

An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification





Abstract
:1. Introduction
- An automated system was developed to reduce the reliance on human experts when it comes to identifying different medicinal plant species. Classically, identifying plant species often requires experts who possess knowledge of botanical characteristics, but this system aims to lessen that dependency by using technology to perform the identification task.
- In this work, we adjusted the hyperparameters, like the learning rates, batch sizes, and regularization techniques, to ensure the model performed optimally for this classification task.
- Also, transfer learning and fine-tuning are being used to extract meaningful and informative features from images of medicinal plant leaves. Instead of training a deep learning model from scratch, the pre-trained models VGG16, VGG19, and DenseNet201 were used as a starting point. These models were leveraged to enhance the ability of identifying and extracting relevant information from medicinal plant images, which were used for species identification or other related purposes.
- Also, a comparative analysis was performed in this study, including several previously state-of-the-art approaches for the identification of medicinal plants using the same dataset, leveraging the complementary features of VGG19 and DenseNet201, the ensemble approach improved the robustness and balanced the performance, making it a potent solution for medicinal plant identification.
2. Related Work
3. Methods and Material
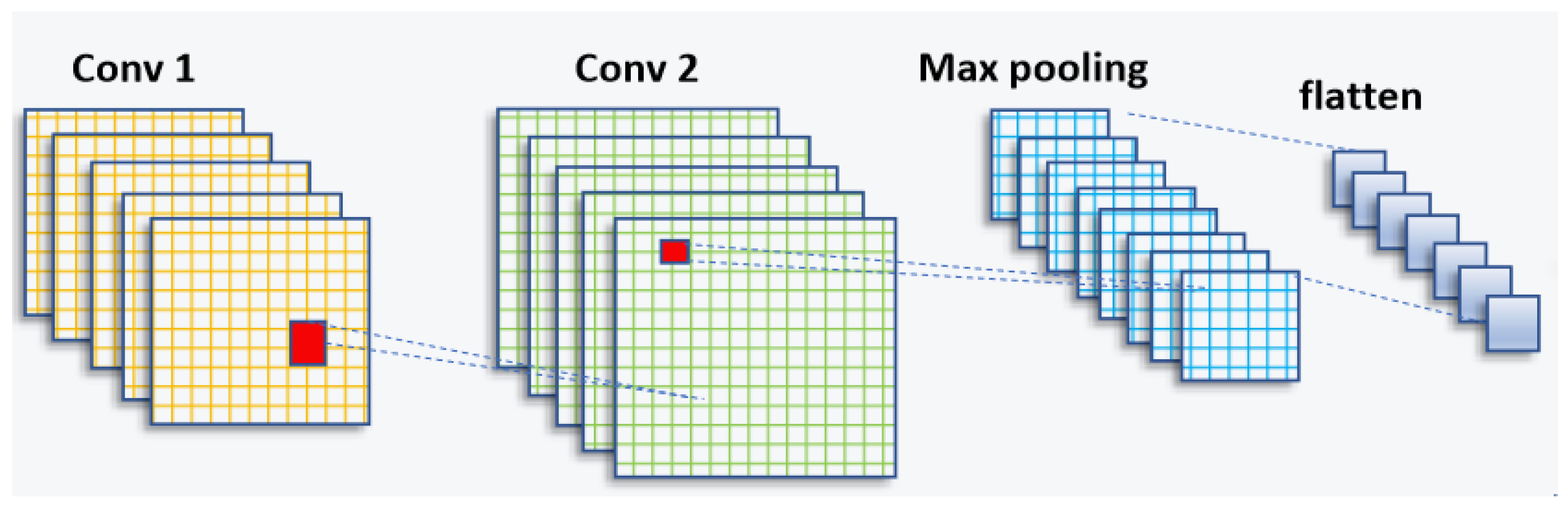
3.1. Convolutional Neural Network
3.2. VGG-16
3.3. VGG-19
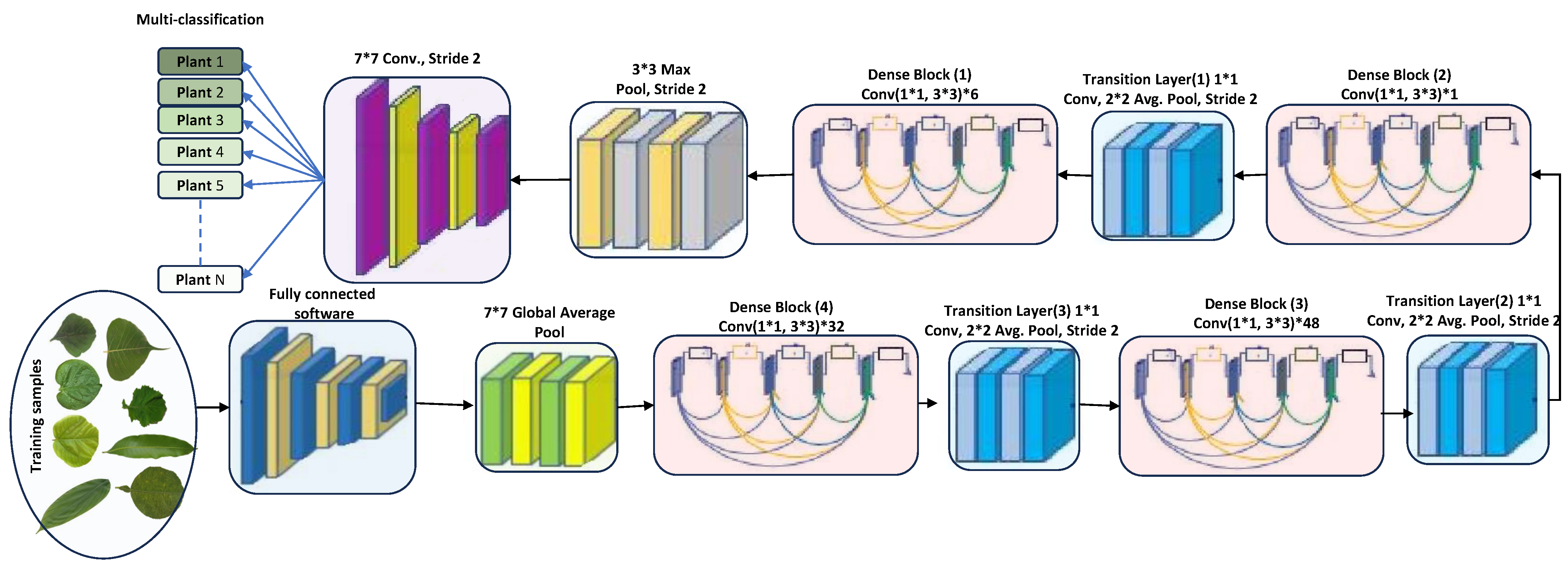
3.4. DenseNet201
3.5. Ensemble Learning Approach
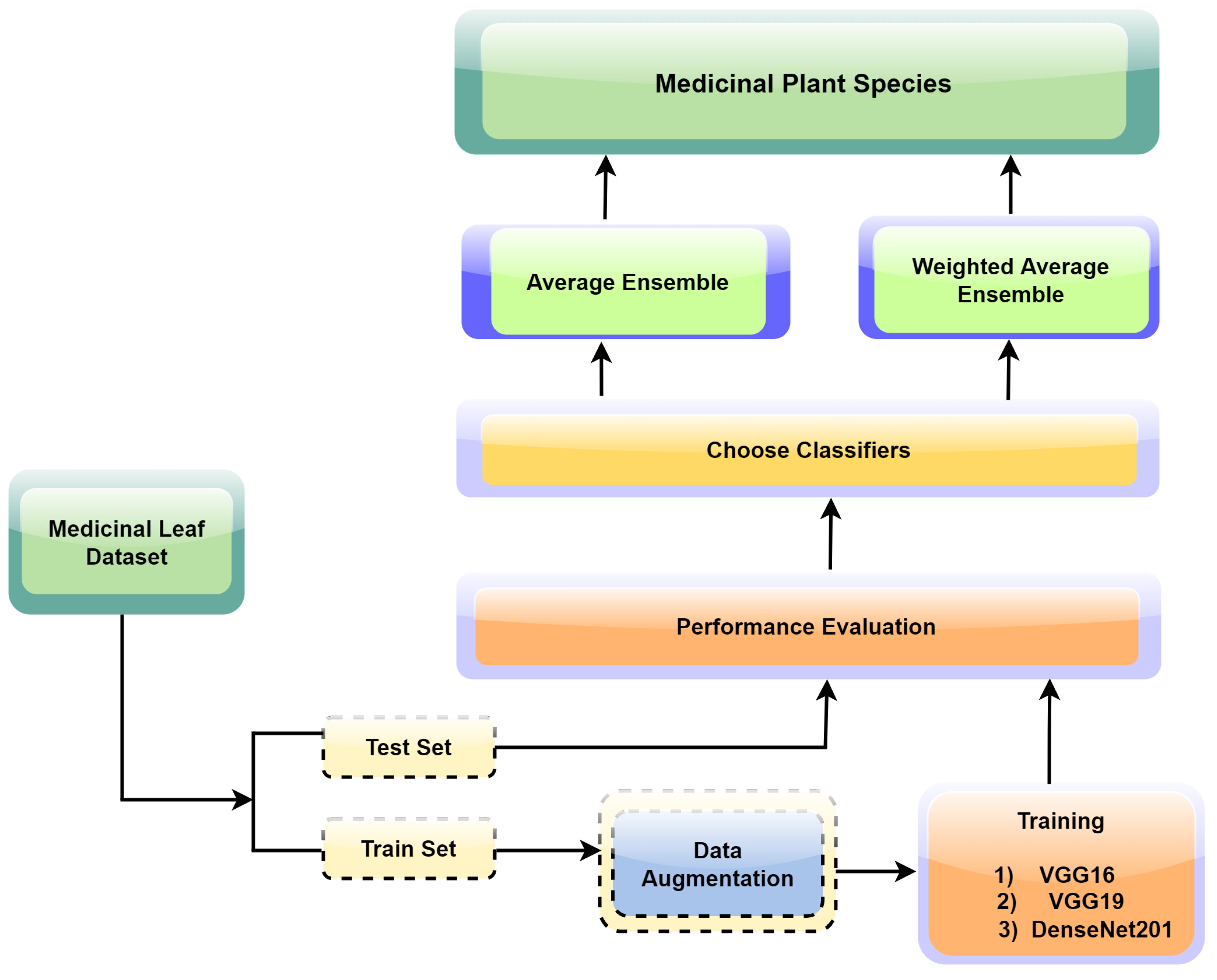
3.6. Proposed Ensemble Learning for Medicinal Plant Leaf Identification
- (1)
- Data loading and splitting: Collect “Mendeley Data–Medicinal Leaf Dataset” (1835 images, 30 species), and split into training (70%) and testing (30%).
- (2)
- Model selection: Choose VGG16, VGG19, and DenseNet201 as the base models.
- (3)
- Image standardization: Resize images to 224 × 224 px, which is compatible with the input size expected by the CNN models.
- (4)
- Data augmentation: Enhance the model learning and diversity by applying random rotations, flips, translations, and adjustments to brightness or contrast. This exposure to image variations during training improves the model’s generalization.
- (5)
- Batch generation: Divide the dataset into smaller subsets of images, which are then fed into the CNN model during training. This approach enhances the computational efficiency by processing a portion of the dataset at a time, rather than the entire dataset at once.
- (6)
- Training and transfer learning: The models were trained individually employing transfer learning with softmax activation [39] for classification using the Adam optimizer and categorical cross-entropy.
- (7)
- Validation models: For each trained model, the prediction was performed by calculating the class probabilities on the test set.
- (8)
- Hybridization models: The ensemble models were created by combining the results generated by individual classifiers, using the averaging and weighted averaging strategies. Using the three components, VGG16, VGG19, and DenseNet201, the feasible ensemble models were created, validated, and compared to select the best-performing model. The proposed learning framework can be seen in Figure 4.
3.7. Hyperparameter Tuning Using Grid Search
3.8. Dataset Description
3.9. Data Preprocessing
4. Evaluation Metrics
4.1. Accuracy
4.2. Recall
4.3. Precision
4.4. F1-Score
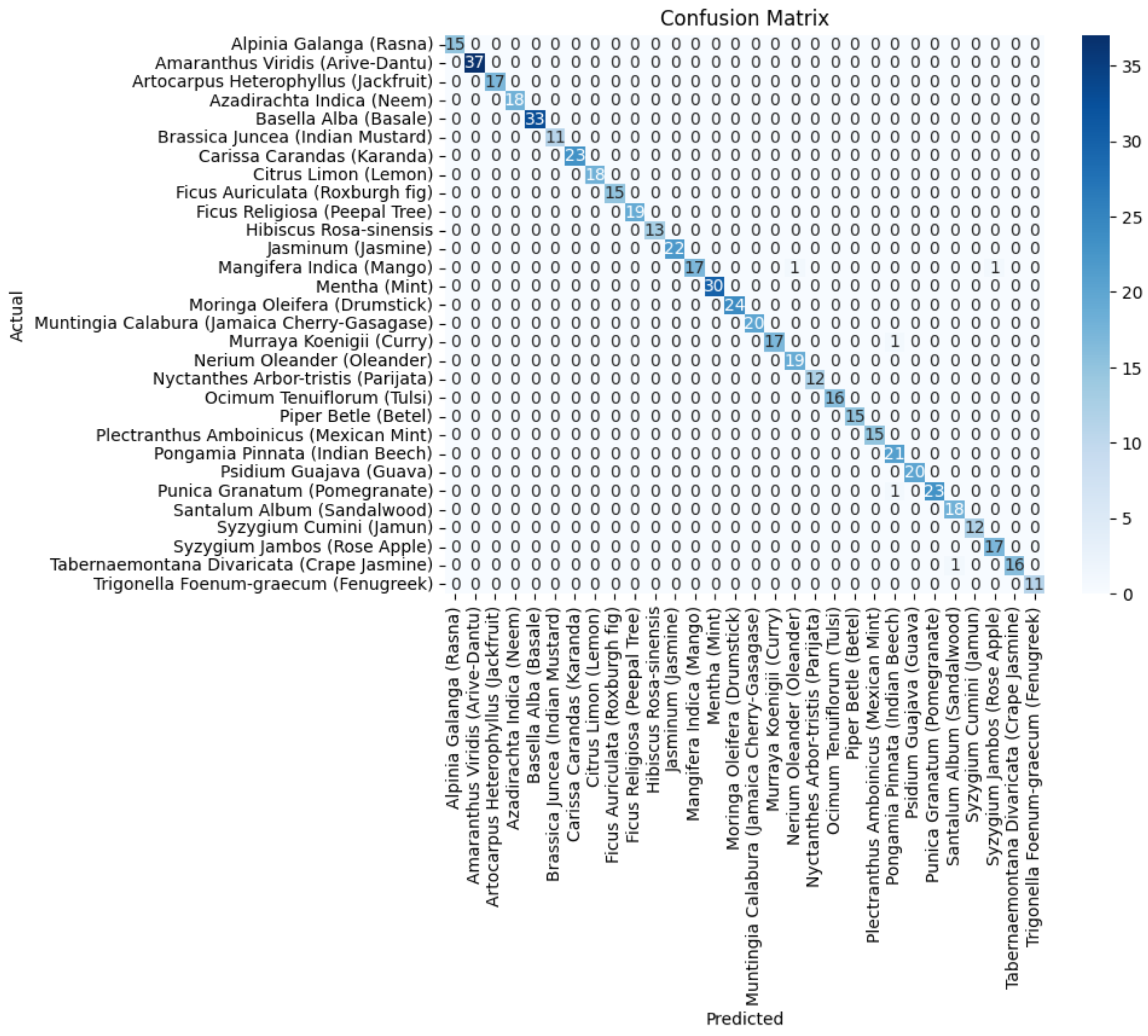
5. Experimental Results
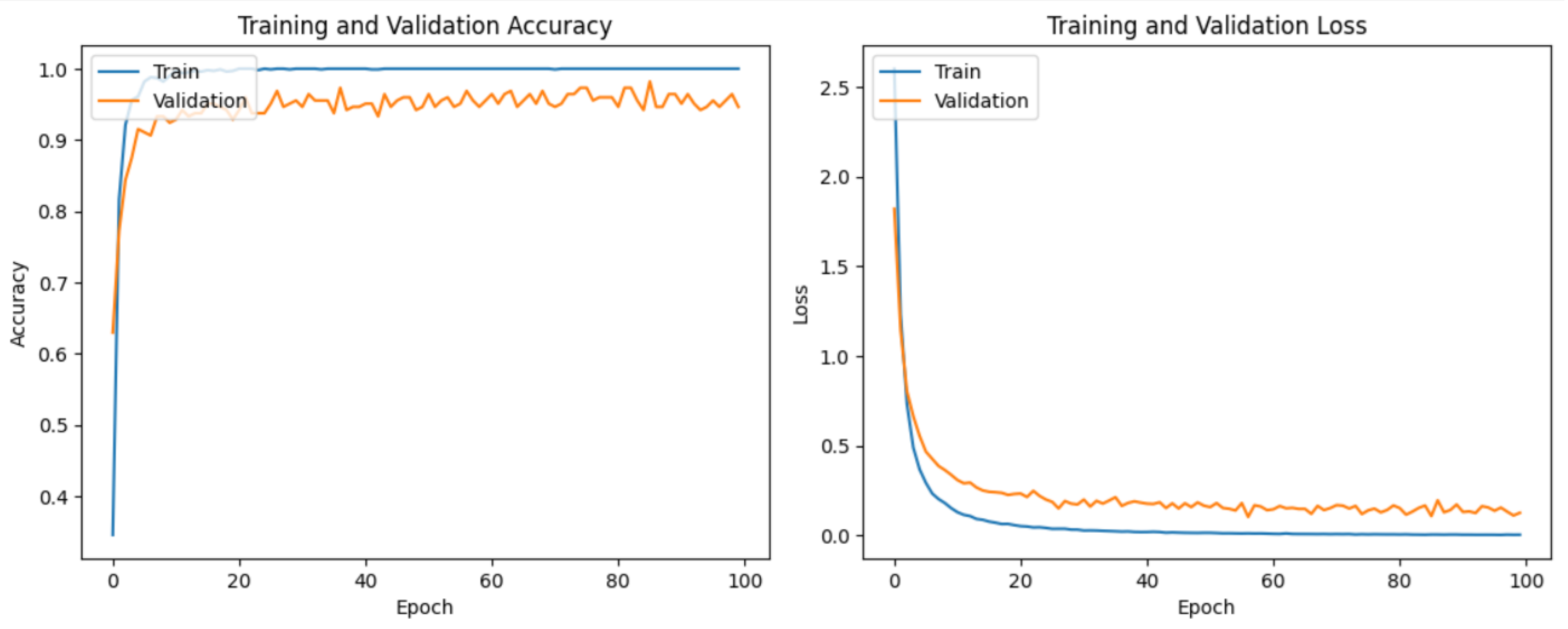
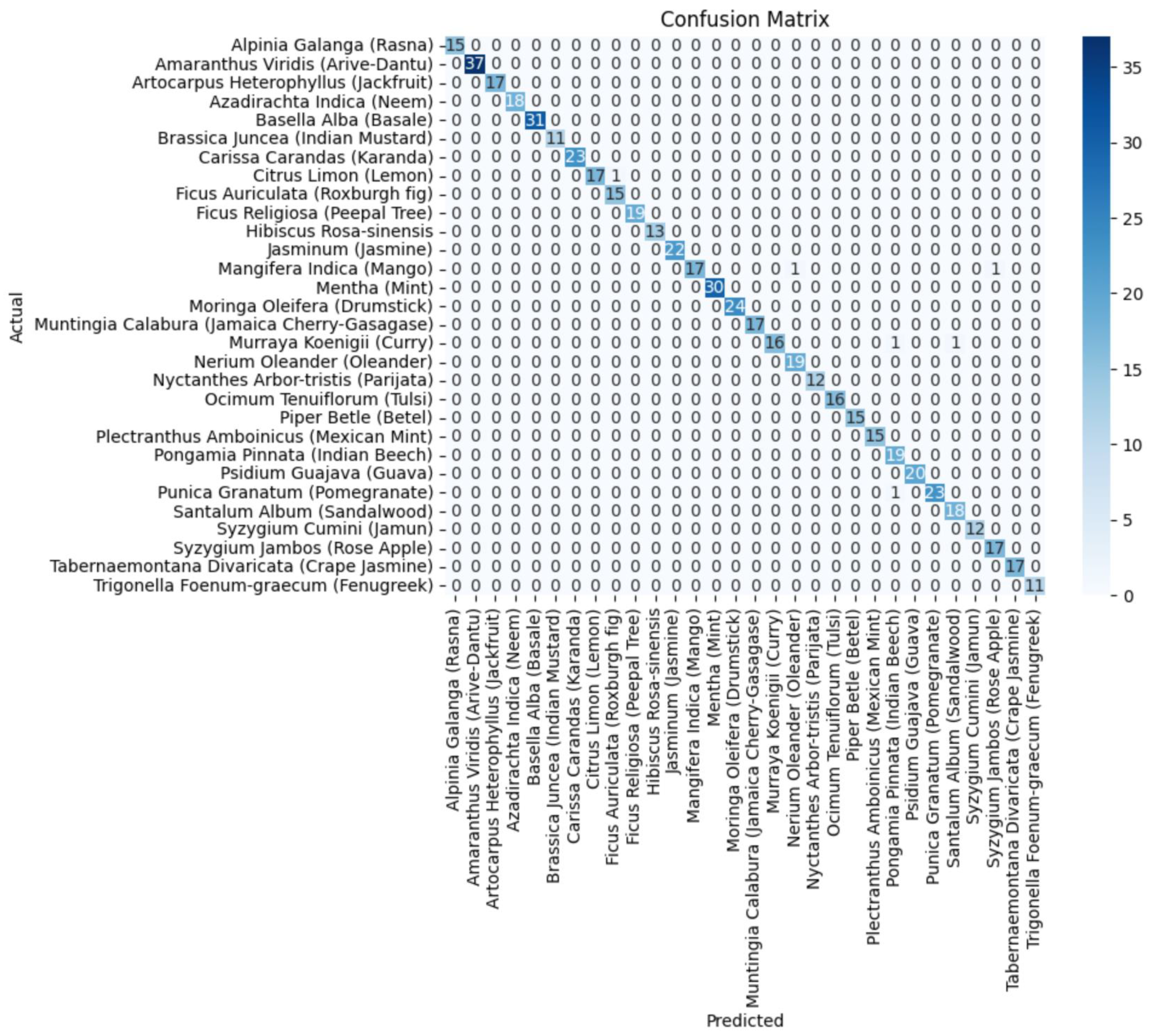
5.1. Classification Outcomes of Component Deep Neural Networks
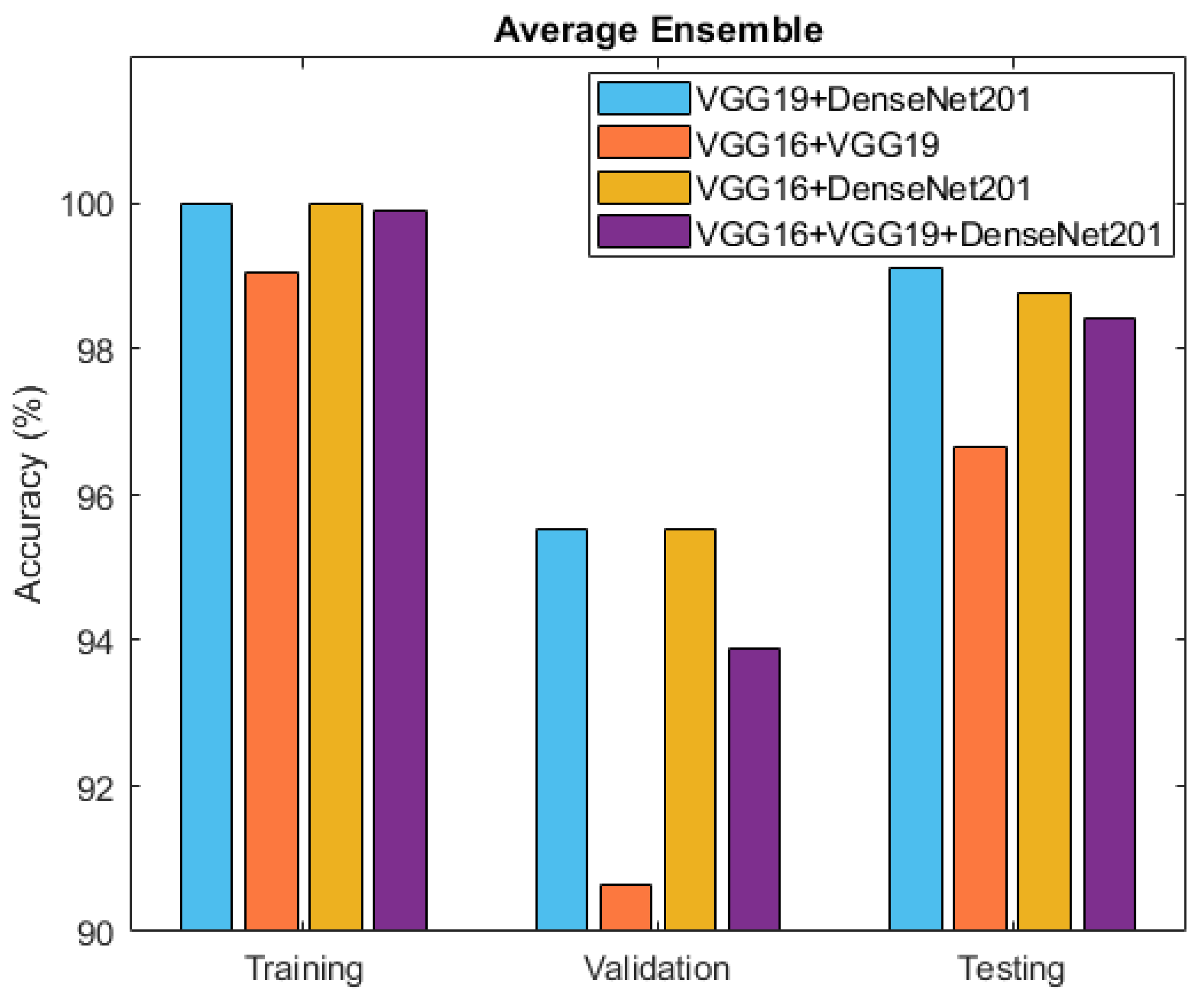
5.2. Ensemble Approaches for Improved Classification Performance
6. Discussion
6.1. Experimental Analysis
6.2. Challenges
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Introduction and Importance of Medicinal Plants and Herbs. Available online: https://www.nhp.gov.in/introduction-and-importance-of-medicinal-plants-and-herbs_mtl (accessed on 9 November 2023).
- Azlah, M.A.F.; Chua, L.S.; Rahmad, F.R.; Abdullah, F.I.; Wan Alwi, S.R. Review on techniques for plant leaf classification and recognition. Computers 2019, 8, 77. [Google Scholar] [CrossRef]
- Tripathi, K.; Khan, F.A.; Khanday, A.M.U.D.; Nisa, K.U. The classification of medical and botanical data through majority voting using artificial neural network. Int. J. Inf. Technol. 2023, 15, 3271–3283. [Google Scholar] [CrossRef]
- Wäldchen, J.; Mäder, P. Plant species identification using computer vision techniques: A systematic literature review. Arch. Comput. Methods Eng. 2018, 25, 507–543. [Google Scholar]
- De Carvalho, M.R.; Bockmann, F.A.; Amorim, D.S.; Brandão, C.R.F.; de Vivo, M.; de Figueiredo, J.L.; Britski, H.A.; de Pinna, M.C.; Menezes, N.A.; Marques, F.P.; et al. Taxonomic impediment or impediment to taxonomy? A commentary on systematics and the cybertaxonomic-automation paradigm. Evol. Biol. 2007, 34, 140–143. [Google Scholar] [CrossRef]
- Rabani, S.T.; Khanday, A.M.U.D.; Khan, Q.R.; Hajam, U.A.; Imran, A.S.; Kastrati, Z. Detecting suicidality on social media: Machine learning at rescue. Egypt. Inform. J. 2023, 24, 291–302. [Google Scholar]
- Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Husin, Z.; Shakaff, A.; Aziz, A.; Farook, R.; Jaafar, M.; Hashim, U.; Harun, A. Embedded portable device for herb leaves recognition using image processing techniques and neural network algorithm. Comput. Electron. Agric. 2012, 89, 18–29. [Google Scholar] [CrossRef]
- Gokhale, A.; Babar, S.; Gawade, S.; Jadhav, S. Identification of medicinal plant using image processing and machine learning. In Proceedings of the Applied Computer Vision and Image Processing; Proceedings of ICCET 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1, pp. 272–282. [Google Scholar]
- Puri, D.; Kumar, A.; Virmani, J.; Kriti. Classification of leaves of medicinal plants using laws texture features. Int. J. Inf. Technol. 2019, 14, 1–12. [Google Scholar] [CrossRef]
- Roopashree, S.; Anitha, J. DeepHerb: A vision based system for medicinal plants using xception features. IEEE Access 2021, 9, 135927–135941. [Google Scholar] [CrossRef]
- Sachar, S.; Kumar, A. Deep ensemble learning for automatic medicinal leaf identification. Int. J. Inf. Technol. 2022, 14, 3089–3097. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Nakata, N.; Siina, T. Ensemble Learning of Multiple Models Using Deep Learning for Multiclass Classification of Ultrasound Images of Hepatic Masses. Bioengineering 2023, 10, 69. [Google Scholar] [CrossRef] [PubMed]
- Kuzinkovas, D.; Clement, S. The detection of COVID-19 in chest x-rays using ensemble cnn techniques. Information 2023, 14, 370. [Google Scholar] [CrossRef]
- D’Angelo, M.; Nanni, L. Deep Learning-Based Human Chromosome Classification: Data Augmentation and Ensemble. Information 2023, 14, 389. [Google Scholar] [CrossRef]
- Nazarenko, D.; Kharyuk, P.; Oseledets, I.; Rodin, I.; Shpigun, O. Machine learning for LC–MS medicinal plants identification. Chemom. Intell. Lab. Syst. 2016, 156, 174–180. [Google Scholar] [CrossRef]
- Kumar, N.; Belhumeur, P.N.; Biswas, A.; Jacobs, D.W.; Kress, W.J.; Lopez, I.C.; Soares, J.V. Leafsnap: A computer vision system for automatic plant species identification. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Part II 12, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 502–516. [Google Scholar]
- Kadir, A.; Nugroho, L.E.; Susanto, A.; Santosa, P.I. Leaf classification using shape, color, and texture features. arXiv 2013, arXiv:1401.4447. [Google Scholar]
- Wu, S.G.; Bao, F.S.; Xu, E.Y.; Wang, Y.X.; Chang, Y.F.; Xiang, Q.L. A leaf recognition algorithm for plant classification using probabilistic neural network. In Proceedings of the 2007 International Symposium on Signal Processing and Information Technology, Giza, Egypt, 15–18 December 2007; pp. 11–16. [Google Scholar]
- Sabu, A.; Sreekumar, K.; Nair, R.R. Recognition of Ayurvedic medicinal plants from leaves: A computer vision approach. In Proceedings of the 2017 4th International Conference on Image Information Processing (ICIIP), Shimla, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- Sundara Sobitha Raj, A.P.; Vajravelu, S.K. DDLA: Dual deep learning architecture for classification of plant species. IET Image Process. 2019, 13, 2176–2182. [Google Scholar] [CrossRef]
- Barré, P.; Stöver, B.C.; Müller, K.F.; Steinhage, V. LeafNet: A computer vision system for automatic plant species identification. Ecol. Inform. 2017, 40, 50–56. [Google Scholar] [CrossRef]
- Geetharamani, G.; Pandian, A. Identification of plant leaf diseases using a nine-layer deep convolutional neural network. Comput. Electr. Eng. 2019, 76, 323–338. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Duong-Trung, N.; Quach, L.D.; Nguyen, M.H.; Nguyen, C.N. A combination of transfer learning and deep learning for medicinal plant classification. In Proceedings of the 2019 4th International Conference on Intelligent Information Technology, New York, NY, USA, 16–17 November 2019; pp. 83–90. [Google Scholar]
- Prashar, N.; Sangal, A. Plant disease detection using deep learning (convolutional neural networks). In Proceedings of the 2nd International Conference on Image Processing and Capsule Networks: ICIPCN 2021 2, Bidar, India, 16–17 December 2016; Springer: Berlin/Heidelberg, Germany, 2022; pp. 635–649. [Google Scholar]
- Khanday, A.M.U.D.; Bhushan, B.; Jhaveri, R.H.; Khan, Q.R.; Raut, R.; Rabani, S.T. Nnpcov19: Artificial neural network-based propaganda identification on social media in COVID-19 era. Mob. Inf. Syst. 2022, 2022, 1–10. [Google Scholar] [CrossRef]
- Patil, S.S.; Patil, S.H.; Azfar, F.N.; Pawar, A.M.; Kumar, S.; Patel, I. Medicinal plant identification using convolutional neural network. In Proceedings of the AIP Conference Proceedings; AIP Publishing: Long Island, NY, USA, 2023; Volume 2890. [Google Scholar]
- Akhtar, M.J.; Mahum, R.; Butt, F.S.; Amin, R.; El-Sherbeeny, A.M.; Lee, S.M.; Shaikh, S. A Robust Framework for Object Detection in a Traffic Surveillance System. Electronics 2022, 11, 3425. [Google Scholar] [CrossRef]
- Dadgar, S.; Neshat, M. Comparative hybrid deep convolutional learning framework with transfer learning for diagnosis of lung cancer. In Proceedings of the International Conference on Soft Computing and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2022; pp. 296–305. [Google Scholar]
- Leonidas, L.A.; Jie, Y. Ship classification based on improved convolutional neural network architecture for intelligent transport systems. Information 2021, 12, 302. [Google Scholar] [CrossRef]
- Ahsan, M.; Naz, S.; Ahmad, R.; Ehsan, H.; Sikandar, A. A deep learning approach for diabetic foot ulcer classification and recognition. Information 2023, 14, 36. [Google Scholar] [CrossRef]
- Neshat, M.; Lee, S.; Momin, M.M.; Truong, B.; van der Werf, J.H.; Lee, S.H. An effective hyper-parameter can increase the prediction accuracy in a single-step genetic evaluation. Front. Genet. 2023, 14, 1104906. [Google Scholar] [CrossRef]
- Al-Kaltakchi, M.T.; Mohammad, A.S.; Woo, W.L. Ensemble System of Deep Neural Networks for Single-Channel Audio Separation. Information 2023, 14, 352. [Google Scholar] [CrossRef]
- Neshat, M.; Ahmedb, M.; Askarid, H.; Thilakaratnee, M.; Mirjalilia, S. Hybrid Inception Architecture with Residual Connection: Fine-tuned Inception-ResNet Deep Learning Model for Lung Inflammation Diagnosis from Chest Radiographs. arXiv 2023, arXiv:2310.02591. [Google Scholar]
- Alibrahim, H.; Ludwig, S.A. Hyperparameter optimization: Comparing genetic algorithm against grid search and bayesian optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Krakow, Poland, 28 June–1 July 2021; pp. 1551–1559. [Google Scholar]
- Medicinal Leaf Dataset—Mendeley Data. Available online: https://data.mendeley.com/datasets/nnytj2v3n5/1 (accessed on 9 December 2023).
- Patil, S.S.; Patil, S.H.; Pawar, A.M.; Patil, N.S.; Rao, G.R. Automatic Classification of Medicinal Plants Using State-Of-The-Art Pre-Trained Neural Networks. J. Adv. Zool. 2022, 43, 80–88. [Google Scholar] [CrossRef]
- Ayumi, V.; Ermatita, E.; Abdiansah, A.; Noprisson, H.; Jumaryadi, Y.; Purba, M.; Utami, M.; Putra, E.D. Transfer Learning for Medicinal Plant Leaves Recognition: A Comparison with and without a Fine-Tuning Strategy. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 138–144. [Google Scholar] [CrossRef]
- Almazaydeh, L.; Alsalameen, R.; Elleithy, K. Herbal leaf recognition using mask-region convolutional neural network (mask R-CNN). J. Theor. Appl. Inf. Technol. 2022, 100, 3664–3671. [Google Scholar]
- Ghosh, S.; Singh, A.; Kumar, S. Identification of medicinal plant using hybrid transfer learning technique. Indones. J. Electr. Eng. Comput. Sci. 2023, 31, 1605–1615. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| Number of Layers | Composed of dense blocks, transition blocks, and a final classification layer | 201 |
| Dense Blocks | For the dense blocks, the number of layers in these blocks was (6, 12, 48, 32) | 4 |
| Growth Rate | Sets the number of feature maps added to each layer in the DenseNet | 32 |
| Learning Rate | Step size at each iteration while moving toward a minimum of a loss function | 0.00001 |
| Batch Size | Number of samples contributing to training | 32 |
| Activation Function | Introduces nonlinearity into the network | ReLU |
| Dropout Factor | Disregards certain nodes in a layer at random during training to prevent overfitting | 0.5 |
| Deep Neural Network | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) |
|---|---|---|---|
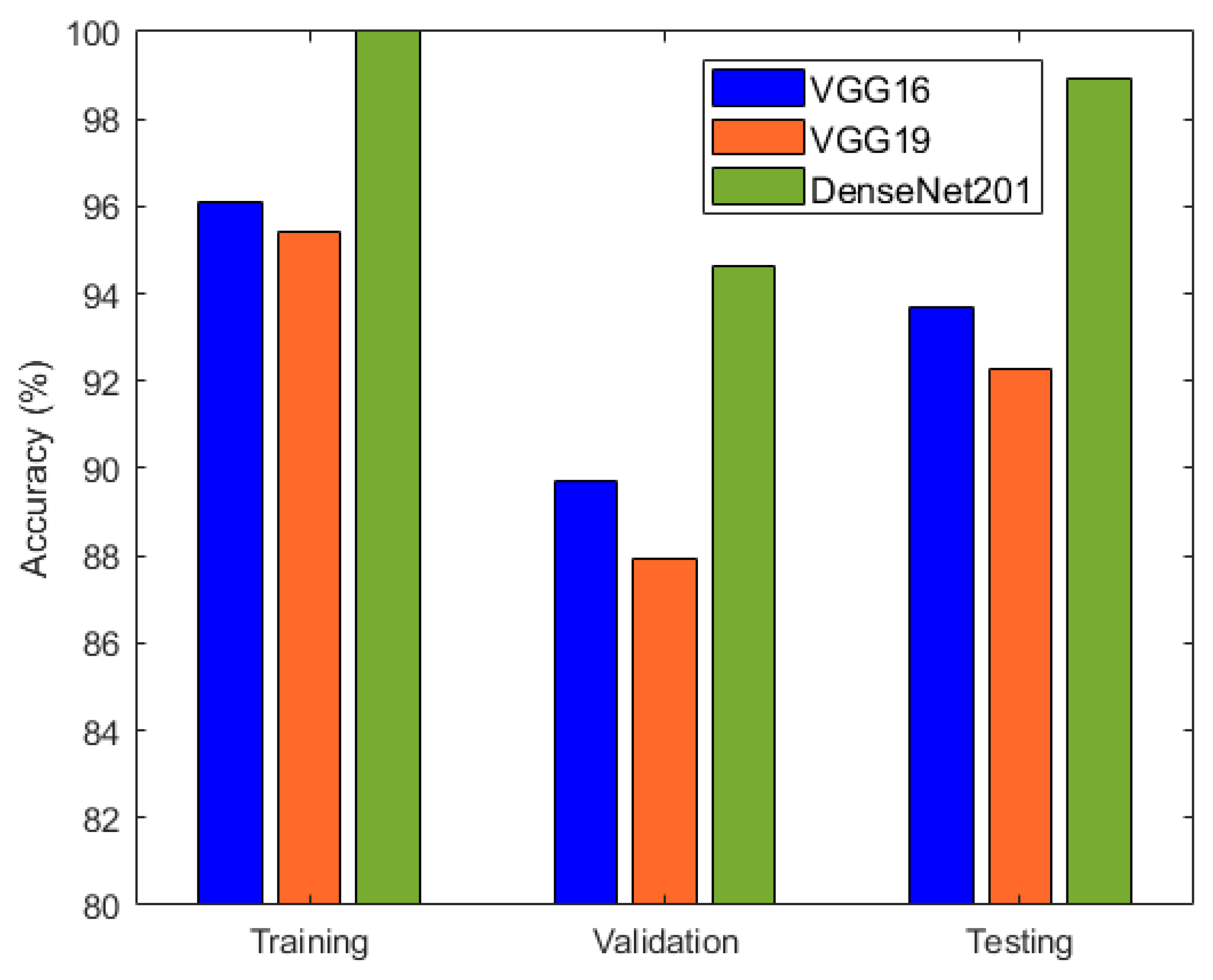
| VGG16 | 96.19 | 89.7 | 93.67 |
| VGG19 | 95.41 | 87.94 | 92.26 |
| DenseNet201 | 100 | 94.64 | 98.93 |
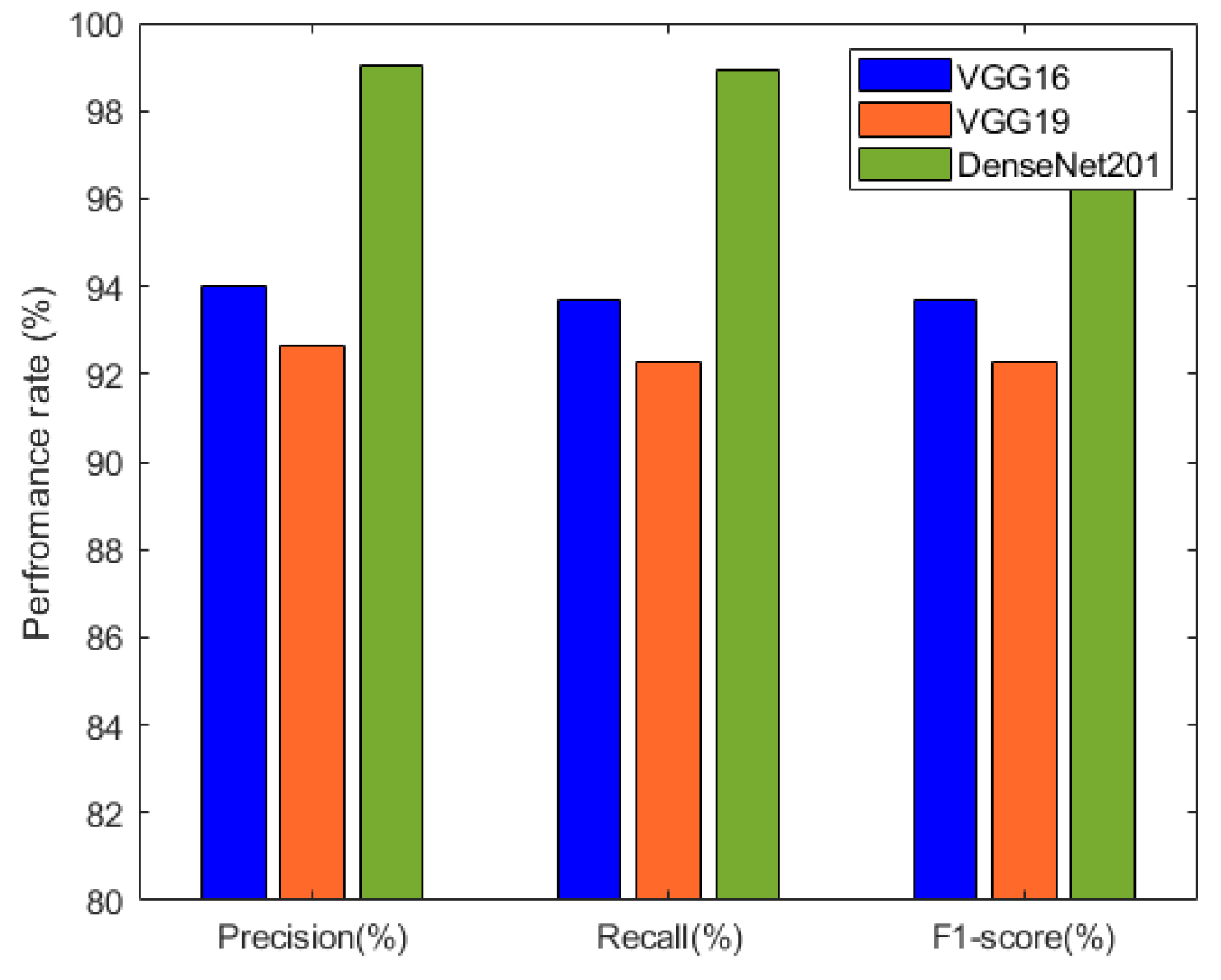
| Deep Neural Network | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| VGG16 | 94.02 | 93.67 | 93.84 |
| VGG19 | 92.67 | 92.26 | 92.46 |
| DenseNet201 | 99.01 | 98.94 | 98.97 |
| Average Ensemble | |||
|---|---|---|---|
| Ensemble Deep Neural Networks | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) |
| VGG19 + DenseNet201 | 100 | 95.52 | 99.12 |
| VGG16 + VGG19 | 99.04 | 90.65 | 96.66 |
| VGG16 + DenseNet201 | 100 | 95.52 | 98.76 |
| VGG16 + VGG19 + DenseNet201 | 99.90 | 93.90 | 98.41 |
| Weighted Average Ensemble | |||
|---|---|---|---|
| Ensemble Deep Neural Networks | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) |
| VGG16 + VGG19 + DenseNet201 | 99.61 | 92.68 | 97.89 |
| VGG19 + DenseNet201 | 99.23 | 91.86 | 96.83 |
| VGG19 + VGG16 | 98.75 | 89.02 | 96.66 |
| VGG16 + DenseNet201 | 99.80 | 91.05 | 98.06 |
| Reference | Technique | Medicinal Leaf Dataset | Accuracy |
|---|---|---|---|
| [42] | MobileNetV1 | Mendeley Medicinal Leaf Dataset | 98% |
| [43] | MobileNetV2 | Mendeley Medicinal Leaf Dataset | 81.82% |
| [44] | Mask RCNN | Mendeley Medicinal Leaf Dataset | 95.7% |
| [45] | Hybrid Transfer | Mendeley Medicinal Leaf Dataset | 95.25% |
| Proposed Approach | Ensemble Learning | Mendeley Medicinal Leaf Dataset | 99.12% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hajam, M.A.; Arif, T.; Khanday, A.M.U.D.; Neshat, M. An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification. Information 2023, 14, 618. https://doi.org/10.3390/info14110618
Hajam MA, Arif T, Khanday AMUD, Neshat M. An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification. Information. 2023; 14(11):618. https://doi.org/10.3390/info14110618
Chicago/Turabian StyleHajam, Mohd Asif, Tasleem Arif, Akib Mohi Ud Din Khanday, and Mehdi Neshat. 2023. "An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification" Information 14, no. 11: 618. https://doi.org/10.3390/info14110618
APA StyleHajam, M. A., Arif, T., Khanday, A. M. U. D., & Neshat, M. (2023). An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification. Information, 14(11), 618. https://doi.org/10.3390/info14110618