
LPCOCN: A Layered Paddy Crop Optimization-Based Capsule Network Approach for Anomaly Detection at IoT Edge

 ,
,  ,
,  and
and
Abstract
1. Introduction
- The layered paddy crop optimization (LPCO) approach for selecting the optimal set of features;
- The architecture of a capsule network for learning;
- A procedure for LPCO to select optimal features;
- The analysis and comparison of the true positive rate, false positive rate, accuracy, and error rate of the proposed anomaly detection system with respect to existing deep learning classifiers and optimization-based feature selection methods.
2. Materials and Methods
2.1. Anomaly Detection
2.2. Feature Selection
2.3. Supervised Learning Based Anomaly Detection
3. Proposed LPCOCN Approach
3.1. Proposed LPCO-Based Feature Selection
3.1.1. Layer 1: Seedling
3.1.2. Layer 2: Tillering
3.1.3. Layer 3: Replantation
3.1.4. Layer 4: Selection
3.1.5. Layer 5: Reproduction
3.1.6. Layer 6: Harvest
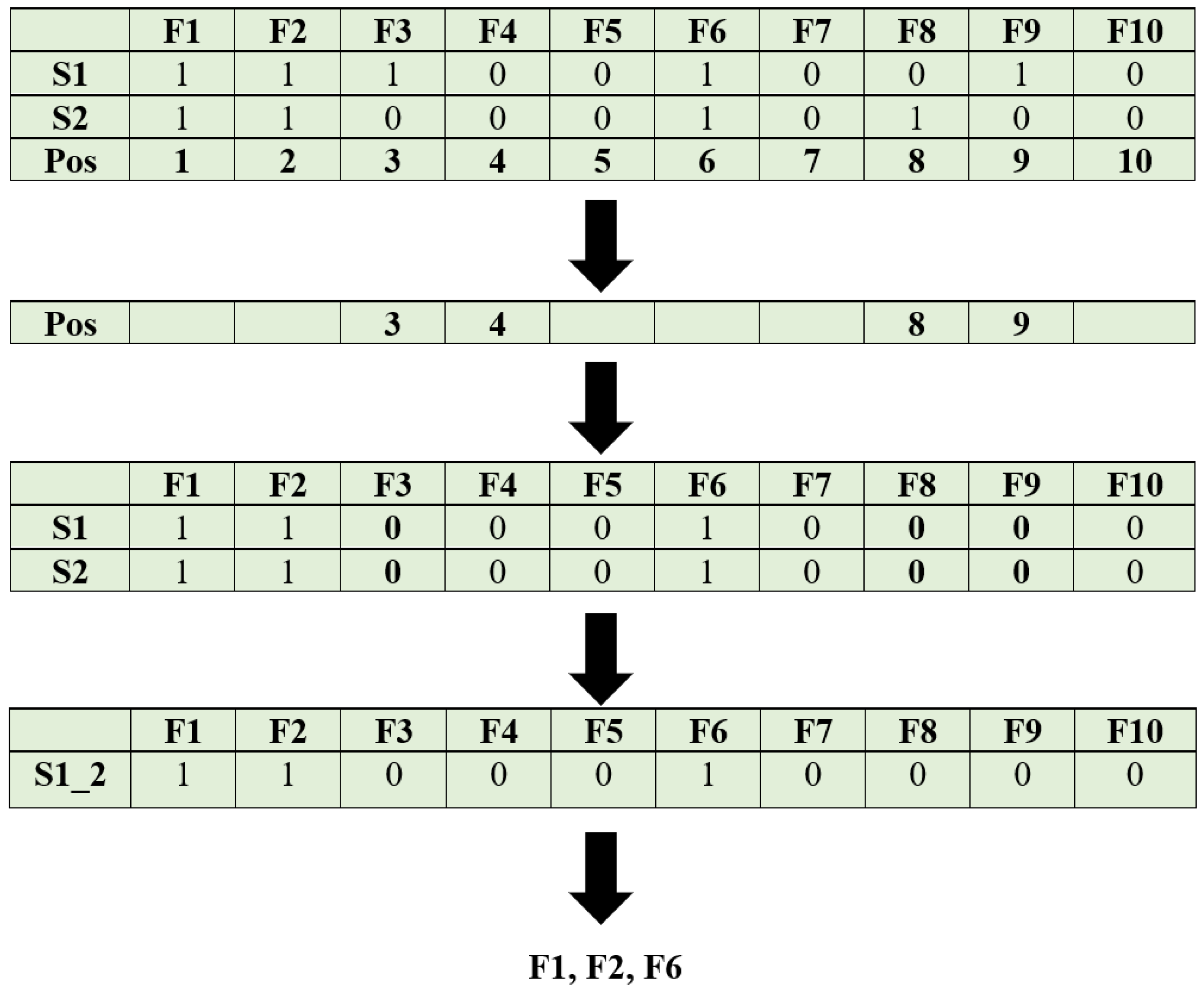
- Step 1: Initialize the number of seeds, total number of plants in a generation, and the number of generations.
- Step 2: The number of seed, s and number of plants, p are binary coded randomly, where 1 represents the presence of a feature, and 0 represents the absence of a feature.
- Step 3: The distance-based classifier receives the plants with the available feature, and the accuracy is calculated.
- Step 4: Rank the plants according to the accuracy, such that the higher the accuracy is, the smaller the rank is.
- Step 5: The top 50% of plants are selected for reproduction.
- Step 6: The remaining 50% are produced as follows:
- –
- Step 6.1: Select the top two plants, i and , and compute the Hamming distance between them.
- –
- Step 6.2: The position of the plant which is involved for Hamming distance computation is converted to ‘0’, i.e., the absence of a feature.
- –
- Step 6.3: Steps 6.1 and 6.2 are repeated until the Hamming distance computation is performed for all the features.
- –
- Step 6.4: The pth plant is produced by finding the Hamming distance of all records.
- Step 7: The new generation is passed to step 3, and this continues until the number of generations.
- Step 8: The features in the last generation are the optimal set of features.
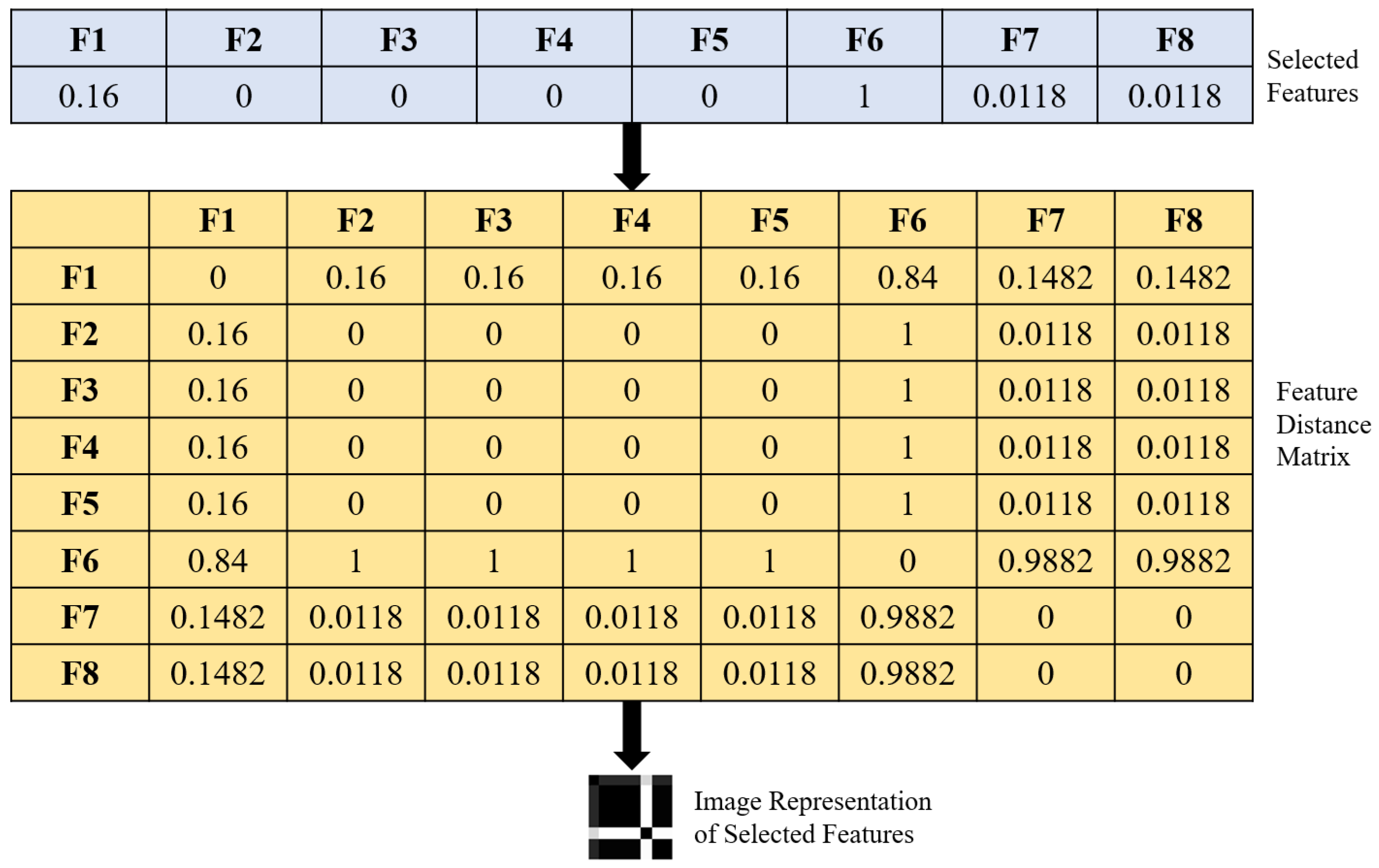
3.2. Conversion of Selected Features to Image
3.3. Capsule Network Based Learning
3.4. LPCOCN Based Anomaly Detection
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shafiq, M.; Nazir, S.; Yu, X. Identification of Attack Traffic Using Machine Learning in Smart IoT Networks. Secur. Commun. Netw. 2022, 2022, 9804596. [Google Scholar] [CrossRef]
- Malhotra, P.; Singh, Y.; Anand, P.; Bangotra, D.K.; Singh, P.K.; Hong, W.C. Internet of things: Evolution, concerns and security challenges. Sensors 2021, 21, 1809. [Google Scholar] [CrossRef] [PubMed]
- NG, B.A.; Selvakumar, S. Anomaly detection framework for Internet of things traffic using vector convolutional deep learning approach in fog environment. Future Gener. Comput. Syst. 2020, 113, 255–265. [Google Scholar]
- Dhelim, S.; Aung, N.; Kechadi, T.; Ning, H.; Chen, L.; Lakas, A. Trust2Vec: Large-Scale IoT Trust Management System based on Signed Network Embeddings. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- IoT Market Forecast. Available online: https://www.iotforall.com/state-of-iot-2022 (accessed on 30 September 2022).
- Bangui, H.; Buhnova, B. Lightweight intrusion detection for edge computing networks using deep forest and bio-inspired algorithms. Comput. Electr. Eng. 2022, 100, 107901. [Google Scholar] [CrossRef]
- Amma, N.B.; Selvakumar, S.; Velusamy, R.L. A statistical approach for detection of denial of service attacks in computer networks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2511–2522. [Google Scholar] [CrossRef]
- Wei, D.; Shi, F.; Dhelim, S. A Self-Supervised Learning Model for Unknown Internet Traffic Identification Based on Surge Period. Future Internet 2022, 14, 289. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Chander, B.; Pal, S.; De, D.; Buyya, R. Artificial intelligence-based internet of things for industry 5.0. In Artificial Intelligence-Based Internet of Things Systems; Springer: Cham, Switzerland, 2022; pp. 3–45. [Google Scholar]
- Alkadi, O.; Moustafa, N.; Turnbull, B.; Choo, K.K.R. A deep blockchain framework-enabled collaborative intrusion detection for protecting IoT and cloud networks. IEEE Internet Things J. 2020, 8, 9463–9472. [Google Scholar] [CrossRef]
- Bebortta, S.; Singh, S.K. An Opportunistic Ensemble Learning Framework for Network Traffic Classification in IoT Environments. In Proceedings of the Seventh International Conference on Mathematics and Computing; Springer: Singapore, 2022; pp. 473–484. [Google Scholar]
- Churcher, A.; Ullah, R.; Ahmad, J.; Ur Rehman, S.; Masood, F.; Gogate, M.; Alqahtani, F.; Nour, B.; Buchanan, W.J. An experimental analysis of attack classification using machine learning in IoT networks. Sensors 2021, 21, 446. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Frappier, M.; Mammar, A. Intrusion detection systems: A cross-domain overview. IEEE Commun. Surv. Tutor. 2019, 21, 3639–3681. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Fusion of statistical importance for feature selection in Deep Neural Network-based Intrusion Detection System. Inf. Fusion 2022, 90, 353–363. [Google Scholar] [CrossRef]
- Zuech, R.; Khoshgoftaar, T.M. A survey on feature selection for intrusion detection. In Proceedings of the 21st ISSAT International Conference on Reliability and Quality in Design, Philadelphia, PA, USA, 6–8 August 2015; pp. 150–155. [Google Scholar]
- Kasongo, S.M.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Shahbaz, M.B.; Wang, X.; Behnad, A.; Samarabandu, J. On efficiency enhancement of the correlation-based feature selection for intrusion detection systems. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–7. [Google Scholar]
- Aparicio-Navarro, F.J.; Kyriakopoulos, K.G.; Parish, D.J. Automatic dataset labelling and feature selection for intrusion detection systems. In Proceedings of the 2014 IEEE Military Communications Conference, Washington, DC, USA, 6–8 October 2014; pp. 46–51. [Google Scholar]
- Ebrahimi, H.; Majidzadeh, K.; Soleimanian Gharehchopogh, F. Integration of deep learning model and feature selection for multi-label classification. Int. J. Nonlinear Anal. Appl. 2022, 13, 2871–2883. [Google Scholar]
- Ibitoye, O.; Shafiq, O.; Matrawy, A. Analyzing adversarial attacks against deep learning for intrusion detection in IoT networks. In Proceedings of the 2019 IEEE global communications conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. CorrAUC: A malicious bot-IoT traffic detection method in IoT network using machine-learning techniques. IEEE Internet Things J. 2020, 8, 3242–3254. [Google Scholar] [CrossRef]
- Zeeshan, M.; Riaz, Q.; Bilal, M.A.; Shahzad, M.K.; Jabeen, H.; Haider, S.A.; Rahim, A. Protocol-Based Deep Intrusion Detection for DoS and DDoS Attacks Using UNSW-NB15 and Bot-IoT Data-Sets. IEEE Access 2021, 10, 2269–2283. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A novel framework for mobile-edge computing by optimizing task offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Magaia, N.; Fonseca, R.; Muhammad, K.; Segundo, A.H.F.N.; Neto, A.V.L.; de Albuquerque, V.H.C. Industrial internet-of-things security enhanced with deep learning approaches for smart cities. IEEE Internet Things J. 2020, 8, 6393–6405. [Google Scholar] [CrossRef]
- Karim, R.; Rizvi, M.; Islam, A.; Arefin, M.S. A Survey on Anomaly Detection Strategies. In Proceedings of the International Conference on Image Processing and Capsule Networks, Bangkok, Thailand, 27–28 May 2021; pp. 289–297. [Google Scholar]
- Popoola, S.I.; Adebisi, B.; Ande, R.; Hammoudeh, M.; Anoh, K.; Atayero, A.A. smote-drnn: A deep learning algorithm for botnet detection in the internet-of-things networks. Sensors 2021, 21, 2985. [Google Scholar] [CrossRef]
- Tsogbaatar, E.; Bhuyan, M.H.; Taenaka, Y.; Fall, D.; Gonchigsumlaa, K.; Elmroth, E.; Kadobayashi, Y. DeL-IoT: A deep ensemble learning approach to uncover anomalies in IoT. Internet Things 2021, 14, 100391. [Google Scholar] [CrossRef]
- Aversano, L.; Bernardi, M.L.; Cimitile, M.; Pecori, R. A systematic review on Deep Learning approaches for IoT security. Comput. Sci. Rev. 2021, 40, 100389. [Google Scholar] [CrossRef]
- Tahaei, H.; Afifi, F.; Asemi, A.; Zaki, F.; Anuar, N.B. The rise of traffic classification in IoT networks: A survey. J. Netw. Comput. Appl. 2020, 154, 102538. [Google Scholar] [CrossRef]
- Amma, N.G.B.; Subramanian, S. Feature correlation map based statistical approach for denial of service attacks detection. In Proceedings of the 2019 5th International Conference on Computing Engineering and Design (ICCED), Singapore, 11–13 April 2019; pp. 1–6. [Google Scholar]
- Nimbalkar, P.; Kshirsagar, D. Feature selection for intrusion detection system in Internet-of-Things (IoT). ICT Express 2021, 7, 177–181. [Google Scholar] [CrossRef]
- Kamalov, F.; Moussa, S.; Zgheib, R.; Mashaal, O. Feature selection for intrusion detection systems. In Proceedings of the 2020 13th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2020; pp. 265–269. [Google Scholar]
- Maza, S.; Touahria, M. Feature selection for intrusion detection using new multi-objective estimation of distribution algorithms. Appl. Intell. 2019, 49, 4237–4257. [Google Scholar] [CrossRef]
- Aghdam, M.H.; Kabiri, P. Feature selection for intrusion detection system using ant colony optimization. Int. J. Netw. Secur. 2016, 18, 420–432. [Google Scholar]
- Kunhare, N.; Tiwari, R.; Dhar, J. Particle swarm optimization and feature selection for intrusion detection system. Sādhanā 2020, 45, 1–14. [Google Scholar] [CrossRef]
- Moukhafi, M.; El Yassini, K.; Bri, S. A novel hybrid GA and SVM with PSO feature selection for intrusion detection system. Int. J. Adv. Sci. Res. Eng 2018, 4, 129–134. [Google Scholar] [CrossRef]
- Maldonado, J.; Riff, M.C.; Neveu, B. A review of recent approaches on wrapper feature selection for intrusion detection. Expert Syst. Appl. 2022, 198, 116822. [Google Scholar] [CrossRef]
- Dahou, A.; Abd Elaziz, M.; Chelloug, S.A.; Awadallah, M.A.; Al-Betar, M.A.; Al-qaness, M.A.; Forestiero, A. Intrusion Detection System for IoT Based on Deep Learning and Modified Reptile Search Algorithm. Comput. Intell. Neurosci. 2022, 2022, 6473507. [Google Scholar] [CrossRef]
- Amma, N.B.; Selvakumar, S.; Velusamy, R.L. SAGRU: A Stacked Autoencoder-Based Gated Recurrent Unit Approach to Intrusion Detection. In Proceedings of the FICTA (2), Karnataka, India, 4–5 January 2020; pp. 41–50. [Google Scholar]
- Krupski, J.; Graniszewski, W.; Iwanowski, M. Data Transformation Schemes for CNN-Based Network Traffic Analysis: A Survey. Electronics 2021, 10, 2042. [Google Scholar] [CrossRef]
- Iglesias, F.; Zseby, T. Analysis of network traffic features for anomaly detection. Mach. Learn. 2015, 101, 59–84. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Inf. Secur. J. Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- CICIDS 2017. Available online: https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 25 July 2022).
- CSE-CIC-IDS 2018. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 25 July 2022).
- UNSW Bot-iot Dataset 2018. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 27 July 2022).
- Yao, H.; Gao, P.; Wang, J.; Zhang, P.; Jiang, C.; Han, Z. Capsule network assisted IoT traffic classification mechanism for smart cities. IEEE Internet Things J. 2019, 6, 7515–7525. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Features | Training Data | Test Data | ||
|---|---|---|---|---|---|
| Normal | Attack | Normal | Attack | ||
| NSL KDD | 42 | 13,449 | 9195 | 2152 | 3603 |
| UNSW NB | 48 | 20,520 | 4076 | 56,000 | 12,264 |
| CICIDS | 83 | 128,737 | 29,285 | 55,173 | 12,550 |
| CSE-CIC-IDS | 78 | 68,403 | 89,619 | 29,315 | 38,408 |
| UNSW Bot-IoT | 44 | 1018 | 303,6915 | 477 | 366,8045 |
| Dataset | Selected Features |
|---|---|
| NSL KDD | |
| UNSW NB | |
| CICIDS | , , , , |
| , , , , , , | |
| , | |
| CSE-CIC-IDS | , , , , |
| , , , , , , | |
| , , , , | |
| UNSW Bot-IoT | , , , , , , , , , , , , , |
| Dataset | Classifiers | TPR | FPR | Precision | Recall | F1-Score | Accuracy | ER |
|---|---|---|---|---|---|---|---|---|
| NSL KDD | CNN | 99.584 | 0.743 | 99.556 | 99.584 | 99.570 | 99.461 | 0.539 |
| CNNLSTM | 99.639 | 0.697 | 99.584 | 99.639 | 99.612 | 99.5135 | 0.4865 | |
| CN | 99.695 | 0.558 | 99.667 | 99.695 | 99.681 | 99.600 | 0.400 | |
| GACN | 99.722 | 0.418 | 99.750 | 99.722 | 99.736 | 99.670 | 0.330 | |
| PSOCN | 99.667 | 0.279 | 99.833 | 99.667 | 99.750 | 99.687 | 0.313 | |
| ACOCN | 99.750 | 0.372 | 99.778 | 99.750 | 99.764 | 99.705 | 0.295 | |
| Proposed LPCOCN | 99.833 | 0.186 | 99.889 | 99.833 | 99.861 | 99.826 | 0.174 | |
| UNSW NB | CNN | 98.785 | 0.605 | 97.278 | 98.785 | 98.026 | 99.285 | 0.715 |
| CNNLSTM | 98.720 | 0.561 | 97.472 | 98.720 | 98.092 | 99.310 | 0.690 | |
| CN | 98.867 | 0.493 | 97.774 | 98.867 | 98.317 | 99.392 | 0.608 | |
| GACN | 99.152 | 0.430 | 98.057 | 99.152 | 98.601 | 99.495 | 0.505 | |
| PSOCN | 99.095 | 0.355 | 98.389 | 99.095 | 98.741 | 99.546 | 0.454 | |
| ACOCN | 99.242 | 0.368 | 98.336 | 99.242 | 98.787 | 99.5620 | 0.438 | |
| Proposed LPCOCN | 99.454 | 0.307 | 98.609 | 99.454 | 99.030 | 99.650 | 0.350 | |
| CICIDS | CNN | 95.227 | 0.437 | 98.023 | 95.227 | 96.605 | 98.760 | 1.240 |
| CNNLSTM | 95.371 | 0.468 | 97.890 | 95.371 | 96.614 | 98.761 | 1.239 | |
| CN | 95.912 | 0.430 | 98.069 | 95.912 | 96.979 | 98.893 | 1.107 | |
| GACN | 96.080 | 0.401 | 98.200 | 96.080 | 97.128 | 98.947 | 1.053 | |
| PSOCN | 96.000 | 0.410 | 98.159 | 96.000 | 97.067 | 98.925 | 1.075 | |
| ACOCN | 96.167 | 0.395 | 98.226 | 96.167 | 97.186 | 98.968 | 1.032 | |
| Proposed LPCOCN | 96.685 | 0.448 | 98.005 | 96.685 | 97.341 | 99.021 | 0.979 | |
| CSE-CIC-IDS | CNN | 98.305 | 0.849 | 99.345 | 98.305 | 98.822 | 98.671 | 1.329 |
| CNNLSTM | 98.336 | 0.795 | 99.385 | 98.336 | 98.859 | 98.712 | 1.288 | |
| CN | 98.328 | 0.904 | 99.303 | 98.328 | 98.813 | 98.661 | 1.339 | |
| GACN | 98.435 | 0.781 | 99.398 | 98.435 | 98.914 | 98.774 | 1.226 | |
| PSOCN | 98.409 | 0.798 | 99.385 | 98.409 | 98.895 | 98.752 | 1.248 | |
| ACOCN | 98.459 | 0.703 | 99.458 | 98.459 | 98.956 | 98.822 | 1.178 | |
| Proposed LPCOCN | 98.519 | 0.628 | 99.516 | 98.519 | 99.015 | 98.888 | 1.112 | |
| UNSW Bot-IoT | CNN | 99.956 | 5.031 | 99.999 | 99.956 | 99.978 | 99.956 | 0.044 |
| CNNLSTM | 99.957 | 5.451 | 99.999 | 99.957 | 99.978 | 99.956 | 0.044 | |
| CN | 99.957 | 3.983 | 99.999 | 99.957 | 99.978 | 99.957 | 0.043 | |
| GACN | 99.959 | 2.725 | 100.0 | 99.959 | 99.979 | 99.959 | 0.041 | |
| PSOCN | 99.961 | 2.096 | 100.0 | 99.961 | 99.980 | 99.961 | 0.039 | |
| ACOCN | 99.965 | 2.306 | 100.0 | 99.965 | 99.982 | 99.965 | 0.035 | |
| Proposed LPCOCN | 99.972 | 1.258 | 100.0 | 99.972 | 99.986 | 99.972 | 0.028 |
| Model | Layer | Parameters |
|---|---|---|
| CN | Convolution | filters = 64, kernel = 3, stride = 1 |
| Convolution capsule | filters = 128, kernel = 2, stride = 1, | |
| capsule vector = 8, capsule = 16 | ||
| Fully connected | capsule vector = 8, capsule = 2 | |
| LSTM | hidden units = 32, bias = 1 | |
| CNN | Convolution | filters = 64, kernel = 3,4,5, stride = 1 |
| CNNLSTM | Convolution | filters = 64, kernel = 3,4,5, stride = 1 |
| LSTM | hidden units = 32, bias = 1 |
| Approach/Year | Accuracy (%) | Error Rate (%) |
|---|---|---|
| FNN [21]/2019 | 95.0 | 5.0 |
| SVM [9]/2019 | 88.3 | 11.7 |
| RNN [9]/2019 | 97.9 | 2.1 |
| LSTM [9]/2019 | 98.0 | 2.0 |
| DT [22]/2020 | 99.99 | 0.01 |
| NB [22]/2020 | 97.5 | 2.5 |
| RF [22]/2020 | 99.98 | 0.02 |
| SVM [22]/2020 | 97.8 | 2.2 |
| VCDL [3]/2020 | 99.76 | 0.24 |
| BiLSTM [11]/2020 | 98.91 | 1.09 |
| LSTM [23]/2021 | 96.3 | 3.7 |
| KNN [13]/2021 | 99.0 | 1.0 |
| SVM [13]/2021 | 79.0 | 21.0 |
| DT [13]/2021 | 96.0 | 4.0 |
| NB [13]/2021 | 94.0 | 6.0 |
| RF [13]/2021 | 95.0 | 5.0 |
| ANN [13]/2021 | 97.0 | 3.0 |
| LR [13]/2021 | 74.0 | 26.0 |
| SMOTE-DRNN [27]/2021 | 100.0 | 0.0 |
| LPCOCN | 99.97 | 0.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narayanavadivoo Gopinathan, B.A.; Sarveshwaran, V.; Ravi, V.; Chaganti, R. LPCOCN: A Layered Paddy Crop Optimization-Based Capsule Network Approach for Anomaly Detection at IoT Edge. Information 2022, 13, 587. https://doi.org/10.3390/info13120587
Narayanavadivoo Gopinathan BA, Sarveshwaran V, Ravi V, Chaganti R. LPCOCN: A Layered Paddy Crop Optimization-Based Capsule Network Approach for Anomaly Detection at IoT Edge. Information. 2022; 13(12):587. https://doi.org/10.3390/info13120587
Chicago/Turabian StyleNarayanavadivoo Gopinathan, Bhuvaneswari Amma, Velliangiri Sarveshwaran, Vinayakumar Ravi, and Rajasekhar Chaganti. 2022. "LPCOCN: A Layered Paddy Crop Optimization-Based Capsule Network Approach for Anomaly Detection at IoT Edge" Information 13, no. 12: 587. https://doi.org/10.3390/info13120587
APA StyleNarayanavadivoo Gopinathan, B. A., Sarveshwaran, V., Ravi, V., & Chaganti, R. (2022). LPCOCN: A Layered Paddy Crop Optimization-Based Capsule Network Approach for Anomaly Detection at IoT Edge. Information, 13(12), 587. https://doi.org/10.3390/info13120587