
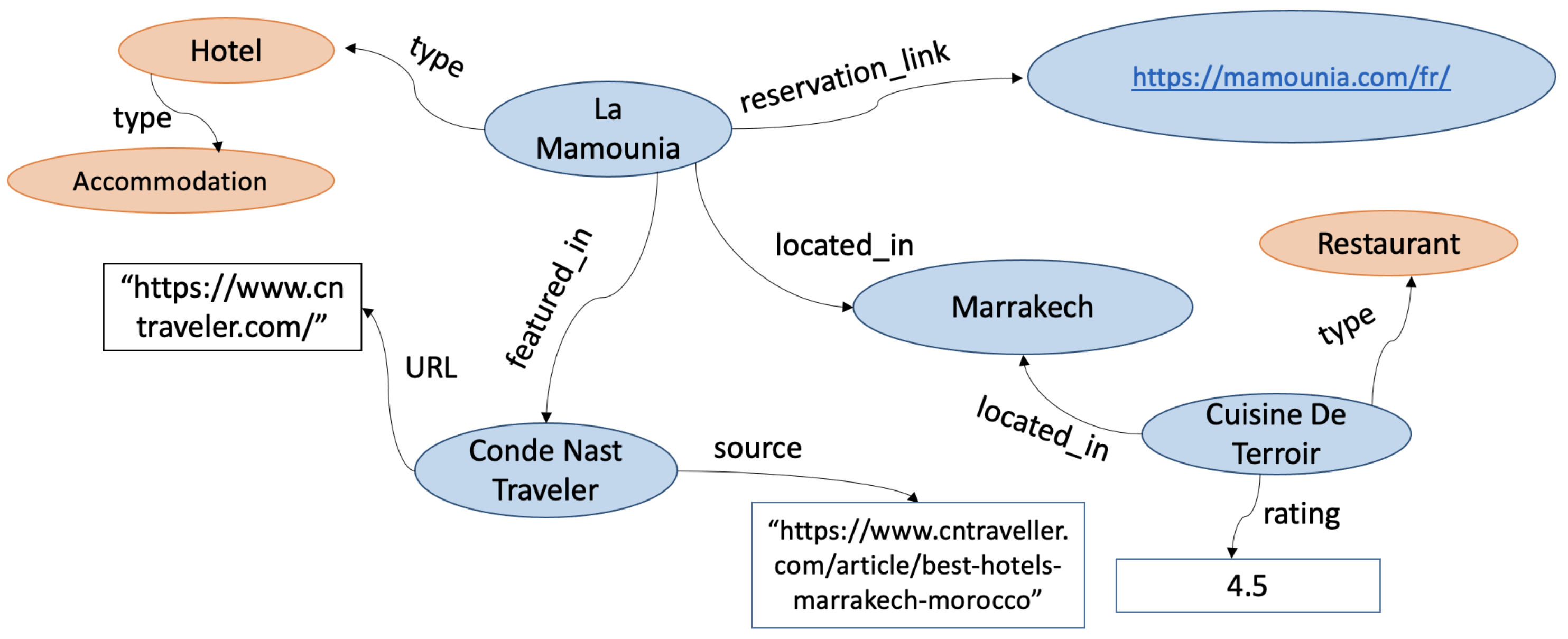
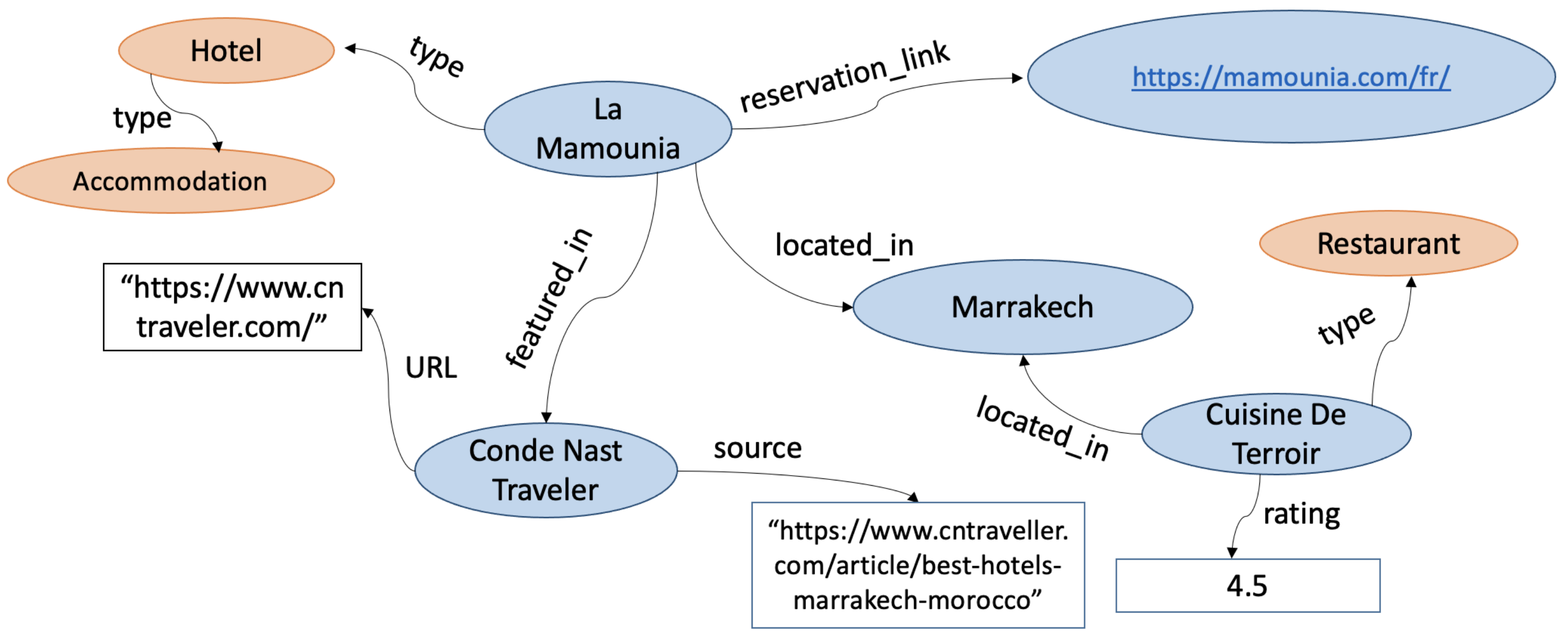
Knowledge Graphs: A Practical Review of the Research Landscape


{kind=link}
{kind=link}
Abstract
:1. Background and Aims
2. Related Work
3. Community-Specific Overview of KG Research
3.1. Natural Language Processing (NLP)
3.2. Semantic Web
3.3. Core Machine Learning: Representation Learning and Probabilistic Graphical Models
3.4. Databases, Data Mining, and Knowledge Discovery in Databases (KDD)
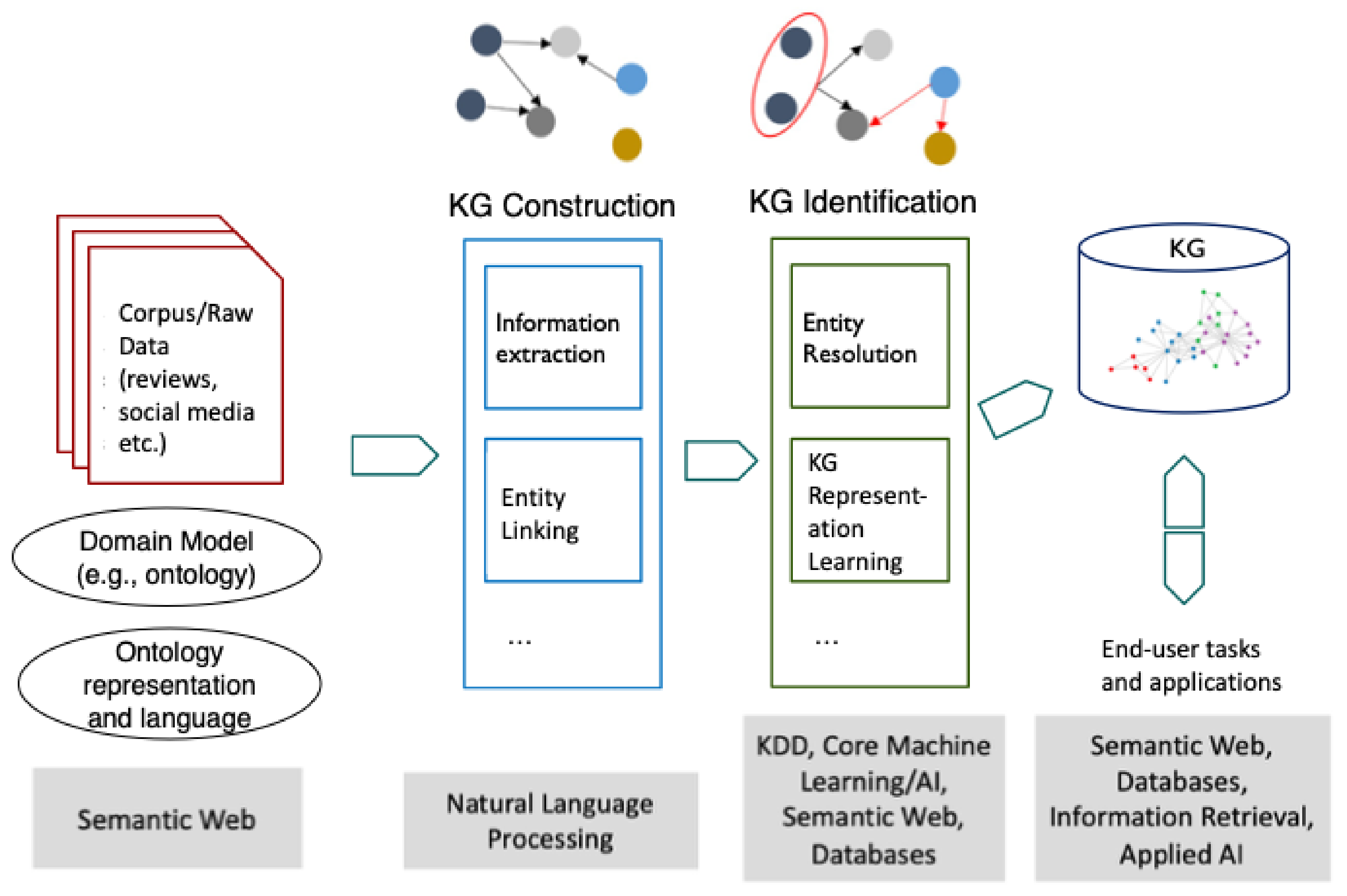
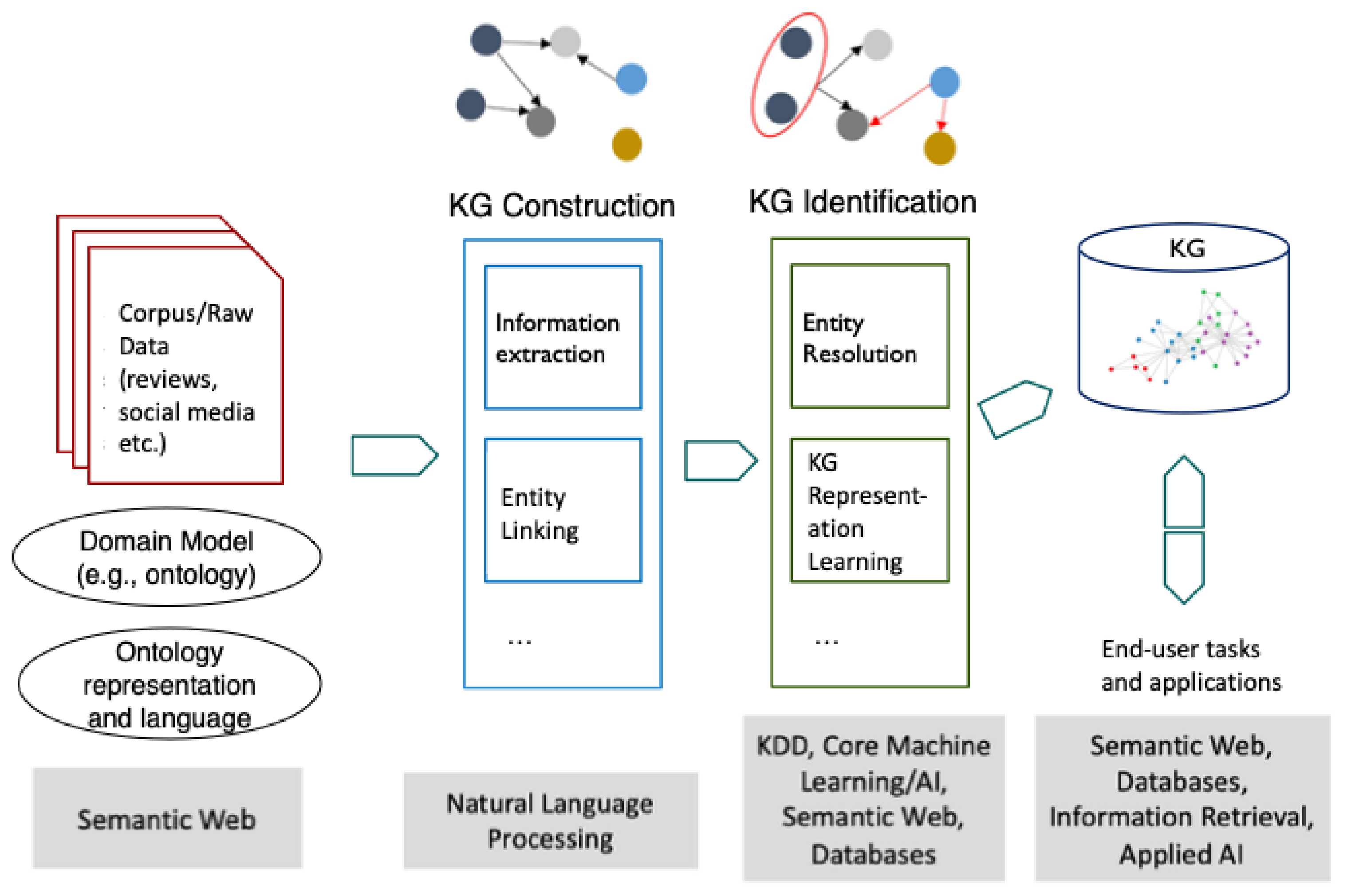
4. A Unified Synthesis
5. Future Directions
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Trudeau, R.J. Introduction to Graph Theory; Courier Corporation: North Chelmsford, MA, USA, 2013. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Asai, M.; Fukunaga, A. Classical planning in deep latent space: Bridging the subsymbolic-symbolic boundary. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Lazer, D.M.; Pentland, A.; Watts, D.J.; Aral, S.; Athey, S.; Contractor, N.; Freelon, D.; Gonzalez-Bailon, S.; King, G.; Margetts, H.; et al. Computational social science: Obstacles and opportunities. Science 2020, 369, 1060–1062. [Google Scholar] [CrossRef]
- Newman, M.E.; Barabási, A.L.E.; Watts, D.J. The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Vespignani, A. Twenty Years of Network Science. 2018. Available online: https://www.nature.com/articles/d41586-018-05444-y (accessed on 6 February 2022).
- Kivelä, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef] [Green Version]
- Bianconi, G. Multilayer Networks: Structure and Function; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Kejriwal, M.; Dang, A. Structural studies of the global networks exposed in the Panama papers. Appl. Netw. Sci. 2020, 5, 1–24. [Google Scholar] [CrossRef]
- Battiston, S.; Glattfelder, J.B.; Garlaschelli, D.; Lillo, F.; Caldarelli, G. The structure of financial networks. In Network Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 131–163. [Google Scholar]
- Kejriwal, M. On using centrality to understand importance of entities in the Panama Papers. PLoS ONE 2021, 16, e0248573. [Google Scholar] [CrossRef] [PubMed]
- Winecoff, W.K. Structural power and the global financial crisis: A network analytical approach. Bus. Polit. 2015, 17, 495–525. [Google Scholar] [CrossRef]
- Sadri, A.M.; Ukkusuri, S.V.; Ahmed, M.A. Review of social influence in crisis communications and evacuation decision-making. Transp. Res. Interdiscip. Perspect. 2021, 9, 100325. [Google Scholar] [CrossRef]
- Kejriwal, M.; Zhou, P. On detecting urgency in short crisis messages using minimal supervision and transfer learning. Soc. Netw. Anal. Min. 2020, 10, 58. [Google Scholar] [CrossRef]
- Gosak, M.; Markovič, R.; Dolenšek, J.; Rupnik, M.S.; Marhl, M.; Stožer, A.; Perc, M. Network science of biological systems at different scales: A review. Phys. Life Rev. 2018, 24, 118–135. [Google Scholar] [CrossRef]
- Koh, G.C.; Porras, P.; Aranda, B.; Hermjakob, H.; Orchard, S.E. Analyzing protein–protein interaction networks. J. Proteome Res. 2012, 11, 2014–2031. [Google Scholar] [CrossRef]
- Szklarczyk, D.; Gable, A.L.; Nastou, K.C.; Lyon, D.; Kirsch, R.; Pyysalo, S.; Doncheva, N.T.; Legeay, M.; Fang, T.; Bork, P.; et al. The STRING database in 2021: Customizable protein–protein networks, and functional characterization of user-uploaded gene/measurement sets. Nucleic Acids Res. 2021, 49, D605–D612. [Google Scholar] [CrossRef]
- Mendel, J.; Sharapov, K. Human trafficking and online networks: Policy, analysis, and ignorance. Antipode 2016, 48, 665–684. [Google Scholar] [CrossRef] [Green Version]
- Kejriwal, M.; Kapoor, R. Network-theoretic information extraction quality assessment in the human trafficking domain. Appl. Netw. Sci. 2019, 4, 44. [Google Scholar] [CrossRef] [Green Version]
- Cockbain, E. Offender and Victim Networks in Human Trafficking; Routledge: London, UK, 2018. [Google Scholar]
- Kejriwal, M.; Gu, Y. Network-theoretic modeling of complex activity using UK online sex advertisements. Appl. Netw. Sci. 2020, 5, 1–23. [Google Scholar] [CrossRef]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. (CSUR) 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Its Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.G. Community detection in multi-layer graphs: A survey. ACM SIGMOD Rec. 2015, 44, 37–48. [Google Scholar] [CrossRef]
- Jin, D.; Yu, Z.; Jiao, P.; Pan, S.; He, D.; Wu, J.; Yu, P.; Zhang, W. A survey of community detection approaches: From statistical modeling to deep learning. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. SEMANTiCS (Posters Demos SuCCESS) 2016, 48, 1–4. [Google Scholar]
- Kejriwal, M. Domain-Specific Knowledge Graph Construction; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hitzler, P. A review of the semantic web field. Commun. ACM 2021, 64, 76–83. [Google Scholar] [CrossRef]
- Getoor, L.; Machanavajjhala, A. Entity resolution for big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11 August 2013; p. 1527. [Google Scholar]
- Christophides, V.; Efthymiou, V.; Palpanas, T.; Papadakis, G.; Stefanidis, K. An Overview of End-to-End Entity Resolution for Big Data. ACM Comput. Surv. (CSUR) 2020, 53, 1–42. [Google Scholar] [CrossRef]
- Kejriwal, M. Populating a Linked Data Entity Name System: A Big Data Solution to Unsupervised Instance Matching; IOS Press: Amsterdam, The Netherlands, 2016; Volume 27. [Google Scholar]
- Winkler, W.E. Matching and record linkage. Wiley Interdiscip. Rev. Comput. Stat. 2014, 6, 313–325. [Google Scholar] [CrossRef] [Green Version]
- Christen, P. The data matching process. In Data Matching; Springer: Berlin/Heidelberg, Germany, 2012; pp. 23–35. [Google Scholar]
- Kolyvakis, P.; Kalousis, A.; Kiritsis, D. Deepalignment: Unsupervised ontology matching with refined word vectors. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 787–798. [Google Scholar]
- Tian, A.; Kejriwal, M.; Miranker, D.P. Schema matching over relations, attributes, and data values. In Proceedings of the 26th International Conference on Scientific and Statistical Database Management, Aalborg, Denmark, 30 June–2 July 2014; pp. 1–12. [Google Scholar]
- Ngo, D.; Bellahsene, Z. YAM++: A multi-strategy based approach for ontology matching task. In International Conference on Knowledge Engineering and Knowledge Management; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–425. [Google Scholar]
- Kejriwal, M.; Miranker, D.P. Experience: Type alignment on DBpedia and Freebase. arXiv 2016, arXiv:1608.04442. [Google Scholar]
- Niedhammer, I.; Bertrais, S.; Witt, K. Psychosocial work exposures and health outcomes: A meta-review of 72 literature reviews with meta-analysis. Scand. J. Work. Environ. Health 2021, 47, 489. [Google Scholar] [CrossRef] [PubMed]
- Paulet, R.; Holland, P.; Morgan, D. A meta-review of 10 years of green human resource management: Is Green HRM headed towards a roadblock or a revitalisation? Asia Pac. J. Hum. Resour. 2021, 59, 159–183. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the knowledge graph: Things, not strings. Off. Google Blog 2012, 5, 16. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Fensel, D.; Şimşek, U.; Angele, K.; Huaman, E.; Kärle, E.; Panasiuk, O.; Toma, I.; Umbrich, J.; Wahler, A. Knowledge Graphs; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Janev, V.; Graux, D.; Jabeen, H.; Sallinger, E. Knowledge Graphs and Big Data Processing; Springer Nature: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Pan, J.Z.; Vetere, G.; Gomez-Perez, J.M.; Wu, H. Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Kejriwal, M.; Knoblock, C.A.; Szekely, P. Knowledge Graphs: Fundamentals, Techniques, and Applications; MIT Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Yan, J.; Wang, C.; Cheng, W.; Gao, M.; Zhou, A. A retrospective of knowledge graphs. Front. Comput. Sci. 2018, 12, 55–74. [Google Scholar] [CrossRef]
- Sikos, L.F.; Philp, D. Provenance-aware knowledge representation: A survey of data models and contextualized knowledge graphs. Data Sci. Eng. 2020, 5, 293–316. [Google Scholar] [CrossRef]
- Abu-Salih, B. Domain-specific knowledge graphs: A survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Wu, T.; Qi, G.; Li, C.; Wang, M. A survey of techniques for constructing Chinese knowledge graphs and their applications. Sustainability 2018, 10, 3245. [Google Scholar] [CrossRef] [Green Version]
- Gottschalk, S.; Demidova, E. EventKG: A multilingual event-centric temporal knowledge graph. In European Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2018; pp. 272–287. [Google Scholar]
- Wu, T.; Wang, H.; Li, C.; Qi, G.; Niu, X.; Wang, M.; Li, L.; Shi, C. Knowledge graph construction from multiple online encyclopedias. World Wide Web 2020, 23, 2671–2698. [Google Scholar] [CrossRef]
- Zhu, X.; Li, Z.; Wang, X.; Jiang, X.; Sun, P.; Wang, X.; Xiao, Y.; Yuan, N.J. Multi-Modal Knowledge Graph Construction and Application: A Survey. arXiv 2022, arXiv:2202.05786. [Google Scholar]
- Domingo-Fernández, D.; Baksi, S.; Schultz, B.; Gadiya, Y.; Karki, R.; Raschka, T.; Ebeling, C.; Hofmann-Apitius, M.; Kodamullil, A.T. COVID-19 Knowledge Graph: A computable, multi-modal, cause-and-effect knowledge model of COVID-19 pathophysiology. Bioinformatics 2021, 37, 1332–1334. [Google Scholar] [CrossRef] [PubMed]
- Kejriwal, M. Knowledge Graphs and COVID-19: Opportunities, Challenges, and Implementation. Harv. Data Sci. Rev. 2020. [Google Scholar] [CrossRef]
- Dong, X.L. Challenges and innovations in building a product knowledge graph. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; p. 2869. [Google Scholar]
- Kejriwal, M. A meta-engine for building domain-specific search engines. Softw. Impacts 2021, 7, 100052. [Google Scholar] [CrossRef]
- Hubauer, T.; Lamparter, S.; Haase, P.; Herzig, D.M. Use Cases of the Industrial Knowledge Graph at Siemens. In Proceedings of the International Semantic Web Conference (P&D/Industry/BlueSky), Monterey, CA, USA, 8–12 October 2018. [Google Scholar]
- Kejriwal, M.; Liu, Q.; Jacob, F.; Javed, F. A pipeline for extracting and deduplicating domain-specific knowledge bases. In Proceedings of the 2015 IEEE International Conference on Big Data (IEEE BigData 2015), Santa Clara, CA, USA, 29 October–1 November 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1144–1153. [Google Scholar] [CrossRef]
- Abu-Rasheed, H.; Weber, C.; Zenkert, J.; Krumm, R.; Fathi, M. Explainable Graph-Based Search for Lessons-Learned Documents in the Semiconductor Industry. In Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1097–1106. [Google Scholar]
- Kejriwal, M.; Szekely, P. Information extraction in illicit web domains. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 997–1006. [Google Scholar]
- Lin, B.Y.; Sheng, Y.; Vo, N.; Tata, S. Freedom: A transferable neural architecture for structured information extraction on web documents. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 1092–1102. [Google Scholar]
- Zhu, Y.; Zhang, C.; Ré, C.; Fei-Fei, L. Building a large-scale multimodal knowledge base system for answering visual queries. arXiv 2015, arXiv:1507.05670. [Google Scholar]
- Grishman, R.; Sundheim, B.M. Message understanding conference-6: A brief history. In Proceedings of the COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 10–14 August 1996. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvist. Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Smirnova, A.; Cudré-Mauroux, P. Relation extraction using distant supervision: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Kumar, S. A survey of deep learning methods for relation extraction. arXiv 2017, arXiv:1705.03645. [Google Scholar]
- Cai, Z.; Zhao, K.; Zhu, K.Q.; Wang, H. Wikification via link co-occurrence. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1087–1096. [Google Scholar]
- Shen, W.; Wang, J.; Han, J. Entity linking with a knowledge base: Issues, techniques, and solutions. IEEE Trans. Knowl. Data Eng. 2014, 27, 443–460. [Google Scholar] [CrossRef]
- Sukthanker, R.; Poria, S.; Cambria, E.; Thirunavukarasu, R. Anaphora and coreference resolution: A review. Inf. Fusion 2020, 59, 139–162. [Google Scholar] [CrossRef]
- Clark, J.H.; Choi, E.; Collins, M.; Garrette, D.; Kwiatkowski, T.; Nikolaev, V.; Palomaki, J. TyDi QA: A Benchmark for Information-Seeking Question Answering in Ty pologically Di verse Languages. Trans. Assoc. Comput. Linguist. 2020, 8, 454–470. [Google Scholar] [CrossRef]
- Niklaus, C.; Cetto, M.; Freitas, A.; Handschuh, S. A survey on open information extraction. arXiv 2018, arXiv:1806.05599. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Nardi, D.; Brachman, R.J. An introduction to description logics. Descr. Log. Handb. 2003, 1, 40. [Google Scholar]
- Baader, F.; Horrocks, I.; Sattler, U. Description logics as ontology languages for the semantic web. In Mechanizing Mathematical Reasoning; Springer: Berlin/Heidelberg, Germany, 2005; pp. 228–248. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Pennsylvania, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Miller, E. An introduction to the resource description framework. Bull. Am. Soc. Inf. Sci. Technol. 1998, 25, 15–19. [Google Scholar] [CrossRef] [Green Version]
- Bauer, F.; Kaltenböck, M. Linked open data: The essentials. Ed. Mono Monochrom Vienna 2011, 710. Available online: https://africa-toolkit.reeep.org/sites/default/files/LOD-the-Essentials_0.pdf (accessed on 17 March 2022).
- Nechaev, Y.; Corcoglioniti, F.; Giuliano, C. Type prediction combining linked open data and social media. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1033–1042. [Google Scholar]
- Sansonetti, G.; Gasparetti, F.; Micarelli, A.; Cena, F.; Gena, C. Enhancing cultural recommendations through social and linked open data. User Model. User-Adapt. Interact. 2019, 29, 121–159. [Google Scholar] [CrossRef]
- Jupp, S.; Malone, J.; Bolleman, J.; Brandizi, M.; Davies, M.; Garcia, L.; Gaulton, A.; Gehant, S.; Laibe, C.; Redaschi, N.; et al. The EBI RDF platform: Linked open data for the life sciences. Bioinformatics 2014, 30, 1338–1339. [Google Scholar] [CrossRef] [Green Version]
- Kamdar, M.R.; Fernández, J.D.; Polleres, A.; Tudorache, T.; Musen, M.A. Enabling web-scale data integration in biomedicine through linked open data. NPJ Digit. Med. 2019, 2, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiarcos, C.; McCrae, J.; Cimiano, P.; Fellbaum, C. Towards open data for linguistics: Linguistic linked data. In New Trends of Research in Ontologies and Lexical Resources; Springer: Berlin/Heidelberg, Germany, 2013; pp. 7–25. [Google Scholar]
- Bond, F.; Foster, R. Linking and extending an open multilingual wordnet. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 1352–1362. [Google Scholar]
- Kejriwal, M. Populating entity name systems for big data integration. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2014; pp. 521–528. [Google Scholar]
- Kejriwal, M.; Miranker, D.P. An unsupervised instance matcher for schema-free RDF data. J. Web Semant. 2015, 35, 102–123. [Google Scholar] [CrossRef]
- Sakr, S.; Al-Naymat, G. Relational processing of RDF queries: A survey. ACM SIGMOD Rec. 2010, 38, 23–28. [Google Scholar] [CrossRef]
- Bebee, B.R.; Choi, D.; Gupta, A.; Gutmans, A.; Khandelwal, A.; Kiran, Y.; Mallidi, S.; McGaughy, B.; Personick, M.; Rajan, K.; et al. Amazon Neptune: Graph Data Management in the Cloud. In Proceedings of the International Semantic Web Conference (P&D/Industry/BlueSky), Monterey, CA, USA, 8–12 October 2018. [Google Scholar]
- Xiao, G.; Ding, L.; Cogrel, B.; Calvanese, D. Virtual knowledge graphs: An overview of systems and use cases. Data Intell. 2019, 1, 201–223. [Google Scholar] [CrossRef]
- Richardson, M.; Domingos, P. Markov logic networks. Mach. Learn. 2006, 62, 107–136. [Google Scholar] [CrossRef] [Green Version]
- Marra, G.; Kuželka, O. Neural markov logic networks. In Proceedings of the Uncertainty in Artificial Intelligence, Online, 27–30 July 2021; pp. 908–917. [Google Scholar]
- Pearl, J. Bayesian Networks. 2011. Available online: https://ftp.cs.ucla.edu/pub/stat_ser/r277.pdf (accessed on 17 March 2022).
- Koski, T.; Noble, J. Bayesian Networks: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 924. [Google Scholar]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning structured embeddings of knowledge bases. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; Volume 25. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Choudhary, S.; Luthra, T.; Mittal, A.; Singh, R. A survey of knowledge graph embedding and their applications. arXiv 2021, arXiv:2107.07842. [Google Scholar]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge graph embedding based question answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 105–113. [Google Scholar]
- Guan, N.; Song, D.; Liao, L. Knowledge graph embedding with concepts. Knowl.-Based Syst. 2019, 164, 38–44. [Google Scholar] [CrossRef]
- Kejriwal, M.; Szekely, P. Neural embeddings for populated geonames locations. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2017; pp. 139–146. [Google Scholar]
- Ristoski, P.; Paulheim, H. Rdf2vec: Rdf graph embeddings for data mining. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2016; pp. 498–514. [Google Scholar]
- Nayyeri, M.; Vahdati, S.; Zhou, X.; Shariat Yazdi, H.; Lehmann, J. Embedding-based recommendations on scholarly knowledge graphs. In European Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2020; pp. 255–270. [Google Scholar]
- Liu, Y.; Hua, W.; Xin, K.; Zhou, X. Context-aware temporal knowledge graph embedding. In International Conference on Web Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2020; pp. 583–598. [Google Scholar]
- Xu, C.; Nayyeri, M.; Alkhoury, F.; Yazdi, H.S.; Lehmann, J. TeRo: A time-aware knowledge graph embedding via temporal rotation. arXiv 2020, arXiv:2010.01029. [Google Scholar]
- Jia, N.; Cheng, X.; Su, S. Improving knowledge graph embedding using locally and globally attentive relation paths. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2020; pp. 17–32. [Google Scholar]
- Xiong, S.; Huang, W.; Duan, P. Knowledge graph embedding via relation paths and dynamic mapping matrix. In International Conference on Conceptual Modeling; Springer: Berlin/Heidelberg, Germany, 2018; pp. 106–118. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Jointly embedding knowledge graphs and logical rules. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 192–202. [Google Scholar]
- Wang, P.; Dou, D.; Wu, F.; de Silva, N.; Jin, L. Logic rules powered knowledge graph embedding. arXiv 2019, arXiv:1903.03772. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Knowledge graph embedding with iterative guidance from soft rules. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Kimmig, A.; Bach, S.; Broecheler, M.; Huang, B.; Getoor, L. A short introduction to probabilistic soft logic. In Proceedings of the NIPS Workshop on Probabilistic Programming: Foundations and Applications, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1–4. [Google Scholar]
- Pujara, J.; Miao, H.; Getoor, L.; Cohen, W. Knowledge graph identification. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 542–557. [Google Scholar]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 968–977. [Google Scholar]
- Palumbo, E.; Rizzo, G.; Troncy, R. Entity2rec: Learning user-item relatedness from knowledge graphs for top-n item recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 32–36. [Google Scholar]
- Gao, Y.; Li, Y.F.; Lin, Y.; Gao, H.; Khan, L. Deep learning on knowledge graph for recommender system: A survey. arXiv 2020, arXiv:2004.00387. [Google Scholar]
- Yin, R.; Li, K.; Zhang, G.; Lu, J. A deeper graph neural network for recommender systems. Knowl.-Based Syst. 2019, 185, 105020. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, X.; Zhao, S.; King, I. Star-gcn: Stacked and reconstructed graph convolutional networks for recommender systems. arXiv 2019, arXiv:1905.13129. [Google Scholar]
- Song, W.; Xiao, Z.; Wang, Y.; Charlin, L.; Zhang, M.; Tang, J. Session-based social recommendation via dynamic graph attention networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 555–563. [Google Scholar]
- Friedrich, G.; Zanker, M. A taxonomy for generating explanations in recommender systems. AI Mag. 2011, 32, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Kejriwal, M.; Shen, K.; Ni, C.C.; Torzec, N. Transfer-based taxonomy induction over concept labels. Eng. Appl. Artif. Intell. 2022, 108, 104548. [Google Scholar] [CrossRef]
- Kejriwal, M.; Shen, K.; Ni, C.C.; Torzec, N. An evaluation and annotation methodology for product category matching in e-commerce. Comput. Ind. 2021, 131, 103497. [Google Scholar] [CrossRef]
- Kanagal, B.; Ahmed, A.; Pandey, S.; Josifovski, V.; Yuan, J.; Garcia-Pueyo, L. Supercharging recommender systems using taxonomies for learning user purchase behavior. arXiv 2012, arXiv:1207.0136. [Google Scholar] [CrossRef] [Green Version]
- Kejriwal, M.; Selvam, R.K.; Ni, C.C.; Torzec, N. Locally constructing product taxonomies from scratch using representation learning. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020; pp. 507–514. [Google Scholar]
- Kejriwal, M.; Shen, K. Unsupervised real-time induction and interactive visualization of taxonomies over domain-specific concepts. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Virtual, The Netherlands, 8–11 November 2021; pp. 301–304. [Google Scholar]
- Liang, H.; Xu, Y.; Li, Y.; Nayak, R.; Weng, L.T. Personalized recommender systems integrating social tags and item taxonomy. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–18 September 2009; Volume 1, pp. 540–547. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2016, 29, 17–37. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J. Mining heterogeneous information networks: Principles and methodologies. Synth. Lect. Data Min. Knowl. Discov. 2012, 3, 1–159. [Google Scholar] [CrossRef]
- Ding, P.; Ouyang, W.; Luo, J.; Kwoh, C.K. Heterogeneous information network and its application to human health and disease. Brief. Bioinform. 2020, 21, 1327–1346. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. Shine: Signed heterogeneous information network embedding for sentiment link prediction. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 592–600. [Google Scholar]
- Lu, Y.; Shi, C.; Hu, L.; Liu, Z. Relation structure-aware heterogeneous information network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4456–4463. [Google Scholar]
- Goasdoué, F.; Manolescu, I.; Roatiş, A. Efficient query answering against dynamic RDF databases. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 299–310. [Google Scholar]
- Tatarinov, I.; Halevy, A. Efficient query reformulation in peer data management systems. In Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data, Paris, France, 13–18 June 2004; pp. 539–550. [Google Scholar]
- Angles, R.; Gutierrez, C. Survey of graph database models. ACM Comput. Surv. (CSUR) 2008, 40, 1–39. [Google Scholar] [CrossRef]
- Bonifati, A.; Fletcher, G.; Voigt, H.; Yakovets, N. Querying graphs. Synth. Lect. Data Manag. 2018, 10, 1–184. [Google Scholar] [CrossRef]
- Sakr, S.; Bonifati, A.; Voigt, H.; Iosup, A.; Ammar, K.; Angles, R.; Aref, W.; Arenas, M.; Besta, M.; Boncz, P.A.; et al. The future is big graphs: A community view on graph processing systems. Commun. ACM 2021, 64, 62–71. [Google Scholar] [CrossRef]
- Angles, R.; Bonifati, A.; Dumbrava, S.; Fletcher, G.; Hare, K.W.; Hidders, J.; Lee, V.E.; Li, B.; Libkin, L.; Martens, W.; et al. Pg-keys: Keys for property graphs. In Proceedings of the 2021 International Conference on Management of Data, Virtual Event, Xi’an, China, 20–25 June 2021; pp. 2423–2436. [Google Scholar]
- Klijn, E.L.; Mannhardt, F.; Fahland, D. Classifying and Detecting Task Executions and Routines in Processes Using Event Graphs. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2021; pp. 212–229. [Google Scholar]
- Lbath, H.; Bonifati, A.; Harmer, R. Schema inference for property graphs. In Proceedings of the EDBT 2021-24th International Conference on Extending Database Technology, Nicosia, Cyprus, 23–26 March 2021; pp. 499–504. [Google Scholar]
- Hoekstra, R. Ontology Representation: Design Patterns and Ontologies That Make Sense. 2009. Available online: https://pure.uva.nl/ws/files/763154/68623_thesis.pdf (accessed on 6 February 2022).
- Guizzardi, G. The role of foundational ontologies for conceptual modeling and domain ontology representation. In Proceedings of the 2006 7th International Baltic Conference on Databases and Information Systems, Vilnius, Lithuania, 3–6 July 2006; pp. 17–25. [Google Scholar]
- Lenzerini, M.; Milano, D.; Poggi, A. Ontology Representation & Reasoning; Universita di Roma La Sapienza: Roma, Italy, 2004; Available online: http://wwwusers.di.uniroma1.it/~estrinfo/1%20Ontology%20representation.pdf (accessed on 6 February 2022).
- Kejriwal, M. Unsupervised DNF Blocking for Efficient Linking of Knowledge Graphs and Tables. Information 2021, 12, 134. [Google Scholar] [CrossRef]
- Kejriwal, M. Link Prediction Between Structured Geopolitical Events: Models and Experiments. Front. Big Data 2021, 4, 779792. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Feng, J.; Huang, M.; Wang, M.; Zhou, M.; Hao, Y.; Zhu, X. Knowledge graph embedding by flexible translation. In Proceedings of the Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning, Cape Town, South Africa, 25–29 April 2016. [Google Scholar]
- Kejriwal, M.; Szekely, P. Knowledge graphs for social good: An entity-centric search engine for the human trafficking domain. IEEE Trans. Big Data 2017. [Google Scholar] [CrossRef]
- Bonifati, A.; Furniss, P.; Green, A.; Harmer, R.; Oshurko, E.; Voigt, H. Schema validation and evolution for graph databases. In International Conference on Conceptual Modeling; Springer: Berlin/Heidelberg, Germany, 2019; pp. 448–456. [Google Scholar]
- Francis, N.; Green, A.; Guagliardo, P.; Libkin, L.; Lindaaker, T.; Marsault, V.; Plantikow, S.; Rydberg, M.; Selmer, P.; Taylor, A. Cypher: An evolving query language for property graphs. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 1433–1445. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Zellers, R.; Bisk, Y.; Farhadi, A.; Choi, Y. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6720–6731. [Google Scholar]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. Kagnet: Knowledge-aware graph networks for commonsense reasoning. arXiv 2019, arXiv:1909.02151. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, H.; Singh, P. ConceptNet—a practical commonsense reasoning tool-kit. BT Technol. J. 2004, 22, 211–226. [Google Scholar] [CrossRef]
- Lenat, D.B. CYC: A large-scale investment in knowledge infrastructure. Commun. ACM 1995, 38, 33–38. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A.H.; Riedel, S. Language models as knowledge bases? arXiv 2019, arXiv:1909.01066. [Google Scholar]
- Yang, Z.; Garcia, N.; Chu, C.; Otani, M.; Nakashima, Y.; Takemura, H. A comparative study of language transformers for video question answering. Neurocomputing 2021, 445, 121–133. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kejriwal, M. Knowledge Graphs: A Practical Review of the Research Landscape. Information 2022, 13, 161. https://doi.org/10.3390/info13040161
Kejriwal M. Knowledge Graphs: A Practical Review of the Research Landscape. Information. 2022; 13(4):161. https://doi.org/10.3390/info13040161
Chicago/Turabian StyleKejriwal, Mayank. 2022. "Knowledge Graphs: A Practical Review of the Research Landscape" Information 13, no. 4: 161. https://doi.org/10.3390/info13040161
APA StyleKejriwal, M. (2022). Knowledge Graphs: A Practical Review of the Research Landscape. Information, 13(4), 161. https://doi.org/10.3390/info13040161