Abstract
There exist various text-classification tasks using user-generated contents (UGC) on social media in the big data era. In view of advantages and disadvantages of feature-engineering-based machine-learning models and deep-learning models, we argue that fusing handcrafted-text representation via feature engineering and data-driven deep-text representations extracted by performing deep-learning methods is conducive to enhancing text-classification capability. Given the characteristics of different deep neural networks, their complementary effect needs to be investigated. Moreover, contributions of these representations need to be adaptively learned when it comes to addressing different tasks or predicting different samples. Therefore, in this paper, we propose a novel fused deep-neural-network architecture with a hierarchical attention mechanism for text classification with social media data. Specifically, in the context that handcraft features are available, we employ the attention mechanism to adaptively fuse totally data-driven-text representation and handcrafted representation. For the generation of the data-driven-text representation, we propose a data-driven encoder that fuses text representations derived from three deep-learning methods with the attention mechanism, to adaptively select discriminative representation and explore their complementary effect. To verify the effectiveness of our approach, we performed two text-classification tasks, i.e., identifying adverse drug reaction (ADR)-relevant tweets from social media and identifying comparative-relevant reviews from an E-commerce platform. Experimental results demonstrate that our approach outperforms other baselines.
1. Introduction
With the rapid development of Web 2.0 technology, people tend to express their ideas and share their experiences on social media. User-generated content (UGC) on social media has been widely used in various applications, such as exploring factors affecting usage intention [1], investigating public sentiment and attention of recycled water [2], stock market forecasting [3], and user interest mining [4]. Social media has enabled a plethora of text-classification tasks, such as recognizing comparative opinion-related reviews [5], identifying fake news and other malicious social media contents [6], classifying opinion spam [7], recognizing adverse drug-reaction (ADR)-related text from Twitter [8] or health forums [9], predicting depression degrees [10], detecting rumors [11], and collecting event-related tweets [12].
To train a text classifier using traditional machine-learning methods, some handcrafted features are extracted and then fed to a classifier algorithm. The performance of the model relies heavily on the quality of feature engineering. For a specific task, there may exist various external domain-specific knowledge resources, which can be naturally encoded into a conventional machine-learning model via feature engineering. However, UGC on social media generally presents unique characteristics. For example, there exist a variety of colloquial terms, creative phrases, inevitable misspellings, and other irregular expressions. Moreover, people frequently express their opinions using implicit language, which necessitates global semantic understandings. Therefore, a traditional feature-engineering-based model faces huge challenges to deal with these characteristics, since it can only explore superficial language information, failing to capture semantic meanings.
In recent years, deep-learning methods have gained increasing attention for addressing various natural-language-processing (NLP) tasks, including text classification [13,14]. The adoption of deep-learning methods, such as Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Bidirectional Encoder Representation from Transformers (BERT) [15], can capture discriminative information by automatically performing feature learning. However, generic deep-learning models do not necessarily have advantages over classic machine-learning models since they ignore external domain-specific knowledge bases and experts’ involvement. For example, Zhou and Li [16] pointed out that traditional machine-learning models exploring various handcrafted features still outperform deep-learning models for paper-section identification.
In view of the abovementioned advantages and disadvantages of feature-engineering-based machine-learning models and deep-learning models, we argue that fusing handcrafted features via feature engineering (referred to as “handcrafted-text representation”) and data-driven features extracted by performing deep-learning methods (referred to as “deep-text representations”) is conducive to enhancing text-classification capability. In terms of fusion strategies, although prior studies have endeavored to incorporate certain knowledge into classic deep neural networks [17], this fusion paradigm needs careful design. Moreover, it is difficult to incorporate various types of knowledge. Explicitly fusing them with attention is a strategy that shows more initiative.
Moreover, when faced with different tasks or samples, different deep neural networks have varied performances. RNNs are well-suited to NLP applications requiring comprehension of sequence dependency. CNN is a competitive method where recognizing local and position-invariant information is important [14]. It presents outstanding capability of capturing local features due to the use of convolutional filters. For example, the key phrase “I like” plays an important role to indicate a positive sentiment polarity in the sentiment-classification task. In addition to the strong capability of capturing long-range dependency via self-attention, BERT is also expert at addressing text requiring global semantic understandings [15].
Given these characteristics of different deep neural networks, we argue that on one hand, there is no deep-learning model that can outperform other models. To deliver a high-performing text classifier, multiple representations derived by different deep-learning methods generally need to be simultaneously explored, since they can capture multi-facets of information, thus complementing each other. On the other hand, contributions of these representations might vary significantly when it comes to addressing different tasks or predicting different samples.
In this paper, we propose a novel fused deep-neural-network architecture with a hierarchical attention mechanism for social-media-based text-classification. Specifically, in the context that handcraft features are available, we employ the attention mechanism to adaptively fuse totally data-driven deep-text representation and handcrafted-text representation. For the generation of deep-text representation, we propose a data-driven encoder that fuses text representations derived from BERT, CNN, and Long Short-Term Memory (LSTM) with the attention mechanism, in order to adaptively select discriminative representation and explore their complementary effect. To assess the generalization capability of our proposed approach, we conducted extensive experiments with two case studies and three real-world datasets. The empirical results demonstrate the effectiveness of our proposed approach. This study is an extension of a preliminary version of the proposed approach [5] from the following aspects. On one hand, we have extended the prior study [5] by proposing the concept of hierarchical attention and simultaneously exploring handcrafted-text representation and deep-text representations. Moreover, apart from comparative-relevant text identification on the phone dataset, we have applied the approach to another task (i.e., adverse drug-reaction-relevant text identification) and added another two datasets to further verify the generalization of the approach.
The remainder of this paper is organized as follows: We review related work in Section 2. Our proposed approach is described in detail in Section 3. We present experimental datasets and settings in Section 4. Experimental results are reported and analyzed in Section 5. We provide conclusions in Section 6.
2. Related Work
2.1. Social-Media-Based Text Classification
In terms of conducting text classification using UGC on social media, apart from the supervised learning, prior studies also investigated the effectiveness of semisupervised learning [7] and active learning [12]. Earlier studies mainly relied on feature engineering, i.e., extracting shallow linguistic features and domain-specific features. For examples, Sarker and Gonzalez [8] explored various features including n-grams with term frequency–inverse document frequency (tf-idf), medical semantic features, ADR-lexicon match-based features, negation features, synonym-expansion features, change-phrase features, sentiword-score features, and topic-based features. Zheng and Sun [12] leveraged n-grams and hash values, and computed the cosine similarity based on bag-of-words features with tf-idf. Yang et al. [9] mainly focused on topics using the latent dirichlet allocation (LDA). Regarding the used classification algorithm, a support vector machine (SVM) was widely used [8,12]. Recent studies have turned to utilizing deep-learning methods; for example, Bing et al. [11] utilized dual coattention to fuse hidden embeddings encoded from user profiles, source tweets, and comments. They explored various deep neural networks, including BERT, CNN, and Bidirectional Gated Recurrent Units (Bi-GRU).
2.2. Deep Learning for Text Classification
In recent years, we have witnessed great success of applying deep learning for text classification. Among deep neural networks, RNN is considered to be an effective architecture for addressing sequential text data since it is capable of capturing long-range dependency. Given the gradient-vanishing problem of conventional RNN, researchers pay attention to LSTM [18], a popular variant of RNN. By incorporating three gates (input gate, forget gate, and output gate) to manage the flow of information into and out of a memory cell, LSTM mitigates the gradient-vanishing issue that conventional RNNs suffer from, and presents strong capability of capturing and maintaining long-term dependencies. Furthermore, researchers also investigated the effectiveness of Bidirectional LSTM [19] due to its capability of considering information conveyed by both previous and next words. Although CNN was originally proposed to process images, its effectiveness has been verified for various NLP tasks. For example, Kim et al. [20] proposed the TextCNN with one convolution layer for sentence classification. Zhang et al. [21] used character-level features. Prior studies have found that RNN and CNN performed differently when addressing different types of tasks [22]. Vu et al. [22] found that CNN and RNN can provide complementary information. Yin et al. [23] compared scenarios in which CNN and LSTM had respective advantages, and pointed out that CNN dominated in tasks that needed key-phrase matching, while RNN was suitable to encode long-range context dependency and order information. Pretrained language models, such as Embeddings from Language Models (ELMo) [24], OpenAI Generative Pre-trained Transformer (GPT) [25], BERT [15], and Enhanced Representation through Knowledge Integration (ERNIE) [26,27] can capture global semantics effectively, and have boosted various NLP tasks. Representations derived by ELMo are a function of output embeddings of different layers of bidirectional LSTM. ELMo can effectively address the issue of modeling polysemy. GPT and BERT are two landmark Transformer-based pretrained models. GPT uses autoregressive language modeling as the pretraining objective that maximizes all words’ conditional probabilities given their previous words. Compared with GPT, BERT treats bidirectional words as contexts and uses two self-supervised tasks to pretrain a model. Previous work also tailored domain-adaptive and task-aware pretraining models [28]. Beyond leveraging a single method, some researchers also proposed hybrid networks by combining different deep-learning architectures. For example, Wang et al. [29], Liu and Guo [30] utilized CNN to extract local features, and then leveraged LSTM to capture long-dependency features.
2.3. Attention in the NLP Domain
Attention, originally proposed for machine translation and inspired by human biological systems, has gained increasing attention in neural-network literature. The attention model is capable of adaptively concerning the input’s certain parts [31]. In addition to being utilized to fuse multimodal information [32], the attention mechanism has been gaining traction in the NLP domain, such as machine translation [33], question answering [34], and text classification [19,35]. One of the typical ways of implementing the attention mechanism in deep neural networks is by focusing on relevant parts of sequences [19,36]. Considering the hierarchical structure of a document (i.e., a document is composed of sentences; a sentence is composed of words), Yang et al. [35] proposed a hierarchical attention network (HAN) at two abstraction levels, i.e., at sentence level and word level, for document classification. HAN is capable to pay attention to important words in a sentence and important sentences in a document. Another type of attention mechanism is called multirepresentational attention, which involves multiple feature representations to capture several facets of the input. Learned attentions describe important weights of different representations. For example, for the same input sentence, Kiela et al. [37] learned importance weights over various word embeddings to improve sentence representation. Moreover, self-attention, an attention mechanism relating to a single sequence’s different positions, is the key to the Transformer’s success [38].
2.4. Research Gap
We identified several research gaps. First, although prior studies have proposed hybrid deep neural networks, they generally combine CNN and RNN in sequence, e.g., using the output of CNN as the input of RNN [29,30]; the complementary nature of various text representations is worth exploring in line with the multirepresentational attention research. Second, the complementary effect of deep-text representation and handcrafted-text representation is overlooked for finding relevant text from social media.
3. The Attention-Based Multirepresentational Fusion Method
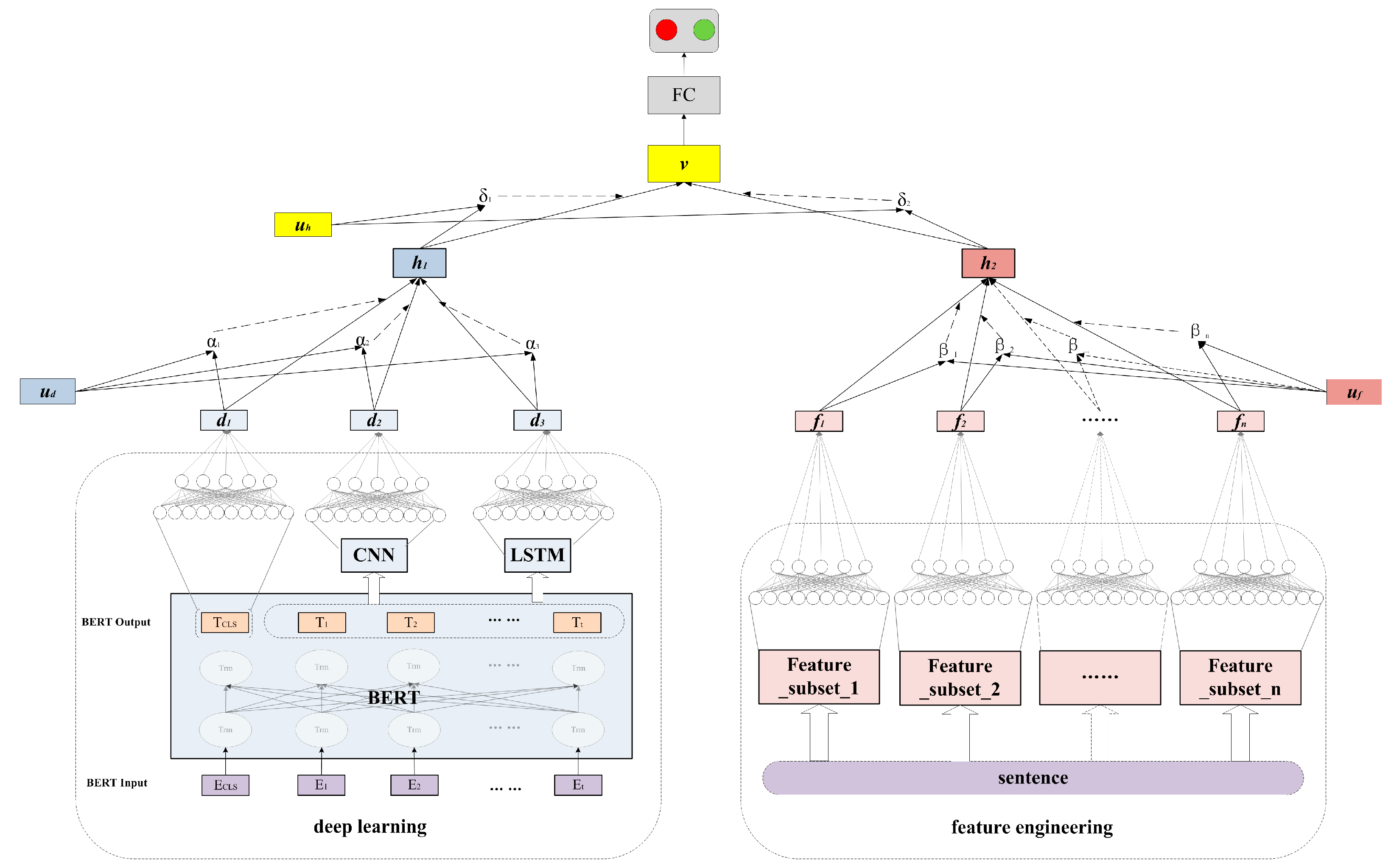
Our proposed attention-based text-representation fusion approach is described in Figure 1. Word embedding aims to transform a word into a vector based on the word’s context. In prior studies, Word2Vec [39] and Glove [40] are popular word-embedding methods. However, they are incompetent at distinguishing the same word with different contexts. In recent years, BERT [15] can solve this problem. Therefore, as the first step, we adopted BERT to generate word embeddings, which served as inputs of CNN and LSTM. In addition, the [CLS] output was regarded as the BERT-generated text representation, waiting for fusion in the data-driven encoder. Subsequently, three deep-text representations, respectively derived by BERT, CNN, and LSTM, were fused to form the data-driven representation with a bottom-level attention mechanism. Meanwhile, different handcraft-feature subsets were transformed to respective hidden embeddings. Another bottom-level attention mechanism was adopted to fuse these hidden embeddings to obtain the handcrafted-text representation. Afterwards, we employed a top-level attention layer to obtain the fused text representation, followed by a fully connected layer to predict the probability for each class.
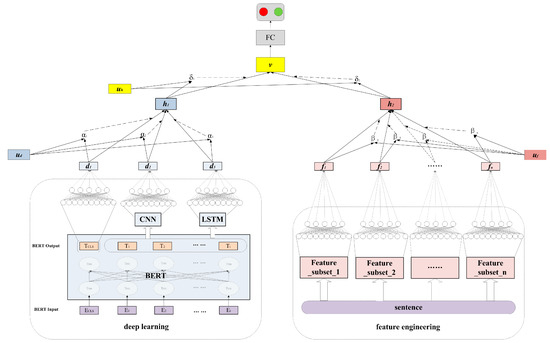
Figure 1.
The attention-based text-representation fusion approach.
3.1. Deep Neural Networks Explored in Our Method
3.1.1. BERT
BERT aims to pretrain deep bidirectional text representations using large amounts of unlabeled text by jointly taking both left and right contexts into account [15]. The Transformer applies self-attention to calculate in parallel the relationship between each word pair in the text, thus modeling the influence each token has on another [38]. As shown in Figure 1, in BERT architecture, the input (i = 1, 2, …, t) corresponding to i-th word in the sentence is the sum of the word’s token embedding, position encoding, and segment embedding. Two self-supervised tasks, i.e., the masked-language model (MLM) and next-sentence prediction (NSP), were performed to guide the language modeling in BERT. The MLM task masks a certain percentage of tokens at random and attempts to predict those masked tokens. The NSP task is aimed at predicting whether two sentences are adjacent, i.e., one sentence following the other. Based on the pretrained model, BERT can be applied to downstream tasks with little architecture modification by jointly fine-tuning all parameters, which is relatively inexpensive compared to pretraining. In this study, we used a fine-tuned BERT model.
3.1.2. CNN
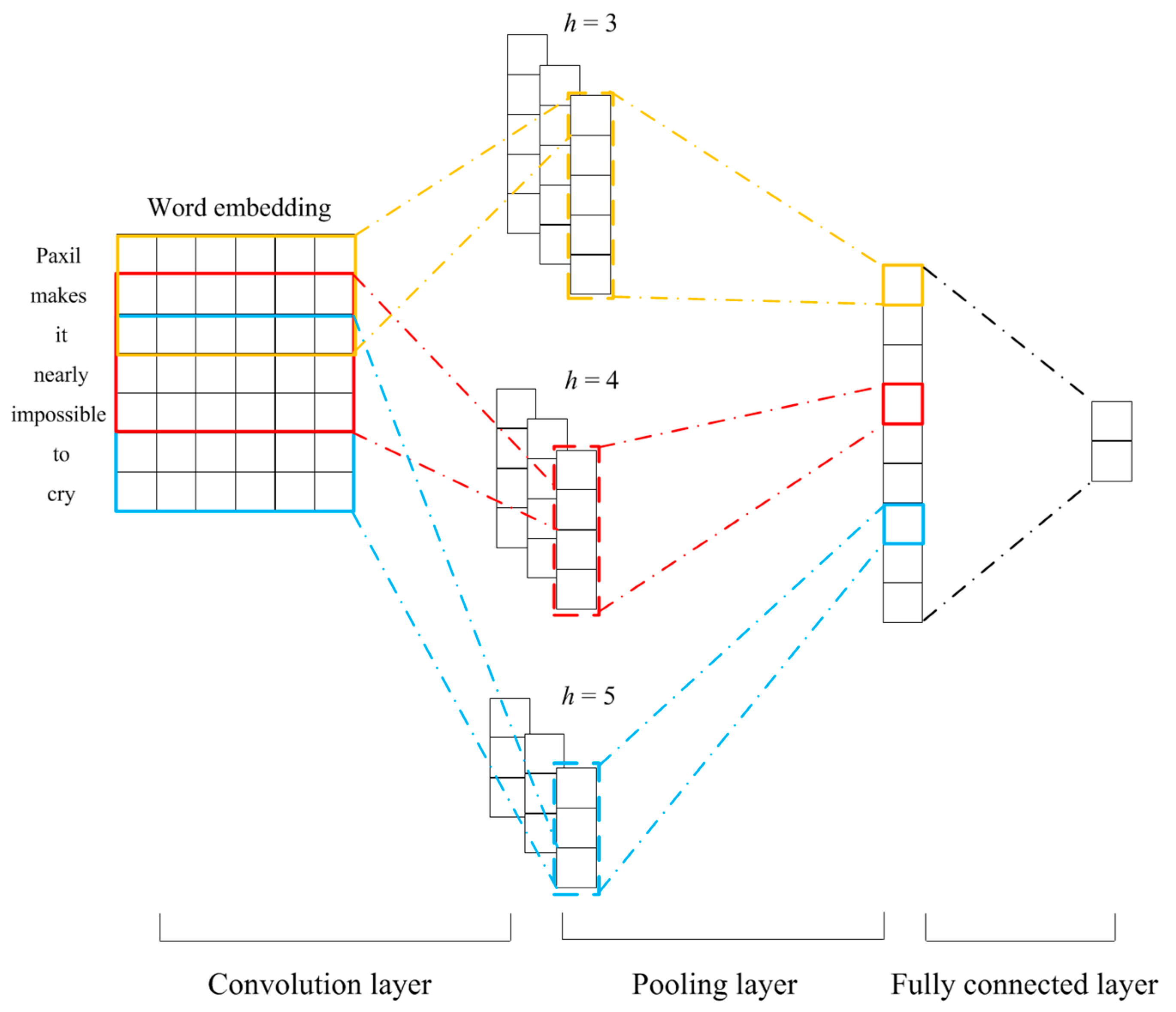
The typical CNN framework originally proposed by Kim et al. [20] was used in this study (as shown in Figure 2). Let denote the -dimensional word embedding of the -th word in the sentence. Therefore, ⊕⊕…⊕ represents a sentence of length (with the padding operation if necessary), where ⊕ stands for the concatenation operator. In each convolution operation, a filter was performed on to generate a feature using the equation (), where stands for a nonlinear activation function and is a bias term. After being applied to all sliding windows of words in the sentence, the filter produced a feature map . The feature map was then fed into a max-pooling layer, i.e., keeping the maximum value = as the final feature obtained by the filter. The max-pooling layer enabled the filter to capture most important information. Suppose filters are used, the obtained text representation via CNN is = . Three types of filters with were implemented in this study.
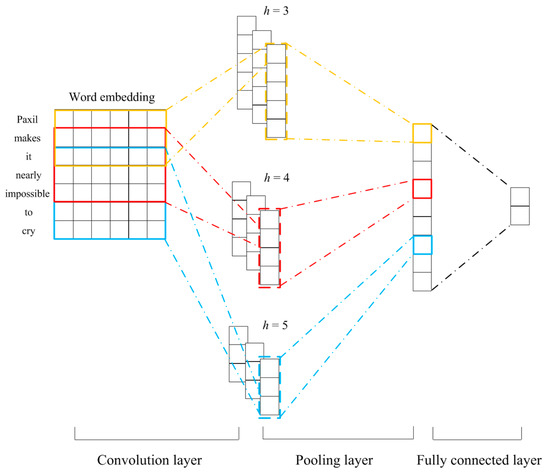
Figure 2.
CNN-model structure.
3.1.3. LSTM
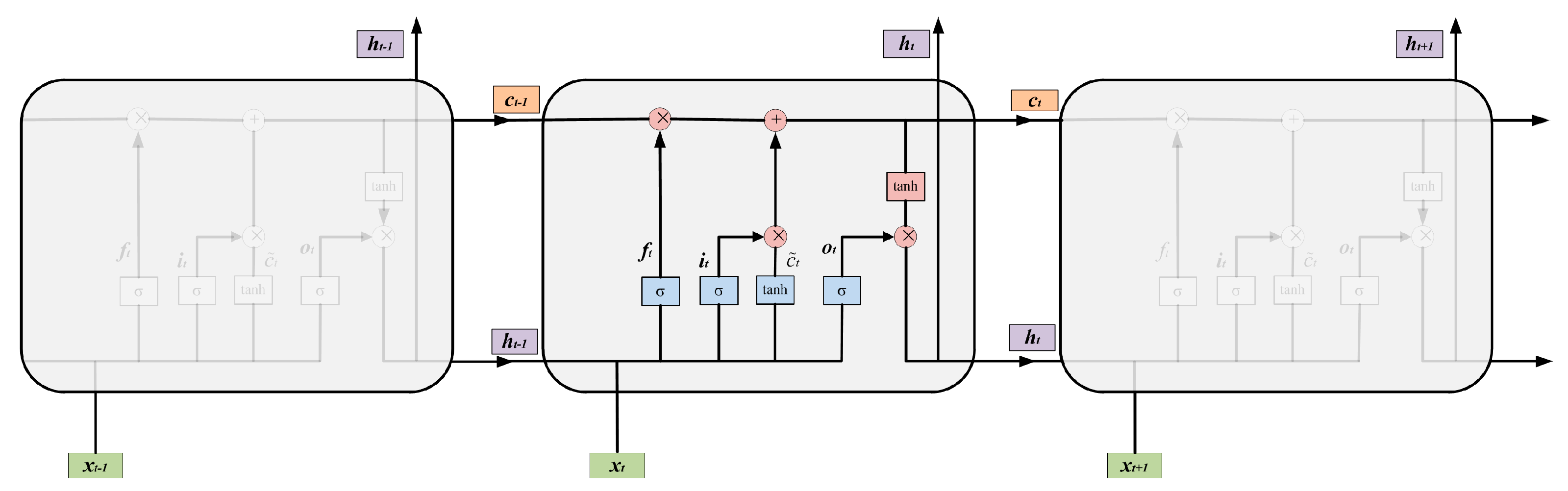
As shown in Figure 3, there are three input values of each LSTM cell, i.e., the input value of the network at the current cell, the output hidden value of the previous cell , and the output cell state of the previous cell . The condition of the unit and the flow of information can be protected and controlled via three gates (i.e., forget gate, input gate, and output gate). The three gates of each LSTM cell are described in detail below.
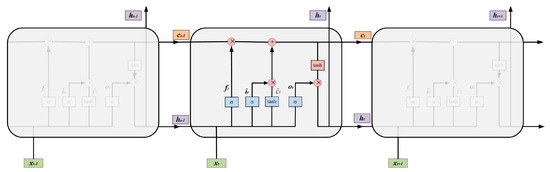
Figure 3.
LSTM structure.
Suppose and ⊙ represent the sigmoid activation function and dot product, respectively. and stand for learnable weight matrices and denotes learnable bias vector. The forget gate controls which part of the information needs to be discarded (forgotten) based on and :
The input gate determines which part of the information should be stored by calculating and :
Based on the above calculation, we can update the current cell state as:
According to the following equations, the output gate determines which parts of the cell state should be outputted.
3.1.4. Data-Driven Encoder with Attention Mechanism
Not all deep-text representations contribute equally to predicting the label of a text. Different deep-learning methods excel at handling different forms of text. We need to adaptively assign varying importance weights to deep-text representations for different samples. Therefore, we introduced the attention mechanism to recognize important and suitable deep-text representations, and aggregated all deep-text representations to form a fused text representation which is totally data-driven. Specifically, we first fed each through a one-layer MLP (multilayer perceptron) to obtain its corresponding hidden representation , where , , are derived by BERT, CNN, and LSTM, respectively. We then measured the importance of each as the similarity of with an introduced context-query vector , and computed the attention weight through a Softmax function. The data-driven text vector was computed as a weighted sum of , and .We randomly initialized the context-query vector and jointly learned it during the training process.
3.2. Feature Engineering
Feature engineering plays an important role for pursuing a satisfactory performance in the conventional machine-learning community. In general, extracted features vary according to tasks, since experts typically resort to external knowledge bases to extract discriminative features. If extracted features can be divided into different subsets, we employ the attention mechanism to combine them. Given the different possible dimensions of different feature subsets, we first fed each feature subset through a one-layer MLP to obtain its corresponding hidden representation where represents the number of feature subsets. Subsequently, similar to the attention mechanism in the data-driven encoder, the attention weight of each was assessed as the similarity of with a learnable context-query vector , and normalized with the Softmax function. The weighted sum of all yielded the handcrafted-text representation.
3.3. Top-Level Representation Fusion with Attention Mechanism
When designing MLPs, we ensured that the dimension of equals that of . We introduced another learnable context vector , with which importance weights of the data-driven text representation and handcrafted-text representation (i.e., and ) could be measured. Then weights were normalized with the Softmax function. The final text representation was obtained as the weighted sum of and .
3.4. Loss
The learning objective function of the model is to minimize the popular cross-entropy-loss function. The cross-entropy loss is calculated as:
where denotes the possible probability under each class category, represents the true label, and denotes the number of samples.
4. Experimental Datasets and Settings
4.1. Experimental Datasets
To verify the effectiveness of our proposed method, we applied it to addressing two text-classification tasks. The first case study was aimed at identifying ADR-relevant tweets from social media (ADR). The second case study was regarding the identification of comparative-relevant reviews from an E-commerce platform (CR). It is noteworthy that for both case studies, in order to alleviate the imbalance issue, oversampling was performed on the training and validation set, while the test set kept its original distribution.
4.1.1. Case Study 1: Identifying ADR-Relevant Tweets from Social Media (ADR)
We collected an open-source dataset (http://diego.asu.edu/Publications/ADRClassify.html (accessed on 1 March 2020)) from Twitter based on the user id and tweet id [8]. Due to the removal of some tweets, we obtained a total of 7060 samples, which included 6304 ADR-irrelevant samples and 756 ADR-relevant samples. To preprocess these tweets, we conducted tokenization, lemmatization, text conversion to lowercase, and removal of hypertext mark-up language (HTML) tags, et al.
4.1.2. Case Study 2: Identifying Comparative-Relevant Reviews from an E-Commerce Platform (CR)
We constructed two real-world datasets that were composed of product reviews from JD (https://www.jd.com (accessed on 1 January 2021)), a famous E-commerce platform in China. We selected two electronic product categories (i.e., phone and camera, referred to as “CR_Phone” and “CR_Camera”, respectively) since they are updated frequently, and customers generally compare different brands and models before making a purchase. In the CR_Phone dataset, we collected 132,696 reviews, 12 product brands, 106 products, and 1011 product subcategories. In the CR_Camera dataset, we obtained 47,364 reviews, 3 explored brands, 47 products, and 121 product subcategories. The time spans of the two collected datasets were 5 February 2017–10 October 2019 and 20 June 2014–22 October 2021, respectively. We randomly labeled 20,000 reviews including 3284 comparative-relevant reviews and 16,716 comparative-irrelevant reviews on the CR_Phone dataset, and annotated 871 comparative-relevant samples and 10,939 comparative-irrelevant samples on the CR_Camera dataset. We conducted preprocessing on the two datasets. Specifically, traditional Chinese characters were converted to simplified Chinese characters, half-angle symbols were converted to full-angle symbols, and meaningless symbols and emoticons were removed.
4.2. Evaluation Metrics
We employed precision, recall, F1-score, and accuracy (Acc), which are popular metrics for evaluating classifiers’ performances. These metrics were computed as follows, based on the confusion matrix shown in Table 1:

Table 1.
Confusion matrix.
4.3. Experimental Procedure
For the ADR task where various external knowledge bases are available, we first conducted handcraft-feature engineering, following [8]. Shallow linguistic features, domain-specific knowledge-based features, and other discriminative features constituted three feature subsets, as shown in Table 2. For more detailed information regarding these features, please refer to work [8]. We compared our approach with several baselines, including using individual deep-learning methods (i.e., BERT, CNN, and LSTM), performing a data-driven method that fuses three different deep-text representations using the attention mechanism, and applying a feature-engineering method that fuses various feature subsets using the attention mechanism.
Table 2.
Explored features for identifying ADR-related text from social media.
For the CR task, we ignored the utilization of handcraft-feature engineering and only explored the data-driven encoder in our approach, verifying the flexibility of our approach. We performed the following baselines:
- 1.
- The traditional method refers to the existing state-of-the-art approach, which extracts rules with CSR (class sequence rule) as features and adopts SVM as the classification algorithm (i.e., CSR+SVM).
- 2.
- Individual deep-text representation by using BERT, CNN, and LSTM, respectively.
- 3.
- Different fusion strategies include model-level fusion, which combines different classifiers with majority voting, and feature-level fusion, which fuses multiple representations by simply concatenating all features.
For all of the experiments in this study, we employed 10-fold cross-validation. We conducted our experiments on a Linux server with GPU and implemented deep-learning methods with PyTorch. We resorted to an open source code (http://diego.asu.edu/Publications/ADRClassify.html (accessed on 15 March 2020)) to perform the feature engineering for the ADR case study. For BERT, we adopted the BERTbase model. After parameter tuning, the learning rate, batch size, and pad size were 0.001, 32, and 40 on the ADR dataset. These parameters were 1 × 10–5, 32, and 120 on the CR_Phone dataset, and 1 × 10–5, 32, and 50 on the CR_Camera dataset. In terms of the number of filters in CNN, we used 256 filters for each size; therefore, 256 × 3 filters were implemented on each of the three datasets.
5. Results and Discussion
As shown in Table 3, our method yielded the highest F1-score (0.5476) and Acc (88.20%) for the task of identifying ADR-relevant tweets from social media. The data-driven method with bottom-layer fusion outperformed all of the individual deep-learning methods. These improvements resulted from the effectiveness of combining different deep-learning models with attention. Moreover, our method with hierarchical attention can deliver improved performance as compared to both the data-driven method and the feature-engineering method. The reason lies in the fact that our method benefits from the complementary effect of data-driven deep-text representation and the handcrafted representation obtained by feature engineering.
Table 3.
Experimental results for the ADR task.
The experimental results for identifying comparative-relevant reviews are shown in Table 4. Our proposed method obtains F1-score improvements of 0.1914 and 9.97% on CR_Phone and CR_Camera, respectively, as compared to CSR+SVM. Adopting individual deep-text representation outperforms CSR+SVM in terms of F1-score due to the automatic feature learning via deep neural networks. Multirepresentational fusions present superiority over using individual deep-learning-based representation, regardless of the adopted fusion strategy. This finding shows that simultaneously combining different representations can contribute to enhancing capability of identifying comparative-relevant text, since different representations can capture varying facets of information and hence complement each other. In comparison to other fusion strategies, our attention-based fusion method achieves higher performance values on the two datasets. The result demonstrates the effectiveness of the attention mechanism in fusing multiple representations, since the attention mechanism can adaptively learn the importance weights of different representations.
Table 4.
Experimental results for the CR task.
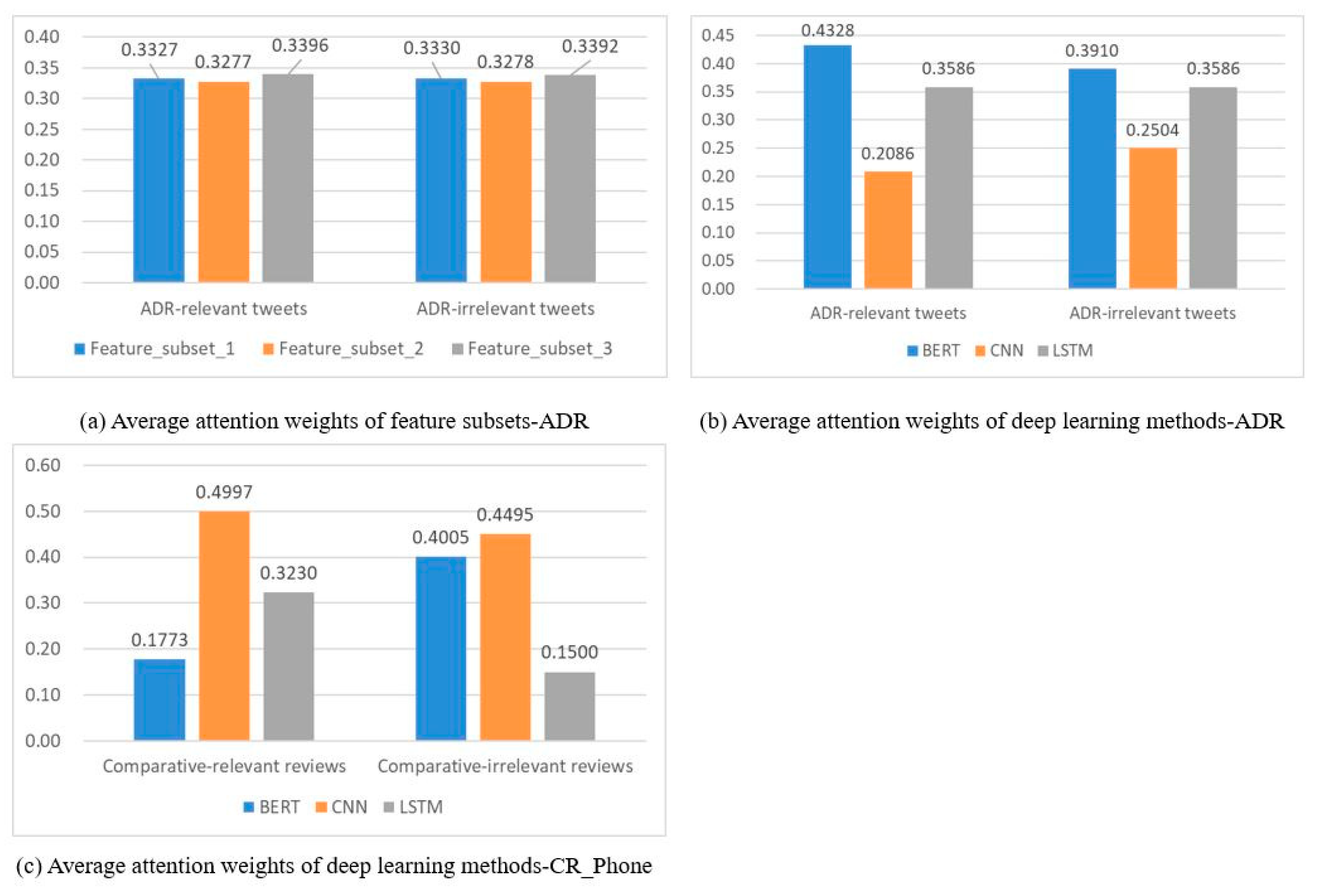
Figure 4a,b show average attention-weight distributions of bottom-level representations (i.e., various feature subsets and multiple deep-text representations, respectively) for the ADR task. Figure 4c presents attention weights assigned to three representations obtained by applying BERT, CNN, and LSTM, respectively, on the CR_Phone dataset. As shown in Figure 4a, we find that all of the attention weights assigned to the three different feature subsets were around 33.33%, presenting an even distribution for both ADR-relevant and ADR-irrelevant tweet identification. These results demonstrate the effectiveness of each feature subset.
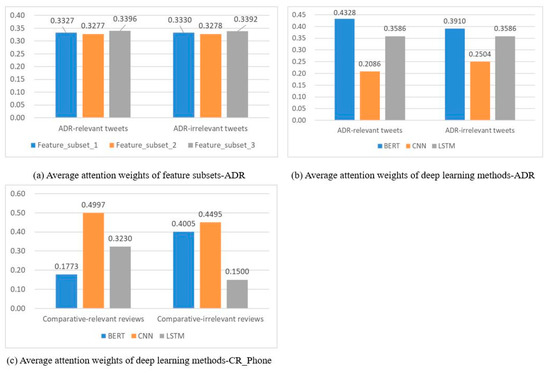
Figure 4.
Attention-weight distribution of different deep-text representations.
As shown in Figure 4b,c, attention-weight distributions for different tasks present a significant difference. For identifying ADR-relevant tweets, BERT plays the dominant role with an attention weight of 43.28%, while CNN contributes the least. On the contrary, for identifying comparative-relevant reviews, CNN dominates with an attention weight of 49.97%, while BERT only contributes 17.73%. Moreover, even for the same task, when identifying relevant and irrelevant text, contributions of different deep-text representations may also present a huge difference. For example, as shown in Figure 4c, the attention distribution of BERT and LSTM varies hugely for comparative-relevant and comparative-irrelevant text recognition.
We explain the reasons for the abovementioned results as follows: In the case of ADR, people prefer colloquial and implicit expressions to describe their ADR experiences, rather than using professional terms. For example, the first example for the ADR task in Table 5 implies “drowsiness” without using the word. To predict this sample correctly, capturing local information is incompetent; we need to capture global semantic and sequence information. Therefore, BERT and LSTM play their important roles while CNN contributes the least for the example. On the contrary, for comparative-relevant text identification, comparative opinion is generally encoded in obvious sequences and keywords, such as “比…高” in Chinese, “superior”, “outperform”; therefore, CNN’s outstanding ability of capturing local information is particularly important. These results demonstrate the advantage of the attention mechanism, since it can adaptively assign importance weights according to expression characteristics of different tasks.
Table 5.
Attention weights of relevant text for the two tasks.
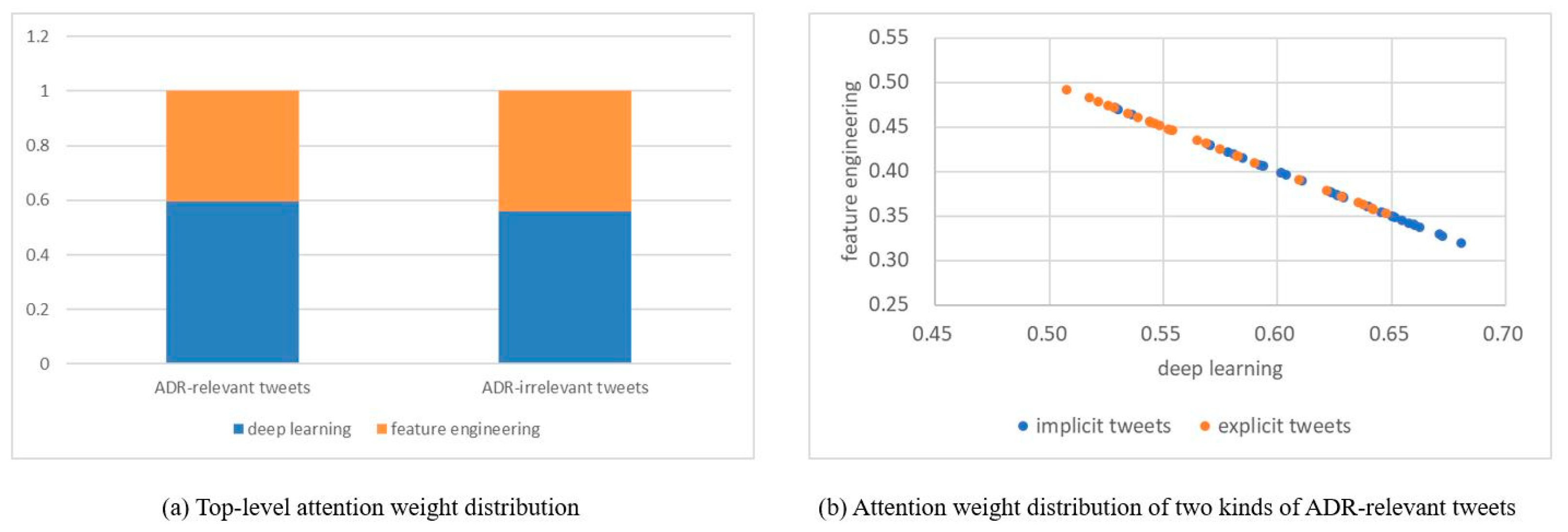
Figure 5a shows average attention weights of feature-engineering-based and data-driven representations for the ADR task. As shown in Figure 5a, for ADR-relevant tweets, the average attention-weight distribution of deep learning vs. feature engineering is approximately 6:4. On one hand, deep-learning methods contribute more as compared to feature engineering due to the implicit, colloquial, and diverse expressions. On the other hand, the results verify their complementary effect. We provide some examples with attention weights of deep learning and feature engineering in Table 6. Moreover, we manually divide tweets into two categories, i.e., implicit tweets and explicit tweets. Implicit tweets refer to using questions, rhetorical questions, or metaphors to express the occurrence of adverse reactions. Explicit tweets directly indicate adverse reactions caused by taking drugs, such as “make me sleepy”. As shown in Figure 5b, deep-learning methods are adept at identifying implicit tweets, while handcrafted-feature engineering is effective in recognizing explicit tweets.
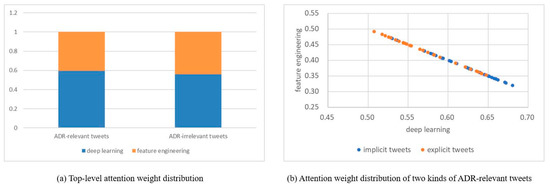
Figure 5.
Attention-weight distribution of feature engineering and deep learning.
Table 6.
Top-level attention-weight distribution of several ADR-relevant tweets.
6. Conclusions
In this paper, we propose a hierarchical attention-based neural-network architecture that fuses multiple text representations for social-media-based text-classification. First, we employed an attention mechanism to decide contributions of deep-text representations derived by performing BERT, CNN, and LSTM. If handcrafted features were available, we also leveraged the attention mechanism to fuse different feature subsets, and designed a top-level attention layer to fuse these handcrafted-text representations and data-driven deep-text representations. Experimental results demonstrate the advantages of our proposed approach over other baselines on three real-world datasets for two relevant text-identification tasks. Our approach verifies the complementary effect of handcrafted and data-driven text representations, as well as that of different learning methods. The incorporation of the attention mechanism can adaptively assign weights to different representations. Moreover, contributions of different deep-text representations vary significantly according to different tasks.
This study has implications for researchers. Our study advances multisource information fusion by treating distinct deep-learning method-derived text representation as separate sources, and investigates the complementary effect of handcrafted features and totally data-driven representations with the attention mechanism. Our approach is scalable by adding any other text representations.
In the future, we would like to apply our approach to other social media-based text-classification tasks. Furthermore, it would be interesting to incorporate strategies that avoid the introduction of redundant information among various representations.
Author Contributions
Conceptualization, J.L.; methodology, J.L. and X.W.; software, X.W. and Y.T.; validation, Y.W.; formal analysis, J.L. and X.W.; investigation, J.L.; resources, J.L. and X.W.; data curation, X.W.; writing—original draft preparation, J.L.; writing—review and editing, J.L., L.H. and Y.W.; visualization, Y.T. and Y.W.; supervision, L.H.; project administration, J.L. and Y.W.; funding acquisition, J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 71701142), China Postdoctoral Science Foundation (No. 2018M640346), and Tianjin Philosophy and Social Science Planning Project (No. TJKS19XSX-015).
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset for the adverse drug-reaction-identification task supporting this article can be obtained from http://diego.asu.edu/Publications/ADRClassify.html (accessed on 1 March 2020). The data are available in this article, which should be cited as “Sarker, A. and G. Gonzalez, Portable automatic text classification for adverse drug reaction detection via multi-corpus training. Journal of biomedical informatics, 2015. 53: p. 196–207.” Other datasets for the comparative-relevant text-identification task are available upon request by contact with the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ray, A.; Bala, P.K. User generated content for exploring factors affecting intention to use travel and food delivery services. Int. J. Hosp. Manag. 2021, 92, 102730. [Google Scholar] [CrossRef]
- Li, L.; Liu, X.; Zhang, X. Public attention and sentiment of recycled water: Evidence from social media text mining in China. J. Clean. Prod. 2021, 303, 126814. [Google Scholar] [CrossRef]
- Carta, S.M.; Consoli, S.; Piras, L.; Podda, A.S.; Recupero, D.R. Explainable machine learning exploiting news and domain-specific lexicon for stock market forecasting. IEEE Access 2021, 9, 30193–30205. [Google Scholar] [CrossRef]
- Dhelim, S.; Ning, H.; Aung, N. ComPath: User interest mining in heterogeneous signed social networks for Internet of people. IEEE Internet Things J. 2020, 8, 7024–7035. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X.; Huang, L. Fusing Various Document Representations for Comparative Text Identification from Product Reviews. In Proceedings of the International Conference on Web Information Systems and Applications, Kaifeng, China, 24–26 September 2021; pp. 531–543. [Google Scholar]
- Bhattacharjee, S.D.; Tolone, W.J.; Paranjape, V.S. Identifying malicious social media contents using multi-view context-aware active learning. Future Gener. Comput. Syst. 2019, 100, 365–379. [Google Scholar] [CrossRef]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Analyzing the effectiveness of semi-supervised learning approaches for opinion spam classification. Appl. Soft Comput. 2021, 101, 107023. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Kiang, M.; Shang, W. Filtering big data from social media–Building an early warning system for adverse drug reactions. J. Biomed. Inform. 2015, 54, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Fatima, I.; Mukhtar, H.; Ahmad, H.F.; Rajpoot, K. Analysis of user-generated content from online social communities to characterise and predict depression degree. J. Inf. Sci. 2018, 44, 683–695. [Google Scholar] [CrossRef]
- Bing, C.; Wu, Y.; Dong, F.; Xu, S.; Liu, X.; Sun, S. Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection. Information 2022, 13, 25. [Google Scholar] [CrossRef]
- Zheng, X.; Sun, A. Collecting event-related tweets from twitter stream. J. Assoc. Inf. Sci. Technol. 2019, 70, 176–186. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Shallow to Deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning--based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhou, S.; Li, X. Feature engineering vs. deep learning for paper section identification: Toward applications in Chinese medical literature. Inf. Processing Manag. 2020, 57, 102206. [Google Scholar] [CrossRef]
- Xie, J.; Liu, X.; Zeng, D.D.; Fang, X. Understanding medication Nonadherence from Social Media: A sentiment-Enriched Deep Learning Approach. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3091923 (accessed on 1 December 2021).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, P.; Li, X.; Ling, C.; Ding, S.; Shen, S. Sentiment classification using attention mechanism and bidirectional long short-term memory network. Appl. Soft Comput. 2021, 112, 107792. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 649–657. [Google Scholar]
- Vu, N.T.; Adel, H.; Gupta, P.; Schütze, H. Combining Recurrent and Convolutional Neural Networks for Relation Classification. In Proceedings of the NAACL 2016, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative Study of CNN and RNN for Natural Language Processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Matthew, E.P.; Mark, N.; Mohit, I.; Matt, G.; Christopher, C.; Kenton, L.; Luke, Z. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 3 March 2022).
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8968–8975. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. Ernie: Enhanced representation through knowledge integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don′t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Wang, J.; Yu, L.-C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jindal, R.; Mukuntha, N.; Ekbal, A.; Bhattachharyya, P. Multi-modality helps in crisis management: An attention-based deep learning approach of leveraging text for image classification. Expert Syst. Appl. 2022, 195, 116626. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015, arXiv:1409.0473. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 1693–1701. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Kiela, D.; Wang, C.; Cho, K. Dynamic meta-embeddings for improved sentence representations. arXiv 2008, arXiv:1804.07983. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 6000–6010. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).