1. Introduction
Domain ontologies express conceptualizations specific to a particular domain [
1]. In transportation, many solutions have emerged. For example, in [
2] a vehicle accident ontology has been defined, in [
3] an ontology for traffic management and control has been defined and tested in a multiagent system. In [
4], an implementation of a semantic web service discovery system for road traffic information has been developed. Details of existing traffic ontologies are analyzed in [
5].
In distributed environments, such as in transportation, data are the key element for developing Intelligent Transport Systems (ITS). The specification of DATEX II XML/UML [
6] provides a description of concepts and data structures pertaining to traffic. However, it is important to note that this description is primarily focused on the syntactic aspects and does not incorporate semantic meaning. Therefore, there is a necessity for a semantic model that describes the contents of DATEX II elements to facilitate linking these data with other vocabularies and ontologies available on the internet. Linked Open Data (LOD) emerges as a methodology for publishing and interlinking structured data on the web, following the principles of the Semantic Web. LOD offers a standardized framework for sharing and connecting data from diverse domains and sources, enabling data integration, enrichment, and reuse. The utility of LOD can be described through various aspects, including data integration and enrichment, data discovery, data reuse, interoperability, and data quality.
Its usefulness has been demonstrated in a variety of domains, such as healthcare [
7,
8] or education [
9,
10].
In the transportation domain, the use of non-LOD formats produces some interoperability problems. For example, in the European project
CROCODILE corridor [
11], to make possible the exchange of information between operators, road administrators and end-users, a middleware was created to provide the translation of different
situation_publication. A
situation_publication is an identifiable instance of a traffic/travel situation comprising one or more traffic/travel circumstances that are linked by one or more causal relationships. Types differ between the different national implementations of DATEX II. However, the middelware requires upgrading when new data concepts are added to any DATEX implementation, making this solution neither efficient nor viable. So, we consider that the use of LOD would be a much more efficient solution, given that sharing the same semantic model (Ontology for DATEX II) could avoid the interoperability problems, since it avoids the semantic ambiguity of specific terms.
In the CEF Action LOD-RoadTran18 reference Nº 2018-EU-IA-0088 [
12], our primary aim was to facilitate the effective reuse of real-time road traffic data in the Czech Republic and Spain. To achieve this objective, we developed the DATEX II Safety Road Traffic Information (SRTI) ontology called
dtx_srti. This ontology, built on the foundation of DATEX II, underwent rigorous testing on diverse datasets using SPARQL queries at a small scale [
13]. In addition, we invested considerable effort in creating tools for model conversion, adaptation, and validation, with specific attention given to the geospatial characteristics of the traffic data.
In order to accomplish our goals, we thoroughly analyzed existing DATEX II models, LOD general concepts, as well as relevant vocabularies and models related to traffic information. This paper provides comprehensive details on the development of the semantic model. The model features a primary ontology housing the fundamental concepts of the DATEX II standard, complemented by two secondary ontologies—one designed for road concepts and the other for administrative units. Considering that traffic events occur across national road networks, the project tasks include analyzing vocabularies, ontologies, and datasets likely to become sources of information linked to the new general ontological model of DATEX II SRTI. Another aspect to consider in various instances of the SRTI general model is territorial organization. Incidents occur in sections of specific roads belonging to municipalities, provinces, and autonomous communities. Therefore, similar to the analysis of roads, a comparable examination is undertaken in the project regarding administrative units or areas.
The separation became essential to manage diverse data domains effectively. The modules will facilitate scalability and will be interconnected with the main ontology. Once the different sub-ontologies are constructed, they merge into a main ontology, consolidating all the main concepts. This ontology only references the key concepts defined in the rest of the sub-ontologies.
Also, modularity is a crucial aspect to consider, as maintaining independent ontologies allows each one to be modified separately. Even within a single ontology, it is highly beneficial to adjust hierarchies based on structures, roles, etc. This approach enables the incorporation of various classifications within a single ontology, creating sub-taxonomies that can be modified and managed independently. In fact, due to the disparities in road and administrative unit concepts between the Czech Republic and Spain (countries participating in the project), we worked independently on the development of secondary ontologies, successfully integrating them in the final stages.
We delve into the most pertinent aspects, providing elaborate explanations of the decisions made regarding the current and potential future usage of vocabularies and datasets. The paper covers the definition of concepts, their inter-relationships, and the utilization of individual instances instead of the generic and specific data types found in the UML/XML schema of DATEX II version 3.2 [
6].
The purpose of this paper is to provide a detailed description of the core dtx_srti ontology, offering a semantic description of its contents based on the UML data model developed as part of the CEF Action.
The main contributions of this research are summarized as follows:
A groundbreaking semantic modeling approach for traffic information was introduced through the development of a novel ontology known as
dtx_srti [
14]. This ontology, accompanied by a couple of secondary ontologies, serves as a comprehensive semantic vocabulary specifically designed to represent the SRTI DATEX II profile [
15] in accordance with the Commission Delegated Regulation (EU) [
16]. The primary purpose of this vocabulary is to facilitate seamless mapping between DATEX II version 3.2 and Linked Open Data (LOD) formats, enabling efficient interoperability and data exchange. By leveraging these semantic resources, a significant step forward has been taken in advancing the representation and integration of traffic information within the context of dynamic data utilization.
Regarding the implementation aspect, the ontologies put forward in this study were constructed using RDF/OWL (Resource Description Framework/Web Ontology Language) [
17]. In order to enhance the depth and breadth of knowledge representation, these ontologies have been interconnected with relevant external ontologies. To consolidate data in the RDF standard [
18], a set of mapping functions has been devised, enabling automatic storage in a shared RDF repository and Endpoint service. Building upon this foundation, an array of sophisticated SPARQL queries has been formulated, designed as an API service. Furthermore, to foster widespread adoption within the research community, a user interface has been developed, streamlining the utilization of these resources. This user-friendly interface aims to facilitate seamless exploration and interaction with the ontologies, empowering researchers to harness their full potential.
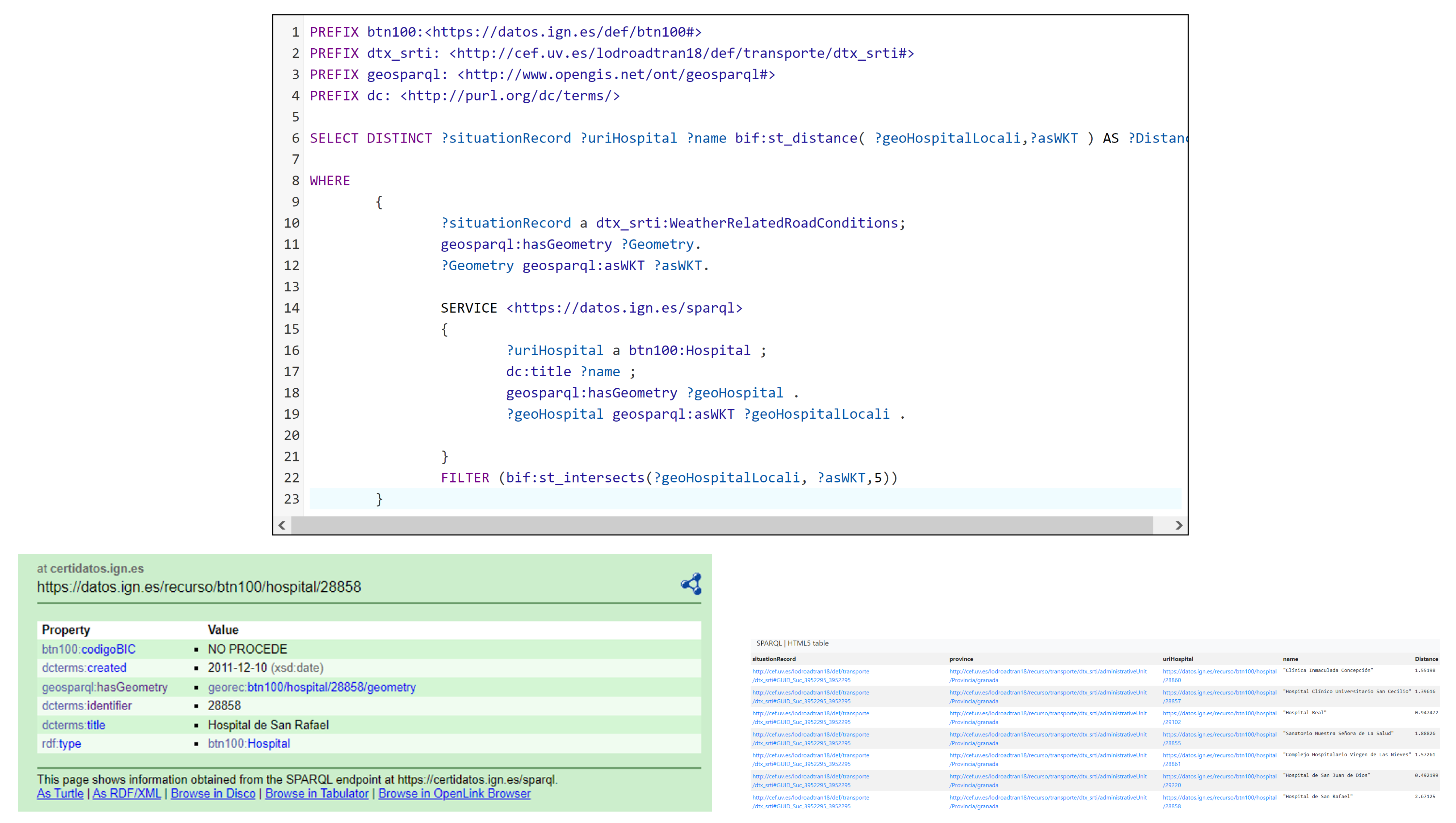
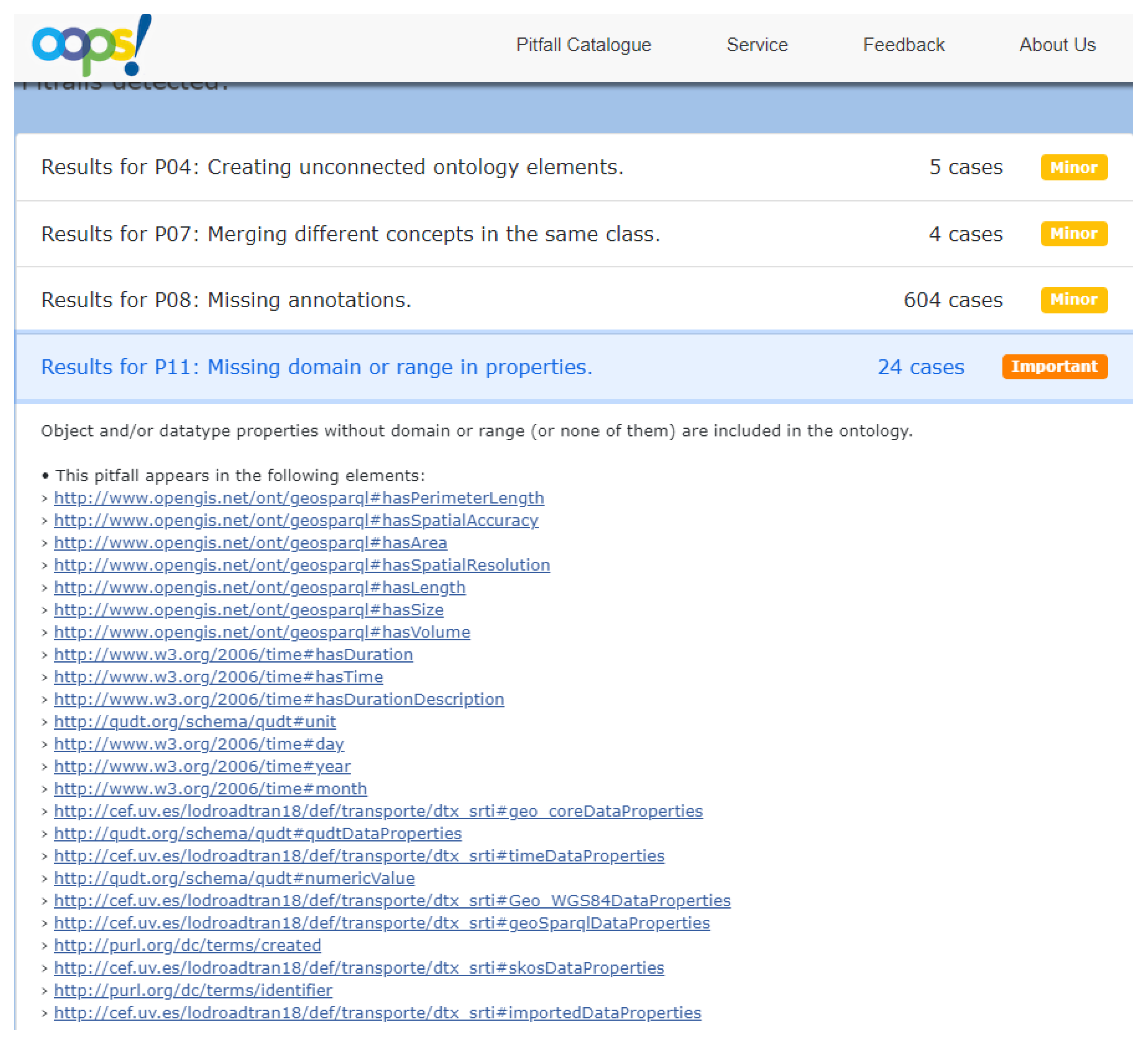
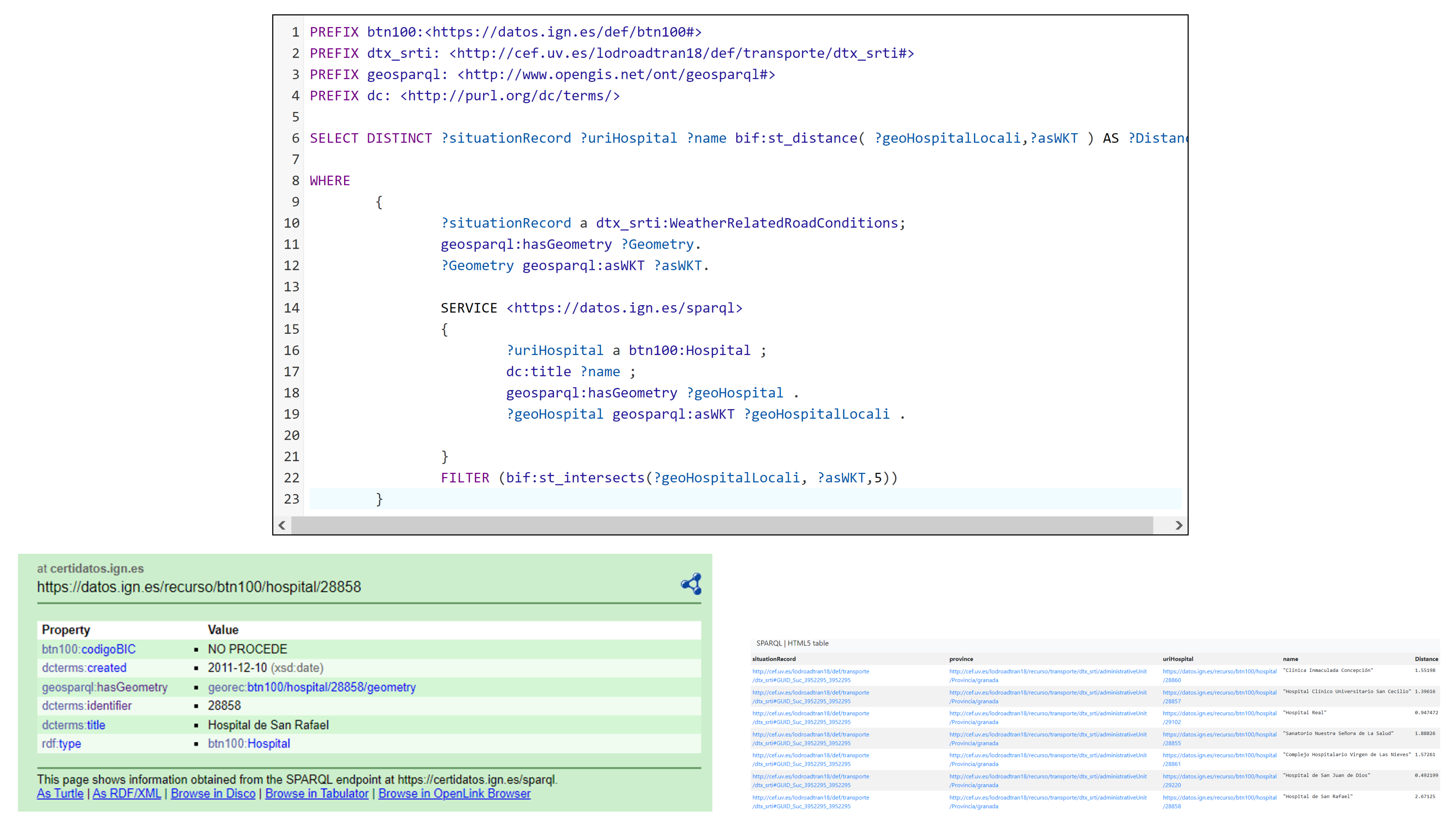
To ensure the robustness and accuracy of the developed ontologies, a comprehensive validation process was undertaken. Multiple tests were conducted, involving various queries on traffic incident data, administrative units, and road information. Furthermore, federated queries were designed to establish connections between the data generated by our LOD Converter and other SPARQL Endpoints, including the esteemed Spanish National Geographic Institute (IGN) [
19]. These tests not only explored the potential of leveraging linked data from diverse datasets but also assessed the intricacies and challenges associated with executing complex SPARQL queries. In doing so, the tests aimed to identify and rectify common errors and shortcomings, contributing to the refinement and optimization of the overall system [
20].
This paper is organized as follows:
Section 2 highlights the required legal and technical aspects related to the research.
Section 3 describes the semantic approach, focusing on the OWL Ontology. The definition and implementation of the Linked Open Traffic Data Model is described in
Section 4. The procedure to validate this approach is described in
Section 5. Finally,
Section 6 concludes with key remarks and future works. All this content not only provides a picture of semantic modelling within Safety Traffic Data but also an example of research and implementation that can be partially replicated for the creation and analysis of other ontologies.
4. Design and Implementation of a Comprehensive LOD Model for Road Traffic
Upon establishing the initial scope of the project, a thorough analysis of the DATEX II model was conducted, with a primary focus on the Safety-Related Traffic Information (SRTI) profile [
15]. This profile represents a subset of the complete DATEX II model (version 3.2). However, after extensive discussions, it was decided to extend the model beyond the SRTI profile by introducing new terms and relationships. This expansion allows the model to accommodate various types of information beyond SRTI, thus paving the way for future extensions. Additionally, previous semantic models related to traffic, such as [
33,
34,
35], were taken into consideration.
In the development of the project, an ontology is constructed to define concepts related to traffic, its situations, and elements present in the DATEX II standard. The Protégé editor [
36] tool, focusing on the OWL-DL ontology description language, is employed for this ontology’s creation.
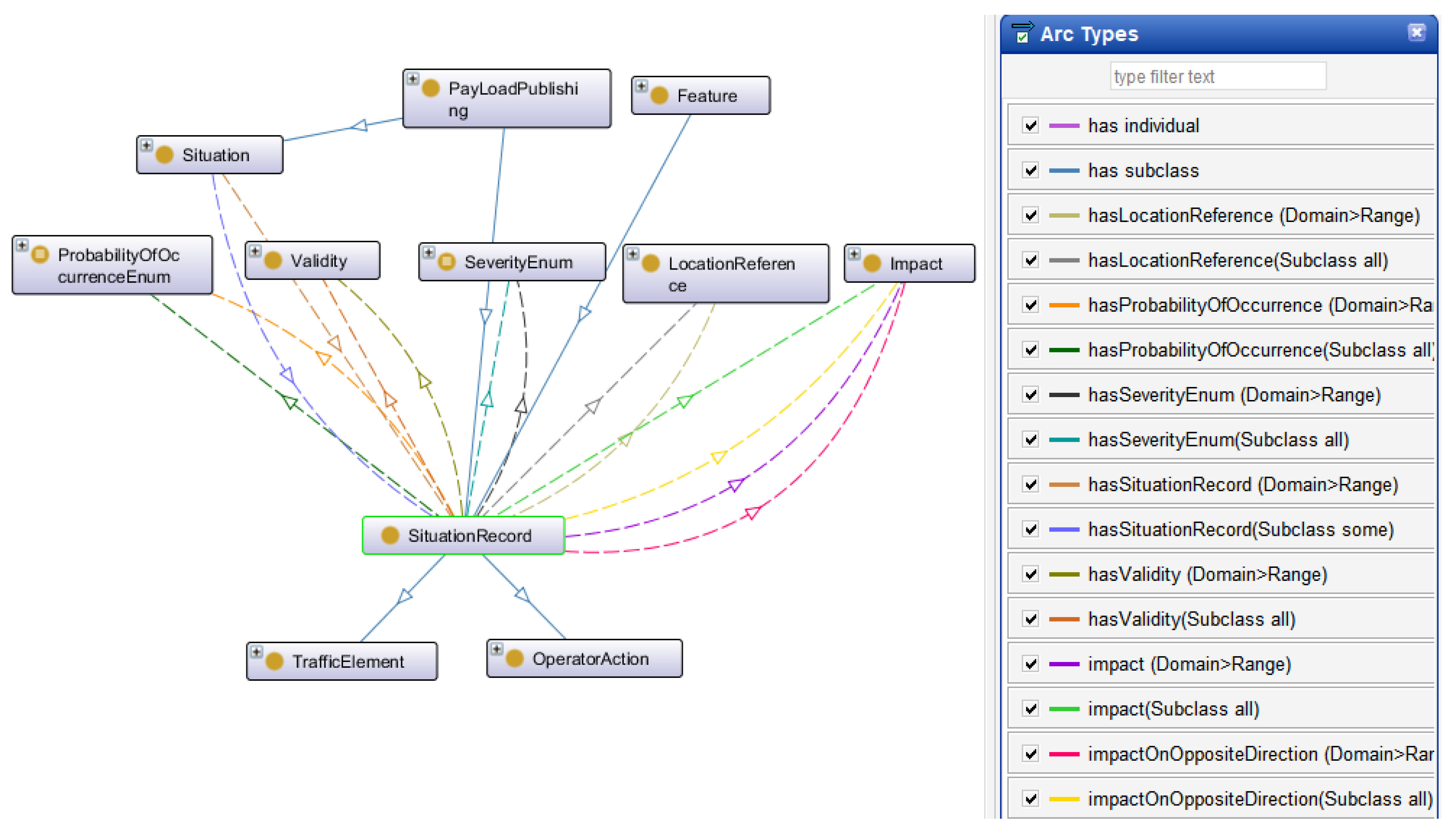
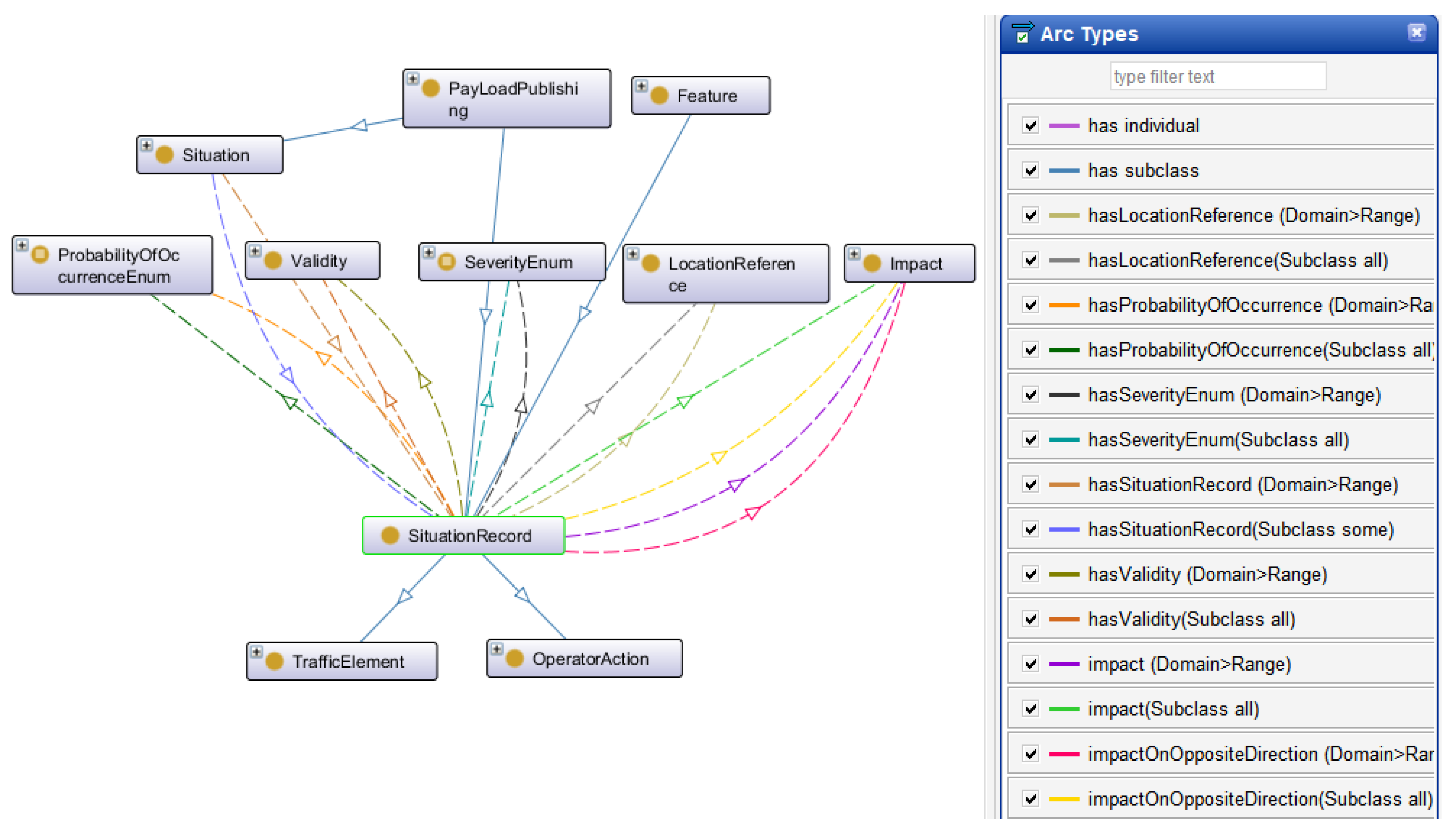
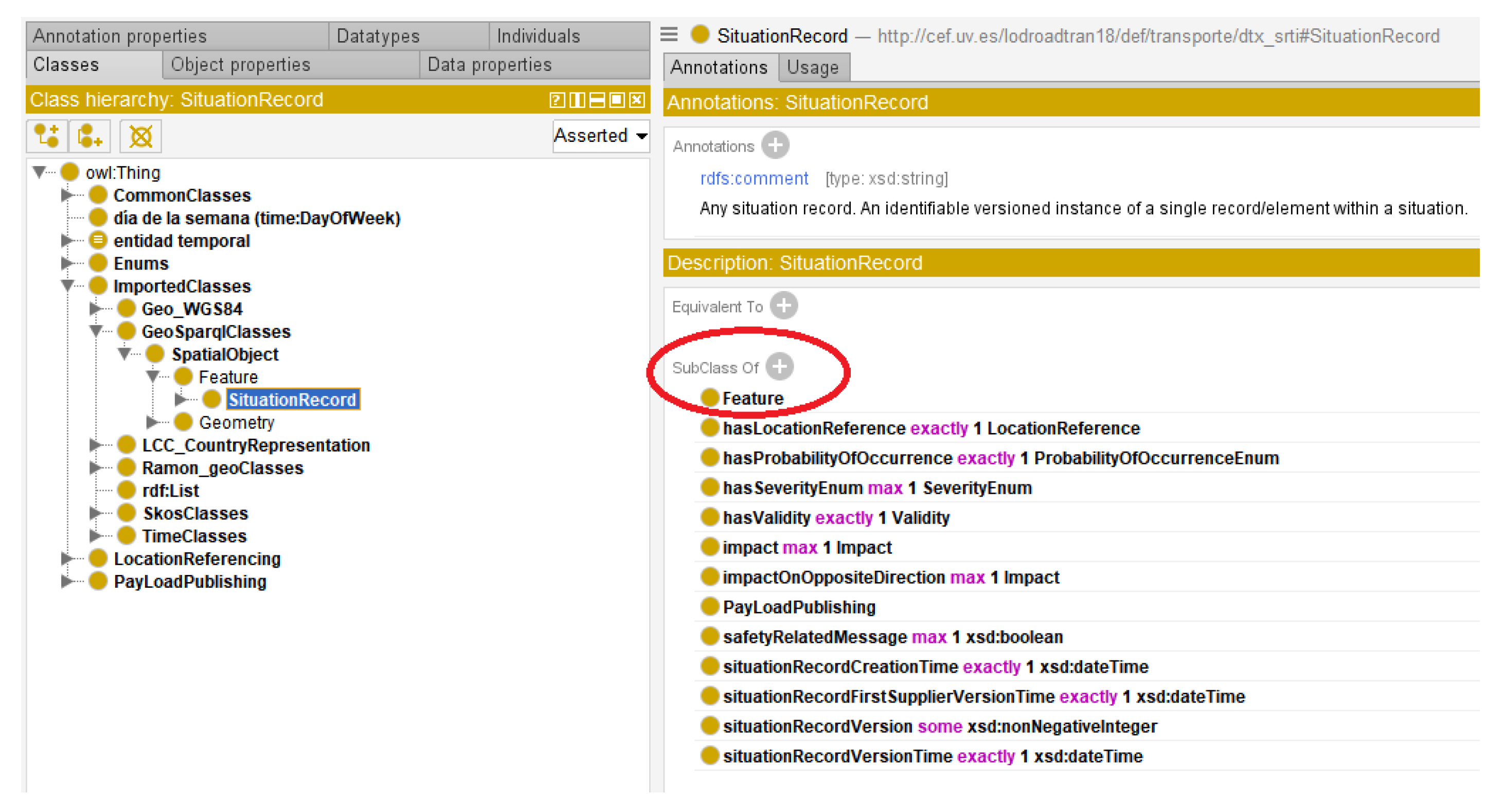
The concept of “situation” in DATEX II encompasses any traffic situation or event that could occur in a real-world scenario. While a detailed discussion of the situation element is beyond this paper’s scope, a brief overview is necessary. DATEX II defines a hierarchy of situation types: those resulting from operator actions on the road, events unrelated to the road, or traffic-related situation elements. Within the latter, further subdivisions include Accidents, Abnormal Traffic... In addition to this hierarchy, each situation contains information about the event itself: its impact, duration, cause, and more. The hierarchical structure of the “SituationRecord” concept in the created ontology is depicted in
Figure 1.
Existing methodologies and practical development experiences as METHONTOLOGY [
37] share certain common steps, such as initiating construction by identifying the purpose and scope of the ontology and the knowledge acquisition needs for a specific domain. However, they differ in their approach and the subsequent steps undertaken.
For developing our model, we can distinguish eight clearly defined phases:
Purpose and Scope Definition: ensuring alignment with the intended purpose and clearly defining the scope.
Standardization and Modularity: establishing standards and promoting modularity by creating subdomains.
Ontology Reuse: leveraging existing ontologies for effective reuse of established concepts.
Basic Translation: initial translation of concepts into a formal ontology structure.
Refinement: iterative refinement of the ontology, considering structures, relationships, and roles.
Knowledge Extension: expanding knowledge by adding instances and specific examples.
Testing or Evaluation: conducting thorough testing and evaluation to ensure ontology effectiveness.
Documentation: comprehensive documentation of the ontology, including its structure and intended use.
More specifically, the construction of the model consists of three steps:
Knowledge Acquisition: Identifying basic classes or terms and their properties.
Definition: Identifying relationships between classes.
Specification of Constraints: Identifying constraints that will limit how descriptions can be formed.
This process is iterative, so once definitions are specified, successive refinements result in much more elaborate definitions. The use of reasoners like “Pellet” is crucial in organizing the model and verifying its consistency.
Information and knowledge related to traffic involve specific concepts such as the current state of the road network, regulations, restrictions, routes, meteorology, etc. These concepts, their properties, the relationships between them, and the specific terms used to designate them are crucial as they provide a basic infrastructure to organize and connect information elements in any specification.
Developing the conceptual infrastructure that we need would be a monumental task if we had to start from scratch. However, there have been significant initiatives in recent years aimed at easing the development process. Libraries of ontologies have been created as part of these initiatives, providing readily available resources that prove invaluable in constructing new ontologies. The knowledge already acquired, conceptualized, and expressed in a formal language within these ontology libraries can be reused to build a new ontology, allowing for the removal, addition, and/or modification of concepts as needed. It is important to highlight the reuse of pre-defined vocabularies such as GeoSPARQL, W3C TIME, QUDT, and others.
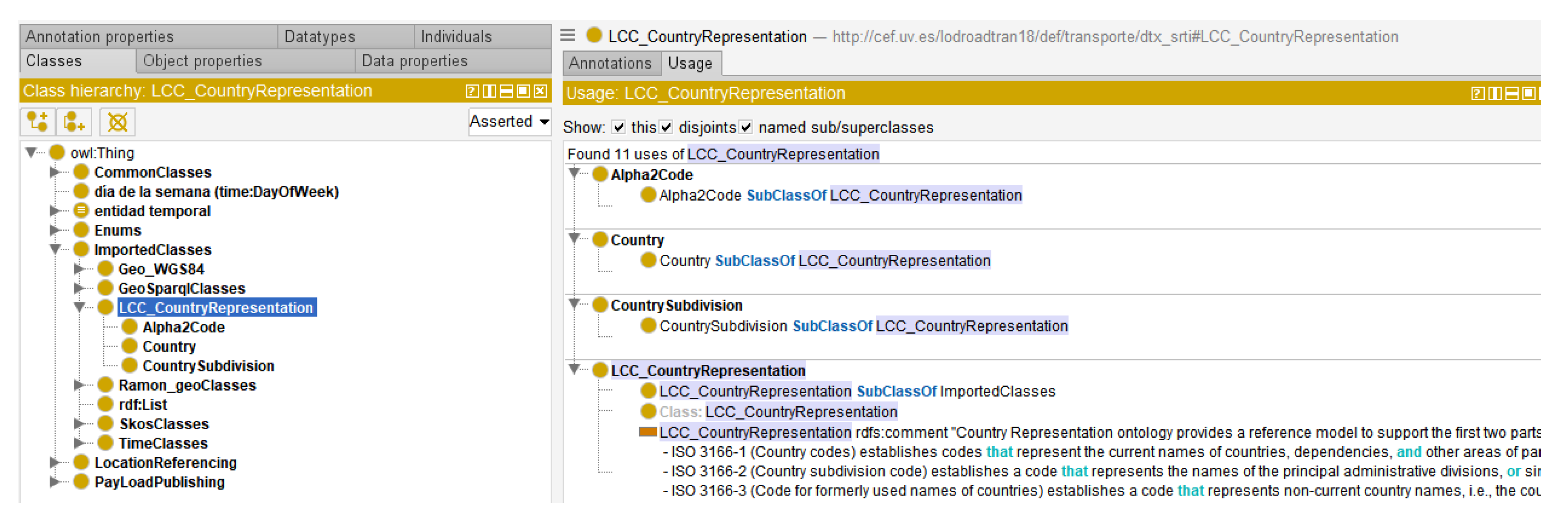
The core ontology is structured between two major groups: the representation of various traffic incidents (Situation Records) occurring within road networks (refer to
Figure 1), and the geographical location aspects (GML, TPEG, OpenLR, and AlertC) associated with these incidents.
It is important highlight that the initial ontology was expanded to incorporate the following non-SRTI elements:
Elements associated with a SituationRecord, including Severity, Source, and Impact.
New items encompassing both old SRTI enumerations and newly introduced non-SRTI enumerations.
The inclusion of the Mobility concept.
To address the development of a traffic ontology, the definition of interconnected subdomains has been proposed. In this context, the relevant subdomains that have been defined are as follows:
Roads’ types and features (Freeway, Toll Road, Connector, Access, Ring Road, etc.)
Administrative Units (Towns, Countries, etc.)
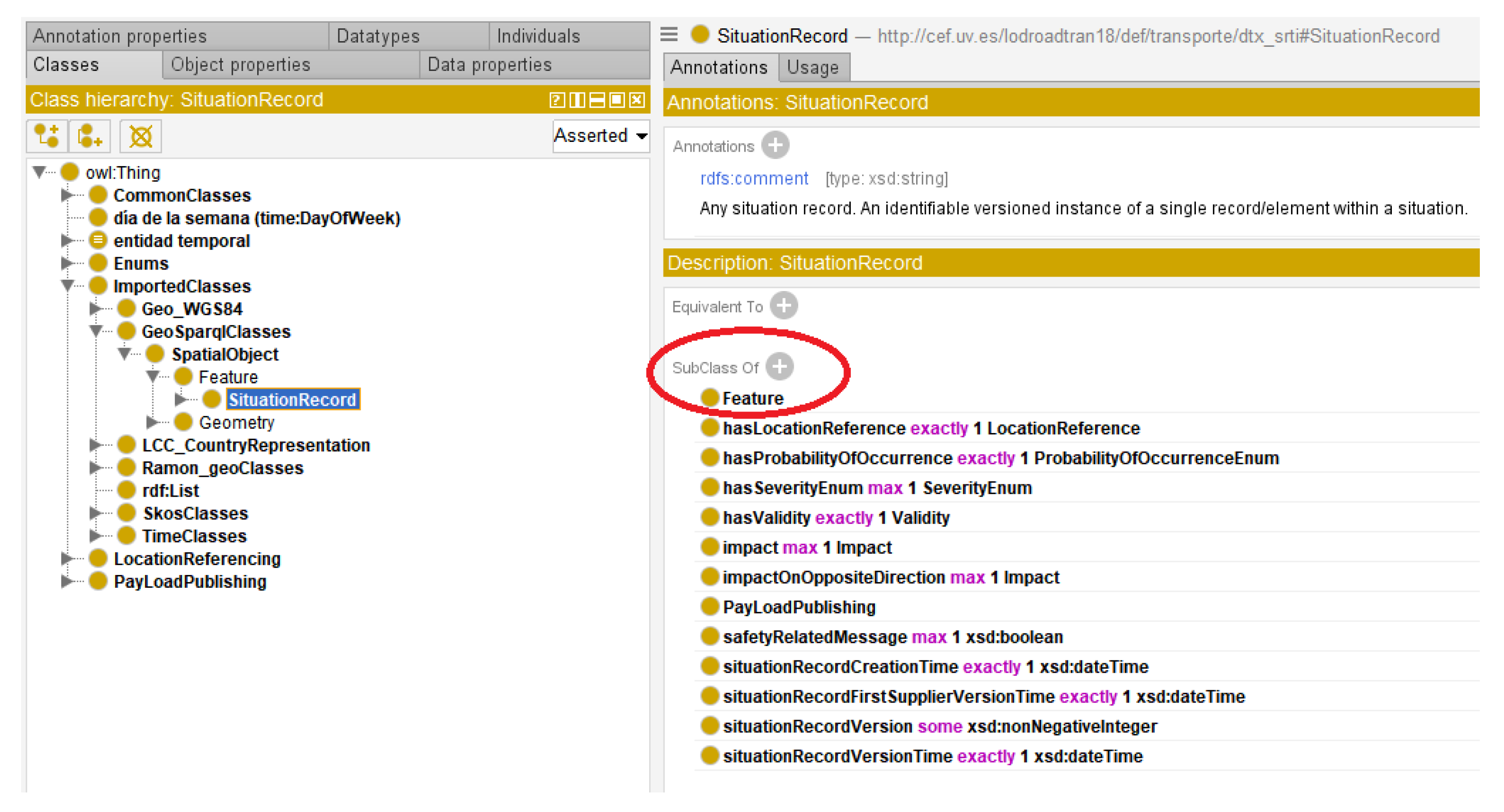
Focusing on this profile SRTI, the central class of the model is the “SituationRecord” concept, along with its various attributes and relationships. The requirement stage of ontology development resulted in the identification of several scenarios and associated Competency Questions (CQs).
- (a)
CQs on the SituationRecord.
- (b)
CQs on the road catalogue.
- (c)
CQs on the data of administrative units.
The following are some of the CQs which were considered:
List of events (SituationRecord) of each Situation and their attributes related to locations: road attributes, administrative units, or geographical coordinates in WGS84 format and WKT.
According to different types of events (Conditions, Roadworks, Abnormal traffic etc.) obtain their probability of occurrence, period of validity, etc.
Obtain all information related to administrative areas responsible to manage each event.
Obtain situation records whose period of validity (OverallStartPeriod in DATEX II) starts before or after a given instant or whose validity period is within a range.
Characteristics from the longest road sections from Autonomous Communities sections, whose lengths are greater than a given length, and the road and its features to which they belong.
Obtain campsites, hostels, points of interest, national inns, train stations, hospitals, petrol stations, etc., around where the traffic incident occurs.
Others.
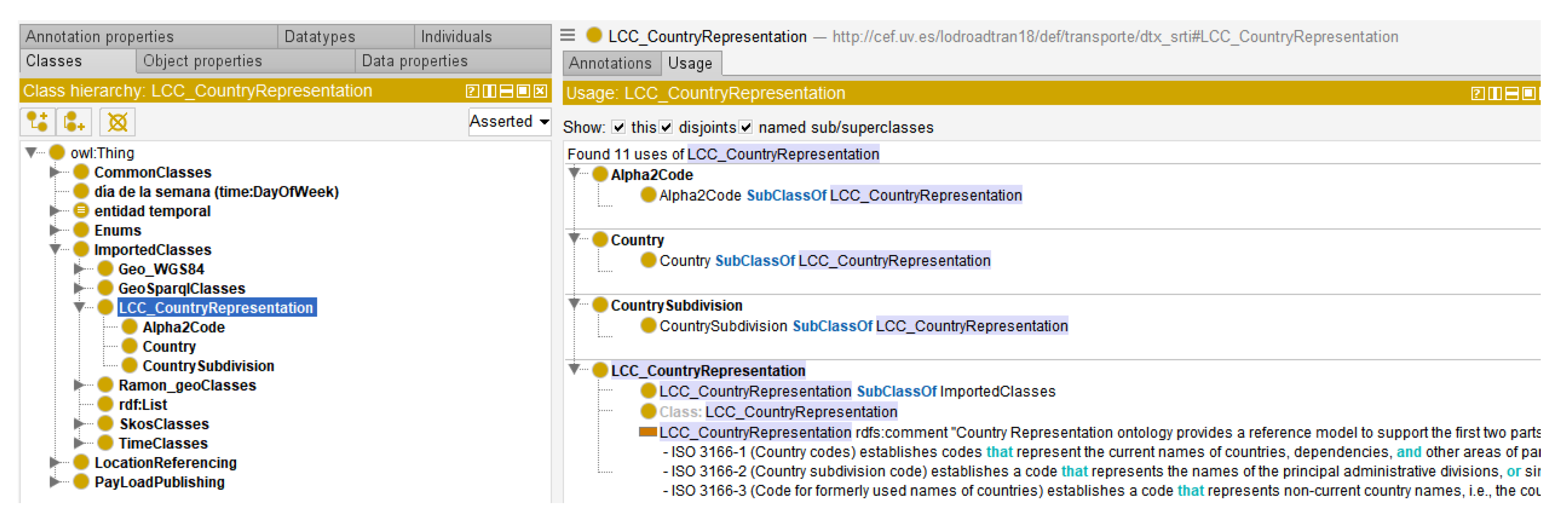
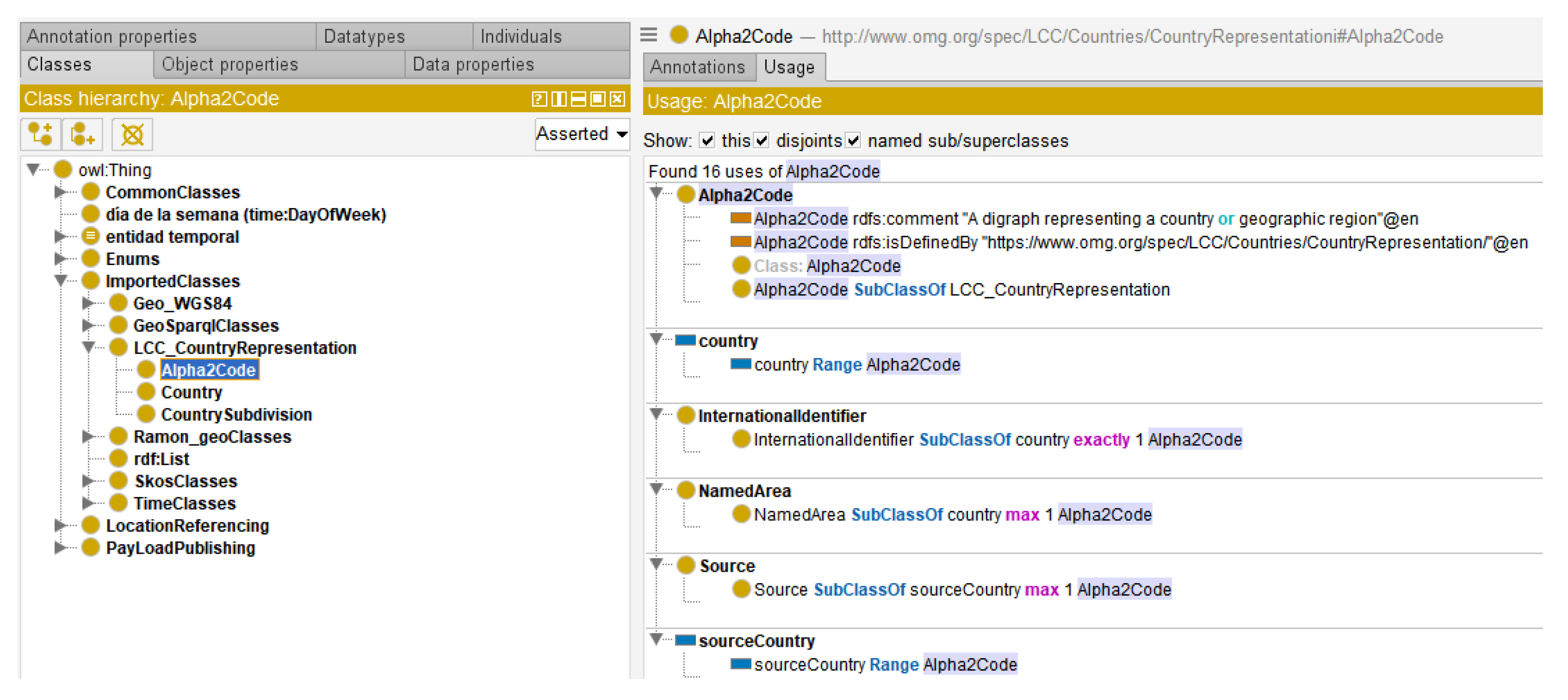
Detailed documentation of the proposed Linked Open Traffic Data Model can be found at [
14]. This ontology enables the definition of concepts related to road traffic, their corresponding situations, and their individual elements as outlined in the DATEX II standard.
Next, let us explore various aspects and how they were addressed through the incorporation of key vocabularies.
4.1. Temporal Considerations
In the DATEX II model, particularly within the SRTI profile, time plays a significant role, and several elements are associated with it. This section describes how temporal aspects have been addressed in the semantic model. Traffic events have a specific time duration, and the SRTI profile specifically focuses on non-recurrent events. These events are not scheduled in advance and do not repeat.
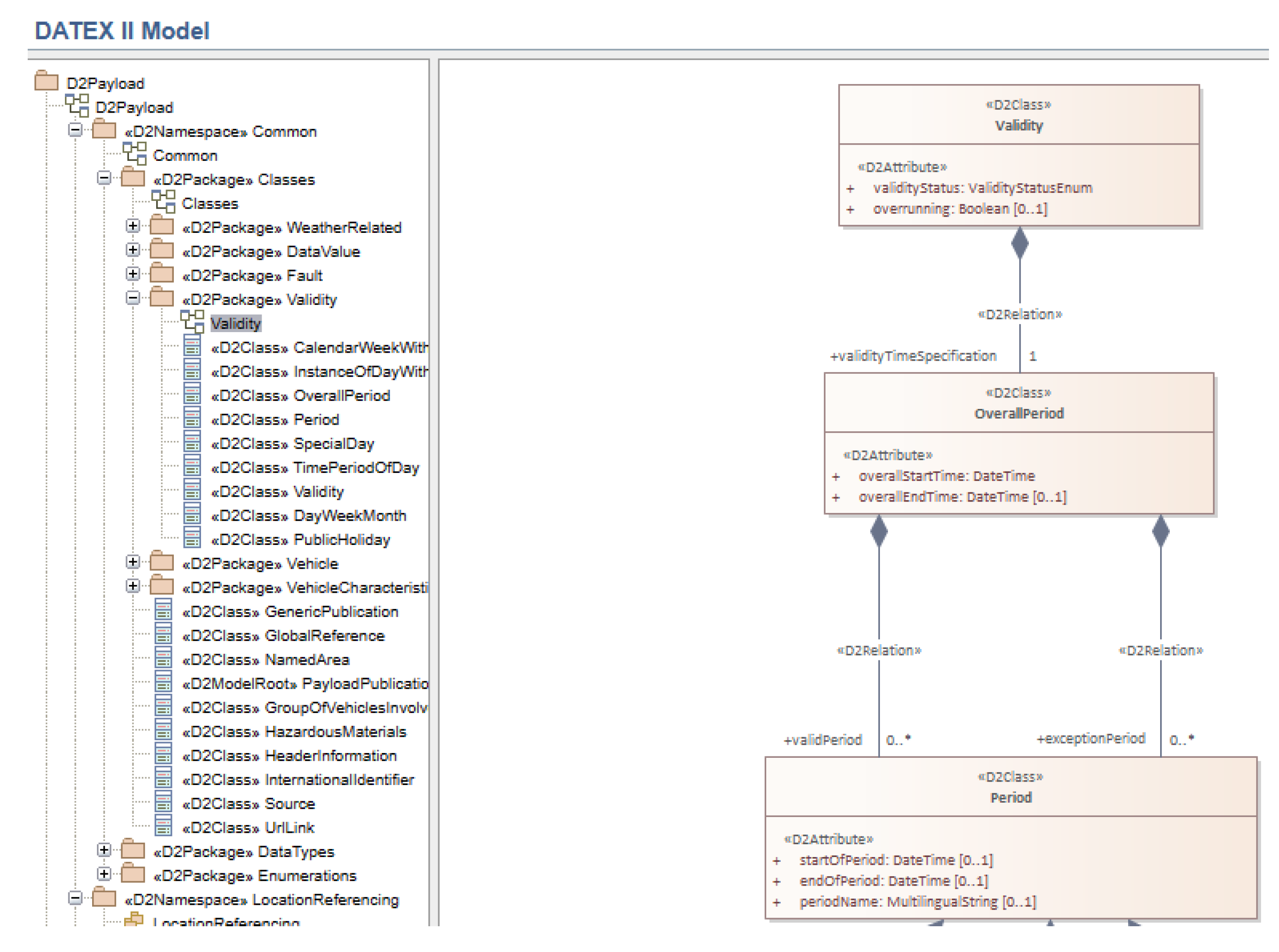
In DATEX II standard, Validity constitutes a sub-model expressly crafted to delineate the temporal validity of a situation element (e.g., as described in a SituationRecord instance) or the ramifications of said situation element. Within this framework, validity pertains to the timeframe in which the real-world event, activity, action, or impact being delineated transpires or is forecasted to occur. Establishing the validity period holds paramount significance, playing a pivotal role in providing real-time information services for traffic. This is particularly crucial for users of road networks who need to know, for example, whether a construction, congestion, or accident is still active, enhancing their ability to make informed decisions.
In the minimal SRTI profile, the
validity concept, along with its associations and attributes, has been simplified, as depicted in
Table 1 and
Table 2.
These tables demonstrate that the association with the
Period class from the full DATEX II model has been removed. Additionally, the
overallEndTime attribute for the
OverallPeriod has been eliminated. However, in our model, we have chosen to retain this attribute, as it is utilized in the full DATEX model to specify the end of a period if necessary (with a multiplicity of 0..1). Furthermore, we have adopted the W3C TIME ontology [
26] for temporal properties, as recommended by NTI-RISP. This ontology allows us to define properties with values related to temporal aspects.
Figure 2 illustrates a portion of the UML schema related to validity in the DATEX II 3.2 model.
Regarding the DATEX Model version 3.2, the properties within the Overall Period had specific data type restrictions, as follows:
To specify these restrictions within the model, several steps were taken. Firstly, the TIME W3C ontology [
26] was imported, taking into consideration the indications provided by [
38] regarding intervals: “Proper intervals are intervals whose extremes are different. Among other things, this allows using standard interval calculus and defining relations between intervals.” By importing W3C TIME, the
dtx_srti:OverallPeriod was defined as a Temporal Entity, specifically a
time:ProperInterval.
By designating the dtx_srti:OverallPeriod as a time:ProperInterval, instances of it were created with the properties time:hasBeginning and time:hasEnd, which have a range of time:Instant. These properties accurately specify the beginning and end of the validity period for a Situation Record (dtx srti:SituationRecord). The related definitions in our model are presented in Listing 1.
Furthermore, in accordance with the W3C TIME Ontology, we can apply various interval relations between time periods within our instances if needed.
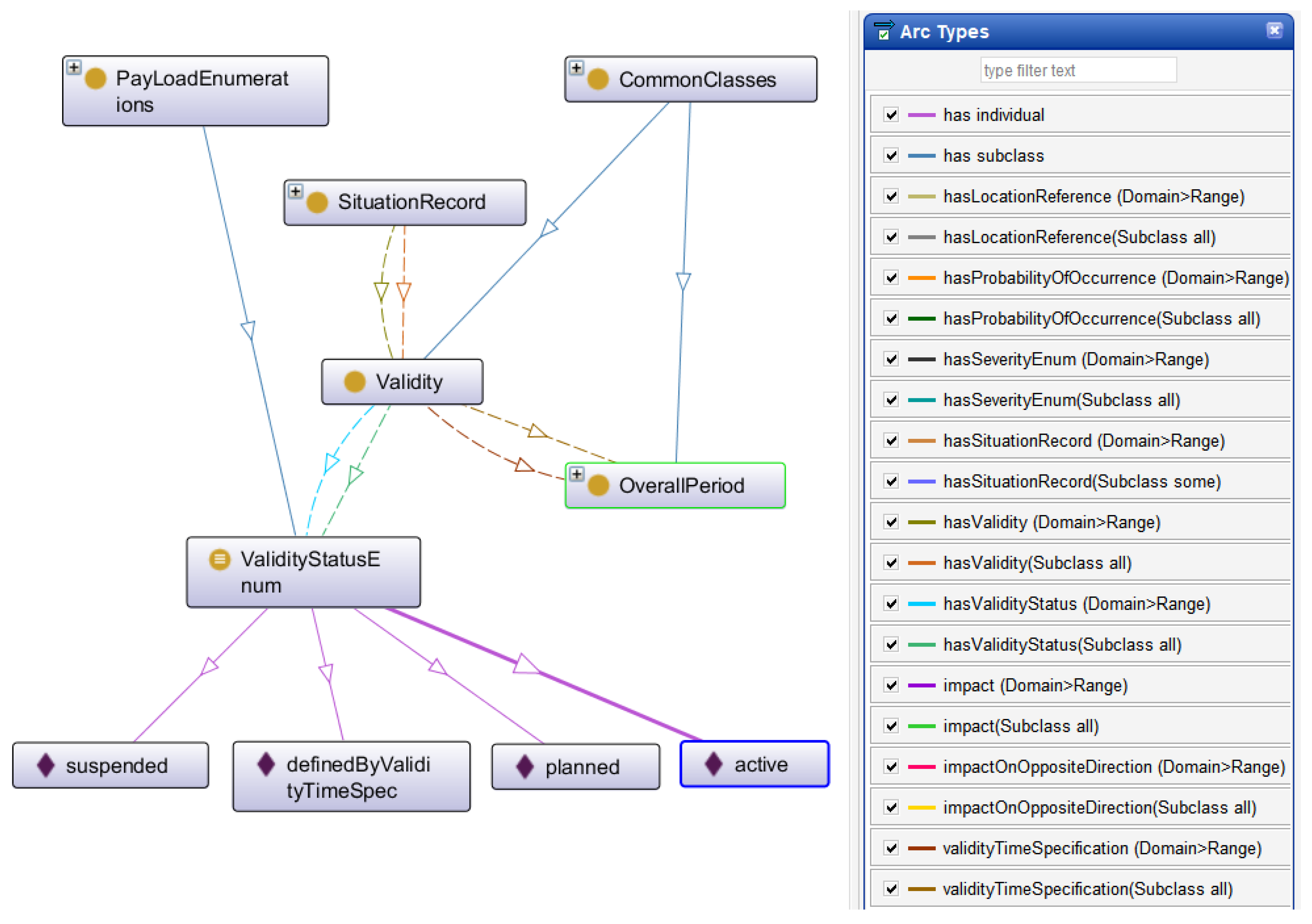
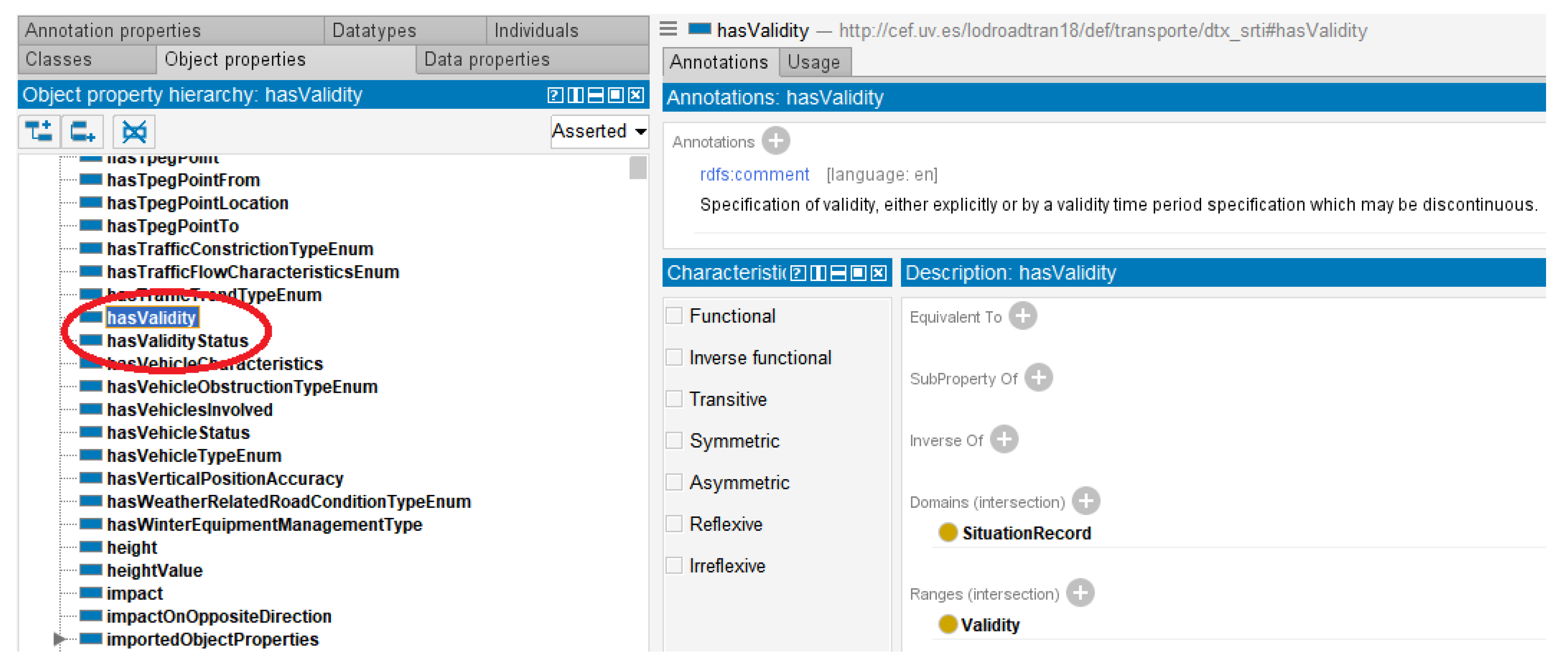
Figure 3 depicts the dtx_srti:Validity class and its relationships using the Protégé software tool.
Figure 4 illustrates how the property
hasValidity allows for the establishment of a validity interval for a
SituationRecord. In addition, Listing 2 presents an example of a partial representation of an instance, considering a
SituationRecord with a specified validity interval. For this, the use of terms from the W3C TIME ontology is crucial. For example, the term “Instant” will allow us to specify the beginning and end of any interval, as specified for the
dtx_srti:Validity concept (Listing 1).
The SituationRecord specification offers a robust framework and provides the capability to query the model using SPARQL, allowing us to retrieve information based on the following criteria:
Retrieve information about a SituationRecord with an OverallPeriod that starts at the time “2022-01-04 T 08:27:04.963 + 01:00” (refer to Listing 3).
Retrieve information about a SituationRecords that started after a specific date, indicated by an OverallStartPeriod greater than “2021-01-04 T 08:26:04.963 + 01:00”. The results should be sorted in ascending order by the OverallStartRecord (refer to Listing 4).
| Listing 1. Definitions and relationships for dtx_srti:Validity concept. |
##Validity
dtx_srti:Validity dtx_srti:validityTimeSpecification exactly 1 dtx_srti:OverallPeriod
dtx_srti:Validity dtx_srti:hasValidityStatus exactly 1 dtx_srti:ValidityStatusEnum
##OverallPeriod
dtx_srti:OverallPeriod rdfs:subClassOf time:ProperInterval
dtx_srti:OverallPeriod rdfs:subClassOf time:hasBeginning exactly 1 time:Instant
dtx_srti:OverallPeriod rdfs:subClassOf time:hasEnd max 1 time:Instant
## ValidityStatusEnum
dtx_srti:ValidityStatusEnum rdfs:subClassOf dtx_srti:PayLoadEnumerations
dtx_srti: ValidityStatusEnum owl:equivalentTo {active , definedByValidityTimeSpec ,
planned , suspended}
|
| Listing 2. SituationRecord Individual with validity intervals. |
<dtx_srti:hasValidity>
<dtx_srti:Validity>
<dtx_srti:validityTimeSpecification>
<dtx_srti:OverallPeriod>
<time:hasEnd>
<time:Instant>
<time:inXSDDateTime
rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">
2021-11-30T17:00:00.019Z
</time:inXSDDateTime>
</time:Instant>
</time:hasEnd>
<time:hasBeginning>
<time:Instant>
<time:inXSDDateTime
rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">
2021-11-30T07:00:00.019Z
</time:inXSDDateTime>
</time:Instant>
</time:hasBeginning>
</dtx_srti:OverallPeriod>
</dtx_srti:validityTimeSpecification>
</dtx_srti:Validity>
</dtx_srti:hasValidity>
|
| Listing 3. TIME SPARQL query 1. |
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dtx_srti: <http://cef.uv.es/lodtran18/def/transporte/dtx_srti#>
PREFIX time: http://www.w3.org/2006/time/
SELECT DISTINCT ?situationRecord ?PO ?Validity ?SRM ?CT ?FSVT ?V ?VT ?OverallPeriod ?
instant
WHERE {
?situationRecord a dtx_srti:SituationRecord;
dtx_srti:hasProbabilityOfOccurrence ?PO;
dtx_srti:hasValidity ?Validity;
dtx_srti:safetyRelatedMessage ?SRM;
dtx_srti:situationRecordCreationTime ?CT;
dtx_srti:situationRecordFirstSupplierVersionTime ?FSVT;
dtx_srti:situationRecordVersion ?V;
dtx_srti:situationRecordVersionTime ?VT.
?Validity dtx_srti:validityTimeSpecification ?OverallPeriod .
?OverallPeriod time:hasBeginning ?instant .
?instant time:inXSDDateTime "2022-01-04T08:27:04.963+01:00"^^xsd:dateTime }
|
| Listing 4. TIME SPARQL query 2. |
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dtx_srti: <http://cef.uv.es/lodtran18/def/transporte/dtx_srti#>
PREFIX time: <http://www.w3.org/2006/time/>
SELECT distinct ?situationRecord ?ProbabilityOfOccurrence ?safetyRelatedMessage ?
CreationTime ?FirstSupplierVersionTime ?Version ?VersionTime ?OverallStartPeriod
WHERE {
?situationRecord a dtx_srti:SituationRecord;
dtx_srti:hasProbabilityOfOccurrence ?ProbabilityOfOccurrence;
dtx_srti:hasValidity ?Validity;
dtx_srti:safetyRelatedMessage ?safetyRelatedMessage;
dtx_srti:situationRecordCreationTime ?CreationTime;
dtx_srti:situationRecordFirstSupplierVersionTime ?FirstSupplierVersionTime;
dtx_srti:situationRecordVersion ?Version;
dtx_srti:situationRecordVersionTime ?VersionTime.
?Validity dtx_srti:validityTimeSpecification ?OverallPeriod .
?OverallPeriod time:hasBeginning ?instant .
?instant time:inXSDDateTime ?OverallStartPeriod
FILTER (?OverallStartPeriod > "2021-01-04T08:26:04.963+01:00"^^xsd:dateTime). }
ORDER BY ?OverallStartPeriod
|
4.2. Reusing QUDT to Implement Units of Measure
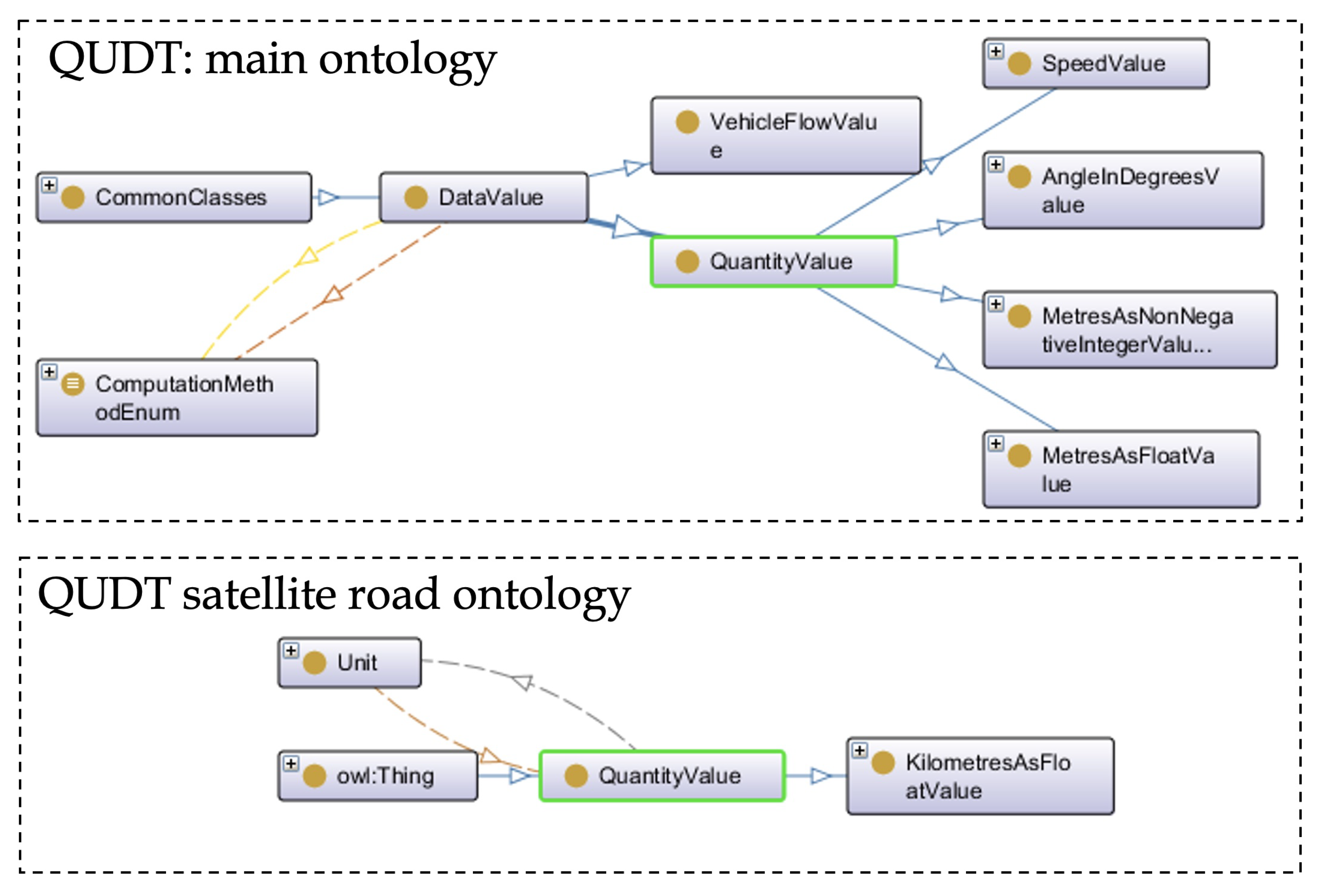
In the DATEX II standard, a highly significant package known as the DataValue package exists, which is designed to describe data values of measurable or calculable entities. This package encompasses types for data values and supplements them with additional quality and error information. Additionally, beyond the basic datatypes, specific datatypes are available, such as AngleInDegrees, MetresAsFloat, Percentage, etc. Given the proliferation of stable vocabularies related to units of measure and their importance in the model, this section aims to address certain aspects of their specification.
In order to express units of measure, we conducted a review of the main vocabularies pertaining to this topic, including the Ontology of units of Measure (OM) [
39], Quantities, Units, Dimensions and Data Types (QUDT) [
40], Custom Data Type (CDT) [
41], and others. After careful consideration, we selected the QUDT vocabulary. QUDT consists of a collection of vocabularies that represent various quantity and unit standards, and it offers solutions to problems in this domain. We utilized the QUDT ontology, specifically focusing on the class
qudt:QuantityValue, which is defined as a value representing a quantity numerically in relation to a chosen unit of measure.
Additionally, the
qudt:unit is an
ObjectProperty with a range of
qudt:Unit. It serves as a reference to the unit of measure associated with a quantity of interest, whether it is a variable or a constant. The concept of
qudt:QuantityValue imposes a restriction on the “unit” property, allowing it to have exactly one unique value from the general concept
owl:Thing. Moreover, the vocabulary
qudt-unit [
42] contains numerous units of measure, each of which is a subtype of
qudt:Unit. For instance, Listing 5 illustrates the specification of the
unit:KiloM (kilometre) unit.
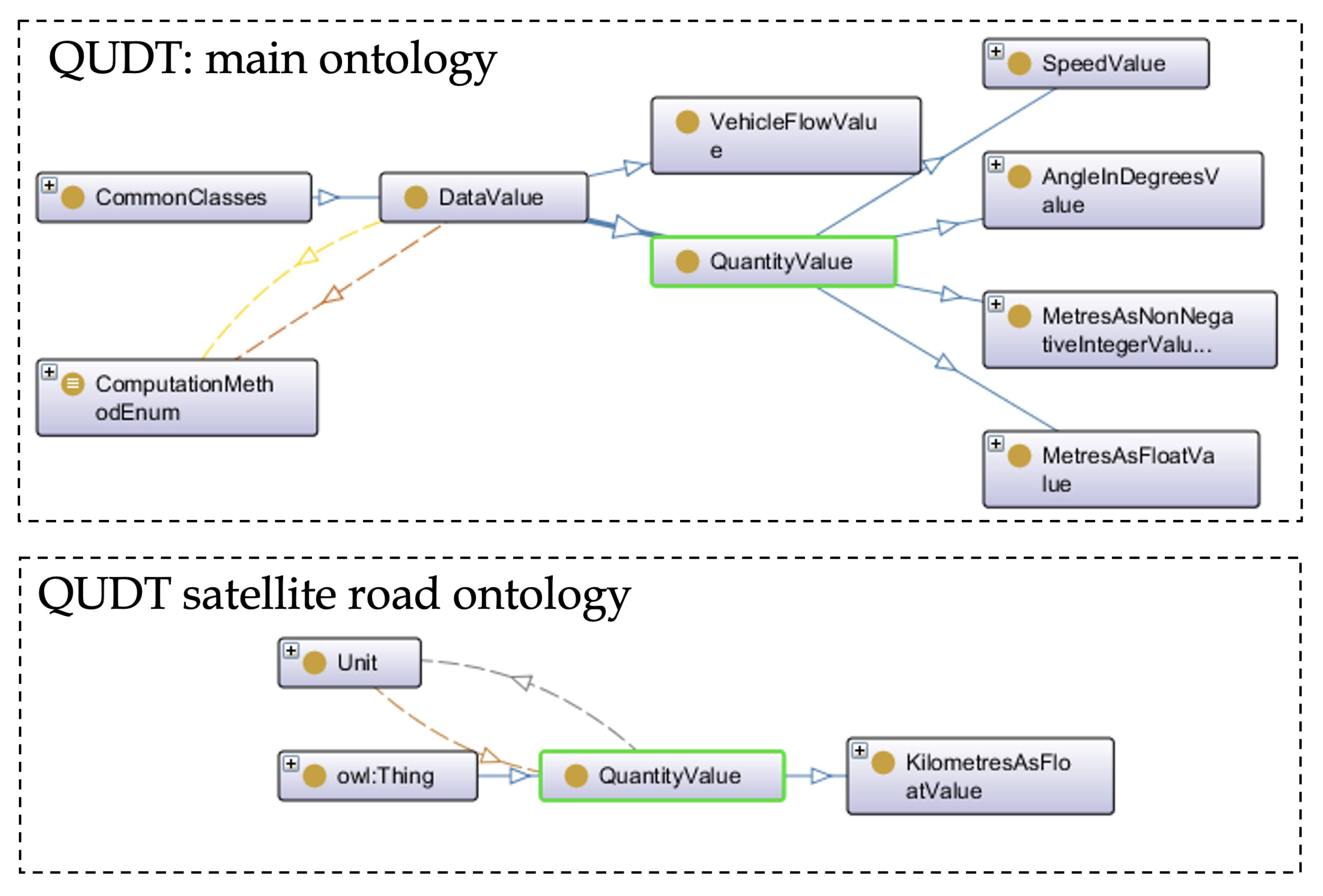
Thus, in our model, the new concepts related to units of measure are subclasses of
qudt:QuantityValue. They also impose similar restrictions on the
qudt:unit property, but with specific ranges that correspond to individual values (units of measure from
qudt:unit) instead of the general class
owl:Thing. Additionally, these concepts have a
numericValue data type property with a multiplicity restriction and a range of XSD (XML Schema Definition) types, in accordance with the DATEX II model, as depicted in
Figure 5 and
Table 3.
The subsequent step involves importing the individuals from the qudt vocabulary using the prefix qudt:unit. Specifically, we import the units “Meter”, “Degree”, “Kilometer per Hour”, and “Kilometer.”
Taking all the aforementioned factors into consideration, we have developed various concepts pertaining to units of measure in our model.
| Listing 5. qudt–unit:KiloM specification. |
unit:KiloM
a qudt:DerivedUnit ;
a qudt:Unit ;
dcterms:description "A␣common␣metric␣unit␣of␣length␣or␣distance.␣One␣kilometer␣equals␣
exactly␣1000␣meters,␣about␣0.621␣371␣19␣mile,␣1093.6133␣yards,␣or␣3280.8399␣feet.␣
Oddly,␣higher␣multiples␣of␣the␣meter␣are␣rarely␣used;␣even␣the␣distances␣to␣the␣
farthest␣galaxies␣are␣usually␣measured␣in␣kilometers.␣"^^rdf:HTML ;
qudt:allowedUnitOfSystem sou:CGS-EMU ;
qudt:allowedUnitOfSystem sou:CGS-GAUSS ;
qudt:allowedUnitOfSystem sou:SI ;
qudt:conversionMultiplier 1000.0 ;
qudt:dbpediaMatch "http://dbpedia.org/resource/Kilometre"^^xsd:anyURI ;
qudt:hasDimensionVector qkdv:A0E0L1I0M0H0T0D0 ;
qudt:hasQuantityKind quantitykind:Length ;
qudt:informativeReference "http://en.wikipedia.org/wiki/Kilometre?oldid=494821851"^^xsd:
anyURI ;
qudt:isScalingOf unit:M ;
qudt:prefix prefix:Kilo ;
qudt:symbol "km" ;
qudt:ucumCode "km"^^qudt:UCUMcs ;
qudt:uneceCommonCode "KMT" ;
qudt:unitOfSystem sou:SI ;
rdfs:isDefinedBy <http://qudt.org/2.1/vocab/unit> ;
rdfs:label "Kilometer"@en-us ;
rdfs:label "Kilometre"@en ;
|
Figure 6 depicts the description of the newly introduced classes, based on the QUDT vocabulary. Each class is associated with two different properties. The first property,
numericValue, has a range that corresponds to a specific XSD type, while the second property,
unit, refers to an individual from the
qudt vocabulary.
In Listing 6, a partial instance of a SituationRecord is presented, demonstrating the usage of the qudt:numericValue and qudt:unit“ properties to define a specific distance of 90.0 m.
| Listing 6. SituationRecord Individual with Quantity Value. |
<dtx_srti:DistanceFromLinearElementStart>
<dtx_srti:distanceAlong>
<qudt:QuantityValue>
<qudt:numericValue rdf:datatype=http://www.w3.org/2001/XMLSchema#
float> 90.0
</qudt:numericValue>
<qudt:unit rdf:resource="http://qudt.org/vocab/unit#M"/>
</qudt:QuantityValue>
</dtx_srti:distanceAlong>
</dtx_srti:DistanceFromLinearElementStart>
|
6. Conclusions
This paper introduces the dtx_srti ontology for semantic modeling of road traffic data and metadata within the context of SRTI. As of the time of writing, dtx_srti stands as the only semantic model based on DATEX II V3.2 and SRTI profile in accordance with the ITS Directive. This model enhances the basic service of accessing open traffic data provided by the traffic National Access Point (nap.dgt.es), the Spanish Open Data Portal (datos.gob.es), and the European Data Portal (data.europa.eu). It not only facilitates data viewing and downloading but also improves the extraction of data meaning and enables other services that are only achievable using LOD.
Its main emphasis lies in the concept of SituationRecord and its attributes and relationships with other concepts. Consequently, this concept assumes the role of the primary class in the ontology. Aspects related to the event’s location and the specification of its geographical coordinates in different formats become essential tools for linking with other location-based services.
To assess the model, queries were designed to verify that the various competency questions initially specified were resolved satisfactorily
The significance of having an LOD dataset for traffic information lies not only in the inclusion of data but also in the incorporation of links to other thematic datasets available on the web. This allows for federated queries that span across datasets from different platforms and sectors, not limited to just traffic data. Incorporating external data from diverse sources can add value to the tools and provide potential benefits for various applications.
The entire research, in addition to the semantic modelling partially shown in this article, has allowed the deployment of traffic information data with metadata collected and it has been made available to the public through Open Data systems and made harvestable by respective national data catalogues and the European Data Portal. Both technical and legal issues in national and European context were addressed, allowing us to tailor our development in accordance with your recommendations and specifications. The Action considered the general and technical requirements/constraints established by the European Data Portal. Once the requirements for being harvested by the European Data Portal were identified, the Action started the federation process. It serves as an integration architecture that allows interoperability between platforms.
Storing historical data (situation records) in SPARQL endpoint will help researchers to perform time and location-based searches, which will significantly improve usability of the LOD-SRTI resource. This, however, will considerably increase the amount of data and, consequently, the storage size needed and will need to be managed in future.
On the other hand, the possibilities for implementing impact measurement can be summarized in two approaches: measuring the impact of each dataset by making them visible (likes, downloads, etc.) or measuring usage through connections to a given system. The availability of tools that make possible to know the behavior of users and the level of use of the data is necessary: to demonstrate the success of the Action; to compare the results with other systems; and potentially establish policies in the area of transport. Understanding user demands beyond compliance with the 2019 PSI Directive enables policies to be established to create high-value data and thematic data ecosystems. Also, “data sharing” between the public and private sector is recommended, respecting intellectual property and privacy.




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}