

Rebuilding Stakeholder Confidence in Health-Relevant Big Data Applications: A Social Representations Perspective


Abstract
1. Introduction
2. General Empirical Approach
2.1. Data Collection and Analysis
2.2. Quality and Ethics
3. Findings
3.1. Word Association Survey
3.1.1. Big Data: Content Analysis
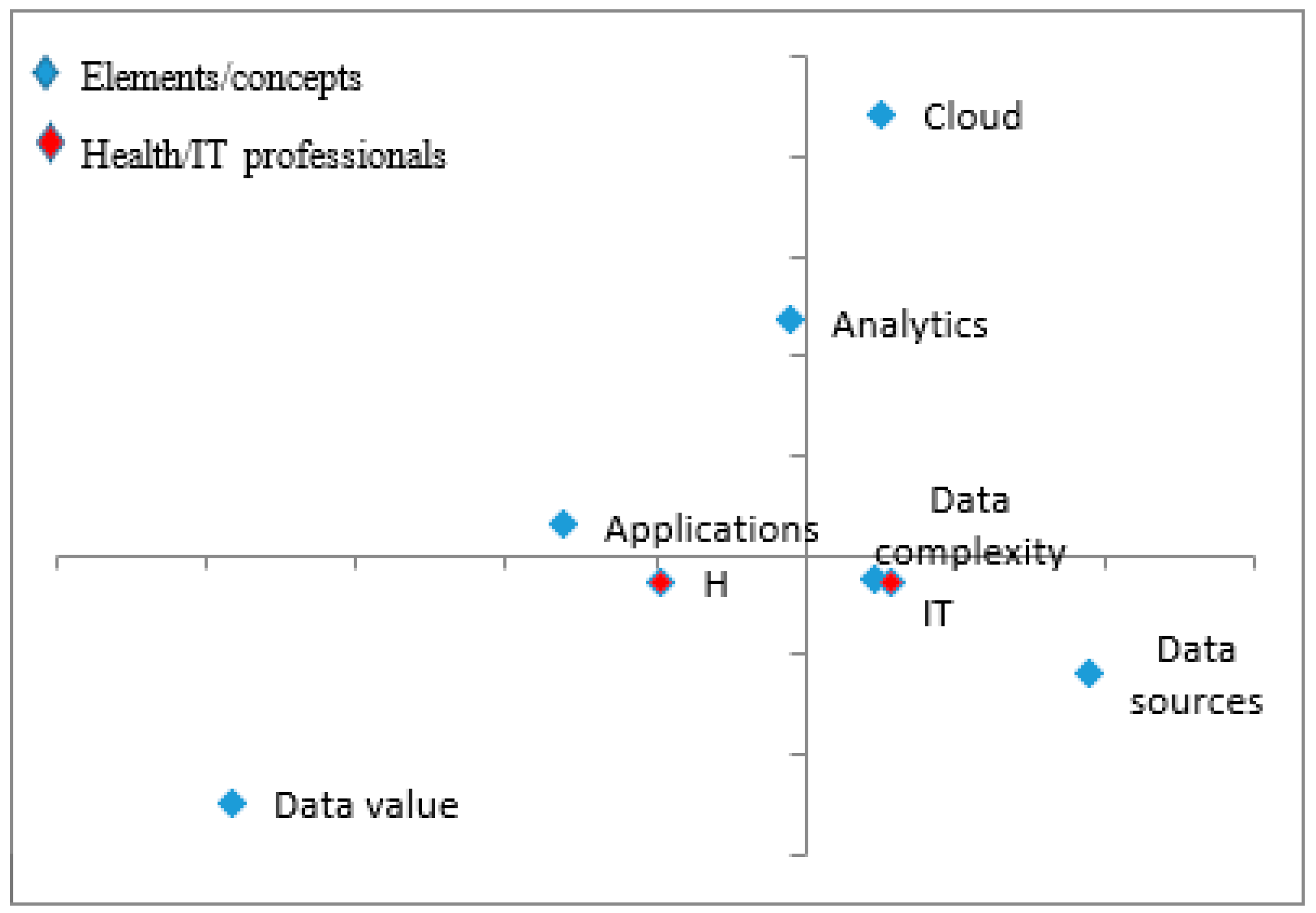
3.1.2. Big Data: Similarity Analysis and Core/Periphery Analysis
3.1.3. Big Data: Interpretations of Social Representations
3.2. Semi-Structured Interviews
3.2.1. Big Data: Content Analysis
3.2.2. Correspondence Analysis: Defining Big Data
My lay understanding of big data is that it starts with collection of data, for example, temperature, blood pressure, and so on, from a single patient. Then you end up collecting such data from many patients… Eventually, you accumulate information to help you answer questions like, ‘What are the variations in body temperature for certain diseases?’ Big data puts together the bigger picture of what is happening…—Interviewee #13
It’s all about being able to collect data about service delivery… Big data analytics then looks at the data that has been collected over time and uses the same data to… improve health services.—Interviewee #16
Traditionally data was structured. Data was structured until social media came, and we discovered that through social media everyone is a generator of information or data… So when we talk about big data it’s about all these uncorrelated data which is everywhere, being generated by different people, being generated by devices, in an unstructured way.—Interviewee #7
When you talk about big data you are talking about large amounts of data that have been collected over time and stored somewhere. And where is this data coming from? It’s coming from transactions either due to human interaction or due to items that have been programmed.—Interviewee #9
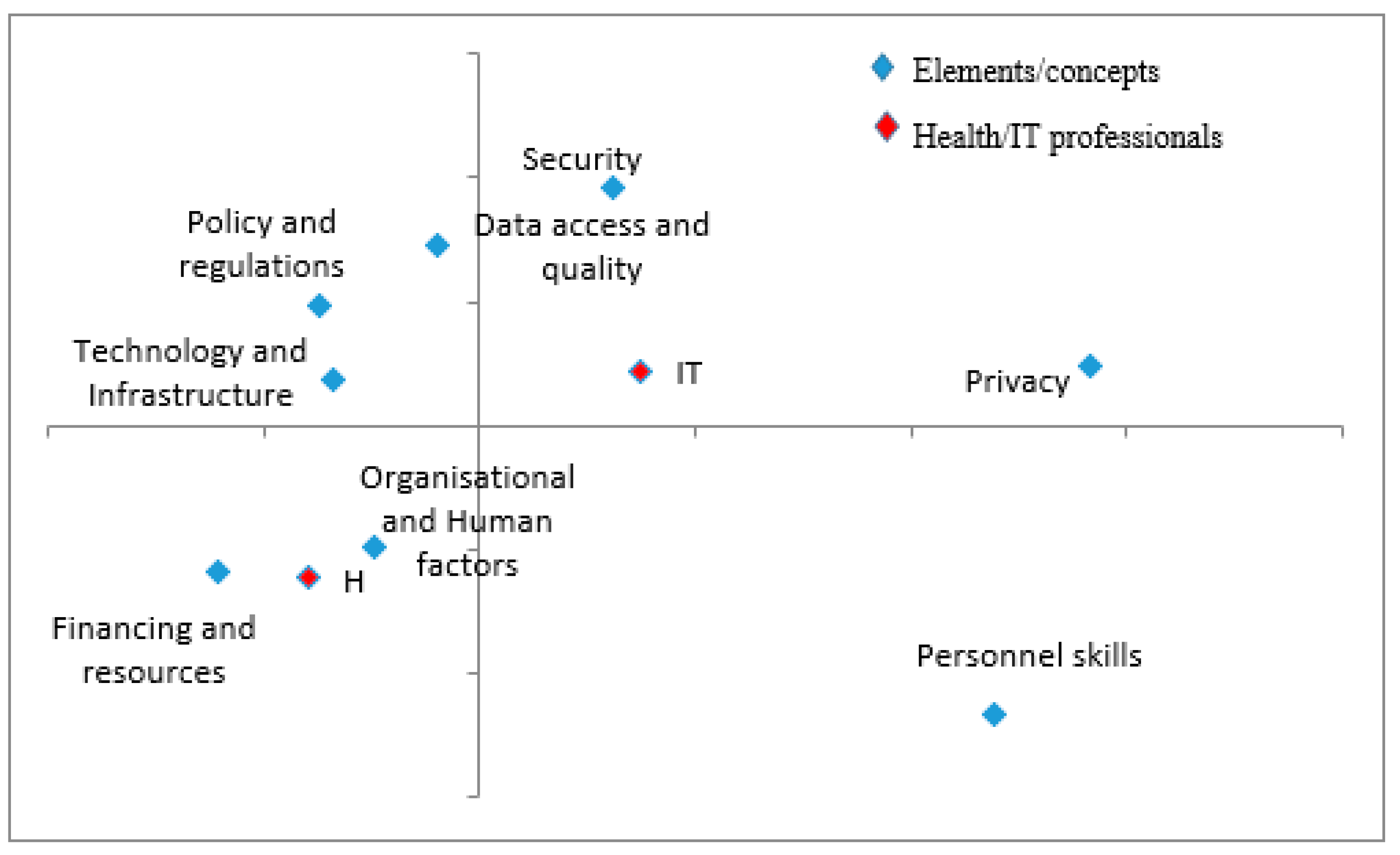
3.2.3. Correspondence Analysis: Benefits of Big Data Technologies
3.2.4. Correspondence Analysis: Challenges of Big Data Technologies
One of the challenges that we face when it comes to scaling up the use of these technologies is the issue of budget constraints. A majority of projects rely on donor funding, and therefore, these initiatives are not sustainable once the donor is unable to continue.—Interviewee #14
The main challenge is the lack of resources. But it is also about resource allocation, lack of prioritisation, and limited understanding about the benefits of these technologies. There are other things considered more basic such as drugs, so that when it comes to things such as the internet it is not considered as basic although they may play a role in making services better.—Interviewee #12
How many people are in technology and understand health informatics? Very few…and those few ones are stretched. County health records officers are trained to keep the records, not run analytics. Data may be exist… but unless they are trained on how to carry out data analytics, they can only wait for somebody else to do it.—Interviewee #8
So let’s say you visited the hospital and underwent some tests… results show you have heart problems and you are given a pacemaker to help your heart keep the rhythm. You perhaps only want your close family members know your health status. Let’s say that that pacemaker is connected to the internet as part of the IoT so that it can update your doctor on your status, how it (pacemaker) is working, and its battery and so on… if a bad guy happens to know that you have this pacemaker and it’s connected to the internet, he could have the device hacked and try to control your life. This can turn out to be a life-and-death issue that you don’t want to contemplate—it seems farfetched but possible.—Interviewee #7
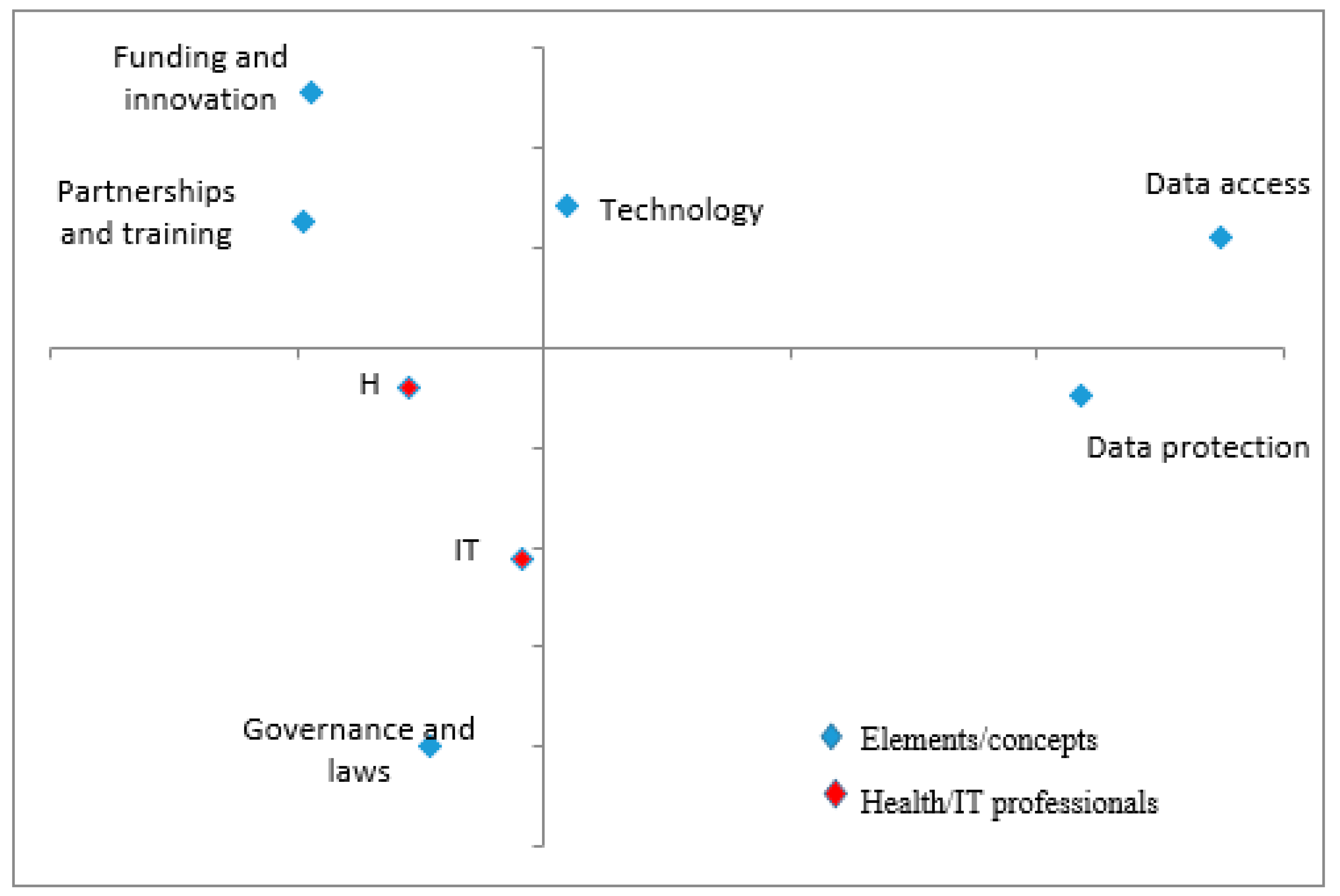
3.2.5. Correspondence Analysis: Solutions to Big Data Challenges
Technology is still seen as a luxury… However, technology is still relevant. If the government allocated more resources in terms of internet and connectivity, that would be helpful. Other players too have responsibility. They can pick and strengthen areas that the government has not been able to address…—Interviewee #14
Traditionally government have existed for policy. So the government needs to provide the relevant policies and laws… Additionally, the government needs to also put in the right environment, for example, in terms of incentives so that the private sector to roll out such projects. The ripple effect would be massive gains for the populace.—Interviewee #12
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jia, Q.; Guo, Y.; Wang, G.; Barnes, S.J. Big Data Analytics in the Fight against Major Public Health Incidents (Including COVID-19): A Conceptual Framework. IJERPH 2020, 17, 6161. [Google Scholar] [CrossRef]
- Kruse, C.S.; Goswamy, R.; Raval, Y.; Marawi, S. Challenges and Opportunities of Big Data in Health Care: A Systematic Review. JMIR Med. Inf. 2016, 4, e38. [Google Scholar] [CrossRef]
- Pastorino, R.; De Vito, C.; Migliara, G.; Glocker, K.; Binenbaum, I.; Ricciardi, W.; Boccia, S. Benefits and Challenges of Big Data in Healthcare: An Overview of the European Initiatives. Eur. J. Public Health 2019, 29 (Suppl. S3), 23–27. [Google Scholar] [CrossRef]
- Auffray, C.; Balling, R.; Barroso, I.; Bencze, L.; Benson, M.; Bergeron, J.; Bernal-Delgado, E.; Blomberg, N.; Bock, C.; Conesa, A.; et al. Making Sense of Big Data in Health Research: Towards an EU Action Plan. Genome Med. 2016, 8, 71. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big Data Analytics in Healthcare: Promise and Potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef]
- Bates, D.W.; Heitmueller, A.; Kakad, M.; Saria, S. Why Policymakers Should Care about “Big Data” in Healthcare. Health Policy Technol. 2018, 7, 211–216. [Google Scholar] [CrossRef]
- Horn, R.; Kerasidou, A. Sharing Whilst Caring: Solidarity and Public Trust in a Data-Driven Healthcare System. BMC Med. Ethics 2020, 21, 110. [Google Scholar] [CrossRef]
- Sánchez, M.; Sarría-Santamera, A. Unlocking Data: Where Is the Key? Bioethics 2019, 33, 367–376. [Google Scholar] [CrossRef]
- van Staa, T.-P.; Goldacre, B.; Buchan, I.; Smeeth, L. Big Health Data: The Need to Earn Public Trust. BMJ 2016, 354, i3636. [Google Scholar] [CrossRef]
- Abouelmehdi, K.; Beni-Hessane, A.; Khaloufi, H. Big Healthcare Data: Preserving Security and Privacy. J. Big Data 2018, 5, 1. [Google Scholar] [CrossRef]
- Grande, D.; Luna Marti, X.; Feuerstein-Simon, R.; Merchant, R.M.; Asch, D.A.; Lewson, A.; Cannuscio, C.C. Health Policy and Privacy Challenges Associated with Digital Technology. JAMA Netw. Open 2020, 3, e208285. [Google Scholar] [CrossRef] [PubMed]
- Vayena, E.; Salathé, M.; Madoff, L.C.; Brownstein, J.S. Ethical Challenges of Big Data in Public Health. PLoS Comput. Biol. 2015, 11, e1003904. [Google Scholar] [CrossRef] [PubMed]
- Godlee, F. What Can We Salvage from Care.Data? BMJ 2016, 354, i3907. [Google Scholar] [CrossRef]
- Jee, C. The UK is Abandoning Its Current Contact Tracing App for Google and Apple’s System. Available online: https://www.technologyreview.com/2020/06/18/1004097/the-uk-is-abandoning-its-current-contact-tracing-app-for-google-and-apples-system/ (accessed on 26 November 2021).
- O’Neill, P. Norway Halts Coronavirus App Over Privacy Concerns. Available online: https://www.technologyreview.com/2020/06/15/1003562/norway-halts-coronavirus-app-over-privacy-concerns/ (accessed on 25 November 2021).
- OSJI. Kenya’s National Integrated Identity Management System. 2020. Available online: https://www.justiceinitiative.org/publications/kenyas-national-integrated-identity-management-scheme-niims (accessed on 26 June 2021).
- Morley, J.; Taddeo, M.; Floridi, L. Google Health and the NHS: Overcoming the Trust Deficit. Lancet Digit. Health 2019, 1, e389. [Google Scholar] [CrossRef]
- Monteiro, J.; Sargent, J. Build Trust in Digital Health. Nat. Med. 2020, 26, 1151. [Google Scholar] [CrossRef]
- Vayena, E.; Haeusermann, T.; Adjekum, A.; Blasimme, A. Digital Health: Meeting the Ethical and Policy Challenges. Swiss Med. Wkly. 2018, 148, w14571. [Google Scholar] [CrossRef]
- Blobel, B.; Lopez, D.M.; Gonzalez, C. Patient Privacy and Security Concerns on Big Data for Personalized Medicine. Health Technol. 2016, 6, 75–81. [Google Scholar] [CrossRef]
- Adjekum, A.; Blasimme, A.; Vayena, E. Elements of Trust in Digital Health Systems: Scoping Review. J. Med. Internet Res. 2018, 20, e11254. [Google Scholar] [CrossRef]
- Gal, U.; Berente, N. A Social Representations Perspective on Information Systems Implementation: Rethinking the Concept of “Frames”. Inf. Technol. People 2008, 21, 133–154. [Google Scholar] [CrossRef]
- Lu, B.; Zhang, S.; Fan, W. Social Representations of Social Media Use in Government: An Analysis of Chinese Government Microblogging from Citizens’ Perspective. Soc. Sci. Comput. Rev. 2016, 34, 416–436. [Google Scholar] [CrossRef]
- Jung, Y.; Pawlowski, S.D.; Wiley-Patton, S. Conducting Social Cognition Research in IS: A Methodology for Eliciting and Analyzing Social Representations. Commun. Assoc. Inf. Syst. 2009, 24, 35. [Google Scholar] [CrossRef]
- Venkatesh, V.; Zhang, X.; Sykes, T.A. “Doctors Do Too Little Technology”: A Longitudinal Field Study of an Electronic Healthcare System Implementation. Inf. Syst. Res. 2011, 22, 523–546. [Google Scholar] [CrossRef]
- Mburu, S.; Angolo, S.; Mwangi, C.; Chemwa, G.; Soti, D.; Cherutich, P.; Kamau, O. Kenya National Health Policy 2016–2030; Ministry of Health: Nairobi, Kenya, 2016. [Google Scholar]
- Barone, B.; Rodrigues, H.; Nogueira, R.M.; Guimarães, K.R.L.S.L.D.Q.; Behrens, J.H. What about Sustainability? Understanding Consumers’ Conceptual Representations through Free Word Association. Int. J. Consum. Stud. 2020, 44, 44–52. [Google Scholar] [CrossRef]
- Wagner, W.; Valencia, J.; Elejabarrieta, F. Relevance, Discourse and the ‘Hot’ Stable Core Social Representations-A Structural Analysis of Word Associations. Br. J. Soc. Psychol. 1996, 35, 331–351. [Google Scholar] [CrossRef]
- Judacewski, P.; Los, P.R.; Lima, L.S.; Alberti, A.; Zielinski, A.A.F.; Nogueira, A. Perceptions of Brazilian Consumers Regarding White Mould Surface-ripened Cheese Using Free Word Association. Int. J. Dairy Technol. 2019, 72, 585–590. [Google Scholar] [CrossRef]
- Barbour, R.S. Mixing Qualitative Methods: Quality Assurance or Qualitative Quagmire? Qual. Health Res. 1998, 8, 352–361. [Google Scholar] [CrossRef]
- Carter, N.; Bryant-Lukosius, D.; DiCenso, A.; Blythe, J.; Neville, A.J. The Use of Triangulation in Qualitative Research. Oncol. Nurs. Forum 2014, 41, 545–547. [Google Scholar] [CrossRef]
- Qualitative Research Methodologies and Methods. Man. Ther. 2012, 17, 378–384. [CrossRef]
- Fleiss, J.L.; Levin, B.; Paik, M.C. Statistical Methods for Rates and Proportions. John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Flament, C. L’analyse de Similitude: Une Technique Pour Les Recherches Sur Les RS in W; L’étude des RS, Delachaux et Nestlé: Paris, French, 1986. [Google Scholar]
- Hammond, S. The Descriptive Analyses of Shared Representations. In Emprical Approaches to Social Representations; Oxford University Press: Oxford, UK, 1993; pp. 205–222. [Google Scholar]
- Abric, J.-C. A Structural Approach to Social Representations. In Representations of the Social: Bridging Theoretical Traditions; Blackwell Publishing: Malden, MA, USA, 2001; pp. 42–47. [Google Scholar]
- Remenyi, D. Researching Information Systems: Data Analysis Methodology Using Content and Correspondence Analysis. J. Inf. Technol. 1992, 7, 76–86. [Google Scholar] [CrossRef]
- Frakt, A.B.; Pizer, S.D. The Promise and Perils of Big Data in Health Care. Am. J. Manag. Care 2016, 22, 98. [Google Scholar]
- Scott, I.A. Hope, Hype and Harms of Big Data: Big Data Critique. Intern. Med. J. 2019, 49, 126–129. [Google Scholar] [CrossRef]
- Kugler, L. What Happens When Big Data Blunders? Commun. ACM 2016, 59, 15–16. [Google Scholar] [CrossRef]
- Newlands, G.; Lutz, C.; Tamò-Larrieux, A.; Villaronga, E.F.; Harasgama, R.; Scheitlin, G. Innovation under Pressure: Implications for Data Privacy during the COVID-19 Pandemic. Big Data Soc. 2020, 7, 2053951720976680. [Google Scholar] [CrossRef]
- Mbuthia, D.; Molyneux, S.; Njue, M.; Mwalukore, S.; Marsh, V. Kenyan Health Stakeholder Views on Individual Consent, General Notification and Governance Processes for the Re-Use of Hospital Inpatient Data to Support Learning on Healthcare Systems. BMC Med. Ethics 2019, 20, 3. [Google Scholar] [CrossRef] [PubMed]
- Ritchie, O.; Reid, S.; Smith, L. Review of Public and Professional Attitudes towards Confidentiality of Healthcare Data; General Medical Council: London, UK, 2015. [Google Scholar]
- Mwaura, J. #Resisthudumanamba: Kenyan Government at a Crossroad. AoIR Sel. Pap. Internet Res. 2019, 1–5. [Google Scholar] [CrossRef]
- Kiplagat, S. High Court Declares Huduma Namba Illegal. Available online: https://www.businessdailyafrica.com/bd/news/high-court-declares-huduma-namba-illegal--3582926 (accessed on 25 August 2022).
- Kimani, D. Are We Ready for a Data Bank? An Analysis of the Sufficiency of Kenya’s Legal and Institutional Framework on Data Protection and Identity Theft. SSRN J. 2019, 2019. [Google Scholar] [CrossRef]
- Gopichandran, V.; Ganeshkumar, P.; Dash, S.; Ramasamy, A. Ethical Challenges of Digital Health Technologies: Aadhaar, India. Bull. World Health Organ. 2020, 98, 277–281. [Google Scholar] [CrossRef]
- MoICND. Huduma Namba. Available online: https://www.hudumanamba.go.ke/ (accessed on 15 September 2021).
- Dror, A.A.; Eisenbach, N.; Taiber, S.; Morozov, N.G.; Mizrachi, M.; Zigron, A.; Srouji, S.; Sela, E. Vaccine Hesitancy: The next Challenge in the Fight against COVID-19. Eur. J. Epidemiol. 2020, 35, 775–779. [Google Scholar] [CrossRef] [PubMed]
- Vergara, R.J.D.; Sarmiento, P.J.D.; Lagman, J.D.N. Building Public Trust: A Response to COVID-19 Vaccine Hesitancy Predicament. J. Public Health 2021, 43, e291–e292. [Google Scholar] [CrossRef]
- Mertes, A.; Brüesch, C. Stakeholder Participation in EHealth Policy: A Swiss Case Study on the Incorporation of Stakeholder Preferences. In Proceedings of the IRSPM 22nd Annual Conference, Edinburgh, Germany, 11–13 April 2018; pp. 1–23. [Google Scholar]
- World Health Organization. Vaccination and Trust: How Concerns Arise and the Role of Communication in Mitigating Crises; World Health Organization Regional Office for Europe: Brussels, Belgium, 2017; p. 50. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Government | Private Sector | Total | |
|---|---|---|---|
| IT | 42 (40%) | 29 (28%) | 71 (68%) |
| Health | 21 (20%) | 13 (12%) | 34 (32%) |
| IT | Health | ||
| Female | 14 (13%) | 12 (11%) | 26 (25%) |
| Male | 57 (54%) | 22 (21%) | 79 (75%) |
| Total respondents | 105 |
| Topic Theme | Sample Codes | Topic Theme | Sample Codes |
|---|---|---|---|
| T1 Size/Volume | massive, large data sets, high volume, huge, colossal, many variables, tonnes of data | T9 Security | security, privacy, hacking, encryption, loss, no privacy |
| T2 Data | raw data, data, streaming data | T10 Unstructured | multimedia, unstructured data, social media, disorganisation |
| T3 Technology | information technology, ICT, blockchain, Hadoop, infrastructure, servers | T11 Insight | information, strategic, knowledge, evidence, patterns, trends, preferences |
| T4 Applications | Google, research, survey, policy, YouTube | T12 Opportunities | transformational, potential, value, gold rush, monetisation, research potential, business opportunities |
| T5 Analytics | integration, analysis, aggregation, processing, data mining, download, consolidation, predictive analytics | T13 Time | time, long time, different times |
| T14 Cost | expensive, money | ||
| T6 Speed | velocity, data stream, data explosion, fast | T15 Cloud/Internet | cloud, online, internet, connectivity |
| T7 Complexity | variety, complex, multiple sources, diversity | T16 Smart/Artificial Intelligence | smart logic, artificial intelligence, intelligence, learning, habits |
| T8 Storage | databases, data repositories, warehouse, data lake, hard drive | T17 Fourth Industrial Revolution | 4th industrial revolution |
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | |
|---|---|---|---|---|---|---|---|---|
| T1 | 1.000 | 0.354 | 0.049 | 0.047 | 0.125 | 0.108 | 0.095 | 0.083 |
| T2 | 0.354 | 1.000 | 0.000 | 0.000 | 0.255 | 0.027 | 0.075 | 0.114 |
| T3 | 0.049 | 0.000 | 1.000 | 0.111 | 0.022 | 0.000 | 0.050 | 0.000 |
| T4 | 0.047 | 0.000 | 0.111 | 1.000 | 0.043 | 0.000 | 0.000 | 0.036 |
| T5 | 0.125 | 0.255 | 0.022 | 0.043 | 1.000 | 0.000 | 0.064 | 0.167 |
| T6 | 0.108 | 0.027 | 0.000 | 0.000 | 0.000 | 1.000 | 0.056 | 0.042 |
| T7 | 0.095 | 0.075 | 0.050 | 0.000 | 0.064 | 0.056 | 1.000 | 0.071 |
| T8 | 0.083 | 0.114 | 0.000 | 0.036 | 0.167 | 0.042 | 0.071 | 1.000 |
| T9 | 0.023 | 0.000 | 0.000 | 0.105 | 0.091 | 0.000 | 0.048 | 0.217 |
| T10 | 0.108 | 0.056 | 0.000 | 0.000 | 0.047 | 0.000 | 0.056 | 0.042 |
| T11 | 0.173 | 0.137 | 0.091 | 0.056 | 0.204 | 0.063 | 0.083 | 0.023 |
| T12 | 0.024 | 0.026 | 0.063 | 0.118 | 0.022 | 0.000 | 0.000 | 0.000 |
| T13 | 0.056 | 0.061 | 0.000 | 0.000 | 0.050 | 0.000 | 0.143 | 0.000 |
| T14 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.125 | 0.000 | 0.000 |
| T15 | 0.000 | 0.025 | 0.118 | 0.050 | 0.067 | 0.133 | 0.048 | 0.037 |
| T16 | 0.024 | 0.054 | 0.063 | 0.056 | 0.122 | 0.000 | 0.000 | 0.000 |
| T17 | 0.000 | 0.000 | 0.000 | 0.000 | 0.026 | 0.000 | 0.000 | 0.000 |
| Sum of similarity | 2.270 | 2.183 | 1.565 | 1.620 | 2.303 | 1.553 | 1.788 | 1.831 |
| T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | T17 | |
|---|---|---|---|---|---|---|---|---|---|
| T1 | 0.023 | 0.108 | 0.173 | 0.024 | 0.056 | 0.000 | 0.000 | 0.024 | 0.000 |
| T2 | 0.000 | 0.056 | 0.137 | 0.026 | 0.061 | 0.000 | 0.025 | 0.054 | 0.000 |
| T3 | 0.000 | 0.000 | 0.091 | 0.063 | 0.000 | 0.000 | 0.118 | 0.063 | 0.000 |
| T4 | 0.105 | 0.000 | 0.056 | 0.118 | 0.000 | 0.000 | 0.050 | 0.056 | 0.000 |
| T5 | 0.091 | 0.047 | 0.204 | 0.022 | 0.050 | 0.000 | 0.067 | 0.122 | 0.026 |
| T6 | 0.000 | 0.000 | 0.063 | 0.000 | 0.000 | 0.125 | 0.133 | 0.000 | 0.000 |
| T7 | 0.048 | 0.056 | 0.083 | 0.000 | 0.143 | 0.000 | 0.048 | 0.000 | 0.000 |
| T8 | 0.217 | 0.042 | 0.023 | 0.000 | 0.000 | 0.000 | 0.037 | 0.000 | 0.000 |
| T9 | 1.000 | 0.000 | 0.000 | 0.125 | 0.000 | 0.000 | 0.111 | 0.000 | 0.000 |
| T10 | 0.000 | 1.000 | 0.000 | 0.071 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| T11 | 0.000 | 0.000 | 1.000 | 0.000 | 0.069 | 0.036 | 0.057 | 0.029 | 0.037 |
| T12 | 0.125 | 0.071 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.067 | 0.000 |
| T13 | 0.000 | 0.000 | 0.069 | 0.000 | 1.000 | 0.200 | 0.000 | 0.000 | 0.000 |
| T14 | 0.000 | 0.000 | 0.036 | 0.000 | 0.200 | 1.000 | 0.091 | 0.000 | 0.000 |
| T15 | 0.111 | 0.000 | 0.057 | 0.000 | 0.000 | 0.091 | 1.000 | 0.000 | 0.000 |
| T16 | 0.000 | 0.000 | 0.029 | 0.067 | 0.000 | 0.000 | 0.000 | 1.000 | 0.000 |
| T17 | 0.000 | 0.000 | 0.037 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| Sum of similarity | 1.721 | 1.379 | 2.057 | 1.516 | 1.578 | 1.452 | 1.736 | 1.415 | 1.063 |
| Topic Theme | Sum of Similarity | Salience (Weighted Frequency) | Coreness | Core/Periphery | |
|---|---|---|---|---|---|
| T5 | Analytics | 2.30 | 16.41 | −0.412 | CORE |
| T1 | Size | 2.27 | 14.02 | −0.422 | |
| T2 | Data | 2.18 | 11.68 | −0.435 | |
| T11 | Insight | 2.06 | 12.31 | −0.341 | |
| T8 | Storage | 1.83 | 8.17 | −0.273 | PERIPHERY |
| T7 | Complexity | 1.79 | 5.33 | −0.238 | |
| T15 | Cloud/Internet | 1.74 | 4.42 | −0.172 | |
| T9 | Security | 1.72 | 4.25 | −0.188 | |
| T4 | Applications | 1.62 | 4.83 | −0.147 | |
| T13 | Time | 1.58 | 0.96 | −0.164 | |
| T3 | Technology | 1.57 | 3.92 | −0.140 | |
| T6 | Speed | 1.55 | 2.50 | −0.155 | |
| T12 | Opportunities | 1.52 | 3.92 | −0.112 | |
| T14 | Cost | 1.45 | 0.67 | −0.090 | |
| T16 | Smart/AI | 1.41 | 3.87 | −0.133 | |
| T10 | Unstructured | 1.38 | 3.25 | −0.137 | |
| T17 | 4th Industrial revolution | 1.06 | 0.25 | −0.026 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maina, A.M.; Singh, U.G. Rebuilding Stakeholder Confidence in Health-Relevant Big Data Applications: A Social Representations Perspective. Information 2022, 13, 441. https://doi.org/10.3390/info13090441
Maina AM, Singh UG. Rebuilding Stakeholder Confidence in Health-Relevant Big Data Applications: A Social Representations Perspective. Information. 2022; 13(9):441. https://doi.org/10.3390/info13090441
Chicago/Turabian StyleMaina, Anthony M., and Upasana G. Singh. 2022. "Rebuilding Stakeholder Confidence in Health-Relevant Big Data Applications: A Social Representations Perspective" Information 13, no. 9: 441. https://doi.org/10.3390/info13090441
APA StyleMaina, A. M., & Singh, U. G. (2022). Rebuilding Stakeholder Confidence in Health-Relevant Big Data Applications: A Social Representations Perspective. Information, 13(9), 441. https://doi.org/10.3390/info13090441