Cyberbullying Detection in Social Networks Using Bi-GRU with Self-Attention Mechanism



Abstract
1. Introduction
- (1)
- We design a model using the advantages of the bidirectional gated recurrent unit (Bi-GRU) optimized with dropout and pooling layers for the avoidance of the vanishing/exploding gradient problem, and appropriate elastic net regularization for better learning convergent.
- (2)
- We leverage the advantages of the multi-head self-attention mechanism to distinguish the importance of each social network post, which helps improve the accuracy and the robustness of the whole model.
- (3)
- Comparing with different methods including traditional machine learning and conventional deep learning, we conduct experiments on three datasets commonly used in recent years. Concerning the fairness and objectivity of performance evaluation, none of the sampling techniques is applied during the whole experiment process. The experiment results show that our proposed model has more advantages than other baselines in all metrics.
2. Related Work
2.1. Definition of Terms
2.2. Cyberbullying Detection
2.3. Recurrent Neural Networks with Attention Mechanism
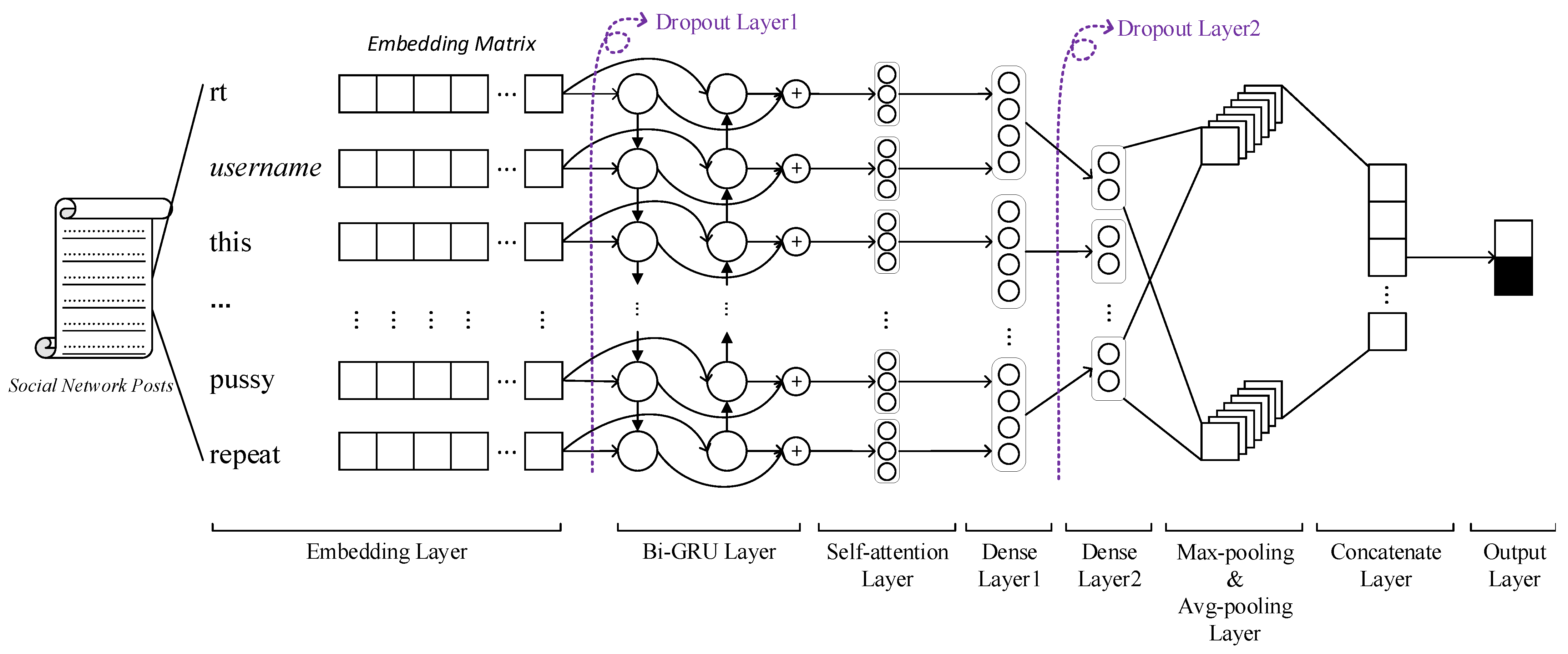
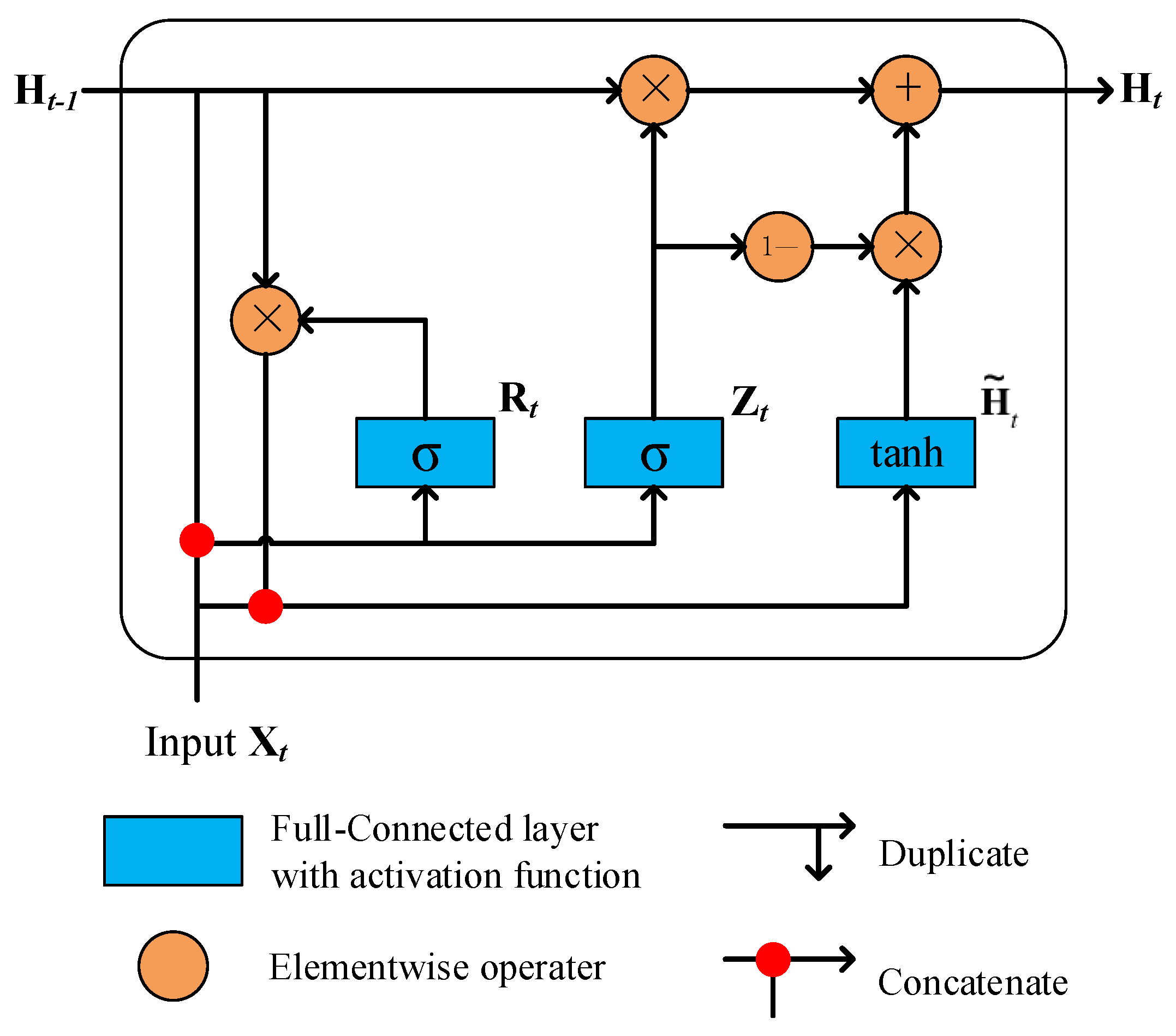
3. Proposed Method
4. Experiment
4.1. Datasets
4.2. Data Preprocessing
4.3. Comparison of Methods
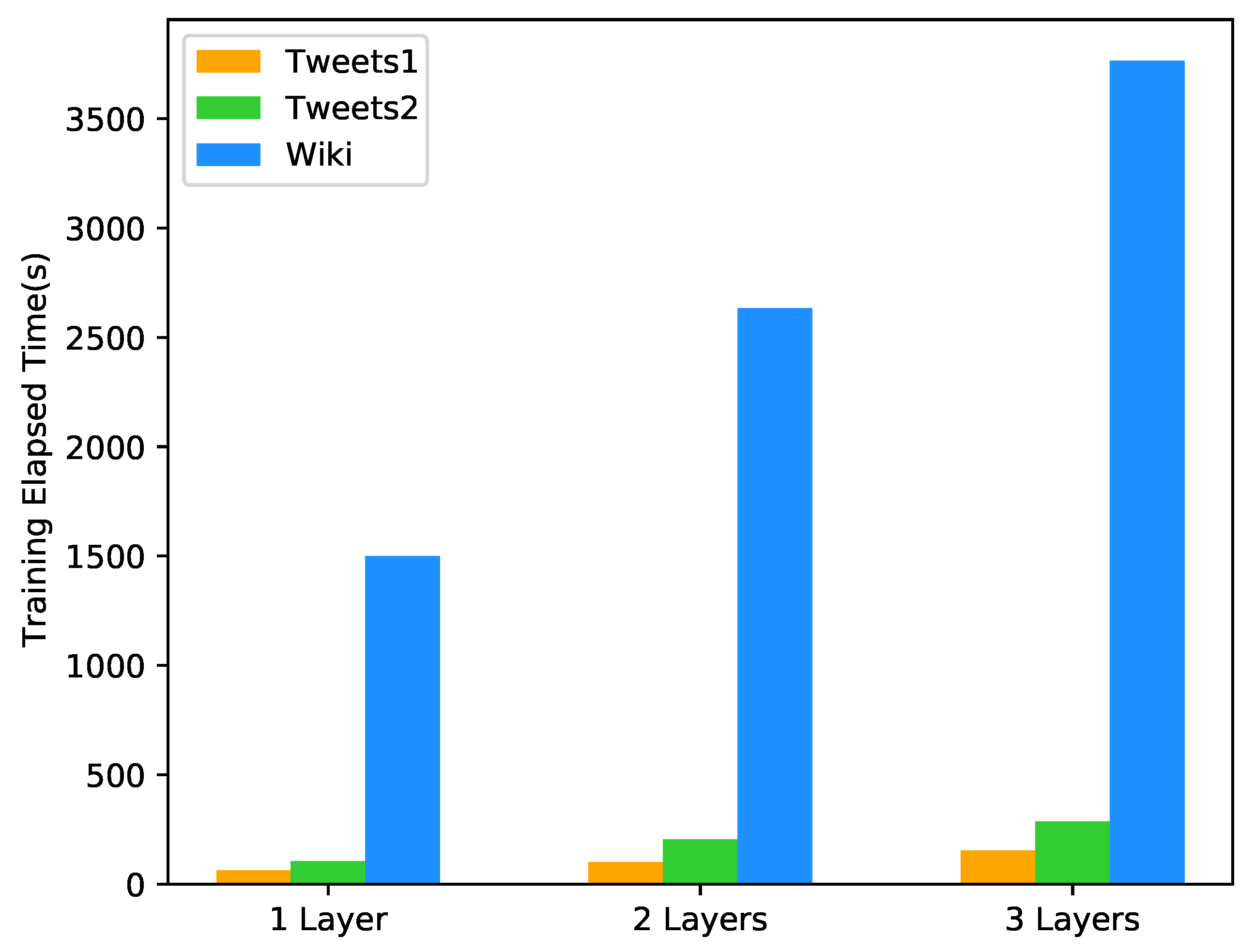
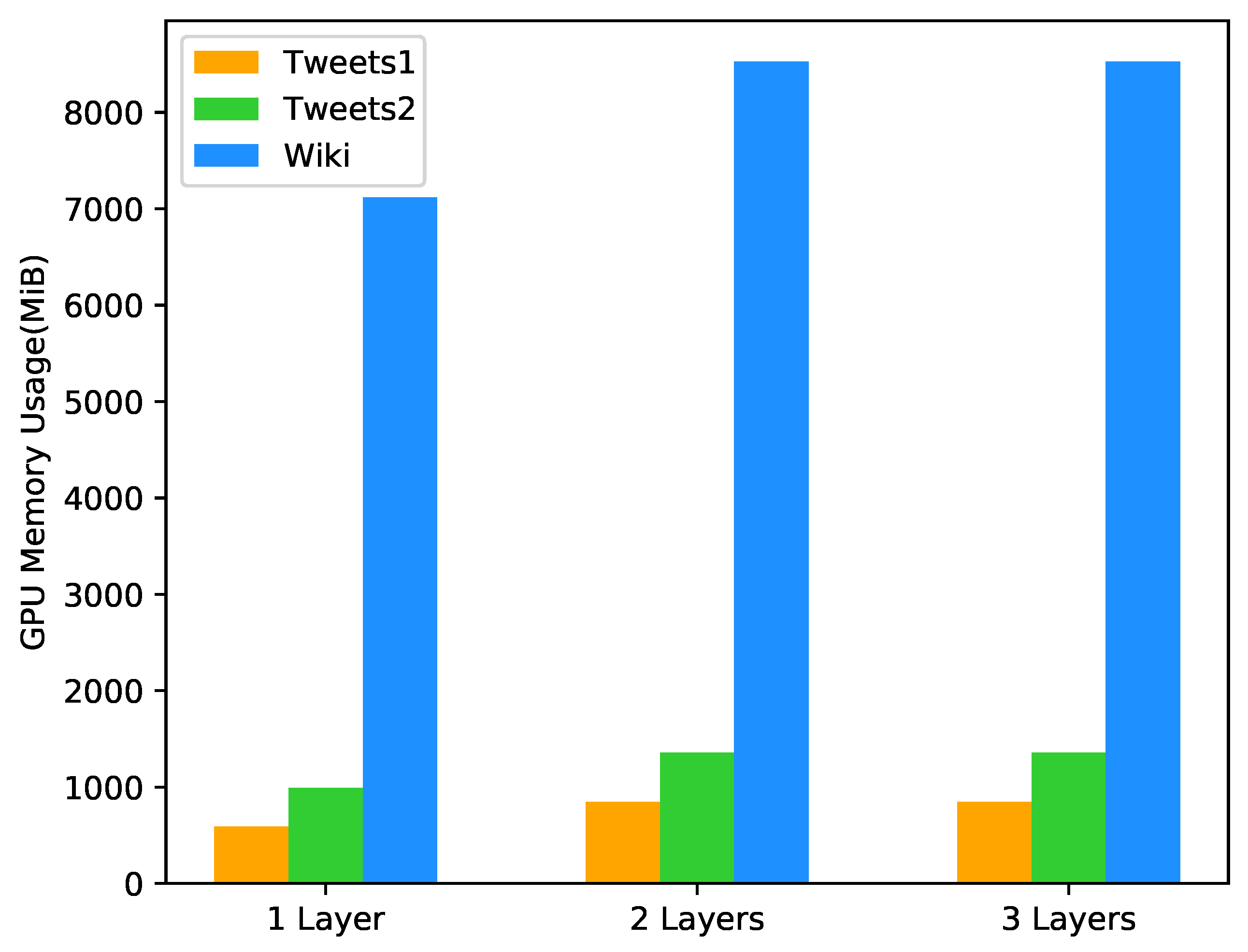
4.4. Experimental Environment
4.5. Hyperparameters Setting
4.6. Evaluation Method
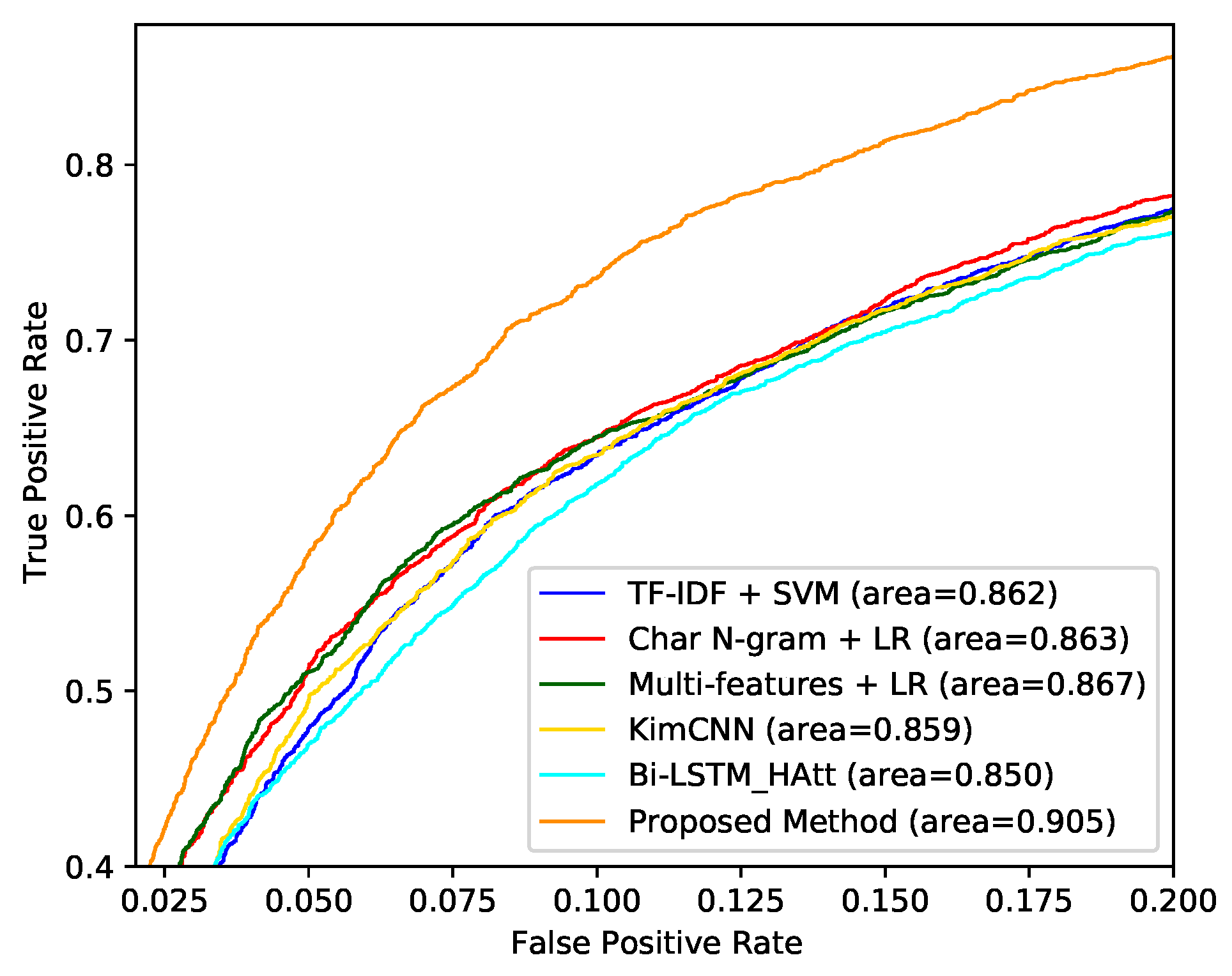
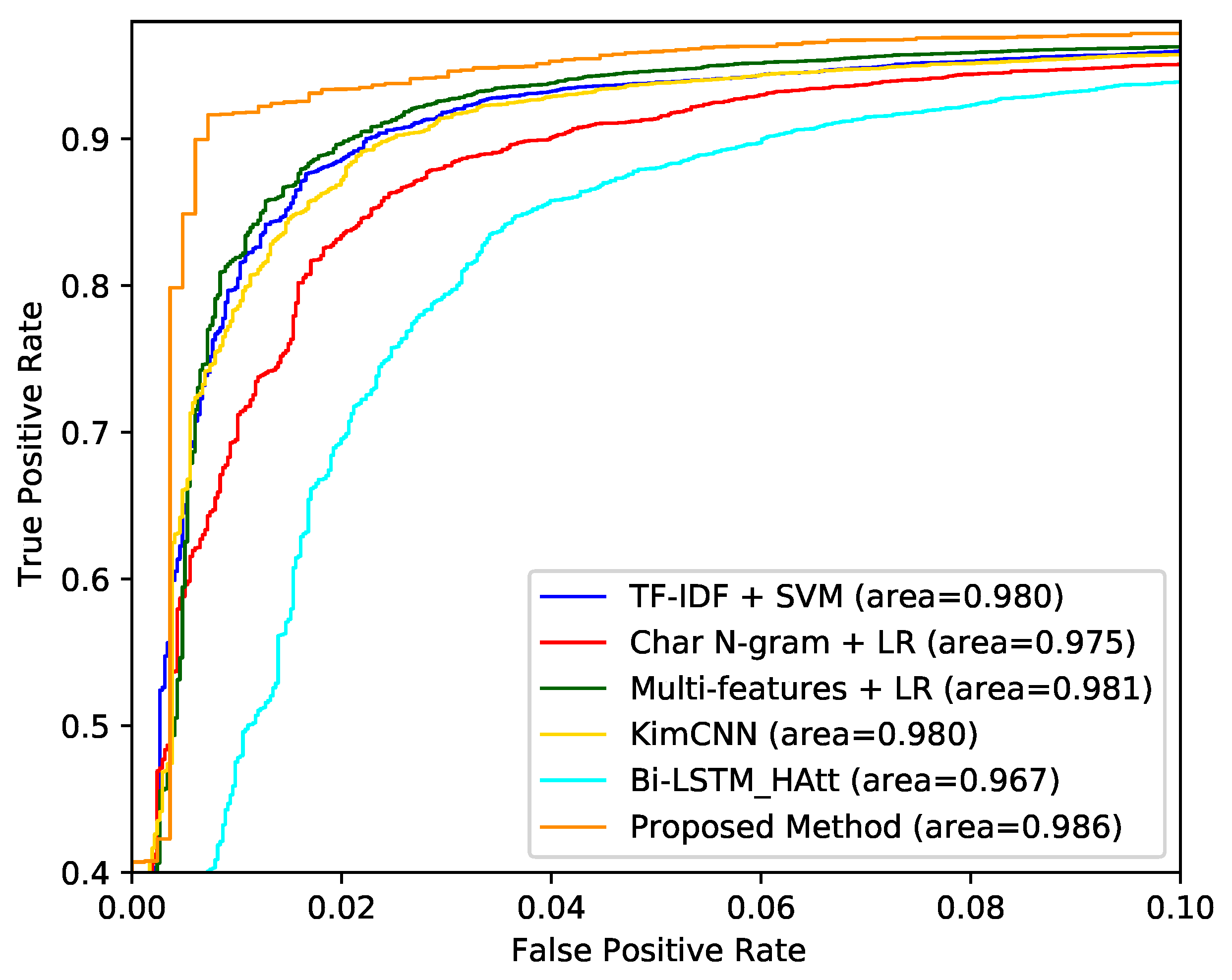
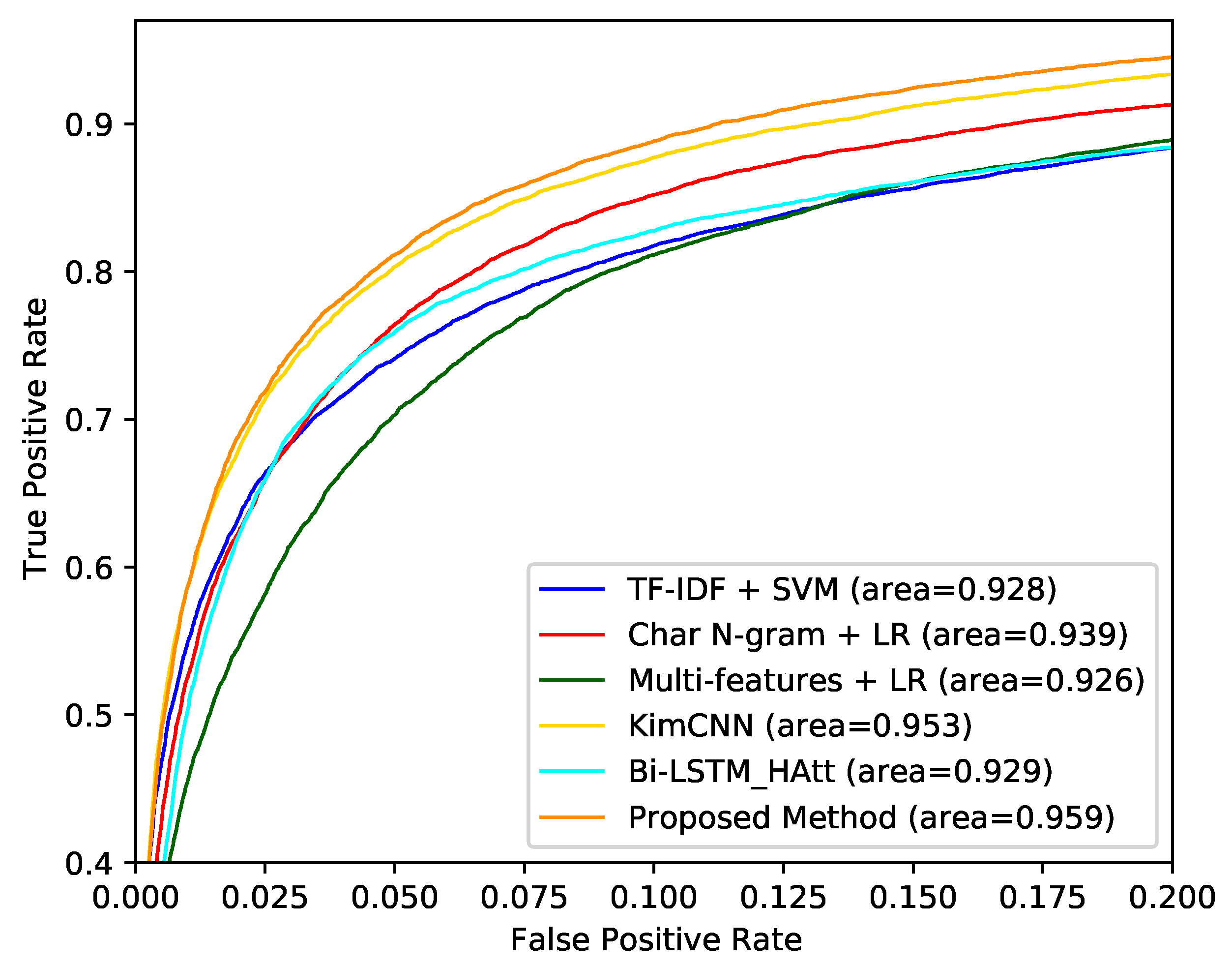
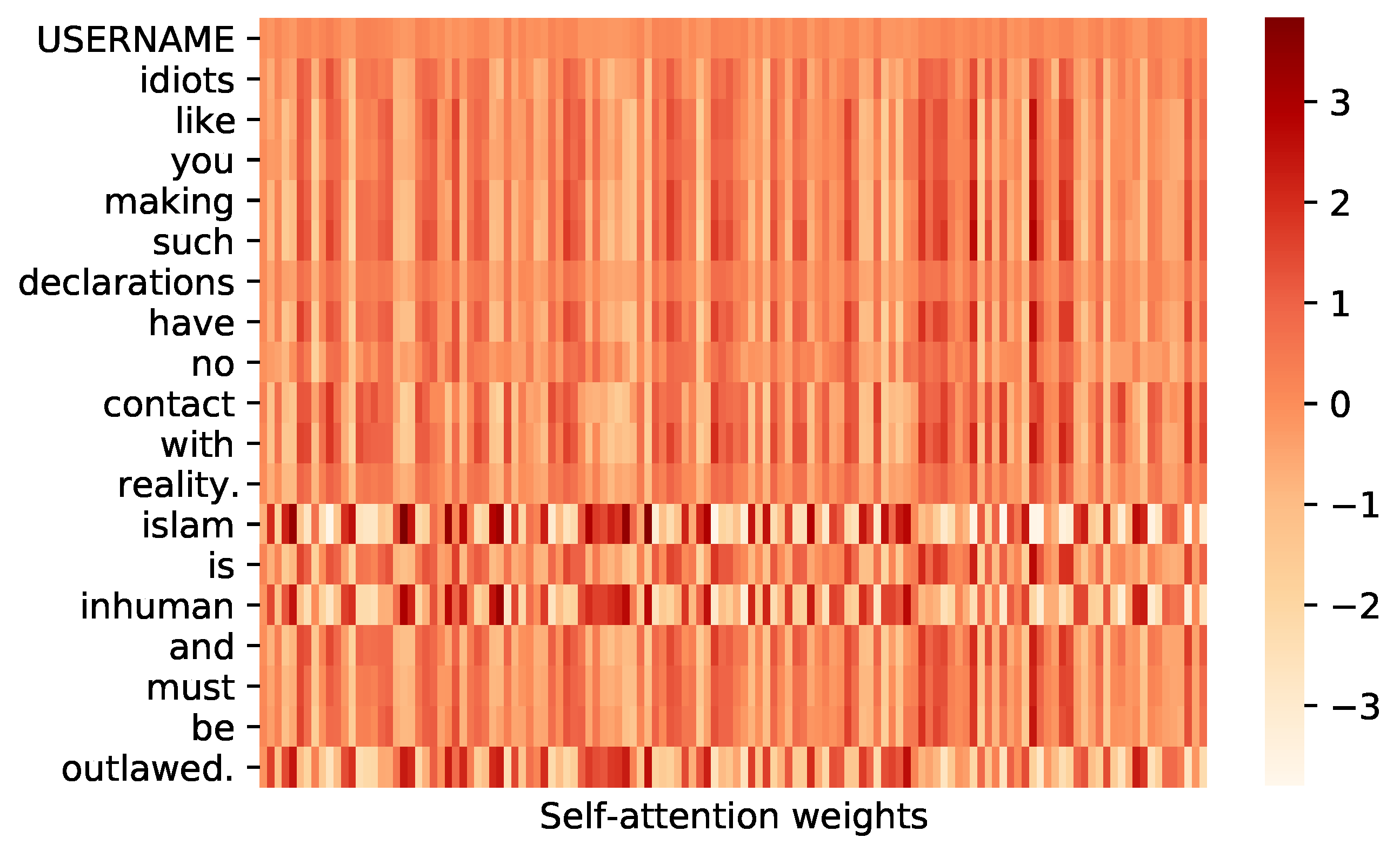
4.7. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stopbullying.gov. What Is Cyberbullying; Stopbullying.gov: Washington, DC, USA, 2020.
- Hinduja, S.; Patchin, J.W. Cyberbullying: Identification, Prevention, and Response; Cyberbullying.org: Boca Raton, FL, USA, 2018. [Google Scholar]
- Cyberbullying Research Center. 2019 Cyberbullying Data; Cyberbullying.org: Boca Raton, FL, USA, 2020. [Google Scholar]
- Cyberbullying Research Center. Summary of Our Cyberbullying Research (2007–2019); Cyberbullying.org: Boca Raton, FL, USA, 2020. [Google Scholar]
- Google. Be Internet Awesome: Online Safety & Parents; Google: Mountain View, CA, USA, 2019. [Google Scholar]
- Al-Garadi, M.A.; Hussain, M.R.; Khan, N.; Murtaza, G.; Nweke, H.F.; Ali, I.; Mujtaba, G.; Chiroma, H.; Khattak, H.A.; Gani, A. Predicting cyberbullying on social media in the big data era using machine learning algorithms: Review of literature and open challenges. IEEE Access 2019, 7, 70701–70718. [Google Scholar] [CrossRef]
- John, A.; Glendenning, A.C.; Marchant, A.; Montgomery, P.; Stewart, A.; Wood, S.; Lloyd, K.; Hawton, K. Self-harm, suicidal behaviours, and cyberbullying in children and young people: Systematic review. J. Med. Internet Res. 2018, 20, e129. [Google Scholar] [CrossRef]
- Hinduja, S.; Patchin, J.W. Bullying, cyberbullying, and suicide. Arch. Suicide Res. 2010, 14, 206–221. [Google Scholar] [CrossRef]
- Sampasa-Kanyinga, H.; Roumeliotis, P.; Xu, H. Associations between Cyberbullying and School Bullying Victimization and Suicidal Ideation, Plans and Attempts among Canadian Schoolchildren. PLoS ONE 2014, 9, e102145. [Google Scholar] [CrossRef]
- Zaborskis, A.; Ilionsky, G.; Tesler, R.; Heinz, A. The Association Between Cyberbullying, School Bullying, and Suicidality among Adolescents. Crisis 2018, 40, 100–114. [Google Scholar] [CrossRef]
- Whittaker, E.; Kowalski, R.M. Cyberbullying via social media. J. Sch. Violence 2015, 14, 11–29. [Google Scholar] [CrossRef]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Baldwin, T.; Cook, P.; Lui, M.; MacKinlay, A.; Wang, L. How noisy social media text, how diffrnt social media sources? In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–19 October 2013; Asian Federation of Natural Language Processing: Nagoya, Japan, 2013; pp. 356–364. [Google Scholar]
- Patchin, J.W.; Hinduja, S. Bullies move beyond the schoolyard: A preliminary look at cyberbullying. Youth Violence Juv. Justice 2006, 4, 148–169. [Google Scholar] [CrossRef]
- Smith, P.K.; Mahdavi, J.; Carvalho, M.; Fisher, S.; Russell, S.; Tippett, N. Cyberbullying: Its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 2008, 49, 376–385. [Google Scholar] [CrossRef]
- Subrahmanian, V.; Kumar, S. Predicting human behavior: The next frontiers. Science 2017, 355, 489. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Xu, J.M.; Jun, K.S.; Zhu, X.; Bellmore, A. Learning from Bullying Traces in Social Media. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 656–666. [Google Scholar]
- Nahar, V.; Li, X.; Pang, C. An effective approach for cyberbullying detection. Commun. Inf. Sci. Manag. Eng. 2013, 3, 238–247. [Google Scholar]
- Zhao, R.; Zhou, A.; Mao, K. Automatic Detection of Cyberbullying on Social Networks Based on Bullying Features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, Singapore, 4–7 January 2016; ACM: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? Predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 88–93. [Google Scholar]
- Lee, H.S.; Lee, H.R.; Park, J.U.; Han, Y.S. An abusive text detection system based on enhanced abusive and non-abusive word lists. Decis. Support Syst. 2018, 113, 22–31. [Google Scholar] [CrossRef]
- Murnion, S.; Buchanan, W.J.; Smales, A.; Russell, G. Machine learning and semantic analysis of in-game chat for cyberbullying. Comput. Secur. 2018, 76, 197–213. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; AAAI Press: Montreal, QC, Canada, 2017; pp. 512–515. [Google Scholar]
- Chatzakou, D.; Kourtellis, N.; Blackburn, J.; De Cristofaro, E.; Stringhini, G.; Vakali, A. Mean Birds: Detecting Aggression and Bullying on Twitter. In Proceedings of the 2017 ACM on Web Science Conference, Troy, NY, USA, 25–28 June 2017; ACM: New York, NY, USA, 2017; pp. 13–22. [Google Scholar]
- Balakrishnan, V.; Khan, S.; Fernandez, T.; Arabnia, H.R. Cyberbullying detection on twitter using Big Five and Dark Triad features. Personal. Individ. Differ. 2019, 141, 252–257. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Cyberbullying detection based on semantic-enhanced marginalized denoising auto-encoder. IEEE Trans. Affect. Comput. 2016, 8, 328–339. [Google Scholar] [CrossRef]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep Learning for Hate Speech Detection in Tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 759–760. [Google Scholar]
- Agrawal, S.; Awekar, A. Deep learning for detecting cyberbullying across multiple social media platforms. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 141–153. [Google Scholar]
- Arango, A.; Pérez, J.; Poblete, B. Hate Speech Detection is Not as Easy as You May Think: A Closer Look at Model Validation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 45–54. [Google Scholar]
- Emmery, C.; Verhoeven, B.; De Pauw, G.; Jacobs, G.; Van Hee, C.; Lefever, E.; Desmet, B.; Hoste, V.; Daelemans, W. Current Limitations in Cyberbullying Detection: On Evaluation Criteria, Reproducibility, and Data Scarcity. 2019. Available online: https://arxiv.org/abs/1910.11922 (accessed on 12 April 2021).
- Lu, N.; Wu, G.; Zhang, Z.; Zheng, Y.; Ren, Y.; Choo, K.K.R. Cyberbullying detection in social media text based on character-level convolutional neural network with shortcuts. Concurr. Comput. Pract. Exp. 2020, 32, e5627. [Google Scholar] [CrossRef]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on twitter using a convolution-gru based deep neural network. In European Semantic Web Conference; Springer International Publishing: Cham, Switzerland, 2018; pp. 745–760. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Investigating the effect of combining GRU neural networks with handcrafted features for religious hatred detection on Arabic Twitter space. Soc. Netw. Anal. Min. 2019, 9, 1–19. [Google Scholar] [CrossRef]
- Cheng, L.; Guo, R.; Silva, Y.; Hall, D.; Liu, H. Hierarchical attention networks for cyberbullying detection on the instagram social network. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 235–243. [Google Scholar]
- Cheng, L.; Li, J.; Silva, Y.N.; Hall, D.L.; Liu, H. Xbully: Cyberbullying detection within a multi-modal context. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 339–347. [Google Scholar]
- Dhelim, S.; Ning, H.; Aung, N. ComPath: User Interest Mining in Heterogeneous Signed Social Networks for Internet of People. IEEE Internet Things J. 2020, 8, 7024–7035. [Google Scholar] [CrossRef]
- Dadvar, M.; Eckert, K. Cyberbullying detection in social networks using deep learning based models; a reproducibility study. arXiv 2018, arXiv:1812.08046. [Google Scholar]
- Dadvar, M.; Eckert, K. Cyberbullying detection in social networks using deep learning based models. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, Bratislava, Slovakia, 14–17 September 2020; Springer: Cham, Switzerland, 2020; pp. 245–255. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Alexandridis, G.; Michalakis, K.; Aliprantis, J.; Polydoras, P.; Tsantilas, P.; Caridakis, G. A Deep Learning Approach to Aspect-Based Sentiment Prediction. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; Springer: Cham, Switzerland, 2020; pp. 397–408. [Google Scholar]
- Korovesis, K.; Alexandridis, G.; Caridakis, G.; Polydoras, P.; Tsantilas, P. Leveraging aspect-based sentiment prediction with textual features and document metadata. In Proceedings of the 11th Hellenic Conference on Artificial Intelligence, Athens, Greece, 2–4 September 2020; pp. 168–174. [Google Scholar]
- Wang, S.; Cui, L.; Liu, L.; Lu, X.; Li, Q. Personality Traits Prediction Based on Users’ Digital Footprints in Social Networks via Attention RNN. In Proceedings of the 2020 IEEE International Conference on Services Computing (SCC), Beijing, China, 7–11 July 2020; pp. 54–56. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; Springer: Cham, Switzerland, 2018; pp. 40–52. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; PMLR: Lille, France, 2015; pp. 2342–2350. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative Study of CNN and RNN for Natural Language Processing. 2017. Available online: https://arxiv.org/abs/1702.01923 (accessed on 12 April 2021).
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. 2020. Available online: https://d2l.ai (accessed on 12 April 2021).
- Ma, C.; Yang, C.; Yang, F.; Zhuang, Y.; Zhang, Z.; Jia, H.; Xie, X. Trajectory factory: Tracklet cleaving and re-connection by deep siamese bi-gru for multiple object tracking. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: San Diego, CA, USA, 2018; pp. 1–6. [Google Scholar]
- Wikipedia. Twitter–Wikipedia; Wikipedia: Washington, DC, USA, 2020. [Google Scholar]
- Omnicore. Twitter by the Numbers: Stats, Demographics & Fun Facts; Omnicore: London, UK, 2020. [Google Scholar]
- Wikipedia. Talk Pages; Wikipedia: Washington, DC, USA, 2021. [Google Scholar]
- McIntosh, P. White Privilege: Unpacking the Invisible Knapsack; ERIC: Norfolk County, MA, USA, 1988.
- DeAngelis, T. Unmasking racial micro aggressions. Monit. Psychol. 2009, 40, 42. [Google Scholar]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex Machina: Personal Attacks Seen at Scale. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 1391–1399. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 2999–3007. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Label | Counts |
|---|---|---|
| Tweets [21] | Racism | 1954 |
| Sexism | 3122 | |
| Neither | 11,014 | |
| Total | 16,090 | |
| Tweets [24] | Hate | 1430 |
| Offensive | 19,190 | |
| Neither | 4163 | |
| Total | 24,783 | |
| Wikipedia [58] | Attack | 13,590 |
| Normal | 102,275 | |
| Total | 115,865 |
| Dataset | Cyberbullying | Non-Cberbullying | Total |
|---|---|---|---|
| Tweets [21] | 5076 | 11,014 | 16,090 |
| Tweets [24] | 20,620 | 4163 | 24,783 |
| Wikipedia [58] | 13,590 | 102,275 | 115,865 |
| Items | Configuration |
|---|---|
| System hardware | Intel® Xeon® CPU E5-2680 v4 @ 2.40 GHz |
| 128 GB RAM | |
| NVIDIA® TITAN RTX™ GPU * 1 | |
| Operating system | Ubuntu 18.04.5 LTS |
| Main python libraries | Keras, TensorFlow, NumPy, scikit-learn, Pytorch |
| Dataset | Method | Non-Cberbullying | Cyberbullying | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| Tweets [21] | TF-IDF + SVM | 0.868 | 0.849 | 0.859 | 0.686 | 0.719 | 0.702 |
| Char N-grams + LR [21] | 0.874 | 0.844 | 0.859 | 0.683 | 0.735 | 0.708 | |
| Multi-features + LR [24] | 0.869 | 0.844 | 0.857 | 0.680 | 0.723 | 0.701 | |
| KimCNN [59] | 0.850 | 0.889 | 0.869 | 0.730 | 0.659 | 0.693 | |
| Bi-LSTM + Attention [29] | 0.857 | 0.864 | 0.861 | 0.698 | 0.686 | 0.692 | |
| Proposed Method | 0.893 | 0.885 | 0.889 | 0.753 | 0.769 | 0.761 | |
| Tweets [24] | TF-IDF + SVM | 0.784 | 0.931 | 0.851 | 0.986 | 0.948 | 0.967 |
| Char N-grams + LR [21] | 0.799 | 0.886 | 0.840 | 0.976 | 0.955 | 0.966 | |
| Multi-features + LR [24] | 0.785 | 0.948 | 0.859 | 0.989 | 0.948 | 0.968 | |
| KimCNN [59] | 0.844 | 0.833 | 0.838 | 0.966 | 0.969 | 0.968 | |
| Bi-LSTM + Attention [29] | 0.848 | 0.761 | 0.802 | 0.953 | 0.970 | 0.962 | |
| Proposed Method | 0.862 | 0.905 | 0.883 | 0.981 | 0.971 | 0.976 | |
| Wikipedia [58] | TF-IDF + SVM | 0.971 | 0.917 | 0.944 | 0.562 | 0.797 | 0.659 |
| Char N-grams + LR [21] | 0.977 | 0.912 | 0.944 | 0.560 | 0.838 | 0.671 | |
| Multi-features + LR [24] | 0.975 | 0.880 | 0.925 | 0.480 | 0.832 | 0.609 | |
| KimCNN [59] | 0.960 | 0.970 | 0.967 | 0.809 | 0.692 | 0.746 | |
| Bi-LSTM + Attention [29] | 0.958 | 0.973 | 0.965 | 0.766 | 0.676 | 0.718 | |
| Proposed Method | 0.965 | 0.973 | 0.969 | 0.780 | 0.734 | 0.756 | |
| Dataset | Method | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Tweets [21] | TF-IDF + SVM | 0.811 | 0.808 | 0.810 |
| Char N-grams + LR [21] | 0.814 | 0.810 | 0.811 | |
| Multi-features + LR [24] | 0.811 | 0.807 | 0.809 | |
| KimCNN [59] | 0.813 | 0.816 | 0.814 | |
| Bi-LSTM + Attention [29] | 0.807 | 0.808 | 0.808 | |
| Proposed Method | 0.849 | 0.848 | 0.849 | |
| Tweets [24] | TF-IDF + SVM | 0.952 | 0.945 | 0.947 |
| Char N-grams + LR [21] | 0.947 | 0.943 | 0.944 | |
| Multi-features + LR [24] | 0.955 | 0.948 | 0.949 | |
| KimCNN [59] | 0.946 | 0.946 | 0.946 | |
| Bi-LSTM + Attention [29] | 0.935 | 0.937 | 0.936 | |
| Proposed Method | 0.961 | 0.960 | 0.960 | |
| Wikipedia [58] | TF-IDF + SVM | 0.923 | 0.903 | 0.910 |
| Char N-grams + LR [21] | 0.928 | 0.904 | 0.912 | |
| Multi-features + LR [24] | 0.917 | 0.875 | 0.888 | |
| KimCNN [59] | 0.939 | 0.940 | 0.939 | |
| Bi-LSTM + Attention [29] | 0.935 | 0.938 | 0.936 | |
| Proposed Method | 0.943 | 0.945 | 0.944 |
| Dataset | Number of Layers | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Tweets [21] | 1 | 0.849 | 0.848 | 0.849 |
| 2 | 0.833 | 0.836 | 0.834 | |
| 3 | 0.830 | 0.831 | 0.830 | |
| Tweets [24] | 1 | 0.961 | 0.960 | 0.960 |
| 2 | 0.958 | 0.957 | 0.957 | |
| 3 | 0.958 | 0.957 | 0.957 | |
| Wikipedia [58] | 1 | 0.943 | 0.945 | 0.944 |
| 2 | 0.943 | 0.944 | 0.944 | |
| 3 | 0.940 | 0.942 | 0.941 |
| Dataset | Self-Attention | Non-Cberbullying | Cyberbullying | Total Weighted | ||
|---|---|---|---|---|---|---|
| F1-Score | F1-Score | Precision | Recall | F1-Score | ||
| Tweets [21] | Y | 0.889 | 0.761 | 0.849 | 0.848 | 0.849 |
| N | 0.879 | 0.720 | 0.828 | 0.831 | 0.829 | |
| Tweets [24] | Y | 0.883 | 0.976 | 0.961 | 0.960 | 0.960 |
| N | 0.846 | 0.969 | 0.948 | 0.948 | 0.948 | |
| Wikipedia [58] | Y | 0.969 | 0.756 | 0.943 | 0.945 | 0.944 |
| N | 0.960 | 0.727 | 0.924 | 0.926 | 0.925 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Yang, S.; Zhao, B.; Huang, C. Cyberbullying Detection in Social Networks Using Bi-GRU with Self-Attention Mechanism. Information 2021, 12, 171. https://doi.org/10.3390/info12040171
Fang Y, Yang S, Zhao B, Huang C. Cyberbullying Detection in Social Networks Using Bi-GRU with Self-Attention Mechanism. Information. 2021; 12(4):171. https://doi.org/10.3390/info12040171
Chicago/Turabian StyleFang, Yong, Shaoshuai Yang, Bin Zhao, and Cheng Huang. 2021. "Cyberbullying Detection in Social Networks Using Bi-GRU with Self-Attention Mechanism" Information 12, no. 4: 171. https://doi.org/10.3390/info12040171
APA StyleFang, Y., Yang, S., Zhao, B., & Huang, C. (2021). Cyberbullying Detection in Social Networks Using Bi-GRU with Self-Attention Mechanism. Information, 12(4), 171. https://doi.org/10.3390/info12040171