1. Introduction
Entity Linking (EL) is considered an integral part of natural language processing and is often used as pre-processing for missions such as information extraction [
1] and intelligent question and answer [
2]; it also plays a critical role in the construction and updating of knowledge bases by linking different texts with structured information.
At present, the reason why entity linking technology has been significantly developed in English is that the language is not limited by word segmentation, and there are many knowledge bases of entity linking. In the early stages, the shortcomings in the development of Chinese entity linking were mainly as follows: (1) Chinese word segmentation and entity recognition have a more significant impact on entity linking; (2) Chinese entity linking started late and lacked a more mature knowledge base. OpenKG integrates 120 Chinese knowledge base projects, such as the graph database of Peking University, the CN-DBpedia, and CN-Probase projects of Fudan University, and the three major Chinese encyclopaedia projects, forming a relatively developed Chinese semantic knowledge base. Chinese entity linking has developed by leaps and bounds. However, the effect of short text entity linking is still not ideal.
Nowadays, Chinese short texts, such as questions and answers, queries, and headlines, are essential in the Internet corpus. For short texts, it is difficult to determine the specific meaning of a word without contextualizing it, so accurately linking entities in short texts remains a significant challenge.
With the rise of pre-training language models, entity linking methods based on pre-training language models have become a focus of research in recent years. Word2Vec and GloVe were widely used until 2019. Kolitsas et al. added contextual information encoding on top of character-level embedding in order to make word embeddings aware of the importance of local context, resulting in better experimental results. Gupta et al. [
3] obtained the meaning of entities in different contexts from introducing external data sources to enrich the semantic and contextual information of the entities. The method utilises GloVe as a source of word embedding, and uses an LSTM-based encoder to capture lexical and syntactic local contextual information of mentions. The word embedding produced by Word2Vec is static and independent of the sentence in which the word is located. For example, in the sentences “I want to access my bank account” and “We went to the river bank”, the vector of “bank” given by Word2Vec is fixed. Often the same entity is represented in different sentences with various meanings, requiring consideration of contextual semantic information. The advantage of BERT lies in the fact that the generated word embedding is dynamic and able to deal with ambiguity.
Entity linking can be seen as a problem of semantic matching between the text where the entity is mentioned and the text describing the candidate entity. Two methods are currently used to calculate the semantic similarity of sentence pairs: Cross-Encoder and Bi-Encoder. Cross-Encoder: two sentences are passed simultaneously to the BERT model, which produces an output value between 0 and 1, indicating the similarity of the input sentence pair. Cheng et al. [
4] stitched the entity text to be disambiguated and the candidate entity description text, and inputted them into the BERT model. The probability of the candidate entity was then obtained by concatenating the vector output at the [CLS] position with the feature vector of the candidate entity. Logeswaran et al. [
5] combined the mention of context and entity description text, using [SEP] to separate the text as input to the BERT, and subsequently scored the output. For many applications, Cross-Encoder is not practical (time-consuming), does not produce sentence embedding, and does not allow comparison using cosine similarity. Whereas Bi-Encoders can generate separate sentence embedding, Siamese networks are those that define two network structures to characterise the sentences in a sentence pair separately. Reimers et al. [
6] modified BERT to use Siamese and triple network structures to derive semantically meaningful sentence embedding that can be compared using cosine similarity. This is improved by considering that in Siamese network, encoding only sentence pairs does not take full advantage of the information in the text of the entities to be disambiguated.
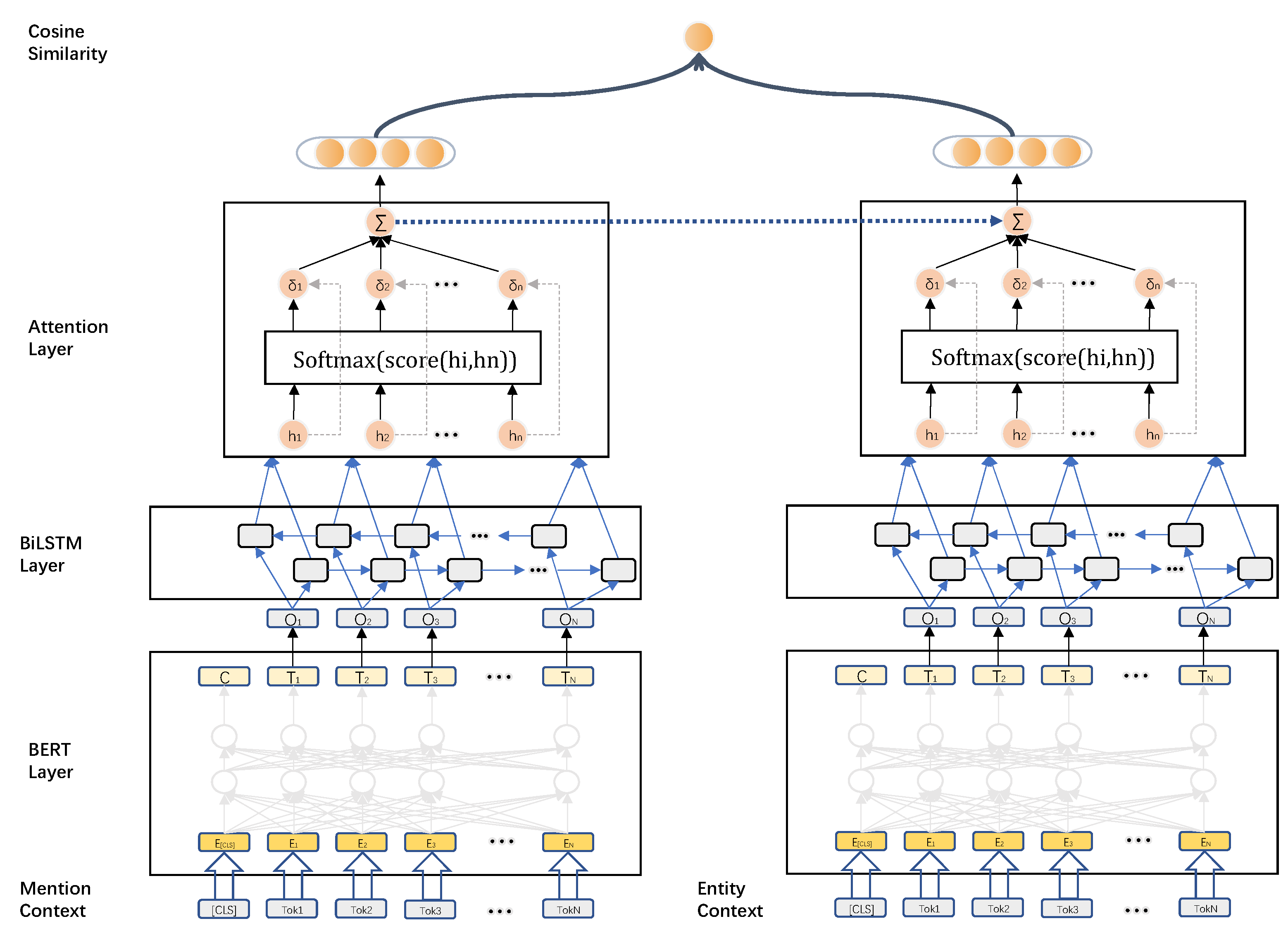
With the advent of pre-training models, the ability of machines to understand text content has become increasingly powerful. However, for disambiguation aspect, the similarity between the entity description text to be disambiguated and the candidate entity description text, is calculated directly through a pre-training model, which has the disadvantage of not making full use of the text information of the entity to be disambiguated. This paper proposes a short Chinese text entity linking method based on a Siamese-like network to solve the above drawbacks. RoBERTa-BiLSTM is used to generate sentence-level embeddings, extract key features in the text through an attention mechanism, and use the properties of the Siamese-like network for information transfer to achieve the purpose of text information reuse. By deeply parsing the semantic relationship of the text, mining the correlation between the entity text to be disambiguated and the candidate entity description text, and leveraging feature information of the text to be disambiguated to solve the ambiguity problem, the accuracy of entity linking in short texts can be improved. Taking kb_data in CCKS2019 as the basic knowledge base, the experimental verification of this method shows that the F1 value reaches 87.29%.
The rest of the paper is structured as follows. The latest techniques and various approaches to entity linking are discussed in
Section 2.
Section 3 introduces the entity linking model, explains the named entity recognition model, and details the entity disambiguation model in this paper.
Section 4 presents the pre-processing and the results of the experiments. In
Section 5, the conclusions and prospects are presented.
2. Related Work
Entity linking is a crucial technique to resolve the problem of words with multiple meanings and multiple words with the same meaning. Entity linking plays a crucial role in question and answer [
7], text analysis [
8], information retrieval [
9], and knowledge base augmentation [
10]. For question and answer, entity linking is an immediate need for KBQA, as the graph database can only be queried for subsequent work after the entity has been accurately linked. Entity linking works in two ways: end-to-end [
11] and linking-only [
12]. In the former, the entities in the text (i.e., NER) are extracted first and then the extracted entities are disambiguated. In the latter, on the other hand, the text and the entities are mentioned directly as input (the default entities are already identified), and candidate entities are found and disambiguated. The ultimate aim of both ways of working is to accurately match ambiguous entities. Most of the time, it is considered that entity disambiguation is equivalent to entity linking, except that the step of named entity recognition is missing. Many scholars [
13,
14] view entity linking as a binary classification problem. For example, given <entity referent term, candidate entity>, a dichotomous model is used to determine whether they match or not. Nowadays, scholars have proposed a series of effective methods to disambiguate entities, divided into two approaches: (1) methods based on graph models; (2) methods based on deep learning.
Alhelbawy et al. [
15] used a graph-based approach to perform joint entity disambiguation. All entities in the text are represented as nodes in the graph, which are ranked based on their PageRank values, and entity disambiguation is performed according to the magnitude of the numerical value. Zhang et al. [
16] designed a unified framework LinKG to merge different types of knowledge graphs, and proposed a Heterogeneous Graph Attention Network (HGAN) to match entities with ambiguous moulds correctly (e.g., human names). Hu et al. [
17] used a graph neural network model to solve the entity disambiguation problem. An entity-word heterogeneous graph is constructed for each document to build global semantic relationships among disambiguated entities in the text, obtain entity graph embeddings that encode global semantic features, and transfer the embedding representation to a statistical model to disambiguate entities. However, graph-based models treat all candidate entities the same, which leads to increased difficulty in differentiation, Fang et al. [
18] designed a Sequence Graph Attention Network (SeqGAT), which takes full advantage of graph and sequence methods to dynamically encode before and after entities, exploiting local consistency and reducing noise interference. In the context-limited short text with insufficient number of entities and relationships, the graph model-based approach ignores the entity-to-entity relationship, and therefore cannot obtain the global semantic features of entities. To address this problem, Zhang et al. [
19] first predicted the classification of entities to be disambiguated, which yielded the set of candidate entities based on category, and then found the association with the candidate entities for disambiguation through a knowledge graph. The knowledge graph itself is a graph-based data structure that not only contains information about entities, but also holds the relationship between entities, which can display the global semantic features of entities. Zhu et al. [
20] designed a Category2Vec embedding model based on joint learning of word and category embeddings to calculate the semantic similarity between contextual and informational words of entities in the knowledge graph, and improve the performance of disambiguation methods based on context similarity.
In 2018, Google proposed the BERT pre-training model [
21]. Since then, the large-scale pre-training language model has become a mainstream approach, allowing the field of natural language processing to develop by leaps and bounds. A large number of researchers have improved and fine-tuned the model and achieved better performance on numerous sub-tasks of natural language processing (e.g., entity linking). Zhan et al. [
22] used BERT as a basic framework to extract the connections between the context of entities to be disambiguated and candidate entities and refine entity associations by analysing entity interrelationships. Later, [
23] introduced a multi-task learning approach into the short textual entity linking process to build a multi-task learning model for entity linking and classification, to mitigate the problem of insufficient information in the short textual entity linking process. Zhang et al. [
24] stitched the context of the entity mention with the description text of the candidate entities and introduced a local attention mechanism to alleviate the long-distance problem and enhance local context information. Zhao et al. [
25] presented a BERT-Random Walk with Restart (BERT-RWR) entity linking model by combining deep neural networks and graph neural networks, aiming to compute the semantic similarity between entity mentions and candidate entities, with better results. Gu et al. [
26] designed a multi-round reading framework to perform the entity linking of short texts. Generating a separate question for each entity to be disambiguated, forming a candidate set through the entities in the knowledge base, and using the linked entities to update the current interrogative is equivalent to adding a contextual description of the entities to be disambiguated, thus improving the accuracy of entity linking. Barbara et al. [
27] defined the entity disambiguation task as a text extraction task, where the text to be disambiguated and all candidate entity texts are stitched together. The output of the model is then the index of words starting and ending with the target option, and the method achieves optimality on several datasets.
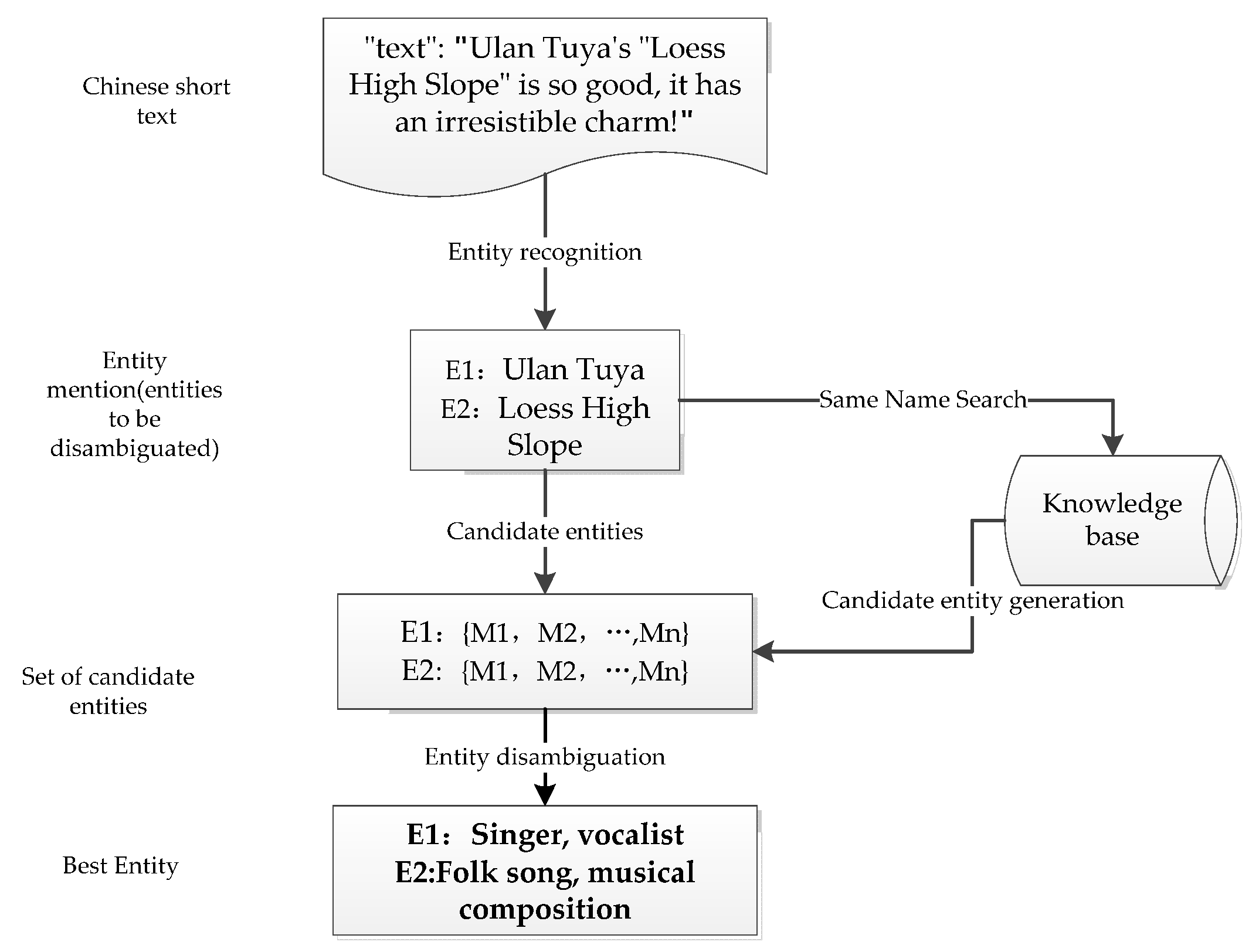
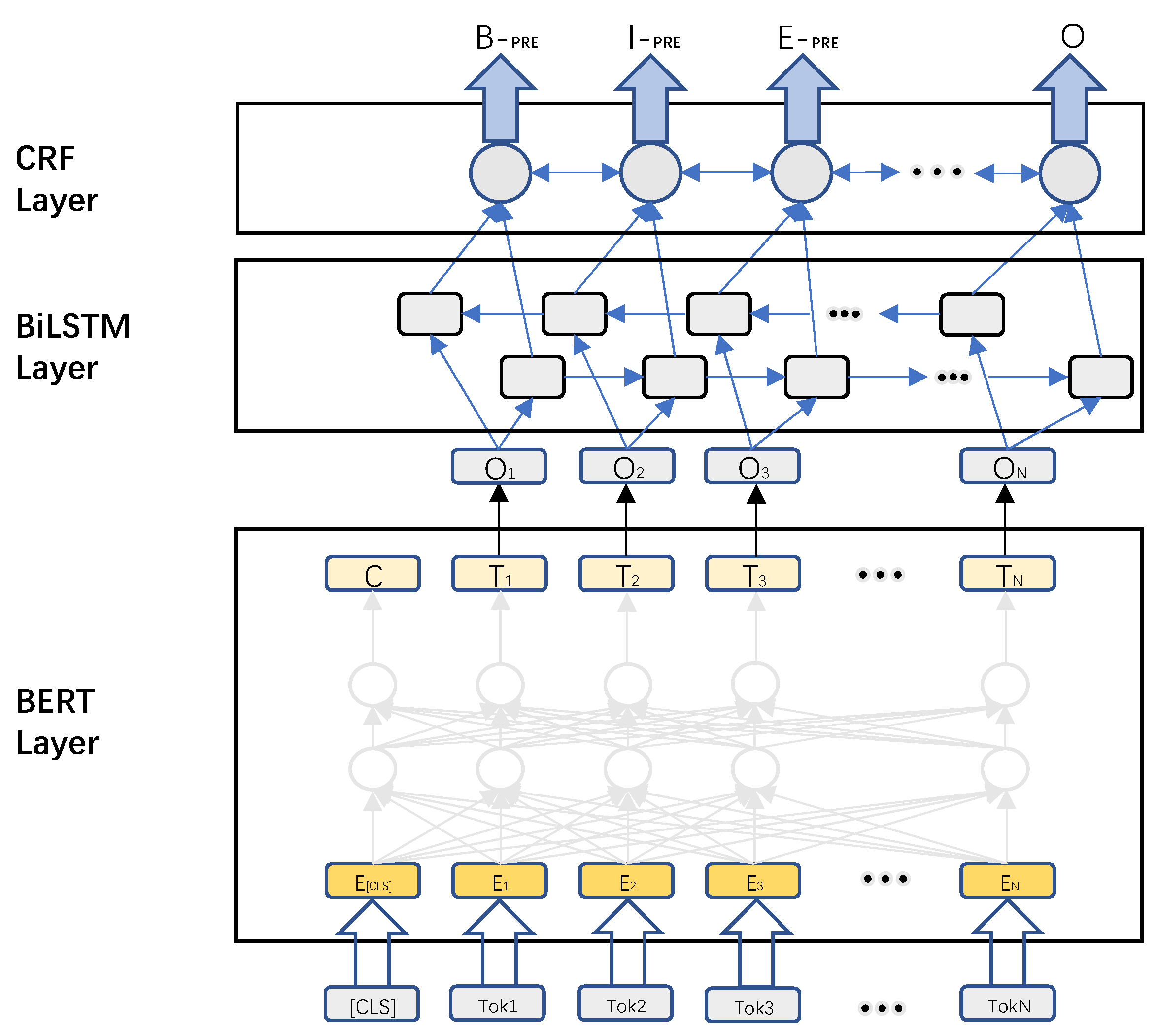
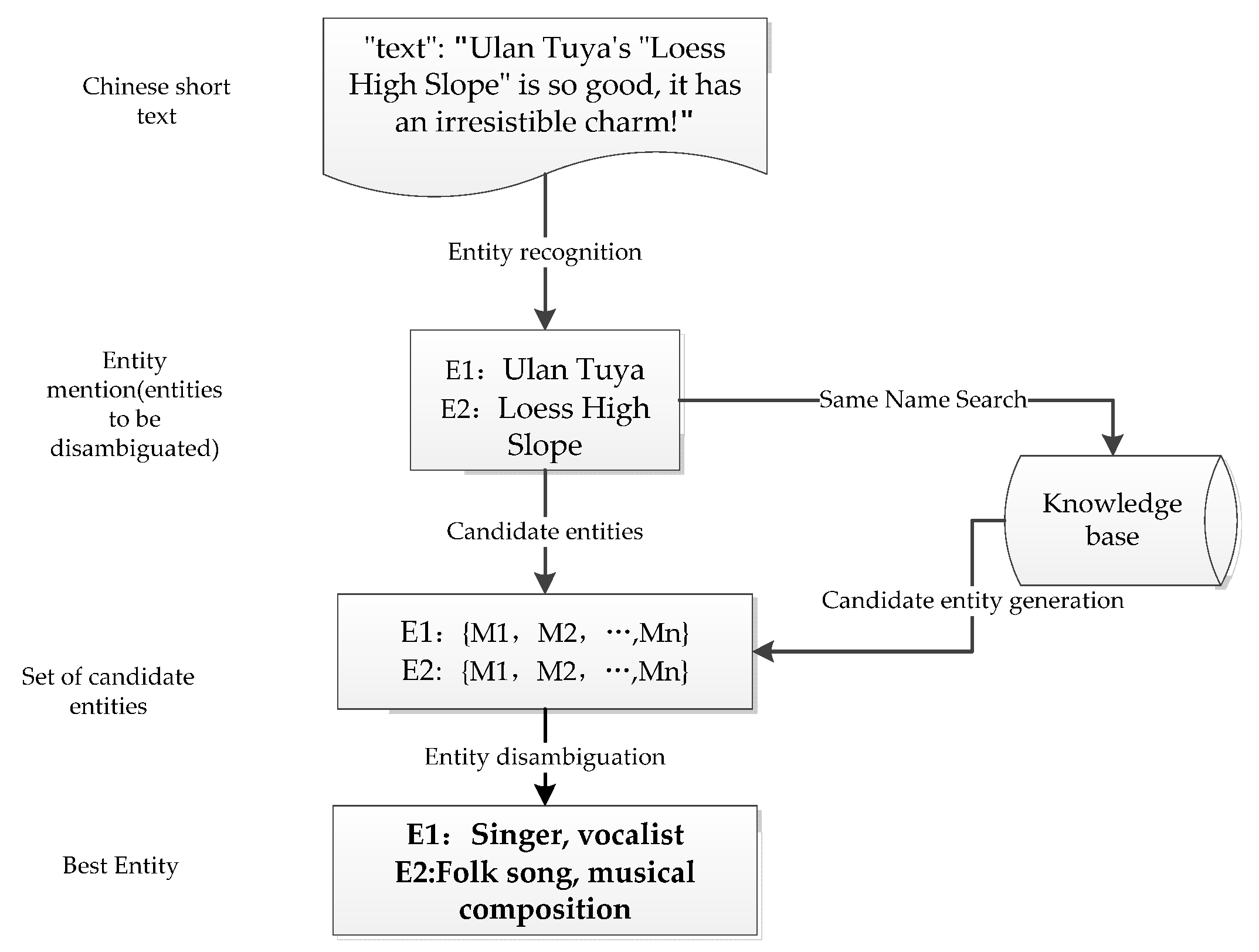
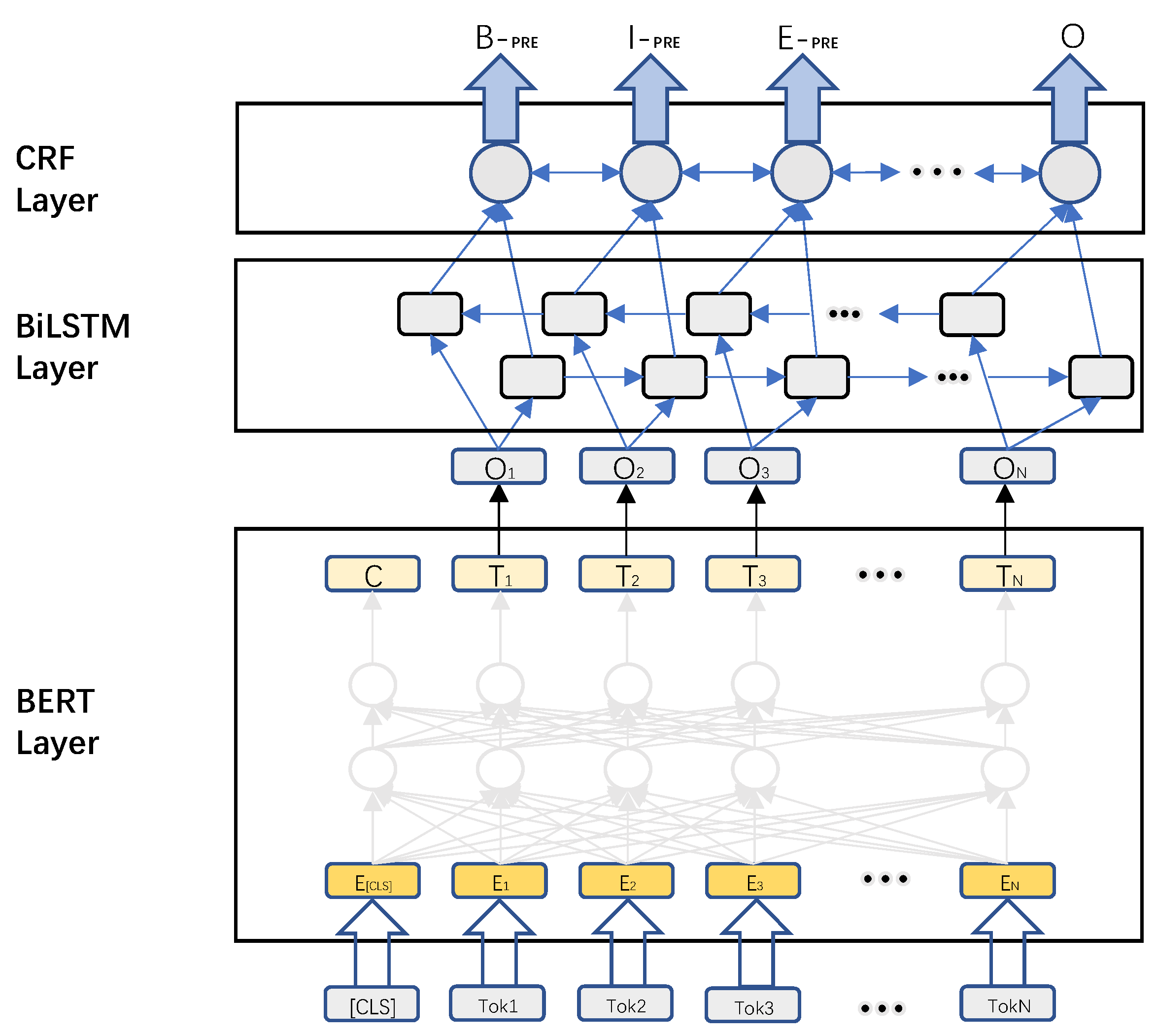
In this paper, the disambiguation entities in the text are identified using the RoBERTa-WWM-BiLSTM-CRF (Conditional Random Field) network framework, and the information of the text to be disambiguated is fully utilized for entity disambiguation using the properties of a Siamese-like Network.
Author Contributions
Conceptualization, Y.Z.; Data curation, B.C.; Investigation, Y.Z. and B.H.; Methodology, J.L.; Project administration, J.L.; Supervision, B.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Scientific and technological innovation 2030—major project of new generation artificial intelligence (2020AAA0109300); National Natural Science Foundation (U1831133); Shanghai Science and Technology Commission Science and Technology Innovation Action Plan (22S31903700, 21S31904200).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wu, F.; Weld, D.S. Open information extraction using Wikipedia. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 118–127. [Google Scholar]
- Fleischman, M.; Hovy, E.; Echihabi, A. Offline strategies for online question answering: Answering questions before they are asked. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, Sapporo, Japan, 7–12 July 2003; pp. 1–7. [Google Scholar]
- Gupta, N.; Singh, S.; Roth, D. Entity linking via joint encoding of types, descriptions, and context. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2681–2690. [Google Scholar]
- Cheng, J.; Pan, C.; Dang, J.; Yang, Z.; Guo, X.; Zhang, L.; Zhang, F. Entity linking for Chinese short texts based on BERT and entity name embeddings. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing, Hangzhou, China, 24–27 August 2019. [Google Scholar]
- Logeswaran, L.; Chang, M.; Lee, K.; Toutanova, K.; Devlin, J.; Lee, H. Zero-shot entity linking by reading entity descriptions. arXiv 2019, arXiv:1906.07348. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Zhang, Y.; He, S.; Liu, K.; Zhao, J. A joint model for question answering over multiple knowledge bases. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; p. 30. [Google Scholar]
- Michelson, M.; Macskassy, S.A. Discovering users’ topics of interest on twitter: A first look. In Proceedings of the Fourth Workshop on Analytics for Noisy Unstructured Text Data, Toronto, ON, Canada, 26–30 October 2010; pp. 73–80. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Ji, H.; Grishman, R. Knowledge base population: Successful approaches and challenges. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1148–1158. [Google Scholar]
- Broscheit, S. Investigating entity knowledge in BERT with simple neural end-to-end entity linking. arXiv 2020, arXiv:2003.05473, 2020. [Google Scholar]
- Nie, F.; Cao, Y.; Wang, J.; Lin, C.-Y.; Pan, R. Mention and entity description co-attention for entity disambiguation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Davletov, A.; Arefyev, N.; Gordeev, D.; Rey, A. LIORI at SemEval-2021 Task 2: Span Prediction and Binary Classification approaches to Word-in-Context Disambiguation. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Online, 5–6 August 2021; pp. 780–786. [Google Scholar]
- Yunfang, W.; Miao, W.; Peng, J.; Shiwen, Y. Ensembles of Classifiers for Chinese Word Sense Disambiguation. Comput. Res. Dev. 2008, 45, 1354–1361. [Google Scholar]
- Alhelbawy, A.; Gaizauskas, R. Graph ranking for collective named entity disambiguation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 75–80. [Google Scholar]
- Zhang, F.; Liu, X.; Tang, J.; Dong, Y.; Yao, P.; Zhang, J.; Gu, X.; Wang, Y.; Shao, B.; Li, R.; et al. OAG: Toward Linking Large-scale Heterogeneous Entity Graphs. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2585–2595. [Google Scholar]
- Hu, L.; Ding, J.; Shi, C.; Shao, C.; Li, S. Graph neural entity disambiguation. Knowl. Based Syst. 2020, 195, 105620. [Google Scholar] [CrossRef]
- Fang, Z.; Cao, Y.; Li, R.; Zhang, Z.; Liu, Y.; Wang, S. High quality candidate generation and sequential graph attention network for entity linking. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 640–650. [Google Scholar]
- Zhang, K.; Zhu, Y.; Gao, W.; Xing, Y.; Zhou, J. An approach for named entity disambiguation with knowledge graph. In Proceedings of the International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 138–143. [Google Scholar]
- Zhu, G.; Iglesias, C.A. Exploiting semantic similarity for named entity disambiguation in knowledge graphs. Expert Syst. Appl. 2018, 101, 8–24. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805, 2018. [Google Scholar]
- Fei, Z.; Yanhui, Z.; Wentong, L.; Xiangbing, J. Entity linking methods based on BERT and TextRank keyword extraction. J. Hunan Univ. Technol. 2020, 34, 63–70. [Google Scholar]
- Fei, Z.; Yanhui, Z.; Wentong, L.; Xu, Z.; Kang, O.; Lingwei, K. Short text entity linking method based on multi-task learning. Comput. Eng. 2022, 48, 6. [Google Scholar]
- Shengqi, Z.; Yuanlong, W.; Ru, L.; Xiaoyue, W.; Xiaohui, W.; Zhichao, Y. Entity Linking of Chinese Short Texts Based on Local Attention Mechanism. Comput. Eng. 2021, 47, 8. [Google Scholar]
- Zhao, Y.; Wang, Y.; Yang, N. Chinese Short Text Entity Linking Based On Semantic Similarity and Entity Correlation. In Proceedings of the 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 426–431. [Google Scholar]
- Gu, Y.; Qu, X.; Wang, Z.; Huai, B.; Yuan, N.J.; Gui, X. Read, retrospect, select: An mrc framework to short text entity linking. arXiv 2021, arXiv:2101.02394. [Google Scholar]
- Barba, E.; Procopio, L.; Navigli, R. ExtEnD: Extractive Entity Disambiguation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2478–2488. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-Training with Whole Word Masking for Chinese BERT. arXiv 2019, arXiv:1906.08101. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cornegruta, S.; Bakewell, R.; Withey, S.; Montana, G. Modelling radiological language with bidirectional long short-term memory networks. arXiv 2016, arXiv:1609.08409. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Morgan Kaufmann, New York, NY, USA, 16–21 July 2022; pp. 282–289. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}