Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges

 ,
,  , , and
, , and 
Abstract
1. Introduction
2. Fake News Definition
- (1)
- Satires and parodies have embedded humorous content, using sarcasms and ironies. It is feasible to have its deceptive character identified;
- (2)
- Rumors that do not originate from news events, but are publicly accepted;
- (3)
- Conspiracy theories, which are not easily verifiable as true or false;
- (4)
- Spams, commonly described as unwanted messages, mainly e-mail, spams are any advertising campaign that reaches readers via social media without being wanted;
- (5)
- Scams and hoaxes, which are motivated just for fun or to trick targeted individuals;
- (6)
- Clickbaits use miniature images, or sensationalist headlines, in the process of convincing users to access and share dubious content. Clickbait is more like a type of false advertising;
- (7)
- Misinformation, that is created involuntarily, without a specific origin or intention to mislead the reader;
- (8)
- Disinformation, which is pieces of information created with the specific intention of confusing the reader.
2.1. Fake News Characterization
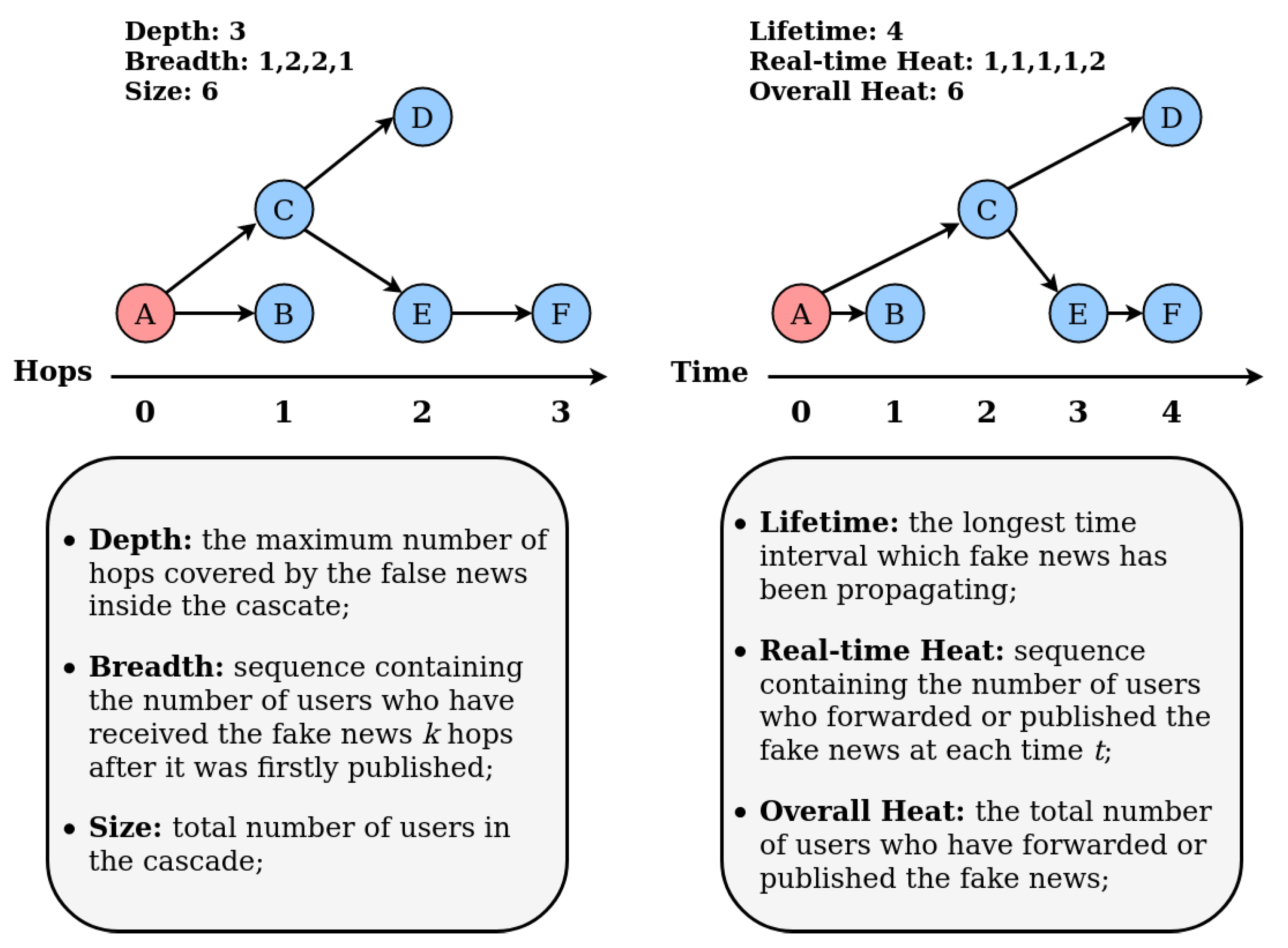
2.2. Fake News Spreading Process
3. Traditional Methods of Detecting Fake News
4. Construction of the Dataset
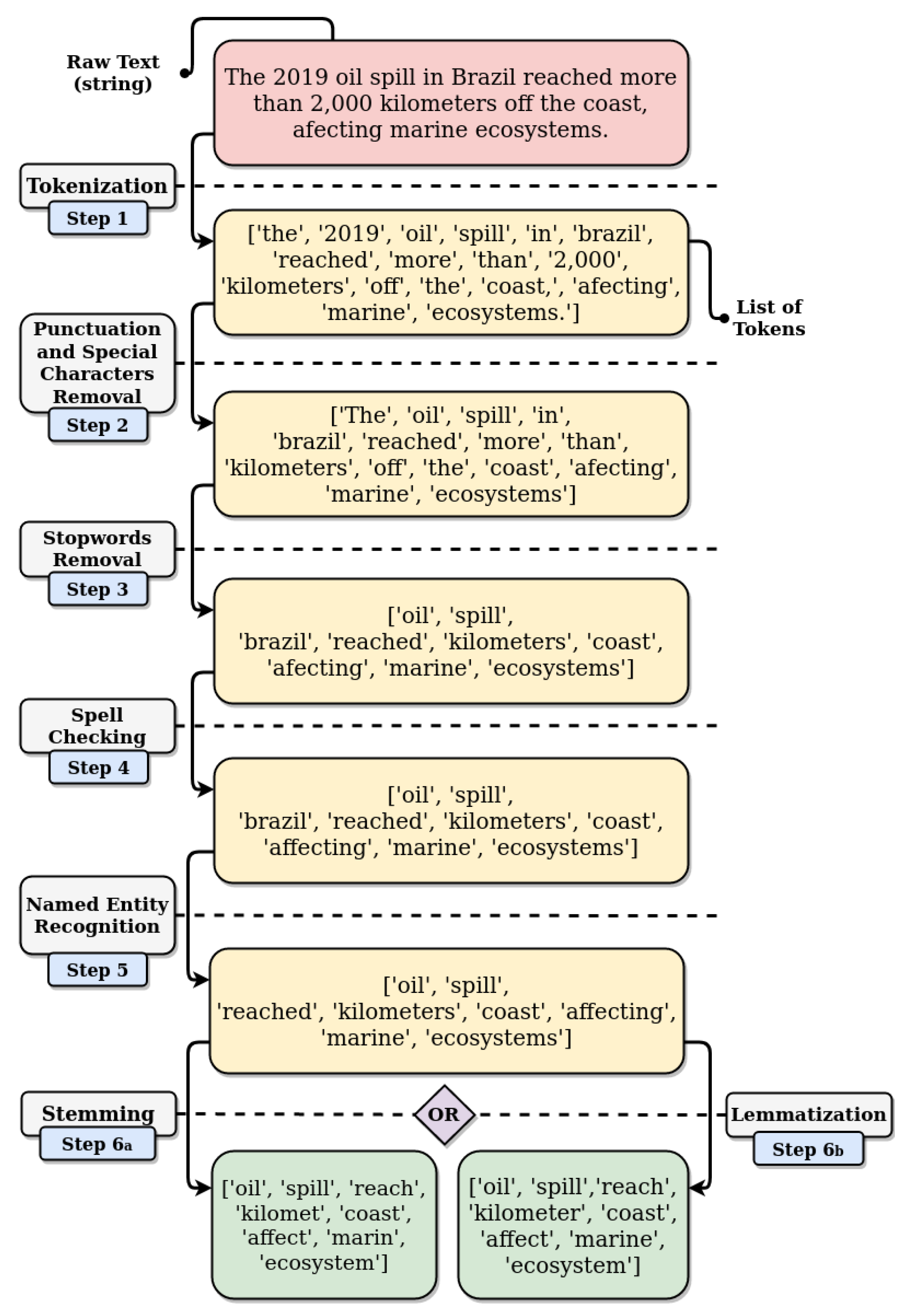
5. Natural Language Processing
6. Vector Representation of Texts
6.1. Binary Vector Space Model
6.2. Vector Space Model of Bag-of-Words
6.3. Vector Space Model Term Frequency-Inverse Document Frequency
6.4. Vector Space Model of Feature Hashing
6.5. Word Embeddings
7. Learning on Natural Language Data from Social Networks
7.1. Dimension Reduction
7.2. Similarity and Dissimilarity Metrics
7.3. Supervised Algorithms
7.3.1. Support Vector Machine
7.3.2. Random Forest
7.3.3. k-Nearest Neighbors
7.4. Unsupervised Algorithms
7.4.1. Partitioning-Based Algorithms
7.4.2. Density-Based Algorithms
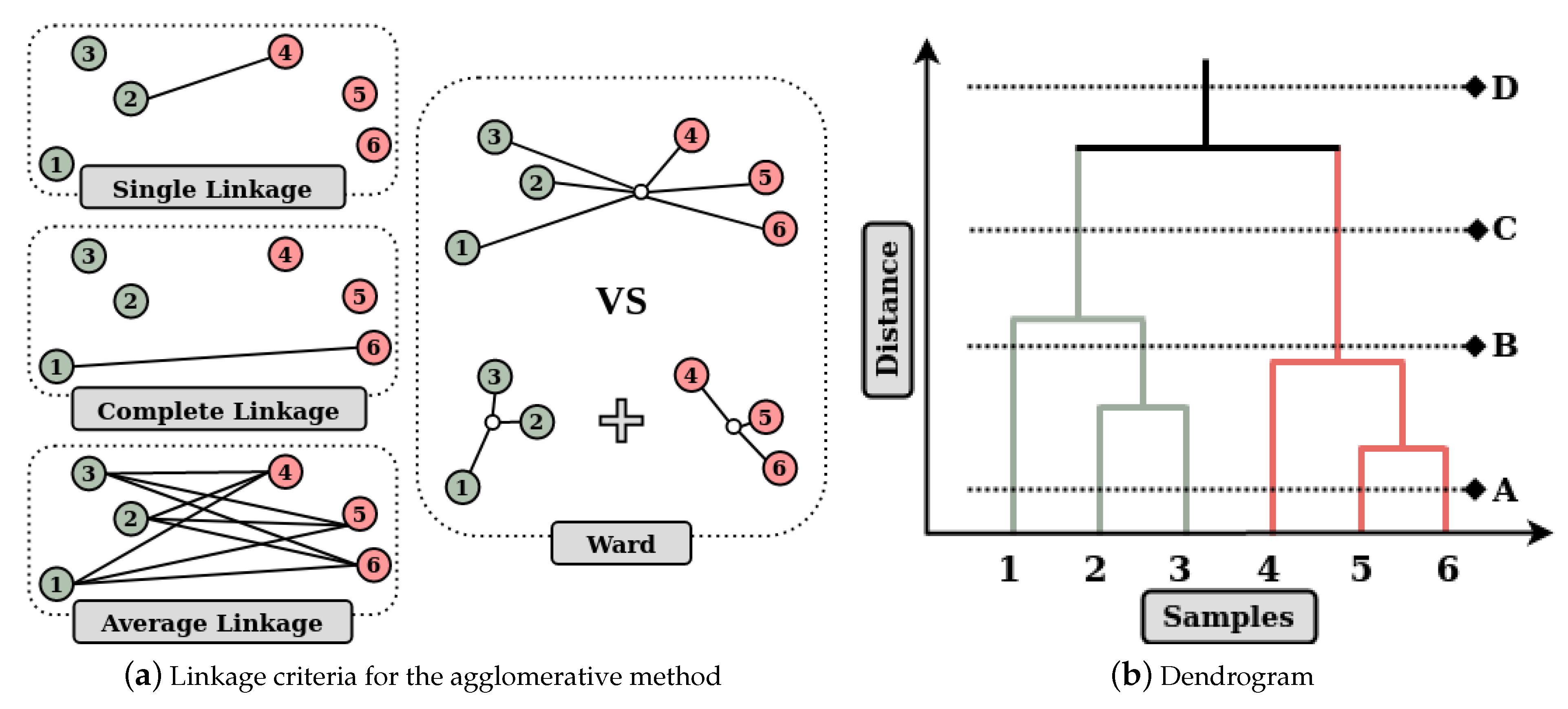
7.4.3. Hierarchical Algorithms
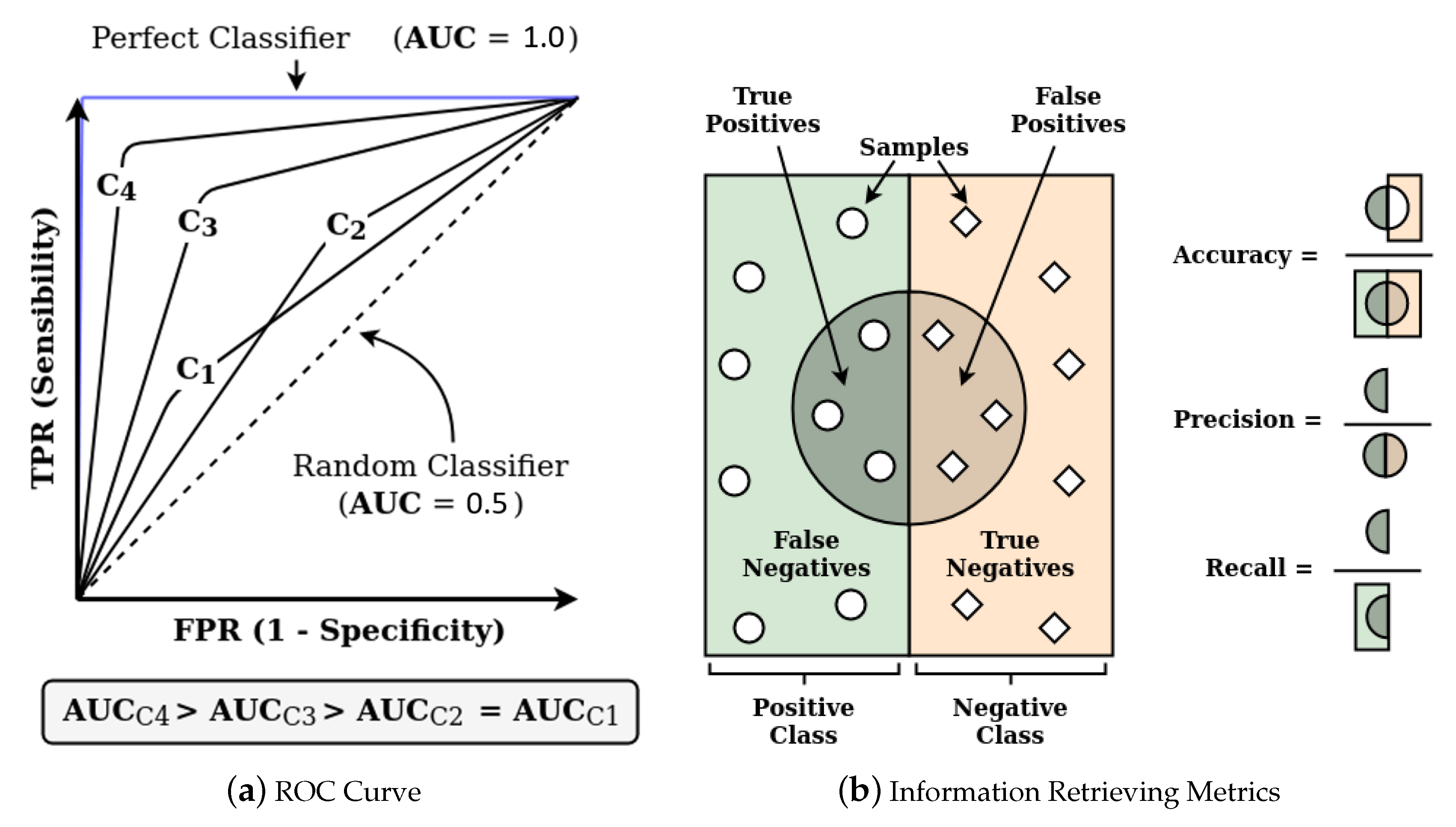
7.5. Evaluation Metrics
- Accuracy () is defined by the ratio of the total of correctly classified samples (TP + TN), by the total number of samples (P + N). For unbalanced data sets, a performance assessment based solely on this metric can generate erroneous conclusions;
- Precision (), given a target class, is the ratio between the number of samples correctly classified for the class in question (TP), by the total set of predictions assigned to that class, i.e., correct and incorrect predictions (TP + FP);
- Sensitivity (), also known as recall or true positive rate, is defined by the ratio of the number of correctly predicted samples (TP) to a positive class and the total of samples that belong to this class, thus including both correct predictions and those that should have indicated this class (TP + FN). The analog for the negative class is called specificity or true negative rate;
- -Score relates precision and sensitivity by a harmonic mean expressed byGenerally, the higher the value of the -Score, the better the classification, reflecting the mutual commitment between precision () and sensitivity ():
- Area under the ROC Curve (AUC) is measured using the Receiver Operation Characteristic (ROC) curve, shown in Figure 7a, which represents the ratio between the true positive rate (TPR) and the false positive rate (FPR), for several cutoff thresholds. This curve graphically describes the performance of a classification model. Briefly, the larger the area under the curve (closer to the unit value), the better the performance of the model, regardless of the cutoff point of the probability of the sample belonging to each class.
8. Research Initiatives
9. Research Challenges and Opportunities
- Great interests and the plurality of actors involved. Due to the volume that the spread of fake news reaches on social networks in a short period, fake news pose a threat to traditional sources of information, such as traditional press. The spread of fake news occurs as a distributed event, and involves multiple entities and technological platforms. Thus, there is an increasing difficulty in studying and designing computational, technological, and business strategies to combat fake news without compromising speed and collaborative access to high-quality information.
- Opponent’s malicious intent. The fake news content is designed to make it difficult for humans to identify the fake news, exploiting our cognitive skills, emotions, and ideological prejudices. Moreover, it is challenging for computational methods to detect fake news, as the way fake news is presented is similar to true news, and sometimes fake news uses artifices to make it difficult to identify the source or falsify the real source of the news.
- Susceptibility and lack of public awareness. The user of social networks is subject to a large amount of information from dubious origins, from information with a humorous nature, such as satires, to information intended to deceive the consumer of the information posing as legitimate news. However, the user of social networks is not able to differentiate fake news from legitimate news just by content. The user does not have information about the credibility of the source or patterns of spreading of the news on the network. Thus, to increase public awareness, several articles and advertising campaigns are run to provide tips on how to differentiate between false and legitimate news. For example, the University of Portland in the United States provides a guide for identifying misinformation (fake news) (available at https://guides.library.pdx.edu/c.php?g=625347&p=4359724).
- Propagation dynamics. The spread of fake news on social media complicates detection and mitigation, as fake information can easily reach and affect large numbers of users in a short time. The information is transmitted quickly and easily, even when its veracity is doubtful [83]. Verification of veracity must be carried out in an agile way, but it must also consider the patterns of propagation of information throughout the network [84].
- Constant changes in the characteristics of fake news. Developments in the automated identification of fake news also drive the adaptation of the generation of new disinformation content to avoid being classified as such. The detection of fake news based on writing style, differentiating false and legitimate news by an analysis based on Natural Language Processing, is one of the most-used alternatives due to the unsolved challenges in automatic fact verification from pre-defined knowledge bases. Thus, current approaches to identify fake news based on the content focus on extracting facts directly from the news content and subsequent verification of the facts against knowledge bases [85].
- Attacks on natural language learning. Zhou et al. argue that the use of Natural Language Processing to identify fake news is vulnerable to attacks on the machine learning itself [86]. Zhou et al. identify three attacks: the distortion of facts, the exchange between subject and object, and the confusion of causes. The distortion is, in fact, to exaggerate or modify some words. Textual elements, such as characters and time, can be distorted to lead to a false interpretation. The exchange between subject and object aims to confuse the reader between those who practice and those who suffer the reported action. The attack of confusion of cause consists of creating non-existent causal relations between two independent events or cutting parts of a story, leaving only the parts that the attacker wishes to present to the reader [86].
- Extracting the most significant features. Determining the most effective features for detecting fake news from multiple data sources is an open research opportunity. Fundamentally, there are two main data sources: news content and social context [13]. From a news content perspective, techniques based on Natural Language Processing and feature extraction can be used to extract information from the text. Embedding techniques, such as word embedding and deep neural networks are the focus of current researches for the extraction of textual characteristics, and they have the potential to learn better representations for the data. Visual characteristics extracted from the images are also important indicators of fake news. The use of deep neural networks is an opportunity for research in the extraction of visual characteristics for the detection of fake news [11,84].
- Detection on different platforms and different domains. Since that users use different social networks, fake news, and rumors spread across different platforms, making it difficult to locate the source of the news or rumor. Tracing the source of false information between different social media platforms is a research opportunity. Therefore, several aspects of the information must be considered. However, most of the existing approach focuses only on one way of detecting false information: analysis of content, propagation, style, among others. The analysis must then consider different attribute domains, such as topics, web sites, images, and URLs [84].
- Identification of echo chambers and bridges between chambers. Social media tends to form echo chambers in communities where users have similar views and ideologies. Users have their views reinforced and are not aware of the opposite beliefs. Therefore, research is needed to identify conflicting echo chambers and connect chambers with opposite positions so that users are faced with different points of view. This bridging also helps in discovering the truth, making users think carefully and rationally in multiple dimensions [84].
- Development of machine learning models. There is a need for research in the development of real-time learning models, such as incremental learning and federated learning, capable of learning from manually verified articles and providing real-time detection of new articles with fraudulent information. Another important point is the development of unsupervised models in which the algorithms learn from real data and, then, articles that escape the behavior of real data are classified as false. There is still a dearth of specific datasets for fake news. The lack of publicly available large-scale datasets implies a lack of tests (benchmarks) for comparing the performance of different algorithms [84].
- Development of data structures capable of handling complex and dynamic network structures. The complexity and dynamics of social network relationship structures make the task of identifying and tracking posts more complicated. Thus, there is a need to develop complex data structures that reflect the dynamics of relationships in social networks to allow the extraction of knowledge about the spread of false information throughout the network [84].
10. Conclusions
Funding
Conflicts of Interest
References
- de Oliveira, N.R.; Medeiros, D.S.V.; Mattos, D.M.F. A Sensitive Stylistic Approach to Identify Fake News on Social Networking. IEEE Signal Process. Lett. 2020, 27, 1250–1254. [Google Scholar] [CrossRef]
- Liu, G.; Wang, Y.; Orgun, M.A. Quality of trust for social trust path selection in complex social networks. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems, Toronto, ON, Canada, 9–13 May 2010; pp. 1575–1576. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, liar pants on fire”: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426. [Google Scholar] [CrossRef]
- Rubin, V.L. On deception and deception detection: Content analysis of computer-mediated stated beliefs. In Proceedings of the 73rd ASIS&T Annual Meeting on Navigating Streams in an Information Ecosystem; American Society for Information Science: Silver Spring, MD, USA, 2010; Volume 47, p. 32. [Google Scholar]
- Rubin, V.; Conroy, N.; Chen, Y.; Cornwell, S. Fake news or truth? using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection; Association for Computational Linguistics: San Diego, CA, USA, 17 June 2016; pp. 7–17. [Google Scholar] [CrossRef]
- Rubin, V.L.; Chen, Y.; Conroy, N.J. Deception detection for news: Three types of fakes. In Proceedings of the 78th ASIS&T Annual Meeting: Information Science with Impact: Research in and for the Community, Silver Spring, MD, USA, 6–10 November 2015; p. 83. [Google Scholar]
- Rubin, V.L.; Conroy, N.J.; Chen, Y. Towards news verification: Deception detection methods for news discourse. In Proceedings of the Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 55–60. [Google Scholar] [CrossRef]
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating fake news: A survey on identification and mitigation techniques. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Golbeck, J.; Mauriello, M.; Auxier, B.; Bhanushali, K.H.; Bonk, C.; Bouzaghrane, M.A.; Buntain, C.; Chanduka, R.; Cheakalos, P.; Everett, J.B.; et al. Fake News vs Satire: A Dataset and Analysis; WebSci ’18; Association for Computing Machinery: New York, NY, USA, 2018; pp. 17–21. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newslett. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading online content: Recognizing clickbait as false news. In Proceedings of the 2015 ACM on Workshop on Multimodal Deception Detection, New York, NY, USA, 13 November 2015; pp. 15–19. [Google Scholar] [CrossRef]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. FakeNewsNet: A Data Repository with News Content, Social Context, and Spatiotemporal Information for Studying Fake News on Social Media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Fuller, C.M.; Biros, D.P.; Wilson, R.L. Decision support for determining veracity via linguistic-based cues. Decis. Support Syst. 2009, 46, 695–703. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, D.K. Fake News Detection: A long way to go. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, UP, India, 21–22 November 2019; pp. 816–821. [Google Scholar] [CrossRef]
- Davis, C.A.; Varol, O.; Ferrara, E.; Flammini, A.; Menczer, F. BotOrNot: A System to Evaluate Social Bots. In Proceedings of the 25th International Conference Companion on World Wide Web, WWW ’16 Companion; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2016; pp. 273–274. [Google Scholar] [CrossRef]
- Mattos, D.M.F.; Velloso, P.B.; Duarte, O.C.M.B. An agile and effective network function virtualization infrastructure for the Internet of Things. J. Internet Serv. Appl. 2019, 10, 6. [Google Scholar] [CrossRef]
- Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, New York, NY, USA, 7–10 December 2013; pp. 1103–1108. [Google Scholar] [CrossRef]
- Zhou, X.; Cao, J.; Jin, Z.; Xie, F.; Su, Y.; Chu, D.; Cao, X.; Zhang, J. Real-time news certification system on Sina Weibo. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 983–988. [Google Scholar] [CrossRef]
- Wang, X.; Kang, Q.; An, J.; Zhou, M. Drifted Twitter Spam Classification Using Multiscale Detection Test on K-L Divergence. IEEE Access 2019, 7, 108384–108394. [Google Scholar] [CrossRef]
- Santia, G.C.; Williams, J.R. Buzzface: A news veracity dataset with facebook user commentary and egos. In Twelfth International AAAI Conference on Web and Social Media; AAAI: Menlo Park, CA, USA, 2018; pp. 531–540. [Google Scholar]
- Monteiro, R.A.; Santos, R.L.; Pardo, T.A.; de Almeida, T.A.; Ruiz, E.E.; Vale, O.A. Contributions to the Study of Fake News in Portuguese: New Corpus and Automatic Detection Results. In International Conference on Computational Processing of the Portuguese Language; Springer: Berlin, Germany, 2018; pp. 324–334. [Google Scholar] [CrossRef]
- Ferreira, W.; Vlachos, A. Emergent: A novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1163–1168. [Google Scholar] [CrossRef]
- Thorne, J.; Vlachos, A.; Christodoulopoulos, C.; Mittal, A. FEVER: A Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 809–819. [Google Scholar] [CrossRef]
- Mitra, T.; Gilbert, E. Credbank: A large-scale social media corpus with associated credibility annotations. In ICWSM; AAAI: Menlo Park, CA, USA, 2015; pp. 258–267. [Google Scholar]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics; ACL: Melbourne, Australia, July 2018; Volume 1, pp. 231–240. [Google Scholar] [CrossRef]
- Zubiaga, A.; Liakata, M.; Procter, R.; Wong Sak Hoi, G.; Tolmie, P. Analysing how people orient to and spread rumours in social media by looking at conversational threads. PLoS ONE 2016, 11, e0150989. [Google Scholar] [CrossRef]
- Rashkin, H.; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2931–2937. [Google Scholar] [CrossRef]
- Oshikawa, R.; Qian, J.; Wang, W.Y. A survey on natural language processing for fake news detection. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC); European Language Resources Association: Marseille, France, May 2018; pp. 6086–6093. [Google Scholar]
- Rubin, V.L. Pragmatic and cultural considerations for deception detection in Asian Languages. ACM Trans. Asian Lang. Inf. Process. 2014, 13. [Google Scholar] [CrossRef]
- Clark, M.; Kim, Y.; Kruschwitz, U.; Song, D.; Albakour, D.; Dignum, S.; Beresi, U.C.; Fasli, M.; De Roeck, A. Automatically structuring domain knowledge from text: An overview of current research. Inf. Process. Manag. 2012, 48, 552–568. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learning Syst. 2020, 1–21. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Zhou, L.; Burgoon, J.K.; Nunamaker, J.F.; Twitchell, D. Automating linguistics-based cues for detecting deception in text-based asynchronous computer-mediated communications. Group Decis. Negotiat. 2004, 13, 81–106. [Google Scholar] [CrossRef]
- Afroz, S.; Brennan, M.; Greenstadt, R. Detecting hoaxes, frauds, and deception in writing style online. In 2012 IEEE Symposium on Security and Privacy; IEEE: New York, NY, USA, 2012; pp. 461–475. [Google Scholar] [CrossRef]
- Hauch, V.; Blandón-Gitlin, I.; Masip, J.; Sporer, S.L. Are computers effective lie detectors? A meta-analysis of linguistic cues to deception. Personal. Soc. Psychol. Rev. 2015, 19, 307–342. [Google Scholar] [CrossRef] [PubMed]
- Indurkhya, N.; Damerau, F.J. Handbook of Natural Language Processing, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- de Oliveira, N.R.; Reis, L.H.; Fernandes, N.C.; Bastos, C.A.M.; de Medeiros, D.S.V.; Mattos, D.M.F. Natural Language Processing Characterization of Recurring Calls in Public Security Services. In Proceedings of the 2020 International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 17–20 February 2020; pp. 1009–1013. [Google Scholar] [CrossRef]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Seattle, WA, USA, 2013; pp. 1631–1642. [Google Scholar]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Inquiry and Word Count: LIWC 2001; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2001; Volume 71. [Google Scholar]
- Balage Filho, P.; Pardo, T.A.S.; Aluísio, S. An evaluation of the Brazilian Portuguese LIWC dictionary for sentiment analysis. In Proceedings of the 9th Brazilian Symposium in Information and Human Language Technology (STIL), Fortaleza, Brazil, 21–23 October 2013. [Google Scholar]
- Manning, C.; Raghavan, P.; Schütze, H. Introduction to information retrieval. Natural Lang. Eng. 2010, 16, 100–103. [Google Scholar]
- Jarmasz, M.; Szpakowicz, S. Not as Easy as It Seems: Automating the Construction of Lexical Chains Using Roget’s Thesaurus. In Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2003; pp. 544–549. [Google Scholar]
- Camacho-Collados, J.; Pilehvar, M.T. From word to sense embeddings: A survey on vector representations of meaning. J. Artif. Intell. Res. 2018, 63, 743–788. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the ICLR Workshop Papers, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Firth, J.R. A synopsis of linguistic theory, 1930–1955. Studi. Linguist. Anal. 1957, 1, 168–205. [Google Scholar]
- Li, Y.; Xu, L.; Tian, F.; Jiang, L.; Zhong, X.; Chen, E. Word embedding revisited: A new representation learning and explicit matrix factorization perspective. In Twenty-Fourth International Joint Conference on Artificial Intelligence; AAAI Press: Buenos Aires, Argentina, 2015; pp. 3650–3656. [Google Scholar]
- Hu, B.; Tang, B.; Chen, Q.; Kang, L. A novel word embedding learning model using the dissociation between nouns and verbs. Neurocomputing 2016, 171, 1108–1117. [Google Scholar] [CrossRef]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: Evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 16. [Google Scholar] [CrossRef]
- Domingos, P.M. A few useful things to know about machine learning. ACM Commun. 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Ayodele, T.O. Types of machine learning algorithms. In New Advances in Machine Learning; IntechOpen: London, UK, 2010. [Google Scholar] [CrossRef]
- Zhai, Y.; Ong, Y.S.; Tsang, I.W. The emerging “big dimensionality”. IEEE Comput. Intell. Mag. 2014, 9, 14–26. [Google Scholar] [CrossRef]
- Andreoni Lopez, M.; Mattos, D.M.F.; Duarte, O.C.M.B.; Pujolle, G. A fast unsupervised preprocessing method for network monitoring. Ann. Telecommun. 2019, 74, 139–155. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Raghavan, P.; Tamaki, H.; Vempala, S. Latent semantic indexing: A probabilistic analysis. J. Comput. Syst. Sci. 2000, 61, 217–235. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and Empirical Analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Perdisci, R.; Gu, G.; Lee, W. Using an Ensemble of One-Class SVM Classifiers to Harden Payload-based Anomaly Detection Systems. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 488–498. [Google Scholar] [CrossRef]
- Gaonkar, S.; Itagi, S.; Chalippatt, R.; Gaonkar, A.; Aswale, S.; Shetgaonkar, P. Detection Of Online Fake News: A Survey. In Proceedings of the 2019 International Conference on Vision Towards Emerging Trends in Communication and Networking (ViTECoN), Vellore, India, 30–31 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Ketchen, D.J.; Shook, C.L. The application of cluster analysis in strategic management research: An analysis and critique. Strateg. Manag. J. 1996, 17, 441–458. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Kaufman, L. Finding Groups in Data; Wiley Online Library: Hoboken, NJ, USA, 1990. [Google Scholar] [CrossRef]
- Gan, J.; Tao, Y. DBSCAN revisited: Mis-claim, un-fixability, and approximation. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data; Association for Computing Machinery: Melborne, Australia, May 2015; pp. 519–530. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Benavent, X.; Castellanos, A.; de Ves, E.; Garcia-Serrano, A.; Cigarran, J. FCA-based knowledge representation and local generalized linear models to address relevance and diversity in diverse social images. Future Gener. Comput. Syst. 2019, 100, 250–265. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Lazer, D.M.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Grinberg, N.; Joseph, K.; Friedland, L.; Swire-Thompson, B.; Lazer, D. Fake news on Twitter during the 2016 US presidential election. Science 2019, 363, 374–378. [Google Scholar] [CrossRef]
- Pennycook, G.; McPhetres, J.; Zhang, Y.; Lu, J.G.; Rand, D.G. Fighting COVID-19 misinformation on social media: Experimental evidence for a scalable accuracy-nudge intervention. Psychol. Sci. 2020, 31, 770–780. [Google Scholar] [CrossRef]
- Van Bavel, J.J.; Baicker, K.; Boggio, P.S.; Capraro, V.; Cichocka, A.; Cikara, M.; Crockett, M.J.; Crum, A.J.; Douglas, K.M.; Druckman, J.N.; et al. Using social and behavioural science to support COVID-19 pandemic response. Nat. Hum. Behav. 2020, 1–12. [Google Scholar] [CrossRef]
- Poddar, K.; Umadevi, K.; Amali, G.B. Comparison of Various Machine Learning Models for Accurate Detection of Fake News. In Proceedings of the 2019 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 22–23 March 2019; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]
- Shu, K.; Mahudeswaran, D.; Liu, H. FakeNewsTracker: A tool for fake news collection, detection, and visualization. Comput. Math. Organ. Theory 2019, 25, 60–71. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Deepak, S.; Chitturi, B. Deep neural approach to Fake-News identification. Procedia Comput. Sci. 2020, 167, 2236–2243. [Google Scholar] [CrossRef]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural User Response Generator: Fake News Detection with Collective User Intelligence. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 3834–3840. [Google Scholar] [CrossRef]
- Friggeri, A.; Adamic, L.; Eckles, D.; Cheng, J. Rumor Cascades. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 1–10. [Google Scholar]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- de Oliveira, N.R.; de Medeiros, D.S.V.; Mattos, D.M.F. A Syntactic-Relationship Approach to Construct Well-Informative Knowledge Graphs Representation. In Proceedings of the 4th Cloud and Internet of Things (CIoT’20), Niterói, Brazil, 7–12 October 2020; pp. 75–82. [Google Scholar] [CrossRef]
- Zhou, Z.; Guan, H.; Bhat, M.M.; Hsu, J. Fake news detection via NLP is vulnerable to adversarial attacks. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence (ICAART), Prague, Czech Republic, 19–21 February 2019; pp. 794–800. [Google Scholar] [CrossRef]
- Giglio, C.; Palmieri, R. Analyzing Informal Learning Patterns in Facebook Communities of International Conferences. Procedia Soc. Behav. Sci. 2017, 237, 223–229. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authenticity | Intention | Reported as News | |
|---|---|---|---|
| Satires and Parodies | False | Not Bad | No |
| Rumors | Unknown | Unknown | Unknown |
| Conspiracy Theories | Unknown | Unknown | No |
| Spam | Possibly True | Bad/Advertising | No |
| Scams and Hoaxes | False | Not Bad | No |
| Clickbait | Possibly True | Advertising | No |
| Disinformation | False | Unknown | Unknown |
| Misinformation | False | Bad | Unknown |
| Content | Quantity | Labeling | Annotator | |
| Buzzface [23] | Social media posts and comments (Facebook) | 2263 | Categorized on four levels (predominantly true, predominantly false, mix of true and false and no factual content) | Previously checked by news agencies (Buzzfeed) |
| FAKENEWSNET [15] | Whole articles | 23,921 | Binary (true or false) | Previously checked by news agencies (PolitiFact and GossipCop) |
| Fake.Br Corpus [24] | Whole articles | 7200 | Binary (true or false) | Considers the credibility of the source |
| LIAR [5] | Short statements (political) | ≈12,800 | Categorized on six levels (true, predominantly true, half-true, almost true, false, pants-fire) | Previously checked by news agencies (PolitiFact) |
| Emergent [25] | Related statements and titles | 300 | Binary (true or false) | Journalistic team |
| FEVER [26] | Short statements (Wikipedia) | ≈185,000 | Categorized on three levels (supported, disproved and not enough information) | Trained human annotators |
| CREDBANK [27] | Social network posts (Twitter) | ≈60,000,000 | Vector with 30 dimensions containing variable scores at five levels of veracity | Crowd-sourcing |
| BuzzfeedNews | Social network posts (Facebook) | 2282 | Categorized on four levels | Journalistic team |
| BuzzFeed-Webis [28] | Social network posts (Facebook) | 1687 | Categorized on four levels | Previously checked by news agencies (Buzzfeed) |
| PHEME [29] | Social media posts (Twitter) | 330 | Binary (true or false) | Journalistic team and crowd-sourcing |
| Zhou et al. [36] | Fuller et al. [16] | Afroz et al. [37] | Hauch et al. [38] | Monteiro et al. [24] | Rashkin et al. [30] | Rubin et al. [7] | ||
|---|---|---|---|---|---|---|---|---|
| Type | Features | |||||||
| Quantity | Character or token count | x | x | x | ||||
| Word count | x | x | x | x | ||||
| Sentence count | x | x | x | x | x | |||
| Verb count | x | x | x | x | ||||
| Nominal phrase count | x | |||||||
| Noun count | x | |||||||
| Stopword count | x | x | ||||||
| Adjective count | x | x | ||||||
| Modifier count | x | x | x | x | x | x | ||
| Informality | Typographical error ratio | x | x | x | ||||
| Complexity | Average of characters per word | x | x | x | x | |||
| Average of words per sentence | x | x | x | x | x | |||
| Average of clauses per sentence | x | |||||||
| Average of punctuation signs per sentence | x | x | x | x | ||||
| Uncertainty | % of modal verbs | x | x | x | x | x | x | |
| % of terms that indicate certainty | x | x | x | x | x | |||
| % of terms that indicate generalization | x | x | x | |||||
| % terms that indicate tendency | x | x | x | |||||
| % of quantifier numbers | x | x | x | |||||
| # of interrogation marks | x | |||||||
| Non-immediacy | % of passive voice | x | x | x | x | |||
| Pronouns in the 1st singular person | x | x | x | x | x | x | x | |
| Pronouns in the 1st plural person | x | x | x | x | x | x | x | |
| Pronouns in the 2nd or 3rd plural person | x | x | x | x | x | x | ||
| Diversity | Lexical diversity: % unique words | x | x | x | x | |||
| Redundancy: % of function words | x | x | x | x | ||||
| % of content words | x | x | x | |||||
| Random named entities | x | |||||||
| Feelings | % of positive words | x | x | x | x | x | ||
| % of negative words | x | x | x | x | x | x | ||
| # of exclamation marks | x | |||||||
| Humorous/sarcastic content | x |
| Document 1 (D1) | First sentence of corpus |
| Document 2 (D2) | The second sentence is short |
| Document 3 (D3) | The third sentence is short |
| Document 4 (D4) | The forth sentence is the biggest of corpus |
| Terms | first | forth | the | corpus | short | of | biggest | second | sentence | third | is |
|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| D2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| D3 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| D4 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| Terms | first | forth | the | corpus | short | of | biggest | second | sentence | third | is |
|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| D2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| D3 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| D4 | 0 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| Terms | first | forth | the | corpus | short | of | biggest | second | sentence | third | is |
|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | 0.614 | 0 | 0 | 0.484 | 0 | 0.484 | 0 | 0 | 0.392 | 0 | 0 |
| D2 | 0 | 0 | 0.378 | 0 | 0.467 | 0 | 0 | 0.592 | 0.378 | 0 | 0.378 |
| D3 | 0 | 0 | 0.408 | 0 | 0.505 | 0 | 0 | 0 | 0 | 0.640 | 0.408 |
| D4 | 0 | 0.419 | 0.535 | 0.330 | 0 | 0.330 | 0.419 | 0 | 0.267 | 0 | 0.267 |
| Hashes | Index 1 | Index 2 | Index 3 | Index 4 | Index 5 |
|---|---|---|---|---|---|
| D1 | 1 | 1 | 1 | 0 | 0 |
| D2 | 0 | 1 | 1 | 1 | 1 |
| D3 | 0 | 1 | 1 | 0 | 1 |
| D4 | 1 | 3 | 1 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M.F. Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information 2021, 12, 38. https://doi.org/10.3390/info12010038
de Oliveira NR, Pisa PS, Lopez MA, de Medeiros DSV, Mattos DMF. Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information. 2021; 12(1):38. https://doi.org/10.3390/info12010038
Chicago/Turabian Stylede Oliveira, Nicollas R., Pedro S. Pisa, Martin Andreoni Lopez, Dianne Scherly V. de Medeiros, and Diogo M. F. Mattos. 2021. "Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges" Information 12, no. 1: 38. https://doi.org/10.3390/info12010038
APA Stylede Oliveira, N. R., Pisa, P. S., Lopez, M. A., de Medeiros, D. S. V., & Mattos, D. M. F. (2021). Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information, 12(1), 38. https://doi.org/10.3390/info12010038