


Hybrid No-Reference Quality Assessment for Surveillance Images
Abstract
1. Introduction
1.1. Related Work
1.1.1. IQA Databases
1.1.2. NR IQA Metrics
1.2. Contributions
1.3. Structure
2. Proposed Method
2.1. Feature Extraction
2.1.1. Preliminaries
2.1.2. Distortion Feature
2.1.3. Semantic Feature Extraction
2.2. Feature Fusion
2.3. Feature Regression
2.3.1. Classification of Distortion Types and Levels
2.3.2. Regression of the Quality Score
3. Experiment
3.1. Benchmark Databases
3.2. Experimental Setup
IQA Competitors
3.3. Evaluation Criteria
3.3.1. Classification of the Distortion Types and Levels
- : The ratio of correctly predicted observations to the total observations for distortion detection.
- : The weighted average of Precision and Recall for distortion detection.
- : The ratio of correctly predicted observations to total observations for distortion detection with severity level identification.
- : The weighted average of Precision and Recall for the distortion detection with severity level identification.
3.3.2. Regression of the Quality Score
- Spearman rank order correlation coefficient (SRCC):where represents the difference between the i-th images’s ranks in subjective evaluations and predicted scores, while N is the number of testing images. SRCC is used to measure the prediction monotonicity. The value of SRCC is between 0 and 1. The larger the value, the better the result predicted by the model.
- Pearson linear correlation coefficient (PLCC):where and represent the i-th image’s subjective score and predicted score, while and are the mean of all and . PLCC can be used to estimate the linearity and consistency of prediction. The value of PLCC is between 0 and 1, with larger values being better.
- Kendall rank order correlation coefficient (KRCC):where and represent the numbers of concordant and discordant pairs in the testing data. Similar to SRCC, KRCC can be used to measure the monotonicity. The value of KRCC is between 0 and 1, with larger values being better.
- Root mean square error (RMSE):RMSE is used to evaluate prediction accuracy. The RMSE value is a positive number; a smaller the value indicates higher accuracy of the model.
3.4. Performance Discussion
3.5. Statistical Test
3.6. Ablation Study
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IVS | Intelligent Video Surveillance |
| IQA | Image Quality Assessment |
| FR IQA | Full-reference IQA |
| RR IQA | Reduced-reference IQA |
| NR IQA | No-reference IQA |
| SI | Surveillance Image |
| SIQA | Surveillance Image Quality Assessment |
| SV | Surveillance Video |
| SIQD | Surveillance Image Quality Database |
| VSQuAD | Video Surveillance Quality Assessment Database |
| ST | Swin Transformer |
| ST-t | Swin Transformer-tiny |
| DF | Distortion Features |
| SF | Semantic Features |
| MSE | Mean Squared Error |
| SRCC | Spearman Rank Order Correlation Coefficient |
| PLCC | Pearson Linear Correlation Coefficient |
| KRCC | Kendall Rank Correlation Coefficient |
| RMSE | Root Mean Squared Error |
References
- Gonzalez-Cepeda, J.; Ramajo, A.; Armingol, J.M. Intelligent Video Surveillance Systems for Vehicle Identification Based on Multinet Architecture. Information 2022, 13, 325. [Google Scholar] [CrossRef]
- Sreenu, G.; Durai, M.S. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 1–27. [Google Scholar] [CrossRef]
- Muller-Schneiders, S.; Jager, T.; Loos, H.S.; Niem, W. Performance evaluation of a real time video surveillance system. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 137–143. [Google Scholar]
- Aqqa, M.; Mantini, P.; Shah, S.K. Understanding How Video Quality Affects Object Detection Algorithms. In Proceedings of the VISIGRAPP (5: VISAPP), Prague, Czech Republic, 25–27 February 2019; pp. 96–104. [Google Scholar]
- Held, C.; Krumm, J.; Markel, P.; Schenke, R.P. Intelligent video surveillance. Computer 2012, 45, 83–84. [Google Scholar] [CrossRef]
- Leszczuk, M.; Romaniak, P.; Janowski, L. Quality assessment in video surveillance. In Recent Developments in Video Surveillance; IntechOpen: London, UK, 2012. [Google Scholar]
- Zhu, W.; Zhai, G.; Yao, C.; Yang, X. SIQD: Surveillance Image Quality Database and Performance Evaluation for Objective Algorithms. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Beghdadi, A.; Qureshi, M.A.; Dakkar, B.E.; Gillani, H.H.; Khan, Z.A.; Kaaniche, M.; Ullah, M.; Cheikh, F.A. A New Video Quality Assessment Dataset for Video Surveillance Applications. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1521–1525. [Google Scholar]
- Bezzine, I.; Khan, Z.A.; Beghdadi, A.; Al-Maadeed, N.; Kaaniche, M.; Al-Maadeed, S.; Bouridane, A.; Cheikh, F.A. Video Quality Assessment Dataset for Smart Public Security Systems. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–5. [Google Scholar]
- Zhang, Z.; Lu, W.; Sun, W.; Min, X.; Wang, T.; Zhai, G. Surveillance Video Quality Assessment Based on Quality Related Retraining. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 4278–4282. [Google Scholar]
- Zhai, G.; Min, X. Perceptual image quality assessment: A survey. Sci. China Inf. Sci. 2020, 63, 1–52. [Google Scholar] [CrossRef]
- Zhai, G.; Sun, W.; Min, X.; Zhou, J. Perceptual quality assessment of low-light image enhancement. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–24. [Google Scholar] [CrossRef]
- Mohammadi, P.; Ebrahimi-Moghadam, A.; Shirani, S. Subjective and objective quality assessment of image: A survey. arXiv 2014, arXiv:1406.7799. [Google Scholar]
- Golestaneh, S.A.; Dadsetan, S.; Kitani, K.M. No-Reference Image Quality Assessment via Transformers, Relative Ranking, and Self-Consistency. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 3209–3218. [Google Scholar]
- Sheikh, H. LIVE Image Quality Assessment Database Release 2. 2005. Available online: http://live.ece.utexas.edu/research/quality (accessed on 20 October 2022).
- Ponomarenko, N.; Lukin, V.; Zelensky, A.; Egiazarian, K.; Carli, M.; Battisti, F. TID2008-a database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectron. 2009, 10, 30–45. [Google Scholar]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Larson, E.C.D. Consumer Subjective Image Quality Database. 2009. Available online: http://visionokstateedu/csiq/ (accessed on 20 October 2022).
- Wang, Z. Applications of objective image quality assessment methods [applications corner]. IEEE Signal Process. Mag. 2011, 28, 137–142. [Google Scholar] [CrossRef]
- Wang, L. A survey on IQA. arXiv 2021, arXiv:2109.00347. [Google Scholar]
- Benoit, A.; Le Callet, P.; Campisi, P.; Cousseau, R. Quality assessment of stereoscopic images. EURASIP J. Image Video Process. 2009, 2008, 1–13. [Google Scholar] [CrossRef]
- Yang, H.; Fang, Y.; Lin, W.; Wang, Z. Subjective quality assessment of screen content images. In Proceedings of the 2014 Sixth International Workshop on Quality of Multimedia Experience (QoMEX), Singapore, 18–20 September 2014; pp. 257–262. [Google Scholar]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, S. Deep blind image quality assessment by employing FR-IQA. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3180–3184. [Google Scholar]
- Ye, P.; Doermann, D. No-reference image quality assessment using visual codebooks. IEEE Trans. Image Process. 2012, 21, 3129–3138. [Google Scholar] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT statistics-based blind image quality index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Lu, W.; Sun, W.; Zhu, W.; Min, X.; Zhang, Z.; Wang, T.; Zhai, G. A cnn-based quality assessment method for pseudo 4k contents. In Proceedings of the International Forum on Digital TV and Wireless Multimedia Communications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 164–176. [Google Scholar]
- Wang, T.; Sun, W.; Min, X.; Lu, W.; Zhang, Z.; Zhai, G. A Multi-dimensional Aesthetic Quality Assessment Model for Mobile Game Images. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–5. [Google Scholar]
- Sun, W.; Min, X.; Zhai, G.; Gu, K.; Duan, H.; Ma, S. MC360IQA: A multi-channel CNN for blind 360-degree image quality assessment. IEEE J. Sel. Top. Signal Process. 2019, 14, 64–77. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Xu, J.; Ye, P.; Li, Q.; Du, H.; Liu, Y.; Doermann, D. Blind image quality assessment based on high order statistics aggregation. IEEE Trans. Image Process. 2016, 25, 4444–4457. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 36–47. [Google Scholar] [CrossRef]
- Su, S.; Yan, Q.; Zhu, Y.; Zhang, C.; Ge, X.; Sun, J.; Zhang, Y. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3667–3676. [Google Scholar]
- Ma, J.; Wu, J.; Li, L.; Dong, W.; Xie, X.; Shi, G.; Lin, W. Blind image quality assessment with active inference. IEEE Trans. Image Process. 2021, 30, 3650–3663. [Google Scholar] [CrossRef]
- Gao, X.; Lu, W.; Tao, D.; Li, X. Image quality assessment and human visual system. In Proceedings of the Visual Communications and Image Processing, Huangshan, China, 11–14 July 2010; Volume 7744, pp. 316–325. [Google Scholar]
- Zhai, G.; Min, X.; Liu, N. Free-energy principle inspired visual quality assessment: An overview. Digit. Signal Process. 2019, 91, 11–20. [Google Scholar] [CrossRef]
- Zhai, G.; Wu, X.; Yang, X.; Lin, W.; Zhang, W. A psychovisual quality metric in free-energy principle. IEEE Trans. Image Process. 2011, 21, 41–52. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W. Using free energy principle for blind image quality assessment. IEEE Trans. Multimed. 2014, 17, 50–63. [Google Scholar] [CrossRef]
- Wang, H.; Fu, J.; Lin, W.; Hu, S.; Kuo, C.C.J.; Zuo, L. Image quality assessment based on local linear information and distortion-specific compensation. IEEE Trans. Image Process. 2016, 26, 915–926. [Google Scholar] [CrossRef] [PubMed]
- Sadbhawna; Jakhetiya, V.; Mumtaz, D.; Jaiswal, S.P. Distortion specific contrast based no-reference quality assessment of DIBR-synthesized views. In Proceedings of the 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 21–24 September 2020; pp. 1–5. [Google Scholar]
- Yan, C.; Teng, T.; Liu, Y.; Zhang, Y.; Wang, H.; Ji, X. Precise no-reference image quality evaluation based on distortion identification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–21. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.J. A new image quality assessment method to detect and measure strength of blocking artifacts. Signal Process. Image Commun. 2012, 27, 31–38. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C.; Cormack, L. No-reference quality assessment using natural scene statistics: JPEG2000. IEEE Trans. Image Process. 2005, 14, 1918–1927. [Google Scholar] [CrossRef]
- Narvekar, N.D.; Karam, L.J. A no-reference image blur metric based on the cumulative probability of blur detection (CPBD). IEEE Trans. Image Process. 2011, 20, 2678–2683. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, W.; Min, X.; Zhou, Q.; He, J.; Wang, Q.; Zhai, G. MM-PCQA: Multi-Modal Learning for No-reference Point Cloud Quality Assessment. arXiv 2022, arXiv:2209.00244. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF CVPR, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Z.; Sun, W.; Min, X.; Zhu, W.; Wang, T.; Lu, W.; Zhai, G. A no-reference evaluation metric for low-light image enhancement. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Chowdhury, D.; Das, S.K.; Nandy, S.; Chakraborty, A.; Goswami, R.; Chakraborty, A. An Atomic Technique for Removal of Gaussian Noise from a Noisy Gray Scale Image Using LowPass-Convoluted Gaussian Filter. In Proceedings of the International Conference on Opto-Electronics and Applied Optics, Kolkata, India, 18–20 March 2019; pp. 1–6. [Google Scholar]
- Chang, C.; Hsiao, J.; Hsieh, C. An Adaptive Median Filter for Image Denoising. In Proceedings of the International Symposium on Intelligent Information Technology Application, Shanghai, China, 20–22 December 2008; Volume 2, pp. 346–350. [Google Scholar]
- Zhang, Z.; Sun, W.; Min, X.; Wang, T.; Lu, W.; Zhai, G. A Full-Reference Quality Assessment Metric for Fine-Grained Compressed Images. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–4. [Google Scholar]
- Zhang, Z.; Sun, W.; Wu, W.; Chen, Y.; Min, X.; Zhai, G. Perceptual Quality Assessment for Fine-Grained Compressed Images. arXiv 2022, arXiv:2206.03862. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, W.; Min, X.; Zhu, W.; Wang, T.; Lu, W.; Zhai, G. A No-Reference Deep Learning Quality Assessment Method for Super-resolution Images Based on Frequency Maps. arXiv 2022, arXiv:2206.04289. [Google Scholar]
- Bar, L.; Sochen, N.; Kiryati, N. Semi-blind image restoration via Mumford-Shah regularization. IEEE Trans. Image Process. 2006, 15, 483–493. [Google Scholar] [CrossRef] [PubMed]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the IEEE QoMEX, Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Li, D.; Jiang, T.; Jiang, M. Quality assessment of in-the-wild videos. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2351–2359. [Google Scholar]
- Sun, W.; Min, X.; Lu, W.; Zhai, G. A Deep Learning based No-reference Quality Assessment Model for UGC Videos. arXiv 2022, arXiv:2204.14047. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF CVPR, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, Diego, CA, USA, 7–9 May 2015; p. 13. [Google Scholar]
- Li, D.; Jiang, T.; Lin, W.; Jiang, M. Which has better visual quality: The clear blue sky or a blurry animal? IEEE Trans. Multimed. 2018, 21, 1221–1234. [Google Scholar] [CrossRef]
- Sheikh, H.; Sabir, M.; Bovik, A. A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
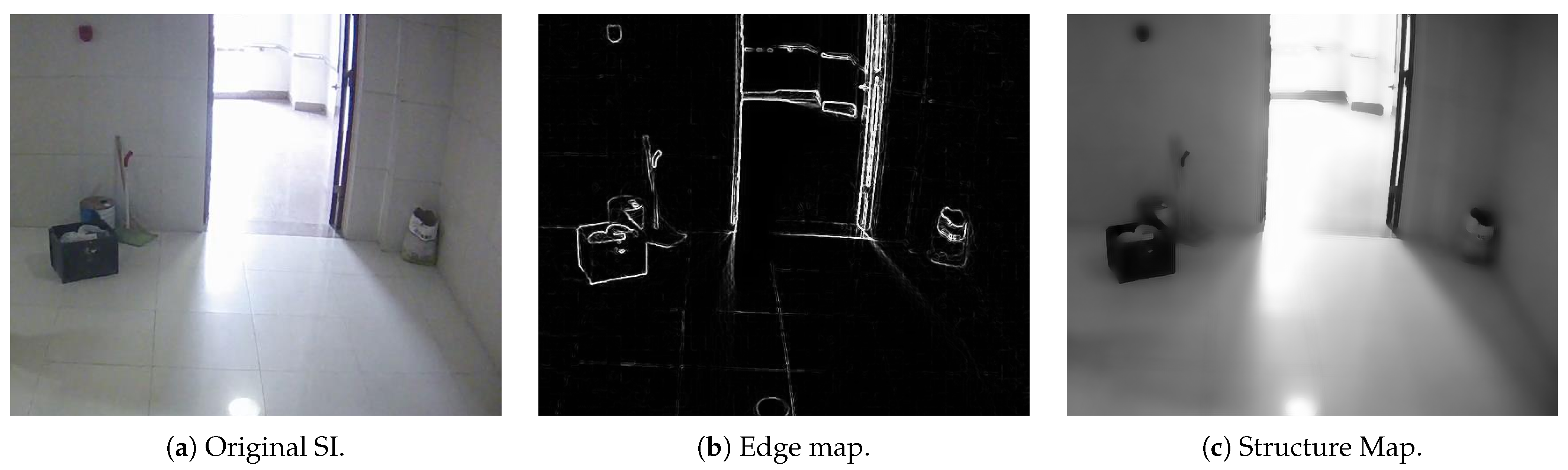{kind=link}
{kind=link}
| Type | Method | SRCC | PLCC | KRCC | RMSE |
|---|---|---|---|---|---|
| Hand-crafted | BLIINDS-II | 0.1584 | 0.2059 | 0.0946 | 0.9030 |
| BRISQUE | 0.3051 | 0.3256 | 0.2497 | 0.8726 | |
| CORNIA | 0.5476 | 0.5641 | 0.4732 | 0.7619 | |
| DIIVINE | 0.0223 | 0.2178 | 0.0132 | 0.9007 | |
| GMLF | 0.0740 | 0.2058 | 0.0533 | 0.9030 | |
| HOSA | 0.2871 | 0.3273 | 0.2064 | 0.8720 | |
| SISBLIM | 0.4206 | 0.5488 | 0.3612 | 0.7714 | |
| NFERM | 0.2576 | 0.3925 | 0.2167 | 0.8488 | |
| Deep-learning | SFA | 0.8702 | 0.8741 | 0.7123 | 0.4153 |
| DBCNN | 0.8727 | 0.8785 | 0.7196 | 0.4033 | |
| HyperIQA | 0.8631 | 0.8687 | 0.6946 | 0.4478 | |
| Proposed | 0.8986 | 0.9103 | 0.7276 | 0.3864 |
| Type | Method | ||||
|---|---|---|---|---|---|
| Hand-crafted | BLIINDS-II | 0.311 | 0.569 | 0.051 | 0.088 |
| BRISQUE | 0.368 | 0.603 | 0.076 | 0.127 | |
| CORNIA | 0.540 | 0.642 | 0.371 | 0.422 | |
| DIIVINE | 0.270 | 0.432 | 0.041 | 0.067 | |
| GMLF | 0.289 | 0.411 | 0.048 | 0.077 | |
| HOSA | 0.378 | 0.615 | 0.086 | 0.167 | |
| SISBLIM | 0.524 | 0.634 | 0.343 | 0.396 | |
| NFERM | 0.603 | 0.723 | 0.413 | 0.487 | |
| Deep-learning | SFA | 0.762 | 0.892 | 0.622 | 0.672 |
| DBCNN | 0.778 | 0.903 | 0.638 | 0.690 | |
| HyperIQA | 0.794 | 0.911 | 0.654 | 0.716 | |
| Proposed | 0.852 | 0.946 | 0.708 | 0.817 |
| Feature | SRCC | PLCC | KRCC | RMSE |
|---|---|---|---|---|
| DF | 0.6143 | 0.6268 | 0.5293 | 0.6923 |
| SF | 0.7738 | 0.7910 | 0.6104 | 0.5312 |
| DF+SF | 0.8986 | 0.9103 | 0.7276 | 0.3864 |
| Feature | ||||
|---|---|---|---|---|
| DF | 0.625 | 0.697 | 0.441 | 0.501 |
| SF | 0.667 | 0.757 | 0.473 | 0.564 |
| DF+SF | 0.852 | 0.946 | 0.708 | 0.817 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Ye, X.; Zhao, Z. Hybrid No-Reference Quality Assessment for Surveillance Images. Information 2022, 13, 588. https://doi.org/10.3390/info13120588
Ye Z, Ye X, Zhao Z. Hybrid No-Reference Quality Assessment for Surveillance Images. Information. 2022; 13(12):588. https://doi.org/10.3390/info13120588
Chicago/Turabian StyleYe, Zhongchang, Xin Ye, and Zhonghua Zhao. 2022. "Hybrid No-Reference Quality Assessment for Surveillance Images" Information 13, no. 12: 588. https://doi.org/10.3390/info13120588
APA StyleYe, Z., Ye, X., & Zhao, Z. (2022). Hybrid No-Reference Quality Assessment for Surveillance Images. Information, 13(12), 588. https://doi.org/10.3390/info13120588