1. Introduction
The occurrence of recent terrorist attacks involving explosives in underground stations and airports, such as in Brussels, Zaventem, 2013 (
https://www.epc.eu/en/Publications/The-fall-out-from-the-Brussels~1d2eb4 (accessed on 20 January 2023)) (suicide bombers) and Parson Green, London, 2017 (
https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/776162/HC1694_The2017Attacks_WhatNeedsToChange.pdf (accessed on 20 January 2023)) (IED detonation), has demonstrated that surveillance systems for soft targets in complex scenarios still do not ensure a sufficient level of security. The difficulties are the huge volume of passengers to keep under control, the vast urban areas of interest, and the ability of terrorists to conceal the threat and to maintain a behavior hardly discernable from normal commuters. The availability of instruments for automatic detection of weapons and explosives (see, for example, [
1,
2]) and of intelligent video systems for persons tracking [
3,
4], and the maturity of IoT-technology for smart city applications [
5], allow one to conceive novel early threat detection systems that activate alarm management processes.
The function of the command-and-control (C&C) software in such a system is the orchestration of the plurality of sensors, deployed in various delimited areas of a public space and targeting potential terroristic persons, e.g., wearing explosive objects hidden under clothes or inside bags. The technological challenge is twofold: to optimize the work of agents on field by providing security checks in a non-intrusive manner and to support localization of the threat in the crowd; also, the second challenge is to strengthen the operations at the security control room of a critical infrastructure through automatic communication of alarms and of any relevant information for the police. The first challenge requires one to integrate and fuse detections of different sensors that produce data in real time and that work unnoticeable to the persons passing through the observed locations. The second requires a robust real time system for automatic alert generation without impacting the passengers’ flow, and which can innovate existing situational awareness systems devoted to public security. Indeed, the control work in security rooms currently is mostly based on direct observation by the operators through the video cameras deployed at different sites of the infrastructure, and alarm communication and management are very much human-based processes.
This paper describes a modular distributed architecture of a command-and-control software, which is independent from the specific detectors and where sensor data fusion is supported by two intelligent video systems. One allows re-identification and tracking of a person previously identified by another camera, and the other delivers position prediction of a person near a sensor to reduce detection misses. Thus, the architecture can fuse sensor detections of the same person realized in non-adjacent sites of a big area and also allows one to set up a network of installations covering different sites of the same infrastructure.
Other than informing the security room in real time, the C&C automatically supplies alerts to a indoor localization system dispatching images of the person to be altered on the smart glasses worn by the security guards, thus enabling their timely reaction on the field.
The architecture comprising the C&C and the two video systems, named INSTEAD (Integrated SysTem for Early Thread Detection), has been implemented for the NATO-SPS funded [
6] DEXTER program and has been successfully tested in a Big City Trial (BCT) at a metro station in Rome, both when integrated with two real detectors of weapons and explosives and as a stand-alone system. The assessment of INSTEAD in the controlled trials is detailed in [
7], whereas a preliminary study of INSTEAD was presented in [
8].
This paper describes the software architecture of the C&C implementation, which is modular, as it integrates completely decoupled components. Two generic types of video sensor data fusion methods are implemented: one suitable for sensors exclusively targeted on movable objects and the other for sensor systems that use their own video system to work towards a target. Thus, these methods can be applied to various sensors, and not only those used for DEXTER. The loosely coupled component communication model and a generic data structure for sensor messages allow extension of the software with additional components. The software design and the results of further experiments performed in the real environment using less constrained scenarios than those presented in [
7] allow one to demonstrate flexibility and re-use of the system in different deployments. Other relevant quality aspects of the software are also discussed.
The rest of the paper is organized as it follows.
Section 2 presents related work.
Section 3 provides the reference system architecture where the C&C has been implemented as part of the INSTEAD system, and the description of the DEXTER deployment is used as a case study. Then, the C&C is detailed in
Section 4.
Section 5 presents the experimental results, while a discussion on quality aspects of the system is presented in
Section 6. Finally,
Section 7 summarizes the conclusion and suggestions for future work.
2. Related Work
The present work includes data fusion methods from sensor data aiming at human activities recognition. These topics, even separately, have been widely treated by the literature as follows.
An increasing number of data fusion approaches depend on the sources of data and the environmental constraints. Papčo et al. [
9], for instance, proposed an extension of the notion of deviation-based aggregation function tailored to aggregate multidimensional data to be used in case temporal constraints are strict. Zhang et al. [
10] presented a survey, including a comprehensive investigation on how to use information fusion to leverage edge data for intelligence in four relevant scenarios: multisource information fusion, real-time information fusion, event-driven information fusion, and context-aware information fusion. Rough set theory (RST) deals with classification issues concerning uncertain data modeling. A survey covering multi-source information fusion (MSIF) based on rough set theory was presented in [
11]. As in these works, we use data fusion algorithms, but we have different environmental constraints due to the specific application for public security.
Several works specifically addressed fusion of data from sensors. Yang et al. [
12] proposed a series of tensor-based knowledge fusion and reasoning models for cyber–physical–social systems, which integrate cyber space, physical space, and social space. Potential use and opportunities of data fusion techniques in IoT-enabled applications for physical activity recognition and measure are investigated in a systematic review by Qi et al. [
13]. Lau et al. [
14] introduced a multi-perspective classification of the data fusion to evaluate the smart city applications in order to evaluate selected applications in different smart city domains. With respect to data from sensors, most of the data of the system we developed originated from physical detectors that are error-prone. Hence, the evaluation of the proposed C&C is critical, since it should distinguish between the errors due to detectors and those to the data fusion algorithm. This aspect has been discussed by Bouma et al. [
7].
Among the most significant works on human activity recognition based on noninvasive environmental sensors, we cite Li et al. [
15], who proposed a methodology for a single user’s daily behavior recognition that can adaptively constrain the sensor noise. Qiu et al. [
16] presented a holistic approach to develop a full understanding of the fusion methods of wearable sensors data for human activity recognition applications. Finally, Al-Sa’d et al. [
3] proposed a privacy-preserving solution for crowd monitoring through cameras aimed at adaptive social distance estimation. We share with this last work the goal of the experimentation that entails the system’s ability in person detection and localization.
Another aspect of the work concerns the definition of a flexible architectural framework for multi-sensor systems for real time defense applications. In this field, the Sensing for Asset Protection with Integrated Electronic Networked Technology (SAPIENT) architectural framework was proposed in [
17], and its Interface Control Document (ICD) [
18] has been recently evaluated as an interoperability standard for multi-sensor counter-UAS systems. SAPIENT has been conceived as a general-purpose framework where both the type of sensors and the decision-making logic are flexible. Modules are of two types: Agent Sensor Modules (ASM), each managing communication with one sensor; and High-Level Decision Making Modules (HLDMM), which perform data fusion and define reactions. The architecture is database-centric. Adding a new sensor in SAPIENT requires implementing a specific data management agent devoted to storing the sensor detection data in a central database. The same is required when adding a new instance of HLDMM.
The INSTEAD architecture has been conceived to integrate autonomous sensor-based systems, where decision-making at sensor/component level is actually performed before message generation for the C&C. Additionally, in INSTEAD, performance issues have been carefully considered at design time due to strict real-time requirements. Therefore, data fusion and threat detection are performed in memory with the goal to increase the system performance. For a similar reason, the message payload of the components uses a simple JavaScript Object Notation (JSON)-based [
19] structure, which is less verbose than that based on XML [
20] defined by SAPIENT.
A comparison of the methods used by the two-dimensional video (2D Video) and the three-dimensional video (3D Video) systems to support data fusion with respect to other works is also relevant.
With respect to 2D Video person localization and re-identification capability, common deep learning technology [
21] can reach high rank-1 accuracy on a large public dataset [
22], but it includes facial information, and, in general, it does not generalize well to other environments, which makes it less suitable for practical applications. The 2D Video pipeline used in the INSTEAD architecture applies a new strategy for rapid Re-ID retraining [
23] on anonymized person detections [
24] to enhance privacy and increase flexibility for deployment in new environments.
Tracking person movements using three-dimensional sensor approaches instead of two-dimensional cameras can offer improved tracking ability and activity estimation accuracy [
25]. Accurate tracking of human movement is essential in multi-sensor systems, where the target is identified with one system, and the confirmation or final analysis is performed with another. High tracking accuracy ensures, especially in crowded spaces, that a hand-over between sensor systems is successful and that the effective analysis is performed on the correct target person. High accuracy requirement is even higher if person movement prediction is required for compensating delays caused by, for example, network communications latencies or adjustment delays in mechanical operations of pan-tilt-zoom (PTZ) sensors.
More generally, Stone Soup is a very recent architectural framework devoted to systems for tracking and state estimation of moving objects. This is an open-source software project that produced a first release in 2019 and which is evolving thanks to a collaborative development, as described in the paper by Barr et al. [
26]. In particular, Stone Soup is primarily promoted as a generic and modular architectural framework for upload, test, and benchmark, which are different types of tracking solutions. To this aim, various implementations are provided in the framework. Person tracking in wide areas based on re-identification is not currently available in the framework, and the possibility to define workflows combining different video sensor data fusion activities as those implemented by INSTEAD is not straightforward. This workflow is implemented by the C&C in a declarative logic-based language for data-stream processing, whereas Stone Soup is a Python project, providing class-based structures and programming interfaces to implement modules. The possibility of interface with Stone Soup could be an interesting direction for future work.
The INSTEAD system has been previously presented in [
7,
8], which illustrate different technical aspects of the system as follows. The first paper [
7] contains more details on the techniques for video systems person tracking hand-over with experiments for later integration in the INSTEAD architecture. The second paper [
8] contains more details about the INSTEAD deployment in DEXTER system and focuses on detection accuracy results at BCT. The technical details of the re-identification method are provided in other papers [
23,
24]. This paper focuses on the INSTEAD internal architecture, and, in particular, it expands on the Command and Control subsystem, with the implementation of the data fusion of the alarm management and of the communication middleware. It further expands on the RNN-based implementation of the 3D Video system. Quality aspects of the architecture and reuse for other scenarios and/or to multi-sensor systems are presented.
4. Command and Control
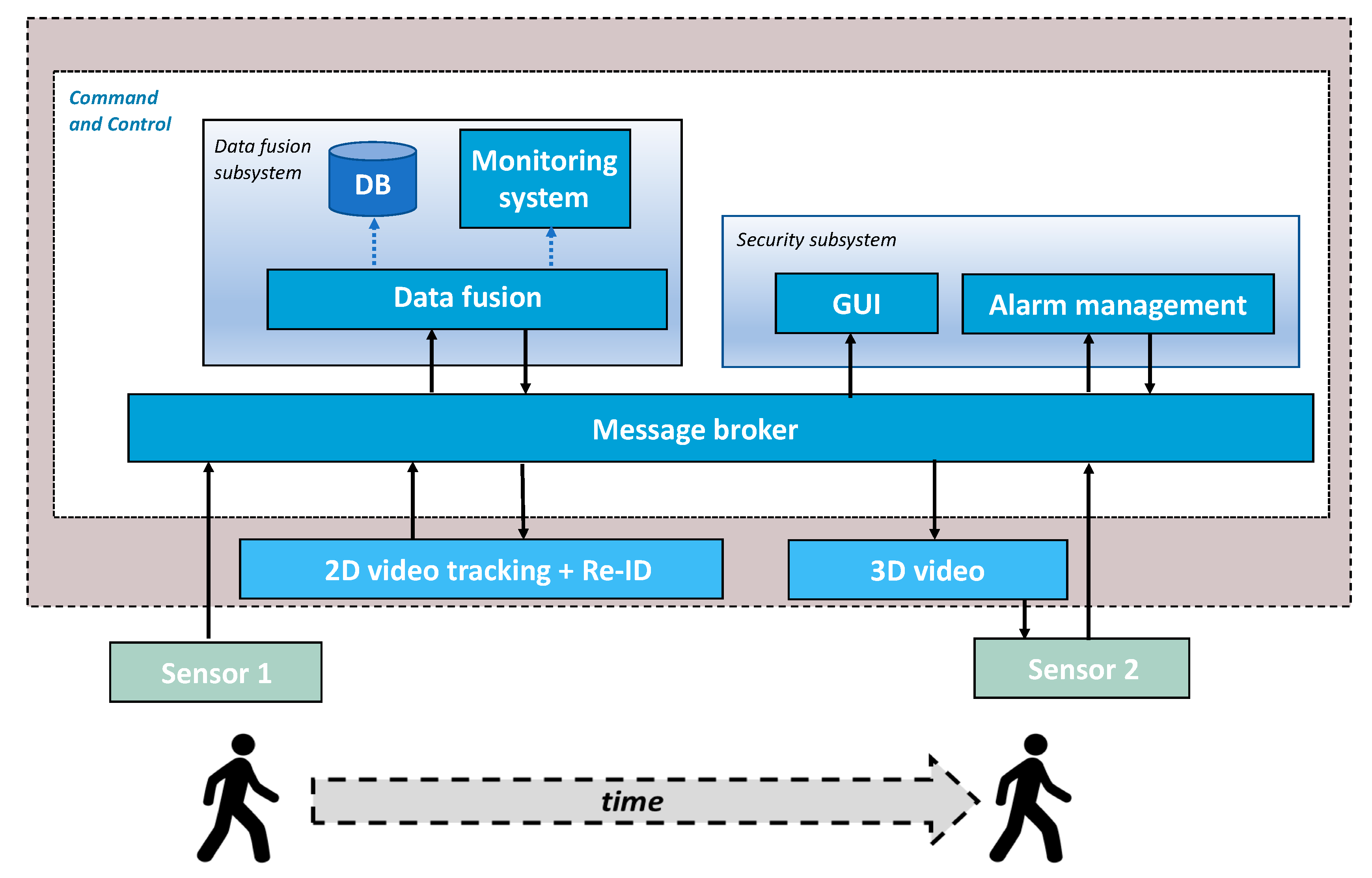
With reference to the architecture of
Figure 2, the C&C is a distributed software component whose responsibilities are: data fusion for situational awareness, implemented by the Data fusion subsystem, smart alarm management, implemented by the Security subsystem, and communication management, implemented by the Message broker.
Data fusion. This is the core functionality of the Data fusion component, intended as a combination of data from multiple sources to improve the interpretation performances of the source data [
27]. This component collects and processes data from the video and sensor-based systems to timely generate triggers and to deliver information related to suspect persons.
Monitoring and persistent storage of data. The data fusion is extended with functions for run time data visualization and storage. The former is accomplished by a Monitoring component providing data for Grafana dashboards [
28]. These display events of interest of system performance at run time, captured by the Prometheus temporal database server [
29]. Persistent storage of all the messages received and sent by the C&C is accomplished by the Instead DB implemented in MySQL [
30]. Recorded data includes partial and complete sensor and video results, useful for system assessment and forensic activity.
Smart alarm management. This function, implemented by the Security subsystem component, concerns dispatching all the results of interest, including alerts, to several security sites, such as the agent smart glasses and a security room. The Security subsystem component includes a web application (GUI) devoted to displaying system results to the various clients that may be registered to this aim and an Alarm management component for dispatching alarms to the smart glasses subsystem and for receiving confirmation messages by the end users.
Communication management. This function is implemented by the Message broker that follows a publish–subscribe protocol to dispatch messages to all the technological components of the architecture.
A more detailed description of the implementation of the C&C components follows.
4.1. Data Fusion Subsystem
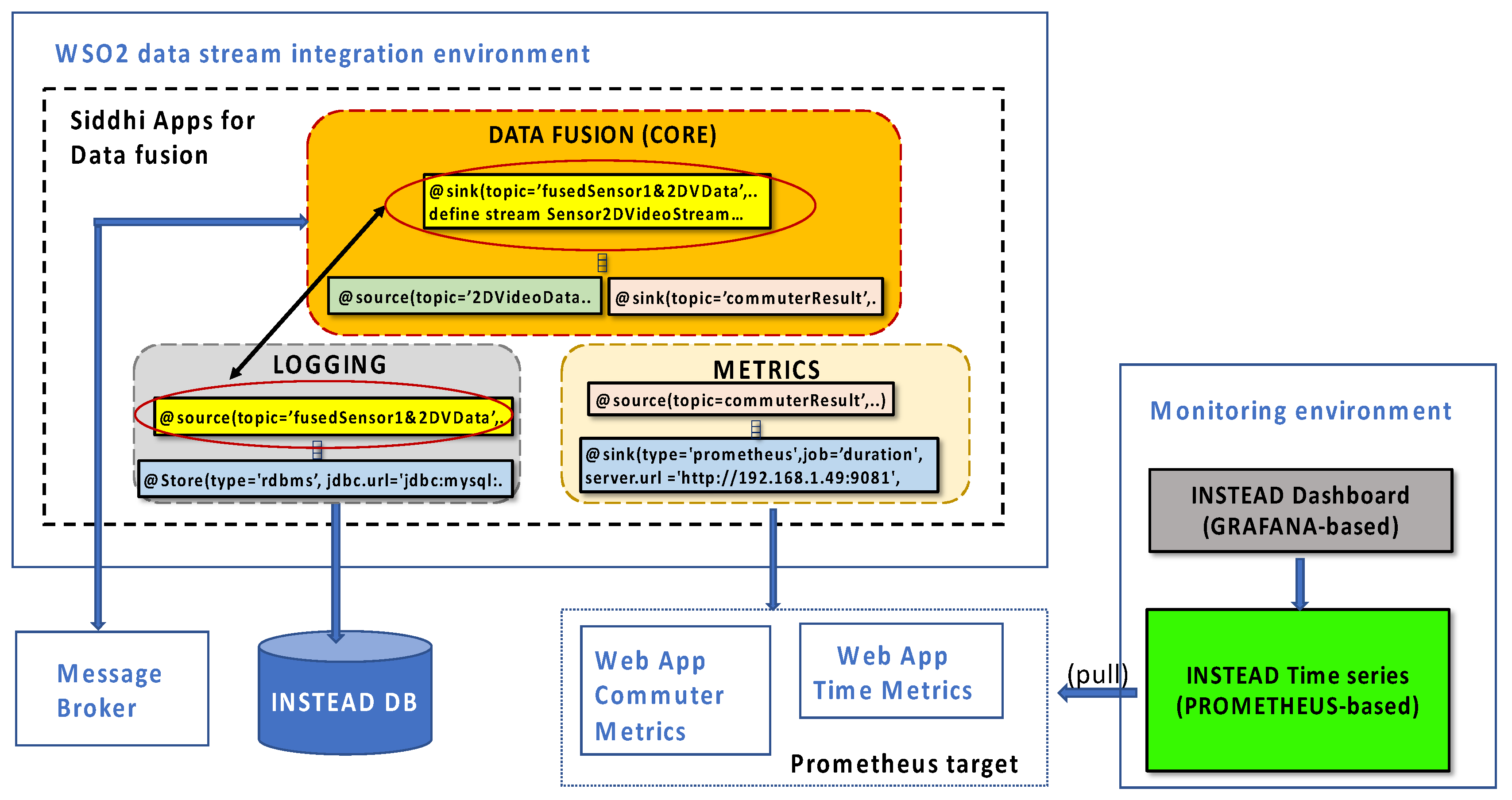
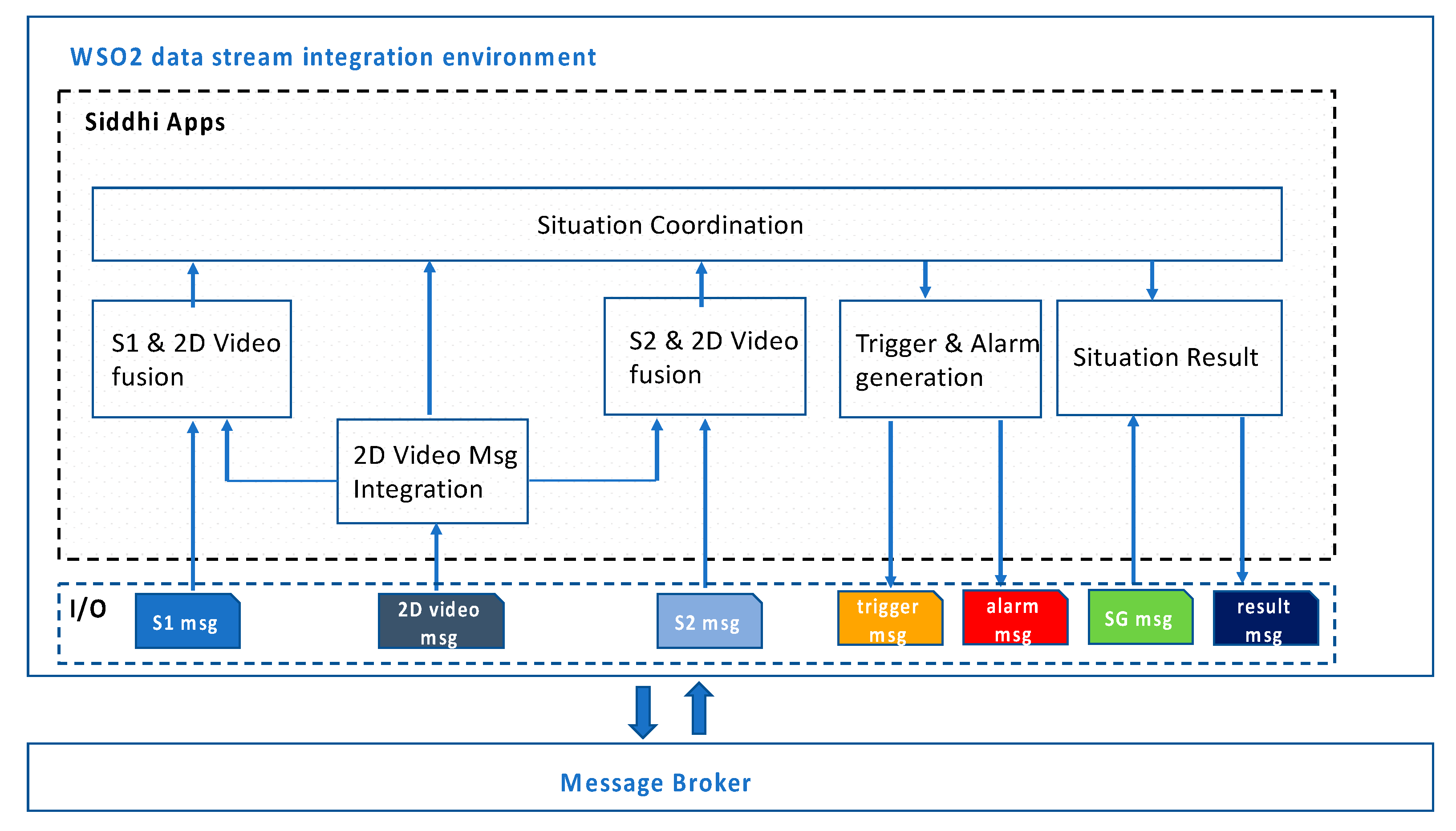
The software architecture of the Data fusion component is depicted in
Figure 4. The Data fusion component has been developed as a collection of Siddhi Apps deployed and hosted by the WSO2 Streaming Integrator [
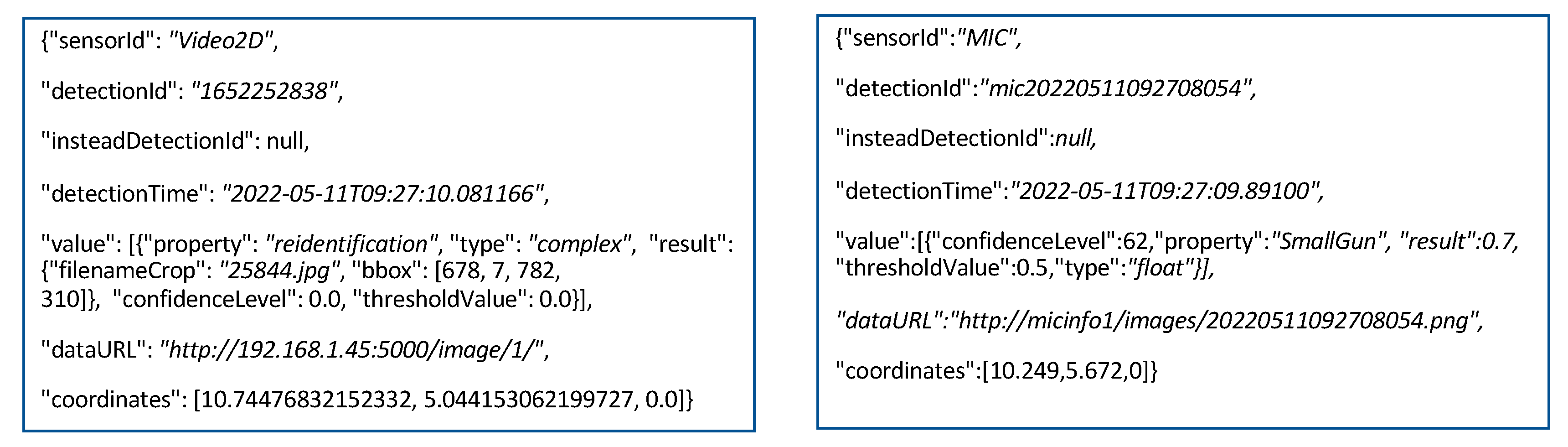
31] technology. A Siddhi App is a processing unit of a declarative language, named Siddhi Streaming SQL, that provides complex event streams processing constructs and built-in communication interfaces with external systems interacting with the application. The set of Siddhi Apps implemented for the INSTEAD system are logically grouped into three modules: a core module, implementing the application logic, and two auxiliary modules for logging and metrics collection. The apps of the core module communicate with the Message broker, the apps for logging capture and compose the messages to be stored as records of the Instead DB, and the apps for metrics collection push raw application data, such as event counters and latency measurements, via HTTP to web pages, which are periodically scraped by a Prometheus server installation.
The Data fusion core apps are detailed in
Figure 5. To meet the real time requirement, these apps run in different threads, each with a specific objective, and synchronize on shared data (i.e., common data streams shared by means of @source and @sink identifiers of Siddhi [
31]). The 2D Video Msg Integration App listens to 2D Video-dimensional messages, provide other apps with relevant data for fusion, and correlates messages referring to the same commuter. For each sensor, a specific app is in charge at fusion with 2D Video data, to associate the sensor result with the image of the person. All the apps share an INSTEAD identifier of the commuter that is used by the Situation Coordination App to temporally align the data in correspondence of that commuter. Triggers and alarm messages are generated according to sensor results and event sequence rules to realize the flow described in
Section 3.3. Situation result messages for the smart glasses and the GUI are built as soon as all the data is available or based on maximum waiting times. These can be empirically defined and adjusted during operation (without stopping the system), as it has been done during the Big City trials.
The modularity of the software architecture of the Data fusion component allows one to minimize the impact of changes on the external components to the corresponding apps handling their messages (e.g., incrementing/decreasing the number of detection lines of a commuter for the 2D Video) and/or on the rules for the triggers. Adding a new sensor would require adding a corresponding Sensor-Video fusion App, coded in a similar manner as the ones already implemented. The composition of the data for the situation result is based on timestamps.
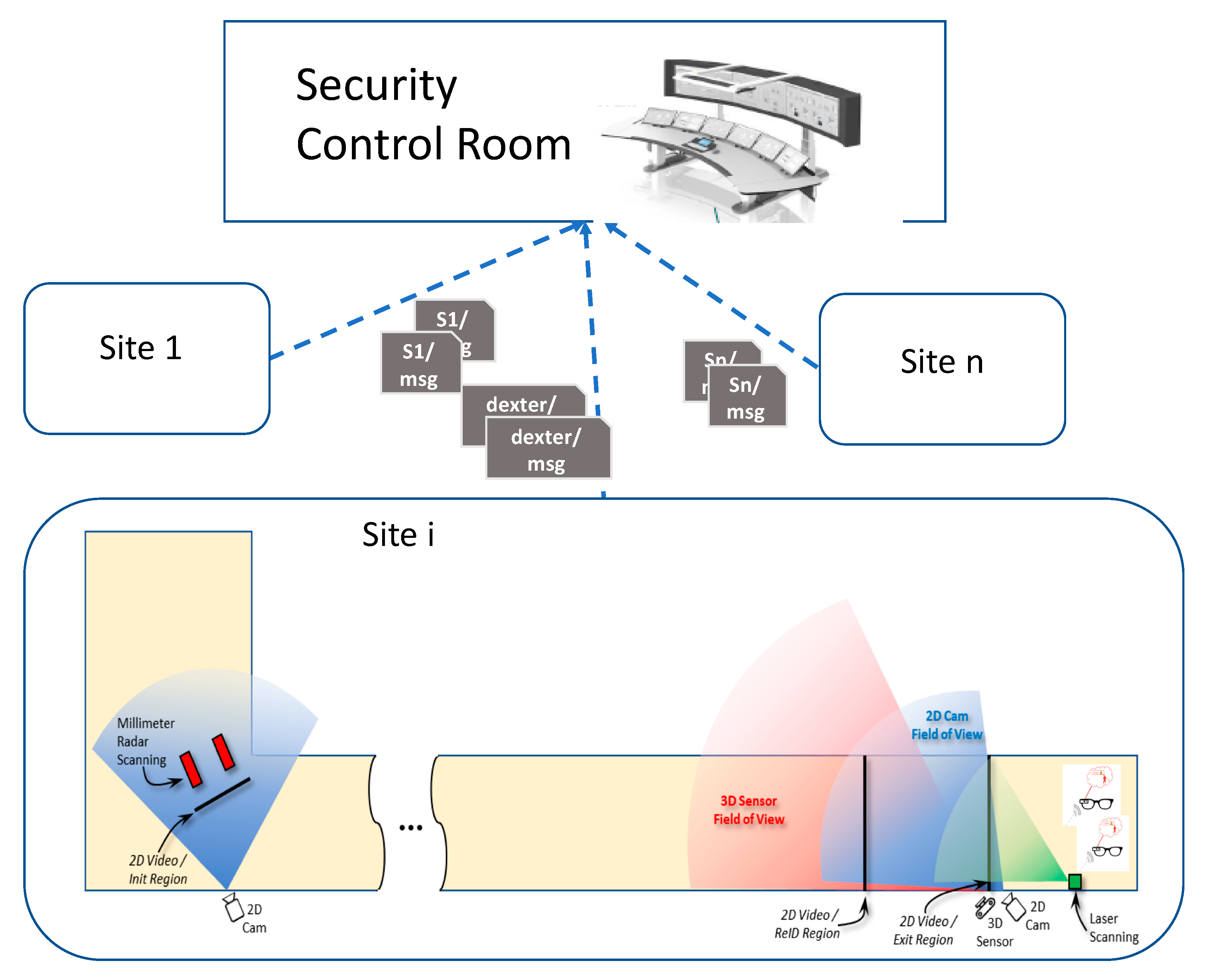
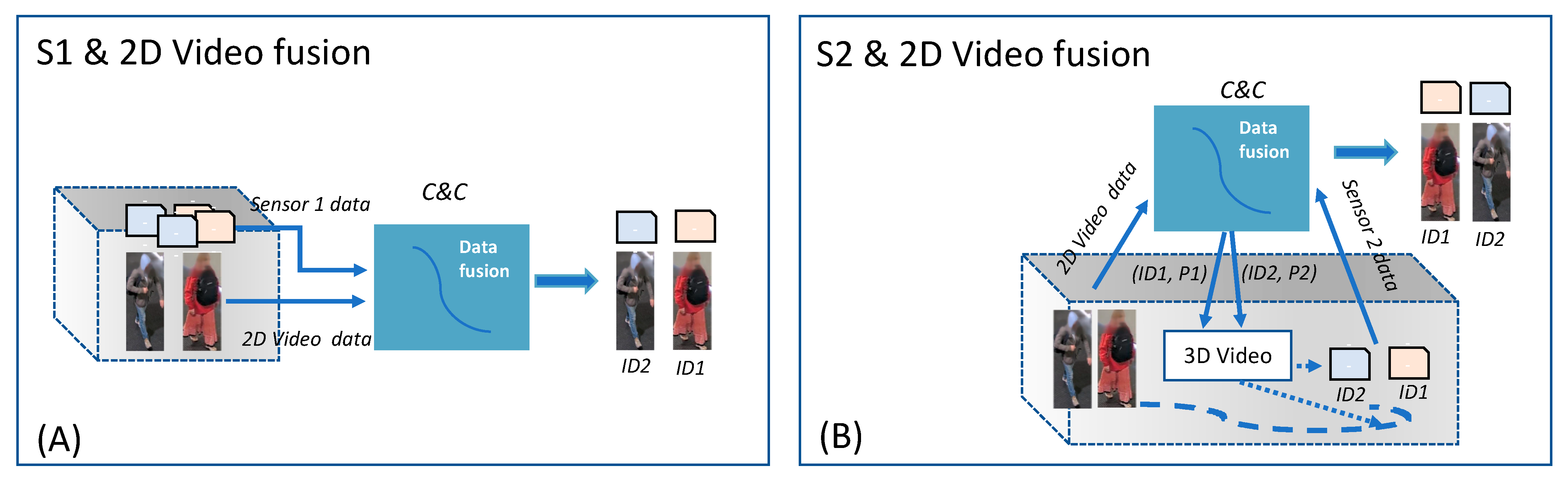
The 2D Video and sensor data fusion method does not assume an ordering for the receival of the messages from the two devices when referring to the same commuter. For the DEXTER system installation (see
Figure 1), two types of video-sensor data fusion methods have been implemented, illustrated in
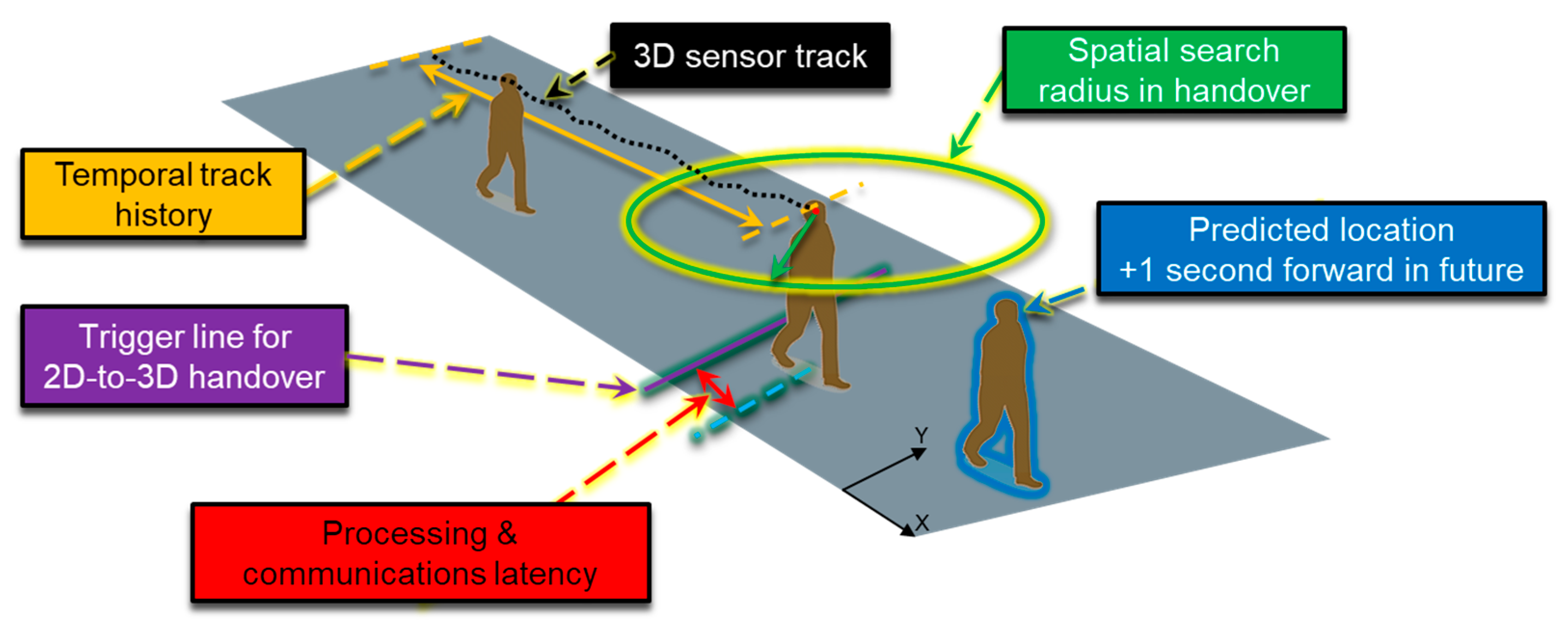
Figure 6. The first method (A) is applicable for location-fixed sensors, such as MIC, that do not require assistance of a video camera for their operation. The second method (B) can be used for movable sensors, such as EXTRAS, that rely on an internal video camera to point on a person’s body before sensing activation. In this case, tracking hand-over between different video systems allows to maintain the association of the identifier of the person with the sensor results. The 2D Video-C&C- 3D Video tracking hand-over method is described in
Section 4.3.3.
The first type of data fusion is challenging for the C&C in case of different commuters crossing the area with a short time distance among each other. The 2D Video and MIC data fusion has been based on the time of the two detections generated by the presence of a person in the common observation area, identified by a shared coordinate system. This time corresponds to the time when the 2D Video detects the person crossing the Init line, and the estimated time when the object identified by MIC before the line would be situated at the line. The last estimation was obtained based on the speed of the object/person while crossing the observed area. As MIC could send more than one message for the same object, to avoid false positives due to close commuters, time delays of about 2 (and 3) seconds between subsequent commuters have been experimented/established at the beginning of the trials.
Essentially, the data fusion method creates a queue of pairs (M, V), where M is a MIC message, and V is a 2D Video message, such that the distance of detection time contained in the M and V messages is less than 2 (or 3) s, and M may be received before or after V. Then, the pair with minimum time distance is chosen. Furthermore, to accommodate eventual non-negligible latency increases for receiving the messages from the external components (including the broker or delays due to the network), a time window of 2 min is applied for the observation of the incoming messages. Critical scenarios for this type of data fusion are described in
Section 5.2.
5. Experiments and Results
The first release of the INSTEAD system, without the sensors and the alarm management system, was deployed at Anagnina during October 2021. This early installation allowed for tuning the deep learning methods used by the video components with real local data and for testing the system also in a non-controlled environment. The modular architecture of the C&C facilitates both upgrading the existing software and extending the architecture with new components without affecting the previous behavior. The testing period lasted until the BCT, which started in May 2022, when the MIC, EXTRAS, and the Alarm management system were integrated, and the controlled environment was introduced. The corridor was protected by barriers to allow entrance and walk only to the project participants and to pre-identified volunteers.
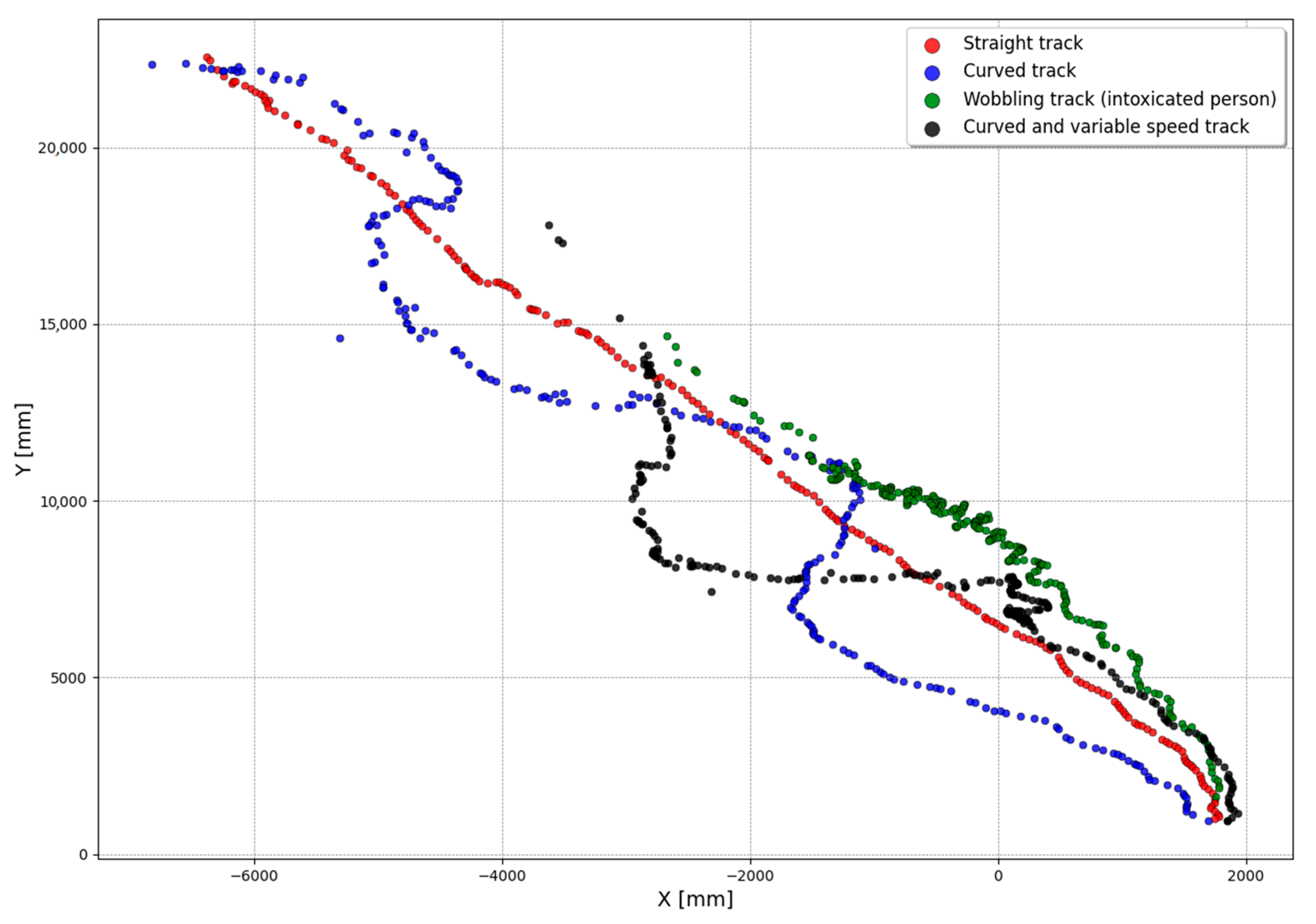
The BCT test runs consisted of tracks, which mimic real-world human walking at a metro station, including various speeds, stops, curved, and wobbling gait patterns.
Figure 12 depicts real-life examples on these cases as captured during the BCT experiments by the 3D Video sensor and illustrated in X–Y plane in real-world coordinates. During the BCT test runs, the average walking speed was 0.8 m/s and 75% of the tracks had their variation within the ±0.3 m/s range.
Data captured at Anagnina using the 3D Video system on 1–19 April 2022 demonstrates that BCT test runs have had commuter speeds close enough to real-life conditions.
In the following, the INSTEAD results on the BCT trials are briefly presented. The system validation was performed in real time by supervisors, including experts appointed by NATO who had prepared the trials, and they were verified after an accurate ex post analysis of the system logs. In particular, the INSTEAD system accuracy and that of the INSTEAD–sensor integration have been evaluated.
The INSTEAD system accuracy has been computed as the number of correctly detected commuters, i.e., in this case, correctly (re)identified by the 2D Video at init, reid, and exit line and correctly tracked by 3D Video over the number of commuters.
The INSTEAD–sensor integration accuracy has been computed as the number of false positive and false negative threat results, considering the messages sent by the sensors, over the number of correctly detected commuters. The details of the system assessment are discussed in [
7].
Here, the focus is on the analysis of the results of the two data-fusion methods described in
Section 4.1 and on lessons learned for further improvement. Additional performance results of INSTEAD when operated in the same environment without the scenario constraints imposed by the two sensors are described in this paper.
6. Discussion
The deployment in an open and real environment for pre-integration testing and the large-scale experimentation of the BCT have been a great opportunity to evaluate the presented architecture against the functional requirements and also some non-functional aspects. An account of aspects such as performance, flexibility, scalability, security, usability, and potentials for re-use follows.
“Performance”. This aspect has been evaluated through: accuracy results, i.e., the number of successful detections over the number of runs, which have been reported in
Section 5 and, for the official BCT runs, have been detailed in [
7]; and latency, i.e., the time delay due to processing and communication. Communication latency depends on the network load and on the performance of the MQTT broker. As the system should be deployed in a private dedicated network and the message payload, described in
Section 4.3, which is negligible in this respect, communication might be delayed when increasing the number of concurrent commuters as the number of exchanged messages increases. However, the experiments discussed in
Section 5 represent realistic numbers of concurrent commuters for the considered environment. Furthermore, latency due to communication and data processing by the C&C, monitored as described in
Section 4.2, has resulted in being more than adequate to meet the real-time requirement of detections, which has been extensively validated by official project evaluators and by the end users during the demonstration.
“Flexibility”. This aspect is related with the capability of the system to adapt to variability of external conditions without undergo significant structural modifications, including extensibility with new features. The experiments have demonstrated robustness with respect to different types of external scenarios: variability of the commuters (group size, physical characteristics and dresses) and paths; and variability of light conditions in the same environment. While these mainly affect the functioning of the two video systems, assuming correctness of their messages, the flexibility of the C&C concerns: continuity of operation (e.g., commuter detection and tracking) in case of unavailability of the sensors and/or their disconnections and reconnections at run time; extensibility of the transmitted data by the components with further information, e.g., more images or data related to the detections, thanks to the data structure described in
Section 4.3.2; and extensibility with new sensor systems by using the same message structure and communication model and with limited development work, as described in
Section 4.1.
“Scalability”. This aspect refers to the capability of the system to correctly handle increasing number of concurrent messages that, in this case, may be generated by the commuters and/or when connecting additional components to the system. For the first aspect, some experiments in that direction have been performed, as discussed in
Section 5.3, but more stress tests should be performed, especially when considering corridors of higher capacity of concurrent commuters. With reference to the number of connected components, the most affected component of the C&C architecture is the MQTT broker, which is a third-party component. The broker used in the experimentation, HiveMQ, has turned suitable to handle the connections of the components of the architecture and of the various user interfaces and clients connected to the system for debugging purpose, which did not affect the presented results.
“Security”. This aspect refers to protection of sensitive data and of the system from unauthorized use. For the aim of privacy protection, the images/data generated by the video systems and by the sensors are kept at the source servers, as only the data urls are supplied in the messages. Indeed, download of such data by the C&C only happens when there is need to display images on the smart glasses (and/or on a security GUI). Moreover, the images of the commuters are anonymized by blurring the upper (approximately 20%) part of the detection, which usually contains the face, and the 3D Video system captures only three-dimensional coordinates of the tracked persons (i.e., no video or image snapshots). The secure communication is natively supported by MQTT, such as client authentication and encrypted communication. The extent to which such security measures may impact on the system performance will be assessed as future work.
“Usability”. The architecture supports processing and packaging of collected multi-source data into a single product of actionable information delivered to the operator. Moreover, as an innovative feature of the system is the support to security guards on field by means of smart glasses, usability of such technology is a key aspect which has been directly and positively evaluated at the BCT by the Italian police.
“Modularity”. This is the main feature of the architecture that allows fusion of disparate technologies into a single modular ensemble, which favor reuse. Furthermore, utilizing a modular “OR” type interface for threat detection is advantageous in data aggregation since it permits the application to adapt flexibly to more scenarios, including, but not limited to, for example, when one sensing opportunity is not present or possible.
“Reuse”. Such an aspect has to be discussed for each component of the system. The C&C has been designed to be: independent from specific sensor and video systems, as the messages provide final detections results, and data fusion only refers to attribution of an object to a person and to combination of the sensor results for alarm triggering; independent from geometrical/environmental characteristics of the place where devices are deployed, the only constraint is that the flux needs to be one-directional. The modularity of the internal architecture of the C&C allows one to re-use the data fusion component with different tools. In this respect, the MQTT broker, the Security client (including the smart alarm management system), and the Monitoring system could each be replaced by a different tool. The two video systems are also reusable. The 2D Video re-identification component can be installed in new environments due to rapid re-training [
23]. This can support tracking and fusion in a region even where the field of views of the cameras are not overlapping. In addition to crowd management solutions, the 3D Video monitoring methods can be utilized in other industrial use cases, including, but not limited to, for example, human mobility and task monitoring in industrial and construction domains providing task monitoring and improved work safety. In addition, location information originating from other sensors, such as, for example, millimeter radar and UWB, which can be fused for obtaining more accurate location and person activity information.
Author Contributions
Conceptualization, M.L.V., A.D.N., H.B., A.v.R., P.R., J.P., S.T., M.G., C.S. and L.D.D.; Methodology, M.L.V., A.D.N., H.B., A.v.R., P.R., J.P. and S.T. and M.G.; Software, M.L.V., A.v.R. and P.R.; Data curation, M.L.V., A.v.R. and P.R.; Supervision, H.B., S.T., C.S. and L.D.D.; Validation, C.S. and L.D.D.; Writing—original draft, M.L.V.; Writing—review and editing, M.L.V., A.D.N., H.B., A.v.R., P.R., J.P., S.T., M.G., C.S. and L.D.D. All authors have read and agreed to the published version of the manuscript.
Funding
The INSTEAD (“INtegrated System for Threats EArly Detection”) project has received funding in the DEXTER (Detection of EXplosives and firearms to counter TERrorism) program from NATO Science for Peace and Security (SPS) under grant agreement number G5605 and G5969.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are not publicly available due to project restrictions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lazic, V.; Palucci, A.; De Dominicis, L.; Nuvoli, M.; Pistilli, M.; Menicucci, I.; Colao, F.; Almaviva, S. Integrated laser sensor (ILS) for remote surface analysis: Application for detecting explosives in fingerprints. Sensors 2019, 19, 4269. [Google Scholar] [CrossRef] [PubMed]
- Deiana, D.; Hanckmann, P. Multi-Sensor Fusion Applied to the Detection of Person-Borne Improvised Explosive Devices (PB-IEDs). In Proceedings of the 2019 PhotonIcs & Electromagnetics Research Symposium—Spring (PIERS-Spring), Rome, Italy, 17–20 June 2019; pp. 3978–3982. [Google Scholar]
- Al-Sa’D, M.; Kiranyaz, S.; Ahmad, I.; Sundell, C.; Vakkuri, M.; Gabbouj, M. A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras. Sensors 2022, 22, 418. [Google Scholar] [CrossRef] [PubMed]
- Bouma, H.; Schutte, K.; Hove, J.-M.T. Flexible human-definable automatic behavior analysis for suspicious activity detection in surveillance cameras to protect critical infrastructures. Proc. SPIE 2018, 10802, 192–203. [Google Scholar]
- Whaiduzzaman, M.; Barros, A.; Chanda, M.; Barman, S.; Sultana, T.; Rahman, M.S.; Roy, S.; Fidge, C. A Review of Emerging Technologies for IoT-Based Smart Cities. Sensors 2022, 22, 9271. [Google Scholar] [CrossRef] [PubMed]
- NATO-SPS. NATO Science for Peace and Security (SPS) Programme; Annual Report; NATO: Brussels, Belgium, 2018; Available online: https://www.nato.int/nato_static_fl2014/assets/pdf/2020/2/pdf/200221_NATO_SPS_AnnualReport2018.pdf (accessed on 30 November 2022).
- Bouma, H.; Villani, M.L.; van Rooijen, A.; Räsänen, P.; Peltola, J.; Toivonen, S.; De Nicola, A.; Guarneri, M.; Stifini, C.; De Dominicis, L. An Integrated Fusion Engine for Early Threat Detection Demonstrated in Public-Space Trials. Sensors 2023, 23, 440. [Google Scholar] [CrossRef]
- De Dominicis, L.; Bouma, H.; Toivonen, S.; Stifini, C.; Villani, M.L.; De Nicola, A.; van Rooijen, A.; Baan, J.; Peltola, J.; Lamsa, A.; et al. Video-based fusion of multiple detectors to counter terrorism. Proc. SPIE 2021, 11869, 75–85. [Google Scholar]
- Papčo, M.; Rodríguez-Martínez, I.; Fumanal-Idocin, J.; Altalhi, A.H.; Bustince, H. A fusion method for multi-valued data. Inf. Fusion 2021, 71, 1–10. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, C.; Yue, B.; Wan, J.; Guizani, M. Information fusion for edge intelligence: A survey. Inf. Fusion 2022, 81, 171–186. [Google Scholar] [CrossRef]
- Zhang, P.; Li, T.; Wang, G.; Luo, C.; Chen, H.; Zhang, J.; Wang, D.; Yu, Z. Multi-source information fusion based on rough set theory: A review. Inf. Fusion 2021, 68, 85–117. [Google Scholar] [CrossRef]
- Yang, J.; Yang, L.T.; Wang, H.; Gao, Y.; Zhao, Y.; Xie, X.; Lu, Y. Representation learning for knowledge fusion and reasoning in Cyber–Physical–Social Systems: Survey and perspectives. Inf. Fusion 2023, 90, 59–73. [Google Scholar] [CrossRef]
- Qi, J.; Yang, P.; Newcombe, L.; Peng, X.; Yang, Y.; Zhao, Z. An overview of data fusion techniques for Internet of Things enabled physical activity recognition and measure. Inf. Fusion 2020, 55, 269–280. [Google Scholar] [CrossRef]
- Lau, B.P.L.; Marakkalage, S.H.; Zhou, Y.; Hassan, N.U.; Yuen, C.; Zhang, M.; Tan, U.-X. A survey of data fusion in smart city applications. Inf. Fusion 2019, 52, 357–374. [Google Scholar] [CrossRef]
- Li, Y.; Yang, G.; Su, Z.; Li, S.; Wang, Y. Human activity recognition based on multi-environment sensor data. Inf. Fusion 2023, 91, 47–63. [Google Scholar] [CrossRef]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Thomas, P.A.; Marshall, G.; Faulkner, D.; Kent, P.; Page, S.; Islip, S.; Oldfield, J.; Breckon, T.P.; Kundegorski, M.E.; Clark, D.J.; et al. Toward sensor modular autonomy for persistent land intelligence surveillance and reconnaissance (ISR). Proc. SPIE 2016, 983108, 27–44. [Google Scholar]
- UK Defence Science and Technology Laboratory, SAPIENT Interface Control Document v6.0. Available online: https://www.gov.uk/government/publications/sapient-interface-control-document (accessed on 30 November 2022).
- JSON. Available online: https://www.json.org/ (accessed on 30 November 2022).
- XML. Available online: https://www.w3.org/standards/xml/ (accessed on 30 November 2022).
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Van Rooijen, A.; Bouma, H.; Baan, J.; Van Leeuwen, M. Rapid person re-identification strategy for flexible deployment in new environments. Proc. SPIE 2022, 12275, 81–89. [Google Scholar]
- Van Rooijen, A.; Bouma, H.; Pruim, R.; Baan, J.; Uijens, W.; Van Mil, J. Anonymized person re-identification. in surveillance cameras. Proc. SPIE 2020, 11542, 63–67. [Google Scholar]
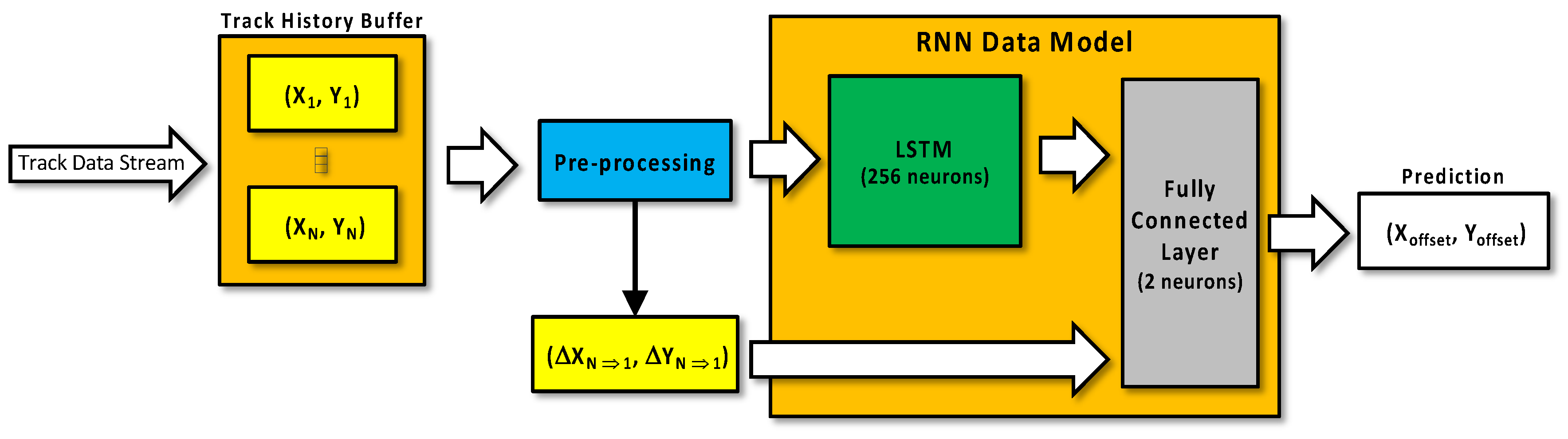
- Chen, K.-Y.; Chou, L.-W.; Lee, H.-M.; Young, S.-T.; Lin, C.-H.; Zhou, Y.-S.; Tang, S.-T.; Lai, Y.-H. Human Motion Tracking Using 3D Image Features with a Long Short-Term Memory Mechanism Model—An Example of Forward Reaching. Sensors 2022, 22, 292. [Google Scholar] [CrossRef]
- Barr, J.; Harrald, O.; Hiscocks, S.; Perree, N.; Pritchett, H.; Vidal, S.; Wright, J.; Carniglia, P.; Hunter, E.; Kirkland, D.; et al. Stone Soup open source framework for tracking and state estimation: Enhancements and applications. Proc. SPIE-Int. Soc. Opt. Eng. 2022, 12122, 43–59. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef]
- Grafana. Available online: https://grafana.com/ (accessed on 30 November 2022).
- Prometheus. Available online: https://prometheus.io/ (accessed on 30 November 2022).
- MySQL. Available online: https://www.mysql.com (accessed on 30 November 2022).
- WSO2. Streaming API Documentation. Available online: https://apim.docs.wso2.com/en/latest/streaming/streaming-overview (accessed on 30 November 2022).
- MQTT. Available online: https://mqtt.org/ (accessed on 30 November 2022).
- HiveMQ. Available online: https://www.hivemq.com/ (accessed on 30 November 2022).
- Zgheib, R.; De Nicola, A.; Villani, M.L.; Conchon, E.; Bastide, R. A flexible architecture for cognitive sensing of activities in ambient assisted living. In Proceedings of the 2017 IEEE 26th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises, WETICE 2017, Poznan, Poland, 21–23 June 2017; pp. 284–289. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Liu, H.; Chang, Q.; Wang, L.; Gao, R.X. Recurrent neural network for motion trajectory prediction in human-robot collaborative assembly. CIRP Ann. Manuf. Technol. 2020, 69, 9–12. [Google Scholar] [CrossRef]
- HiveMQ Client. Available online: https://github.com/hivemq/hivemq-mqtt-client (accessed on 30 November 2022).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}