
Digital-Reported Outcome from Medical Notes of Schizophrenia and Bipolar Patients Using Hierarchical BERT

 , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Study Cohort
- Schizophrenia: This cohort includes patients with at least two clinical visits with schizophrenia disease codes and anti-psychotic medication use for at least 3 continuous months.
- Bipolar: The bipolar cohort consists of patients with at least two clinical visits with bipolar type I or mixed bipolar disease codes and anti-psychotic medication use for at least 3 continuous months.
3.2. Data Annotation and Preprocessing
- The severe impairment level corresponds to a GAF score of less than 50. As per the GAF scale, scores in this range are assigned when the patient is in danger of severely hurting himself or others; exhibits delusions; experiences hallucinations; or shows major impairment in several areas, such as work, school, family relations, judgment, thinking, or mood.
- The moderate impairment level corresponds to a GAF score above 51. This GAF range is characterized by the absence or presence of moderate symptoms such as occasional panic attacks, depressed mood, mild insomnia, and difficulty concentrating.
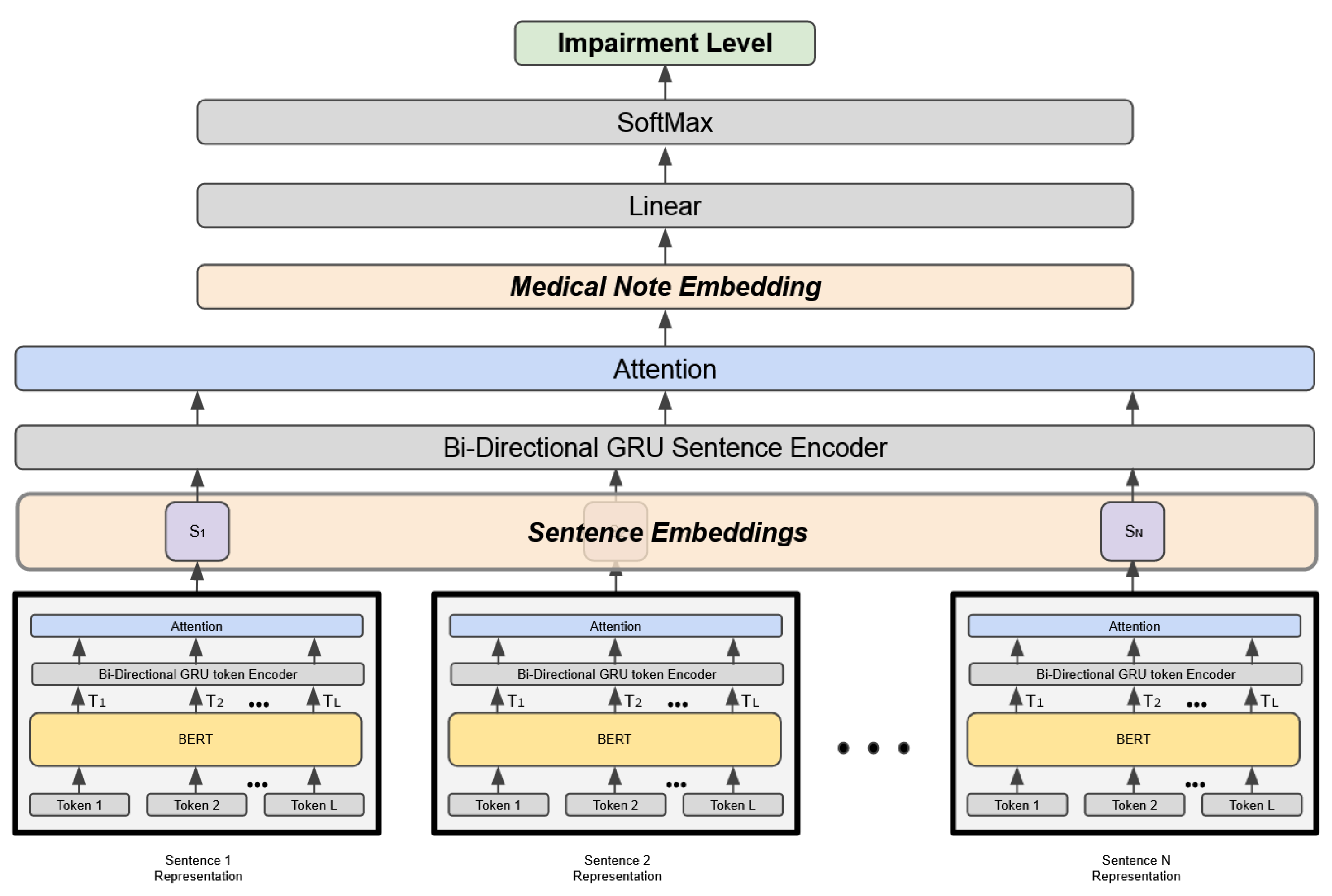
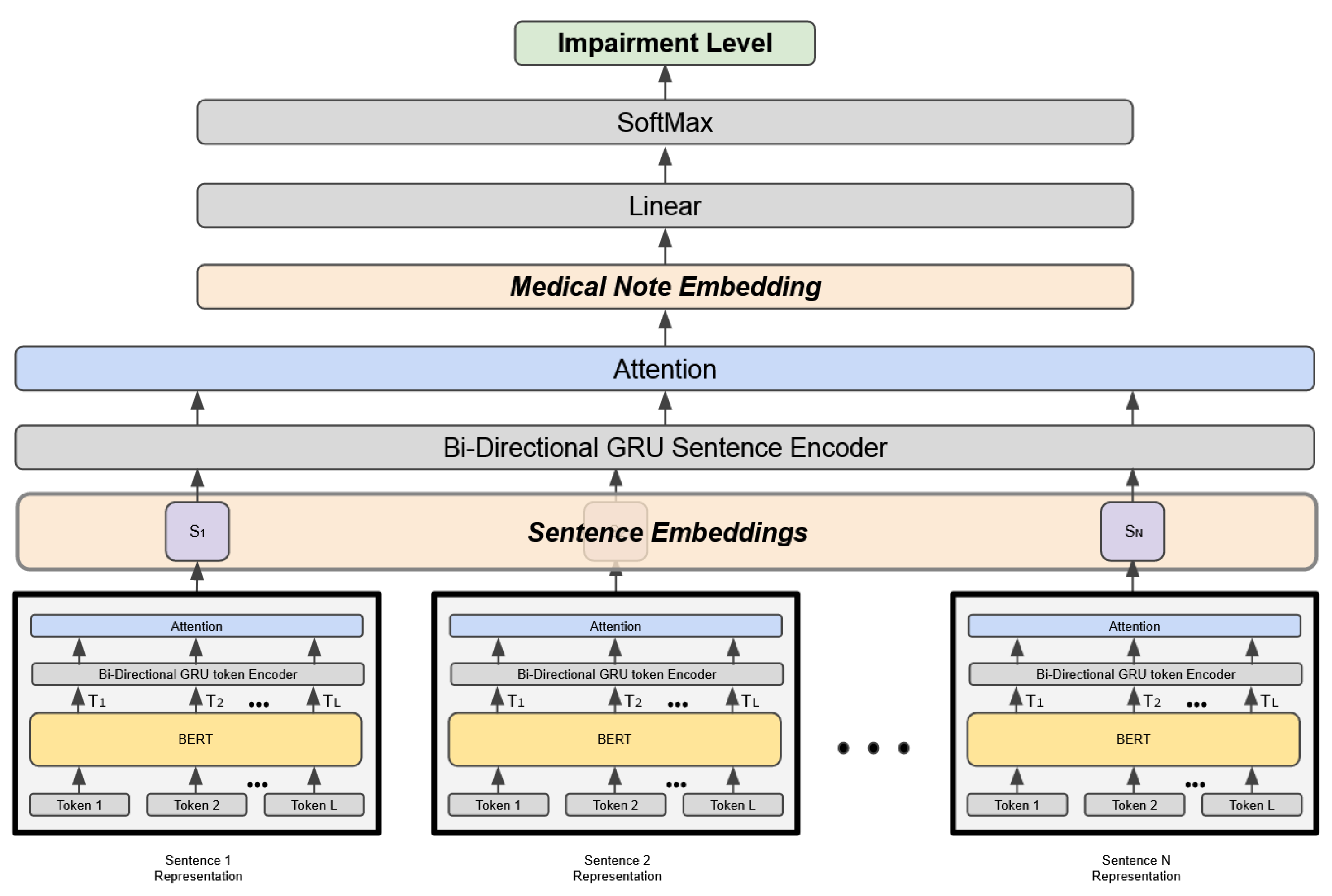
3.3. Hierarchical Attention Model
4. Results
4.1. Impairment Classifiers
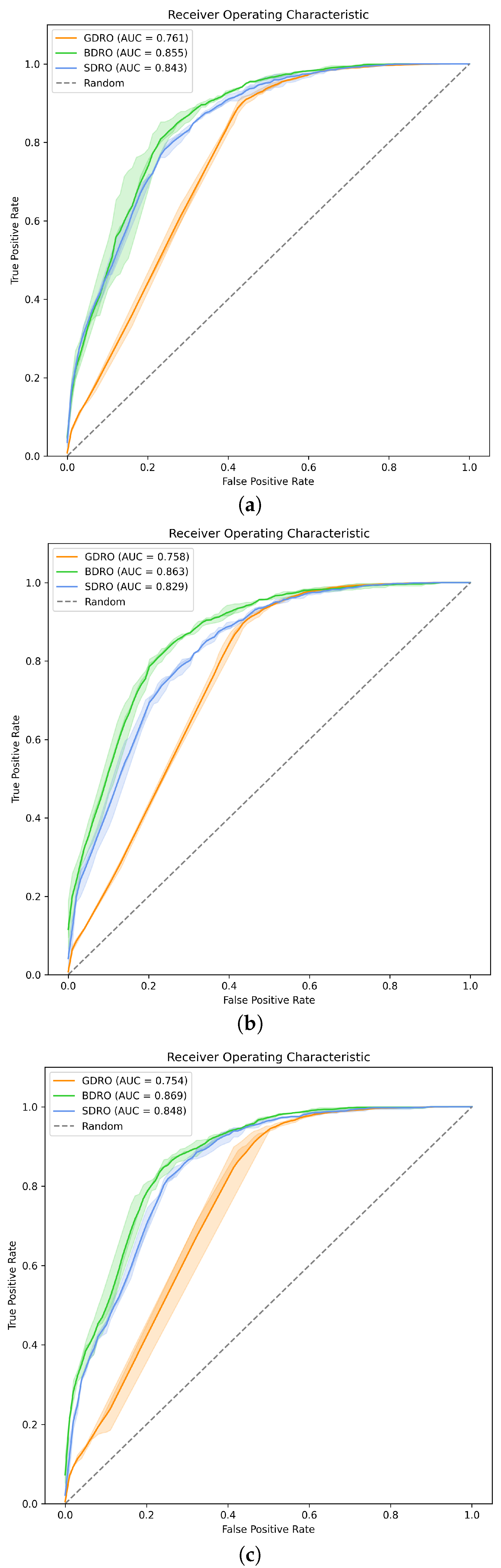
4.2. Attention Mechanism
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATC | Anatomical therapeutic chemical classification system |
| BDRO | Bipolar digital-reported outcome |
| BERT | Bidirectional encoder representations from transformers |
| CRO | Clinician-reported outcome |
| DRO | Digital-reported outcome |
| GAF | General assessment of functioning |
| GRU | Gated recurrent unit |
| HAN | Hierarchical attention network |
| INPC | Indiana network for patient care |
| PRO | Patient-reported outcome |
| SDRO | Schizophrenia digital-reported outcome |
References
- Moreno-Küstner, B.; Martin, C.; Pastor, L. Prevalence of psychotic disorders and its association with methodological issues. A systematic review and meta-analyses. PLoS ONE 2018, 13, e0195687. [Google Scholar]
- Lish, J.D.; Dime-Meenan, S.; Whybrow, P.C.; Price, R.A.; Hirschfeld, R.M. The National Depressive and Manic-depressive Association (DMDA) survey of bipolar members. J. Affect. Disord. 1994, 31, 281–294. [Google Scholar] [CrossRef]
- Patel, K.R.; Cherian, J.; Gohil, K.; Atkinson, D. Schizophrenia: Overview and treatment options. Pharm. Ther. 2014, 39, 638. [Google Scholar]
- Fonseka, T.M.; Bhat, V.; Kennedy, S.H. The utility of artificial intelligence in suicide risk prediction and the management of suicidal behaviors. Aust. N. Z. J. Psychiatry 2019, 53, 954–964. [Google Scholar] [CrossRef]
- Corcoran, C.M.; Cecchi, G.A. Using language processing and speech analysis for the identification of psychosis and other disorders. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2020, 5, 770–779. [Google Scholar] [CrossRef]
- AlHamed, F.; Ive, J.; Specia, L. Predicting moments of mood changes overtime from imbalanced social media data. In Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology, Seattle, WA, USA, 15 July 2022; pp. 239–244. [Google Scholar]
- Spitzer, R.L.; Kroenke, K.; Williams, J.B.; Patient Health Questionnaire Primary Care Study Group; Patient Health Questionnaire Primary Care Study Group. Validation and utility of a self-report version of PRIME-MD: The PHQ primary care study. JAMA 1999, 282, 1737–1744. [Google Scholar] [CrossRef]
- Young, R.C.; Biggs, J.T.; Ziegler, V.E.; Meyer, D.A. A rating scale for mania: Reliability, validity and sensitivity. Br. J. Psychiatry 1978, 133, 429–435. [Google Scholar] [CrossRef]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B. The PHQ-9: Validity of a brief depression severity measure. J. Gen. Intern. Med. 2001, 16, 606–613. [Google Scholar] [CrossRef]
- Kay, S.R.; Fiszbein, A.; Opler, L.A. The positive and negative syndrome scale (PANSS) for schizophrenia. Schizophr. Bull. 1987, 13, 261–276. [Google Scholar] [CrossRef]
- Frances, A.; Pincus, H.A.; First, M.B. Global Assessment of functioning scale (GAF). In Diagnostic and Statistical Manual for Mental Disorders, 4th ed.; (DSM-IV); American Psychiatric Association: Washington, DC, USA, 2006. [Google Scholar]
- Aas, I. Global Assessment of Functioning (GAF): Properties and frontier of current knowledge. Ann. Gen. Psychiatry 2010, 9, 20. [Google Scholar] [CrossRef]
- Gold, L.H. DSM-5 and the assessment of functioning: The World Health Organization Disability Assessment Schedule 2.0 (WHODAS 2.0). J. Am. Acad. Psychiatry Law Online 2014, 42, 173–181. [Google Scholar]
- Ustun, T.B.; Kostanjesek, N.; Chatterji, S.; Rehm, J.; World Health Organization. Measuring Health and Disability: Manual of WHO Disability Assessment Schedule WHODAS 2.0; World Health Organization: Geneva, Switzerland, 2010. [Google Scholar]
- Kotei, E.; Thirunavukarasu, R. A Systematic Review of Transformer-Based Pre-Trained Language Models through Self-Supervised Learning. Information 2023, 14, 187. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Turc, I.; Chang, M.; Lee, K.; Toutanova, K. Well-Read Students Learn Better: On the Importance of Pre-training Compact Models. arXiv 2019, arXiv:1908.08962. Available online: https://arxiv.org/abs/1908.08962 (accessed on 1 June 2023).
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.H.; Jindi, D.; Naumann, T.; McDermott, M. Publicly Available clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 72–78. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Yang, W.; Xie, Y.; Lin, A.; Li, X.; Tan, L.; Xiong, K.; Li, M.; Lin, J. End-to-End Open-Domain Question Answering with BERTserini. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 72–77. [Google Scholar]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3730–3740. [Google Scholar]
- Mulyar, A.; Uzuner, O.; McInnes, B. MT-clinical BERT: Scaling clinical information extraction with multitask learning. J. Am. Med. Inform. Assoc. 2021, 28, 2108–2115. [Google Scholar] [CrossRef]
- Hu, P.; Lin, C.; Su, H.; Li, S.; Han, X.; Zhang, Y.; Mei, J. Bluememo: Depression analysis through twitter posts. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 5252–5254. [Google Scholar]
- Jeong, L.; Lee, M.; Eyre, B.; Balagopalan, A.; Rudzicz, F.; Gabilondo, C. Exploring the Use of Natural Language Processing for Objective Assessment of Disorganized Speech in schizophrenia. Psychiatr. Res. Clin. Pract. 2023. [Google Scholar] [CrossRef]
- Kshatriya, B.S.A.; Nunez, N.A.; Resendez, M.G.; Ryu, E.; Coombes, B.J.; Fu, S.; Frye, M.A.; Biernacka, J.M.; Wang, Y. Neural language models with distant supervision to identify major depressive disorder from clinical notes. arXiv 2021, arXiv:2104.09644. [Google Scholar]
- Zhang, T.; Schoene, A.M.; Ji, S.; Ananiadou, S. Natural language processing applied to mental illness detection: A narrative review. Npj Digit. Med. 2022, 5, 46. [Google Scholar] [CrossRef]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. DocBERT: BERT for Document Classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Gao, S.; Alawad, M.; Young, M.T.; Gounley, J.; Schaefferkoetter, N.; Yoon, H.J.; Wu, X.C.; Durbin, E.B.; Doherty, J.; Stroup, A.; et al. Limitations of transformers on clinical text classification. IEEE J. Biomed. Health Inform. 2021, 25, 3596–3607. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the China National Conference on Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; Springer Nature Switzerland AG: Cham, Switzerland, 2019; pp. 194–206. [Google Scholar]
- Wang, L.; Lakin, J.; Riley, C.; Korach, Z.; Frain, L.N.; Zhou, L. Disease trajectories and end-of-life care for dementias: Latent topic modeling and trend analysis using clinical notes. In Proceedings of the AMIA Annual Symposium Proceedings, San Francisco, CA, USA, 3–7 November 2018; American Medical Informatics Association: Washington, DC, USA, 2018; Volume 2018, p. 1056. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Francisco, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Zhang, N.; Jankowski, M. Hierarchical BERT for medical document understanding. arXiv 2022, arXiv:2204.09600. [Google Scholar]
- World Health Organization. ICD-10: International Statistical Classification of Diseases and Related Health Problems: Tenth Revision, 2nd ed.; World Health Organization: Geneva, Switzerland, 2004. [Google Scholar]
- Goldman, H.H.; Skodol, A.E.; Lave, T.R. Revising axis V for DSM-IV: A review of measures of social functioning. Am. J. Psychiatry 1992, 149, 9. [Google Scholar]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- World Health Organization. Collaborating centre for drug statistics methodology. In Guidelines for ATC Classification and DDD Assignment; World Health Organization: Geneva, Switzerland, 2013; Volume 3. [Google Scholar]
- Imming, P.; Buss, T.; Dailey, L.; Meyer, A.; Morck, H.; Ramadan, M.; Rogosch, T. A classification of drug substances according to their mechanism of action. Die-Pharm.-Int. J. Pharm. Sci. 2004, 59, 579–589. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN encoder–decoder for Statistical Machine Translation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [PubMed]
- Webb, C.A.; Cohen, Z.D.; Beard, C.; Forgeard, M.; Peckham, A.D.; Björgvinsson, T. Personalized prognostic prediction of treatment outcome for depressed patients in a naturalistic psychiatric hospital setting: A comparison of machine learning approaches. J. Consult. Clin. Psychol. 2020, 88, 25. [Google Scholar] [CrossRef]
- Librenza-Garcia, D.; Kotzian, B.J.; Yang, J.; Mwangi, B.; Cao, B.; Lima, L.N.P.; Bermudez, M.B.; Boeira, M.V.; Kapczinski, F.; Passos, I.C. The impact of machine learning techniques in the study of bipolar disorder: A systematic review. Neurosci. Biobehav. Rev. 2017, 80, 538–554. [Google Scholar] [CrossRef]
- Chandran, D.; Robbins, D.A.; Chang, C.K.; Shetty, H.; Sanyal, J.; Downs, J.; Fok, M.; Ball, M.; Jackson, R.; Stewart, R.; et al. Use of natural language processing to identify obsessive compulsive symptoms in patients with schizophrenia, schizoaffective disorder or bipolar disorder. Sci. Rep. 2019, 9, 14146. [Google Scholar] [CrossRef]
- Dimsdale, J.E.; Jeste, D.V.; Patterson, T.L. Beyond the global assessment of functioning: Learning from Virginia Apgar. Psychosomatics 2010, 51, 515–519. [Google Scholar] [CrossRef]
- Hall, R.C. Global assessment of functioning: A modified scale. Psychosomatics 1995, 36, 267–275. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Index Period | Post-Index Period | |||
|---|---|---|---|---|
| Severe | Moderate | Severe | Moderate | |
| Bipolar | 2324 | 2803 | 3408 | 1548 |
| (45%) | (55%) | (69%) | (31%) | |
| Schizophrenia | 3387 | 2612 | 5363 | 1487 |
| (56%) | (44%) | (78%) | (22%) | |
| Training | Testing | |||
|---|---|---|---|---|
| Model | Severe | Moderate | Severe | Moderate |
| GDRO | 3100 | 3100 | 1548 | 1548 |
| BDRO/SDRO | 991 | 991 | 496 | 496 |
| Model | AUC | Accuracy | Sensitivity | Specificity | |
|---|---|---|---|---|---|
| BERT | GDRO | 76.09 (0.44) | 72.97 (0.16) | 55.48 (1.61) | 90.42 (1.84) |
| BDRO | 85.57 (1.33) | 77.76 (1.06) | 78.55 (3.52) | 77.00 (4.61) | |
| SDRO | 84.36 (0.33) | 75.38 (0.42) | 60.37 (2.67) | 90.50 (1.83) | |
| BERT mini | GDRO | 75.81 (0.35) | 72.73 (0.55) | 56.60 (3.41) | 88.83 (2.51) |
| BDRO | 86.29 (0.63) | 79.42 (0.64) | 77.48 (2.70) | 81.36 (1.42) | |
| SDRO | 82.89 (0.55) | 74.83 (0.54) | 73.38 (4.94) | 76.31 (4.44) | |
| clinical BERT | GDRO | 75.28 (1.75) | 72.80 (1.15) | 53.47 (4.51) | 92.08 (2.35) |
| BDRO | 86.92 (0.76) | 79.66 (0.45) | 75.59 (2.38) | 83.77 (2.48) | |
| SDRO | 84.84 (0.14) | 78.00 (0.43) | 72.73 (1.07) | 83.31 (1.77) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khandker, R.K.; Prince, M.R.I.; Chekani, F.; Dexter, P.R.; Boustani, M.A.; Ben Miled, Z. Digital-Reported Outcome from Medical Notes of Schizophrenia and Bipolar Patients Using Hierarchical BERT. Information 2023, 14, 471. https://doi.org/10.3390/info14090471
Khandker RK, Prince MRI, Chekani F, Dexter PR, Boustani MA, Ben Miled Z. Digital-Reported Outcome from Medical Notes of Schizophrenia and Bipolar Patients Using Hierarchical BERT. Information. 2023; 14(9):471. https://doi.org/10.3390/info14090471
Chicago/Turabian StyleKhandker, Rezaul K., Md Rakibul Islam Prince, Farid Chekani, Paul Richard Dexter, Malaz A. Boustani, and Zina Ben Miled. 2023. "Digital-Reported Outcome from Medical Notes of Schizophrenia and Bipolar Patients Using Hierarchical BERT" Information 14, no. 9: 471. https://doi.org/10.3390/info14090471
APA StyleKhandker, R. K., Prince, M. R. I., Chekani, F., Dexter, P. R., Boustani, M. A., & Ben Miled, Z. (2023). Digital-Reported Outcome from Medical Notes of Schizophrenia and Bipolar Patients Using Hierarchical BERT. Information, 14(9), 471. https://doi.org/10.3390/info14090471