
Anticheat System Based on Reinforcement Learning Agents in Unity



Abstract
:1. Introduction
2. Related Work
3. Methods and Implementation
- the development of a multiplayer game;
- the implementation of state machines (bots);
- the implementation of security agents using ML-Agents.
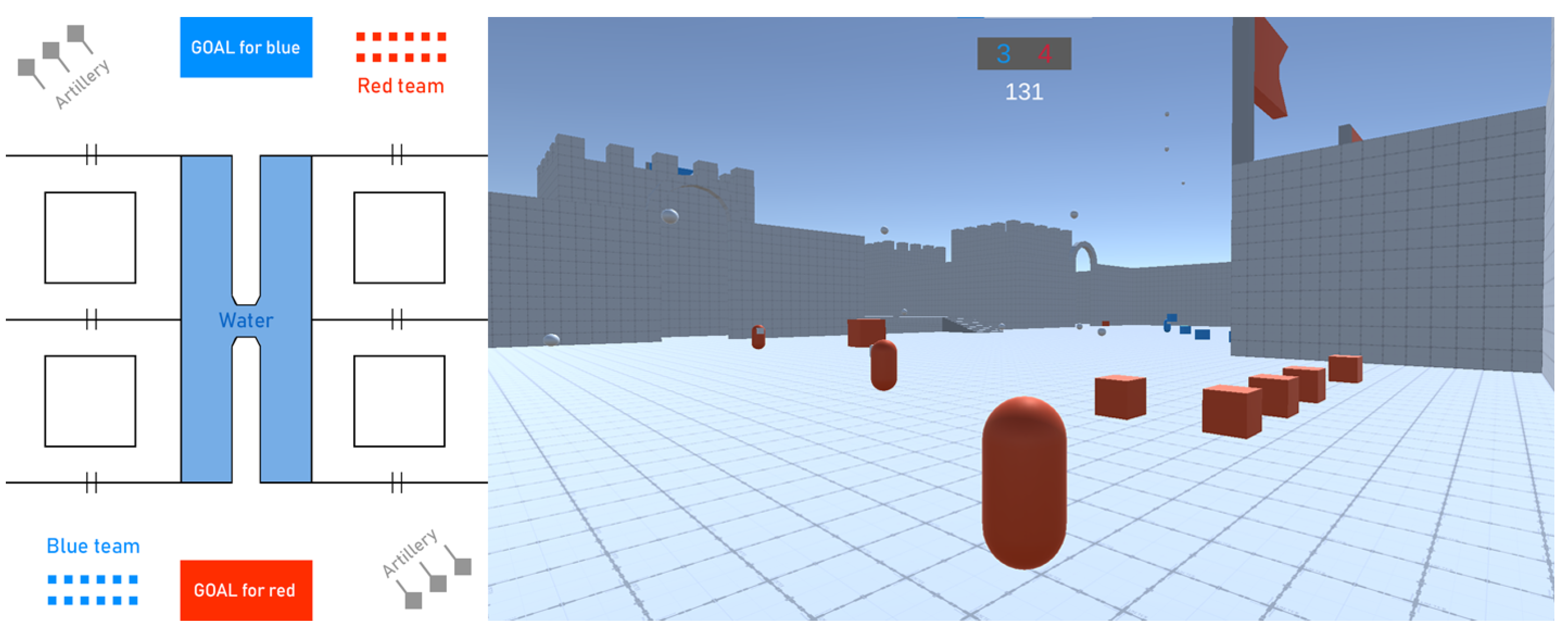
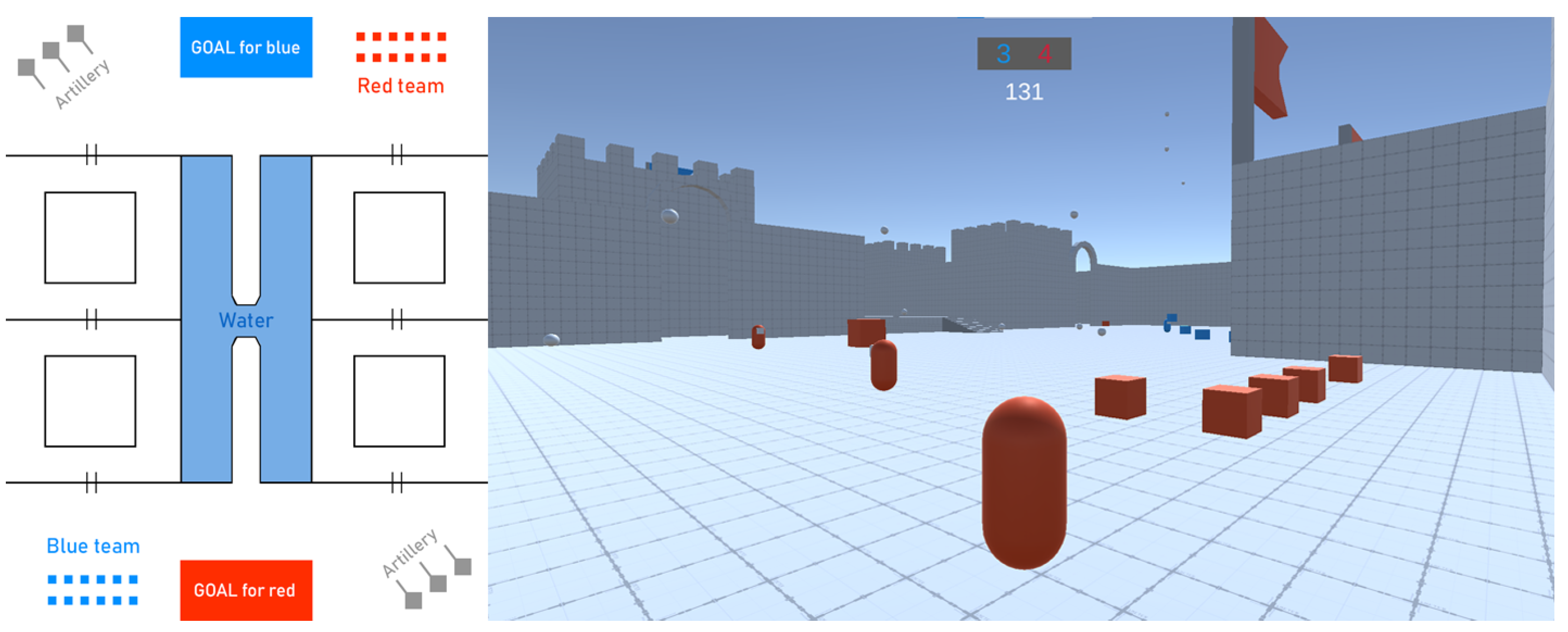
3.1. Game Implementation
3.2. Implementation of Bots
3.3. Implementation of Security Agents (ML-Agents)
3.3.1. Proximal Policy Optimization
3.3.2. Observations
- local position;
- local rotation on Y axis;
- velocity;
- is player carrying a box;
- box positions of your team and rotations;
- blue team score;
- red team score
3.3.3. Rewards
3.3.4. Training Configuration
3.3.5. Description of Agent Decisions
3.3.6. Testing
4. Experiments
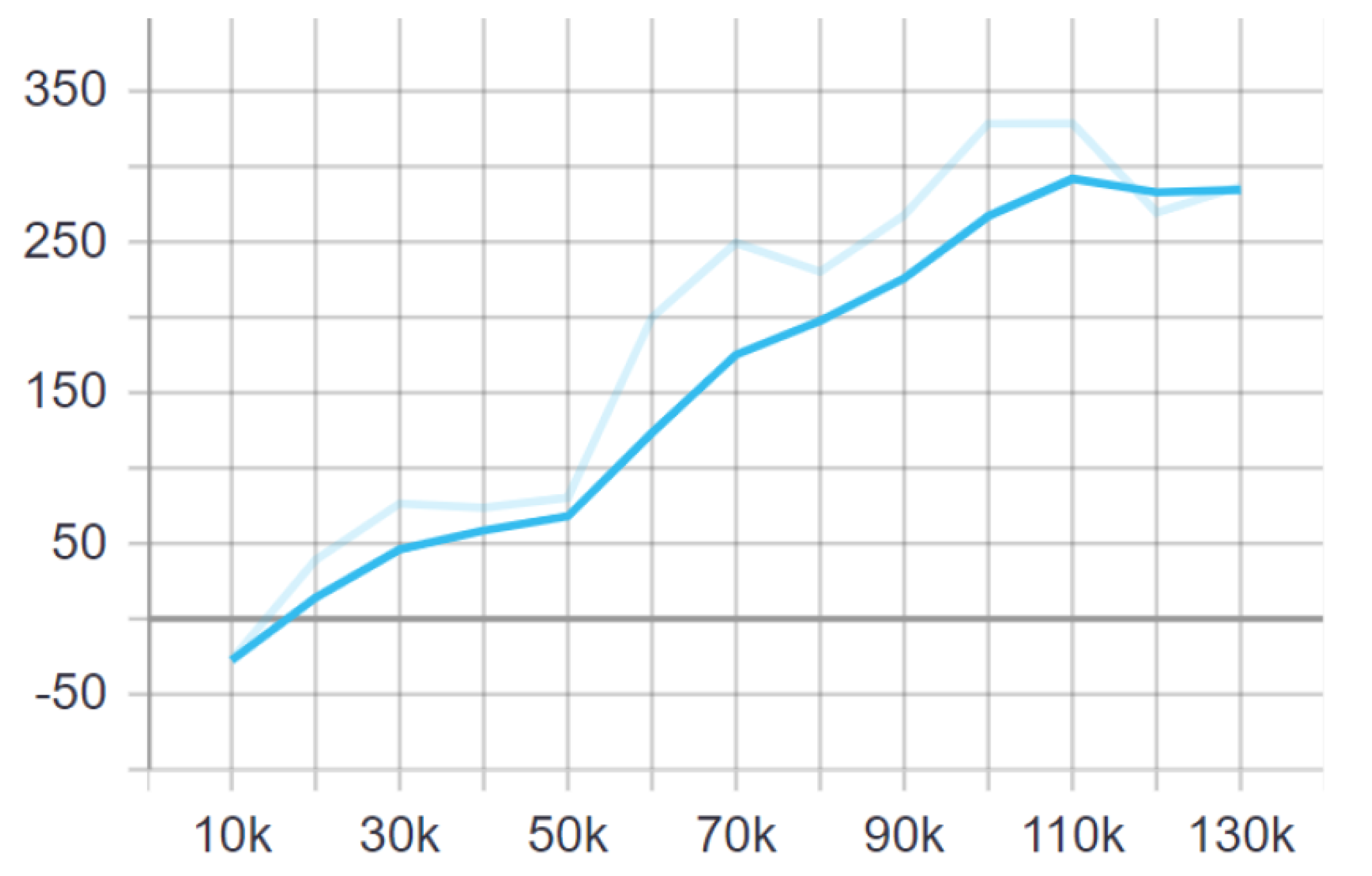
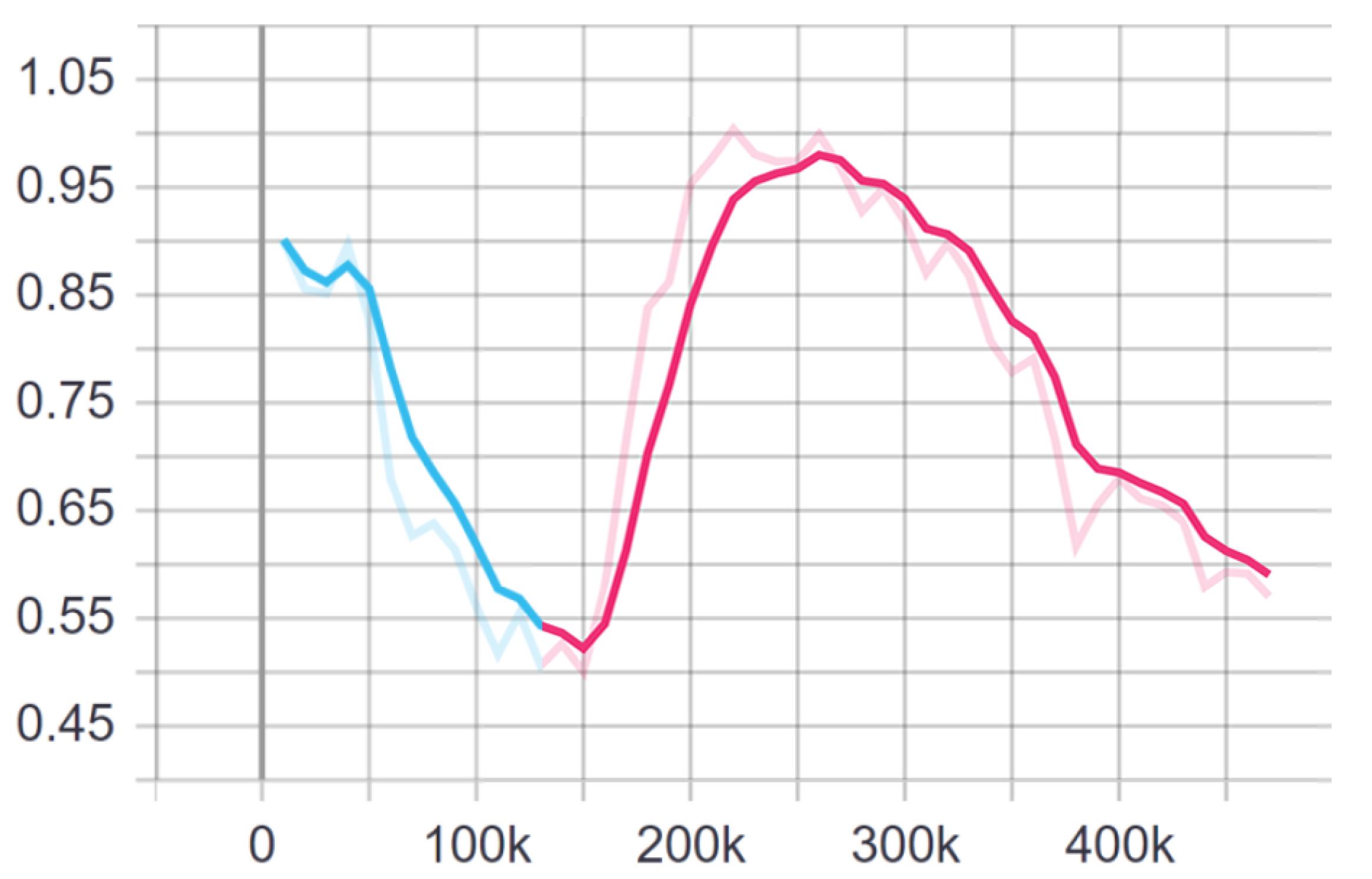
4.1. Training 1v1
4.2. Result Evaluation for 1v1
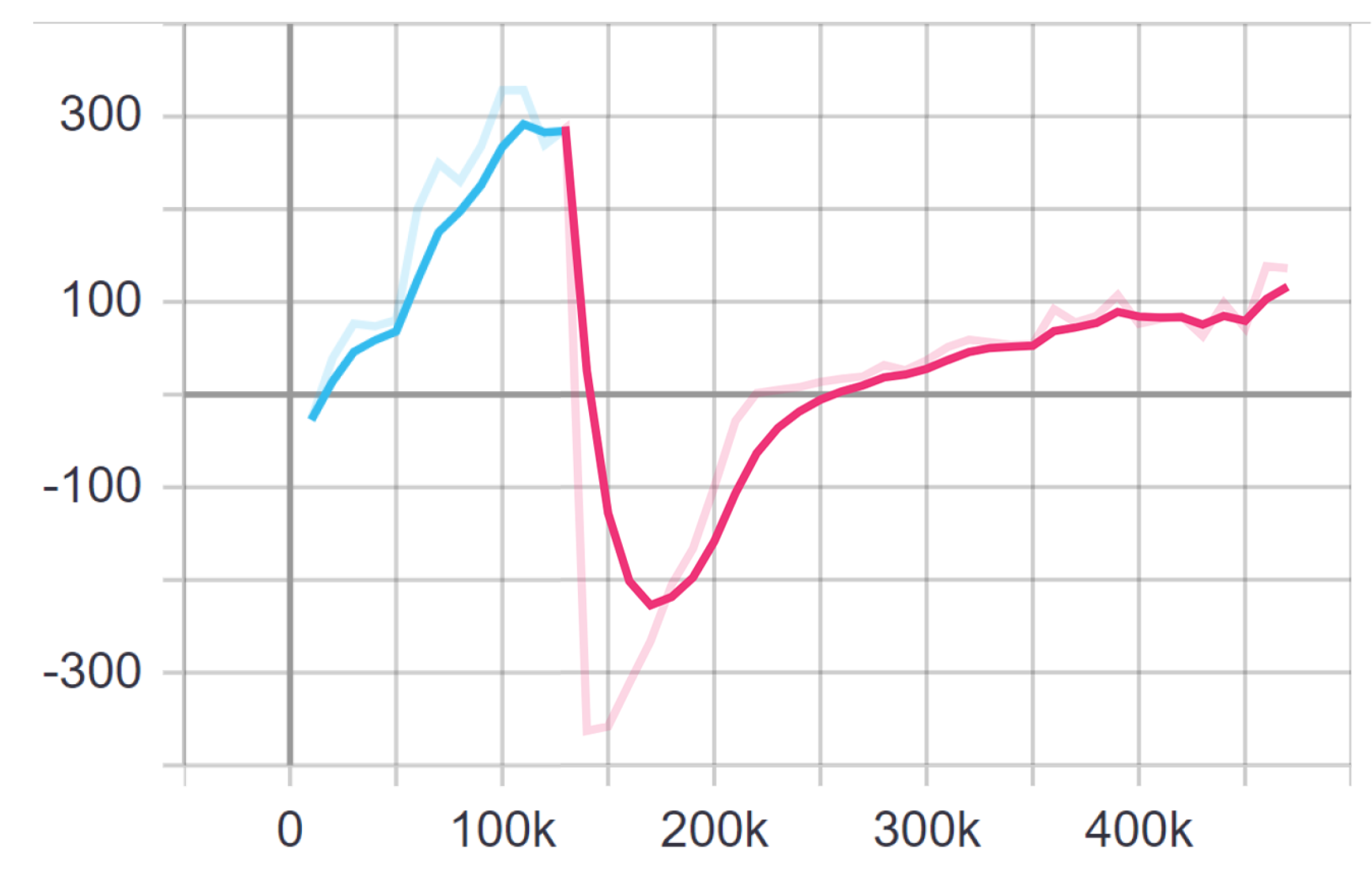
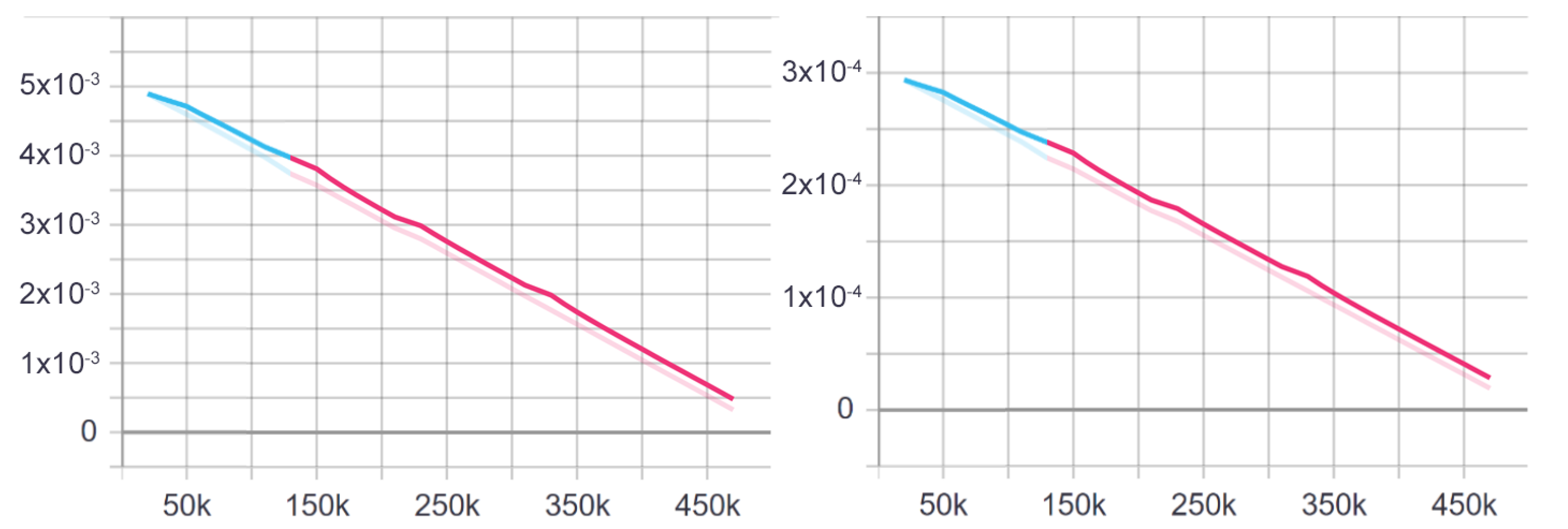
4.3. Training 2v2
4.4. Result Evaluation for 2v2
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ML-Agents. ML-Agents Toolkit Overview. 2021. Available online: https://github.com/Unity-Technologies/ml-agents/blob/main/docs/ML-Agents-Overview.md (accessed on 10 February 2022).
- Mwiti, D. 10 Real-Life Applications of Reinforcement Learning. 2021. Available online: https://neptune.ai/blog/reinforcement-learning-applications (accessed on 25 January 2022).
- Alayed, H.; Frangoudes, F.; Neuman, C. Behavioral-Based Cheating Detection in Online First Person Shooters Using Machine Learning Techniques. 2013. Available online: https://ieeexplore.ieee.org/abstract/document/6633617 (accessed on 5 February 2022).
- Chapel, L.; Botvich, D.; Malone, D. Probabilistic Approaches to Cheating Detection in Online Games. 2010. Available online: https://www.researchgate.net/publication/221157498_Probabilistic_Approaches_to_Cheating_Detection_in_Online_Games (accessed on 5 February 2022).
- Pao, H.K.; Chen, K.T.; Chang, H.C. Game Bot Detection via Avatar Trajectory Analysis. 2010. Available online: https://ieeexplore.ieee.org/document/5560779 (accessed on 5 February 2022).
- Galli, L.; Loiacono, D.; Cardamone, L.; Lanzi, P. A Cheating Detection Framework for Unreal Tournament III: A Machine Learning Approach. 2011. Available online: https://ieeexplore.ieee.org/abstract/document/6032016 (accessed on 14 February 2022).
- Khalifa, S. Machine Learning and Anti-Cheating in FPS Games. 2016. Available online: https://www.researchgate.net/publication/308785899_Machine_Learning_and_Anti-Cheating_in_FPS_Games (accessed on 15 February 2022).
- Willman, M. Machine Learning to Identify Cheaters in Online Games. 2020. Available online: https://www.diva-portal.org/smash/get/diva2:1431282/FULLTEXT01.pdf (accessed on 16 February 2022).
- Islam, M.; Dong, B.; Chandra, S.; Khan, L. GCI: A GPU Based Transfer Learning Approach for Detecting Cheats of Computer Game. 2020. Available online: https://ieeexplore.ieee.org/abstract/document/9154512 (accessed on 16 February 2022).
- Platzer, C. Sequence-Based Bot Detection in Massive Multiplayer Online Games. 2011. Available online: https://ieeexplore.ieee.org/abstract/document/6174239 (accessed on 23 March 2022).
- Lample, G.; Chaplot, D. Playing FPS Games with Deep Reinforcement Learning. 2017. Available online: https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14456/14385 (accessed on 21 March 2022).
- Unity. About ProGrids. 2020. Available online: https://docs.unity3d.com/Packages/com.unity.progrids@3.0/manual/index.html (accessed on 6 February 2022).
- Unity. ProBuilder. Available online: https://unity.com/features/probuilder (accessed on 6 February 2022).
- Tadevosyan, G. Unity AI Development: A Finite-State Machine Tutorial. Available online: https://www.toptal.com/unity-unity3d/unity-ai-development-finite-state-machine-tutorial (accessed on 21 March 2022).
- Unity. NavMesh Agent. 2020. Available online: https://docs.unity3d.com/Manual/class-NavMeshAgent.html (accessed on 6 February 2022).
- Wang, Y.; He, H.; Wen, C.; Tan, X. Truly Proximal Policy Optimization. 2019. Available online: https://arxiv.org/abs/1903.07940 (accessed on 10 February 2022).
- ML-Agents. Training with Proximal Policy Optimization. 2018. Available online: https://github.com/miyamotok0105/unity-ml-agents/blob/master/docs/Training-PPO.md (accessed on 10 February 2022).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2017. Available online: https://arxiv.org/abs/1707.06347 (accessed on 10 February 2022).
- Mattar, M.; Berges, V.P.; Cohen, A.; Teng, E.; Elion, C. ML-Agents v2.0 Release: Now Supports Training Complex Cooperative Behaviors. 2021. Available online: https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors (accessed on 21 March 2022).
- ML-Agents. Training Configuration File. 2021. Available online: https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md#ppo-specific-configurations (accessed on 11 February 2022).
- Lisowski, E. What is Entropy in Machine Learning? 2021. Available online: https://addepto.com/what-is-entropy-in-machine-learning/?utm_source=rss&utm_medium=rss&utm_campaign=what-is-entropy-in-machine-learning (accessed on 11 February 2022).
- ML-Agents. Using TensorBoard to Observe Training. 2021. Available online: https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Using-Tensorboard.md (accessed on 21 March 2022).
- Anaconda. Data Science Technology for Human Sensemaking. Available online: https://www.anaconda.com/ (accessed on 11 February 2022).
- Zhang, J. Ultimate Volleyball: A Multi-Agent Reinforcement Learning Environment Built Using Unity ML-Agents. 2021. Available online: https://towardsdatascience.com/ultimate-volleyball-a-3d-volleyball-environment-built-using-unity-ml-agents-c9d3213f3064 (accessed on 21 March 2022).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Current State | Next State | Condition |
|---|---|---|---|
| 1. | Search | Go toward box | If box found |
| 2. | Go toward box | Search | If stuck for more than 0.5 s |
| 3. | Go toward box | Pick up the box | If near box |
| 4. | Pick up the box | Search | If box is not picked |
| 5. | Pick up the box | Go to the destination | If box is picked |
| 6. | Go to the destination | Drop the box | If arrived at the destination |
| 7. | Drop the box | Search | If not carrying the box |
| 8. | From any state | Dead | If health is zero or less than zero |
| 9. | Dead | Search | If health is greater than zero |
| Blue Team | Red Team | |||
|---|---|---|---|---|
| Player | Cheating Percentage | Player | Cheating Percentage | |
| Test 1 | Bot | 84.15% | Person | 12.18% |
| Test 2 | Person | 71.92% | Bot | 6.34% |
| Blue Team | Red Team | |||
|---|---|---|---|---|
| Player | Cheating Percentage | Player | Cheating Percentage | |
| Test 1 | Person 1 | 28.98% | Person 2 | 14.28% |
| Bot 1 | 38.43% | Bot 2 | 67.78% | |
| Test 2 | Person 2 | 17.90% | Person 1 | 31.72% |
| Bot 2 | 40.54% | Bot 1 | 62.61% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lukas, M.; Tomicic, I.; Bernik, A. Anticheat System Based on Reinforcement Learning Agents in Unity. Information 2022, 13, 173. https://doi.org/10.3390/info13040173
Lukas M, Tomicic I, Bernik A. Anticheat System Based on Reinforcement Learning Agents in Unity. Information. 2022; 13(4):173. https://doi.org/10.3390/info13040173
Chicago/Turabian StyleLukas, Mihael, Igor Tomicic, and Andrija Bernik. 2022. "Anticheat System Based on Reinforcement Learning Agents in Unity" Information 13, no. 4: 173. https://doi.org/10.3390/info13040173
APA StyleLukas, M., Tomicic, I., & Bernik, A. (2022). Anticheat System Based on Reinforcement Learning Agents in Unity. Information, 13(4), 173. https://doi.org/10.3390/info13040173