
Face Identification Using Data Augmentation Based on the Combination of DCGANs and Basic Manipulations



Abstract
:1. Introduction
- We propose a novel data augmentation technique in which DCGAN and basic manipulations are combined. We use the Wasserstein loss to replace the standard DCGAN cross-entropy loss to solve the problem of DCGAN training instability. We show that our model improves face recognition performance by considering the LFW dataset [7], VGGFace2 dataset [8], and ChokePoint video database [9].
- We demonstrate the benefits of the proposed augmentation strategy for face recognition by comparing our approach with approaches using only basic manipulations and only a generative approach.
- We show that the use of SVM instead of the Softmax function with a FaceNet model may improve face recognition accuracy compared to the other tested techniques.
2. Related Works
2.1. Image Data Augmentation Techniques
2.2. Face Recognition Techniques
2.2.1. Conventional Methods
2.2.2. Deep Learning Methods
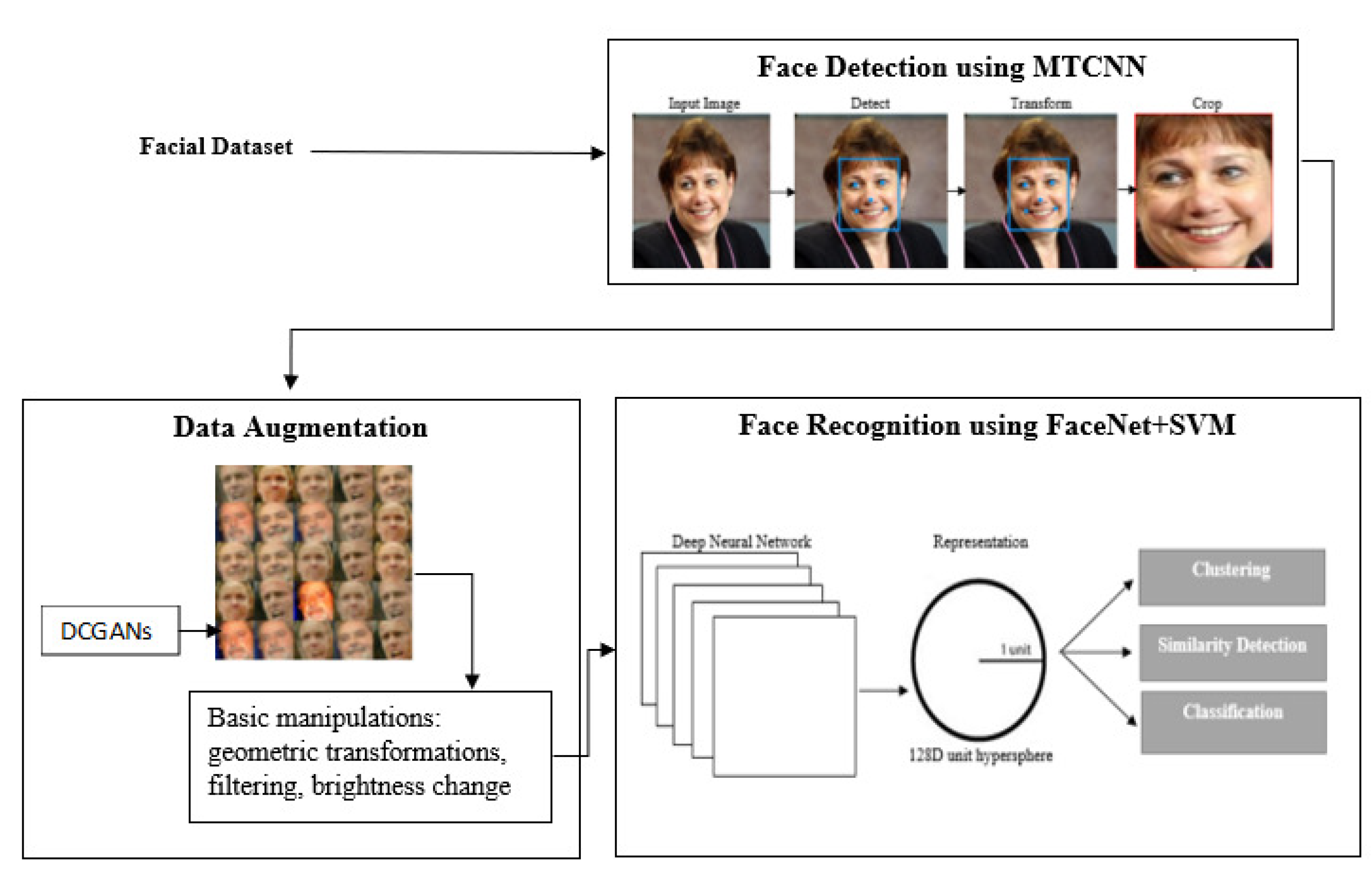
3. Proposed Approach
3.1. Face Detection Using MTCNN
3.2. Data Augmentation Using DCGAN Combined with Basic Manipulations
3.3. Face Recognition Using FaceNet Combined with SVM
4. Results and Discussions
4.1. Datasets
4.1.1. Labeled Faces in the Wild (LFW) Dataset
4.1.2. VGGFace2 Dataset
4.1.3. ChokePoint Dataset
4.2. Evaluation
4.2.1. Quality of Generated Images
4.2.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, R.; Yan, S.; Shan, Y.; Dang, Q.; Sun, G. Deep image: Scaling up image recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Torfi, A.; Shirvani, R.; Keneshloo, Y.; Fox, E. Natural language processing advancements by deep learning: A survey. arXiv 2020, arXiv:2003.01200. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Agarap, A.F. An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification. arXiv 2019, arXiv:1712.03541v2. [Google Scholar]
- Suguna, G.C.; Kavitha, H.S.; Sunita, S. Face Recognition System For Realtime Applications Using SVM Combined With FaceNet And MTCNN. Int. J. Electr. Eng. Technol. (IJEET) 2021, 12, 328–335. [Google Scholar]
- Ammar, S.; Bouwmans, T.; Zaghden, N.; Neji, M. Towards an Effective Approach for Face Recognition with DCGANs Data Augmentation. Adv. Vis. Comput. 2020, 12509. [Google Scholar]
- Huang, G.B.; Mattar, M.; Tamara, B.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Tuscany, Italy, 28 July–3 August 2008. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A dataset for recognising face across pose and age. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Xi’an, China, 15–19 May 2018. [Google Scholar]
- Wong, Y.; Chen, S.; Mau, S.; Sanderson, C.; Lovell, B.C. Patch-based Probabilistic Image Quality Assessment for Face Selection and Improved Video-based Face Recognition. In Proceedings of the IEEE Biometrics Workshop, Computer Vision and Pattern Recognition (CVPR) Workshops, Colorado Springs, CO, USA, 20–25 June 2011; pp. 81–88. [Google Scholar]
- Kwasigroch, A.; Mikołajczyk, A.; Grochowski, M. Deep neural networks approach to skin lesions classification—A comparative analysis. In Proceedings of the International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 28–31 August 2017; pp. 1069–1074. [Google Scholar]
- Ben Fredj, H.; Bouguezzi, S.; Souani, C. Face recognition in unconstrained environment with CNN. Vis. Comput. 2020, 37, 217–226. [Google Scholar] [CrossRef]
- Noh, H.; You, T.; You, M.J.; Han, B. Regularizing deep neural networks by noise: Its interpretation and optimization. Adv. Neural Inf. Process. Syst. 2017, 5109–5118. [Google Scholar]
- Francisco, J.M.-B.; Fiammetta, S.; Jose, M.J.; Daniel, U.; Leonardo, F. Forward noise adjustment scheme for data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018. [Google Scholar]
- Xu, Y.; Li, X.; Yang, J.; Zhang, D. Integrate the original face image and its mirror image for face recognition. Neurocomputing 2014, 131, 191–199. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13001–13008. [Google Scholar] [CrossRef]
- Mohammadzade, H.; Hatzinakos, D. Projection into expression subspaces for face recognition from single sample per person. IEEE Trans. Affect. Comput. 2013, 4, 69–82. [Google Scholar] [CrossRef]
- Kang, G.; Dong, X.; Zheng, L.; Yang, Y. PatchShuffle regularization. arXiv 2017, arXiv:1707.07103. [Google Scholar]
- Lv, J.; Shao, X.; Huang, J.; Zhou, X.; Zhou, X. Data augmentation for face recognition. Neurocomputing 2017, 230, 184–196. [Google Scholar] [CrossRef]
- Li, B.; Wu, F.; Lim, S.; Weinberger, K. On feature normalization and data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12383–12392. [Google Scholar]
- Zheng, X.; Chalasani, T.; Ghosal, K.; Lutz, S. Stada: Style transfer as data augmentation. arXiv 2019, arXiv:1909.01056. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Christopher, B.; Liang, C.; Ricardo, G.P.B.; Roger, G.; Hammers, A.; David, A.D.; Maria, V.H. GAN augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Yi, W.; Sun, Y.; He, S. Data Augmentation Using Conditional GANs for Facial Emotion Recognition. In Proceedings of the Progress in Electromagnetics Research Symposium, Toyama, Japan, 1–4 August 2018. [Google Scholar]
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Ammar, S.; Zaghden, N.; Neji, M. A Framework for People Re-Identification in Multi-Camera Surveillance Systems; International Association for Development of the Information Society: Lisbon, Portugal, 2017. [Google Scholar]
- Ammar, S.; Bouwmans, T.; Zaghden, N.; Neji, M. From Moving Objects Detection to Classification And Recognition: A Review for Smart Cities. In Handbook on Towards Smart World: Homes to Cities using Internet of Things Publisher; CRC Press, Taylor and Francis Group: Boca Raton, FL, USA, 2017. [Google Scholar]
- Anzar, S.M.; Amrutha, T. Efficient wavelet based scale invariant feature transform for partial face recognition. In AIP Conference Proceedings; AIP Publishing LLC: New York, NY, USA, 2020; Volume 2222, p. 030017. [Google Scholar]
- Ghorbel, A.; Tajouri, I.; Aydi, W.; Masmoudi, N. A comparative study of GOM, uLBP, VLC and fractional Eigenfaces for face recognition. In Proceedings of the 2016 International Image Processing, Applications and Systems (IPAS), Virtual Event, Italy, 9–11 December 2016; pp. 1–5. [Google Scholar]
- Johannes, R.; Armin, S. Face Recognition with Machine Learning in OpenCV Fusion of the results with the Localization Data of an Acoustic Camera for Speaker Identification. arXiv 2017, arXiv:1707.00835. [Google Scholar]
- Khoi, P.; Thien, L.H.; Viet, V.H. Face Retrieval Based on Local Binary Pattern and Its Variants: A Comprehensive Study. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 249–258. [Google Scholar] [CrossRef] [Green Version]
- Xi, M.; Chen, M.; Polajnar, D.; Tong, W. Local binary pattern network: A deep learning approach for face recognition. IEEE ICIP 2016, 25, 3224–3228. [Google Scholar]
- Laure Kambi, I.; Guo, C. Enhancing face identification using local binary patterns and k-nearest neighbors. J. Imaging 2017, 3, 37. [Google Scholar]
- Kumar, D.; Garaina, J.; Kisku, D.R.; Sing, J.K.; Gupta, P. Unconstrained and Constrained Face Recognition Using Dense Local Descriptor with Ensemble Framework. Neurocomputing 2020, 408, 273–284. [Google Scholar] [CrossRef]
- Karraba, M.; Surinta, O.; Schomaker, L.; Wiering, M. Robust face recognition by computing distances from multiple histograms of oriented gradients. IEEE Symp. Ser. Comput. Intell. 2015, 7, 10. [Google Scholar]
- Arigbabu, O.; Ahmad, S.; Adnan, W.A.W.; Yussof, S.; Mahmood, S. Soft biometrics: Gender recognition from unconstrained face images using local feature descriptor. arXiv 2017, arXiv:1702.02537. [Google Scholar]
- Napoléon, T.; Alfalou, A. Local binary patterns preprocessing for face identification/verification using the VanderLugt correlator. In Optical Pattern Recognition; SPIE: Bellingham, DC, USA, 2014; pp. 408–909. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W. Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Shuting, C.; Luo, Q.; Yang, M.; Xiao, M. Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Appl. Sci. 2019, 9, 7. [Google Scholar]
- Liu, Y. Tensors for Data Processing: Theory, Methods and Applications, 1st ed.; Academic Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Qian, Y.; Gong, M.; Cheng, L. Stocs: An efficient self-tuning multiclass classification approach. In Proceedings of the Canadian Conference on Artificial Intelligence, Halifax, NS, Canada, 2–5 June 2015; pp. 291–306. [Google Scholar]
- Wu, Z.; Peng, M.; Chen, T. Thermal face recognition using convolutional neural network. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing (ICOIP), Warsaw, Poland, 10–12 June 2016; pp. 6–9. [Google Scholar]
- Song, L.; Gong, D.; Li, Z.; Liu, C.; Liu, W. Occlusion Robust Face Recognition Based on Mask Learning with Pairwise Differential Siamese Network. In Proceedings of the 2019 International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance metric learning for large margin nearset neighbor classification. J. Mach. Learn. Res. Adv. Neural Inf. Process. Syst. 2009, 10, 207–244. [Google Scholar]
- Liu, W.; Wren, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July; pp. 212–220.
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4690–4699. [Google Scholar]
- Tornincasa, S.; Vezzetti, E.; Moos, S.; Violante, M.G.; Marcolin, F.; Dagnes, N.; Ulrich, L.; Tregnaghi, G.F. 3D Facial Action Units and Expression Recognition using a Crisp Logic. Comput. Aided Des. Appl. 2019, 16, 256–268. [Google Scholar] [CrossRef]
- Dagnes, N.; Marcolin, F.; Vazzetti, E.; Sarhan, F.R.; Dakpé, S.; Marin, F.; Nonis, F.; Mansour, K.B. Optimal marker set assessment for motion capture of 3D mimic facial movements. J. Biomech. 2019, 93, 86–93. [Google Scholar] [CrossRef]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Recover Canonical-View Faces in the Wild with Deep Neural Networks. arXiv 2014, arXiv:1404.3543. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708. [Google Scholar]
- Simonyan, K.; Zisserman, K. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predecting 10,000 classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitionhl, Columbus, OH, USA, 24–27 June 2014; Volume 23, pp. 1891–1898. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep Learning Face representation by joint identification-verification. In Proceedings of the NIPS’14: Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Chen, D.; Cao, X.; Wang, L.; Wen, F.; Sun, J. Bayesian face revisited: A joint formulation. In Proceedings of the Computer Vision ECCV, Florence, Italy, 7–13 October 2012; pp. 566–579. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning grained image similarity with deep ranking. In Proceedings of the CVPR 2014: 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Duan, Q.; Zhang, L. Look more into occlusion: Realistic face frontalization and recognition with boostgan. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 214–228. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.078757. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
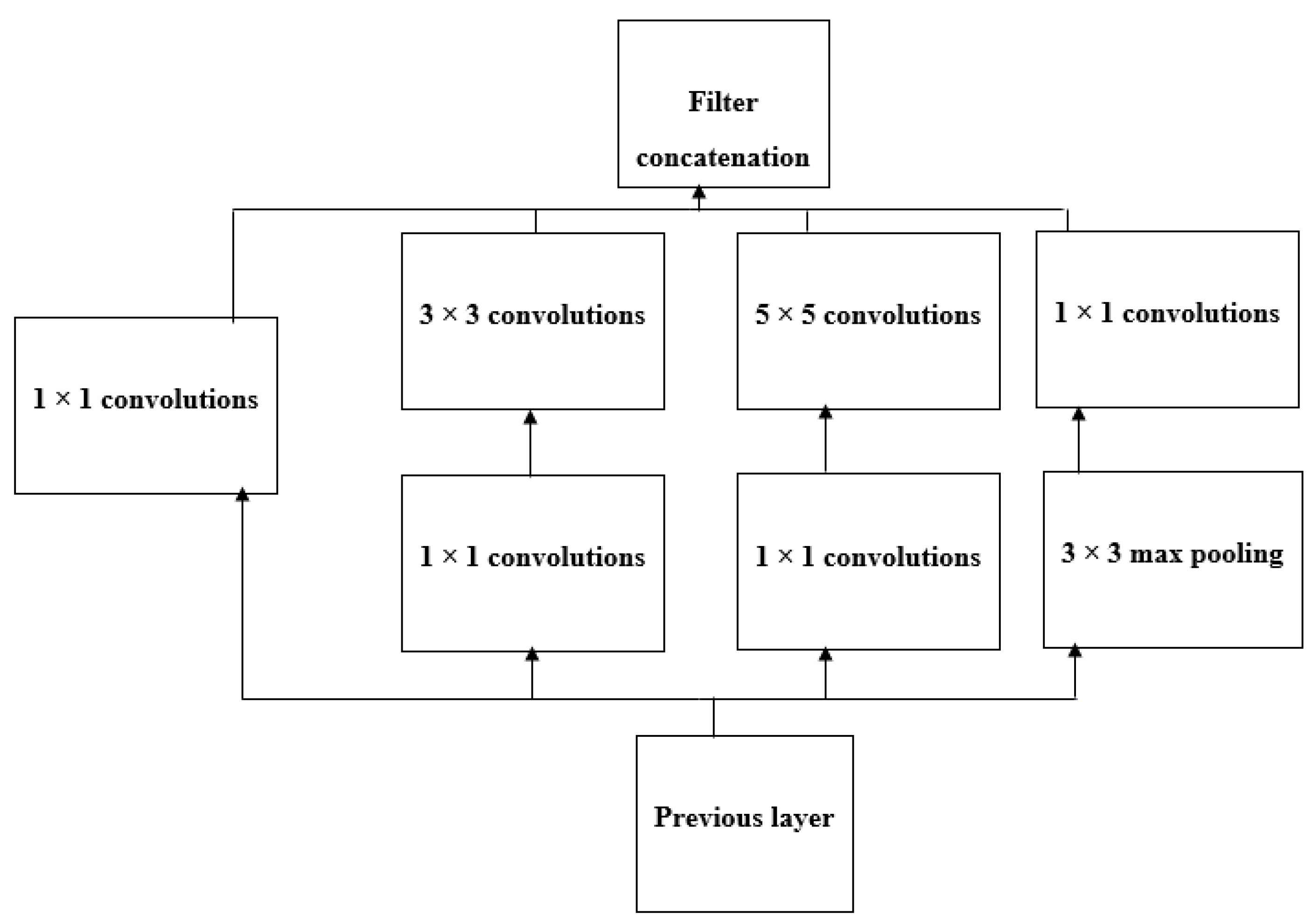
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Pei, Z.; Xu, H.; Zhang, Y.; Guo, M.; Yang, Y. Face recognition via deep learning using data augmentation based on orthogonal experiments. Electronics 2019, 8, 1088. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Augmented Samples per Class | ||||
| +0 | +100 | +250 | +500 | |
| LFW [7] | 0.64 | 0.79 | 0.90 | 0.945 |
| VGG [8] | 0.61 | 0.83 | 0.88 | 0.922 |
| +0 | +100 | |
| ChokePoint dataset [9] | 94.71% | 96.4% |
| PCA method | 50% |
| Tensor RPCA [38] | 60.5% |
| LBPH method | 37% |
| CNN with filter operation augmentation method [63] | 65.4% |
| CNN with geometric transformations and brightness augmentation method [63] | 83.6% |
| FaceNet + SVM with filter operation augmentation method | 78.40% |
| FaceNet + SVM with geometric transformations and brightness augmentation method | 85.23% |
| FaceNet + SVM with DCGANs augmentation method [6] | 92.12% |
| Proposed approach (FaceNet + SVM + DCGANs + filter operation) | 93.4% |
| Proposed approach (FaceNet + SVM + DCGANs + geometric transformations + brightness) | 94.5% |
| PCA method | 40% |
| Tensor RPCA [38] | 41.5% |
| LBPH method | 32% |
| CNN with filter operation augmentation method [63] | 64.85% |
| CNN with geometric transformations and brightness augmentation method [63] | 74.21% |
| FaceNet + SVM with filter operation augmentation method | 79.6% |
| FaceNet + SVM with geometric transformations and brightness augmentation method | 78.94% |
| FaceNet + SVM with DCGANs augmentation method [6] | 91.83% |
| Proposed approach (FaceNet + SVM + DCGANs + filter operation) | 91.97% |
| Proposed approach (FaceNet + SVM + DCGANs + geometric transformations + brightness) | 92.21% |
| Number of Augmented Samples per Class | |
| PCA method | 50.4% |
| Tensor RPCA method [38] | 61.2 |
| LBPH method | 34.09% |
| CNN with filter operation augmentation method [63] | 69.83% |
| CNN with geometric transformations and brightness augmentation method [63] | 74.66% |
| FaceNet + SVM with filter operation augmentation method | 81.26% |
| FaceNet + SVM with geometric transformations and brightness augmentation method | 83.18% |
| FaceNet + SVM with DCGANs augmentation method [6] | 95.18% |
| Proposed approach (FaceNet + SVM + DCGANs + filter operation) | 95.8% |
| Proposed approach (FaceNet + SVM + DCGANs + geometric transformations + brightness) | 96.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ammar, S.; Bouwmans, T.; Neji, M. Face Identification Using Data Augmentation Based on the Combination of DCGANs and Basic Manipulations. Information 2022, 13, 370. https://doi.org/10.3390/info13080370
Ammar S, Bouwmans T, Neji M. Face Identification Using Data Augmentation Based on the Combination of DCGANs and Basic Manipulations. Information. 2022; 13(8):370. https://doi.org/10.3390/info13080370
Chicago/Turabian StyleAmmar, Sirine, Thierry Bouwmans, and Mahmoud Neji. 2022. "Face Identification Using Data Augmentation Based on the Combination of DCGANs and Basic Manipulations" Information 13, no. 8: 370. https://doi.org/10.3390/info13080370
APA StyleAmmar, S., Bouwmans, T., & Neji, M. (2022). Face Identification Using Data Augmentation Based on the Combination of DCGANs and Basic Manipulations. Information, 13(8), 370. https://doi.org/10.3390/info13080370