
SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network




Abstract
:1. Introduction
- We model an effective Hashtag Recommendation system using a Deep Residual Network Classifier, trained by the SCPO algorithm, which is derived by integrating the SCA and the PO algorithm;
- The incorporation of features in the optimization algorithm pushes the solution towards the global optimum rather than local optima;
- We conduct extensive experiments on different datasets, in which the proposed method is shown to outperform state-of-the-art methods in the Hashtag Recommendation task.
2. Related Work
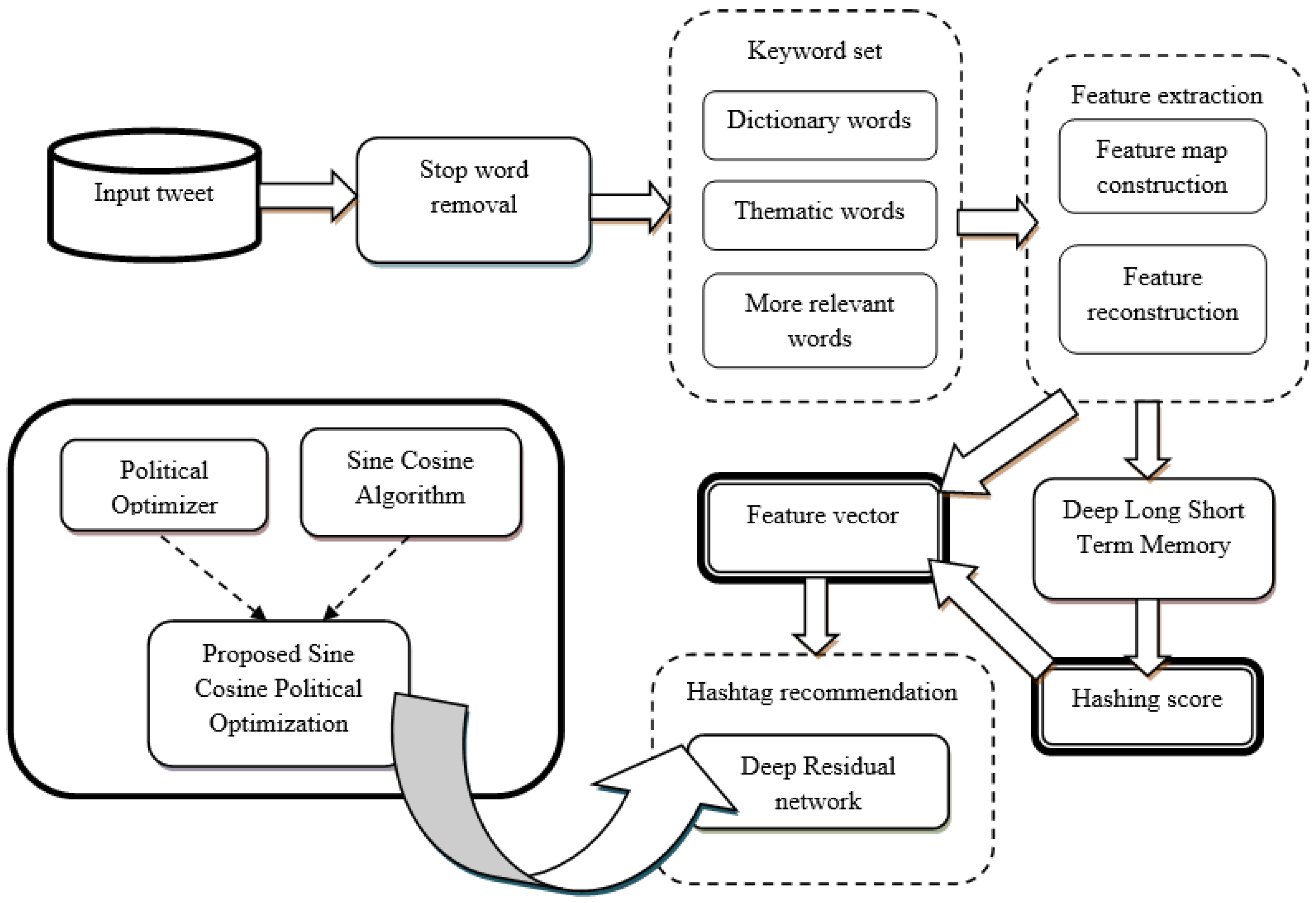
3. Proposed Framework
3.1. Removal of Stop Words from Input Tweet
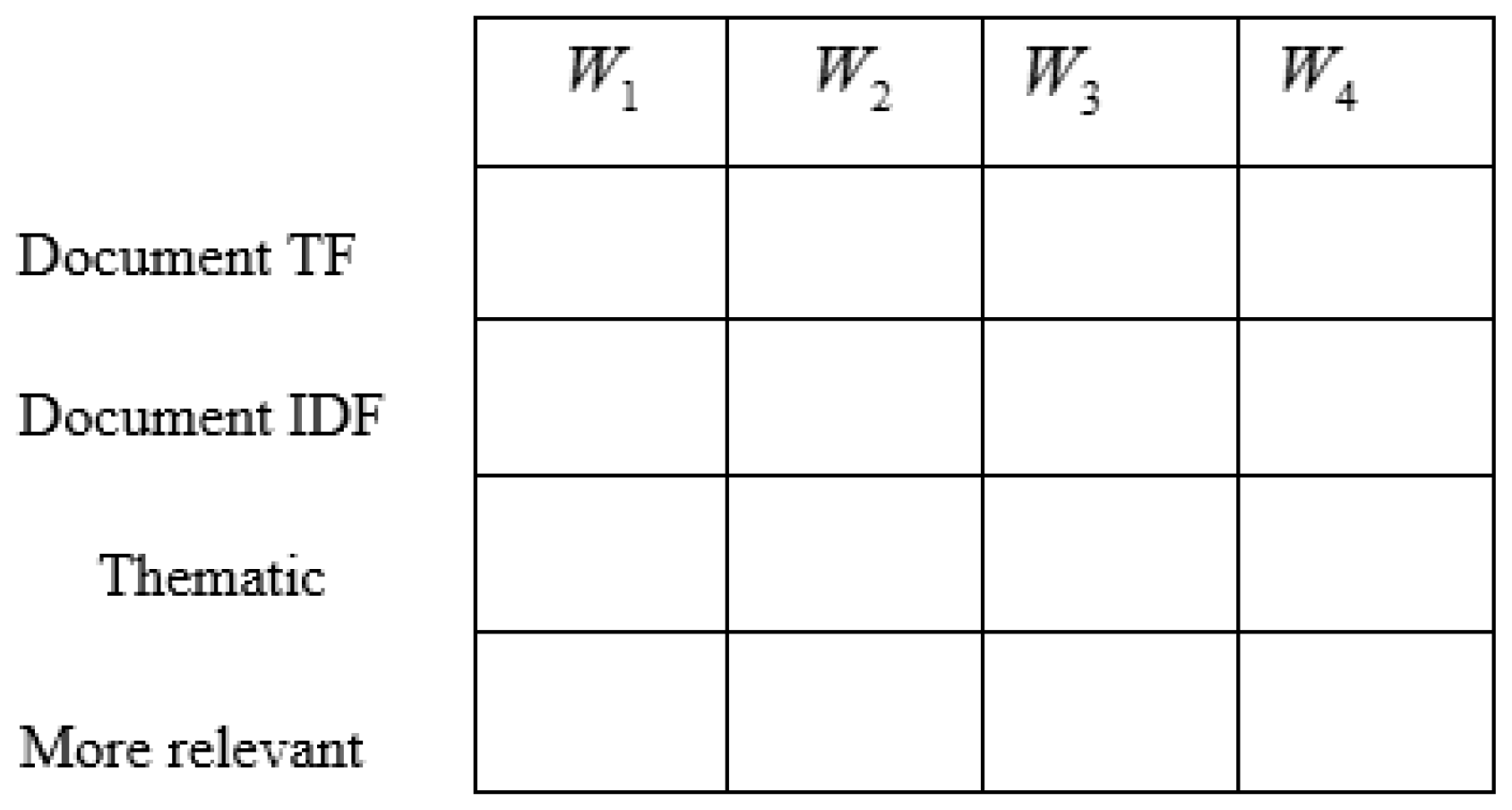
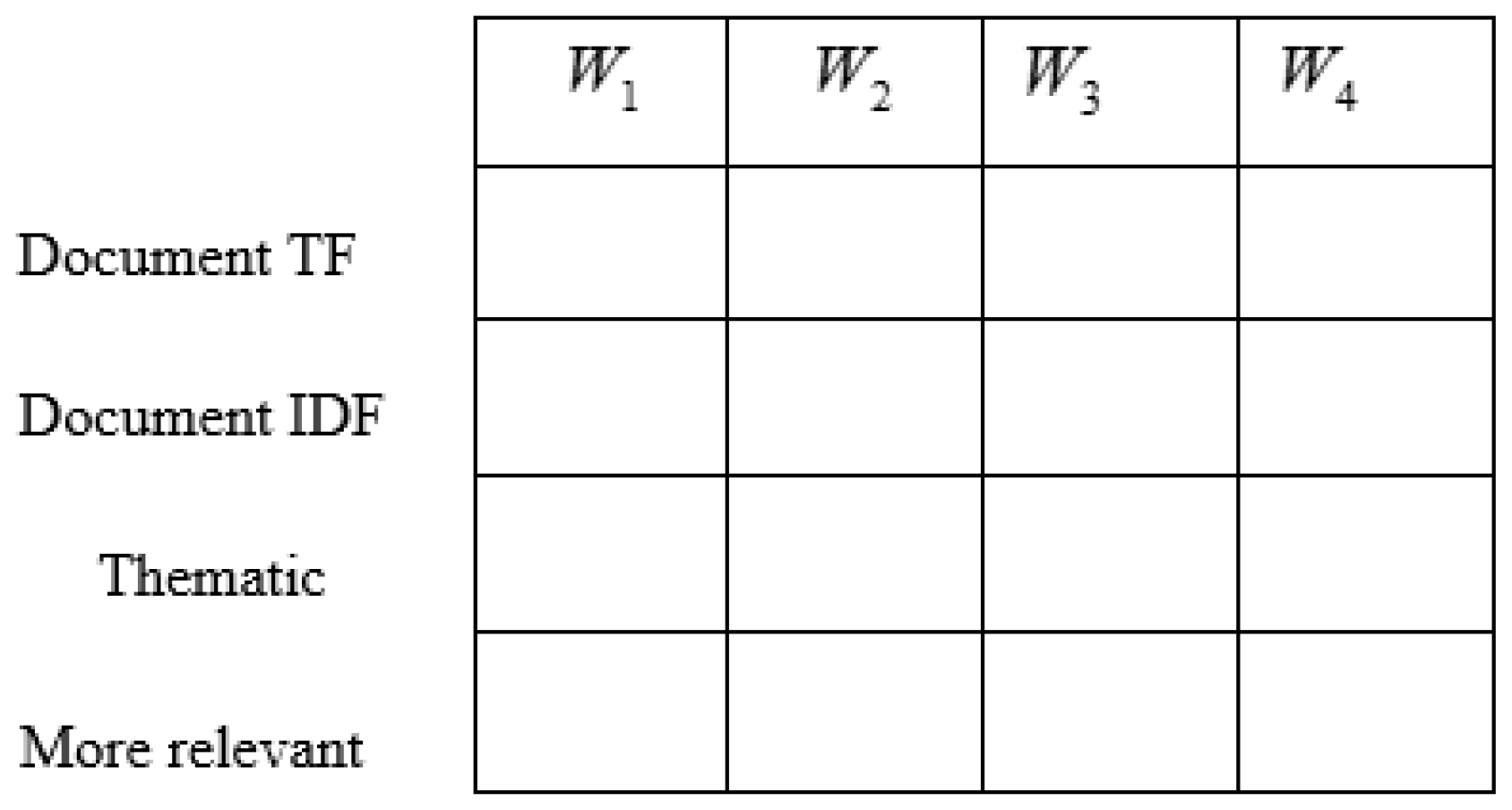
3.2. Keyword Set: Dictionary, Thematic and More Relevant Words
3.3. Feature Extraction Based on Keyword Set
3.3.1. Feature Map Construction
3.3.2. Feature Reconstruction
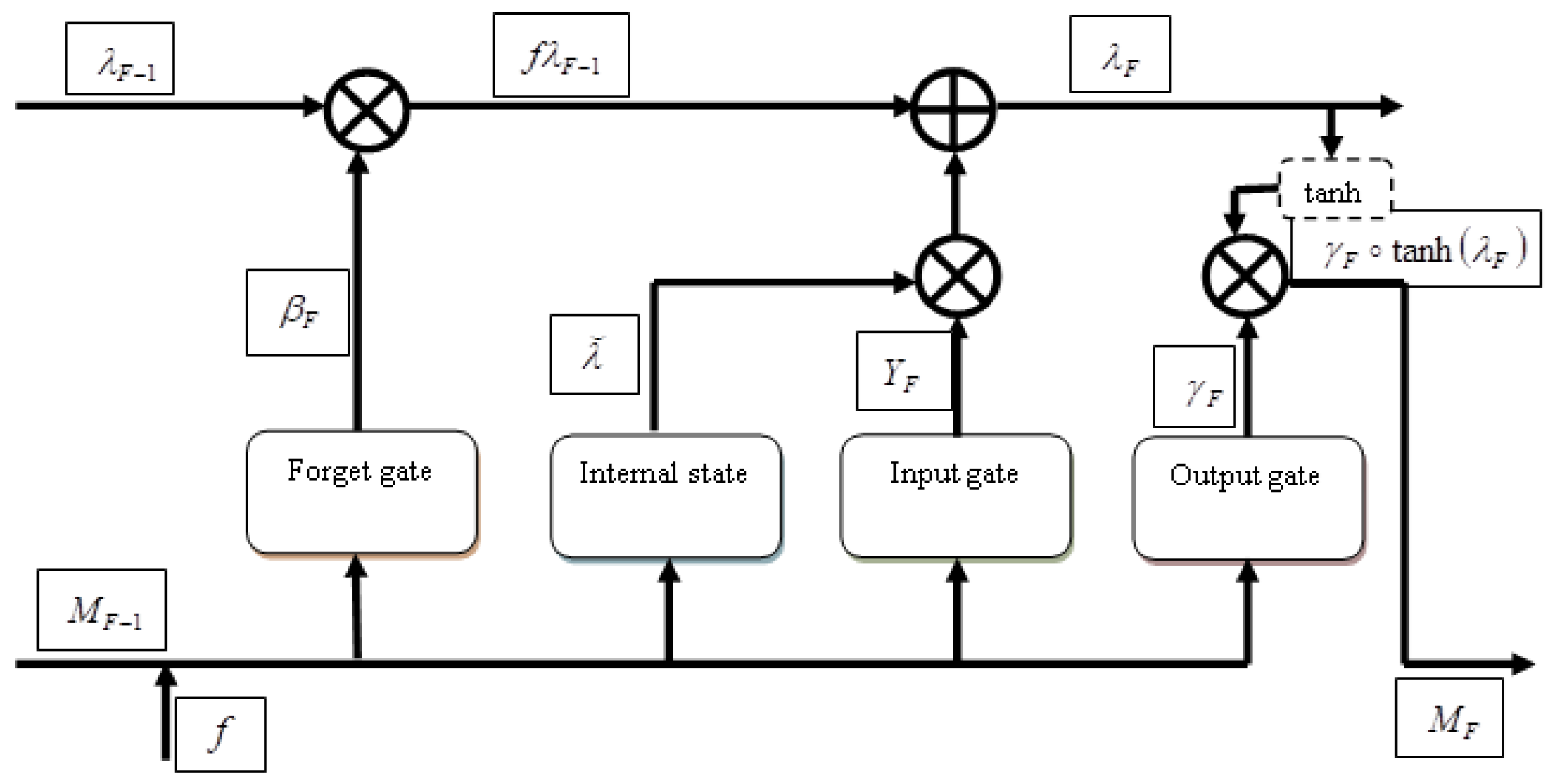
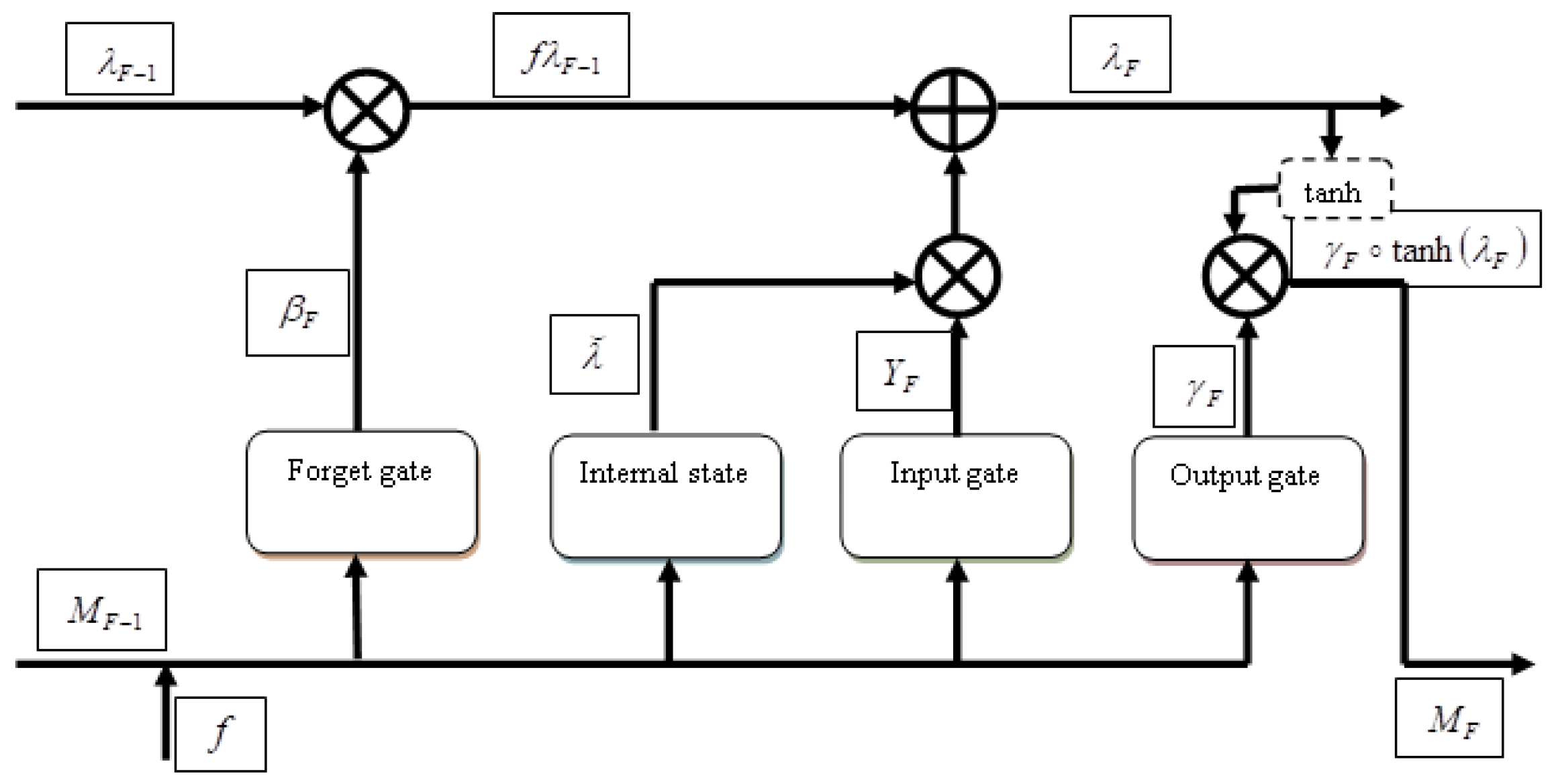
3.3.3. Hashing Score Prediction by Deep LSTM
3.3.4. Computation of Feature Vector
3.4. Hashtag Recommendation Using Proposed SC-Political ResNet
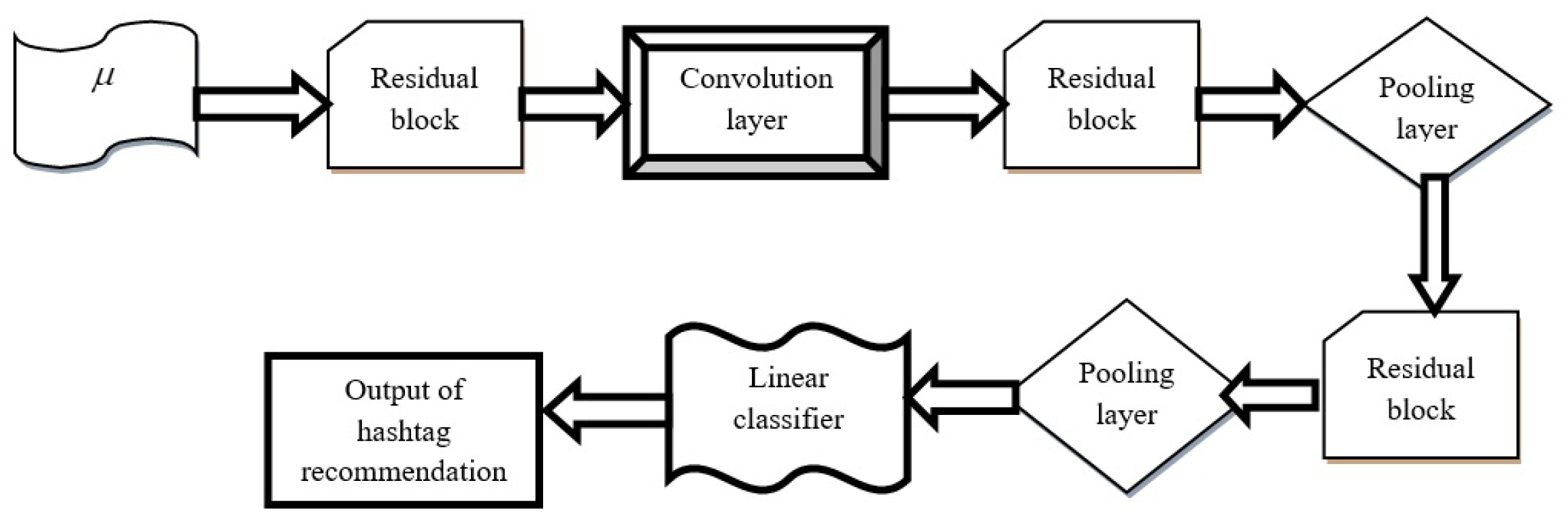
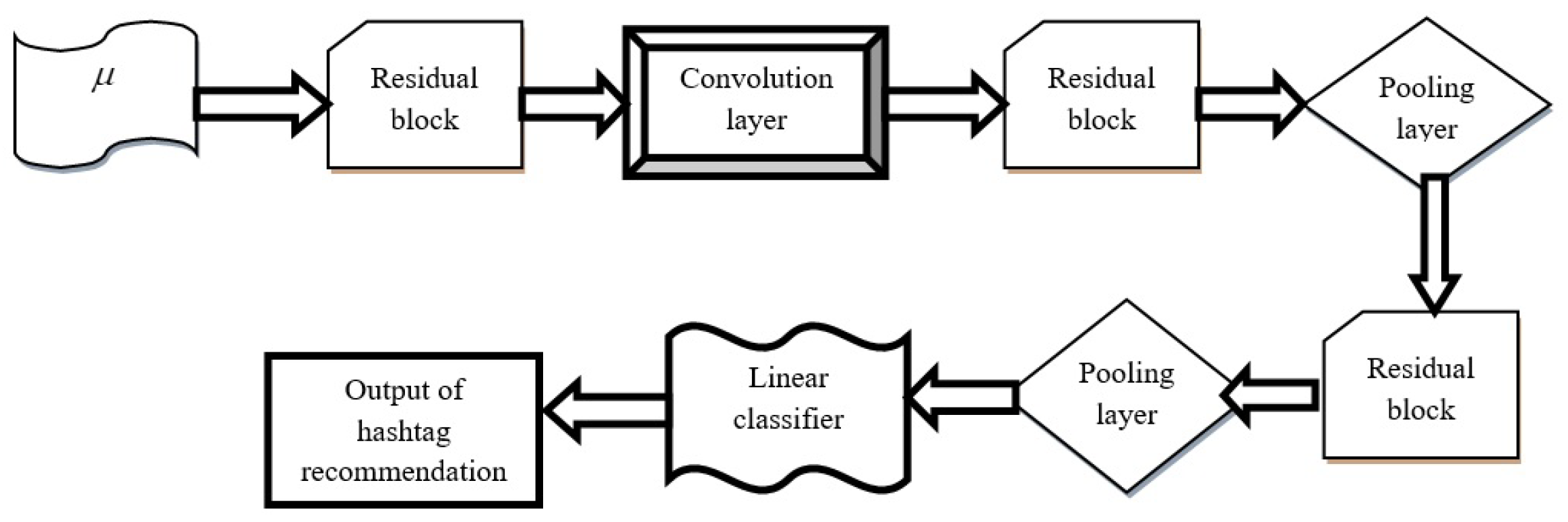
3.4.1. Architecture of Deep Residual Network
3.4.2. Training Process of Deep Residual Network Using SCPO
| Algorithm 1: Pseudo-code of proposed SCPO-based Deep Residual network. |
| 1 Input: |
| 2 Output: |
| 3 |
| 4 Compute fitness measure |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 Do |
| 13 |
| 14 |
| 15 |
| 16 Do |
| 17 |
| 18 Do |
| 19 |
| 20 End |
| 21 End |
| 22 |
| 23 |
| 24 |
| 25 |
| 26 |
| 27 |
| 28 |
| 29 End |
4. System Implementation and Evaluation
4.1. Description of Datasets
- Apple Twitter Sentiment Dataset: This dataset contains 12 columns and 3886 rows, including a number of fields; namely, id, sentiment, query, text, and so on. The size of the dataset is 798.47 KB. However, the text contains hashtags with positive, negative, or neutral tweet sentiments.
- Twitter Dataset: This dataset contains 10,000 records acquired from the twitter of the trending domain “AvengersEndgame”. These data can be used for sentiment analysis. It contains 17 columns with the 8 string-type variables, 4 Boolean-type variables, 3 Integer-type variables, and two other types of variables.
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Baseline Methods
- LSTM-RNN Network [15]: For this, the hashtag recommendation was designed by encoding the tweet vector using the LSTM-RNN technique;
- Pattern Mining for Hashtag Recommendation (PMHRec) [19]: PMHRec was designed using the top k high-average utility patterns for temporal transformation tweets, from which the hashtag recommendation was devised;
- Attention-based multimodal neural network model (AMNN) [21]: The AMNN was designed to extract the features from text and images, after which correlations are captured for hashtag recommendation;
- Deep LSTM [26]: Deep-LSTM was designed to evaluate the daily pan evaporation;
- Emhash [30]: For this method, the hashtag recommendation was developed using a neural network-based BERT embedding;
- Community-based hashtag recommendation [20]: For this, the hashtag recommendation was designed using the communities extracted from social Networks.
5. Results and Discussion
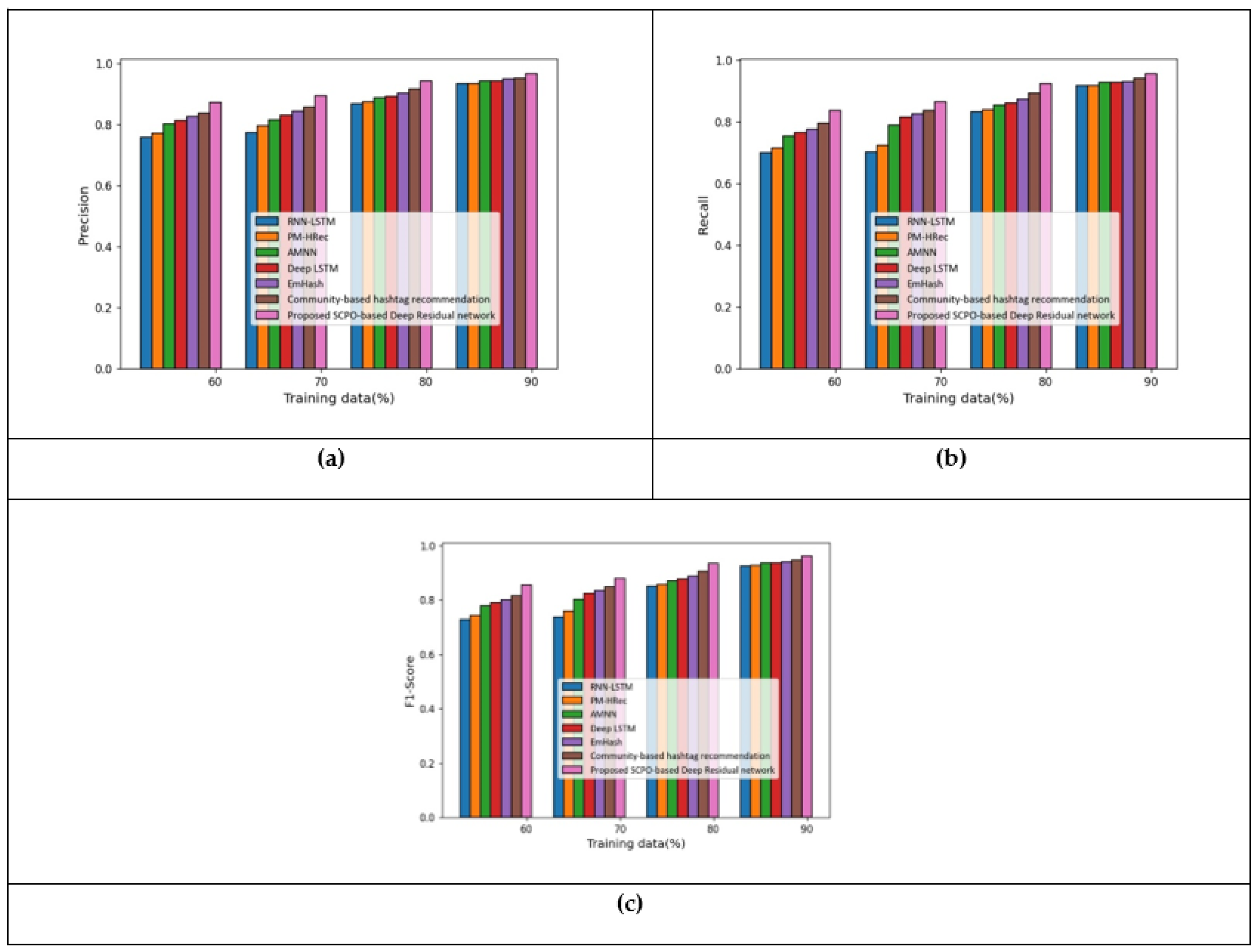
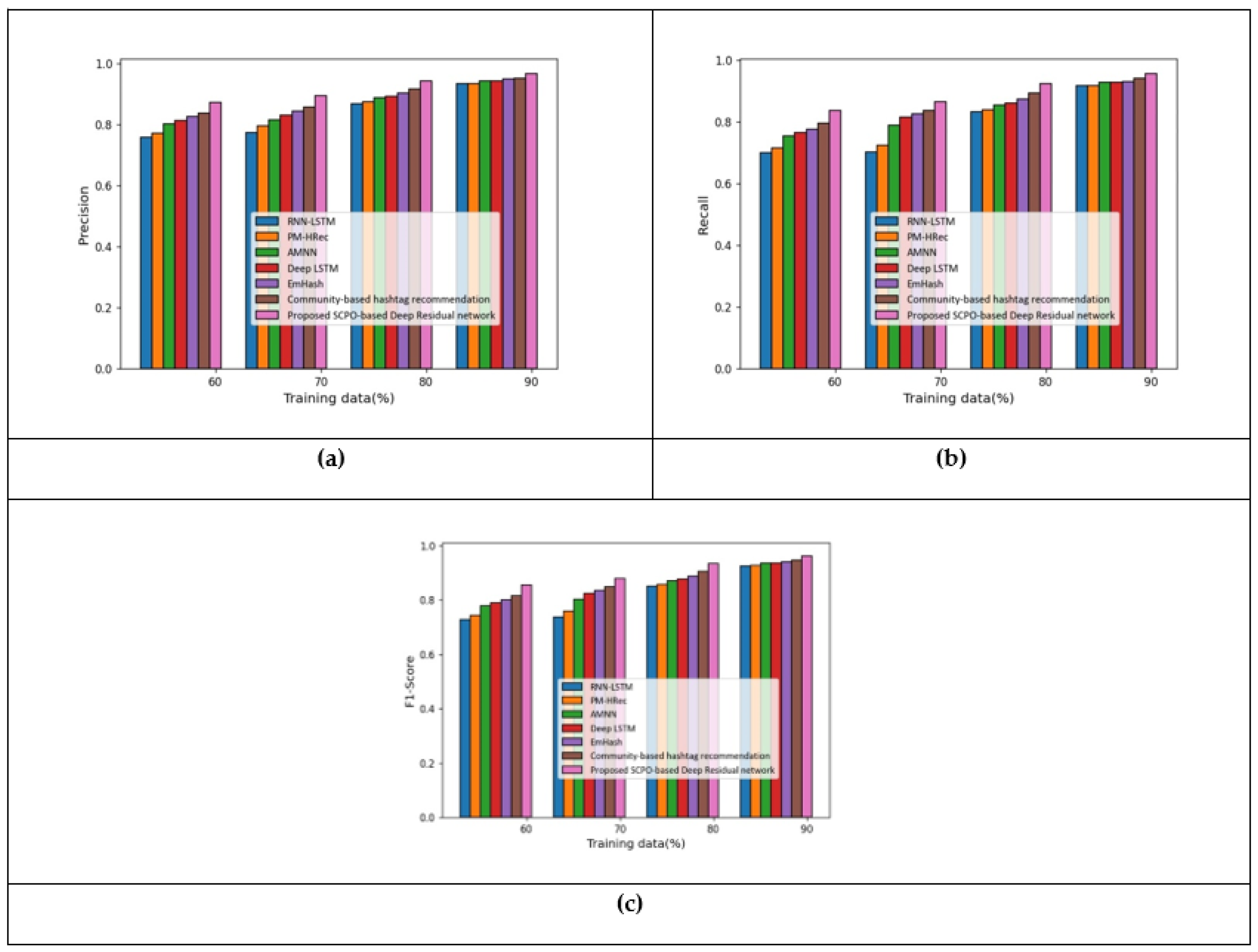
5.1. Results Based on Apple Twitter Sentiment Dataset
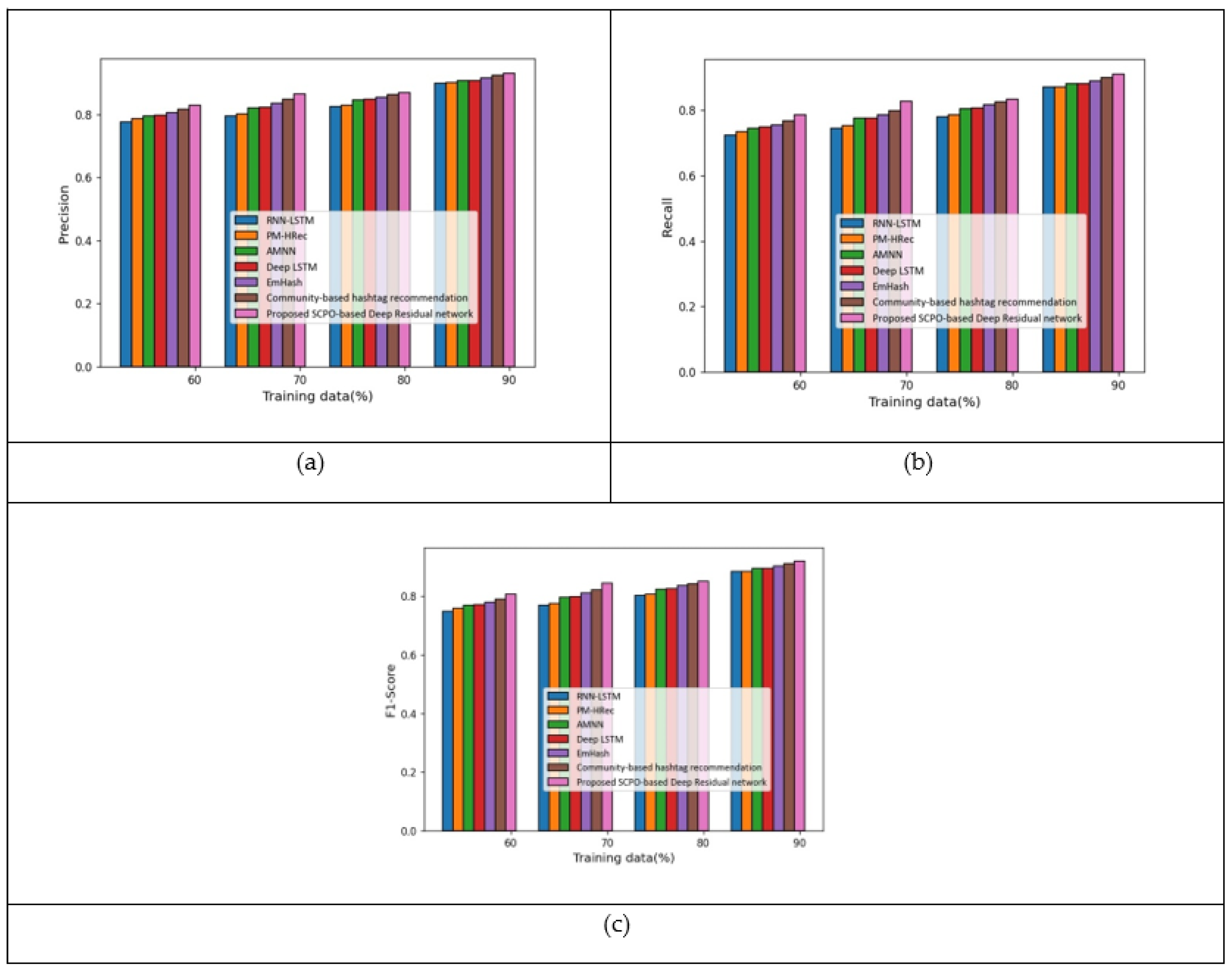
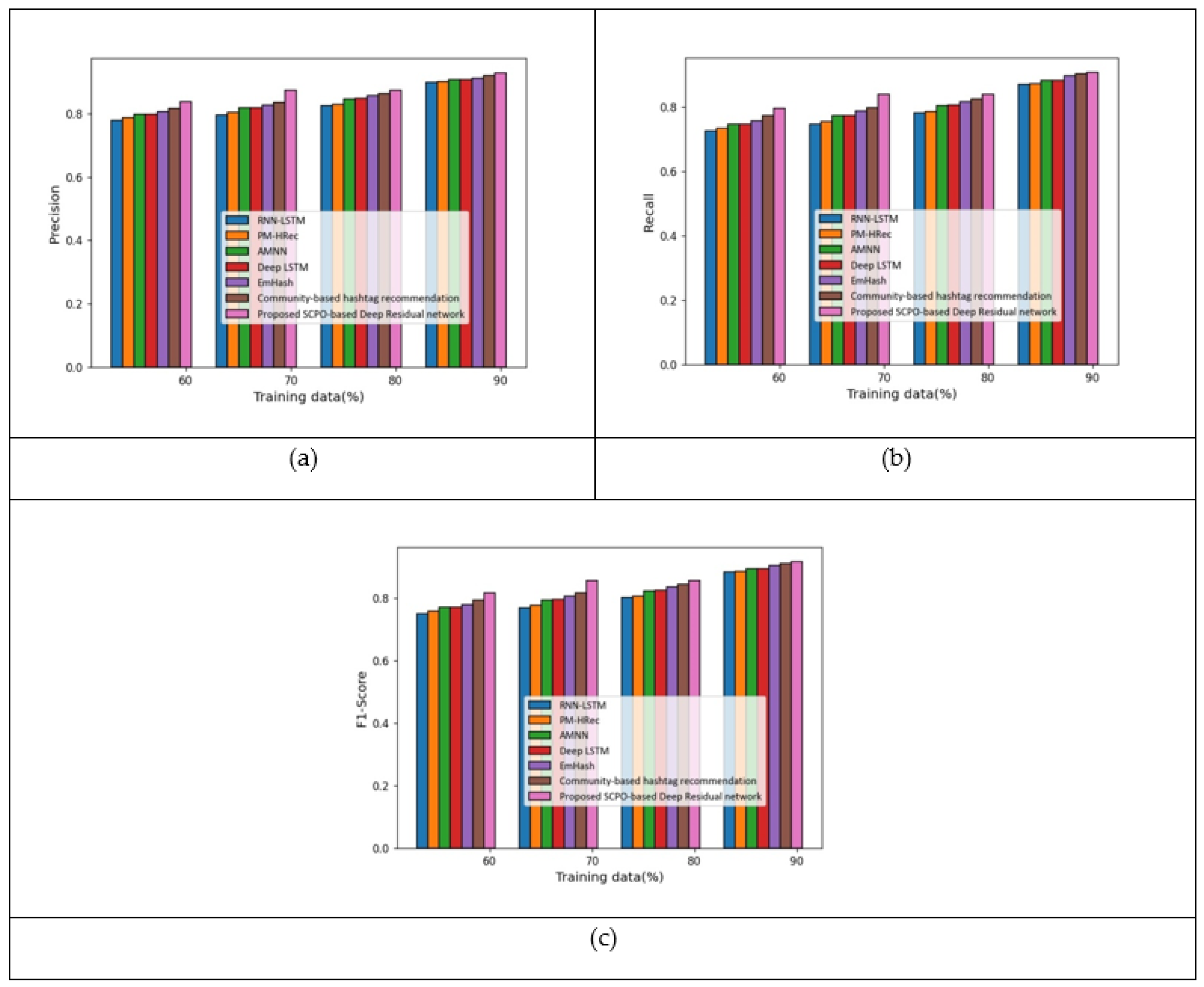
5.2. Results Based on Twitter Dataset
5.3. Comparative Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMNN | Attention-based Multi-model Neural Network |
| BoW | Bag of Words |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Networks |
| LSTM | Long Short-Term Memory |
| NB | Naive Bayes |
| NLP | Natural Language Processing |
| PO | Political Optimizer |
| RNN | Recurrent Neural Network |
| SCA | Sine Cosine Algorithm |
References
- Kowald, D.; Pujari, S.C.; Lex, E. Temporal effects on hashtag reuse in twitter: A cognitive-inspired hashtag recommendation approach. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1401–1410. [Google Scholar]
- Godin, F.; Slavkovikj, V.; De Neve, W.; Schrauwen, B.; Van de Walle, R. Using topic models for twitter hashtag recommendation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 593–596. [Google Scholar]
- Alvari, H. Twitter hashtag recommendation using matrix factorization. arXiv 2017, arXiv:1705.10453. [Google Scholar]
- Kabakus, A.T.; Kara, R. “TwitterSpamDetector”: A Spam Detection Framework for Twitter. Int. J. Knowl. Syst. Sci. (IJKSS) 2019, 10, 1–14. [Google Scholar] [CrossRef]
- Otsuka, E.; Wallace, S.A.; Chiu, D. A hashtag recommendation system for twitter data streams. Comput. Soc. Netw. 2016, 3, 1–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dey, K.; Shrivastava, R.; Kaushik, S.; Subramaniam, L.V. Emtagger: A word embedding based novel method for hashtag recommendation on twitter. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1025–1032. [Google Scholar]
- Cui, A.; Zhang, M.; Liu, Y.; Ma, S.; Zhang, K. Discover breaking events with popular hashtags in twitter. In Proceedings of the 21st ACM international conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1794–1798. [Google Scholar]
- Li, T.; Wu, Y.; Zhang, Y. Twitter hash tag prediction algorithm. In Proceedings of the International Conference on Internet Computing (ICOMP), Las Vegas, NV, USA, 18–21 July 2011. [Google Scholar]
- Krestel, R.; Fankhauser, P.; Nejdl, W. Latent dirichlet allocation for tag recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 61–68. [Google Scholar]
- Khabiri, E.; Caverlee, J.; Kamath, K.Y. Predicting semantic annotations on the real-time web. In Proceedings of the 23rd ACM Conference on Hypertext and Social Media, Milwaukee, WI, USA, 25–28 June 2012; pp. 219–228. [Google Scholar]
- Weston, J.; Chopra, S.; Adams, K. # tagspace: Semantic embeddings from hashtags. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1822–1827. [Google Scholar]
- Cristin, R.; Cyril Raj, V.; Marimuthu, R. Face image forgery detection by weight optimized neural network model. Multimed. Res. 2019, 2, 19–27. [Google Scholar]
- Gangappa, M.; Mai, C.; Sammulal, P. Enhanced Crow Search Optimization Algorithm and Hybrid NN-CNN Classifiers for Classification of Land Cover Images. Multimed. Res. 2019, 2, 12–22. [Google Scholar]
- Vidyadhari, C.; Sandhya, N.; Premchand, P. A semantic word processing using enhanced cat swarm optimization algorithm for automatic text clustering. Multimed. Res. 2019, 2, 23–32. [Google Scholar]
- Ben-Lhachemi, N.; Boumhidi, J. Hashtag Recommender System Based on LSTM Neural Reccurent Network. In Proceedings of the 2019 Third International Conference on Intelligent Computing in Data Sciences (ICDS), Marrakech, Morocco, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, T.; Hu, J.; Jiang, J. Topical co-attention networks for hashtag recommendation on microblogs. Neurocomputing 2019, 331, 356–365. [Google Scholar] [CrossRef] [Green Version]
- Ben-Lhachemi, N. Using tweets embeddings for hashtag recommendation in Twitter. Procedia Comput. Sci. 2018, 127, 7–15. [Google Scholar] [CrossRef]
- Belhadi, A.; Djenouri, Y.; Lin, J.C.W.; Cano, A. A data-driven approach for Twitter hashtag recommendation. IEEE Access 2020, 8, 79182–79191. [Google Scholar] [CrossRef]
- Alsini, A.; Datta, A.; Huynh, D.Q. On utilizing communities detected from social networks in hashtag recommendation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 971–982. [Google Scholar] [CrossRef]
- Yang, Q.; Wu, G.; Li, Y.; Li, R.; Gu, X.; Deng, H.; Wu, J. AMNN: Attention-Based Multimodal Neural Network Model for Hashtag Recommendation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 768–779. [Google Scholar] [CrossRef]
- Ma, R.; Qiu, X.; Zhang, Q.; Hu, X.; Jiang, Y.G.; Huang, X. Co-attention Memory Network for Multimodal Microblog’s Hashtag Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 33, 388–400. [Google Scholar] [CrossRef]
- Cao, D.; Miao, L.; Rong, H.; Qin, Z.; Nie, L. Hashtag our stories: Hashtag recommendation for micro-videos via harnessing multiple modalities. Knowl. Based Syst. 2020, 203, 106114. [Google Scholar] [CrossRef]
- Li, C.; Xu, L.; Yan, M.; Lei, Y. TagDC: A tag recommendation method for software information sites with a combination of deep learning and collaborative filtering. J. Syst. Softw. 2020, 170, 110783. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl.-Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Majhi, B.; Naidu, D.; Mishra, A.P.; Satapathy, S.C. Improved prediction of daily pan evaporation using Deep-LSTM model. Neural Comput. Appl. 2020, 32, 7823–7838. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Wu, L.; Cheng, S.; Lin, P. Deep residual network based fault detection and diagnosis of photovoltaic arrays using current-voltage curves and ambient conditions. Energy Convers. Manag. 2019, 198, 111793. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Askari, Q.; Younas, I.; Saeed, M. Political optimizer: A novel socio-inspired meta-heuristic for global optimization. Knowl. Based Syst. 2020, 195, 105709. [Google Scholar] [CrossRef]
- Kaviani, M.; Rahmani, H. Emhash: Hashtag recommendation using neural network based on bert embedding. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 113–118. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | Advantages | Disadvantages |
|---|---|---|---|
| Ben-Lhachemi, N. et al. [18] | DBSCAN clustering technique. | Has the potential to recommend pertinent hashtags syntactically and semantically from a given tweet. | Fails to involve deep architectures on various semantic knowledge bases to enhance accuracy. |
| Li, Y. et al. [17] | Topical Co-Attention Network (TCAN). | Useful for determining structures from large documents. | Fails to involve temporal information. |
| Ben-Lhachemi, N. and Boumhidi, J. [15] | Long Short-Term Memory Recurrent Neural Network. | Capable of recommending suitable hashtags. | Fails to utilize semantic knowledge bases to improve accuracy. |
| Belhadi, A. et al. [19] | Pattern Mining for Hashtag Recommendation (PM-HRec). | Works effectively on huge data. | Fails to include parallel methods (e.g., GPUs) to handle large data. |
| Alsini, A. et al. [20] | Community-based hashtag recommendation model. | Easy to understand different factors that influence hashtag recommendation. | Lengthy process. |
| Yang, Q. et al. [21] | Attention-based multimodal neural network model (AMNN). | Able to attain improved performance with multimodal micro-blogs. | Fails to adapt external knowledge, such as comments and user information, for recommendation. |
| Ma, R. et al. [22] | Co-attention memory network. | Can manage a huge number of hashtags. | The generation of high-quality candidate sets is complex. |
| Cao, D. et al. [23] | Neural network-based LOGO. | Assists in capturing sequential and considerate features at the same time. | Fails to include recommendation on micro-videos. |
| Can Li et al. [24] | Tag recommendation method with Deep learning and Collaborative filtering (TagDC) | Helps to locate similar software. | Fails to consider unpopular tags. |
| Sahraoui et al. [25] | Hybrid filtering technique in a social network for data mining. | Predicts the user’s interest in a social network. | Fails to evaluate the performance in the signed Network. |
| Metrics/Method | RNN-LSTM | PM-HRec | AMNN | Deep LSTM | Emhash | Commu. Based | Proposed SCPO-DRN | |
|---|---|---|---|---|---|---|---|---|
| Apple | Precision | 0.934 | 0.936 | 0.943 | 0.944 | 0.950 | 0.953 | 0.968 |
| Recall | 0.917 | 0.919 | 0.929 | 0.930 | 0.932 | 0.943 | 0.958 | |
| F1-score | 0.926 | 0.927 | 0.936 | 0.937 | 0.941 | 0.948 | 0.963 | |
| Precision | 0.899 | 0.900 | 0.908 | 0.909 | 0.913 | 0.921 | 0.929 | |
| Recall | 0.870 | 0.871 | 0.882 | 0.882 | 0.898 | 0.904 | 0.907 | |
| F1-score | 0.884 | 0.886 | 0.895 | 0.895 | 0.905 | 0.912 | 0.918 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banbhrani, S.K.; Xu, B.; Liu, H.; Lin, H. SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network. Information 2021, 12, 389. https://doi.org/10.3390/info12100389
Banbhrani SK, Xu B, Liu H, Lin H. SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network. Information. 2021; 12(10):389. https://doi.org/10.3390/info12100389
Chicago/Turabian StyleBanbhrani, Santosh Kumar, Bo Xu, Haifeng Liu, and Hongfei Lin. 2021. "SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network" Information 12, no. 10: 389. https://doi.org/10.3390/info12100389
APA StyleBanbhrani, S. K., Xu, B., Liu, H., & Lin, H. (2021). SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network. Information, 12(10), 389. https://doi.org/10.3390/info12100389