
A Literature Survey of Recent Advances in Chatbots




Abstract
:1. Introduction
2. Chatbots Background
3. Methodology
3.1. Stage One: Information Gathering
Search Terms and Databases Identification
3.2. Stage Two: Article Filtering and Reviewing
3.2.1. Filtering Articles
3.2.2. Reviewing Articles
- Chatbots’ History and Evolution: this aspect encompasses all papers that presented a detailed description of chatbots’ evolution over time. This category is fundamental since it helped us understand the trends and technologies that ascended or discarded over time, indicating the evolution of the chatbot. It also helped us discover how and why chatbots emerged and how their applications and purposes changed over time. Section 2 offers overview of our finding on chatbots history and evolution.
- Chatbots’ Implementation: this aspect includes papers that present examples of chatbots architectural design and implementation. This category allowed us to identify the commonly used algorithms for chatbots and the specific algorithms that are used for diverse types of chatbots based on the purpose of chatbot application. This also allowed to identify the industry standards in terms of chatbots’ models and algorithms, as well as their shortcomings and limitations. Detailed implementation approaches to chatbots are given in Section 4.1.
- Chatbots’ Evaluation: For this aspect, some articles focused on the evaluation methods and metrics used for measuring chatbots performance. It was important to identify these papers in order to understand the way chatbots are evaluated and the evaluation metrics and methods used. We outline the various evaluation metrics in Section 4.3.
- Chatbots’ Applications: this aspect encompasses all examples of chatbots applied to a specific domain, such as education, finance, customer support and psychology. Papers pertaining to this category helped us tie information from previous categories and get a better understanding of what models and what features are used for which applications in order to serve different purposes. We identify and offer overview on the application of chatbots in Section 4.4.
- Dataset: this category was used to classify chatbots depending on the dataset used to train machine learning algorithms for the development of language model. Section 4.2 highlights the main datasets that have been used in previous studies.
4. Literature Review Analysis
4.1. Implementation Approaches to Chatbots
4.1.1. Rule-Based Chatbots
4.1.2. Artificial Intelligence Chatbots
4.2. Datasets Used
4.3. Evaluation
4.4. Applications of Chatbots
- Machine Learning in general and Deep Learning in particular, require a large amount of training data; although training data is becoming increasingly available but finding a suitable dataset might still represent a challenge. Furthermore, data needs to be preprocessed in order to be used and might often contain unwanted noise.
- Training is costly in terms of infrastructure and human resources, and time consuming.
- Chatbots, when they are not used for social or companion chatbots, are usually applied to a specific domain, which means that they require domain-specific training data (e.g., products information and details, financial information, educational material, healthcare information). This type of data is often confidential due to its nature; they are not readily available in open access to train a Deep Learning engine. Furthermore, given the nature of the data needed and of the tasks the chatbot is required to carry out (e.g., access a customer’s purchase history, or give more information about a product feature), Information Retrieval might be the best solution for most use-case applications.
5. Related Works
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, J. The Study of the Application of a Keywords-based Chatbot System on the Teaching of Foreign Languages. arXiv 2003, arXiv:cs/0310018. [Google Scholar]
- Sojasingarayar, A. Seq2Seq AI Chatbot with Attention Mechanism. Master’s Thesis, Department of Artificial Intelligence, IA School/University-GEMA Group, Boulogne-Billancourt, France, 2020. [Google Scholar]
- Bala, K.; Kumar, M.; Hulawale, S.; Pandita, S. Chat-Bot For College Management System Using A.I. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 4. [Google Scholar]
- Ayanouz, S.; Abdelhakim, B.A.; Benhmed, M. A Smart Chatbot Architecture based NLP and Machine Learning for Health Care Assistance. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March–2 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kumar, R.; Ali, M.M. A Review on Chatbot Design and Implementation Techniques. Int. J. Eng. Technol. 2020, 7, 11. [Google Scholar] [CrossRef] [Green Version]
- Cahn, J. CHATBOT: Architecture, Design, & Development. Ph.D. Thesis, University of Pennsylvania, School of Engineering and Applied Science, Philadelphia, PA, USA, 2017. [Google Scholar]
- Okuda, T.; Shoda, S. AI-based Chatbot Service for Financial Industry. FUJITSU Sci. Tech. J. 2018, 54, 5. [Google Scholar]
- Brandtzaeg, P.B.; Følstad, A. Why People Use Chatbots. In Internet Science; Kompatsiaris, I., Cave, J., Satsiou, A., Carle, G., Passani, A., Kontopoulos, E., Diplaris, S., McMillan, D., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 10673, pp. 377–392. [Google Scholar]
- Costa, P. Conversing with personal digital assistants: On gender and artificial intelligence. J. Sci. Technol. Arts 2018, 10, 59–72. [Google Scholar] [CrossRef] [Green Version]
- Go, E.; Sundar, S.S. Humanizing chatbots: The effects of visual, identity and conversational cues on humanness perceptions. Comput. Hum. Behav. 2019, 97, 304–316. [Google Scholar] [CrossRef]
- Luo, X.; Tong, S.; Fang, Z.; Qu, Z. Frontiers: Machines vs. Humans: The Impact of Artificial Intelligence Chatbot Disclosure on Customer Purchases. Mark. Sci. 2019, 38, 913–1084. [Google Scholar] [CrossRef]
- Christensen, S.; Johnsrud, S.; Ruocco, M.; Ramampiaro, H. Context-Aware Sequence-to-Sequence Models for Conversational Systems. arXiv 2018, arXiv:1805.08455. [Google Scholar]
- Fernandes, A. NLP, NLU, NLG and How Chatbots Work. 2018. Available online: https://chatbotslife.com/nlp-nlu-nlg-and-how-chatbots-work-dd7861dfc9df (accessed on 19 May 2021).
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, LIX, 433–460. [Google Scholar] [CrossRef]
- Weizenbaum, J. ELIZA–A Computer Program for the Study of Natural Language Communication between Man and Machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Shum, H.y.; He, X.d.; Li, D. From Eliza to XiaoIce: Challenges and opportunities with social chatbots. Front. Inf. Technol. Electron. Eng. 2018, 19, 10–26. [Google Scholar] [CrossRef] [Green Version]
- Zemčík, T. A Brief History of Chatbots. DEStech Trans. Comput. Sci. Eng. 2019, 2019, 14–18. [Google Scholar] [CrossRef]
- Bradeško, L.; Mladenić, D. A Survey of Chabot Systems through a Loebner Prize Competition. In Proceedings of the Slovenian Language Technologies Society Eighth Conference of Language Technologies, Ljubljana, Slovenia, 8–9 October 2012; Institut Jožef Stefan: Ljubljana, Slovenia, 2012; pp. 34–37. [Google Scholar]
- Wilcox, B. Winning the Loebner’s. 2014. Available online: https://www.gamasutra.com/blogs/BruceWilcox/20141020/228091/Winning_the_Loebners.php (accessed on 26 November 2020).
- AbuShawar, B.; Atwell, E. ALICE Chatbot: Trials and Outputs. Comput. Y Sist. 2015, 19, 4. [Google Scholar] [CrossRef]
- Dormehl, L. Microsoft’s Friendly Xiaoice A.I Can Figure out What You Want—Before You Ask. 2018. Available online: https://www.digitaltrends.com/cool-tech/xiaoice-microsoft-future-of-ai-assistants/ (accessed on 5 May 2021).
- Spencer, G. Much More Than a Chatbot: China’s Xiaoice Mixes AI with Emotions and Wins over Millions of Fans. Microsoft Asia News Cent. 2018. Available online: https://news.microsoft.com/apac/features/much-more-than-a-chatbot-chinas-xiaoice-mixes-ai-with-emotions-and-wins-over-millions-of-fans/ (accessed on 29 June 2021).
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. arXiv 2019, arXiv:1812.08989. [Google Scholar] [CrossRef]
- Radziwill, N.; Benton, M. Evaluating Quality of Chatbots and Intelligent Conversational Agents. arXiv 2017, arXiv:1704.04579. [Google Scholar]
- Sheehan, B.; Jin, H.S.; Gottlieb, U. Customer service chatbots: Anthropomorphism and adoption. J. Bus. Res. 2020, 115, 14–24. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. An Overview of Chatbot Technology. Artif. Intell. Appl. Innov. 2020, 584, 373–383. [Google Scholar] [CrossRef]
- Nuruzzaman, M.; Hussain, O.K. A Survey on Chatbot Implementation in Customer Service Industry through Deep Neural Networks. In Proceedings of the 2018 IEEE 15th International Conference on e-Business Engineering (ICEBE), Xi’an, China, 12–14 October 2018; pp. 54–61. [Google Scholar] [CrossRef]
- Ketakee, N.; Champaneria, T. Chatbots: An Overview Types, Architecture, Tools and Future Possibilities. IJSRD-Int. J. Sci. Res. Dev. 2017, 5, 6. [Google Scholar]
- Yan, R.; Song, Y.; Wu, H. Learning to Respond with Deep Neural Networks for Retrieval-Based Human-Computer Conversation System. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval-SIGIR ’16, Pisa, Italy, 17–21July 2016; ACM Press: Pisa, Italy, 2016; pp. 55–64. [Google Scholar] [CrossRef]
- Abdul-Kader, S.A.; Woods, D.J. Survey on Chatbot Design Techniques in Speech Conversation Systems. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 9. [Google Scholar]
- Lu, Z.; Li, H. A Deep Architecture for Matching Short Texts. Adv. Neural Inf. Process. Syst. 2013, 26, 1367–1375. [Google Scholar]
- Shang, L.; Lu, Z.; Li, H. Neural Responding Machine for Short-Text Conversation. arXiv 2015, arXiv:1503.02364. [Google Scholar]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.Y.; Gao, J.; Dolan, B. A Neural Network Approach to Context-Sensitive Generation of Conversational Responses. arXiv 2015, arXiv:1506.06714. [Google Scholar]
- Vinyals, O.; Le, Q. A Neural Conversational Model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 2, 3104–3112. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Dorling Kindersley Pvt, Limited: London, UK, 2020; Volume 2. [Google Scholar]
- Strigér, A. End-to-End Trainable Chatbot for Restaurant Recommendations. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Adiwardana, D.; Luong, M.T.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a Human-like Open-Domain Chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- So, D.R.; Liang, C.; Le, Q.V. The Evolved Transformer. arXiv 2019, arXiv:1901.11117. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2017, arXiv:cs.CL/1612.08083. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:cs.NE/1710.05941. [Google Scholar]
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; pp. 923–929. [Google Scholar]
- Zhong, P.; Wang, D.; Miao, C. An Affect-Rich Neural Conversational Model with Biased Attention and Weighted Cross-Entropy Loss. arXiv 2018, arXiv:1811.07078. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the ACL 2017, System Demonstrations, Vancouver, QC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, QC, Canada, 2017; pp. 67–72. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep Reinforcement Learning for Dialogue Generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 986–995. [Google Scholar]
- Li, J.; Monroe, W.; Shi, T.; Jean, S.; Ritter, A.; Jurafsky, D. Adversarial Learning for Neural Dialogue Generation. arXiv 2017, arXiv:1701.06547. [Google Scholar]
- Danescu-Niculescu-Mizil, C.; Lee, L. Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs. In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, Portland, OR, USA, 23 June 2011. [Google Scholar]
- He, T.; Liu, J.; Cho, K.; Ott, M.; Liu, B.; Glass, J.; Peng, F. Analyzing the Forgetting Problem in the Pretrain-Finetuning of Dialogue Response Models. arXiv 2021, arXiv:1910.07117. [Google Scholar]
- Roller, S.; Dinan, E.; Goyal, N.; Ju, D.; Williamson, M.; Liu, Y.; Xu, J.; Ott, M.; Shuster, K.; Smith, E.M.; et al. Recipes for building an open-domain chatbot. arXiv 2020, arXiv:2004.13637. [Google Scholar]
- Ghandeharioun, A.; Shen, J.H.; Jaques, N.; Ferguson, C.; Jones, N.; Lapedriza, A.; Picard, R. Approximating Interactive Human Evaluation with Self-Play for Open-Domain Dialog Systems. arXiv 2019, arXiv:1906.09308. [Google Scholar]
- Kim, J.; Oh, S.; Kwon, O.W.; Kim, H. Multi-Turn Chatbot Based on Query-Context Attentions and Dual Wasserstein Generative Adversarial Networks. Appl. Sci. 2019, 9, 3908. [Google Scholar] [CrossRef] [Green Version]
- Walker, M.A.; Litman, D.J.; Kamm, C.A.; Abella, A. PARADISE: A framework for evaluating spoken dialogue agents. In Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics, Madrid, Spain, 7–12 July 1997; pp. 271–280. [Google Scholar] [CrossRef]
- Hung, V.; Elvir, M.; Gonzalez, A.; DeMara, R. Towards a method for evaluating naturalness in conversational dialog systems. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009. [Google Scholar]
- Kempson, R.; Gargett, A.; Gregoromichelaki, E. Clarification Requests: An Incremental Account. Decalog 2007, 2007, 65. [Google Scholar]
- Li, M.; Weston, J.; Roller, S. ACUTE-EVAL: Improved Dialogue Evaluation with Optimized Questions and Multi-turn Comparisons. arXiv 2019, arXiv:1909.03087. [Google Scholar]
- Lin, Z.; Liu, Z.; Winata, G.I.; Cahyawijaya, S.; Madotto, A.; Bang, Y.; Ishii, E.; Fung, P. XPersona: Evaluating Multilingual Personalized Chatbot. arXiv 2020, arXiv:2003.07568. [Google Scholar]
- Sedoc, J.; Ippolito, D.; Kirubarajan, A.; Thirani, J.; Ungar, L.; Callison-Burch, C. ChatEval: A Tool for Chatbot Evaluation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 60–65. [Google Scholar] [CrossRef]
- Przegalinska, A.; Ciechanowski, L.; Stroz, A.; Gloor, P.; Mazurek, G. In bot we trust: A new methodology of chatbot performance measures. Bus. Horizons 2019, 62, 785–797. [Google Scholar] [CrossRef]
- Saikh, T.; Naskar, S.K.; Ekbal, A.; Bandyopadhyay, S. Textual Entailment Using Machine Translation Evaluation Metrics. In Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Series Title: Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 10761, pp. 317–328. [Google Scholar] [CrossRef]
- Wood, T. F-Score. Available online: https://deepai.org/machine-learning-glossary-and-terms/f-score (accessed on 1 November 2021).
- Xu, J.; Ju, D.; Li, M.; Boureau, Y.L.; Weston, J.; Dinan, E. Recipes for Safety in Open-domain Chatbots. arXiv 2020, arXiv:2010.07079. [Google Scholar]
- Cuayáhuitl, H.; Lee, D.; Ryu, S.; Cho, Y.; Choi, S.; Indurthi, S.; Yu, S.; Choi, H.; Hwang, I.; Kim, J. Ensemble-based deep reinforcement learning for chatbots. Neurocomputing 2019, 366, 118–130. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Beeferman, D.; Rosenfeld, R. Evaluation Metrics for Language Models. 1998, p. 6. Available online: https://kilthub.cmu.edu/articles/journalcontribution/EvaluationMetricsForLanguageModels/6605324 (accessed on 8 June 2021).
- Dhyani, M.; Kumar, R. An intelligent Chatbot using deep learning with Bidirectional RNN and attention model. Mater. Today Proc. 2020, 34, 817–824. [Google Scholar] [CrossRef]
- John, A.; Di Caro, L.; Robaldo, L.; Boella, G. Legalbot: A Deep Learning-Based Conversational Agent in the Legal Domain; Springer: Berlin/Heidelberg, Germany, 2017; p. 273. [Google Scholar] [CrossRef] [Green Version]
- Higashinaka, R.; Imamura, K.; Meguro, T.; Miyazaki, C.; Kobayashi, N.; Sugiyama, H.; Hirano, T.; Makino, T.; Matsuo, Y. Towards an open-domain conversational system fully based on natural language processing. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; p. 12. [Google Scholar]
- Agarwal, A.; Lavie, A. Meteor, M-BLEU and M-TER: Evaluation Metrics for High-Correlation with Human Rankings of Machine Translation Output. In Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, OH, USA, 19 June 2008; Association for Computational Linguistics: Columbus, OH, USA, 2008; pp. 115–118. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; p. 8. [Google Scholar]
- Xu, K.; Lei, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image CaptionGeneration with Visual Attention. Proc. Int. Conf. Mach. Learn. 2015, 37, 10. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A Study of Translation Edit Rate with Targeted Human Annotation. In Proceedings of the Association for Machine Translation in the Americas, Cambridge, MA, USA, 8–12 August 2006; p. 9. [Google Scholar]
- Kannan, A.; Vinyals, O. Adversarial Evaluation of Dialogue Models. arXiv 2017, arXiv:1701.08198. [Google Scholar]
- Kuksenok, K.; Martyniv, A. Evaluation and Improvement of Chatbot Text Classification Data Quality Using Plausible Negative Examples. In Proceedings of the First Workshop on NLP for Conversational AI, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 87–95. [Google Scholar] [CrossRef]
- Ebner, M.; Ebner, M. Potential of Bots for Encyclopedia. IPSI BgD Trans. 2020, 16, 54–60. [Google Scholar]
- Arifi, J.; Ebner, M.; Ebner, M. Potentials of Chatbots for Spell Check among Youngsters. Int. J. Learn. Anal. Artif. Intell. Educ. 2019, 1, 77. [Google Scholar] [CrossRef] [Green Version]
- Palasundram, K.; Sharef, N.M.; Nasharuddin, N.A.; Kasmiran, K.A.; Azman, A. Sequence to Sequence Model Performance for Education Chatbot. Int. J. Emerg. Technol. Learn. 2019, 14, 56–68. [Google Scholar] [CrossRef]
- Nwankwo, W. Interactive Advising with Bots: Improving Academic Excellence in Educational Establishments. Am. J. Oper. Manag. Inf. Syst. 2018, 3, 6. [Google Scholar] [CrossRef]
- Fei, Y.; Petrina, S. Using Learning Analytics to Understand the Design of an Intelligent Language Tutor—Chatbot Lucy. Int. J. Adv. Comput. Sci. Appl. 2013, 4, 124–131. [Google Scholar] [CrossRef] [Green Version]
- Augello, A.; Pilato, G.; Machi, A.; Gaglio, S. An Approach to Enhance Chatbot Semantic Power and Maintainability: Experiences within the FRASI Project. In Proceedings of the 2012 IEEE Sixth International Conference on Semantic Computing, Palermo, Italy, 19–21 September 2012. [Google Scholar]
- Berger, R.; Ebner, M.; Ebner, M. Conception of a Conversational Interface to Provide a Guided Search of Study Related Data. Int. J. Emerg. Technol. Learn. (IJET) 2019, 14, 37. [Google Scholar] [CrossRef]
- Athota, L.; Shukla, V.K.; Pandey, N.; Rana, A. Chatbot for Healthcare System Using Artificial Intelligence. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; IEEE: Noida, India, 2020; pp. 619–622. [Google Scholar] [CrossRef]
- Cui, L.; Huang, S.; Wei, F.; Tan, C.; Duan, C.; Zhou, M. SuperAgent: A Customer Service Chatbot for E-commerce Websites. In Proceedings of the ACL 2017, System Demonstrations, Vancouver, QC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, QC, Canada, 2017; pp. 97–102. [Google Scholar] [CrossRef] [Green Version]
- Ikumoro, A.O.; Jawad, M.S. Intention to Use Intelligent Conversational Agents in e-Commerce among Malaysian SMEs: An Integrated Conceptual Framework Based on Tri-theories including Unified Theory of Acceptance, Use of Technology (UTAUT), and T-O-E. Int. J. Acad. Res. Bus. Soc. Sci. 2019, 9, 205–235. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Paste, M.; Shinde, N.; Patel, H.; Mishra, N. Chatbot using TensorFlow for small Businesses. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 1614–1619. [Google Scholar] [CrossRef]
- Casillo, M.; Colace, F.; Fabbri, L.; Lombardi, M.; Romano, A.; Santaniello, D. Chatbot in Industry 4.0: An Approach for Training New Employees. In Proceedings of the 2020 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Takamatsu, Japan, 8–11 December 2020; pp. 371–376. [Google Scholar] [CrossRef]
- Melo, G.; Law, E.; Alencar, P.; Cowan, D. Exploring Context-Aware Conversational Agents in Software Development. arXiv 2020, arXiv:2006.02370. [Google Scholar]
- Sheikh, S.; Tiwari, V.; Bansal, S. Generative model chatbot for Human Resource using Deep Learning. In Proceedings of the 2019 International Conference on Data Science and Engineering, Patna, India, 26–28 September 2019; p. 132. [Google Scholar] [CrossRef]
- Rahman, A.M.; Mamun, A.A.; Islam, A. Programming challenges of chatbot: Current and future prospective. In Proceedings of the 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Dhaka, Bangladesh, 21–23 December 2017; pp. 75–78. [Google Scholar] [CrossRef]
- Bernardini, A.A.; Sônego, A.A.; Pozzebon, E. Chatbots: An Analysis of the State of Art of Literature. In Proceedings of the 1st Workshop on Advanced Virtual Environments and Education (WAVE2 2018), Florianópolis, Brazil, 4–5 October 2018; Brazilian Computer Society (Sociedade Brasileira de Computação-SBC): Florianópolis, Santa Catarina, Brazil, 2018; p. 1. [Google Scholar] [CrossRef] [Green Version]
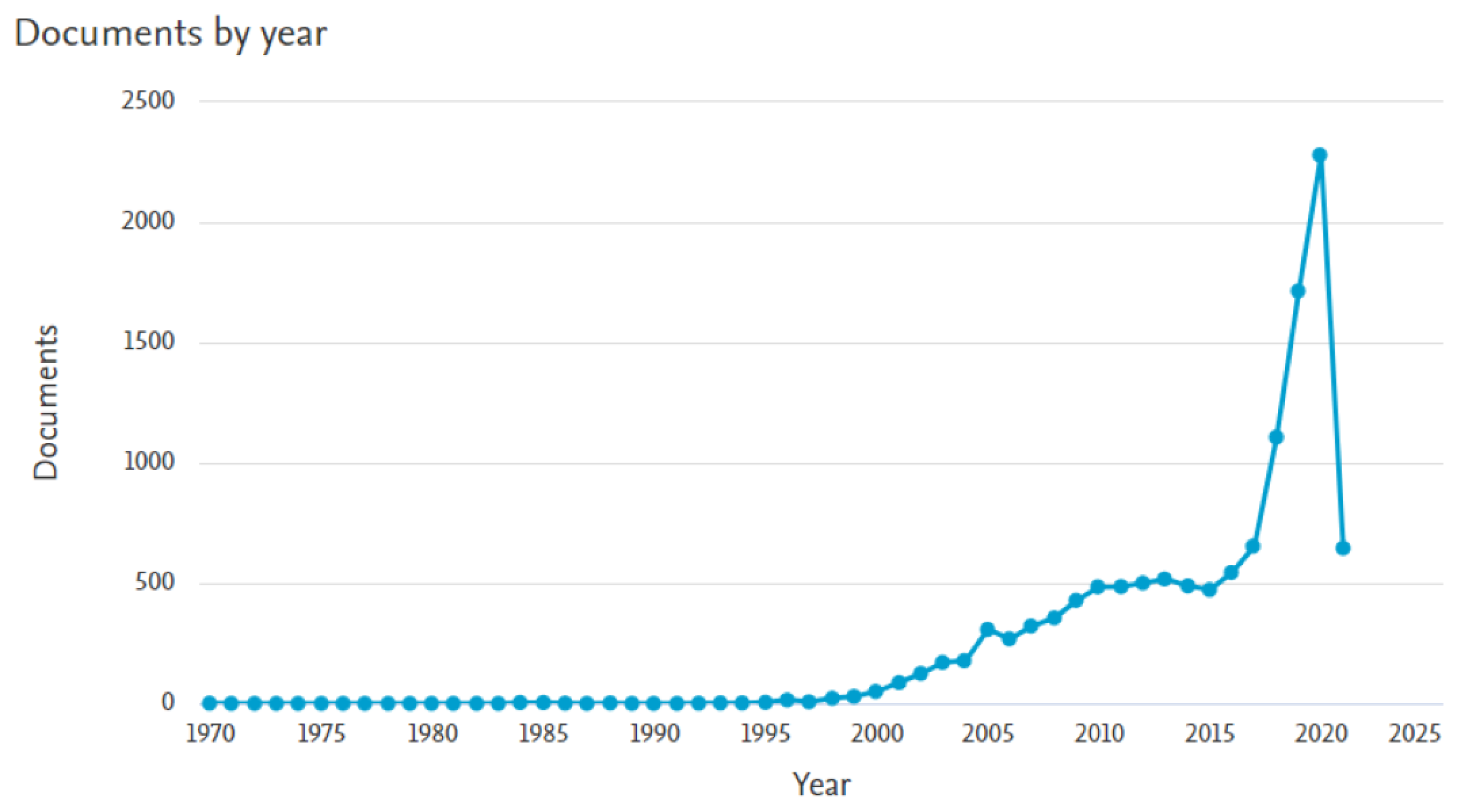

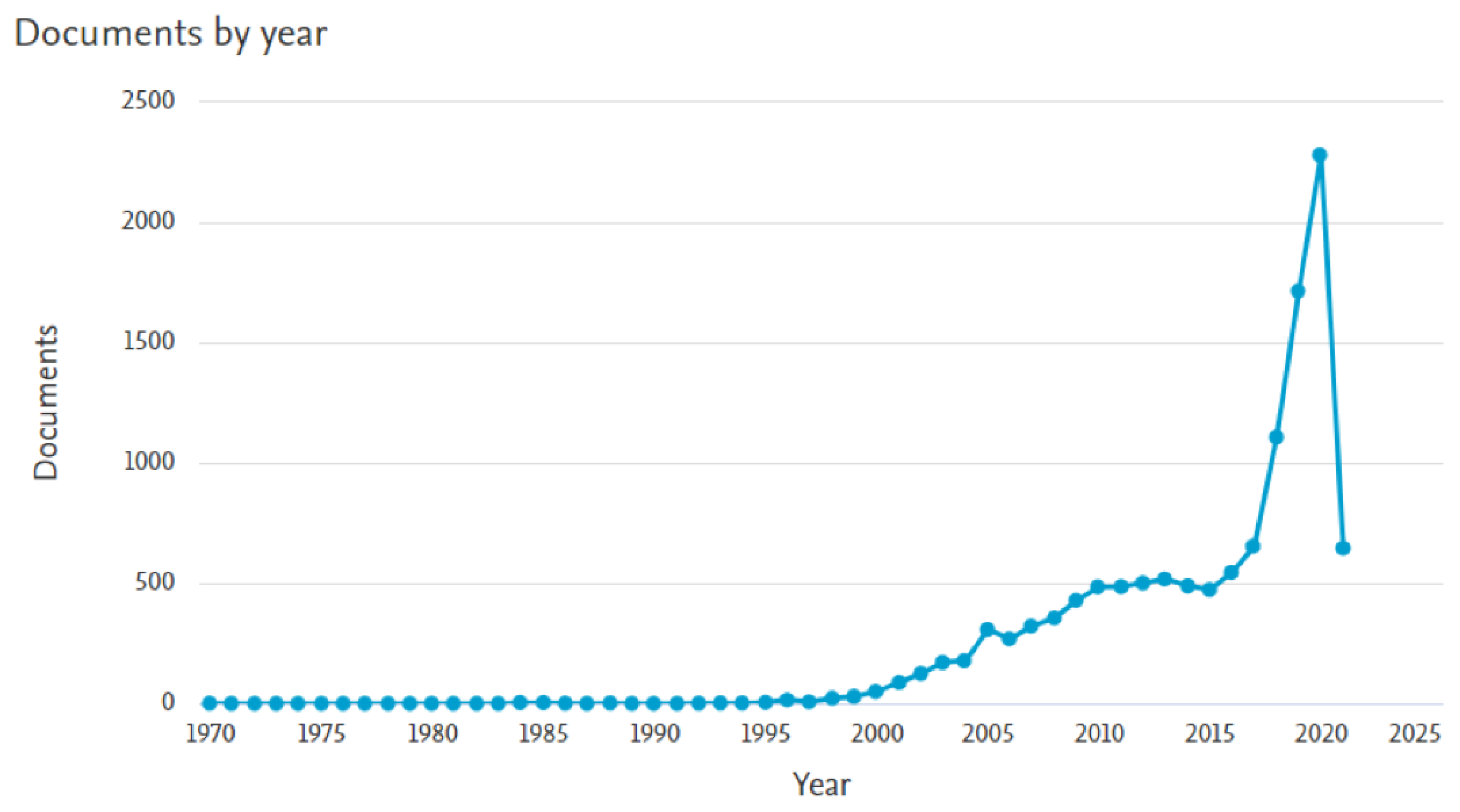{kind=link}
| Database and Repositories | Keyword | Total Number of Articles | Total Articles between 2007 and 2021 | Number of Articles Selected for Reviewing |
|---|---|---|---|---|
| IEEE | chatbot | 666 | 664 | 22 |
| conversational modelling | 1152 | 831 | ||
| conversational system | 42 | 23 | ||
| conversation system | 3099 | 2321 | ||
| conversational entities | 51 | 42 | ||
| conversational agents | 590 | 503 | ||
| embodied conversational agents | 160 | 137 | ||
| human-computer conversational systems | 217 | 181 | ||
| ScienceDirect | chatbot | 1063 | 1058 | 20 |
| conversational modelling | 188 | 105 | ||
| conversational system | 318 | 119 | ||
| conversation system | 185 | 137 | ||
| conversational entities | 9 | 8 | ||
| conversational agents | 674 | 597 | ||
| embodied conversational agents | 282 | 243 | ||
| human-computer conversational systems | 2 | 2 | ||
| Springer | chatbot | 2046 | 2010 | 16 |
| conversational modelling | 441 | 293 | ||
| conversational system | 862 | 564 | ||
| conversation system | 337 | 257 | ||
| conversational entities | 26 | 23 | ||
| conversational agents | 3247 | 2721 | ||
| embodied conversational agents | 1550 | 1225 | ||
| human-computer conversational systems | 0 | 0 | ||
| arXiv | chatbot | 132 | 131 | 56 |
| conversational modelling | 43 | 43 | ||
| conversational system | 48 | 46 | ||
| conversation system | 48 | 46 | ||
| conversational entities | 2 | 2 | ||
| conversational agents | 77 | 77 | ||
| embodied conversational agents | 4 | 4 | ||
| human-computer conversational systems | 0 | 0 | ||
| Google Scholar | chatbot | 36,000 | 16,400 | 201 |
| conversational modelling | 183 | 116 | ||
| conversational system | 4,510 | 2460 | ||
| conversation system | 2850 | 2,190 | ||
| conversational entities | 162 | 127 | ||
| conversational agents | 23,600 | 16,900 | ||
| embodied conversational agents | 9960 | 7510 | ||
| human-computer conversational systems | 26 | 8 | ||
| JSTOR | chatbot | 318 | 311 | 1 |
| conversational modelling | 1291 | 537 | ||
| conversational system | 1962 | 498 | ||
| conversation system | 1962 | 498 | ||
| conversational entities | 31 | 14 | ||
| conversational agents | 310 | 204 | ||
| embodied conversational agents | 88 | 68 | ||
| human-computer conversational systems | 0 | 0 |
| Dataset | Content Type and Source | # Phrases | # Tokens | Source |
|---|---|---|---|---|
| OpenSubtitles | Movie subtitles. Entire database of the OpenSubtitles.org repository | 441.5 M (2018 release) | 3.2 G (2018 release) | [47] |
| Cornell | Raw movie scripts. Fictional conversations extracted from raw movie scripts | 304,713 | 48,177 | [53] |
| DailyDialog | Dialogues for English learners. Raw data crawled from various websites that provide content for English learners | 103,632 (13,118 dialogues with 7.9 turns each on average) | 17,812 | [51] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caldarini, G.; Jaf, S.; McGarry, K. A Literature Survey of Recent Advances in Chatbots. Information 2022, 13, 41. https://doi.org/10.3390/info13010041
Caldarini G, Jaf S, McGarry K. A Literature Survey of Recent Advances in Chatbots. Information. 2022; 13(1):41. https://doi.org/10.3390/info13010041
Chicago/Turabian StyleCaldarini, Guendalina, Sardar Jaf, and Kenneth McGarry. 2022. "A Literature Survey of Recent Advances in Chatbots" Information 13, no. 1: 41. https://doi.org/10.3390/info13010041
APA StyleCaldarini, G., Jaf, S., & McGarry, K. (2022). A Literature Survey of Recent Advances in Chatbots. Information, 13(1), 41. https://doi.org/10.3390/info13010041