1. Introduction
Many organisations are complex entities that perform heterogeneous processing on diverse personal data, often organised using multiple organisational units or outsourced processing partners and sometimes under the jurisdiction of multiple Data Protection Authorities (DPAs). Under the EU’s General Data Protection Regulation (GDPR), organisations that act as a ‘Data Controller’ are obliged to create and maintain a “Register of Processing Activities (ROPA)” as a comprehensive record of personal data processing activities carried out under their responsibility (GDPR Art.30). The ROPA, as described in the GDPR, is a temporal snapshot of the organisation’s practices and is the point of initiating communication or investigation regarding compliance such as with a DPA. It is thus an important part of the organisation’s processes related to ensuring and documenting its compliance.
In practice, organisations struggle to keep accurate and up-to-date ROPAs [
1]. They often fail to integrate the maintenance and management of the Register of Processing Activities into their day-to-day operations [
1]. This can result in a breakdown in the GDPR accountability principle (GDPR Article 5.2) as there is a lack of clarity as to the who, how, and when the ROPA is updated. To assist organisations with their ROPA-related duties, DPAs have provided guidance and templates that intend to ease the task of understanding requirements and harmonise the documentation through commonly used formats and environments such as spreadsheets [
2,
3]. In providing these templates, DPAs indicate what can be considered ‘good practice’ regarding what information should be documented within a ROPA. However, despite being based on a common legal obligation (GDPR Art.30), there is variance in the templates provided by DPAs where additional fields (not in the GDPR) are also encouraged to be documented [
2]. An organisation operating in multiple jurisdictions is thus tasked with consolidating differing requirements from each DPA as either a distinct set of ROPA documents or a single combined one.
Furthermore, the exercise of gathering the information necessary to create a ROPA is not a one-off activity [
4] as there may be several data sources both internally (e.g., departments) [
5] and externally (e.g., data processors) [
5,
6]. Therefore, ROPA creation requires communication between these distinct units to collate information pooled from ’heterogeneous sources’ into a singular location to produce a ROPA. This necessitates some form of information management process for the tasks associated with documents such as reading or viewing, writing all or parts of it, exchanging them between relevant stakeholders, and ensuring their correctness and availability (e.g., backups or version control).
To address such requirements, the market vendors offer dedicated solutions for ROPA management, often as part of a larger suite of the GDPR compliance tools [
7]. This follows the increasing trend of organisations adopting regulatory technology (RegTech) [
8,
9] to assist with legal compliance and requirements. The utilisation of a ROPA is poised to be an important and key feature given its importance in the GDPR compliance processes.
However, these RegTech solutions are primarily centralised and proprietary, and they emphasise custom processes that cannot be utilised outside vendor-defined use cases. In particular, the information being exchanged between internal and external stakeholders has been poorly researched in academia and commercial offerings (see
Section 2) despite the need for shared business and regulatory taxonomies for facilitating semantic interoperability [
10] between stakeholders to identify feasible and compliant software solutions for data protection and privacy regulations [
11,
12].
There is a lack of ROPA-related explorations in academic research, with existing efforts limited to early-stage work involving enterprise architecture models [
13] or data [
14]. For larger projects that have focused on GDPR compliance with explicit requirements regarding non-proprietary technologies and focusing on interoperability (e.g., semantic web), there is a distinct absence of research addressing ROPA-related tasks despite overlapping with the same information requirements. In terms of ongoing work, the ONTOROPA project [
12] proposes building a semantics-based ROPA with blockchain-based trust guarantees.
We propose an approach to solving these challenges, whereby we identify what data is required to complete the ROPA, who the ROPA stakeholders are, how they utilise the ROPA, and what information flows requiring interoperability and machine-readability of the ROPA are required. To address the identified challenges and their solutions, we present our work based on the following research objectives:
- RO1
Identify information and information flows relevant for a ROPA in terms of stakeholders based on the GDPR and EU DPAs guidelines and templates;
- RO2
Develop a machine-readable specification for representing and exchanging ROPA relevant information in an interoperable manner;
- RO3
Specify a mechanism for using developed machine-readable formats for aggregation, querying, validation, and exporting of information based on identified ROPA-related information flows.
Our previous work on this topic consisted of creating a semantic model of a ROPA [
5]. In this, we evaluated the GDPR and six DPA templates and guidelines to identify a set of concepts required for the representation of ROPA-related information and proposed its formulation as a ‘
common semantic model’ for representing commonality across the EU. We utilised the data privacy vocabulary (DPV) [
15], developed by the W3C Data Privacy Vocabularies and Controls Community Group (DPVCG), as a vocabulary for representing identified concepts (Note: H. J. Pandit chairs DPVCG and is the editor of DPV
https://www.w3.org/community/dpvcg/ as of 5 May 2022). We found and reported missing concepts to DPVCG, which subsequently extended the DPV with our contribution. We further developed our common semantic model into a proposal for establishing a ‘Data Processing Catalogue (DPCat) [
16] that utilises the Data Catalog Vocabulary (DCAT) [
17] and its extension, the DCAT Application profile for data portals in Europe (DCAT-AP) [
18], to represent the ROPA-related information in the form of ’datasets’ and ’catalogues’ that could be maintained, used, and shared consistently.
This article expands on our prior work to provide a more complete and feasible solution for establishing a common machine-readable and interoperable mechanism for a common representation of a ROPA. We extended the common semantic model to incorporate ROPA templates from all EU DPAs (17 of 31 DPAs have published templates) and updated the DPCat specification and the DPV to support representing this information. To demonstrate its practical application and usefulness, we applied the DPCat specification to ROPA documents published by the European Data Protection Supervisor (EDPS) for each identified use case (see
Section 6). Finally, we go beyond state of the art by demonstrating the potential of our solution in realising the EU’s ‘Data Spaces’ vision [
19] by creating ‘compliance-related specifications’ that support representation (RDF), querying (SPARQL), validation (SHACL), and exchange (DCAT + DPV) of information.
The principal contributions of this paper are summarised as follows:
use cases exploring ROPA data governance and stakeholders (RO1);
A Common Semantic Model for ROPA (CSM-ROPA) representing information requirements from EU DPAs (RO2);
Data Processing Catalogue (DPCat) specifications for representing and exchanging ROPA-related information and provenance (RO2);
Demonstration of representation, querying, validation, and exchange of ROPA-related information using DPCat and semantic web technologies (RO3);
Discussion on the practicality and application of DPCat as a ’common mechanism’ for exchanging compliance information.
All associated data in documents, analysis, code, and executable artefacts are available under an open and permissive licence at
https://w3id.org/dpcat/repo.
The remainder of the paper is structured as follows:
Section 2 discusses the state of the art and related work, and
Section 3 describes the development of the Common Semantic Model for ROPA (CSM-ROPA) development. In
Section 4, we discuss ROPA information flows and data governance requirements for ROPA.
Section 5 describes the DPCat data processing catalogue to enable ROPA information sharing, aggregation, and querying for ROPA stakeholder interoperability.
Section 6 provides an application use case to demonstrate the practicality and feasibility of DPCat. The remainder of the paper discusses the impact of our approach on real-world use cases based on enabling better automation and tooling for regulatory compliance and critically for authorities to ease investigative burdens towards effective enforcement, and we provide our conclusions and recommendations for future work.
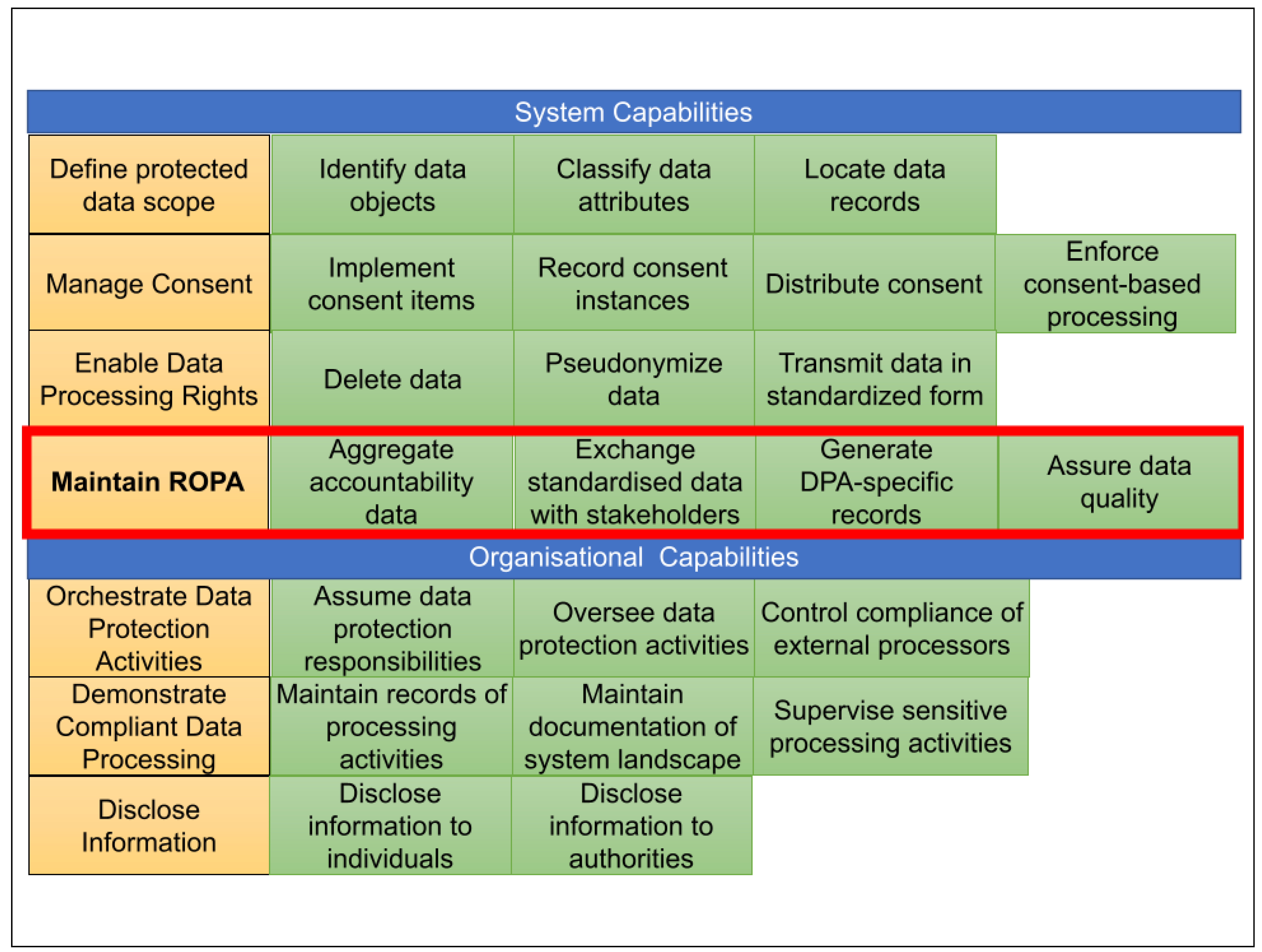
4. Information and Data Governance for ROPA
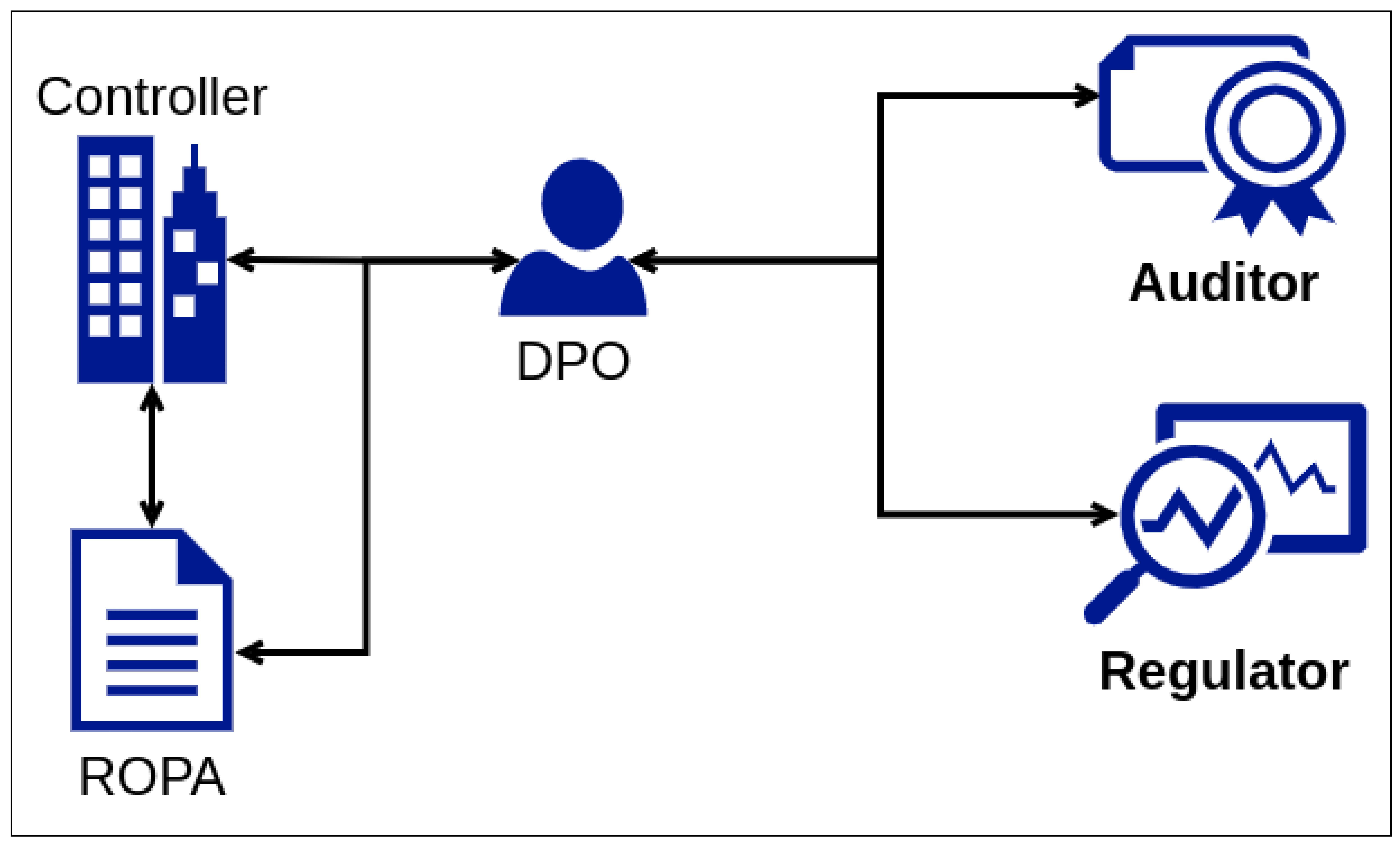
The CSM-ROPA, described in the previous section, enables the representation of a ROPA in a machine-readable and interoperable manner and covers information requirements from the GDPR and DPA ROPA templates. However, a ROPA is not a single document in practice but is a related set of evolving information that must be periodically collected and maintained. The information required for maintaining a ROPA thus may have one or more internal sources such as a department, unit, or assigned person where such ‘organisational units’ provide data about their respective processes and activities. A ROPA may also have one or more external sources—such as processors, contractors, vendors—where such ‘external entities’ provide the information required for establishing records of agreed activities and assurance of compliance obligations.
The ROPA provides the DPO with an important overview of the organisation’s practices [
22] and is part of the DPO’s obligations regarding compliance (GDPR Art.39) [
40]. This requires communication between internal stakeholders such as units or departments and external stakeholders such as DPAs, auditors, and certification bodies to collate necessary information for ROPA governance.
We present five use cases that explore the key stakeholders and their roles regarding the ‘
heterogeneous sources’ in ROPA-related data governance. This follows the methodology from prior work [
6] regarding identifying stakeholders and information flows related to GDPR compliance and establishing the utility of developing machine-readability and semantic interoperability mechanisms based on it. (Note: In this, we relied on P. Ryan’s experience as an active DPO for over 30 legal entities).
In our analysis, we considered the DPO as the nominated entity with responsibility within an organisation to oversee the ROPA-related processes as per the obligations from the GDPR (Art. 39). From this perspective, we explore possible combinations based on the existence or involvement of specific stakeholders and their effect on the DPO’s duties to collect and maintain ROPA-related information. We also considered a data controller as the primary type of organisation despite a data processor being required to maintain a ROPA and involve a DPO as a stakeholder. The data controller’s use cases are more complex than a data processor’s, and a solution satisfying a controller’s ROPA requirements can be trivially modified for use by a processor.
This exercise concludes with an argument for the expression of ROPA-related information in a machine-readable and interoperable format.
Section 6 then presents DPCat as our solution to communicate or exchange ROPA-relevant information between stakeholders and assist in the automation of compliance processes.
5. DPCat: A Data Processing Catalogue
In the earlier sections, we presented a ‘Common Semantic Model for ROPA’ (CSM-ROPA) representing a consolidated set of information requirements based on an analysis of DPA ROPA templates that can be used as a machine-readable and interoperable vocabulary through the use of DPV (see
Section 3). We then explored the sources and use of ROPA in terms of data flows between stakeholders and identified five use cases that provided further requirements regarding using CSM-ROPA in practical settings. In this section, we present the data processing catalogue (DPCat) specification, also published online (
https://w3id.org/dpcat), that addresses identified requirements and facilitates governance of information from intra- and inter-organisational heterogeneous sources to enable representation of a ROPA in a machine-readable and interoperable manner.
DPCat extends the Data Catalog Vocabulary (DCAT)—a W3C standard for facilitating interoperability between data catalogues [
17], with concepts identified in CSM-ROPA using DPV to enable representation of ROPA and associated information as ‘catalogues’ and ‘datasets’, respectively, that can be recorded and exchanged between stakeholders. DPCat also aims to maintain compatibility with the ‘DCAT Application profile for data portals in Europe’ (DCAT-AP) [
18] which represents the EU’s efforts at standardising catalogue metadata in data portals. The compatibility with DCAT-AP is based on our vision for DPCat to be usable in all DCAT-AP based catalogue information management tools and data portals to present a mechanism for sharing ROPA related information using an EU-advocated standard and to promote the possibility of reusing existing data portal infrastructures for compliance-related purposes - such as requirements for ROPA between controllers, processors, and DPAs.
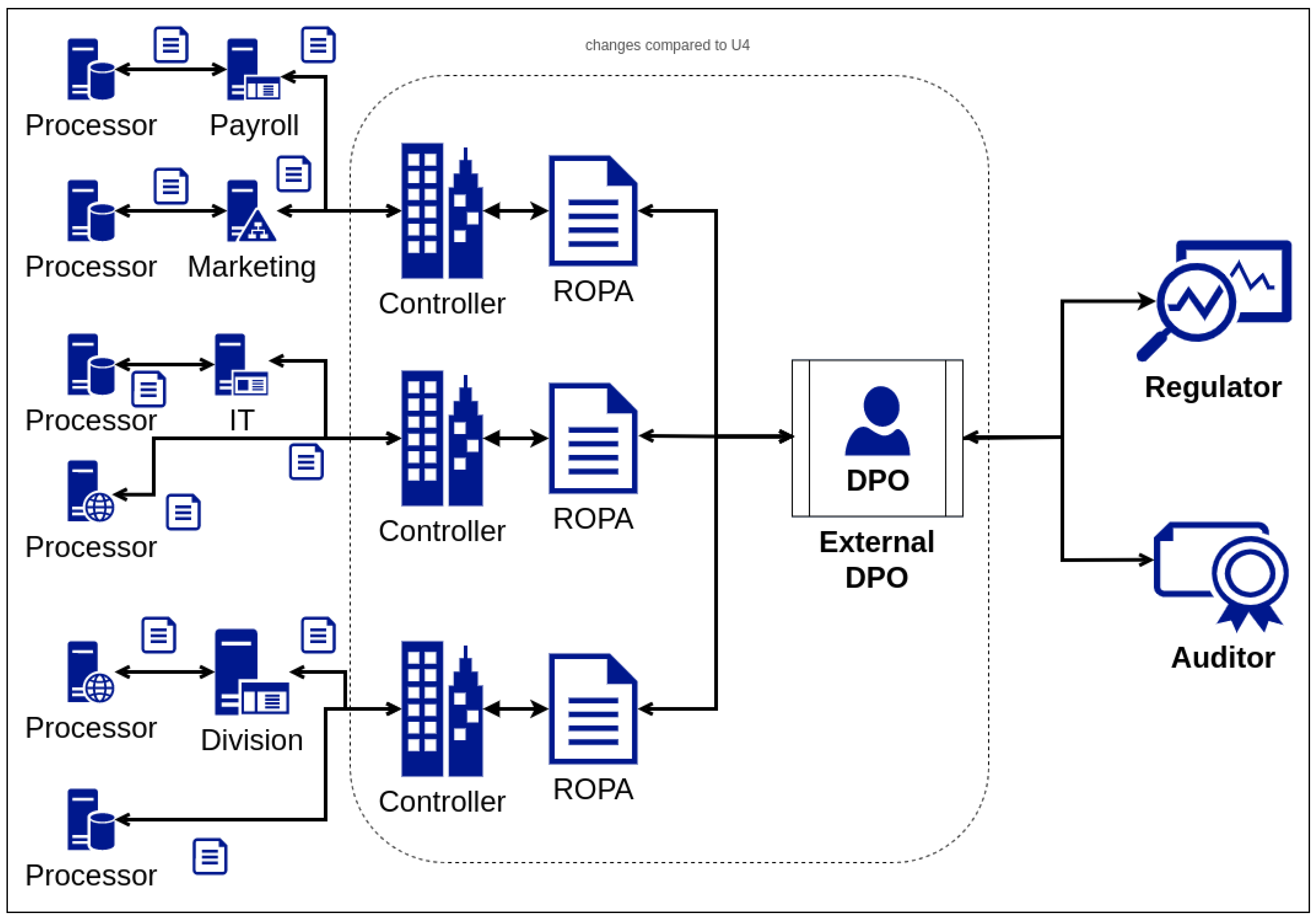
Our prior work [
2,
3] regarding DPCat was based on the CSM-ROPA developed from six DPA ROPA templates that addressed two (U2: organisational units, U3: processors) of the five use cases. This work incorporates updated CSM-ROPA for 17 DPA ROPA templates, updates made to the DPV (from v0.2 to v0.5), and integration of DCAT and DCAT-AP requirements (e.g., cardinality) for compatibility.
5.2. Using DPCat for ROPA Information Management
As we elaborated on in
Section 4, the information and data governance requirements within the use cases show a need for each entity to organise, maintain, and exchange relevant information to carry out ROPA-related processes. DPCat, as a specification, supports automation through integration into tools used for information storage and retrieval (e.g., databases) and information management practices (e.g., documents and data catalogues). It can represent all ROPA-related information or only catalogue metadata with links to the actual information stored externally (e.g., spreadsheets) as datasets. In either case, DPCat provides a consistent information structure that enables technological solutions such as querying, validation, and exporting (see next sections) to assist the relevant stakeholders in their tasks.
DPCat facilitates data governance for ROPA by incorporating the organisation’s structural and managerial requirements. For U1, where a ROPA has to be maintained at the organisational level, the ROPA and ROPARecord data can be maintained centrally. For U2–U4, where there are heterogeneous sources of information, and it is desirable to record them in the same manner for provenance and follow-ups, the DCAT relations enable provenance of publishers and points of contact. In contrast, ROPACatalog enables collections of related information issued by, e.g., a department or a processor.
The semantics of DCAT provides flexibility in determining how ROPA information could be organised and stored without determining a single method or structure. For example, in addition to the structuring based on organisational units and external entities, it may be desirable to keep records based on contextual information—such as specific business processes related to a product or service. This can be achieved by creating additional ROPACatalog entries representing the other collection and linking them to relevant ROPA entries. Through this, organisations can achieve multifaceted approaches in using the ROPA information without data duplication.
The use of technological solutions advocated by DPCat faces a hurdle in that the sources of information in ROPA-related workflows may not necessarily have the technical knowledge to produce consistent and valid metadata. For example, a DPO with the necessary legal knowledge does not necessarily have or is concerned with the underlying technicalities of information storage and retrieval beyond what is necessary to perform their duties. In such cases, existing information storage and management mechanisms such as databases and spreadsheets can continue to be used by DPCat being integrated into them rather than acting as a replacement. For example, using a SQL database, the information represented in its tables would utilise the DPCat as a schema with the input provided through existing means, e.g., input forms or importing spreadsheets using controlled structures. Alternatively, using an RDF-based solution such as a triple-store, the forms or spreadsheets could be converted to DPCat by utilising mappings.
We envision DPCat to be integrated into a typical workflow (i.e., U2–U4) for recording ROPA as follows. The source (e.g., department representative) generates a ROPARecord containing relevant information with provenance as the department. They use mechanisms available to them, e.g., a series of forms or a script that converts spreadsheets. This information is collated into a ROPA collection representing contextual grouping as determined by the organisational structure (e.g., maintained per department). For sources external to the organisation (e.g., a processor), the provided information is similarly stored in dedicated ROPA and ROPARecord entries and optionally integrated directly into relevant datasets (e.g., controller listing processor’s technical measures in its ROPA). This can use technological solutions such as a database or a portal. To facilitate the structuring of ROPA records in an organised manner, ROPACatalog entries are used to collect and group ROPA entries according to some criteria, e.g., temporal period, legal counsel, or responsible managers.
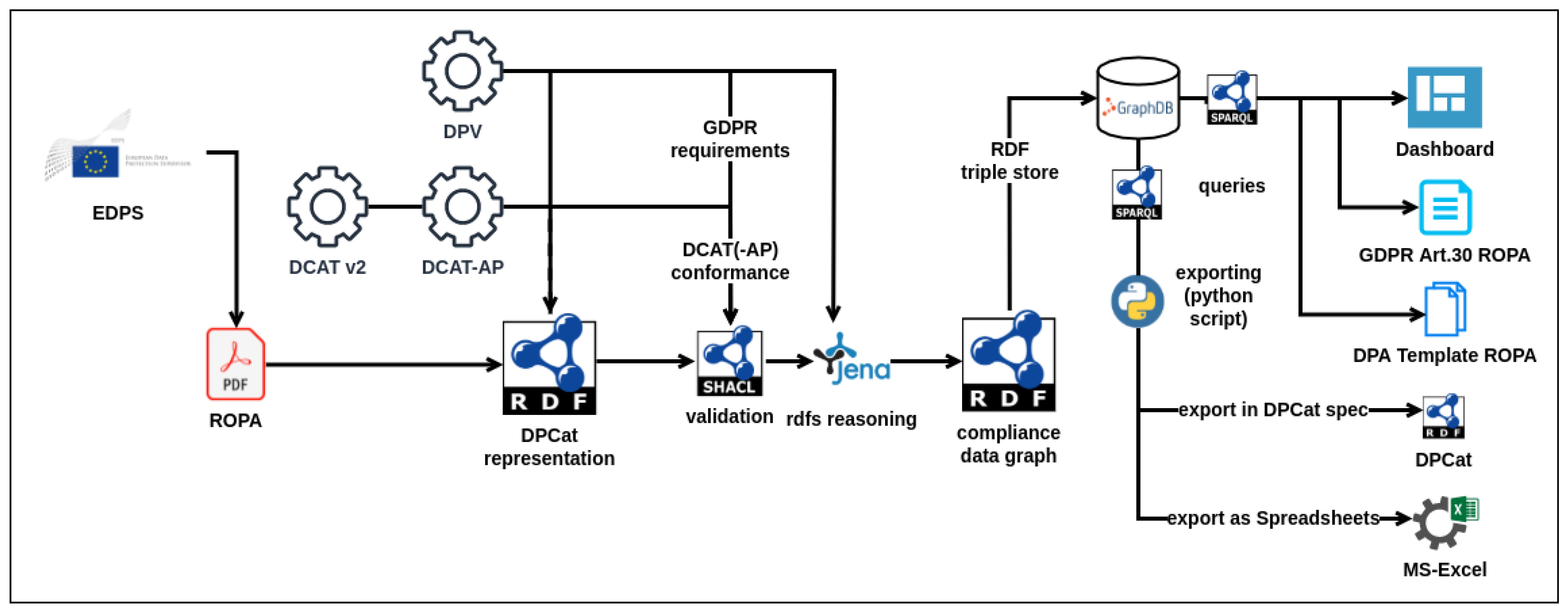
6. Demonstration of DPCat in a Real-World Use Case
In this section, we demonstrate the application of DPCat in representing real-world ROPA documents published by the European Data Protection Supervisor (EDPS) [
41] (EDPS), perform validations of them using SHACL, retrieve relevant information using SPARQL queries, and export it as RDF graphs as well as spreadsheets adhering to DPA templates. We provide evidence for the practicality and feasibility of DPCat and its benefits in ROPA information management processes. The data, code, and outputs are available online (
https://w3id.org/dpcat/demo/edps-ropa).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







