1. Introduction
Social networks are a newly introduced concept of interconnected media for everyday interaction. As an integral part of modern digital lives, they generate, through popular social platforms (i.e., Facebook, Twitter etc.), a wealth of data and subsequently knowledge, which may provide useful information, through topics concerning broadly social life, or about a particular topic (i.e., politics). Its mesh-like structure reflects the interconnected associations and relationships between the interacting actors in a network, as it interacts across the world wide web. These are based on standards and technologies, enabling processes of shaping and sharing information through a framework within which they are supported by virtual communities and networks. This framework allows users to communicate and share information, ideas, interests and aspects of their daily lives in a dynamic and responsive way. It is worth mentioning that, given the potential of social networks, information management can be specialised by domain of interest, such as in culture, through the existing dissemination capabilities. Social networks have provided new fields for analysis of unique data types, which depicts structures of the relations between the given entities, also known as a graph. In light of the above, the analytics of graphs appears to address a multitude of practical applications.
The network, as a system with a complex structure, consists of interconnected sets of objects operating under given objectives. To date, various types of networks have developed, usually reflecting social trends, namely social networks, and the widespread adoption of web applications determines their absorptive capacity when they are created and their further adoption by society [
1]. In this context, the development of methods to identify social trends from social media is of particular research interest. The present article focuses on network entities and the relationships between them resulting from user interaction. For instance, community detection can be used to support various other tasks by aligning social networks and big data in everyday life. Moreover, the importance of leveraging graphs, i.e., analyzing unique data structure types that represent the relationships between entities [
2], has been highlighted while introducing graph analytics as a tool for this purpose [
3].
Through their daily use of social networks, users produce and share digital content and can also share opinions and keep up to date on issues that are relevant to them. With the increasing diversity of social networks over the past decade, and thus their users, scientists are challenged to produce high quality services for users. Through user clustering, new patterns of interaction are emerging to identify commonalities between people in real-world interactions. Moreover, social networks typically comprise individuals who communicate with one another and belong to linked communities, and their analysis is a fundamental task for a task called “social network analysis” [
4]. Because those networks have a complex and dynamic structure, these communities cannot be easily identified, leading to the conclusion that this is an open and often difficult issue that can be characterized as an optimization constraint. Thus, identifying node groups with more interfaces is an important research goal that can equally work in identifying fewer interconnections between them. Consequently, as a non-deterministic polynomial-time (NP-Hard) topic, community detection has in recent years allowed evolutionary algorithms to develop a new field of research [
5,
6].
Nowadays, a wider range of social media has been developed, including Twitter, an online social media service that allows users to manage profiles, which are made up of larger interacting communities in the sense of achieving individual or group goals. In particular, the popularity of online social networking among millions of people allows service beneficiaries to stay connected to their immediate social circle. Furthermore, Twitter offers the possibility of exchanging short messages (“tweets”), while contributing to the enrichment of data mining methods thanks to its available API, which allows data to be collected with minimal human input [
7].
It is undoubted that a wealth of data is generated daily by user groups that require new analysis methods to efficiently process with high frequency the diversity, complexity, and characteristics that distinguish big data. Considering the above, social networks are regarded as an integral part of modern life, as they typically express by graphs consisting of tens of thousands of vertices and edges. More specifically, and in the context of the interactive function of the media, we consider vertices as the operators and edges as the interrelation between them. The process of discovering common features between groups of users, called “community detection”, is a fundamental feature for social networks analysis [
8].
A network, i.e., every intricately interacting and interlinked group, serves a specific purpose, and is based on the notion that the allocation of a clustering factor obeys the rule of strength within social networking, hence decreasing as the degree of nodes grows. In this context, grouping procedures are also distinguished, the most basic of which is the clustering coefficient, as it constitutes a key factor in calculating the propensity of the nodes to be clustered with each other. This feature suggests that interconnected communities form social networks, presupposing their discovery for the purpose of further understanding the network architecture. In this, a community is thus considered to be a set of nodes having multiple ties to each other, while fewer external connections further their kind.
Cultural heritage management through social media engagement [
9,
10] can contribute to the development of numerical graph segmentation and automatic topic detection algorithms. In addition, they allow researchers to shed light on members’ personal preferences on specific topics of interest related to culture in general. Based on the above, we examine the evolution of graphs over time, by detecting the source nodes that initiated the evolution on a purely site-specific (topological) basis. In addition, we examine whether it is achievable to categorize nodes based on their age with no metrics. Social network analysis aims to improve the comprehension of the concepts of connectivity, centrality, and relevance of users in a social network. Other tasks that can be successfully implemented are predictive analysis for link formation, evaluation of betweenness centrality, visual representation, etc.
Online social networking is a new paradigm within the framework of big data analysis, where large volumes of data about heterogeneous social events and interactions are stored, with a very high degree of variability. The present research work was motivated by the important problems that arise, such as diffusion and influence maximization, community detection, and user recommendation, which require the intervention of skilled users with multidisciplinary backgrounds, making the current research activity quite challenging. Furthermore, social network constructs are distinct among other communication system configurations (natural, transit, and telecommunication) because of the occurrence of positive grade correlations called assortativity [
11].
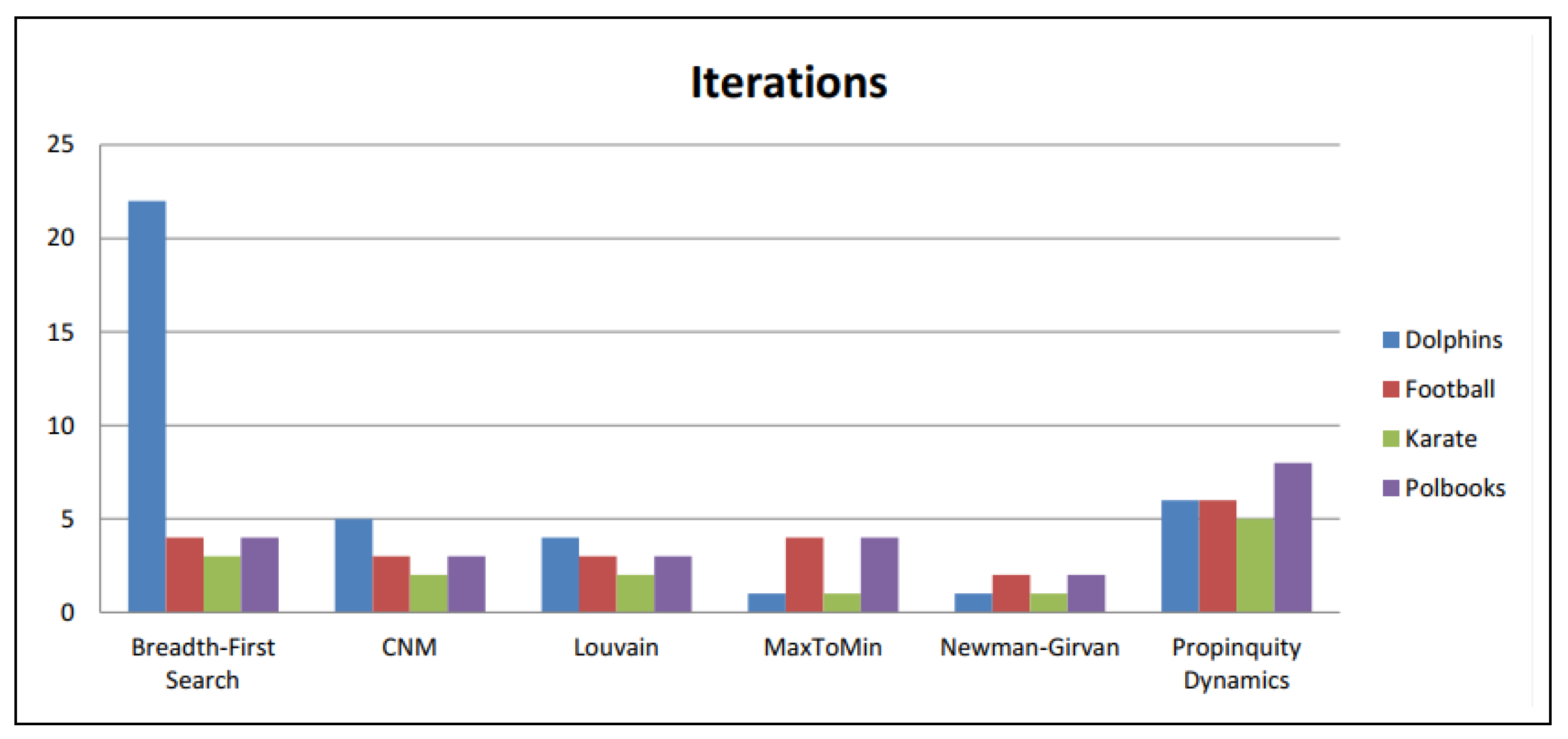
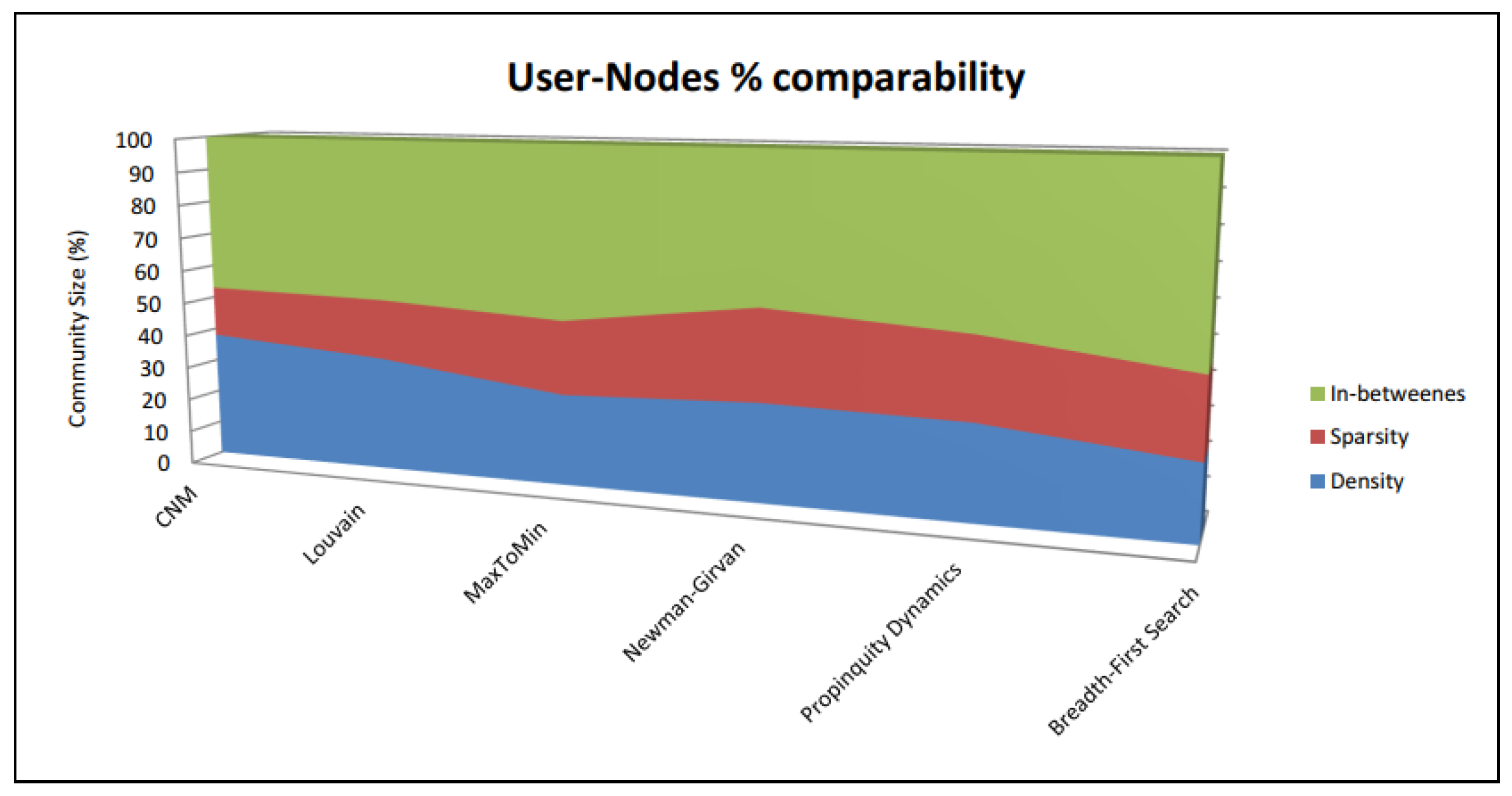
Herein, we aim to evaluate different community discovery algorithms for effective community discovery in social networks. Initially, six popular community detection paradigms, i.e., Breadth-First Search, CNM, Louvain, MaxToMin, Newman–Girvan and Propinquity Dynamics, are evaluated on four extensively exploited datasets based on normalized mutual information (NMI), number of iterations as well as the modularity metric. Moreover, we determined how large individual community sizes, expressed as a proportion of the overall pool of vertices, are for the six specific algorithms. As a next step, we used a set of data extracted from Twitter on cultural and natural heritage information in the Greek domain, which is related to several heritage sites, certain tourist sites and activities. Users evaluated the downloaded the Twitter dataset by selecting whether every extracted community had users with comparable characteristics. Three different options were considered for the exported communities, i.e., “dense community”, “sparse community” and “in-between” [
12]. We proved that the application of each algorithm is directly proportional to its implementation domain as well as by the fundamental principles that characterize the network under study.
The remainder of the paper is structured as follows:
Section 2 presents the related work regarding the community discovery algorithms, and
Section 3 analyzes network centralities, such as centrality measures and modularity metric, and network indices.
Section 4 presents the algorithms implemented in our paper along with their major characteristics. Furthermore, in
Section 5, the implementation details, the four graphs and the derived Twitter dataset are highlighted, whereas
Section 6 presents the evaluation experiments conducted and the results gathered. Ultimately,
Section 7 presents conclusions and draws directions for future work.
2. Related Work
User relevance assessment appeared much earlier than the advent of social networks, as social ties were discovered before the web and online communities. Betweenness-type centrality is described in work specialised in centrality measures [
13,
14]. Instead, today’s multitude of different types of networks pose many computational issues. As previously mentioned, social network analytics is closely associated with graph clustering, whereas predictive text extraction or text analytics incorporates natural language processing (NLP) for thematic analysis. This section presents our brief overview of the work on community detection and topic-modeling techniques, focusing on social networks, especially Twitter. Recent studies have demonstrated that analytic sequences, through their integration into malleable information, aid researchers in harnessing and integrating user behavioral concepts into synthetic graphs with the ultimate goal of automatic topic detection.
Authors in [
15] introduce an actual task of developing methods for determining information support of the web community-members’ personal data verification system. The level of information support of web community member personal data verification system allows evaluating the effectiveness of verification system in web-community management. Also, for identifying possible threats reflected by the user’s behavior towards a specific event, an approach for estimating aggression shown by different users in different Facebook groups or community pages, is presented in [
16]. The experimental evaluation was conducted on a set of real data to prove that the method is efficient in extracting the intensity of the aggression shown by the users.
In their work, the authors in [
16] addressed community discovery for topic modeling through a data store by employing a data analytics engine (i.e., Apache Spark) based on a database structure (a NoSQL-type such as MongoDB). The solution is implemented by using PSCAN [
12,
17], in tandem with LDA [
18]. The latter topic modelling is of individuals in exported groupings. The latter operates on topic modelling of users in the extracted communities, which has an important role in their platform. For their research needs, they have employed a Twitter dataset, accounting solely for users with followers to guarantee that the respective graph for community detection is associated.
Subsequently, the social network analysis is inextricably linked to graph clustering algorithms and web search algorithms [
8,
19,
20,
21]. In particular, high density of network nodes has the characteristics of a community, which refers to several clusters of separate nodes in a graph with shared attributes in the operation of a system. The domain is associated with HITS [
22], and web link analytics with the milestone of analyzing important web pages exploiting PageRank [
23] reporting measure, and countless other variations suggested in [
24]. On the other hand, HITS has two metrics, for use with a website as the information authority and with a node. Also, the aforementioned algorithm, i.e., PageRank, exploits one metric that relies on the level of importance of inbound links.
As previously mentioned, we refer to a community as a set of nodes in a communication system with strong ties between them [
25], where various techniques have been introduced to detect the complex structures of the corresponding communities with application to social networks [
8,
20,
21]. Some of the existing approaches for data clustering (segmental, spectral and hierarchical clustering) are commonly adapted for clustering of graphs [
1,
20,
26,
27]. Authors in [
28] chose to use feature selection methods as a common approach to identify communities on Twitter. The PSCAN algorithm is usually implemented in the context of a Hadoop cloud, as a parallel scheme for the MapReduce model in extended applications (e.g., Twitter) [
17]. Also, the superimposed topics can be identified; the identification of the desired topics is implemented via a generative statistical model (Latent Dirichlet allocation (LDA)) [
29].
A plethora of automata have been reported in the context of community detection in the bibliography [
1,
20,
26,
30]. In particular, the HITS-type algorithm can be exploited in community computation when employed for the examination of non-major latent vectors. In the literature, we have also encountered the graph-partitioning problem related to communities, based on algorithms dealing primarily with spectral distribution approaches for partitioning objects via matrix eigenvectors [
31,
32]. At this point, it is worth noting that spectral partitioning was proposed in [
27,
33]. However, the study in [
34] highlights the use of hierarchical clustering for graph partitioning.
Furthermore, Hong et al. proposed the use of various performance metrics for topic modelling under an empirical study [
7]. More to this point, authors in [
35] addressed the issue of topic modeling through LDA, which is a widely used probabilistic method. In particular, this is a standard tool and in this context, several extensions are proposed to address its limitations, especially in the field of social networks. Addressing the inadequacy of LDA in the sparseness of short documents in the tweet, several types of aggregation techniques were proposed in [
36]. Consequently, it was demonstrated that clustering of similar tweets in individual documents significantly increases thematic coherence. Alvarez et al. [
37] introduced the concept of aggregation techniques in thematic modeling by aggregating tweets from conversations.
Moreover, in the context of community detection, authors in [
38] proposed the concept of modularity, which, alongside the divisive method, represents an initiative for further research. In addition, some works [
39,
40,
41] lie in the context of exploiting a partitioning algorithm that can maximize modularity. In particular, the algorithm applies it as a quality indicator of the segmentation based on the modularity criterion, and by extension it is distinguished as an essential tool for locating community structures, as it quantifies the perceived community quality. It is noteworthy that dense internal connections and the small number of inter-connections are identified as the main criteria for the separation of communities. Moreover, existing research [
42,
43,
44,
45] has considered different algorithms under the notion of modularity; for example, intricate network structures determine the degree of performance of these algorithms, in contrast to other cases where network state is a necessary condition.
It is worth noting that through the works [
44,
46,
47], it becomes clear that the significance and notion of leverage beyond the user perspective to the communication system perspective, as well as personality is the main criterion for the identification of influential communication systems. This results in the creation of such communities within the graphs of Twitter, using a grouping detection strategy based on modularity, which takes into consideration the individual personality traits of users. In addition, graph vertices derived from the above personality-based algorithms are discarded by introducing pre-processing sequences. Additionally, the user behaviour is highlighted on an emotional dimension, as it is reinforced by the introduction of a novel methodology, which effectively helps to identify communities [
48,
49,
50].
Similarly, the existence of a multitude of methods for evaluating the quality of clustering, i.e., the coherence of the community [
51], is apparent. Nevertheless, the majority of current cohesion metrics remain prohibitively expensive (i.e., peak distance among vertices) or susceptible to value extremes, such as metrics based on the graph diameter [
52,
53]. Finally, the works of [
54,
55] describe some of the realizations derived from standard community discovery, and researchers focus mainly on the graph partitioning resulting from this type of algorithm and how it maps to Twitter operational field rather than to other structural criteria more broadly. The aforementioned problematic is related to dedicated analytical methods such as CNM, Louvain, Walktrap, and Newman–Girvan’s Neo4j, and Edge Betweeness, in order to effectively evaluate their use in the field.
In addition, there are a number of studies which aim at improving suggestion-mining results; one of them considered the word-embedding approach and the XGBoost classifier in order to capture context and similarity with other words [
56]. Authors contribute by improving the classifier performance through the XGBoost classifier, as compared with Naive Bayes and Random Forest.
4. Algorithms for Community Detection
This section takes a look at five common community-detection techniques. Note that these algorithms are based on higher-order information that is discovered in the form of graph constructs. The latter is denoted as the count of vertices or edges that the graph computational function needs to address or cross, respectively. Standard applications involve the dimension or the actual amount of traces linking two specified vertices. This is justified, still partially, to the inherent need for link graphs for balancing local and global information. Graph-processing systems will therefore need to have comparable qualities if relevant information is to be derived.
A highest-class manifestation of the graph-community detection task is given by the fact that the smallest grouping is a triangular formation. From a vertex point of view, it can be considered as a tertiary level of quantity ordering. Furthermore, if a triangular formation is surrounded, that is also a tertiary quantity. This follows from the point that a simple association between subjects (an edge on a social graph) does not qualify as a community. Therefore, within a group, there must a minimum of one shared knowledge that connects the persons belonging to that team. Therefore, the above is mirrored in the conception that succeeding community-detection methodology is based directly or indirectly on higher-order measures. Graph-aggregation or spectral graph-separation algorithms, for example, use high-order constructs like principal eigenvectors or graph adjacency matrices [
64].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}