
Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques


 ,
, 
 , and
, and
Abstract
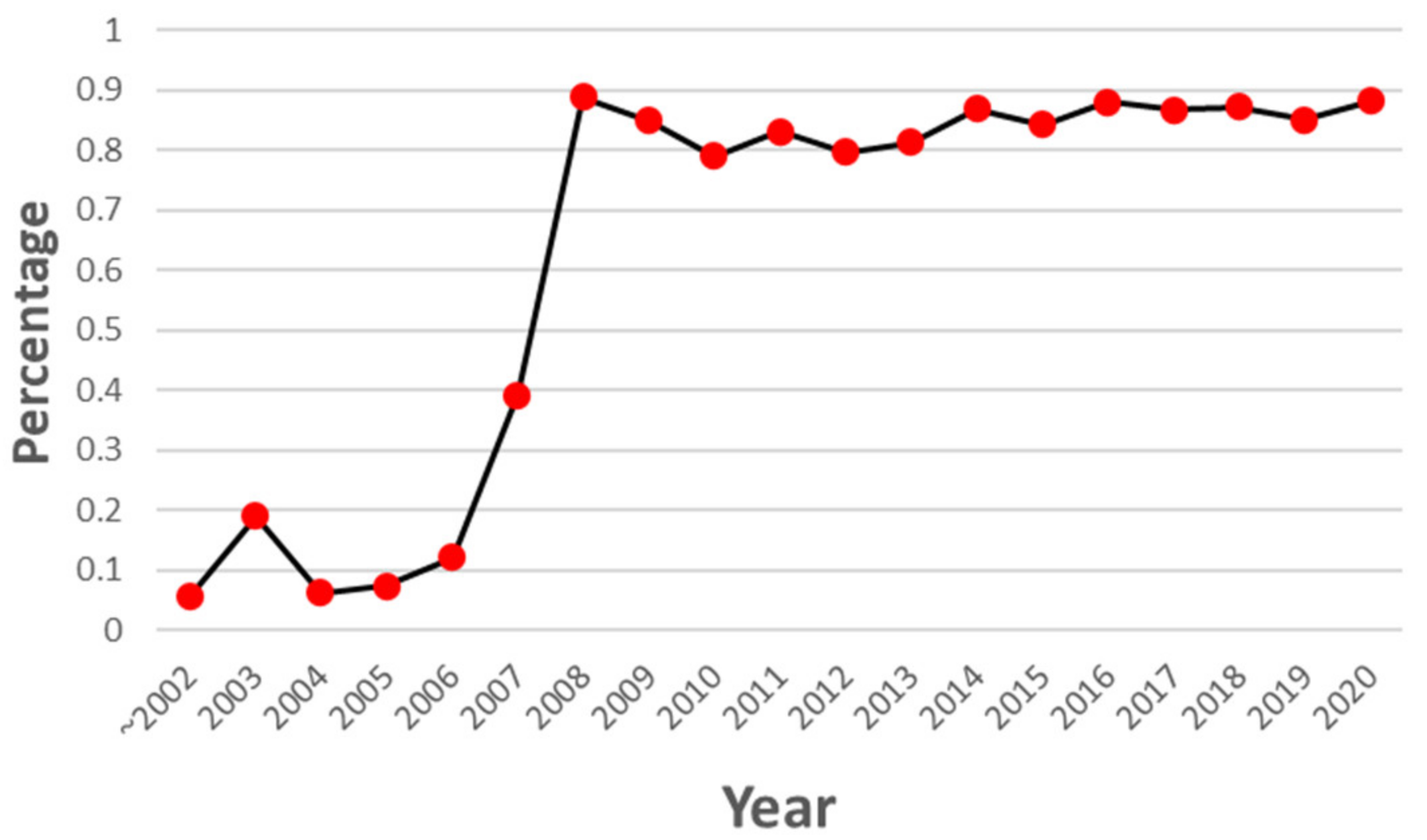
1. Introduction
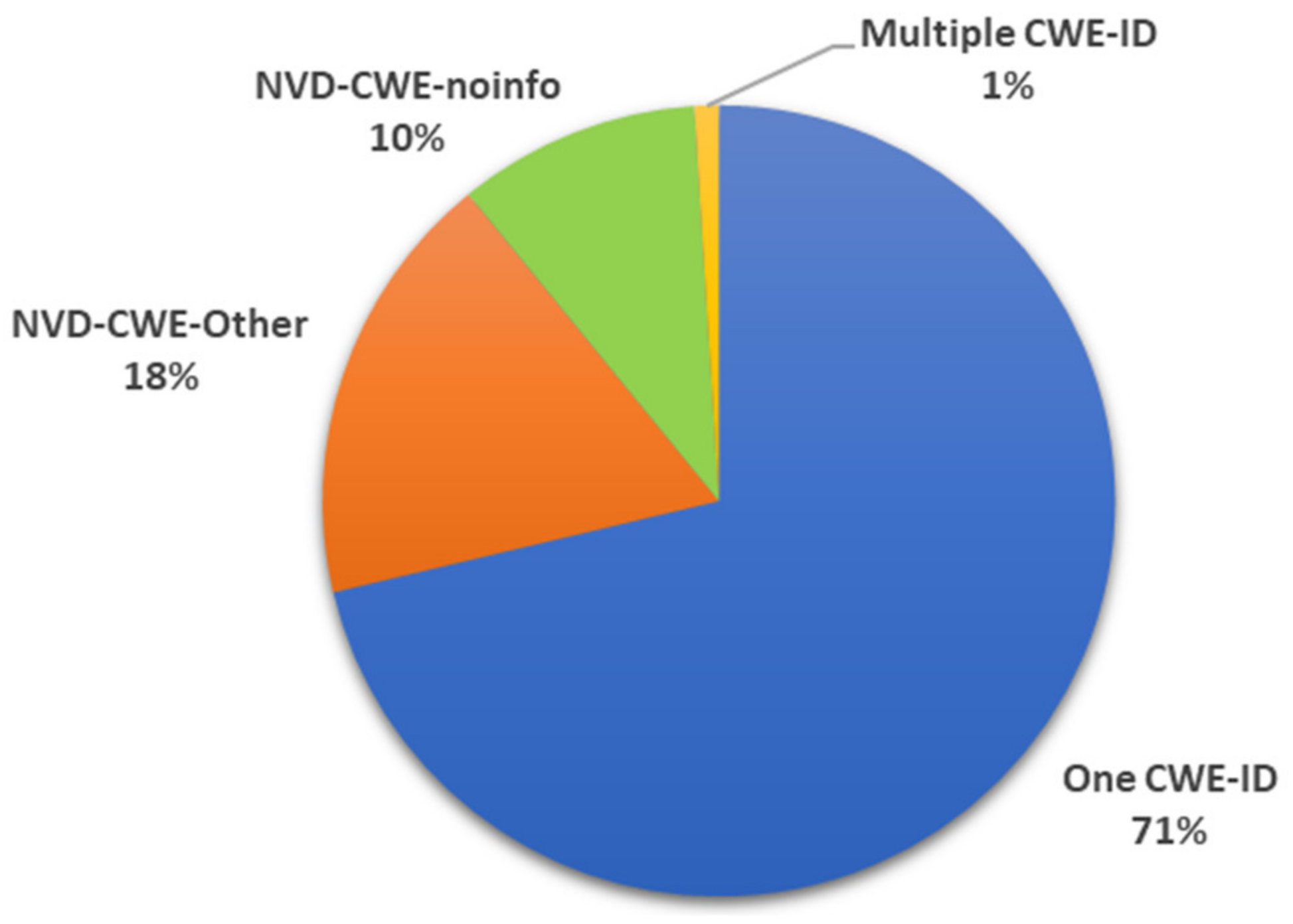
- When using CWE, some patterns cannot trace from the CVE-ID to the related CAPEC-ID. Section 3 and Section 5.2 provide specific cases and conditions;
- The linking between CVE–CWE and CWE–CAPEC is carried out manually. Manual linking cannot handle the growing amount of vulnerability information. In addition, more link failures may occur.
- RQ1.
- When tracing relationships between security repositories, how accurately can it be traced from CVE-ID to CAPEC-ID? This question researches the tracing accuracy of CVE-ID to CAPEC-ID;
- RQ2
- When using a similarity measurement based on natural language processing techniques, how accurately can CVE-IDs be traced to CAPEC-IDs? This question confirms the usefulness of our proposed approach;
- RQ3
- Which of the three evaluated methods provides the best results? This question identifies the most useful method among the three methods proposed in RQ2.
- We elucidate the linking accuracy between CVE–CWE and CWE–CAPEC;
- Our method can easily identify CAPEC-IDs that are link candidates and assist in the linking process;
- The person reporting the vulnerability information can determine whether the report contains sufficient security information.
2. Related Work
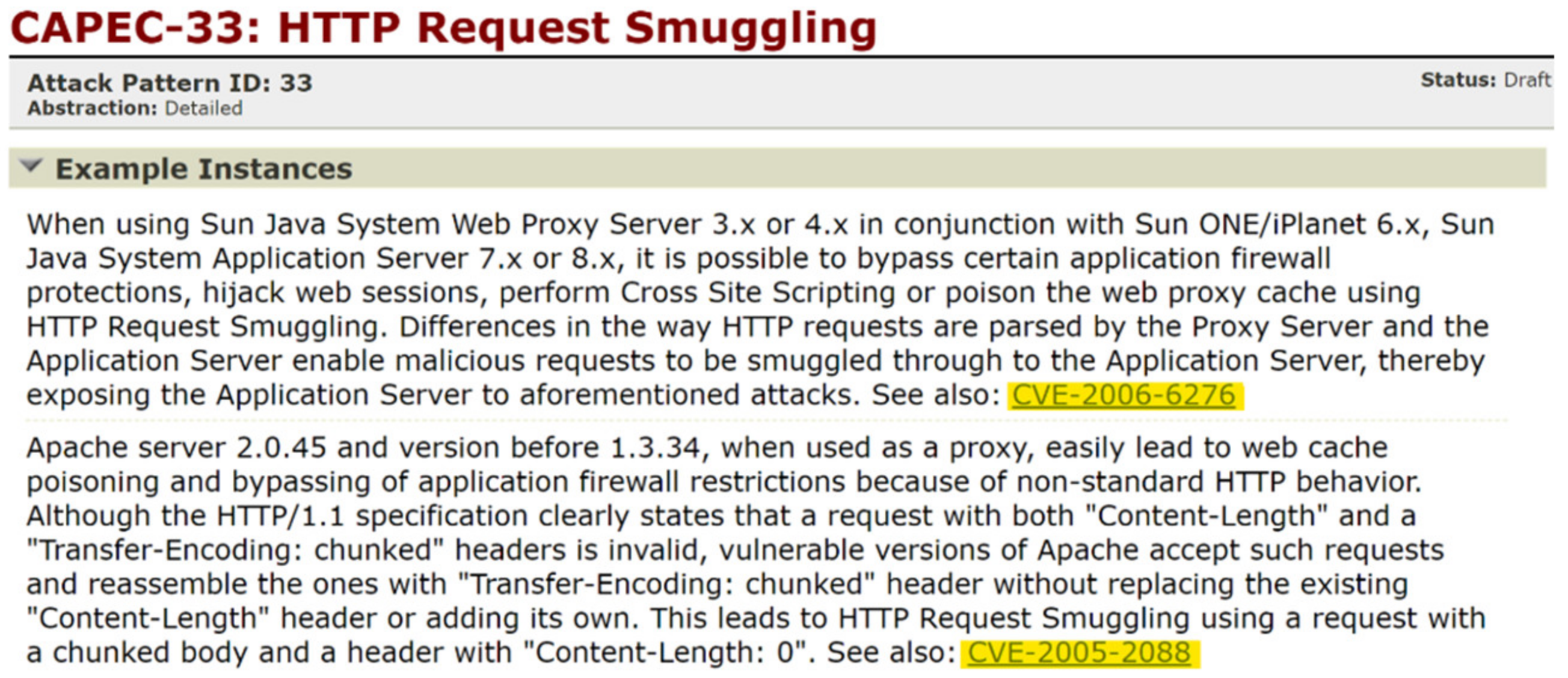
3. Motivating Example
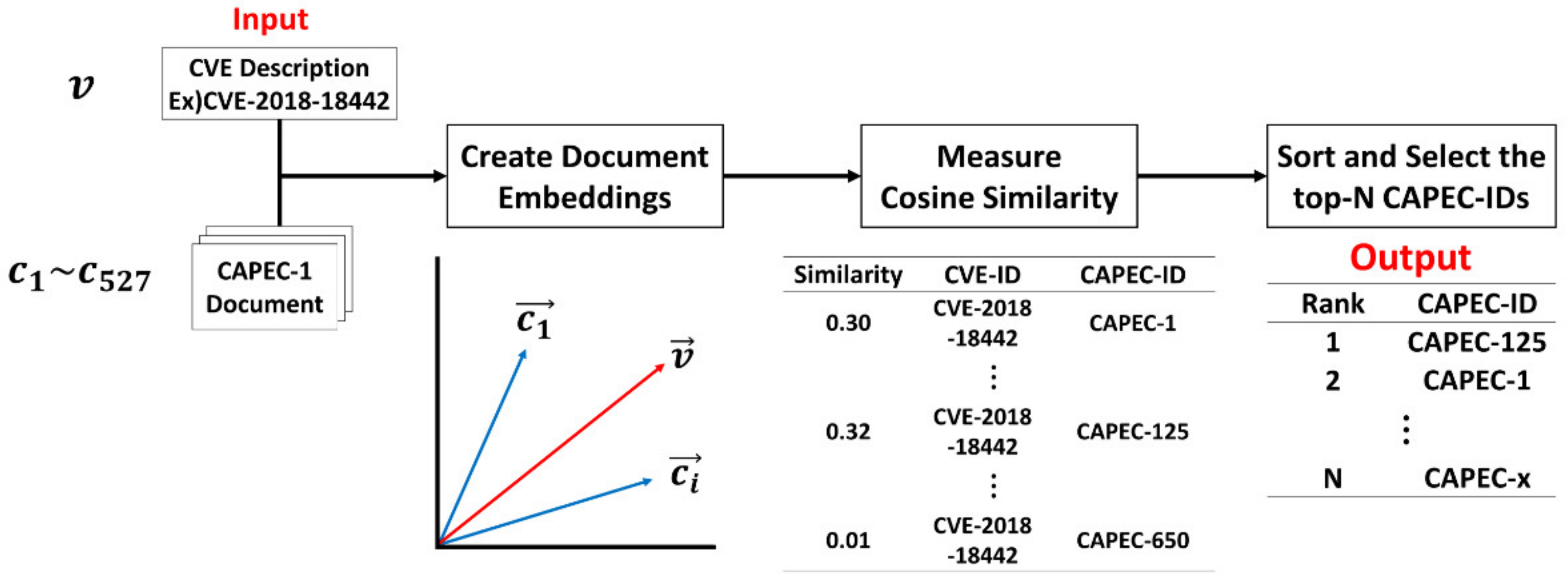
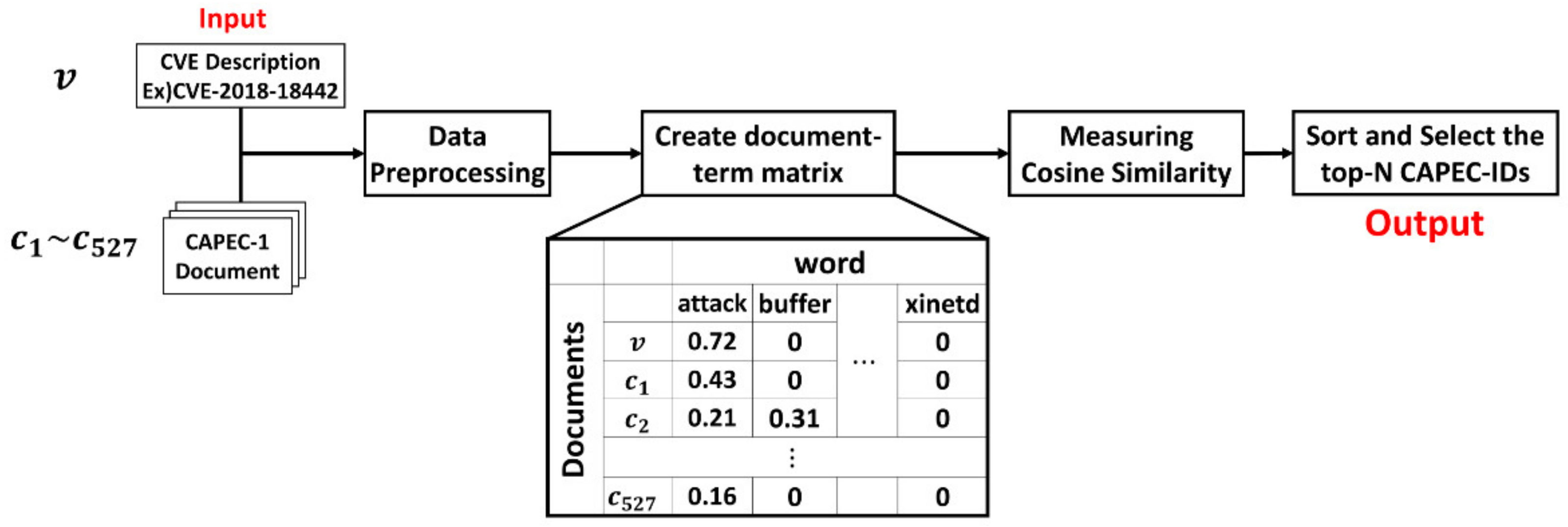
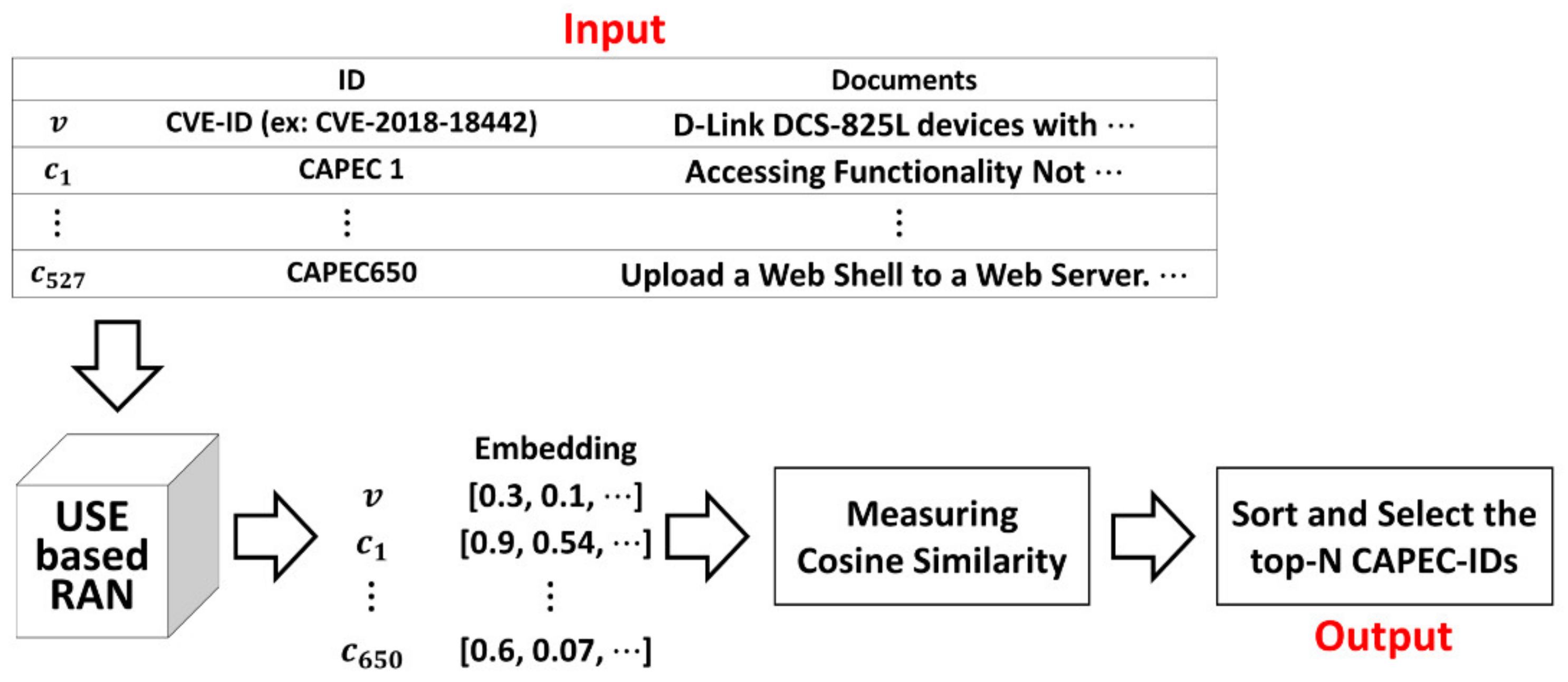
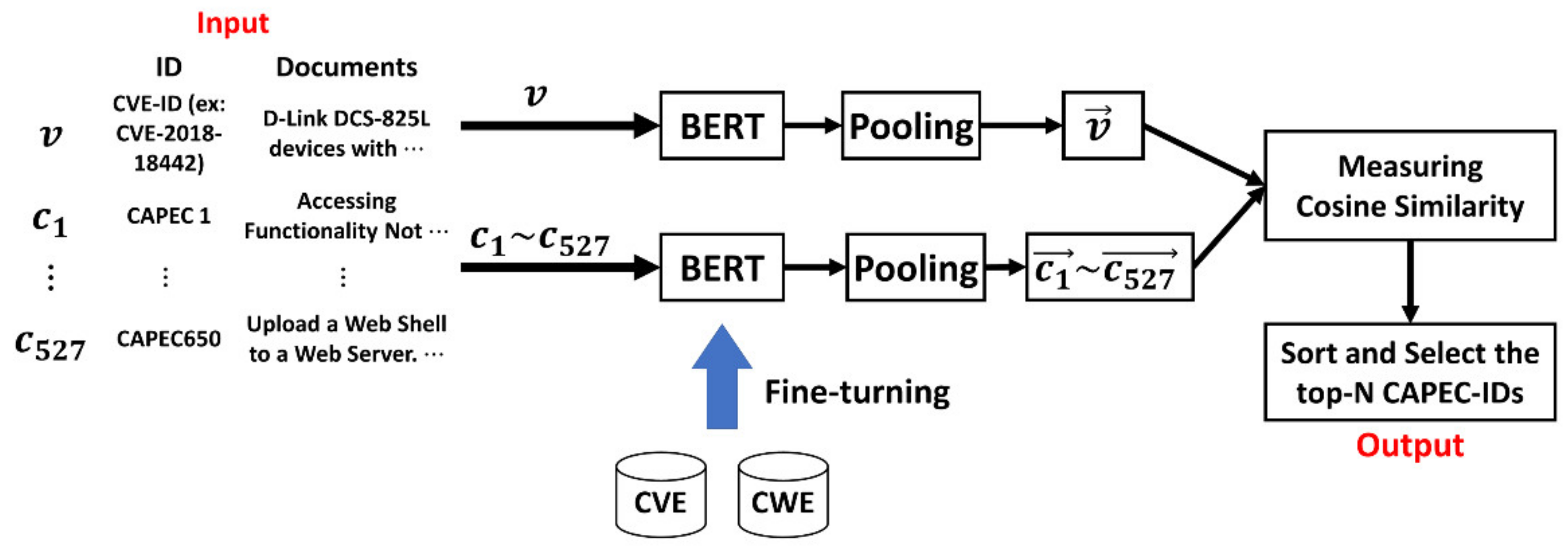
D-Link DCS-825L devices with firmware 1.08 do not employ a suitable mechanism to prevent denial-of-service (DoS) attacks. An attacker can harm the device availability (i.e., live-online video/audio streaming) by using the hping3 tool to perform an IPv4 flood attack. Verified attacks includes SYN flooding, UDP flooding, ICMP flooding, and SYN-ACK flooding.(https://cve.mitre.org/cgi-bin/cvename.cgi?name=2018-18442, accessed on 16 June 2021)
4. Tracing Method from CVE-ID to CAPEC-ID
4.1. Tracing Method Based on TF–IDF
4.2. Tracing Method Based on USE
4.3. Tracing Method Based on Sentence-BERT
5. Experiments and Results
5.1. Fifty-Eight CVE-IDs
5.2. RQ 1. When Tracing Relationships between Security Repositories, How Accurately Can It Be Traced from CVE-ID to CAPEC-ID?
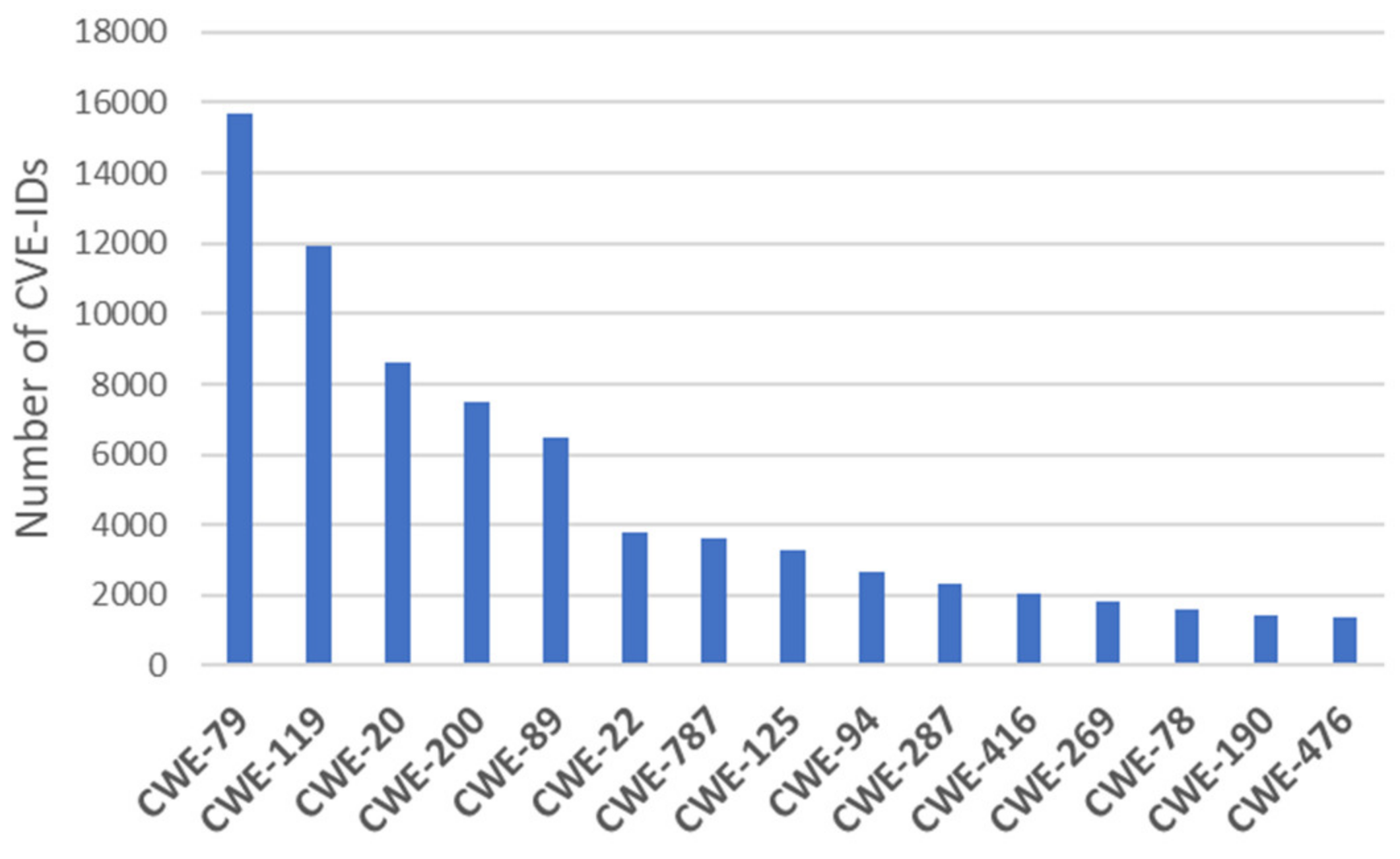
The “input validation” term is extremely common, but it is used in many different ways. In some cases its usage can obscure the real underlying weakness or otherwise hide chaining and composite relationships.Some people use “input validation” as a general term that covers many different neutralization techniques for ensuring that input is appropriate, such as filtering, canonicalization, and escaping. Others use the term in a more narrow context to simply mean “checking if an input conforms to expectations without changing it.”(https://cwe.mitre.org/data/definitions/20.html, accessed on 16 June 2021)
The (1) TLS and (2) DTLS implementations in OpenSSL 1.0.1 before 1.0.1g do not properly handle Heartbeat Extension packets, which allows remote attackers to obtain sensitive information from process memory via crafted packets that trigger a buffer over-read, as demonstrated by reading private keys, related to d1_both.c and t1_lib.c, aka the Heartbleed bug.(https://cve.mitre.org/cgi-bin/cvename.cgi?name=cve-2014-0160, accessed on 16 June 2021)
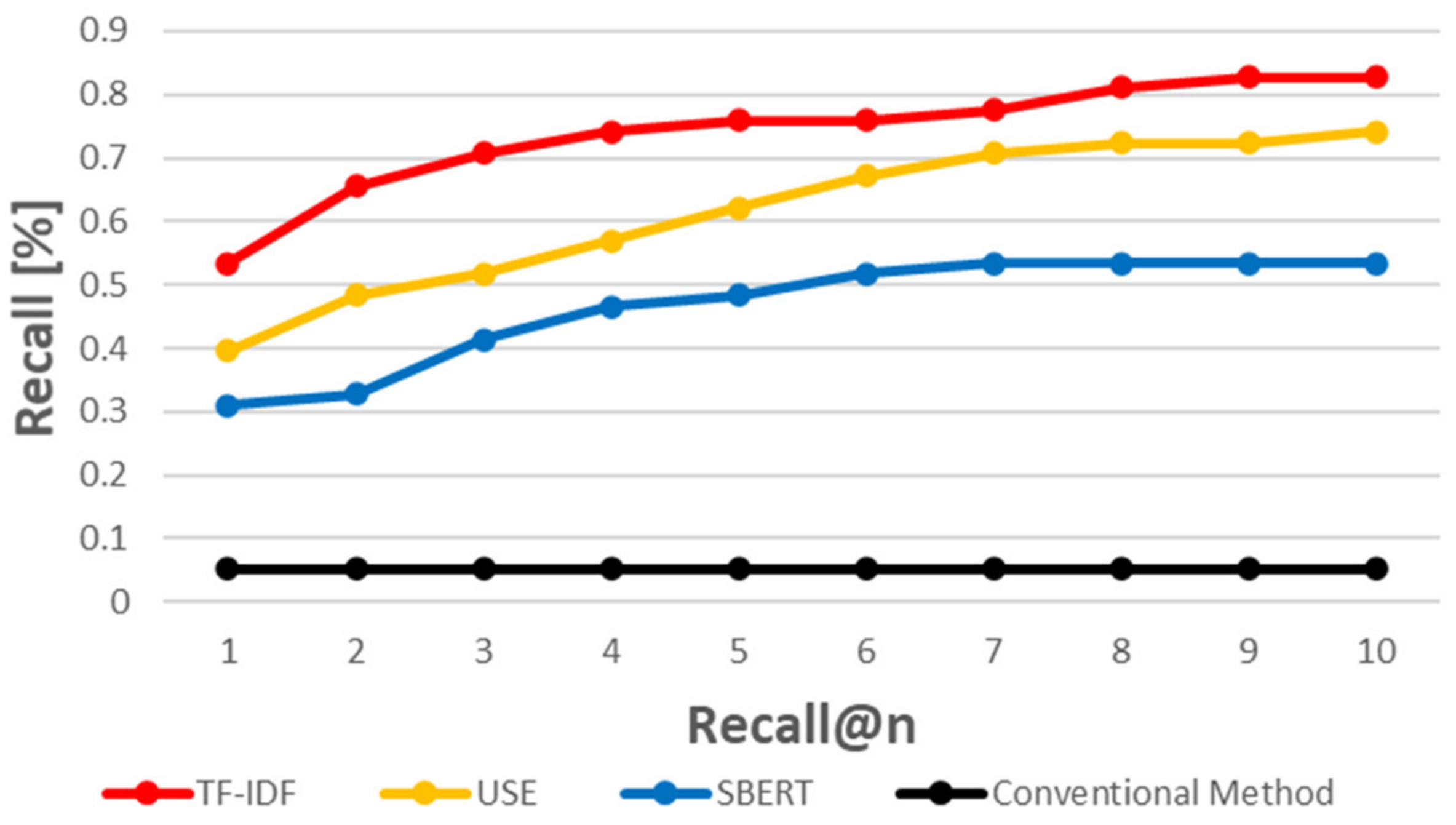
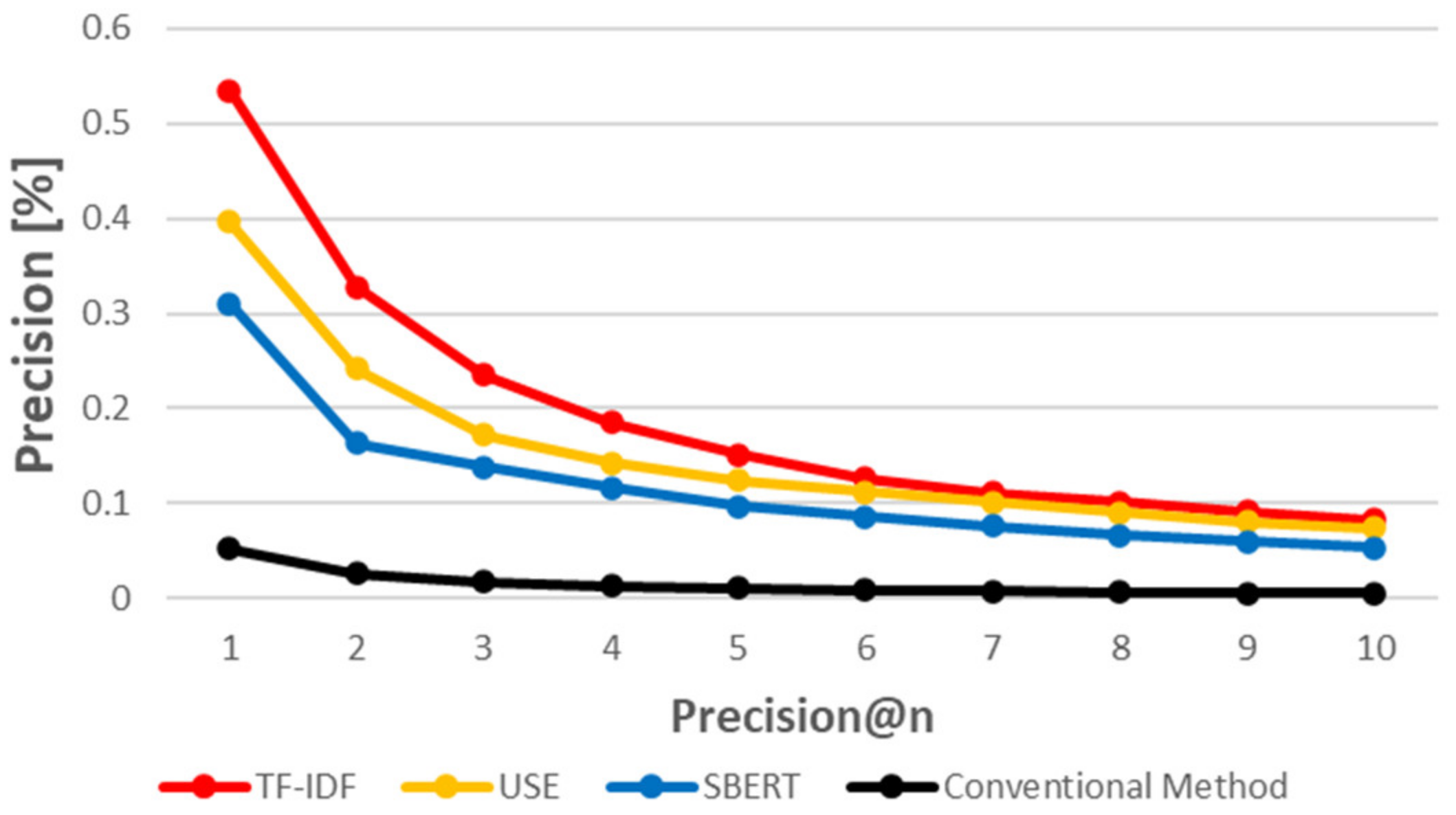
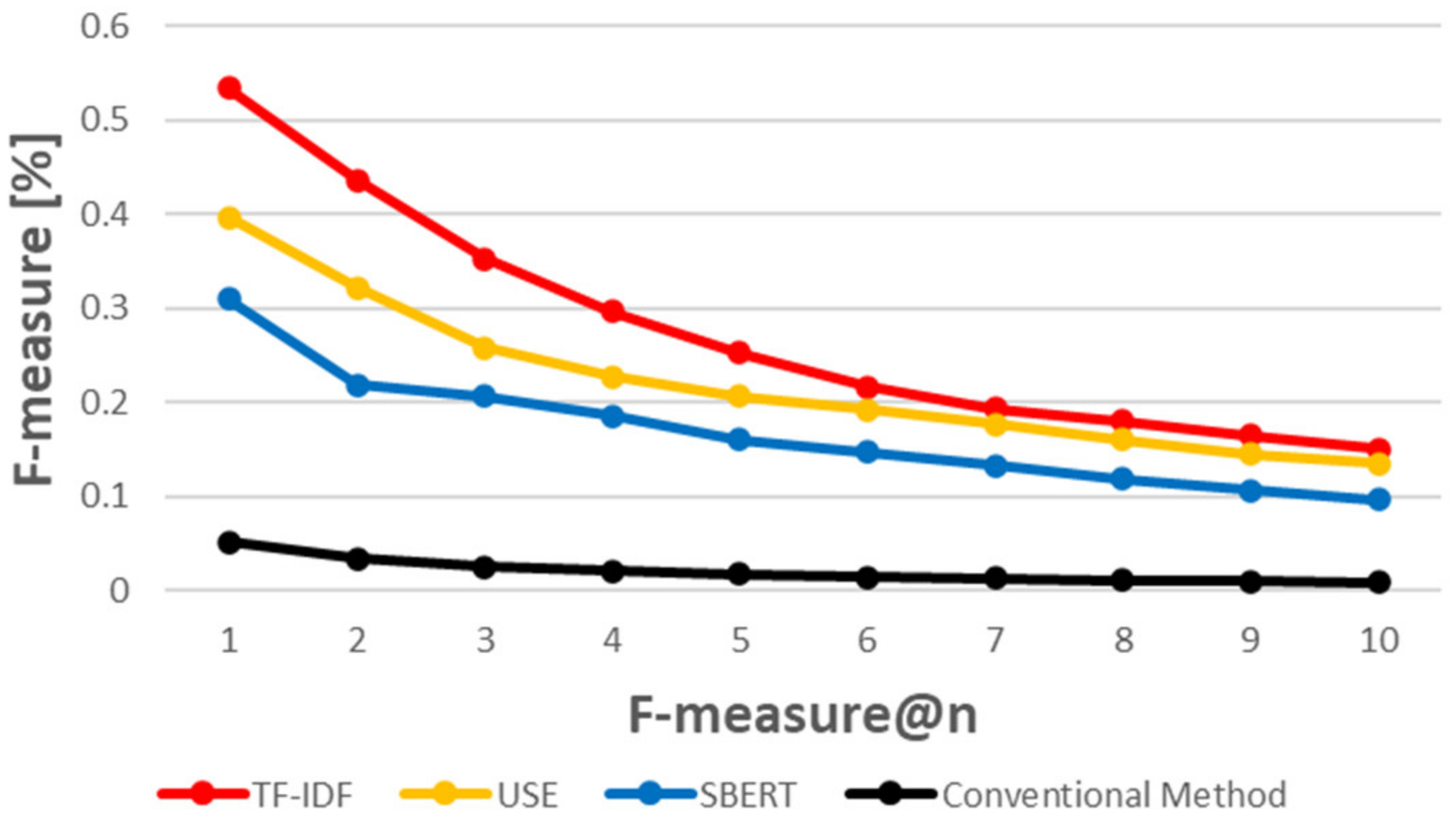
5.3. When Using a Similarity Measurement Based on Natural Language Processing Techniques, How Accurately Can CVE-IDs Be Traced to CAPEC-IDs?
5.4. RQ 3. Which of the Three Evaluated Methods Provides the Best Results?
5.4.1. Word Count-Based Method vs. Inference-Based Method
A spoofing vulnerability exists in the way Windows CryptoAPI (Crypt32.dll) validates Elliptic Curve Cryptography (ECC) certificates. An attacker could exploit the vulnerability by using a spoofed code-signing certificate to sign a malicious executable, making it appear the file was from a trusted, legitimate source, aka ‘Windows CryptoAPI Spoofing Vulnerability’.(https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-0601, accessed on 16 June 2021)
5.4.2. USE vs. SBERT
5.5. Threats to Validity
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | CAPEC-ID | CVE-ID | CVE Word Count |
|---|---|---|---|
| 1 | CAPEC-7 | CVE-2006-4705 | 26 |
| 2 | CAPEC-10 | CVE-1999-0046 | 9 |
| 3 | CAPEC-10 | CVE-1999-0906 | 16 |
| 4 | CAPEC-13 | CVE-1999-0073 | 24 |
| 5 | CAPEC-16 | CVE-2003-1096 | 33 |
| 6 | CAPEC-26 | CVE-2007-1057 | 64 |
| 7 | CAPEC-27 | CVE-2000-0972 | 27 |
| 8 | CAPEC-27 | CVE-2005-0894 | 30 |
| 9 | CAPEC-27 | CVE-2006-6939 | 24 |
| 10 | CAPEC-29 | CVE-2007-1057 | 64 |
| 11 | CAPEC-31 | CVE-2010-5148 | 45 |
| 12 | CAPEC-31 | CVE-2016-0353 | 47 |
| 13 | CAPEC-33 | CVE-2005-2088 | 80 |
| 14 | CAPEC-33 | CVE-2006-6276 | 49 |
| 15 | CAPEC-34 | CVE-2006-0207 | 34 |
| 16 | CAPEC-39 | CVE-2006-0944 | 16 |
| 17 | CAPEC-42 | CVE-1999-0047 | 10 |
| 18 | CAPEC-46 | CVE-1999-0946 | 13 |
| 19 | CAPEC-46 | CVE-1999-0971 | 20 |
| 20 | CAPEC-47 | CVE-2001-0249 | 32 |
| 21 | CAPEC-47 | CVE-2006-6652 | 51 |
| 22 | CAPEC-49 | CVE-2004-1143 | 28 |
| 23 | CAPEC-50 | CVE-2006-3013 | 81 |
| 24 | CAPEC-52 | CVE-2004-0629 | 42 |
| 25 | CAPEC-54 | CVE-2006-4705 | 26 |
| 26 | CAPEC-55 | CVE-2006-1058 | 31 |
| 27 | CAPEC-59 | CVE-2001-1534 | 41 |
| 28 | CAPEC-59 | CVE-2006-6969 | 45 |
| 29 | CAPEC-60 | CVE-1999-0428 | 14 |
| 30 | CAPEC-60 | CVE-2002-0258 | 48 |
| 31 | CAPEC-61 | CVE-2004-2182 | 26 |
| 32 | CAPEC-64 | CVE-2001-1335 | 32 |
| 33 | CAPEC-66 | CVE-2006-5525 | 55 |
| 34 | CAPEC-67 | CVE-2002-0412 | 50 |
| 35 | CAPEC-70 | CVE-2006-5288 | 29 |
| 36 | CAPEC-71 | CVE-2000-0884 | 35 |
| 37 | CAPEC-72 | CVE-2001-0784 | 26 |
| 38 | CAPEC-77 | CVE-2000-0860 | 32 |
| 39 | CAPEC-80 | CVE-2000-0884 | 35 |
| 40 | CAPEC-92 | CVE-2007-1544 | 37 |
| 41 | CAPEC-93 | CVE-2006-0201 | 34 |
| 42 | CAPEC-108 | CVE-2006-6799 | 55 |
| 43 | CAPEC-135 | CVE-2007-2027 | 41 |
| 44 | CAPEC-136 | CVE-2005-2301 | 37 |
| 45 | CAPEC-267 | CVE-2010-0488 | 42 |
| 46 | CAPEC-459 | CVE-2004-2761 | 36 |
| 47 | CAPEC-459 | CVE-2005-4900 | 54 |
| 48 | CAPEC-475 | CVE-2020-0601 | 48 |
| 49 | CAPEC-632 | CVE-2005-0233 | 50 |
| 50 | CAPEC-632 | CVE-2005-0234 | 44 |
| 51 | CAPEC-632 | CVE-2005-0235 | 44 |
| 52 | CAPEC-632 | CVE-2005-0236 | 44 |
| 53 | CAPEC-632 | CVE-2005-0237 | 47 |
| 54 | CAPEC-632 | CVE-2005-0238 | 43 |
| 55 | CAPEC-632 | CVE-2009-0652 | 81 |
| 56 | CAPEC-632 | CVE-2012-0584 | 33 |
| 57 | CAPEC-657 | CVE-2006-3976 | 16 |
| 58 | CAPEC-657 | CVE-2006-3977 | 23 |
References
- Common Vulnerabilities and Exploits. Available online: https://cve.mitre.org/ (accessed on 16 June 2021).
- Common Attack Pattern Enumeration and Classification. Available online: https://capec.mitre.org/ (accessed on 16 June 2021).
- Common Weakness Enumeration. Available online: https://cwe.mitre.org/ (accessed on 16 June 2021).
- Dang, Q.; François, J. Utilizing attack enumerations to study SDN/NFV vulnerabilities. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 356–361. [Google Scholar] [CrossRef]
- Navarro, J.; Legrand, V.; Lagraa, S.; Francois, J.; Lahmadi, A.; Santis, G.D.; Festor, O.; Lammari, N.; Hamdi, F.; Deruyver, A.; et al. HuMa: A multi-layer framework for threat analysis in a heterogeneous log environment. In Proceedings of the 10th International Symposium on Foundations & Practice of Security, Nancy, France, 23–25 October 2017; pp. 144–159. [Google Scholar] [CrossRef]
- Aghaei, E.; Shaer, E.A. ThreatZoom: Neural Network for Automated Vulnerability Mitigation. In Proceedings of the 6th Annual Symposium on Hot Topics in the Science of Security, New York, NY, USA, 1–3 April 2019; pp. 1–3. [Google Scholar] [CrossRef]
- Scarabeo, N.; Fung, B.C.M.; Khokhar, R.H. Mining known attack patterns from security-related events. PeerJ Comput. Sci. 2015, 1, e25. [Google Scholar] [CrossRef][Green Version]
- Ma, X.; Davoodi, E.; Kosseim, L.; Scarabeo, N. Semantic Mapping of Security Events to Known Attack Patterns. In Proceedings of the 23rd International Conference on Natural Language and Information Systems, Paris, France, 13–15 June 2018; Volume 10859, pp. 91–98. [Google Scholar]
- Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Tracing CAPEC Attack Patterns from CVE Vulnerability Information using Natural Language Processing Technique. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 4–8 January 2021; pp. 6996–7004. [Google Scholar] [CrossRef]
- Miller, D.; Leek, T.; Schwartz, R. A hidden Markov model information retrieval system. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 15–19 August 1999; pp. 214–221. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October−4 November 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Ouchn, J.N. Method and System for Automated Computer Vulnerability Tracking. The United States Patent and Trademark Office. U.S. Patent 9,871,815, 16 January 2018. [Google Scholar]
- Adams, S.; Carter, B.; Fleming, C.; Beling, P.A. Selecting system specific cybersecurity attack patterns using topic modeling. In Proceedings of the 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications and 12th IEEE International Conference on Big Data Science and Engineering, Trustcom, New York, NY, USA, 31 July 2018–3 August 2018; pp. 490–497. [Google Scholar] [CrossRef]
- Mounika, V.; Yuan, X.; Bandaru, K. Analyzing CVE Database Using Unsupervised Topic Modelling. In Proceedings of the 6th Annual Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 5–7 December 2019; pp. 72–77. [Google Scholar] [CrossRef]
- Ou, S.; Kim, H. Unsupervised Citation Sentence Identification Based on Similarity Measurement. In Proceedings of the 13th International Conference on Transforming Digital Worlds, Sheffield, UK, 25–28 March 2018; pp. 384–394. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. J. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Z.; Xia, G.; Jiang, C. Research on Vulnerability Ontology Model. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 24–26 May 2019; pp. 657–661. [Google Scholar] [CrossRef]
- Gao, J.B.; Zhang, B.W.; Chen, X.H.; Luo, Z. Ontology-based model of network and computer attacks for security assessment. J. Shanghai Jiaotong Univ. Sci. 2013, 18, 554–562. [Google Scholar] [CrossRef]
- Ansarinia, M.; Asghari, S.A.; Souzani, A.; Ghaznavi, A. Ontology-based modeling of DDoS attacks for attack plan detection. In Proceedings of the 6th International Symposium on Telecommunications, Tehran, Iran, 6–8 November 2012; pp. 993–998. [Google Scholar] [CrossRef]
- Wang, J.A.; Wang, H.; Guo, M.; Zhou, L.; Camargo, J. Ranking attacks based on vulnerability analysis. In Proceedings of the 43rd Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Wita, R.; Jiamnapanon, N.; Teng-Amnuay, Y. An ontology for vulnerability lifecycle. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Jinggangshan, China, 2–4 April 2010; pp. 553–557. [Google Scholar] [CrossRef]
- Lee, Y.; Woo, S.; Song, Y.; Lee, J.; Lee, D.H. Practical Vulnerability-Information-Sharing Architecture for Automotive Security-Risk Analysis. IEEE Access 2020, 8, 120009–120018. [Google Scholar] [CrossRef]
- Stellios, I.; Kotzanikolaou, P.; Grigoriadis, C. Assessing IoT enabled cyber-physical attack paths against critical system. J. Comput. Secur. 2021, 107, 102316. [Google Scholar] [CrossRef]
- Rostami, S.; Kleszcz, A.; Dimanov, D.; Katos, V. A Machine Learning Approach to Dataset Imputation for Software Vulnerabilities. In Proceedings of the 10th International Conference on Multimedia Communications, Services and Security, Krakow, Poland, 8–9 October 2020; pp. 25–36. [Google Scholar] [CrossRef]
- Sion, L.; Tuma, K.; Scandariato, R.; Yskout, K.; Joosen, W. Towards Automated Security Design Flaw Detection. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering Workshops, San Diego, CA, USA, 10–15 November 2019; pp. 49–56. [Google Scholar] [CrossRef]
- Almorsy, M.; Grundy, J.; Ibrahim, A.S. Collaboration-based cloud computing security management framework. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 364–371. [Google Scholar] [CrossRef]
- Kotenko, I.; Doynikova, E. The CAPEC based generator of attack scenarios for network security evaluation. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Warsaw, Poland, 24–26 September 2015; pp. 436–441. [Google Scholar] [CrossRef]
- Xianghui, Z.; Yong, P.; Zan, Z.; Yi, J.; Yuangang, Y. Research on parallel vulnerabilities discovery based on open source database and text mining. In Proceedings of the 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Adelaide, Australia, 23–25 September 2015; pp. 327–332. [Google Scholar] [CrossRef]
- Ruohonen, J.; Leppanen, V. Toward Validation of Textual Information Retrieval Techniques for Software Weaknesses. Commun. Comput. Inf. Sci. 2018, 903, 265–277. [Google Scholar] [CrossRef]
- Guo, M.; Wang, J. An ontology-based approach to model common vulnerabilities and exposures in information security. In Proceedings of the ASEE Southest Section Conference, Marietta, GA, USA, 5–7 April 2009. [Google Scholar]
- Shah, S.; Mehtre, B.M. An overview of vulnerability assessment and penetration testing techniques. J. Comput. Virol. Hacking Tech. 2015, 11, 27–49. [Google Scholar] [CrossRef]
- Khera, Y.; Kumar, D.; Sujay, S.; Garg, N. Analysis and Impact of Vulnerability Assessment and Penetration Testing. In Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing: Trends, Prespectives and Prospects, Faridabad, India, 14–16 February 2019; pp. 525–530. [Google Scholar] [CrossRef]
- Grigoriadis, C. Identification and Assessment of Security Attacks and Vulnerabilities, Utilizing CVE, CWE and CAPEC. Master’s Thesis, University of Piraeus, Piraeus, Greece, 2019. [Google Scholar]
- Scikit-Learn. Available online: https://scikit-learn.org/stable/ (accessed on 16 June 2021).
- Tensorflow Hub. Available online: https://tfhub.dev/ (accessed on 16 June 2021).
- Sentence Transformers Documentation. Available online: https://www.sbert.net/ (accessed on 16 June 2021).
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Hafiz, M.; Adamczyk, P.; Johnson, R. Growing a pattern language (for security). In Proceedings of the ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, Tucson, AZ, USA, 19–26 October 2012; pp. 139–158. [Google Scholar] [CrossRef]
- Biswas, B.; Mukhopadhyay, A.; Gupta, G. “Leadership in Action: How Top Hackers Behave” A Big-Data Approach with Text-Mining and Sentiment Analysis. In Proceedings of the 51st Hawaii International Conference on System Sciences, Honolulu, HI, USA, 2–6 January 2018; pp. 1752–1761. [Google Scholar] [CrossRef]
- Samtani, S.; Chinn, R.; Chen, H.; Nunamaker, J.F., Jr. Exploring emerging hacker assets and key hackers for proactive cyber threat intelligence. J. Manag. Inf. Syst. 2017, 34, 1023–1053. [Google Scholar] [CrossRef]
- Xia, T.; Washizaki, H.; Fukazawa, Y.; Kaiya, H.; Ogata, S.; Fernandez, E.B.; Kato, T.; Kanuka, H.; Okubo, T.; Yoshioka, N.; et al. CSPM: Metamodel for Handling Security and Privacy Knowledge in Cloud Service Development. J. Syst. Softw. Secur. Prot. 2021, 12, 1–18. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques. Information 2021, 12, 298. https://doi.org/10.3390/info12080298
Kanakogi K, Washizaki H, Fukazawa Y, Ogata S, Okubo T, Kato T, Kanuka H, Hazeyama A, Yoshioka N. Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques. Information. 2021; 12(8):298. https://doi.org/10.3390/info12080298
Chicago/Turabian StyleKanakogi, Kenta, Hironori Washizaki, Yoshiaki Fukazawa, Shinpei Ogata, Takao Okubo, Takehisa Kato, Hideyuki Kanuka, Atsuo Hazeyama, and Nobukazu Yoshioka. 2021. "Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques" Information 12, no. 8: 298. https://doi.org/10.3390/info12080298
APA StyleKanakogi, K., Washizaki, H., Fukazawa, Y., Ogata, S., Okubo, T., Kato, T., Kanuka, H., Hazeyama, A., & Yoshioka, N. (2021). Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques. Information, 12(8), 298. https://doi.org/10.3390/info12080298