
Computationally Efficient Context-Free Named Entity Disambiguation with Wikipedia



Abstract
:1. Introduction
2. Brief Related-Work Background
2.1. Named Entity Disambiguation with Wikipedia Entities Methodologies
2.2. Recent Compute Intensive Approaches
3. Materials and Methods
- Extraction, transformation, and loading phase of our underlying knowledge base.
- Mention parsing and identification of candidate mentions within the unstructured text input.
- Mention disambiguation/entity linking for selecting mention annotations.
- Mention annotation scoring and pruning based on confidence evaluation.
- The notion p will be used for Wikipedia articles, i.e., entities.
- A mention will refer to a hyperlink to a p.
- A mention to a p will be referred to as a. Consequently, sequences of such mentions may be using indexing for reference, starting from a1 and ranging to am, hence, m will be referring to the cardinality of the input mentions.
- The ensemble of linkable Wikipedia entities of a specific mention text will be denoted as Pg(a).
3.1. Preprocessing, Knowledge Extraction, Transformation, and Load
- Mention text: the anchor hyperlink text of the specific mention occurrence.
- Source article Wikipedia ID: the Wiki ID [43] of the page of occurrence of the specific mention.
- |Pg(a0)| = 2, Pg(a0) = {p00, p01} and
- P(p00|a0) = 0.8,
- P(p01|a0) = 0.2,
- |Pg(a1)| = 3, Pg(a1) = {p10, p11, p12} and
- P(p10|a1) = 0.8,
- P(p11|a1) = 0.1,
- P(p12|a1) = 0.1,
3.2. Entity Linking
3.2.1. Mention Parsing
3.2.2. Mention Disambiguation
3.2.3. Confidence Evaluation Score
3.3. Experimental Evaluation Methodology
4. Results and Discussion
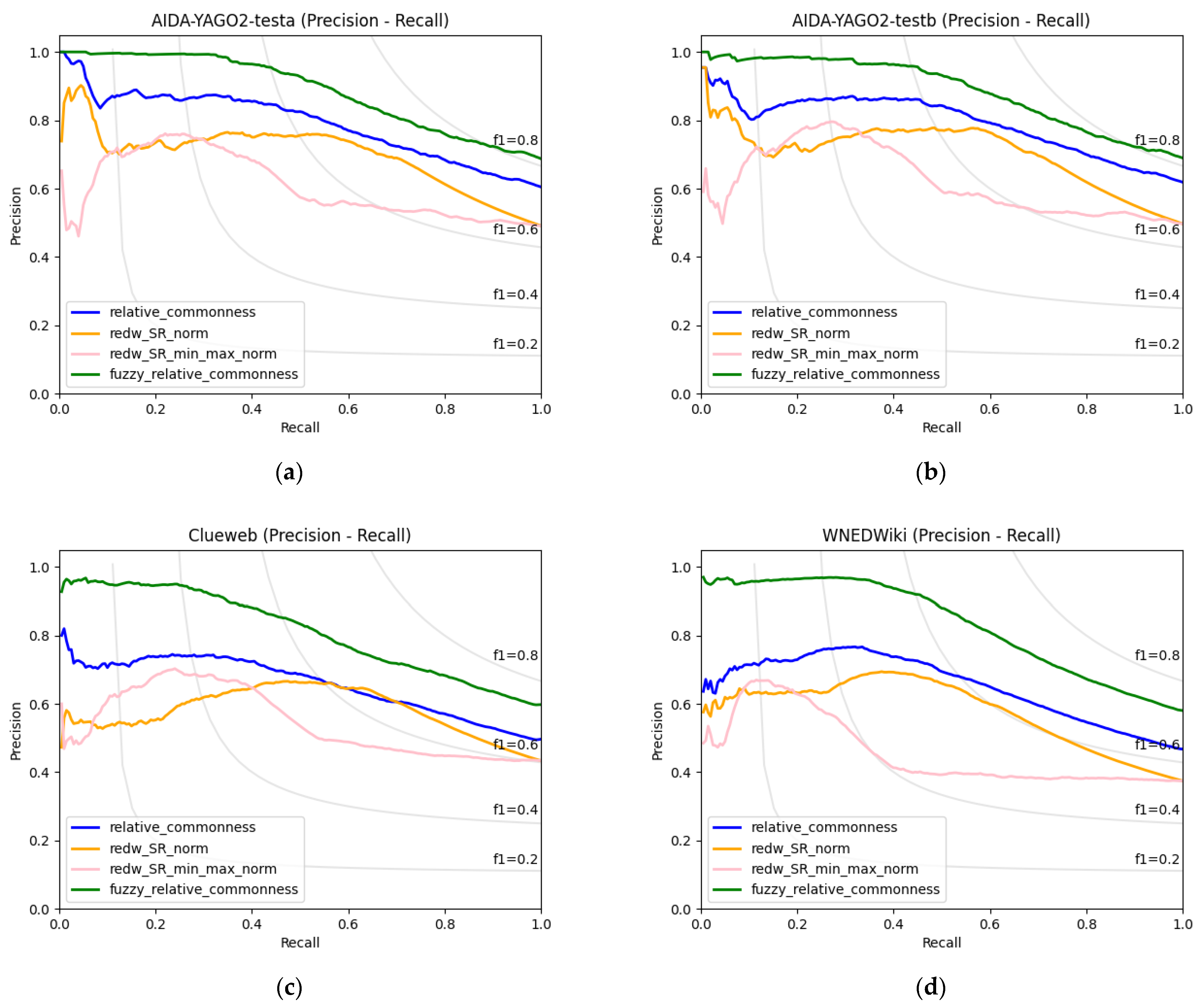
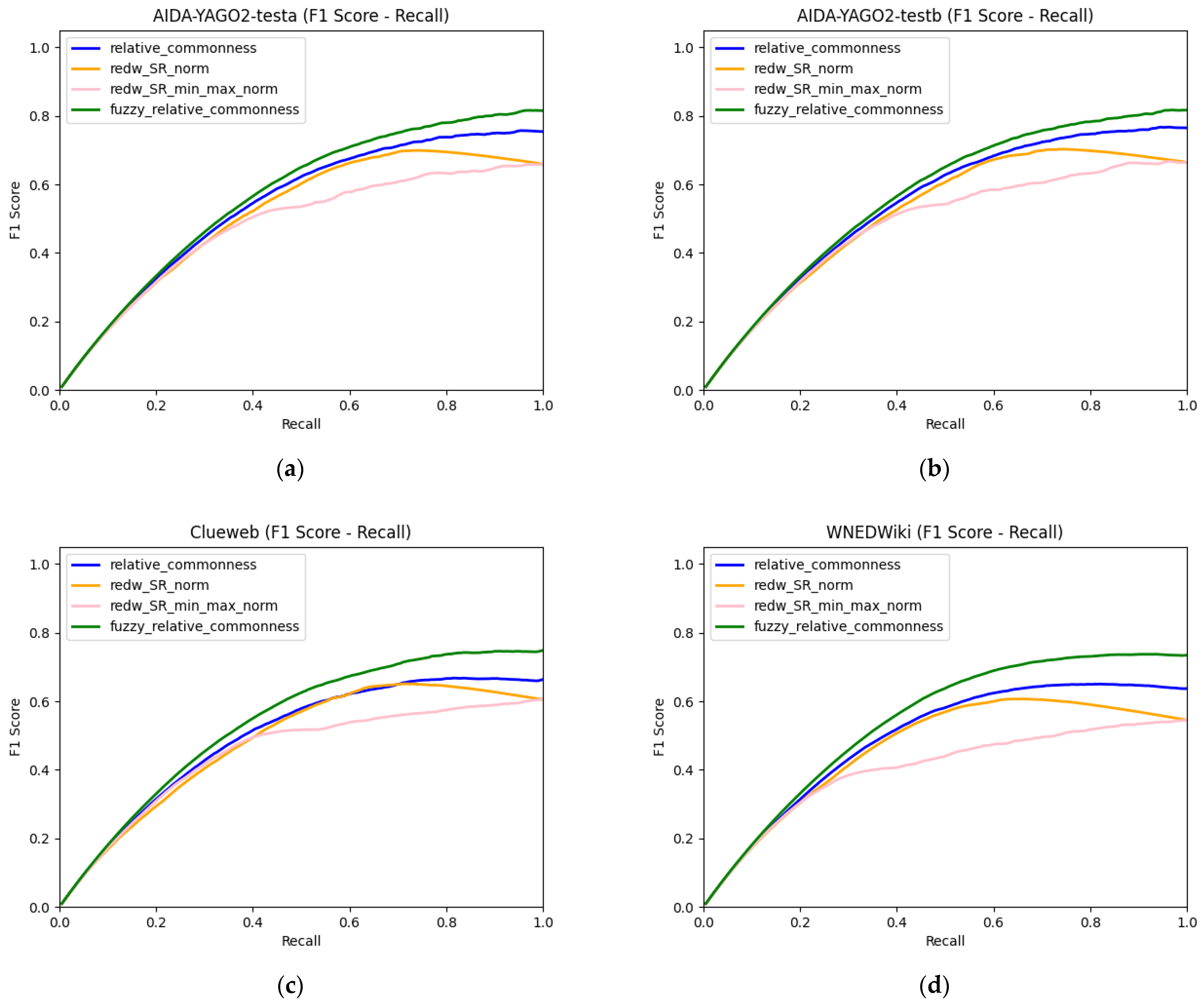
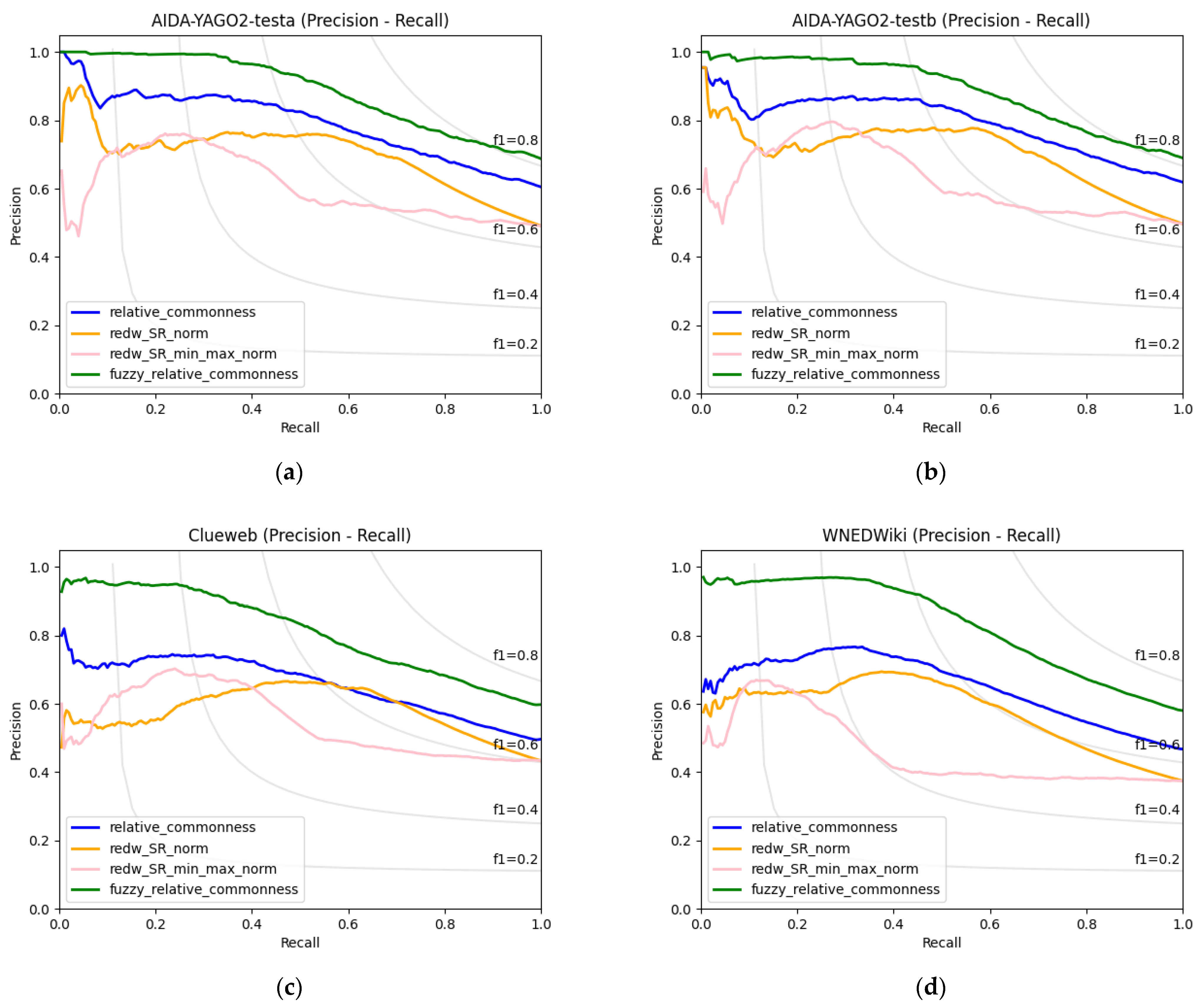
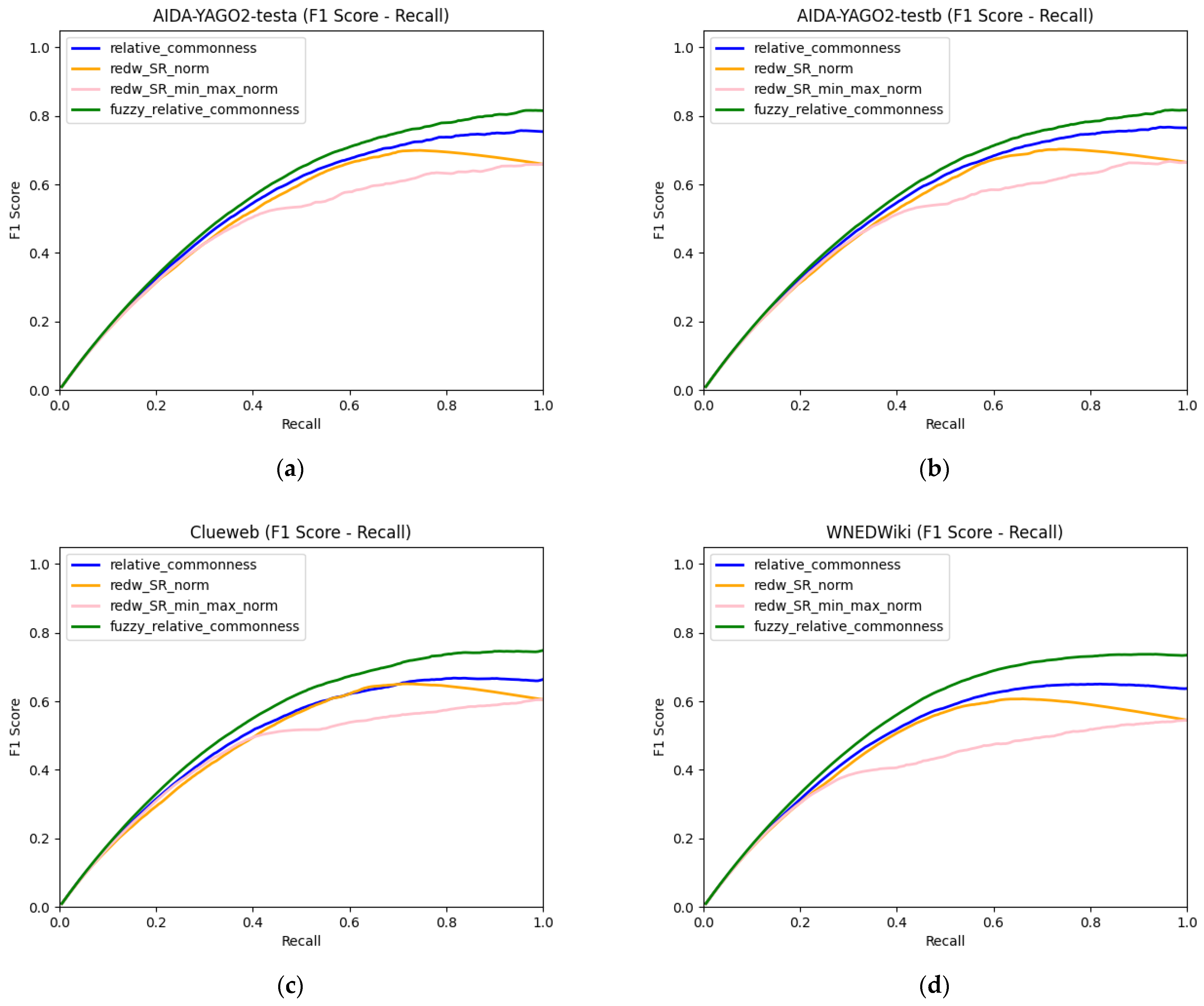
4.1. Experimental Results
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mihalcea, R.; Csomai, A. Wikify! In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management—CIKM ’07, Lisbon, Portugal, 6–10 November 2007; ACM Press: New York, NY, USA, 2007; p. 233. [Google Scholar] [CrossRef]
- Shnayderman, I.; Ein-Dor, L.; Mass, Y.; Halfon, A.; Sznajder, B.; Spector, A.; Katz, Y.; Sheinwald, D.; Aharonov, R.; Slonim, N. Fast End-to-End Wikification. arXiv 2019. [Google Scholar] [CrossRef]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Mining—CIKM ’08, Napa Valley, CA, USA, 26–30 October 2008; ACM Press: New York, NY, USA, 2008; p. 509. [Google Scholar] [CrossRef] [Green Version]
- Makris, C.; Simos, M.A. Novel Techniques for Text Annotation with Wikipedia Entities. In Proceedings of the 10th IFIP WG 12.5 International Conference, AIAI 2014, Rhodes, Greece, 19–21 September 2014; pp. 508–518. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, S.; Singh, A.; Ramakrishnan, G.; Chakrabarti, S. Collective annotation of Wikipedia entities in web text. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’09, Paris, France, 28 June–1 July 2009; ACM Press: New York, NY, USA, 2009; p. 457. [Google Scholar] [CrossRef] [Green Version]
- Cucerzan, S. Large-Scale Named Entity Disambiguation Based on Wikipedia Data. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 708–716. [Google Scholar]
- Milne, D.; Witten, I.H. An Effective, Low-Cost Measure of Semantic Relatedness Obtained from Wikipedia Links. In Proceedings of the AAAI 2008, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Ferragina, P.; Scaiella, U. TAGME. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management—CIKM ’10, Toronto, ON, Canada, 26–30 October 2010; ACM Press: New York, NY, USA, 2010; p. 1625. [Google Scholar] [CrossRef]
- Piccinno, F.; Ferragina, P. From TagME to WAT. In Proceedings of the First International Workshop on Entity Recognition & Disambiguation—ERD ’14, Gold Coast, Queensland, Australia, 11 July 2014; ACM Press: New York, NY, USA, 2014; pp. 55–62. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W.T. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Yoon, S.-H.; Yu, H.-J. A Simple Distortion-Free Method to Handle Variable Length Sequences for Recurrent Neural Networks in Text Dependent Speaker Verification. Appl. Sci. 2020, 10, 4092. [Google Scholar] [CrossRef]
- Trinh Van, L.; Dao Thi Le, T.; le Xuan, T.; Castelli, E. Emotional Speech Recognition Using Deep Neural Networks. Sensors 2022, 22, 1414. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.; Chang, J.-H. Augmented Latent Features of Deep Neural Network-Based Automatic Speech Recognition for Motor-Driven Robots. Appl. Sci. 2020, 10, 4602. [Google Scholar] [CrossRef]
- Raghavan, P.; Gayar, N. el Fraud Detection using Machine Learning and Deep Learning. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 334–339. [Google Scholar] [CrossRef]
- Jang, H.-J.; Cho, K.-O. Applications of deep learning for the analysis of medical data. Arch. Pharmacal. Res. 2019, 42, 492–504. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef] [PubMed]
- Pandey, B.; Kumar Pandey, D.; Pratap Mishra, B.; Rhmann, W. A comprehensive survey of deep learning in the field of medical imaging and medical natural language processing: Challenges and research directions. J. King Saud Univ. Comput. Inf. Sci. 2021, in press. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Makris, C.; Simos, M.A. OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology. Big Data Cogn. Comput. 2020, 4, 31. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakraborty, S.; Tomsett, R.; Raghavendra, R.; Harborne, D.; Alzantot, M.; Cerutti, F.; Srivastava, M.; Preece, A.; Julier, S.; Rao, R.M.; et al. Interpretability of deep learning models: A survey of results. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Thompson, N.C.; Greenewald, K.; Lee, K.; Manso, G.F. The Computational Limits of Deep Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Navigli, R. Word sense disambiguation. ACM Comput. Surv. 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Scarlini, B.; Pasini, T.; Navigli, R. Sense-Annotated Corpora for Word Sense Disambiguation in Multiple Languages and Domains. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Marseille, France, 2020; pp. 5905–5911. [Google Scholar]
- Pasini, T. The Knowledge Acquisition Bottleneck Problem in Multilingual Word Sense Disambiguation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4936–4942. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks. arXiv 2013. [Google Scholar] [CrossRef]
- Sil, A.; Kundu, G.; Florian, R.; Hamza, W. Neural cross-lingual entity linking. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5464–5472. [Google Scholar]
- Gmach, D.; Chen, Y.; Shah, A.; Rolia, J.; Bash, C.; Christian, T.; Sharma, R. Profiling Sustainability of Data Centers. Proceedings of 2010 IEEE International Symposium on Sustainable Systems and Technology, Arlington, VA, USA, 17–19 May 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Freitag, C.; Berners-Lee, M.; Widdicks, K.; Knowles, B.; Blair, G.; Friday, A. The climate impact of ICT: A review of estimates, trends and regulations. arXiv 2021. [Google Scholar] [CrossRef]
- Gale, W.A.; Church, K.W.; Yarowsky, D. A method for disambiguating word senses in a large corpus. Comput. Humanit. 1992, 26, 415–439. [Google Scholar] [CrossRef] [Green Version]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust Disambiguation of Named Entities in Text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective entity linking in web text. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information—SIGIR ’11, Beijing, China, 24–28 July 2011; ACM Press: New York, NY, USA, 2011; p. 765. [Google Scholar] [CrossRef]
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling Mention, Context and Entity with Neural Networks for Entity Disambiguation. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1333–1339. [Google Scholar]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 250–259. [Google Scholar] [CrossRef] [Green Version]
- Ganea, O.-E.; Hofmann, T. Deep Joint Entity Disambiguation with Local Neural Attention. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2619–2629. [Google Scholar] [CrossRef]
- Le, P.; Titov, I. Improving Entity Linking by Modeling Latent Relations between Mentions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1595–1604. [Google Scholar] [CrossRef] [Green Version]
- Radhakrishnan, P.; Talukdar, P.; Varma, V. ELDEN: Improved Entity Linking Using Densified Knowledge Graphs. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1844–1853. [Google Scholar] [CrossRef]
- Fang, Z.; Cao, Y.; Li, Q.; Zhang, D.; Zhang, Z.; Liu, Y. Joint Entity Linking with Deep Reinforcement Learning. In Proceedings of the The World Wide Web Conference on—WWW ’19, San Francisco, CA, USA, 13–17 May 2019; ACM Press: New York, NY, USA, 2019; pp. 438–447. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Petroni, F.; Josifoski, M.; Riedel, S.; Zettlemoyer, L. Scalable Zero-shot Entity Linking with Dense Entity Retrieval. arXiv 2019. [Google Scholar] [CrossRef]
- MediaWiki/Help:Namespaces. Available online: https://MediaWiki/Help:Namespaces (accessed on 25 April 2022).
- MediaWiki:Wiki_ID. Available online: https://www.mediawiki.org/wiki/Manual:Wiki_ID (accessed on 25 April 2022).
- EnWiki Dump 20220420. Available online: https://dumps.wikimedia.org/mkwiki/20220420/ (accessed on 25 April 2022).
- Zadeh, L.A. From computing with numbers to computing with words. From manipulation of measurements to manipulation of perceptions. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1999, 46, 105–119. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- RedW CodeBase. Available online: https://github.com/mikesimos/redw (accessed on 25 May 2022).
- EnWiki Dump 20220420 Pages-Articles. Available online: https://dumps.wikimedia.org/mkwiki/20220420/mkwiki-20220420-pages-articles.xml.bz2 (accessed on 25 April 2022).
- Specs/wikitext/1.0.0 MediaWiki. Available online: https://www.mediawiki.org/wiki/Specs/wikitext/1.0.0 (accessed on 25 April 2022).
- AIDA CoNLL-YAGO Dataset. Available online: http://resources.mpi-inf.mpg.de/yago-naga/aida/download/aida-yago2-dataset.zip (accessed on 25 April 2022).
- Tjong Kim Sang, E.F.; de Meulder, F. Introduction to the CoNLL-2003 shared task. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; Association for Computational Linguistics: Morristown, NJ, USA, 2003; pp. 142–147. [Google Scholar] [CrossRef]
- The ClueWeb12 Dataset. Available online: https://lemurproject.org/clueweb12/ (accessed on 20 July 2022).
- Guo, Z.; Barbosa, D. Robust named entity disambiguation with random walks. Semant. Web 2018, 9, 459–479. [Google Scholar] [CrossRef]
- BLINK Source Code. Available online: https://github.com/facebookresearch/BLINK (accessed on 25 April 2022).
- Spark. Available online: https://spark.apache.org/downloads.html (accessed on 25 April 2022).
- PySpark. Available online: https://spark.apache.org/docs/3.2.1/api/python/ (accessed on 25 April 2022).
- Python 3.8.10. Available online: https://www.python.org/downloads/release/python-3810/ (accessed on 25 April 2022).
- Methods CodeBase. Available online: https://github.com/mikesimos/fast-wikification (accessed on 25 May 2022).

{kind=link}
{kind=link}
| Recall | RedW SRnorm | RedW SRmin–max | Relative Commonness | Fuzzy Relative Commonness |
|---|---|---|---|---|
| 0.1 | 0.7411 | 0.6942 | 0.8058 | 0.9799 |
| 0.2 | 0.7246 | 0.7637 | 0.8573 | 0.9844 |
| 0.3 | 0.7517 | 0.7755 | 0.8654 | 0.9792 |
| 0.4 | 0.7670 | 0.7129 | 0.8623 | 0.9638 |
| 0.5 | 0.7707 | 0.5923 | 0.8430 | 0.9318 |
| 0.6 | 0.7640 | 0.5693 | 0.7930 | 0.8777 |
| 0.7 | 0.6964 | 0.5323 | 0.7483 | 0.8235 |
| 0.8 | 0.6193 | 0.5223 | 0.6998 | 0.7659 |
| 0.9 | 0.5508 | 0.5240 | 0.6558 | 0.7227 |
| 1.0 | 0.4972 | 0.4972 | 0.6190 | 0.6899 |
| Recall | RedW SRnorm | RedW SRmin–max | Relative Commonness | Fuzzy Relative Commonness |
|---|---|---|---|---|
| 0.1 | 0.1762 | 0.1748 | 0.1779 | 0.1815 |
| 0.2 | 0.3135 | 0.3170 | 0.3243 | 0.3325 |
| 0.3 | 0.4288 | 0.4326 | 0.4456 | 0.4593 |
| 0.4 | 0.5258 | 0.5125 | 0.5465 | 0.5654 |
| 0.5 | 0.6065 | 0.5423 | 0.6277 | 0.6508 |
| 0.6 | 0.6722 | 0.5842 | 0.6831 | 0.7128 |
| 0.7 | 0.6982 | 0.6048 | 0.7234 | 0.7567 |
| 0.8 | 0.6981 | 0.6320 | 0.7466 | 0.7826 |
| 0.9 | 0.6834 | 0.6624 | 0.7588 | 0.8017 |
| 1.0 | 0.6642 | 0.6642 | 0.7646 | 0.8165 |
| Dataset | RedW SRnorm | RedW SRmin–max | Relative Commonness | Fuzzy Relative Commonness |
|---|---|---|---|---|
| AIDA CoNLL test-a | 10.282576 | 10.245567 | 8.561391 | 32.421240 |
| AIDA CoNLL test-b | 6.675579 | 6.700371 | 4.936130 | 18.709551 |
| Clueweb12-wned | 85.141593 | 83.307072 | 72.562388 | 193.694214 |
| WNED-WIKI | 11.431783 | 11.233509 | 9.852915 | 37.373979 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simos, M.A.; Makris, C. Computationally Efficient Context-Free Named Entity Disambiguation with Wikipedia. Information 2022, 13, 367. https://doi.org/10.3390/info13080367
Simos MA, Makris C. Computationally Efficient Context-Free Named Entity Disambiguation with Wikipedia. Information. 2022; 13(8):367. https://doi.org/10.3390/info13080367
Chicago/Turabian StyleSimos, Michael Angelos, and Christos Makris. 2022. "Computationally Efficient Context-Free Named Entity Disambiguation with Wikipedia" Information 13, no. 8: 367. https://doi.org/10.3390/info13080367
APA StyleSimos, M. A., & Makris, C. (2022). Computationally Efficient Context-Free Named Entity Disambiguation with Wikipedia. Information, 13(8), 367. https://doi.org/10.3390/info13080367