FSCR: A Deep Social Recommendation Model for Misleading Information


Abstract
1. Introduction
- 1.
- We introduce and analyze the emergency consumption problem caused by misleading information. To solve this problem, we optimize the recommendation model by combining user side information.
- 2.
- We introduce the FSCR model, which fuses user side information, historical preference features, and social trust features to build the user model and make recommendations.
- 3.
- We introduce a misleading information detection mechanism in our model to deal with misleading information.
- 4.
- We conduct comprehensive experiments in multiple real-world datasets to show the effectiveness and the robustness of the FSCR model.
2. Related Work
2.1. Recommender System
2.2. The Harm of Misleading Information
2.3. Promoters of Misleading Information Dissemination
2.3.1. Individuals
2.3.2. Society
2.4. How to Deal with Misleading Information
2.4.1. Detection of Misleading Information
2.4.2. Improve the Robustness of the System
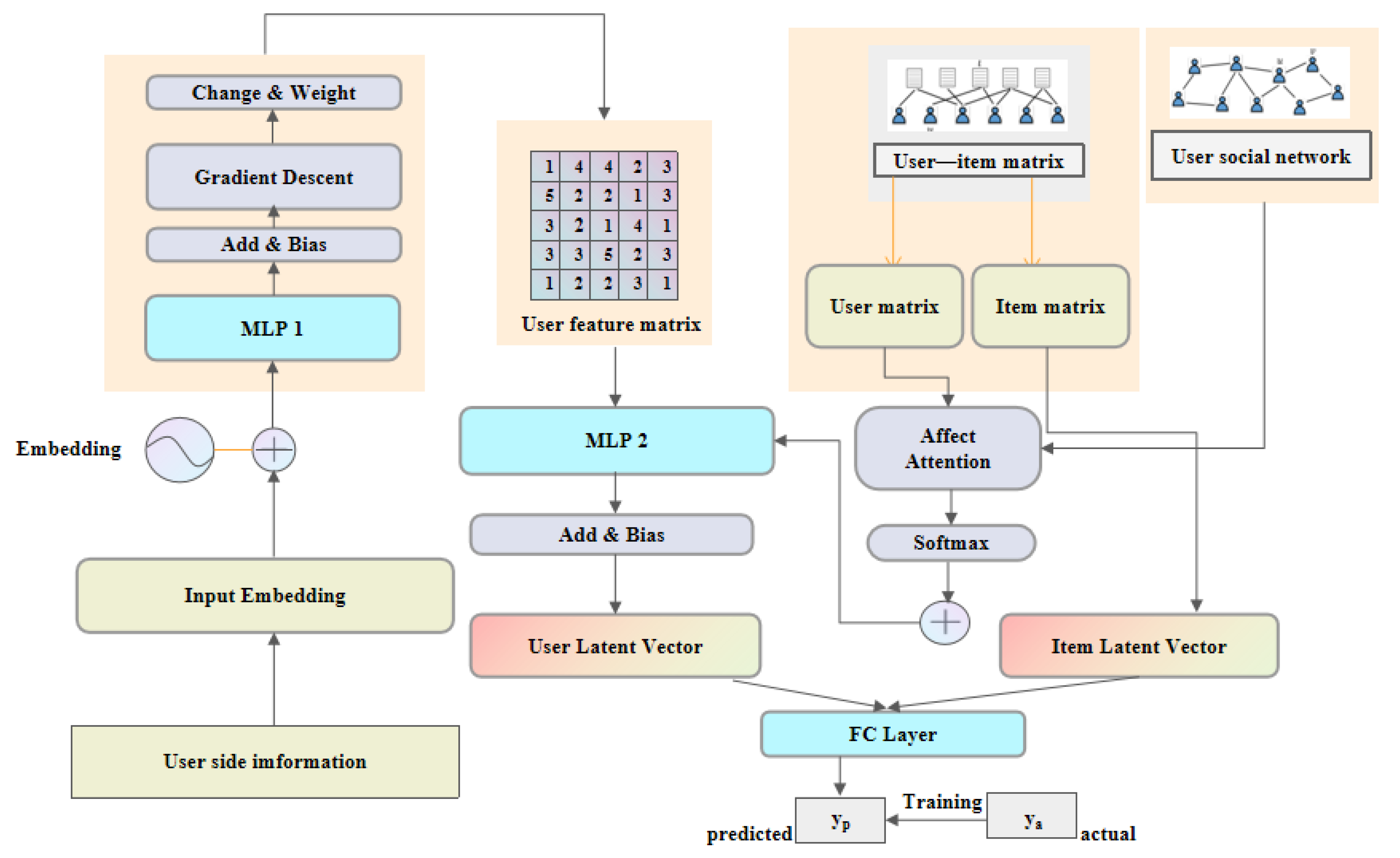
3. Model Implementation
3.1. Problem Definition
3.2. FSCR Model Architecture
3.3. Embedding Layer
3.4. MF Layer
3.5. The Social Influence Diffusion Layer
3.6. FC Layer
3.7. Prediction Layer
3.8. A Mechanism to Deal with Misleading Information
4. Experiment and Results Analysis
4.1. Datasets
4.2. Comparison Methods
4.3. Evaluation Metrics
4.4. Parameter Setting
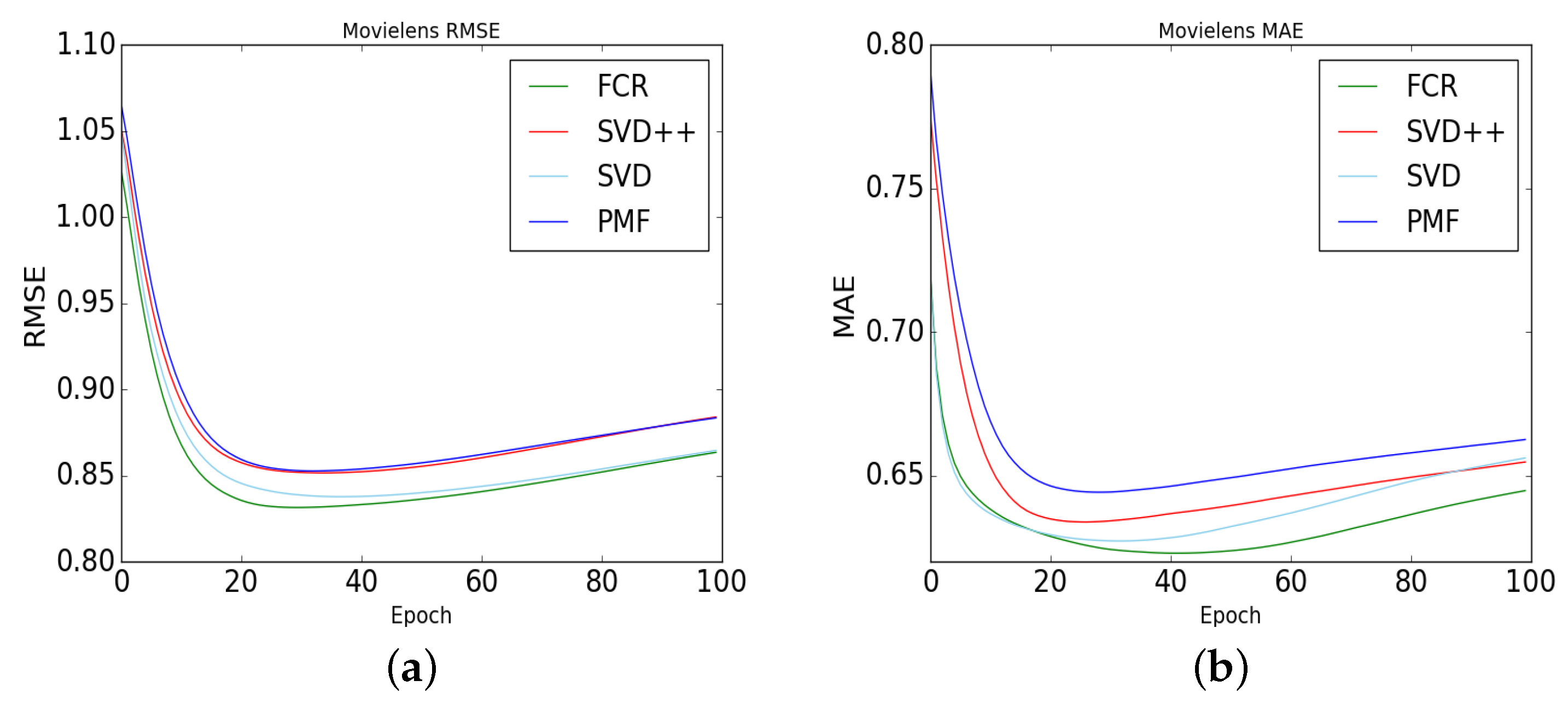
4.5. Comparison of FCR with Other Recommendation Models
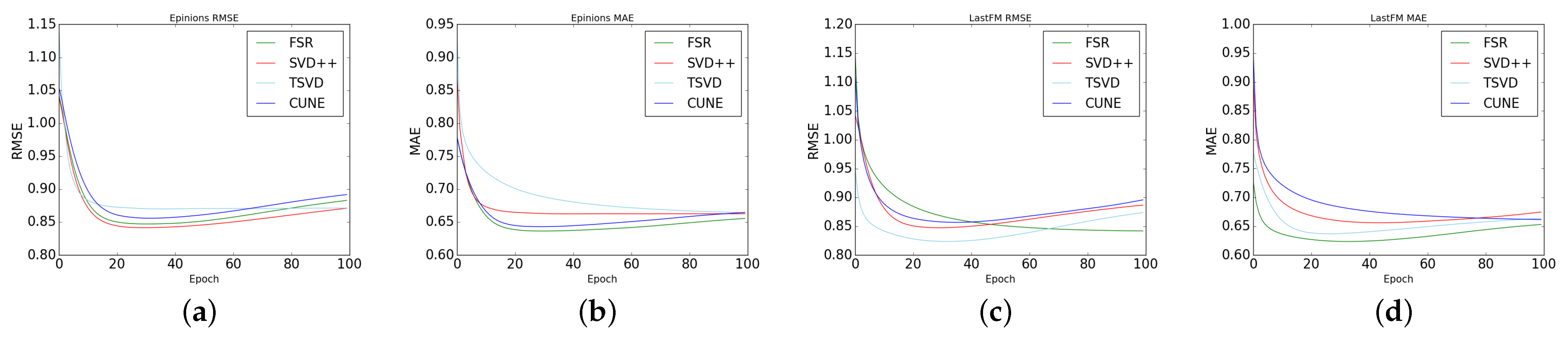
4.6. Comparison of FSR with Other Social Recommendation Models
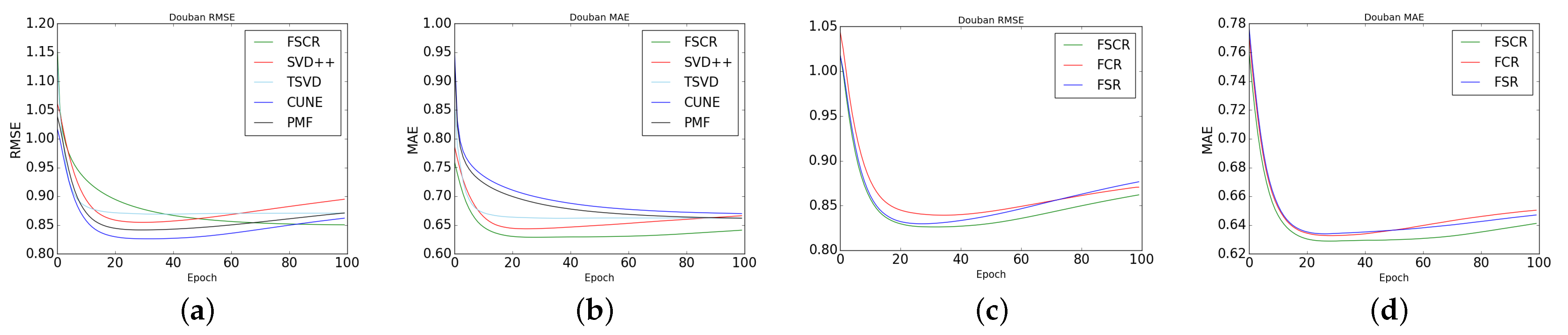
4.7. Comparison of FSCR with Other Baseline Models
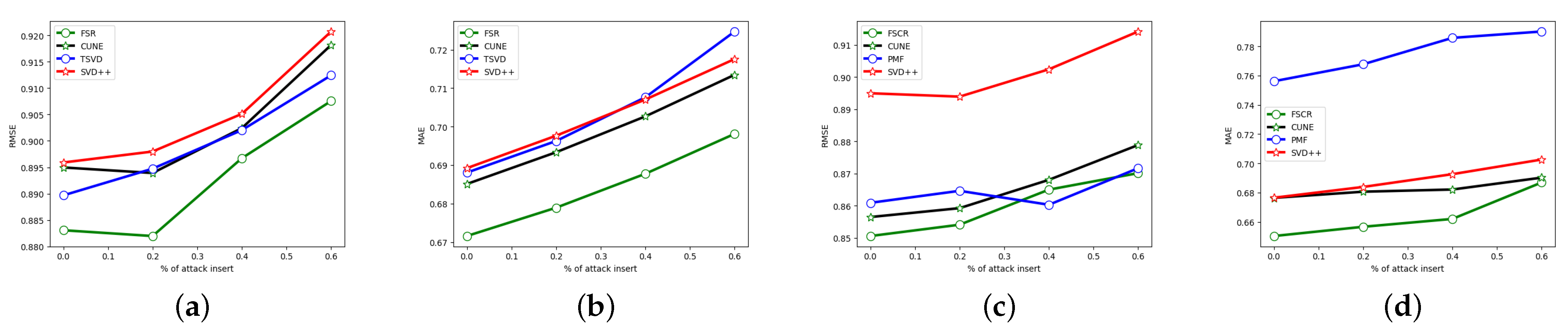
4.8. The Robustness of Our Model
4.9. The Advantages and Disadvantages of FSCR
- 1.
- Misleading information can only affect users in a short period. In the long run, users’ long-term preferences are not affected.
- 2.
- Our model starts from the user’s side information, combines the user’s consumption preferences, and balances the diffusion of users’ friends’ preferences in social networks, to avoid users blindly following misleading information.
- 3.
- We used a discriminator to identify misleading users in the user–item interaction matrix, and updated their user representation.
- 4.
- In this work, the user model comes from a variety of relationships, so it can accurately describe user preferences and make recommendations.
- 1.
- We only rely on identifying misleading users to deal with misleading information. The misleading information in the recommendation system is diverse, so we need to further optimize our model.
- 2.
- The model needs to identify misleading users, which leads to a long training time for the model.
- 3.
- Industry recommendation systems often filter out misleading information before training, while FSCR filters out abnormal users and updates their user representation during training.
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Moscato, V.; Picariello, A.; Sperli, G. An emotional recommender system for music. IEEE Intell. Syst. 2020. [Google Scholar] [CrossRef]
- Amato, F.; Castiglione, A.; Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A.; Sperlì, G. Multimedia story creation on social networks. Future Gener. Comput. Syst. 2018, 86, 412–420. [Google Scholar] [CrossRef]
- Guo, L.; Jiang, H.; Wang, X.; Liu, F. Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information 2017, 8, 20. [Google Scholar] [CrossRef]
- Zhang, S.; Yin, H.; Chen, T.; Hung, Q.V.N.; Huang, Z.; Cui, L. GCN-Based User Representation Learning for Unifying Robust Recommendation and Fraudster Detection. SIGIR 2020, 689–698. [Google Scholar]
- Vilakone, P.; Park, D.-S. The Efficiency of a DoParallel Algorithm and an FCA Network Graph Applied to Recommendation System. Appl. Sci. 2020, 10, 2939. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Liao, X.; Li, X.; Xu, Q.; Wu, H.; Wang, Y. Improving Ant Collaborative Filtering on Sparsity via Dimension Reduction. Appl. Sci. 2020, 10, 7245. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Pazzani, M.J. A Framework for Collaborative, Content-Based and Demographic Filtering. Artif. Intell. Rev. 1999, 13, 393–408. [Google Scholar] [CrossRef]
- Vozalis, M.G.; Margaritis, K.G. Using SVD and demographic data for the enhancement of generalized Collaborative Filtering. Inf. Sci. 2007, 177, 3017–3037. [Google Scholar] [CrossRef]
- Li, R.; Wu, X.; Wu, X.; Wang, W. Few-Shot Learning for New User Recommendation in Location-based Social Networks. In Proceedings of the WWW ’20: The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Liu, Y.; Chen, L.; He, X.; Peng, J.; Zheng, Z.; Tang, J. Modelling high-order social relations for item recommendation. arXiv 2020, arXiv:2003.10149. [Google Scholar]
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating Fake News: A Survey on Identification and Mitigation Techniques. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Budak, C.; Agrawal, D.; El Abbadi, A. Limiting the spread of misinformation in social networks. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 665–674. [Google Scholar]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Takayasu, M.; Sato, K.; Sano, Y.; Yamada, K.; Miura, W.; Takayasu, H. Rumor diffusion and convergence during the 3.11 earthquake: A Twitter case study. PLoS ONE 2015, 10, e0121443. [Google Scholar] [CrossRef]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on twitter. In International Conference on Social Informatics; Springer: Cham, Switzerland, 2014; pp. 228–243. [Google Scholar]
- Mejova, Y.; Kalimeri, K. COVID-19 on Facebook Ads: Competing Agendas around a Public Health Crisis. In Proceedings of the COMPASS ’20: ACM SIGCAS Conference on Computing and Sustainable Societies, Guayaquil, Ecuador, 15–17 June 2020; ACM: New York, NY, USA, 2020; Volume 285, pp. 22–31. [Google Scholar]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural user response generator: Fake news detection with collective user intelligence. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence IJCAI-18, Stockholm, Sweden, 13–19 July 2018; pp. 3834–3840. [Google Scholar] [CrossRef]
- Ott, M.; Cardie, C.; Hancock, J.T. Negative deceptive opinion spam. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT), Westin Peachtree Plaza Hotel, Atlanta, GA, USA, 9–14 June 2013; pp. 497–501. [Google Scholar]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding deceptive opinion spam by any stretch of the imagination. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 309–319. [Google Scholar]
- Gu, Y.; Shibukawa, T.; Kondo, Y.; Nagao, S.; Kamijo, S. Prediction of Stock Performance Using Deep Neural Networks. Appl. Sci. 2020, 10, 8142. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Z.; Yan, J.; Zhang, N.; Zha, H.; Li, G.; Li, Y.; Yu, Q. A Deep Learning Approach with Feature Derivation and Selection for Overdue Repayment Forecasting. Appl. Sci. 2020, 10, 8491. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426. [Google Scholar]
- He, X.; He, Z.; Du, X.; Chua, T.S. Adversarial Personalized Ranking for Recommendation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 355–364. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Deldjoo, Y.; Di Noia, T.; Merra, F.A. A survey on Adversarial Recommender Systems: From Attack/Defense strategies to Generative Adversarial Networks. arXiv 2020, arXiv:2005.10322. [Google Scholar]
- Tang, J.; Du, X.; He, X.; Yuan, F.; Tian, Q.; Chua, T. Adversarial Training Towards Robust Multimedia Recommender System. IEEE Trans. Knowl. Data Eng. 2020, 32, 855–867. [Google Scholar] [CrossRef]
- Anelli, V.W.; Deldjoo, Y.; Di Noia, T.; Merra, F.A. Adversarial Learning for Recommendation: Applications for Security and Generative Tasks-Concept to Code. In Proceedings of the 14th ACM Conference on Recommender Systems (RecSys’20), Rio de Janeiro, Brazil, 26 September 2020; pp. 738–741. [Google Scholar]
- Di Noia, T.; Malitesta, D.; Merra, F.A. TAaMR: Targeted Adversarial Attack against Multimedia Recommender Systems. In Proceedings of the 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Valencia, Spain, 29 June–2 July 2020. [Google Scholar]
- Li, R.; Wu, X.; Wang, W. Adversarial Learning to Compare: Self-Attentive Prospective Customer Recommendation in Location based Social Networks. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston TX, USA, 3–7 February 2020; pp. 349–357. [Google Scholar]
- Zhou, F.; Yin, R.; Zhang, K.; Trajcevski, G.; Zhong, T.; Wu, J. Adversarial Point-of-Interest Recommendation. In World Wide Web Conference; ACM: New York, NY, USA, 2019; pp. 3462–34618. [Google Scholar]
- Kumar, S.; Gupta, M.D. C+GAN: Complementary Fashion Item Recommendation. arXiv 2019, arXiv:1906.05596. [Google Scholar]
- Yu, X.; Zhang, X.; Cao, Y.; Xia, M. VAEGAN: A Collaborative Filtering Framework based on Adversarial Variational Autoencoders. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19, Macao, China, 10–16 August 2019; pp. 4206–4212. [Google Scholar]
- Koren, Y. Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Trans. Knowl. Discov. Data (TKDD) 2010, 4, 1–24. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. IEEE Comput. J. 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Mnih, A. Probabilistic matrix factorization. In Proceedings of the NIPS’07: Proceedings of the 20th International Conference on Neural Information Processing Systems, NIPS 2007, Vancouver, BC, Canada, 3–4 December 2007; Curran Associates Inc.: Red Hook, NY, USA, 2007; pp. 1257–1264. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q. Graph neural networks for social recommendation. In The World Wide Web Conference 2019; ACM: New York, NY, USA, 2019; pp. 417–426. [Google Scholar]
- Hao, M.; Yang, H. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the CIKM ’08: Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; ACM: New York, NY, USA, 2008. [Google Scholar]
- Zhang, C.; Lu, Y.; Yan, W.; Shah, C. Collaborative user network embedding for social recommender systems. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Representation |
|---|---|
| rating matrix | |
| user side information | |
| user trust matrix | |
| user feature matrix | |
| item feature matrix | |
| n | the number of users |
| t | the number of items |
| s | the types of user features |
| k | the characteristic dimension |
| m | the number of items that interact with the user |
| user’s side information embedding | |
| w | neural network weight |
| b | bias |
| the Relu activation function | |
| the prediction rating | |
| the actual rating | |
| the mean square of all rating prediction errors on the interaction item |
| Data | User | Item | Friends Links | User–Item | Types of Side Information |
|---|---|---|---|---|---|
| LastFM | 2100 | 17,635 | 24,435 | 92,835 | # |
| Movielens | 6040 | 3883 | # | 1,000,209 | 3 |
| Epinions | 40,163 | 139,738 | 487,183 | 664,824 | # |
| Douban movie | 129,490 | 58,541 | 1,692,952 | 1,683,839 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Wu, H.; Yang, F. FSCR: A Deep Social Recommendation Model for Misleading Information. Information 2021, 12, 37. https://doi.org/10.3390/info12010037
Zhang D, Wu H, Yang F. FSCR: A Deep Social Recommendation Model for Misleading Information. Information. 2021; 12(1):37. https://doi.org/10.3390/info12010037
Chicago/Turabian StyleZhang, Depeng, Hongchen Wu, and Feng Yang. 2021. "FSCR: A Deep Social Recommendation Model for Misleading Information" Information 12, no. 1: 37. https://doi.org/10.3390/info12010037
APA StyleZhang, D., Wu, H., & Yang, F. (2021). FSCR: A Deep Social Recommendation Model for Misleading Information. Information, 12(1), 37. https://doi.org/10.3390/info12010037