Leveraging Edge Intelligence for Video Analytics in Smart City Applications

 ,
,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
- (i)
- obtaining high-level semantic information from raw data by breaking the burdensome processing of large-scale video streams into various tasks;
- (ii)
- deploying these tasks as a workflow of data processing in MI processors near the stream producers to improve the usage efficiency of the edge node resources while keeping low delays; and
- (iii)
- improving the system’s throughput by leveraging the reuse of processors running tasks shared by multiple applications.
2. Background
2.1. Processing Large-Scale Data Streams
- Volume: The camera’s sensor resolution (quantity of pixels in width and height) determines the size in bytes of each frame. Most cameras use the following resolutions: HD (1280 × 720 p), Full HD (1920 × 1080 p) and Ultra HD 4K (3840 × 2160 p). Without compression, a Full HD frame (2,073,600 pixels) with the color of each pixel determined by the combination of three color bytes (RGB, Red, Green and Blue) is 6.22 MB in size.
- Velocity: This is related to the rate of data generation and transmission. In the context of the video stream, the unit used is FPS (frames per second). Most CCTV (closed-circuit TV) cameras use a frame-rate of 20 FPS. Thus, within 1 s, for a Full HD camera, we have 124 MB of data to process.
- Variability: This feature refers to the different data flow rates, which may vary from time to time or place to place. Many videos are manipulated in some compression formats to save on bandwidth and storage. The compression CODEC H.264 is quite common in the industry [17]. The CODEC compresses pixels that have not changed between subsequent frames. In this way, the more movement there is in the images, the less the flow compression will be. The bit rate of a Full HD camera at 20 FPS ranges from 4 to 32 Mbps [18].
- Veracity: One of the most important aspects of any data is that they are true. This importance increases when, for example, a smart city application uses the data to apply some decision rule, such as fining a vehicle for an illegal movement. To not leave room for doubt, the image of the license plate identifying the car must be of good quality, i.e., with high-resolution, ensuring the data integrity and accuracy required for the decision-maker.
- Value: The data to be processed must have some value; otherwise, their processing loses its meaning. In the context of surveillance cameras, most of the time they will be capturing only images of the monitored environment, that is, without any object that could generate an event of interest. Thus, some pre-processing scheme is required to filter out those frames whose processing is unnecessary. Generally, some motion detection technique works as a filter to gather the frames to be processed, and many modern cameras have this filter embedded.
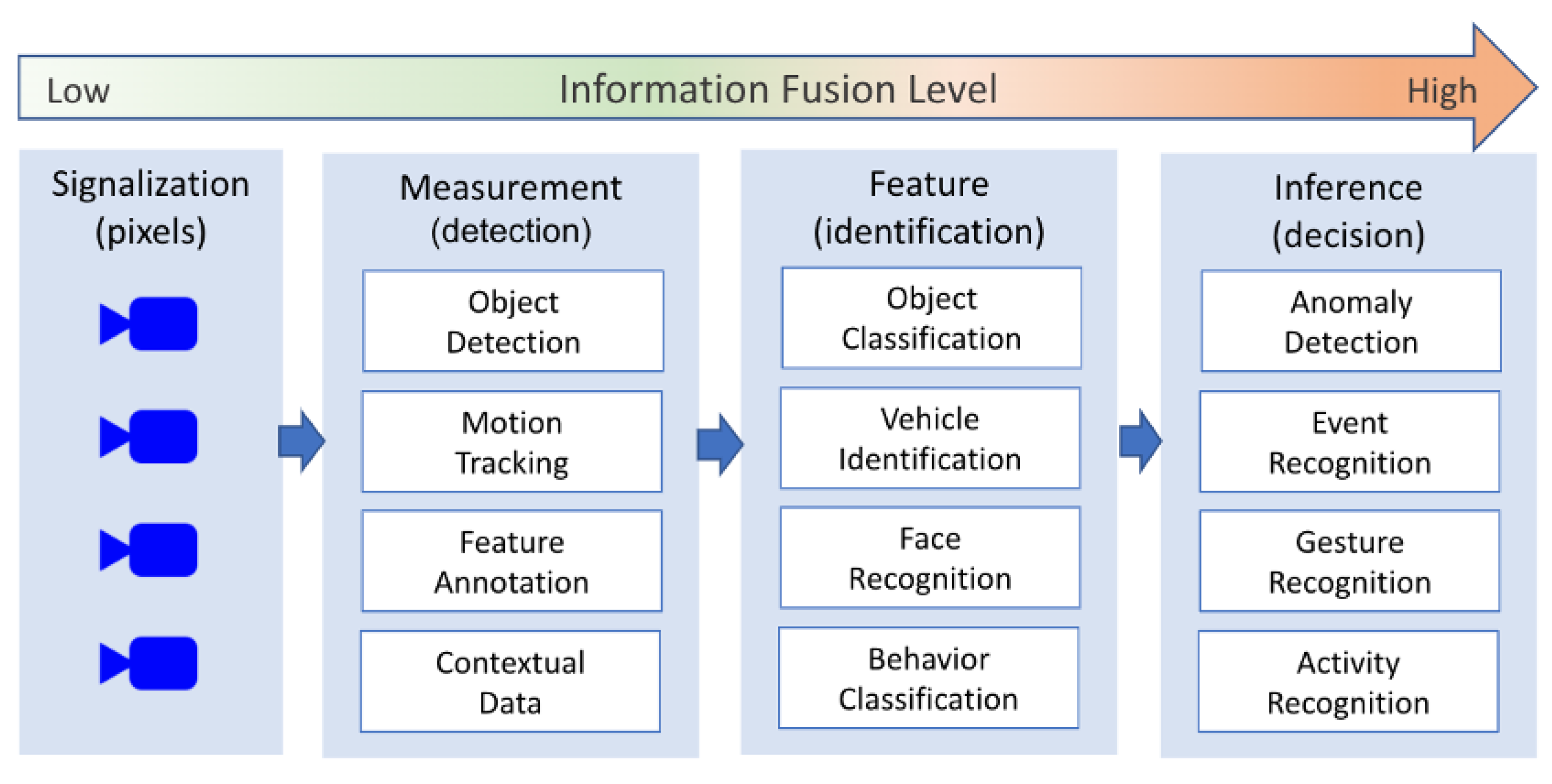
2.2. Extracting Insights from Video Analytics
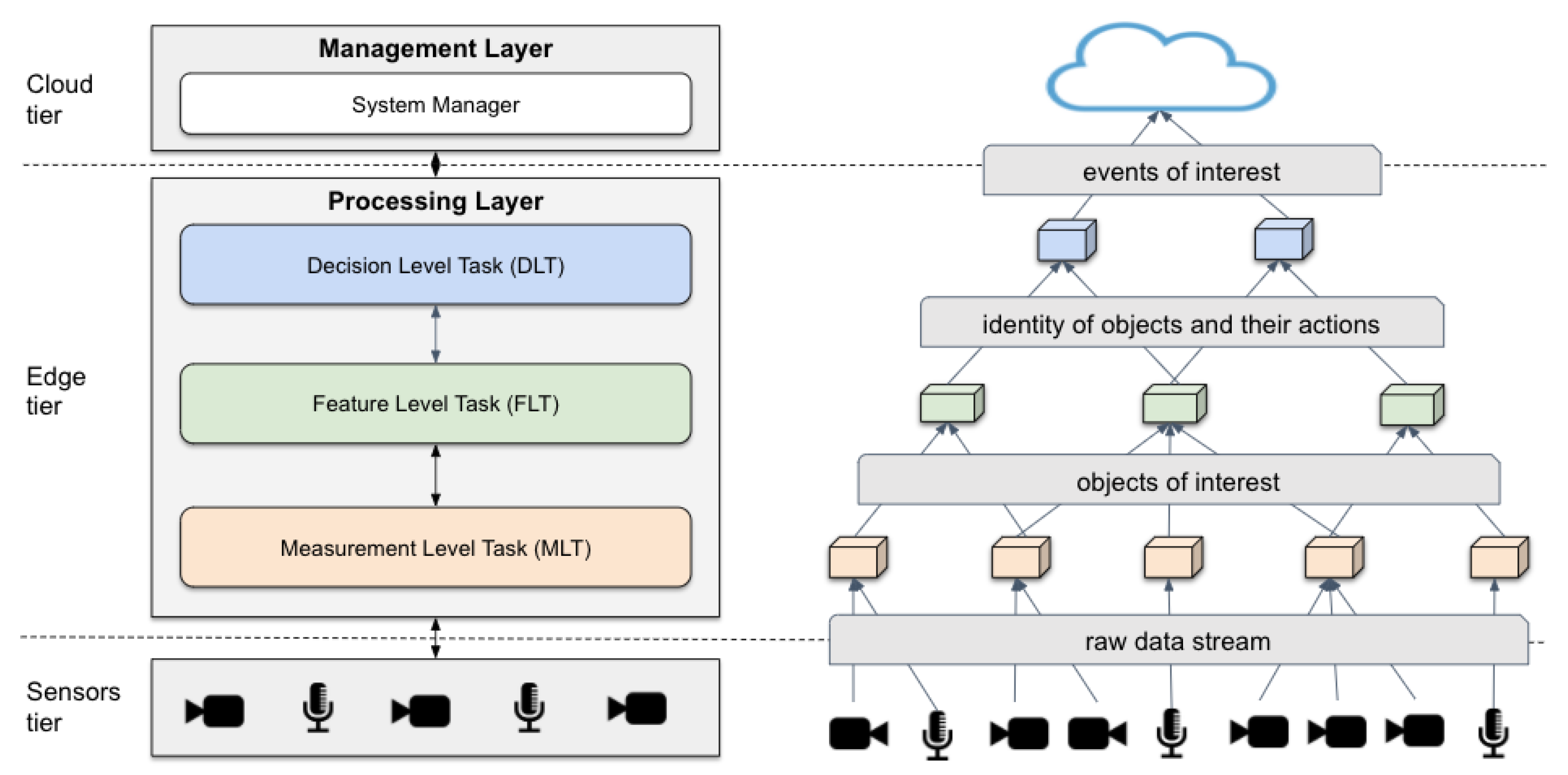
3. A Distributed System for Video Analytics Based on Edge Capabilities
3.1. MELINDA Architecture
- he filtering of the video stream from cameras selecting only those frames that have the object of interest to feed the workflow;
- the identification of this object; and
- the interpretation of the event triggered by the object in the monitored environment for later decision making.
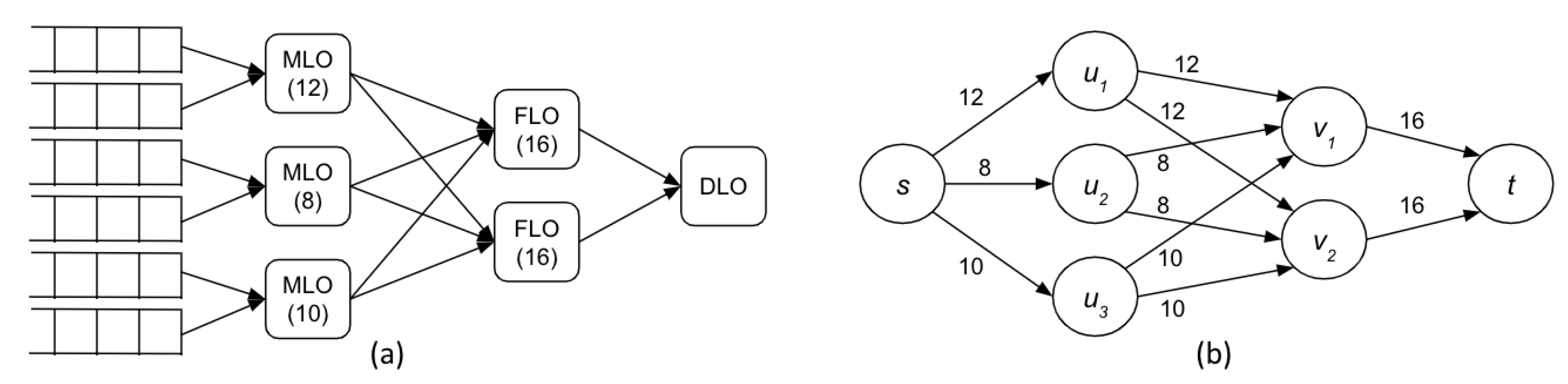
3.2. General Definitions and Parameters
3.3. Workflow Deployment
- The total processing time of MLT and FLT tasks at the respective chosen edge nodes must not exceed the MaxDelay attribute of the workflow.
- If the object identification task (FLT) is an intelligence service, it must be shared between different workflows to maximize their use.
| Algorithm 1: Orchestrator workflow provision |
 |
3.4. Workload Distribution
| Algorithm 2: Broker’s load balance mechanism |
 |
4. Evaluation
4.1. Running Example
- Face Detection as the measurement level task (MLT): The object of interest is people’s faces. When this task detects faces in the video stream from the cameras, it generates an image of interest message () containing the frame with these faces and contextual data.
- Face Recognition as the feature level task (FLT): It recognizes people in the image of interest from the detected faces, generating an event.
- Decision Rule as the decision-level task (DLT): It employs the application’s decision rule in the detected event. The decision rule is to check if the identified person is authorized to be in that restricted area of the camera, alerting the security system if necessary.
4.2. Evaluation Methodology
4.3. Experimental Setup
4.4. Results
5. Related Work
6. Final Remarks and Ongoing Work
Sample Availability
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DLO | Decision Level Operator |
| DLT | Decision Level Task |
| DNN | Deep Neural Network |
| FLO | Feature Level Operator |
| FLT | Feature Level Task |
| FPS | Frames Per Second |
| IIM | Image of Interest Message |
| IoT | Internet of Things |
| IS | Intelligence Service |
| ISS | Intelligent Surveillance System |
| MELINDA | Multilevel Information Distributed Processing Architecture |
| MIF | Multilevel Information Fusion |
| MI | Machine Intelligence |
| ML | Machine Learning |
| MLO | Measurement Level Operator |
| MLT | Measurement Level Task |
| MSA | Microservice Architecture |
References
- Ashton, K. That ‘Internet of Things’ Thing. 2009. Available online: https://www.rfidjournal.com/articles/view?4986 (accessed on 24 June 2020).
- Alvi, S.A.; Afzal, B.; Shah, G.A.; Atzori, L.; Mahmood, W. Internet of multimedia things: Vision and challenges. Ad Hoc Netw. 2015, 33, 87–111. [Google Scholar] [CrossRef]
- Nauman, A.; Qadri, Y.A.; Amjad, M.; Zikria, Y.B.; Afzal, M.K.; Kim, S.W. Multimedia Internet of Things: A Comprehensive Survey. IEEE Access 2020, 8, 8202–8250. [Google Scholar] [CrossRef]
- Barnett, T.; Jain, S.; Andra, U.; Khurana, T. Cisco Visual Networking Index (VNI) Complete Forecast Update, 2017–2022. Cisco Systems. 2018. Available online: https://bit.ly/385BAhJ (accessed on 14 December 2020).
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEE Proc. Vision Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Nazare, A.C.; Schwartz, W.R. A scalable and flexible framework for smart video surveillance. Comput. Vis. Image Underst. 2016, 144, 258–275. [Google Scholar] [CrossRef]
- Gualtieri, M.; Curran, R. The Forrester WaveTM: Big Data Streaming Analytics, Q1 2016. Available online: https://bit.ly/3oR3ftA (accessed on 14 December 2020).
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for big data processing. EURASIP J. Adv. Signal Process. 2016, 2016, 67. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef]
- Garcia Lopez, P.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-centric Computing: Vision and Challenges. SIGCOMM Comput. Commun. Rev. 2015, 45, 37–42. [Google Scholar] [CrossRef]
- Nakamura, E.F.; Loureiro, A.A.F.; Frery, A.C. Information Fusion for Wireless Sensor Networks: Methods, Models, and Classifications. ACM Comput. Surv. 2007, 39, 9-es. [Google Scholar] [CrossRef]
- Ganz, F.; Puschmann, D.; Barnaghi, P.; Carrez, F. A Practical Evaluation of Information Processing and Abstraction Techniques for the Internet of Things. IEEE Internet Things J. 2015, 2, 340–354. [Google Scholar] [CrossRef]
- Ramos, E.; Morabito, R.; Kainulainen, J. Distributing Intelligence to the Edge and Beyond [Research Frontier]. IEEE Comput. Intell. Mag. 2019, 14, 65–92. [Google Scholar] [CrossRef]
- Rocha Neto, A.; Silva, T.P.; Batista, T.V.; Delicato, F.C.; Pires, P.F.; Lopes, F. An Architecture for Distributed Video Stream Processing in IoMT Systems. Open J. Internet Things (OJIOT) 2020, 6, 89–104. [Google Scholar]
- Razzaq, A. A Systematic Review on Software Architectures for IoT Systems and Future Direction to the Adoption of Microservices Architecture. SN Comput. Sci. 2020, 1, 350. [Google Scholar] [CrossRef]
- Rocha Neto, A.; Delicato, F.C.; Batista, T.V.; Pires, P.F. Distributed Machine Learning for IoT Applications in the Fog. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/9781119551713.ch12 (accessed on 16 October 2020).
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Forret, P. Toolstud.io. 2006. Available online: https://toolstud.io/video/bitrate.php (accessed on 6 November 2020).
- Garofalakis, M.N.; Gehrke, J.; Rastogi, R. (Eds.) Data Stream Management—Processing High-Speed Data Streams; Data-Centric Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Rosebrock, A. Deep Learning for Computer Vision with Python, 1.3.0 ed. 2018. Available online: https://www.pyimagesearch.com/static/cv_dl_resource_guide.pdf (accessed on 14 December 2020).
- Etzion, O.; Niblett, P. Event Processing in Action; Manning Publications Company: Shelter Island, NY, USA, 2010; pp. 1–360. [Google Scholar]
- Dautov, R.; Distefano, S.; Bruneo, D.; Longo, F.; Merlino, G.; Puliafito, A. Pushing Intelligence to the Edge with a Stream Processing Architecture. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 792–799. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: https://mitpress.mit.edu/books/deep-learning (accessed on 14 December 2020).
- Ali, M.; Anjum, A.; Yaseen, M.U.; Zamani, A.R.; Balouek-Thomert, D.; Rana, O.F.; Parashar, M. Edge Enhanced Deep Learning System for Large-Scale Video Stream Analytics. In Proceedings of the 2018 IEEE 2nd International Conference on Fog and Edge Computing (ICFEC), Washington, DC, USA, 1–3 May 2018; pp. 1–10. [Google Scholar]
- Ledakis, I.; Bouras, T.; Kioumourtzis, G.; Skitsas, M. Adaptive Edge and Fog Computing Paradigm for Wide Area Video and Audio Surveillance. In Proceedings of the 2018 9th International Conference on Information, Intelligence, Systems and Applications (IISA), Zakynthos, Greece, 23–25 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- NVIDIA. NVIDIA Metropolis. 2018. Available online: https://www.nvidia.com/en-us/autonomous-machines/intelligent-video-analytics-platform (accessed on 14 December 2020).
- Google. Coral. 2019. Available online: https://coral.ai (accessed on 3 December 2019).
- Movidius. Applications for the Intel NCS 2 (or Original NCS) with OpenVINO Toolkit. 2019. Available online: https://github.com/movidius/ncappzoo/blob/master/apps/README.md (accessed on 14 April 2020).
- NVIDIA. TensorFlow/TensorRT Models on Jetson. 2018. Available online: https://github.com/NVIDIA-AI-IOT/tf_trt_models (accessed on 10 February 2020).
- Google. Models Built for the Edge TPU. 2019. Available online: https://coral.ai/models (accessed on 13 October 2019).
- Mittal, G.; Yagnik, K.B.; Garg, M.; Krishnan, N.C. SpotGarbage: Smartphone App to Detect Garbage Using Deep Learning. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp ’16, Heidelberg, Germany, 12–16 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 940–945. [Google Scholar] [CrossRef]
- Ma, X.; Yu, H.; Wang, Y.; Wang, Y. Large-Scale Transportation Network Congestion Evolution Prediction Using Deep Learning Theory. PLoS ONE 2015, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Pan, L. Predicting Short-Term Traffic Flow by Long Short-Term Memory Recurrent Neural Network. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 153–158. [Google Scholar] [CrossRef]
- Ling, X.; Sheng, J.; Baiocchi, O.; Liu, X.; Tolentino, M.E. Identifying parking spaces detecting occupancy using vision-based IoT devices. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C.; Meghini, C.; Vairo, C. Deep learning for decentralized parking lot occupancy detection. Expert Syst. Appl. 2017, 72, 327–334. [Google Scholar] [CrossRef]
- Rocha Neto, A.; Soares, B.; Barbalho, F.; Santos, L.; Batista, T.; Delicato, F.C.; Pires, P.F. Classifying Smart IoT Devices for Running Machine Learning Algorithms. In 45o̠ Seminário Integrado de Software e Hardware 2018 (SEMISH 2018); SBC: Porto Alegre, Brazil, 2018; Volume 45. [Google Scholar]
- de Assunç ao, M.D.; Veith, A.D.S.; Buyya, R. Resource Elasticity for Distributed Data Stream Processing: A Survey and Future Directions. Available online: https://arxiv.org/abs/1709.01363 (accessed on 15 July 2019).
- Röger, H.; Mayer, R. A Comprehensive Survey on Parallelization and Elasticity in Stream Processing. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef]
- Lera, I.; Guerrero, C.; Juiz, C. YAFS: A Simulator for IoT Scenarios in Fog Computing. IEEE Access 2019, 7, 91745–91758. [Google Scholar] [CrossRef]
- University of Essex. Face Recognition Data. 2019. Available online: https://cswww.essex.ac.uk/mv/allfaces/ (accessed on 5 May 2019).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the Computer Vision and Pattern Recognition (cs.CV), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. Available online: https://arxiv.org/abs/1503.03832 (accessed on 26 May 2019).
- Geitgey, A. Face Recognition Library. 2018. Available online: https://github.com/ageitgey/face_recognition (accessed on 19 October 2019).
- OpenCV.org. Open Source Computer Vision Library. 2018. Available online: https://opencv.org/ (accessed on 17 April 2019).
- Bass, J. imageZMQ: Transporting OpenCV Images. 2019. Available online: https://github.com/jeffbass/imagezmq (accessed on 4 September 2019).
- ZeroMQ.org. ZeroMQ—An Open-Source Universal Messaging Library. 2018. Available online: https://zeromq.org/ (accessed on 4 September 2019).
- Ananthanarayanan, G.; Bahl, P.; Bodík, P.; Chintalapudi, K.; Philipose, M.; Ravindranath, L.; Sinha, S. Real-Time Video Analytics: The Killer App for Edge Computing. Computer 2017, 50, 58–67. [Google Scholar] [CrossRef]
- James, A.; Sirakoulis, G.C.; Roy, K. Smart cameras everywhere: AI vision on edge with emerging memories. In Proceedings of the 2019 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Genoa, Italy, 27–29 November 2019; pp. 422–425. [Google Scholar]
- Apache.org. Apache NiFi—An Easy to Use, Powerful, And Reliable System To Process and Distribute Data. 2018. Available online: https://nifi.apache.org/ (accessed on 6 October 2018).
- Ben Sada, A.; Bouras, M.A.; Ma, J.; Runhe, H.; Ning, H. A Distributed Video Analytics Architecture Based on Edge-Computing and Federated Learning. In Proceedings of the 2019 IEEE International Conference Dependable, Autonomic and Secure Computing, Fukuoka, Japan, 5–8 August 2019; pp. 215–220. [Google Scholar] [CrossRef]
- Ke, R.; Zhuang, Y.; Pu, Z.; Wang, Y. A Smart, Efficient, and Reliable Parking Surveillance System With Edge Artificial Intelligence on IoT Devices. IEEE Trans. Intell. Transp. Syst. 2020, 90, 1–13. [Google Scholar] [CrossRef]
- Yau, S. Battle of Edge AI— Nvidia vs. Google vs. Intel. 2019. Available online: https://medium.com/p/8a3b87243028 (accessed on 7 August 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Face Detection * (Raspberry Pi 4 + TPU) | Face Recognition ** (NVIDIA Jetson Nano) | Decision Rule (Raspberry Pi 3) | Total | |
|---|---|---|---|---|
| Average | 0.018 | 0.051 | 0.008 | 0.078 |
| Minimum | 0.014 | 0.047 | 0.008 | 0.068 |
| Maximum | 0.029 | 0.058 | 0.008 | 0.098 |
| Standard Deviation | 0.004 | 0.003 | 0.001 |
| Metric | Description |
|---|---|
| MWT | Maximum Workflow Time (MWT): This metric calculates the total processing time of the deployment plan of workflow to process an . |
| DMR | Delayed Messages Ratio (DMR): Given a workflow , a delayed message takes time to be processed higher than its MWT. This metric calculates the ratio of delayed messages processed within a period when different workflows compete for the same FLO (IS) nodes. |
| WB | Workload Balancing (WB): This metric analyzes how fair the distribution of the workload is among the edge nodes, considering their different processing capacities. |
| PT | Processing Throughput (PT): This metric evaluates the number of messages processed per unit of time. |
| Parameter | Value |
|---|---|
| Number of edge nodes available | 15 nodes |
| Types of edge nodes | 5 MLO nodes (1.5 GHz and 4 GB RAM + TPU) with image processing capacity of 40 FPS; 5 FLO nodes (1.43 GHz and 4 GB RAM, GPU) with image processing capacity of 20 FPS; 5 DLO nodes (1 GHz and 1 GB RAM) |
| Type of cameras | 20 FPS, Full HD, using H.264 Base - High Quality as compression method |
| Data sensing interval of cameras | 50 ms |
| Number of cameras per MLO node | 2 |
| Bandwidth | 100 Mbps between cameras and edge nodes; 100 Mbps between edge nodes |
| Delay between cameras and edge nodes | 4 ms |
| Delay between edge nodes | 4 ms |
| Average Message average size | 50 kB |
| Simulation time | 3000 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rocha Neto, A.; Silva, T.P.; Batista, T.; Delicato, F.C.; Pires, P.F.; Lopes, F. Leveraging Edge Intelligence for Video Analytics in Smart City Applications. Information 2021, 12, 14. https://doi.org/10.3390/info12010014
Rocha Neto A, Silva TP, Batista T, Delicato FC, Pires PF, Lopes F. Leveraging Edge Intelligence for Video Analytics in Smart City Applications. Information. 2021; 12(1):14. https://doi.org/10.3390/info12010014
Chicago/Turabian StyleRocha Neto, Aluizio, Thiago P. Silva, Thais Batista, Flávia C. Delicato, Paulo F. Pires, and Frederico Lopes. 2021. "Leveraging Edge Intelligence for Video Analytics in Smart City Applications" Information 12, no. 1: 14. https://doi.org/10.3390/info12010014
APA StyleRocha Neto, A., Silva, T. P., Batista, T., Delicato, F. C., Pires, P. F., & Lopes, F. (2021). Leveraging Edge Intelligence for Video Analytics in Smart City Applications. Information, 12(1), 14. https://doi.org/10.3390/info12010014