
A Feature-Weighted Support Vector Regression Machine Based on Hilbert–Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator


Abstract

1. Introduction
2. Preliminaries
2.1. Review of SVR
2.2. HSIC LASSO
3. Training FWSVR with HSIC LASSO
3.1. Modifying Kernel Function
3.2. Constructing HL-FWSVR
4. Experiments
4.1. Comparison Approaches and Evaluation Criteria
- SVR: The classical SVR machine.
- GCD-FWSVR: A feature-weighted SVR machine with correlation between input and output evaluated by GCD [19].
- MIC-FWSVR: The MIC is applied to obtain the weighted kernel of SVR, which can measure the linear and nonlinear correlation between two variables [20].
- MP-FWSVR: The feature weighting method of this approach adopts a PSO algorithm [22]. The MIC of each feature is calculated to constrain the search range of weights. It is an improved PSO search method.
4.2. Experiment Setup
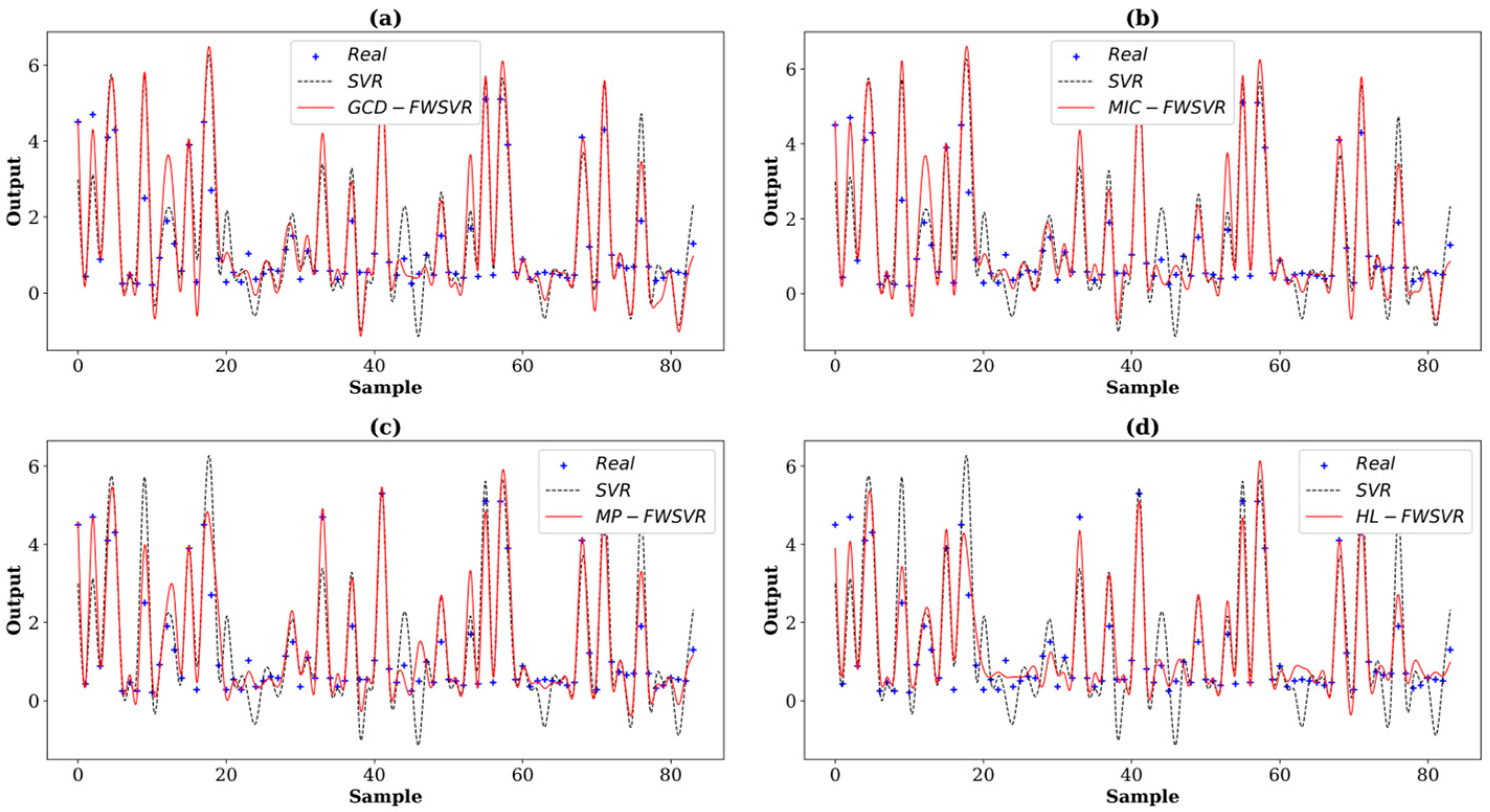
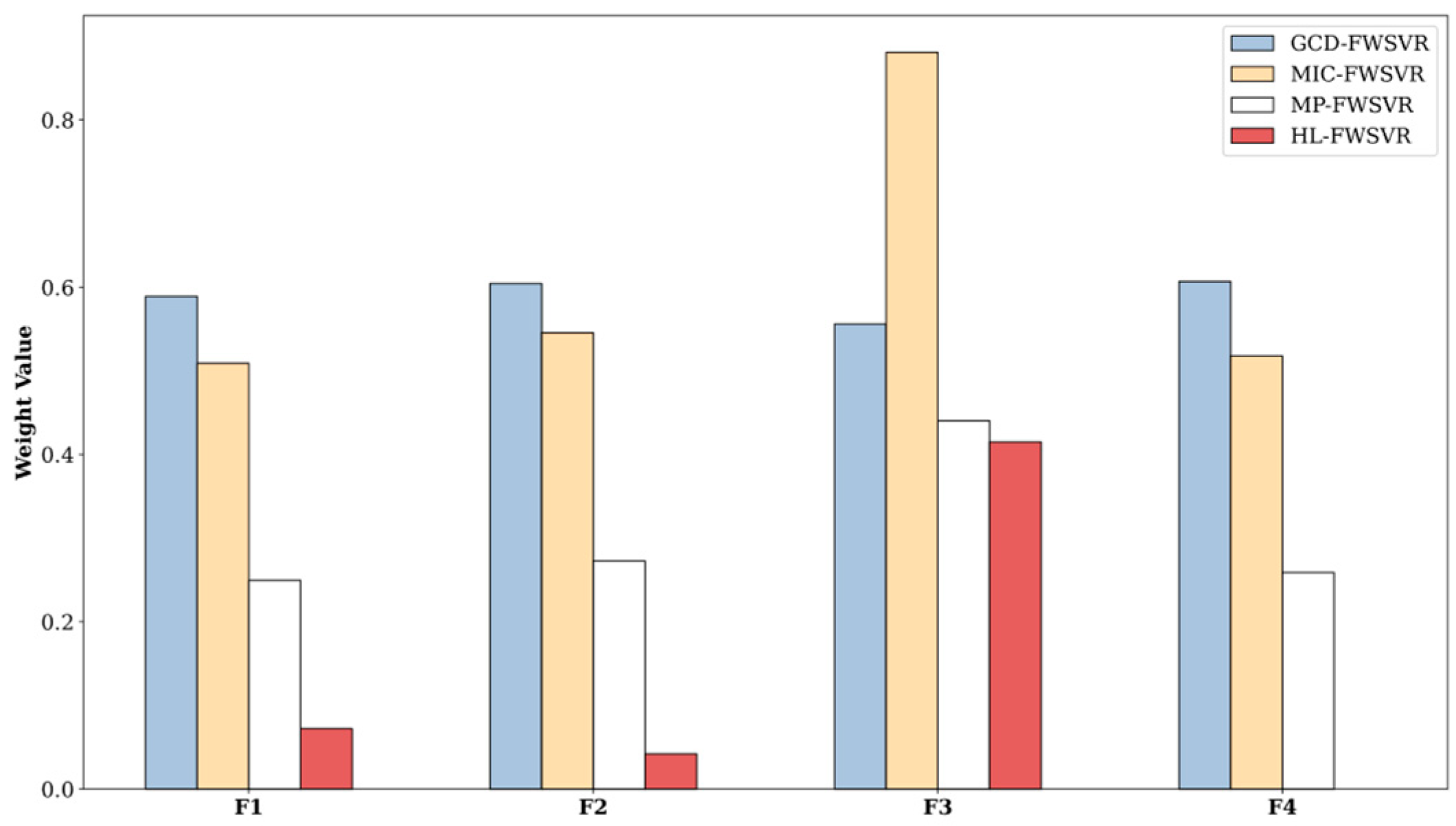
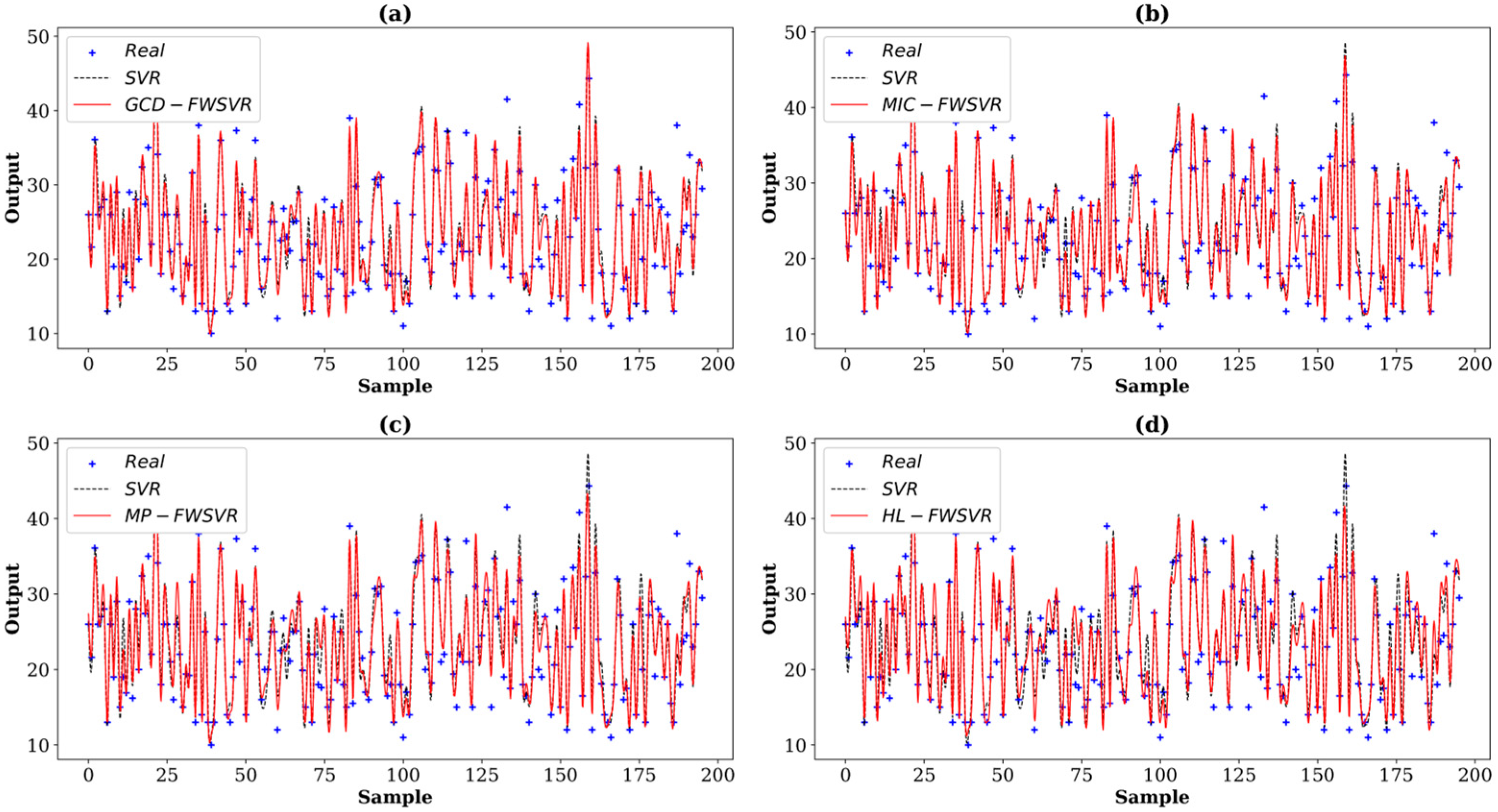
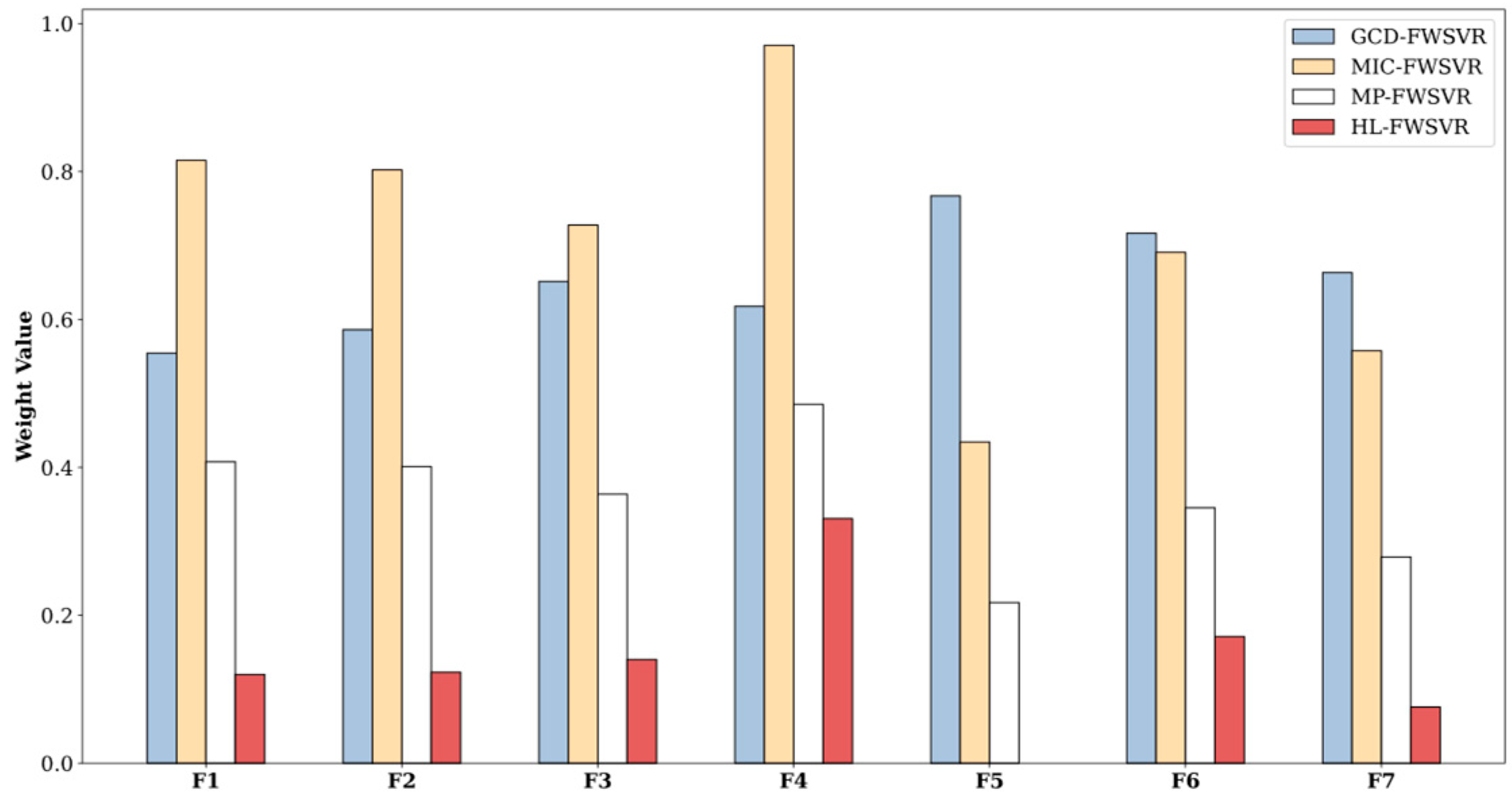
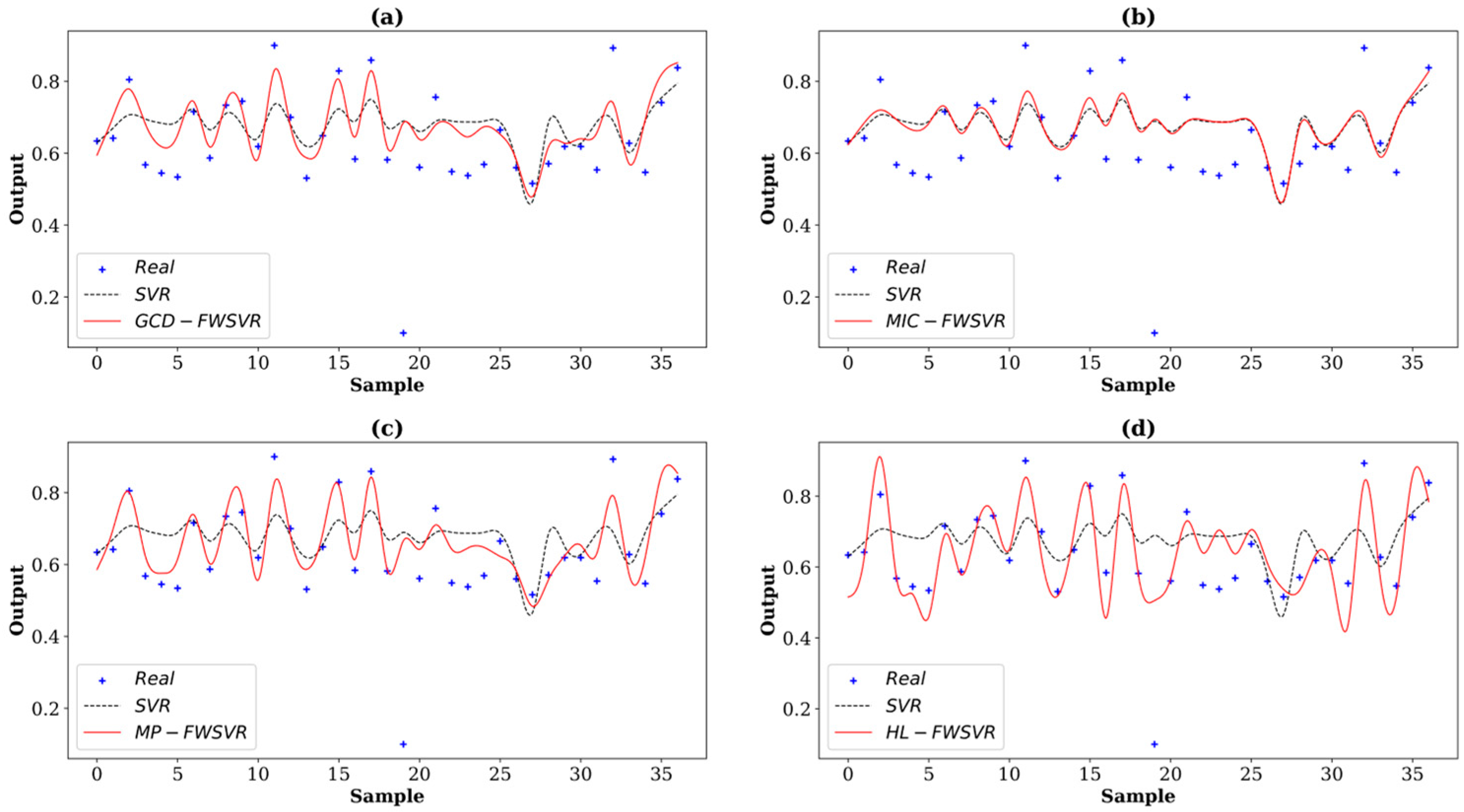
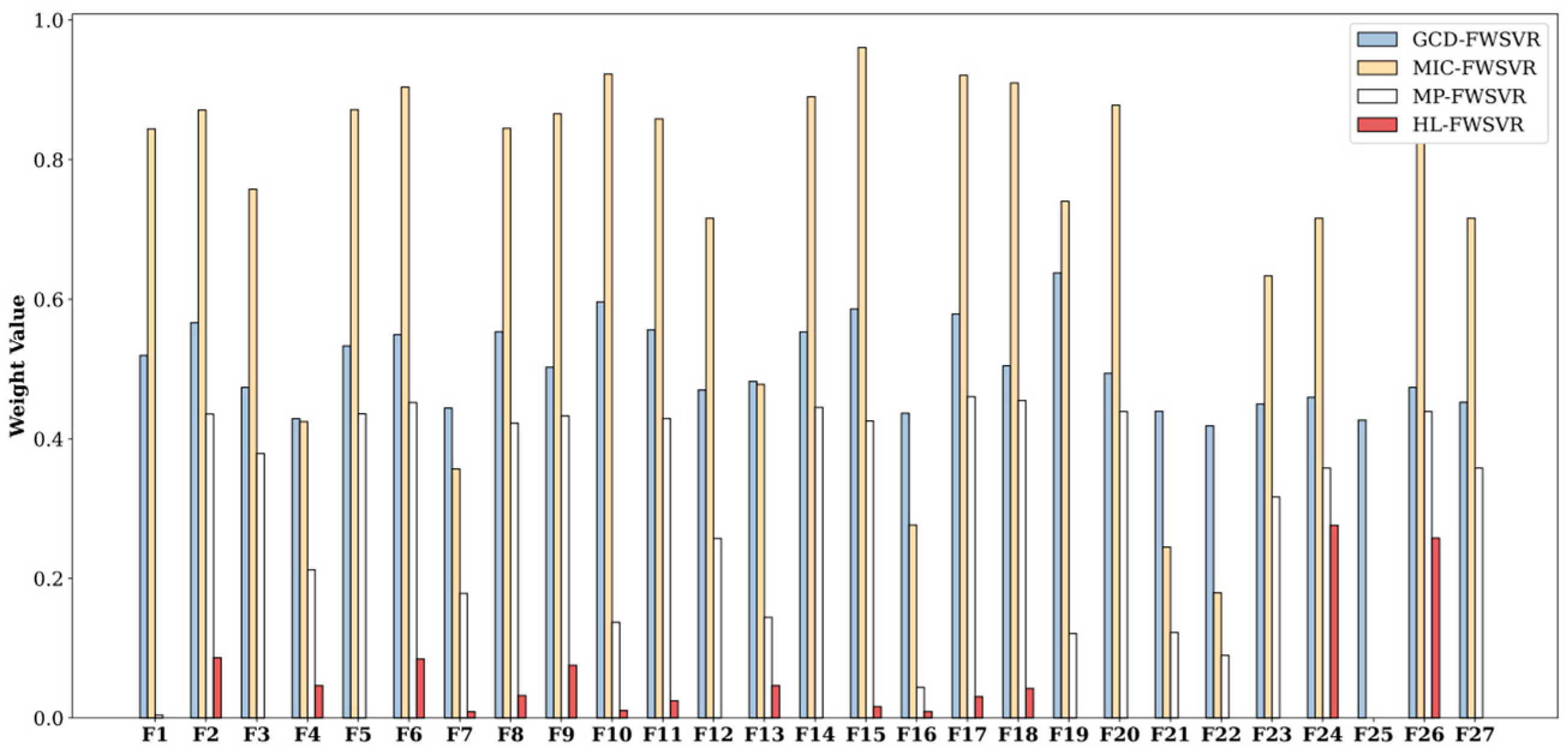
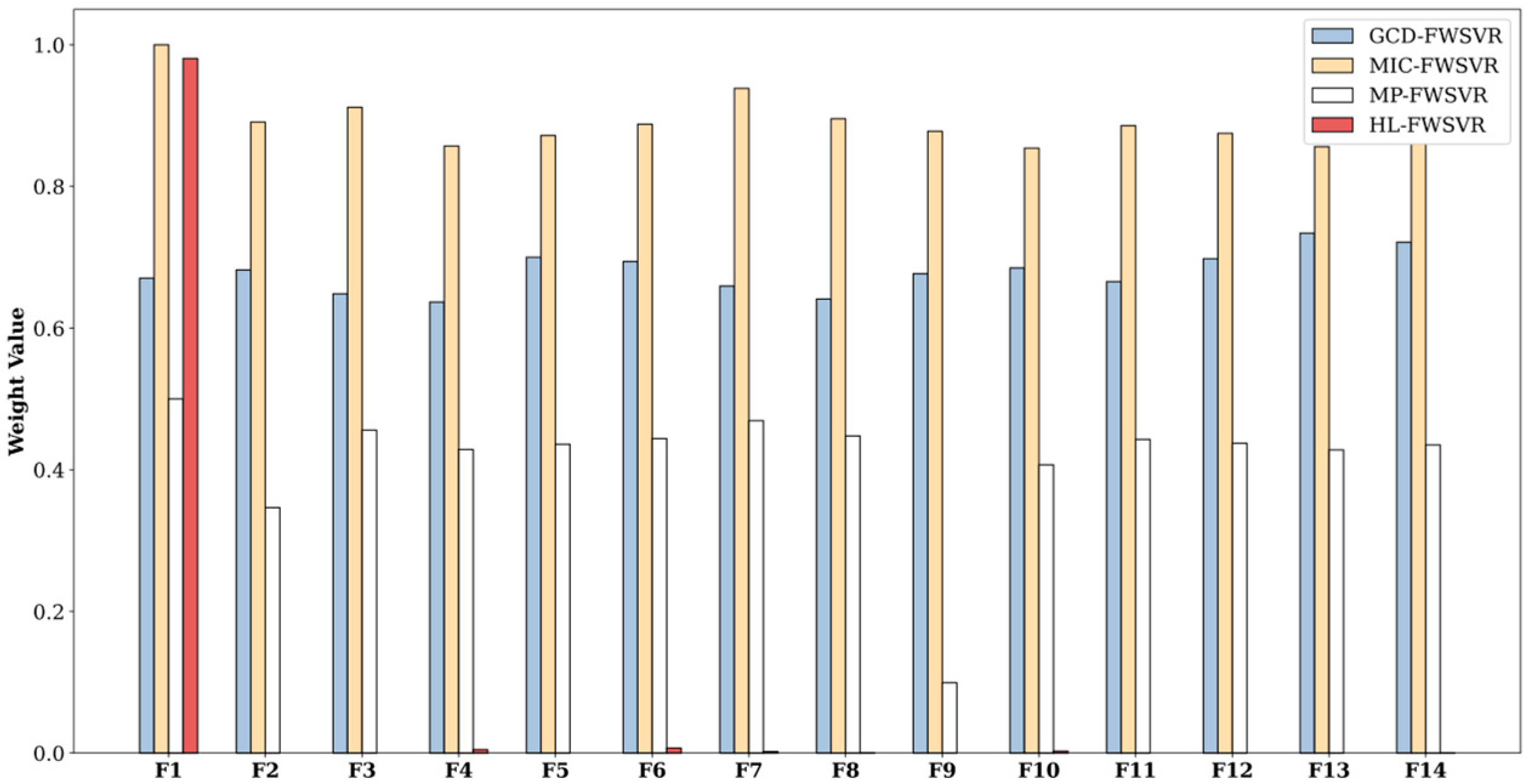
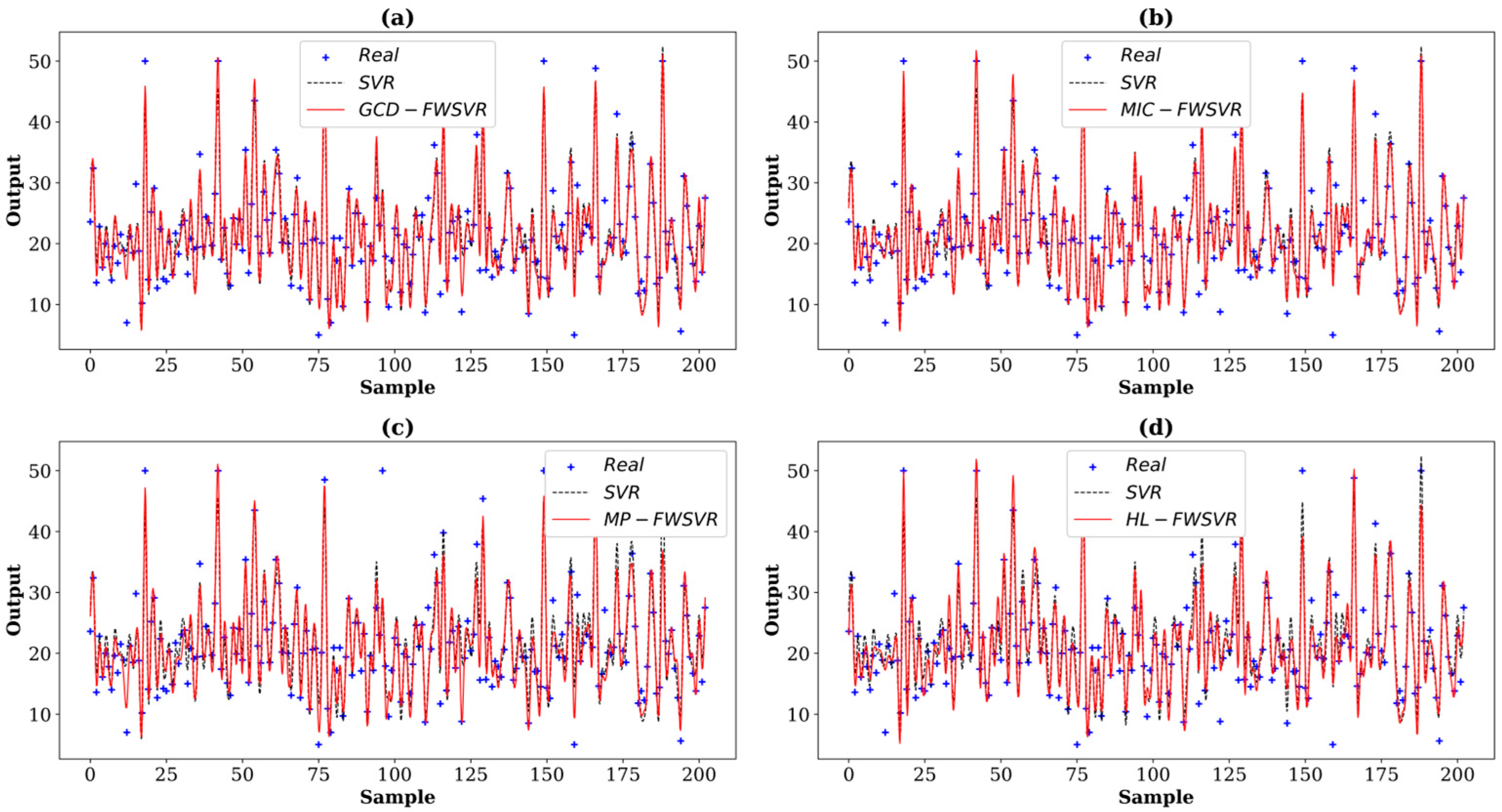
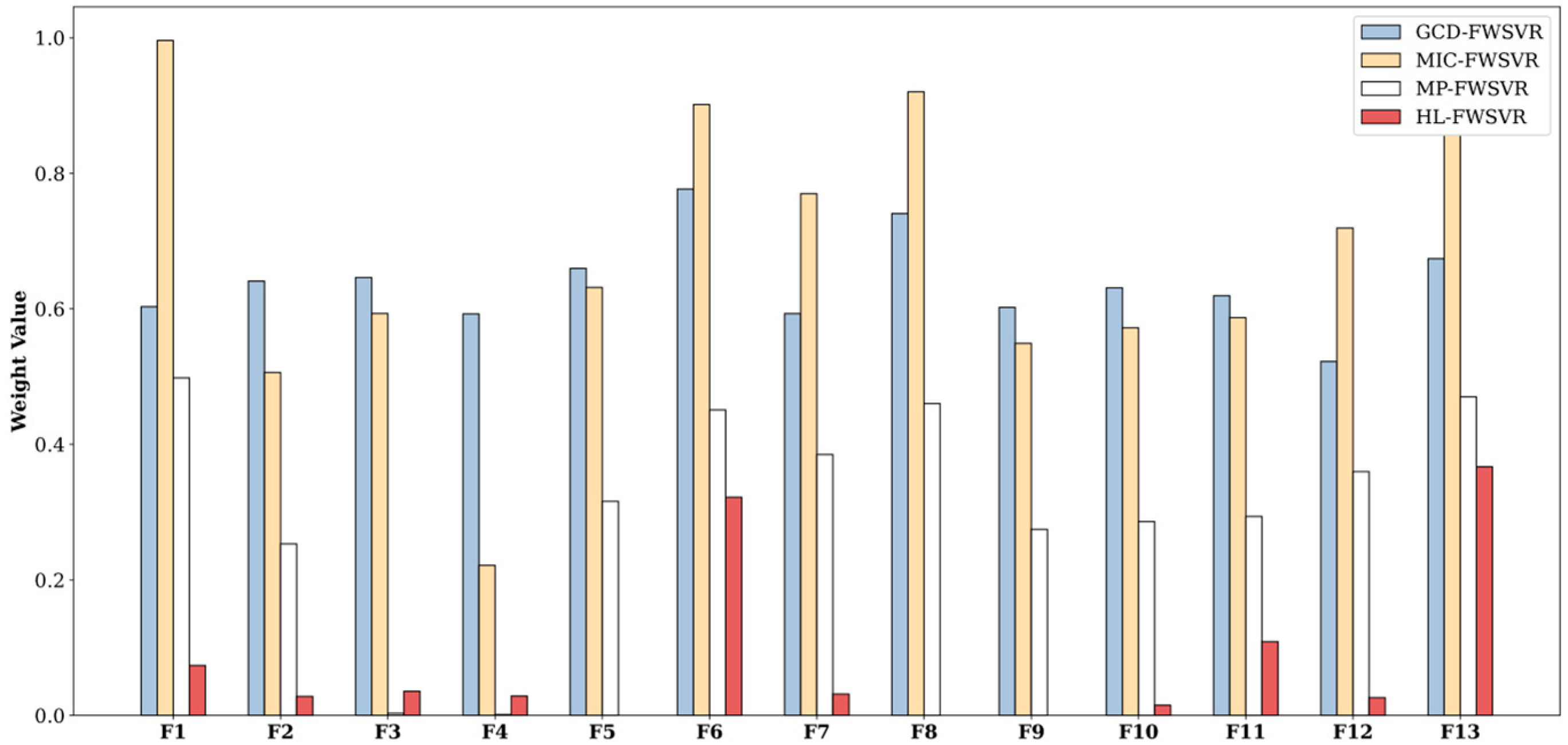
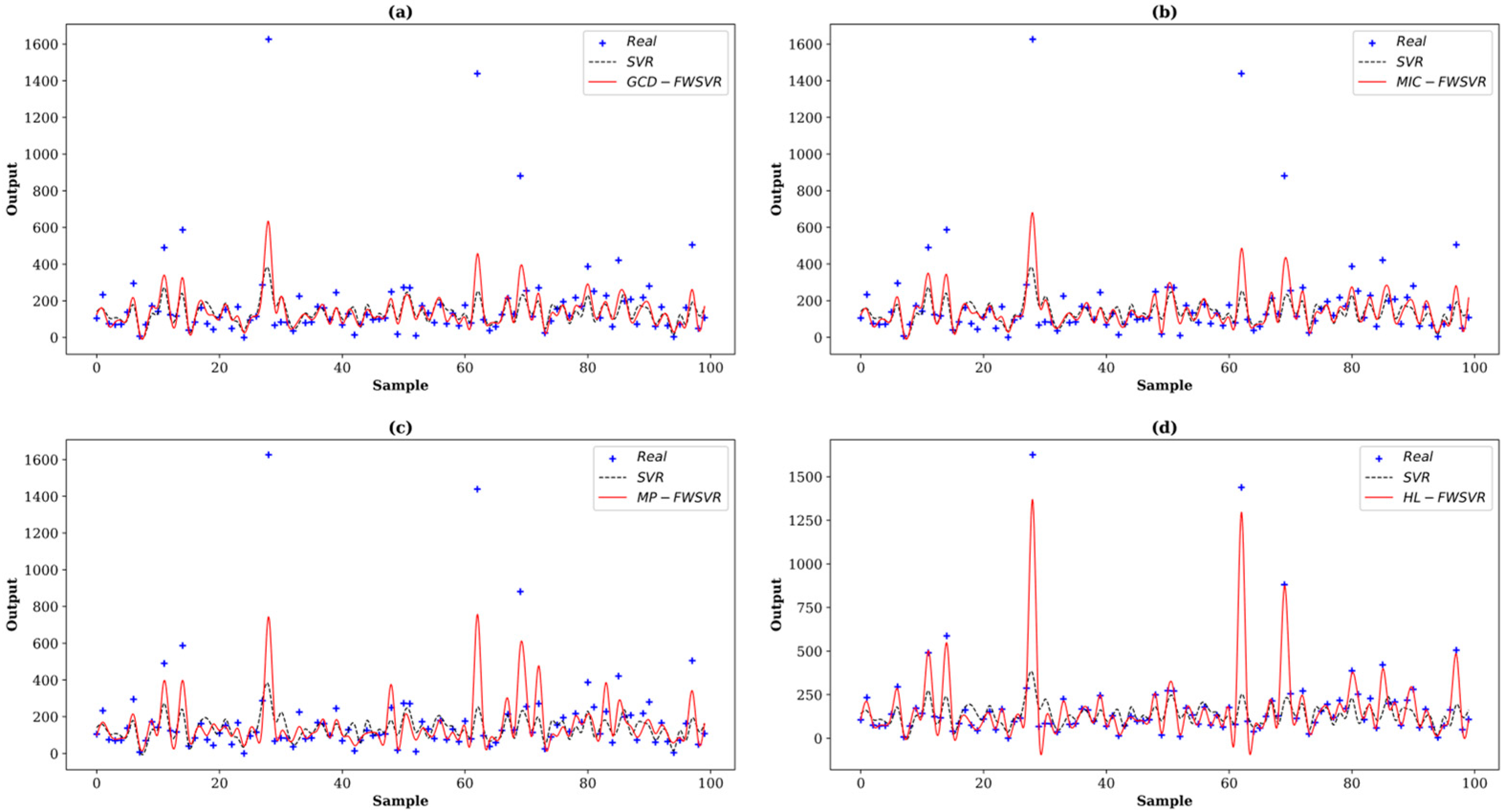
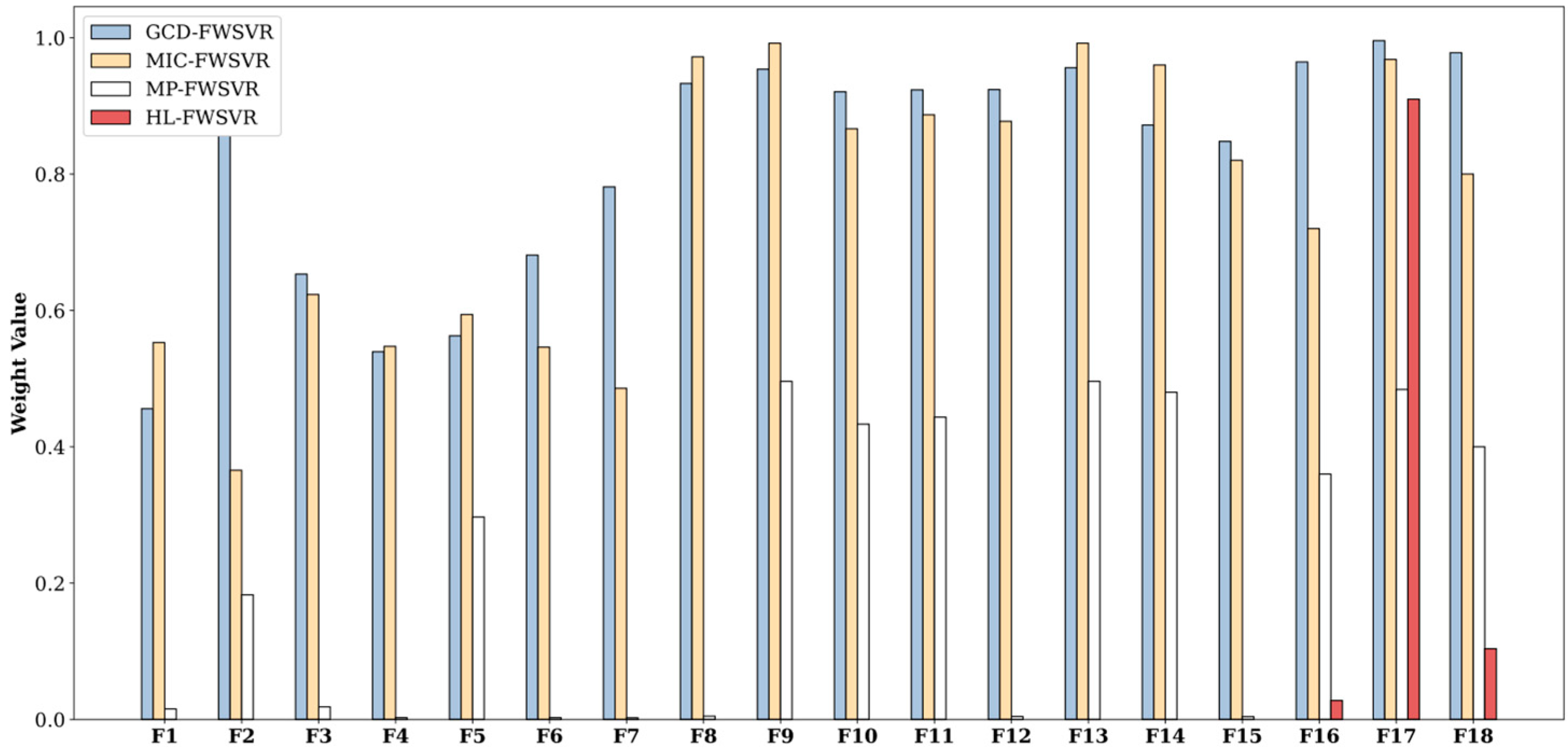
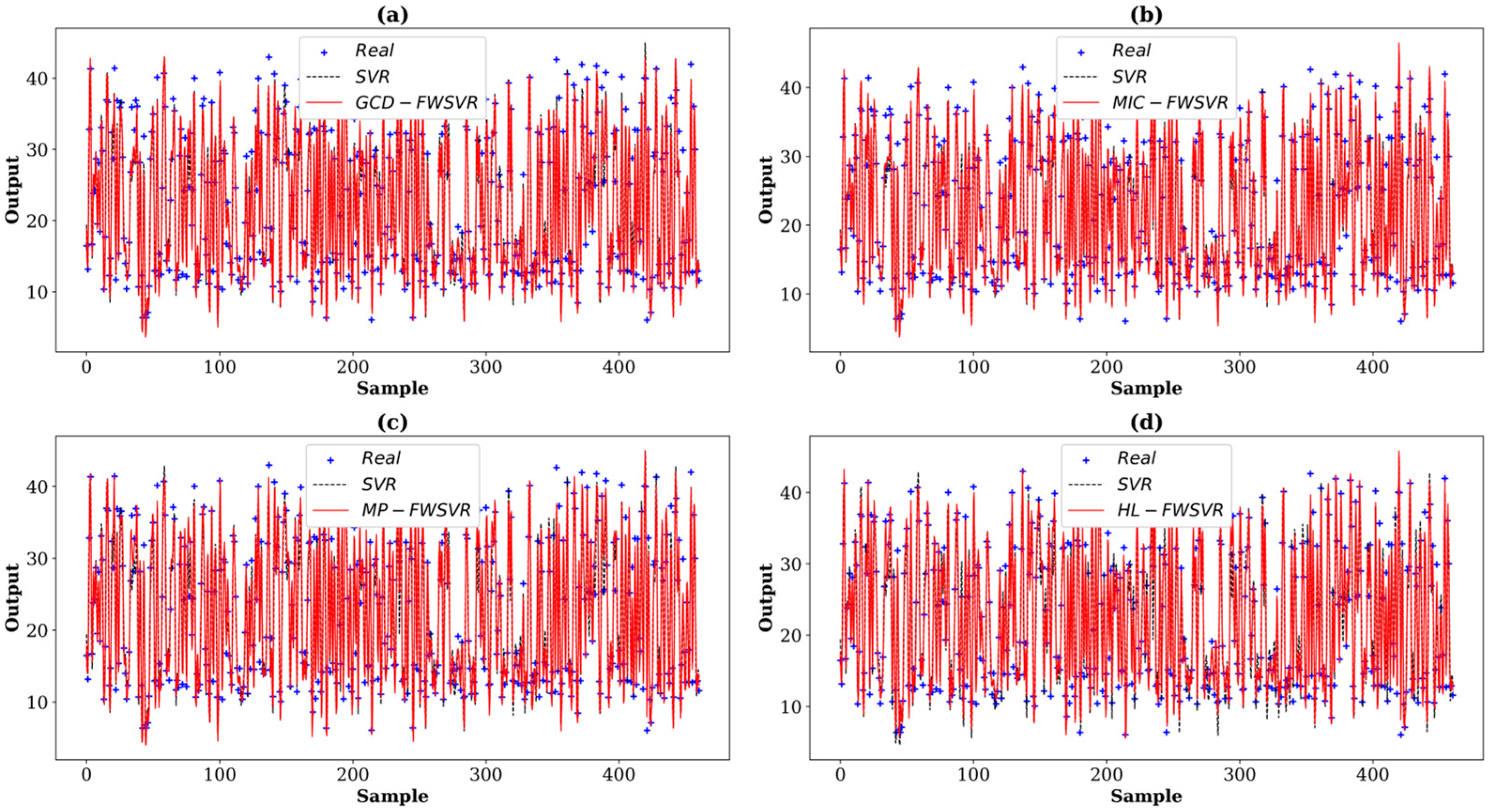
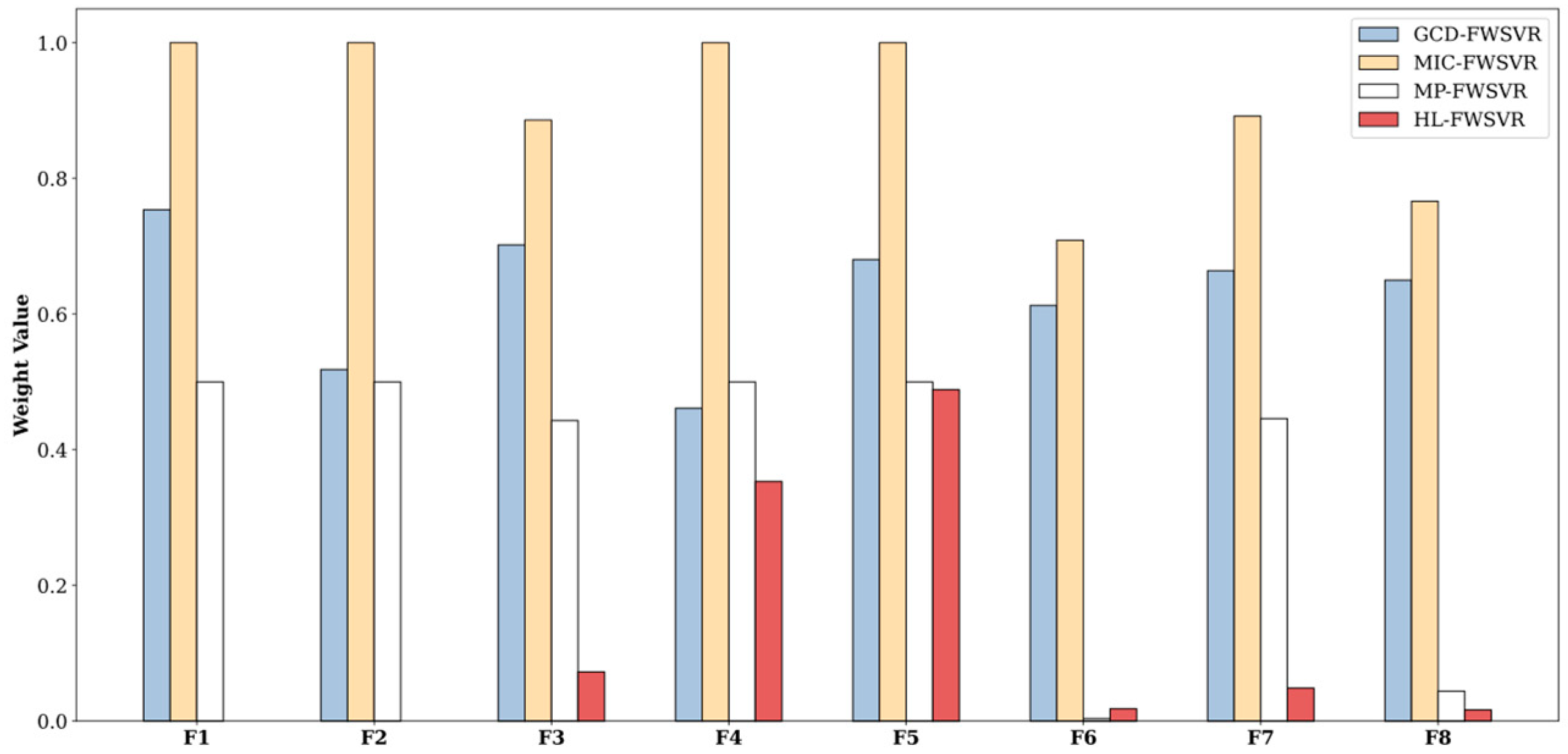
4.3. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vapnik, V. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1996, 9, 155–161. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015. [Google Scholar]
- Vapnik, V. Principles of risk minimization for learning theory. Adv. Neural Inf. Process. Syst. 1991, 4, 831–838. [Google Scholar]
- Cheng, K.; Lu, Z. Active learning Bayesian support vector regression model for global approximation. Inf. Sci. 2021, 544, 549–563. [Google Scholar] [CrossRef]
- Lu, C.; Lee, T.; Chiu, C. Financial time series forecasting using independent component analysis and support vector regression. Decis. Support Syst. 2009, 47, 115–125. [Google Scholar] [CrossRef]
- Kazem, A.; Sharifi, E.; Hussain, F.; Saberi, M.; Hussian, O. Support vector regression with chaos-based firefly algorithm for stock market price forecasting. Appl. Soft Comput. 2013, 13, 947–958. [Google Scholar] [CrossRef]
- Yang, H.; Huang, K.; King, I.; Lyu, M. Localized support vector regression for time series prediction. Neurocomputing 2009, 72, 2659–2669. [Google Scholar] [CrossRef]
- Pai, P.; Lin, K.; Lin, C.; Chang, P. Time series forecasting by a seasonal support vector regression model. Expert Syst. Appl. 2010, 37, 4261–4265. [Google Scholar] [CrossRef]
- Zhong, H.; Wang, J.; Jia, H.; Mu, Y.; Lv, S. Vector field-based support vector regression for building energy consumption prediction. Appl. Energy 2019, 242, 403–414. [Google Scholar] [CrossRef]
- Kavaklioglu, K. Modeling and prediction of Turkey’s electricity consumption using support vector regression. Appl. Energy 2011, 88, 368–375. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Wang, X.; Wang, Y.; Wang, L. Improving fuzzy c-means clustering based on feature-weight learning. Pattern Recognit. Lett. 2004, 25, 1123–1132. [Google Scholar] [CrossRef]
- Wang, T.; Tian, S.; Huang, H. Feature weighted support vector machine. J. Electron. Inf. Technol. 2009, 31, 514–518. [Google Scholar]
- Xie, M.; Wang, D.; Xie, L. One SVR modeling method based on kernel space feature. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 168–174. [Google Scholar] [CrossRef]
- Xie, M.; Wang, D.; Xie, L. A feature-weighted SVR method based on kernel space feature. Algorithms 2018, 11, 62. [Google Scholar] [CrossRef]
- Liu, J.; Hu, Y. Application of feature-weighted support vector regression using grey correlation degree to stock price forecasting. Neural Comput. Appl. 2013, 22, 143–152. [Google Scholar] [CrossRef]
- Hou, H.; Gao, Y.; Liu, D. A support vector machine with maximal information coefficient weighted kernel functions for regression. In Proceedings of the 2014 2nd International Conference on Systems and Informatics, Shanghai, China, 15–17 November 2014; pp. 938–942. [Google Scholar]
- Reshef, D.; Reshef, Y.; Finucane, H.; Grossman, S.; McVean, G.; Turnbaugh, P.; Lander, E.; Mitzenmacher, M.; Sabeti, P. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef]
- Xie, M.; Xie, L.; Zhu, P. An efficient feature weighting method for support vector regression. Math. Probl. Eng. 2021, 2021, 6675218. [Google Scholar] [CrossRef]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Pathak, J.; Hunt, B.; Girvan, M.; Lu, Z.; Ott, E. Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach. Phys. Rev. Lett. 2018, 120, 024102. [Google Scholar] [CrossRef]
- Vlachas, P.; Pathak, J.; Hunt, B.; Sapsis, T.; Girvan, M.; Ott, E. Backpropagation algorithms and reservoir computing in recurrent neural networks for the forecasting of complex spatiotemporal dynamics. Neural Netw. 2020, 126, 191–217. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Jia, Q. Weighted feature Gaussian kernel SVM for emotion recognition. Comput. Intell. Neurosci. 2016, 2016, 7696035. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Zhou, J.; Chen, J.; Yang, J.; Clawson, K.; Peng, Y. A feature weighted support vector machine and artificial neural network algorithm for academic course performance prediction. Neural Comput. Appl. 2023, 35, 11517–11529. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Gretton, A.; Bousquet, O.; Smola, A.; Schölkopf, B. Measuring statistical dependence with Hilbert-Schmidt norms. In Proceedings of the 16th International Conference on Algorithmic Learning Theory, Singapore, 8 October 2005; pp. 63–77. [Google Scholar]
- Yamada, M.; Jitkrittum, W.; Sigal, L.; Xing, E.; Sugiyama, M. High-dimensional feature selection by feature-wise kernelized lasso. Neural Comput. 2014, 26, 185–207. [Google Scholar] [CrossRef]
- Wang, T.; Hu, Z.; Liu, H. A unified view of feature selection based on Hilbert-Schmidt independence criterion. Chemom. Intell. Lab. Syst. 2023, 236, 104807. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Hofmann, T.; Schölkopf, B.; Smola, A. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef]
- Tomioka, R.; Suzuki, T.; Sugiyama, M. Super-linear convergence of dual augmented Lagrangian algorithm for sparsity regularized estimation. J. Mach. Learn. Res. 2011, 12, 1537–1586. [Google Scholar]
- Li, F.; Yang, Y.; Xing, E. From lasso regression to feature vector machine. Adv. Neural Inf. Process. Syst. 2005, 18, 779–786. [Google Scholar]
- Chicco, D.; Warrens, M.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 6 March 2024).
- Domingo, L.; Grande, M.; Borondo, F.; Borondo, J. Anticipating food price crises by reservoir computing. Chaos Solitons Fractals 2023, 174, 113854. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel | Definition | Parameters |
|---|---|---|
| Linear | - | |
| Polynomial | ||
| Gaussian | ||
| Sigmoid |
| Step 1: Collect a dataset (input , output ). |
| Step 2: Normalize and . |
| Step 3: Choose kernel functions (kernel matrices) K and L |
| Step 4: Solve optimization problem of Formula (5) and obtain regression coefficients . |
| Step 5: Construct transformation matrix and weighted kernel . |
| Step 6: Train the FWSVR machine with the weighted kernel . |
| Dataset | Numbers of Samples (S/T) | Number of Features | Original Dataset |
|---|---|---|---|
| Servo | 167 (83/84) | 4 | Servo |
| Mpg | 392 (196/196) | 7 | Auto MPG |
| Pyrim | 74 (37/37) | 27 | Qualitative Structure–Activity Relationships |
| Bodyfat | 252 (101/151) | 14 | Bodyfat |
| Boston | 506 (304/202) | 13 | Boston Housing |
| 500 (400/100) | 18 | Facebook Metrics | |
| Energy | 768 (307/461) | 8 | Energy Efficiency |
| Concrete | 1030 (309/721) | 8 | Concrete Compressive Strength |
| Dataset | Results | SVR | GCD-FWSVR | MIC-FWSVR | MP-FWSVR | HL-FWSVR |
|---|---|---|---|---|---|---|
| Servo | RMSE | 0.8536 | 0.7591 | 0.7695 | 0.5076 | 0.4260 |
| R2 | 0.6524 | 0.7251 | 0.7175 | 0.8771 | 0.9134 | |
| Mpg | RMSE | 3.0961 | 2.8210 | 2.8288 | 2.7287 | 2.8729 |
| R2 | 0.8293 | 0.8583 | 0.8575 | 0.8674 | 0.8530 | |
| Pyrim | RMSE | 0.1353 | 0.1185 | 0.1315 | 0.1099 | 0.0918 |
| R2 | 0.0941 | 0.3046 | 0.1440 | 0.4065 | 0.5827 | |
| Bodyfat | RMSE | 0.0086 | 0.0075 | 0.0081 | 0.0068 | 0.0036 |
| R2 | 0.7859 | 0.8363 | 0.8088 | 0.8615 | 0.9630 | |
| Boston | RMSE | 3.4476 | 3.1924 | 3.2411 | 3.3440 | 3.7108 |
| R2 | 0.8435 | 0.8658 | 0.8617 | 0.8527 | 0.8187 | |
| RMSE | 203.2279 | 161.6840 | 155.3245 | 134.7371 | 31.1309 | |
| R2 | 0.2376 | 0.5174 | 0.5547 | 0.6644 | 0.9821 | |
| Energy | RMSE | 2.3179 | 2.3176 | 1.7891 | 2.1380 | 0.8879 |
| R2 | 0.9487 | 0.9487 | 0.9694 | 0.9559 | 0.9925 | |
| Concrete | RMSE | 8.2259 | 7.8540 | 8.2476 | 8.0698 | 7.8910 |
| R2 | 0.7695 | 0.7898 | 0.7682 | 0.7781 | 0.7879 | |
| Average ranking | 4.75 | 2.375 | 3.375 | 2.25 | 2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wang, T.; Lai, Z. A Feature-Weighted Support Vector Regression Machine Based on Hilbert–Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator. Information 2024, 15, 639. https://doi.org/10.3390/info15100639
Zhang X, Wang T, Lai Z. A Feature-Weighted Support Vector Regression Machine Based on Hilbert–Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator. Information. 2024; 15(10):639. https://doi.org/10.3390/info15100639
Chicago/Turabian StyleZhang, Xin, Tinghua Wang, and Zhiyong Lai. 2024. "A Feature-Weighted Support Vector Regression Machine Based on Hilbert–Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator" Information 15, no. 10: 639. https://doi.org/10.3390/info15100639
APA StyleZhang, X., Wang, T., & Lai, Z. (2024). A Feature-Weighted Support Vector Regression Machine Based on Hilbert–Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator. Information, 15(10), 639. https://doi.org/10.3390/info15100639