1. Introduction
Tracking misinformation has become a task with rapidly increasing importance in recent years. Massive disinformation campaigns influencing the U.S. 2016 elections and the Brexit referendum have suggested that the spread of false information can have a large scale political impact [
1,
2]. Even outside a U.S. or UK context, in the last five years, democratic regimes have become more vulnerable to foreign influence efforts directed to sow mistrust in authorities [
3,
4,
5]. Particularly during the COVID-19 pandemic, false information can influence the well-being and life of many. In the midst of rising infection rates, narratives misrepresenting official responses to the virus are among the most common in recent news [
6]. The problem has become so widespread that the World Health Organization is talking about an “infodemic” (information epidemic) accompanying the spread of COVID-19 [
7], and scientists have called for an interdisciplinary approach to battle misinformation [
8].
For all these reasons, it is crucial to be able to detect false information in real time, shortly after it is produced and distributed. However, traditional fact checking requires trained journalists carefully examining each piece of information and labeling it individually. This is hard to do when facing a
firehose of falsehood [
9] directed by malicious or uninformed actors toward the online public sphere. Existing automated disinformation detection tools are often tested on pre-labeled datasets, and it is not clear how precise they can detect disinformation on unseen topics and how often the labels need to be updated. In contrast, user comments represent a self-perpetuating stream of labels that can be used to complement existing methods.
From media studies, we know that audiences are not just passive recipients of information [
10,
11]. Especially in online communication, we observe how social media and internet forum users are often actively involved in removing, reporting, or commenting on posts that they suspect present false information. Fact checking and reporting of misinformation are then not performed by software or external experts, but rather by the community itself. In fact, while much research is involved with the spread of misinformation [
12,
13,
14,
15,
16,
17,
18,
19], the prevention of misinformation from the user side is rarely considered. The aim of our research is to operationalize and analyze one central mechanism of gatekeeping from the user side called
informal flagging.
This paper looks into the possibility of externalizing some of the labeling to users of online platforms and aims to build an easy accessible online tool to help investigate Reddit users’ claims of disinformation. Reddit is one of the largest platforms for news sharing, but it is less often studied in comparison to Twitter. Reddit is the ideal platform to perform this task for several reasons: its content is fully accessible and can be easily scraped (unlike Facebook), it is a decentralized platform covering a large number of topics and diverse perspectives from all around the world (unlike blogs, news websites or magazines), it does not limit the character input of its posts (unlike Twitter), it contains posts with links to external websites (that can be fact checked), and it has been the target of disinformation campaigns in the past [
20].
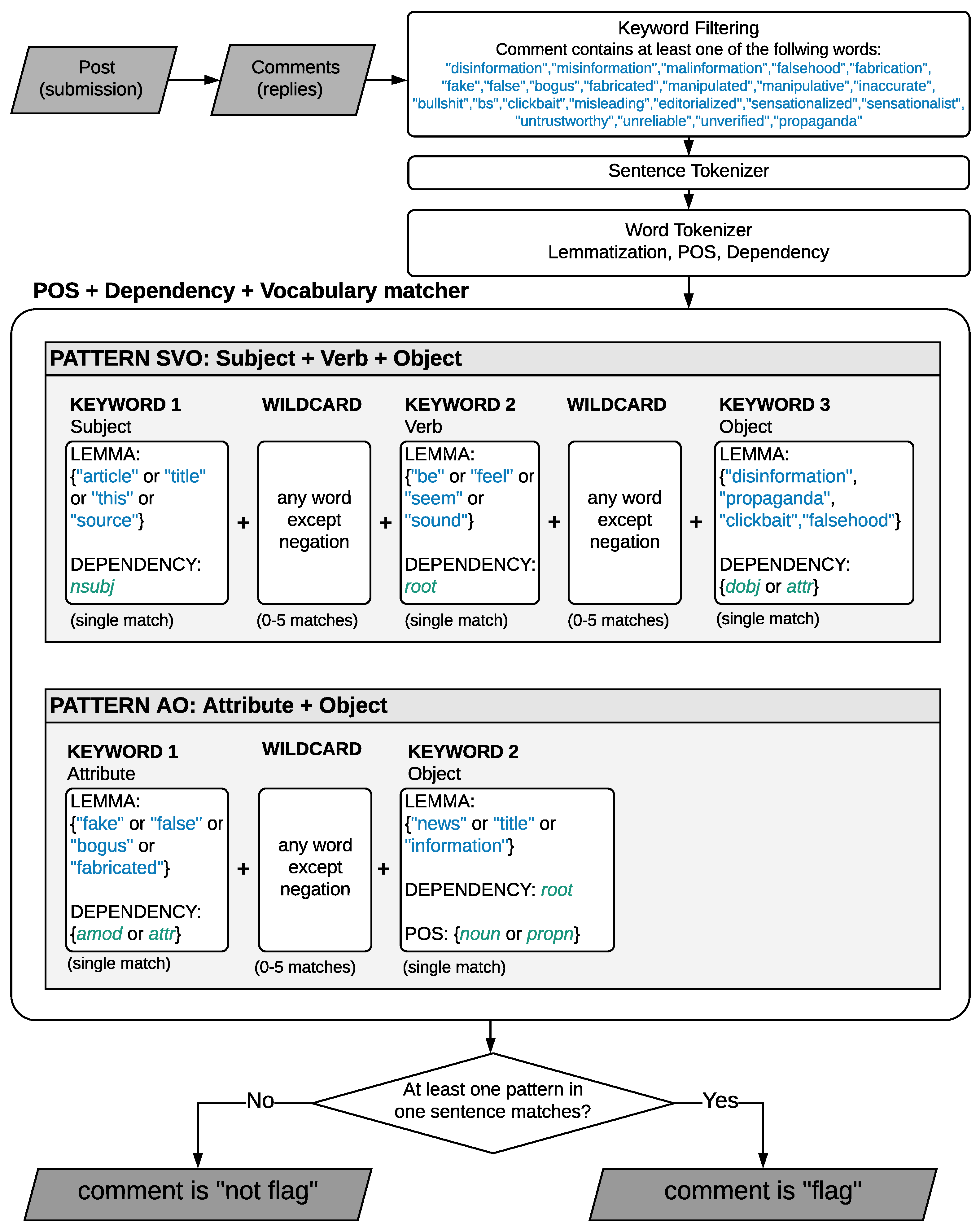
We develop a rule-based natural language processing model that can extract and filter posts and comments (using keywords), and detect user flags among the comments (using part of speech tags and dependency parsing). We test the precision and recall scores of our model against a simple keyword matcher and two supervised machine learning models, on a manually labeled set of comments. While it was developed with Reddit in mind, our model is very flexible. It can be customized by adding or removing keywords or dependency rules. It can be applied to any website that has a similar structure to Reddit (text comments replying to posts), since it takes only the content of the comment as input.
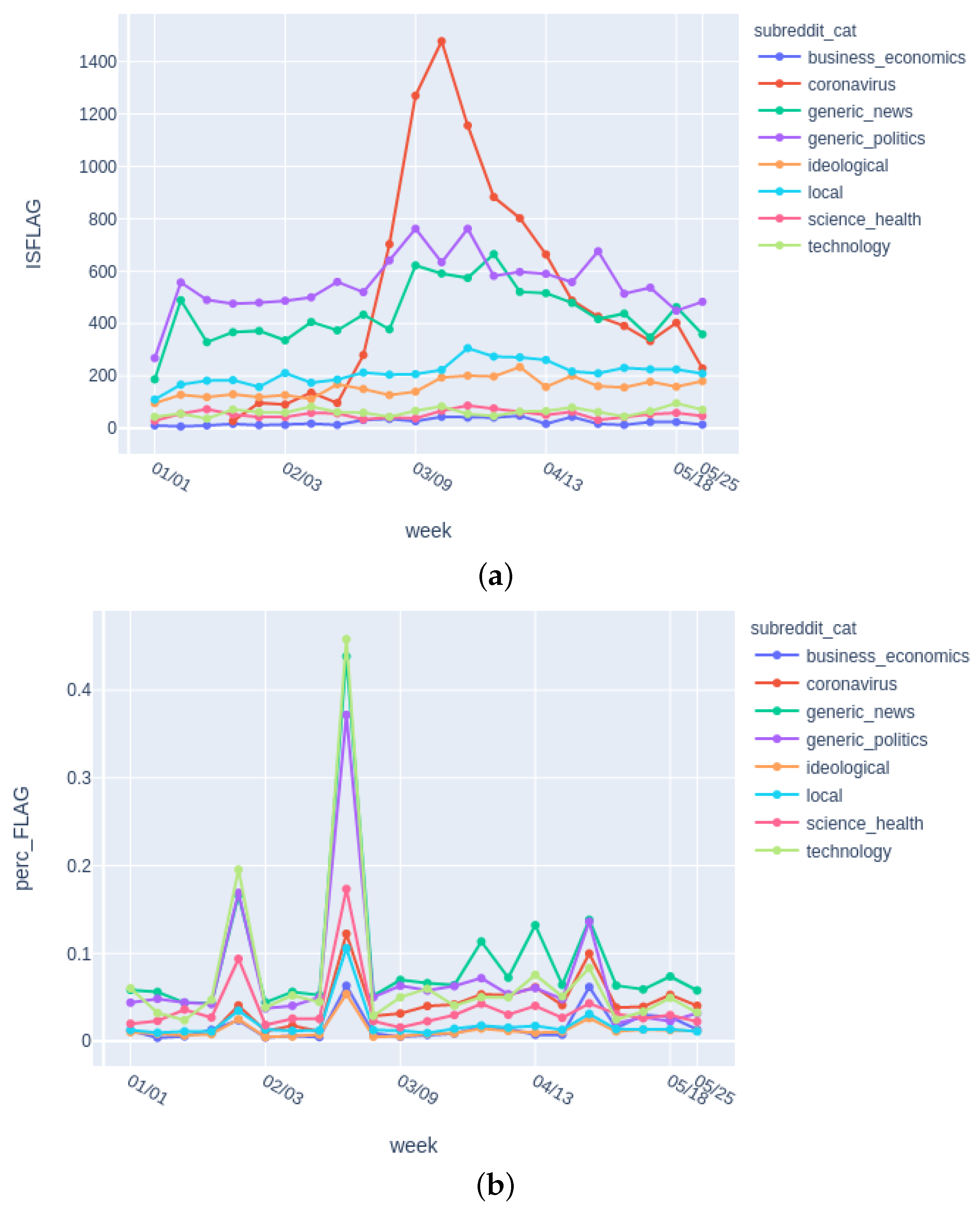
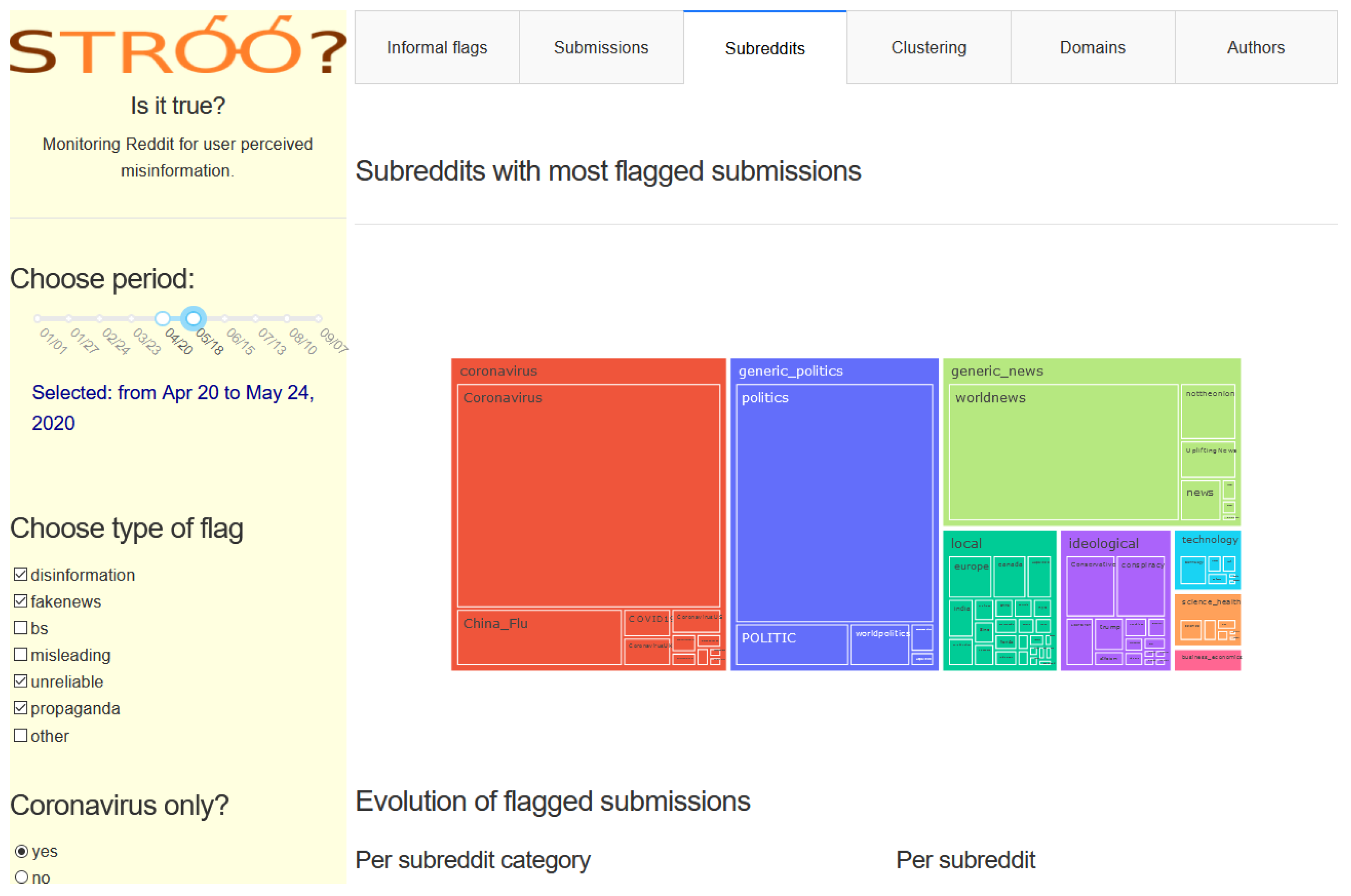
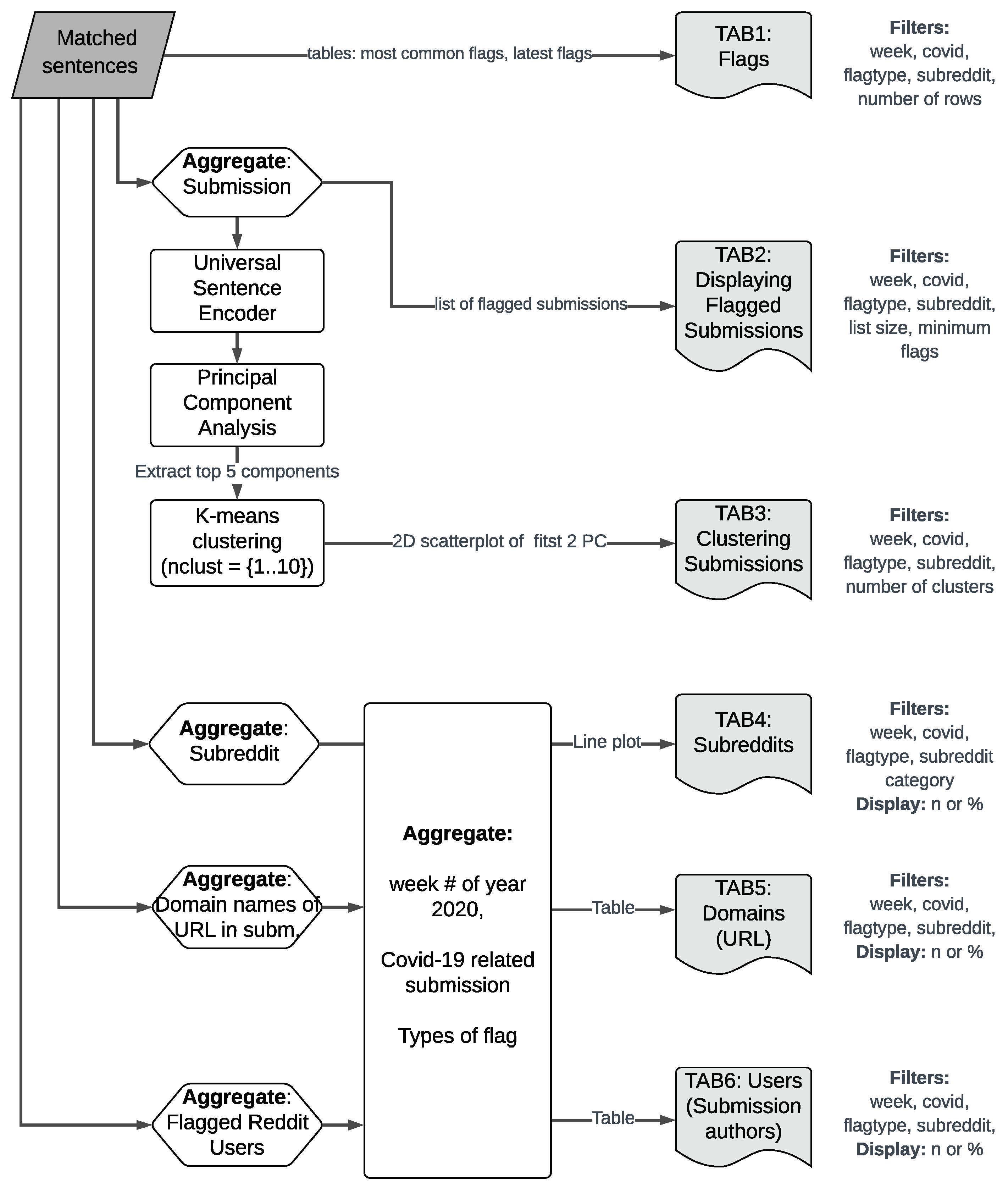
For monitoring new Reddit posts, we created a Python+Plotly/Dash powered dashboard freely available online (see
Section 7). It shows daily descriptive statistics about flagged posts and permits the user to filter and cluster the posts. The dashboard is named
STROO? (short for “Is it true?”), as a reference to the Reddit mascot [
21], the alien SNOO (short for “What’s new?”). This dashboard is updated daily, and it can serve as a source for researchers, journalists, or fact checkers to analyze the content and spread of information online. It illustrates both the merits and the downfalls of using informal flags to detect false information spread online.
6. Discussion
We agree that, for the task of detecting false information, “tools should be designed to augment human judgement, not replace it.” [
36]. Our project aims to fulfill this goal, by narrowing down the list of potential false information to posts flagged as false by members of online communities. Using this method, we highlight what can be considered an informal vote of non-confidence from parts of an online community toward individual posts. Aggregating such information in real time can then be used as a barometer of how much misinformation is perceived by users at a specific time. Such a technology is complementary to expert based fact-checking. We also agree that the methods should be fully transparent, and our patterns can be easily inspected and modified even by less technical users.
Our tool does not require training on manually labeled data and is less vulnerable to the particularities of a specific training set. It is highly customizable and can be adapted to any internet forum where news are discussed. It performs better than a keyword filtering model, and not significantly worse than machine learning models. Our model extracts labels in real time, by unobtrusively tapping into the actual behavior of online platform users.
There are several limitations to this method. We are aware that it is a rather simple model of text analysis. However, compared to novel developments in Natural Language Processing and Deep Learning, we find our approach to be more conductive for user transparency, especially for users who might not have a background in machine learning. Efficient machine learning requires a large amount of costly manual labeling for training data, and it is sensitive to concept drift. The simple vocabulary and matchers can be easily changed to accommodate new patterns or to remove irrelevant ones. The qualitative derivation of the keywords for the POS matcher was the chosen way to operationalize flagging, as we are currently not aware of any literature defining online sanctioning behavior in a consistent manner. Therefore, this method may not capture “flagging” exhaustively, as the recall measures show. It does, however, leave the possibility of improvement by adjusting the vocabulary or rules.
It should be kept in mind that the model is potentially detecting user-perceived false information, and not necessarily actual false information. Reddit users are probably less informed compared to professional fact checkers and have their own ideological lenses by which they judge a piece of news as true or false. The Reddit demographics are highly skewed toward young and male [
50], and their evaluations might not reflect the views of the general U.S. population. Online anonymity can encourage antisocial behavior; therefore, some informal flagging may not be done in full honesty, especially if it is infiltrated by bots and paid trolls [
20]. In addition, given Reddit’s meme-centric ethos and creativity, irony, and sarcasm cannot always be filtered out. The intensity of an informal flag can vary (from “absolutely false” to “slightly misleading”), and so does the target of the flag (from the content of article, to the source referenced, or Reddit user). In addition, in terms of flagging accuracy, not all subreddits are created equal. There is a risk that malevolent actors become aware that their content is being flagged, and attempt to break the algorithm by “flooding the zone” with false flags. This is why future research should also take into consideration user reputation and their tenure on the platform, and to find a way to filter out the false flaggers.
That being said, even if many of the flagged posts are not objectively presenting false information, the dataset of user flags can be used by social scientists to study how perception about what is true and what is false online emerges and changes over time. As an example, sociologists have long theorized that actors with ambivalent traits concerning valuation can receive sanctions from an audience for not adhering to role-based expectations [
55,
56]. This in turn may enhance conformity and reduce innovations in a field. However, which acts of communication constitute sanctions and which do not is something that has not been systematically analyzed. In a similar manner, Bratich [
11] has argued for revising classical communication models of audience interaction, so that the active production of meaning as well as the influence of the audience on media production can be included. Our analysis in this respect not only traces flags, therefore including an active process of meaning generation. It is also possible for researchers to use these techniques to trace how the production of posts might change as a consequence of flagging.
Within this project, we are building a dataset that is made public, and we are providing the source code for the data collection and for recreating the dashboard (see
Section 8). The next steps will involve bringing more external data from known datasets of fact checked information, and further inquiries into the relationship between the veracity (reflected by expert reviews) and credibility (reflected by user flagging) of news published online, as well as the effects of being flagged on posting behavior.
When detecting whether flagging correctly predicts false information (based on reports of fact checkers), more information should be considered as possible moderators. Previous research shows that a wider range of features can be used to predict disinformation or propaganda, such as metadata [
17,
46], emotional cues [
24,
25], or visual data [
51]. Useful metadata can include the weekday and time of posting, the time spent by the user on the platform, the rating of the post or comment, and the concentration or dispersion of user posts among subreddits. Emotional signals, extracted through sentiment scores, might help in separating between flag types or types of false information. The memes and other images shared on these forums can be also mined for useful features. More advanced deep learning models [
53,
54] can be incorporated to filter out sarcastic comments.
Finally, we aim to expand the current approach to problems beyond the current COVID-19 pandemic and online contexts different from Reddit. The model only depends on the text content of a reply to a post, so it can be easily adapted to other online platforms, including Twitter or online newspaper websites. The dictionary and rules are fully customizable, as long as the input text is in the English language (although similar tools can be created for other languages). We hope the tool will be of use to academics, journalists, fact checkers, data scientists, medical experts, Reddit users and moderators, and all members of society.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









