
A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation

Abstract
:1. Introduction
- The graph is enhanced to relieve sparsity. The edge is connected according to the similarity threshold between the user–user and item–item in the graph, which combines user–item interaction and item attributes. The strategy can better model user portraits and item features;
- We propose a new model, MAKR, based on the GNN in a knowledge graph for recommendation tasks. Furthermore, we conducted experiments on three top-N recommender data sets with different settings that indicate that MAKR obtained a state-of-the-art position in the top-N recommendation.
2. Related Work
2.1. Graph Neural Network
2.2. Knowledge Graph
2.3. Traditional Recommender System
2.4. GNN-Based Recommender System
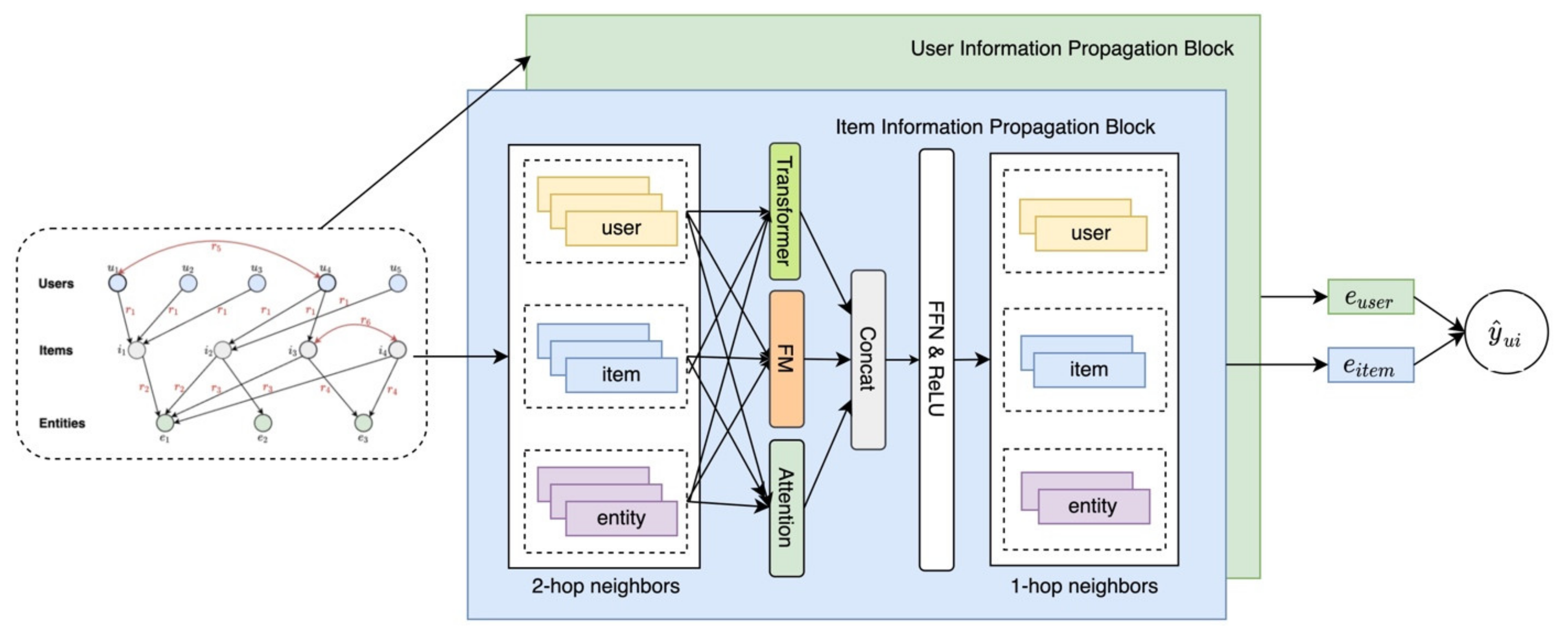
3. Methods
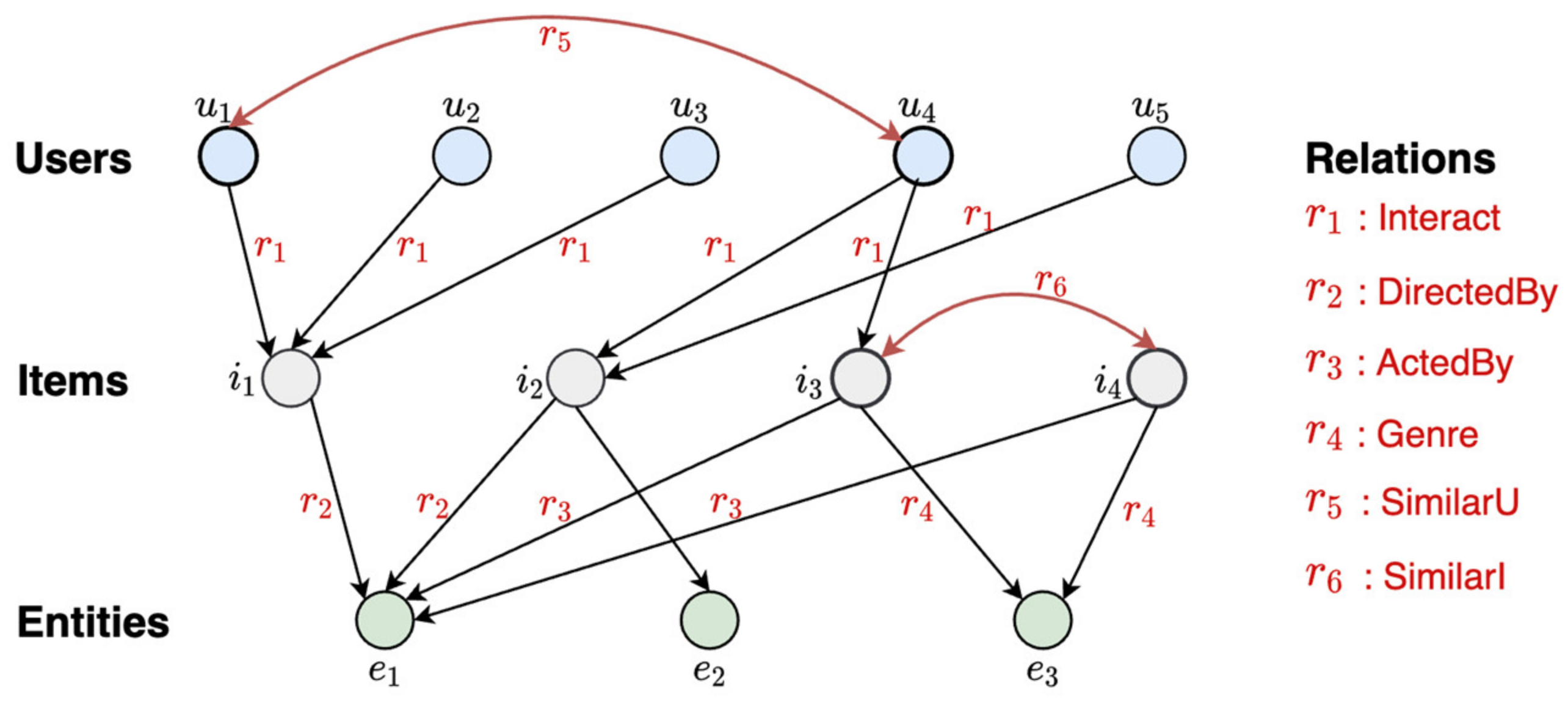
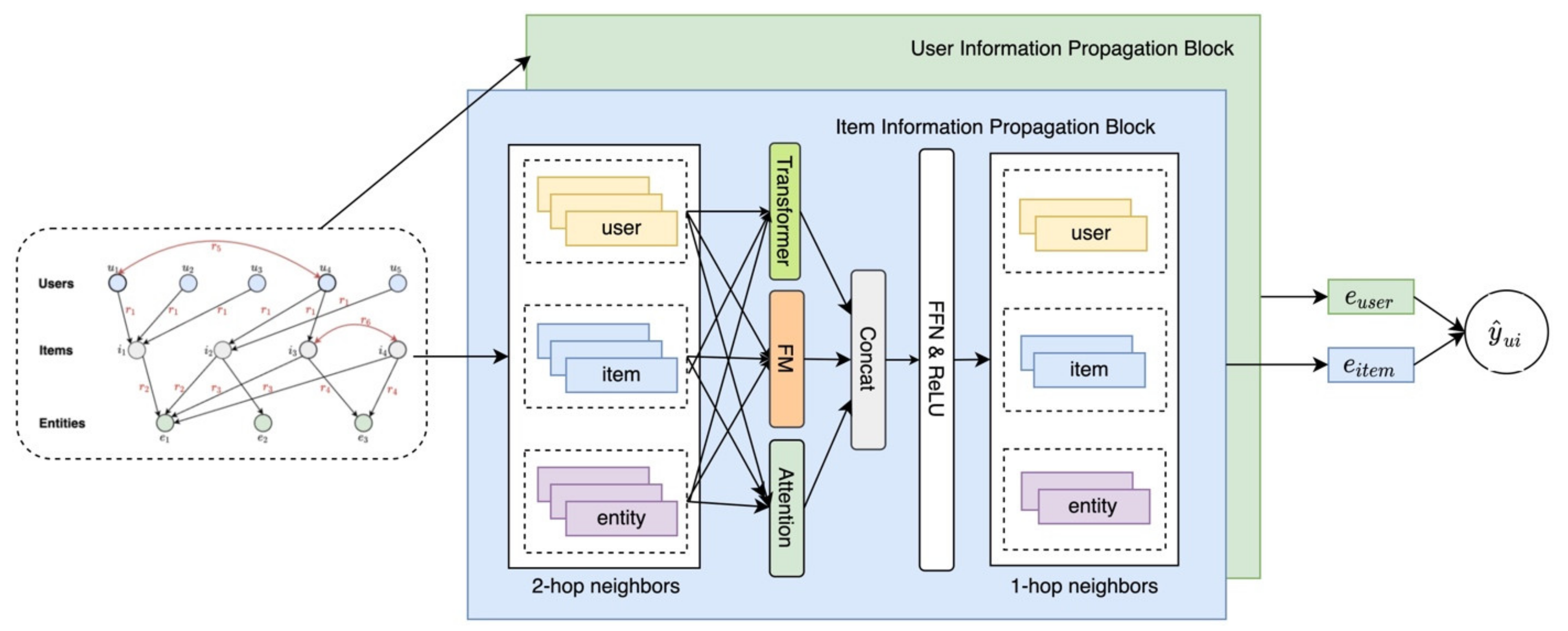
3.1. Graph Construction
- User–Item Bipartite Graph: User historical behavior, purchases, and clicks are important and widely used in recommender systems. We constructed the user–item interaction behavior as a user–item bipartite graph, , with the user set on the left and the item set on the right. Users and items are connected to each other. There is no connection between users and no connection between items. is defined as , where is the user set and is the item set, and if there is a user–item interaction; otherwise, .
- Knowledge Graph: User–item interaction information is sparse. In order to enrich the data, many studies have tried to add item attributes or external knowledge into the recommender system as side information. Here, we formed an item attribute knowledge graph, , by integrating the item, its attributes, and the relationship between them. This knowledge graph is composed of triples, expressed as , where represents the head entity, represents the tail entity, and represents the relationship between them. For example, () states the fact that Timothy Donald Cook manages Apple. Note that contains relations in both the canonical direction (e.g., ) and inverse direction (e.g., ). Moreover, establishing a set of item–entity alignments is necessary. Alignments are depicted as , where indicates that item aligns with in the knowledge graph.
- Collaborative Knowledge Graph (CKG): In order to enrich the data of the recommender system and enhance the expression ability of the model, we integrated the user–item bipartite graph and item attributes knowledge graph into one graph to build a more complete graph. Here, we define the concept of the CKG, which encodes user behaviors and item knowledge as a unified relational graph [32]. Firstly, we represent the interaction behavior of each user–item pair as a triple , where represents the user, represents the item, and is the relationship between the user and item. Then, based on the item entity alignment mentioned above, and can seamlessly form a unified CKG = , where and .
- Improved Collaborative Knowledge Graph (ICKG): Although CKE has strong presentation ability, including both user interaction information and item knowledge, in the bipartite graph of user interaction, there is neither an edge between the users nor between goods, ignoring the influence of users and goods. Whether the user–user is connected or not is calculated by the similarity of the two users:where represents the user–item interaction vector of the user (click 1, otherwise 0), and represents the DeepWalk pre-training vector of the user (described in detail in Section 3.2). , that is, the similarity between two users, is determined by the user’s historical behavior and the DeepWalk vector. After calculating the similarity, it takes the neighbors with the greatest similarity to each user.
3.2. Embedding Layer
3.3. Embedding Propagation Layers
3.3.1. Aggregator Based on Attention Mechanism
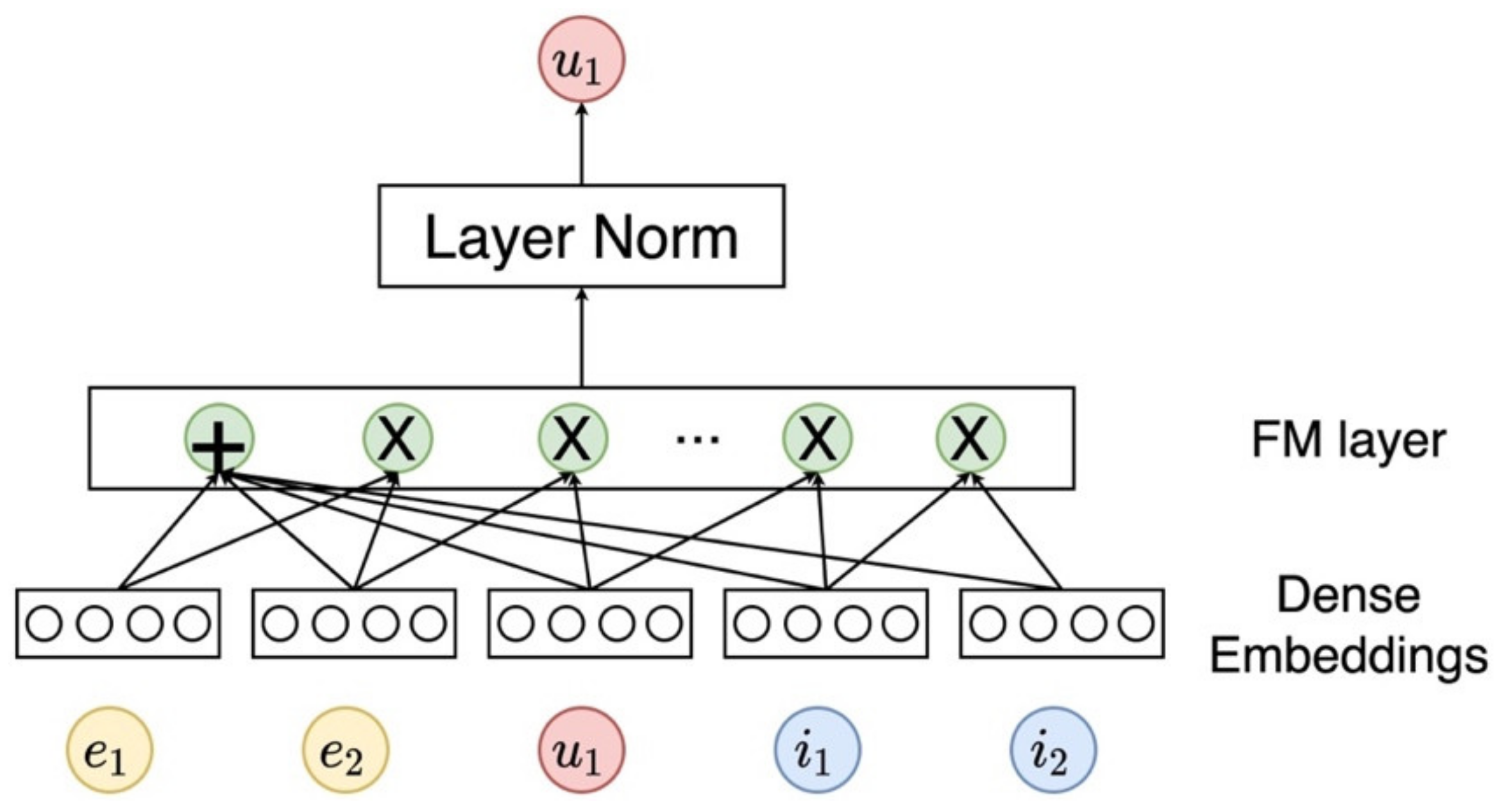
3.3.2. Aggregator Based on Factorization Machine
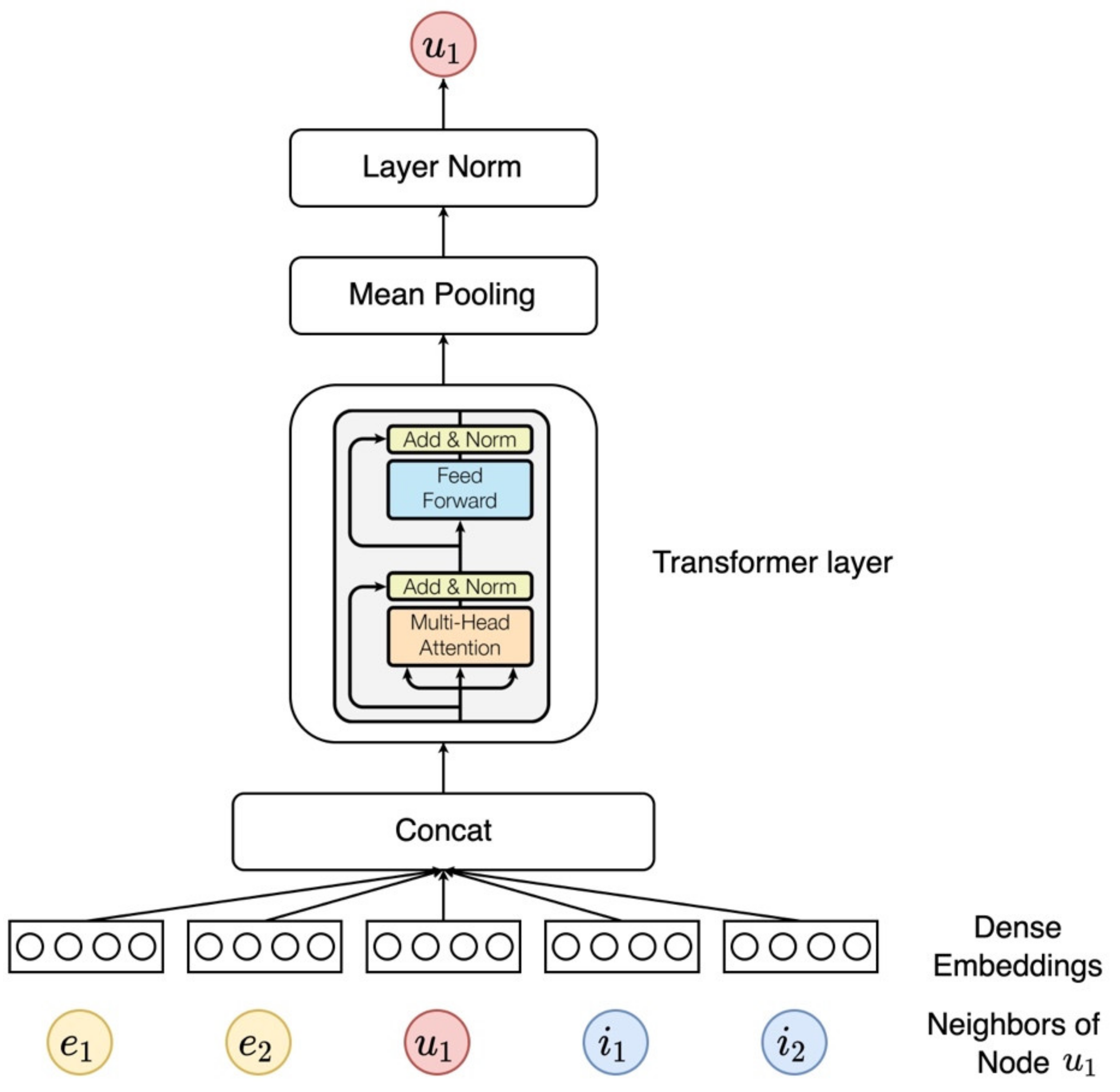
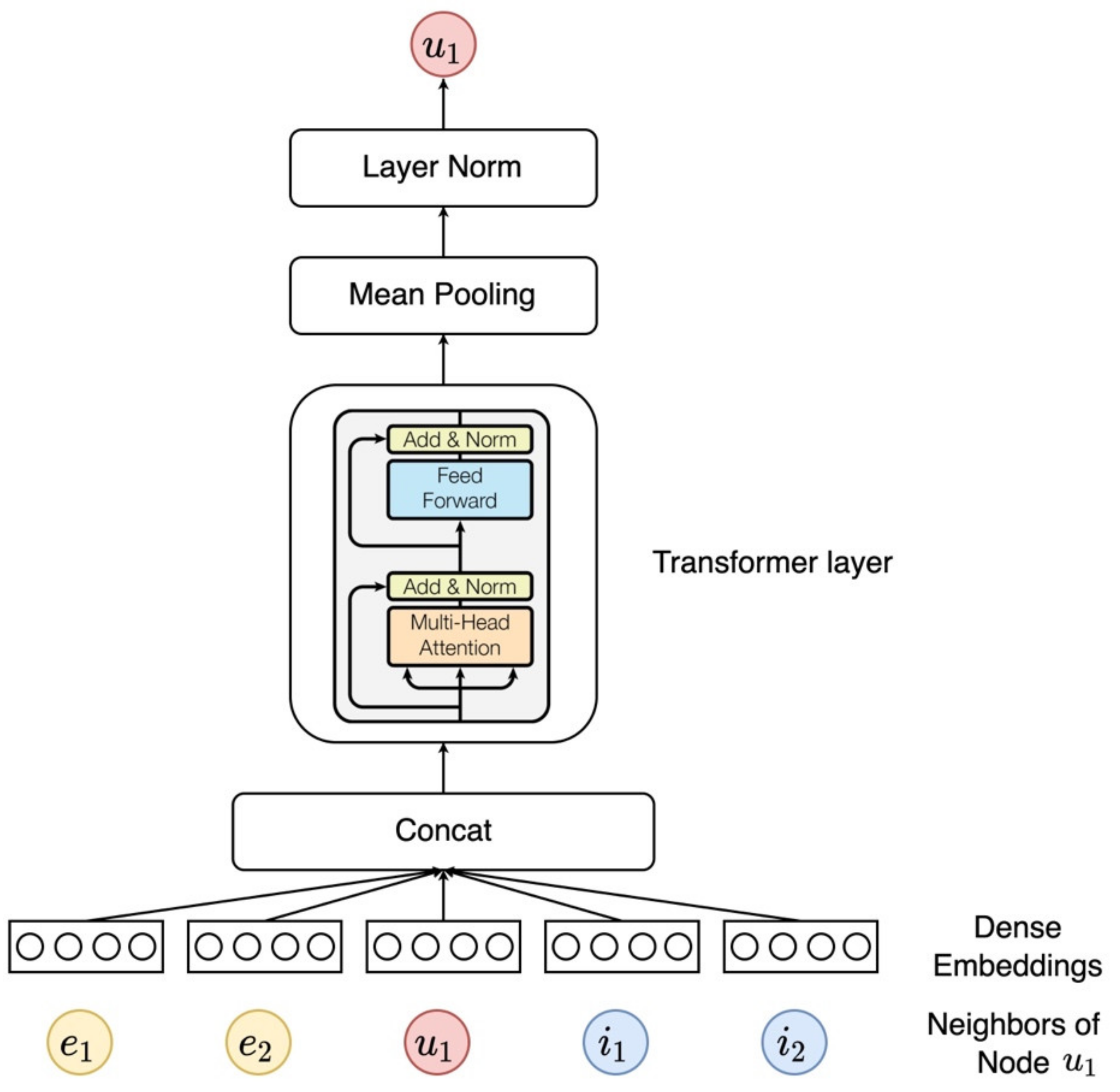
3.3.3. Aggregator Based on Transformer
3.4. Model Prediction
3.5. Optimization
4. Materials and Experiments
4.1. Data sets
- Yelp2018: This data set is about hotel management. We considered restaurants and bars as the items. We collected the data set from the 2018 edition of the Yelp challenge (https://www.yelp.com/dataset/challenge) (accessed on 5 March 2022);
- Amazon-Book: The Amazon-Book data set records the book information of Amazon and users’ ratings of Amazon books. Here, we viewed the books as the items. (http://jmcauley.ucsd.edu/data/amazon) (accessed on 5 March 2022);
- Last-FM: Last-FM is a data set about the sequence of users listening to songs that is provided by the Last-FM online music system. We took tracks as the items. We used the subset of the data set from January 2015 to June 2015. (https://grouplens.org/datasets/hetrec-2011/) (accessed on 5 March 2022).
4.2. Baselines
- FM [23]: Factorization machine (FM) is a classical recommendation method that performs second-order interaction on all input features. Here, the IDs of a user, an item, and the knowledge consisted of the entities as input features;
- CKE [10]: This is an embedding-based method that uses an item’s attributes graph as the knowledge graph. The latent vector is encoded with the TransR algorithm;
- CFKG [50]: CFKG considers user behaviors as a relation in the user–item KG, which includes the user–item interaction and item attributes;
- RippleNet [18]: RippleNet merges the embedding-based and path-based methods to enhance user representations by propagating the user’s preferences from historical interests along the path in the KG;
- GC-MC [51]: GC-MC applies the GCN method to the user–item bipartite graph. The model consists of three parts: ordinal mixture GCN, dense, and bilinear mixture.
- KGAT [32]: This method is a state-of-the-art knowledge graph-based model that applies the attention mechanism to the KG convolution for modeling high-order relations.
4.3. Evaluation Metrics
4.4. Experiment Settings
5. Results and Discussion
5.1. Overall Comparison
5.2. Parameter Sensitivity Analysis
5.2.1. Effect of Depth
5.2.2. Effect of Aggregators
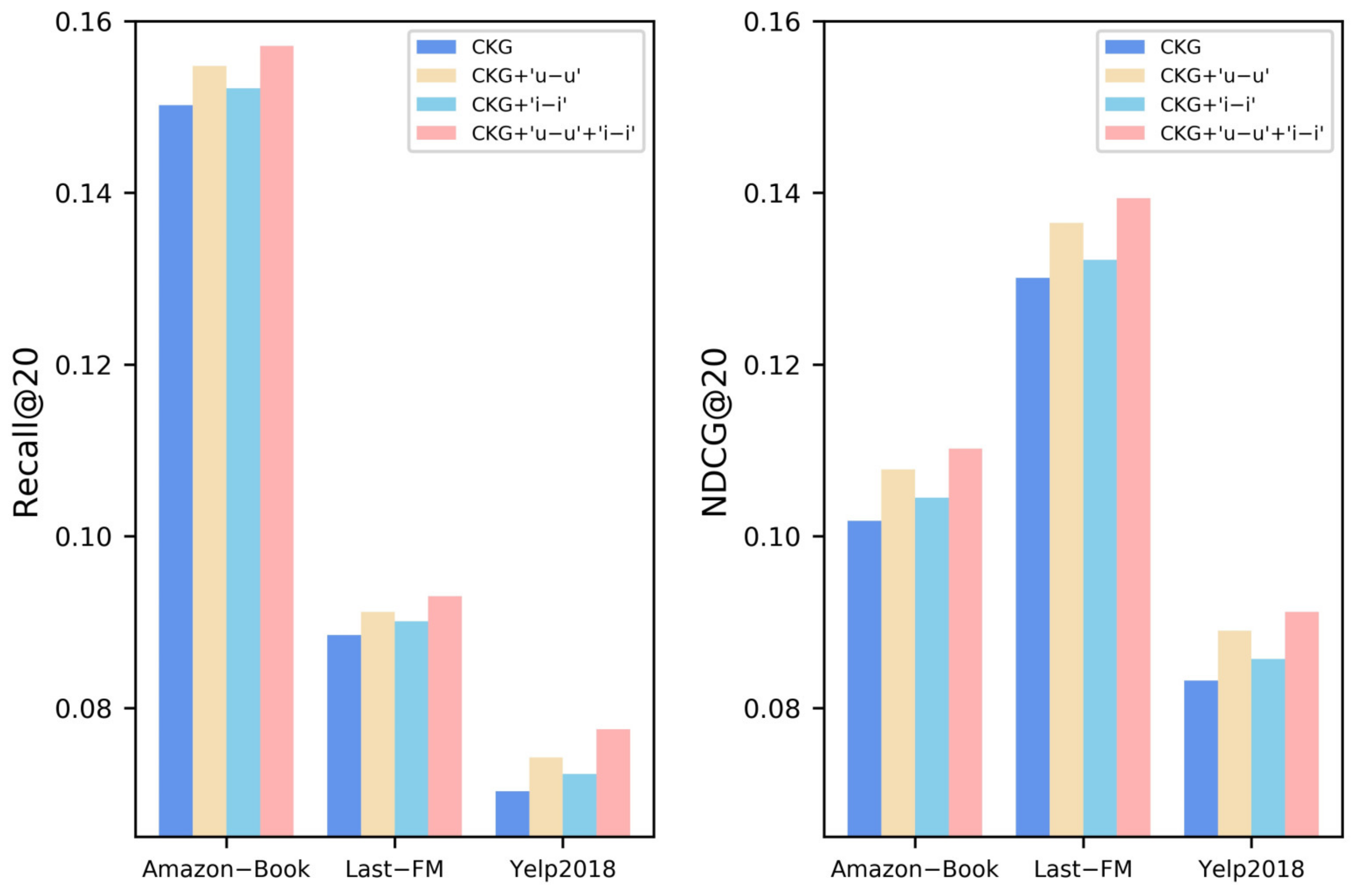
5.2.3. Ablation Study about the Improvement of ICKG
5.2.4. Effect of the Number of Adding Edges
- The smaller K is, the more edges are connected. However, noise is introduced, resulting in a decline in the model effect;
- The larger K is, the fewer edges are connected. Therefore, some effective information between nodes is not connected, and the collaborative knowledge graph cannot be learned.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Warren, J.; Marz, N. Big Data: Principles and Best Practices of Scalable Realtime Data Systems; Simon and Schuster: New York, NY, USA, 2015. [Google Scholar]
- Feng, X.; Zeng, Y. A deep learning model of dynamic aspect attention ecommerce recommendation based on user comments. Comput. Appl. Softw. 2020, 37, 38–44. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Balabanovic’, M.; Shoham, Y. Fab: Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Basu, C.; Hirsh, H.; Cohen, W. Recommendation as classification: Using social and content-based information in recommendation. In Proceedings of the AAAI/IAAI, Madison, WI, USA, 27–29 July 1998; pp. 714–720. [Google Scholar]
- Zhang, Z.K.; Liu, C.; Zhang, Y.C.; Zhou, T. Solving the cold-start problem in recommender systems with social tags. Europhys. Lett. 2010, 92, 28002. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Zhen, Y.; Li, W.J.; Yeung, D.Y. TagiCoFi: Tag informed collaborative filtering. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 69–76. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Zhang, Y.; Ai, Q.; Chen, X.; Wang, P. Learning over knowledge-base embeddings for recommendation. arXiv 2018, arXiv:1803.06540. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A Survey on Knowledge Graph-Based Recommender Systems; IEEE: Piscataway, NJ, USA, 2020; abs/2003.00911. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 687–696. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Wang, X.; Wang, D.; Xu, C.; He, X.; Cao, Y.; Chua, T.S. Explainable reasoning over knowledge graphs for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5329–5336. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Knudsen, E.I. Fundamental components of attention. Annu. Rev. Neurosci. 2007, 30, 57–78. [Google Scholar] [CrossRef] [PubMed]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13 December 2010; pp. 995–1000. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Bollacker, K.D.; Evans, C.; Paritosh, P.K.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an Architecture for Never-Ending Language Learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Lecture Notes in Computer Science, Proceedings of the Semantic Web—15th International Conference, ESWC 2018, Heraklion, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10843, pp. 593–607. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Lops, P.; de Gemmis, M.; Semeraro, G. Content-based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 73–105. [Google Scholar]
- Nguyen, P.T.; Tomeo, P.; Noia, T.D.; Sciascio, E.D. Content-Based Recommendations via DBpedia and Freebase: A Case Study in the Music Domain. In Lecture Notes in Computer Science, Proceedings, Part I, Proceedings of the The Semantic Web—ISWC 2015—14th International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9366, pp. 605–621. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-Based Recommendation Systems. In Lecture Notes in Computer Science, Proceedings of the Adaptive Web, Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 413–424. [Google Scholar]
- Wu, L.; Li, J.; Sun, P.; Hong, R.; Ge, Y.; Wang, M. DiffNet++: A Neural Influence and Interest Diffusion Network for Social Recommendation; IEEE: Piscataway, NJ, USA, 2020; abs/2002.00844. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, W.; Sun, F.; Cui, B. Graph Neural Networks in Recommender Systems: A Survey. arXiv 2020, arXiv:2011.02260. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2020, Xi’an, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-Based Recommendation with Graph Neural Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial; AAAI Press: Palo Alto, CA, USA, 2019; pp. 346–353. [Google Scholar]
- Mnih, A.; Hinton, G.E. A scalable hierarchical distributed language model. Adv. Neural Inf. Process. Syst. 2008, 21, 1081–1088. [Google Scholar]
- Morin, F.; Bengio, Y. Hierarchical probabilistic neural network language model. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; pp. 246–252. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450 2016. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.I.; Jegelka, S. Representation learning on graphs with jumping knowledge networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5453–5462. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618 2012. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Ai, Q.; Azizi, V.; Chen, X.; Zhang, Y. Learning heterogeneous knowledge base embeddings for explainable recommendation. Algorithms 2018, 11, 137. [Google Scholar] [CrossRef] [Green Version]
- Berg, R.V.D.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263 2017. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Yang, J.H.; Chen, C.M.; Wang, C.J.; Tsai, M.F. HOP-rec: High-order proximity for implicit recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 140–144. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Yelp2018 | Last-FM | Amazon-Book | ||
|---|---|---|---|---|
| User–Item Interaction | Users | 45,919 | 23,566 | 70,679 |
| Items | 45,538 | 48,123 | 24,915 | |
| Interactions | 1,185,068 | 3,034,796 | 847,733 | |
| Knowledge Graph | Entities | 90,961 | 58,266 | 88,572 |
| Relations | 42 | 9 | 39 | |
| Triplets | 1,853,704 | 464,567 | 2,557,746 | |
| Amazon-Book | Last-FM | Yelp2018 | ||||
|---|---|---|---|---|---|---|
| Recall | Ndcg | Recall | Ndcg | Recall | Ndcg | |
| FM | 0.1345 | 0.0886 | 0.0778 | 0.1181 | 0.0627 | 0.0768 |
| NFM | 0.1366 | 0.0913 | 0.0829 | 0.1214 | 0.0660 | 0.0810 |
| CKE | 0.1343 | 0.0885 | 0.0736 | 0.1184 | 0.0657 | 0.0805 |
| CFKG | 0.1142 | 0.0770 | 0.0723 | 0.1143 | 0.0522 | 0.0644 |
| RippleNet | 0.1336 | 0.0910 | 0.0791 | 0.1238 | 0.0664 | 0.0822 |
| GC-MC | 0.1316 | 0.0874 | 0.0818 | 0.1253 | 0.0659 | 0.0790 |
| KGAT | 0.1489 | 0.1006 | 0.0870 | 0.1325 | 0.0712 | 0.0867 |
| MAKR | 0.1571 | 0.1102 | 0.0930 | 0.1394 | 0.0775 | 0.0912 |
| % Improvement | 5.51% | 9.54% | 6.90% | 5.21% | 8.85% | 5.19% |
| Amazon-Book | Last-FM | Yelp2018 | ||||
|---|---|---|---|---|---|---|
| Recall | Ndcg | Recall | Ndcg | Recall | Ndcg | |
| MAKR-1 | 0.1450 | 0.1007 | 0.0843 | 0.1302 | 0.0705 | 0.0810 |
| MAKR-2 | 0.1525 | 0.1053 | 0.0902 | 0.1324 | 0.0723 | 0.0873 |
| MAKR-3 | 0.1571 | 0.1102 | 0.0930 | 0.1394 | 0.0775 | 0.0912 |
| MAKR-4 | 0.1575 | 0.1110 | 0.0923 | 0.1387 | 0.0772 | 0.0920 |
| Amazon-Book | Last-FM | Yelp2018 | ||||
|---|---|---|---|---|---|---|
| Recall | Ndcg | Recall | Ndcg | Recall | Ndcg | |
| Mean | 0.1452 | 0.0978 | 0.0854 | 0.1289 | 0.0698 | 0.0834 |
| Attention (Att) | 0.1480 | 0.1022 | 0.0890 | 0.1322 | 0.0720 | 0.0856 |
| FM | 0.1438 | 0.0965 | 0.0834 | 0.1284 | 0.0692 | 0.0812 |
| Transformer (Trm) | 0.1455 | 0.1016 | 0.0845 | 0.1275 | 0.0687 | 0.0820 |
| Att + FM | 0.1493 | 0.1077 | 0.0901 | 0.1340 | 0.0743 | 0.0893 |
| Att + Trm | 0.1522 | 0.1095 | 0.0912 | 0.1367 | 0.0750 | 0.0901 |
| Att + Trm + FM | 0.1571 | 0.1102 | 0.0930 | 0.1394 | 0.0775 | 0.0912 |
| Amazon-Book | Last-FM | Yelp2018 | ||||
|---|---|---|---|---|---|---|
| Recall | Ndcg | Recall | Ndcg | Recall | Ndcg | |
| 5 | 0.1520 | 0.1075 | 0.0905 | 0.1380 | 0.0734 | 0.0880 |
| 10 | 0.1532 | 0.1097 | 0.0912 | 0.1388 | 0.0750 | 0.0875 |
| 15 | 0.1554 | 0.1094 | 0.0921 | 0.1401 | 0.0766 | 0.0905 |
| 20 | 0.1571 | 0.1102 | 0.0930 | 0.1394 | 0.0775 | 0.0912 |
| 25 | 0.1578 | 0.1089 | 0.0912 | 0.1395 | 0.0765 | 0.0902 |
| 30 | 0.1544 | 0.1080 | 0.0905 | 0.1368 | 0.0754 | 0.0895 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Song, R.; Wang, Y.; Xu, H. A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation. Information 2022, 13, 229. https://doi.org/10.3390/info13050229
Liu X, Song R, Wang Y, Xu H. A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation. Information. 2022; 13(5):229. https://doi.org/10.3390/info13050229
Chicago/Turabian StyleLiu, Xi, Rui Song, Yuhang Wang, and Hao Xu. 2022. "A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation" Information 13, no. 5: 229. https://doi.org/10.3390/info13050229
APA StyleLiu, X., Song, R., Wang, Y., & Xu, H. (2022). A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation. Information, 13(5), 229. https://doi.org/10.3390/info13050229