2. Related Work
Recent studies have extensively utilized AI algorithms across diverse domains with various data formats including images, text, and tabular data due to their remarkable performance. However, a notable dedicated concern to the inherent black-box nature of these models, forming a lack of trust, especially around sensitive domains where the risk of mispredictions poses a substantial risk to human life. Scapin et al. [
15] applied RFto tabular heart disease data, achieving an accuracy of 85%. In a comparative study using the same dataset, Gurgul, Paździerz, and Wydra [
16] normalized K-Nearest Neighbors achieved an optimal classifier with minimum misprediction. Building upon this, Bhatt et al. [
17] achieved an even higher accuracy of 87.28% through the application of a multilayer perceptron. Employing feature engineering techniques, different optimizers, hyperparameter-tuning, and cross-validation regardless of machine/deep learning techniques utilized, reveals remarkable improvement in accuracy [
18]. Dileep et al. [
19] exhibit a significantly higher accuracy of 94.78% by proposing cluster-based bi-directional long-short-term memory (C-BiLSTM).
Deep transfer learning demonstrates even better efficiency, particularly with image data. For instance, Enhance-Net models established an accuracy of 96.74% in X-ray real-time medical image testing [
20]. However, their adoption in tabular data remains unexplored by most literature. Extensive research encourages converting tabular data to images to leverage transfer learning methodologies, such as SuperTML [
21]. However, this approach is not applicable in the medical domain as transforming data domains might potentially damage the data integrity, thereby influencing prediction outcomes and reducing the trust and credibility of these algorithms. The literature review represents limited work around direct training of tabular data. To address this gap, this study employs TabNet and TabPFN to assess their explanation credibility in comparison to already established methods such as SHAP and LIME. In addition, the study utilizes TabNet without inputting prior knowledge to assess its behavior.
Other examples of deep tabular transfer learning models include PTab [
22] which is trained for modeling tabular data and visualized instance-based interpretability and TransTab [
23] which converts tabular data to sequence input to train using downstream sequence models. By combining transfer learning, the study aims to bring greater adaptability in working with tabular data.
XAI draws attention for its ability to provide the logic underlying complex black-box prediction. XAI techniques address the gap in interpretability particularly in situations where a significant correlation exists between model accuracy and complexity [
2]. XAI demonstrated significant impact in various areas of study, specifically in a data-driven learning such as flood prediction modeling [
24,
25], and medical data. XAI practice, specifically in the medical domain, improves trust by ensuring reasonable judgment in arriving at the predicted outcome. Due to new GDPR (General Data Protection Regulation) policies, AI models must possess the qualities of interpretability, and accountability, which are now becoming legal requirements to ensure AI functions [
26]. Karim et al. [
1] explored multiple XAI libraries in the medical field by discussing the trade-off between explainability and application-use aspects. Based on their findings, not all predictions require explanation due to their time-consuming, reduction in model efficiency, and high development costs. Explainability becomes redundant when the risk of misinterpretations is negligible or the task is deeply comprehended, studied, and evaluated multiple times in practice. This ensures confidence that the result predicted by the black-box models is trustworthy [
2].
Despite the numerous tabular data across various domains, it is surprising that most XAI techniques are not inherently suitable for such data format, and engaging their applications constantly presents challenges [
27]. The majority of literature concerning explainability revolves around SHAP and LIME, primarily due to their model-agnostic nature, and versatility across various data domains. In addition, Anchors explanations are used in this study as an example of a rule-based explanation method. Other explainers in the literature include MAPLE (Model Agnostic suPervised Local Explanations) [
28], GRAD-CAM (Gradient-weighted Class Activation Mapping) [
29], and MUSE (Model Understanding through Subspace Explanations) [
30].
Dieber and Kirrane [
31], employed LIME on a tabular data trained on XGBoost with the highest accuracy of 85%. They investigate the quality of LIME on both local and global levels by conducting user interviews. Their outcome demonstrated LIME explanations are difficult to comprehend without documentation. Moreover, the relationship between prediction probability and feature probability graph is deemed unclear and, thereby, less effective on a global level. Another study [
24] applied LIME and SHAP across five distinct models to utilize flood prediction modeling. As a result of this study, LIME and SHAP agreed on selecting the same features for explaining the predictions.
Numerous studies employed layer-wise relevance propagation (LRP) [
32] due to its’ pixel-level representation of the input values, highlighting the most contributed to diagnosis results. For example, Grenzmak et al. [
33] employed LRP to understand the working logic of CNN. Another recent study by Mandloi, Zuber, and Gupta on brain tumor detection applied Layer-wise relevance propagation on deep neural pre-trained models starts by utilizing a conditional generative adversarial network (cGAN) to image data augmentation, employing classification using pre-trained models including MobileNet, InceptionResNet, EfficientNet, and VGGNet. Lastly, layer-wise relevance propagation (LRP) is employed to Interpret the model outcome [
34]. Hassan et al. [
35] compared three different deep learning explainability methods including Composite LRP, Single Taylor Decomposition, and Deep Taylor Decomposition for the prediction covid-19 using radiography X-ray images while applying two deep learning models including VGG11, and VGG16. Their research considered input perturbation, explainability selectivity, and explainability continuity as evaluation factors. The findings of their work identified Composite LRF can identify the most important pixels up to a certain threshold followed by Deep Taylor Decomposition, outperforming in selectivity and continuity.
Another recent study by Dieber and Kirrane [
8], introduced a novel framework called Model Usability Evaluation (MUsE) to assess the UX efficiency of LIME explanations resulting in optimal usability achieved when interacting with AI-experts. Furthermore, to enhance global explanations, the researchers suggested the integration of self-explanatory data visualizations. This article presents various frameworks, intended to assess their technical limitations, and offer design and evaluation alternatives across tabular data. In addition, it aims to support diverse design goals and evaluation in XAI research and offer a thorough review of XAI-related papers. This study presents a mapping between design goals for different XAI user groups and their evaluation metrics. Upon a comprehensive review of the literature and study of the tools and framework which will be expanded further in this section, it is evident that prior studies have predominantly focused on specific methods and explainability, often combined with a particular scenario. The novelty of our study lies in the innovation to develop a consensus within existing literature that is capable of evaluating the broader methods and scenarios across different data domains. We contribute by presenting a layer-wise framework that systematically considers each explainability critera while prioritizing the specific requirements of the application domain to prevent any misinterpretation. In contrast to previous literature, where the evaluation framework relied either on user interviews or explainability tools, our study scrutinizes the combined impacts.
XAI integration assists in understanding, debugging, and improving model performance to improve robustness, security, and user trust by reducing faulty behavior. However, XAI could lead to misinterpretations which highlight the need for evaluation frameworks. While interpretability is crucial, it is not sufficient for evaluating explainability [
1]. We argue that neither of the explainer approaches is without limitations. Scalability is one of the challenges discussed by Saeed and Omlin [
2] concerns that local explanations often struggle when explaining numerous instances. SHAP’s complexity raises an issue from considering combinations of variables, making it computationally expensive to contribute variable contributions with a vast number of data instances. To ensure interpretability, explanations must be evaluated using languages familiar to humans. Moreover, data quality must be assessed. Low-quality data resulted in low-quality models, thereby, low-quality explanations. User interactivity is vital in engaging explanations with end-users. In addition, balancing the reliance on XAI-generated advice is crucial to avoid unintended consequences such as relying too much or too little on explanations [
2].
This study aims to conduct a comprehensive assessment in evaluating the strengths and weaknesses of this explainer. Similarly, a metareview conducted by Clement et al. [
36] demonstrates a high correlation between the evaluation method and the complexity of the development process. They primarily considered computational evaluation by calculating time, resources, and expenses in producing explanations without human intervention. In addition, the importance of robustness is highlighted. A well-performed explainer should remain stable in similar perturbed input. The reason is that users expect similar model behavior from similar data, hence, similar explanations. The paper also considers faithfulness and complexity. Stassin et al. [
3] state that perturbation-based methods analyze the model’s behavior in variations of perturbed input to estimate the loss due to the perturbing input and determine the effect on the prediction score. A study conducted by Carvalho et al. [
6] showed that when two models contribute similar features to arrive at a prediction with consistent explanations, they exhibit a high degree of consistency, signifying a robust explanatory characteristic. Conversely, when two models reflect on disparate aspects of the same data’s features, the respective explanations should naturally be diverse.
An interesting study examined the impact of model accuracy and explanation fidelity on user trust. The study discovered that the model’s accuracy has the highest impact on gaining user trust. The results represent that the highest trust is obtained with no explanation, and low fidelity always harms the trust. Therefore, when explanation is involved in a system, high fidelity is most preferred in assisting user trust [
7].
The research exploration on pattern discovery for reliable and explainable AI identified reliability as an assurance metric to identify whether the system’s output is spurious and can be trusted [
37]. Spurious correlations happen when a model learns correlations from the data that are not valid under natural distribution shifts. This is because the model extracts unreliable features from the data, which is one of the drawbacks of data-driven learning. In practice, spurious features might occur due to existing biases during data collection or measurement errors [
38,
39]. Based on the work of Lapuschkin et al. [
40], a model relying on the spurious correlation’s decision strategy would mostly fail in identifying the correct classification and, therefore, lead to overfitting when applied to real-world applications. This can damage the precision and robustness of the model.
An example of a user interview was presented by Dieber and Kirrane [
31] identified that LIME explanations tend to be time-consuming and exhaustive for non-AI-experts. The study outlined a gap for further studies to improve LIME’s user experience, developing tools, and techniques to enhance global comparisons. In addition, TabularLIME was recognized as less effective at the global level, with the potential risk of misinterpretation. Duell et al. [
9] aimed to understand clinicians’ expectations by analyzing explanations produced by LIME, SHAP, and Anchors on a medical tabular dataset. As a result, SHAP was identified with superior comprehensibility on both global and local levels. Hailemariam et al. [
41] examined LIME and SHAP on neural models on image data, substantiating SHAP’s superior performance on stability, identity, and separability in security-sensitive domains. Conversely, Burger et al. [
42] highlighted LIME’s potential instability. Zhang et al. [
10] introduced the Mean Degree of Metrics Change (MDMC) to evaluate the explanations by removing the contributed features and calculating the average loss (R
2, MSE, and MAE). Since these metrics are more suitable for regression tasks, this study aims to provide such evaluation for the classification by calculating the relative performance on logarithmic loss. Despite the vast body of knowledge developed around the concept of XAI evaluation, these studies lack consensus among scholars on how to arrive at an optimal explainer. To address this diversity, our proposed study aims to agree on a three-layered top-down approach to assess the credibility of explanations to arrive at the best explainer for specific applications.
The literature around XAI tools includes Xplique [
43], a neural network explainability toolbox for image data, that assists in extracting human-interpretable aspects within an image and examines their contribution to the prediction outcomes. The toolbox encompasses several explainers such as Saliency Map [
44], Grad-CAM [
29], Integrated Gradients [
45], etc. Dalex [
46] is a model-agnostic explanation toolbox that supports popular models such as Caret [
47], random forests, and Gradient Boosting Machines. It offers a selection of tools to enhance the understanding of a conditional model’s response with respect to a single variable. Dalex incorporates explainers such as PDP [
48], ALE [
49], and Margin Path Plot [
50]. AIX360 [
51] is an alternative tool supporting tabular, text, image, and time-series data. It is a directly interpretable tool capable of providing data-level local and global explanations. It supports faithfulness and monotonicity metrics in evaluating the quality of explanations. ALIBI [
52] can provide a high-quality implementation of complex models at both local and global levels. Quantus [
53] is a notable advancement for evaluating the explanations for neural networks based on the six explainability criteria including faithfulness, robustness, localization, complexity, randomization, and axiomatic. Although the tools were initially designed for images, newer versions support tabular data. OpenXAI [
54] is another alternative capable of providing explanations for black-box models and evaluating the post-hoc explainers based on the evaluation criteria.
Another tool for evaluating the XAI explainers is CompareXAI [
55] which uses metrics including comprehensibility, portability, and average execution time. Further contribution includes the Local Explanation Evaluation Framework (LEAF) [
56] which can evaluate the explanation produced by SHAP and LIME with respect to stability, local concordance, fidelity, and prescriptivity. Upon reviewing existing literature on the XAI tool and its evaluation metrics, it is evident that there is a substantial gap necessitating the development of a toolbox that addresses various explanations and their evaluation criteria by achieving consensus in the field. Additionally, a gap is identified in the availability of a tool for evaluating rule-based explanations such as Anchors. LEAF is employed to contribute to the current study. However, in contrast to most instance-wise explanation techniques, the goal of our study is to rely on the global feature effect because it underlines the rationale of the model, not just providing relevant details to individual prediction. Ultimately, our research prioritized global explainability over individual explanations.
9. Analysis of the XAI Evaluation
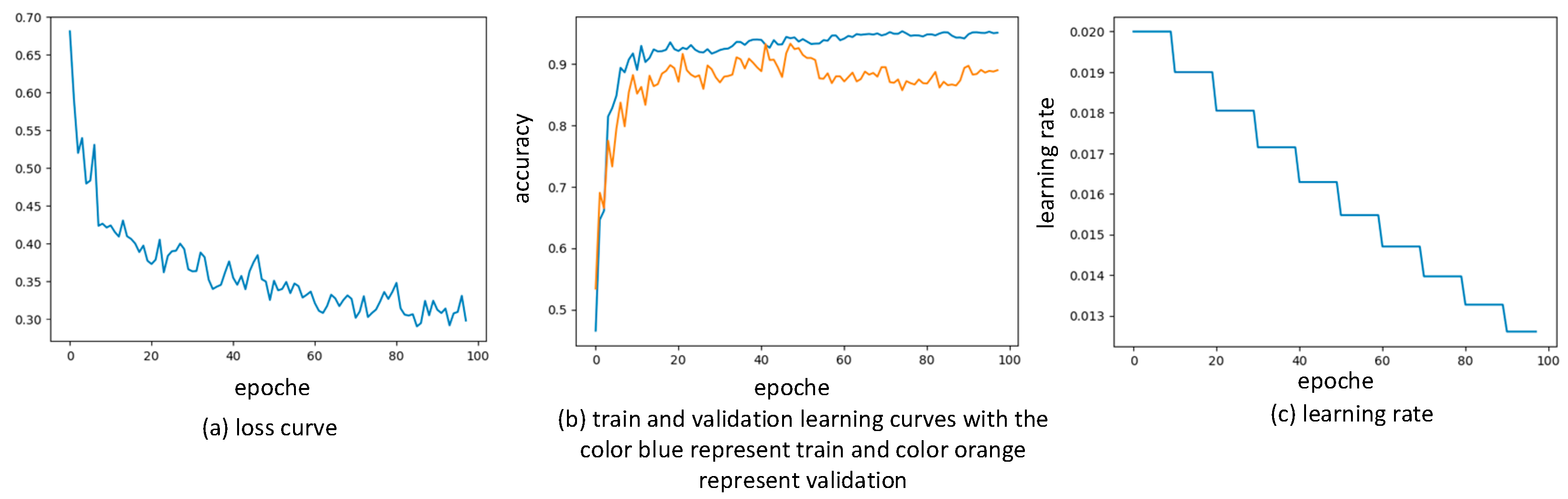
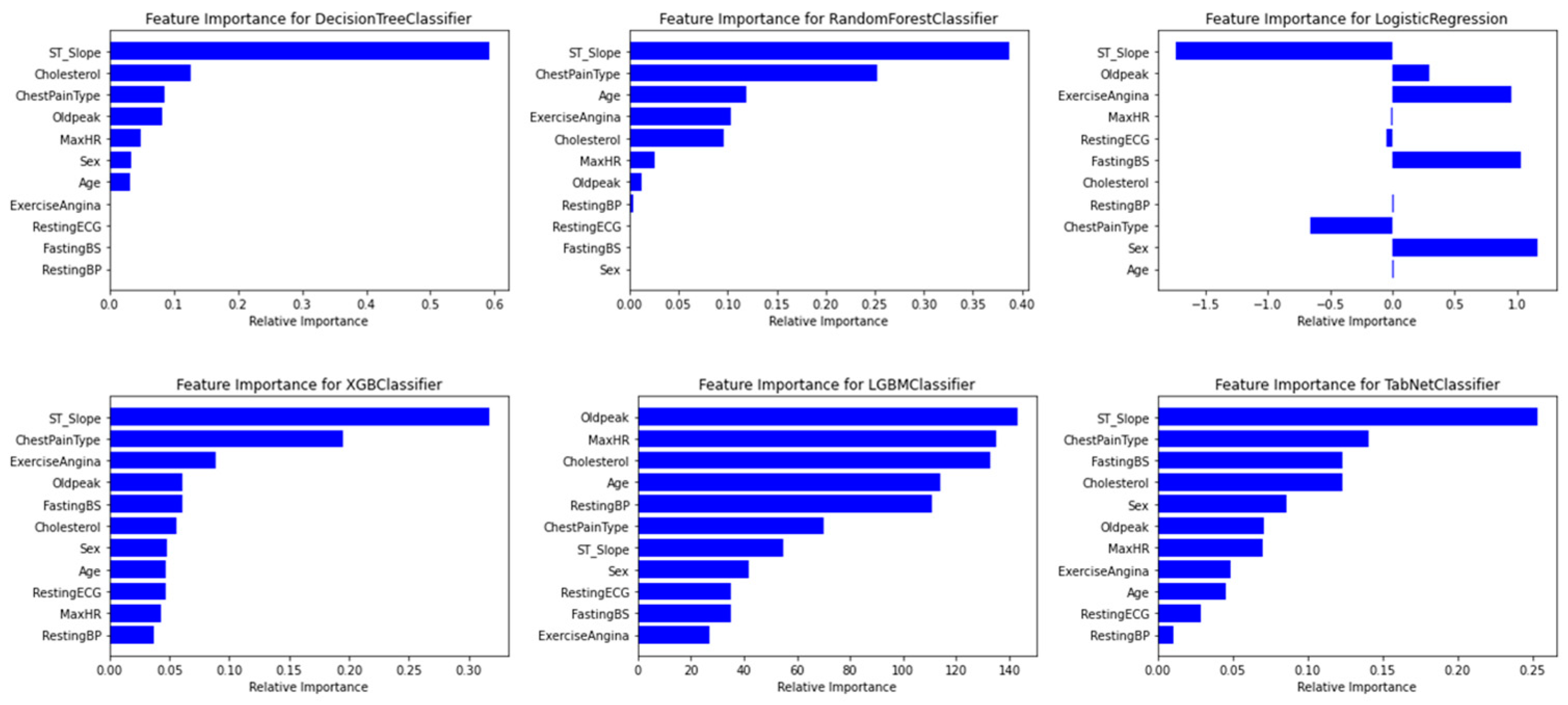
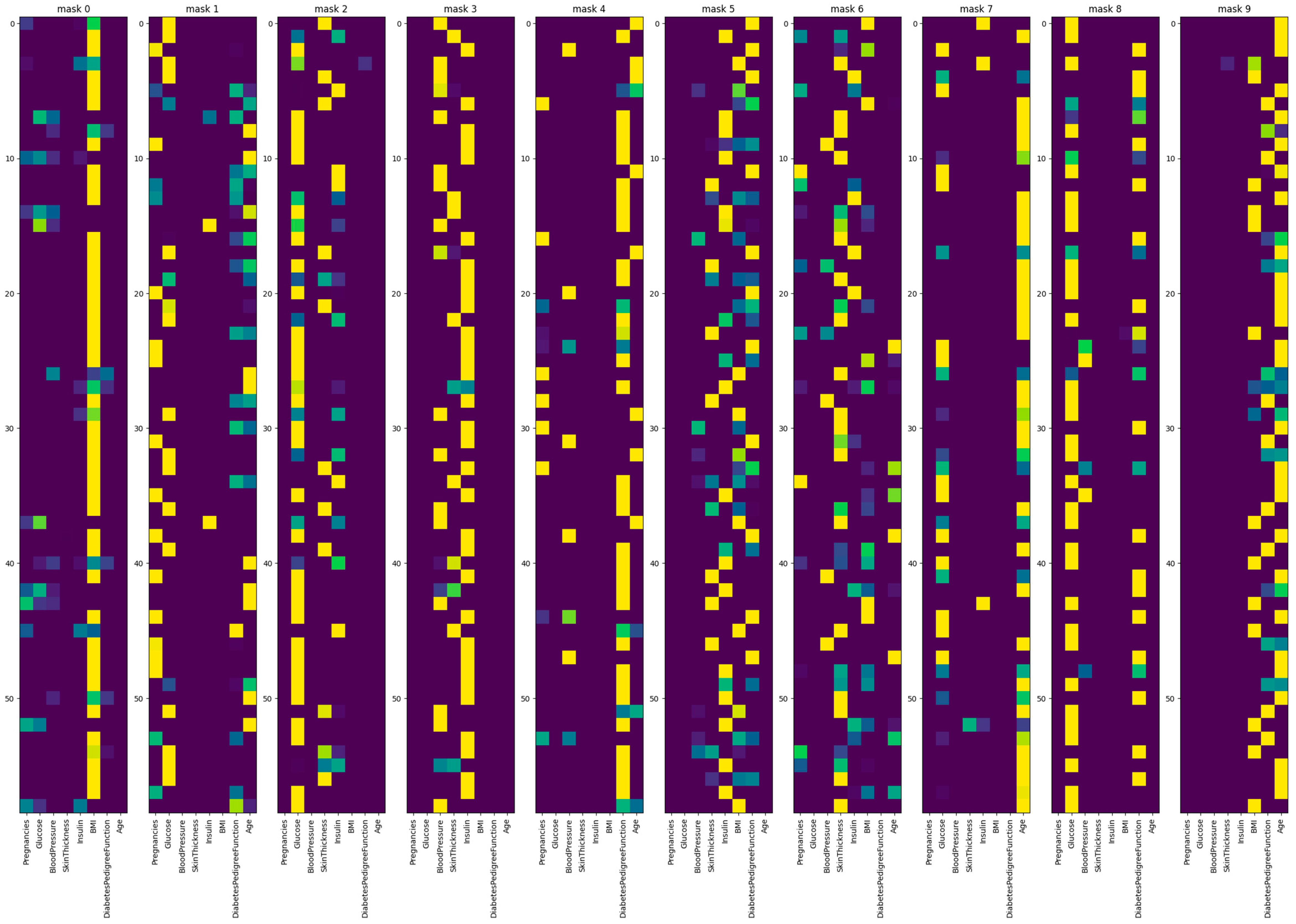
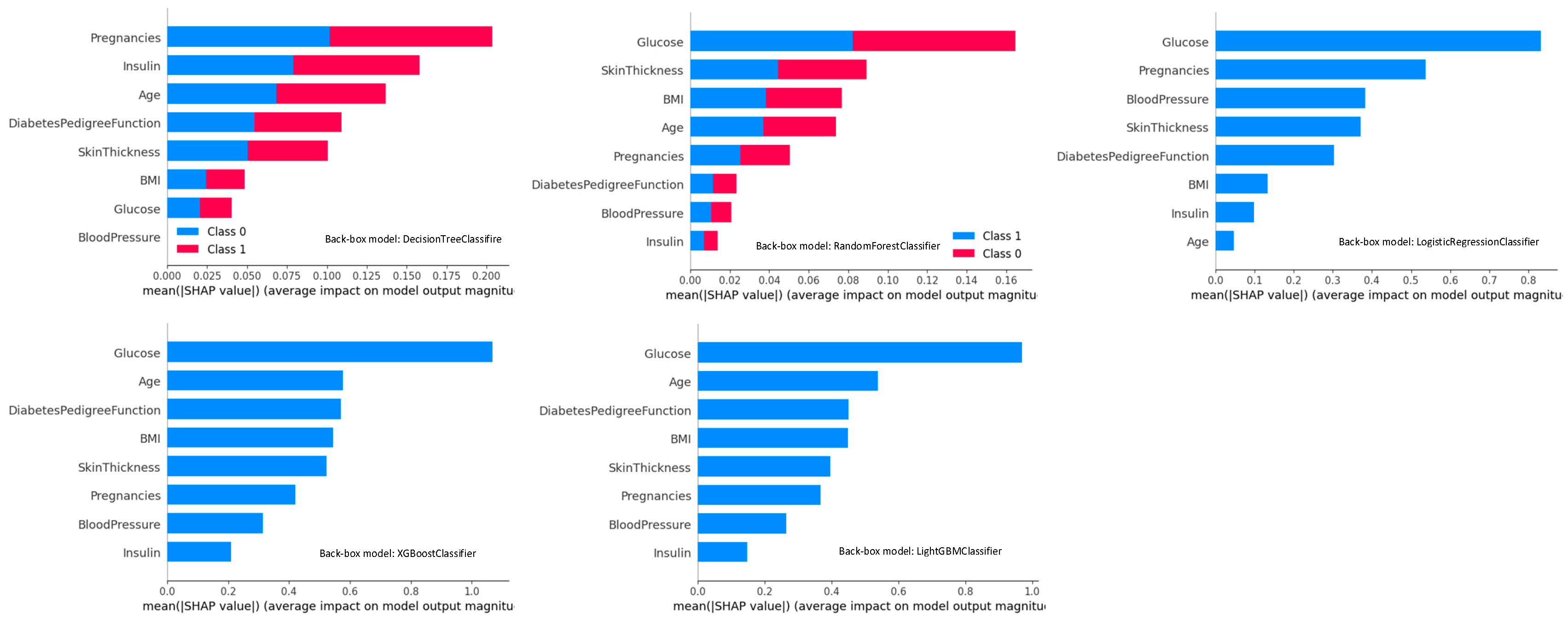
This study aimed to address the question of how to effectively select an optimal explainer to reduce misinterpretations. The study evaluated various classification models with a focus on recall across two medical tabular datasets. In both studies, XGBoost emerged as the top-performing model for classification and explainability tasks. This is followed by TabNet and TabPFN. A notable strength of utilizing TabNet lies in its model-specific explainability and capability to inject additional knowledge into the model. While TabPFN demonstrated satisfactory performance, it comprises multiple challenges within the scope of explainability including the lack of built-in model-specific interpretability struggles with providing feature importance, and incompatibility with the majority of model-agnostic explainers due to its black-box nature and time-consuming process. Furthermore, the study examined the intrinsic feature importance of these models. The result demonstrates a consensus with XGboost, LightGBM, and TabNet. Additionally, DT, RF, and LR are unsuccessful in generating reasonable logic as they failed to capture the correct feature relations in both studies.
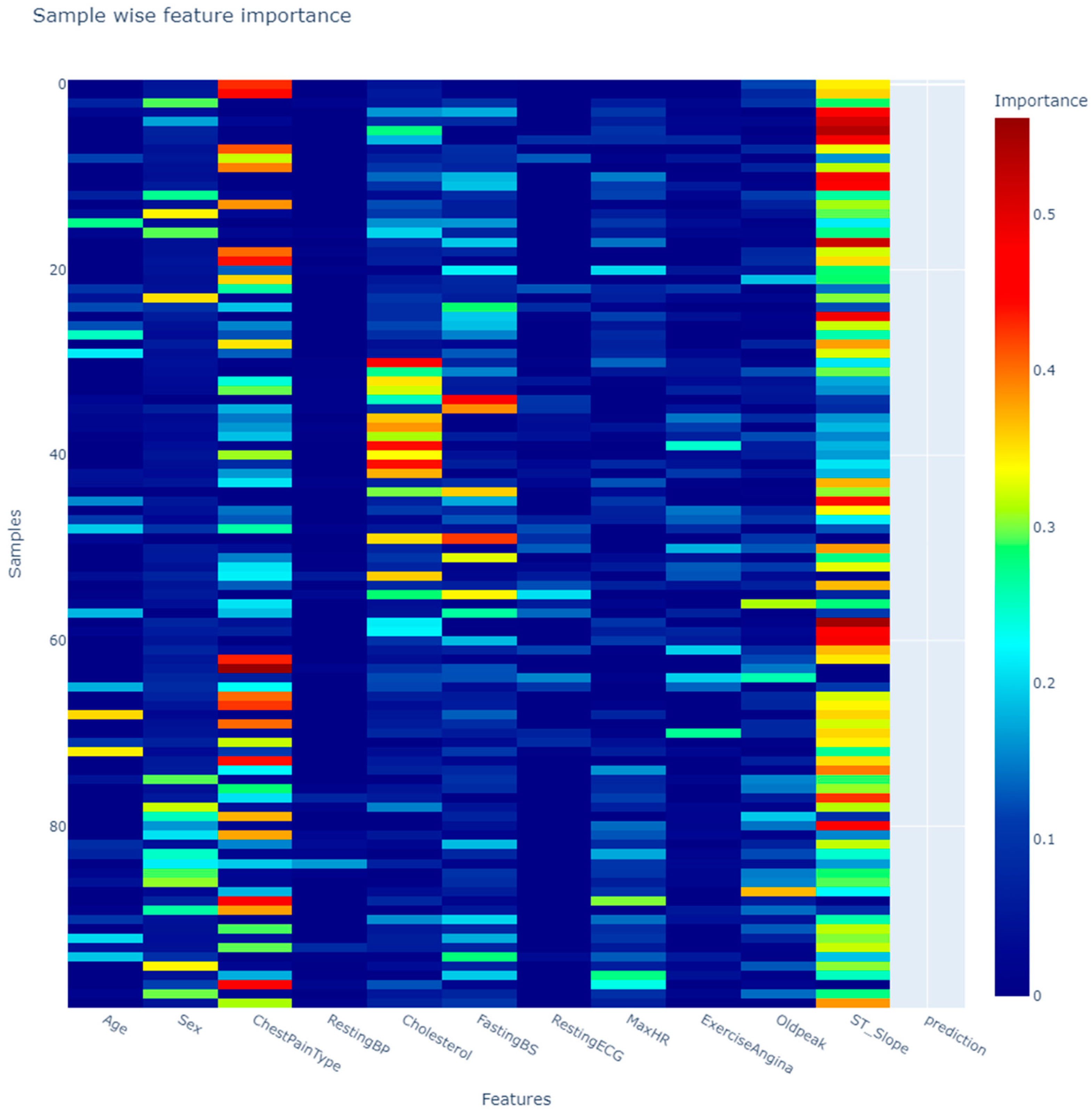
In addition, the study utilized LIME, SHAP, and Anchors to generate explanations. Consequently, LIME stands out as the most unstable model specifically at the local level, endangering user trust. In LIME explanations, TabNet and TabPFN identified similar behaviors, however, they represent different prediction probabilities in many test cases. In addition, TabNet displayed unique behavior in comparison to all models. DT and RF were found to pose a higher risk of misinterpretations across all techniques, which is not surprising based on their unreasonable behavior from global feature importance. XGBoost maintained a consistent ranking for certain features, with slight differences. Anchors consistently demonstrated the highest precision across all models within both experiments. However, Anchors represent significantly less coverage for the second dataset.
In addition, this study compared global feature importance across different techniques, including intrinsic and post-hoc model explainability at the global level. This resulted in a varying feature importance ranking for each technique. The results derived from both experiments, model-agnostic explanations including SHAP, and LIME exhibit similar behavior for XGBoost and LightGBM. However, model-specific explainers, particularly TabNet in this study, demonstrate advanced precision in explaining the decision. Across both studies, DT is recognized as the least-performing model due to its inaccuracies in either eliminating necessary features or learning the incorrect feature relations. In contrast, there was no consensus on the topmost important features of RF and LR across all four techniques. This disparity resulted because intrinsic model explanations rely on impurity-based feature importance, which is based on differences in entropy whereas LIME uses linear model coefficients, and SHAP aggregates Shapley values [
65] across all instances [
4,
13,
66]. On the contrary, feature contributions obtained from the interpretable ensemble models were incorporated into the models as part of their optimization process. These interpretabilities are directly incorporated from model structure whereas post-hoc model-agnostic explanations are limited in their strength in approximating the black box. Their key difference lies in the trade-off between model accuracy and explanation fidelity [
67].
Our study underscores the consistency in feature importance with certain findings across the literature. As an example, our results aligned with the research conducted by Tasin et al. (2022), where LIME and SHAP were employed as their explainer, identifying XGBoost as the best-performing model. Remarkably, Glucose, BMI, and Age were recognized as the most salient features [
68]. Similarly, another study employed similar methods including RF and XGBoost, and employed LIM and SHAP as explainers [
69].
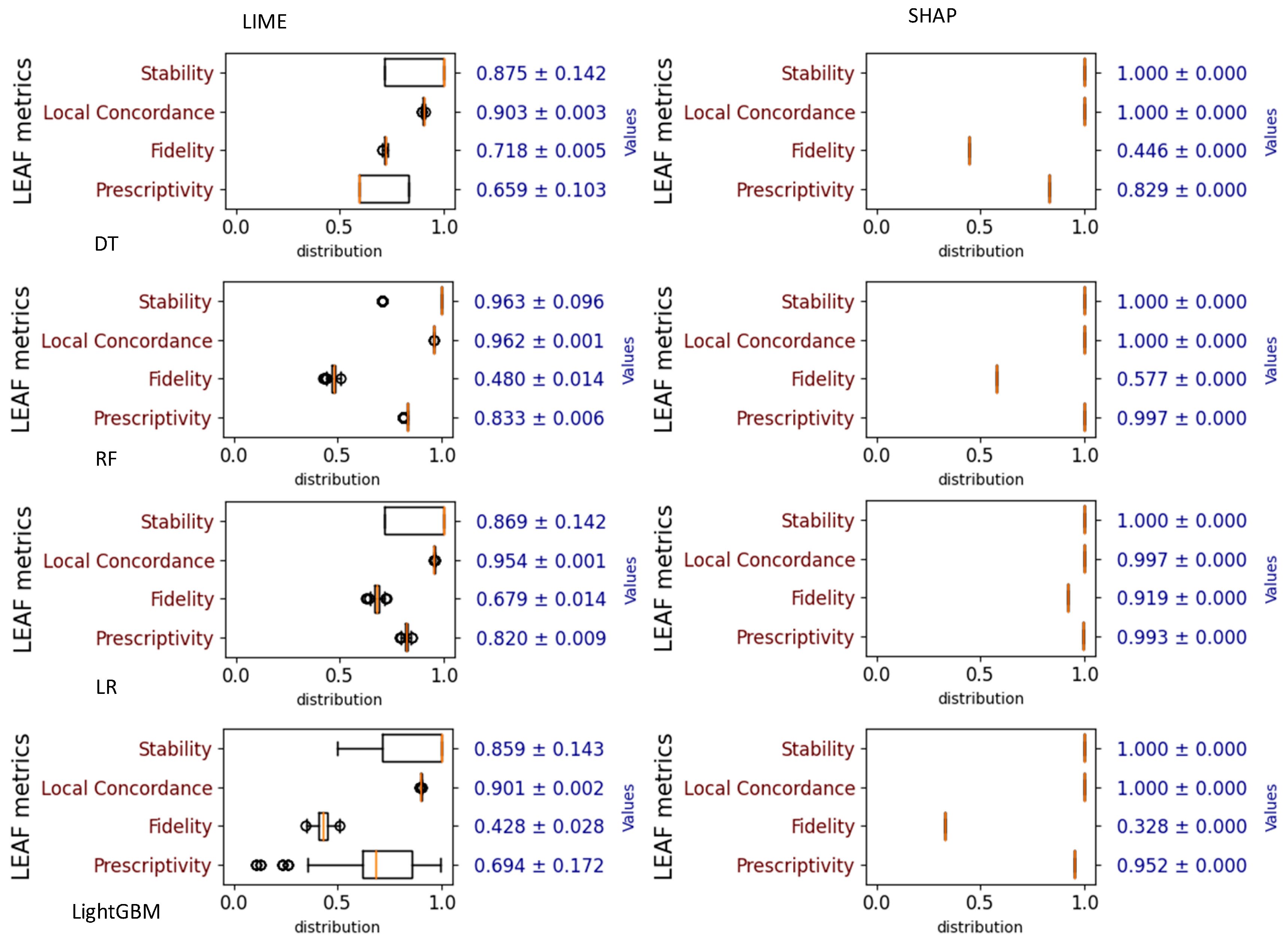
LEAF was employed to evaluate the explainers at the local level. Subsequently, LIME achieved the best stability with LightGBM, with the highest local concordance score for LR and the best prescriptivity for RF for the heart disease dataset and best stability with RF, the highest local concordance with RF and LR, and the best prescriptivity with RF. However, LIME performed poorly in terms of fidelity, with slightly better results for RF for the first dataset whereas for the second one, SHAP is identified with the lowest fidelity score, except for LR with a fidelity of 0.91. In general, SHAP demonstrates better performance with optimal stability, local concordance, and presciptivity across all models.
In evaluating global feature importance for a classification, this study recommends Relative Performance Loss as a metric that calculates the impact of global feature contributions on model loss. As a result, XGBoost demonstrates excellent compatibility with all three model-agnostic explainers within both experiments. In the first experiment, DT and LightGBM performed best with Anchors, RF with SHAP, and LR with LIME. Furthermore, TabNet demonstrates the most effective global feature importance, followed by XGBoost and TabPFN. For the second dataset, the best explainer is devoted to XGBoost with the best results across all explainers, this choice is followed by TabNet and TabPFN.
12. Conclusions and Future Work
This paper has aimed to examine the relevant literature for the field of explainability evaluation and arrive at a conclusion on which approaches to consider when adding XAI to AI-system. This work has combined various approaches to conduct a comparative evaluation of techniques used across literature. In evaluating the explainers applied in the study, the research contributed to gathering relevant work on literature to converge on the most important criteria, then the study proposed relative performance loss as the metric to evaluate global explainability. One positive contribution of this study is that even though the research has focused on the classification task, the three-layered top-down approach can be considered for all applications as it generally evaluates the important principles prioritized sequentially, and the metrics themselves, such as loss can be tailored for a specific task. For classification, this study has contributed to the relative performance evaluation of log loss. The contribution of this research is accomplished as a guideline for evaluating whether the explainers should be trusted. Performance measurement in the context of XAI is a challenging task. Multiple explanations and application criteria such as fidelity, complexity, selectivity, etc. must be considered which are discussed in the study. The novelty of this study is to combine both qualitative and quantitative methods. The main goal of such XAI frameworks is to eliminate the human in the decision loop due to many reasons including limited access to domain experts in multiple scenarios, time-sensitivity of the task, or increasing the precision and to allow XAI to explain itself to end-users. However, for a highly sensitive task such as medical, XAI requires domain supervision which is included in the first layer of this framework. Even in this case, the XAI will assist medical practitioners to enhance their precision and reduce misinterpretation in the decision-making process.
On the concept of improving user trust, several studies have argued that adding the calibration layer has a significant effect on improving the quality of explanations, therefore, increasing user trust. The research conducted by Scafarto, Posocco, and Bonnefoy [
70] on image data demonstrates that post-hoc calibration can positively impact the quality of saliency maps in terms of faithfulness, stability, and visual coherence. In addition, the authors argue that applying the calibration before interpretability will lead to more trustworthy and accurate explanations. Another study by Mohammad Naiseh et al. [
71] explored four different explainability methods including local, example-based, counterfactual, and global explanations during human-AI collaborative decision-making tasks to investigate how different explanations impact trust calibration in clinical decision-making. Their work highlighted that local explanations are more efficient in explaining unfair model decisions and, therefore, more beneficial in calibrating the user fairness judgment. In addition, they argue that including the confidence score enhances the user’s trust calibration. As a result of their study, example-based and counterfactual explanations were more interpretable than others. Moreover, the study conducted by Zhang, Liao, and Bellamy [
72] supports the idea that including confidence score in end-users decision-making- process will positively impact the trust calibration. The major findings of the study argue that local explanations significantly improve user trust and AI accuracy even more than confidence score. The main study by Löfström et al. [
73] investigates the impacts of the calibration in the explanation quality by utilizing misleading explainers such as LIME. The study indicates that adding a layer of calibration will significantly enhance the accuracy and fidelity of explanations. In the experiment with LIME, a well-calibrated black-box model will lead to well-calibrated explanations. They also argue that for a poorly calibrated model, the confidence score may not reflect true probabilities, leading to misinterpretations. In addition, in a poorly calibrated model, the explanations produce a higher log loss, indicating the larger errors by the explanations. The calibration layer will assist in ensuring that the model’s confidence is aligned with its accuracy. To improve calibration, their study employed Platt scaling and Venn–Abers. However, Venn–Abers is considered the optimal choice. Another framework was developed by Famiglini, Campagner, and Cabitza [
74] to assess the calibration. Therefore, based on the recent study and the positive and required effect of calibration, the focus is on further investigating the effect of calibration within the framework by adding a layer of calibration evaluation and re-calibration to the pipeline before explanations and evaluating the quality of explanations to deeper investigate the XAI evaluation.
In addition, since the requirements of medical AI systems are different, special attention must be given to models that can process medical applications based on their specific criteria. A future might benefit from XAI explainers that are more detailed and perform along with human logic systems in order to be trusted within the medical community. Extracting the strengths and weaknesses of each explainer will assist in detecting the gap in developing enhanced explainers, therefore, developing a more accurate framework. The future work must be aware to provide evaluations that are capable of evaluating various explainers. Moreover, the techniques proposed in this paper will benefit from further enhancement in future work by examining various datasets across various domains. For this reason, the research emphasizes the importance of future work in expanding this work in various approaches.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}