

Advancements in On-Device Deep Neural Networks


Abstract
:1. Introduction
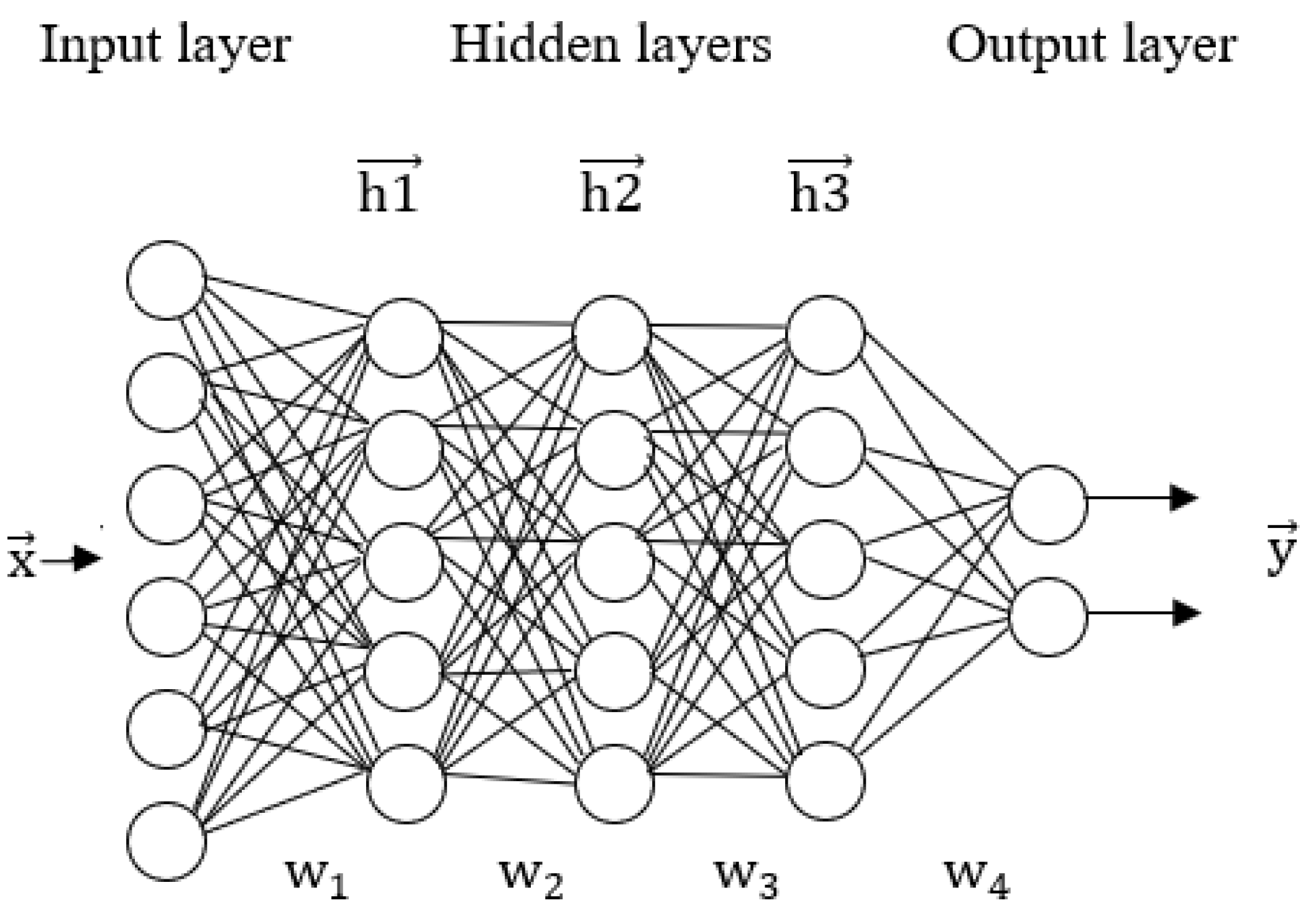
2. Overview of DNN
3. Implementation of DNN On-Device
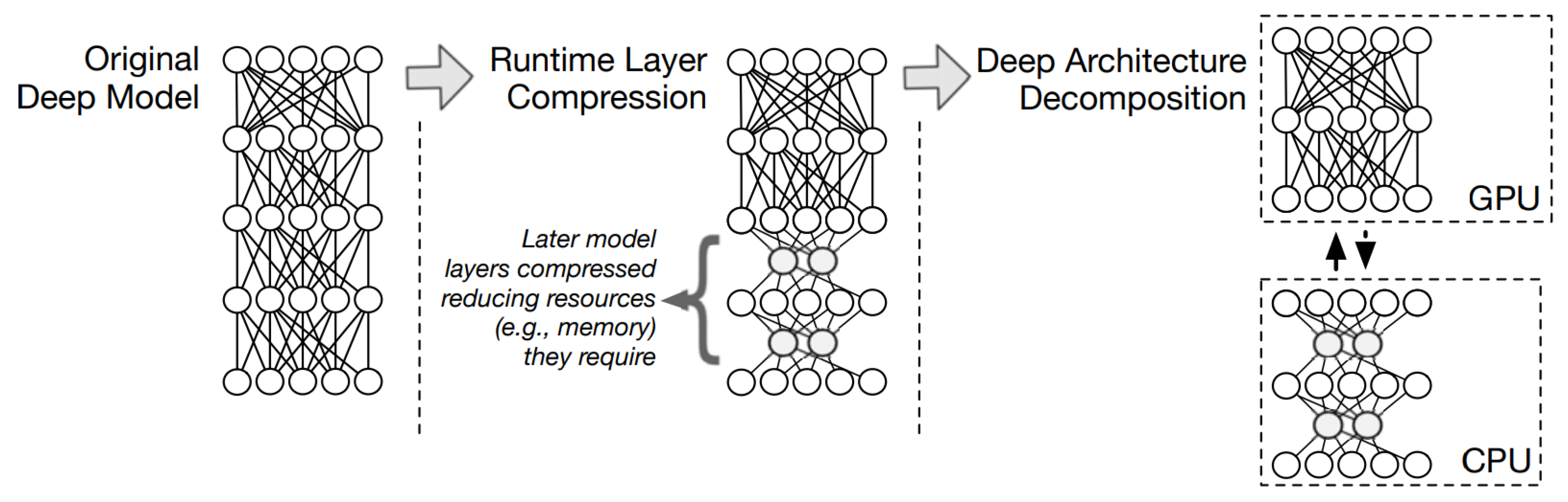
3.1. Software Approaches
3.2. Hardware Approaches
3.3. Hardware/Software Co-Design Approaches
4. Existing On-Device DNNs
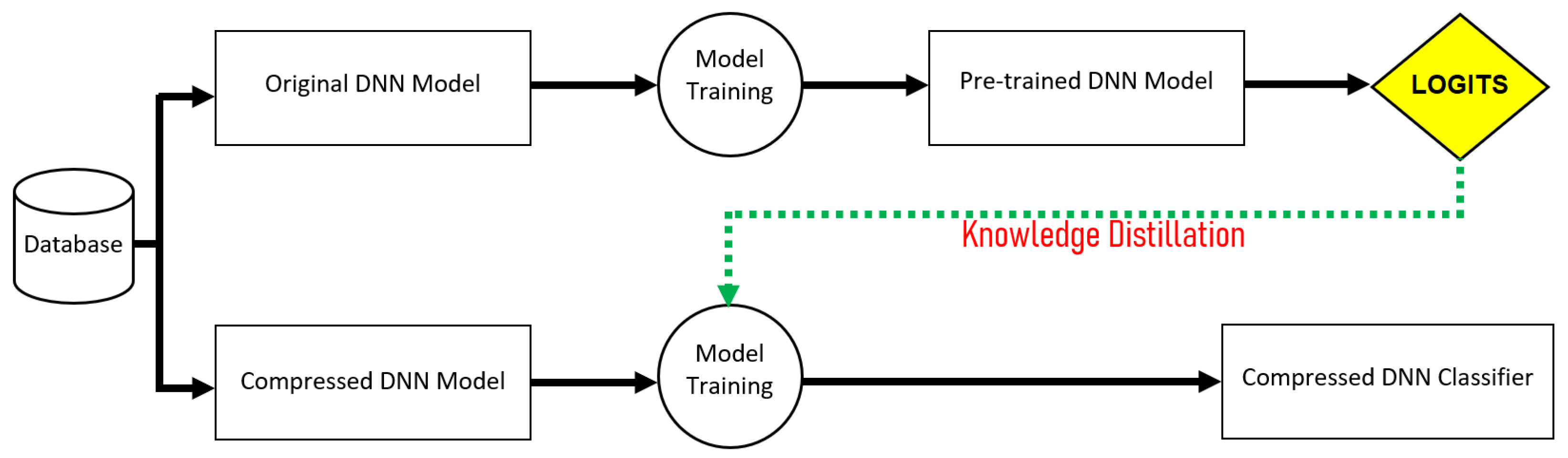
4.1. Current Works Based on Software Approaches
4.2. Current Works Based on Hardware Approaches
4.3. Current Works Based on Hardware/Software Co-Design Approaches
5. Analysis and Comparison
5.1. Comparison of Software-Based Approaches
5.2. Comparison of Hardware-Based Approaches
5.3. Comparison of Hardware-/Software-Based Approaches
6. Discussions
7. Future Prospectus, Challenges, Advantages, Applications
8. Conclusions
Funding
Conflicts of Interest
References
- Fowers, J.; Ovtcharov, K.; Papamichael, M.; Massengill, T.; Liu, M.; Lo, D.; Alkalay, S.; Haselman, M.; Adams, L.; Ghandi, M.; et al. A configurable cloud-scale DNN processor for real-time AI. In Proceedings of the 45th Annual International Symposium on Computer Architecture, Los Angeles, CA, USA, 1–6 June 2018. [Google Scholar]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled IoT devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef]
- Mishra, R.; Gupta, H.P.; Dutta, T. A survey on deep neural network compression: Challenges, overview, and solutions. arXiv 2020, arXiv:2010.03954. [Google Scholar]
- Zhichao, Z.; Abbas, Z.K. Implementation of DNNs on IoT devices. Neural Comput. Appl. 2020, 1, 1327–1356. [Google Scholar]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices. In Proceedings of the 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar]
- Wu, B.; Wan, A.; Iandola, F.; Jin, P.H.; Keutzer, K. SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 446–454. [Google Scholar]
- Ramasubramanian, A.K.; Mathew, R.; Preet, I.; Papakostas, N. Review and application of Edge AI solutions for mobile collaborative robotic platforms. Procedia CIRP 2022, 107, 1083–1088. [Google Scholar] [CrossRef]
- Dupuis, E.; Novo, D.; O’Connor, I.; Bosio, A. Fast exploration of weight sharing opportunities for CNN compression. arXiv 2021, arXiv:2102.01345. [Google Scholar]
- Chmiel, B.; Baskin, C.; Banner, R.; Zheltonozhskii, E.; Yermolin, Y.; Karbachevsky, A.; Bronstein, A.M.; Mendelson, A. Feature map transform coding for energy-efficient cnn inference. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Roy, S.K.; Harandi, M.; Nock, R.; Hartley, R. Siamese networks: The tale of two manifolds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3046–3055. [Google Scholar]
- Diaconu, N.; Worrall, D. Learning to convolve: A generalized weight-tying approach. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1586–1595. [Google Scholar]
- Jain, S.; Hamidi-Rad, S.; Racapé, F. Low rank based end-to-end deep neural network compression. In Proceedings of the 2021 Data Compression Conference (DCC), Snowbird, UH, USA, 23–26 March 2021; pp. 233–242. [Google Scholar]
- Zhang, Q.; Cheng, X.; Chen, Y.; Rao, Z. Quantifying the knowledge in a DNN to explain knowledge distillation for classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5099–5113. [Google Scholar] [CrossRef] [PubMed]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the Computer Vision–ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9908, pp. 525–542. [Google Scholar]
- C.C.A. License. TensorFlow Lite for Microcontrollers. Available online: https://www.tensorflow.org/lite/microcontrollers (accessed on 22 July 2022).
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A systematic approach to dnn accelerator evaluation. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 304–315. [Google Scholar]
- Yao, S.; Zhao, Y.; Zhang, A.; Su, L.; Abdelzaher, T.F. DeepIoT: Compressing Deep Neural Network Structures for Sensing Systems with a Compressor-Critic Framework. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; pp. 1–14. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convo-lutional Neural Networks for Resource Efficient Inference. In Proceedings of the International Conference on Learning Representation (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Anwar, S.; Sung, W. Compact Deep Convolutional Neural Networks with Coarse Pruning. arXiv 2016, arXiv:1610.09639. [Google Scholar]
- Yang, T.-J.; Chen, Y.-H.; Sze, V. Designing Energy-Efficient Convo- lutional Neural Networks Using Energy-Aware Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 18–20 June 2017; pp. 5687–5695. [Google Scholar]
- Narang, S.; Diamos, G.; Sengupta, S.; Elsen, E. Exploring Sparsity in Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic Network Surgery for Efficient DNNs. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5 December 2016; pp. 1387–1395. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. In Proceedings of the NIPS Deep Learning and Representation Learning Workshop, Montréal, QC, Canada, 11 December 2015. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.-Z. A Deep Learning Approach to on-Node Sensor Data Analytics for Mobile or Wearable Devices. IEEE J. Biomed. Health Inform. 2017, 21, 56–64. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ham, M.; Moon, J.; Lim, G.; Jung, J.; Ahn, H.; Song, W.; Woo, S.; Kapoor, P.; Chae, D.; Jang, G.; et al. NNStreamer: Efficient and Agile Development of On- Device AI Systems. In Proceedings of the IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Madrid, Spain, 25–28 May 2021; pp. 198–207. [Google Scholar]
- Shen, F.-J.; Chen, J.-H.; Wang, W.-Y.; Tsai, D.-L.; Shen, L.-C.; Tseng, C.-T. A CNN-Based Human Head Detection Algorithm Implemented on Edge AI Chip. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Kagawa, Japan, 31 August–3 September 2020; pp. 1–5. [Google Scholar]
- Dong, L.; Yang, Z.; Cai, X.; Zhao, Y.; Ma, Q.; Miao, X. WAVE: Edge-Device Cooperated Real-time Object Detection for Open-air Applications. IEEE Trans. Mob. Comput. 2022, 22, 4347–4357. [Google Scholar] [CrossRef]
- Suleiman, A.; Zhang, Z.; Carlone, L.; Karaman, S.; Sze, V. Navion: A 2-mW Fully Integrated Real-Time Visual-Inertial Odometry Accelerator for Autonomous Navigation of Nano Drones. IEEE J. Solid-State Circuits 2019, 54, 1106–1119. [Google Scholar] [CrossRef]
- Li, H.; Fan, X.; Jiao, L.; Cao, W.; Zhou, X.; Wang, L. A high performance FPGA-based accelerator for large-scale convolutional neural networks. In Proceedings of the 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, France, 29 August–2 September 2016; pp. 1–9. [Google Scholar]
- Dinelli, G.; Meoni, G.; Rapuano, E.; Benelli, G.; Fanucci, L. An FPGA-Based Hardware Accelerator for CNNs Using On-Chip Memories Only: Design and Benchmarking with Intel Movidius Neural Compute Stick. Int. J. Reconfigurable Comput. 2019, 2019, 7218758. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Yang, T.-J.; Emer, J.S.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef]
- Ding, R.; Liu, Z.; Blanton, R.D.S.; Marculescu, D. Quantized Deep Neural Networks for Energy Efficient Hardware-based Inference. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018; pp. 1–8. [Google Scholar]
- Zhang, Z.; Mahmud, M.P.; Kouzani, A.Z. FitNN: A Low-Resource FPGA-Based CNN Accelerator for Drones. IEEE Internet Things J. 2022, 9, 21357–21369. [Google Scholar] [CrossRef]
- Sarker, I.H. AI-Based Modeling: Techniques, Applications and Research Issues. SN Comput. Sci. 2022, 3, 158. [Google Scholar] [CrossRef] [PubMed]
- Tan, B.; Karri, R. Challenges and New Directions for AI and Hard-ware Security. In Proceedings of the 2020 IEEE 63rd International Midwest Symposium on Circuits and Systems (MWSCAS), Springfield, MA, USA, 9–12 August 2020; pp. 277–280. [Google Scholar]
- Pabby, G.; Kumar, N. A Review on Artificial Intelligence, Challenges Involved and Its Applications. Int. J. Adv. Res. Comput. Eng. Technol. 2017, 6. [Google Scholar]
- Bezboruah, T.; Bora, A. Artificial intelligence: The technology, challenges and applications. Trans. Mach. Learn. Artif. Intell. 2020, 8, 44–51. [Google Scholar]
- Hu, Y.; Li, W.; Wright, D.; Aydin, O.; Wilson, D.; Maher, O.; Raad, M. Artificial Intelligence Approaches. The Geographic Information Science and Technology Body of Knowledge (3rd Quarter 2019 Edition). arXiv 2019, arXiv:1908.10345. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Author | Architecture | Compression Rate | Memory |
|---|---|---|---|
| Yao et al. [19] | DNN | Not Available | Before: 90% After: 98.9% |
| Molchanov et al. [20] | CNN | Before: 9× After: 13× | Not Available |
| Anwar et al. [21] | Deep CNN | Not Available | Before: Not Available After: 10× |
| Yang et al. [22] | CNN | Before: Not Available After: 13× | Not Available |
| Narang et al. [23] | RNN | Before: Not Available After: 16× | Before: Not Available After: 90% |
| Guo et al. [24] | DNN | Before: Not Available After: 17.7× | Before: Not Available After: 108× |
| Hinton et al. [25] | DNN | Not Available | Before: Not Available After: 30× |
| Ravi et al. [26] | CNN | Not Available | Not Available |
| He et al. [27] | DNN | Not Available | Before: Not Available After: 52 MB |
| Author | Speed | Power Consumption | Compression Ratio | Accuracy |
|---|---|---|---|---|
| Yao et al. [19] | Not Available | Before: Not Available After: 90.6% | Before: 71.4% After: 94.5% | Not Available |
| Molchanov et al. [20] | Before: 2× After: 4× | Not Available | Not Available | Before: 2× After: 4× |
| Anwar et al. [21] | Not Available | Not Available | Before: 98.88% After: 98.78% | Not Available |
| Yang et al. [22] | Before: Not Available After: 3.7× | Before: Not Available After: 13× | Before: Not Available After: 1% | Not Available |
| Narang et al. [23] | Not Available | Not Available | Not Available | Before: 2× After: 7× |
| Guo et al. [24] | Not Available | Not Available | Not Available | Not Available |
| Hinton et al. [25] | Not Available | Not Available | Before: Not Available After: 80% | Not Available |
| Ravi et al. [26] | Not Available | Not Available | Not Available | Not Available |
| He et al. [27] | Not Available | Not Available | Before: Not Available After 3.57%. | Before: Not Available After: 34% |
| Author | Network Type | Accelerator | Platform | Size |
|---|---|---|---|---|
| Shen et al. [29] | CNN | NA | SoC | Not Available |
| Dong et al. [30] | CNN | Nvidia Jetson TX2 | Not Available | Not Available |
| Suleiman et al. [31] | CNN | VIO accelerator | CMOS | Before: Not Available After: 6.4 mm |
| Li et al. [32] | CNN | Xilinx VC709 | FPGA | Before: Not Available After: 1.45 |
| Dinelli et al. [33] | CNN | Xilinx, Intel | FPGA | Not Available |
| Chen et al. [34] | CNN | Eyeriss | NOC | Before: Not Available After: 168 PEs |
| Chen et al. [35] | DNN | Eyeriss v2 | NoC | Before: Not Available After: 1024 PEs |
| Author | Speed | Power Consumption | Accuracy |
|---|---|---|---|
| Shen et al. [29] | Not Available | Not Available | Before: Not Available After: 98.7% |
| Dong et al. [30] | Before: Not Available After: 30 FPS | Not Available | Not Available |
| Suleiman et al. [31] | Before: Not Available After: 200 FPS | 2 mW | Before: Not Available After: 2.3% |
| Li et al. [32] | Before: Not Available After: 156 MHz | Before: Not Available After: 330 W | Not Available |
| Dinelli et al. [33] | Not Available | Before: Not Available After: 2.259 | Before: Not Available After: 90.23% |
| Chen et al. [34] | Before: Not Available After: 35 FPS | Before: Not Available After: 45% | Not Available |
| Chen et al. [35] | Before: Not Available After: 42.5× | Before: Not Available After: 11.3× | Before: Not Available After: 80.43% |
| Author | Network Type | Accelerator | Platform | Memory |
|---|---|---|---|---|
| Lane et al. [35] | DNN | Deepx | SoC | Not Available |
| Ding et al. [36] | DNN | Not Available | Custom | Not Available |
| Zhang et al. [37] | CNN | FitNN | FPGA | Not Available |
| Author | Speed | Power Consumption | Accuracy |
|---|---|---|---|
| Lane et al. [35] | Before: Not Available After: 5.8 faster | Not Available | Before: Not Available After: 15% |
| Ding et al. [36] | Not Available | Before: Not Available After: 61.6% | Not Available |
| Zhang et al. [37] | Before: Not Available After: 9 FPS | Before: Not Available After: 1.97 W | Not Available |
| Parameter | Approach | Author | Network Type | Accelerator | Obtained Result |
|---|---|---|---|---|---|
| Power consumption | Software | Yao et al. [19] | DNN | Not available | 90.6% |
| Hardware | Suleiman et al. [31] | CNN | VIO accelerator | 2 mW | |
| Hardware/ software co-design | Zhang et al. [37] | CNN | FitNN | 1.97 W | |
| Compression rate | Software | Guo et al. [24] | DNN | Not available | 17.7× |
| Hardware | Not available | Not available | Not available | Not available | |
| Hardware/ software co-design | Not available | Not available | Not available | Not available | |
| Speed | Software | Molchanov et al. [20] | CNN | Not available | 4× |
| Hardware | Suleiman et al. [31] | CNN | VIO accelerator | 200 FPS | |
| Hardware/ software co-design | Zhang et al. [37] | CNN | FitNN | 9 FPS | |
| Memory | Software | Yao et al. [19] | DNN | Not available | 98.8% |
| Hardware | Not available | Not available | Not available | Not available | |
| Hardware/ software co-design | Not available | Not available | Not available | Not available | |
| Accuracy | Software | Molchanov et al. [20] | CNN | Not available | 94.2% |
| Hardware | Shen et al. [29] | CNN | Not available | 98.7% | |
| Hardware/ software co-design | Lane et al. [35] | DNN | DeepX | 15% increase |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saravanan, K.; Kouzani, A.Z. Advancements in On-Device Deep Neural Networks. Information 2023, 14, 470. https://doi.org/10.3390/info14080470
Saravanan K, Kouzani AZ. Advancements in On-Device Deep Neural Networks. Information. 2023; 14(8):470. https://doi.org/10.3390/info14080470
Chicago/Turabian StyleSaravanan, Kavya, and Abbas Z. Kouzani. 2023. "Advancements in On-Device Deep Neural Networks" Information 14, no. 8: 470. https://doi.org/10.3390/info14080470
APA StyleSaravanan, K., & Kouzani, A. Z. (2023). Advancements in On-Device Deep Neural Networks. Information, 14(8), 470. https://doi.org/10.3390/info14080470