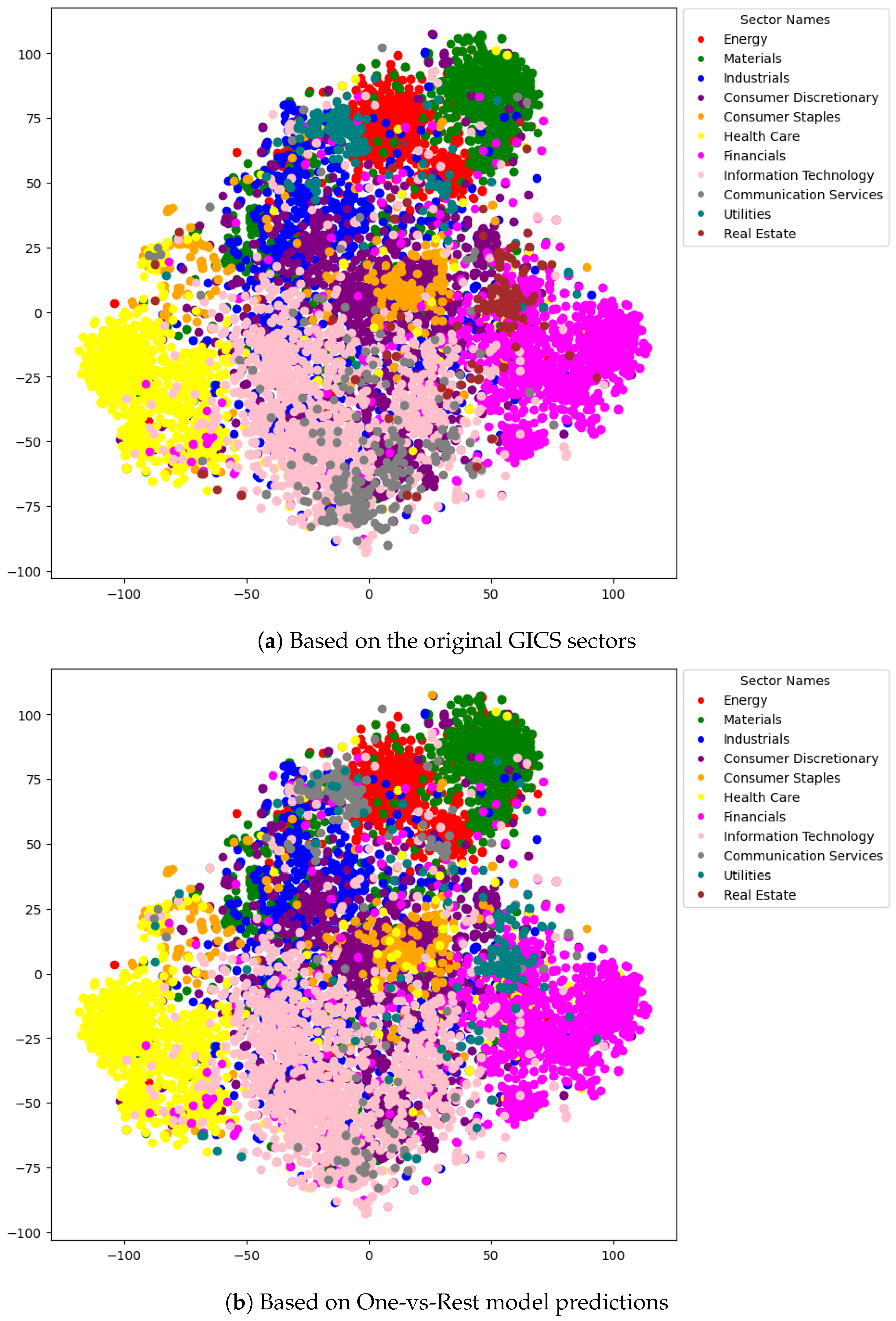
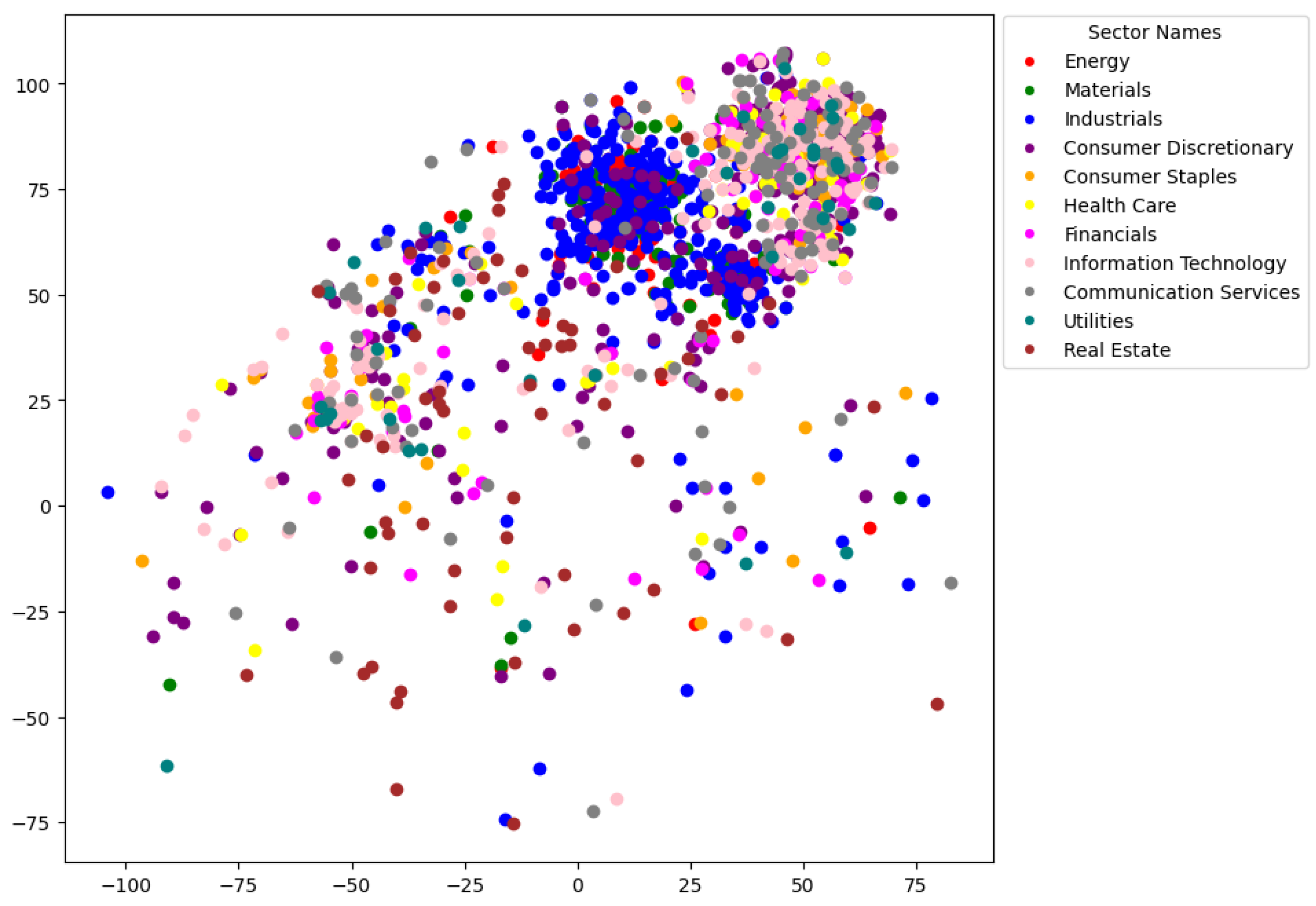
5.5. Analysis by GICS Sectors
5.6. Discussion and Model Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part 1 | Part 2 | Part 3 |
|---|---|---|
| Auto Components | Aerospace & Defense | Airlines |
| Beverages | Air Freight & Logistics | Banks |
| Capital Markets | Automobiles | Biotechnology |
| Construction & Engineering | Containers & Packaging | Building Products |
| Construction Materials | Distributors | Chemicals |
| Diversified Consumer Services | Diversified Financial Services | Commercial Services & Supplies |
| Diversified Telecommunication Services | Electrical Equipment | Communications Equipment |
| Energy Equipment & Services | Electronic Equipment, Instruments & Components | Consumer Finance |
| Entertainment | Equity Real Estate Investment Trusts (REITs) | Electric Utilities |
| Gas Utilities | Food Products | Food & Staples Retailing |
| Health Care Providers & Services | Health Care Technology | Health Care Equipment & Supplies |
| Household Products | Interactive Media & Services | Hotels, Restaurants & Leisure |
| IT Services | Life Sciences Tools & Services | Household Durables |
| Independent Power and Renewable Electricity Producers | Mortgage Real Estate Investment Trusts (REITs) | Industrial Conglomerates |
| Leisure Products | Multi-Utilities | Insurance |
| Machinery | Oil, Gas & Consumable Fuels | Internet & Direct Marketing Retail |
| Marine | Personal Products | Media |
| Multiline Retail | Road & Rail | Metals & Mining |
| Paper & Forest Products | Software | Real Estate Management & Development |
| Pharmaceuticals | Specialty Retail | Semiconductors & Semiconductor Equipment |
| Professional Services | Textiles, Apparel & Luxury Goods | Tobacco |
| Technology Hardware, Storage & Peripherals | Trading Companies & Distributors | Transportation Infrastructure |
| Thrifts & Mortgage Finance | Wireless Telecommunication Services | Water Utilities |
Appendix B
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.68 | 0.61 | 0.64 | 5363 |
| Communication Services | 0.32 | 0.63 | 0.42 | 1285 |
| Consumer Staples (Consumer Defensive) | 0.20 | 0.01 | 0.02 | 1433 |
| Health Care | 0.83 | 0.84 | 0.83 | 4565 |
| Industrials | 0.42 | 0.20 | 0.27 | 3934 |
| Consumer Discretionary (Consumer Cyclical) | 0.41 | 0.46 | 0.43 | 4662 |
| Energy | 0.56 | 0.91 | 0.69 | 2822 |
| Materials | 0.54 | 0.65 | 0.59 | 3833 |
| Real Estate | 0.29 | 0.89 | 0.44 | 509 |
| Information Technology | 0.71 | 0.54 | 0.61 | 5192 |
| Utilities | 0.44 | 0.25 | 0.32 | 740 |
| accuracy | 0.56 | 34,338 | ||
| macro avg | 0.49 | 0.54 | 0.48 | 34,338 |
| weighted avg | 0.57 | 0.56 | 0.55 | 34,338 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Banking and Lending | 0.84 | 0.71 | 0.77 | 5363 |
| Communications, Telecommunications, Networking, Media and Entertainment | 0.39 | 0.62 | 0.48 | 1285 |
| Food, Beverages and Household Products | 0.51 | 0.21 | 0.30 | 1433 |
| Health Care | 0.80 | 0.89 | 0.84 | 4565 |
| Industrials and Transportation | 0.57 | 0.29 | 0.39 | 3934 |
| Non-Essential Goods, Retail and E-Commerce | 0.44 | 0.54 | 0.48 | 4662 |
| Oil, Natural Gas, Consumable Fuels and Petroleum | 0.86 | 0.76 | 0.81 | 2822 |
| Raw Materials, Mining, Minerals and Metals (Gold, Silver and Copper) | 0.86 | 0.67 | 0.75 | 3833 |
| Real Estate Properties | 0.25 | 0.90 | 0.39 | 509 |
| Software, Technology and Systems | 0.61 | 0.66 | 0.63 | 5192 |
| Utilities, Energy Distribution and Renewable Energy | 0.47 | 0.80 | 0.59 | 740 |
| accuracy | 0.64 | 34,338 | ||
| macro avg | 0.60 | 0.64 | 0.58 | 34,338 |
| weighted avg | 0.67 | 0.64 | 0.64 | 34,338 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.88 | 0.89 | 0.89 | 545 |
| Communication Services | 0.85 | 0.86 | 0.85 | 793 |
| Consumer Staples (Consumer Defensive) | 0.65 | 0.62 | 0.63 | 769 |
| Health Care | 0.75 | 0.71 | 0.73 | 960 |
| Industrials | 0.71 | 0.75 | 0.73 | 260 |
| Consumer Discretionary (Consumer Cyclical) | 0.85 | 0.91 | 0.87 | 878 |
| Energy | 0.89 | 0.91 | 0.90 | 1058 |
| Materials | 0.80 | 0.80 | 0.80 | 1106 |
| Real Estate | 0.61 | 0.62 | 0.61 | 236 |
| Information Technology | 0.77 | 0.84 | 0.81 | 150 |
| Utilities | 0.77 | 0.50 | 0.60 | 113 |
| accuracy | 0.80 | 6868 | ||
| macro avg | 0.77 | 0.76 | 0.77 | 6868 |
| weighted avg | 0.80 | 0.80 | 0.80 | 6868 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.88 | 0.91 | 0.90 | 1058 |
| Communication Services | 0.62 | 0.46 | 0.53 | 236 |
| Consumer Staples (Consumer Defensive) | 0.70 | 0.73 | 0.71 | 260 |
| Health Care | 0.86 | 0.93 | 0.89 | 878 |
| Industrials | 0.69 | 0.59 | 0.63 | 769 |
| Consumer Discretionary (Consumer Cyclical) | 0.72 | 0.72 | 0.72 | 960 |
| Energy | 0.85 | 0.88 | 0.87 | 545 |
| Materials | 0.85 | 0.86 | 0.86 | 793 |
| Real Estate | 0.75 | 0.44 | 0.56 | 113 |
| Information Technology | 0.76 | 0.83 | 0.79 | 1106 |
| Utilities | 0.85 | 0.74 | 0.79 | 150 |
| accuracy | 0.80 | 6868 | ||
| macro avg | 0.78 | 0.74 | 0.75 | 6868 |
| weighted avg | 0.79 | 0.80 | 0.79 | 6868 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.58 | 0.48 | 0.53 | 131 |
| Communication Services | 0.88 | 0.83 | 0.85 | 183 |
| Consumer Staples (Consumer Defensive) | 0.88 | 0.91 | 0.89 | 214 |
| Health Care | 0.85 | 0.94 | 0.89 | 171 |
| Industrials | 0.72 | 0.65 | 0.68 | 48 |
| Consumer Discretionary (Consumer Cyclical) | 0.82 | 0.90 | 0.86 | 104 |
| Energy | 0.53 | 0.36 | 0.43 | 50 |
| Materials | 0.69 | 0.71 | 0.70 | 196 |
| Real Estate | 0.75 | 0.73 | 0.74 | 33 |
| Information Technology | 0.75 | 0.83 | 0.78 | 224 |
| Utilities | 0.73 | 0.40 | 0.52 | 20 |
| accuracy | 0.78 | 1374 | ||
| macro avg | 0.74 | 0.70 | 0.72 | 1374 |
| weighted avg | 0.77 | 0.78 | 0.77 | 1374 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.86 | 0.91 | 0.89 | 1058 |
| Communication Services | 0.71 | 0.36 | 0.48 | 236 |
| Consumer Staples (Consumer Defensive) | 0.70 | 0.71 | 0.70 | 260 |
| Health Care | 0.86 | 0.93 | 0.89 | 878 |
| Industrials | 0.68 | 0.56 | 0.61 | 769 |
| Consumer Discretionary (Consumer Cyclical) | 0.70 | 0.70 | 0.70 | 960 |
| Energy | 0.84 | 0.87 | 0.86 | 545 |
| Materials | 0.83 | 0.85 | 0.84 | 793 |
| Real Estate | 0.82 | 0.33 | 0.47 | 113 |
| Information Technology | 0.73 | 0.84 | 0.78 | 1106 |
| Utilities | 0.80 | 0.69 | 0.74 | 150 |
| accuracy | 0.78 | 6868 | ||
| macro avg | 0.78 | 0.70 | 0.72 | 6868 |
| weighted avg | 0.78 | 0.78 | 0.77 | 6868 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Financials | 0.86 | 0.92 | 0.89 | 1058 |
| Communication Services | 0.69 | 0.45 | 0.55 | 236 |
| Consumer Staples (Consumer Defensive) | 0.72 | 0.74 | 0.73 | 0.73 |
| Health Care | 0.84 | 0.93 | 0.88 | 878 |
| Industrials | 0.68 | 0.57 | 0.62 | 769 |
| Consumer Discretionary (Consumer Cyclical) | 0.74 | 0.73 | 0.73 | 960 |
| Energy | 0.84 | 0.85 | 0.84 | 545 |
| Materials | 0.84 | 0.86 | 0.85 | 793 |
| Real Estate | 0.82 | 0.29 | 0.43 | 113 |
| Information Technology | 0.76 | 0.84 | 0.80 | 1106 |
| Utilities | 0.79 | 0.73 | 0.76 | 150 |
| accuracy | 0.79 | 6868 | ||
| macro avg | 0.78 | 0.72 | 0.73 | 6868 |
| weighted avg | 0.79 | 0.79 | 0.78 | 6868 |
References
- Ozbayoglu, A.M.; Gudelek, M.U.; Sezer, O.B. Deep learning for financial applications: A survey. Appl. Soft Comput. 2020, 93, 106384. [Google Scholar] [CrossRef]
- Goodell, J.W.; Kumar, S.; Lim, W.M.; Pattnaik, D. Artificial intelligence and machine learning in finance: Identifying foundations, themes, and research clusters from bibliometric analysis. J. Behav. Exp. Financ. 2021, 32, 100577. [Google Scholar] [CrossRef]
- Kumar, S.; Sharma, D.; Rao, S.; Lim, W.M.; Mangla, S.K. Past, present, and future of sustainable finance: Insights from big data analytics through machine learning of scholarly research. Ann. Oper. Res. 2022, 1–44. [Google Scholar]
- Kraus, M.; Feuerriegel, S.; Oztekin, A. Deep learning in business analytics and operations research: Models, applications and managerial implications. Eur. J. Oper. Res. 2020, 281, 628–641. [Google Scholar] [CrossRef]
- Delen, D.; Ram, S. Research challenges and opportunities in business analytics. J. Bus. Anal. 2018, 1, 2–12. [Google Scholar] [CrossRef]
- Ajah, I.A.; Nweke, H.F. Big data and business analytics: Trends, platforms, success factors and applications. Big Data Cogn. Comput. 2019, 3, 32. [Google Scholar] [CrossRef]
- Zhang, J.Z.; Srivastava, P.R.; Sharma, D.; Eachempati, P. Big data analytics and machine learning: A retrospective overview and bibliometric analysis. Expert Syst. Appl. 2021, 184, 115561. [Google Scholar] [CrossRef]
- Lin, W.Y.; Hu, Y.H.; Tsai, C.F. Machine learning in financial crisis prediction: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 42, 421–436. [Google Scholar]
- Chen, N.; Ribeiro, B.; Chen, A. Financial credit risk assessment: A recent review. Artif. Intell. Rev. 2016, 45, 1–23. [Google Scholar] [CrossRef]
- Bhatore, S.; Mohan, L.; Reddy, Y.R. Machine learning techniques for credit risk evaluation: A systematic literature review. J. Bank. Financ. Technol. 2020, 4, 111–138. [Google Scholar] [CrossRef]
- Nassirtoussi, A.K.; Aghabozorgi, S.; Wah, T.Y.; Ngo, D.C.L. Text mining for market prediction: A systematic review. Expert Syst. Appl. 2014, 41, 7653–7670. [Google Scholar] [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A systematic review of fundamental and technical analysis of stock market predictions. Artif. Intell. Rev. 2020, 53, 3007–3057. [Google Scholar] [CrossRef]
- Kumbure, M.M.; Lohrmann, C.; Luukka, P.; Porras, J. Machine learning techniques and data for stock market forecasting: A literature review. Expert Syst. Appl. 2022, 197, 116659. [Google Scholar] [CrossRef]
- Sohangir, S.; Wang, D.; Pomeranets, A.; Khoshgoftaar, T.M. Big Data: Deep Learning for financial sentiment analysis. J. Big Data 2018, 5, 1–25. [Google Scholar] [CrossRef]
- Araci, D. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of sentiment analysis in finance: From lexicons to transformers. IEEE Access 2020, 8, 131662–131682. [Google Scholar] [CrossRef]
- Rizinski, M.; Peshov, H.; Mishev, K.; Jovanovik, M.; Trajanov, D. Sentiment Analysis in Finance: From Transformers Back to eXplainable Lexicons (XLex). IEEE Access 2024, 12, 7170–7198. [Google Scholar] [CrossRef]
- Bhojraj, S.; Lee, C.M.; Oler, D.K. What’s my line? A comparison of industry classification schemes for capital market research. J. Account. Res. 2003, 41, 745–774. [Google Scholar] [CrossRef]
- Lyocsa, S.; Vyrost, T. Industry Classification: Review, Hurdles and Methodologies: Hurdles and Methodologies (30 September 2009). 2009. Available online: https://ssrn.com/abstract=1480563 (accessed on 15 January 2024).
- Chan, L.K.; Lakonishok, J.; Swaminathan, B. Industry classifications and return comovement. Financ. Anal. J. 2007, 63, 56–70. [Google Scholar] [CrossRef]
- Wood, S.; Muthyala, R.; Jin, Y.; Qin, Y.; Rukadikar, N.; Rai, A.; Gao, H. Automated industry classification with deep learning. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 122–129. [Google Scholar]
- Porter, M.E.; Strategy, C. Techniques for Analyzing Industries and Competitors; The Free Press USA: New York, NY, USA, 1980. [Google Scholar]
- Phillips, R.L.; Ormsby, R. Industry classification schemes: An analysis and review. J. Bus. Financ. Librariansh. 2016, 21, 1–25. [Google Scholar] [CrossRef]
- Yang, H.; Lee, H.J.; Cho, S.; Cho, E. Automatic classification of securities using hierarchical clustering of the 10-Ks. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3936–3943. [Google Scholar]
- Lamby, M.; Isemann, D. Classifying companies by industry using word embeddings. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Paris, France, 13–15 June 2018; Springer: Cham, Switzerland, 2018; pp. 377–388. [Google Scholar]
- Fama, E.F.; French, K.R. Industry costs of equity. J. Financ. Econ. 1997, 43, 153–193. [Google Scholar] [CrossRef]
- Kile, C.O.; Phillips, M.E. Using industry classification codes to sample high-technology firms: Analysis and recommendations. J. Account. Audit. Financ. 2009, 24, 35–58. [Google Scholar] [CrossRef]
- Hrazdil, K.; Zhang, R. The importance of industry classification in estimating concentration ratios. Econ. Lett. 2012, 114, 224–227. [Google Scholar] [CrossRef]
- Boni, L.; Womack, K.L. Analysts, industries, and price momentum. J. Financ. Quant. Anal. 2006, 41, 85–109. [Google Scholar] [CrossRef]
- Hrazdil, K.; Trottier, K.; Zhang, R. A comparison of industry classification schemes: A large sample study. Econ. Lett. 2013, 118, 77–80. [Google Scholar] [CrossRef]
- Slavov, S.; Tagarev, A.; Tulechki, N.; Boytcheva, S. Company Industry Classification with Neural and Attention-Based Learning Models. In Proceedings of the 2019 Big Data, Knowledge and Control Systems Engineering (BdKCSE), Sofia, Bulgaria, 21–22 November 2019; pp. 1–7. [Google Scholar]
- Kahle, K.M.; Walkling, R.A. The impact of industry classifications on financial research. J. Financ. Quant. Anal. 1996, 31, 309–335. [Google Scholar] [CrossRef]
- Katselas, D.; Sidhu, B.K.; Yu, C. Know your industry: The implications of using static GICS classifications in financial research. Account. Financ. 2019, 59, 1131–1162. [Google Scholar] [CrossRef]
- Tagarev, A.; Tulechki, N.; Boytcheva, S. Comparison of Machine Learning Approaches for Industry Classification Based on Textual Descriptions of Companies. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 1169–1175. [Google Scholar]
- He, J.; Chen, K. Exploring Machine Learning Techniques for Text-Based Industry Classification. 2020. Available online: https://ssrn.com/abstract=3640205 (accessed on 15 January 2024).
- Wu, D.; Wang, Q.; Olson, D.L. Industry classification based on supply chain network information using Graph Neural Networks. Appl. Soft Comput. 2023, 132, 109849. [Google Scholar] [CrossRef]
- Ito, T.; Camacho-Collados, J.; Sakaji, H.; Schockaert, S. Learning company embeddings from annual reports for fine-grained industry characterization. In Proceedings of the Second Workshop on Financial Technology and Natural Language Processing, Kyoto, Japan, 5 January 2020; pp. 27–33. [Google Scholar]
- Wang, S.; Pan, Y.; Xu, Z.; Hu, B.; Wang, X. Enriching BERT with Knowledge Graph Embedding for Industry Classification. In Proceedings of the International Conference on Neural Information Processing, Sanur, Bali, Indonesia, 8–12 December 2021; Springer: Cham, Switzerland, 2021; pp. 709–717. [Google Scholar]
- Dolphin, R.; Smyth, B.; Dong, R. A Machine Learning Approach to Industry Classification in Financial Markets. In Proceedings of the Irish Conference on Artificial Intelligence and Cognitive Science, Munster, Ireland, 8–9 December 2022; Springer: Cham, Switzerland, 2022; pp. 81–94. [Google Scholar]
- Zhao, X.; Fang, X.; He, J.; Huang, L. Exploiting Expert Knowledge for Assigning Firms to Industries: A Novel Deep Learning Method. arXiv 2022, arXiv:2209.05943. [Google Scholar]
- Husmann, S.; Shivarova, A.; Steinert, R. Company classification using machine learning. Expert Syst. Appl. 2022, 195, 116598. [Google Scholar] [CrossRef]
- Kim, D.; Kang, H.G.; Bae, K.; Jeon, S. An artificial intelligence-enabled industry classification and its interpretation. Internet Res. 2021, 32, 406–424. [Google Scholar] [CrossRef]
- Bernstein, A.; Clearwater, S.; Provost, F. The relational vector-space model and industry classification. In Proceedings of the Learning Statistical Models from Relational Data Workshop at the Nineteenth International Joint Conference on Artificial Intelligence (IJCAI), Acapulco, Mexico, 9–15 August 2003. [Google Scholar]
- Drury, B.; Almeida, J.J. Identification, extraction and population of collective named entities from business news. In Proceedings of the Entity 2010—Workshop on Resources and Evaluation for Entity Resolution and Entity Management, Valletta, Malta, 22 May 2010. [Google Scholar]
- Gerling, C. Company2Vec—German Company Embeddings based on Corporate Websites. arXiv 2023, arXiv:2307.09332. [Google Scholar] [CrossRef]
- Vamvourellis, D.; Toth, M.; Bhagat, S.; Desai, D.; Mehta, D.; Pasquali, S. Company Similarity using Large Language Models. arXiv 2023, arXiv:2308.08031. [Google Scholar]
- de Carvalho, A.C.; Freitas, A.A. A tutorial on multi-label classification techniques. In Foundations of Computational Intelligence Volume 5: Function Approximation and Classification; Springer: Berlin/Heidelberg, Germany, 2009; pp. 177–195. [Google Scholar]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Tanha, J.; Abdi, Y.; Samadi, N.; Razzaghi, N.; Asadpour, M. Boosting methods for multi-class imbalanced data classification: An experimental review. J. Big Data 2020, 7, 70. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 38–45. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA; Volume 30.
- Pushp, P.K.; Srivastava, M.M. Train once, test anywhere: Zero-shot learning for text classification. arXiv 2017, arXiv:1712.05972. [Google Scholar]
- Rizinski, M.; Jankov, A.; Sankaradas, V.; Pinsky, E.; Miskovski, I.; Trajanov, D. Company classification using zero-shot learning. arXiv 2023, arXiv:2305.01028. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Su, H.; Shi, W.; Kasai, J.; Wang, Y.; Hu, Y.; Ostendorf, M.; Yih, W.t.; Smith, N.A.; Zettlemoyer, L.; Yu, T. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. arXiv 2022, arXiv:2212.09741. [Google Scholar]
| GICS Taxonomy | |||
|---|---|---|---|
| Level | Title | Number of Categories | Digits |
| Level 1 (broadest) | Sector | 11 | first 2 digits |
| Level 2 | Industry Group | 24 | first 4 digits |
| Level 3 | Industry | 64 | first 6 digits |
| Level 4 (narrowest) | Sub-industry | 139 | all 8 digits |
| Referenced Paper | Year of Publication | Description |
|---|---|---|
| [24] | 2016 | Introduces a model called Business Text Industry Classification (BTIC), developed on a dataset comprising Form 10-K documents of S&P500 companies. |
| [21] | 2017 | Employs a deep neural network based on a multilayer perceptron architecture and trained on a dataset from the proprietary EverString database with the goal of classifying companies into six-digit NAICS codes. |
| [25] | 2018 | Uses Word2Vec models with varying window sizes, different SVM kernels, and logistic regression solvers. The models are trained on a corpus of Guardian articles, which consists of 600 million words. Evaluation is performed on company–industry mappings extracted from DBpedia. |
| [34] | 2019 | Compares Glove and ULMfit with two baseline models (one-hot unigram and one-hot bigram) using a dataset extracted from the English DBpedia. The dataset comprises 300,000 uniform-length textual descriptions of companies from 32 industries in DBpedia. |
| [31] | 2019 | Uses the same experimental setup as in [34] to assess BERT and XLNet, in addition to Glove and ULMfit. |
| [35] | 2020 | Investigates various word and document embedding techniques combined with clustering algorithms on datasets comprising publicly traded companies in the US and China. Compares the obtained results with GICS. |
| [37] | 2020 | Proposes a method for fine-tuning a pretrained BERT model, which is evaluated on datasets consisting of US and Japanese company data from Form 10-K documents and data from the Tokyo Stock Exchange, respectively. |
| [38] | 2021 | Introduces a model called knowledge graph enriched BERT (KGEB), tested on publicly listed Chinese companies. KGEB enhances word representations by learning the graph structure of the underlying dataset, and is capable of loading pretrained BERT and fine-tuning it for company classification. |
| [39] | 2022 | Employs a multimodal neural model that facilitates the identification of related companies by leveraging similarities found in historical prices and financial news. |
| [40] | 2022 | Proposes a deep learning method that leverages various sources of knowledge for company classification, such as assignment-based, definition-based, and structure-based knowledge. |
| [41] | 2022 | Uses unsupervised learning, employing t-SNE and spectral clustering, to reduce the dimensionality of large datasets and generate visualizations that assist domain experts in making informed decisions about company classification. |
| [45] | 2023 | Presents a model called Company2Vec based on Word2Vec and dimensionality reduction as well as on unstructured textual and visual data from German company webpages, aiming to predict companies’ business activities based on NACE codes. |
| [46] | 2023 | Utilizes large language models to generate company embeddings by analyzing raw business descriptions extracted SEC 10-K filings. Assesses the ability of the embeddings to replicate GICS sector/industry classifications. |
| [36] | 2023 | Employs graph neural networks (GNNs) for classification of Chinese companies based on the China Securities Regulatory Commission (CSRC) classification scheme. |
| WRDS Dataset | |
|---|---|
| GICS Sector | Number of Companies |
| Energy | 2822 |
| Materials | 3833 |
| Industrials | 3934 |
| Consumer Discretionary | 4662 |
| Consumer Staples | 1433 |
| Health Care | 4565 |
| Financials | 5363 |
| Information Technology | 5192 |
| Communication Services | 1285 |
| Utilities | 740 |
| Real Estate | 509 |
| Dataset | Description | Purpose | Size |
|---|---|---|---|
| W-Full | Full size of the WRDS dataset | Test | 34,338 |
| W-Train | 80% of the WRDS dataset | Train | 27,470 |
| W-Train-C | W-Train cleaned with K-Fold | Train | 21,716 |
| W-Test | 20% of the WRDS dataset | Test | 6868 |
| W-Full-R | WRDS dataset with removed company names | Test | 34,338 |
| W-Train-R | 80% of the W-Full-R dataset | Train | 27,470 |
| W-Test-R | 20% of the W-Full-R dataset | Test | 6868 |
| CG-Full | Full size of the ChatGPT-generated dataset | Test | 220 |
| CG-Train | 80% of the ChatGPT-generated dataset | Train | 176 |
| CG-Test | 20% of the ChatGPT-generated dataset | Test | 44 |
| Kaggle | Kaggle dataset | Test | 158 |
| W-AE-Full | W-Test compressed to 100 dim. using autoencoder | Test | 6868 |
| W-AE-Train | 80% of the W-AE-Full dataset | Train | 5494 |
| W-AE-Test | 20% of the W-AE-Full dataset | Test | 1374 |
| W-MC | Dataset of misclassified company descriptions | Test | 1445 |
| Datasets | Macro Average | Weighted Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Precision | Recall | F1 Score | Precision | Recall | F1 Score | Support | Final F1 Score | |
| Zero-shot classification with valhalla/distilbart-mnli-12-3 | ||||||||||
| Using original GICS sector names | — | W-Full | 0.49 | 0.54 | 0.48 | 0.57 | 0.56 | 0.55 | 34338 | 0.56 |
| Using GICS sector names enhanced with TF-IDF | — | W-Full | 0.60 | 0.64 | 0.58 | 0.67 | 0.64 | 0.64 | 34338 | 0.64 |
| Zero-shot classification on industries (part 1) | — | W-Full | 0.51 | 0.10 | 0.12 | 0.72 | 0.77 | 0.69 | 34338 | 0.77 |
| Zero-shot classification on industries (part 2) | — | W-Full | 0.44 | 0.09 | 0.12 | 0.68 | 0.71 | 0.61 | 34338 | 0.71 |
| Zero-shot classification on industries (part 3) | — | W-Full | 0.61 | 0.13 | 0.17 | 0.65 | 0.60 | 0.48 | 34338 | 0.60 |
| Multi-class classifier based on RoBERTa-base | ||||||||||
| Using GICS sectors | W-Train | W-Test | 0.77 | 0.76 | 0.77 | 0.80 | 0.80 | 0.80 | 6868 | 0.80 |
| Using GICS industrial groups | W-Train | W-Test | 0.72 | 0.70 | 0.71 | 0.75 | 0.75 | 0.75 | 6868 | 0.75 |
| One-vs-Rest (OvR) classification with all-mpnet-base-v2 | ||||||||||
| OvR classifier using SVC estimator with RBF kernel | W-Train | W-Test | 0.78 | 0.74 | 0.75 | 0.79 | 0.80 | 0.79 | 6868 | 0.80 |
| OvR classifier using SVC estimator with cosine similarity kernel | W-Train | W-Test | 0.76 | 0.72 | 0.73 | 0.77 | 0.78 | 0.77 | 6868 | 0.78 |
| Using dimensionality reduction with PCA to 100 dim. | W-Train | W-Test | 0.27 | 0.29 | 0.27 | 0.37 | 0.42 | 0.39 | 6868 | 0.42 |
| Using dimensionality reduction with autoenc. arch. to 100 dim. | W-AE-Train | W-AE-Test | 0.74 | 0.70 | 0.72 | 0.77 | 0.78 | 0.77 | 1374 | 0.78 |
| Trained on W-Train-C and tested on W-Test | W-Train-C | W-Test | 0.78 | 0.70 | 0.72 | 0.78 | 0.78 | 0.77 | 6868 | 0.78 |
| Evaluated on WRDS with removed company names | W-Train-R | W-Test-R | 0.77 | 0.73 | 0.75 | 0.77 | 0.78 | 0.77 | 6868 | 0.78 |
| Using contextual sentence transformer (hkunlp/instructor-large) | W-Train | W-Test | 0.78 | 0.72 | 0.73 | 0.79 | 0.79 | 0.78 | 6868 | 0.79 |
| ChatGPT-based classification | ||||||||||
| Using zero-shot classification with label descriptions | — | W-Full | 0.60 | 0.67 | 0.58 | 0.69 | 0.61 | 0.61 | 34338 | 0.61 |
| OvR with ChatGPT descriptions | CG-Train | CG-Test | 0.52 | 0.55 | 0.50 | 0.59 | 0.52 | 0.51 | 44 | 0.52 |
| OvR with ChatGPT descriptions | CG-Train | W-Full | 0.56 | 0.52 | 0.40 | 0.66 | 0.46 | 0.39 | 34338 | 0.46 |
| ChatGPT predicting on W-Test | — | W-Test | 0.71 | 0.66 | 0.67 | 0.82 | 0.71 | 0.75 | 3434 | 0.71 |
| ChatGPT predicting the W-MC | — | W-MC | 0.24 | 0.21 | 0.21 | 0.28 | 0.22 | 0.23 | 1445 | 0.22 |
| Sector Names | |
|---|---|
| Original GICS Names | Names after TF-IDF |
| Energy | Oil, Natural Gas, Consumable Fuels and Petroleum |
| Materials | Raw Materials, Mining, Minerals and Metals (Gold, Silver and Copper) |
| Industrials | Industrials and Transportation |
| Consumer Discretionary | Non-Essential Goods, Retail and E-Commerce |
| Consumer Staples | Food, Beverages and Household Products |
| Health Care | Health Care |
| Financials | Banking and Lending |
| Information Technology | Software, Technology and Systems |
| Communication Services | Communications, Telecommunications, Networking, Media and Entertainment |
| Utilities | Utilities, Energy Distribution and Renewable Energy |
| Real Estate | Real Estate Properties |
| Datasets | Macro Average | Weighted Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Precision | Recall | F1 Score | Precision | Recall | F1 Score | Support | Final F1 Score | |
| One-vs-Rest classifier based on all-mpnet-base-v2 | W-Train-C | Kaggle | 0.90 | 0.84 | 0.84 | 0.87 | 0.85 | 0.84 | 158 | 0.85 |
| Multi-class classifier based on RoBERTa-base | W-Train | Kaggle | 0.93 | 0.85 | 0.85 | 0.90 | 0.87 | 0.86 | 158 | 0.87 |
| F1 Scores | ||
|---|---|---|
| GICS Sectors | Multi-Class Classifier | One-vs-Rest Classifier |
| Financials | 0.89 | 0.90 |
| Communication Services | 0.85 | 0.53 |
| Consumer Staples (Consumer Defensive) | 0.63 | 0.71 |
| Health Care | 0.73 | 0.89 |
| Industrials | 0.73 | 0.63 |
| Consumer Discretionary (Consumer Cyclical) | 0.87 | 0.72 |
| Energy | 0.90 | 0.87 |
| Materials | 0.80 | 0.86 |
| Real Estate | 0.61 | 0.56 |
| Information Technology | 0.81 | 0.79 |
| Utilities | 0.60 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizinski, M.; Jankov, A.; Sankaradas, V.; Pinsky, E.; Mishkovski, I.; Trajanov, D. Comparative Analysis of NLP-Based Models for Company Classification. Information 2024, 15, 77. https://doi.org/10.3390/info15020077
Rizinski M, Jankov A, Sankaradas V, Pinsky E, Mishkovski I, Trajanov D. Comparative Analysis of NLP-Based Models for Company Classification. Information. 2024; 15(2):77. https://doi.org/10.3390/info15020077
Chicago/Turabian StyleRizinski, Maryan, Andrej Jankov, Vignesh Sankaradas, Eugene Pinsky, Igor Mishkovski, and Dimitar Trajanov. 2024. "Comparative Analysis of NLP-Based Models for Company Classification" Information 15, no. 2: 77. https://doi.org/10.3390/info15020077
APA StyleRizinski, M., Jankov, A., Sankaradas, V., Pinsky, E., Mishkovski, I., & Trajanov, D. (2024). Comparative Analysis of NLP-Based Models for Company Classification. Information, 15(2), 77. https://doi.org/10.3390/info15020077