1. Introduction
BERT (Bidirectional Encoder Representations from Transformers) [
1] is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning left and right contexts. BERT is generally a two-stage model, and it first provides a general pretraining model with rich linguistic knowledge and then solves downstream tasks via a fine-tuning mode. It achieved state-of-the-art results on as many as 11 different NLP tasks and has been widely used ever since.
After continuous developments, many studies attempted to break the traditional two-stage process and use some other methods to enhance the ability of BERT. Among them, there are two mainstream approaches. One is a three-stage process approach in which an additional stage is added between the pretraining stage and fine-tuning stage, and an additional corpus is used for incremental training in the extra stage. The other is the transform model approach in which the model’s structure is transformed and additional training tasks are designed in the traditional pretraining process of BERT.
The well-known three-stage process approach was proposed by Li et al. [
2], who added a second stage of pretraining in the middle of the traditional BERT pretraining stage and the fine-tuning stage. The new stage is used to train causal task-related supervised tasks with respect to external causal knowledge. By utilizing three specific transfer tasks, including natural language inference, emotion classification, and action prediction, the prediction accuracy of the Story Cloze Test (SCT) is improved.
Transform models, such as the models proposed in references [
3,
4,
5], attempt to incorporate external knowledge into pretrained language models. These models focus on the integration of a knowledge graph and a language model. One study of this approach was conducted by Zhang et al. [
4] who integrated knowledge into BERT. In their research study, a unified vector space is formed by using a large-scale text corpus and knowledge graph to train an enhanced language representation model ERNIE. This model can simultaneously use lexical, syntactic, and knowledge information.
The above studies show that compared with the traditional two-stage design, the three-stage process and the transform model are able to enhance the effect of BERT in some specific tasks. Inspired by the above approaches, we propose a three-stage model,
enhanced language
representation with
event
chains (EREC), which is a combination of the above two approaches. We apply the model in commonsense causal reasoning tasks and story ending prediction task. The EREC model contains the following: (1) a pretrained BERT model [
1] in stage 1; (2) a denoising autoencoder (DAE) [
6] in stage 2—similarly to the model structure proposed by [
4], in which the event chains contained in a text corpus are extracted and aligned with the text. Then, it is unified with the graph network’s representation; this enables the model to have incremental pretraining capabilities. With this synchronous alignment of text and event chains, EREC achieves the effective fusion of linguistic representation and event association. Finally, there is a (3) fine-tuned component in stage 3: the model produced in stage 2 is fine-tuned for specific downstream tasks.
The second stage is the core of EREC, which includes modules for preprocessing the corpus, extracting event chains, aligning text, fusing graph network representations, and incremental training. Since the core of the model proposed in this paper includes event chains, which are extracted from the corpus containing causal or event relations, the model is then evaluated in two specific downstream tasks: choice of plausible alternatives (COPA) [
7] and story cloze test (SCT) [
8]. The experimental results show that EREC significantly outperforms the state-of-the-art BERT model on the task by taking full advantage of the events’ relations.
In summary, this paper contributes to the following areas:
This research proposes an enhanced language representation model, named EREC, which incorporates the semantics of the text and the causal event relationships contained in it, and such relationships are extracted and used as event chains to enhance the ability of the model to understand the text’s information.
A three-stage process model is used, and an incremental training process is conducted in the second stage to integrate the above extracted event chains and to achieve better results in the two downstream tasks.
In the process of merging the event chains into the embeddings, multiple experiments are compared. These experiments are conducted in the form of network + algorithm combinations in which three graph networks and two different algorithms (Deepwalk and Line) are compared. By using comparisions, a particular setting was found to be more effective for two downstream tasks.
2. Related Work
Many efforts are devoted to improving the semantic understanding and representation capabilities of pretrained language models so as to accurately capture linguistic information from the text and to utilize it for specific NLP tasks. From the perspective deciding whether to change the model’s structure, this type of enhancement method can be divided into two classes, i.e., knowledge fusion and incremental training.
A typical work of knowledge fusion is the ERNIE model proposed by Zhang et al. [
4], which integrates the knowledge graph into BERT. In the
fine-tune stage, the knowledge graph is extracted by the
TagMe tool before entity linking, and ERNIE only verifies
entity typing and
relation classification and does not extend to other NLP tasks. In addition, there has also been a great deal of research in knowledge augmentation, such as [
9,
10,
11,
12,
13], both of which have made improvements to models for downstream tasks and achieved effective enhancements.
For incremental training, Gururangan et al. [
14] proposed useing domain-related corpora, task-related corpora, or a combination of them to continue incremental pretraining on the basis of BERT, and the obtained model achieved significant improvements in a variety of NLP tasks. Furthermore, Gu et al. [
15] combined the domain-related corpus with the task-related corpus and adopted incremental training to enhance the capability of the model. It is worth noting that Gu et al. designed an algorithm to mark task-related keywords in the corpus, such as
like and
hate, which play important roles in sentiment classification tasks, while Clark et al. [
16] extracted the keywords in the text and presented them in the form of event chains.
In this paper, we combine the above two methods to integrate external knowledge into the language model during the process of incremental training. Nouns and verbs are usually used to understand semantic relationships [
17,
18], so they are also chosen as external knowledge; for example, event/casual relations implied in the nouns and verbs of a text corpora and those explicitly expressed in a network can be used to enhance the reasoning ability of the model. Among the causal-relation-mining studies, Luo et al. [
19] showed that a complete pair of causal statements usually contains a pair of words with causal relations. For example, in the two statements,
I knocked on my neighbor’s door and my neighbor invited me in,
knocked and
invited have a causal relationship. Luo et al. also extracted a large number of causality pairs similar to
knock and
invite from a large data set and constructed a rich causality network called causalNet. Li et al. [
20] conducted a further study on the basis of causalNet and provided a corpus with causal characteristics (CausalBank) and a large lexical causal knowledge graph (cause effect graph). Li et al. designed intermediate tasks to incrementally train BERT using the CausalBank corpus and achieved good results in the COPA task.
In addition to the above studies, the graph’s embedding may have an impact on the results of tasks. Among the generation algorithms for graph embedding,
deepwalk [
21] is more common, which is derived from word2vec [
22] and its core comprises random walk. However,
deepwalk only works on undirected graphs and not directed graphs, and it does not take into account the weight between nodes. Tang et al. [
23] propose a large-scale network coding model,
Line, in which the calculation of second-order similarities is used on directed or undirected graphs, and the weight between nodes is taken into account. In this paper, we use these two algorithms to conduct comparative experiments.
3. Approach and Model Structure
In this section, we present EREC’s model structure in
Section 3.1 and the details of integrating the event chains in the corpus and network embedding into the model, which includes events’ extraction in
Section 3.2, network embedding in
Section 3.3, and tokens and events Alignment in
Section 3.4.
3.1. Model Structure
As shown in
Figure 1, we adopt a three-stage experimental model, EREC, in this paper, including a pretrained BERT model [
1] in stage 1, incremental training in stage 2, and specific fine-tuning tasks, COPA and SCT, in stage 3. The core of EREC is the external knowledge fusion and incremental training in the second stage. In this stage, the underlying semantics of the input tokens are derived primarily from the textual encoder (T-Encoder) of the model, which is an encoder similar to BERT and sums the token embedding, segment embedding, and positional embedding for each token to compute its input embedding. Another encoder, a knowledgeable encoder named K-Encoder, is contained in stage 2, which is similar to ERNIE and takes the event and event embedding as inputs, where the details of event embedding are described in
Section 3.3. Then, multi-tasks, including next sentence prediction (NSP), masked language model (MLM), and denoising autoencoder (DAE), are trained to integrate their knowledge with the semantics derived from T-Encoder, where the details of multi-task training will be described in
Section 4.2.
The generalization ability of the model is improved by introducing noise. This is based on the fact that partially corrupted data have the same expressive power. Therefore, a good representation can capture the stable characteristic structure of its observed input distribution. For high-dimensional redundant inputs (such as text), similar stable structures can be collected through the combination of multiple dimensions, so the sentence can be repaired from partial corruption. For example, “a thief entered the store and stole the necklace”, after masking the word “steal”, we may still “guess” the word or some word that has similar meaning. For example, in this paper, DAE encodes masked event sequence, then need the decoder to reconstruct the origin event sequence from the sequence embedding. This property is similar to the ability of humans to recognize partially occluded or damaged sentences, which means that humans can abstract higher-level concepts from various association of things, and even if some forms disappear, they can still make identifications from them.
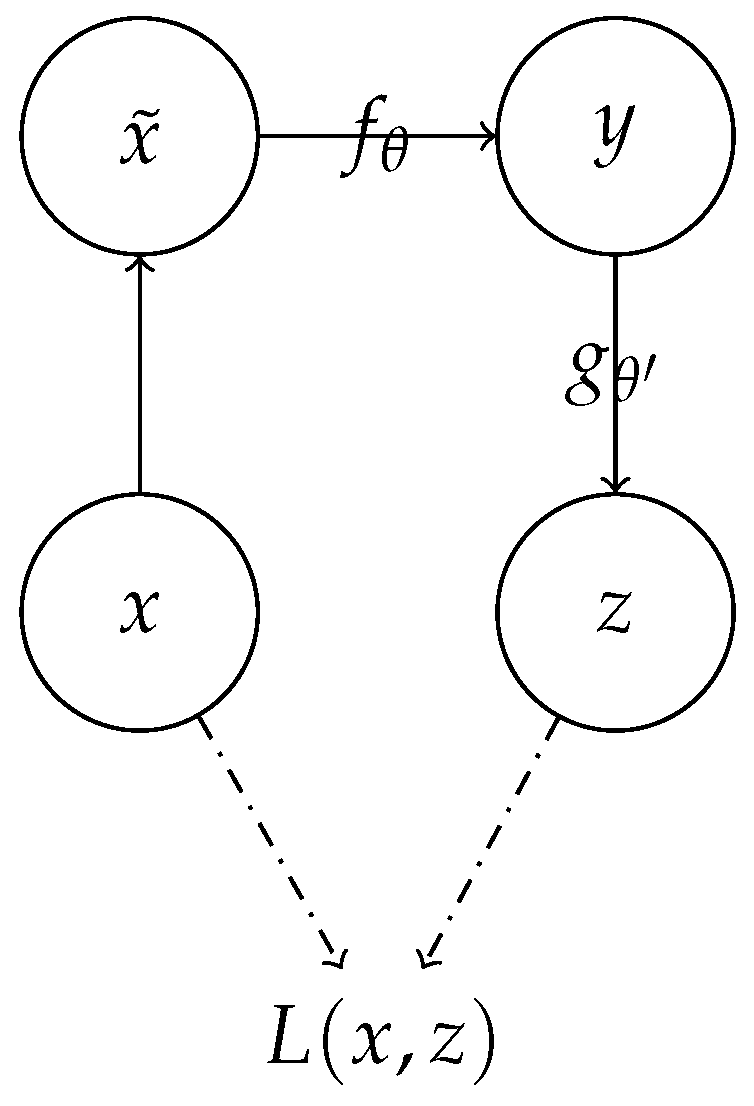
Thus, we add a noise-processing mechanism at K-Encoder, similarly to the denoising autoencoder (DAE) [
6]. As shown in
Figure 2, the specific step is to obtain
by random masking with respect to input
x.
refers to the mean of a stochastic mapping, where
D = {x,
x,
x…
x} is the input sequence. In the experiment, the following masking form is used. For each input x, given a random mask proportion
v, the masked values are completely removed, and the rest remained unchanged. Masked input
is mapped to
y by the autoencoder,
, and further reconstructs
. We use the
traditional squared error (TSE) loss during training by building a reconstruction error function
LThat is, the reconstructed z should be as close as possible to the original sample input x.
Similar to denoising autoencoder (DAE), after the random mask, the token’s sequence {t, t, t, t…t}, where t represents the i-th token in the sequence, is mapped to event sequence {e, e, e, e…e}, where e represents the j-th event in the sequence. In order to obtain the masked input, the following strategies are used for the original input tokens:
- (1)
The probability of 80% remains unchanged;
- (2)
A probability of 10% is used to mask the event aligned with the token, and it is set to , which aims to make the model to predict the masked events;
- (3)
A probability of 10% is used to replace the event aligned with the token with other events. For example, the event’s id is replaced, corresponding to knock in the original corpus with the event id corresponding to strike, which is intended for training the model in order to correct errors.
3.4. Tokens and Events Alignment
A key part of the integration between the language model and event chains is to align tokens and events, which is the basis of incremental training in this paper. Therefore, it is necessary to mark the events in the original text corpus. To perform this, the location of events (marked in the text corpus) is used, and the events (verbs) are wrapped with the ‘sepsepsep’ separator. After transformations, for example, the previous sentence, ‘I knocked on my neighbor’s door’, becomes the following form.
| I sepsepsep knocked sepsepsep on my neighbor’s door. |
The event extraction process (mentioned in
Section 3.2) uses OpenNLP to perform preliminary sentence and word segmentation operations on the text. In order to meet the input format of the BERT model, it is necessary to perform more refined word segmentation on the text.
For example, the model used in this paper is bert-base-uncased, its vocabulary size is 30,522, and the letters are all in lowercase form. We use BERT FullTokenizer to divide all the corpus into tokens contained in this vocabulary.Then, there will be one problem: after using BERT for word segmentation, each sentence is divided into a sequence of tokens, that is, TS = {t, t, t, t…t}. The events corresponding to tokens in the sequence TS form another sequence: ES = {e, e, e, e…e}. In order to align the events to the corresponding tokens. We define an alignment function as f({t, t, t, t…t}) = {e, e, e, e…e} to perform this step. Thus, tokens and events are semantically aligned. Please note that the number of events is different from the number of tokens. This is because we only use verbs as indicators of events in this paper; moreover, a verb will form multiple morphemes after word segmentation via the BERT FullTokenizer. For example, resuscitate (regarded as an event) is aligned with res, ##us, ##cit, ##ate.
The first idea will be adopted in subsequent experiments in this paper. After word segmentation, the text can be converted into the id sequence in the BERT vocabulary. For example, the id of
knocked in the BERT vocabulary is 6573. It is worth noting that a large number of
sepsepsep separators have been inserted into the text to mark events. As the maximum id of the vocabulary of BERT is 30,521; thus, we set the id of ‘sepsepsep’ as 30,522. Actually, it can be skipped and remain unused in the model. Before subsequent processing, we record the correspondence from the event between the two delimiters to the event in the
events dictionary generated in
Section 3.3, such as
knocked → knock → 2404, and we align other non-event tokens to #UNK#. After the above process, as shown in
Figure 3, two sequences (token sequence and event sequence) are generated from each sentence in the text, which is ready for subsequent processing.
MASK in
Figure 3 means to mask or replace the original event with other events. For details, please refer to
Section 4.
Author Contributions
Conceptualization, H.W. and Y.W.; methodology, H.W.; software, H.W.; validation, H.W.; formal analysis, H.W.; investigation, H.W.; resources, H.W. and Y.W.; data curation, H.W.; writing—original draft preparation, H.W.; writing—review and editing, H.W. and Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (under Project No. 61375053).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The
CausalBank data presented in this study are available in [
20].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, Z.; Ding, X.; Liu, T. Story ending prediction by transferable bert. arXiv 2019, arXiv:1905.07504. [Google Scholar]
- Peters, M.E.; Neumann, M.; Logan IV, R.L.; Schwartz, R.; Joshi, V.; Singh, S.; Smith, N.A. Knowledge enhanced contextual word representations. arXiv 2019, arXiv:1909.04164. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2901–2908. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Roemmele, M.; Bejan, C.A.; Gordon, A.S. Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. In Proceedings of the AAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning, Stanford, CA, USA, 21–23 March 2011; pp. 90–95. [Google Scholar]
- Mostafazadeh, N.; Chambers, N.; He, X.; Parikh, D.; Batra, D.; Vanderwende, L.; Kohli, P.; Allen, J. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 839–849. [Google Scholar]
- Li, J.; Katsis, Y.; Baldwin, T.; Kim, H.C.; Bartko, A.; McAuley, J.; Hsu, C.N. SPOT: Knowledge-Enhanced Language Representations for Information Extraction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–22 October 2022; pp. 1124–1134. [Google Scholar]
- Zhang, K.; Lv, G.; Wu, L.; Chen, E.; Liu, Q.; Wu, H.; Xie, X.; Wu, F. Multilevel image-enhanced sentence representation net for natural language inference. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 3781–3795. [Google Scholar] [CrossRef]
- Xiao, S.; Fang, Y.; Ni, L. Multi-modal Sign Language Recognition with Enhanced Spatiotemporal Representation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Virtual, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Selamat, A.; Akosu, N. Word-length algorithm for language identification of under-resourced languages. J. King Saud-Univ. Comput. Inf. Sci. 2016, 28, 457–469. [Google Scholar] [CrossRef]
- Hajmohammadi, M.S.; Ibrahim, R.; Selamat, A. Cross-lingual sentiment classification using multiple source languages in multi-view semi-supervised learning. Eng. Appl. Artif. Intell. 2014, 36, 195–203. [Google Scholar] [CrossRef]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Gu, Y.; Zhang, Z.; Wang, X.; Liu, Z.; Sun, M. Train no evil: Selective masking for task-guided pre-training. arXiv 2020, arXiv:2004.09733. [Google Scholar]
- Granroth-Wilding, M.; Clark, S. What happens next? event prediction using a compositional neural network model. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Li, X.; Zhang, B.; Zhang, Z.; Stefanidis, K. A sentiment-statistical approach for identifying problematic mobile app updates based on user reviews. Information 2020, 11, 152. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Z.; Stefanidis, K. Mobile app evolution analysis based on user reviews. In New Trends in Intelligent Software Methodologies, Tools and Techniques; IOS Press: Amsterdam, The Netherlands, 2018; pp. 773–786. [Google Scholar]
- Luo, Z.; Sha, Y.; Zhu, K.Q.; Hwang, S.W.; Wang, Z. Commonsense causal reasoning between short texts. In Proceedings of the Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning, Cape Town, South Africa, 25–29 April 2016. [Google Scholar]
- Li, Z.; Ding, X.; Liu, T.; Hu, J.E.; Van Durme, B. Guided generation of cause and effect. arXiv 2021, arXiv:2107.09846. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Chambers, N.; Jurafsky, D. Unsupervised learning of narrative event chains. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 16–18 June 2008; pp. 789–797. [Google Scholar]
- Ding, X.; Zhang, Y.; Liu, T.; Duan, J. Using structured events to predict stock price movement: An empirical investigation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1415–1425. [Google Scholar]
- Li, Z.; Chen, T.; Van Durme, B. Learning to rank for plausible plausibility. arXiv 2019, arXiv:1906.02079. [Google Scholar]
- Li, Z.; Ding, X.; Liu, T. Constructing narrative event evolutionary graph for script event prediction. arXiv 2018, arXiv:1805.05081. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2018, arXiv:1711.05101. [Google Scholar]
- Zhang, T.; Wu, F.; Katiyar, A.; Weinberger, K.Q.; Artzi, Y. Revisiting few-sample BERT fine-tuning. arXiv 2020, arXiv:2006.05987. [Google Scholar]
- Sharma, R.; Allen, J.; Bakhshandeh, O.; Mostafazadeh, N. Tackling the story ending biases in the story cloze test. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 752–757. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}