

Blockchain Data Availability Scheme with Strong Data Privacy Protection

Abstract
:1. Introduction
2. Related Work
3. System and Security Models
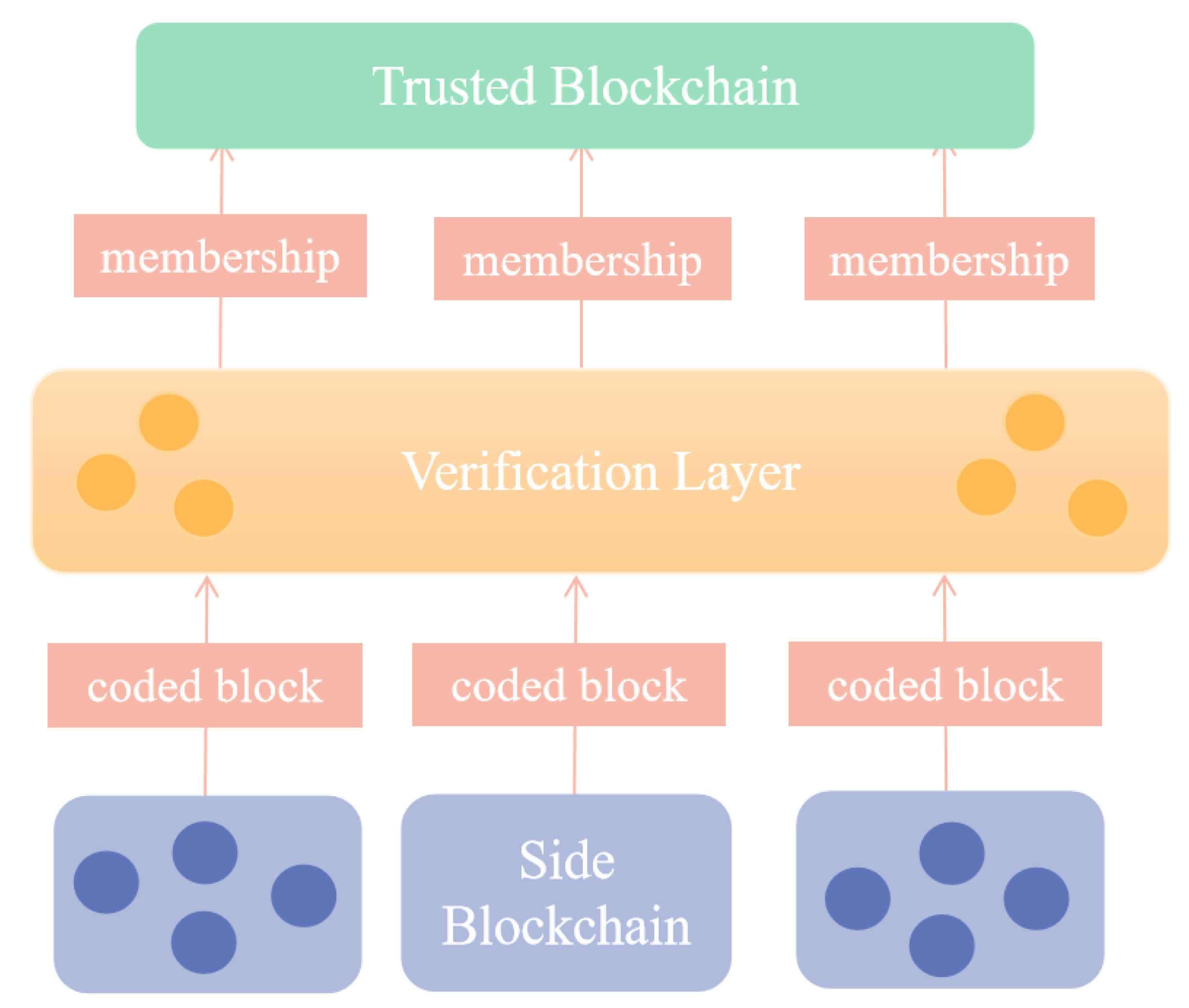
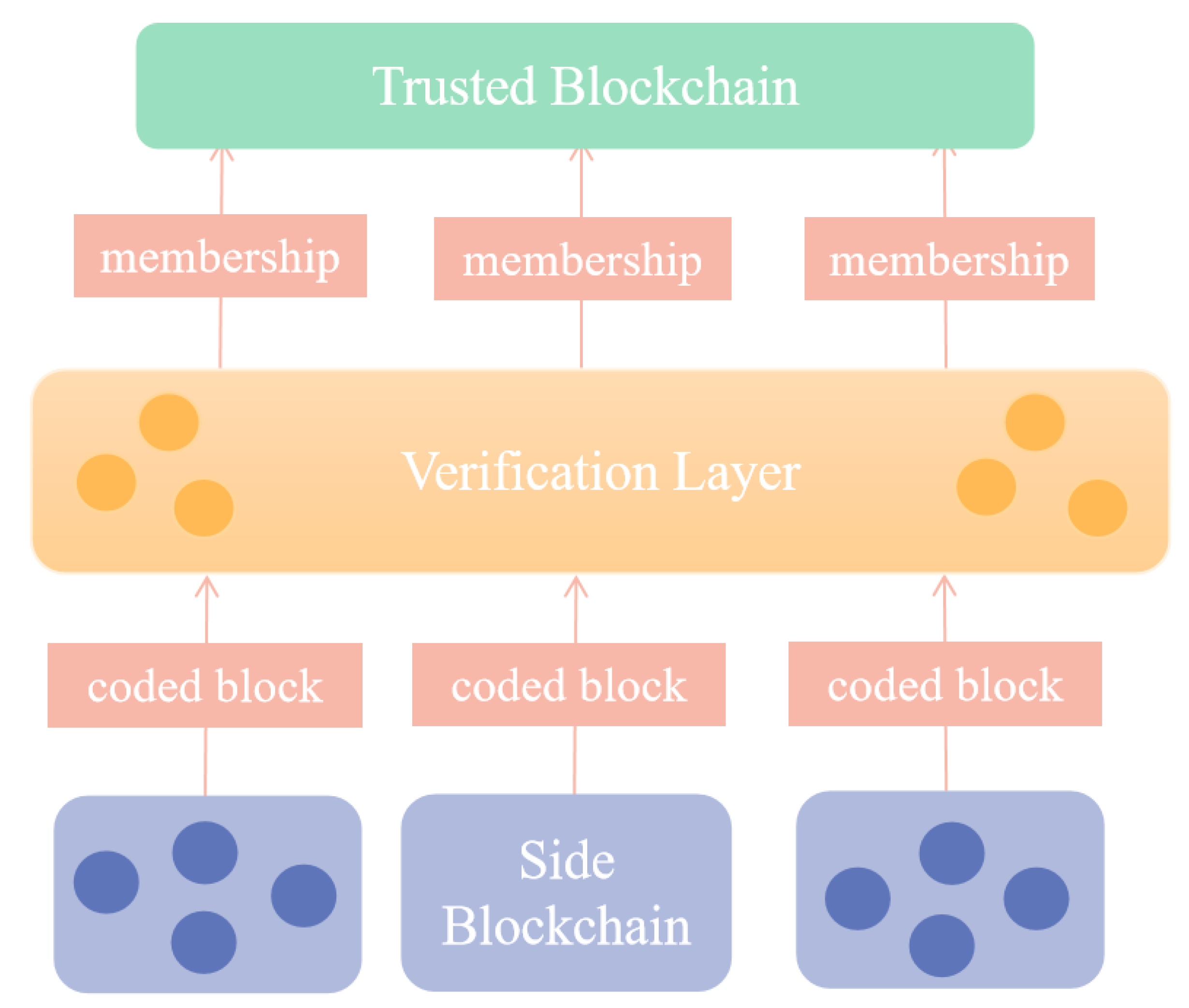
3.1. Network Models and Assumptions
3.2. Data Privacy Protection Model
3.3. Verification Model
- Generation blocks: When a client wants to commit block b to a trusted blockchain, it runs the accumulation set of accumulators connected to the block to generate membership witnesses for block b and a set of D blocks generates membership witnesses .
- Dispersion blocks: The client runs the decentralized protocol disperse , N), and specifies that different data blocks are sent to N different verification nodes.
- Verification termination: Verification nodes query membership witnesses to finalize and accept their witnesses to write certain blocks in the trusted blockchain.
- Retrieve data: The client retrieves a set of blocks of any witnesses that has been verified by the verification layer by initiating a request (retrieve, Wit).
- Decoded data: Any client can run primitive decoding to decode the blocks in the retrieved block . The decoder also returns the proof of the membership associated with the witness for decoding block b.
- Termination: When an honest client requests block b decentralized, block b will eventually be approved and the witness will be transferred to the trusted blockchain.
- Availability: Dispersion is acceptable if a client wants to retrieve and the verification layer is able to provide it with block b or empty block Ø and prove that the client is related to .
- Correctness: If two honest clients running (Retrieve, Wit) at the same time receive and , then . If the client initiating the dispersion is honest, it needs to satisfy the original dispersion block .
4. Technical Description
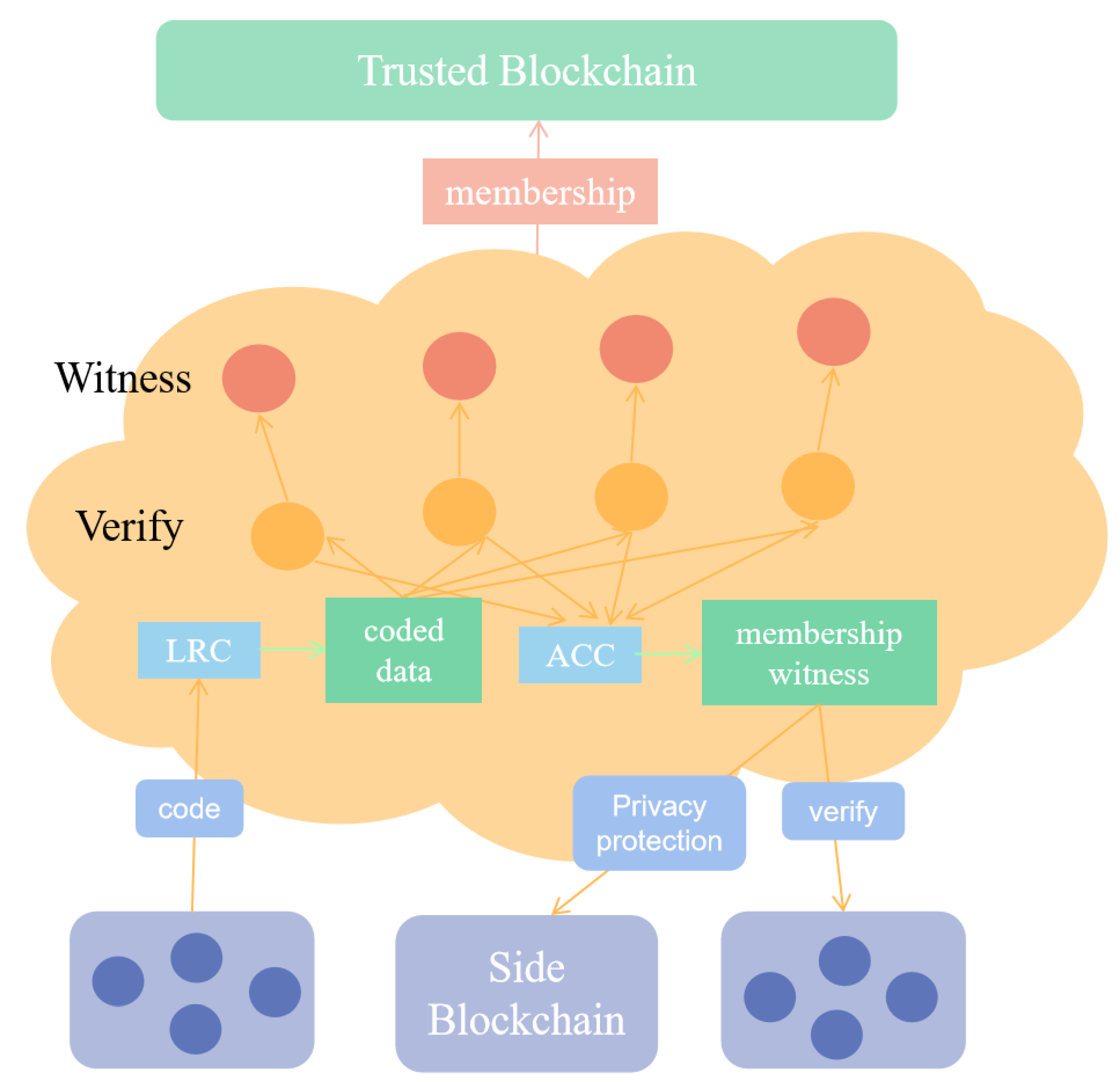
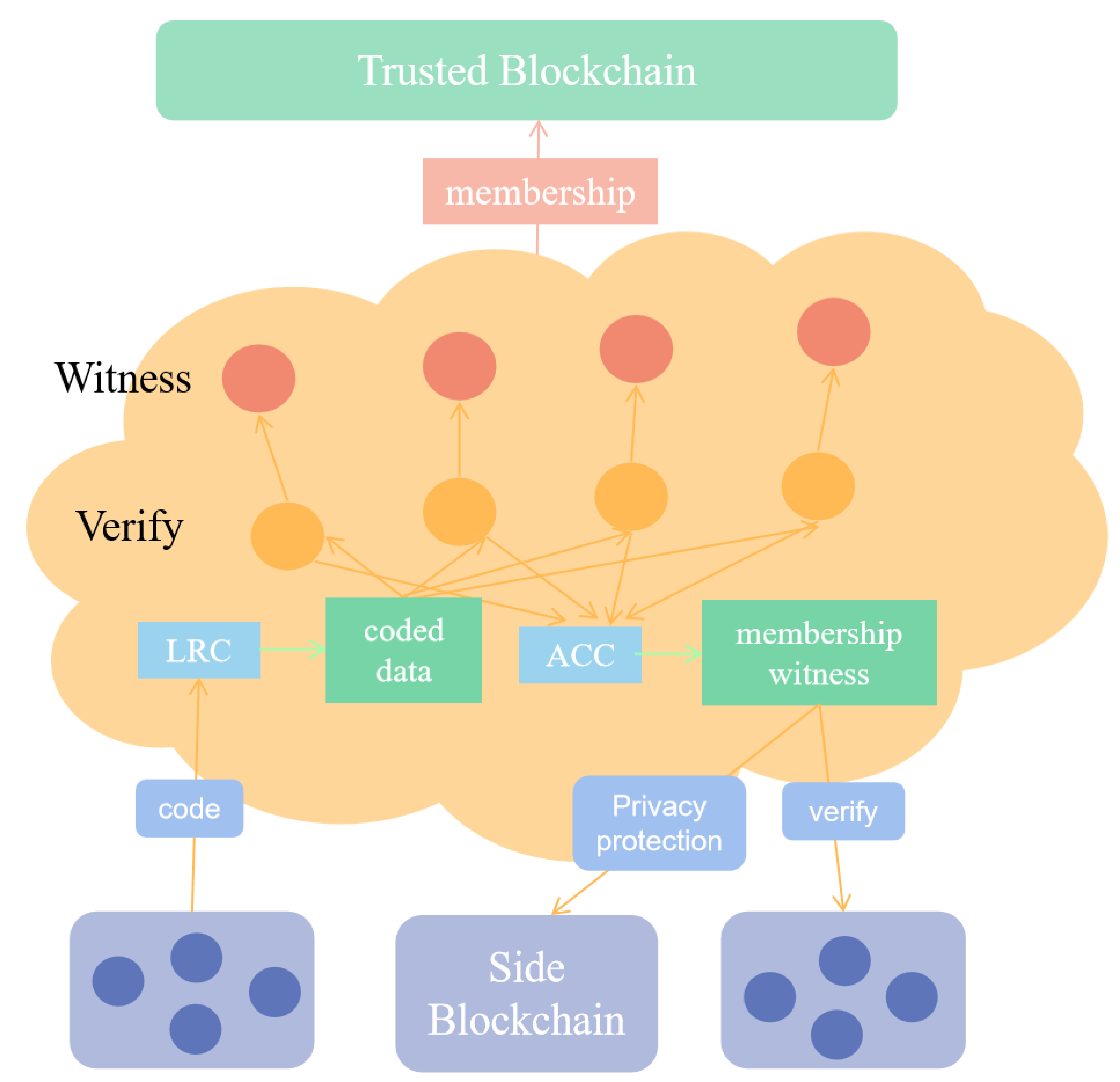
4.1. Bilinear Mapping
4.2. Zero-Knowledge Accumulator
4.3. Local Repair Code
5. Performance Guarantee
5.1. Data Privacy Protection Security Analysis
5.2. Security Analysis of Data Availability Scheme
6. Performance Analysis
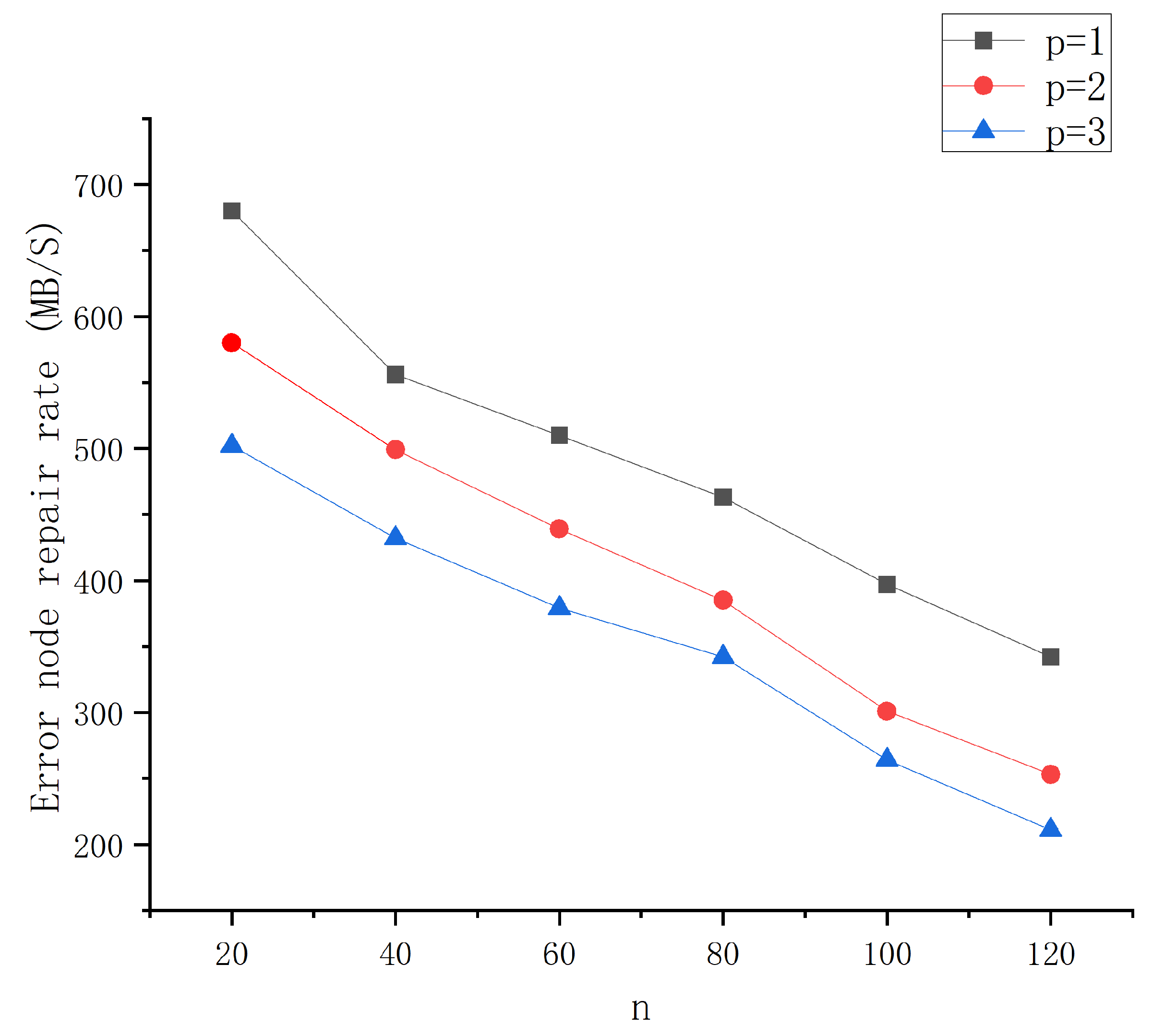
6.1. Storage and Communication
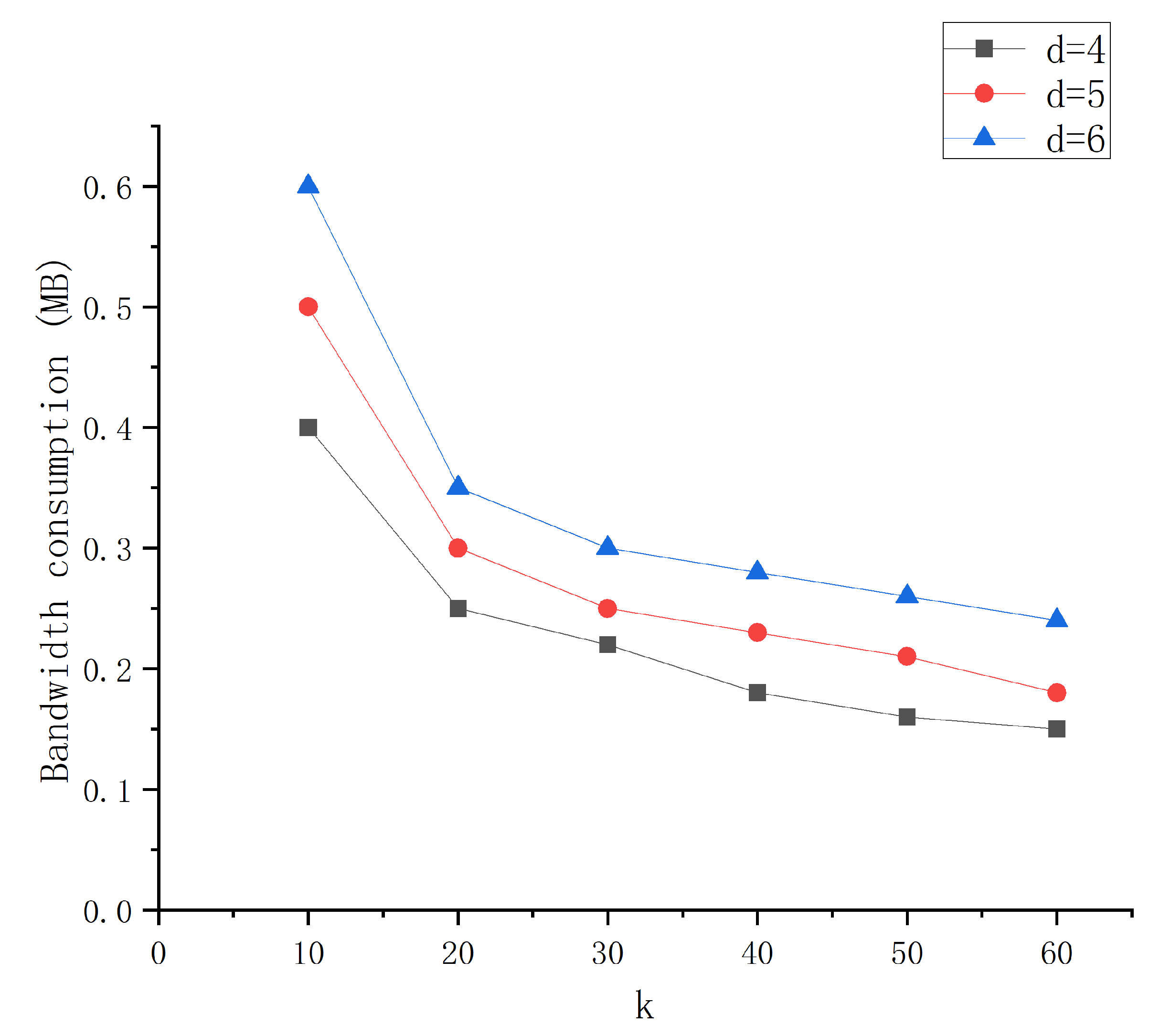
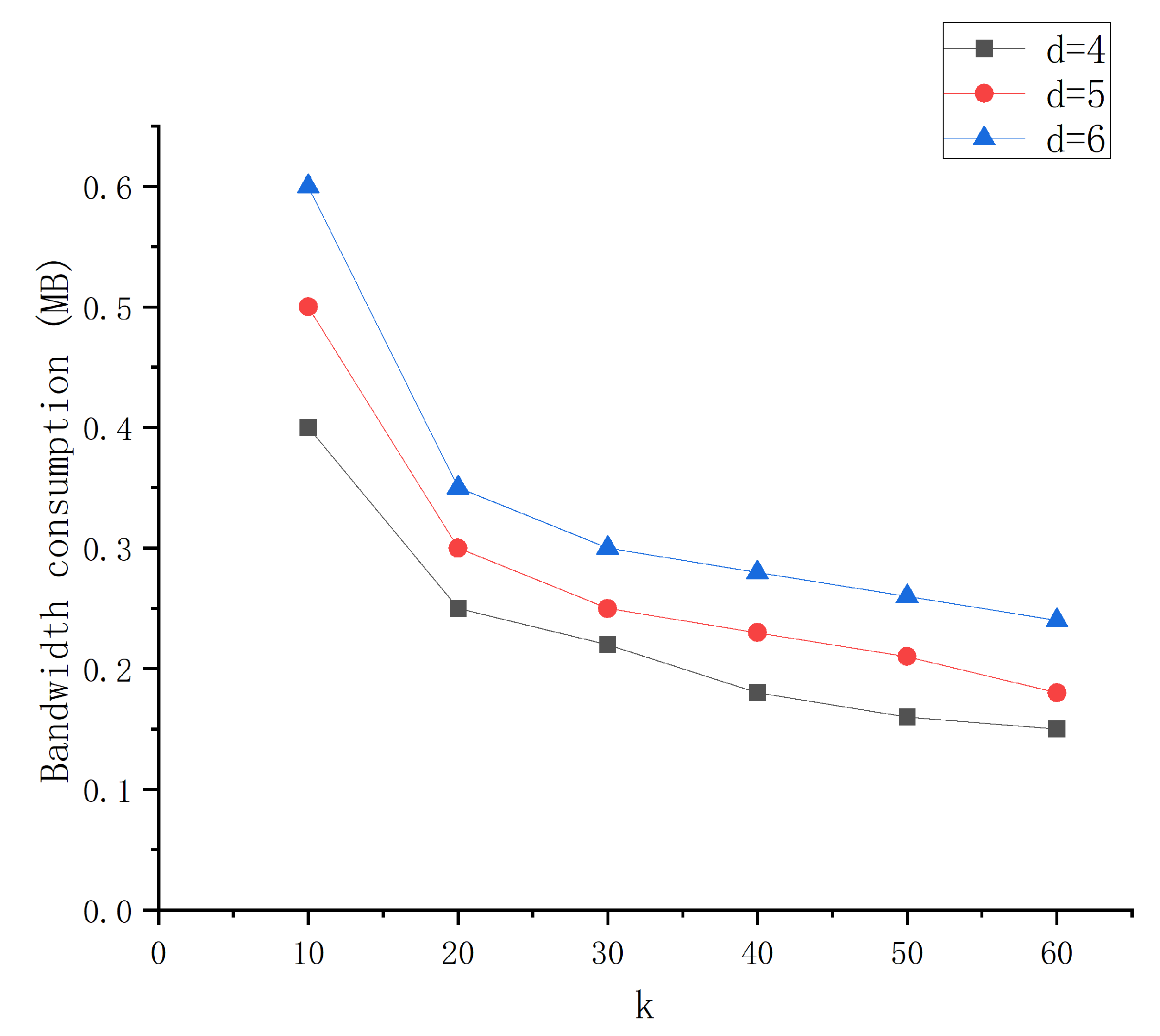
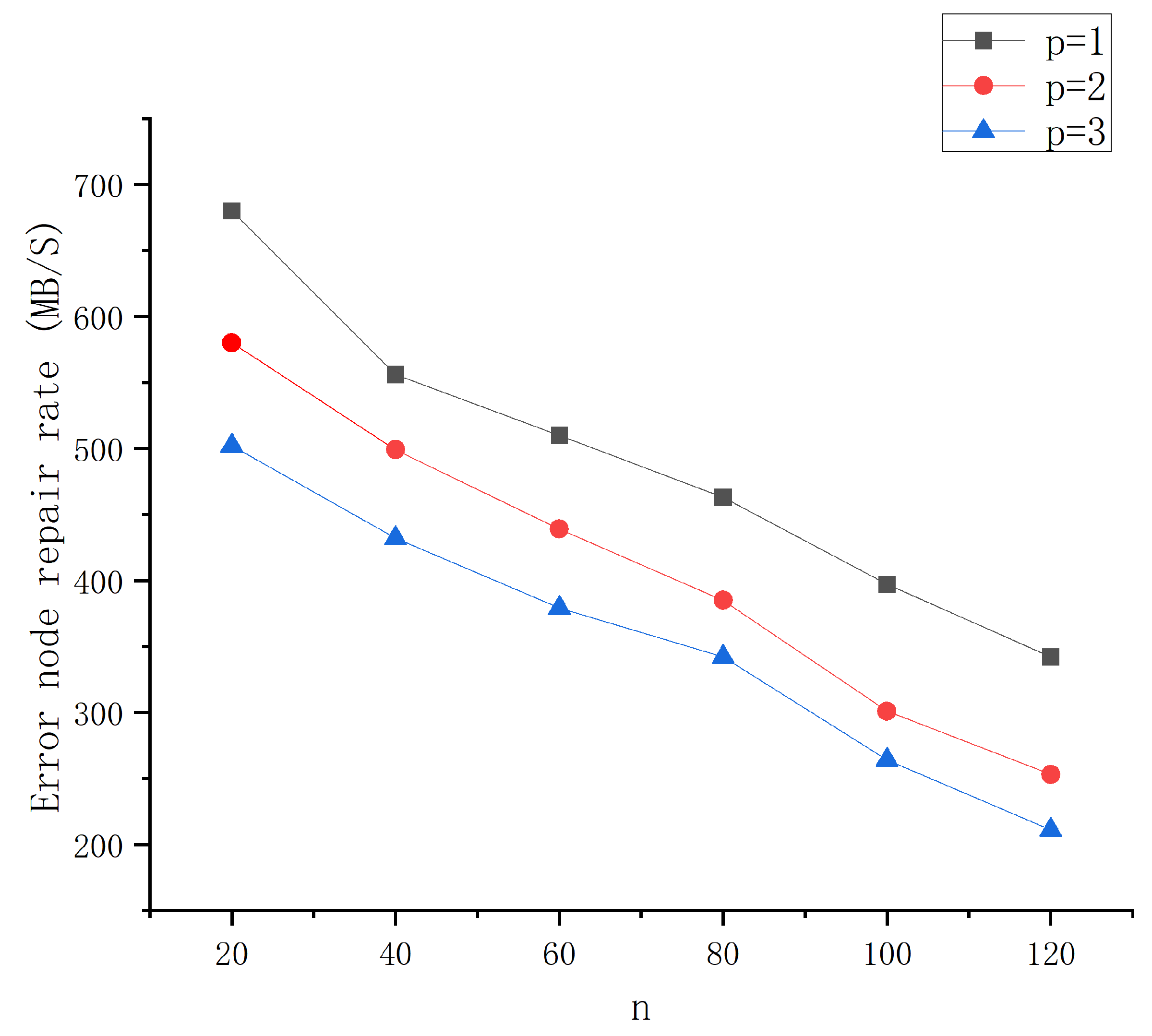
6.2. Bandwidth Consumption during Local Repair Code Encoding
6.3. Comparison of Schemes
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Bus. Rev. 2008, 21260, 21260. [Google Scholar]
- Chen, H.; Pendleton, M.; Njilla, L.; Xu, S.H. A survey on Ethereum systems security: Vulnerabilities, attacks, and defenses. ACM Comput. Surv. 2021, 53, 1–43. [Google Scholar] [CrossRef]
- Ren, Y.J.; Zhu, F.; Wang, J.; Sharma, P.; Ghosh, U. Novel vote scheme for decision-making feedback based on blockchain in internet of vehicles. IEEE Trans. Intell. Transp. 2021, 21, 1639–1648. [Google Scholar] [CrossRef]
- Sheng, P.Y.; Xue, B.W.; Kannan, S.; Viswanath, P. ACeD: Scalable data availability oracle. In Proceedings of the International Conference on Financial Cryptography and Data Security, Virtual Event, 1–5 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 299–318. [Google Scholar]
- Papailiopoulos, D.S.; Dimakis, A.G. Locally repairable codes. IEEE Trans. Inf. Theory 2014, 60, 5843–5855. [Google Scholar] [CrossRef]
- Huang, P.; Yaakobi, E.; Uchikawa, H.; Siegel, P.H. Binary linear locally repairable codes. IEEE Trans. Inf. Theory 2016, 62, 6268–6283. [Google Scholar] [CrossRef]
- Luo, Y.; Xing, C.; Yuan, C. Optimal locally repairable codes of distance 3 and 4 via cyclic codes. IEEE Trans. Inf. Theory 2019, 65, 1048–1053. [Google Scholar] [CrossRef]
- Esha, G.; Olga, O.; Dimitrios, P.; Roberto, T.; Nikos, T. Zero-knowledge accumulators and set operations. Cryptol. Eprint Arch. 2016, 10032, 1–46. [Google Scholar]
- Campanelli, M.; Mathias, H. Curve trees: Practical and transparent zero-knowledge accumulators. Cryptol. Eprint Arch. 2022, 756, 1–18. [Google Scholar]
- Li, T.; Qian, Q.; Ren, Y.J.; Ren, Y.Z.; Xia, J.Y. Privacy-preserving recommendation based on kernel method in cloud computing. Comput. Mater. Contin. 2021, 66, 779–791. [Google Scholar] [CrossRef]
- Feng, Q.; He, D.B.; Zeadally, S.; KhurramKhan, M.; Kumar, N. A survey on privacy protection in blockchain system. J. Netw. Comput. Appl. 2019, 126, 45–58. [Google Scholar] [CrossRef]
- Mohammed, B.; Abdulghani, A.A.; Mohd, A.B.I.; Ali, S.S.; Muhammad, K.K. Comprehensive Survey on Big Data Privacy Protection. IEEE Access 2022, 8, 20067–20079. [Google Scholar]
- Liang, W.; Yang, Y.; Yang, C.; Hu, Y.H.; Xie, S.Y.; Li, K.C.; Cao, J.N. PDPChain: A consortium blockchain-based privacy protection scheme for personal data. IEEE Trans. Reliab. 2022, 1–13. [Google Scholar] [CrossRef]
- Ren, Y.J.; Huang, D.; Wang, W.H.; Yu, X.F. BSMD: A blockchain-based secure storage mechanism for big spatio-temporal data. Future Gener. Comput. Syst. 2023, 138, 328–338. [Google Scholar] [CrossRef]
- Benarroch, D.; Campanelli, M.; Fiore, D.; Kobi, G.; Dimitris, K. Zero-knowledge proofs for set membership: Efficient, succinct, modular. In Proceedings of the International Conference on Financial Cryptography and Data Security, Virtual Event, 1–5 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 393–414. [Google Scholar]
- Sun, X.Q.; Yu, F.R.; Zhang, P.; Sun, Z.W.; Xie, W.X.; Peng, X. A survey on zero-knowledge proof in blockchain. IEEE Netw. 2021, 35, 198–205. [Google Scholar] [CrossRef]
- Ren, Y.J.; Qi, J.; Liu, Y.P.; Wang, J.; Kim, G. Integrity verification mechanism of sensor data based on bilinear map accumulator. ACM Trans. Internet Technol. 2021, 21, 1–20. [Google Scholar] [CrossRef]
- Zhou, Q.H.; Huang, H.W.; Zheng, Z.B.; Bian, J. Solutions to scalability of blockchain: A survey. IEEE Access 2020, 8, 16440–16455. [Google Scholar] [CrossRef]
- Novo, O. Scalable access management in IoT using blockchain: A performance evaluation. IEEE Internet Things J. 2019, 6, 4694–4701. [Google Scholar] [CrossRef]
- Panda, S.S.; Mohanta, B.K.; Satapathy, U.; Jena, D.; Gountia, D.; Patra, T.K. Study of blockchain based decentralized consensus algorithms. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 908–913. [Google Scholar]
- Ren, Y.J.; Zhu, F.J.; Kumar, S.P.; Wang, T.; Wang, J. Data query mechanism based on hash computing power of blockchain in internet of things. Sensors 2020, 20, 207. [Google Scholar] [CrossRef]
- Eyal, I.; Gencer, A.E.; Renesse, R.V. Bitcoin-NG: A scalable blockchain protocol. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI’16), Santa Clara, CA, USA, 16–18 March 2016; pp. 45–59. [Google Scholar]
- Yun, J.; Goh, Y.; Chung, J.M. DQN-based optimization framework for secure sharded blockchain systems. IEEE Internet Things J. 2021, 8, 708–722. [Google Scholar] [CrossRef]
- Mizrahi, A.; Rottenstreich, O. Blockchain state sharding with space-aware representations. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1571–1583. [Google Scholar] [CrossRef]
- Yu, M.C.; Saeid, S.; Li, S.Z.; Salman, A.; Sreeram, K.; Pramod, V. Coded merkle tree: Solving data availability attacks in blockchains. In Proceedings of the International Conference on Financial Cryptography and Data Security, Kota Kinabalu, Malaysia, 10–14 February 2020; Springer: Cham, Switzerland, 2020; Volume 12059, pp. 114–134. [Google Scholar]
- Martńnez-Peñas, U.; Kschischang, F.R. Reliable and secure multishot network coding using linearized reed-solomon codes. IEEE Trans. Inf. Theory 2019, 65, 4785–4803. [Google Scholar] [CrossRef]
- Papamanthou, C.; Roberto, T.; Nikos, T. Authenticated hash tables based on cryptographic accumulators. Algorithmica 2016, 74, 664–712. [Google Scholar] [CrossRef]
- Ren, Y.J.; Leng, Y.; Cheng, Y.P.; Wang, J. Secure data storage based on blockchain and coding in edge computing. Math. Biosci. Eng. 2019, 16, 1874–1892. [Google Scholar] [CrossRef] [PubMed]
- Tavani, H.T.; Moor, J.H. Privacy protection, control of information, and privacy-enhancing technologies. ACM Sigcas Comput. Soc. 2001, 31, 6–11. [Google Scholar] [CrossRef]
- Gong, J.; Mei, Y.R.; Xiang, F.; Hong, H.S.; Sun, Y.B.; Sun, Z.X. A data privacy protection scheme for Internet of things based on blockchain. Trans. Emerg. Telecommun. Technol. 2021, 32, e4010. [Google Scholar] [CrossRef]
- Ren, Y.J.; Leng, Y.; Qi, J.; Pradip, K.S.; Wang, J. Multiple cloud storage mechanism based on blockchain in smart homes. Future Gener. Comput. Syst. 2021, 115, 304–313. [Google Scholar] [CrossRef]
- Boneh, D.; Bunz, B.; Fisch, B. Batching techniques for accumulators with applications to IOPs and stateless blockchains. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2019; Springer: Cham, Switzerland, 2019; pp. 561–586. [Google Scholar]
- Thakur, S. Batching non-membership proofs with bilinear accumulators. IACR Cryptol. ePrint Arch. 2019, 1–22. Available online: https://eprint.iacr.org/2019/1147 (accessed on 8 November 2022).
- Halbawi, W.; Liu, Z.; Hassibi, B. Balanced Reed-Solomon codes. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 935–939. [Google Scholar]
- Sarkar, M.N.I.; Meegahapola, L.G.; Datta, M. Reactive power management in renewable rich power grids: A review of grid-codes, renewable generators, support devices, control strategies and optimization algorithms. IEEE Access 2018, 6, 41458–41489. [Google Scholar] [CrossRef]
- Chen, H.C.H.; Lee, P.P.C. Enabling data integrity protection in regenerating-coding-based cloud storage: Theory and implementation. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 407–416. [Google Scholar] [CrossRef]
- Cachin, C.; Tessaro, S. Asynchronous verifiable information dispersal. IEEE Symp. Reliab. Distrib. Syst. 2014, 25, 191–201. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Tolerance | Scalability | Storage Overhead | Communication Efficiency |
|---|---|---|---|
| O(b) | O(N) | O(Logb) | O(B) |
| Metrics | ACeD | 1D-RS | AVID | DPP-DA |
|---|---|---|---|---|
| Latency | around 80 s | around 100 s | around 90 s | around 75 s |
| Throughput | around 1300 tps | around 1000 tps | around 1200 tps | more than 1500 tps |
| Fault tolerance | affected by code repair rate | affected by code repair rate | affected by code repair rate | affected by code repair rate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Ji, S.; Wang, X.; Liu, L.; Ren, Y. Blockchain Data Availability Scheme with Strong Data Privacy Protection. Information 2023, 14, 88. https://doi.org/10.3390/info14020088
Liu X, Ji S, Wang X, Liu L, Ren Y. Blockchain Data Availability Scheme with Strong Data Privacy Protection. Information. 2023; 14(2):88. https://doi.org/10.3390/info14020088
Chicago/Turabian StyleLiu, Xinyu, Shan Ji, Xiaowan Wang, Liang Liu, and Yongjun Ren. 2023. "Blockchain Data Availability Scheme with Strong Data Privacy Protection" Information 14, no. 2: 88. https://doi.org/10.3390/info14020088
APA StyleLiu, X., Ji, S., Wang, X., Liu, L., & Ren, Y. (2023). Blockchain Data Availability Scheme with Strong Data Privacy Protection. Information, 14(2), 88. https://doi.org/10.3390/info14020088