
No-Show in Medical Appointments with Machine Learning Techniques: A Systematic Literature Review

 ,
,  ,
,  and
and 
Abstract
1. Introduction
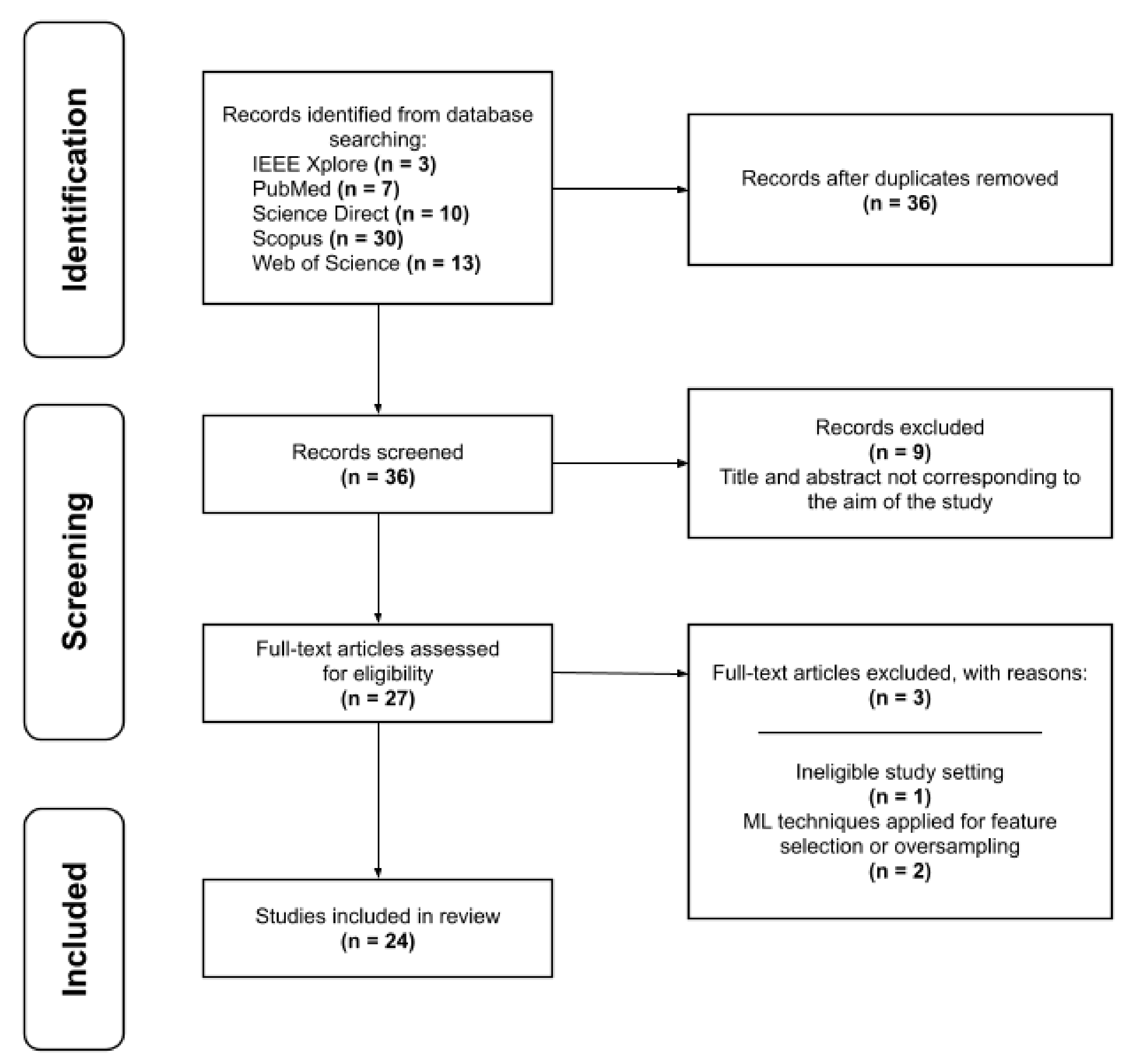
2. Materials and Methods
- Year of publication.
- Dataset attributes.
- (a)
- Number of patients
- (b)
- Number of medical appointments
- (c)
- Data collection period (year)
- (d)
- Country
- No-show rate: percentage of absenteeism across the entire dataset.
- Medical specialty: area of medicine in which the study was applied.
- Algorithms used.
- Selected attributes: most important predictors that influence the behavior of the model.
- Model performance: evaluation metrics applied.
3. Results
- Q1.
- How much data is used to train machine learning models for no-show prediction?In total, 18 different data sets were used in the 24 studies found. Two studies [3,6] did not report the volume of data used. Only five studies used an amount of data greater than one million records, while the others used around 120 thousand records, on average. Seven works developed their solutions with the same dataset. Despite this, the works presented different approaches in the exploratory analysis of the data and in the algorithms used.Regarding the dimensionality of the datasets, on average, 17 attributes were used to build the model in each work. The number of attributes for each work was counted based on the amount used to train the model, and not necessarily with the original attributes of the dataset. In this way, in most cases, not only the attributes of the original dataset were used, but new attributes were added through feature selection, for example.The origin of the data was concentrated in nine different countries. Only the work by Qureshi et al. [10] did not describe the origin of the data used. Followed by the United States, Brazil was the country of origin of eight studies, seven of which used the same dataset. Regarding the data domain, that is, which context or specialty the data refer to, the vast majority concerns the primary care of patients or centers with care of multiple specialties.With regard to the no-show rate present in the initial dataset, the highest rate observed was 85% [11]. Although this percentage represents a discrepant value compared to other works, the average absenteeism rate remained around 18% and the lowest rate was 10%. Of the 24, six works did not clearly describe the percentage of no-shows of the explored datasets. Table 5 summarizes the results in relation to the volume of data, in descending order with reference to the volume of data explored.
- Q2.
- Which machine learning algorithms are used in the predictive models and which presented the best performance?Table 6 summarizes the data found regarding the algorithms used in each work. They are presented in ascending chronological order and, for each work, the symbol “x” was inserted in the algorithms used and the symbol “o” for the algorithms used, and that obtained the best performance during the tests. The last row (“Total”) shows the number of times the algorithm was used and obtained the best performance.In general, the works used more than one machine learning algorithm to build the model, except for work [3]. Because the present work focuses on predictive models, most of the algorithms used in the works found were for classification, such as decision trees and logistic regression. However, regression algorithms such as linear regression and support vector regression (SVR) were also used in studies in which the objective was also to predict the number of patients who would not attend consultations in a given time window [3,25].
- Q3.
- What characteristics most influence patients not to attend a scheduled medical appointment?The attributes of the datasets explored in the works represent the characteristics related to the patients demographics, the appointment, and the patients’ behavior during the appointment. Most of the works found created new attributes based on the existing ones or added new datasets, in order to have more characteristics of the problem represented through the data. The lead time attribute was created in all works, where the appointment and appointment date information was available. This attribute represents the distance from the day of appointment scheduling to the appointment day and has a considerable impact on the models.Except for three works [11,20,25], all others consider that the most influential factors in the built model are related to the patient’s age, whether the patient missed a previous appointment (previous no-show), and the distance between the appointment and the patient’s scheduling (lead time). Other attributes, such as the geographical distance from the patient’s home to the clinic location, appointment date and shift, medical specialty, and whether there was prior confirmation of the appointment, had a low impact on the algorithms. Table 8 presents a summary of this information.
- Q4.
- What is the no-show rate reduction in medical appointments that solutions developed with the help of machine learning techniques achieve?Only the work by Chong et. al [8] described the experiment performed in which there was a reduction in the number of no-show appointments in practice. During the six months of the experiment, there was a reduction from 19.3% to 15.9% in abstentions, by sending a reminder to 25% of the patients who were pointed out by the model as at greater risk of not attending the appointment. The other works did not present metrics that demonstrate the reduction of no-shows in medical appointments, after the machine learning model development.Four works [10,18,20,26] only presented the exploratory analysis of the data and the steps for the model building. However, they did not implement or discuss software and/or process management solutions that could be developed based on the study.Prior communication with patients through electronic reminders, such as SMS or phone calls, was presented as a solution in most studies, as in [5,6,7]. In order to avoid the high cost of sending reminder notifications to every patient, some studies have proposed to optimize the sending and make them only for patients who are at high risk of no-show [2,7,16].The study by Srinivas and Salah [24] proposes, as an alternative to reduce absenteeism in medical appointments, the subsidy for the patient’s transport to the health center, regarding the economic profile of the patients. Other studies [2,3,4] propose the use of overbooking techniques as a way of mitigating the patients’ non-attendance.The optimization of appointment planning through the integration of the predictive model developed in the scheduling system [3,5,16,21], the collection of basic information for new patients through an online form [24], and the remodeling of workflow and scheduling policies [21] are alternatives mentioned in the studies as a way of reducing absenteeism.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mesa, M.J.; Asencio, J.M.; Ruiz, F.R.; González, M.P. Análisis del coste económico del absentismo de pacientes en consultas externas. Rev. De Calid. Asist. 2017, 32, 194–199. [Google Scholar] [CrossRef] [PubMed]
- Batool, T.; Abuelnoor, M.; El Boutari, O.; Aloul, F.; Sagahyroon, A. Predicting hospital no-shows using machine learning. In Proceedings of the 2020 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 27–28 January 2021; pp. 142–148. [Google Scholar] [CrossRef]
- Ahmad, M.U.; Zhang, A.; Mhaskar, R. A predictive model for decreasing clinical no-show rates in a primary care setting. Int. J. Healthc. Manag. 2021, 14, 829–836. [Google Scholar] [CrossRef]
- Nasir, M.; Summerfield, N.; Dag, A.; Oztekin, A. A service analytic approach to studying patient no-shows. Serv. Bus. 2020, 14, 287–313. [Google Scholar] [CrossRef]
- Abu Lekham, L.; Wang, Y.; Hey, E.; Lam, S.S.; Khasawneh, M.T. A multi-stage predictive model for missed appointments at outpatient primary care settings serving rural areas. IISE Trans. Healthc. Syst. Eng. 2021, 11, 79–94. [Google Scholar] [CrossRef]
- Incze, E.; Holborn, P.; Higgs, G.; Ware, A. Using machine learning tools to investigate factors associated with trends in ‘no-shows’ in outpatient appointments. Health Place 2021, 67, 102496. [Google Scholar] [CrossRef]
- Fan, G.; Deng, Z.; Ye, Q.; Wang, B. Machine learning-based prediction models for patients no-show in online outpatient appointments. Data Sci. Manag. 2021, 2, 45–52. [Google Scholar] [CrossRef]
- Chong, L.R.; Tsai, K.T.; Lee, L.L.; Foo, S.G.; Chang, P.C. Artificial intelligence predictive analytics in the management of outpatient MRI appointment no-shows. Am. J. Roentgenol. 2020, 215, 1155–1162. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; The PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef]
- Qureshi, Z.; Maqbool, A.; Mirza, A.; Iqbal, M.Z.; Afzal, F.; Kanubala, D.D.; Rana, T.; Umair, M.Y.; Wakeel, A.; Shah, S.K. Efficient Prediction of Missed Clinical Appointment Using Machine Learning. Comput. Math. Methods Med. 2021, 2021, 2376391. [Google Scholar] [CrossRef]
- Alshammari, R.; Daghistani, T.; Alshammari, A. The Prediction of Outpatient No-Show Visits by using Deep Neural Network from Large Data. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 533–539. [Google Scholar] [CrossRef]
- Elvira, C.; Ochoa, A.; Gonzalvez, J.C.; Mochón, F. Machine-learning-based no show prediction in outpatient visits. Int. J. Interact. Multimed. Artif. Intell. 2018, 4, 29–34. [Google Scholar] [CrossRef]
- Daghistani, T.; AlGhamdi, H.; Alshammari, R.; AlHazme, R.H. Predictors of outpatients’ no-show: Big data analytics using Apache Spark. J. Big Data 2020, 7, 108. [Google Scholar] [CrossRef]
- AlMuhaideb, S.; Alswailem, O.; Alsubaie, N.; Ferwana, I.; Alnajem, A. Prediction of hospital no-show appointments through artificial intelligence algorithms. Ann. Saudi Med. 2019, 39, 373–381. [Google Scholar] [CrossRef]
- Ahmadi, E.; Garcia-Arce, A.; Masel, D.T.; Reich, E.; Puckey, J.; Maff, R. A metaheuristic-based stacking model for predicting the risk of patient no-show and late cancellation for neurology appointments. IISE Trans. Healthc. Syst. Eng. 2019, 9, 272–291. [Google Scholar] [CrossRef]
- Alshammari, A.; Almalki, R.; Alshammari, R. Developing a Predictive Model of Predicting Appointment No-Show by Using Machine Learning Algorithms. J. Adv. Inf. Technol. 2021, 12, 234–239. [Google Scholar] [CrossRef]
- Almeida, R.; Silva, N.A.; Vasconcelos, A. A Machine Learning Approach for Real Time Prediction of Last Minute Medical Appointments No-shows. In Proceedings of the HEALTHINF, Vienna, Austria, 11–13 February 2021; pp. 328–336. [Google Scholar] [CrossRef]
- Salazar, L.H.; Fernandes, A.M.; Dazzi, R.; Raduenz, J.; Garcia, N.M.; Leithardt, V.R. Prediction of attendance at medical appointments based on machine learning. In Proceedings of the 2020 15th Iberian Conference on Information Systems and Technologies (CISTI), Seville, Spain, 24–27 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ferreira, I.; Vasconcelos, A. MedClick: Last Minute Medical Appointments No-Show Management. In Proceedings of the HEALTHINF, Prague, Czech Republic, 22–24 February 2019; pp. 206–215. [Google Scholar] [CrossRef]
- Alshaya, S.; McCarren, A.; Al-Rasheed, A. Predicting no-show medical appointments using machine learning. In Proceedings of the International Conference on Computing, Riyadh, Saudi Arabia, 10–12 December 2019; Springer: Cham, Switzerland, 2019; pp. 211–223. [Google Scholar] [CrossRef]
- Moharram, A.; Altamimi, S.; Alshammari, R. Data Analytics and Predictive Modeling for Appointments No-show at a Tertiary Care Hospital. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 275–277. [Google Scholar] [CrossRef]
- Srinivas, S.; Ravindran, A.R. Optimizing outpatient appointment system using machine learning algorithms and scheduling rules: A prescriptive analytics framework. Expert Syst. Appl. 2018, 102, 245–261. [Google Scholar] [CrossRef]
- Ferro, D.B.; Brailsford, S.; Bravo, C.; Smith, H. Improving healthcare access management by predicting patient no-show behaviour. Decis. Support Syst. 2020, 138, 113398. [Google Scholar] [CrossRef]
- Srinivas, S.; Salah, H. Consultation length and no-show prediction for improving appointment scheduling efficiency at a cardiology clinic: A data analytics approach. Int. J. Med. Inform. 2021, 145, 104290. [Google Scholar] [CrossRef]
- Chen, J.; Goldstein, I.H.; Lin, W.C.; Chiang, M.F.; Hribar, M.R. Application of Machine Learning to Predict Patient No-Shows in an Academic Pediatric Ophthalmology Clinic. AMIA Annu. Symp. Proc. 2020, 2020, 293. [Google Scholar]
- Salazar, L.H.A.; Leithardt, V.R.; Parreira, W.D.; da Rocha Fernandes, A.M.; Barbosa, J.L.V.; Correia, S.D. Application of machine learning techniques to predict a patient’s no-show in the healthcare sector. Future Internet 2021, 14, 3. [Google Scholar] [CrossRef]
- Sestrem Ochôa, I.; Silva, L.A.; de Mello, G.; Alves da Silva, B.; de Paz, J.F.; Villarrubia González, G.; Garcia, N.M.; Reis Quietinho Leithardt, V. PRICHAIN: A Partially Decentralized Implementation of UbiPri Middleware Using Blockchain. Sensors 2019, 19, 4483. [Google Scholar] [CrossRef]
- Lopes, H.; Pires, I.M.; Sánchez San Blas, H.; García-Ovejero, R.; Leithardt, V. PriADA: Management and Adaptation of Information Based on Data Privacy in Public Environments. Computers 2020, 9, 77. [Google Scholar] [CrossRef]
- Verri Lucca, A.; Augusto Silva, L.; Luchtenberg, R.; Garcez, L.; Mao, X.; García Ovejero, R.; Miguel Pires, I.; Luis Victória Barbosa, J.; Reis Quietinho Leithardt, V. A Case Study on the Development of a Data Privacy Management Solution Based on Patient Information. Sensors 2020, 20, 6030. [Google Scholar] [CrossRef]
- Pereira, F.; Crocker, P.; Leithardt, V.R. PADRES: Tool for PrivAcy, Data REgulation and Security. SoftwareX 2022, 17, 100895. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| ID | Research Question |
|---|---|
| Q1 | How much data is used to train machine learning models for no-show prediction? |
| Q2 | Which machine learning algorithms are used in the predictive models and which of these presented the best performance? |
| Q3 | What characteristics most influence patients not to attend a scheduled medical appointment? |
| Q4 | What is the no-show rate reduction in medical appointments that solutions developed with the help of machine learning techniques achieve? |
| Database | Search Strings |
|---|---|
| Scopus | (TITLE-ABS-KEY(no-show) OR TITLE-ABS-KEY(absenteeism)) AND TITLE-ABS-KEY(“machine learning”) AND (TITLE-ABS-KEY(medical) OR TITLE-ABS-KEY(healthcare)) AND (TITLE-ABS-KEY(appointment) OR TITLE-ABS-KEY(consultation)) |
| IEEE Xplore | (((“All Metadata”:“no-show”) OR (“All Metadata”:absenteeism)) AND (“All Metadata”:“machine learning”) AND ((“All Metadata”:medical) OR (“All Metadata”:healthcare)) AND ((“All Metadata”:appointment) OR (“All Metadata”:consultation))) |
| Science Direct | (“no-show” OR “absenteeism”) AND (“machine learning”) AND (“medical” OR “healthcare”) AND (“appointment” OR “consultation”) |
| PubMed | ((no-show) OR (absenteeism)) AND (“machine learning”) AND ((medical) OR (healthcare)) AND ((appointment) OR (consultation)) |
| Web of Science | ((no-show) OR (absenteeism)) AND (“machine learning”) AND ((medical) OR (healthcare)) AND ((appointment) OR (consultation)) |
| Category | Inclusion and Exclusion Criteria |
|---|---|
| Inclusion Criteria | The article must: Contain an abstract; Be written in English; Have been published between 1 January 2017 and 1 January 2022 |
| Exclusion Criteria | The article has a focus on: Medical attendance prediction in other fields than health appointments; Medical attendance prediction without the use of machine learning techniques; Literature reviews |
| Database | Discovered | 1st Stage | 2nd Stage |
|---|---|---|---|
| IEEE Xplore | 3 | 3 | 3 |
| PubMed | 7 | 7 | 6 |
| Science Direct | 10 | 9 | 4 |
| Scopus | 30 | 15 | 10 |
| Web of Science | 13 | 2 | 1 |
| Total | 63 | 36 | 24 |
| Articles | Volume | No-Show Rate | No. of Features | Service | Country |
|---|---|---|---|---|---|
| [11] | 33,050,363 | 85% | 29 | Primary Care | Saudi Arabia |
| [10] | 6,000,000 | - | 17 | Multiple Specialty | - |
| [12] | 2,362,850 | 10% | 12 | Multiple Specialty | Spain |
| [13] | 2,011,813 | 26.71% | 20 | Multiple Specialty | Saudi Arabia |
| [14] | 1,087,979 | 11.3% | 11 | Multiple Specialty | Saudi Arabia |
| [7] | 454,217 | 11.10% | 15 | Multiple Specialty | China |
| [5] | 374,072 | 26% | 26 | Primary Care | United States |
| [15] | 194,458 | - | 30 | Neurology | United States |
| [2,4,16,17,18,19,20] | 110,528 | 20.19% | 14 | Primary Care | Brazil |
| [21] | 101,534 | 11.39% | - | Pediatrics | Saudi Arabia |
| [22] | 76,285 | 30% | 18 | Family Medicine | United States |
| [23] | 53,311 | 21–39% | 7 | Primary Care | Colombia |
| [8] | 32,957 | 17.40% | 21 | Radiology | Singapore |
| [24] | 25,523 | - | 16 | Cardiology | United States |
| [25] | 8,794 | 13.40% | 14 | Pediatrics | United States |
| [26] | 4,812 | - | 11 | Pediatrics | Brazil |
| [3] | - | - | 9 | Primary Care | United States |
| [6] | - | 8.60% | 20 | Multiple Specialty | Wales |
| AdaBoost | Artificial Neural Networks (ANN) | Bagging | Decision Tree (DT) | Deep Neural Networks (DNN) | Gradient Boosting (GB) | Gradient Boosting Machine (GBM) | General Linear Model (GLM) | Hoeffding Tree | JRip | K-Nearest Neighbors (KNN) | Linear Regression | LightGBM | Logistic Regression | Multilayer Perceptron (MLP) | Naive Bayes (NB) | Random Forest (RF) | Stochastic Gradient Descent (SGD) | Stacking | Support Vector Classifier (SVC) | Support Vector Machine (SVM) | Support Vector Regression (SVR) | XGBoost | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [24] | x | x | ○ | ||||||||||||||||||||
| [26] | x | x | ○ | ||||||||||||||||||||
| [10] | x | x | x | x | x | x | ○ | x | x | x | |||||||||||||
| [21] | ○ | ○ | ○ | ||||||||||||||||||||
| [5] | ○ | ○ | x | ○ | x | ○ | |||||||||||||||||
| [6] | ○ | x | |||||||||||||||||||||
| [7] | ○ | x | x | x | x | x | |||||||||||||||||
| [2] | ○ | x | x | x | |||||||||||||||||||
| [16] | x | ○ | |||||||||||||||||||||
| [17] | x | ○ | x | x | |||||||||||||||||||
| [3] | ○ | ||||||||||||||||||||||
| [18] | ○ | x | x | ||||||||||||||||||||
| [4] | x | x | ○ | x | |||||||||||||||||||
| [13] | ○ | x | x | x | x | ||||||||||||||||||
| [8] | x | x | x | ○ | |||||||||||||||||||
| [25] | x | x | ○ | ||||||||||||||||||||
| [23] | ○ | x | x | ||||||||||||||||||||
| [11] | x | ○ | x | ||||||||||||||||||||
| [19] | ○ | x | x | x | |||||||||||||||||||
| [20] | x | x | x | ○ | ○ | ||||||||||||||||||
| [14] | ○ | x | |||||||||||||||||||||
| [15] | x | x | ○ | ||||||||||||||||||||
| [22] | x | x | x | x | ○ | ||||||||||||||||||
| [12] | x | ○ | x | ||||||||||||||||||||
| Total | 1 | 1 | 2 | 3 | 1 | 4 | 1 | - | 2 | 1 | - | 1 | 1 | 1 | - | - | 5 | 2 | 1 | 1 | - | - | 2 |
| Articles | Algorithms | Performance |
|---|---|---|
| [24] | Stochastic Gradient Descent | 0.85 (AUC-ROC) |
| [26] | Random Forest | 0.969 (AUC-ROC) |
| [10] | Random Forest | 0.9209 (AUC) |
| [21] | Logistic regression, JRip and Hoeffding Tree | 0.86 (F-Score) |
| [5] | Random Forest, Ada Boost, Gradient Boosting and Bagging | 0.73 (F-Score) |
| [6] | LightGBM | 0.37 (F1-Score) |
| [7] | Bagging | 0.990 (AUC) |
| [2] | Decision Tree | 95% accuracy |
| [16] | Decision Tree | 0.88 (AUC-ROC) |
| [17] | Gradient Boosting | - |
| [3] | Linear Regression | 0.72 (AUC-ROC) |
| [18] | Decision Tree | 78–80% accuracy |
| [4] | Random Forest | 0.8678 (AUC-ROC) |
| [13] | Gradient Boosting | 0.81 (AUC-ROC) |
| [8] | XGBoost | 0.746 (AUC-ROC) |
| [25] | XGBoost | 0.90 (AUC-ROC) |
| [23] | Artifical Neural Network | 0.90 (AUROC) |
| [11] | Deep Neural Networks | 0.982 (precision), 0.943 (recall) |
| [19] | Gradient Boosting | 80.91% accuracy |
| [20] | Support Vector Classifier and Stochastic Gradient Descent | 0.68 (AUC-ROC) |
| [14] | Hoeffding Tree | 77.13% accuracy |
| [15] | Random Forest | 0.68 (AUC) |
| [22] | Stacking | 0.846 (AUC) |
| [12] | Gradient Boosting Machine | 0.7404 (AUC-ROC) |
| Patient Demographics | Appointment | Patient Behavior | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Articles | Age | Distance | Month | Shift | Confirmation | Type | Specialty | Previous No-Show (%) | Lead Time |
| [24] | X | X | |||||||
| [26] | X | X | |||||||
| [10] | X | X | X | ||||||
| [21] | X | X | X | X | |||||
| [5] | X | X | |||||||
| [6] | X | X | X | ||||||
| [7] | X | X | X | ||||||
| [2] | X | ||||||||
| [16] | X | X | X | ||||||
| [17] | X | X | |||||||
| [3] | X | X | X | ||||||
| [18] | X | X | |||||||
| [4] | X | X | X | ||||||
| [13] | X | X | |||||||
| [8] | X | X | |||||||
| [25] | |||||||||
| [23] | X | X | X | ||||||
| [11] | |||||||||
| [19] | X | X | |||||||
| [20] | |||||||||
| [14] | X | X | |||||||
| [15] | X | X | X | X | |||||
| [22] | X | X | X | ||||||
| [12] | X | X | X | ||||||
| Total | 11 | 5 | 4 | 2 | 4 | 4 | 4 | 6 | 14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salazar, L.H.A.; Parreira, W.D.; Fernandes, A.M.d.R.; Leithardt, V.R.Q. No-Show in Medical Appointments with Machine Learning Techniques: A Systematic Literature Review. Information 2022, 13, 507. https://doi.org/10.3390/info13110507
Salazar LHA, Parreira WD, Fernandes AMdR, Leithardt VRQ. No-Show in Medical Appointments with Machine Learning Techniques: A Systematic Literature Review. Information. 2022; 13(11):507. https://doi.org/10.3390/info13110507
Chicago/Turabian StyleSalazar, Luiz Henrique Américo, Wemerson Delcio Parreira, Anita Maria da Rocha Fernandes, and Valderi Reis Quietinho Leithardt. 2022. "No-Show in Medical Appointments with Machine Learning Techniques: A Systematic Literature Review" Information 13, no. 11: 507. https://doi.org/10.3390/info13110507
APA StyleSalazar, L. H. A., Parreira, W. D., Fernandes, A. M. d. R., & Leithardt, V. R. Q. (2022). No-Show in Medical Appointments with Machine Learning Techniques: A Systematic Literature Review. Information, 13(11), 507. https://doi.org/10.3390/info13110507