1. Introduction
Hate speech is a characterisation of communication that is ‘hateful’, controversial, generates intolerance and in some way is divisive and demeaning. There is no legal definition of hate speech, but on several accounts accepted meaning of the term deals with communication in speech, behaviour or writing, remarks which are pejorative or discriminatory concerning a person or a group of persons, either directly or indirectly. Such remarks are based on their religion, ethnicity, nationality, descent, race, colour, gender or other identity factors [
1].
Many countries have adopted new laws and frameworks have been constituted. However, due to the pervasive nature of online communications, only 3% of malicious communication offenders are charged [
2]. This is because of a lack of clarity and certainty in this area. Several of these frameworks prohibit the incitement to discrimination, hostility and violence rather than prohibiting hate speech. There is a need for quick identification of such remarks and an automatic system which can identify and take measures to prevent the instigation and incitement.
There are several examples of hate speech (
Figure 1) which either implicitly or explicitly target an individual or a group of individuals and inflict mental pain that may eventually cause of social revolts or protests.
In this work, we study the existing methods designed to tackle hate speech. We curated the data from the most prominent social media platform, Twitter. We also combine the existing datasets into one, as these are pre-annotated and previous researchers have used these to target several cases of hate speeches. Individually, these are small datasets, but, after we combine the existing datasets into one dataset, we obtain a large corpus of hate speech sequences. This dataset is a combination of the hateful content of five different categories: sexual orientation, religion, nationality, gender and ethnicity. We create models which classify the content of a text as hateful, abusive or neither. The total size of the dataset is around seventy-six thousand samples, and, due to the high variance and low bias, we avoid sub-categorisation of hate classes.
We also study some state-of-the-art models which claim to give superior accuracy. Since these models are built on specific languages (English or Hindi), we utilise the work and propose our model which is multilingual. Finally, we use our optimised models to create a simple tool which identifies and scores a page if hateful content is found and uses the same as the feedback to re-train the model. While the vast majority of previous works have investigated the development of hate speech detection models for specific languages [
3], here we propose a multilingual model which we experiment in two languages, English and Hindi, leading to competitive performance and superior to most monolingual models.
The main contributions of this work are as follows:
We create a system which is trained on a sufficiently large corpus of hate speech text.
A multilingual system that can work on different languages is proposed, and another language be added and trained quickly using our transfer learning models.
We propose system which can learn a new form of hateful remark or Zipfian nature of language by re-training in an online environment.
The resulting system has models which are simple, lightweight and optimised to be used in a near-real-time online environment.
In this way, the system holds potential as a product for safer social media utilisation as well as reduces the need for human annotators and moderators to tag disturbing online messages.
The rest of the paper is organised as follows. An overview of hate speech datasets and existing models is provided in the Related Work Section. In the Model Section, we critically analyse the existing models and discuss their limitations. We also discuss our model and several optimisations we performed to achieve a desirable performance score. Furthermore, we talk about the feedback mechanism for the optimised model and its usage in an online environment.
4. Results and Discussion
We show that the logistic regression model supplemented with TFIDF and POS features gave relatively good results in comparison to other models. However, the time taken for the model to converge is very long. The results presented are in line with those of previous research [
5,
9,
33].
The deep learning model gave similar performance scores without much feature engineering and the model converged quickly too. Such results can be attributed to the use of embedding layers in the neural network. We also tried to use the glove and Twitter embedding layers, but, due to the high number of unknown words, desirable results were not obtained.
The logistic regression model has fewer system requirements, is very quick to infer a single sample instance and has great performance scores. Due to its inability to scale on a large dataset and the time taken to build the model is very high, it can only be used as a benchmark for other models and cannot be used in an online environment, where models are continuously re-trained on the feedback loop.
The CNN LSTM model is an average model which has a mediocre performance but its performance can be perfected. The random search optimisation used in this study is a test-driven approach. Other optimisation techniques such as Bayesian optimisation can find better hyperparameters. However, the time taken to build the model will increase considerably. The CNN LSTM model requires moderate GPU processing and infers a single sample instance in near-real-time. Thus, we utilise this model in our online web application.
The BERT model is a high-performance state-of-the-art model. It has the highest accuracy among all the models. If the system requirement (TPU) criteria are fulfilled, it can be used in an online environment. This model has much less training time and is very quick to infer a single sample instance. The only constraint is the use of the TPU. Although the model size is 1000 times the size of a logistics regression model, memory and disk space consumption is hardly a worry these days due to their easy availability. Unlike GPU, the cost of a single TPU instance is very high. However, the scope of TPU usage as the mainstream processing unit for machine learning in the future is high. Thus, the research done in this study is futuristic and this novel state-of-the-art model is very much applicable to be used in the real world.
To give a fair comparison of our models to existing ones, we apply our models to the datasets in isolation. We find that our models outperform on most of the datasets.
Table 10 shows these results. The dataset was segmented in the exact proportions of test and train as it was done in the original research. Further, out of the many models described here, we chose the best results (after optimising it to work on smaller datasets) of CNN LSTM model as it works more quickly in loading the data as well as giving inference. The results are consistent with the performance and the performance is consistent across the datasets as well.
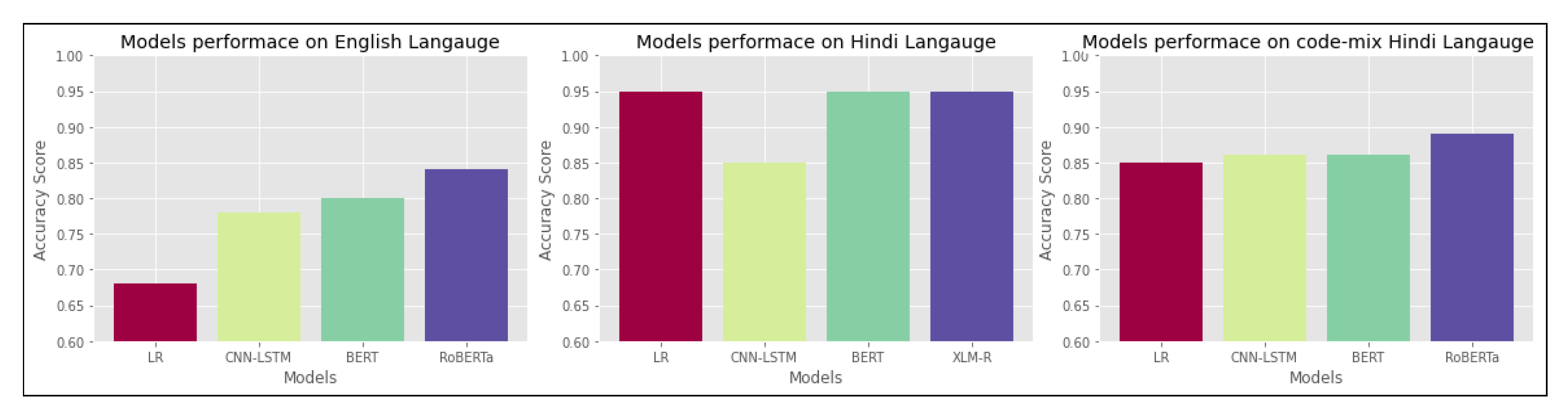
We also undertook and extended our study to compare our models with the state-of-the-art models RoBERTa [
34] for English and code-mixed Hindi and XLM-R (cross-lingual RoBERTa model) [
35] for Hindi. We found that our model’s performance is comparable to the existing pre-trained models. Our BERT-based model and CNN-LSTM model performance match fairly against RoBERTa.
Figure 4 describes the accuracy scores of different models in different languages.
Ablation Study and Modes of Errors
Performance layer-by-layer, without fine-tuning. To understand which layers are critical for classification performance, we analysed results on the English dataset for CNN-LSTM- and BERT-based models. We checked the importance of CNNs and LSTM in CNN-LSTM network and LSTM in the BERT-based model.
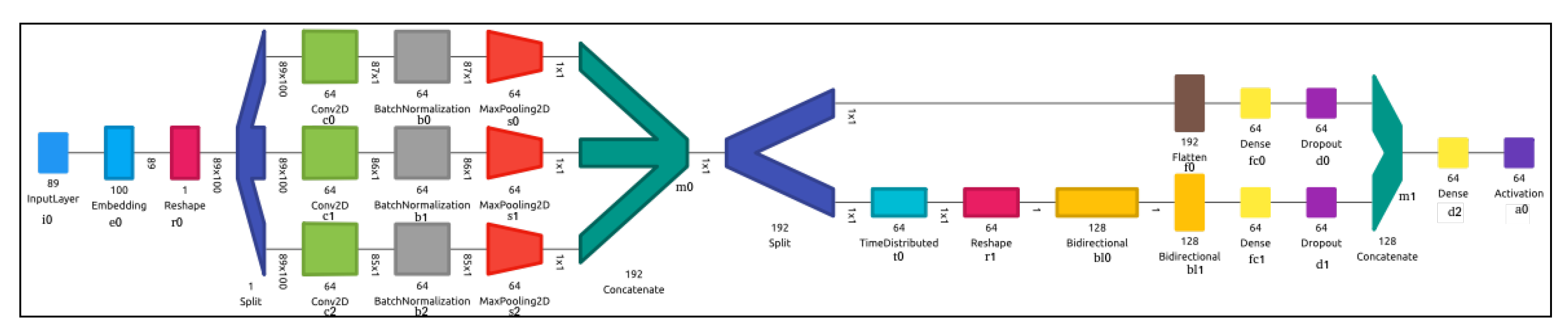
In
Figure 2, we have three parallel convolution kernels that are convoluted with the reshaped input layer to produce a tensor of outputs each are of shape 1 × 6, which are then concatenated at m0 resulting into a 1 × 192 tensor. As explained above, the main reason to employ three parallel CNNs is to learn textual information in each utterance, which is then used for classification. The output of CNN is time distributed in t0 over Bidirectional LSTMs (bl0,bl1). The outputs of both CNNs and LSTMs are passed through dense layer fc0 and fc1, respectively, and are finally concatenated at m1 before passing through another dense layer fc2 and activation a0. We focus the usage of first CNN C1 (c0,b0,s0), second CNN C2 (c1,b1,s1) and third CNN C3 (c2,b2,s2) along with the role of BiLSTM bl0 and bl1, on the performance of the entire network. The first five rows of
Table 11 give the details of the performance of our network on a layer-by-layer basis. We understand that both CNN and BiLSTM are important in the network to attain good performance score. If we remove the CNN layers entirely, then we get an average model but there is a considerable increase in performance when CNN layers are added.
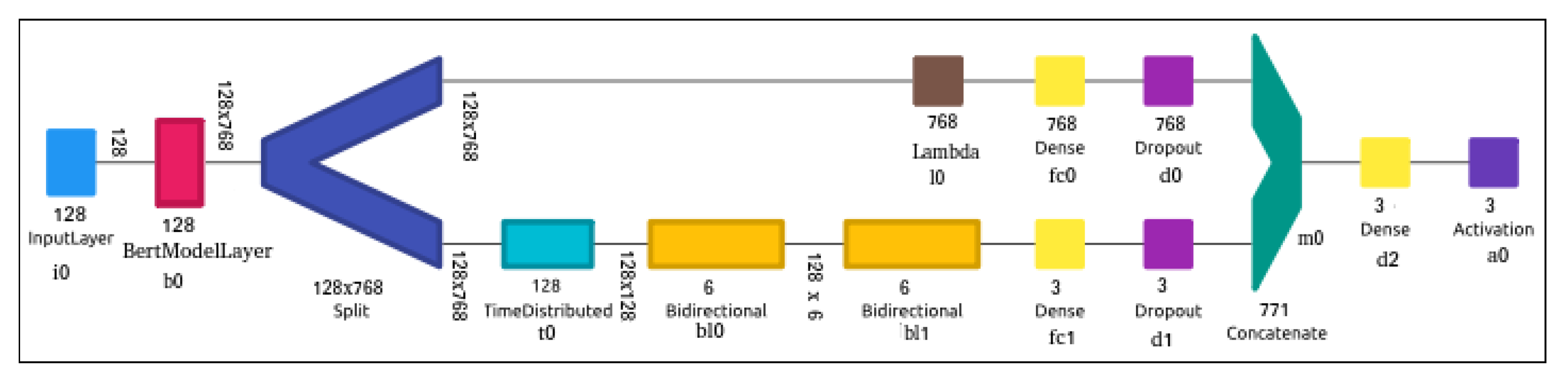
In
Figure 3, we use BERT + BiLSTM to capture both utterance level and sentence level understanding of hate speech sequence. To understand how the performance is affected, we removed bl1 and bl0, simultaneously. Rows 6–7 present the performance of the model when both BiLSTM layers are removed and when only one is kept. The overall performance of the model is unaffected with or without the presence BiLSTM as there are 109,584,881 parameters of which only 102,641 belong to BiLSTM part of the network, but, with the split and BiLSTM layers, a slight improvement is added nonetheless.
Performance layer-by-layer, with fine-tuning. We now analyse the results from our CNN-LSTM and BERT models after having fine-tuned their parameters on the English dataset. The improvement is marginal in both the cases (
Table 11, Rows 8–11): fine-tuning increases the accuracy by 1–2%. The best hyperparameters to give this result are shown in
Table 6 and
Table 8.
Modes of Error Further, we discuss some categories of errors that were observed in the deep learning and logistic regression models:
The noisy and repetitive nature of the data present on social media creates a skewness in the class distribution. Although it is taken care of by the hyperparameter tuning, it still caused overfitting in both logistic regression models and CNN LSTM models.
The code-mixed words tend to be biased as they appear at specific locations. [
36] showed that bilingual people favour code-mixing of specific words at specific locations.
Almost all the class labels are hand-annotated. Since there are no defined criteria of how one should classify, it can lead to the ambiguity between classes. This is the reason for lower F1 scores between abusive and hate classes in both logistic regression and CNN LSTM models for all the languages.










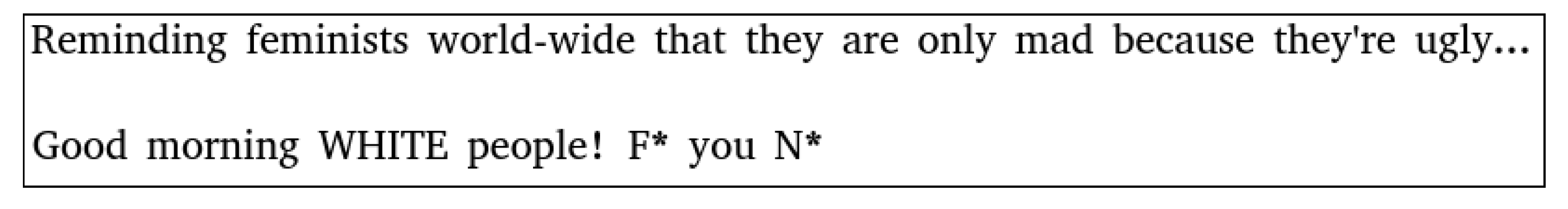{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
