
Ensemble Convolutional Neural Network Classification for Pancreatic Steatosis Assessment in Biopsy Images


 ,
,  ,
,  ,
,  , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
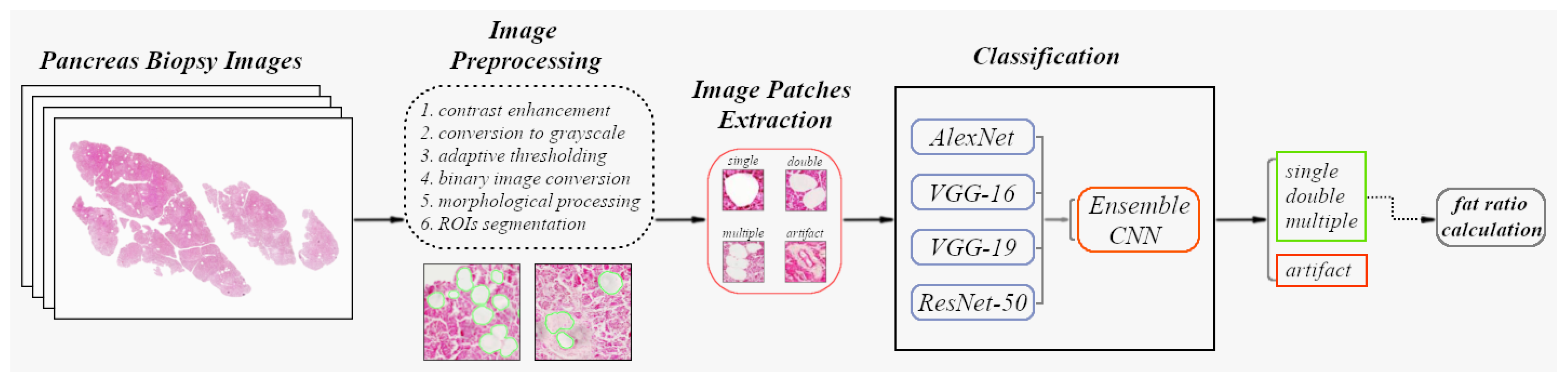
2. Materials and Methods
- An image segmentation stage employing image thresholding and morphological filtering techniques in 20 pancreatic biopsy images (with 20× magnification) to extract the tissue area from its background and filter circular white structures.
- Manual annotation of objects of interest in each 20× histological image and calculation of the semi-quantitative degree of steatosis by clinicians. At the same time, export of annotated objects in the form of image patches for applying transfer learning in four pretrained convolutional neural networks (CNNs).
- Classification of the segmented regions of interest in step 1 based on the majority of trained CNN models’ votes and eliminating most false-positive fat segmentation results.
- Calculation of the fat ratio for each 20× biopsy image and evaluation of the automated diagnostic method by determining its deviation from the semi-quantitative estimates of doctors.
2.1. Histological Image Dataset
2.2. Image Processing and Segmentation Stage
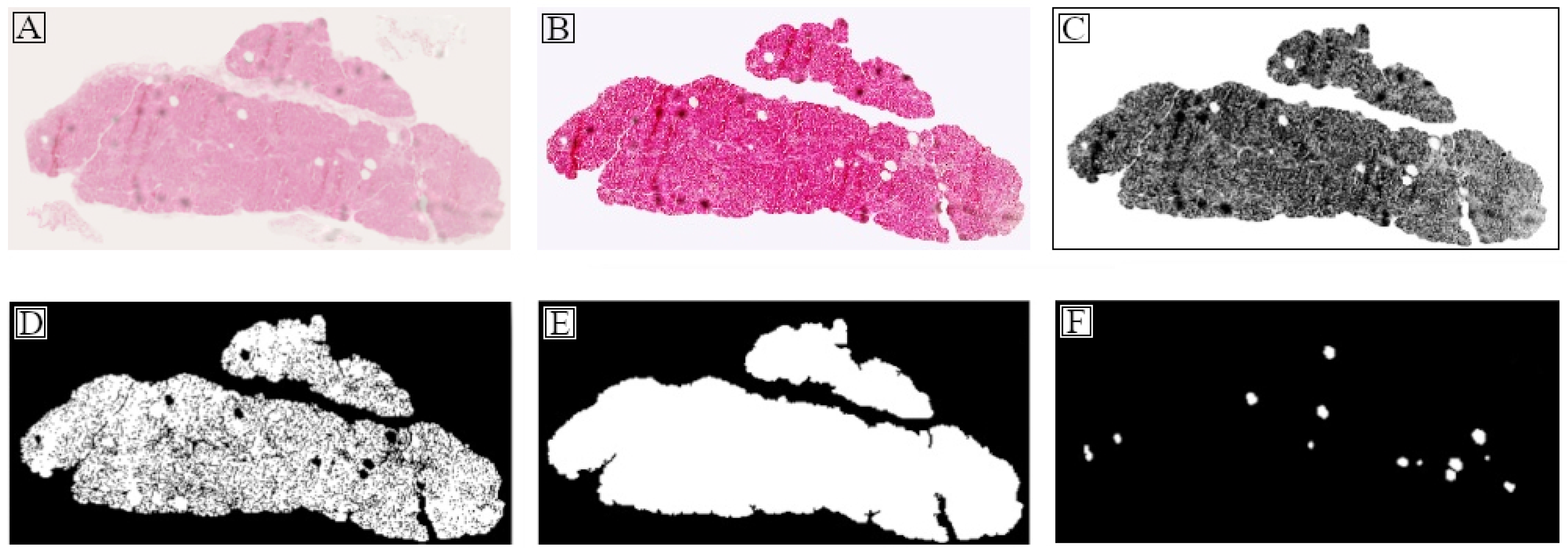
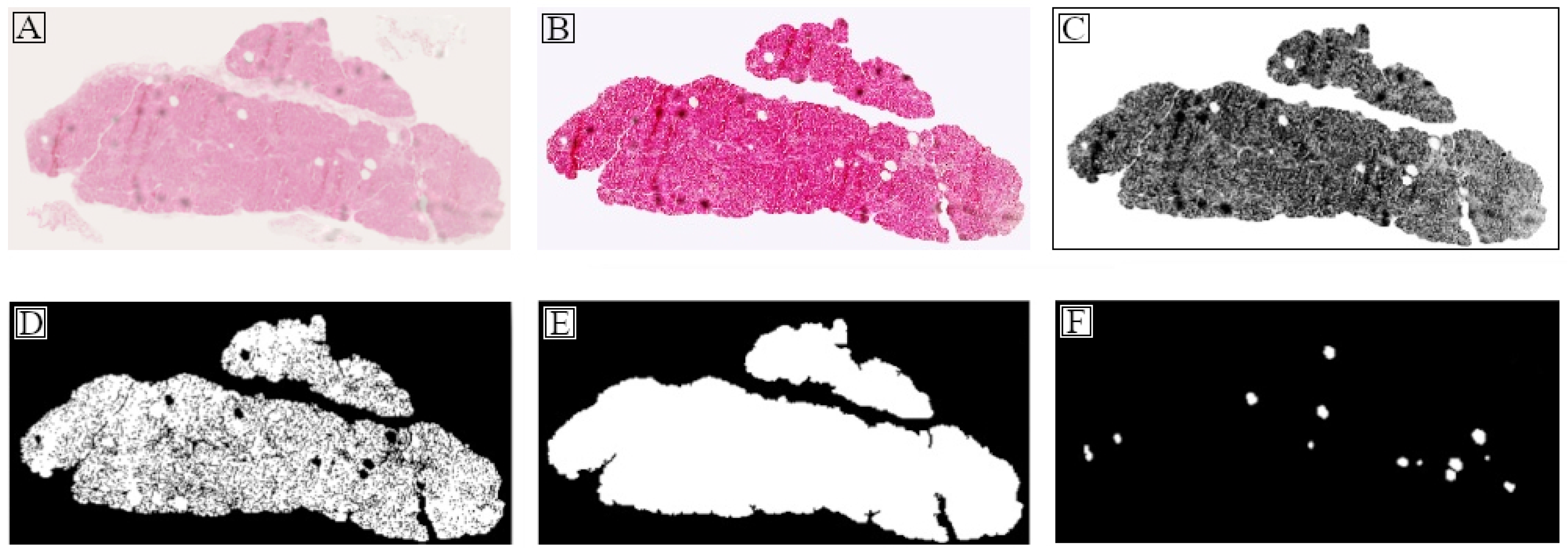
2.2.1. Tissue Region Extraction
2.2.2. Objects of Interest Segmentation
2.3. Histological Images Annotation
2.3.1. Semi-Quantitative Steatosis Evaluation
2.3.2. Exporting Training Data from Manual Annotations
2.4. Data Preprocessing and Deep Learning
2.4.1. Image Augmentation and Class Balancing
2.4.2. Transfer Learning in Pretrained CNN Models
2.4.3. Classification of Tissue Objects and Fat Ratio Calculation
| Algorithm 1 Ensemble CNN System |
|
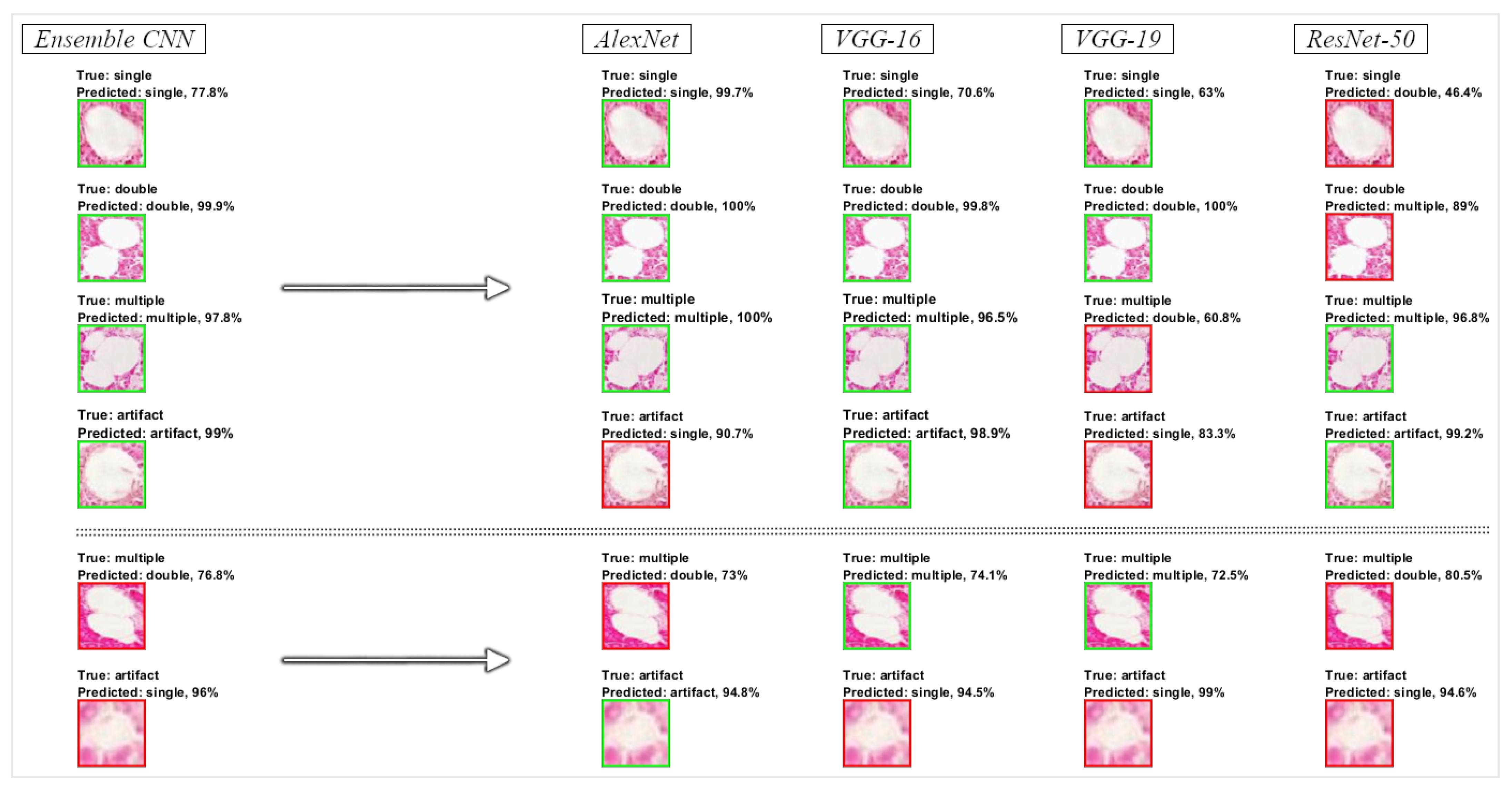
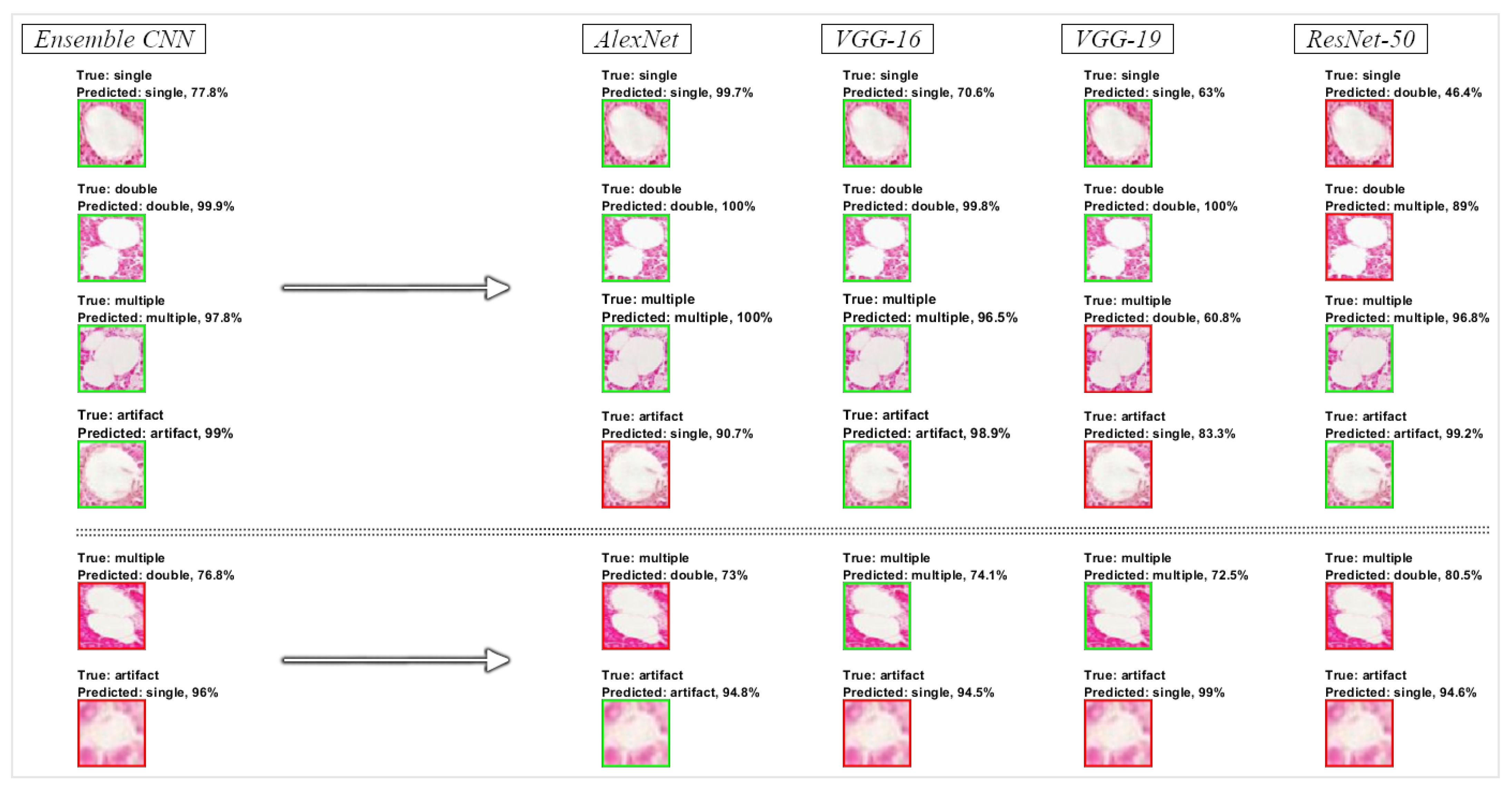
3. Results
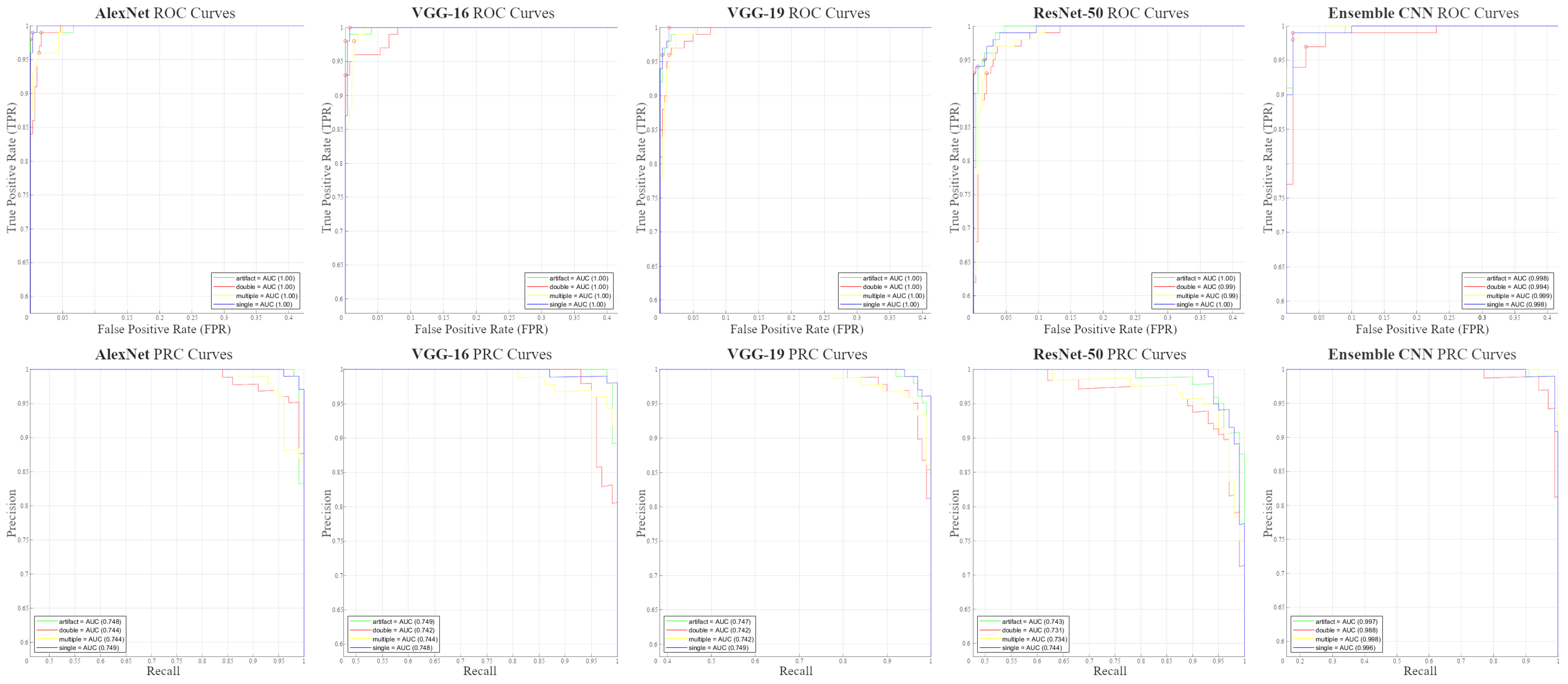
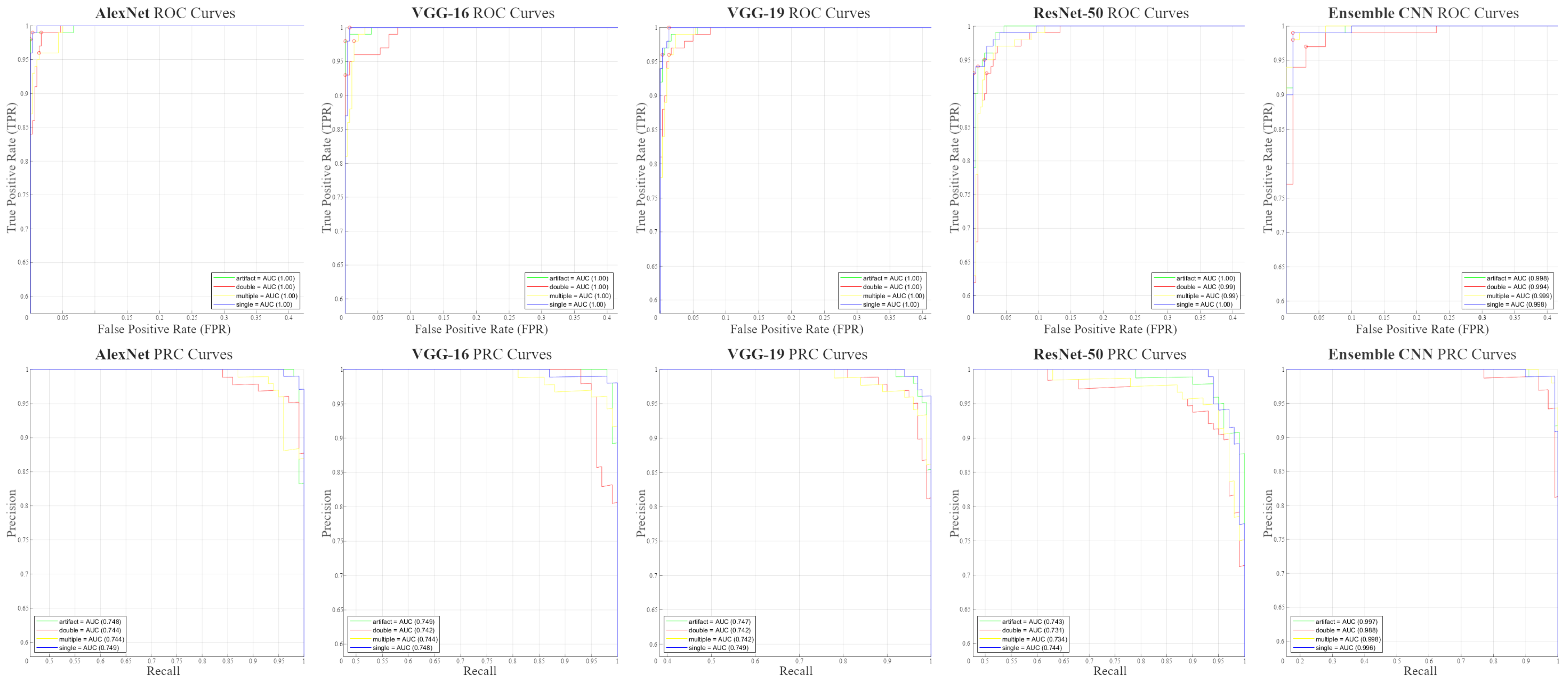
3.1. Testing Performance Measurements
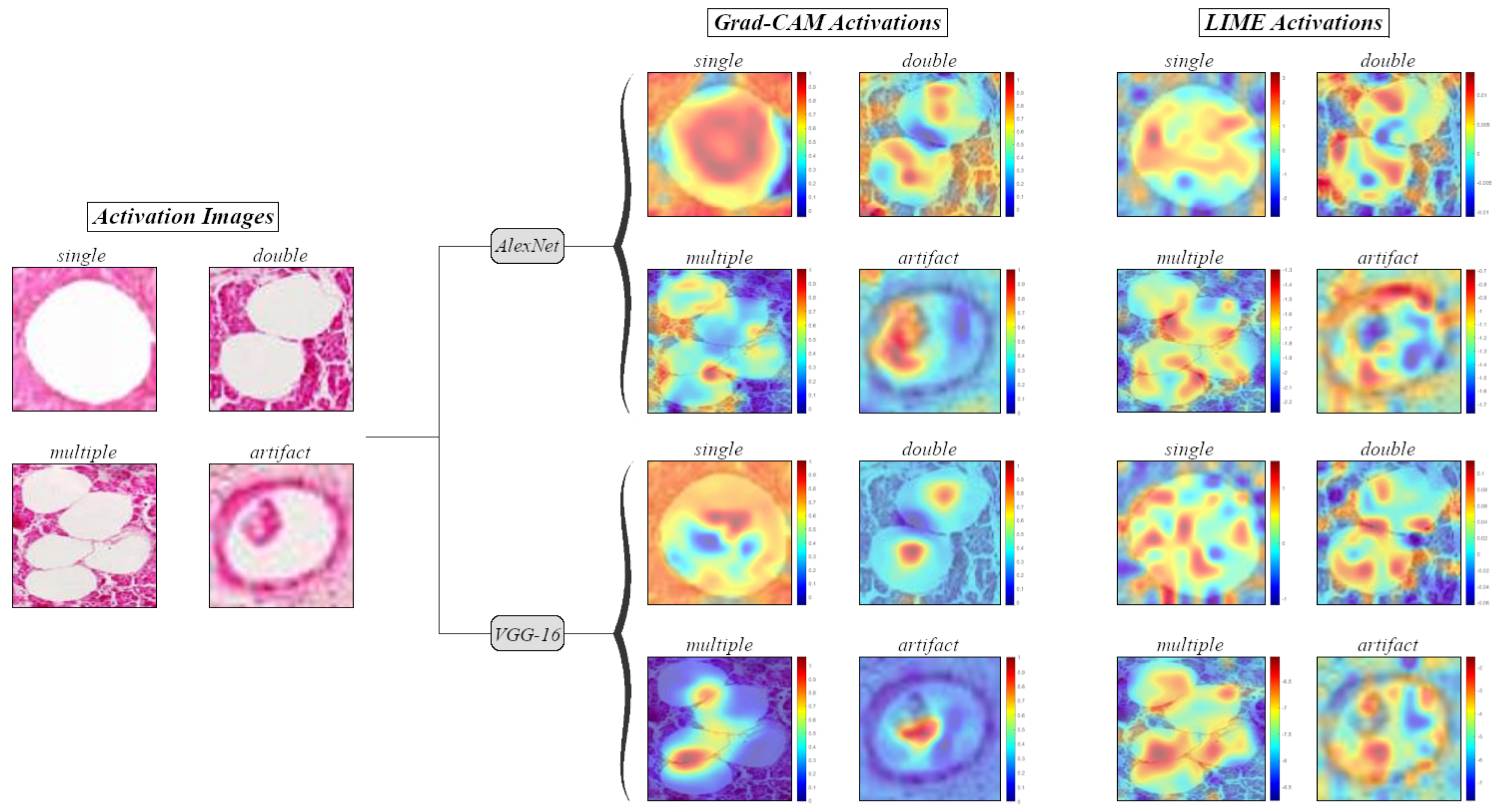
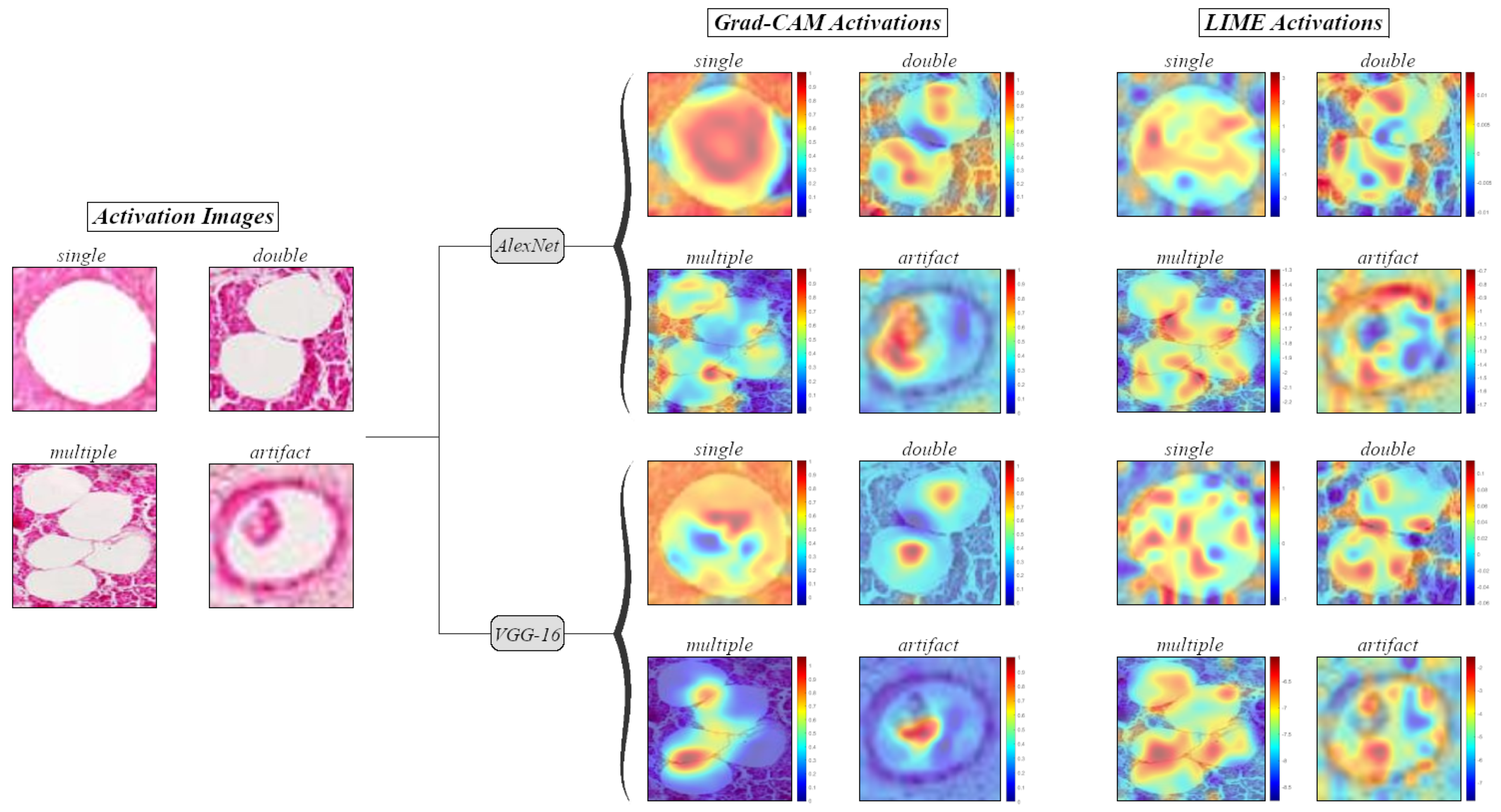
3.2. Visualization of Informative Features
3.3. Pancreatic Steatosis Quantification Results
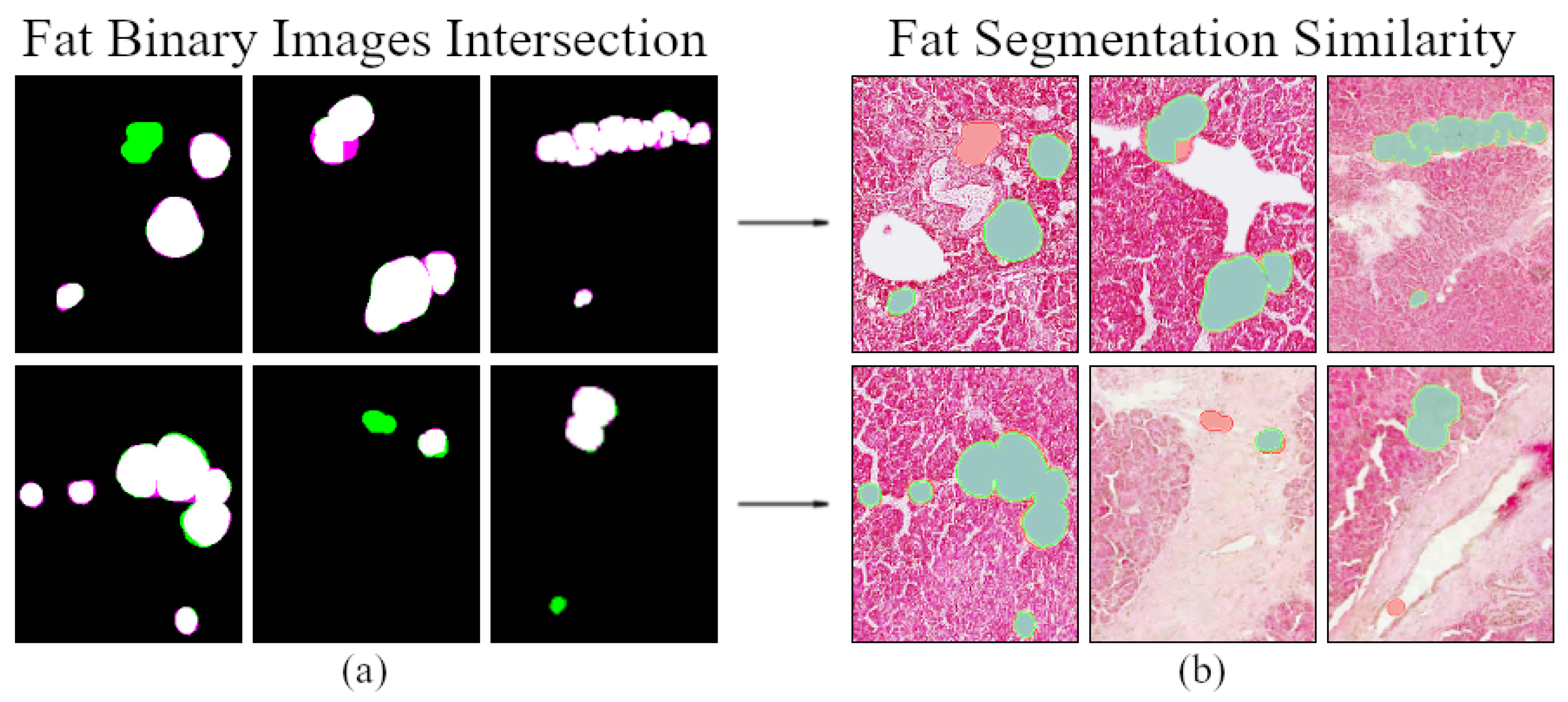
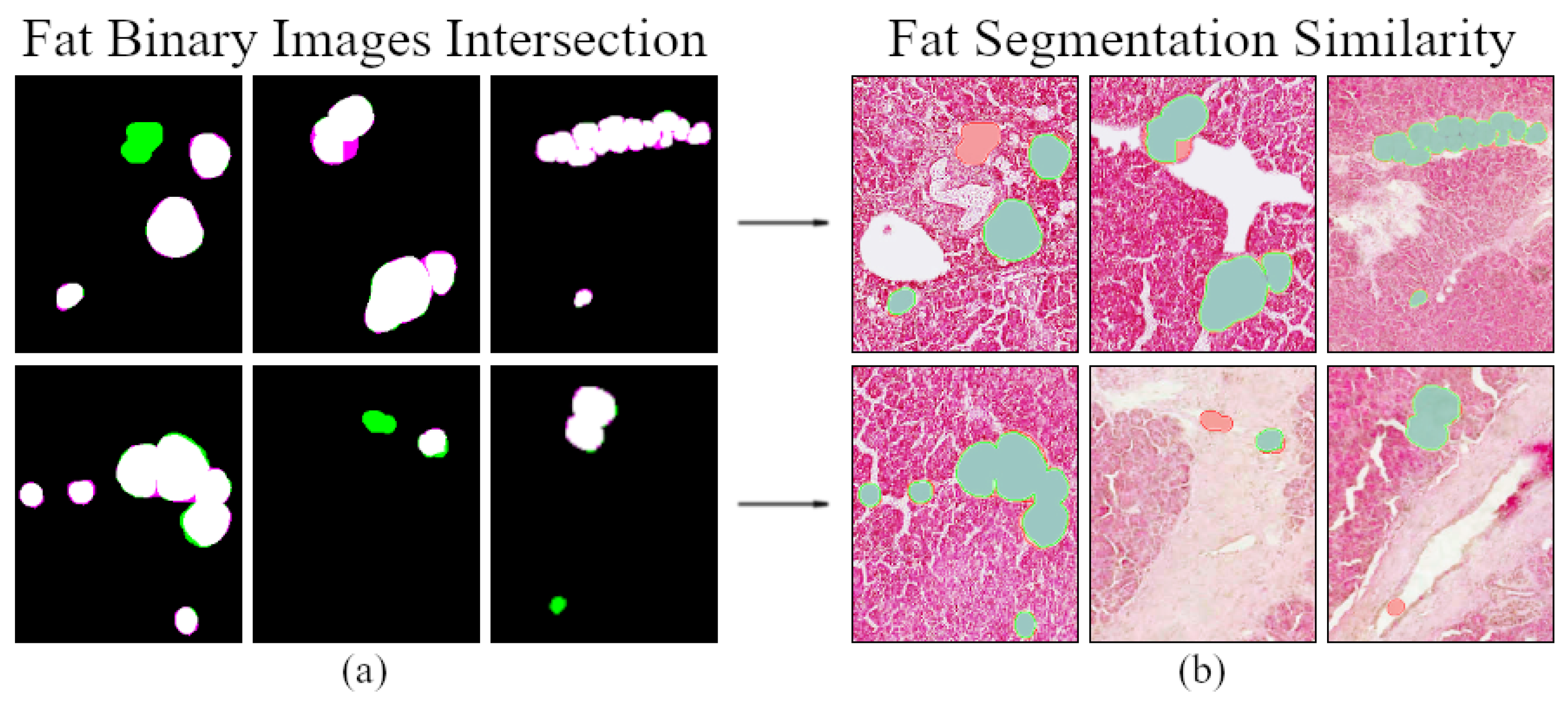
3.4. Fat Regions Segmentation Similarity
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Catanzaro, R.; Cuffari, B.; Italia, A.; Marotta, F. Exploring the metabolic syndrome: Nonalcoholic fatty pancreas disease. World J. Gastroenterol. 2016, 22, 7660–7675. [Google Scholar] [CrossRef] [PubMed]
- Prachayakul, V.; Aswakul, P. Pancreatic steatosis: What should gastroenterologists know? JOP. J. Pancreas 2015, 16, 227–231. [Google Scholar]
- Guglielmi, V.; Sbraccia, P. Type 2 diabetes: Does pancreatic fat really matter? Diabetes Metab. Res. Rev. 2017, 34, 2. [Google Scholar] [CrossRef] [Green Version]
- Lightwood, R.; Reber, H.A.; Way, L.W. The risk and accuracy of pancreatic biopsy. Am. J. Surg. 1976, 132, 189–194. [Google Scholar] [CrossRef]
- Olsen, T.S. Lipomatosis of the pancreas in autopsy material and its relation to age and overweight. Acta Pathol. Microbiol. Scand. A 1978, 86A, 367–373. [Google Scholar] [CrossRef] [PubMed]
- Wilson, J.S.; Colley, P.W.; Sosula, L.; Pirola, R.C.; Chapman, B.A.; Somer, J.B. Alcohol causes a fatty pancreas. A rat model of ethanol-induced pancreatic steatosis. Alcohol Clin. Exp. Res. 1982, 6, 117–121. [Google Scholar] [CrossRef] [PubMed]
- Nghiem, D.D.; Olson, P.R.; Ormond, D. The “fatty pancreas allograft”: Anatomopathologic findings and clinical experience. Transplant Proc. 2004, 36, 1045–1047. [Google Scholar] [CrossRef]
- Mathur, A.; Pitt, H.A.; Marine, M.; Saxena, R.; Schmidt, C.M.; Howard, T.J.; Nakeeb, A.; Zyromski, N.J.; Lillemoe, K.D. Fatty pancreas: A factor in postoperative pancreatic fistula. Ann. Surg. 2007, 246, 1058–1064. [Google Scholar] [CrossRef]
- Mathur, A.; Zyromski, N.J.; Pitt, H.A.; Al-Azzawi, H.; Walker, J.J.; Saxena, R.; Lillemoe, K.D. Pancreatic steatosis promotes dissemination and lethality of pancreatic cancer. J. Am. Coll. Surg. 2009, 208, 989–994. [Google Scholar] [CrossRef]
- Pinnick, K.E.; Collins, S.C.; Londos, C.; Gauguier, D.; Clark, A.; Fielding, B.A. Pancreatic ectopic fat is characterized by adipocyte infiltration and altered lipid composition. J. Obes. 2008, 16, 522–530. [Google Scholar] [CrossRef]
- Rosso, E.; Casnedi, S.; Pessaux, P.; Oussoultzoglou, E.; Panaro, F.; Mahfud, M.; Jaeck, D.; Bachellier, P. The role of “fatty pancreas” and of BMI in the occurrence of pancreatic fistula after pancreaticoduodenectomy. J. Gastrointest. Surg. 2009, 13, 1845–1851. [Google Scholar] [CrossRef] [PubMed]
- Fraulob, J.C.; Ogg-Diamantino, R.; Fernandes-Santos, C.; Aguila, M.B.; Mandarim-de-Lacerda, C.A. A mouse model of metabolic syndrome: Insulin resistance, fatty liver and non-alcoholic fatty pancreas disease (NAFPD) in C57BL/6 mice fed a high fat diet. J. Clin. Biochem. Nutr. 2010, 46, 212–223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaujoux, S.; Cortes, A.; Couvelard, A.; Noullet, S.; Clavel, L.; Rebours, V.; Levy, P.; Sauvanet, A.; Ruszniewski, P.; Belghiti, J. Fatty pancreas and increased body mass index are risk factors of pancreatic fistula after pancreaticoduodenectomy. Surgery 2010, 148, 15–23. [Google Scholar] [CrossRef]
- Van Geenen, E.J.M.; Smits, M.M.; Schreuder, T.C.M.A.; Van Der Peet, D.L.; Bloemena, E.; Mulder, C.J.J. Nonalcoholic fatty liver disease is related to nonalcoholic fatty pancreas disease. Pancreas 2010, 39, 1185–1190. [Google Scholar] [CrossRef] [PubMed]
- Forlano, R.; Mullish, B.H.; Giannakeas, N.; Maurice, J.B.; Angkathunyakul, N.; Lloyd, J.; Tzallas, A.T.; Tsipouras, M.; Yee, M.; Thursz, M.R.; et al. High-throughput, machine learning-based quantification of steatosis, inflammation, ballooning, and fibrosis in biopsies from patients with nonalcoholic fatty liver disease. Clin. Gastroenterol. Hepatol. 2020, 39, 2081–2090. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Wang, F.; Teodorou, G.; Farris, A.B.; Kong, J. Liver steatosis segmentation with deep learning methods. In Proceedings of the 26th IEEE International Symposium on Biomedical Imaging (ISBI), Venice, Italy, 8–11 April 2019; pp. 24–27. [Google Scholar]
- Gandomkar, Z.; Brennan, P.C.; Mello-Thoms, C. MuDeRN: Multi-category classification of breast histopathological image using deep residual networks. Artif. Intell. Med. 2018, 88, 14–24. [Google Scholar] [CrossRef]
- Wang, Y.; Lei, B.; Elazab, A.; Tan, E.L.; Wang, W.; Huang, F.; Gong, X.; Wang, T. Breast cancer image classification via multi-network features and dual-network orthogonal low-rank learning. IEEE Access 2020, 8, 27779–27792. [Google Scholar] [CrossRef]
- Tian, K.; Rubadue, C.A.; Lin, D.I.; Veta, M.; Pyle, M.E.; Irshad, H.; Heng, Y.J. Automated clear cell renal carcinoma grade classification with prognostic significance. PLoS ONE 2019, 14, e0222641. [Google Scholar] [CrossRef] [Green Version]
- Tabibu, S.; Vinod, P.K.; Jawahar, C.V. Pan-renal cell carcinoma classification and survival prediction from histopathology images using deep learning. Sci. Rep. 2019, 9, 10509. [Google Scholar] [CrossRef] [Green Version]
- Koh, J.E.W.; De Michele, S.; Sudarshan, V.K.; Jahmunah, V.; Ciaccio, E.J.; Ooi, C.P.; Gururajan, R.; Gururajan, R.; Oh, S.L.; Lewis, S.K.; et al. Automated interpretation of biopsy images for the detection of celiac disease using a machine learning approach. Comput. Methods Programs. Biomed. 2021, 203, 106010. [Google Scholar] [CrossRef]
- Sali, R.; Ehsan, L.; Kowsari, K.; Khan, M.; Moskaluk, C.A.; Syed, S.; Brown, D.E. CeliacNet: Celiac disease severity diagnosis on duodenal histopathological images using deep residual networks. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 962–967. [Google Scholar]
- Bradley, D.; Roth, G. Adaptive thresholding using the integral image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Unal, I. Defining an optimal cut-point value in ROC analysis: An alternative approach. Comput. Math. Methods Med. 2017, 2017, 3762651. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. arXiv 2019, arXiv:1610.02391. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Shamir, R.R.; Duchin, Y.; Kim, J.; Sapiro, G.; Harel, N. Continuous Dice coefficient: A method for evaluating probabilistic segmentations. arXiv 2018, arXiv:1906.11031. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the 8th International Workshop on Machine Learning in Medical Imaging (MLMI), Quebec City, QC, Canada, 10 September 2017; pp. 379–387. [Google Scholar]
- Paul, J.; Shiha, A.V.H. Pancreatic steatosis: A new diagnosis and therapeutic challenge in Gastroenterology. Arq. Gastroenterol. 2020, 57, 216–220. [Google Scholar] [CrossRef] [PubMed]
- Silva, L.L.S.; Fernandes, M.S.S.; Lima, E.A.; Stefano, J.T.; Oliveira, C.P.; Jukemura, J. Fatty pancreas: Disease or finding? Clinics 2021, 76, e2439. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Label | Initial Count | Removed Images | Image Augmentation | Augmented Count | Final Count |
|---|---|---|---|---|---|
| single | 2400 | 1080 | - | - | 1320 |
| double | 342 | - | • horizontal flip (x-axis) • vertical flip (y-axis) • horizontal + vertical flip | 1026 | 1368 |
| multiple | 335 | - | • horizontal flip (x-axis) • vertical flip (y-axis) • horizontal + vertical flip | 1005 | 1340 |
| artifact | 870 | - | • horizontal + vertical flip | 870 | 1740 |
| CNN Model | Trainable Parameters (Initial) | Frozen Weights | Trainable Parameters (Final) | Weight Learn Rate Factor | Bias Learn Rate Factor |
|---|---|---|---|---|---|
| AlexNet | 60,965,224 | - | 56,868,224 | 10 | 10 |
| VGG-16 | 138,357,544 | • conv. block 1 • conv. block 2 | 134,260,544 | 20 | 20 |
| VGG-19 | 143,667,240 | • conv. block 1 • conv. block 2 | 139,570,240 | 20 | 20 |
| ResNet-50 | 25,583,592 | - | 23,534,592 | 10 | 10 |
| CNN Model | Mean Performance Metrics (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision/PPV | Sensitivity/Recall | F1-Score | Specificity/TNR | NPV | ROC AUC | PRC AUC | |
| AlexNet | 97.25 | 97.25 | 97.25 | 97.25 | 99.08 | 99.08 | 99.87 | 74.64 |
| VGG-16 | 97 | 97.08 | 97 | 97.04 | 99 | 99.01 | 99.86 | 74.59 |
| VGG-19 | 95.25 | 95.37 | 95.25 | 95.31 | 98.42 | 98.43 | 99.83 | 74.50 |
| ResNet-50 | 94.25 | 94.37 | 94.25 | 94.31 | 98.08 | 98.11 | 99.58 | 73.80 |
| Ensemble CNN | 98.25 | 98.25 | 98.25 | 98.25 | 99.42 | 99.42 | 99.73 | 99.47 |
| Testing Image (20×) | Fat Ratio (%) Image Segmentation (FSegm) | Fat Ratio(%) Regions Classification (FClass) | Fat Ratio (%) Manual Annotations (FDoc) | |||||
|---|---|---|---|---|---|---|---|---|
| FACM | FAlexNet | FVGG-16 | FVGG-19 | FResNet-50 | FEnsembleCNN | FAnnot | ||
| 1 | 120216-Head | 1.83 | 1.72 | 1.63 | 1.70 | 1.59 | 1.66 | 1.74 |
| 2 | 120216-Tail | 1.58 | 1.37 | 1.21 | 1.32 | 1.30 | 1.29 | 1.31 |
| 3 | 120485-Tail | 1.89 | 1.71 | 1.59 | 1.65 | 1.65 | 1.66 | 1.77 |
| 4 | 120495-Body | 2.56 | 1.71 | 1.44 | 1.48 | 1.40 | 1.48 | 1.63 |
| 5 | 120495-Head | 1.88 | 1.64 | 1.55 | 1.57 | 1.57 | 1.62 | 1.79 |
| 6 | 121543-Body | 5.75 | 5.11 | 4.82 | 4.86 | 4.88 | 4.92 | 5.08 |
| 7 | 121543-Head | 6.54 | 6.12 | 5.76 | 5.89 | 5.89 | 6.00 | 5.99 |
| 8 | 122020-Body | 0.70 | 0.39 | 0.28 | 0.39 | 0.32 | 0.36 | 0.24 |
| 9 | 122020-Head | 1.15 | 0.59 | 0.39 | 0.53 | 0.43 | 0.53 | 0.41 |
| 10 | 122020-Tail | 1.22 | 0.61 | 0.45 | 0.50 | 0.48 | 0.47 | 0.44 |
| 11 | 122088-Body | 0.52 | 0.40 | 0.35 | 0.36 | 0.33 | 0.35 | 0.36 |
| 12 | 122088-Tail | 1.47 | 0.79 | 0.63 | 0.73 | 0.68 | 0.71 | 0.63 |
| 13 | 122288-Body | 3.22 | 1.82 | 0.97 | 1.07 | 1.26 | 1.07 | 0.99 |
| 14 | 122288-Tail | 0.68 | 0.41 | 0.34 | 0.42 | 0.36 | 0.39 | 0.35 |
| 15 | 122662-Body | 1.38 | 0.16 | 0.08 | 0.11 | 0.09 | 0.10 | 0.05 |
| 16 | 122662-Tail | 1.05 | 0.30 | 0.25 | 0.30 | 0.25 | 0.28 | 0.25 |
| 17 | 123538-Head | 3.04 | 2.52 | 2.40 | 2.50 | 2.50 | 2.47 | 2.55 |
| 18 | 123883-Tail | 2.84 | 2.62 | 2.41 | 2.52 | 2.33 | 2.56 | 2.39 |
| 19 | 123948-Tail | 1.84 | 1.57 | 1.42 | 1.51 | 1.41 | 1.50 | 1.44 |
| 20 | HP-0937 | 2.41 | 2.10 | 2.05 | 2.10 | 2.10 | 2.08 | 2.14 |
| Mean Value: | 2.18 | 1.68 | 1.50 | 1.58 | 1.54 | 1.58 | 1.58 | |
| StD: | 1.57 | 1.55 | 1.49 | 1.50 | 1.51 | 1.53 | 1.57 | |
| Testing Image (20×) | Classification Error (%) from Annotations (Cerr) | Image Segmentation Error (%) from Annotations (Serr) | |||||
|---|---|---|---|---|---|---|---|
| AlexNeterr | VGG-16err | VGG-19err | ResNet-50err | EnsembleCNNerr | ACMerr | ||
| 1 | 120216-Head | 0.02 | 0.11 | 0.04 | 0.15 | 0.08 | 0.09 |
| 2 | 120216-Tail | 0.06 | 0.10 | 0.01 | 0.02 | 0.02 | 0.26 |
| 3 | 120485-Tail | 0.06 | 0.18 | 0.12 | 0.12 | 0.11 | 0.13 |
| 4 | 120495-Body | 0.08 | 0.19 | 0.15 | 0.22 | 0.14 | 0.93 |
| 5 | 120495-Head | 0.16 | 0.24 | 0.23 | 0.22 | 0.18 | 0.09 |
| 6 | 121543-Body | 0.03 | 0.26 | 0.21 | 0.20 | 0.16 | 0.67 |
| 7 | 121543-Head | 0.13 | 0.23 | 0.10 | 0.10 | 0.00 | 0.54 |
| 8 | 122020-Body | 0.15 | 0.04 | 0.15 | 0.07 | 0.12 | 0.46 |
| 9 | 122020-Head | 0.18 | 0.02 | 0.12 | 0.02 | 0.12 | 0.74 |
| 10 | 122020-Tail | 0.17 | 0.01 | 0.07 | 0.04 | 0.03 | 0.78 |
| 11 | 122088-Body | 0.04 | 0.01 | 0.00 | 0.03 | 0.01 | 0.16 |
| 12 | 122088-Tail | 0.15 | 0.01 | 0.10 | 0.05 | 0.08 | 0.84 |
| 13 | 122288-Body | 0.83 | 0.02 | 0.08 | 0.27 | 0.08 | 2.22 |
| 14 | 122288-Tail | 0.06 | 0.01 | 0.06 | 0.01 | 0.04 | 0.33 |
| 15 | 122662-Body | 0.11 | 0.03 | 0.07 | 0.04 | 0.05 | 1.33 |
| 16 | 122662-Tail | 0.05 | 0.01 | 0.05 | 0.00 | 0.04 | 0.80 |
| 17 | 123538-Head | 0.03 | 0.15 | 0.05 | 0.05 | 0.09 | 0.49 |
| 18 | 123883-Tail | 0.23 | 0.02 | 0.13 | 0.06 | 0.17 | 0.45 |
| 19 | 123948-Tail | 0.13 | 0.02 | 0.07 | 0.04 | 0.05 | 0.39 |
| 20 | HP-0937 | 0.05 | 0.09 | 0.04 | 0.04 | 0.06 | 0.27 |
| Mean Value: | 0.14 | 0.09 | 0.09 | 0.09 | 0.08 | 0.60 | |
| StD: | 0.17 | 0.09 | 0.06 | 0.08 | 0.05 | 0.50 | |
| Testing Image (20×) | AlexNetDice | VGG-16Dice | VGG-19Dice | ResNet-50Dice | EnsembleCNNDice | |
|---|---|---|---|---|---|---|
| 1 | 120216-Head | 91.8 | 90.3 | 91.6 | 91.7 | 91.0 |
| 2 | 120216-Tail | 88.0 | 91.0 | 89.1 | 90.0 | 90.3 |
| 3 | 120485-Tail | 87.7 | 86.4 | 86.5 | 86.2 | 87.0 |
| 4 | 120495-Body | 78.1 | 82.4 | 80.5 | 82.3 | 82.3 |
| 5 | 120495-Head | 87.0 | 87.5 | 86.4 | 87.0 | 88.5 |
| 6 | 121543-Body | 89.0 | 90.1 | 89.5 | 89.8 | 90.2 |
| 7 | 121543-Head | 90.5 | 91.7 | 91.2 | 90.7 | 90.9 |
| 8 | 122020-Body | 60.2 | 66.0 | 60.5 | 64.9 | 63.4 |
| 9 | 122020-Head | 70.0 | 76.9 | 73.1 | 66.4 | 73.3 |
| 10 | 122020-Tail | 71.6 | 80.7 | 77.5 | 77.4 | 79.9 |
| 11 | 122088-Body | 81.9 | 83.0 | 86.1 | 84.1 | 85.9 |
| 12 | 122088-Tail | 78.9 | 83.4 | 82.5 | 80.9 | 81.9 |
| 13 | 122288-Body | 63.1 | 84.2 | 80.5 | 77.4 | 83.6 |
| 14 | 122288-Tail | 79.9 | 86.9 | 79.7 | 79.0 | 81.3 |
| 15 | 122662-Body | 36.2 | 57.8 | 47.7 | 54.6 | 53.1 |
| 16 | 122662-Tail | 82.7 | 86.8 | 82.9 | 80.0 | 85.4 |
| 17 | 123538-Head | 90.6 | 92.5 | 91.6 | 89.0 | 91.6 |
| 18 | 123883-Tail | 87.7 | 89.8 | 89.5 | 83.6 | 88.2 |
| 19 | 123948-Tail | 84.4 | 88.4 | 87.0 | 85.6 | 87.0 |
| 20 | HP-0937 | 91.0 | 91.8 | 88.4 | 91.3 | 91.3 |
| Mean Value: | 79.5 | 84.4 | 82.1 | 81.6 | 83.3 | |
| StD: | 13.76 | 8.82 | 11.00 | 9.81 | 9.90 | |
| CNN Model | Time Complexity | Performance (%) | |||
|---|---|---|---|---|---|
| Training (min) | Testing (s) | Testing Accuracy | Fat Ratio Error (Mean) | Fat Ratio Error (StD) | |
| AlexNet | 1.38 | 0.5 | 97.25 | 0.14 | 0.17 |
| VGG-16 | 11.07 | 2.1 | 97 | 0.0879 | 0.09 |
| VGG-19 | 13.56 | 2.3 | 95.25 | 0.0927 | 0.06 |
| ResNet-50 | 9.58 | 1.9 | 94.25 | 0.088 | 0.08 |
| Ensemble CNN | 35.59 | 15.1 | 98.25 | 0.08 | 0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arjmand, A.; Tsakai, O.; Christou, V.; Tzallas, A.T.; Tsipouras, M.G.; Forlano, R.; Manousou, P.; Goldin, R.D.; Gogos , C.; Glavas, E.; et al. Ensemble Convolutional Neural Network Classification for Pancreatic Steatosis Assessment in Biopsy Images. Information 2022, 13, 160. https://doi.org/10.3390/info13040160
Arjmand A, Tsakai O, Christou V, Tzallas AT, Tsipouras MG, Forlano R, Manousou P, Goldin RD, Gogos C, Glavas E, et al. Ensemble Convolutional Neural Network Classification for Pancreatic Steatosis Assessment in Biopsy Images. Information. 2022; 13(4):160. https://doi.org/10.3390/info13040160
Chicago/Turabian StyleArjmand, Alexandros, Odysseas Tsakai, Vasileios Christou, Alexandros T. Tzallas, Markos G. Tsipouras, Roberta Forlano, Pinelopi Manousou, Robert D. Goldin, Christos Gogos , Evripidis Glavas, and et al. 2022. "Ensemble Convolutional Neural Network Classification for Pancreatic Steatosis Assessment in Biopsy Images" Information 13, no. 4: 160. https://doi.org/10.3390/info13040160
APA StyleArjmand, A., Tsakai, O., Christou, V., Tzallas, A. T., Tsipouras, M. G., Forlano, R., Manousou, P., Goldin, R. D., Gogos , C., Glavas, E., & Giannakeas, N. (2022). Ensemble Convolutional Neural Network Classification for Pancreatic Steatosis Assessment in Biopsy Images. Information, 13(4), 160. https://doi.org/10.3390/info13040160