
Selected Methods of Predicting Financial Health of Companies: Neural Networks Versus Discriminant Analysis


Abstract
:1. Introduction
2. Literature Review
2.1. Definitions of Financial Distress as a Prerequisite for Bankruptcy
2.2. Rerview of the Studies Dealing with Financial Distress and Bankruptcy Applying MDA and NN
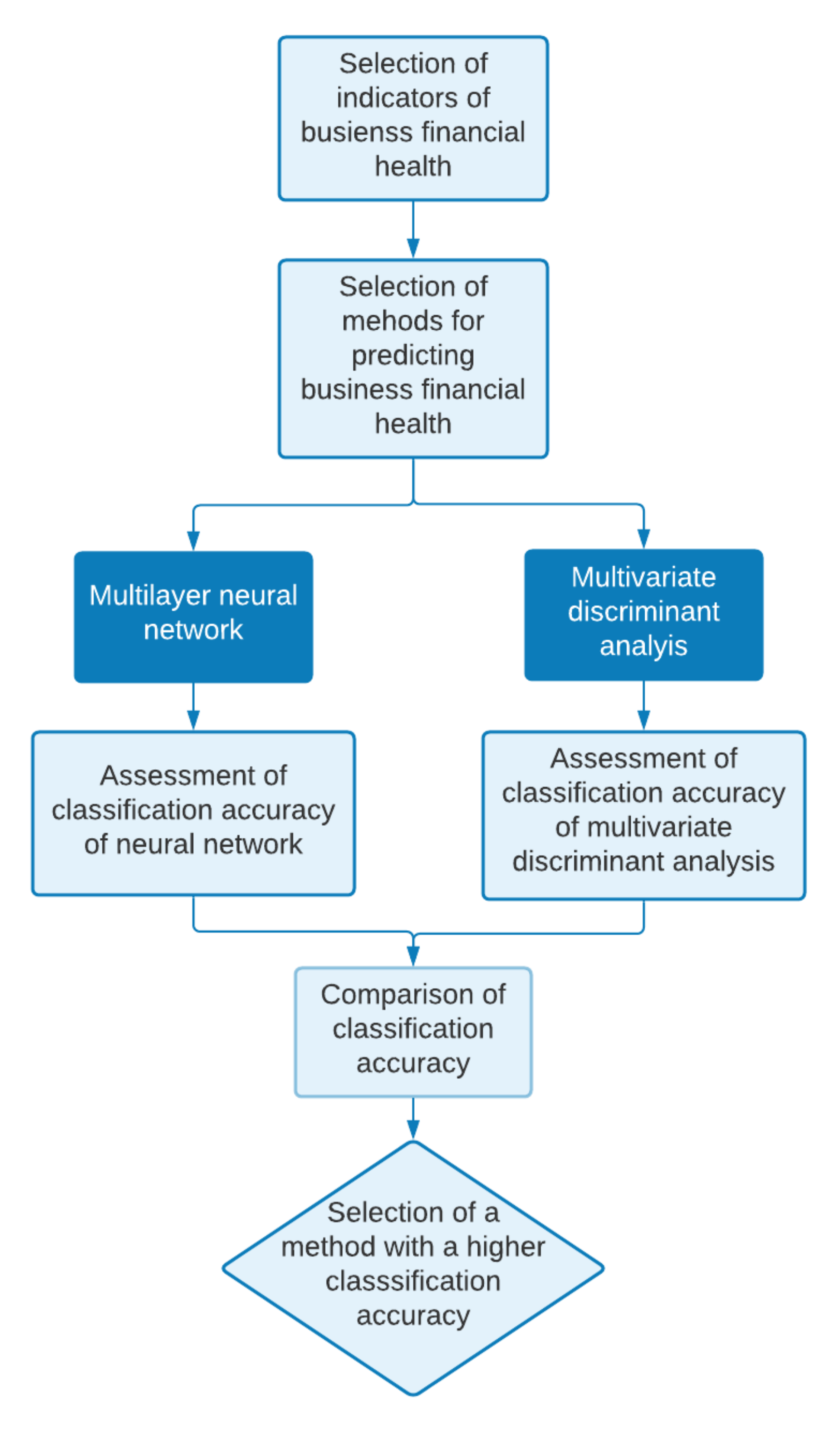
3. Data and Methodology
- quantitative or binary characters;
- none of the characters may be a linear combination of another character or characters;
- it is not appropriate to use two or more strongly correlated characters at the same time;
- the covariance matrices for each group must be approximately identical;
- the characteristics describing each group should meet the requirement of a multidimensional normal distribution.
- test other initial values for the instrument;
- modify the MLP scheme (change the number of vertices, layers);
- try another ANN method;
- reject ANN as a suitable method.
4. Results
4.1. Results of Discriminant Analysis
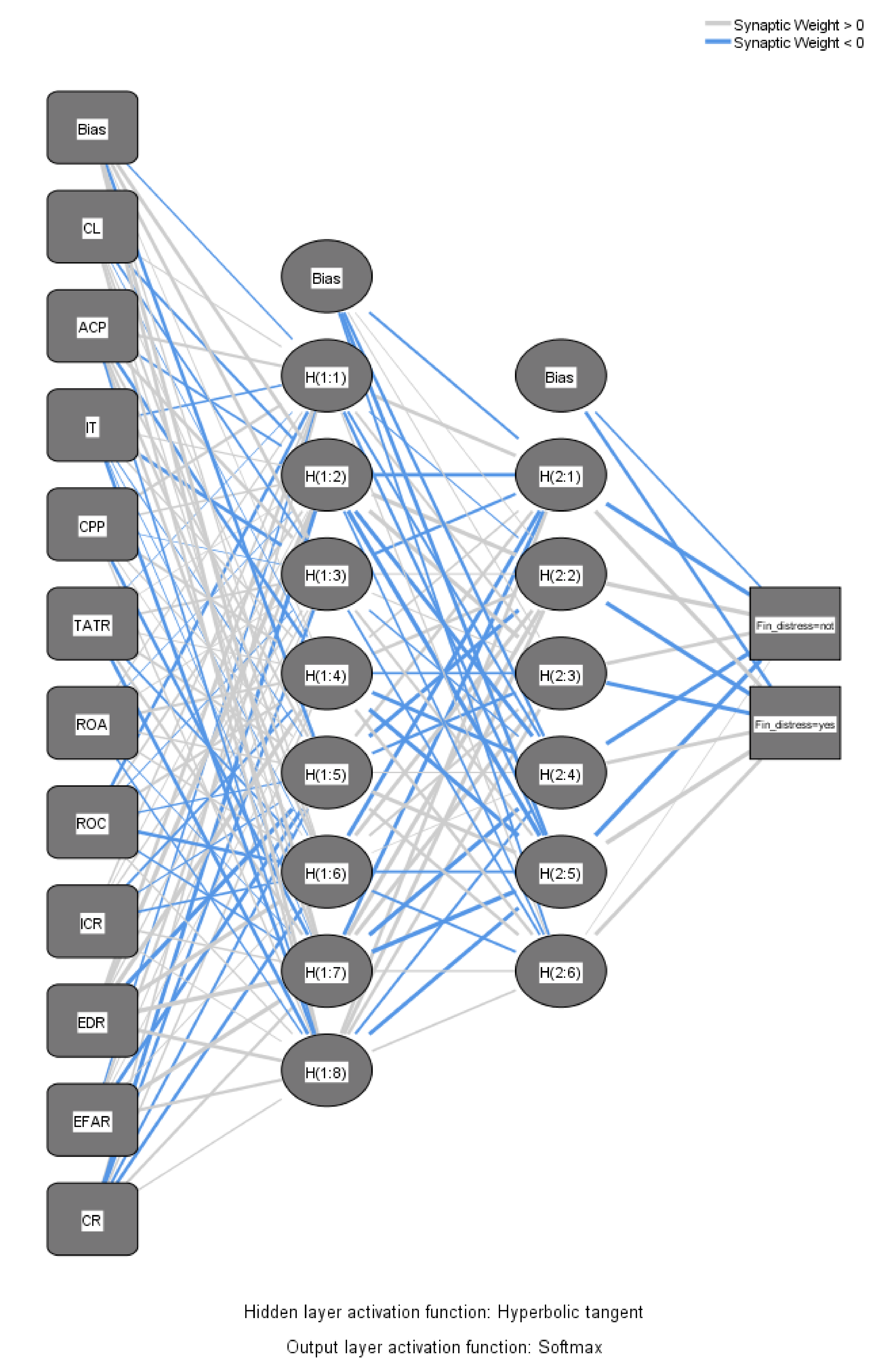
4.2. Results of Neural Networks
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Variable | Marked Correlations Are Significant at p < 0.05000 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TL | CL | QR | ACP | IT | CPP | CTC | TATR | ROA | ROE | ROS | ROC | TDTA | ER | ICR | EDR | EFAR | ELFAR | CR | |
| TL | 1.0000 | 0.9998 | 0.9187 | 0.0058 | −0.0046 | −0.0099 | 0.0128 | −0.0795 | 0.0125 | −0.0108 | 0.0126 | 0.0249 | −0.0142 | 0.0142 | −0.0122 | 0.0374 | 0.0061 | 0.0073 | −0.0144 |
| p = −−− | p = 0.00 | p = 0.00 | p = 0.901 | p = 0.921 | p = 0.832 | p = 0.785 | p = 0.089 | p = 0.790 | p = 0.817 | p = 0.787 | p = 0.595 | p = 0.762 | p = 0.762 | p = 0.794 | p = 0.424 | p = 0.896 | p = 0.877 | p = 0.758 | |
| CL | 0.9998 | 1.0000 | 0.9163 | 0.0057 | −0.0055 | −0.0100 | 0.0128 | −0.0798 | 0.0125 | −0.0107 | 0.0126 | 0.0265 | −0.0139 | 0.0139 | −0.0119 | 0.0379 | 0.0065 | 0.0077 | −0.0142 |
| p = 0.00 | p = −−− | p = 0.00 | p = 0.903 | p = 0.906 | p = 0.831 | p = 0.784 | p = 0.088 | p = 0.789 | p = 0.819 | p = 0.787 | p = 0.572 | p = 0.766 | p = 0.766 | p = 0.799 | p = 0.418 | p = 0.890 | p = 0.870 | p = 0.762 | |
| QR | 0.9187 | 0.9163 | 1.0000 | 0.0056 | −0.0054 | −0.0084 | 0.0110 | −0.0858 | 0.0082 | −0.0095 | 0.0108 | 0.0220 | −0.0120 | 0.0120 | −0.0145 | 0.0426 | 0.0119 | 0.0132 | −0.0127 |
| p = 0.00 | p = 0.00 | p = −−− | p = 0.906 | p = 0.907 | p = 0.857 | p = 0.814 | p = 0.066 | p = 0.861 | p = 0.840 | p = 0.817 | p = 0.639 | p = 0.798 | p = 0.798 | p = 0.757 | p = 0.363 | p = 0.799 | p = 0.777 | p = 0.786 | |
| ACP | 0.0058 | 0.0057 | 0.0056 | 1.0000 | 0.0186 | 0.5913 | −0.4051 | 0.0051 | 0.0015 | −0.0003 | −0.3983 | −0.0159 | 0.0009 | −0.0010 | 0.0014 | 0.0076 | 0.0013 | 0.0012 | 0.0010 |
| p = 0.901 | p = 0.903 | p = 0.906 | p = −−− | p = 0.691 | p = 0.00 | p = 0.00 | p = 0.913 | p = 0.974 | p = 0.995 | p = 0.000 | p = 0.735 | p = 0.985 | p = 0.982 | p = 0.976 | p = 0.872 | p = 0.978 | p = 0.980 | p = 0.983 | |
| IT | −0.0046 | −0.0055 | −0.0054 | 0.0186 | 1.0000 | 0.0564 | −0.0578 | 0.0437 | 0.0001 | −0.0167 | −0.0166 | −0.0218 | −0.0037 | 0.0036 | −0.0043 | −0.0161 | −0.0038 | −0.0043 | −0.0036 |
| p = 0.921 | p = 0.906 | p = 0.907 | p = 0.691 | p = −−− | p = 0.228 | p = 0.217 | p = 0.350 | p = 0.998 | p = 0.721 | p = 0.722 | p = 0.641 | p = 0.937 | p = 0.938 | p = 0.927 | p = 0.731 | p = 0.935 | p = 0.926 | p = 0.939 | |
| CPP | −0.0099 | −0.0100 | −0.0084 | 0.5913 | 0.0564 | 1.0000 | −0.9769 | −0.0154 | −0.0012 | 0.0031 | −0.9740 | −0.0304 | −0.0017 | 0.0017 | −0.0020 | −0.0006 | −0.0018 | −0.0021 | −0.0016 |
| p = 0.832 | p = 0.831 | p = 0.857 | p = 0.00 | p = 0.228 | p = −−− | p = 0.00 | p = 0.742 | p = 0.979 | p = 0.947 | p = 0.00 | p = 0.517 | p = 0.971 | p = 0.972 | p = 0.967 | p = 0.991 | p = 0.969 | p = 0.965 | p = 0.973 | |
| CTC | 0.0128 | 0.0128 | 0.0110 | −0.4051 | −0.0578 | −0.9769 | 1.0000 | 0.0189 | 0.0018 | −0.0036 | 0.9987 | 0.0302 | 0.0022 | −0.0022 | 0.0026 | 0.0026 | 0.0024 | 0.0026 | 0.0021 |
| p = 0.785 | p = 0.784 | p = 0.814 | p = 0.00 | p = 0.217 | p = 0.00 | p = −−− | p = 0.686 | p = 0.969 | p = 0.938 | p = 0.00 | p = 0.519 | p = 0.963 | p = 0.963 | p = 0.956 | p = 0.955 | p = 0.959 | p = 0.955 | p = 0.965 | |
| TATR | −0.0795 | −0.0798 | −0.0858 | 0.0051 | 0.0437 | −0.0154 | 0.0189 | 1.0000 | 0.0124 | 0.0254 | 0.0221 | 0.0244 | −0.0239 | 0.0239 | 0.0486 | −0.0075 | −0.0031 | −0.0053 | −0.0273 |
| p = 0.089 | p = 0.088 | p = 0.066 | p = 0.913 | p = 0.350 | p = 0.742 | p = 0.686 | p = −−− | p = 0.792 | p = 0.588 | p = 0.637 | p = 0.602 | p = 0.610 | p = 0.610 | p = 0.298 | p = 0.873 | p = 0.947 | p = 0.909 | p = 0.559 | |
| ROA | 0.0125 | 0.0125 | 0.0082 | 0.0015 | 0.0001 | −0.0012 | 0.0018 | 0.0124 | 1.0000 | 0.0601 | 0.0026 | 0.1063 | −0.0084 | 0.0085 | 0.0089 | 0.0226 | 0.0153 | 0.0156 | −0.0044 |
| p = 0.790 | p = 0.789 | p = 0.861 | p = 0.974 | p = 0.998 | p = 0.979 | p = 0.969 | p = 0.792 | p = −−− | p = 0.199 | p = 0.956 | p = 0.023 | p = 0.857 | p = 0.857 | p = 0.849 | p = 0.629 | p = 0.744 | p = 0.738 | p = 0.925 | |
| ROE | −0.0108 | −0.0107 | −0.0095 | −0.0003 | −0.0167 | 0.0031 | −0.0036 | 0.0254 | 0.0601 | 1.0000 | −0.0025 | 0.0452 | −0.0040 | 0.0040 | 0.0075 | −0.0179 | 0.0061 | 0.0079 | −0.0098 |
| p = 0.817 | p = 0.819 | p = 0.840 | p = 0.995 | p = 0.721 | p = 0.947 | p = 0.938 | p = 0.588 | p = 0.199 | p = −−− | p = 0.957 | p = 0.333 | p = 0.932 | p = 0.932 | p = 0.873 | p = 0.702 | p = 0.896 | p = 0.867 | p = 0.835 | |
| ROS | 0.0126 | 0.0126 | 0.0108 | −0.3983 | −0.0166 | −0.9740 | 0.9987 | 0.0221 | 0.0026 | −0.0025 | 1.0000 | 0.0303 | 0.0021 | −0.0021 | 0.0025 | 0.0023 | 0.0024 | 0.0026 | 0.0022 |
| p = 0.787 | p = 0.787 | p = 0.817 | p = 0.000 | p = 0.722 | p = 0.00 | p = 0.00 | p = 0.637 | p = 0.956 | p = 0.957 | p = −−− | p = 0.518 | p = 0.964 | p = 0.964 | p = 0.957 | p = 0.961 | p = 0.959 | p = 0.955 | p = 0.962 | |
| ROC | 0.0249 | 0.0265 | 0.0220 | −0.0159 | −0.0218 | −0.0304 | 0.0302 | 0.0244 | 0.1063 | 0.0452 | 0.0303 | 1.0000 | 0.0017 | −0.0017 | 0.0057 | 0.0201 | 0.0060 | 0.0077 | −0.0058 |
| p = 0.595 | p = 0.572 | p = 0.639 | p = 0.735 | p = 0.641 | p = 0.517 | p = 0.519 | p = 0.602 | p = 0.023 | p = 0.333 | p = 0.518 | p = −−− | p = 0.972 | p = 0.972 | p = 0.903 | p = 0.668 | p = 0.899 | p = 0.870 | p = 0.902 | |
| TDTA | −0.0142 | −0.0139 | −0.0120 | 0.0009 | −0.0037 | −0.0017 | 0.0022 | −0.0239 | −0.0084 | −0.0040 | 0.0021 | 0.0017 | 1.0000 | −1.0000 | −0.0024 | −0.0210 | −0.0028 | −0.0033 | −0.0005 |
| p = 0.762 | p = 0.766 | p = 0.798 | p = 0.985 | p = 0.937 | p = 0.971 | p = 0.963 | p = 0.610 | p = 0.857 | p = 0.932 | p = 0.964 | p = 0.972 | p = −−− | p = 0.00 | p = 0.958 | p = 0.654 | p = 0.952 | p = 0.944 | p = 0.991 | |
| ER | 0.0142 | 0.0139 | 0.0120 | −0.0010 | 0.0036 | 0.0017 | −0.0022 | 0.0239 | 0.0085 | 0.0040 | −0.0021 | −0.0017 | −1.0000 | 1.0000 | 0.0024 | 0.0210 | 0.0028 | 0.0033 | 0.0005 |
| p = 0.762 | p = 0.766 | p = 0.798 | p = 0.982 | p = 0.938 | p = 0.972 | p = 0.963 | p = 0.610 | p = 0.857 | p = 0.932 | p = 0.964 | p = 0.972 | p = 0.00 | p = −−− | p = 0.958 | p = 0.653 | p = 0.952 | p = 0.944 | p = 0.992 | |
| ICR | −0.0122 | −0.0119 | −0.0145 | 0.0014 | −0.0043 | −0.0020 | 0.0026 | 0.0486 | 0.0089 | 0.0075 | 0.0025 | 0.0057 | −0.0024 | 0.0024 | 1.0000 | 0.0036 | −0.0007 | −0.0015 | −0.0028 |
| p = 0.794 | p = 0.799 | p = 0.757 | p = 0.976 | p = 0.927 | p = 0.967 | p = 0.956 | p = 0.298 | p = 0.849 | p = 0.873 | p = 0.957 | p = 0.903 | p = 0.958 | p = 0.958 | p = −−− | p = 0.939 | p = 0.988 | p = 0.974 | p = 0.953 | |
| EDR | 0.0374 | 0.0379 | 0.0426 | 0.0076 | −0.0161 | −0.0006 | 0.0026 | −0.0075 | 0.0226 | −0.0179 | 0.0023 | 0.0201 | −0.0210 | 0.0210 | 0.0036 | 1.0000 | 0.0294 | 0.0236 | −0.0176 |
| p = 0.424 | p = 0.418 | p = 0.363 | p = 0.872 | p = 0.731 | p = 0.991 | p = 0.955 | p = 0.873 | p = 0.629 | p = 0.702 | p = 0.961 | p = 0.668 | p = 0.654 | p = 0.653 | p = 0.939 | p = −−− | p = 0.530 | p = 0.614 | p = 0.707 | |
| EFAR | 0.0061 | 0.0065 | 0.0119 | 0.0013 | −0.0038 | −0.0018 | 0.0024 | −0.0031 | 0.0153 | 0.0061 | 0.0024 | 0.0060 | −0.0028 | 0.0028 | −0.0007 | 0.0294 | 1.0000 | 0.9979 | −0.0035 |
| p = 0.896 | p = 0.890 | p = 0.799 | p = 0.978 | p = 0.935 | p = 0.969 | p = 0.959 | p = 0.947 | p = 0.744 | p = 0.896 | p = 0.959 | p = 0.899 | p = 0.952 | p = 0.952 | p = 0.988 | p = 0.530 | p = −−− | p = 0.00 | p = 0.940 | |
| ELFAR | 0.0073 | 0.0077 | 0.0132 | 0.0012 | −0.0043 | −0.0021 | 0.0026 | −0.0053 | 0.0156 | 0.0079 | 0.0026 | 0.0077 | −0.0033 | 0.0033 | −0.0015 | 0.0236 | 0.9979 | 1.0000 | −0.0039 |
| p = 0.877 | p = 0.870 | p = 0.777 | p = 0.980 | p = 0.926 | p = 0.965 | p = 0.955 | p = 0.909 | p = 0.738 | p = 0.867 | p = 0.955 | p = 0.870 | p = 0.944 | p = 0.944 | p = 0.974 | p = 0.614 | p = 0.00 | p = −−− | p = 0.934 | |
| CR | −0.0144 | −0.0142 | −0.0127 | 0.0010 | −0.0036 | −0.0016 | 0.0021 | −0.0273 | −0.0044 | −0.0098 | 0.0022 | −0.0058 | −0.0005 | 0.0005 | −0.0028 | −0.0176 | −0.0035 | −0.0039 | 1.0000 |
| p = 0.758 | p = 0.762 | p = 0.786 | p = 0.983 | p = 0.939 | p = 0.973 | p = 0.965 | p = 0.559 | p = 0.925 | p = 0.835 | p = 0.962 | p = 0.902 | p = 0.991 | p = 0.992 | p = 0.953 | p = 0.707 | p = 0.940 | p = 0.934 | p = −−− | |
Appendix B
| Variable | Obs | W | V | z | Prob > z |
|---|---|---|---|---|---|
| CL | 366 | 0.29307 | 179.757 | 12.302 | 0.00000 |
| ACP | 366 | 0.25657 | 189.037 | 12.421 | 0.00000 |
| IT | 366 | 0.19004 | 205.956 | 12.625 | 0.00000 |
| CPP | 366 | 0.25360 | 189.793 | 12.431 | 0.00000 |
| TATR | 366 | 0.55332 | 113.581 | 11.214 | 0.00000 |
| ROA | 366 | 0.35685 | 163.540 | 12.078 | 0.00000 |
| ROC | 366 | 0.39979 | 152.621 | 11.914 | 0.00000 |
| ICR | 366 | 0.11195 | 225.811 | 12.843 | 0.00000 |
| EDR | 366 | 0.24298 | 192.493 | 12.464 | 0.00000 |
| EFAR | 366 | 0.21987 | 198.371 | 12.536 | 0.00000 |
| CR | 366 | 0.22825 | 196.239 | 12.510 | 0.00000 |
Appendix C
| Variable | Obs | W | V | z | Prob > z |
|---|---|---|---|---|---|
| CL | 78 | 0.28634 | 47.979 | 8.469 | 0.00000 |
| ACP | 78 | 0.54110 | 30.852 | 7.503 | 0.00000 |
| IT | 78 | 0.32882 | 45.124 | 8.335 | 0.00000 |
| CPP | 78 | 0.33201 | 44.909 | 8.324 | 0.00000 |
| TATR | 78 | 0.41853 | 39.092 | 8.021 | 0.00000 |
| ROA | 78 | 0.21245 | 52.947 | 8.685 | 0.00000 |
| ROC | 78 | 0.22597 | 52.038 | 8.647 | 0.00000 |
| ICR | 78 | 0.17952 | 55.161 | 8.774 | 0.00000 |
| EDR | 78 | 0.87917 | 8.124 | 4.583 | 0.00000 |
| EFAR | 78 | 0.30125 | 46.977 | 8.423 | 0.00000 |
| CR | 78 | 0.67947 | 21.549 | 6.718 | 0.00000 |
References
- Mokrišová, M.; Horváthová, J. Bankruptcy Prediction Applying Multivariate Techniques. J. Manag. Bus. Res. Pract. 2020, 12, 52–69. Available online: http://www.journalmb.eu/archiv/JMB−2−2020.pdf#page=52 (accessed on 1 June 2021).
- Coats, P.K.; Fant, F.L. Recognizing financial distress patterns using a neural network tool. Financ. Manag. 1993, 22, 142–155. [Google Scholar] [CrossRef]
- Anandarajan, M.; Lee, P.; Anandarajan, A. Bankruptcy prediction of financially stressed firms: An examination of the predictive accuracy of artificial neural networks. Int. J. Intell. Syst. Account. Financ. Manag. 2001, 10, 69–81. [Google Scholar] [CrossRef]
- Etheridge, H.L.; Sriram, R.S. A comparison of the relative costs of financial distress models: Artificial neural networks, logit and multivariate discriminant analysis. Intell. Syst. Account. Financ. Manag. 1997, 6, 235–248. [Google Scholar] [CrossRef]
- Abid, F.; Zouari, A. Financial Distress Prediction Using Neural Networks. In Proceedings of the MS’ 2000 International Conference on Modeling and Simulation, Las Palmas de Gran Canaria, Spain, 25–27 September 2000; pp. 399–406. [Google Scholar] [CrossRef]
- Antimonopoly Office of the Slovak Republic. Functioning and Problems in the Heat Management Sector in the Slovak Republic with a Focus on Local Central Heat Supply Systems from the Perspective of the Antimonopoly Office of the Slovak Republic. 2013. Available online: http://www.antimon.gov.sk/data/att/365.pdf (accessed on 21 June 2021).
- Klieštik, T.; Válášková, K.; Klieštiková, J.; Kováčová, M.; Švábová, L. Predikcia Finančného Zdravia Podnikov Tranzitívnych Ekonomík; EDIS: Žilina, Slovakia, 2019. [Google Scholar]
- Dimitras, A.I.; Zanakis, S.H.; Zopounidis, C. A survey of business failures with an emphasis on prediction methods and industrial applications. Eur. J. Oper. Res. 1996, 90, 487–513. [Google Scholar] [CrossRef]
- Ding, Y.S.; Song, X.P.; Zen, Y.M. Forecasting Financial Condition of Chinese Listed Companies Based on Support Vector Machine. Expert Syst. Appl. 2008, 34, 3081–3089. [Google Scholar] [CrossRef]
- Pervan, I.; Pervan, M.; Vukoja, B. Prediction of company bankruptcy using statistical techniques. Croat. Oper. Res. Rev. 2011, 11, 158–166. Available online: https://hrcak.srce.hr/96660 (accessed on 11 February 2021).
- Altman, E.I.; Hotchkiss, E. Corporate Financial Distress and Bankruptcy: Predict and Avoid Bankruptcy, Analyze and Invest in Distressed Debt; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Hendel, I. Competition under financial Distress. J. Ind. Econ. 1996, 54, 309–324. [Google Scholar] [CrossRef]
- Platt, H.D.; Platt, M. Comparing Financial Distress and Bankruptcy. Rev. Appl. Econ. 2006, 2, 1–27. Available online: https://ssrn.com/abstract=876470 (accessed on 18 November 2021).
- Pham, B.; Do, T.; Vo, D. Financial distress and bankruptcy prediction: An appropriate model for listed firms in Vietnam. Econ. Syst. 2018, 42, 616–624. [Google Scholar] [CrossRef]
- Foster, G. Financial Statement Analysis, 2nd ed.; Prentice−Hall: Englewood Cliffs, NJ, USA, 1986; pp. 31–53. [Google Scholar]
- Wruck, K.H. Financial Distress, Reorganization, and Organizational Efficiency. J. Financ. Econ. 1990, 27, 419–444. [Google Scholar] [CrossRef]
- Opler, T.; Titman, S. Financial Distress and Corporate Performance. J. Financ. 1994, 49, 1015–1040. [Google Scholar] [CrossRef]
- Andrade, G.; Kaplan, S.N. How Costly is Financial (Not Economic) Distress? Evidence from Highly Leveraged Transactions that Became Distressed. J. Financ. 1998, 53, 1443–1493. [Google Scholar] [CrossRef] [Green Version]
- Gestel, T.V.; Baesens, B.; Suykens, J.A.K.; Den Poel, D.V.; Baestaens, D.E.; Willekens, M. Bayesian Kernel Based Classification for Financial Distress Detection. Eur. J. Oper. Res. 2006, 172, 979–1003. [Google Scholar] [CrossRef]
- Purnanandam, A. Financial Distress and Corporate Risk Management: Theory and Evidence. J. Financ. Econ. 2008, 87, 706–739. [Google Scholar] [CrossRef]
- Gibson, C.H. Financial Reporting & Analyses: Using Financial Accounting Information, 11th ed.; South Western Cengage Learning: Mason, OH, USA, 2010. [Google Scholar]
- Hofer, C.W. Turnaround Strategies. J. Bus. Strategy 1980, 1, 19–31. [Google Scholar] [CrossRef]
- Asquith, P.; Gertner, R.; Scharfstein, D. Anatomy of Financial Distress: An Examination of Junk−Bond Issuers; Working paper no. 3942; Cambridge: Cambridge, UK, 1991. [Google Scholar]
- Asquith, P.; Gertner, R.; Scharfstein, D. Anatomy of Financial Distress: An Examination of Junk−bond Issuers. Q. J. Econ. 1994, 109, 625–658. [Google Scholar] [CrossRef]
- Jensen, M.C. Is Leverage an Invitation to Bankruptcy? Wall Str. J. 1989. [Google Scholar] [CrossRef]
- Whitaker, R. The early stages of financial distress. J. Econ. Financ. 1999, 23, 123–132. Available online: http://hdl.handle.net/10.1007/BF02745946 (accessed on 22 April 2021). [CrossRef]
- Gordon, M.J. Towards a Theory of Financial Distress. J. Financ. 1971, 26, 347–356. [Google Scholar] [CrossRef]
- Gilbert, L.R.; Menon, K.; Schwartz, K.B. Predicting Bankruptcy for Firms in Financial Distress. J. Bus. Financ. Account. 1990, 17, 161–171. [Google Scholar] [CrossRef]
- John, K.; Lang, L.H.P.; Netter, J. The Voluntary Restructuring of Large Firms in Response to Performance Decline. J. Financ. 1992, 47, 891–917. [Google Scholar] [CrossRef]
- Messier, V.F.; Hansen, J.V. Including rules for expert system development: An example using default and bankruptcy data. Manag. Sci. 1988, 34, 1403–1415. [Google Scholar] [CrossRef]
- Vlachos, D.; Tolias, Y.A. Neuro−fuzzy modelling in bankruptcy prediction. Yugosl. J. Oper. Res. 2003, 13, 165–174. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Vochozka, M.; Jelínek, J.; Váchal, J.; Straková, J.; Stehel, V. Využití Neurónových Sítí PŘI komplexním Hodnocení Podniku, 1st ed.; C.H. Beck: Praha, Czech Republic, 2017. [Google Scholar]
- Tučková, J. Úvod do Teorie a Aplikací Neuronových Sítí; Vydavatelství ČVUT: Praha, Czech Republic, 2003. [Google Scholar]
- Šíma, J.; Neruda, R. Teoretické otázky Neurónových Sítí; Matfyzpress: Praha, Czech Republic, 1996. [Google Scholar]
- Volná, E. Neuronové Síťe. Ostravská Univerzita v Ostravě: Ostrava. 2008. Available online: http://www1.osu.cz/~volna/Neuronove_site_skripta.pdf (accessed on 15 April 2021).
- Koklu, M.; Tutuncu, K. Qualitative Bankruptcy Prediction Rules Using Artificial Intelligence Techniques. In Proceedings of the International Conference on challenges in IT, Engineering and Technology (ICCIET’2014), Phuket, Thailand, 17–18 July 2014. [Google Scholar] [CrossRef]
- Wilson, R.; Sharda, R. Bankruptcy prediction using neural networks. Decis. Support Syst. 1994, 11, 545–557. [Google Scholar] [CrossRef]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Atiya, A.F. Bankruptcy prediction for credit risk using neural networks: A survey and new results. IEEE Trans. Neural Netw. 2001, 12, 929–935. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Argyrou, A. Predicting Financial Distress Using Neural Network: Another Episode to the Serial? Master’s Thesis, Swedish School of Economics and Business Administration, Helsinky, Finland, 2006. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.112.8950&rep=rep1&type=pdf (accessed on 15 May 2021).
- Kohonen, T. Self−organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Odom, M.D.; Sharda, R. A neural network model for bankruptcy prediction. In Proceedings of the IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; Volume 2, pp. 163–168. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.−C. Artificial neural networks in manufacturing: Concepts, applications, and perspectives. IEEE Trans. Compon. Packag. Manuf. Technol. Part A 1994, 17, 212–228. [Google Scholar] [CrossRef]
- Chen, N.; Ribeiro, B.; Vieira, A.; Chen, A. Clustering and visualization of bankruptcy trajectory using self−organizing map. Expert Syst. Appl. 2013, 40, 385–393. [Google Scholar] [CrossRef]
- Lee, S.; Choi, W.S. A multi−industry bankruptcy prediction model using back−propagation neural network and multivariate discriminant analysis. Expert Syst. Appl. 2012, 40, 2941–2946. [Google Scholar] [CrossRef]
- Raghupathi, W.; Schkade, L.; Raju, B.S. A neural network application for bankruptcy prediction. In Proceedings of the Twenty−Fourth Annual Hawaii International Conference on System Sciences, Kauai, HI, USA, 8–11 January 1991; IEEE Computer Society Press: Los Alamitos, CA, USA, 1991; Volume 4, pp. 147–155. [Google Scholar] [CrossRef]
- Shah, J.R.; Murtaza, M.B. A neural network based clustering procedure for bankruptcy prediction. Am. Bus. Rev. 2000, 18, 80–86. Available online: https://www.proquest.com/docview/216292621/fulltextPDF/90819152D23D4FAEPQ/1?accountid=14716 (accessed on 8 March 2021).
- Altman, E.I. Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bancruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Blum, M. Failing company discriminant analysis. J. Account. Res. 1974, 12, 1–25. [Google Scholar] [CrossRef]
- Deakin, E.B. A Discriminant Analysis of Predictors of Business Failure. J. Account. Res. 1972, 10, 167–179. [Google Scholar] [CrossRef]
- Elam, R. The effect of lease data on the predictive ability of financial ratios. Account. Rev. 1975, 5, 25–43. Available online: https://www.jstor.org/stable/244661 (accessed on 22 February 2021).
- Norton, C.L.; Smith, R.E. A comparison of general price level and historical cost financial statements in the prediction of bankruptcy. Account. Rev. 1979, 54, 72–87. Available online: https://www.jstor.org/stable/246235 (accessed on 13 April 2021).
- Wilcox, J.W. A prediction of business failure using accounting data. J. Account. Res. Sel. Stud. 1973, 11, 163–179. [Google Scholar] [CrossRef]
- Taffler, R.J. The assessment of company solvency and performance using a statistical model. Account. Bus. Res. 1983, 13, 295–308. [Google Scholar] [CrossRef]
- Martin, A.; Aswathy, V.; Balaji, S.; Miranda Lakshmi, T.; Prasanna Venkatesan, V. An Analysis on Qualitative Bankruptcy Prediction Using Fuzzy ID3 and Ant Colony Optimization Algorithm. Proceeding of the International Conference on Pattern Recognition, Informatics and Medical Engineering (PRIME 2012), Periyar University, Salem, Tamilnadu, India, 21–23 March 2012. [Google Scholar] [CrossRef]
- Ohlson, J.A. Financial Ratios and the Probabilistic Prediction of Bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Simak, P.C. DEA Based Analysis of Coporate Failure. Master’s Thesis, Faculty of Applied Sciences and Engineering, University of Toronto, Toronto, ON, Canada, 1997. [Google Scholar]
- Hongkyu, J.; Ingoo, H.; Hoonyoung, L. Bankruptcy prediction using case−based reasoning, neural networks, and discriminant analysis. Expert Syst. Appl. 1997, 13, 97–108. [Google Scholar] [CrossRef]
- Gherghina, S.C. An Artificial Intelligence Approach towards Investigating Corporate Bankruptcy. Rev. Eur. Stud. 2015, 7, 5–22. [Google Scholar] [CrossRef] [Green Version]
- Altman, E.I.; Marco, G.; Varetto, F. Corporate distress diagnosis: Comparisons using linear discriminant analysis and neural networks (the Italian experience). J. Bank. Financ. 1994, 18, 505–529. [Google Scholar] [CrossRef]
- Abid, F.; Zouari, A. Predicting corporate financial distress: A neural networks approach. Financ. India 2002, 16, 601–612. Available online: https://ssrn.com/abstract=1300290 (accessed on 20 April 2021).
- Du Jardin, P. Predicting bankruptcy using neural networks and other classification methods: The influence of variable selection techniques on model accuracy. Neurocomputing 2010, 73, 2047–2060. [Google Scholar] [CrossRef] [Green Version]
- Zouari, A. Discriminating Firm Financial Health Using Self−Organizing Maps: The Case of Saudi Arabia; Department of Finance and Investment, College of Economics and Administrative Sciences, Imam Muhammad Bin Saud Islamic University: Riyadh, Saudi Arabia, 2012. [Google Scholar]
- Vochozka, M.; Rowland, Z. The Evaluation and Prediction of the Viability of Construction Enterprises. Littera Scr. 2015, 8, 60–75. Available online: https://www.infona.pl/resource/bwmeta1.element.desklight-e31ba48c-db5f-44d4-ae7c-86f0be534bfb (accessed on 15 April 2021).
- Csikosova, A.; Janoskova, M.; Culkova, K. Application of Discriminant Analysis for Avoiding the Risk of Quarry Operation Failure. J. Risk Financ. Manag. 2020, 13, 231. [Google Scholar] [CrossRef]
- Kočišová, K.; Mišanková, M. Discriminant analysis as a tool for forecasting company‘s financial health. Procedia—Soc. Behav. Sci. 2014, 110, 1148–1157. [Google Scholar] [CrossRef] [Green Version]
- Stankovičová, I.; Vojtková, M. Viacrozmerné Štatistické Metódy s Aplikáciami; Iura Edition: Bratislava, Slovakia, 2007. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back−propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- CRIF. Financial Statements of Businesses; Slovak Credit Bureau, s.r.o.: Bratislava, Slovakia, 2016. [Google Scholar]
- Khemais, Z.; Nesrine, D.; Mohamed, M. Credit Scoring and Deafult Risk Prediction: A Comparative Study between Disriminant Analysis & Logistic Regression. Int. J. Econ. Financ. 2016, 18, 39–53. [Google Scholar] [CrossRef]
- Mihalovič, M. 2016. Performance Comparison of Multiple Discriminant Analysis and Logit Models in Bankruptcy Prediction. Econ. Sociol. 2016, 9, 101–118. [Google Scholar] [CrossRef] [PubMed]
- Mihalovič, M. Využitie skóringových modelov pri predikcii úpadku ekonomických subjektov v Slovenskej republike. Politická Ekon. 2018, 66, 689–708. [Google Scholar] [CrossRef] [Green Version]
- Sun, K.; Huang, S.−H.; Wong, D.S.−H.; Jang, S.S. Design and Application of a Variable Selection Method for Multilayer Perceptron Neural Network with LASSO. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1386–1396. [Google Scholar] [CrossRef]


| Author/Authors | Definition |
|---|---|
| Studies that Equate Distress to Inability to Pay Liabilities, Interest Loans or Dividends | |
| Foster [15] | Defines financial distress as a “serious liquidity problem which is impossible to be resolved without the large-scale restructuring of the operation or structure of economic entities” |
| Wruck [16] | Defines financial distress “as where net cash-flows are not adequate to pay off current liabilities for example interest cost or accruals” |
| Opler, Titman [17] | Define financial distress as non-sporadic situation when companies can no longer meet their liabilities when they become due and their break their commitments with or face them with severe difficulties |
| Andrade and Kaplan [18] | Financial distress is a circumstance in which a firm is unable to meet its debt obligations to creditors, which in turn leads to either restructuring or bankruptcy |
| Gestel [19] | Characterizes financial distress and financial failure because of chronic losses that cause a disproportionate increase in liabilities accompanied by a loss of asset value |
| Purnanandam [20] | Defines financial distress as the loss of solvency. He also considers financial distress to be a transitional stage between solvency and insolvency. The company is in distress when it fails to pay interest or violates debt agreements |
| Gibson [21] | Believes that distress is a company’s inability to pay its dividend preference shares, short-term liabilities and interest on loans |
| Studies that link financial distress with low profitability | |
| Hofer [22] | Links financial distress to negative net income before special items |
| Asquith et al. [23] | Firm is classified as financially distressed if in any 2 years after issuing junk bonds, its EBITDA is less than its interest expense, or if in any one year EB1TDA is less than 80% of its interest expense |
| Asquith et al. [24] Andrade and Kaplan [18] | Firm is in financial distress when its EBITDA is smaller than its financial expenses |
| Platt and Platt [13] | Adopt a multidimensional approach to financial distress. They consider a company to be financially distressed when it meets three criteria: negative EBIT, negative EBITDA and negative net income before special items |
| Ding, Song and Zen [9] | Confirmed the relationship between financial distress and low profitability |
| Studies that link financial distress with low business performance and efficiency | |
| Jensen [25] | Argues that financial distress forces management to implement efficiency measures that improve the company’s performance |
| Whitaker [26] | Agrees with Jensen and argues that a state of financial distress is actually beneficial for a company at an early stage, as it forces it to introduce measures to improve efficiency and thus performance |
| Studies that combine more above-mentioned approaches | |
| Gordon [27] | Emphasizes that financial distress is only a state of a long-evolving process, followed by failure and restructuring. This process should be defined in terms of optimizing the financial structure and financial security measures. The company experiences this situation when its ability to generate profit weakens and the amount of debt exceeds the value of the company’s total assets |
| Gilbert et al. [28] | Financial distress is characterized by negative cumulative income for at least several consecutive years, loss and poor performance. A company in financial distress may restructure its debt and achieve an adequate level of solvency, or merge, thereby ceasing to exist as an independent business entity, or to file for bankruptcy as a strategic response by management or owners to financial problems |
| John, Lang and Netter [29] | Link financial distress to change in equity price and negative EBIT |
| Input Neurons | Indicator | Indicators’ Description | Method of Calculation |
|---|---|---|---|
| x1 | CL | Current ratio | |
| x2 | ACP | Average collection period | |
| x3 | IT | Inventory turnover | |
| x4 | CPP | Creditors payment period | |
| x5 | TATR | Total assets turnover ratio | |
| x6 | ROA | Return on assets | |
| X7 | ROC | Return on costs | |
| X8 | ICR | Interest coverage ratio | |
| X9 | EDR | Equity to debt ratio | |
| x10 | EFAR | Equity to fixed assets ratio | |
| x11 | CR | Cost ratio |
| Prosperous Businesses (n = 366) | Non-Prosperous Businesses (n = 78) | |||||
|---|---|---|---|---|---|---|
| Indicator | Mean | Median | Standard Deviation | Mean | Median | Standard Deviation |
| Current Ratio | 3.89 | 1.01 | 12.13 | 2.92 | 0.64 | 9.87 |
| Average collection period | 0.5 | 0.16 | 1.59 | 0.24 | 0.11 | 0.39 |
| Inventory turnover | 0.05 | 0.00 | 0.31 | 0.05 | 0.00 | 0.2 |
| Creditors payment period | 2.12 | 0.48 | 7.47 | 1.47 | 0.52 | 3.87 |
| Total assets turnover ratio | 1.01 | 0.37 | 1.66 | 0.7 | 0.24 | 1.54 |
| Return on assets | 0.03 | 0.04 | 0.31 | −0.04 | 0.07 | 0.9 |
| Return on costs | −0.03 | 0.02 | 1.05 | −0.32 | 0.04 | 2.7 |
| Interest coverage ratio | 61.68 | 2.02 | 567.17 | 28.19 | 0.00 | 615.18 |
| Equity to debt ratio | 1.06 | 0.28 | 3.56 | −0.28 | −0.22 | 0.24 |
| Equity to fixed assets ratio | 1.63 | 0.3 | 6.52 | −4.26 | −0.4 | 14.64 |
| Cost ratio | 0.97 | 0.94 | 0.78 | 1.6 | 1.16 | 1.12 |
| CL | ACP | IT | CPP | TATR | ROA | ROC | ICR | EDR | EFAR | CR | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mann–Whitney U | 10,297.0 | 11,958.0 | 13,842.0 | 14,255.0 | 10,386.0 | 12,165.0 | 13,037.0 | 6559.0 | 114.0 | 124.0 | 4592.0 |
| Wilcoxon W | 13,378.0 | 15,039.0 | 16,923.0 | 17,336.0 | 13,467.0 | 79,326.0 | 80,198.0 | 9640.0 | 3195.0 | 3205.0 | 71,753.0 |
| Z | −3.865 | −2.251 | −0.444 | −0.018 | −3.779 | −2.050 | −1.202 | −7.518 | −13.762 | −13.753 | −9.410 |
| Asymp. Sig. (2-tailed) | 0.000 | 0.024 | 0.657 | 0.985 | 0.000 | 0.040 | 0.229 | 0.000 | 0.000 | 0.000 | 0.000 |
| Box‘s M | 1246.287 | |
|---|---|---|
| F | Approx. | 17.896 |
| df1 | 66 | |
| df2 | 62,925.997 | |
| Sig. | 0.000 |
| Indicators | Coeficients |
|---|---|
| Current Ratio | 0.037 |
| Average collection period | −0.121 |
| Inventory turnover | 0.017 |
| Creditors payment period | 0.065 |
| Total assets turnover ratio | 0.155 |
| Return on assets | 0.103 |
| Return on costs | 0.191 |
| Interest coverage ratio | −0.074 |
| Equity to debt ratio | 0.386 |
| Equity to fixed assets ratio | 0.567 |
| Cost ratio | −0.659 |
| Test of Function(s) | Wilks’ Lambda | Chi-Square | df | Sig. |
|---|---|---|---|---|
| 1 | 0.838 | 77.302 | 11 | 0.000 |
| Classification Results | |||||
|---|---|---|---|---|---|
| Membership | Total | ||||
| 1 | 2 | ||||
| Original | Count | 1 | 362 | 4 | 366 |
| 2 | 66 | 12 | 78 | ||
| % | 1 | 98.9 | 1.1 | 100.0 | |
| 2 | 84.6 | 15.4 | 100.0 | ||
| Cross-validated | Count | 1 | 360 | 6 | 366 |
| 2 | 68 | 10 | 78 | ||
| % | 1 | 98.4 | 1.6 | 100.0 | |
| 2 | 87.2 | 12.8 | 100.0 | ||
| Input Layer | Covariates | 1 | Current Ratio |
| 2 | Average collection period | ||
| 3 | Inventory turnover | ||
| 4 | Creditors payment period | ||
| 5 | Total assets turnover ratio | ||
| 6 | Return on assets | ||
| 7 | Return on costs | ||
| 8 | Interest coverage ratio | ||
| 9 | Equity to debt ratio | ||
| 10 | Equity to fixed assets ratio | ||
| 11 | Cost ratio | ||
| Number of Units | 11 | ||
| Rescaling Method for Covariates | Standardized | ||
| Hidden Layer(s) | Number of Hidden Layers | 2 | |
| Number of Units in Hidden Layer 1 a | 8 | ||
| Number of Units in Hidden Layer 2 a | 6 | ||
| Activation Function | Hyperbolic tangent | ||
| Output Layer | Dependent Variables | 1 | Financial distress |
| Number of Units | 2 | ||
| Activation Function | Identity | ||
| Error Function | Sum of Squares | ||
| Training sample | Sum of Squares Error | 5.292 |
| Percent Incorrect Predictions | 1.9% | |
| Testing sample | Sum of Squares Error | 6.226 |
| Percent Incorrect Predictions | 5.9% |
| Sample | Predicted | |||
|---|---|---|---|---|
| 1 | 2 | Percent Correct | ||
| Training | 1 | 248 | 2 | 99.2% |
| 2 | 3 | 45 | 93.8% | |
| Overall Percent | 84.2% | 15.8% | 98.3% | |
| Testing | 1 | 114 | 2 | 98.3% |
| 2 | 4 | 26 | 86.7% | |
| Overall Percent | 80.8% | 19.2% | 95.9% | |
| MLP | MDA | |
|---|---|---|
| Brier score | 0.0338 | 0.1577 |
| Somers’ D | 0.8278 | 0.1429 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horváthová, J.; Mokrišová, M.; Petruška, I. Selected Methods of Predicting Financial Health of Companies: Neural Networks Versus Discriminant Analysis. Information 2021, 12, 505. https://doi.org/10.3390/info12120505
Horváthová J, Mokrišová M, Petruška I. Selected Methods of Predicting Financial Health of Companies: Neural Networks Versus Discriminant Analysis. Information. 2021; 12(12):505. https://doi.org/10.3390/info12120505
Chicago/Turabian StyleHorváthová, Jarmila, Martina Mokrišová, and Igor Petruška. 2021. "Selected Methods of Predicting Financial Health of Companies: Neural Networks Versus Discriminant Analysis" Information 12, no. 12: 505. https://doi.org/10.3390/info12120505
APA StyleHorváthová, J., Mokrišová, M., & Petruška, I. (2021). Selected Methods of Predicting Financial Health of Companies: Neural Networks Versus Discriminant Analysis. Information, 12(12), 505. https://doi.org/10.3390/info12120505