
A Joint Summarization and Pre-Trained Model for Review-Based Recommendation


Abstract
1. Introduction
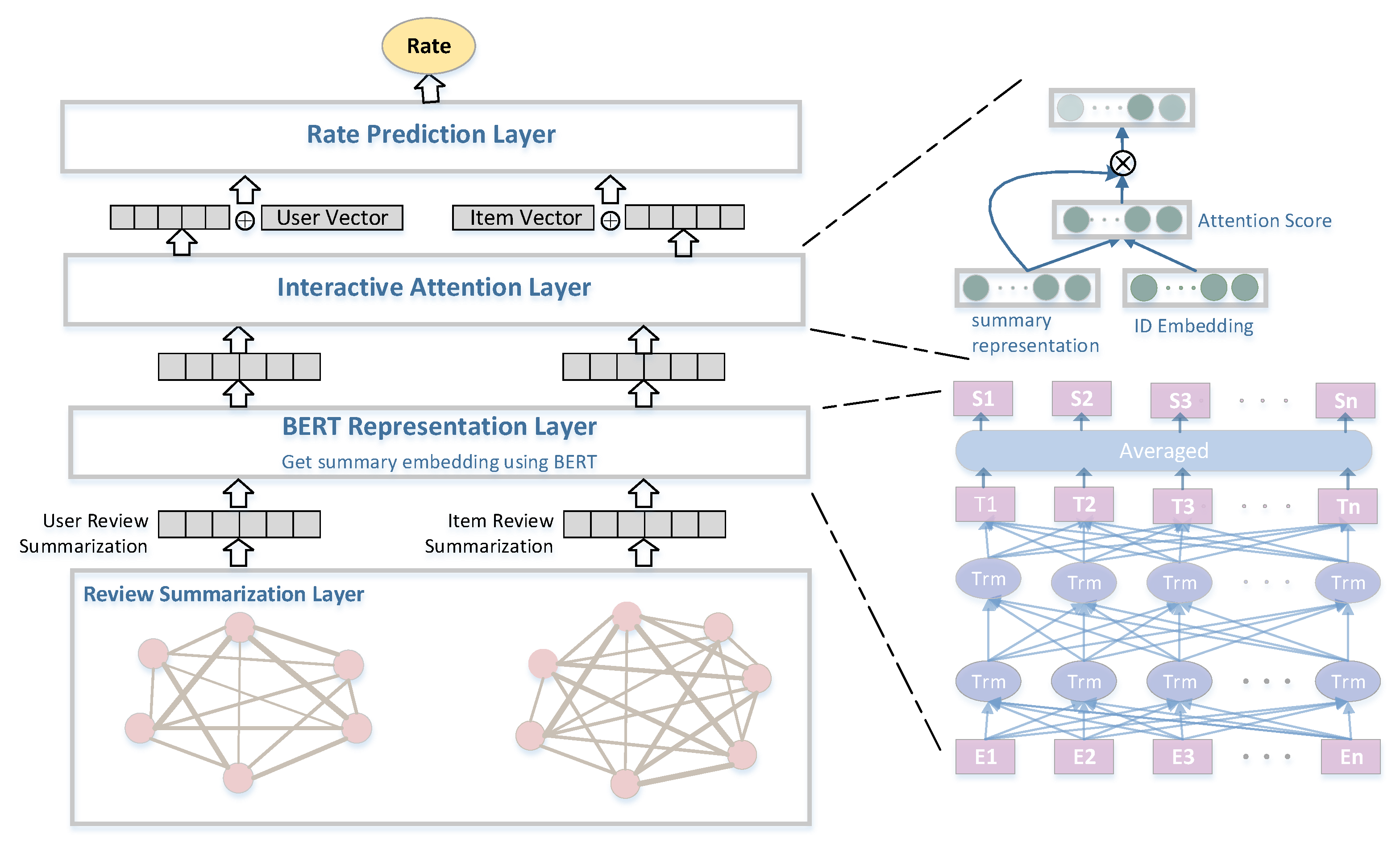
2. Methods
2.1. Review Summarization Layer
2.2. BERT Representation Layer
2.3. Interactive Attention Layer
2.4. Rate Prediction Layer
3. Results and Discussion
3.1. Dataset and Evaluation Metric
3.2. Compared Methods
- Probabilistic matrix factorization (PMF (https://github.com/JieniChen/Recommender-System) (accessed on 21 April 2020)) [18]: PMF is a widely used rating-based CF method. PMF assumes that the elements in the scoring matrix are determined by the inner product of the user’s potential preference vector and the item’s potential attribute vector.
- Nonnegative matrix factorization (NMF (https://github.com/JieniChen/Recommender-System) (accessed on 21 April 2020)) [19]: NMF is also a rating-based CF method. It assumes that the decomposed matrix should satisfy nonnegativity constraints. NMF can decompose a nonnegative matrix into two nonnegative matrices.
- Hidden factors and hidden topics (HFT (http://cseweb.ucsd.edu/jmcauley/code/code_RecSys13.tar.gz) (accessed on 9 February 2021)) [20]: HFT models the given ratings using a matrix factorization model with an exponential transformation function to link the stochastic topic distribution obtained from modeling the review text and the latent vector obtained from modeling the ratings. It assumes that the topic distribution of each review is produced on either user factors or item factors. In this way, HFT can provide an interpretation of each latent factor because factors and topics are located in the same space.
- Deep Cooperative Neural Networks (DeepCoNN (https://github.com/richdewey/DeepCoNN) (accessed on 16 March 2019)) [6]: DeepCoNN uses a CNN to model user reviews to learn the underlying user behaviors and product attributes. DeepCoNN constructs two parallel networks and connects them with a shared additional layer so that the interaction between the user and the product can be used to predict the final score.
- Multipointer coattention network (MPCN (https://github.com/vanzytay/kdd2018_mpcn) (accessed on 17 March 2019)) [10]: The MPCN is based on the idea that a few reviews are important and that the importance depends dynamically on the current target. To extract important reviews, the MPCN contains a review-by-review pointer-based learning scheme that matches reviews in a word-by-word fashion. The pointer mechanism used in the MPCN is essentially coattentive and can learn the dependencies between users and items.
- Dual attention-based model (D-Attn (https://hub.fastgit.org/seongjunyun/CNN-with-Dual-Local-and-Global-Attention) (accessed on 17 March 2019)) [2]: D-Attn uses aggregated review texts from a user and an item to learn the embeddings of the user and the item. D-Attn applies CNNs with dual (local and global) attention mechanisms. Local attention is used to capture a user’s preferences or an item’s properties. Global attention helps the CNNs focus on the semantic information of the review text.
- Neural attentional regression model with review-level explanations (NARRE (https://github.com/chenchongthu/narre) (accessed on 6 April 2019)) [21]: The NARRE proposes an attention mechanism to explore the usefulness of different reviews. The weights of reviews are learned by an attention mechanism in a distant supervised manner. Moreover, the NARRE learns the latent features of users and items using two parallel neural networks.
3.3. Experimental Settings
3.4. Experimental Results
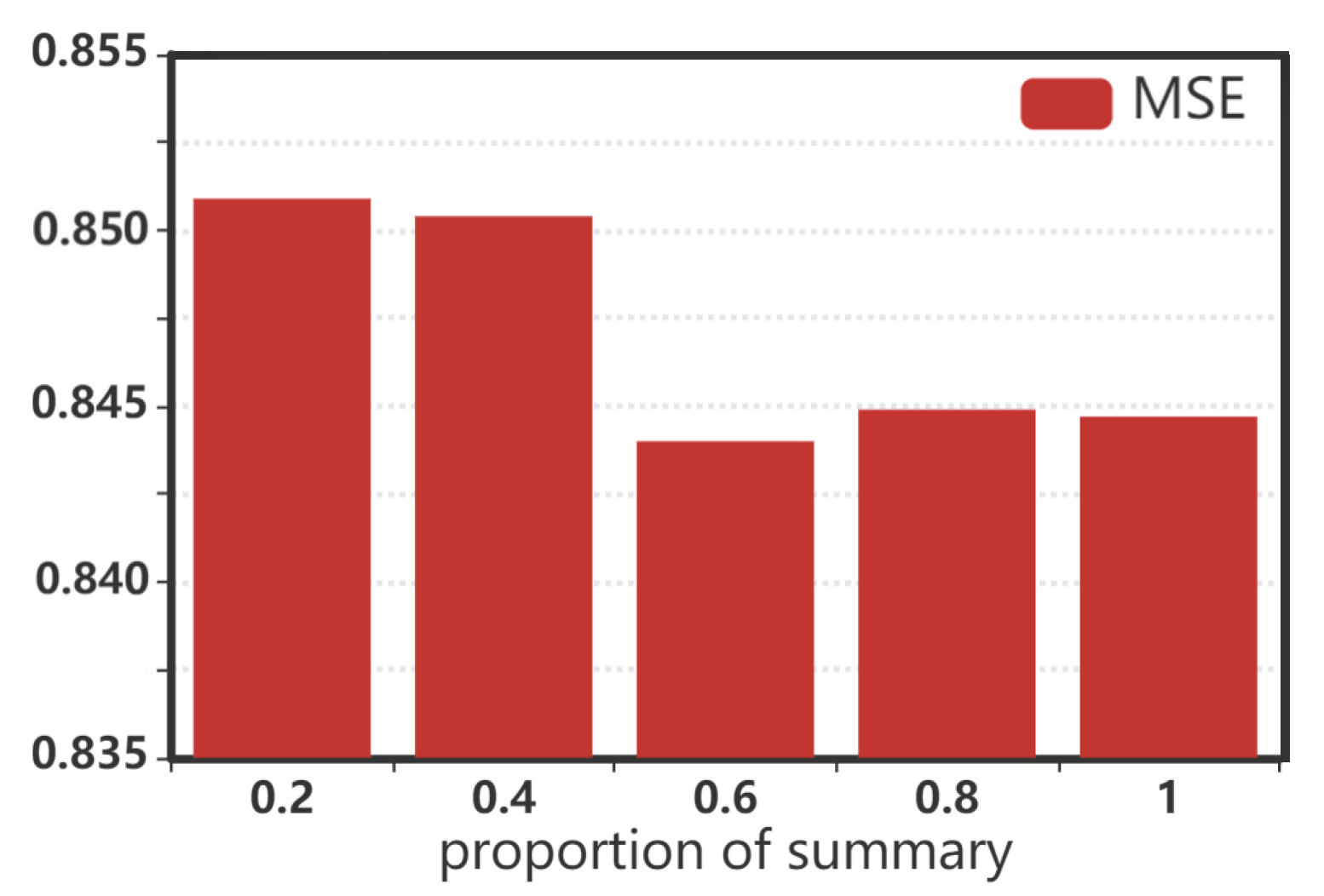
3.5. Parameter Sensitivity Analysis
3.6. Ablation Study
4. Related Work
4.1. Collaborative Filtering Based Recommendation
4.2. Review Summarization
4.3. Deep Learning Based Review Modeling
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shakhovska, N.; Fedushko, S.; Shvorob, I.; Syerov, Y. Development of Mobile System for Medical Recommendations. Procedia Comput. Sci. 2019, 155, 43–50. [Google Scholar] [CrossRef]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable convolutional neural networks with dual local and global attention for review rating prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 297–305. [Google Scholar]
- Wang, H.; Wu, F.; Liu, Z.; Xie, X. Fine-grained Interest Matching for Neural News Recommendation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 5–10 July 2020; pp. 836–845. [Google Scholar]
- Bouvrie, J. Notes on Convolutional Neural Networks; Neural Nets. MIT CBCL Tech Report. 2006. Available online: http://cogprints.org/5869/1/cnn_tutorial.pdf (accessed on 25 April 2020).
- Gong, Y.; Zhang, Q. Hashtag recommendation using attention-based convolutional neural network. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2782–2788. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Wu, Y.; DuBois, C.; Zheng, A.X.; Ester, M. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems. In Proceedings of the ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; pp. 153–162. [Google Scholar]
- Jing, H.; Smola, A.J. Neural survival recommender. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 515–524. [Google Scholar]
- Bansal, T.; Belanger, D.; McCallum, A. Ask the gru: Multi-task learning for deep text recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 107–114. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C. Multi-pointer co-attention networks for recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2309–2318. [Google Scholar]
- Luo, A.; Zhao, P.; Liu, Y.; Zhuang, F.; Sheng, V.S. Collaborative Self-Attention Network for Session-based Recommendation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence and Seventeenth Pacific Rim International Conference on Artificial Intelligence IJCAI-PRICAI-20, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Dong, X.; Ni, J.; Cheng, W.; Chen, Z.; Melo, G.D. Asymmetrical Hierarchical Networks with Attentive Interactions for Interpretable Review-Based Recommendation. Proc. Aaai Conf. Artif. Intell. 2020, 34, 7667–7674. [Google Scholar] [CrossRef]
- Zhou, J.P.; Cheng, Z.; Pérez, F.; Volkovs, M. TAFA: Two-headed attention fused autoencoder for context-aware recommendations. In Proceedings of the Fourteenth ACM Conference on Recommender Systems, Rio de Janeiro, Brazil, 22–26 September 2020; pp. 338–347. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, WA, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic Matrix Factorization. Adv. Neural Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]
- Lee, D.D.; Seung, H.S. Algorithms for Non-Negative Matrix Factorization. In Proceedings of the Advances in neural information processing systems (NIPS), Vancouver, BC, Canada, 3–8 December 2001; pp. 556–562. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text. In Proceedings of the 7th ACM conference on Recommender systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Balabanović, M.; Shoham, Y. Fab: Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. Internet Comput. IEEE 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Das, A.S.; Datar, M.; Garg, A.; Rajaram, S. Google news personalization: Scal-able online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 271–280. [Google Scholar]
- Dhelim, S.; Ning, H.; Aung, N.; Huang, R.; Ma, J. Personality-Aware Product Recommendation System Based on User Interests Mining and Metapath Discovery. IEEE Trans. Comput. Soc. Syst. 2020. [Google Scholar] [CrossRef]
- Khelloufi, A.; Ning, H.; Dhelim, S.; Qiu, T.; Atzori, L. A Social Relationships Based Service Recommendation System For SIoT Devices. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Ning, H.; Dhelim, S.; Aung, N. PersoNet: Friend Recommendation System Based on Big-Five Personality Traits and Hybrid Filtering. IEEE Trans. Comput. Soc. Syst. 2019, 6, 394–402. [Google Scholar] [CrossRef]
- Wang, C.; Blei, D.M. Collaborative Topic Modeling for Recommending Scientific Articles. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- King, G.L.L. Ratings Meet Reviews, a Combined Approach to Recommend. In Proceedings of the RecSys ’14, Silicon Valley, CA, USA, 6–10 October 2014; pp. 105–112. [Google Scholar]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 791–798. [Google Scholar]
- Wu, P.; Li, X.; Shen, S.; He, D. Social media opinion summarization using emotion cognition and convolutional neural networks. Int. J. Inf. Manag. 2020, 51, 101978. [Google Scholar] [CrossRef]
- Al-Natour, S.; Turetken, O. A comparative assessment of sentiment analysis and star ratings for consumer reviews—ScienceDirect. Int. J. Inf. Manag. 2020, 54, 102132. [Google Scholar] [CrossRef]
- Shimada, K.; Tadano, R.; Endo, T. Multi-aspects review summarization with objective information. Procedia Soc. Behav. Sci. 2011, 27, 140–149. [Google Scholar] [CrossRef]
- Nyaung, D.E.; Thein, T.L.L. Feature-Based Summarizing and Ranking from Customer Reviews. Int. J. Eng. 2015, 9, 734–739. [Google Scholar]
- Mabrouk, A.; Redondo, R.; Kayed, M. SEOpinion: Summarization and Exploration of Opinion from E-Commerce Websites. Sensors 2021, 21, 636. [Google Scholar] [CrossRef]
- Su, F.; Wang, X.; Zhang, Z. Review Summarization Generation Based on Attention Mechanism. J. Beijing Univ. Posts Telecommun. 2018, 41, 7. [Google Scholar]
- Xu, H.; Liu, H.; Zhang, W.; Jiao, P.; Wang, W. Rating-boosted abstractive review summarization with neural personalized generation. Knowl.-Based Syst. 2021, 218, 106858. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Li, Y.; Liu, T.; Jiang, J.; Zhang, L. Hashtag recommendation with topical attention-based LSTM. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 943–952. [Google Scholar]
- Liu, Q.; Zhang, H.; Zeng, Y.; Huang, Z.; Wu, Z. Content attention model for aspect based sentiment analysis. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1023–1032. [Google Scholar]
- Manotumruksa, J.; Macdonald, C.; Ounis, I. A contextual attention recurrent architecture for context-aware venue recommendation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 555–564. [Google Scholar]
- Li, P.; Wang, Z.; Ren, Z.; Bing, L.; Lam, W. Neural rating regression with abstractive tips generation for recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 345–354. [Google Scholar]
- Chin, J.Y.; Zhao, K.; Joty, S.; Cong, G. ANR: Aspect-based neural recommender. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 147–156. [Google Scholar]
- Liu, D.; Li, J.; Du, B.; Chang, J.; Gao, R. Daml: Dual attention mutual learning between ratings and reviews for item recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 344–352. [Google Scholar]
- Zhao, G.; Lei, X.; Qian, X.; Mei, T. Exploring users’ internal influence from reviews for social recommendation. IEEE Trans. Multimed. 2018, 21, 771–781. [Google Scholar] [CrossRef]
- Cheng, Z.; Ding, Y.; He, X.; Zhu, L.; Song, X.; Kankanhalli, M.S. Aˆ3NCF: An Adaptive Aspect Attention Model for Rating Prediction. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 3748–3754. [Google Scholar]
- Mei, L.; Ren, P.; Chen, Z.; Nie, L.; Ma, J.; Nie, J.Y. An attentive interaction network for context-aware recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 157–166. [Google Scholar]
- Wu, L.; Quan, C.; Li, C.; Wang, Q.; Zheng, B.; Luo, X. A context-aware user-item representation learning for item recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–29. [Google Scholar] [CrossRef]
- Ye, W.; Zhang, Y.; Zhao, W.X.; Chen, X.; Qin, Z. A collaborative neural model for rating prediction by leveraging user reviews and product images. In Asia Information Retrieval Symposium; Springer: Berlin/Heidelberg, Germany, 2017; pp. 99–111. [Google Scholar]
- Lei, X.; Qian, X.; Zhao, G. Rating prediction based on social sentiment from textual reviews. IEEE Trans. Multimed. 2016, 18, 1910–1921. [Google Scholar] [CrossRef]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 15 May 2020).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Chronopoulou, A.; Baziotis, C.; Potamianos, A. An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models. In Proceedings of the 17th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 2089–2095. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| User u’s vector | |
| Item i’s vector | |
| n | The number of reviews for a user |
| m | The number of reviews for an item |
| User u’s j-th review | |
| User u’s review set | |
| The corresponding item id embedding of user u’s review | |
| User u’s j-th review summary | |
| User u’s summary set | |
| Item i’s j-th review | |
| Item i’s review set | |
| The corresponding user id embedding of item i’s review | |
| Item i’s j-th review summary | |
| Item i’s summary set | |
| User u’s rate score for item i |
| Dataset | Users | Items | Reviews |
|---|---|---|---|
| Automotive | 2928 | 1835 | 20,468 |
| Digital Music | 2986 | 551 | 9999 |
| Musical Instruments | 1429 | 900 | 10,255 |
| Patio Lawn and Garden | 1686 | 962 | 13,254 |
| Dataset | Automotive | Digital Music | Musical Instruments | Patio Lawn |
|---|---|---|---|---|
| PMF | 1.1515 | 0.9769 | 1.1251 | 1.7378 |
| NMF | 1.0878 | 0.7699 | 1.0058 | 1.2330 |
| HFT | 1.1415 | 0.7744 | 1.0104 | 1.1406 |
| DeepCoNN | 0.8681 | 0.9830 | 0.7146 | 1.1193 |
| D-Attn | 0.8615 | 0.8600 | 0.7493 | 1.0958 |
| MPCN | 0.9400 | 0.7433 | 0.7314 | 1.0835 |
| NARRE | 0.8225 | 0.8396 | 0.6829 | 1.1055 |
| JSPTRec | 0.8191 | 0.7130 | 0.6856 | 1.0361 |
| Dataset | Automotive | Digital Music | Musical Instruments | Patio Lawn |
|---|---|---|---|---|
| JSPTRec-BERT | 0.7845 | 0.6632 | 0.8493 | 1.0402 |
| JSPTRec-TR | 0.7803 | 0.6765 | 0.8447 | 1.0369 |
| JSPTRec-ATT | 0.8490 | 0.6811 | 0.8493 | 1.0539 |
| JSPTRec | 0.7771 | 0.6314 | 0.8440 | 0.9967 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Li, Y.; Wang, L. A Joint Summarization and Pre-Trained Model for Review-Based Recommendation. Information 2021, 12, 223. https://doi.org/10.3390/info12060223
Bai Y, Li Y, Wang L. A Joint Summarization and Pre-Trained Model for Review-Based Recommendation. Information. 2021; 12(6):223. https://doi.org/10.3390/info12060223
Chicago/Turabian StyleBai, Yi, Yang Li, and Letian Wang. 2021. "A Joint Summarization and Pre-Trained Model for Review-Based Recommendation" Information 12, no. 6: 223. https://doi.org/10.3390/info12060223
APA StyleBai, Y., Li, Y., & Wang, L. (2021). A Joint Summarization and Pre-Trained Model for Review-Based Recommendation. Information, 12(6), 223. https://doi.org/10.3390/info12060223