
Energy-Efficient Parallel Computing: Challenges to Scaling


Abstract
1. Introduction
2. Terminology for Energy-Efficient Computing
Brief on Bi-Objective Optimization
3. Experimental Methodology
3.1. Precautions to Reduce Noise in Measurements
- The disk consumption is monitored before and during the application run and ensures no I/O is performed by the application using tools such as sar and iotop.
- The workload used in the execution of an application does not exceed the main memory, and swapping (paging) does not occur.
- The application does not use the network by monitoring using tools such as sar and atop.
- The application kernel’s CPU affinity mask is set using SCHED API’s system call, SCHED_SETAFFINITY().
- Standard: Baseboard management controller (BMC) controls both fan zones, with the CPU and peripheral zones set at speed 50%;
- Optimal: BMC sets the CPU zone at speed 30% and the peripheral zone at 30%;
- Heavy IO: BMC sets the CPU zone at speed 50% and the Peripheral zone at 75%;
- Full: All fans run at 100%.
3.2. Statistical Confidence in Our Experiments
4. Application-Level Optimization Methods on Modern Heterogeneous HPC Platforms for Energy and Performance
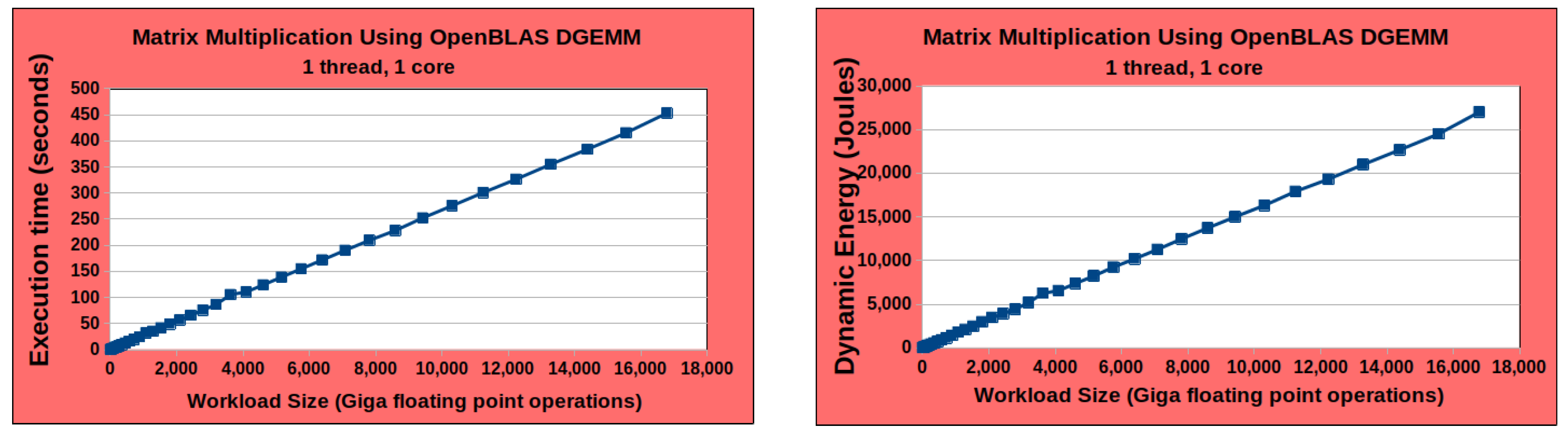
4.1. Linearity and Homogeneity
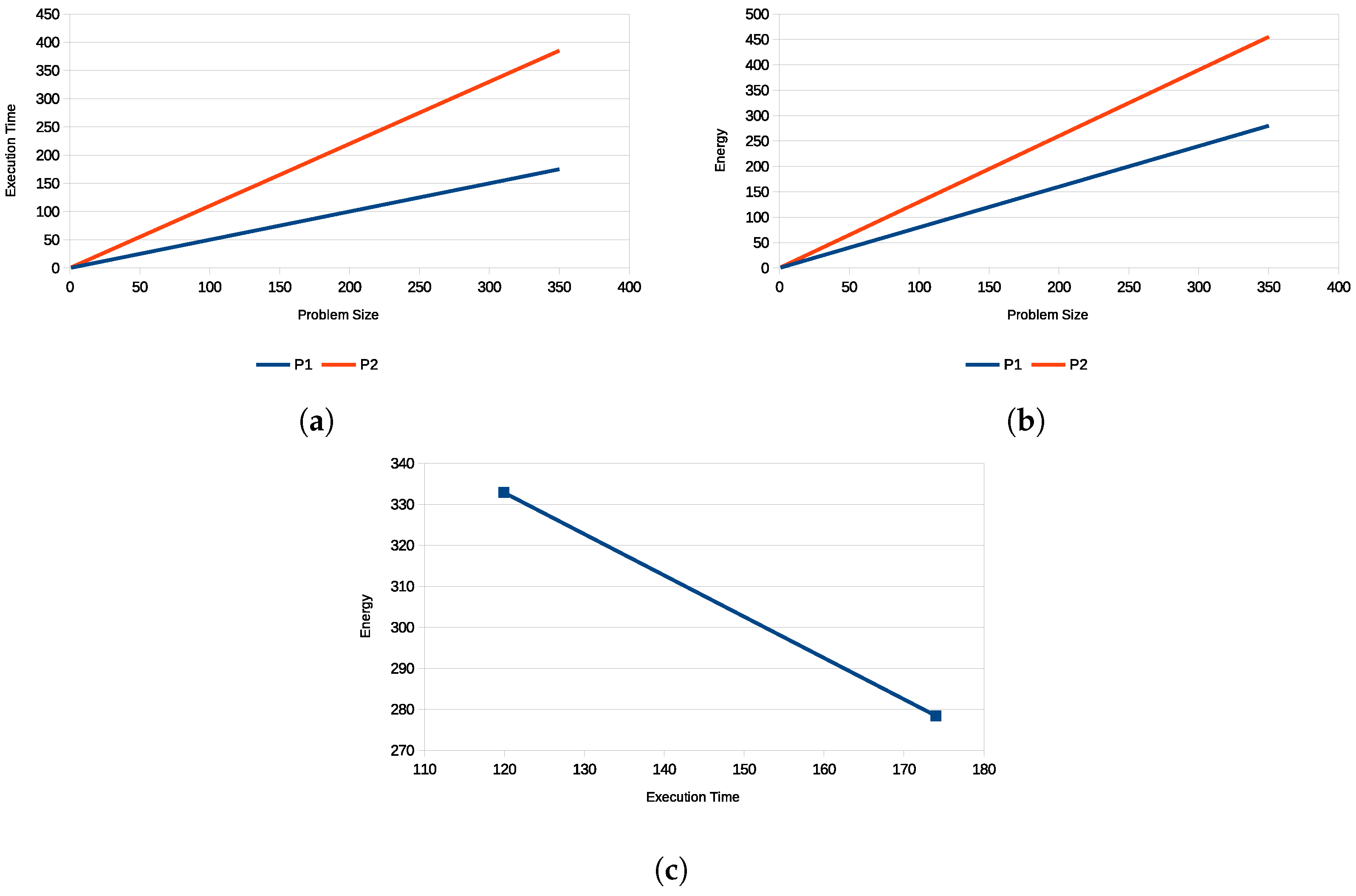
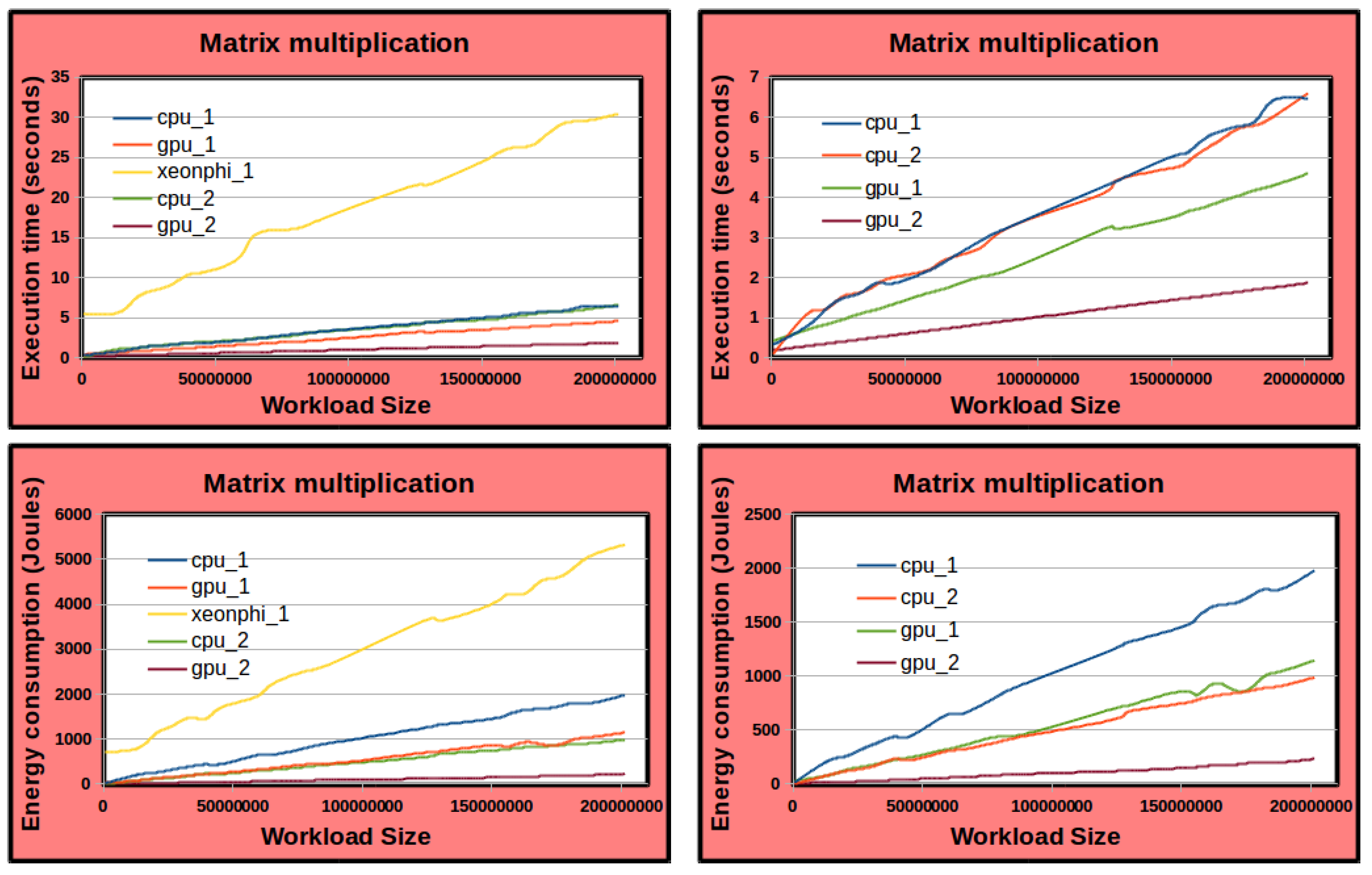
4.2. Impact of Heterogeneity
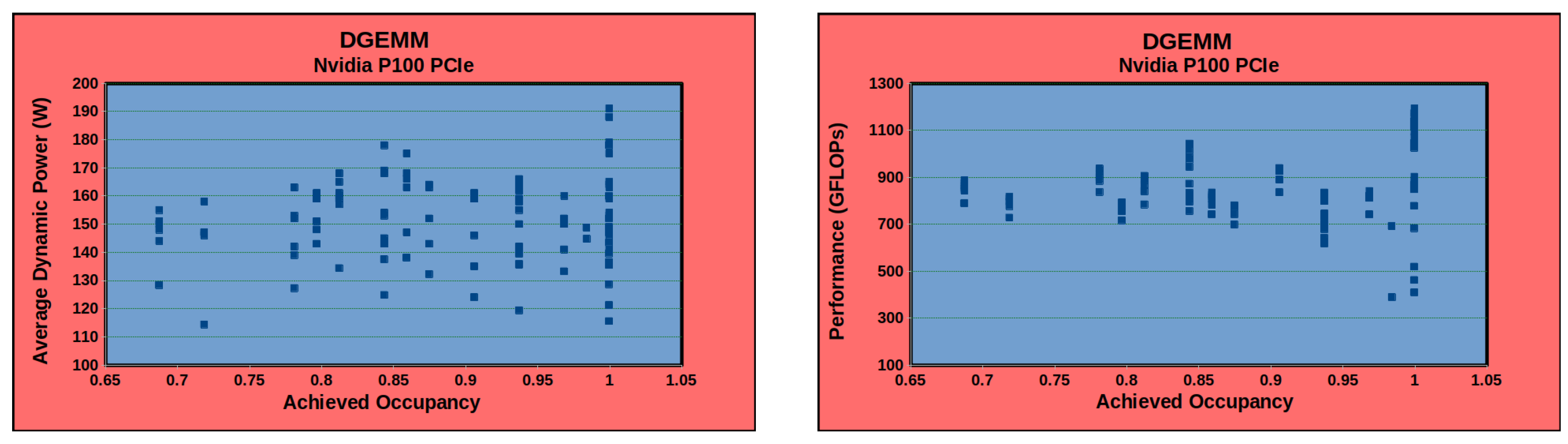
4.3. Impact of Non-Linearity
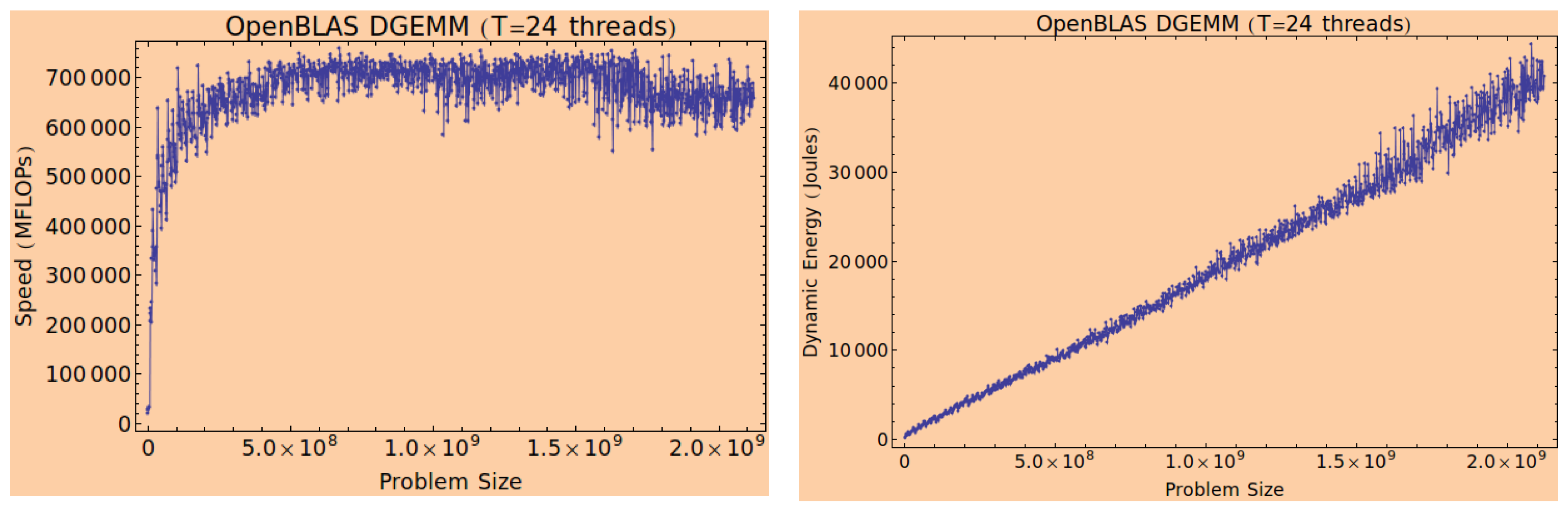
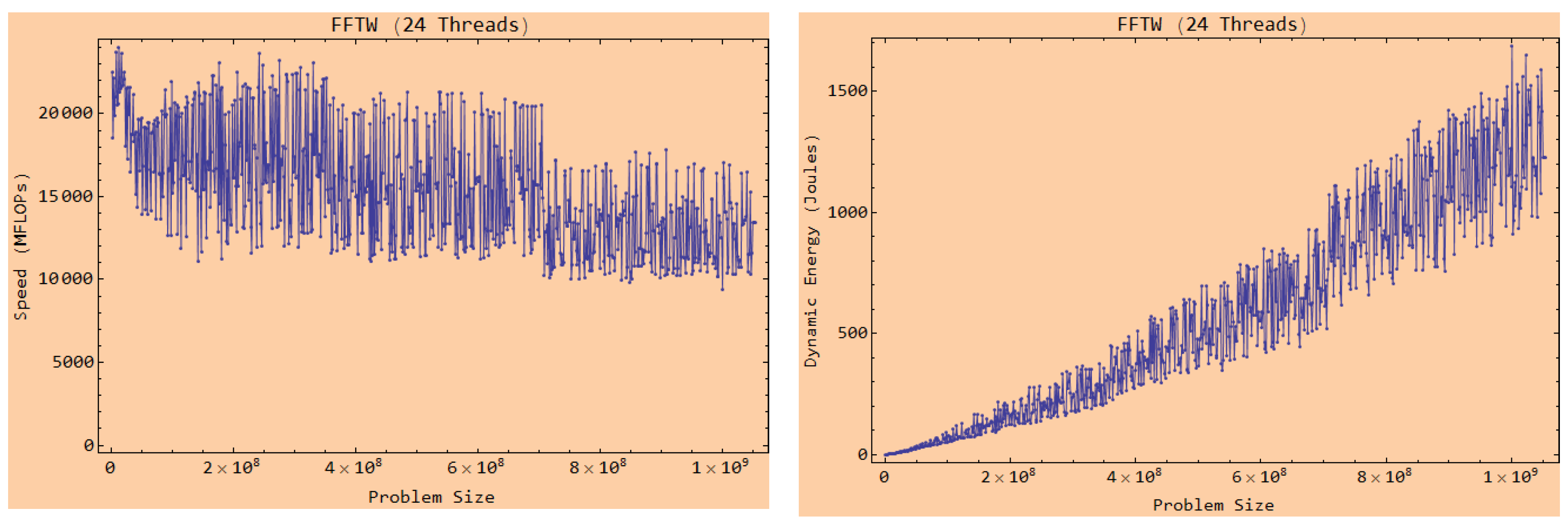
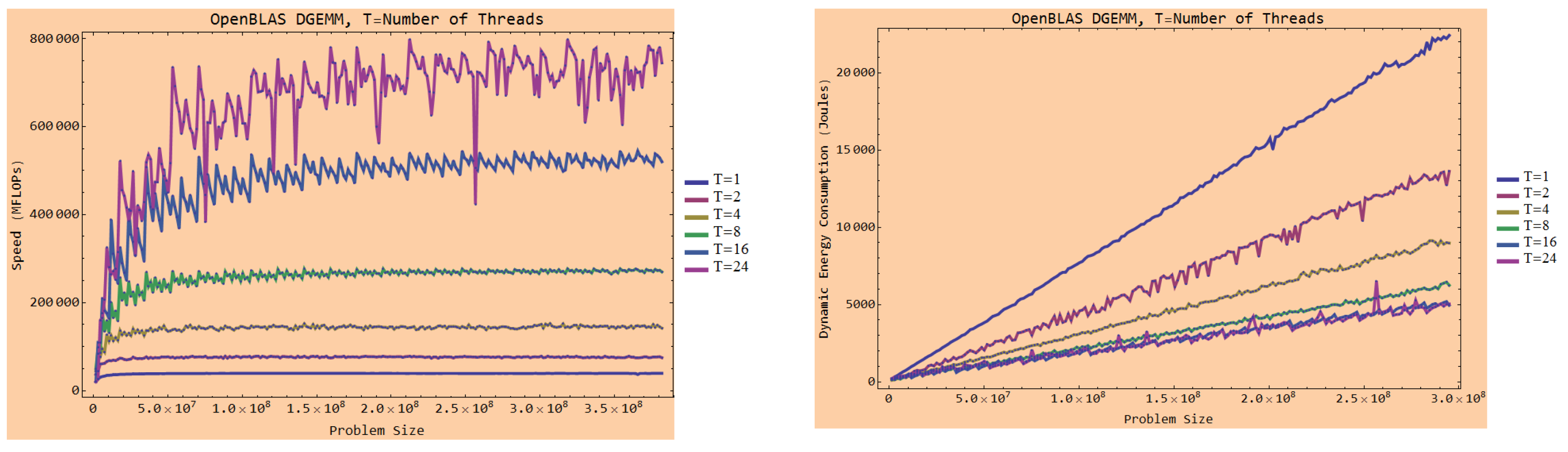
4.3.1. Multicore CPUs
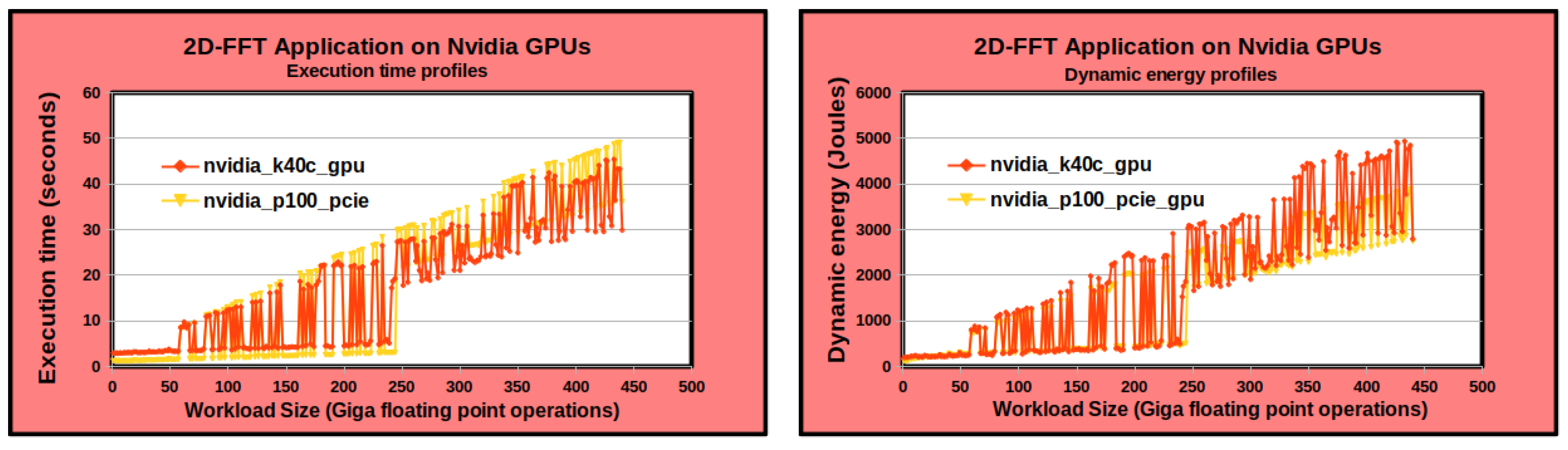
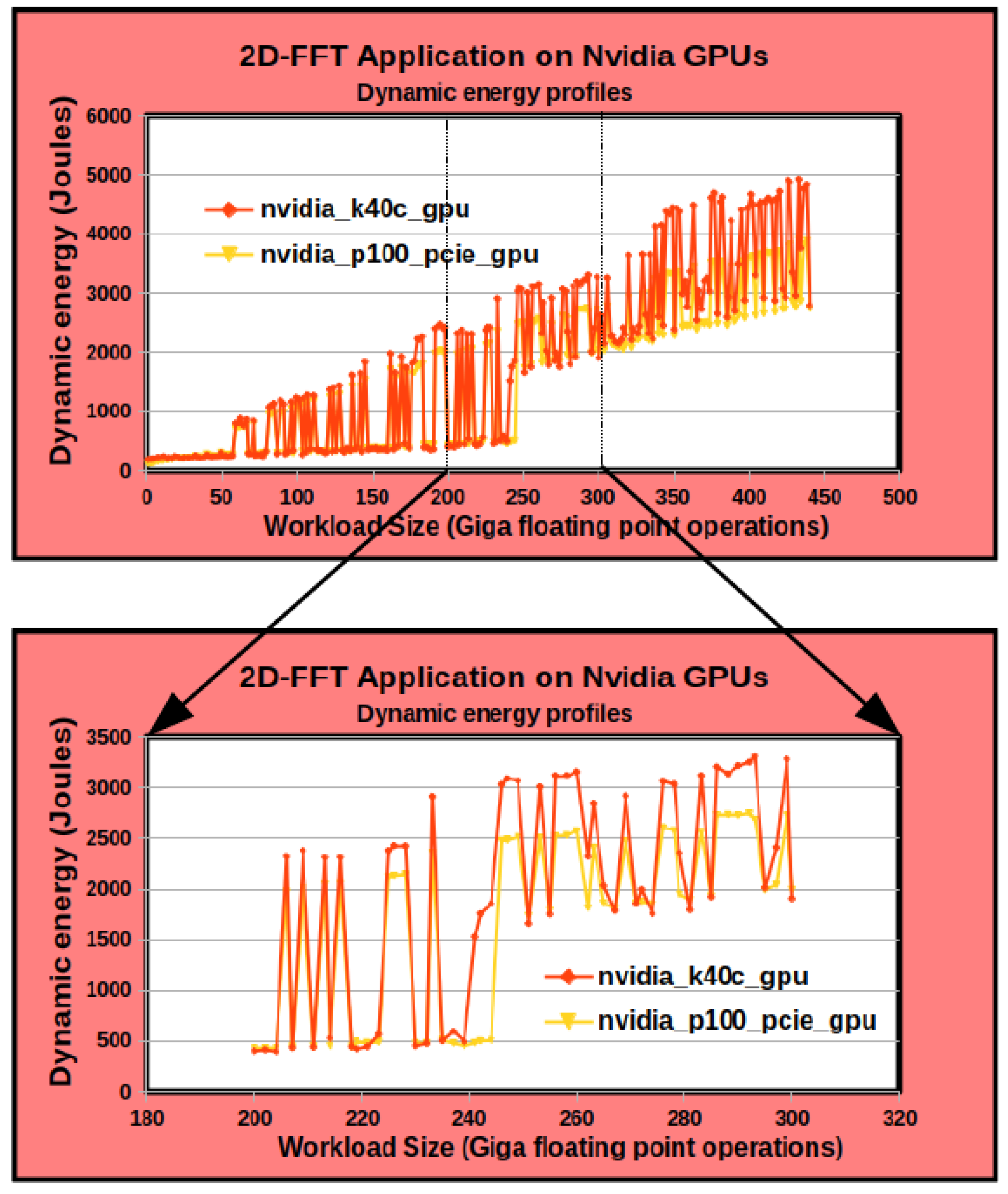
4.3.2. Graphics Processing Units (GPUs)
4.4. Optimization Methods for Energy and Performance on Modern HPC Platforms
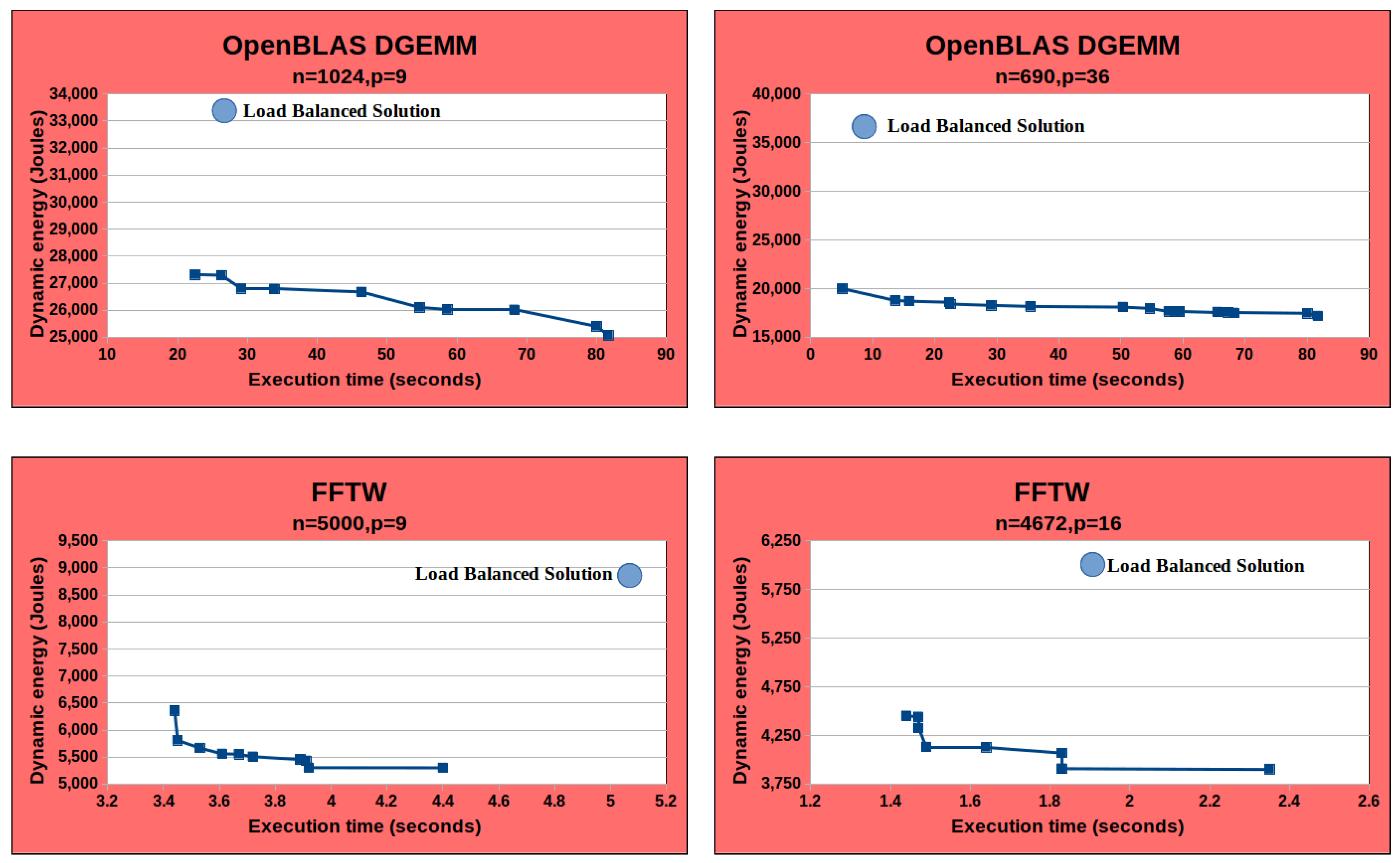
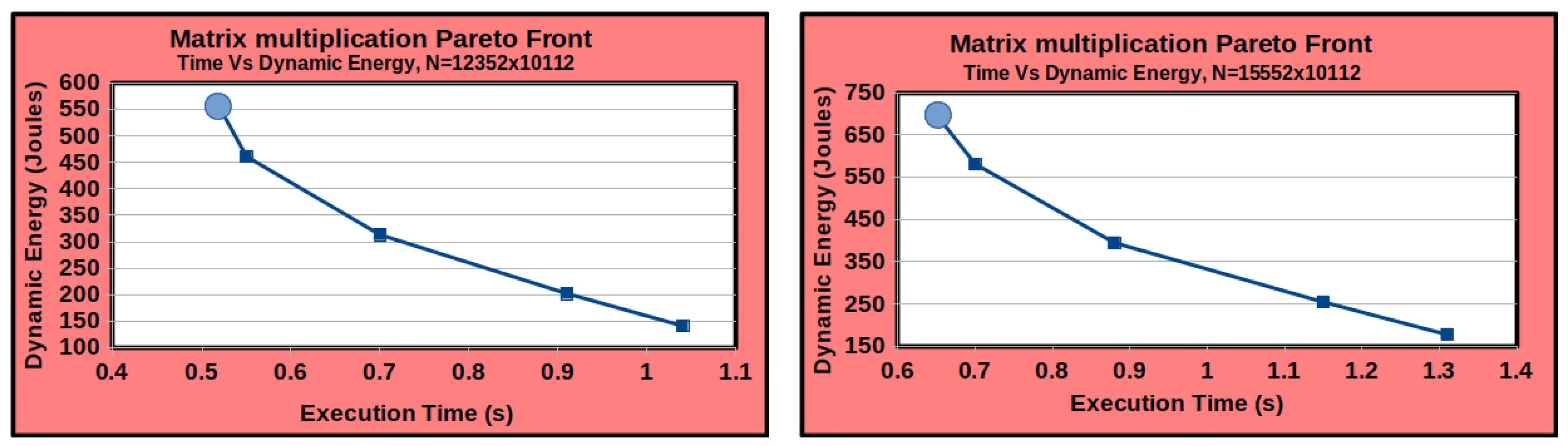
4.4.1. Non-Linearity on Homogeneous Platforms
4.4.2. Non-Linearity on Heterogeneous Platforms
5. State-of-the-Art Energy Measurement Methods
5.1. System-Level Physical Power Measurements Using External Power Meters
5.2. On-Chip Power Sensors
5.2.1. Intel Running Average Power Limit (RAPL)
5.2.2. AMD Application Power Management (APM)
5.2.3. Intel Manycore Platform Software Stack (Intel MPSS)
5.2.4. Nvidia Management Library (NVML)
5.2.5. Summary
5.3. Software Energy Predictive Models
5.3.1. Additivity of Performance Monitoring Counters
5.3.2. Selection of Model Variables Based on Energy Conservation Laws
5.3.3. Best Linear Energy Predictive Models for Intel Multicore CPUs
5.3.4. Runtime Energy Modeling on Nvidia GPU Accelerators
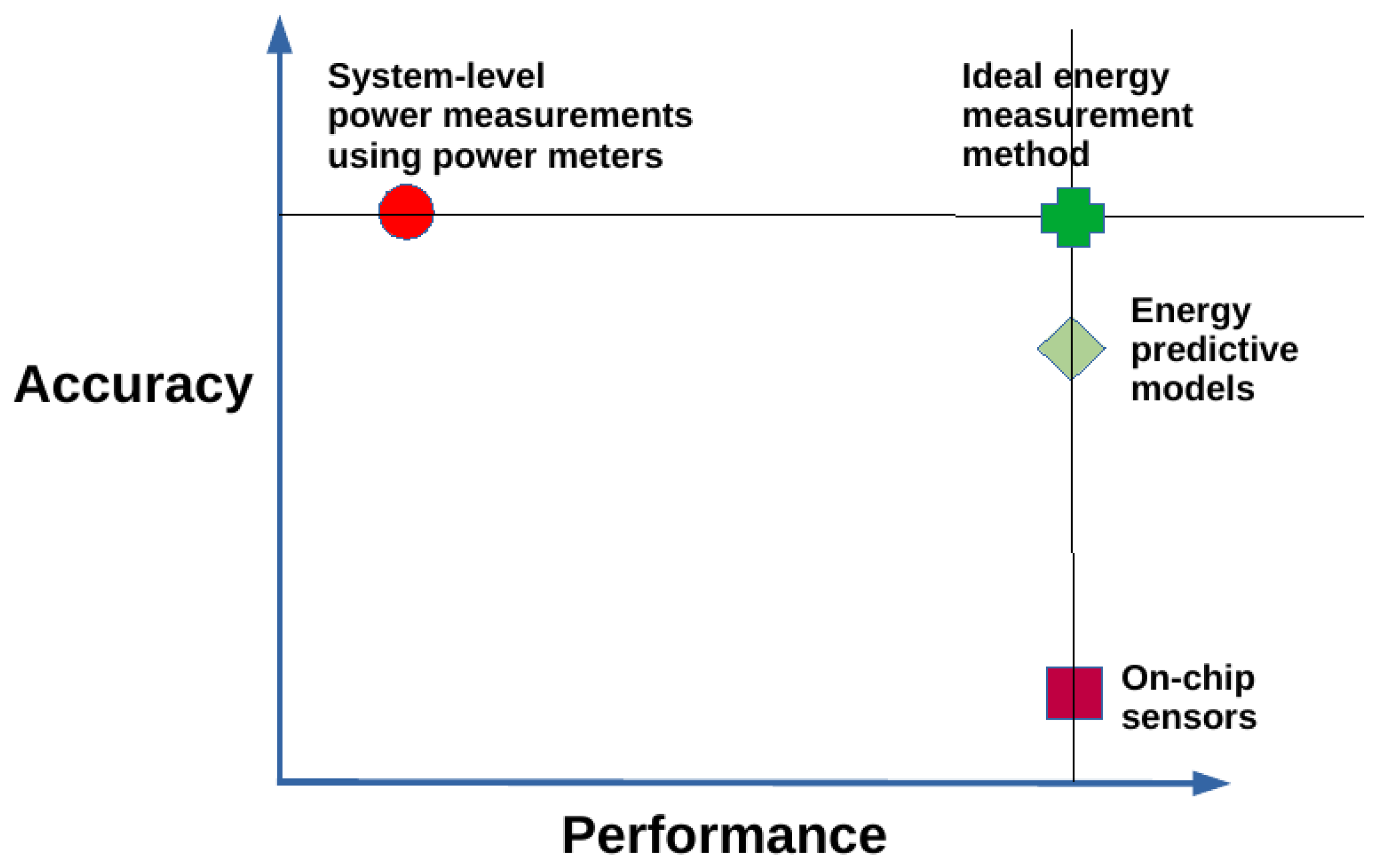
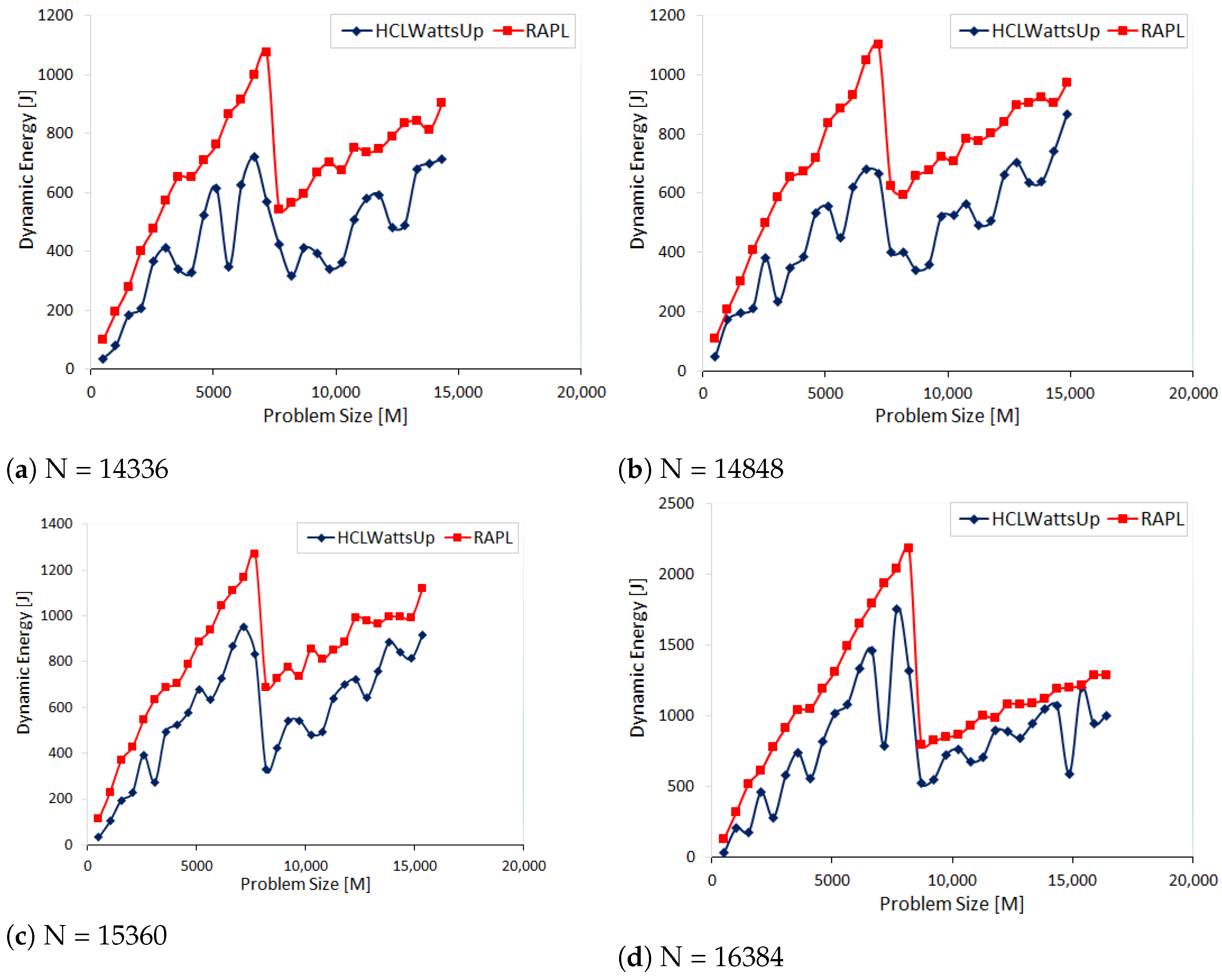
5.4. Accuracy vs. Performance of Component-Level Energy Measurement Methods
6. Building Blocks for Scaling for Energy-Efficient Parallel Computing
- Acceleration of the sequential optimization algorithms allowing fast runtime computation of Pareto-optimal solutions optimizing the application for performance and energy.
- Software energy sensors for multicore CPUs and accelerators that are implemented using energy-predictive models employing model variables that are highly additive and satisfying energy conservation laws and based on statistical tests such as high positive correlation.
- Fast runtime construction of performance and dynamic energy profiles using the software energy sensors.
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| ICT | Information and Communications Technology |
| HPC | High-performance Computing |
| DVFS | Dynamic Voltage and Frequency Scaling |
| DPM | Dynamic Power Management |
| RAPL | Running Average Power Limit |
| APM | AMD Application Power Management |
| NVML | NVIDIA Management Library |
| CUPTI | NVIDIA CUDA Profiling Tools Interface |
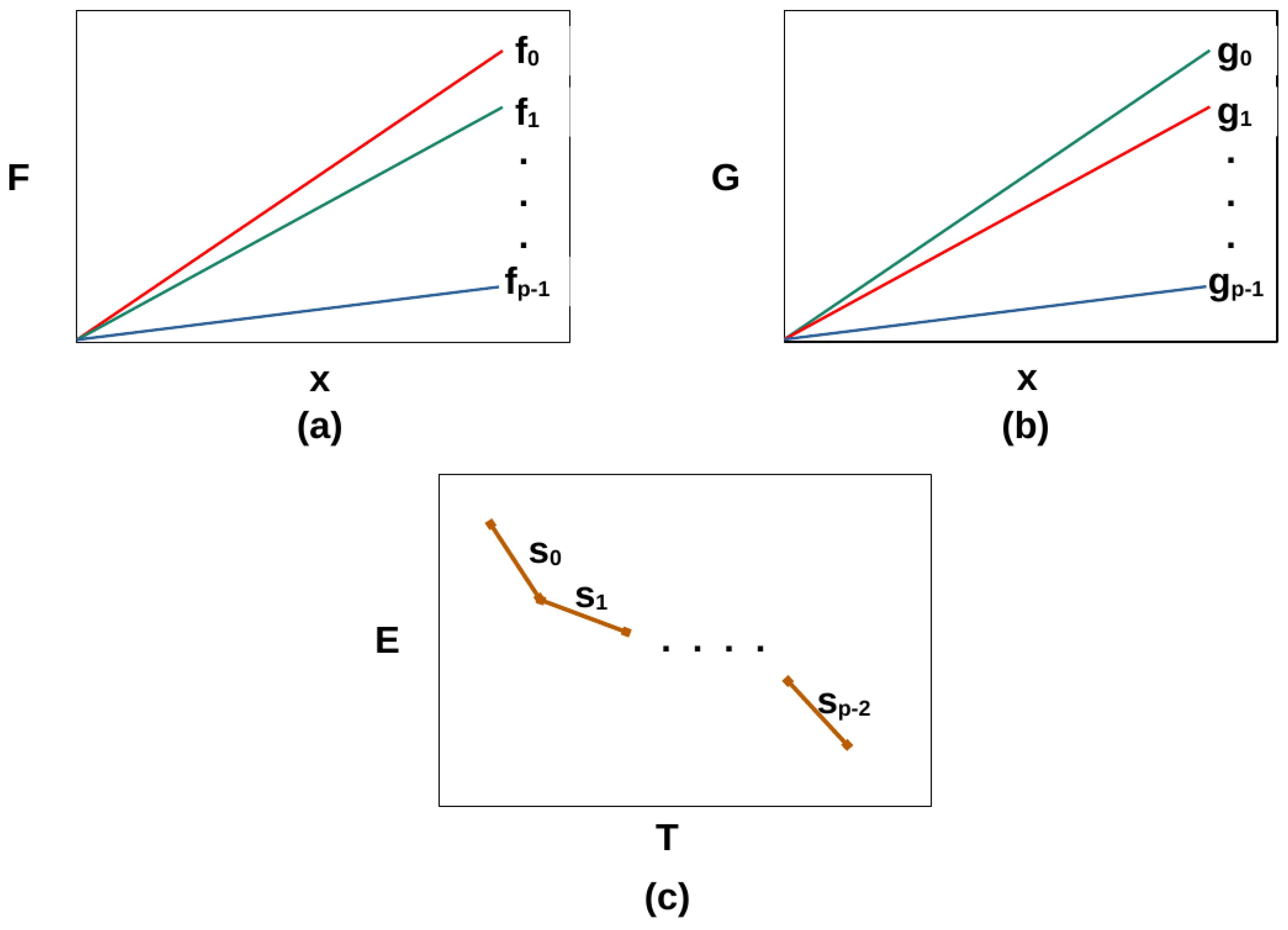
Appendix A. Optimization for Performance and Energy Using p Identical Linear Parallel Processors
Appendix B. Optimization for Performance and Energy Using p Heterogeneous Linear Parallel Processors


Appendix C. Intel RAPL


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Workload Size (N) | Min | Max | Avg |
|---|---|---|---|
| 14,336 | 17% | 172% | 65% |
| 14,848 | 12% | 153% | 58% |
| 15,360 | 13% | 240% | 56% |
| 16,384 | 2% | 300% | 56% |
Appendix D. Accuracy of MPSS against Ground Truth on Intel Xeon Phi Co-Processor
| Without Calibration | |||
|---|---|---|---|
| Application | Min | Max | Avg |
| Intel MKL DGEMM | 45.1% | 93.06% | 64.5% |
| Intel MKL FFT | 22.58% | 55.78% | 40.68% |
| With Calibration | |||
| Application | Min | Max | Avg |
| Intel MKL DGEMM | 0.06% | 9.54% | 2.75% |
| Intel MKL FFT | 0.06% | 32.3% | 9.58% |
Appendix E. Accuracy of NVML against Ground-Truth on Nvidia K40c GPU and Nvidia P100 PCIe
| Without Calibration | |||
|---|---|---|---|
| Application | Min | Max | Avg |
| CUBLAS DGEMM | 0.076% | 35.32% | 10.62% |
| CUBLAS FFT | 0.52% | 57.77% | 12.45% |
| With Calibration | |||
| Application | Min | Max | Avg |
| CUBLAS DGEMM | 0.19% | 30.50% | 10.43% |
| CUBLAS FFT | 0.18% | 94.55% | 10.87% |
| Without Calibration | |||
|---|---|---|---|
| Application | Min | Max | Avg |
| CUBLAS DGEMM | 13.11% | 84.84% | 40.06% |
| CUBLAS FFT | 17.91% | 175.97% | 73.34% |
| With Calibration | |||
| Application | Min | Max | Avg |
| CUBLAS DGEMM | 0.07% | 26.07% | 11.62% |
| CUBLAS FFT | 0.025% | 51.24% | 16.95% |
Appendix F. Additivity of Performance Monitoring Counters (PMCs)
Appendix G. Selection of Model Variables Based on Energy Conservation Laws
- In a dedicated and stable environment, the PMC vector of the serial execution of two applications will always be the same if the same PMC vector represents each application run.
- An application run that does not consume energy has a null PMC vector.
- An application with a non-null PMC vector must consume some energy.
- Finally, the consumed energy of a compound application is equal to the sum of the energies consumed by the individual applications.
- Each model variable must be deterministic and reproducible.
- Each model variable must be additive.
- The model intercept must be zero.
- Each model coefficient must be positive.
Appendix H. Best Linear Energy Predictive Models for Intel Multicore CPUs
References
- Andrae, A. New perspectives on internet electricity use in 2030. Eng. Appl. Sci. Lett. 2020, 3, 19–31. [Google Scholar]
- Lastovetsky, A.; Reddy, R. New Model-Based Methods and Algorithms for Performance and Energy Optimization of Data Parallel Applications on Homogeneous Multicore Clusters. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1119–1133. [Google Scholar] [CrossRef]
- Reddy, R.; Lastovetsky, A. Bi-Objective Optimization of Data-Parallel Applications on Homogeneous Multicore Clusters for Performance and Energy. IEEE Trans. Comput. 2018, 67, 160–177. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer: New York, NY, USA, 1998. [Google Scholar]
- Talbi, E.G. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 74. [Google Scholar]
- Fahad, M.; Manumachu, R.R. HCLWattsUp: Energy API Using System-Level Physical Power Measurements Provided by Power Meters; Heterogeneous Computing Laboratory, University College Dublin: Dublin, Ireland, 2023. [Google Scholar]
- OpenBLAS. OpenBLAS: An Optimized BLAS Library. Available online: https://github.com/xianyi/OpenBLAS (accessed on 1 December 2022).
- Fahad, M.; Shahid, A.; Reddy, R.; Lastovetsky, A. A Comparative Study of Methods for Measurement of Energy of Computing. Energies 2019, 12, 2204. [Google Scholar] [CrossRef]
- Top500. The Top500 Supercomputers List. Available online: https://www.top500.org (accessed on 1 December 2022).
- Krommydas, K.; Feng, W.C.; Antonopoulos, C.D.; Bellas, N. OpenDwarfs: Characterization of Dwarf-Based Benchmarks on Fixed and Reconfigurable Architectures. J. Signal Process. Syst. 2016, 85, 373–392. [Google Scholar] [CrossRef]
- Kreutzer, M.; Thies, J.; Röhrig-Zöllner, M.; Pieper, A.; Shahzad, F.; Galgon, M.; Basermann, A.; Fehske, H.; Hager, G.; Wellein, G. GHOST: Building Blocks for High Performance Sparse Linear Algebra on Heterogeneous Systems. Int. J. Parallel Program. 2016, 45, 1046–1072. [Google Scholar] [CrossRef]
- Papadrakakis, M.; Stavroulakis, G.; Karatarakis, A. A new era in scientific computing: Domain decomposition methods in hybrid CPU–GPU architectures. Comput. Methods Appl. Mech. Eng. 2011, 200, 1490–1508. [Google Scholar] [CrossRef]
- Khaleghzadeh, H.; Fahad, M.; Shahid, A.; Reddy, R.; Lastovetsky, A. Bi-Objective Optimization of Data-Parallel Applications on Heterogeneous HPC Platforms for Performance and Energy Through Workload Distribution. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 543–560. [Google Scholar] [CrossRef]
- Khaleghzadeh, H.; Reddy, R.; Lastovetsky, A. Efficient exact algorithms for continuous bi-objective performance-energy optimization of applications with linear energy and monotonically increasing performance profiles on heterogeneous high performance computing platforms. Concurr. Comput. Pract. Exp. 2022, e7285. [Google Scholar] [CrossRef]
- FFTW. FFTW: A Fast, Free C FFT Library. Available online: https://www.fftw.org (accessed on 1 December 2022).
- Lastovetsky, A.L.; Reddy, R. Data partitioning with a realistic performance model of networks of heterogeneous computers. In Proceedings of the Parallel and Distributed Processing Symposium, Hong Kong, China, 13–15 December 2004. [Google Scholar]
- Lastovetsky, A.; Reddy, R. Data partitioning with a functional performance model of heterogeneous processors. Int. J. High Perform. Comput. Appl. 2007, 21, 76–90. [Google Scholar] [CrossRef]
- Lastovetsky, A.; Twamley, J. Towards a realistic performance model for networks of heterogeneous computers. In High Performance Computational Science and Engineering; Springer: Berlin, Germany, 2005; pp. 39–57. [Google Scholar]
- Khaleghzadeh, H.; Reddy, R.; Lastovetsky, A. A novel data-partitioning algorithm for performance optimization of data-parallel applications on heterogeneous HPC platforms. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2176–2190. [Google Scholar] [CrossRef]
- Khaleghzadeh, H.; Fahad, M.; Reddy, R.; Lastovetsky, A. A novel data partitioning algorithm for dynamic energy optimization on heterogeneous high-performance computing platforms. Concurr. Comput. Pract. Exp. 2020, 32, e5928. [Google Scholar] [CrossRef]
- Fahad, M.; Shahid, A.; Manumachu, R.R.; Lastovetsky, A. Accurate Energy Modelling of Hybrid Parallel Applications on Modern Heterogeneous Computing Platforms Using System-Level Measurements. IEEE Access 2020, 8, 93793–93829. [Google Scholar] [CrossRef]
- Rotem, E.; Naveh, A.; Ananthakrishnan, A.; Weissmann, E.; Rajwan, D. Power-Management Architecture of the Intel Microarchitecture Code-Named Sandy Bridge. IEEE Micro 2012, 32, 20–27. [Google Scholar] [CrossRef]
- Treibig, J.; Hager, G.; Wellein, G. Likwid: A lightweight performance-oriented tool suite for x86 multicore environments. In Proceedings of the Parallel Processing Workshops (ICPPW), San Diego, CA, USA, 13–16 September 2010; pp. 207–216. [Google Scholar]
- Devices, A.M. AMD uProf User Guide. Available online: https://www.amd.com/content/dam/amd/en/documents/developer/uprof-v4.0-gaGA-user-guide.pdf (accessed on 1 December 2022).
- Devices, A.M. BIOS and Kernel Developer’s Guide (BKDG) for AMD Family 15h Models 00h-0Fh Processors. Available online: https://www.amd.com/system/files/TechDocs/42301_15h_Mod_00h-0Fh_BKDG.pdf (accessed on 1 December 2022).
- Hackenberg, D.; Ilsche, T.; Schöne, R.; Molka, D.; Schmidt, M.; Nagel, W.E. Power measurement techniques on standard compute nodes: A quantitative comparison. In Proceedings of the 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 194–204. [Google Scholar]
- Intel Corporation. Intel Xeon Phi Coprocessor System Software Developers Guide. Available online: https://www.intel.com/content/dam/develop/external/us/en/documents/intel-xeon-phi-coprocessor-quick-start-developers-guide-windows-v1-2.pdf (accessed on 1 December 2022).
- Intel Corporation. Intel Manycore Platform Software Stack (Intel MPSS). Available online: https://www.intel.com/content/www/us/en/developer/articles/tool/manycore-platform-software-stack-mpss.html (accessed on 1 December 2022).
- Nvidia. Nvidia Management Library: NVML API Reference Guide. Available online: https://docs.nvidia.com/deploy/nvml-api/index.html (accessed on 1 December 2022).
- O’Brien, K.; Pietri, I.; Reddy, R.; Lastovetsky, A.; Sakellariou, R. A Survey of Power and Energy Predictive Models in HPC Systems and Applications. ACM Comput. Surv. 2017, 50, 1–38. [Google Scholar] [CrossRef]
- Shahid, A.; Fahad, M.; Reddy, R.; Lastovetsky, A. Additivity: A Selection Criterion for Performance Events for Reliable Energy Predictive Modeling. Supercomput. Front. Innov. Int. J. 2017, 4, 50–65. [Google Scholar]
- Shahid, A.; Fahad, M.; Reddy, R.; Lastovetsky, A.L. Energy Predictive Models of Computing: Theory, Practical Implications and Experimental Analysis on Multicore Processors. IEEE Access 2021, 9, 63149–63172. [Google Scholar] [CrossRef]
- Shahid, A.; Fahad, M.; Reddy, R.; Lastovetsky, A. Improving the Accuracy of Energy Predictive Models for Multicore CPUs Using Additivity of Performance Monitoring Counters. In Proceedings of the Parallel Computing Technologies; Malyshkin, V., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 51–66. [Google Scholar]
- Shahid, A.; Fahad, M.; Manumachu, R.R.; Lastovetsky, A. Improving the accuracy of energy predictive models for multicore CPUs by combining utilization and performance events model variables. J. Parallel Distrib. Comput. 2021, 151, 38–51. [Google Scholar] [CrossRef]
- NVIDIA Corporation. CUDA Profiling Tools Interface (CUPTI)—1.0. Available online: https://developer.nvidia.com/cuda-profiling-tools-interface (accessed on 1 December 2022).
- Nagasaka, H.; Maruyama, N.; Nukada, A.; Endo, T.; Matsuoka, S. Statistical power modeling of GPU kernels using performance counters. In Proceedings of the International Green Computing Conference and Workshops (IGCC), Chicago, IL, USA, 15–18 August 2010. [Google Scholar]
- Zhang, Y.; Hu, Y.; Li, B.; Peng, L. Performance and Power Analysis of ATI GPU: A Statistical Approach. In Proceedings of the IEEE Sixth International Conference on Networking, Architecture, and Storage, IEEE Computer Society, Washington, DC, USA, 28–30 July 2011; pp. 149–158. [Google Scholar]
- Song, S.; Su, C.; Rountree, B.; Cameron, K.W. A Simplified and Accurate Model of Power-Performance Efficiency on Emergent GPU Architectures. In Proceedings of the 27th IEEE International Parallel and Distributed Processing Symposium (IPDPS), Cambridge, MA, USA, 20–24 May 2013; pp. 673–686. [Google Scholar]
- Al-Hashimi, M.; Saleh, M.; Abulnaja, O.; Aljabri, N. Evaluation of control loop statements power efficiency: An experimental study. In Proceedings of the 2014 9th International Conference on Informatics and Systems, Cairo, Egypt, 15–17 December 2014; pp. PDC-45–PDC-48. [Google Scholar]
- Coplin, J.; Burtscher, M. Effects of Source-Code Optimizations on GPU Performance and Energy Consumption. In Proceedings of the 8th Workshop on General Purpose Processing Using GPUs, San Francisco, CA, USA, 7 February 2015; pp. 48–58. [Google Scholar]
- Lee, S.; Kim, K.; Koo, G.; Jeon, H.; Ro, W.W.; Annavaram, M. Warped-Compression: Enabling power efficient GPUs through register compression. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 502–514. [Google Scholar]
- Ikram, M.J.; Saleh, M.E.; Al-Hashimi, M.A.; Abulnaja, O.A. Investigating the effect of varying block size on power and energy consumption of GPU kernels. J. Supercomput. 2022, 78, 14919–14939. [Google Scholar] [CrossRef]
- Zhong, Z.; Rychkov, V.; Lastovetsky, A. Data partitioning on multicore and multi-GPU platforms using functional performance models. Comput. IEEE Trans. 2015, 64, 2506–2518. [Google Scholar] [CrossRef]
- David, H.; Gorbatov, E.; Hanebutte, U.R.; Khanna, R.; Le, C. RAPL: Memory power estimation and capping. In Proceedings of the 2010 ACM/IEEE International Symposium on Low-Power Electronics and Design (ISLPED), Austin, TX, USA, 18–20 August 2010; pp. 189–194. [Google Scholar]
- Gough, C.; Steiner, I.; Saunders, W. Energy Efficient Servers Blueprints for Data Center Optimization; Apress: New York, NY, USA, 2015. [Google Scholar]
- Hackenberg, D.; Schöne, R.; Ilsche, T.; Molka, D.; Schuchart, J.; Geyer, R. An Energy Efficiency Feature Survey of the Intel Haswell Processor. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium Workshop, Washington, DC, USA, 25–29 May 2015; pp. 896–904. [Google Scholar]
- Reddy, R.; Lastovetsky, A. On Energy Nonproportionality of CPUs and GPUs. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lyon, France, 30 May–3 June 2022; pp. 34–44. [Google Scholar] [CrossRef]












| Specification | Description |
|---|---|
| GPU architecture | NVIDIA Ampere |
| GPU memory | 48 GB GDDR6 |
| No. of CUDA cores | 10,752 |
| TDP | 300 W |
| CUDA Version | 12.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lastovetsky, A.; Manumachu, R.R. Energy-Efficient Parallel Computing: Challenges to Scaling. Information 2023, 14, 248. https://doi.org/10.3390/info14040248
Lastovetsky A, Manumachu RR. Energy-Efficient Parallel Computing: Challenges to Scaling. Information. 2023; 14(4):248. https://doi.org/10.3390/info14040248
Chicago/Turabian StyleLastovetsky, Alexey, and Ravi Reddy Manumachu. 2023. "Energy-Efficient Parallel Computing: Challenges to Scaling" Information 14, no. 4: 248. https://doi.org/10.3390/info14040248
APA StyleLastovetsky, A., & Manumachu, R. R. (2023). Energy-Efficient Parallel Computing: Challenges to Scaling. Information, 14(4), 248. https://doi.org/10.3390/info14040248