
Context-Aware Music Recommender Systems for Groups: A Comparative Study



Abstract
:1. Introduction
- To provide an overview of algorithms used in GRS, group types, aggregation methods, evaluation metrics, and context-aware recommender systems.
- To review the current state of GRS in the field of music. This is an application domain where the literature is poor, despite the fact that it is one of the fields where recommendations to groups acquire great relevance.
- To conduct an extensive comparative study of the performance of the eight main aggregation strategies used with the most important collaborative filtering algorithms in different contexts and for different types of groups.
2. State of the Art
2.1. Types of Groups
- Homogeneous groups: groups whose members have similar interests.
- Heterogeneous groups: groups whose members have diverse interests, which can become very disparate.
- Established groups: formed by individuals who explicitly choose to belong to the group because they have certain particular interests.
- Occasional groups: formed by people who occasionally perform some activity together. Members may have some particular tastes, with respect to a specific topic or activity.
- Random groups: groups of people who share the same environment at the same time, for a certain period of time, and whose members may not have much relationship with each other.
- Automatically identified groups: formed automatically by bringing together individuals with similar preferences, such as groups of article reviewers who are proficient in certain topics.
2.2. Algorithms Used
- Content-based recommender systems: content-based filtering [22] applied to groups is based on the idea of recommending new items, similar to those previously consumed or liked by the user. For example, recommending books to a bookstore customer based on characteristics such as genres read or favorite authors.
- Recommender systems based on collaborative filtering (CF): these are based on user-item interactions, in the form of ratings or other behavior from which implicit ratings are obtained [2]. CF systems use user-item rating matrices to provide recommendations from other user preferences or on ratings received by items. Continuing with the previous example, instead of focusing on the properties of previously read books, the CF algorithm would take into consideration the book ratings of other users similar to him/her when generating the preference for an individual.
- Constraint-based recommendations: this type of recommendations uses constraints proposed by group members that must be met in the proposed recommendations.
- Critique-based recommendations: the user is shown reference items, so that they can provide feedback through an iterative process to improve the recommendation.
2.3. Aggregation Methods
2.4. Evaluation Metrics
2.5. Context-Aware Recommender Systems
3. Experimental Study
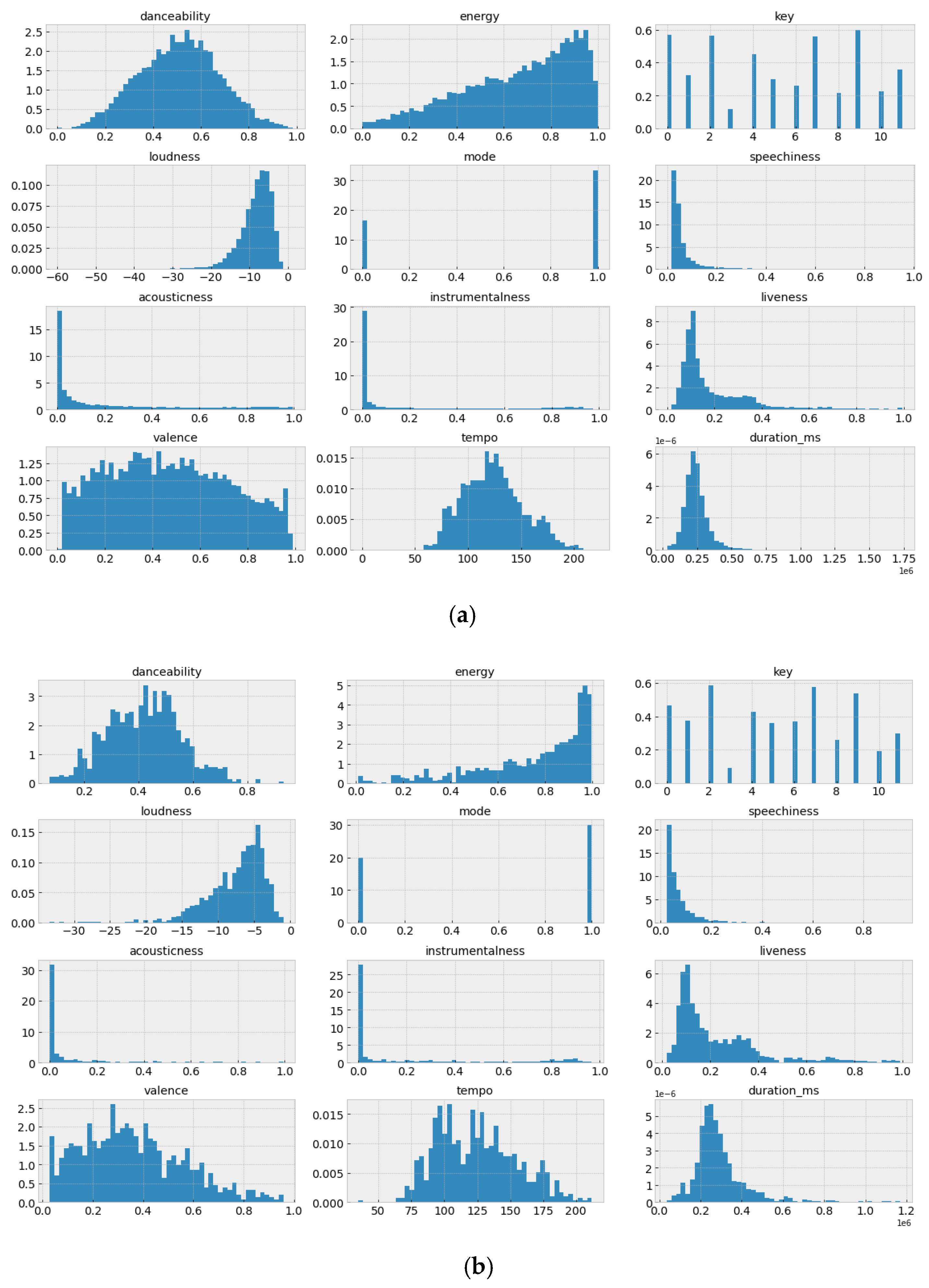
3.1. Dataset Description
- No context: Does not consider any property. This context includes all songs, without making any distinction by property.
- Party: A song is considered appropriate for a party environment when the danceability value exceeds the value of 0.65.
- Fitness: A song is considered appropriate for a sport environment when the energy value exceeds 0.90.
- Chill: A song is considered appropriate for relaxation when the energy value is less than 0.10.
- LastFM-lk-spotify, with a total of 988 users and 9093 songs.
- LFM-lb-small-spotify, with a total of 2713 users and 827 songs.
3.2. Description of the Experiments
- Random groups: individuals were randomly considered from the total users in the datasets.
- Contextual groups: random individuals were considered after filtering the dataset according to the contexts, and the results obtained were taken from those individuals who had a certain number of relevant songs in that context (fitness, party, and chill), 20 in this case, so that these users can be considered to have a criterion formed in that context.
- 4 contexts: no context, party, fitness, and chill.
- 50 groups of 5 members for each context.
- 4 recommendations algorithms: KNN, NMF, CoClustering, and SVD. All of them included in the surprise library [33].
- 8 aggregation methods: AVG, ADD, MUL, AVM, APP, LMS, MAJ, and MPL.
- 3 evaluation metrics: precision, recall, and NDCG.
- 4 different lengths for top-n lists (@k values): comprised between 5 and 20, hereafter referred to as the @k length of the re-recommendation.
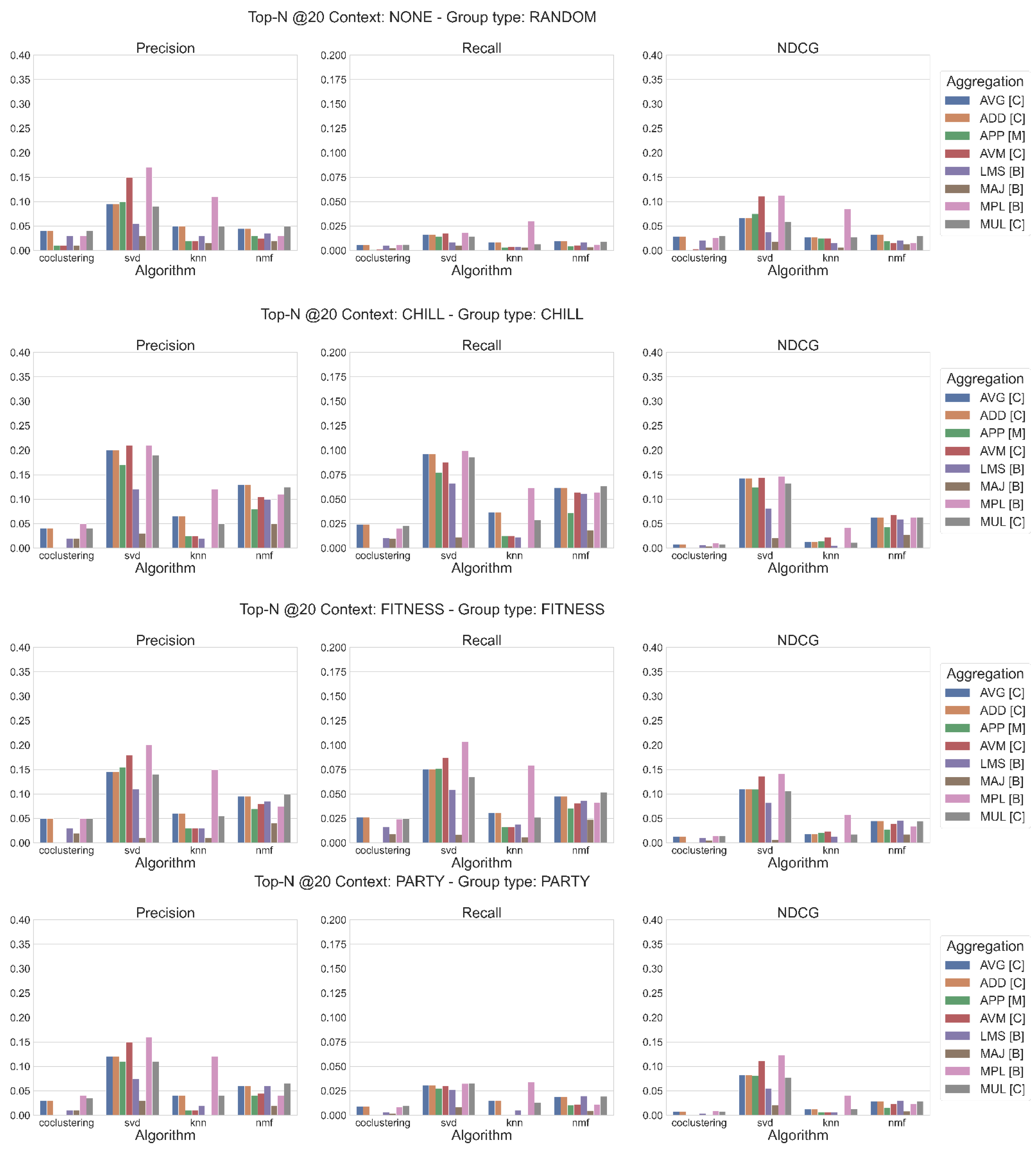
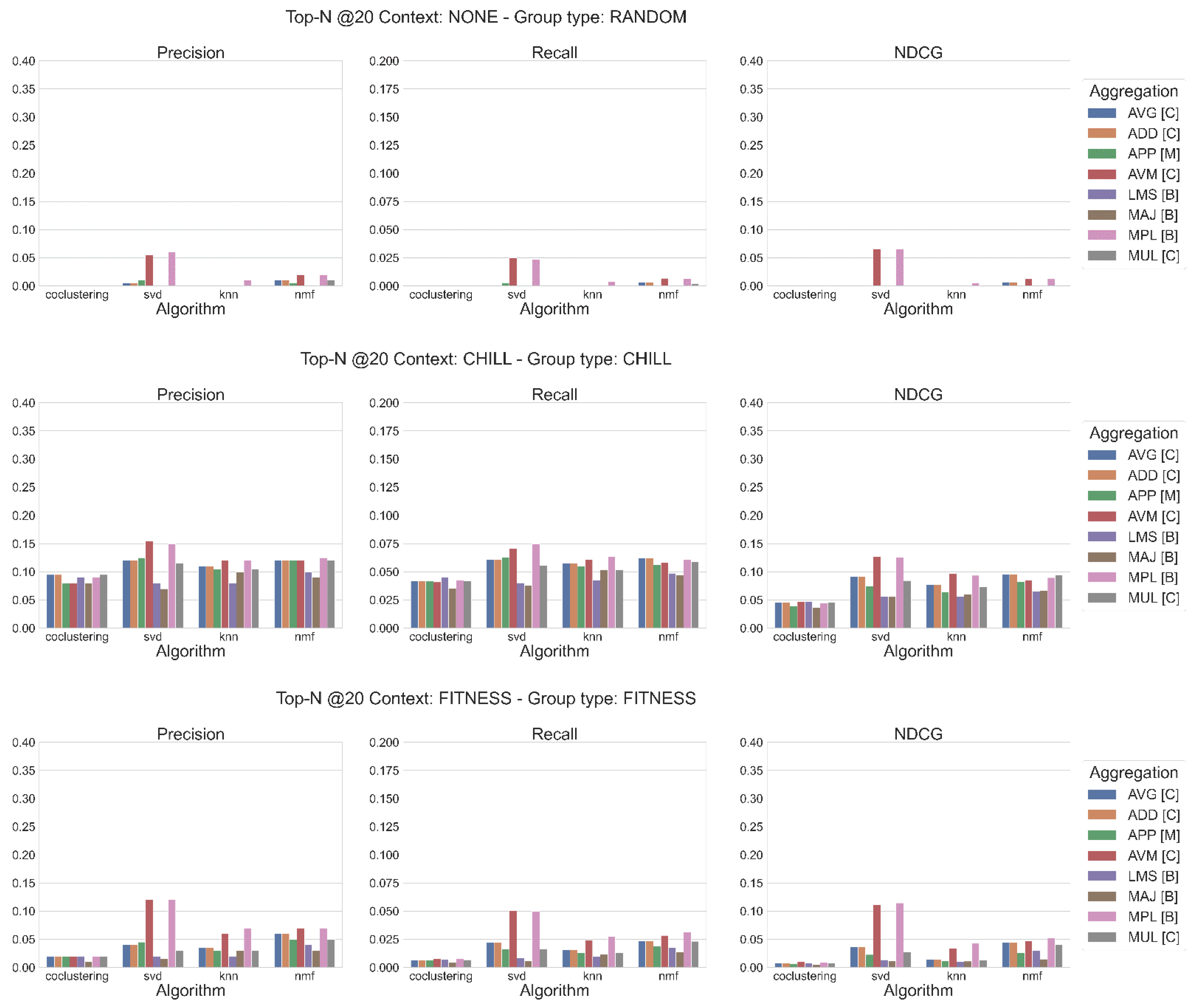
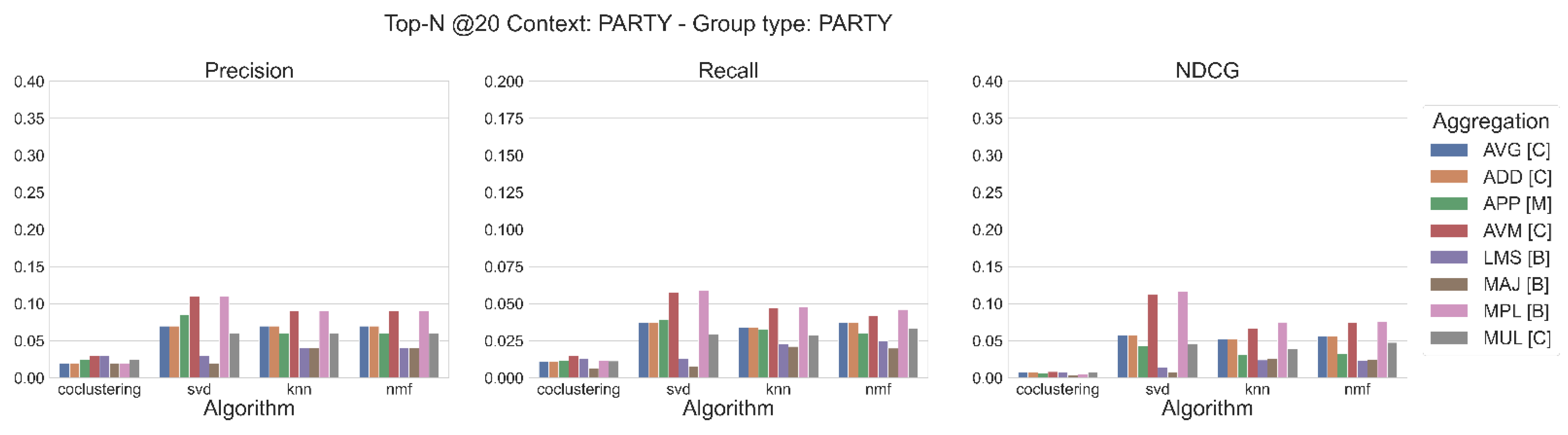
4. Results
- What are the main results of each algorithm for the relevant metrics (precision, recall, and NDCG)?
- What are the best aggregation methods, depending on the algorithm, and how does the application of a context affect the values of the metric?
- What is the best performing algorithm at a fixed @k?
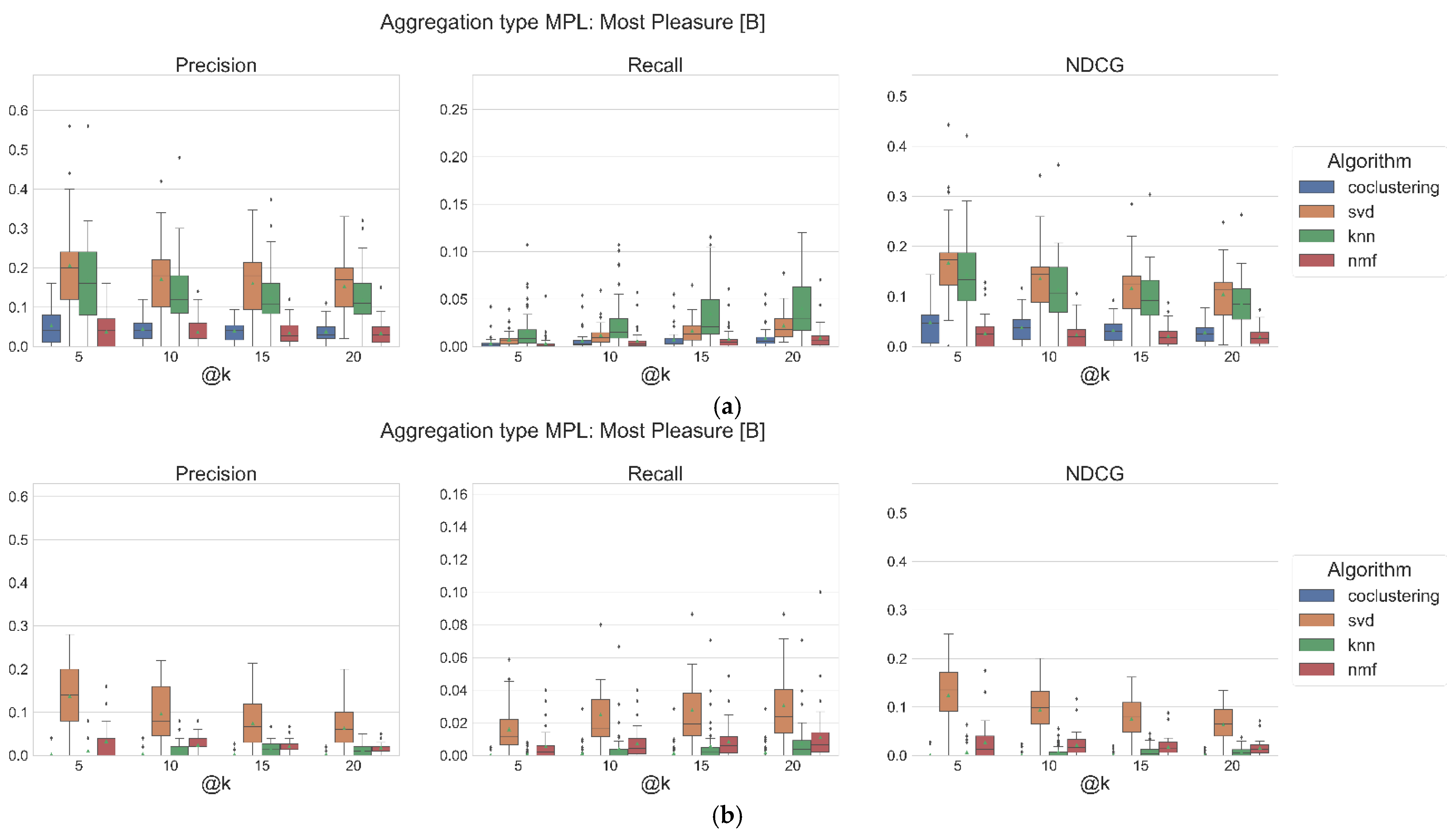
4.1. Main Results of Each Algorithm, in Terms of Precision, Recall, and NDCG
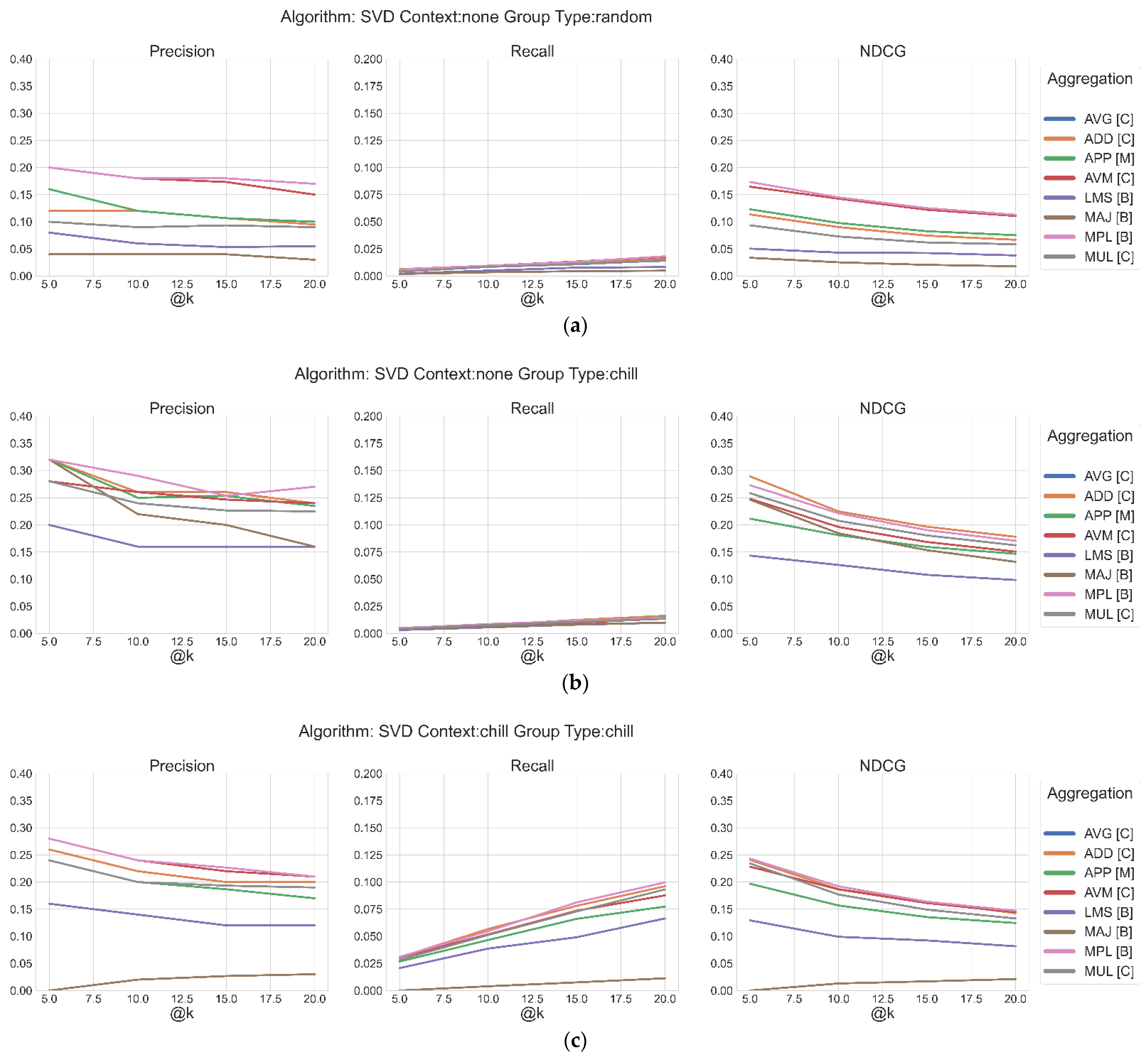
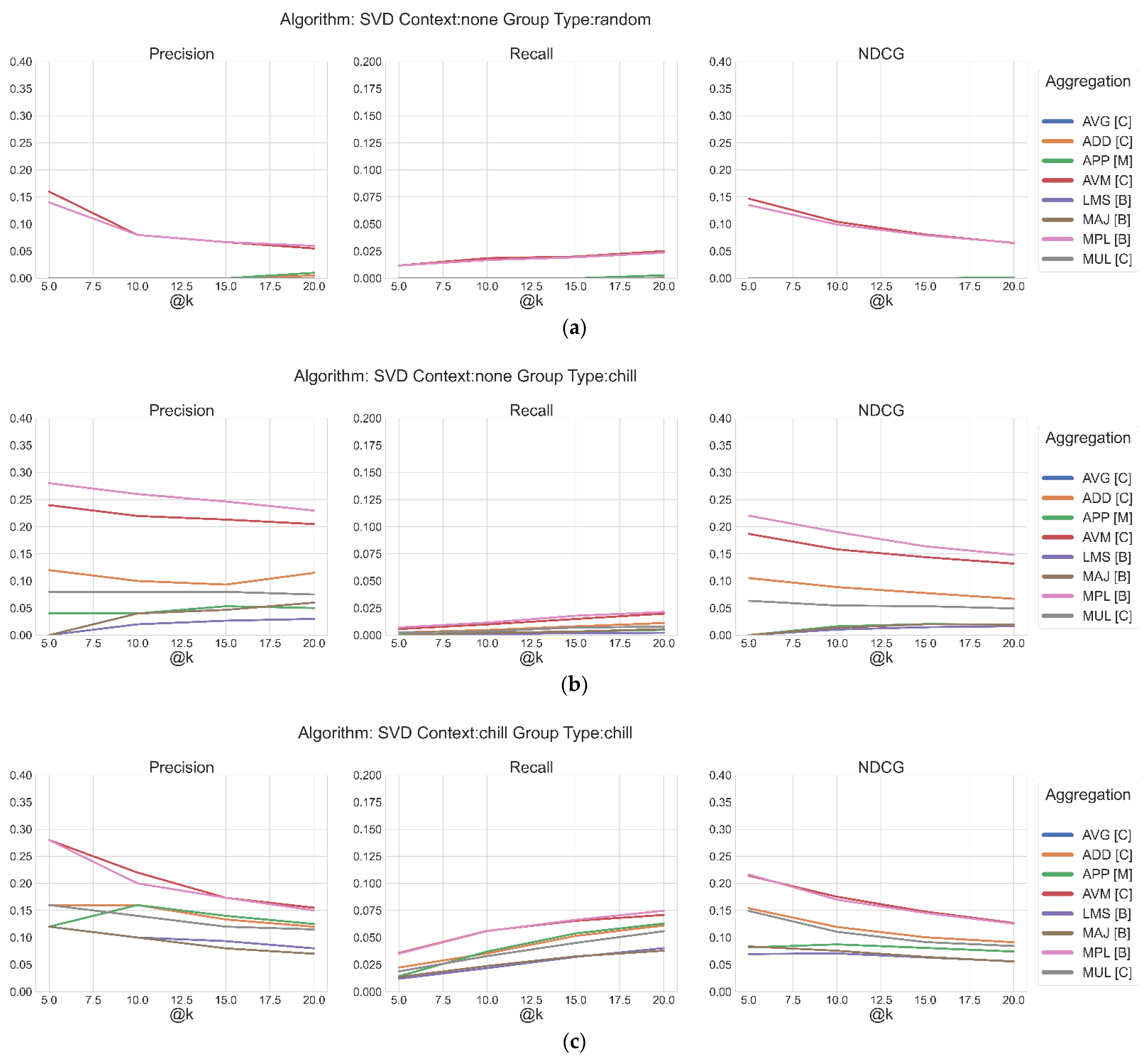
4.2. What Are the Best Aggregation Methods, Depending on the Algorithm, and How Does the Application of a Context Affect the Values of the Metric?
4.3. What Is the Best Performing Algorithm at a Fixed @k?
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ricci, F.; Shapira, B.; Rokach, L. Recommender Systems Handbook, 2nd ed.; Springer: New York, NY, USA, 2015; pp. 1–1003. [Google Scholar]
- Aggarwal, C.C. Recommender Systems; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Schedl, M.; Zamani, H.; Chen, C.W.; Deldjoo, Y.; Elahi, M. Current challenges and visions in music recommender systems research. Int. J. Multimed. Inf. Retr. 2018, 7, 95–116. [Google Scholar] [CrossRef] [Green Version]
- Schedl, M.; Knees, P.; McFee, B.; Bogdanov, D.; Kaminskas, M. Music Recommender Systems. In Recommender Systems Handbook; Springer: New York, NY, USA, 2015; pp. 453–492. [Google Scholar]
- Murciego, Á.L.; Jiménez-Bravo, D.M.; Román, A.V.; Santana, J.F.D.P.; Moreno-García, M.N. Context-aware recommender systems in the music domain: A systematic literature review. Electronics 2021, 10, 1555. [Google Scholar] [CrossRef]
- Valera, A.; Murciego, A.L.; Moreno-Garcia, M.N. Group Recommender Systems in the Music Domain: A Systematic Literature Review. In New Trends in Disruptive Technologies, Tech Ethics and Artificial Intelligence. DiTTEt 2021; de Paz Santana, J.F., de la Iglesia, D.H., López Rivero, A.J., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2022; Volume 1410, pp. 296–307. [Google Scholar]
- Mezei, Z.; Eickhoff, C. Evaluating Music Recommender Systems for Groups. arXiv 2017, arXiv:1707.09790. [Google Scholar]
- McCarthy, J.F.; Anagnost, T.D. MusicFX: An arbiter of group preferences for computer supported collaborative workouts. In Proceedings of the 1998 ACM Conference on Computer Supported Cooperative Work, Washington, DC, USA, 14–18 November 1998; pp. 363–372. [Google Scholar]
- O’Connor, M.; Cosley, D.; Konstan, J.A.; Riedl, J. PolyLens: A Recommender System for Groups of Users. In ECSCW 2001; Springer: Dordrecht, The Netherlands, 2001; pp. 199–218. [Google Scholar]
- Masthoff, J. Group Modeling: Selecting a Sequence of Television Items to Suit a Group of Viewers. In Personalized Digital Television; Springer: Dordrecht, The Netherlands, 2004; pp. 93–141. [Google Scholar]
- Yu, Z.; Zhou, X.; Hao, Y.; Gu, J. TV program recommendation for multiple viewers based on user profile merging. User Model. User-Adapt. Interact. 2006, 16, 63–82. [Google Scholar] [CrossRef]
- Smyth, B.; Mcginty, L.; Reilly, J.; Mccarthy, K. Compound Critiques for Conversational Recommender Systems. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’04), Beijing, China, 20–24 September 2004. [Google Scholar]
- Garcia, I.; Sebastia, L.; Onaindia, E.; Guzman, C. A group recommender system for tourist activities. In Proceedings of the International Conference on Electronic Commerce and Web Technologies, Linz, Austria, 1–4 September 2009; Volume 5692, pp. 26–37. [Google Scholar]
- Delic, A.; Masthoff, J. Group recommender systems. In UMAP 2018, Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, Singapore, Singapore, 8–11 July 2018; ACM: New York, NY, USA, 2018; pp. 377–378. [Google Scholar]
- Boratto, L.; Carta, S. State-of-the-art in group recommendation and new approaches for automatic identification of groups. Stud. Comput. Intell. 2010, 324, 1–20. [Google Scholar]
- Dara, S.; Chowdary, C.R.; Kumar, C. A survey on group recommender systems. J. Intell. Inf. Syst. 2020, 54, 271–295. [Google Scholar] [CrossRef]
- Kompan, M.; Bielikova, M. Group recommendations: Survey and perspectives. Comput. Inform. 2014, 33, 446–476. [Google Scholar]
- Jameson, A.; Smyth, B. Recommendation to groups. In The Adaptive Web; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4321, pp. 596–627. [Google Scholar]
- Yang, Q.; Zhan, L.; Han, L.; Zhang, J.; Bi, Z. Recommending more suitable music based on users’ real context. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing, London, UK, 19–22 August 2019; Volume 268, pp. 124–137. [Google Scholar]
- Li, H.W.; Sou, S.I.; Hsieh, H.P. Room-based Playlist Arrangement System using Group Recommendation. In Proceedings of the 2020 International Computer Symposium (ICS), Tainan, Taiwan, 17–19 December 2020; pp. 50–54. [Google Scholar]
- De Carolis, B.; Ferilli, S.; Orio, N. Recommending music to groups in fitness classes. Music Technology Meets Philosophy: From Digital Echos to Virtual Ethos. In Proceedings of the 40th International Computer Music Conference Joint with the 11th Sound and Music Computing Conference, Athens, Greece, 14–20 September 2014; pp. 1759–1765. [Google Scholar]
- Deldjoo, Y.; Schedl, M.; Knees, P. Content-driven Music Recommendation: Evolution, State of the Art, and Challenges. arXiv 2021, arXiv:2107.11803. [Google Scholar]
- Piliponyte, A.; Ricci, F.; Koschwitz, J. Sequential music recommendations for groups by balancing user satisfaction. In Proceedings of the UMAP Workshops, Rome, Italy, 10–14 June 2013; Volume 997. [Google Scholar]
- Chen, J.; Liu, Y.; Li, D. Dynamic group recommendation with modified collaborative filtering and temporal factor. Int. Arab J. Inf. Technol. 2016, 13, 294–301. [Google Scholar]
- Liu, N.H. Design of an intelligent car radio and music player system. Multimed. Tools Appl. 2014, 72, 1341–1361. [Google Scholar] [CrossRef]
- Felfernig, A.; Burke, R. Constraint-based recommender systems: Technologies and research issues. In Proceedings of the 10th International Conference on Electronic Commerce, Innsbruck, Austria, 19–22 August 2008; ACM: New York, NY, USA, 2008. [Google Scholar]
- Felfernig, A.; Schubert, M. A Diagnosis Algorithm for Inconsistent Constraint Sets. In Proceedings of the 21st International Workshop on the Principles of Diagnosis, Held Jointly with the Annual Conference of the PHM Society 2010, Portland, OR, USA, 13–16 October 2010; pp. 1–8. [Google Scholar]
- Guzzi, F.; Ricci, F.; Burke, R. Interactive multi-party critiquing for group recommendation. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; ACM: New York, NY, USA, 2011; pp. 265–268. [Google Scholar]
- Chao, D.L.; Balthrop, J.; Forrest, S. Adaptive radio: Achieving consensus using negative preferences. In Proceedings of the 2005 International ACM SIGGROUP Conference on Supporting Group Work, Sanibel Island, FL, USA, 6–9 November 2005; pp. 120–123. [Google Scholar]
- Baskin, J.P.; Krishnamurthi, S. Preference aggregation in group recommender systems for committee decision-making. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 337–340. [Google Scholar]
- Alhamid, M.F.; Rawashdeh, M.; Dong, H.; Hossain, M.A.; Alelaiwi, A.; El Saddik, A. RecAm: A collaborative context-aware framework for multimedia recommendations in an ambient intelligence environment. Multimed. Syst. 2016, 22, 587–601. [Google Scholar] [CrossRef]
- Gillhofer, M.; Schedl, M. Iron maiden while jogging, debussy for dinner? An analysis of music listening behavior in context. In Proceedings of the International Conference on Multimedia Modeling, Sydney, NSW, Australia, 5–7 January 2015; Volume 8936, pp. 380–391. [Google Scholar]
- Hug, N. Surprise: A Python library for recommender systems. J. Open Source Softw. 2020, 5, 2174. [Google Scholar] [CrossRef]
- LastFM. LastFM 1k Dataset. Available online: http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html (accessed on 15 October 2021).
- Celma, Ò. Music recommendation and discovery: The long tail, long fail, and long play in the digital music space. Music Recomm. Discov. 2010, 1, 1–194. [Google Scholar]
- Spotify Spotify for Developers. Available online: https://developer.spotify.com/ (accessed on 15 October 2021).
- Kowald, D.; Schedl, M.; Lex, E. The unfairness of popularity bias in music recommendation: A reproducibility study. Adv. Inf. Retr. 2020, 12036, 35–42. [Google Scholar]
- Schedl, M. The LFM-1b dataset for music retrieval and recommendation. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; ACM: New York, NY, USA, 2016; pp. 103–110. [Google Scholar]
- Pacula, M. A Matrix Factorization Algorithm for Music Recommendation Using Implicit User Feedback. 2009. Available online: mpacula.com (accessed on 1 October 2021).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aggregation Strategy | Description | Function |
|---|---|---|
| Additive Utilitarian (ADD) [C] | Sum of the predicted ratings for an item. | |
| Multiplicative (MUL) [C] | Multiplication of the predicted values for an item. | |
| Average (AVG) [C] | Average of the predicted values for an item. | |
| Average without Misery (AVM) [C] | Average of predicted predictions that exceed a certain threshold of relevance. | |
| Approval Voting (APP) [M] | Number of predicted ratings that exceed a certain threshold of relevance. | |
| Most Pleasure (MPL) [B] | Maximum rating of an item. | |
| Least Misery (LMS) [B] | Minimum prediction of an item. | |
| Majority Voting (MAJ) [B] | Maximum prediction of an item. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valera, A.; Lozano Murciego, Á.; Moreno-García, M.N. Context-Aware Music Recommender Systems for Groups: A Comparative Study. Information 2021, 12, 506. https://doi.org/10.3390/info12120506
Valera A, Lozano Murciego Á, Moreno-García MN. Context-Aware Music Recommender Systems for Groups: A Comparative Study. Information. 2021; 12(12):506. https://doi.org/10.3390/info12120506
Chicago/Turabian StyleValera, Adrián, Álvaro Lozano Murciego, and María N. Moreno-García. 2021. "Context-Aware Music Recommender Systems for Groups: A Comparative Study" Information 12, no. 12: 506. https://doi.org/10.3390/info12120506
APA StyleValera, A., Lozano Murciego, Á., & Moreno-García, M. N. (2021). Context-Aware Music Recommender Systems for Groups: A Comparative Study. Information, 12(12), 506. https://doi.org/10.3390/info12120506