


Automatic Construction of Educational Knowledge Graphs: A Word Embedding-Based Approach

 , ,
, ,
Abstract
:1. Introduction
2. Background and Related Work
2.1. Educational Knowledge Graphs
2.2. Automatic Concept Extraction
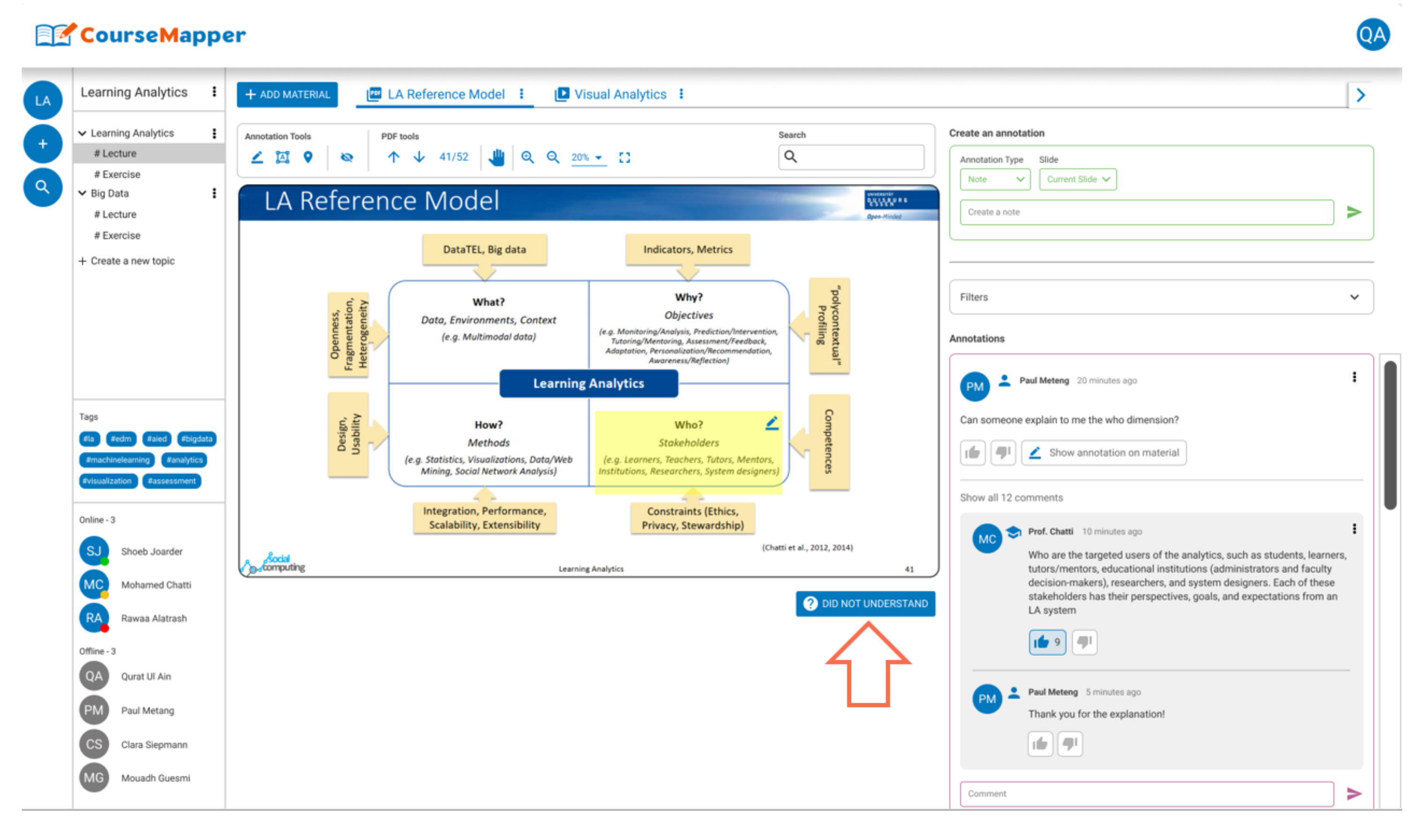
3. EduKG in CourseMapper
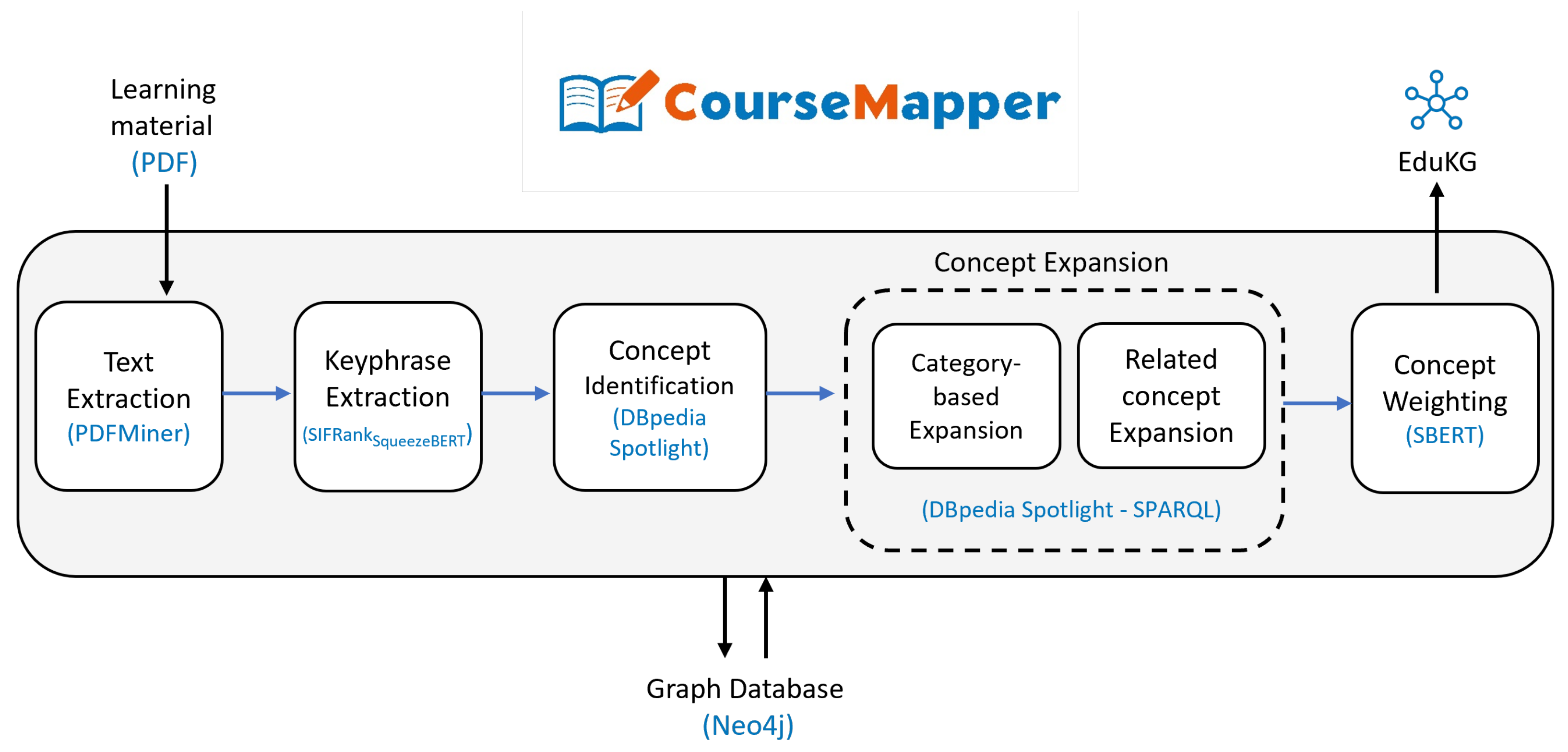
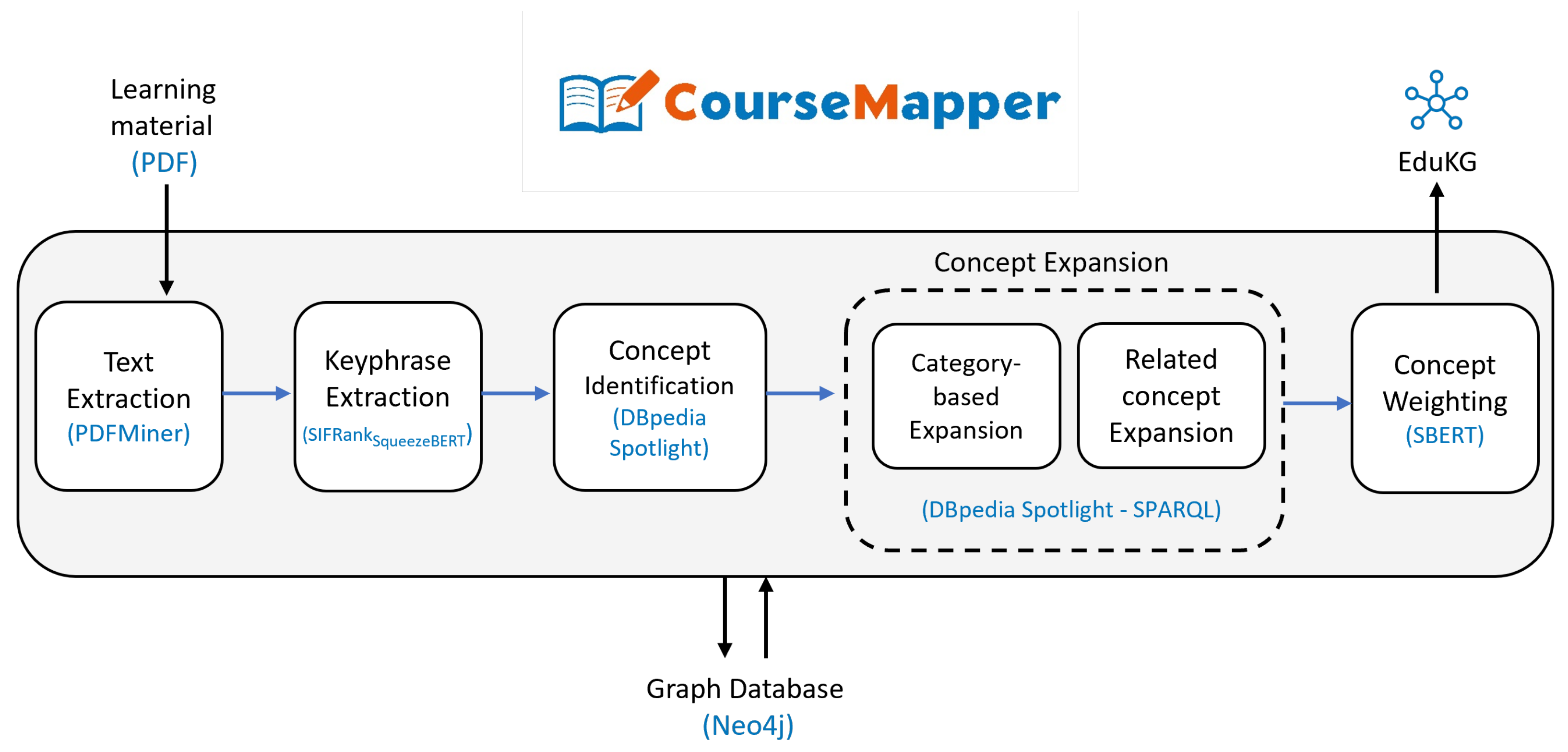
4. Methodology
4.1. Text Extraction
4.2. Keyphrase Extraction
4.3. Concept Identification
4.4. Concept Expansion
4.4.1. Category-Based Expansion
4.4.2. Related Concept Expansion
4.5. Concept Weighting
4.5.1. Concept Weighting
4.5.2. Related Concept Weighting
4.5.3. Category Weighting
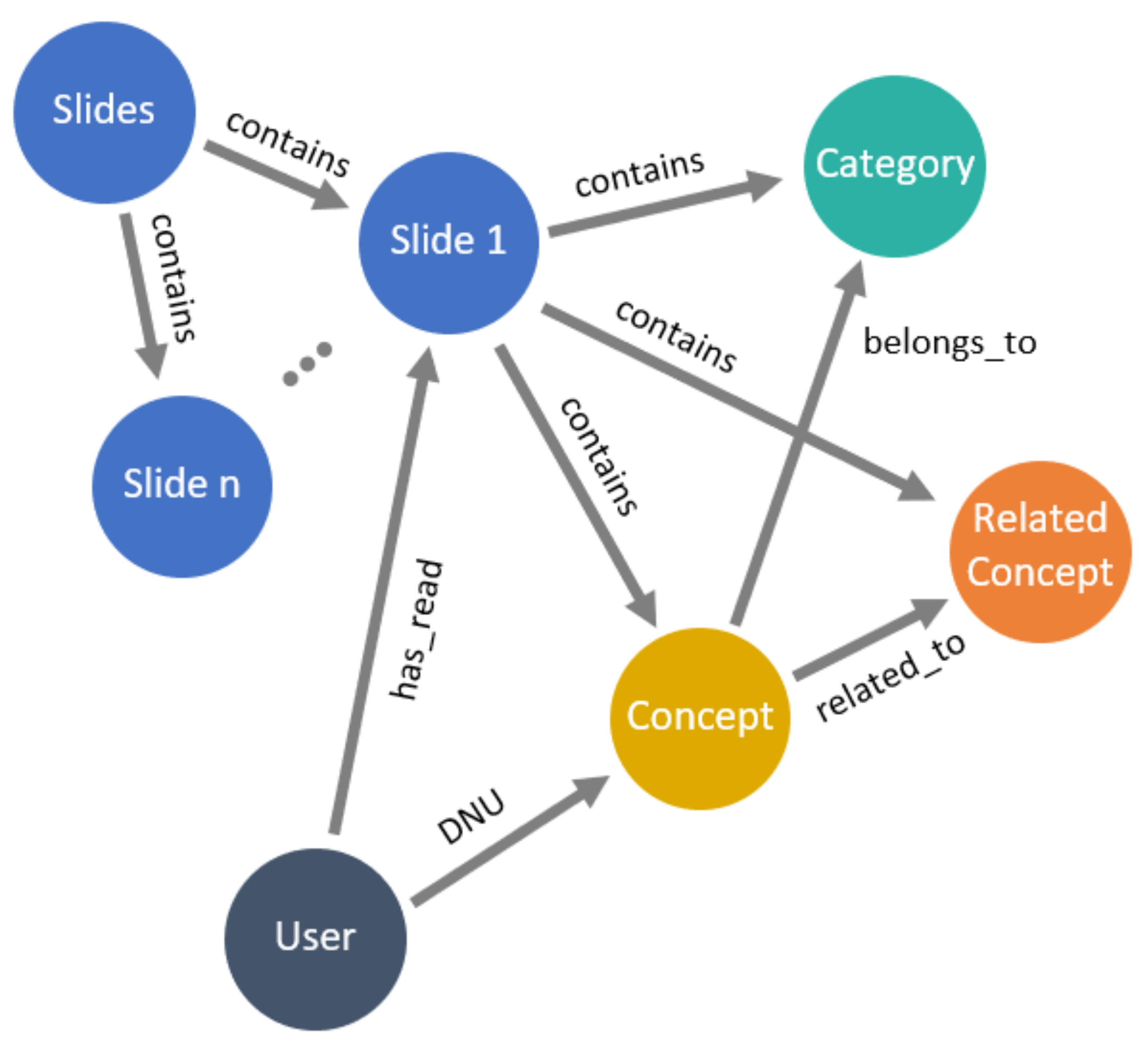
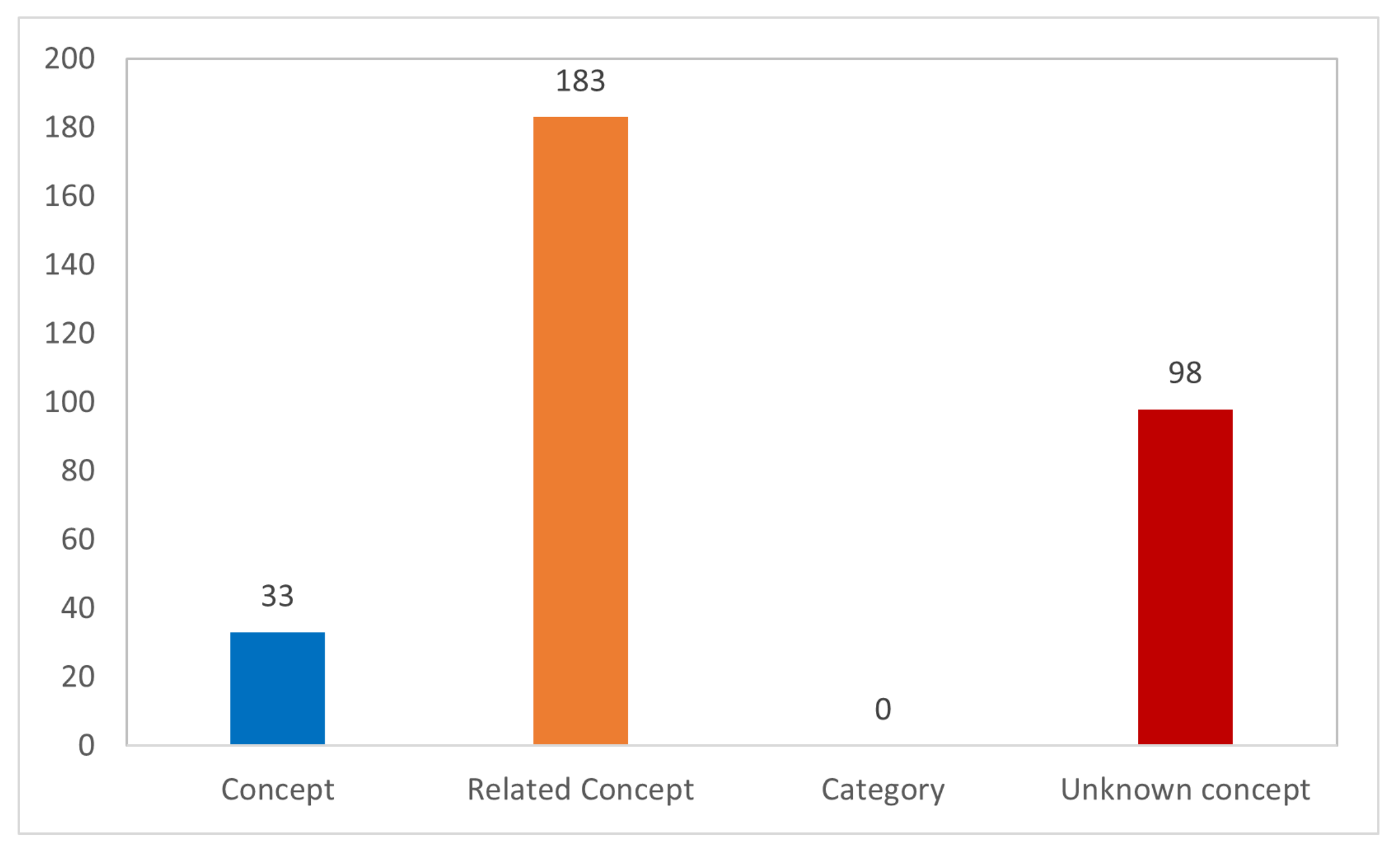
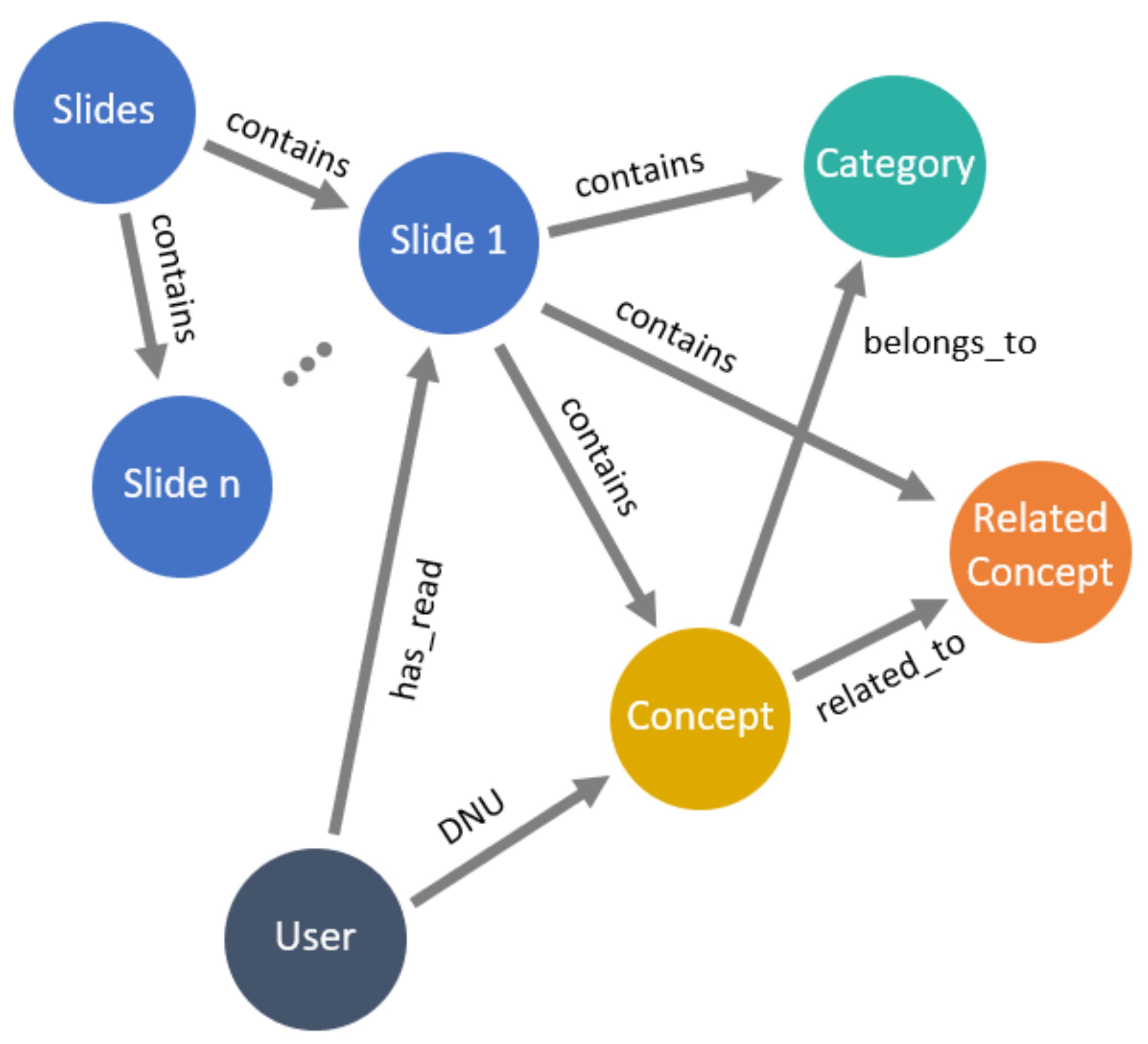
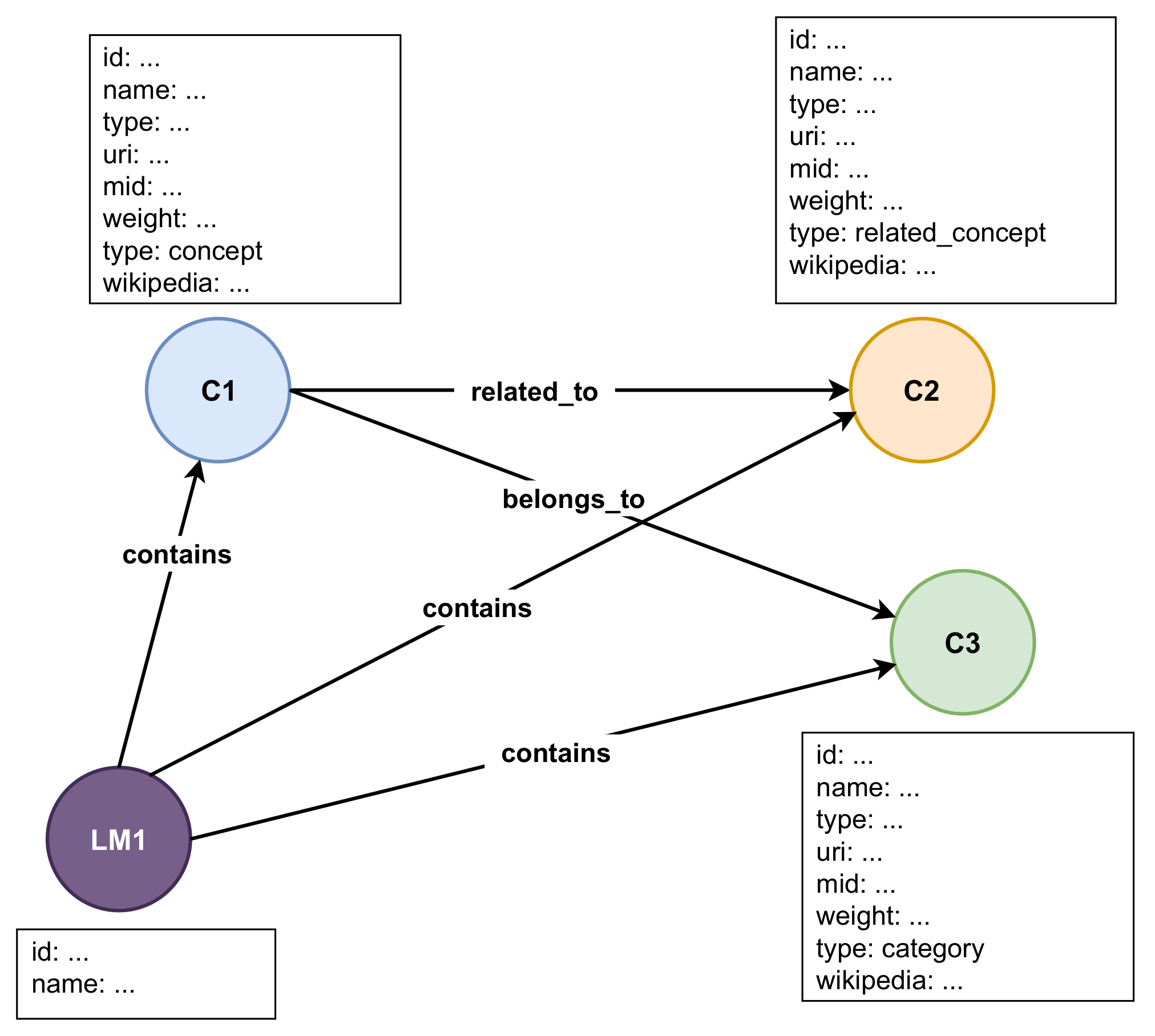
4.6. Knowledge Graph Storage
- Each concept in the KG is stored as a node. The concept is attached to properties, such as the name of the concept.
- A relationship of the type related_to is stored to connect two nodes, either a concept from the identification module or a related concept from the expansion module.
- A relationship of the type belongs_to is stored to connect a node to a node of the type category.
- The learning material is stored as a node.
- A relationship of the type contains is stored to connect the learning material to the concepts.
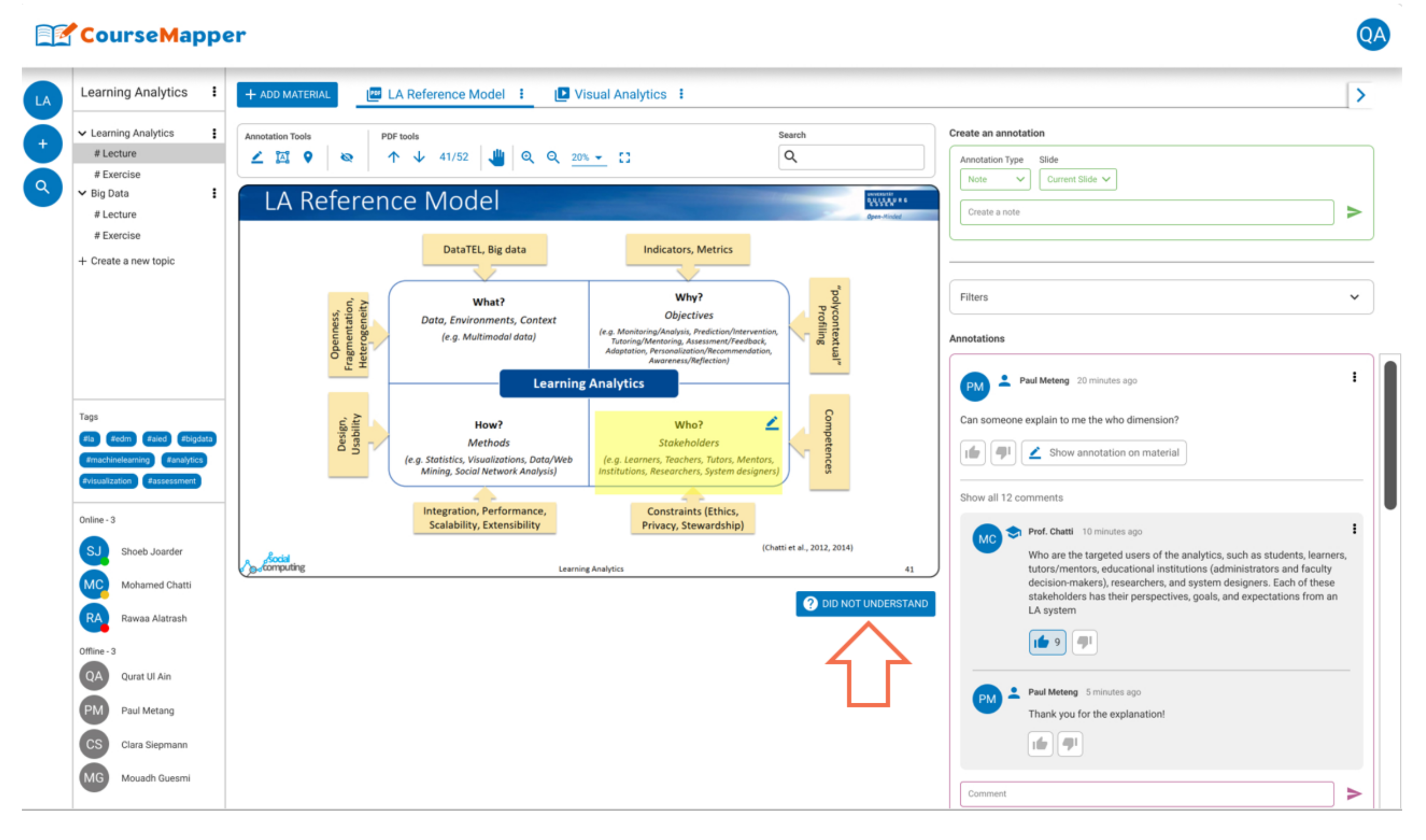
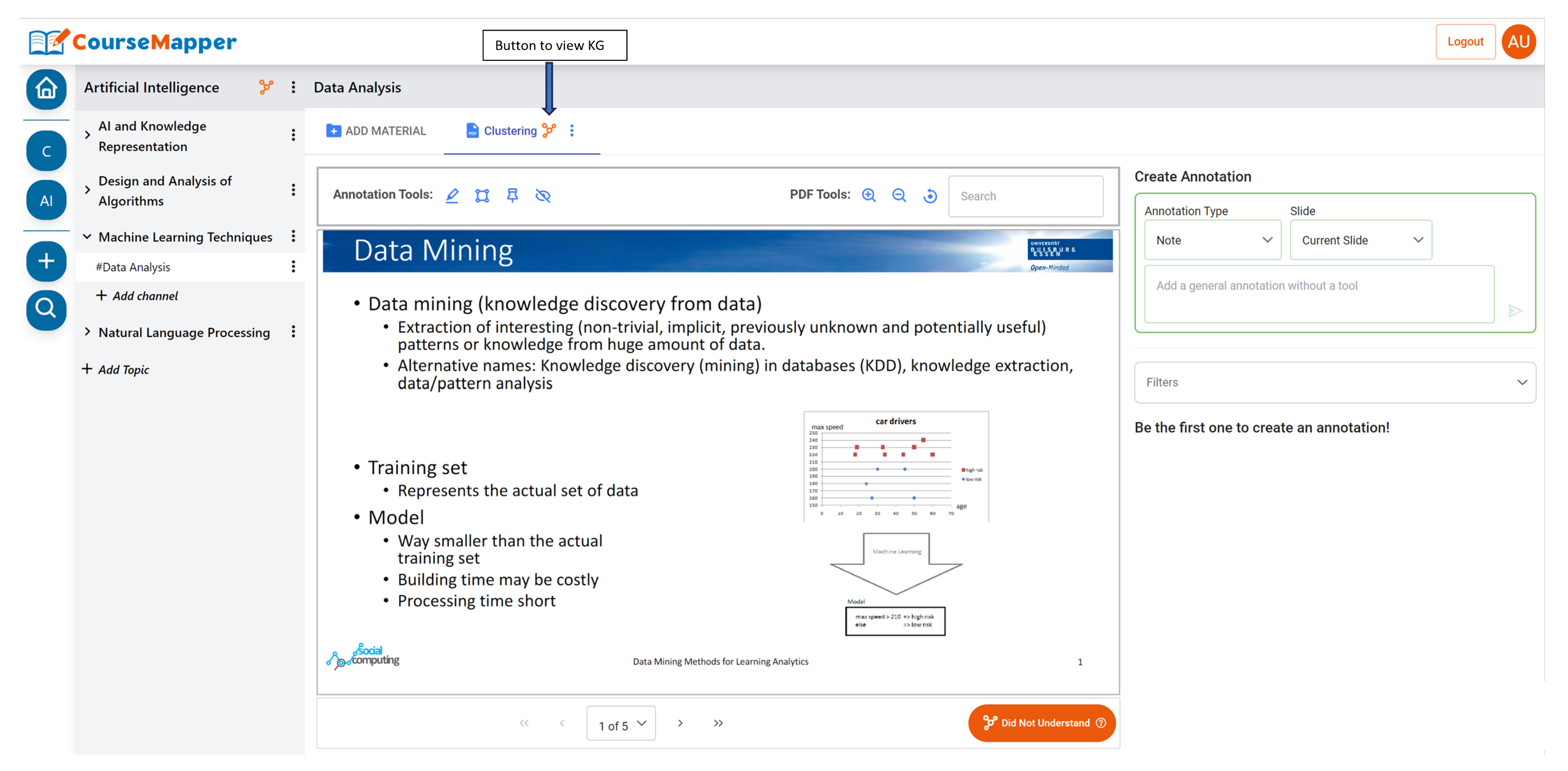
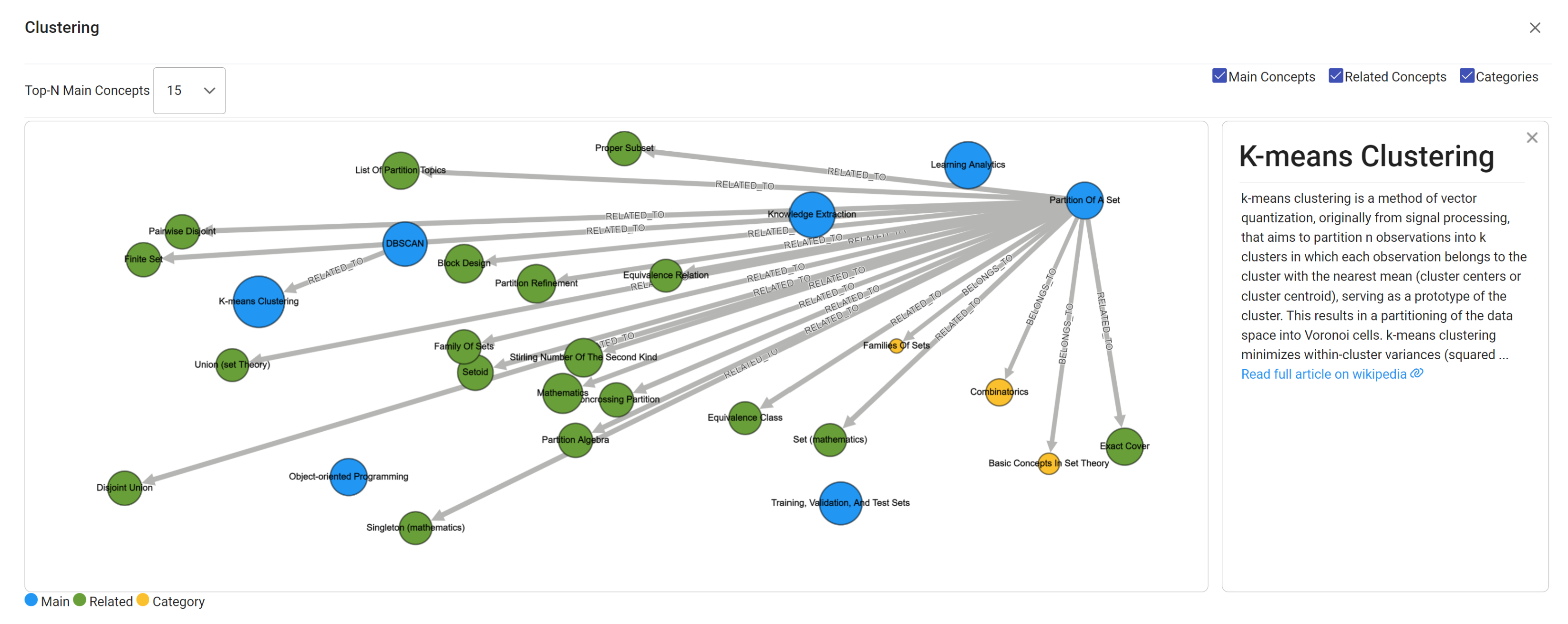
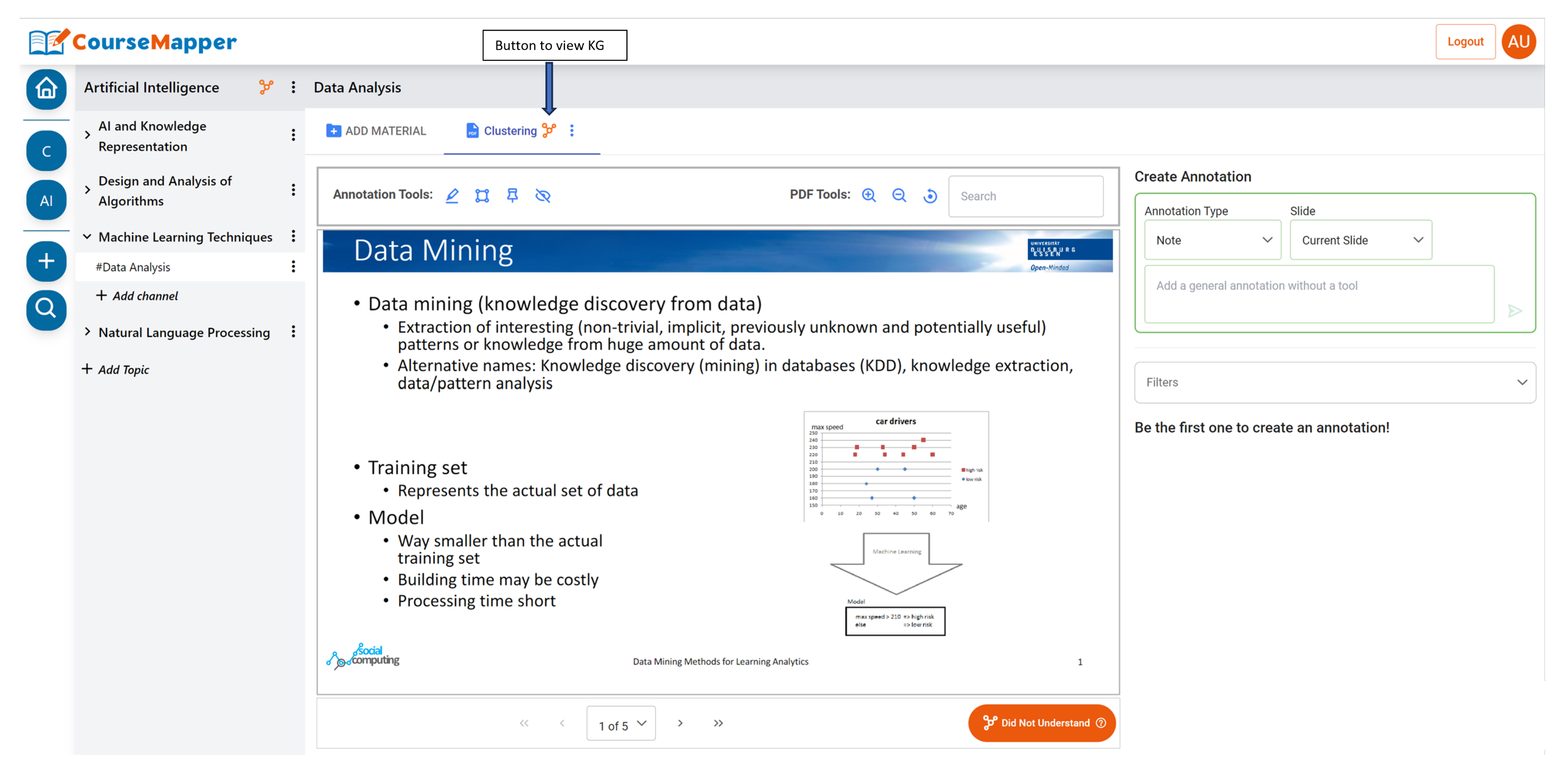
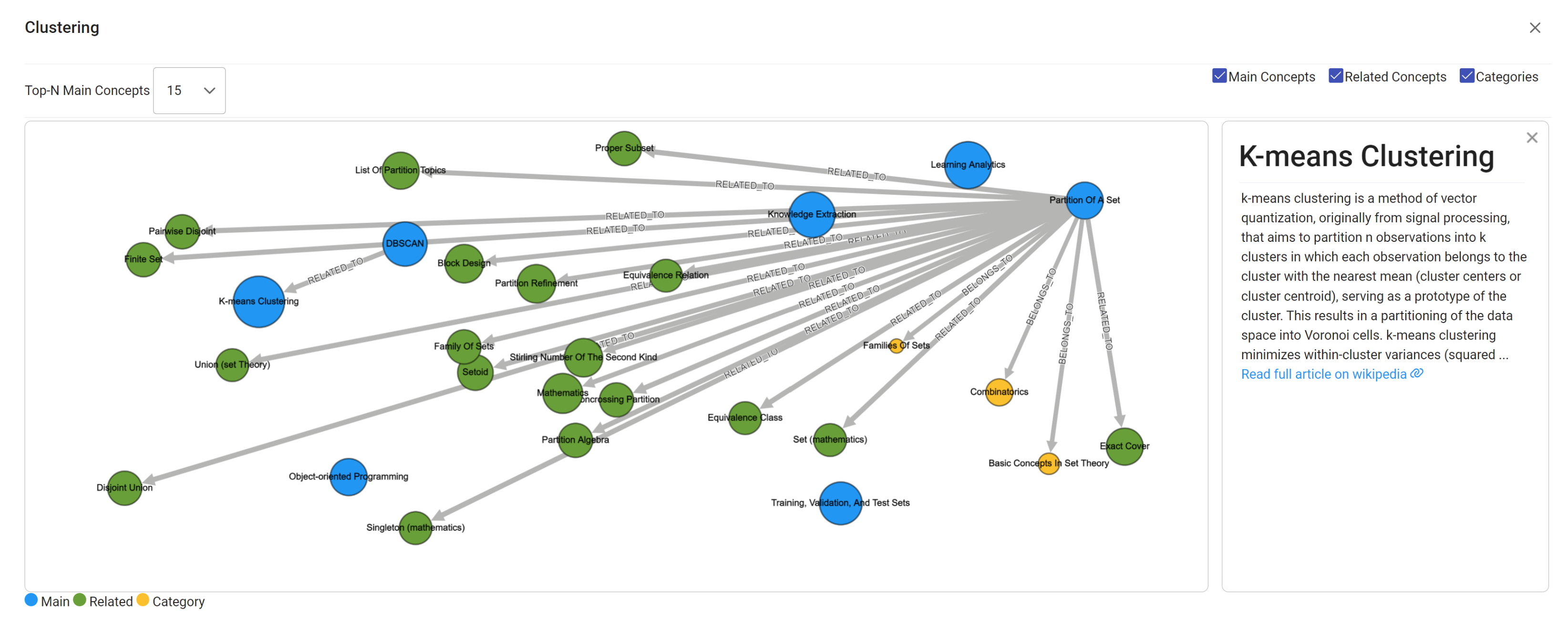
4.7. Knowledge Graph Visualization
5. Experimental Evaluation
5.1. Keyphrase Extraction Evaluation
5.1.1. Datasets
5.1.2. Baselines
5.1.3. Results and Analysis
5.2. Concept-Weighting Evaluation
5.2.1. Experimental Setup
5.2.2. Baselines
5.2.3. Results and Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Chen, P.; Lu, Y.; Zheng, V.W.; Chen, X.; Yang, B. Knowedu: A system to construct knowledge graph for education. IEEE Access 2018, 6, 31553–31563. [Google Scholar] [CrossRef]
- Novak, J.D.; Cañas, A.J. The theory underlying concept maps and how to construct and use them. Fla. Inst. Hum. Mach. Cogn. 2008, 1, 1–31. [Google Scholar]
- Netflix. Available online: https://www.netflix.com/de/ (accessed on 3 April 2023).
- Apple Siri. 2017. Available online: https://www.apple.com/siri/ (accessed on 23 April 2023).
- IBM Watson. 2017. Available online: https://www.ibm.com/watson/ (accessed on 30 April 2023).
- Wolfram Alpha. Available online: https://www.wolframalpha.com/ (accessed on 30 April 2023).
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Liu, H.; Carbonell, J.; Ma, W. Concept graph learning from educational data. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 159–168. [Google Scholar]
- Shukla, H.; Kakkar, M. Keyword extraction from Educational Video transcripts using NLP techniques. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 105–108. [Google Scholar] [CrossRef]
- Wang, S. Knowledge Graph Creation from Structure Knowledge; The Pennsylvania State University: State College, PA, USA, 2017. [Google Scholar]
- Sun, Y.; Qiu, H.; Zheng, Y.; Wang, Z.; Zhang, C. SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-Trained Language Model. IEEE Access 2020, 8, 10896–10906. [Google Scholar] [CrossRef]
- Iandola, F.N.; Shaw, A.E.; Krishna, R.; Keutzer, K.W. SqueezeBERT: What can computer vision teach NLP about efficient neural networks? arXiv 2020, arXiv:2006.11316. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Liu, H.; Ma, W.; Yang, Y.; Carbonell, J. Learning concept graphs from online educational data. J. Artif. Intell. Res. 2016, 55, 1059–1090. [Google Scholar] [CrossRef]
- Shen, Y.; Chen, Z.; Cheng, G.; Qu, Y. CKGG: A Chinese knowledge graph for high-school geography education and beyond. In Proceedings of the Semantic Web—ISWC 2021: 20th International Semantic Web Conference, ISWC 2021, Virtual Event, 24–28 October 2021; Proceedings 20. Springer: Berlin/Heidelberg, Germany, 2021; pp. 429–445. [Google Scholar]
- Chi, Y.; Qin, Y.; Song, R.; Xu, H. Knowledge graph in smart education: A case study of entrepreneurship scientific publication management. Sustainability 2018, 10, 995. [Google Scholar] [CrossRef]
- Yang, X.; Tan, L. The Construction of Accurate Recommendation Model of Learning Resources of Knowledge Graph under Deep Learning. Sci. Program. 2022, 2022, 1010122. [Google Scholar] [CrossRef]
- Chen, Q.; Xia, J.; Feng, J.; Tong, M. Research on Knowledge Graph Construction for Python Programming Language. In Proceedings of the International Conference on Smart Learning Environments, Hangzhou, China, 18–20 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 119–126. [Google Scholar]
- Hubert, N.; Brun, A.; Monticolo, D. New Ontology and Knowledge Graph for University Curriculum Recommendation. In Proceedings of the ISWC 2022—The 21st International Semantic Web Conference, Virtual Event, 23–27 October 2022. [Google Scholar]
- Morsi, R.; Ibrahim, W.; Williams, F. Concept maps: Development and validation of engineering curricula. In Proceedings of the 2007 37th Annual Frontiers in Education Conference-Global Engineering: Knowledge without Borders, Opportunities without Passports, Milwaukee, WI, USA, 10–13 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. T3H-3–T3H-6. [Google Scholar]
- Zhu, P.; Zhong, W.; Yao, X. Auto-Construction of Course Knowledge Graph based on Course Knowledge. Int. J. Perform. Eng. 2019, 15, 2228. [Google Scholar]
- Yang, Z.; Wang, Y.; Gan, J.; Li, H.; Lei, N. Design and research of intelligent question-answering (Q&A) system based on high school course knowledge graph. Mob. Netw. Appl. 2021, 26, 1884–1890. [Google Scholar]
- Manrique, R.; Grévisse, C.; Mariño, O.; Rothkugel, S. Knowledge graph-based core concept identification in learning resources. In Proceedings of the Joint International Semantic Technology Conference, Awaji, Japan, 26–28 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 36–51. [Google Scholar]
- Zheng, Y.; Liu, R.; Hou, J. The construction of high educational knowledge graph based on MOOC. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 260–263. [Google Scholar]
- Deng, Y.; Lu, D.; Huang, D.; Chung, C.J.; Lin, F. Knowledge graph based learning guidance for cybersecurity hands-on labs. In Proceedings of the ACM Conference on Global Computing Education, Chengdu, China, 17–19 May 2019; pp. 194–200. [Google Scholar]
- Rahdari, B.; Brusilovsky, P.; Thaker, K.; Barria-Pineda, J. Using knowledge graph for explainable recommendation of external content in electronic textbooks. In Proceedings of the iTextbooks@ AIED, Virtual, 6–9 July 2020. [Google Scholar]
- Qiao, L.; Yin, C.; Chen, H.; Sun, H.; Rong, W.; Xiong, Z. Automated Construction of Course Knowledge Graph Based on China MOOC Platform. In Proceedings of the 2019 IEEE International Conference on Engineering, Technology and Education (TALE), Yogyakarta, Indonesia, 10–13 December 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, H.; Yin, C.; Fan, X.; Qiao, L.; Rong, W.; Zhang, X. Learning path recommendation for MOOC platforms based on a knowledge graph. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Tokyo, Japan, 14–16 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 600–611. [Google Scholar]
- Su, Y.; Zhang, Y. Automatic construction of subject knowledge graph based on educational big data. In Proceedings of the 3rd International Conference on Big Data and Education, Chengdu, China, 21–23 August 2020; pp. 30–36. [Google Scholar]
- Dang, F.R.; Tang, J.T.; Pang, K.Y.; Wang, T.; Li, S.S.; Li, X. Constructing an Educational Knowledge Graph with Concepts Linked to Wikipedia. J. Comput. Sci. Technol. 2021, 36, 1200–1211. [Google Scholar] [CrossRef]
- Rahdari, B.; Brusilovsky, P. Building a Knowledge Graph for Recommending Experts. In Proceedings of the DI2KG@ KDD, Anchorage, Alaska, 5 August 2019. [Google Scholar]
- Mondal, I.; Hou, Y.; Jochim, C. End-to-end construction of NLP knowledge graph. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 1885–1895. [Google Scholar]
- Stewart, M.; Liu, W. Seq2kg: An end-to-end neural model for domain agnostic knowledge graph (not text graph) construction from text. In Proceedings of the International Conference on Principles of Knowledge Representation and Reasoning, Rhodes, Greece, 12–18 September 2020; Volume 17, pp. 748–757. [Google Scholar]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2778–2788. [Google Scholar]
- Wang, T.; Li, H. Coreference resolution improves educational knowledge graph construction. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph (ICKG), Nanjing, China, 9–11 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 629–634. [Google Scholar]
- Qin, Y.; Cao, H.; Xue, L. Research and Application of Knowledge Graph in Teaching: Take the database course as an example. Proc. J. Phys. Conf. Ser. 2020, 1607, 012127. [Google Scholar] [CrossRef]
- Grévisse, C.; Manrique, R.; Mariño, O.; Rothkugel, S. Knowledge graph-based teacher support for learning material authoring. In Proceedings of the Colombian Conference on Computing, Cartagena, Colombia, 26–28 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 177–191. [Google Scholar]
- Chau, H.; Labutov, I.; Thaker, K.; He, D.; Brusilovsky, P. Automatic concept extraction for domain and student modeling in adaptive textbooks. Int. J. Artif. Intell. Educ. 2021, 31, 820–846. [Google Scholar] [CrossRef]
- Zhao, B.; Sun, J.; Xu, B.; Lu, X.; Li, Y.; Yu, J.; Liu, M.; Zhang, T.; Chen, Q.; Li, H.; et al. EDUKG: A Heterogeneous Sustainable K-12 Educational Knowledge Graph. arXiv 2022, arXiv:2210.12228. [Google Scholar]
- Zhang, N.; Xu, X.; Tao, L.; Yu, H.; Ye, H.; Qiao, S.; Xie, X.; Chen, X.; Li, Z.; Li, L.; et al. Deepke: A deep learning based knowledge extraction toolkit for knowledge base population. arXiv 2022, arXiv:2201.03335. [Google Scholar]
- Sultan, M.A.; Bethard, S.; Sumner, T. Towards automatic identification of core concepts in educational resources. In Proceedings of the IEEE/ACM Joint Conference on Digital Libraries, London, UK, 8–12 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 379–388. [Google Scholar]
- Wang, X.; Feng, W.; Tang, J.; Zhong, Q. Course concept extraction in MOOC via explicit/implicit representation. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 339–345. [Google Scholar]
- Ain, Q.U.; Chatti, M.A.; Joarder, S.; Nassif, I.; Wobiwo Teda, B.S.; Guesmi, M.; Alatrash, R. Learning Channels to Support Interaction and Collaboration in CourseMapper. In Proceedings of the 14th International Conference on Education Technology and Computers, Barcelona, Spain, 28–30 October 2022; pp. 252–260. [Google Scholar]
- Bonwell, C.C. Using active learning to enhance lectures. Appl. Econ. Perspect. Policy 1999, 21, 542–550. [Google Scholar] [CrossRef]
- Ramakrishnan, C.; Patnia, A.; Hovy, E.; Burns, G.A. Layout-aware text extraction from full-text PDF of scientific articles. Source Code Biol. Med. 2012, 7, 1–10. [Google Scholar] [CrossRef]
- Shinyama, Y. PDFMiner—Python PDF Parser. 2007. Available online: https://unixuser.org/~euske/python/pdfminer/ (accessed on 23 April 2023).
- ELMo. Available online: https://allenai.org/allennlp/software/elmo (accessed on 23 April 2023).
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In Proceedings of the 7th International Conference on Semantic Systems, Graz, Austria, 7–9 September 2011; pp. 1–8. [Google Scholar]
- Manrique, R.; Marino, O. Knowledge Graph-based Weighting Strategies for a Scholarly Paper Recommendation Scenario. In Proceedings of the KaRS@ RecSys, Vancouver, BC, Canada, 7 October 2018; pp. 5–8. [Google Scholar]
- Manrique, R.; Herazo, O.; Mariño, O. Exploring the use of linked open data for user research interest modeling. In Proceedings of the Colombian Conference on Computing, Cali, Colombia, 19–22 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 3–16. [Google Scholar]
- Hassan, H.A.M. Personalized research paper recommendation using deep learning. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 327–330. [Google Scholar]
- Hassan, H.A.M.; Sansonetti, G.; Gasparetti, F.; Micarelli, A.; Beel, J. Bert, elmo, use and infersent sentence encoders: The panacea for research-paper recommendation? In Proceedings of the RecSys (Late-Breaking Results), Copenhagen, Denmark, 16–20 September 2019; pp. 6–10. [Google Scholar]
- Hulth, A. Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 216–223. [Google Scholar]
- Augenstein, I.; Das, M.; Riedel, S.; Vikraman, L.; McCallum, A. Semeval 2017 task 10: Scienceie-extracting keyphrases and relations from scientific publications. arXiv 2017, arXiv:1704.02853. [Google Scholar]
- Wan, X.; Xiao, J. Single document keyphrase extraction using neighborhood knowledge. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 855–860. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic Keyword Extraction from Individual Documents. In Text Mining: Applications and Theory; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010; pp. 1–20. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Boudin, F. Unsupervised Keyphrase Extraction with Multipartite Graphs. In Proceedings of the NAACL, New Orleans, LA, 26–30 June 2018; pp. 667–672. [Google Scholar] [CrossRef]
- Jardine, J.G.; Teufel, S. Topical PageRank: A Model of Scientific Expertise for Bibliographic Search. In Proceedings of the EACL, Gothenburg, Sweden, 26–30 April 2014. [Google Scholar]
- Bougouin, A.; Boudin, F.; Daille, B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction. In Proceedings of the IJCNLP, Nagoya, Japan, 14–19 October 2013. [Google Scholar]
- Florescu, C.; Caragea, C. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1105–1115. [Google Scholar] [CrossRef]
- Wan, X.; Xiao, J. CollabRank: Towards a Collaborative Approach to Single-Document Keyphrase Extraction. In Proceedings of the COLING, Manchester, UK, 18–22 August 2008. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the EMNLP, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple Unsupervised Keyphrase Extraction Using Sentence Embeddings. arXiv 2018, arXiv:1801.04470. [Google Scholar]
- Roy, D.; Sarkar, S.; Ghose, S. Automatic Extraction of Pedagogic Metadata from Learning Content. Int. J. Artif. Intell. Educ. 2008, 18, 97–118. [Google Scholar]
- Boudin, F. A Comparison of Centrality Measures for Graph-Based Keyphrase Extraction. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–19 October 2013; Asian Federation of Natural Language Processing: Nagoya, Japan, 2013; pp. 834–838. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
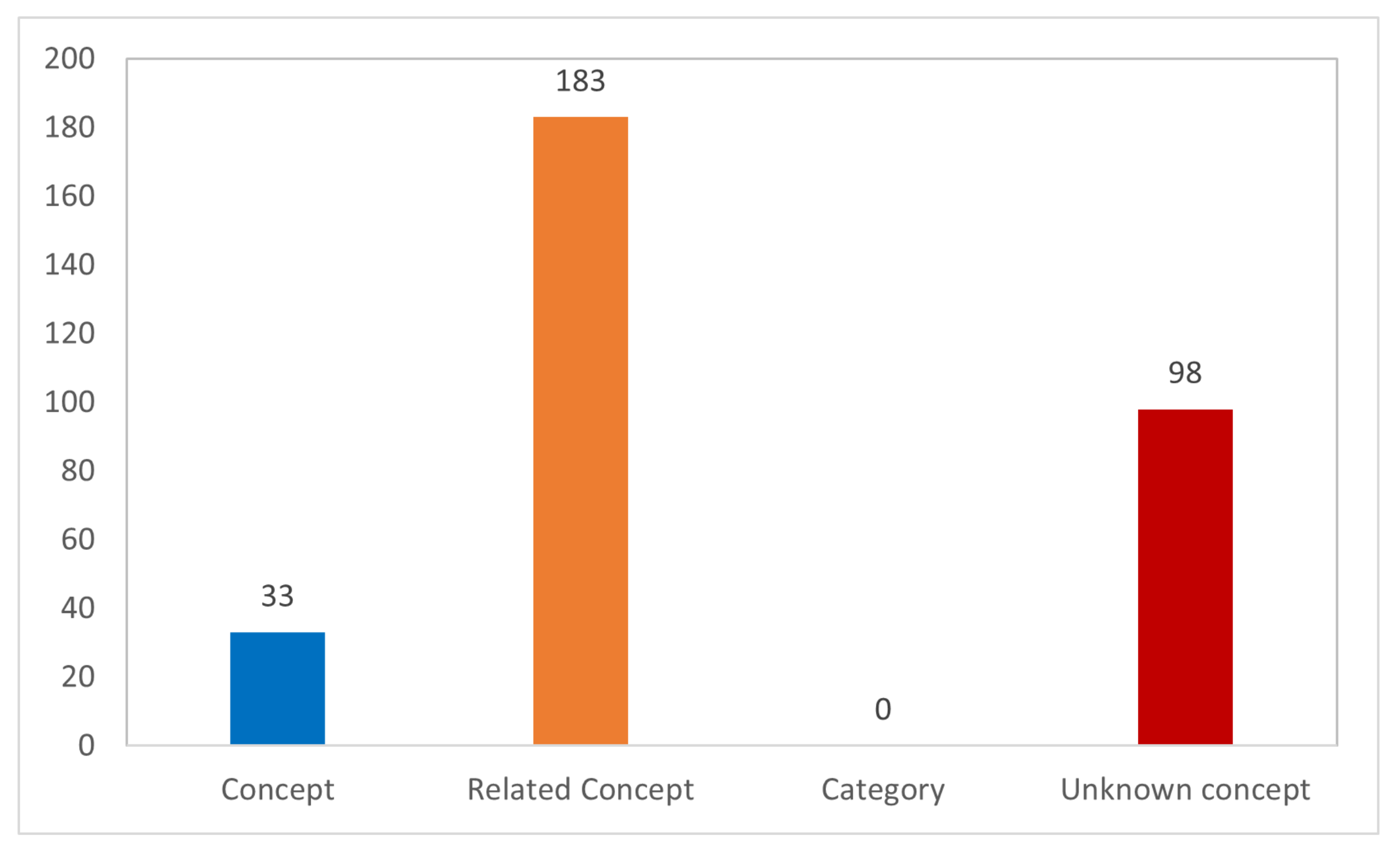{kind=link}
| Dataset | Inspec | SemEval2017 | DUC2001 |
|---|---|---|---|
| Type of Documents | Abstracts | Paragraph | News |
| No. of Documents | 500 | 493 | 308 |
| Average Words | 134.4 | 194.7 | 828.4 |
| Average keyphrases | 9.8 | 17.3 | 8.1 |
| K | Method | Inspec | SemEval2017 | DUC2001 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | ||
| 5 | 22.48 | 11.44 | 15.16 | 25.15 | 7.27 | 11.28 | - | - | - | |
| 30.33 | 15.43 | 20.45 | 29.61 | 8.56 | 13.28 | - | - | - | ||
| 16.52 | 8.41 | 11.14 | 30.06 | 8.69 | 13.48 | - | - | - | ||
| 28.94 | 14.72 | 19.51 | 34.40 | 9.94 | 15.43 | - | - | - | ||
| 32.96 | 16.77 | 22.23 | 35.74 | 10.33 | 16.03 | - | - | - | ||
| 28.66 | 14.57 | 19.32 | 33.95 | 9.81 | 15.23 | - | - | - | ||
| 31.98 | 16.27 | 21.56 | 35.82 | 10.35 | 16.06 | - | - | - | ||
| 31.52 | 16.04 | 21.26 | 34.04 | 9.84 | 15.26 | - | - | - | ||
| 17.85 | 8.81 | 11.80 | 18.33 | 5.30 | 8.22 | - | - | - | ||
| 26.36 | 13.41 | 17.78 | 29.24 | 8.45 | 13.11 | 9.70 | 6.00 | 7.42 | ||
| 40.24 | 20.48 | 27.14 | 47.74 | 13.79 | 21.41 | 33.81 | 20.91 | 25.84 | ||
| 43.20 | 21.99 | 29.14 | 48.64 | 14.06 | 21.81 | 31.79 | 19.67 | 24.30 | ||
| 42.12 | 21.44 | 28.41 | 47.99 | 13.87 | 21.52 | 40.26 | 24.91 | 30.78 | ||
| 44.00 | 22.39 | 29.68 | 49.21 | 14.22 | 22.07 | 30.75 | 19.02 | 23.50 | ||
| - | - | - | - | - | - | 41.69 | 25.80 | 31.87 | ||
| Improvement (%) | 1.85 | 1.81 | 1.85 | 1.17 | 1.14 | 1.19 | 3.51 | 3.57 | 3.54 | |
| 10 | 18.00 | 18.32 | 18.16 | 22.74 | 13.14 | 16.66 | - | - | - | |
| 27.60 | 27.89 | 27.74 | 28.42 | 16.43 | 20.82 | - | - | - | ||
| 14.62 | 14.88 | 14.75 | 24.16 | 13.96 | 17.70 | - | - | - | ||
| 24.19 | 24.28 | 24.24 | 29.00 | 16.75 | 21.24 | - | - | - | ||
| 29.60 | 29.86 | 29.73 | 33.04 | 19.10 | 24.21 | - | - | - | ||
| 24.09 | 23.92 | 24.00 | 27.41 | 15.84 | 20.08 | - | - | - | ||
| 27.45 | 27.62 | 27.54 | 31.87 | 18.42 | 23.34 | - | - | - | ||
| 28.77 | 29.11 | 28.94 | 32.45 | 18.76 | 23.77 | - | - | - | ||
| 14.81 | 12.70 | 13.68 | 17.31 | 9.72 | 12.45 | - | - | - | ||
| 24.90 | 25.02 | 24.96 | 27.44 | 15.86 | 20.10 | 8.91 | 11.00 | 9.85 | ||
| 34.96 | 35.09 | 35.03 | 42.88 | 24.78 | 31.41 | 28.05 | 34.62 | 30.99 | ||
| 38.63 | 38.84 | 38.73 | 43.45 | 25.11 | 31.83 | 24.97 | 30.83 | 27.60 | ||
| 36.44 | 36.64 | 36.54 | 42.49 | 24.56 | 31.13 | 30.20 | 37.28 | 33.37 | ||
| 39.36 | 39.58 | 39.47 | 43.73 | 25.28 | 32.04 | 26.04 | 32.16 | 28.78 | ||
| - | - | - | - | - | - | 31.79 | 39.26 | 35.13 | ||
| Improvement (%) | 1.89 | 1.9 | 1.91 | 0.64 | 0.67 | 0.65 | 5.26 | 5.31 | 5.27 | |
| 15 | 16.10 | 24.59 | 19.46 | 21.73 | 18.84 | 20.18 | - | - | - | |
| 24.34 | 36.20 | 29.11 | 25.79 | 22.35 | 23.94 | - | - | - | ||
| 13.88 | 21.19 | 16.77 | 20.76 | 18.00 | 19.28 | - | - | - | ||
| 22.16 | 32.14 | 26.23 | 25.95 | 22.45 | 24.07 | - | - | - | ||
| 26.65 | 39.15 | 31.71 | 30.52 | 26.44 | 28.33 | - | - | - | ||
| 21.49 | 30.09 | 25.08 | 24.02 | 20.68 | 22.23 | - | - | - | ||
| 24.31 | 35.50 | 28.86 | 29.12 | 25.21 | 27.02 | - | - | - | ||
| 25.71 | 38.05 | 30.69 | 29.84 | 25.85 | 27.70 | - | - | - | ||
| 13.00 | 13.64 | 13.31 | 15.80 | 12.05 | 13.68 | - | - | - | ||
| 23.58 | 34.30 | 27.95 | 26.90 | 23.28 | 24.96 | 8.31 | 15.31 | 10.77 | ||
| 31.70 | 45.98 | 37.53 | 38.43 | 33.26 | 35.66 | 24.12 | 44.45 | 31.27 | ||
| 33.49 | 48.76 | 39.71 | 39.14 | 33.88 | 36.32 | 21.56 | 39.74 | 27.95 | ||
| 32.64 | 47.52 | 38.70 | 38.61 | 33.43 | 35.83 | 24.86 | 45.83 | 32.24 | ||
| 34.06 | 49.59 | 40.38 | 39.78 | 34.43 | 36.91 | 23.06 | 42.52 | 29.91 | ||
| - | - | - | - | - | - | 26.91 | 49.62 | 34.90 | ||
| Improvement (%) | 1.7 | 1.7 | 1.68 | 1.63 | 1.62 | 1.63 | 8.24 | 8.26 | 8.25 | |
| K | Method | Layers | Inspec | SemEval2017 | DUC2001 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |||
| 5 | ALL | 43.16 | 21.97 | 29.11 | 48.23 | 13.94 | 21.63 | - | - | - | |
| L3 | 43.0 | 21.88 | 29.00 | 49.13 | 14.20 | 22.03 | - | - | - | ||
| L3_5 | 44.0 | 22.39 | 29.68 | 49.21 | 14.22 | 22.06 | - | - | - | ||
| 5 | L0 | - | - | - | - | - | - | 41.17 | 25.47 | 31.47 | |
| L1 | - | - | - | - | - | - | 39.93 | 24.70 | 30.52 | ||
| L0_1 | - | - | - | - | - | - | 41.69 | 25.79 | 31.87 | ||
| K | Method | Without Harmonic Mean | With Harmonic Mean | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| 23.6 | 20.5 | 21.9 | 23.6 | 20.5 | 21.9 | ||
| 24.2 | 25.4 | 24.8 | 24.2 | 25.4 | 24.8 | ||
| 3 | 18.5 | 17.1 | 17.8 | 18.5 | 17.1 | 17.8 | |
| 19.4 | 20.3 | 19.8 | 19.4 | 20.3 | 19.8 | ||
| 23.9 | 30.1 | 26.6 | 23.9 | 30.1 | 26.6 | ||
| 24.3 | 20.7 | 22.3 | 23.9 | 20.3 | 22.0 | ||
| Improvement (%) | 0.4 | - | - | - | - | - | |
| 17.9 | 25.7 | 21.1 | 17.9 | 25.7 | 21.1 | ||
| 19.2 | 27.2 | 22.5 | 19.2 | 27.2 | 22.5 | ||
| 5 | 14.9 | 20.1 | 17.1 | 14.9 | 20.1 | 17.1 | |
| 16.7 | 26.3 | 20.4 | 16.7 | 26.3 | 20.4 | ||
| 18.7 | 35.1 | 24.4 | 18.7 | 35.1 | 24.4 | ||
| 20.0 | 28.3 | 23.4 | 21.3 | 30.2 | 25.0 | ||
| Improvement (%) | 4.1 | - | - | 11 | - | 2.5 | |
| 11.4 | 32.7 | 16.8 | 11.4 | 32.7 | 16.8 | ||
| 11.8 | 37.3 | 17.9 | 11.8 | 37.3 | 17.9 | ||
| 10 | 8.5 | 28.1 | 13.1 | 08.5 | 28.1 | 13.1 | |
| 9.6 | 33.2 | 14.9 | 09.6 | 33.2 | 14.9 | ||
| 11.6 | 39.7 | 18.0 | 11.6 | 39.7 | 18.0 | ||
| 13.9 | 39.5 | 20.6 | 14.0 | 39.8 | 20.7 | ||
| Improvement (%) | 17.8 | - | 14.5 | 18.6 | 0.25 | 15 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ain, Q.U.; Chatti, M.A.; Bakar, K.G.C.; Joarder, S.; Alatrash, R. Automatic Construction of Educational Knowledge Graphs: A Word Embedding-Based Approach. Information 2023, 14, 526. https://doi.org/10.3390/info14100526
Ain QU, Chatti MA, Bakar KGC, Joarder S, Alatrash R. Automatic Construction of Educational Knowledge Graphs: A Word Embedding-Based Approach. Information. 2023; 14(10):526. https://doi.org/10.3390/info14100526
Chicago/Turabian StyleAin, Qurat Ul, Mohamed Amine Chatti, Komlan Gluck Charles Bakar, Shoeb Joarder, and Rawaa Alatrash. 2023. "Automatic Construction of Educational Knowledge Graphs: A Word Embedding-Based Approach" Information 14, no. 10: 526. https://doi.org/10.3390/info14100526
APA StyleAin, Q. U., Chatti, M. A., Bakar, K. G. C., Joarder, S., & Alatrash, R. (2023). Automatic Construction of Educational Knowledge Graphs: A Word Embedding-Based Approach. Information, 14(10), 526. https://doi.org/10.3390/info14100526